Putting Kafka In Jail – Best Practices To Run Kafka On Kubernetes & DC/OS

Apache Kafka–part of Lightbend Fast Data Platform–is a distributed streaming platform that is best suited to run close to the metal on dedicated machines in statically defined clusters. For most enterprises, however, these fixed clusters are quickly becoming extinct in favor of mixed-use clusters that take advantage of all infrastructure resources available. In this webinar by Sean Glover, Fast Data Engineer at Lightbend, we will review leading Kafka implementations on DC/OS and Kubernetes to see how they reliably run Kafka in container orchestrated clusters and reduce the overhead for a number of common operational tasks with standard cluster resource manager features. You will learn specifically about concerns like: * The need for greater operational knowhow to do common tasks with Kafka in static clusters, such as applying broker configuration updates, upgrading to a new version, and adding or decommissioning brokers. * The best way to provide resources to stateful technologies while in a mixed-use cluster, noting the importance of disk space as one of Kafka’s most important resource requirements. * How to address the particular needs of stateful services in a model that natively favors stateless, transient services.

























![Installing DC/OS Kafka Package
Track deploy progress
$ dcos kafka plan status deploy
deploy (serial strategy) (COMPLETE)
└─ broker (serial strategy) (COMPLETE)
├─ kafka-0:[broker] (COMPLETE)
├─ kafka-1:[broker] (COMPLETE)
└─ kafka-2:[broker] (COMPLETE)
27
View broker client connection info
$ dcos kafka endpoints broker
{
"address": [
"10.0.13.209:1025",
"10.0.5.88:1025",
"10.0.7.216:1025"
],
"dns": [
"kafka-0-broker.kafka.autoip.dcos.thisdcos.directory:1025",
"kafka-1-broker.kafka.autoip.dcos.thisdcos.directory:1025",
"kafka-2-broker.kafka.autoip.dcos.thisdcos.directory:1025"
],
"vip": "broker.kafka.l4lb.thisdcos.directory:9092"
}](https://image.slidesharecdn.com/puttingkafkainjail-bestpracticestorunkafkaonkubernetesdcos-180614163820/85/Putting-Kafka-In-Jail-Best-Practices-To-Run-Kafka-On-Kubernetes-DC-OS-27-320.jpg)



![Rolling Broker Upgrades
Upgrading brokers uses the same rolling
update process as previous operations.
Similar to a rolling configuration update,
upgrade will do the following.
• Restart Kafka scheduler with new
version
• Restart each broker task serially with
new version, while maintaining identity
(no data loss)
31
Pick a compatible package version
$ dcos kafka update package-versions
Current package version is: "2.2.0-1.0.0"
Package can be upgraded to: ["2.3.0-1.0.0"]
Package can be downgraded to: ["2.1.0-1.0.0"]
Install a new version of the Kafka subcommand on the DC/OS CLI (1-to-1 with a package
version)
$ dcos package uninstall --cli kafka
$ dcos package install --cli kafka --package-version="2.3.0-1.0.0"
Initiate the upgrade process
$ dcos kafka update start --options=<new options json>
--package-version="2.3.0-1.0.0"
To upgrade using the same workflow as in Motivating Example we perform rolling updates for
inter.broker.protocol.version and log.message.format.version before and after the actual broker
update.](https://image.slidesharecdn.com/puttingkafkainjail-bestpracticestorunkafkaonkubernetesdcos-180614163820/85/Putting-Kafka-In-Jail-Best-Practices-To-Run-Kafka-On-Kubernetes-DC-OS-31-320.jpg)














































More Related Content
What's hot (20)
Similar to Putting Kafka In Jail – Best Practices To Run Kafka On Kubernetes & DC/OS (20)


















More from Lightbend (20)




















Recently uploaded (20)




















Putting Kafka In Jail – Best Practices To Run Kafka On Kubernetes & DC/OS
- 2. Who am I? I’m Sean Glover • Senior Software Engineer at Lightbend • Member of the Fast Data Platform team • Contributor to projects in the Kafka ecosystem including: Kafka, Alpakka Kafka Connector (reactive- kafka), DC/OS Commons SDK Contact Details • @seg1o • in/seanaglover • [email protected] 2
- 3. Operations Is Hard “Technology will make our lives easier” What technology makes running technology easier? How much operations work can we automate? 3 Designed by Freepik
- 4. What is Kafka in one slide • Distributed streaming platform • Simple architecture, smart clients • A Topic is comprised of 1 or more Partitions • A Partition can have 0 or more Replicas • High Volume - Partitions spread across cluster • Fault Tolerant - Partition replicas, consistency guarantees, disk persistence • Fast - Zero-copy, PageCache, Append-only 4 Kafka Documentation
- 6. Motivating Example: Upgrading Kafka High level steps to upgrade Kafka 1. Rolling update to explicitly define broker properties inter.broker.protocol.version and log.message.format.version 2. Download new Kafka distribution and perform rolling upgrade 1 broker at a time 3. Rolling update to upgrade inter.broker.protocol.version to new version 4. Upgrade Kafka clients 5. Rolling update to upgrade log.message.format.version to new version 6
- 7. Motivating Example: Upgrading Kafka Any update to the Kafka cluster must be performed in a serial “rolling update”. The complete Kafka upgrade process requires 3 “rolling updates” Each broker update requires • Secure login • Configuration linting - Any change to a broker requires a rolling broker update • Graceful shutdown - Send SIGINT signal to broker • Broker initialization - Wait for Broker to join cluster and signal it’s ready This operation is error-prone to do manually and difficult to model declaratively using generalized infrastructure automation tools. 7
- 8. Automation “If it hurts, do it more frequently, and bring the pain forward.” - Jez Humble, Continuous Delivery 8
- 9. Automation of Operations Upgrading Kafka is just one of many complex operational concerns. For example) • Initial deployment • Manage ZooKeeper • Replacing brokers • Topic partition rebalancing • Decommissioning or adding brokers How do we automate complex operational workflows in a reliable way? 9
- 12. Task Isolation with Containers • Cluster Resource Manager’s use Linux Containers to constrain resources and provide isolation • cgroups constrain resources • Namespaces isolate file system/process trees • Docker is just a project to describe and share containers efficiently • Mesos supports Docker and Mesos containerizers • Containers are available for several platforms 12 Physical or Virtual Machine Linux Kernel Namespaces cgroups Modules Cluster Resource Manager Container Engine Container ContainerContainer UserspaceKernelspace Drivers Linux Containers (LXC) Jail Linux Container (LXC) Windows Container
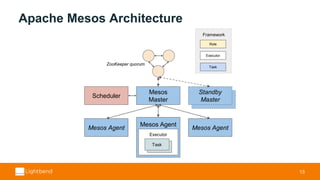
- 13. Standby Apache Mesos Architecture 13 Mesos Master Standby Master Scheduler ZooKeeper quorum Mesos Agent Task Executor Task Mesos Agent Mesos Agent Framework Role Executor Task
- 15. What are schedulers? ● Similar to system init daemons like systemd ● systemd is a system scheduler that keeps services running smoothly ○ Run a process on boot ○ Restart a process on failure ○ Unified admin interface ○ Gracefully stop ● A Mesos scheduler schedules tasks on behalf of an application framework ● Schedulers provide features like task restart strategy, stable identity, and scaling ● Scheduler projects for generalized workloads: Marathon, Aurora ● Custom schedulers are required for complex and app-specific workloads 15
- 16. The Marathon Scheduler • Open Source scheduler by Mesosphere • Easy way to deploy on Mesos • Provides similar guarantees as Kubernetes resources • Useful for most workloads, but still limits user to declarative specification 16 Marathon Application Definition
- 17. DC/OS Commons SDK • A toolkit to help build schedulers for apps with complex operational needs • The goal of DC/OS Commons is to make it easier to develop, package, and use services within DC/OS • Commons SDK Java library to build a custom scheduler (details next slide) • ServiceSpec YAML to describe service declaratively • Shared configuration specification with DC/OS Catalog • Extend DC/OS CLI with a sub command • DC/OS Commons is used by to build production-ready frameworks to run Kafka, HDFS, ElasticSearch, and Cassandra 17
- 18. DC/OS Commons SDK Scheduler • A YAML ServiceSpec is a starting point for the scheduler • The scheduler is a JVM application written in Java • Programmatically alter the ServiceSpec at runtime • Custom logic as a result of a task failing • Run a plan based on a runtime state change • Run anomaly detection and do preventative maintenance • RESTful API for Metrics and Pod & Plan actions 18
- 19. DC/OS Commons SDK The ServiceSpec is both a YAML specification and a JVM type hierarchy that can be used together. Two main components of a ServiceSpec are pods and plans 19 Plan Phase Service Pod Instance Task Instance Step 1:1 1:many Although similar to Kubernetes pods DC/OS commons pods have different concerns.
- 20. DC/OS Commons Pods • A task represents a single operation or command • A Goal defines the end state of the task. RUNNING or ONCE • Resource constraints are applied with a cgroup • readiness-check’s are conditions that must evaluate successfully to move to the goal state. RUNNING or COMPLETED • health-check’s signal to the scheduler that the task is unhealthy and must be restarted 20 Service Pod Instance Task
- 21. DC/OS Commons Plans ● Plans define workflows of an operation (i.e. initial deployment) ● Deployment strategy is applied at phase and step levels ○ serial - each phase/step executed one at a time ○ parallel - all phase/step executed at the same time ● Plans can be automatically or manually triggered ● phases are 1:1 with a pod ● A single step is COMPLETE once all tasks reach their Goal ● Plan is executed from top to bottom ● Each step is defined with an ordinal value or default special case ● Plan is complete once all phases are COMPLETE 21 Plan Phase Instance Step
- 22. DC/OS Commons ServiceSpec Example 22 ... ...
- 23. The DC/OS Kafka Package
- 24. DC/OS Kafka Package Finally we can discuss the DC/OS Kafka package. The best production-ready Apache Kafka implementation you can use today on a container orchestrated cluster. * Features include: 24 * The confluent-operator project for Kubernetes was recently announced and could change the game. At this time few details are known about its features and license model. ● One command install into an existing DC/OS cluster ● Rolling broker configuration updates ● Broker upgrades ● Broker replacement/move ● Stable broker/agent identity ● Scaling brokers up ● Virtual IP for client connections ● Topic administration ● TLS security ● Support for DC/OS metrics ● Multiple cluster installs
- 25. Installing DC/OS Kafka Package We can deploy a simple 3 broker cluster with a single command $ dcos package install kafka 25
- 26. Installing DC/OS Kafka Package 26 DC/OS Cosmos API /package/install ZooKeeper master.mesos:2181/dcos-service-kafka Mesos Master Marathon Scheduler Mesos Agent DC/OS Commons Executor Kafka Scheduler Mesos Agent DC/OS Commons Executor Broker 0 Mesos Agent DC/OS Commons Executor Broker 1 Mesos Agent DC/OS Commons Executor Broker 2 DC/OS CLI Kafka Command dcos package install kafka 1 2 3 4 5 6 Install Sequence 1. Install Kafka from DC/OS CLI calls Cosmos API 2. Cosmos API installs Kafka scheduler as Marathon app 3. Marathon deploys the Kafka scheduler 4, 5, 6. Kafka scheduler executes deploy plan for broker pod
- 27. Installing DC/OS Kafka Package Track deploy progress $ dcos kafka plan status deploy deploy (serial strategy) (COMPLETE) └─ broker (serial strategy) (COMPLETE) ├─ kafka-0:[broker] (COMPLETE) ├─ kafka-1:[broker] (COMPLETE) └─ kafka-2:[broker] (COMPLETE) 27 View broker client connection info $ dcos kafka endpoints broker { "address": [ "10.0.13.209:1025", "10.0.5.88:1025", "10.0.7.216:1025" ], "dns": [ "kafka-0-broker.kafka.autoip.dcos.thisdcos.directory:1025", "kafka-1-broker.kafka.autoip.dcos.thisdcos.directory:1025", "kafka-2-broker.kafka.autoip.dcos.thisdcos.directory:1025" ], "vip": "broker.kafka.l4lb.thisdcos.directory:9092" }
- 29. Rolling Configuration Updates Updates are applied using the same deploy plan as the install. • Package configuration is supplied and templated into broker.properties • Scheduler updates each broker in serial by restarting each task one at a time with new configuration applied Full configuration can be found from project repo, or using CLI command: dcos kafka describe 29 The default delete_topic_enable config ... "delete_topic_enable": { "title": "delete.topic.enable", "description": "Enables delete topic. Delete topic through the admin tool will have no effect if this config is turned off", "type": "boolean", "default": false }, ... Enable delete_topic_enable with an override file kafka-options.json { "kafka": { "delete_topic_enable": true } } Apply configuration changes with the DC/OS CLI $ dcos kafka update start --options=kafka-options.json
- 30. Scaling up Brokers Brokers can be added by making a configuration change too. • Config not mapped to broker.properties, existing broker tasks are not restarted • Config is mapped to ServiceSpec broker pod count • Scheduler reconciles cluster/ServiceSpec by adding deploying additional brokers using deploy plan 30 The default brokers.count config ... "count": { "description": "Number of brokers to run", "type": "number", "default": 3 }, ... Increase brokers.count with an override file kafka-options.json { "brokers": { "count": 5 } } Apply configuration changes with the DC/OS CLI $ dcos kafka update start --options=kafka-options.json Find new broker IPs and hostnames using endpoints command $ dcos kafka endpoints broker
- 31. Rolling Broker Upgrades Upgrading brokers uses the same rolling update process as previous operations. Similar to a rolling configuration update, upgrade will do the following. • Restart Kafka scheduler with new version • Restart each broker task serially with new version, while maintaining identity (no data loss) 31 Pick a compatible package version $ dcos kafka update package-versions Current package version is: "2.2.0-1.0.0" Package can be upgraded to: ["2.3.0-1.0.0"] Package can be downgraded to: ["2.1.0-1.0.0"] Install a new version of the Kafka subcommand on the DC/OS CLI (1-to-1 with a package version) $ dcos package uninstall --cli kafka $ dcos package install --cli kafka --package-version="2.3.0-1.0.0" Initiate the upgrade process $ dcos kafka update start --options=<new options json> --package-version="2.3.0-1.0.0" To upgrade using the same workflow as in Motivating Example we perform rolling updates for inter.broker.protocol.version and log.message.format.version before and after the actual broker update.
- 32. Broker Replace & Movement Replacing brokers is common with large busy clusters $ dcos kafka pod replace kafka-3-broker Broker replacement also useful to facilitate broker movement across the cluster 1. Research the max bitrate per partition for your cluster 2. Move partitions from broker to replace 3. Replace broker 4. Rebalance/move partitions to new broker 32
- 33. Broker Replace & Movement 1. Research the max bitrate per partition for your cluster Run a controlled test • Bitrate depends on message size, producer batch, and consumer fetch size • Create a standalone cluster with 1 broker, 1 topic, and 1 partition • Run producer and consumer perf tests using average message/client properties • Measure broker metric for average bitrate kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec 33
- 34. Broker Replace & Movement 2. Move partitions from broker to replace Use Kafka partition reassignment tool • Generate an assignment plan without old broker 1 • Pick a fraction of the measured max bitrate found in step 1 (Ex. 75%, 80%) • Apply plan with bitrate throttle • Wait till complete 34 Broker 0 P P P P Broker 1 P P P P Broker 2 P P P P Broker 0 P P P P Broker 1 P P Broker 2 P P P P P P kafka-reassign-partitions … --topics-to-move-json-file topics.json --broker-list "0,2" --generate kafka-reassign-partitions … --reassignment-json-file reassignment.json --execute --throttle 10000000 kafka-reassign-partitions … --topics-to-move-json-file topics.json --reassignment-json-file reassignment.json --verify
- 35. Broker Replace & Movement 3. Replace broker Replace broker pod instance with DC/OS CLI $ dcos kafka pod replace kafka-3-broker • Old broker 1 instance is shutdown and resources deallocated • Deploy plan provisions a new broker 1 instance • New broker 1 is assigned same id as old broker 1: 1 35 Broker 0 P P P P Broker 1 P P Broker 2 P P P P P P Broker 1 X
- 36. Broker Replace & Movement 4. Rebalance/move partitions to new broker Use Kafka partition reassignment tool • Generate an assignment plan with new broker 1 • Pick a fraction of the measured max bitrate found in step 1 (Ex. 75%, 80%) • Apply plan with bitrate throttle • Wait till complete 36 Broker 0 P P P P Broker 1 P P P P Broker 2 P P P P Broker 0 P P P P Broker 1 P P Broker 2 P P P P P P
- 37. Kubernetes and The Operator Pattern
- 38. Kubernetes • Kubernetes (K8s) is a popular choice for Cluster Resource Manager • K8s is analogous to the DC/OS platform with its support for DNS/service discovery, ingress, load balancers, advanced scheduler features, and more. • K8s has an easier to use UI (kubectl) and faster ramp up time than Mesos with DC/OS • Mesos, Marathon, and Commons SDK basic DSL’s overlap with one another, but K8s provides a simple well defined set of resource types. • Basic resource types are declaratively defined as YAML. Therefore they’re limited in their ability to describe advanced operational concerns. 38
- 39. The Operator Pattern • The Operator Pattern is an architecture to extend Kubernetes • K8s internally implements its features using this pattern • Introduced by CoreOS several years ago, and now there are many operator-based projects • It has two components • CustomResourceDefinition (CRD) - configuration • Controller application instance - operational logic • A Controller is any application which works with the API server to satisfy the operational needs of what it is operationalizing. • It has the same function as a DC/OS Commons SDK-based scheduler. • The role of the controller is to actively reconcile the configured state from a CRD with the actual state of the service it operates 39 Simplified workflow of a controller performing Active Reconciliation for { desired := getDesiredState() current := getCurrentState() makeChanges(desired, current) }
- 40. strimzi An operator-based Kafka on Kubernetes project
- 41. strimzi strimzi is an open source operator-based Apache Kafka project for Kubernetes and OpenShift • Announced Feb 25th, 2018 • Evolved from non-operator project known as Barnabas by Paulo Patierno, RedHat • Part of RedHat Developer Program • Composed of two JVM-based controllers • Cluster Controller • Topic Controller 41
- 42. strimzi Architecture Cluster Controller ● Uses ConfigMaps to define the cluster (cluster config, Broker config, ZK config, etc.) ● Reconciles state of ConfigMap with running state ● Deploys Topic Controller ● Supports two storage modes ○ Ephemeral (emptyDir) ○ Persistent (PersistentVolume’s and Claims) ● Can host persistent KafkaConnect instances 42 strimzi documentation http://strimzi.io/docs/0.4.0/
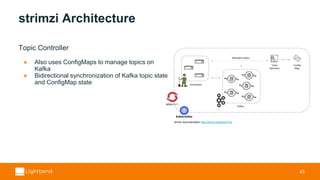
- 43. strimzi Architecture Topic Controller ● Also uses ConfigMaps to manage topics on Kafka ● Bidirectional synchronization of Kafka topic state and ConfigMap state 43 strimzi documentation http://strimzi.io/docs/0.4.0/
- 44. strimzi Project details • Apache Kafka project for Kubernetes and OpenShift • Licensed under Apache License 2.0 • Web site: http://strimzi.io/ • GitHub: https://github.com/strimzi • Slack: strimzi.slack.com • Mailing list: [email protected] • Twitter: @strimziio 44
- 45. Conclusion
- 46. To Recap • Containers are very useful to encapsulate any workload. • Advanced operational needs can be satisfied with schedulers (Mesos) and controllers (K8s) • Schedulers and Controllers let you operate “smart”/automated Kafka clusters, which lessen the burden of infrastructure or Kafka-expertise • Movement of Kafka Brokers is possible, but requires careful planning Putting Kafka in Jail (containers) actually liberates it! 46
- 47. Lightbend Fast Data Platform 47 http://lightbend.com/fast-data-platform
Editor's Notes
- #4: Running distributed systems like Kafka requires a wide array of underlying technology and operations know how to achieve “Technology will make our lives easier”. Iceberg analogy. Hidden: Army of Hardware Vendor, Operating System Platforms, work of Software & Operations Engineers Good UX can hide 1000’s of person hours of work Automation of operation Kafka is infamous for its profusion of metrics and configuration choices. Writing software to address pain of operations reduces manual work, custom “roll your own” scripts, and alleviates some need for deep expertise on participating hardware, platform, and software
- #7: Upgrading Kafka touches on many common Kafka deployment and operational concerns Assumption: Statically defined Kafka cluster Steps (See slide) To properly perform a zero downtime I upgrade we must Manage API/message format versions cleanly Apply broker changes one a time so replicated topics are never down Upgrade process glosses over many operational details
- #8: Rolling broker config updates. We need to update broker configuration 3 times during this process. If brokers have different configuration then you can break or severely incapacitate the whole cluster. Any update to a broker requires us to: Login Shutdown the broker gracefully Update and lint the broker config Start the broker process Wait until it’s fully online before moving on Configuration linting Verify that configuration update or code update is compatible Graceful shutdown Send SIGINT - Interrupt signal to broker process Brokers can recover from unclean stop (i.e. power failure), but not ideal and adds latency to clients Graceful shutdown means: Drain PageCache, start partition leader re-assignment, no log integrity check on next start Broker initialization Wait for broker to rejoin cluster and report that it’s successfully started Parse logs for INFO line `Kafka is started` Diagram ideas Rolling update (several stages diagrammed indicating serial update strategy) Sending interrupt signal to running Kafka broker Waiting for Kafka is online log message
- #10: Upgrading Kafka is just one of many complex operational concern (see slide) Infrastructure tooling like Terraform and Ansible make some things easy, but their declarative models make it modeling some Kafka operational workflow too difficult How do we automate complex operational workflows? Need infrastructure to host generalized workloads and software solutions Perform active reconciliation of common operational tasks to self-heal without human intervention Easily change from one running state to another.
- #12: Apache Mesos and Kubernetes are infrastructure platforms that let us generalize workloads Allow us to think of our cluster as one large pool of resources abstractly Apache Mesos Developed a University of Berkeley RAD lab Benjamin Hindman (co-founder of Mesosphere), Andy Konwinski (co-founder of Databricks), and Matei Zaharia (co-founder of Databricks and Spark project) First released 2009 Developed in parallel with Spark DC/OS - Data Center Operating System A higher-level platform on top of Apache Mesos By Mesosphere, company that stewards the Apache Mesos and many projects that make up its ecosystem Bundles a number of higher level functions to make running Apache Mesos easier. DC/OS’s core components are Marathon (generalized scheduler), the DC/OS catalog (package manager), a GUI and CLI, monitoring, and several core services based on a project known as the Commons SDK Kubernetes Developed by Google as friendlier alternative to inhouse solution known as Borg First released in 2015 Google partnered with the Linux Foundation to form the Cloud Native Computing Foundation (CNCF) and offered Kubernetes as a seed technology.
- #13: Cluster Resource Manager’s use Containers to control resources associated with tasks and provide task isolation In Container Orchestrated Environments it’s important to isolate and track resources used on each node For example) if a broker task is sharing an agent with another task then it’s important it always has all resources assigned to it, otherwise could be starved Without containers it’s easier for processes to hog resources from one another Containers are like VM’s, with much less overhead Container runs in user space Shared kernel Running a process in a container is only marginally more heavyweight than a process running on the host platform Use cgroups to limit resources to a container Use Namespaces to limit filesystem, process trees, and user/groups to a container Docker is the most popular Container Engine, but there are others. Mesos supports Docker and Mesos containerizers Mesos containerizer is a simple cgroup implementation Containers are available for several platforms Implemented per platform Not as mature or comprehensive as LXC “Running a container” on a non-Linux platform usually involves a Linux host VM that has the kernel to be shared by Linux containers As an aside, FreeBSD Jails are what inspired the name of this talk, but I will not actually discuss running Kafka on FreeBSD. I used the term Jail as a synonym to the term Container.
- #14: Cluster Resource Managers share similar requirements as Operating Systems I’ll introduce Mesos’ architecture and standard resource offer cycle, but conceptually similar to K8s Mesos Architecture ZooKeeper is used for for Mesos Master HA and leader election Odd number of Mesos Master’s, one active at a time, rest on standby n Mesos Agents Frameworks A generalized application with several components Has mesos resources offered to it Scheduler - The thing that initiates resource requests Could itself be running as a task scheduled by something else Executor - Runs on an agent to bootstrap tasks Task - Basic unit of execution doing the work of the framework
- #16: Already covered simple resource offer lifecycle, but apps have more needs More is required to keep tasks running smoothly. For example, should one task die should it be restarted again? Stateless tasks can easily run anywhere, but what about those that require state and identity? How do we scale tasks horizontally to meet more demand? There are several generalized workload schedulers available for Mesos, Marathon and Aurora
- #17: Marathon is an Open Source project used to keep tasks running on Apache Mesos. It provides basic primitives that can be used to restart, replicate, update, and scale tasks on Mesos. If you’re more familiar with Kubernetes, then you’ll immediately see the overlap to different resource types you can use to satisfy the same requirements with pods. The Marathon application definition defines the command or docker image to run along with deployment configuration. Marathon is well suited to run general purpose applications with simple deployment requirements like standalone user apps Distributed applications usually have their own operational requirements that are too simplistic or not available in Marathon. The Commons SDK takes the concept of schedulers one step further.
- #18: The Commons SDK is a toolkit to help build schedulers for apps with complex operational needs It’s goal is to make services easier to develop, package, and use in DC/OS Integrates with Marathon, ZooKeeper, Mesos, DC/OS Catalog Mesosphere provides implementations of the Commons SDK which make it possible to run Kafka, HDFS, ElasticSearch, and Cassandra on DC/OS in a production-ready way.
- #19: Defining a ServiceSpec in YAML can satisfy the majority of the concerns of your service, but to provide the highest level of control the Commons SDK also lets you work with the ServiceSpec programmatically. This is achieved by subclassing the Commons SDK in a JVM application to extend its functionality, the YAML ServiceSpec is typically used as a starting point because its DSL can satisfy most if not all of a services needs. Then you can extend ServiceSpec using whatever custom logic you require. For example, you may want to add custom logic some sort of reconciliation process as a result of a task (a pod instance) failing. In a more advanced use case you may want to connect directly to pod instances metrics in order to run an anomaly detection process that will kick off a preventative maintenance plan automatically. This sort of closed-loop automated cluster healing process is considered the holy grail in operations and is an active area of development for many platform companies. The Commons SDK gives us the tools to make building such solutions easier, vendors can focus on reconciliation logic itself instead of mundane machinery and boilerplate typically associated with operational concerns. Subclassing the Commons SDK also will expose a RESTful API server that will automatically expose endpoints for scheduler metrics and ways to trigger and monitor status of deployment plans. This API can be extended to add your own arbitrary endpoints. This application is compiled into a JVM application that serves as the custom scheduler for your service which is then bundled into a DC/OS package that can be published to a DC/OS Catalog so endusers can install it. At package installation time the custom scheduler is itself scheduled by the general-purpose Marathon scheduler. The custom scheduler’s needs are relatively simple because it just needs to have 1 instance of itself online per deployment. Once the scheduler is online then the default deployment plan is evaluated so the pods can be installed for the first time.
- #20: The ServiceSpec can be implemented declaratively or programmatically The Commons SDK defines a data format known as the Service Specification Inside a ServiceSpec we define the different components of the service as pods and the various operational tasks to perform as plans Ex) Kafka’s implementation only has one type of pod: broker, whereas HDFS has several: journal, name, and data nodes Each pod defines a set of tasks used to perform a single function in the cluster. A task could be long-lived, such as starting an instance of a daemon, or job-oriented, such as running an initialization process before some other task is run. Each plan defines a set of phases and steps used to perform some kind of operation: deployment, updates, something custom A phase is 1:1 with a pod and a step is 1:many
- #21: Each pod task performs a single operation A task could be: long-lived, such as starting an instance of a daemon, or job-oriented, such as running an initialization process before some other task is run A readiness check and is important so that we wait for an instance to be ready before moving on to the next step in a plan. It’s implemented as a command with simple polling config to assert that the instance is in a ready state and online. A health-check will periodically run a command to assert that the instance is still healthy. Runs indefinitely as long as the pod instance is online. It’s used to determine if a pod instance is healthy as well as a trigger to do something about it (i.e. kill and restart it).
- #22: Plans define the workflow of an operation The concept of a deployment strategy is reused throughout the layers of the plan. It defines whether the layer it’s associated with can be performed in serial or parallel (one at a time, or all at the same time). A phase is 1-to-1 with a pod so that different pods can have different deployment strategies and steps. Each phase contains steps, which reference a specific pod task. All the phases run either in serial or parallel depending on its deployment strategy. For each phase all steps are run either in serial or parallel depending on its own deployment strategy. A step is complete once it reaches the task’s Goal. RUNNING for long-lived daemon service ONCE for a one-time task to setup, cleanup, or perform some arbitrary function on the service. A plan is executed in order from top to bottom in the ServiceSpec until all steps in all phases have reached a COMPLETE state. Each step can be defined with an ordinal value, or `default` special case
- #23: Highlight resource-set’s, steps and goal’s
- #27: Oversimplified sequence diagram of default kafka package install The DC/OS package API (part of the DC/OS Cosmos project) receives a request to install Kafka and uses Marathon to install the Kafka scheduler. From the perspective of the DC/OS package API the installation is only responsible for the deployment of the scheduler as a Marathon application definition. The scheduler maintains state about the install in a zookeeper namespace The rest of the cluster deployment is then handled by the scheduler when it comes online Brokers download resources from various 3rd party sources, but also from Kafka scheduler HTTP endpoint (i.e. broker.properties)
- #28: When the Kafka scheduler is online we can observe the status of the default deployment plan by using the DC/OS CLI. Once the deploy plan is COMPLETE the cluster is immediately ready to be used. Each pod instance of ServiceSpec can be referenced using a DC/OS infrastructure service known as mesos-dns. To begin using Kafka we need to know the IPs or hostnames of the brokers. They can be found using the scheduler’s “endpoints” endpoint via the DC/OS CLI. The VIP provides a convenient and reliable way for clients to connect to a Kafka cluster. In DC/OS VIP’s are enabled by service called minuteman, a distributed, highly available, internal load balancer. VIPs operate on a virtual network within the cluster and as a result can only be used from tasks actually running on Mesos agents. Common topic administration tasks can be performed through the CLI, sparing you from having to provide ZooKeeper and Kafka connection details that are required when working with the standard Kafka distribution scripts.
- #30: When we installed the Kafka package we used default configuration. The package configuration controls all aspects of the install including the name of the cluster, placement rules for where brokers should be deployed, run time params and resource constraints for each broker, and all the possible options in a broker’s own configuration file. This gives us an easy centralized way of performing operational changes to the cluster without making changes to lots of different files spread across lots of different machines. The default configuration for Kafka can be overridden by providing a JSON file at the time the package is installed or when you perform an update. You can also update configuration through the DC/OS UI. To update configuration of an existing install look at the configuration specification for the package (or call dcos kafka describe) and find value you wish to change. For example, by default the broker setting allowing the deletion of topics is disabled, we can turn it on by enabling the `kafka.delete_topic_enable` value in our JSON config overrides file. The default delete_topic_enable config "delete_topic_enable": { "title": "delete.topic.enable", "description": "Enables delete topic. Delete topic through the admin tool will have no effect if this config is turned off", "type": "boolean", "default": false } Our override file `kafka-options.json` { "kafka": { "delete_topic_enable": true } } Update the configuration with the DC/OS CLI dcos kafka update start --options=kafka-options.json When we initiate the update the Kafka scheduler is redeployed with the new configuration and begins a task reconciliation process. The task reconciliation indicates that an existing Kafka cluster already exists and a rolling update occurs using the “serial” deployment plan strategy. You can watch through the DC/OS UI, Mesos UI, or by looking at the status of the deployment plan as each broker task is gracefully stopped, broker properties re-applied, and started again one at a time. The serial deployment strategy ensures that as long as your Kafka topics are provisioned with a replication factor greater than 1 and your minimum ISR (usually 1) config isn’t violated that your clients can continue producing to and consuming from topics.
- #31: For the end user the act of scaling up a Kafka cluster to add additional brokers is done by updating the configuration in the way that was just described. By default 3 Kafka brokers are provisioned, so if we increase this configuration and apply an update then the scheduler will see that number of broker tasks Mesos is aware about does not match the requested number of brokers in the ServiceSpec pod and will begin provisioning new brokers in the same way as during the initial deployment. After the new deployment plan reaches the COMPLETE state again you can view the broker endpoints using the DC/OS CLI and see that two new brokers have been provisioned. Keep in mind that just because new brokers are now active in the cluster, they are not used until new topics are provisioned, or existing topics partitions are rebalanced across the new brokers. Unfortunately this action still requires human operator experience using the kafka admin scripts, OSS tools (i.e. Yahoo! Kafka Manager), or Confluent Enterprise solutions.
- #32: To upgrade the DC/OS Kafka to a new version we roughly follow the same process as we do for a rolling update. The update process implicitly would use the installed version, but --package-version requires upgrade. If you need to manage a new `inter.broker.protocol.version` and `log.message.format.version` configuration then at a high level we must perform the same steps that were outlined in the Motivating Example we began this presentation with, but now that you know how to perform simple broker property changes you can begin to appreciate how much simpler upgrading a DC/OS Kafka cluster is then one defined statically. To actually upgrade the version of the brokers we must identify a new DC/OS Kafka package version to upgrade to (or downgrade to). We pick a version and then use the same update command we’ve used to do Rolling Configuration Updates and Broker Scaling with an additional parameter to specify the new package version. We may also optionally specify new configuration (i.e. if new configuration options exist in a package that we want to set for the new broker versions) using the same method as before. Once we execute the update command it will perform the same serial rolling update as before, but it will also download and unpack the new version of the Kafka scheduler as well as Kafka brokers.
- #33: Stopping, starting and replacing machines is a typical part of managing any cluster. To assist with these operations the DC/OS Kafka CLI can be used (as well most other DC/OS package using the Commons SDK). For instance you may want to gracefully stop a broker as preparation to service its underlying platform or machine hardware. After the upgrade and machine is back online you may start the broker again. If a machine fails unexpectedly and is irrecoverable then you also have the option to replace a broker. Performing this action tells the scheduler to redeploy a broker with the same id to another machine using the same process as during initial deployment or scaling. Once the broker comes online then Kafka will know to automatically recover partitions because it has come online with a previous broker’s id and its log directory is empty. Moving brokers These operations allow us to move brokers across the cluster. Anyone with some experience with Kafka knows that this can be an expensive operation because of the resulting inter-broker network traffic it incurs because of the partition resynchronization process, but with some foresight we can lessen the impact of these concerns using Kafka topic partition management. For instance, if we need to migrate brokers to a new a set of machines with minimal interruption to Kafka clients and limited network traffic then we can use the `kafka-reassign-partitions` admin script to move topic partitions assigned to one broker to another. This can be done by creating a new topic assignment plan using a subset of brokers. The admin script will generate a new proposed plan that we can use for the reassignment, or use as a starting point and tweak manually. Once we’re happy with the new assignment plan we can execute it with a throttle so that we don’t flood the network as partitions are migrated. Obviously a lot of thought needs to go into the details of this plan if we want to provide the least amount of disruption possible. We should have a sense of the throughput rates of the partitions we want to move. We should understand how saturated our current network equipment to determine a throttle that it can handle. We can’t be too relaxed on the throttle or we run the possibility of partitions getting too far out of synch to the point that they never actually catch up. We need to find the correct balance and select a throttle that is higher than our average throughput, but won’t saturate the network beyond capacity. When the partition migration is complete then you can gracefully stop the broker, re-use its underlying mesos agent, and replace the broker. The new broker will be deployed and should be available very quickly because it no longer has any partitions to manage. To spread partitions to this node we repeat the process we used to reassign partitions, but instead of excluding a broker ID, we include it so that the partition assignment proposal includes it. This is obviously a super involved process, but in a well monitored cluster and a little bit of patience then theoretically Kafka brokers can actually move across your Container Orchestrated Cluster while still being highly available!
- #39: We’ve talked at length about DC/OS and Mesos because at this time it remains the best choice for running Kafka in a Container Orchestrated Cluster, but Kubernetes is one of the hottest technologies in the tech industry right now and it’s easy to foresee that emerging Kubernetes-based Kafka projects will reach the same level as DC/OS Kafka and likely surpass it. Therefore I want to describe the options available in Kubernetes to wrap up this post. The basic deployment unit in Kubernetes is a pod. A pod is defined using a resource definition that describes one or more containers to run for a single pod instance. Kubernetes has many core resource definition types that provide similar functionality to the Marathon and Commons SDK-based schedulers in mesos. This is nice because there are less things an enduser has to learn about before they become proficient with using the Kubernetes platform. As someone who has spent several years running workloads on mesos and DC/OS firsthand I can assure you that the ramp up experience with Kubernetes has been much easier and faster. It’s true that a background in these concepts from Mesos has been helpful, but I think the key difference is that instead of learning the various components of DC/OS low level mesos API’s and concepts, Marathon, Mesos DNS, Minuteman, and the Commons SDK, instead I can find documentation to achieve all the same requirements by reading the Kubernetes documentation and working with the `kubectl` CLI and easy to understand YAML resource definitions. Core Kubernetes resource definitions will take you far. They satisfy just about any application use case, but there’s a point where a simple declarative resource definition cannot perfectly fit the operational requirements of an advanced software deployment. When you reach a point where you need to implement application-specific concerns you need to consider using The Operator Pattern.
- #40: The Operator pattern was introduced in a CoreOS blog post several years ago. It can be broken down into two main components: A Custom Resource Definition (CRD) and an application called the controller. The controller is an application that reacts to operational events of the thing it is controlling. It can also respond to events triggered by Kubernetes (or human operators through Kubernetes). For example, the controller will listen for events about creating or deleting the CRD it’s associated with and respond by instructing Kubernetes on how to proceed. The Kubernetes architecture uses the same operator pattern when implementing functionality for a given resource. For example, the StatefulSet resource would have a resource definition to declare all the properties required and an internal controller which manages the lifecycle of any StatefulSet instance. When something goes wrong with a custom resource the controller can choose to handle the problem in some custom way. This is known as an active reconciliation process. It watches some object for the world's desired state, and it watches the world's actual state, too. Then, it sends instructions to try and make the world's current state be more like the desired state. The simplest implementation of this is a loop: for { desired := getDesiredState() current := getCurrentState() makeChanges(desired, current) } A controller is basically any application that talks with the API Server. There are SDK’s and libraries for multiple programming languages. CoreOS recently announced an Operator framework project to make it easier to write operators using the Go language. However, there are multiple options for implementing a controller as a JVM application with lower level libraries, such as Fabric8 (Java) and Skuber (Scala). Controllers are deployed into Kubernetes as a pod, just like any other application. Generally their only requirement is to keep one instance of the controller online at any given time, therefore a basic pod definition is usually sufficient. The operator pattern and more specifically the controller implementation is very similar to the idea of a Commons SDK-based scheduler.
- #42: The Strimzi project evolved from a non-operator based Kafka on Kubernetes project known as Barnabas. As more operator-based projects have been published and the operator pattern itself starting to enter the public consciousness the principal author decided to create a new operator-based implementation. Strimzi was announced on Feb 25th, 2018, so it’s obviously a very new and unmature project. It is part of the RedHat developer program and is lead by Paulo Patierno, Principal Software Engineer in the Messaging and IoT department at RedHat. It can be deployed into native Kubernetes and OpenShift clusters. It uses the base Apache Kafka distribution.
- #43: Cluster controller actually manages two cluster: Kafka brokers and ZooKeeper The cluster controller running on Kubernetes (or OpenShift) is in charge to deploy an Apache Kafka cluster based on the configuration provided by the user through a “cluster” ConfigMap resource. Its main work is to watch for a ConfigMap which contains the cluster configuration (i.e. number of broker nodes, number of Zookeeper nodes, healthcheck information, broker configuration properties, metrics configuration and so on) and then deploying the cluster based on such information. During its life, the cluster controller is also in charge to check updates on the ConfigMap and reflecting the changes on the already deployed cluster (i.e. the user increase the number of broker nodes in order to scale up the cluster or change some metrics parameters and so on). It supports two flavours of deployment depending on your workload. For throwaway clusters for testing and development you can use the ephemeral deployment mode, which uses the `emptyDir` local volume type which get reclaimed (deleted) if any of the pods stop for any reason. The second flavour of deployment is known as persistent mode. This mode uses PersistentVolumes and any of the PersistentVolume type’s available (hostPath, EBS, etc.) in order to provide stable storage for broker pods that can survive the failure of a pod. Strimzi has several other features including support to host persistent KafkaConnect instances, an in-process HTTP server for controller health metrics.
- #44: The topic controller provides a way to manage the Kafka topics without interacting with the Kafka brokers directly but using a ConfigMap approach. In the same way as the cluster controller, the topic controller is in charge to watch for specific ConfigMap resources which describe topics. This allows the user to use ConfigMaps to define topic information (i.e. name, number of partitions, replication factor and so on) and the topic controller will process it to create or update the topic in the cluster. If topics are modified or created by some other means then the topic controller will synchronize topic ConfigMap(s) so they can be operated on through strimzi as well.