











![The PG-Strom Project
Multi Version Concurrency Control (1/2)
Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries13
データベース
テーブル
データ領域
Table
タプル ヘッダ領域
struct HeapTupleHeaderData
{
struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} t_heap;
ItemPointerData t_ctid; /* current TID of this or newer tuple */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};](https://image.slidesharecdn.com/20160727dbloungetokyo01parallelpostgresql-160727151825/85/PostgreSQL-13-320.jpg)
![The PG-Strom Project
Multi Version Concurrency Control (2/2)
Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries14
▌可視性を判定するルール(ざっくり)
xmin: タプルを作った人のトランザクションID。十分に古い時は Freezed (無限遠)。
xmin: このタプルを更新/削除した人のトランザクションID。
ざっくり言えば xmin ≦ 自分のXID ≦ xmax である時にタプルが見えるイメージ。
※もちろん、並行トランザクションやSAVEPOINTの扱いで色々やっているので、↑をま
んま信じないでください。
▌並列クエリがビューを共有するには
トランザクションのスナップショットをExport、ワーカー側でこれを再現してやる。
同一のスナップショットからは同一のビューが得られる。
xmin xmax cmax/cmin x y z
14684 0 0 100 ‘aaa’ 200
14684 0 0 101 ‘bbb’ 200
14684 14691 1 102 ‘ccc’ 210
14685 14691 0 103 ‘ddd’ 205
14685 0 1 104 ‘eee’ 210
snapshot
xmin, xmax, xip[],
...など
ユーザー列システム列](https://image.slidesharecdn.com/20160727dbloungetokyo01parallelpostgresql-160727151825/85/PostgreSQL-14-320.jpg)















![The PG-Strom Project
【拡散希望】 – ユーザを探しています (2/2)
Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries30
CREATE OR REPLACE FUNCTION
gpu_similarity(int[], -- key bitmap (1xM matrix)
int[], -- ID array (Nx1 matrix)
int[]) -- fingerprint bitmap (NxM matrix)
RETURNS float4[]
AS $$
#plcuda_begin
#plcuda_num_threads gpu_similarity_main_num_threads
:
fp_map = (cl_uint *)ARRAY_MATRIX_DATAPTR(arg3.value);
for (i=0; i < width; i++, fp_map += height)
{
bitmap = fp_map[get_global_id()];
sum_and += __popc(keymap[i] & bitmap);
sum_or += __popc(keymap[i] | bitmap);
}
/* similarity */
dest[get_global_id()] =
(sum_or > 0 ? (cl_float)sum_and / (cl_float)sum_or : 0.0);
:
#plcuda_end
$$ LANGUAGE 'plcuda';](https://image.slidesharecdn.com/20160727dbloungetokyo01parallelpostgresql-160727151825/85/PostgreSQL-30-320.jpg)
















![[B23] PostgreSQLのインデックス・チューニング by Tomonari Katsumata](https://cdn.slidesharecdn.com/ss_thumbnails/b23ntt-140624233630-phpapp02-thumbnail.jpg?width=560&fit=bounds)















Ad
More Related Content
What's hot (20)
Viewers also liked (13)
![[9.5新機能]追加されたgroupbyの使い方](https://cdn.slidesharecdn.com/ss_thumbnails/9-151214013505-thumbnail.jpg?width=560&fit=bounds)










Ad
Similar to 並列クエリを実行するPostgreSQLのアーキテクチャ (20)




















Ad
More from Kohei KaiGai (20)




















並列クエリを実行するPostgreSQLのアーキテクチャ
- 2. The PG-Strom Project PostgreSQL v9.6の目玉機能 Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries2 パラレルクエリ 並列に クエリを処理すること
- 3. The PG-Strom Project 本日のアジェンダ Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries3 ▌先史時代 (~v9.2) ▌要素技術 (v9.3~v9.5) ▌並列クエリの実現 (v9.6) ▌今後の動向 (v9.7~) ▌お知らせとお願い
- 4. The PG-Strom Project fork(2) accept(2) PostgreSQLのアーキテクチャ (1/3) – postmasterと子プロセス Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries4 ▌マルチプロセス 1プロセス:1スレッド プロセス内に閉じた処理であれば、 同期/排他を考える必要なし ▌postmasterの役割 PostgreSQL起動時の初期化 共有メモリ、ロック、管理構造体、etc... accept(2)してfork(2) 子プロセスの動作状況を管理 postmaster bgwriter autovacuum backend backend backend backend walwriter shared memory storage
- 5. The PG-Strom Project PostgreSQLのアーキテクチャ (2/3) – postmasterと子プロセス Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries5 ▌子プロセスの上限 max_connections + max_workers PGPROC配列他、プロセス管理に 必要なデータ構造を初期化時に 確保するため。 サイジング的観点も。 ▌例:PGPROC配列 pid、ラッチ、待機中ロック等を含む postmasterや他のbackendが、 並行プロセスの状態を知る。 postmaster bgwriter autovacuum backend backend backend backend walwriter pg_ctl NUM_AUXILIARY_PROCS MaxBackends SIGTERM SIGTERM PGPROC配列
- 6. The PG-Strom Project PostgreSQLのアーキテクチャ (3/3) – postmasterと子プロセス Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries6 ▌子プロセスの上限 max_connections + max_workers PGPROC配列他、プロセス管理に 必要なデータ構造を初期化時に 確保するため。 サイジング的観点も。 ▌例:PGPROC配列 pid、ラッチ、待機中ロック等を含む postmasterや他のbackendが、 並行プロセスの状態を知る。 postmaster bgwriter autovacuum backend backend backend backend walwriter NUM_AUXILIARY_PROCS MaxBackends SIGCHLD Crash reaper SIGQUIT
- 7. The PG-Strom Project fork(2) accept(2) postmasterと子プロセス – 先史時代 (~v9.2以前) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries7 postmaster bgwriter autovacuum backend backend backend backend walwriter shared memory storage 特定用途の ワーカープロセス PostgreSQLの ユーザセッションに対応 “何か”をするために ワーカープロセスを 起動する事ができなかった。 (....自分でインフラを作れば別だけど....)
- 8. The PG-Strom Project 拡張モジュールだって非同期処理がしたい! (1/2) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries8 拡張モジュール独自の 処理を行うワーカープロセス DB Tech Showcase 2014/Tokyo 発表資料より
- 9. The PG-Strom Project 拡張モジュールだって非同期処理がしたい! (2/2) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries9 To: pgsql-hackers 拡張モジュールが独自にワーカーを 定義できるよう、postmasterを拡張して みました。いかがなものでしょ? From: Alvaro Herrera 同感。Windows対応機能とかが必要な ので、Simonが送ってくれたパッチと併 せて作り直してみました。 2012年4月頃: To: pgsql-hackers ありがとうございます。じゃあ、私は レビューの方で協力させてください。 (FDWのタスクもあるので....) と、いった話もあり、、、 PgSQL 9.3 新機能
- 10. The PG-Strom Project 並列クエリの実現に向けて – 必要な要素技術 Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries10 ▌オンデマンドでワーカープロセスを起動する Dynamic background worker ▌バックエンドプロセス~ワーカープロセス間で通信する Dynamic shared memory Shared memory message queue / Shared memory table of contents ▌一貫したトランザクションのイメージを使用する Parallel context ▌処理を複数のワーカーに分割し、後で集約する Gather node & Partial SeqScan Plan Serialization / Deserialization ▌並列処理を意識したクエリ実行計画 Optimizer enhancement Upper Path Optimization ▌拡張モジュールとの連携 FDW/Custom-Scan
- 11. The PG-Strom Project bgworker bgworker bgworker bgworker Dynamic Background Worker Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries11 max_worker_processes の範囲内なら、 動的にbgworkerを登録可能に 登録と同時にpostmasterへシグナルを送り、 可及的速やかにbgworkerプロセスを起動 する。 誰かが大量に bgworker を使っていると、 必ずしも十分な数の bgworker を確保でき ない可能性がある。 PostgreSQLのパラレルクエリは、仮に bgworkerを一個も使えない状況であっても、 動作はするよう設計されている。 v9.4 課題: postmaster起動時にしかBackground Workerを登録できなかった。 postmaster backend backend PGPROC配列 BackgroundWorker配列 max_worker_processes RegisterDynamic- BackgroundWorker() SIGUSR1
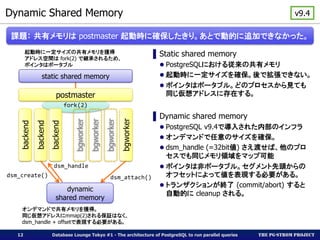
- 12. The PG-Strom Project fork(2) bgworker bgworker bgworker bgworker Dynamic Shared Memory Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries12 ▌Static shared memory PostgreSQLにおける従来の共有メモリ 起動時に一定サイズを確保。後で拡張できない。 ポインタはポータブル。どのプロセスから見ても 同じ仮想アドレスに存在する。 ▌Dynamic shared memory PostgreSQL v9.4で導入された内部のインフラ オンデマンドで任意のサイズを確保。 dsm_handle (=32bit値) さえ渡せば、他のプロ セスでも同じメモリ領域をマップ可能 ポインタは非ポータブル。セグメント先頭からの オフセットによって値を表現する必要がある。 トランザクションが終了 (commit/abort) すると 自動的に cleanup される。 v9.4 課題: 共有メモリは postmaster 起動時に確保したきり。あとで動的に追加できなかった。 backend backend static shared memory backend postmaster dynamic shared memory 起動時に一定サイズの共有メモリを獲得 アドレス空間は fork(2) で継承されるため、 ポインタはポータブル オンデマンドで共有メモリを獲得。 同じ仮想アドレスにmmap(2)される保証はなく、 dsm_handle + offsetで表現する必要がある。 dsm_create() dsm_handle dsm_attach()
- 13. The PG-Strom Project Multi Version Concurrency Control (1/2) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries13 データベース テーブル データ領域 Table タプル ヘッダ領域 struct HeapTupleHeaderData { struct HeapTupleFields { TransactionId t_xmin; /* inserting xact ID */ TransactionId t_xmax; /* deleting or locking xact ID */ union { CommandId t_cid; /* inserting or deleting command ID, or both */ TransactionId t_xvac; /* old-style VACUUM FULL xact ID */ } t_field3; } t_heap; ItemPointerData t_ctid; /* current TID of this or newer tuple */ uint16 t_infomask2; /* number of attributes + various flags */ uint16 t_infomask; /* various flag bits, see below */ uint8 t_hoff; /* sizeof header incl. bitmap, padding */ /* ^ - 23 bytes - ^ */ bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */ /* MORE DATA FOLLOWS AT END OF STRUCT */ };
- 14. The PG-Strom Project Multi Version Concurrency Control (2/2) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries14 ▌可視性を判定するルール(ざっくり) xmin: タプルを作った人のトランザクションID。十分に古い時は Freezed (無限遠)。 xmin: このタプルを更新/削除した人のトランザクションID。 ざっくり言えば xmin ≦ 自分のXID ≦ xmax である時にタプルが見えるイメージ。 ※もちろん、並行トランザクションやSAVEPOINTの扱いで色々やっているので、↑をま んま信じないでください。 ▌並列クエリがビューを共有するには トランザクションのスナップショットをExport、ワーカー側でこれを再現してやる。 同一のスナップショットからは同一のビューが得られる。 xmin xmax cmax/cmin x y z 14684 0 0 100 ‘aaa’ 200 14684 0 0 101 ‘bbb’ 200 14684 14691 1 102 ‘ccc’ 210 14685 14691 0 103 ‘ddd’ 205 14685 0 1 104 ‘eee’ 210 snapshot xmin, xmax, xip[], ...など ユーザー列システム列
- 15. The PG-Strom Project Parallel Context Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries15 ▌プランを実行して同一の結果が返ってくるためには 同一のトランザクション分離レベルを持つ 同一の Snapshot を持つ GUC変数の設定が同一である 同一の拡張モジュールがロードされている volatileなSQL関数が含まれていない .....など。 ▌ParallelContext 特定の Backend の状態をシリアライズして共有メモリ上に記録。 Bgworker側では、共有メモリの dsm_handle を使用してシリアライズされた 呼び出し元 Backend の状態を取得し、状態を再現する。 初期設定を終えた後、Parallel Contextに紐付けられた関数を呼び出す。 この状態で表スキャンを行うと、呼び出し元 Backend と同一の可視性判定が 行われる。 課題:各bgworkerは同一のMVCC判定、同一の実行環境を持たねばならない。 v9.5
- 16. The PG-Strom Project Gather & Partial SeqScan (1/3) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries16 table shared buffer storage manager shared state Partial SeqScan Partial SeqScan Partial SeqScan Partial SeqScan Gather 結果 shm_mq shared memory message queue bgworker1個あたり、 平均 nrows/4行を 読み出す v9.6
- 17. The PG-Strom Project Gather & Partial SeqScan (2/3) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries17 shared state Partial SeqScan Partial SeqScan Partial SeqScan Partial SeqScan Gather 結果 shm_mq shared memory message queue qualifier qualifier qualifier qualifier 行数を削る 行数を削る 行数を削る 行数を削る v9.6
- 18. The PG-Strom Project Gather & Partial SeqScan (3/3) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries18 ▌Gatherノードの役割 bgworkerを起動する。 もし起動できなかったら? 従来のPostgreSQLと同様に、シングルプロセスで動作。 parallel-contextを介してbgworkerに実行コンテキストを渡す Gatherノード配下のPlan-SubTreeや、トランザクション状態など。 shm_mqを介してbgworkerから結果を受け取る メッセージ受け渡しコストが意外と高く、バッファも大きくない (64KB/worker)。 ▌Gatherノード配下で動作するノードの働き 行を生成するノード その他のノード シングルプロセス実行と同様 入力に対して出力を行う 互いに出力が重複しないよう 出力を行う v9.6
- 19. The PG-Strom Project Nested-Loop in Parallel Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries19 Nested- Loop Parallel SeqScan Index Scan outer table inner table Nested- Loop Parallel SeqScan Index Scan inner table Nested- Loop Parallel SeqScan Index Scan inner table Gather 結果 nrows/3 行nrows/3 行 nrows/3 行 こっち側がNULLになる可能性の あるOUTER JOINは無理 v9.6
- 20. The PG-Strom Project Hash-Join in Parallel Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries20 Hash-Join Parallel SeqScanSeqScan outer table inner table Hash-Join Parallel SeqScanSeqScan inner table Hash-Join Parallel SeqScanSeqScan inner table Gather nrows/3 行nrows/3 行 nrows/3 行 Hash Hash Hash 結果 こっち側がNULLになる可能性の あるOUTER JOINは無理 v9.6
- 21. The PG-Strom Project Aggregation in Parallel Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries21 table nrows/4 行nrows/4 行 Final Aggregate Parallel SeqScan Parallel SeqScan Parallel SeqScan Parallel SeqScan Partial Aggregate Partial Aggregate Partial Aggregate Partial Aggregate Gather count(X), sum(X) 結果 count(X), sum(X) count(X), sum(X) count(X), sum(X) AVG(X) = 𝑠𝑢𝑚(𝑋) 𝑐𝑜𝑢𝑛𝑡(𝑋) SELECT AVG(X) FROM tbl GROUP BY category; v9.6
- 22. The PG-Strom Project 並列クエリ実行例 (1/2) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries22 postgres=# set max_parallel_workers_per_gather = 1000; SET postgres=# EXPLAIN ANALYZE SELECT cat, avg(ax) FROM t0 NATURAL JOIN t1 GROUP BY cat; QUERY PLAN ---------------------------------------------------------------------------------------------------------- Finalize GroupAggregate (cost=1789416.68..1789418.37 rows=26 width=12) (actual time=10958.136..10958.196 rows=26 loops=1) Group Key: t0.cat -> Sort (cost=1789416.68..1789417.14 rows=182 width=36) (actual time=10958.119..10958.129 rows=208 loops=1) Sort Key: t0.cat Sort Method: quicksort Memory: 55kB -> Gather (cost=1789391.39..1789409.85 rows=182 width=36) (actual time=10957.874..10957.968 rows=208 loops=1) Workers Planned: 7 Workers Launched: 7 -> Partial HashAggregate (cost=1788391.39..1788391.65 rows=26 width=36) (actual time=10818.246..10818.257 rows=26 loops=8) Group Key: t0.cat -> Hash Join (cost=3674.00..1288390.99 rows=100000080 width=12) (actual time=69.367..7900.751 rows=12500000 loops=8) Hash Cond: (t0.aid = t1.aid) -> Parallel Seq Scan on t0 (cost=0.00..976191.26 rows=14285726 width=8) (actual time=0.024..2181.170 rows=12500000 loops=8) -> Hash (cost=1935.00..1935.00 rows=100000 width=12) (actual time=68.117..68.117 rows=100000 loops=8) Buckets: 131072 Batches: 2 Memory Usage: 3180kB -> Seq Scan on t1 (cost=0.00..1935.00 rows=100000 width=12) (actual time=0.039..31.157 rows=100000 loops=8) Planning time: 0.328 ms Execution time: 10958.825 ms (18 rows)
- 23. The PG-Strom Project 並列クエリ実行例 (2/2) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries23 postgres=# EXPLAIN ANALYZE SELECT cat, avg(ax) FROM t0 NATURAL JOIN t1 GROUP BY cat; QUERY PLAN -------------------------------------------------------------------------------------- HashAggregate (cost=4493751.30..4493751.63 rows=26 width=12) (actual time=77128.158..77128.165 rows=26 loops=1) Group Key: t0.cat -> Hash Join (cost=3674.00..3993750.90 rows=100000080 width=12) (actual time=69.294..54734.212 rows=100000000 loops=1) Hash Cond: (t0.aid = t1.aid) -> Seq Scan on t0 (cost=0.00..1833334.80 rows=100000080 width=8) (actual time=0.032..18499.375 rows=100000000 loops=1) -> Hash (cost=1935.00..1935.00 rows=100000 width=12) (actual time=68.404..68.404 rows=100000 loops=1) Buckets: 131072 Batches: 2 Memory Usage: 3180kB -> Seq Scan on t1 (cost=0.00..1935.00 rows=100000 width=12) (actual time=0.015..31.322 rows=100000 loops=1) Planning time: 0.900 ms Execution time: 77128.944 ms (10 rows)
- 24. The PG-Strom Project CPU+GPU Hybrid Parallel Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries24 SeqScan outer table inner table Gather nrows/3 行nrows/3 行 結果 Final Aggregate GpuPreAgg GpuHashJoin SeqScan inner table GpuPreAgg GpuHashJoin SeqScan inner table GpuPreAgg GpuHashJoin nrows/3 行 CustomScanノード上に CPU+GPUパラレル機能を 実装 v9.6+PG-Strom
- 25. The PG-Strom Project オプティマイザの改良 (1/3) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries25 ▌従来のオプティマイザ 前半: Scan + Joinの組合せをコストベースで判断 後半: ソート、集約、Window関数など、その他のロジックを問答無用で付加 改善ポイント ① 並列化してはならないサブプランは排除しなければならない。 ② 後半のプラン生成もコストベースで行う必要がある。 v9.6 課題:並列処理を実行するか(できるか)否か、コストベースで判断しなければならない。 SELECT cat, avg(X) FROM t1 NATURAL JOIN t2 NATURAL JOIN t3 GROUP BY cat ORDER BY cat; HJ: t1x(t2xt3) cost=100 HJ: (t1xt2)xt3 cost=5000 HJ: (t1xt3)xt2 cost=200 NL: (t1xt2)xt3 cost=3000 NL: (t1xt3)xt2 cost=240 NL: t1x(t2xt3) cost=50 前半 後半 NL: t1x(t2xt3) cost=50 Agg by cat NL: t1x(t2xt3) cost=50 Sort by cat Agg by cat
- 26. The PG-Strom Project オプティマイザの改良 (2/3) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries26 ▌consider_parallel このScan/JoinがGatherノード配下で 実行してよいかどうかを示すフラグ ▌partial_pathlist Gatherノード配下で実行する際に、 各bgworker間で重複排除ができる 候補パスのリスト 必ずしも cheapest とは限らない。 ▌例) JOINのパスを作る時 inner/outer側が共に consider_parallel=trueで、 JOIN自身も並列化可能ならOK partial_pathlist 中のパスでコスト最安 のパスに GatherPath を付加し、シーケ ンシャル実行も含む、最も安いパスを 選択する。 typedef struct RelOptInfo { NodeTag type; RelOptKind reloptkind; /* all relations included in */ Relids relids; /* size estimates */ double rows; : /* consider parallel paths? */ bool consider_parallel; : /* Path structures */ List *pathlist; List *ppilist; /* partial Paths */ List *partial_pathlist; struct Path *cheapest_startup_path; struct Path *cheapest_total_path; struct Path *cheapest_unique_path; : }
- 27. The PG-Strom Project オプティマイザの改良 (3/3) – 二段階集約 Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries27 ▌後半のプラン生成もコストベースに変更 現状、集約演算がこれに対応。ソート等も可能性?はありそう。 ▌従来の集約演算 シーケンシャルに処理するが、プロセス間データコピーは必要ない。 ▌二段階集約(Partial + Final Aggregation) 並列処理可能だが、件数が増えるに伴ってshm_mqがボトルネックとなる。 Partial Agg) 集約関数の中間結果を生成する。各プロセスにMapした結果の生成。 Final Agg) 中間結果を受け取り、平均値や標準偏差などを出力。Reduceに相当。 HJ: t1x(t2xt3) cost=100 HJ: (t1xt2)xt3 cost=5000 HJ: (t1xt3)xt2 cost=200 NL: (t1xt2)xt3 cost=3000 NL: (t1xt3)xt2 cost=240 NL: t1x(t2xt3) cost=50 前半 後半 NL: t1x(t2xt3) cost=50 Agg by cat NL: t1x(t2xt3) cost=50 Final Agg by cat Partial Agg by cat Or Gather どちらのパスを使用して集約演算を行うか?
- 28. The PG-Strom Project 今後の展望 Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries28 ▌Partial Sort + Merge Join ▌Hash table in shared memory ▌Declarative Partitioning Append Pushdown Inner-Hash size reduction ▌Asynchronous Execution ▌Better Plan Construction v9.7~
- 29. The PG-Strom Project 【拡散希望】 – ユーザを探しています (1/2) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries29 ▌試用ユーザ募集中 GPUを活用した高速 In-database Analytics/Computing に興味のある方。 教師なし学習アルゴリズム (非階層/階層型クラスタリング) を実装し、実データによる 評価を行いたい。 評価環境の提供と、アルゴリズムの実装はPG-Stromプロジェクトで実施。 ワークロードと評価用データをご提供いただける方を探しています。 評価環境: CPU: E5-2670v3 x2, RAM: 384GB, GPU: Tesla K20 or GTX1080 CREATE FUNCTION kmeans(matrix, int) RETURNS vector AS $$ $$ LANGUAGE ‘plcuda’; User define CUDA logic (通常のSQL関数として記述可能) User defined CUDA code PG-Strom’s matrix support routines GPU Kernel for SQL function ‘kmeans()’ 実行時ビルド PG-Strom Input buffer Output buffer SQL関数実行結果 matrixのロード ユーザCUDAロジックの定義:
- 30. The PG-Strom Project 【拡散希望】 – ユーザを探しています (2/2) Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries30 CREATE OR REPLACE FUNCTION gpu_similarity(int[], -- key bitmap (1xM matrix) int[], -- ID array (Nx1 matrix) int[]) -- fingerprint bitmap (NxM matrix) RETURNS float4[] AS $$ #plcuda_begin #plcuda_num_threads gpu_similarity_main_num_threads : fp_map = (cl_uint *)ARRAY_MATRIX_DATAPTR(arg3.value); for (i=0; i < width; i++, fp_map += height) { bitmap = fp_map[get_global_id()]; sum_and += __popc(keymap[i] & bitmap); sum_or += __popc(keymap[i] | bitmap); } /* similarity */ dest[get_global_id()] = (sum_or > 0 ? (cl_float)sum_and / (cl_float)sum_or : 0.0); : #plcuda_end $$ LANGUAGE 'plcuda';
- 31. The PG-Strom Project まとめ Database Lounge Tokyo #1 - The architecture of PostgreSQL to run parallel queries31 ▌PostgreSQLのプロセスモデル 1プロセス – 1スレッド postmasterが子プロセスの起動生成を管理。 ▌PostgreSQLの並列クエリの考え方 “並列” 向けの特別対応は必要最小限に。既存のコードをAs-Isで動作させる。 各コアでPartial xxxScanが一部分を読出し、最後にGatherで集約 スタースキーマ / 典型的OLAPワークロードでの効果が期待。 一方、各コアで効率的にデータを削減できないと却って非効率になる事も…。 ▌過去数バージョンにおけるインフラ強化 v9.3 Background Worker v9.4 Dynamic Background Worker, Dynamic Shared Memory, shm_mq, shm_toc, etc... v9.5 Parallel Context, Sub-plan serialization, etc... v9.6 Gather & Partial SeqScan, Two phase aggregation, Upper Path Optimization, etc...