




















































Postgres indexes
- 1. POSTGRES INDEXES: A DEEP DIVE
- 2. INTRODUCTION Bartosz Sypytkowski ▪ @Horusiath ▪ [email protected] ▪ bartoszsypytkowski.com
- 3. B+Tree: how databases manage data? How indexes work Query plans & execution Types of indexes AGENDA
- 4. B+TREE
- 5. HEADER HEADER HEADER HEADER HEADER HEADER HEADER 4 32 4 25 4 DATA 32 49 8 DATA 16 DATA 20 DATA 25 DATA 27 DATA 30 DATA 32 DATA 42 DATA 43 DATA 44 DATA 49 DATA 62 DATA 64 DATA 8KB B+TREE link link link link
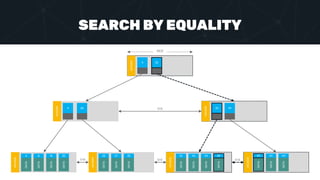
- 6. HEADER HEADER HEADER HEADER HEADER HEADER HEADER 4 32 4 25 4 DATA 32 49 8 DATA 16 DATA 20 DATA 25 DATA 27 DATA 30 DATA 32 DATA 42 DATA 43 DATA 49 DATA 49 DATA 62 DATA 64 DATA 8KB SEARCH BY EQUALITY link link link link
- 7. HEADER HEADER HEADER HEADER HEADER HEADER HEADER 4 32 4 25 4 DATA 32 49 8 DATA 16 DATA 20 DATA 25 DATA 27 DATA 30 DATA 32 DATA 42 DATA 43 DATA 44 DATA 49 DATA 62 DATA 64 DATA 8KB RANGE SCAN link link link link
- 8. HEADER 4 32 HEADER 4 25 HEADER 32 49 HEADER 4 DATA 8 DATA 16 DATA 20 DATA HEADER 25 DATA 27 DATA 30 DATA HEADER 32 DATA 42 DATA 43 DATA 44 DATA HEADER 49 DATA 62 DATA 64 DATA 8KB OVERFLOW PAGES link link link link HEADER OVERFLOW DATA OVERFLOW HEADER HEADER DATA HEADER
- 9. POSTGRESQL TOAST TABLES book_id title content 1 ‘Haikus’ ‘In the twilight rain these brilliant-hued hibiscus - A lovely sunset.’ 2 ‘Moby Dick’ public.books chunk_id chunk_seq chunk_data 16403 0 0xFF2F000000436 16403 1 0x6167F27521F25B 16403 2 0x23FB21030E6F6 16403 3 0x7974686108676 pg_toast.pg_toast_{$OID} select relname from pg_class where oid = ( select reltoastrelid from pg_class where relname='books') Find name of a corresponding TOAST table if(compress(content).len > 2000)
- 10. HEADER HEADER HEADER HEADER HEADER 4 25 4 DATA 8 DATA 16 DATA 20 DATA 25 DATA 27 DATA 30 DATA TUPLE IDs link Table Heap Index Storage 4 TID 8 TID 16 TID 20 TID 25 TID 27 TID 30 TID 32 TID 32 DATA <block id, tuple offset> select ctid from my_table
- 11. QUERY EXECUTION
- 12. select * from books where author_id = 10 SEQ SCAN
- 13. SEQ SCAN M1 T1 I1 T2 T3 I2 I3 Index Storage T4 T5 T6 T7 Table Heap 1. (Hopefully) sequential I/O 2. Scans all table’s related pages 3. Doesn’t use index pages
- 14. create index on books(publication_date); select publication_date from books where publication_date > ‘2020/01/01’ INDEX ONLY SCAN
- 15. INDEX ONLY SCAN M1 T1 I1 T2 T3 I2 I3 Index Storage T4 T5 T6 T7 Table Heap 1. Sequential I/O over index pages 2. Doesn’t use table’s related pages
- 16. create index on books(publication_date); select title, publication_date from books where publication_date > ‘2020/01/01’ INDEX SCAN
- 17. INDEX SCAN M1 T1 I1 T2 T3 I2 I3 Index Storage T4 T5 T6 T7 Table Heap 1. Uses index to find a first page of the related table…
- 18. INDEX SCAN M1 T1 I1 T2 T3 I2 I3 Index Storage T4 T5 T6 T7 Table Heap 1. Uses index to find a first page of the related table… 2. Position read cursor on the first page…
- 19. INDEX SCAN M1 T1 I1 T2 T3 I2 I3 Index Storage T4 T5 T6 T7 Table Heap 1. Uses index to find a first page of the related table… 2. Position read cursor on the first page… 3. Sequential I/O over all table’s pages until condition is done
- 20. create index on books using gist(description_lex); select title, publication_date from books where description_lex @@ ‘epic’ BITMAP SCAN
- 21. BITMAP SCAN M1 T1 I1 T2 T3 I2 I3 Index Storage T4 T5 T6 T7 Table Heap 1. Using index create bitmap of matching pages Bitmap
- 22. BITMAP SCAN M1 T1 I1 T2 T3 I2 I3 Index Storage T4 T5 T6 T7 Table Heap 1. Using index create bitmap of matching pages 2. Random I/O over pages covered by bitmap Bitmap
- 23. INCLUDE & PARTIAL INDEXES create index ix_books_by_author on books(author_id) include (created_at) where author_id is not null; HEADER HEADER 4 25 HEADER HEADER HEADER 4 DATA 7 DATA 13 DATA 16 DATA 19 DATA 25 DATA 32 DATA 47 DATA 61 DATA 4 TID INC 16 TID INC 25 TID INC 32 TID INC duplicated columns
- 24. BTREE INDEX create index ix_users_birthdate on users(birthdate desc);
- 25. COMPAR ING VECTOR CLOCKS B-TREE INDEX 1. Default 2. Access time: always O(logN) 3. Supports most of the index features create index ix_users_birthdate on users(birthdate desc);
- 26. HASH INDEX create index ix_orders_no on orders using hash(order_no);
- 27. HEADER HEADER 0x 01 0x 02 HEADER HEADER HEADER Meta page HASH INDEX HEADER Bucket 0 Overflow page Bitmap page Bucket 1 4 TID 71 TID 13 TID 73 TID 42 TID 67 TID 86 TID 99 TID 5 TID 38 TID 7 TID 51 TID 14 TID 34 TID 66 TID 70 TID 72 TID 90 TID 79 TID 91 TID 82 TID
- 28. COMPAR ING VECTOR CLOCKS HASH INDEX 1. Access time: O(1) – O(N) 2. Doesn’t shrink in size* create index ix_orders_no on orders using hash(order_no);
- 29. BRIN INDEX create index ih_events_created_at on events using brin(created_at) with (pages_per_range = 128);
- 31. select tablename, attname, correlation from pg_stats where tablename = 'film' tablename attname correlation film film_id 0.9979791 film title 0.9979791 film description 0.04854498 film release_year 1 film rating 0.1953281 film last_update 1 film fulltext <null> COLUMN-TUPLE CORRELATION
- 32. COMPAR ING VECTOR CLOCKS BRIN INDEX 1. Imprecise 2. Very small in size 3. Good for columns aligned with tuple insert order and immutable records create index ih_events_created_at on events using brin(created_at) with (pages_per_range = 128);
- 33. BLOOM INDEX create index ix_active_codes on active_codes using bloom(keycode) with (length=80, col1=2);
- 34. BLOOM FILTER INSERT(C) = h1(C)/len | h2(C)/len .. | hn(C)/len INSERT(D) = h1(D)/len | h2(D)/len .. | hn(D)/len CONTAINS(A) = h1(A)/len | h2(A)/len .. | hn(A)/len CONTAINS(B) = h1(B)/len | h2(B)/len .. | hn(B)/len FALSE MAYBE?
- 35. COMPAR ING VECTOR CLOCKS BLOOM INDEX 1. Small in size 2. Good for exclusion/narrowing 3. False positive ratio: hur.st/bloomfilter/ create extension bloom; create index ix_active_codes on active_codes using bloom(keycode) with (length=80, col1=2); number of bits per record number of hashes for each column
- 36. GiST INDEX create index ix_books_content on books using gist(content_lex);
- 37. GiST INDEX GEO POINTS image: https://postgrespro.com/blog/pgsql/4175817
- 38. GiST INDEX TSVECTOR -- gist cannot be applied directly on text columns alter table film add column description_lex tsvector generated always as (to_tsvector('english', description)) stored; create index idx_film_description_lex on film using gist(description_lex); select * from film where description_lex @@ 'epic'; Bitmap Heap Scan on film (cost=4.18..20.32 rows=5 width=416) Recheck Cond: (description_lex @@ '''epic'''::tsquery) -> Bitmap Index Scan on idx_film_description_lex (cost=0.00..4.18 rows=5 width=0) Index Cond: (description_lex @@ '''epic'''::tsquery) Query Plan
- 39. GiST INDEX TSVECTOR HEADER 011011 110111 HEADER 010011 011010 HEADER 100110 110001 HEADER aab TID aac TID aba TID HEADER adf TID azf TID bac TID HEADER brc TID caa TID cdl TID HEADER cff TID fre TID klm TID
- 40. COMPAR ING VECTOR CLOCKS GiST INDEX 1. Supports specialized operators 2. Index is not updated during deletes create index ix_books_content on books using gist(content_lex);
- 41. SP-GiST INDEX create index ix_files_path on files using spgist(path);
- 42. SP-GiST INDEX GEO POINTS image: https://postgrespro.com/blog/pgsql/4220639
- 43. SP-GiST INDEX TSVECTOR -- spgist can be created on text column but not on nvarchar create index idx_film_title on film using spgist(title); select * from film where title like ‘A Fast-Paced% in New Orleans'; Bitmap Heap Scan on film (cost=8.66..79.03 rows=51 width=416) Filter: (description ~~ 'A Fast-Paced%'::text) -> Bitmap Index Scan on idx_film_title (cost=0.00..8.64 rows=50 width=0) Index Cond: ((description ~>=~ 'A Fast-Paced'::text) AND (description ~<~ 'A Fast-Pacee'::text)) Query Plan
- 44. COMPAR ING VECTOR CLOCKS GiST INDEX 1. Just like GiST, but faster for some ops… 2. … but unable to perform some other 3. Indexed space is partitioned into non- overlapping regions create index ix_files_path on files using spgist(path);
- 45. GIN INDEX create index ix_books_content on books using gin(content_lex);
- 46. GIN INDEX -- gist cannot be applied directly on text columns alter table film add column description_lex tsvector generated always as (to_tsvector('english', description)) stored; create index idx_film_description_lex on film using gin(description_lex); select * from film where description_lex @@ 'epic'; Bitmap Heap Scan on film (cost=8.04..24.18 rows=5 width=416) Recheck Cond: (description_lex @@ '''epic'''::tsquery) -> Bitmap Index Scan on idx_film_description_lex (cost=0.00..8.04 rows=5 width=0) Index Cond: (description_lex @@ '''epic'''::tsquery) Query Plan
- 47. GIN INDEX HEADER ever gone HEADER HEADER HEADER HEADER omit call (1,1) (3,1) dome (1,2) ever (1,1) (2,1) faucet (4,0) gather (2,1) (3,2) gone leather (2,1) omit (2,1) (3,2) (2,2) (3,1) HEADER HEADER (1,1) (1,6) (1,9) (1,2) (1,3) (1,7) (1,8) (2,1) (2,2) (2,3) (2,6) (2,8) (2,5) (2,7) (3,1) Posting list Posting tree
- 48. COMPAR ING VECTOR CLOCKS GIN INDEX create index ix_books_content on books using gin(content_lex); 1. Reads usually faster than GiST 2. Writes are usually slower than GiST 3. Index size greater than GiST
- 49. RUM INDEX create index ix_books_content on books using rum(content_lex);
- 50. RUM INDEX HEADER ever gone HEADER HEADER HEADER HEADER omit call (1,1) (3,1) dome (1,2) ever (1,1) (2,1) faucet (4,0) gather (2,1) (3,2) gone leather (2,1) omit (2,1) (3,2) (2,2) (3,1) HEADER HEADER (1,1) (1,6) (1,9) (1,2) (1,3) (1,7) (1,8) (2,1) (2,2) 1, 14 5 2, 5 25 1, 9 45 1, 21 9, 11 2, 10 45 1, 22 13 1 211 2, 4 2, 21 13 25 5 4, 7 (2,3) (2,6) (2,8) (2,5) (2,7) (3,1) 2 3 1, 7 8, 13 17 1
- 51. RUM INDEX -- similarity ranking select description_lex <=> to_tsquery('epic’) as similarity from books; -- find description with 2 words located one after another select * from books where description_lex @@ to_tsquery(‘hello <-> world’);
- 52. COMPAR ING VECTOR CLOCKS RUM INDEX 1. GIN on steroids (bigger but more capable) 2. Allows to query for terms and their relative positions in text 3. Supports Index Scan and EXCLUDE create extension rum; create index ix_books_content on books using rum(content_lex);
- 53. SUMMARY
- 54. THANK YOU