Quadrupling your elephants - RDF and the Hadoop ecosystem
Download as PPTX, PDF6 likes4,985 views

This document discusses enabling the Resource Description Framework (RDF) within the Hadoop ecosystem. It describes existing open source projects like Apache Jena Hadoop RDF Tools and GraphBuilder that aim to fill gaps in representing RDF concepts and processing RDF data with Hadoop. The document also provides an overview of the components in Jena Hadoop RDF Tools, sample code, and encourages users to test the tools and provide feedback to the developer community.



















![2
0
-- Declare our mappings
x = FOREACH propertyGraph GENERATE (*,
[ 'idBase' # 'http://example.org/instances/',
'base' # 'http://example.org/ontology/',
'namespaces' # [ 'foaf' # 'http://xmlns.com/foaf/0.1/' ],
'propertyMap' # [ 'type' # 'a',
'name' # 'foaf:name',
'age' # 'foaf:age' ],
'idProperty' # 'id' ]);
-- Convert to NTriples
rdf_triples = FOREACH propertyGraphWithMappings GENERATE FLATTEN(RDF(*));
-- Write out NTriples
STORE rdf_triples INTO '/tmp/rdf_triples' USING PigStorage();](https://image.slidesharecdn.com/quadruplingyourelephants-141119091947-conversion-gate01/85/Quadrupling-your-elephants-RDF-and-the-Hadoop-ecosystem-20-320.jpg)















![public abstract class AbstractNodeTupleNodeCountMapper<TKey, TValue, T extends AbstractNodeTupleWritable<TValue>>
extends Mapper<TKey, T, NodeWritable, LongWritable> {
3
7
private LongWritable initialCount = new LongWritable(1);
@Override
protected void map(TKey key, T value, Context context) throws IOException, InterruptedException {
NodeWritable[] ns = this.getNodes(value);
for (NodeWritable n : ns) {
context.write(n, this.initialCount);
}
}
protected abstract NodeWritable[] getNodes(T tuple);
}
public class TripleNodeCountMapper<TKey> extends AbstractNodeTupleNodeCountMapper<TKey, Triple, TripleWritable> {
@Override
protected NodeWritable[] getNodes(TripleWritable tuple) {
Triple t = tuple.get();
return new NodeWritable[] { new NodeWritable(t.getSubject()), new NodeWritable(t.getPredicate()),
new NodeWritable(t.getObject()) };
}
}](https://image.slidesharecdn.com/quadruplingyourelephants-141119091947-conversion-gate01/85/Quadrupling-your-elephants-RDF-and-the-Hadoop-ecosystem-37-320.jpg)

































Ad
More Related Content
What's hot (20)
Similar to Quadrupling your elephants - RDF and the Hadoop ecosystem (20)


















Ad
More from Rob Vesse (6)






Ad
Recently uploaded (20)
![Download Wondershare Filmora Crack [2025] With Latest](https://cdn.slidesharecdn.com/ss_thumbnails/neo4j-howkgsareshapingthefutureofgenerativeaiatawssummitlondonapril2024-240426125209-2d9db05d-250419-250428115407-a04afffa-thumbnail.jpg?width=560&fit=bounds)



















Quadrupling your elephants - RDF and the Hadoop ecosystem
- 1. 1 RDF and the Hadoop Ecosystem Rob Vesse Twitter: @RobVesse Email: [email protected]
- 2. 2 Software Engineer at YarcData (part of Cray Inc) Working on big data analytics products Active open source contributor primarily to RDF & SPARQL related projects Apache Jena Committer and PMC Member dotNetRDF Lead Developer Primarily interested in RDF, SPARQL and Big Data Analytics technologies
- 3. 3 What's missing in the Hadoop ecosystem? What's needed to fill the gap? What's already available? Jena Hadoop RDF Tools GraphBuilder Other Projects Getting Involved Questions
- 4. 4
- 5. 5 Apache, the projects and their logo shown here are registered trademarks or trademarks of The Apache Software Foundation in the U.S. and/or other countries
- 6. 6 No first class projects Some limited support in other projects E.g. Giraph supports RDF by bridging through the Tinkerpop stack Some existing external projects Lots of academic proof of concepts Some open source efforts but mostly task specific E.g. Infovore targeted at creating curated Freebase and DBPedia datasets
- 7. 7
- 8. 8 Need to efficiently represent RDF concepts as Writable types Nodes, Triples, Quads, Graphs, Datasets, Query Results etc What's the minimum viable subset?
- 9. 9 Need to be able to get data in and out of RDF formats Without this we can't use the power of the Hadoop ecosystem to do useful work Lots of serializations out there: RDF/XML Turtle NTriples NQuads JSON-LD etc Also would like to be able to produce end results as RDF
- 10. 1 0 Map/Reduce building blocks Common operations e.g. splitting Enable developers to focus on their applications User Friendly tooling i.e. non-programmer tools
- 11. 1 1
- 12. 1 2 CC BY-SA 3.0 Wikimedia Commons
- 13. 1 3 Set of modules part of the Apache Jena project Originally developed at Cray and donated to the project earlier this year Experimental modules on the hadoop-rdf branch of our Currently only available as development SNAPSHOT releases Group ID: org.apache.jena Artifact IDs: jena-hadoop-rdf-common jena-hadoop-rdf-io jena-hadoop-rdf-mapreduce Latest Version: 0.9.0-SNAPSHOT Aims to fulfill all the basic requirements for enabling RDF on Hadoop Built against Hadoop Map/Reduce 2.x APIs
- 14. 1 4 Provides the Writable types for RDF primitives NodeWritable TripleWritable QuadWritable NodeTupleWritable All backed by RDF Thrift A compact binary serialization for RDF using Apache Thrift See http://afs.github.io/rdf-thrift/ Extremely efficient to serialize and deserialize Allows for efficient WritableComparator implementations that perform binary comparisons
- 15. Provides InputFormat and OutputFormat implementations 1 5 Supports most formats that Jena supports Designed to be extendable with new formats Will split and parallelize inputs where the RDF serialization is amenable to this Also transparently handles compressed inputs and outputs Note that compression blocks splitting i.e. trade off between IO and parallelism
- 16. 1 6 Various reusable building block Mapper and Reducer implementations: Counting Filtering Grouping Splitting Transforming Can be used as-is to do some basic Hadoop tasks or used as building blocks for more complex tasks
- 17. 1 7
- 18. For NTriples inputs compared performance of a Text based node count versus RDF based node count 1 8 Performance as good (within 10%) and sometimes significantly better Heavily dataset dependent Varies considerably with cluster setup Also depends on how the input is processed YMMV! For other RDF formats you would struggle to implement this at all
- 19. 1 9 Originally developed by Intel Some contributions by Cray - awaiting merging at time of writing Open source under Apache License https://github.com/01org/graphbuilder/tree/2.0.alpha 2.0.alpha is the Pig based branch Allows data to be transformed into graphs using Pig scripts Provides set of Pig UDFs for translating data to graph formats Supports both property graphs and RDF graphs
- 20. 2 0 -- Declare our mappings x = FOREACH propertyGraph GENERATE (*, [ 'idBase' # 'http://example.org/instances/', 'base' # 'http://example.org/ontology/', 'namespaces' # [ 'foaf' # 'http://xmlns.com/foaf/0.1/' ], 'propertyMap' # [ 'type' # 'a', 'name' # 'foaf:name', 'age' # 'foaf:age' ], 'idProperty' # 'id' ]); -- Convert to NTriples rdf_triples = FOREACH propertyGraphWithMappings GENERATE FLATTEN(RDF(*)); -- Write out NTriples STORE rdf_triples INTO '/tmp/rdf_triples' USING PigStorage();
- 21. 2 1 Uses a declarative mapping based on Pig primitives Maps and Tuples Have to be explicitly joined to the data because Pig UDFs can only be called with String arguments Has some benefits e.g. conditional mappings RDF Mappings operate on Property Graphs Requires original data to be mapped to a property graph first Direct mapping to RDF is a future enhancement that has yet to be implemented
- 22. 2 2
- 23. 2 3 Infovore - Paul Houle https://github.com/paulhoule/infovore/wiki Cleaned and curated Freebase datasets processed with Hadoop CumulusRDF - Institute of Applied Informatics and Formal Description Methods https://code.google.com/p/cumulusrdf/ RDF store backed by Apache Cassandra
- 24. 2 4 Please start playing with these projects Please interact with the community: [email protected] What works? What is broken? What is missing? Contribute Apache projects are ultimately driven by the community If there's a feature you want please suggest it Or better still contribute it yourself!
- 25. 2 5 Questions? Personal Email: [email protected] Jena Mailing List: [email protected]
- 26. 2 6
- 27. 2 7 > bin/hadoop jar jena-hadoop-rdf-stats-0.9.0-SNAPSHOT-hadoop-job.jar org.apache.jena.hadoop.rdf.stats.RdfStats --node-count --output /user/output --input-type triples /user/input --node-count requests the Node Count statistics be calculated Assumes mixed quads and triples input if no --input-type specified Using this for triples only data can skew statistics e.g. can result in high node counts for default graph node Hence we explicitly specify input as triples
- 28. 2 8
- 29. 2 9
- 30. 3 0
- 31. 3 1
- 32. 3 2
- 33. 3 3 > ./pig -x local examples/property_graphs_and_rdf.pig > cat /tmp/rdf_triples/part-m-00000 Running in local mode for this demo Output goes to /tmp/rdf_triples
- 34. 3 4
- 35. 3 5
- 36. 3 6
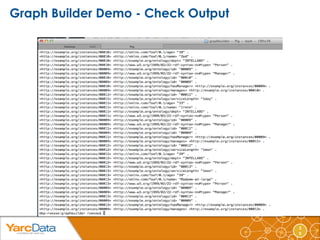
- 37. public abstract class AbstractNodeTupleNodeCountMapper<TKey, TValue, T extends AbstractNodeTupleWritable<TValue>> extends Mapper<TKey, T, NodeWritable, LongWritable> { 3 7 private LongWritable initialCount = new LongWritable(1); @Override protected void map(TKey key, T value, Context context) throws IOException, InterruptedException { NodeWritable[] ns = this.getNodes(value); for (NodeWritable n : ns) { context.write(n, this.initialCount); } } protected abstract NodeWritable[] getNodes(T tuple); } public class TripleNodeCountMapper<TKey> extends AbstractNodeTupleNodeCountMapper<TKey, Triple, TripleWritable> { @Override protected NodeWritable[] getNodes(TripleWritable tuple) { Triple t = tuple.get(); return new NodeWritable[] { new NodeWritable(t.getSubject()), new NodeWritable(t.getPredicate()), new NodeWritable(t.getObject()) }; } }
- 38. 3 8 public class NodeCountReducer extends Reducer<NodeWritable, LongWritable, NodeWritable, LongWritable> { @Override protected void reduce(NodeWritable key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long count = 0; Iterator<LongWritable> iter = values.iterator(); while (iter.hasNext()) { count += iter.next().get(); } context.write(key, new LongWritable(count)); } }
- 39. 3 9 Job job = Job.getInstance(config); job.setJarByClass(JobFactory.class); job.setJobName("RDF Triples Node Usage Count"); // Map/Reduce classes job.setMapperClass(TripleNodeCountMapper.class); job.setMapOutputKeyClass(NodeWritable.class); job.setMapOutputValueClass(LongWritable.class); job.setReducerClass(NodeCountReducer.class); // Input and Output job.setInputFormatClass(TriplesInputFormat.class); job.setOutputFormatClass(NTriplesNodeOutputFormat.class); FileInputFormat.setInputPaths(job, StringUtils.arrayToString(inputPaths)); FileOutputFormat.setOutputPath(job, new Path(outputPath)); return job;
Editor's Notes
- #6: Tons of active projects Accumulo, Ambari, Avro, Cassandra, Chukwa, Giraph, Ham, HBase, Hive, Mahout, Pig, Spark, Tez, ZooKeeper And those are just off the top of my head (and ignoring Incubating projects) However mostly focused on traditional data sources e.g. logs, relational databases, unstructured data
- #15: Highlight benefit of WritableComparator - significant speed up in reduce phase
- #18: Project also provides a demo JAR which shows how to use the building blocks to perform common Hadoop tasks on RDF So Node Count is essentially the Word Count "Hello World" of Hadoop programming
- #21: Mention that Intel may not have yet merged our pull request that adds the declarative mapping approach
- #38: ~20 lines of code (less if you remove unnecessary formatting)
- #39: 11 lines of code