

























Presentacion_Procesamiento_Lenguaje.pptx
- 1. Saturdays.AI Madrid Machine Learning #6 NLP by Saturdays.AI
- 2. Week 6 Schedule State of the course Session 6 Practice Review Notes on NLP Challenge preview
- 3. State of the course #1 Exploratory Data Analysis & Bias ✅ #2 Supervised Learning: Regresión ✅ #3 Supervised Learning: Clasificación ✅ #4 Unsupervised Learning ✅ #5 Neural Networks, Gradient Descent ✅ #6 NLP 🔴 Today!
- 4. Session 6 practice review
- 5. NLP ● Definitions ● Use cases ● History ● NLP state of the art ● NLP challenges ● Language models ● Text analysis ● Vectorization ● NLP libraries ● Naïve bayes
- 6. NLP: Definition Natural Language Processing (NLP) is a field straddling artificial intelligence, computer science and linguistics that seeks to give machines the ability to read, understand, and derive meaning from human languages.
- 7. NLP: Components Source: "Introduction to Natural Language Generation"
- 8. NLP: NLU ● Map natural language input to a representation in the form of structured data that is understandable and useful for computers.. ● Uses a wide variety of techniques to extract certain structure and information from data in text form. ● Analyze the different aspects of language at different levels: 1. Phonetic level 2. Morphological level 3. Syntactic level 4. Semantic level 5. Discursive level 6. Pragmatic level
- 9. NLP: NLG ● NLG is the process of generating meaningful phrases and statements in the form of natural language from some structured data. ● Automatically generates narratives that describe, summarize or explain input structured data in a human-like manner. ● Allows machines to write and speak.
- 10. NLP: Use cases ● Document/text classification (topic modeling) ● Sentiment analysis ● Information extraction / data mining / NER ● Chatbots ● Text summarization ● Search engines / recommendation systems ● Identify text similarity (plagiarism) ● Text translation (machine translation) ● Question-answering ● Voice recognition ● Autocomplete (predictive text) ● Grammar and spelling checking (autocorrect) ● Automatic text/speech generation
- 11. NLP: History Source: "Complete Natural Language Processing Guide For Beginners In 2021"
- 12. NLP: State of the art Source: "Dan Jurafsky - NLP Course - Stanford University"
- 13. NLP challenges: Ambiguity Source: "Wikilengua en español - Ambigüedad" Lexical ambiguity Pluma Cubo Compró los libros baratos Arregló el camión rápido La cura de su enfermedad Syntactic ambiguity Why is NLP so hard? Context Disambiguation →
- 14. NLP challenges: Co-references Source: "Wikilengua en español - Ambigüedad" Pronoun resolution A. Los ladrones robaron los cuadros. Estos posteriormente fueron vendidos. B. Los ladrones robaron los cuadros. Estos posteriormente fueron atrapados. C. Los ladrones robaron los cuadros. Estos posteriormente fueron encontrados. “Who did what to whom”
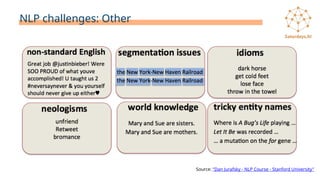
- 15. NLP challenges: Other Source: "Dan Jurafsky - NLP Course - Stanford University"
- 16. NLP: Language models A statistical language model contains estimates of the probabilistic distribution of a series of linguistic units such as characters, words and/or phrases within a corpus of texts. Source: "The GPT-3 language model, revolution or evolution?" Language knowledge + World knowledge
- 17. NLP: Language models ● ML algorithms generate statistical models that detect patterns in large volumes of data in the form of text. ● Allow us to make predictions about the syntactic structure and meaning in new data that have not been seen before. ● Text is predictable and that we can use context to derive its meaning. ● Same word can behave as a different part of speech and several meanings depending on the context. ● Contain info as word vectors and linguistic annotations. ● Based on neural networks (stored in binary format). ● Having updated models is a big problem.
- 18. NLP: Corpus, token and lexicon A linguistic corpus is a large and structured set of real examples of language use (text dataset). Token is the technical term to describe a sequence of characters that we want to treat as a unit. The lexicon (vocabulary) of a text or corpus is the ordered set of unique occurrences of tokens that we find in it.
- 19. NLP: Text analysis ● We need to determine which features of our text best encode its meaning and underlying structure. ● Text analysis consists of dividing large amounts of text into its constituent components and then applying statistical mechanisms to them. ● By learning based on these components, we can create models of the language that allow us to create applications with predictive capacity.
- 20. NLP: Syntactic analysis ● Tokenization (token ≠ word) ● Stemming ● Lemmatization ● Part-of-speech tagging ● Dependency parsing ● Sentence segmentation
- 21. NLP: Semantic analysis ● Stopwords ● Named Entity Recognition ● Word sense disambiguation ● Relationship extraction
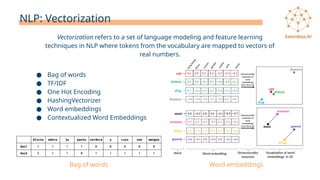
- 22. NLP: Vectorization ● Bag of words ● TF/IDF ● One Hot Encoding ● HashingVectorizer ● Word embeddings ● Contextualized Word Embeddings Vectorization refers to a set of language modeling and feature learning techniques in NLP where tokens from the vocabulary are mapped to vectors of real numbers. Word embeddings Bag of words
- 23. NLP: Libraries ● Scikit-Learn - https://scikit-learn.org/stable/index.html ● Natural Language Toolkit (NLTK) - https://www.nltk.org ● Gensim - https://radimrehurek.com/gensim/ ● Glove - https://nlp.stanford.edu/projects/glove/ ● spaCy - https://spacy.io ● CoreNLP - https://stanfordnlp.github.io/CoreNLP/ ● TextBlob - https://textblob.readthedocs.io/en/dev/ ● AllenNLP - https://github.com/allenai/allennlp ● Hugging Face - https://huggingface.co
- 24. NLP: Naïve Bayes algorithm ● Probabilistic algorithm used for classification (binary and multi-class). ● Based on Bayes Theorem. ● All attributes are independent and have same weight (naive). Simplify calculations. ● Very fast when training and predicting. ● Generalizes somewhat worse than other algorithms (baseline). ● Works well with high dimensional data.
- 25. NLP: Naïve Bayes algorithm
- 26. Challenge!
- 27. Bibliography 1. - spaCy 101 (Tutorial) - https://spacy.io/usage/spacy-101 2. - Somos NLP (NLP en español) - https://somosnlp.org 3. - NLP Course (YouTube) - Stanford - shorturl.at/huCQU 4. - “NLP with Python” (Book) - https://www.nltk.org/book/ 5. - Embedding projector - https://projector.tensorflow.org 6. - CS224N: NLP with Deep Learning (YouTube) - Stanford - shorturl.at/vBEN4 7. - Recursos Lingüísticos Abiertos del Español - https://github.com/sbosio/rla-es 8. - “Practical NLP” (Book) - https://github.com/practical-nlp/practical-nlp-code 9. - “NLP with transformers” (Book) - https://github.com/nlp-with-transformers/notebooks
- 28. Questions
- 29. Gracias a nuestros partners por ayudar a Saturdays AI a salvar la brecha de las habilidades de la 4ª Revolución Industrial acercando la IA a todo el mundo
Editor's Notes
- #1: Bienvenid@s a la 6ª y última sesión de teoría/práctica de AI Saturdays correspondiente al itinerario de ML que va a tratar sobre un área de la IA con infinidad de aplicaciones como es el NLP.
- #2: Como es habitual, este es el programa que tenemos preparado para esta primera parte más teórica: Repaso del itinerario del curso Resolución de dudas de los JNB de práctica para esta sesión Una parte teórica que nos va a ocupar la mayor parte de la charla en la que hablaremos sobre NLP Presentación del reto que tendréis que resolver en esta sesión
- #3: En cuanto al itinerario del curso, como vemos hemos llegado ya a la recta final de las sesiones teóricas del curso de ML. Han sido unas semanas muy intensas en las que hemos aprendido y puesto en práctica muchos conceptos sobre aprendizaje automático. Hoy vamos dar unas pinceladas sobre qué es eso del NLP y cuáles son sus aplicaciones. El NLP es un área amplísima dentro de la IA, una especialización en sí misma, por lo que hoy solo vamos a hacer una pequeña introducción de este campo tan complicado y a la vez interesante a ver si a alguno os pica el gusanillo y os decidís a tirar por esta rama. También vamos a ver un nuevo algoritmo de clasificación muy usado en NLP llamado Naive Bayes que usareis para resolver el reto de esta semana.
- #4: ¿Habéis podido echarle un ojo a los materiales de Eduflow para esta semana? ¿Tenéis alguna duda? Sé que era mucho contenido y me imagino que no habréis podido verlo todo, pero la idea es que os sirva a modo de referencia para la sesión de hoy y en el futuro. Como en ocasiones anteriores muchas de las cosas que hay en el practice y en los recursos de Eduflow os van a servir para resolver el challenge de hoy.
- #5: Bueno, pues aquí tenéis lo que vamos a ir viendo en esta parte más teórica. Empecemos definiendo qué es el NLP.
- #6: El NLP es un campo interdisciplinario a caballo entre la inteligencia artificial, las ciencias de la computación y la lingüística que busca dar a las máquinas la capacidad de leer, entender y derivar significados de los lenguajes humanos (lenguajes que se han desarrollado de manera natural) tanto en su forma escrita como hablada. Haciendo uso del NLP las computadoras analizan el lenguaje humano, lo interpretan y le dan significado para que pueda ser utilizado de manera práctica. Este procesamiento generalmente implica traducir el lenguaje natural en datos (números) que una computadora puede usar para aprender sobre el mundo y luego usar este conocimiento para diferentes aplicaciones. Esta comprensión del mundo a veces se usa para generar texto en lenguaje natural que refleje ese aprendizaje.
- #7: Así, dentro del NLP encontramos dos componentes o subáreas diferentes pero relacionadas entre sí: Comprensión del lenguaje natural Generación del lenguaje natural
- #8: NLU consiste en: Mapear el input en lenguaje natural a una representación en forma de datos estructurados que sea útil. Para ello, el NLP usa una gran variedad de técnicas para extraer cierta estructura e información de los datos en forma de texto, es decir, funciona tomando datos no estructurados y convirtiéndolos en un formato de datos estructurados. Analizar los diferentes aspectos del lenguaje a distintos niveles. En general, en NLP se utilizan seis niveles de comprensión con el objetivo de descubrir el significado del discurso. Estos niveles son: Nivel fonético. Se presta atención a la forma en que las palabras son pronunciadas. Este nivel es importante cuando procesamos la palabra hablada, no así cuando trabajamos con texto escrito. Nivel morfológico. Aquí se realiza un análisis morfológico del discurso, es decir, se estudia la estructura de las palabras para delimitarlas y clasificarlas. Distingue los distintos tipos de palabras (verbos, sustantivos, preposiciones, etc.) y sus variaciones (género, número, tiempo, etc.). Nivel sintáctico. Aquí se realiza un análisis de la sintaxis del texto, el cual incluye la acción de dividir una oración en cada uno de sus componentes gramaticales (sujeto, verbo, predicado). Nivel semántico. En el análisis semántico se busca entender el significado de la oración. Las palabras pueden tener múltiples significados, la idea es identificar el significado apropiado por medio del contexto de la oración. Nivel discursivo. Examina el significado de cada oración en relación a otra oración del texto o párrafo del mismo documento. Nivel pragmático. Nos permite entender lo que el texto está tratando de comunicar (ironía, un estado de ánimo en particular…).
- #9: NLG es el proceso de generar frases significativas y sentencias en forma de lenguaje natural a partir de datos estructurados. En esencia, genera automáticamente narrativas que describen, resumen o explican los datos estructurados de entrada de forma similar a como lo hacemos los humanos. NLG permite a las máquinas escribir y hablar.
- #10: El NLP tienes innumerables usos siendo los que veis en la diapositiva algunos de los más importantes. ¿Se os ocurre algún ejemplo de la vida real en el que esté implicado el NLP? Asistentes virtuales (Siri, Alexa, Cortana) El autocompletar del móvil Detección de spam
- #11: El NLP tiene más de 80 de historia: 1940 → Surge la idea de la primera aplicación informática relacionada con el NLP, la traducción automática de textos, y durante los próximos años se realizan una serie de experimentos de traducción automática basados en reglas y diccionarios pero aún con pobres resultados. 1950 → En 1950, Alan Turing propone el "Test de Turing" que establece que si una máquina puede participar en una conversación con humanos sin ser detectada como una máquina, entonces será considerada como una máquina con inteligencia artificial. 1957 → Noam Chomsky publica un libro revolucionario sobre lingüística llamado "Estructuras sintácticas" donde propone la idea de una gramática universal, un sistema de estructuras sintácticas basado en reglas que ayudó a mejorar estos primeros sistemas de traducción basada en reglas. 1960 → Se desarrollaron algunos de los primeros sistemas de NLP como SHRDLU (robot simulado que usaba lenguaje natural para consultar y manipular objetos dentro de un mundo virtual muy simple basado en bloques) y ELIZA (replica la conversación entre un psicólogo y un paciente de forma bastante creíble). 1970 → Durante este tiempo se escriben muchos chatbots, como por ejemplo PARRY que intentaba simular una persona con esquizofrenia paranoide. 1980 y 1990 → Se introducen los primeros algoritmos de ML para NLP, es decir, los primeros modelos basados en inferencia estadística. Esto fue gracias al aumento en el poder de cómputo de las máquinas como a la disminución gradual del dominio de las teorías de Noam Chomsky. Hasta ese momento, la mayoría de los algoritmos de NLP estaban basados en un conjunto de reglas y excepciones codificadas a mano. La ventaja de los modelos estadísticos es que son más fiables a la hora de analizar otros textos y realizar comparaciones en busca de patrones con el objetivo de aprender nuevas palabras o de detectar errores en los textos. La mayoría de los sistemas actuales utilizan una combinación de modelos simbólicos y estadísticos. 2000 → El aumento en la disponibilidad de grandes cantidades de datos gracias al crecimiento de internet, permite a los sistemas NLP aprender de la combinación de datos anotados y no anotados a mano con las respuestas deseadas así como la aparición de los primeros modelos basados en redes neuronales. 2010 → Comienza a aplicarse el deep learning al NLP y se populariza el uso de técnicas como los word embedding, el aprendizaje secuancia-secuencia, los mecanismos de atención y el transfer learning que hoy en día son el estado del arte en este campo.
- #12: A pesar de todos los avances conseguidos en las últimas décadas aún existen una serie de tareas relacionadas con el NLP que no se ha logrado dominar del todo. Aquí podemos ver algunos ejemplos.
- #13: Pero, ¿qué es lo que hace que el NLP sea una disciplina tan complicada? Pues lo que pasa es que el NLP se enfrenta a una serie de retos que si bien para nosotros como seres humanos nos pueden parecer sencillos, desde el punto de vista de una máquina son muy difíciles de resolver. Uno de los problemas más complicados del NLP es la ambigüedad. Hay dos tipos de ambigüedades: Ambigüedad léxica, es la existencia de dos o más significados dentro de una misma palabra (homonimia y polisemia). Ambigüedad sintáctica es cuando una frase se puede interpretar de varias formas. Con la desambiguación lo que intentamos es saber cuál es el significado de una palabra en un contexto dado. Las personas hacemos esto de forma automática pero esto es un reto para las máquinas. Estos son los tipos de ambigüedad más comunes pero hay más tipos (fonética, morfológica, semántica, etc.) ¿Se os ocurre algún otro ejemplo de ambigüedad? Por ejemplo la palabra “vela”.
- #14: Otro reto es el de las co-referencias, es decir, saber a quién o qué se hace referencia con un pronombre de los nombres que ya han sido antes mencionados en la frase. Así, una forma de conocimiento profundo del lenguaje es saber “quién hizo qué a quién”, es decir, detectar los sujetos y los objetos de los verbos, lo que se conoce como la resolución pronombres.
- #15: El uso de escritura no estándar como mayúsculas, palabras mal escritas o abreviadas, hashtags, emoticonos, etc. Si los modelos están entrenados con textos escritos en perfecto español no hay mucho que pueda hacer con estos textos, lo que nos obligará a hacer un importante trabajo de normalización previo. ¿Se os ocurre un ejemplo en español? Por ejemplo el famoso “ola ke ase”. Dudas a la hora de segmentar correctamente las frases. Son lo que se conoce en español como modismos, que son expresiones fijas, privativa de una lengua, cuyo significado no se deduce de las palabras que la forman: “Irse por las ramas”, “ahogarse en un vaso de agua”, “Es pan comido”... Problemas con neologismos y palabras que nunca vistas antes. Conocimiento sobre el mundo. Necesitas saber que biológicamente dos personas nos pueden ser madre una de la otra a la vez. Nosotros sabemos que eso no es posible, ¿pero cómo lo pueden saber las máquinas? El reto que plantea el reconocimiento de algunas entidades dentro de los textos ya que están formadas por palabras que pertenecen al idioma y es difícil saber dónde empiezan y terminan. No es como por ejemplo la palabra Coca-Cola que al no pertenecer al castellano es más sencillo reconocerla como una entidad nombrada. Pasa por ejemplo en biología donde tenemos nombre de genes y proteínas que son palabras en inglés. También plantea un reto el detectar la ironía y el sarcasmo, los coloquialismos (chungo, guay) y las jergas (pipa-pistola), las palabras muy específicas de un dominio y aquellos idiomas para los que hay pocos recursos.
- #16: Como vemos, el NLP es una tarea difícil para la que las técnicas de programación deterministas basadas en reglas no terminan de funcionar. Esto se debe a que necesitamos: Conocimiento del lenguaje Conocimiento del mundo Y una forma de combinar ambos Una forma de hacer esto es usar modelos del lenguaje probabilísticos construidos a partir de textos en lenguaje natural. Pero, ¿qué es un modelo del lenguaje? En NLP, un MdeL estadístico contiene las estimaciones de la distribución probabilística de una serie de unidades lingüísticas como caracteres, palabras y/o frases dentro de un corpus de textos.
- #17: Los algoritmos de ML generan modelos estadísticos que detectan patrones en grandes volúmenes de datos en forma de texto, y nos permiten realizar predicciones sobre la estructura sintáctica y el significado en nuevos datos que no han sido vistos con anterioridad. La hipótesis básica detrás del aprendizaje automático aplicado al lenguaje es que el texto es predecible y que podemos usar el contexto para derivar su significado. Recordemos que una misma palabra puede comportarse como una parte del discurso diferente (diferente etiqueta gramatical) y tener varios significados en función del contexto en el que aparezca, y tenemos que ser capaces de detectar cuál es la correcta. Los modelos estadísticos suelen contener información como vectores de palabras y anotaciones lingüísticas. Las anotaciones lingüísticas pueden incluir características como etiquetas gramaticales, anotaciones sintácticas... Estos modelos estadísticos generalmente están almacenados en formato binario, ya que es así son más fáciles de almacenar y rápidos de usar y generalmente están basados en redes neuronales. Algunos de estos MdeL nos van a intentar tomar como entrada una frase incompleta e inferir las palabras subsiguientes con mayor probabilidad de completar el enunciado. La necesidad de entrenar modelos cada vez más grandes para obtener un mayor grado de exactitud para usos cada vez más complejos lleva aparejado una serie de problemas relacionados con el tiempo y la infraestructura necesarios para realizar el entrenamiento, lo que junto a que los datos cambian de manera constante, hace que tener modelos actualizados sea un gran problema.
- #18: Un corpus lingüístico es un conjunto amplio y estructurado de ejemplos reales de uso de la lengua. Estos ejemplos pueden obtenerse de textos escritos o muestras orales. Son los dataset de texto. Un corpus puede ser grande o pequeño, aunque generalmente consiste en decenas o incluso cientos de gigabytes de datos dentro de miles de documentos de diferentes tamaños, desde tuits hasta libros. La idea es que representen al lenguaje de la mejor forma posible para que los modelos de NLP puedan aprender los patrones necesarios para entender el lenguaje. Los corpus pueden ser anotados, lo que significa que el texto o los documentos están etiquetados, o sin anotar y esto como siempre influirá en los algoritmos que podremos aplicar. La palabra token es el término técnico para describir una secuencia de caracteres que queremos tratar como una unidad. Puede ser una palabra o más palabras, un signo de puntuación, etc. El vocabulario o lexicón de un texto es el conjunto ordenado de apariciones únicas de tokens que encontramos en él, que es menor que el número total de tokens, ya que algunos tokens se repetirán varias veces en el texto. El lexicón puede llevar además información sobre la categoría gramatical y el significado de los tokens.
- #19: Al igual que con cualquier aplicación de aprendizaje automático, el desafío principal es el proceso de análisis de atributos o features, es decir, determinar qué características de nuestro texto codifican mejor su significado y estructura subyacente. El análisis de textos consiste en dividir grandes cantidades de texto en sus componentes constitutivos: vocabularios de palabras únicas, frases comunes, patrones sintácticos, etc., y luego aplicarles mecanismos estadísticos. Al aprender en base a estos componentes, podemos crear modelos del lenguaje que nos permitan crear aplicaciones con capacidad predictiva. Las tareas en NLP se llevan a cabo usando técnicas de preprocesamiento y análisis sintáctico y semántico.
- #20: Tokenization. Consiste en separar el texto en unidades lingüísticas identificables más pequeñas llamadas tokens con las que haremos el análisis de los textos. Pueden ser palabras, números, signos de puntuación o incluso caracteres dependiendo de a qué nivel tokenizemos. Son los componentes constituyentes básicos del lenguaje natural. Stemming. Implica cortar las palabras flexionadas por su raíz. Generalmente el stemming usa un conjunto fijo de reglas, por lo tanto, las raíces obtenidas pueden no ser correctas. Lemmatization. Implica reducir las diversas formas flexionadas de una palabra en una sola forma para facilitar el análisis y mostrar su significado primitivo. Para ello usa diccionarios detallados en los que el algoritmo pueda buscar y vincular palabras con sus lexemas correspondientes. Como hace un análisis tanto de vocabulario como morfológico funciona mejor que el stemming. Part-of-speech tagging. Consiste en clasificar las palabras de un texto por su categoría gramatical basándonos tanto en su definición como en su contexto. Esto nos permite clasificar las palabras de las oraciones en verbo, sustantivo, adjetivo preposición, etc. Dependency parsing. Implica realizar una análisis gramatical de la oración proporcionada para descubrir las relaciones sintácticas entre sus token individuales y conectar sintácticamente pares relacionados de palabras. Nos devuelve las etiquetas de las dependencias sintácticas de cada palabra que podemos visualizar usando un árbol de dependencias. Sentence segmentation. Implica localizar los límites de las oraciones dentro de un texto.
- #21: Las palabras vacías son aquellas palabras en el texto que no agregan ningún significado a la oración y su eliminación no afectará el procesamiento del texto para el propósito definido. Se eliminan del vocabulario para reducir el ruido y la dimensión del conjunto de características. ¿Qué ejemplos de palabras vacías se os ocurren? El NER conlleva determinar las partes de un texto que pueden ser identificadas y categorizadas en grupos predeterminados. Algunos de estos grupos incluyen los nombres de personas, nombres de organizaciones, lugares, etc. Una entidad con nombre es un objeto u abstracción de la vida real al que se le ha asignado un nombre propio. La desambiguación del sentido de las palabras consiste en identificar qué sentido de una palabra (es decir, qué significado) se usa en una oración cuando la palabra tiene múltiples significados. La extracción de relaciones consiste implica identificar varias entidades presentes en la oración y luego extraer las relaciones entre esas entidades.
- #22: Por último nos queda hablar de un concepto muy importante, es de la vectorización. La gran mayoría de algoritmos de aprendizaje automático no pueden trabajar con el texto en bruto. Necesitamos extraer una serie de características de esos textos de modo que lo que pasemos al algoritmo sean atributos numéricos que es lo que las máquinas pueden entender. Esto es lo que se conoce como representación del texto o vectorización y hace referencia a un conjunto de técnicas de modelado de lenguaje y aprendizaje de características en NLP donde los tokens del vocabulario se asignan a vectores de números reales. Una vez vectorizado el texto podremos extraer atributos o características del mismo y procesarlo usando los algoritmos de aprendizaje automático. Hay diferentes técnicas de vectorización que de más sencillas a más complejas se pueden resumir en esta lista. No podemos repasarlas todas aquí, por eso tenéis subido un JNB donde os explicamos con detalle las 3 primeras que son las más sencillas y las que primero debéis aprender.
- #23: Aquí os dejo a modo de referencia algunas de las librerías más usadas en NLP, desde las más clásicas como NLTK a las que representan el estado del arte hoy en día como en Hugging Face y sus transformers.
- #24: Naïve Bayes es un algoritmo probabilístico simple que normalmente se usa para problemas de clasificación, tanto binaria como multi-clase. Los clasificadores Naïve Bayes se basan en el teorema de Bayes. Se denominan ingenuos porque hacen la suposición simplificadora de que dada una clase todas las característica de una instancia son independientes entre sí, es decir, que no existe ninguna correlación entre ellas. Además, a cada característica se le da el mismo peso o importancia. En la práctica, esto no suele ser verdad, pero el hacer uso de esta simplificación del teorema de Bayes facilita en gran medida los cálculos necesarios a la hora de clasificar, al tiempo que mantiene resultados bastante aceptables. Esta suposición hace que este algoritmo sea muy rápido a la hora de entrenar y aprender. Por otro lado, esta simplificación hace que el rendimiento a la hora de generalizar de los clasificadores Naïve Bayes a menudo puede ser un poco peor que con otros algoritmos. Aun así, especialmente para conjuntos de datos de alta dimensionalidad, pueden resultar útiles. A la derecha tenéis la fórmula del teorema de Bayes que nos dice que podemos calcular la probabilidad condicional de que dadas una serie de características para una instancia esta pertenezca a cierta clase. Si no hiciésemos la suposición de que las características son independientes usando el teorema de Bayes tendríamos que calcular la probabilidad de cada combinación posible de opciones para todas las variables para cada clase lo que sería muy costoso y requeriría disponer de muchos datos. Pero gracias a que hacemos la simplificación de que todas las variables son independientes entre sí podemos simplificar esta fórmula y usar la que podéis ver aquí abajo.
- #25: Vamos a ver cómo funciona este algoritmo con un ejemplo sencillo. Ahora imaginad que en lugar de estas características lo que tenemos aquí en las columnas son todas las posibles palabras que pueden aparecer en nuestro corpus (vocabulario) y para cada texto o registro indicamos si esa palabra está o no presente y la clase a la que pertenece ese texto. Así, si nos dan un texto nuevo lo transformaremos en un vector de esta dimensión que nos diga si las palabras están o no presentes y ya solo tendremos que hacer unos cálculos similares a los que hemos hecho en este ejemplo para poder clasificar ese nuevo texto dentro de una clase u otra. Como os podéis imaginar esto es una simplificación pero nos sirve para entender la idea básica de cómo funciona este algoritmo. Para el que quiera profundizar en las matemáticas del teorema de Bayes y los algoritmos Naïve Bayes os he subido al apartado de Eduflow de esta semana un JNB con teoría y práctica adicionales.
- #26: Pues llegó el momento del challenge. En esta ocasión os toca crear un clasificador de textos capaz de clasificar las reseñas de películas de IMDB en castellano en dos categorías: negativa o positiva. Para ello tendréis que analizar y normalizar los textos y usar el Naïve Bayes que hemos aprendido hoy.
- #27: Aquí os dejamos una serie de recursos útiles (libros, tutoriales y webs) con muchos contenidos para aprender sobre NLP.
- #28: ¿Hay alguna duda? El NLP es una disciplina amplísima y, como hemos visto, plantea algunos retos bastante complicados. Pero que esto no os desanime a decantaros por este campo porque es súper interesante y tiene infinidad de aplicaciones en multitud de áreas del conocimiento. Además en castellano aún queda mucho por hacer e investigar y en los próximos años no va a faltar trabajo.