Querying Linked Data with SPARQL
34 likes15,490 views

This slideset was part of our "How to consume Linked Data" tutorial at the International Semantic Web Conference (ISWC), Oct. 2009









![{
"head": { "link": [], "vars": ["name", "bday"] },
"results": { "distinct": false, "ordered": true, "bindings": [
{ "name": { "type": "literal",
"xml:lang": "en",
"value": "Alexander von Humboldt" } ,
"bday": { "type": "typed-literal",
"datatype": "http://www.w3.org/2001/XMLSchema#date",
"value": "1769-09-14" }
},
{ "name": { "type": "literal",
"xml:lang": "en",
"value": "Ernst Lubitsch" } ,
"bday": { "type": "typed-literal",
"datatype": "http://www.w3.org/2001/XMLSchema#date",
"value": "1892-01-28" }
},
// ...
] } http://www.w3.org/TR/rdf-sparql-json-res/
}
ISWC 2009 Tutorial "How to Consume Linked Data on the Web"](https://image.slidesharecdn.com/consumingld-consumingsection-091025103403-phpapp02/85/Querying-Linked-Data-with-SPARQL-10-320.jpg)



































































Ad
More Related Content
What's hot (20)
Similar to Querying Linked Data with SPARQL (20)


















Ad
More from Olaf Hartig (20)




















Ad
Recently uploaded (20)




















Querying Linked Data with SPARQL
- 1. Querying Linked Data with SPARQL ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 2. Brief Introduction to SPARQL ● SPARQL: Query Language for RDF data ● Main idea: pattern matching ● Describe subgraphs of the queried RDF graph ● Subgraphs that match your description yield a result ● Mean: graph patterns (i.e. RDF graphs /w variables) ?v rdf:type http://.../Volcano ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 3. Brief Introduction to SPARQL Queried graph: rdf:type http://.../Mount_Baker http://.../Volcano p:lastEruption rdf:type "1880" htp://.../Mount_Etna ?v rdf:type Results: http://.../Volcano ?v http://.../Mount_Baker http://.../Mount_Etna ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 4. SPARQL Endpoints ● Linked data sources usually provide a SPARQL endpoint for their dataset(s) ● SPARQL endpoint: SPARQL query processing service that supports the SPARQL protocol* ● Send your SPARQL query, receive the result * http://www.w3.org/TR/rdf-sparql-protocol/ ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 5. SPARQL Endpoints Data Source Endpoint Address DBpedia http://dbpedia.org/sparql Musicbrainz http://dbtune.org/musicbrainz/sparql U.S. Census http://www.rdfabout.com/sparql Semantic Crunchbase http://cb.semsol.org/sparql More complete list: http://esw.w3.org/topic/SparqlEndpoints ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 6. Accessing a SPARQL Endpoint ● SPARQL endpoints: RESTful Web services ● Issuing SPARQL queries to a remote SPARQL endpoint is basically an HTTP GET request to the SPARQL endpoint with parameter query GET /sparql?query=PREFIX+rd... HTTP/1.1 Host: dbpedia.org User-agent: my-sparql-client/0.1 URL-encoded string with the SPARQL query ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 7. Query Results Formats ● SPARQL endpoints usually support different result formats: ● XML, JSON, plain text (for ASK and SELECT queries) ● RDF/XML, NTriples, Turtle, N3 (for DESCRIBE and CONSTRUCT queries) ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 8. Query Results Formats PREFIX dbp: <http://dbpedia.org/ontology/> PREFIX dbpprop: <http://dbpedia.org/property/> SELECT ?name ?bday WHERE { ?p dbp:birthplace <http://dbpedia.org/resource/Berlin> ; dbpprop:dateOfBirth ?bday ; dbpprop:name ?name . } name | bday ------------------------+------------ Alexander von Humboldt | 1769-09-14 Ernst Lubitsch | 1892-01-28 ... ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 9. <?xml version="1.0"?> <sparql xmlns="http://www.w3.org/2005/sparql-results#"> <head> <variable name="name"/> <variable name="bday"/> </head> <results distinct="false" ordered="true"> <result> <binding name="name"> <literal xml:lang="en">Alexander von Humboldt</literal> </binding> <binding name="bday"> <literal datatype="http://www.w3.org/2001/XMLSchema#date">1769-09-14</literal> </binding> </result> <result> <binding name="name"> <literal xml:lang="en">Ernst Lubitsch</literal> </binding> <binding name="bday"> <literal datatype="http://www.w3.org/2001/XMLSchema#date">1892-01-28</literal> </binding> </result> http://www.w3.org/TR/rdf-sparql-XMLres/ <!-- … --> </results> ISWC 2009 Tutorial "How to Consume Linked Data on the Web" </sparql>
- 10. { "head": { "link": [], "vars": ["name", "bday"] }, "results": { "distinct": false, "ordered": true, "bindings": [ { "name": { "type": "literal", "xml:lang": "en", "value": "Alexander von Humboldt" } , "bday": { "type": "typed-literal", "datatype": "http://www.w3.org/2001/XMLSchema#date", "value": "1769-09-14" } }, { "name": { "type": "literal", "xml:lang": "en", "value": "Ernst Lubitsch" } , "bday": { "type": "typed-literal", "datatype": "http://www.w3.org/2001/XMLSchema#date", "value": "1892-01-28" } }, // ... ] } http://www.w3.org/TR/rdf-sparql-json-res/ } ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 11. Query Result Formats ● Use the ACCEPT header to request the preferred result format: GET /sparql?query=PREFIX+rd... HTTP/1.1 Host: dbpedia.org User-agent: my-sparql-client/0.1 Accept: application/sparql-results+json ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 12. Query Result Formats ● As an alternative some SPARQL endpoint implementations (e.g. Joseki) provide an additional parameter out GET /sparql?out=json&query=... HTTP/1.1 Host: dbpedia.org User-agent: my-sparql-client/0.1 ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 13. Accessing a SPARQL Endpoint ● More convenient: use a library ● Libraries: ● SPARQL JavaScript Library http://www.thefigtrees.net/lee/blog/2006/04/sparql_calendar_demo_a_sparql.html ● ARC for PHP http://arc.semsol.org/ ● RAP – RDF API for PHP http://www4.wiwiss.fu-berlin.de/bizer/rdfapi/index.html ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 14. Accessing a SPARQL Endpoint ● Libraries (cont.): ● Jena / ARQ (Java) http://jena.sourceforge.net/ ● Sesame (Java) http://www.openrdf.org/ ● SPARQL Wrapper (Python) http://sparql-wrapper.sourceforge.net/ ● PySPARQL (Python) http://code.google.com/p/pysparql/ ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 15. Accessing a SPARQL Endpoint ● Example with Jena / ARQ: import com.hp.hpl.jena.query.*; String service = "..."; // address of the SPARQL endpoint String query = "SELECT ..."; // your SPARQL query QueryExecution e = QueryExecutionFactory.sparqlService( service, query ); ResultSet results = e.execSelect(); while ( results.hasNext() ) { QuerySolution s = results.nextSolution(); // … } e.close(); ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 16. ● Querying a single dataset is quite boring compared to: ● Issuing SPARQL queries over multiple datasets ● How can you do this? 1. Issue follow-up queries to different endpoints 2. Querying a central collection of datasets 3. Build store with copies of relevant datasets 4. Use query federation system ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 17. Follow-up Queries ● Idea: issue follow-up queries over other datasets based on results from previous queries ● Substituting placeholders in query templates ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 18. String s1 = "http://cb.semsol.org/sparql"; String s2 = "http://dbpedia.org/sparql"; String qTmpl = "SELECT ?c WHERE{ <%s> rdfs:comment ?c }"; String q1 = "SELECT ?s WHERE { ..."; QueryExecution e1 = QueryExecutionFactory.sparqlService(s1,q1); ResultSet results1 = e1.execSelect(); while ( results1.hasNext() ) { QuerySolution s1 = results.nextSolution(); String q2 = String.format( qTmpl, s1.getResource("s"),getURI() ); QueryExecution e2= QueryExecutionFactory.sparqlService(s2,q2); ResultSet results2 = e2.execSelect(); while ( results2.hasNext() ) { // ... } Find a list of companies e2.close(); } filtered by some criteria and e1.close(); return DBpedia URIs of them ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 19. Follow-up Queries ● Advantage: ● Queried data is up-to-date ● Drawbacks: ● Requires the existence of a SPARQL endpoint for each dataset ● Requires program logic ● Very inefficient ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 20. Querying a Collection of Datasets ● Idea: Use an existing SPARQL endpoint that provides access to a set of copies of relevant datasets ● Example: ● SPARQL endpoint by OpenLink SW over a majority of datasets from the LOD cloud at: http://lod.openlinksw.com/sparql ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 21. Querying a Collection of Datasets ● Advantage: ● No need for specific program logic ● Drawbacks: ● Queried data might be out of date ● Not all relevant datasets in the collection ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 22. Own Store of Dataset Copies ● Idea: Build your own store with copies of relevant datasets and query it ● Possible stores: ● Jena TDB http://jena.hpl.hp.com/wiki/TDB ● Sesame http://www.openrdf.org/ ● OpenLink Virtuoso http://virtuoso.openlinksw.com/ ● 4store http://4store.org/ ● AllegroGraph http://www.franz.com/agraph/ ● etc. ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 23. Own Store of Dataset Copies ● Advantages: ● No need for specific program logic ● Can include all datasets ● Independent of the existence, availability, and efficiency of SPARQL endpoints ● Drawbacks: ● Requires effort to set up and to operate the store ● Ideally, data sources provide RDF dumps; if not? ● How to keep the copies in sync with the originals? ● Queried data might be out of date ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 24. Federated Query Processing ● Idea: Querying a mediator which ? distributes subqueries to relevant sources and integrates the results ? ? ? ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 25. Federated Query Processing ● Instance-based federation ● Each thing described by only one data source ● Untypical for the Web of Data ● Triple-based federation ● No restrictions ● Requires more distributed joins ● Statistics about datasets requires (both cases) ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 26. Federated Query Processing ● DARQ (Distributed ARQ) http://darq.sourceforge.net/ ● Query engine for federated SPARQL queries ● Extension of ARQ (query engine for Jena) ● Last update: June 28, 2006 ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 27. Federated Query Processing ● Semantic Web Integrator and Query Engine (SemWIQ) http://semwiq.sourceforge.net/ ● Actively maintained by Andreas Langegger ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 28. Federated Query Processing ● Advantages: ● No need for specific program logic ● Queried data is up to date ● Drawbacks: ● Requires the existence of a SPARQL endpoint for each dataset ● Requires effort to set up and configure the mediator ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 29. In any case: ● You have to know the relevant data sources ● When developing the app using follow-up queries ● When selecting an existing SPARQL endpoint over a collection of dataset copies ● When setting up your own store with a collection of dataset copies ● When configuring your query federation system ● You restrict yourself to the selected sources ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 30. In any case: ● You have to know the relevant data sources ● When developing the app using follow-up queries ● When selecting an existing SPARQL endpoint over a collection of dataset copies ● When setting up your own store with a collection of dataset copies ● When configuring your query federation system ● You restrict yourself to the selected sources There is an alternative: Remember, URIs link to data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 31. Automated Link Traversal ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 32. Automated Link Traversal ● Idea: Discover further data by looking-up relevant URIs in your application ● Can be combined with the previous approaches ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
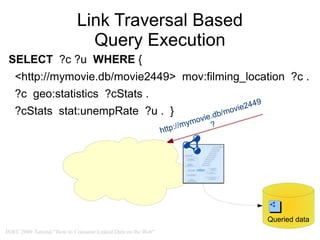
- 33. Link Traversal Based Query Execution ● Applies the idea of automated link traversal to the execution of SPARQL queries ● Idea: ● Intertwine query evaluation with traversal of RDF links ● Discover data that might contribute to query results during query execution ● Alternately: ● Evaluate parts of the query ● Look up URIs in intermediate solutions Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 34. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?cStats stat:unempRate ?u . } ● Example: Return unemployment rate of the countries in which the movie http://mymovie.db/movie2449 was filmed. Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 35. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . 49 v ie24 ?cStats stat:unempRate ?u . } .d b/mo m ovie http ://my ? Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 36. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?cStats stat:unempRate ?u . } Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 37. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?cStats stat:unempRate ?u . } ... <http://mymovie.db/movie2449> mov:filming_location <http://geo.../Italy> . Queried data ... ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 38. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?loc ?cStats stat:unempRate ?u . } http://geo.../Italy ... <http://mymovie.db/movie2449> mov:filming_location <http://geo.../Italy> . Queried data ... ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 39. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?loc ?cStats stat:unempRate ?u . } http://geo.../Italy taly o.../I / / ge ? http: Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 40. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?loc ?cStats stat:unempRate ?u . } ly http://geo.../Italy eo .../Ita http://g ? Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 41. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?loc ?cStats stat:unempRate ?u . } http://geo.../Italy Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 42. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?loc ?cStats stat:unempRate ?u . } http://geo.../Italy ... <http://geo.../Italy> geo:statistics <http://example.db/stat/IT> . ... Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 43. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?loc ?cStats stat:unempRate ?u . } http://geo.../Italy ?loc ?stat http://geo.../Italy http://stats.db/../it ... <http://geo.../Italy> geo:statistics <http://example.db/stat/IT> . ... Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 44. Link Traversal Based Query Execution SELECT ?c ?u WHERE { <http://mymovie.db/movie2449> mov:filming_location ?c . ?c geo:statistics ?cStats . ?loc ?cStats stat:unempRate ?u . } http://geo.../Italy ?loc ?stat http://geo.../Italy http://stats.db/../it ● Proceed with this strategy (traverse RDF links during query execution) Queried data ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 45. Link Traversal Based Query Execution ● Advantages: ● No need to know all data sources in advance ● No need for specific programming logic ● Queried data is up to date ● Independent of the existence of SPARQL endpoints provided by the data sources ● Drawbacks: ● Not as fast as a centralized collection of copies ● Unsuitable for some queries ● Results might be incomplete ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 46. Implementations ● Semantic Web Client library (SWClLib) for Java http://www4.wiwiss.fu-berlin.de/bizer/ng4j/semwebclient/ ● SWIC for Prolog http://moustaki.org/swic/ ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 47. Implementations ● SQUIN http://squin.org ● Provides SWClLib functionality as a Web service ● Accessible like a SPARQL endpoint ● Public SQUIN service at: http://squin.informatik.hu-berlin.de/SQUIN/ ● Install package: unzip and start ● Convenient access with SQUIN PHP tools: $s = 'http:// …'; // address of the SQUIN service $q = new SparqlQuerySock( $s, '… SELECT ...' ); $res = $q->getJsonResult(); // or getXmlResult() ISWC 2009 Tutorial "How to Consume Linked Data on the Web"
- 48. Real-World Examples SELECT DISTINCT ?author ?phone WHERE { ?pub swc:isPartOf <http://data.semanticweb.org/conference/eswc/2009/proceedings> . ?pub swc:hasTopic ?topic . ?topic rdfs:label ?topicLabel . FILTER regex( str(?topicLabel), "ontology engineering", "i" ) . # of query results 2 ?pub swrc:author ?author . # of retrieved graphs 297 { ?author owl:sameAs ?authorAlt } # of accessed servers 16 UNION avg. execution time 1min 30sec { ?authorAlt owl:sameAs ?author } Return ?authorAlt foaf:phone ?phone . phone numbers of authors of ontology engineering papers } at ESWC'09. ISWC 2009 Tutorial "How to Consume Linked Data on the Web"