


















![© 2025 NTT DATA Group Corporation 20
(やってみる)pg_duckdb+オブジェクトストレージ
⚫ Google Cloud Storage上のParquetのファイルを読み取る例。
⚫ PostgreSQLへのファイルロードは不要、処理も高速。
# SELECT COUNT(r[‘id']),AVG(r['price']) FROM
read_parquet('gs://htap-test/items.parquet') r;
⚫ クエリの結果をS3にファイルで格納する例。
⚫ 使い慣れたSQL関数やCOPY句で、データ加工等も行いながら
データレイクへの書出しが完了。
# COPY (SELECT * FROM items ) TO 'gs://htap-test/items.parquet';](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-20-320.jpg)











![© 2025 NTT DATA Group Corporation 33
1.ベクトル検索+スカラー属性フィルタリング
例)商品名:意味的に似ている(ベクトル検索) & カテゴリ:5(スカラーフィルタリング)
SELECT * FROM items WHERE category_id = 5 ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
☆高速に検索するためには?
• 一致する行の割合が小さいとき…
• フィルタ列に対するインデックスを作成する
• CREATE INDEX ON items (category_id);
• 近似インデックスは使わないので、抜け漏れが発生しない
• 一致する行の割合が大きいとき…
• ベクトル列に対する近似インデックスを作成する
• CREATE INDEX ON items USING hnsw (embedding vector_l2_ops);
• 近似インデックスなので、完全に正確ではない
• 取得される結果が少なくなる可能性あり →後述](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-33-320.jpg)



![© 2025 NTT DATA Group Corporation 37
Iterative Index Scansの結果順序のオプション
iterative_scanオプション
• off: 反復インデックススキャンを利用しない。デフォルト。
• strict_order:取得結果が厳密に距離順になる。HNSWのみ。 IVFFlatは選択できない。
• relaxed_order:取得結果が厳密に距離順でない。ただし、取りこぼしがない。IVFFlatはこっちだけ。
⇒近い集団からまずスキャンするので、基本的に見つかるベクトルとの距離は徐々に遠くなっていく
が、前のスキャンよりも短い距離のベクトルが見つかることもある。
relaxed_orderは、これをそのまま出力するので、距離順が一部入れ替わっている箇所が発生しうる
strict_orderは、短い距離のベクトルが見つかったら、結果を破棄するので、必ず昇順になるが、結果が減る
結果を失わず、順序を厳密にしたいときは?
• relaxed_orderで取得した結果を、マテリアライズドCTEとして、最後に並び替える
例)
WITH nearest_results AS MATERIALIZED (
SELECT id, embedding <-> '[1,2,3]' AS distance FROM items ORDER BY distance LIMIT 5
) SELECT * FROM nearest_results WHERE distance < 5 ORDER BY distance;](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-37-320.jpg)


![© 2025 NTT DATA Group Corporation 40
2.全文検索とベクトル検索
例)商品の説明:意味的に似ている(ベクトル検索)& 商品の説明:キーワードが含まれる(全文検索)
商品の説明(vector型)
embedding
商品の説明(text型)
[0.00058671045, -
0.004581401, .......]
世界的デザイナーAyumi Ishiiが
デザインした爽やかなグリーンの
レースをあしらったスカートです。
検索:「Ayumi Ishii 緑 スカート」
意味的な検索
⇒ 文脈や、緑=グリーンなどを捉えられる。
キーワード検索
⇒(Ayumi Ishiiなど必須なキーワードを捉えられる)
ベクトル化](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-40-320.jpg)





![© 2025 NTT DATA Group Corporation 47
3.ベクトル検索+疎ベクトル検索
疎ベクトルとは(対義語:密ベクトル)
• ほとんどの要素が0のベクトル [0, 0, 1, 0, 0 …]など。
• 圧縮して保存できるので、精度を落とさずサイズを小さくできる
• pgvectorでは0.7.0からsparsevec型が追加された。
CREATE TABLE items (id bigserial PRIMARY KEY, embedding sparsevec(5));
INSERT INTO items (embedding) VALUES ('{1:1,3:2,5:3}/5'), ('{1:4,3:5,5:6}/5’);
表記方法
• {インデックス:値, インデックス:値,…}/次元数
• 値が0以外のところだけ書く。あとは0。
• インデックスは1から始まる(0ではないので注意)
{1:1,3:2,5:3}/5 は、[1, 0, 2, 0, 3]](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-47-320.jpg)


![© 2025 NTT DATA Group Corporation 50
ハイブリッド検索の価値は? BGE-M3で動かしてみる。
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
sentences_1 = ["デリシャスパーティプリキュアの主人公は誰ですか。"]
sentences_2 = ["ひろがるスカイ!プリキュアの主人公ソラ・ハレワタールはスカイランドという異世界から来た人です。",
"デリシャスパーティプリキュアの和実ゆいは、すぐにお腹が減ります。コメコメに力をわけてもらい、キュアプ
レシャスに変身します。" ]
sentence_pairs = [[i,j] for i in sentences_1 for j in sentences_2]
print(model.compute_score(
sentence_pairs,
max_passage_length=128,
weights_for_different_modes=[0.4, 0.4, 0.2]))
密ベクトル、疎ベクトルそれぞれのスコアを計算する
↑密:疎=1:1の重みでスコアを計算
質問①
答え①
答え②
[質問①ー答え①]のペアと、[質問①ー答え②]のペア](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-50-320.jpg)
![© 2025 NTT DATA Group Corporation 51
この場合の結果
"dense": [
0.47555941343307495,
0.4559279978275299
],
"sparse": [
0.10498249530792236,
0.13451407849788666
],
"sparse+dense": [
0.29027095437049866,
0.2952210307121277
],
デリシャスパーティプリキュアの主人公は誰ですか。
1. ひろがるスカイ!プリキュアの主人公ソラ・ハレワタールはスカイランドという異世界から来た人です。
2. デリシャスパーティプリキュアの和実ゆいは、すぐにお腹が減ります。コメコメに力をわけてもらい、キュアプレシャスに変身します。
疎ベクトル(キーワードベース)では2が上。
密ベクトル(意味ベース)では1が上。
疎:密=1:1で結果を合わせると、2が上。
より正解に近いほうが
上位に来た](https://image.slidesharecdn.com/postgresqlcolumnarstoregenaiosc2025tokyospringnttdata-250226100929-86118385/85/PostgreSQL-AI-Open-Source-Conference-2025-Tokyo-Spring-51-320.jpg)





![[Cloud OnAir] 最新アップデート Google Cloud データ関連ソリューション 2020年5月14日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0514-200514080330-thumbnail.jpg?width=560&fit=bounds)












![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=560&fit=bounds)













![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [概要編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180215-180219043331-thumbnail.jpg?width=560&fit=bounds)


Ad
More Related Content
Similar to PostgreSQL最新動向 ~カラムナストアから生成AI連携まで~ (Open Source Conference 2025 Tokyo/Spring 発表資料) (20)
More from NTT DATA Technology & Innovation (20)


















Ad
PostgreSQL最新動向 ~カラムナストアから生成AI連携まで~ (Open Source Conference 2025 Tokyo/Spring 発表資料)
- 1. © 2025 NTT DATA Group Corporation PostgreSQL最新動向 ~カラムナストアから生成AI連携まで~ 2025/2/21 株式会社NTTデータグループ 小林 隆浩/石井 愛弓
- 2. © 2025 NTT DATA Group Corporation 2 アジェンダ 01. データベースの技術トレンドと各種データ対応 02. 生成AI時代のPostgreSQLハイブリッド検索 03. まとめ
- 3. © 2025 NTT DATA Group Corporation 3 今日お話しする内容 ⚫ リレーショナルデータベースであるPostgreSQLを中心におき、 様々な形式のデータを格納したり活用する例が見られるように なってきました。 ⚫ 本日のセッションでは、 ✓ カラムナやJSONなど様々なデータを利活用する拡張の紹介 ✓ 生成AI向けにPostgreSQLを利用する際の実例 ⚫ について、お話しします。
- 4. © 2025 NTT DATA Group Corporation 4 © 2025 NTT DATA Japan Corporation データベースの技術トレンドと 各種データ対応 2025/2/21 株式会社NTTデータグループ 小林 隆浩
- 5. © 2025 NTT DATA Group Corporation 5 最近のデータベースでは … ⚫ クラウドサービス(DBaaS)を使うことが当たり前 • マネージドなハイパースケールデータベースが続々登場 ⚫ 一つで色々まかなうコンバージドなデータベースが復権 • NewSQLの拡大 • OLTPも分析も1つのデータベースで ⇒ HTAP • JSONやVectorなども専用のデータベースを用意せずに、 RDBのオプションとして利用可能に
- 6. © 2025 NTT DATA Group Corporation 6 今日のテーマ:HTAPとは? ⚫ Hybrid Transactional and Analytical Processingの略語 ⚫ OLTPとOLAPを結ぶETLを作りこむ必要がないのが利点 HTAP OLTP OLAP オンラインクエリ • トランザクション • 単発、短時間 • 低レイテンシ ETL 分析クエリ • Selectのみ • 高負荷 • レイテンシは 重要でない
- 7. © 2025 NTT DATA Group Corporation 7 HTAPのデータ格納方式(例) 行ストア カラムナストア レコード: B レコード: A ⚫ レコードがデュアルフォーマット(行/列形式)で格納される。 テーブル ディスク ディスク メモリ トランザクション/更新クエリ 分析クエリ 列: X 列: Y 列: Z
- 8. © 2025 NTT DATA Group Corporation 8 HTAPデータベースの比較
- 9. © 2025 NTT DATA Group Corporation 9 HTAPデータベース (クラウド/OSS) DB 提供 OSS デュアル フォーマット カラムナ更新 可能? 分散配置 可能? TiDB/TiFlash PingCAP Yes ◎ / on-disk ◎ ◎ AlloyDB Omni Google No ◎ / in-memory disk-cache ◎ 設定可能 Citus Microsoft Yes △ / on-disk × (更新不可) 設定可能 Hydra/pg_duckdb Hydra Yes (外部ストレージ) - -
- 10. © 2025 NTT DATA Group Corporation 10 TiDB/TiFlash ⚫ TiDB/TiFlashはMySQL互換のスケーラビリティの高いデータベース。 ⚫ オンディスクのデュアルフォーマット構成でHTAPをサポート。
- 11. © 2025 NTT DATA Group Corporation 11 Google AlloyDB Omni ⚫ AlloyDBは、Google CloudのPostgreSQL互換のDBaaS。 ⚫ Omniは他クラウドやオンプレで稼働可能なAlloyDBパッケージ版。 ⚫ OSSではなく、フリーでもない。Google Cloudがサポートを提供。 ⚫ キャッシュとしてカラムナストアを持つデュアルフォーマットの 構成。 ⚫ 最近のリリースで、カラムナストアをディスクキャッシュに持つ 構成も可能に。
- 12. © 2025 NTT DATA Group Corporation 12 (やってみる) Google AlloyDB Omni ⚫ AlloyDB OmniはDocker上で実行可能。 $ sudo alloydb database-server install --data-dir=/home/$USER/alloydb-data $ sudo docker ps CONTAINER ID IMAGE …. 2a09a3cb906f gcr.io/alloydb-omni/memory-agent:15.5.2 …. 409392c2b26e gcr.io/alloydb-omni/pg-service:15.5.2 …. $ sudo docker exec -it pg-service psql -h localhost -U postgres postgres=# ¥l List of databases Name | Owner | alloydbadmin | alloydbadmin | alloydbmetadata | alloydbadmin | postgres | alloydbadmin | template0 | alloydbadmin | template1 | alloydbadmin | AlloyDB Omniの インストール Omniのコンテナにpsqlで 接続して確認
- 13. © 2025 NTT DATA Group Corporation 13 (やってみる)Google AlloyDB Omni – カラムナキャッシュ ① - # show google_columnar_engine.enabled; google_columnar_engine.enabled -------------------------------- on # SELECT google_columnar_engine_add( relation => 'lineitem', columns => 'l_orderkey,l_extendedprice’); google_columnar_engine_add ---------------------------- 92 ⚫ columnar_engineを利用可にし、対象のテーブルやカラムを選択。 postgresql.confで設定 手動でテーブルや列を選択して、 カラムナキャッシュを設定する
- 14. © 2025 NTT DATA Group Corporation 14 (やってみる)Google AlloyDB Omni – カラムナキャッシュ ② - # explain analyze SELECT COUNT(l_orderkey), AVG(l_extendedprice) FROM lineitem; QUERY PLAN ------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (cost=74529.47..74529.48 rows=1 width=40) (actual time=725.176..725.277 rows=1 l -> Gather (cost=74529.24..74529.45 rows=2 width=40) (actual time=623.643..725.253 rows=3 loops=1 Workers Planned: 2 Workers Launched: 2 -> Partial Aggregate (cost=73529.24..73529.25 rows=1 width=40) (actual time=202.669..202.672 ro -> Parallel Append (cost=20.00..58528.37 rows=3000173 width=14) (actual time=4.981..202.64 -> Parallel Custom Scan (columnar scan) on lineitem (cost=20.00..58519.03 rows=2999950 Rows Removed by Columnar Filter: 0 Rows Aggregated by Columnar Scan: 1999967 Columnar cache search mode: native -> Parallel Seq Scan on lineitem (cost=0.00..9.34 rows=223 width=14) (never executed) Planning Time: 290.928 ms Execution Time: 752.699 ms ⚫ 集約クエリはカラムナキャッシュを利用して実行される。 カラムナキャッシュの利用
- 15. © 2025 NTT DATA Group Corporation 15 Citus ⚫ OSSのPostgreSQLのシャーディング拡張、カラムナストアを持つ。 ⚫ デュアルフォーマットではなく、行または列形式のどちらか。 ⚫ カラムナストアは追記のみ可能、個別の更新や削除はできない。 ⚫ オンディスクのカラムナストアは高い圧縮率を実現。
- 16. © 2025 NTT DATA Group Corporation 16 (やってみる)Citus カラムナストア # create table lineitem_col USING COLUMNAR as (select * from lineitem); SELECT 6000664 # update lineitem_col set l_comment = 'updated.' where l_linenumber=1; ERROR: UPDATE and CTID scans not supported for ColumnarScan # delete from lineitem_col where l_linenumber=1; ERROR: UPDATE and CTID scans not supported for ColumnarScan ⚫ アクセスメソッド COLUMNAR を指定してテーブルを作成。 Create tableで カラムナストアであることを指定 カラムナストアは 個別の行を更新/削除すること ができない
- 17. © 2025 NTT DATA Group Corporation 17 (やってみる) Citus カラムナストア – Explain plan - # explain SELECT COUNT(l_orderkey), AVG(l_extendedprice) FROM lineitem_col; QUERY PLAN ---------------------------------------------------------------------------------------------- Aggregate (cost=33312.81..33312.82 rows=1 width=40) -> Custom Scan (ColumnarScan) on lineitem_col (cost=0.00..3309.49 rows=6000664 width=14) Columnar Projected Columns: l_orderkey, l_extendedprice ⚫ 集約クエリではシンプルな実行計画を確認。 カラムナストアを利用
- 18. © 2025 NTT DATA Group Corporation 18 ここまではPostgreSQLの中の話、しかし ⚫ そもそも分析用データをPostgreSQLに持つ必要があるのか? ⚫ 入れたり出したりするファイルの考慮が結局必要では? Citus AlloyDB PostgreSQL データレイク / オブジェクトストレージ ETL ETL このファイルをカラムナ形式にして 直接読めない? ⇒ pg_duckdb
- 19. © 2025 NTT DATA Group Corporation 19 https://docs.hydra.so/start/architecture pg_duckdb? ⚫ PostgreSQLの埋め込みとして機能するduckdb。 ⚫ オブジェクトストアにあるデータレイクから、各種形式のファイ ルを読み込み/書き出すことが可能。 • トランザクションクエリはPostgreSQLの通常テーブルで 受ける(左図のHeap)。 • 分析用データはDuckDB経由で列形式ファイルを読み 込み、行形式とJoinも可能。 • 過去データなどはParquetやIcebergなどの形式でオブ ジェクトストアに格納。これまではETLツールを介していた が、SQLでデータ処理と抽出が可能。 • 低コストのオブジェクトストレージに、高圧縮率のファイル を格納。
- 20. © 2025 NTT DATA Group Corporation 20 (やってみる)pg_duckdb+オブジェクトストレージ ⚫ Google Cloud Storage上のParquetのファイルを読み取る例。 ⚫ PostgreSQLへのファイルロードは不要、処理も高速。 # SELECT COUNT(r[‘id']),AVG(r['price']) FROM read_parquet('gs://htap-test/items.parquet') r; ⚫ クエリの結果をS3にファイルで格納する例。 ⚫ 使い慣れたSQL関数やCOPY句で、データ加工等も行いながら データレイクへの書出しが完了。 # COPY (SELECT * FROM items ) TO 'gs://htap-test/items.parquet';
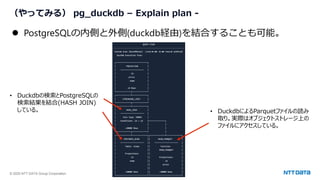
- 21. © 2025 NTT DATA Group Corporation 21 (やってみる) pg_duckdb – Explain plan - ⚫ PostgreSQLの内側と外側(duckdb経由)を結合することも可能。 • Duckdbの検索とPostgreSQLの 検索結果を結合(HASH JOIN) している。 • DuckdbによるParquetファイルの読み 取り。実際はオブジェクトストレージ上の ファイルにアクセスしている。
- 22. © 2025 NTT DATA Group Corporation 22 (参考)Crunchy Data Warehouse ⚫ Crunchy DataのPGaaSであるCrunchy Bridgeで利用できる分析用DB。 ⚫ pg_duckdbに先行して、データレイクからIceberg形式のファイルの 読込み/書出しに対応。 ⚫ 同社が開発中のpg_parquetがOSSとして公開されている。 https://www.crunchydata.com/blog/how-we-fused-duckdb-into-postgres-with-crunchy-bridge-for-analytics
- 23. © 2025 NTT DATA Group Corporation 23 (参考)JSON対応も一層進むPostgreSQL ⚫ 2025年1月にDocumentDBがOSSとして公開された。 ⚫ Azure Cosmos DB for MongoDBのOSS実装。 ⚫ AWSのDocumentDBとは別物。 ⚫ PostgreSQLをベースとしており、BSONをサポート、全文検索や ベクトル検索などの各種ワークロードに対応。 ⚫ OSSとして提供されているのは以下の2つ。 ⚫ pg_documentdb_core :BSONサポートのための拡張 ⚫ pg_documentdb :DocumentDBのAPIを提供
- 24. © 2025 NTT DATA Group Corporation 24 ここまでのまとめ
- 25. © 2025 NTT DATA Group Corporation 25 HTAP向けPostgreSQL:最近の流れ Citus AlloyDB pg_parquet pg_duckdb • シングルフォーマット • カラムナストアは追記のみ • カラムナキャッシュ、高速ディスクキャッシュ • デュアルフォーマット • ストレージ外部化 • データレイク連携 2020 2021 2022 2023 2024 ⚫ HTAP適応ではデータレイク連携が主流になる可能性あり。
- 26. © 2025 NTT DATA Group Corporation 26 © 2025 NTT DATA Japan Corporation 生成AI時代の PostgreSQLハイブリッド検索
- 27. © 2025 NTT DATA Group Corporation 27 後半のテーマ RAGで使われるベクトル検索。 後半のテーマは、通常のベクトル検索に+αの検索方法を組み合わたハイブリッド検索です。 ベクトル検索だけで精度の高い結果を得ようとすると、サイズが大きくなるか、レイテンシが遅くなるデメリットも。 ハイブリッド検索を使えば、サイズやレイテンシを犠牲にせず、より精度の高い結果を得られるケースがあります。 本資料では、PostgreSQLでハイブリッド検索を使いこなすためのヒントをとりあげます。 • ハイブリッド検索とは何か • ハイブリッド検索のパターン • 各パターンでハイブリッド検索を行うために必要な前提知識とサンプル
- 28. © 2025 NTT DATA Group Corporation 28 ベクトル検索とは? 生成AIのAPIを使うと、自然言語をベクトル化できる。 ベクトルは、自然言語の意味を捉えることができるので、意味が近い言葉は、近いベクトルになる。 お菓子 チョコ PostgreSQL MySQL データベース デザート ベクトル間の距離を計算することで、 単語の類似度を計算できるようになる。 ※実際は1536次元だが、2次元でイメージ ベクトル検索が有用なのはRAGだけでなく、 意味検索ができるところ!
- 29. © 2025 NTT DATA Group Corporation 29 pgvector • PostgreSQLでベクトル類似性検索ができるようになる拡張機能 • 現在の最新バージョンはv0.8.0(2025年2月現在) • 頻繁に機能追加&リリースされている • sparsevec(0.7.0~) • halfvec (0.7.0~) • ビットベクトル(0.7.0~) • Iterative Index Scans(0.8.0~) • サブベクトル(0.7.0~) • …etc • 本資料では新しい機能を駆使しながらハイブリッド検索について紹介
- 30. © 2025 NTT DATA Group Corporation 30 ハイブリッド検索とは 画像の類似検索 (ベクトル検索) 属性値検索 キーワード検索 ハイブリッド検索とは、複数の検索を組み合わせること。 単一の検索方法では、よい結果を得ようとすると、インデックスサイズやクエリのレイテンシが犠牲になりやすい。 ハイブリッド検索は、サイズやレイテンシを抑えながらよい結果を得るための解決策の1つ。 複雑な問いあわせにおいては、ベクトル検索以外の検索も組み合わせるとよいケースもある。 例) 「画像と同じデザインの〇〇ブランドのワンピースのMサイズの在庫はありますか?」
- 31. © 2025 NTT DATA Group Corporation 31 ハイブリッド検索のパターン ハイブリッド検索のパターン 1. ベクトル検索+スカラー属性フィルタリング 例)商品名:意味的に似ている(ベクトル検索) & 値段:〇〇円以下(スカラーフィルタリング) 2. ベクトル検索+全文検索 例)商品の説明:意味的に似ている(ベクトル検索)& 商品の説明:キーワードが含まれる(全文検索) 3. ベクトル検索+疎ベクトル検索 例)商品の説明:意味的に似ている(ベクトル検索)& 商品の説明:キーワードが含まれる(疎ベクトル検索) ※ベクトル検索=密ベクトル検索とする。
- 32. © 2025 NTT DATA Group Corporation 32 パターン1: ベクトル検索+スカラー属性フィルタリング
- 33. © 2025 NTT DATA Group Corporation 33 1.ベクトル検索+スカラー属性フィルタリング 例)商品名:意味的に似ている(ベクトル検索) & カテゴリ:5(スカラーフィルタリング) SELECT * FROM items WHERE category_id = 5 ORDER BY embedding <-> '[3,1,2]' LIMIT 5; ☆高速に検索するためには? • 一致する行の割合が小さいとき… • フィルタ列に対するインデックスを作成する • CREATE INDEX ON items (category_id); • 近似インデックスは使わないので、抜け漏れが発生しない • 一致する行の割合が大きいとき… • ベクトル列に対する近似インデックスを作成する • CREATE INDEX ON items USING hnsw (embedding vector_l2_ops); • 近似インデックスなので、完全に正確ではない • 取得される結果が少なくなる可能性あり →後述
- 34. © 2025 NTT DATA Group Corporation 34 近似インデックス+フィルタリングの課題 • HNSWなどの近似インデックスでは、インデックスがスキャンされた後にフィルタリングされる • フィルタリング条件によっては、返される結果が少なくなる可能性がある • 例えばフィルタ条件が行の 10% に一致する場合、デフォルトhnsw.ef_searchの 40 では、4 件のみ取得 • フィルタ条件に指定した集団がターゲットベクトルの近くにない場合、結果が0件になる可能性も • 十分検索結果を得るには、 取得数(hnsw.ef_search)を増やして検索範囲を広げるしかなかった。 対策 1. 部分インデックス 2. パーティション分割 3. Iterative Index Scans (反復インデックススキャン)
- 35. © 2025 NTT DATA Group Corporation 35 部分インデックス/パーティション • フィルタリングの値が絞られているときは、部分インデックスが効果的。 • CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WHERE (category_id = 5); • インデックス検索を行うことで、フィルタリングも兼ねているので、高速 • 色々な値でフィルタリングする場合は、パーティションを使う方法がある。 • CREATE TABLE items (embedding vector(3), category_id int) PARTITION BY LIST(category_id); • 個々のパーティションにインデックスを作成
- 36. © 2025 NTT DATA Group Corporation 36 Iterative Index Scans (反復インデックススキャン) • 0.8.0から実装された機能 • デフォルトはOFF • 十分な結果が見つかるまで自動的にインデックスをさらにスキャンする IVFFlatの場合、次に近い集団をスキャン 1 2 3 引用元:https://www.pinecone.io/learn/series/faiss/hnsw/ HNSWの場合、一番下の層で捨てた候補を拾う さらに必要な場合は、エントリポイントを次に近い候補にして探索
- 37. © 2025 NTT DATA Group Corporation 37 Iterative Index Scansの結果順序のオプション iterative_scanオプション • off: 反復インデックススキャンを利用しない。デフォルト。 • strict_order:取得結果が厳密に距離順になる。HNSWのみ。 IVFFlatは選択できない。 • relaxed_order:取得結果が厳密に距離順でない。ただし、取りこぼしがない。IVFFlatはこっちだけ。 ⇒近い集団からまずスキャンするので、基本的に見つかるベクトルとの距離は徐々に遠くなっていく が、前のスキャンよりも短い距離のベクトルが見つかることもある。 relaxed_orderは、これをそのまま出力するので、距離順が一部入れ替わっている箇所が発生しうる strict_orderは、短い距離のベクトルが見つかったら、結果を破棄するので、必ず昇順になるが、結果が減る 結果を失わず、順序を厳密にしたいときは? • relaxed_orderで取得した結果を、マテリアライズドCTEとして、最後に並び替える 例) WITH nearest_results AS MATERIALIZED ( SELECT id, embedding <-> '[1,2,3]' AS distance FROM items ORDER BY distance LIMIT 5 ) SELECT * FROM nearest_results WHERE distance < 5 ORDER BY distance;
- 38. © 2025 NTT DATA Group Corporation 38 Iterative Index Scansを終了するタイミングを制御するオプション 十分な結果がなかなか得られない場合、どんどん探索範囲が広がっていく 大部分をスキャンするのはコストがかかるので、十分な結果が得られない場合も上限値に達したら終了する HNSW • 探索するタプルの最大数 • hnsw.max_scan_tuples = 20000; • 使用するメモリの最大量(work_memの倍数を指定する) • hnsw.scan_mem_multiplier = 2; IVFFlat • 何個のクラスタを探索するか(プローブ)の最大数 • ivfflat.max_probes = 100;
- 39. © 2025 NTT DATA Group Corporation 39 パターン2: ベクトル検索+全文検索
- 40. © 2025 NTT DATA Group Corporation 40 2.全文検索とベクトル検索 例)商品の説明:意味的に似ている(ベクトル検索)& 商品の説明:キーワードが含まれる(全文検索) 商品の説明(vector型) embedding 商品の説明(text型) [0.00058671045, - 0.004581401, .......] 世界的デザイナーAyumi Ishiiが デザインした爽やかなグリーンの レースをあしらったスカートです。 検索:「Ayumi Ishii 緑 スカート」 意味的な検索 ⇒ 文脈や、緑=グリーンなどを捉えられる。 キーワード検索 ⇒(Ayumi Ishiiなど必須なキーワードを捉えられる) ベクトル化
- 41. © 2025 NTT DATA Group Corporation 41 2.全文検索とベクトル検索 SELECT searches.id, searches.description, sum(rrf_score(searches.rank)) AS score FROM (( SELECT id, description, rank() OVER (ORDER BY $1 <=> embedding) AS rank FROM products ORDER BY $1 <=> embedding LIMIT 40 )UNION ALL( SELECT id, description, rank() OVER (ORDER BY ts_rank_cd(to_tsvector(description), plainto_tsquery('travel computer')) DESC) AS rank FROM products WHERE plainto_tsquery('english', 'travel computer') @@ to_tsvector('english', description) ORDER BY rank LIMIT 40 )) searches GROUP BY searches.id, searches.description ORDER BY score DESC LIMIT 10; ベクトル検索で40件ピックアップ 全文検索で40件ピックアップ 両方の検索結果をあわせて、全体の順位付けをする 全体の上位10件ピックアップ
- 42. © 2025 NTT DATA Group Corporation 42 ハイブリッド検索のスコアリング (RRF) • Reciprocal Rank Fusion (RRF) • 複数の検索で取得した結果をあわせて、類似度の高い順に並べ替えるためのアルゴリズム • 検索方法が違うと類似度を単純に比較できないので、それぞれの順位をスコアに利用する • 各検索方法のスコア = 1/(順位+k) を足し合わせる 例)k=60のとき 結果 順位 スコア りんご 1 1/61 みかん 2 1/62 いちご 3 1/63 結果 順位 スコア れもん 1 1/61 みかん 2 1/62 りんご 3 1/63 最終順位 結果 スコア 1 りんご 1/61 + 1/63 = 0.03226 2 みかん 1/62 + 1/62 = 0.03225 3 れもん 0 + 1/61 = 0.01639 4 いちご 1/63 + 0 = 0.01587 全文検索結果 ベクトル検索結果 順位が高いほど、 スコアも高くなる 1位:1 点 2位:1/2 点 3位:1/3 点 ※K=0
- 43. © 2025 NTT DATA Group Corporation 43 参考:RRFの関数 CREATE OR REPLACE FUNCTION rrf_score(rank bigint, rrf_k int DEFAULT 60) RETURNS numeric LANGUAGE SQL IMMUTABLE PARALLEL SAFE AS $$ SELECT COALESCE(1.0 / ($1 + $2), 0.0); $$;
- 44. © 2025 NTT DATA Group Corporation 44 RRFのkについて kの値は任意に決定できる。 kが大きいほど、上位と下位のスコアの差が縮まる ⇒下位でも、他の検索結果でランクインすれば、足し合わ せて順位が上がる。 kが小さいほど、上位の影響が大きい 上位なら、他の検索結果で圏外でも、上位のまま。 kは一般的に60がよく利用される
- 45. © 2025 NTT DATA Group Corporation 45 もう1つの再ランク付け方法:cross encoder 引用:https://www.sbert.net/examples/applications/cross-encoder/README.html 質問文と文書をそれぞれベクトル化し、 2つのベクトルの類似度を計算する (RAGで通常使われる方法) 質問文と文書をペアにして類似度を計算する 2つの文章の関連を評価するので、Bi-Encoderより 細部の関連性を拾うことができ、精度が高い。 必ずペアの入力が必要なので、計算量が多い。 Bi-Encoderで類似度の高いも のをある程度絞り込み、 Cross-Encoderで再ランク付け して精度を上げれば 効率がよい! ←使い方は以下参照 https://github.com/pgvector/pgvector- python/blob/master/examples/hybrid_search/cross_encoder. py
- 46. © 2025 NTT DATA Group Corporation 46 パターン3: ベクトル検索+疎ベクトル検索
- 47. © 2025 NTT DATA Group Corporation 47 3.ベクトル検索+疎ベクトル検索 疎ベクトルとは(対義語:密ベクトル) • ほとんどの要素が0のベクトル [0, 0, 1, 0, 0 …]など。 • 圧縮して保存できるので、精度を落とさずサイズを小さくできる • pgvectorでは0.7.0からsparsevec型が追加された。 CREATE TABLE items (id bigserial PRIMARY KEY, embedding sparsevec(5)); INSERT INTO items (embedding) VALUES ('{1:1,3:2,5:3}/5'), ('{1:4,3:5,5:6}/5’); 表記方法 • {インデックス:値, インデックス:値,…}/次元数 • 値が0以外のところだけ書く。あとは0。 • インデックスは1から始まる(0ではないので注意) {1:1,3:2,5:3}/5 は、[1, 0, 2, 0, 3]
- 48. © 2025 NTT DATA Group Corporation 48 疎ベクトルの使いどころ OpenAIのembeddingモデルなどの出力結果は、密ベクトル。 文脈を理解するときに使うのは密ベクトル。 →疎ベクトルはどんなときに使う? • ある文章に対し、事前に用意された単語集をもとに、各単語の出現回数をカウントし、ベクトルとする • このとき、ほとんどの単語は含まれないので、作成したベクトルは疎ベクトルになる • 単語集に含まれる特定のキーワードを検索したいとき、この疎ベクトルを参照すれば、単語の出現頻度がすぐにわかる • キーワード検索に使える 密ベクトル 文章の意味をとらえて数値にしたとき 使いどころ例) 靴/スニーカー⇒「くつ」と検索したとき、文字は違うが 意味が似ているので検索結果に出る 疎ベクトル 文章の文字情報を整理したとき 使いどころ例) 23cm/24cm⇒「23cm」と検索すれば、23cmと一致 するものだけ出る
- 49. © 2025 NTT DATA Group Corporation 49 ベクトル検索+疎ベクトル検索 • 疎ベクトルは、キーワード検索の代わりになる • やりたいことは、全文検索+密ベクトルと同じだが、ベクトル検索だけで、意味ベース&キーワードベースの両方の検索を実現で きるのがメリット • BGE-M3など密ベクトルと疎ベクトルを両方取得できるモデルも存在する。 • 2つの検索結果を合わせて、ランク付けして上位を取り出す • BGE-M3の場合はRerankerモデル(再ランク付け)が用意されている • このRerankerは、前述のcross encoderアプローチ(計算コストは高いが精度も高い) 使い方の例) • テーブルに密ベクトルの列(vector)、疎ベクトルの列(svector)を作成する。 • 密ベクトルと疎ベクトルで、それぞれ上位50件取得 • Rerankerモデルで100件を並び替える
- 50. © 2025 NTT DATA Group Corporation 50 ハイブリッド検索の価値は? BGE-M3で動かしてみる。 from FlagEmbedding import BGEM3FlagModel model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) sentences_1 = ["デリシャスパーティプリキュアの主人公は誰ですか。"] sentences_2 = ["ひろがるスカイ!プリキュアの主人公ソラ・ハレワタールはスカイランドという異世界から来た人です。", "デリシャスパーティプリキュアの和実ゆいは、すぐにお腹が減ります。コメコメに力をわけてもらい、キュアプ レシャスに変身します。" ] sentence_pairs = [[i,j] for i in sentences_1 for j in sentences_2] print(model.compute_score( sentence_pairs, max_passage_length=128, weights_for_different_modes=[0.4, 0.4, 0.2])) 密ベクトル、疎ベクトルそれぞれのスコアを計算する ↑密:疎=1:1の重みでスコアを計算 質問① 答え① 答え② [質問①ー答え①]のペアと、[質問①ー答え②]のペア
- 51. © 2025 NTT DATA Group Corporation 51 この場合の結果 "dense": [ 0.47555941343307495, 0.4559279978275299 ], "sparse": [ 0.10498249530792236, 0.13451407849788666 ], "sparse+dense": [ 0.29027095437049866, 0.2952210307121277 ], デリシャスパーティプリキュアの主人公は誰ですか。 1. ひろがるスカイ!プリキュアの主人公ソラ・ハレワタールはスカイランドという異世界から来た人です。 2. デリシャスパーティプリキュアの和実ゆいは、すぐにお腹が減ります。コメコメに力をわけてもらい、キュアプレシャスに変身します。 疎ベクトル(キーワードベース)では2が上。 密ベクトル(意味ベース)では1が上。 疎:密=1:1で結果を合わせると、2が上。 より正解に近いほうが 上位に来た
- 52. © 2025 NTT DATA Group Corporation 52 結果について • このケースでは、密ベクトルだけでなく、疎ベクトルを考慮することで、順位が入れ替わった。 • より正解に近い答えを持つ文章の類似度が上がった。 • キーワードが重要な場合、疎ベクトルとのハイブリッド検索は有用である可能性あり • しかし…色々な文章で試したところ、疎ベクトルと密ベクトルの順位が逆転しないケースも多かった • ケースによっては、密ベクトルだけで十分というケースもある
- 53. © 2025 NTT DATA Group Corporation 53 後半のまとめ
- 54. © 2025 NTT DATA Group Corporation 54 後半のまとめ • 意味ベース&キーワードベースの組み合わせで、よりよい結果が得られるかも • ベクトル検索(意味ベース)だけでも優秀だが、固有名詞、品番、略語、記号、専門用語などが含まれる場合、キーワー ド検索も組み合わせると精度があがる • キーワードベースは全文検索で可能だが、疎ベクトルを使う方法もある • 2つの検索結果をどう再ランク付けするかも奥が深い(RRF, cross encoder)
- 55. © 2025 NTT DATA Group Corporation 55 全体のまとめ
- 56. © 2025 NTT DATA Group Corporation 56 まとめ ⚫ PostgreSQLでは、カラムナ、JSON、ベクトルなど様々なデータを 利活用できる ⚫ 使い慣れたインタフェースを使いながら、新しい活用場面に展開 できることはメリット