Php resque
Download as KEY, PDF8 likes4,941 views

This talk presents php-resque which is a php port of resque which was built by the cool folks @ github.

























































































































Ad
More Related Content
What's hot (20)
Viewers also liked (8)






Ad
Similar to Php resque (20)




















Ad
Recently uploaded (20)




















Php resque
- 2. php-resque
- 4. php-resque author: @surifchris speaker: @chaitanyakuber
- 5. introduction
- 6. introduction context
- 7. introduction context what & how
- 8. introduction context what & how move to php
- 9. introduction context what & how move to php @bigcommerce
- 10. context
- 12. context it’s about ms create a thumbnail
- 13. context it’s about ms create a thumbnail upload videos
- 14. context it’s about ms create a thumbnail upload videos download a tarball
- 15. context it’s about ms create a thumbnail upload videos download a tarball send an email
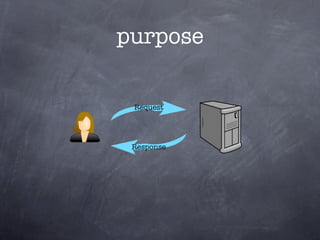
- 16. purpose
- 17. purpose
- 18. where ?
- 20. where ? background jobs asynchronous processing
- 21. how ?
- 22. how ? fork :)
- 23. how ? fork :) backgroundjob
- 24. how ? fork :) backgroundjob delayedjob
- 25. how ? fork :) backgroundjob delayedjob beanstalkd
- 26. how ? fork :) backgroundjob delayedjob beanstalkd gearman
- 27. how ? fork :) backgroundjob delayedjob beanstalkd gearman others ?
- 28. resque
- 30. resque developed by github ruby
- 31. resque developed by github ruby memory leak resistant
- 32. resque developed by github ruby memory leak resistant multiple queues
- 33. resque developed by github ruby memory leak resistant multiple queues queues processed by workers
- 34. resque developed by github ruby memory leak resistant multiple queues queues processed by workers distributed processing
- 35. resque https://github.com/defunkt/resque developed by github ruby memory leak resistant multiple queues queues processed by workers distributed processing
- 36. resque
- 38. resque priorities stored in redis
- 39. resque priorities stored in redis persistent queues
- 40. resque priorities stored in redis persistent queues web interface
- 41. resque priorities stored in redis persistent queues web interface plugins
- 42. redis
- 44. redis key value store atomic operations
- 45. redis key value store atomic operations O(1)
- 46. redis key value store atomic operations O(1) strings, hashes, lists
- 47. redis key value store atomic operations O(1) strings, hashes, lists sets and sorted sets
- 48. redis http://redis.io/topics/introduction key value store atomic operations O(1) strings, hashes, lists sets and sorted sets
- 49. resque @ github
- 50. resque @ github warming a cache
- 51. resque @ github warming a cache counting disk usage
- 52. resque @ github warming a cache counting disk usage building tarballs, rubygems
- 53. resque @ github warming a cache counting disk usage building tarballs, rubygems firing off web hooks
- 54. resque @ github warming a cache counting disk usage building tarballs, rubygems firing off web hooks building graphs
- 55. resque @ github warming a cache counting disk usage building tarballs, rubygems firing off web hooks building graphs deleting users
- 56. does it scale ?
- 57. does it scale ? > 10 million jobs
- 58. does it scale ? > 10 million jobs November 3, 2009
- 59. what’s resque?
- 60. what’s resque?
- 61. php-resque
- 63. php-resque interface parity queues
- 64. php-resque interface parity queues workers
- 65. php-resque interface parity queues workers persistence
- 66. php-resque interface parity queues workers persistence resilience
- 67. php-resque interface parity queues workers persistence resilience php @ bigcommerce
- 68. php-resque https://github.com/chrisboulton/php-resque/ interface parity queues workers persistence resilience php @ bigcommerce
- 69. php-resque
- 70. php-resque in addition
- 71. php-resque in addition setUp and tearDown
- 72. php-resque in addition setUp and tearDown marks jobs as failed
- 73. php-resque in addition setUp and tearDown marks jobs as failed ability to track job status
- 74. how ?
- 75. how ? jobs are queued as follows
- 76. how ? jobs are queued as follows require_once 'lib/Resque.php'; // Required if redis is located elsewhere Resque::setBackend('localhost:6379'); $args = array( 'name' => 'Chris' ); Resque::enqueue('default', 'My_Job', $args);
- 77. job class
- 78. job class class My_Job { public function setUp() { // ... Set up environment for this job } public function perform() { // .. Run job } public function tearDown() { // ... Remove environment for this job } }
- 79. house keeping
- 80. house keeping part of your app
- 81. house keeping part of your app resque loads app into memory
- 82. house keeping part of your app resque loads app into memory instantiates the job class
- 83. house keeping part of your app resque loads app into memory instantiates the job class runs it
- 84. @bigcommerce
- 85. @bigcommerce email
- 86. @bigcommerce email uploads/downloads
- 87. @bigcommerce email uploads/downloads statsd
- 88. @bigcommerce email uploads/downloads statsd totango
- 89. @bigcommerce email uploads/downloads statsd totango monitoring
- 90. @bigcommerce email uploads/downloads statsd totango monitoring ….
- 92. Questions?
Editor's Notes
- #2: hello and welcome to my talk on php-resque\nbefore we proceed i have to tell you all that php-resque was developed by chris boulton\nmy name is chaitanya kuber and can be contacted via twitter\n
- #3: hello and welcome to my talk on php-resque\nbefore we proceed i have to tell you all that php-resque was developed by chris boulton\nmy name is chaitanya kuber and can be contacted via twitter\n
- #4: hello and welcome to my talk on php-resque\nbefore we proceed i have to tell you all that php-resque was developed by chris boulton\nmy name is chaitanya kuber and can be contacted via twitter\n
- #5: standing here and doing this presentaiton is a little strange because i know everyone in the audience is smarter than myself\nthat said, i want to provide a little bit of context about our world\ntalk about what resque is and how it works\nthe move to php\nwhat we use it for @ bigcommerce\n\n
- #6: standing here and doing this presentaiton is a little strange because i know everyone in the audience is smarter than myself\nthat said, i want to provide a little bit of context about our world\ntalk about what resque is and how it works\nthe move to php\nwhat we use it for @ bigcommerce\n\n
- #7: standing here and doing this presentaiton is a little strange because i know everyone in the audience is smarter than myself\nthat said, i want to provide a little bit of context about our world\ntalk about what resque is and how it works\nthe move to php\nwhat we use it for @ bigcommerce\n\n
- #8: standing here and doing this presentaiton is a little strange because i know everyone in the audience is smarter than myself\nthat said, i want to provide a little bit of context about our world\ntalk about what resque is and how it works\nthe move to php\nwhat we use it for @ bigcommerce\n\n
- #9: context, it really is everything\nin engineering web applications its all about the milliseconds\ntasks like …. take time\nthey not only take time, often they are supporting tasks\nthings that do not directly impact servicing a request form the user\n
- #10: context, it really is everything\nin engineering web applications its all about the milliseconds\ntasks like …. take time\nthey not only take time, often they are supporting tasks\nthings that do not directly impact servicing a request form the user\n
- #11: context, it really is everything\nin engineering web applications its all about the milliseconds\ntasks like …. take time\nthey not only take time, often they are supporting tasks\nthings that do not directly impact servicing a request form the user\n
- #12: context, it really is everything\nin engineering web applications its all about the milliseconds\ntasks like …. take time\nthey not only take time, often they are supporting tasks\nthings that do not directly impact servicing a request form the user\n
- #13: context, it really is everything\nin engineering web applications its all about the milliseconds\ntasks like …. take time\nthey not only take time, often they are supporting tasks\nthings that do not directly impact servicing a request form the user\n
- #14: users are fickle\ni like to think that a web application should focus on responding as fast possible to the request form its user\nif not they will leave\nso, any operation thats not directly related to the request can and probably should go elsewhere\n\n
- #15: where ?\nbackground jobs … whats that\nthink asynchronous\nsupermarket shelves are stacked in the night to ensure shoppers can walk in get there things and walk out\nit would be a sucky experience to walk in and wait for them to stock the milk before you could buy it\n
- #16: where ?\nbackground jobs … whats that\nthink asynchronous\nsupermarket shelves are stacked in the night to ensure shoppers can walk in get there things and walk out\nit would be a sucky experience to walk in and wait for them to stock the milk before you could buy it\n
- #17: there are various systems to do background/async processing\nbackgroundjob is a zero admin background priority queue for rails\ndelayedjob is similar with the advantage that it doesn’t load the entire rails env into memory\nbeanstalk is a simple, fast work queue. its interface is generic, was designed for increase response times for high-volume web apps\ngearman is quite similar to resque as it supports persistant queues, is open source, fault tolerant and is distributed\n
- #18: there are various systems to do background/async processing\nbackgroundjob is a zero admin background priority queue for rails\ndelayedjob is similar with the advantage that it doesn’t load the entire rails env into memory\nbeanstalk is a simple, fast work queue. its interface is generic, was designed for increase response times for high-volume web apps\ngearman is quite similar to resque as it supports persistant queues, is open source, fault tolerant and is distributed\n
- #19: there are various systems to do background/async processing\nbackgroundjob is a zero admin background priority queue for rails\ndelayedjob is similar with the advantage that it doesn’t load the entire rails env into memory\nbeanstalk is a simple, fast work queue. its interface is generic, was designed for increase response times for high-volume web apps\ngearman is quite similar to resque as it supports persistant queues, is open source, fault tolerant and is distributed\n
- #20: there are various systems to do background/async processing\nbackgroundjob is a zero admin background priority queue for rails\ndelayedjob is similar with the advantage that it doesn’t load the entire rails env into memory\nbeanstalk is a simple, fast work queue. its interface is generic, was designed for increase response times for high-volume web apps\ngearman is quite similar to resque as it supports persistant queues, is open source, fault tolerant and is distributed\n
- #21: there are various systems to do background/async processing\nbackgroundjob is a zero admin background priority queue for rails\ndelayedjob is similar with the advantage that it doesn’t load the entire rails env into memory\nbeanstalk is a simple, fast work queue. its interface is generic, was designed for increase response times for high-volume web apps\ngearman is quite similar to resque as it supports persistant queues, is open source, fault tolerant and is distributed\n
- #22: there are various systems to do background/async processing\nbackgroundjob is a zero admin background priority queue for rails\ndelayedjob is similar with the advantage that it doesn’t load the entire rails env into memory\nbeanstalk is a simple, fast work queue. its interface is generic, was designed for increase response times for high-volume web apps\ngearman is quite similar to resque as it supports persistant queues, is open source, fault tolerant and is distributed\n
- #23: it was developed by the cool folks @github, it was inspired by delayedjob\nresque is written in ruby which is a redis backed library for creating background jobs, placing them in queues and processing them later\nworkers can process one or multiple queues\nworkers can be run on different servers\n
- #24: it was developed by the cool folks @github, it was inspired by delayedjob\nresque is written in ruby which is a redis backed library for creating background jobs, placing them in queues and processing them later\nworkers can process one or multiple queues\nworkers can be run on different servers\n
- #25: it was developed by the cool folks @github, it was inspired by delayedjob\nresque is written in ruby which is a redis backed library for creating background jobs, placing them in queues and processing them later\nworkers can process one or multiple queues\nworkers can be run on different servers\n
- #26: it was developed by the cool folks @github, it was inspired by delayedjob\nresque is written in ruby which is a redis backed library for creating background jobs, placing them in queues and processing them later\nworkers can process one or multiple queues\nworkers can be run on different servers\n
- #27: it was developed by the cool folks @github, it was inspired by delayedjob\nresque is written in ruby which is a redis backed library for creating background jobs, placing them in queues and processing them later\nworkers can process one or multiple queues\nworkers can be run on different servers\n
- #28: it was developed by the cool folks @github, it was inspired by delayedjob\nresque is written in ruby which is a redis backed library for creating background jobs, placing them in queues and processing them later\nworkers can process one or multiple queues\nworkers can be run on different servers\n
- #29: it was developed by the cool folks @github, it was inspired by delayedjob\nresque is written in ruby which is a redis backed library for creating background jobs, placing them in queues and processing them later\nworkers can process one or multiple queues\nworkers can be run on different servers\n
- #30: resque supports prioritising jobs by prioritising queues against each other\njobs are persisted to queues as JSON objects and the queues are stored in redis as lists\na nice web interface, a sinatra app, is also included for monitoring the workers\nplugin system using a event framework for events like after_fork, before_fork etc \n
- #31: resque supports prioritising jobs by prioritising queues against each other\njobs are persisted to queues as JSON objects and the queues are stored in redis as lists\na nice web interface, a sinatra app, is also included for monitoring the workers\nplugin system using a event framework for events like after_fork, before_fork etc \n
- #32: resque supports prioritising jobs by prioritising queues against each other\njobs are persisted to queues as JSON objects and the queues are stored in redis as lists\na nice web interface, a sinatra app, is also included for monitoring the workers\nplugin system using a event framework for events like after_fork, before_fork etc \n
- #33: resque supports prioritising jobs by prioritising queues against each other\njobs are persisted to queues as JSON objects and the queues are stored in redis as lists\na nice web interface, a sinatra app, is also included for monitoring the workers\nplugin system using a event framework for events like after_fork, before_fork etc \n
- #34: resque supports prioritising jobs by prioritising queues against each other\njobs are persisted to queues as JSON objects and the queues are stored in redis as lists\na nice web interface, a sinatra app, is also included for monitoring the workers\nplugin system using a event framework for events like after_fork, before_fork etc \n
- #35: this is a little tangent, but i quickly want to talk about redis\nit’s a key-value store, all its operations are atomic and O(1) meaning they will always complete in a constant amount of time\nthis means speed and its really important when you want to set and forget\n\n
- #36: this is a little tangent, but i quickly want to talk about redis\nit’s a key-value store, all its operations are atomic and O(1) meaning they will always complete in a constant amount of time\nthis means speed and its really important when you want to set and forget\n\n
- #37: this is a little tangent, but i quickly want to talk about redis\nit’s a key-value store, all its operations are atomic and O(1) meaning they will always complete in a constant amount of time\nthis means speed and its really important when you want to set and forget\n\n
- #38: this is a little tangent, but i quickly want to talk about redis\nit’s a key-value store, all its operations are atomic and O(1) meaning they will always complete in a constant amount of time\nthis means speed and its really important when you want to set and forget\n\n
- #39: this is a little tangent, but i quickly want to talk about redis\nit’s a key-value store, all its operations are atomic and O(1) meaning they will always complete in a constant amount of time\nthis means speed and its really important when you want to set and forget\n\n
- #40: this is a little tangent, but i quickly want to talk about redis\nit’s a key-value store, all its operations are atomic and O(1) meaning they will always complete in a constant amount of time\nthis means speed and its really important when you want to set and forget\n\n
- #41: they use it for a whole host of things\n
- #42: they use it for a whole host of things\n
- #43: they use it for a whole host of things\n
- #44: they use it for a whole host of things\n
- #45: they use it for a whole host of things\n
- #46: they use it for a whole host of things\n
- #47: around 2009 when they released this library they had already processed over 10 million jobs\nwow … right\n
- #48: around 2009 when they released this library they had already processed over 10 million jobs\nwow … right\n
- #49: so, how does it do what it does ?\nas a user of the resque library in your app you essentially interact with redis\nwhen you ask resque to queue up a job, it will push it onto the queue in redis\na resque worker comes along at some point in time and pops a job of the queue and forks that into its own process and runs the job\n\n
- #50: \n
- #51: \n
- #52: \n
- #53: \n
- #54: \n
- #55: \n
- #56: \n
- #57: \n
- #58: \n
- #59: \n
- #60: \n
- #61: \n
- #62: \n
- #63: but it can also have a setUp and tearDown method if there are pre and post actions you wish to do or conditions you wish to check etc\n
- #64: \n
- #65: \n
- #66: \n
- #67: \n
- #68: \n
- #69: \n
- #70: \n
- #71: \n
- #72: \n
- #73: \n
- #74: \n
- #75: \n