Practical Machine Learning Pipelines with MLlib
29 likes8,080 views

The document presents a detailed overview of practical machine learning workflows using Spark MLlib, which aims to simplify the development of scalable machine learning applications. It discusses the key components of ML workflows such as data preparation, model training, evaluation, and the integration of pipelines introduced in Spark 1.2 and 1.3. Additionally, it highlights the challenges faced in machine learning processes and the solutions provided through new abstractions like dataframes and estimators.







![Example ML Workflow
Training
Train
model
labels
+
predicEons
Evaluate
Load
data
labels
+
plain
text
labels
+
feature
vectors
Extract
features
Explicitly
unzip
&
zip
RDDs
labels.zip(predictions).map {
if (_._1 == _._2) ...
}
val features: RDD[Vector]
val predictions: RDD[Double]
Create
many
RDDs
val labels: RDD[Double] =
data.map(_.label)
Pain
point](https://image.slidesharecdn.com/15-03-18ssemlpipelines-150325000457-conversion-gate01/85/Practical-Machine-Learning-Pipelines-with-MLlib-8-320.jpg)






![DataFrame: The ML Dataset
DataFrame: RDD + schema + DSL
Named
columns
with
types
label: Double
text: String
words: Seq[String]
features: Vector
prediction: Double
label
text
words
features
0
This
is
...
[“This”,
“is”,
…]
[0.5,
1.2,
…]
0
When
we
...
[“When”,
...]
[1.9,
-‐0.8,
…]](https://image.slidesharecdn.com/15-03-18ssemlpipelines-150325000457-conversion-gate01/85/Practical-Machine-Learning-Pipelines-with-MLlib-15-320.jpg)










![Demo
Set Footer from Insert Dropdown Menu 27
Transformer
DataFrame
Estimator
Evaluator
label: Double
text: String
features: Vector
Current
data
schema
prediction: Double
Training
Logis'cRegression
BinaryClassifica'on
Evaluator
Load
data
Tokenizer
Transformer HashingTF
words: Seq[String]](https://image.slidesharecdn.com/15-03-18ssemlpipelines-150325000457-conversion-gate01/85/Practical-Machine-Learning-Pipelines-with-MLlib-27-320.jpg)








Practical Machine Learning Pipelines with MLlib
- 1. Practical Machine Learning Pipelines with MLlib Joseph K. Bradley March 18, 2015 Spark Summit East 2015
- 2. About Spark MLlib Started in UC Berkeley AMPLab • Shipped with Spark 0.8 Currently (Spark 1.3) • Contributions from 50+ orgs, 100+ individuals • Good coverage of algorithms classifica'on regression clustering recommenda'on feature extrac'on, selec'on frequent itemsets sta's'cs linear algebra
- 3. MLlib’s Mission How can we move beyond this list of algorithms and help users developer real ML workflows? MLlib’s mission is to make practical machine learning easy and scalable. • Capable of learning from large-scale datasets • Easy to build machine learning applications
- 6. Example: Text Classification Set Footer from Insert Dropdown Menu 6 Goal: Given a text document, predict its topic. Subject: Re: Lexan Polish?! Suggest McQuires #1 plastic polish. It will help somewhat but nothing will remove deep scratches without making it worse than it already is.! McQuires will do something...! 1: about science 0: not about science Label Features text, image, vector, ... CTR, inches of rainfall, ... Dataset: “20 Newsgroups” From UCI KDD Archive
- 7. Training & Testing Set Footer from Insert Dropdown Menu 7 Training Tes*ng/Produc*on Given labeled data: RDD of (features, label) Subject: Re: Lexan Polish?! Suggest McQuires #1 plastic polish. It will help...! Subject: RIPEM FAQ! RIPEM is a program which performs Privacy Enhanced...! ... Label 0! Label 1! Learn a model. Given new unlabeled data: RDD of features Subject: Apollo Training! The Apollo astronauts also trained at (in) Meteor...! Subject: A demo of Nonsense! How can you lie about something that no one...! Use model to make predic'ons. Label 1! Label 0!
- 8. Example ML Workflow Training Train model labels + predicEons Evaluate Load data labels + plain text labels + feature vectors Extract features Explicitly unzip & zip RDDs labels.zip(predictions).map { if (_._1 == _._2) ... } val features: RDD[Vector] val predictions: RDD[Double] Create many RDDs val labels: RDD[Double] = data.map(_.label) Pain point
- 9. Example ML Workflow Write as a script Pain point • Not modular • Difficult to re-‐use workflow Training labels + feature vectors Train model labels + predicEons Evaluate Load data labels + plain text Extract features
- 10. Example ML Workflow Training labels + feature vectors Train model labels + predicEons Evaluate Load data labels + plain text Extract features Testing/Production feature vectors Predict using model predicEons Act on predic'ons Load new data plain text Extract features Almost iden-cal workflow
- 11. Example ML Workflow Training labels + feature vectors Train model labels + predicEons Evaluate Load data labels + plain text Extract features Pain point Parameter tuning • Key part of ML • Involves training many models • For different splits of the data • For different sets of parameters
- 12. Pain Points Create & handle many RDDs and data types Write as a script Tune parameters Enter... Pipelines! in Spark 1.2 & 1.3
- 14. Key Concepts DataFrame: The ML Dataset Abstractions: Transformers, Estimators, & Evaluators Parameters: API & tuning
- 15. DataFrame: The ML Dataset DataFrame: RDD + schema + DSL Named columns with types label: Double text: String words: Seq[String] features: Vector prediction: Double label text words features 0 This is ... [“This”, “is”, …] [0.5, 1.2, …] 0 When we ... [“When”, ...] [1.9, -‐0.8, …]
- 16. DataFrame: The ML Dataset DataFrame: RDD + schema + DSL Named columns with types Domain-‐Specific Language # Select science articles sciDocs = data.filter(“label” == 1) # Scale labels data(“label”) * 0.5
- 17. DataFrame: The ML Dataset DataFrame: RDD + schema + DSL • Shipped with Spark 1.3 • APIs for Python, Java & Scala (+R in dev) • Integra'on with Spark SQL • Data import/export • Internal op'miza'ons Named columns with types Domain-‐Specific Language Pain point: Create & handle many RDDs and data types BIG data
- 18. Abstractions Set Footer from Insert Dropdown Menu 18 Training Train model Evaluate Load data Extract features
- 19. Abstraction: Transformer Set Footer from Insert Dropdown Menu 19 Training Train model Evaluate Extract features def transform(DataFrame): DataFrame label: Double text: String label: Double text: String features: Vector
- 20. Abstraction: Estimator Set Footer from Insert Dropdown Menu 20 Training Train model Evaluate Extract features label: Double text: String features: Vector LogisticRegression Model def fit(DataFrame): Model
- 21. Train model Abstraction: Evaluator Set Footer from Insert Dropdown Menu 21 Training Evaluate Extract features label: Double text: String features: Vector prediction: Double Metric: accuracy AUC MSE ... def evaluate(DataFrame): Double
- 22. Act on predic'ons Abstraction: Model Set Footer from Insert Dropdown Menu 22 Model is a type of Transformer def transform(DataFrame): DataFrame text: String features: Vector Testing/Production Predict using model Extract features text: String features: Vector prediction: Double
- 23. (Recall) Abstraction: Estimator Set Footer from Insert Dropdown Menu 23 Training Train model Evaluate Load data Extract features label: Double text: String features: Vector LogisticRegression Model def fit(DataFrame): Model
- 24. Abstraction: Pipeline Set Footer from Insert Dropdown Menu 24 Training Train model Evaluate Load data Extract features label: Double text: String PipelineModel Pipeline is a type of Es*mator def fit(DataFrame): Model
- 25. Abstraction: PipelineModel Set Footer from Insert Dropdown Menu 25 text: String PipelineModel is a type of Transformer def transform(DataFrame): DataFrame Testing/Production Predict using model Load data Extract features text: String features: Vector prediction: Double Act on predic'ons
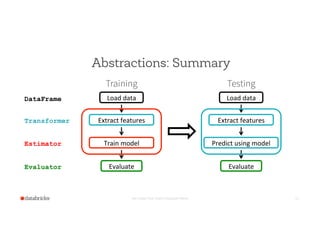
- 26. Abstractions: Summary Set Footer from Insert Dropdown Menu 26 Training Train model Evaluate Load data Extract features Transformer DataFrame Estimator Evaluator Testing Predict using model Evaluate Load data Extract features
- 27. Demo Set Footer from Insert Dropdown Menu 27 Transformer DataFrame Estimator Evaluator label: Double text: String features: Vector Current data schema prediction: Double Training Logis'cRegression BinaryClassifica'on Evaluator Load data Tokenizer Transformer HashingTF words: Seq[String]
- 28. Demo Set Footer from Insert Dropdown Menu 28 Transformer DataFrame Estimator Evaluator Training Logis'cRegression BinaryClassifica'on Evaluator Load data Tokenizer Transformer HashingTF Pain point: Write as a script
- 29. Parameters Set Footer from Insert Dropdown Menu 29 > hashingTF.numFeaturesStandard API • Typed • Defaults • Built-‐in doc • Autocomplete org.apache.spark.ml.param.IntParam = numFeatures: number of features (default: 262144) > hashingTF.setNumFeatures(1000) > hashingTF.getNumFeatures
- 30. Parameter Tuning Given: • Estimator • Parameter grid • Evaluator Find best parameters lr.regParam {0.01, 0.1, 0.5} hashingTF.numFeatures {100, 1000, 10000} Logis'cRegression Tokenizer HashingTF BinaryClassifica'on Evaluator CrossValidator
- 31. Parameter Tuning Given: • Estimator • Parameter grid • Evaluator Find best parameters Logis'cRegression Tokenizer HashingTF BinaryClassifica'on Evaluator CrossValidator Pain point: Tune parameters
- 32. Pipelines: Recap Inspira'ons scikit-‐learn + Spark DataFrame, Param API MLBase (Berkeley AMPLab) Ongoing collaboraEons Create & handle many RDDs and data types Write as a script Tune parameters DataFrame Abstrac'ons Parameter API * Groundwork done; full support WIP. Also • Python, Scala, Java APIs • Schema valida'on • User-‐Defined Types* • Feature metadata* • Mul'-‐model training op'miza'ons*
- 34. Roadmap spark.mllib: Primary ML package spark.ml: High-‐level Pipelines API for algorithms in spark.mllib (experimental in Spark 1.2-‐1.3) Near future • Feature aoributes • Feature transformers • More algorithms under Pipeline API Farther ahead • Ideas from AMPLab MLBase (auto-‐tuning models) • SparkR integra'on
- 35. Thank you! Outline • ML workflows • Pipelines • DataFrame • Abstrac*ons • Parameter tuning • Roadmap Spark documenta'on hop://spark.apache.org/ Pipelines blog post hops://databricks.com/blog/2015/01/07