[OUTDATED] Quick Start Tutorial of KH Coder 3
1 like4,550 views

Quantitative Content Analysis or Text Mining of English Language Data with an easy to use tool "KH Coder"




![Purpose of Analysis
6
To confirm whether the quantitative analysis can
also illustrate the centrality of Marilla
It has been pointed out that the heroine Anne’s foster mother Marilla
plays an essential role in the novel and that Marilla is more central
than Anne's best friend Diana, and Gilbert with whom Anne has a
faint romance.
To demonstrate a quantitative content analysis
approach that comprises the following two steps:
[Step 1] Extract words automatically from data and statistically
analyze them to obtain a whole picture and explore the features of
the data while avoiding the prejudices of the researcher.
[Step 2] Specify coding rules, such as "if there is a particular
expression, we regard it as an appearance of the concept A", and
extract concepts from the data. Then, statistically analyze the
concepts to deepen the analysis.
Introduction](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-6-320.jpg)



![Configure Stopwords
10
(2) Click
(3) Open the “tutorial_en”
folder,drag the file
“stopwords_sample.txt”
and drop here.
(Alternatively, simply paste
the content of the file here.)
(4) Click
(1) Go to [Project] [Settings] in the menu of KH Coder
Preparation
Black balloons indicate
operations you have to
perform.](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-10-320.jpg)

![Create a Project & Run Pre-Processing
12
If you get “could not find JAVA” error, please install JAVA.
Next time you start KH Coder, go to [Project] [Open] in the
menu and open the project you have created here.
KH Coder “concentrates” on the task. So it may look frozen
or “not responding”. But it is normal when it is busy.
(1) Go to [Project] [New] in the menu of KH Coder
(2) Click [Browse] and open “anne.xls” in the “tutorial_en” folder
(3) Make sure [text] and [English] are
selected
(4) Click
(5) Go to [Pre-Processing] [Run Pre-Processing] in the menu and click [OK]
Preparation](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-12-320.jpg)

![Word Frequency List (1/2)
14
Go to [Tools] [Words] [Frequency List (Excel)] in the menu
These numbers are counts of base forms / lemma
Step 1](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-14-320.jpg)

![The Context Where a Word is Used
16
Step 1
(1) Go to [Tools] [Words] [KWIC Concordance] in the menu
(2) Type a word and hit the [Enter] key
(3) Double click a line to view
the whole paragraph](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-16-320.jpg)
![Co-Occurrence Network of Words (1/2)
17
Step 1
(1) Go to [Tools] [Words] [Co-Occurrence Network] in the menu
(3) Select [Subgraph:
modularity] here
(2) Configure as shown in
this screen and click [OK]](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-17-320.jpg)


![Correspondence Analysis of Words (1/2)
20
Step 1
(1) Go to [Tools] [Words] [Correspondence Analysis] in the menu
(3) Select [grayscale] here
(2) Configure as shown in
this screen and click [OK]](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-20-320.jpg)
![Correspondence Analysis of Words (2/2)
21
Step 1
−0.50
−0.25
0.00
0.25
0.50
−1.0 −0.5 0.0 0.5
Dimension 1 (0.1417, 54.59% )
Dimension2(0.07,26.97%)
Frequency
300
600
900
01−07
08−19
20−28
29−38
Allan
Diana
Stacy
ANNE
Jane
Josie
minister
Cuthbert
child
Matthew
Ruby
Rachel Gilbert
imagine
school
boy
Barry
Pyeroad
Gillis
year
old
MARILLAlittle
new
Blythe
evening
heart
place
room
bed
walk
hair
friend
want
stay
lifeimagination
house
night
In the beginning [01-07],
the “child” Anne was
allowed to “stay” in
“Cuthbert’s house”.
Then in [08-19], she
met a neighbor girl
“Diana” and started
going to “school”. At the
school, she met
“Gilbert”.
In the latter half of the
novel, Anne and Diana
went separate ways,
and Anne's schoolmates,
such as “Josie”, “Jane”,
and “Ruby”, become
characteristic. Anne also
learned a lot from adult
women such as Mrs.
“Allan” and Miss “Stacy”.
We can understand the story flow throughout the novel
by checking characteristic words of each part.](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-21-320.jpg)
![Characteristic Words of each Part
Step 1
(1) Go to [Tools] [Variables & Headings] in the menu
(2) Click “part”
(3) Select “Sentences”
(4) Select “catalogue: Excel”
Top 10 characteristic words
of each part are tabulated. It
can be used as an alternative
for correspondence analysis.](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-22-320.jpg)



![Retrieve Documents Assigned a Specific Code
26
Step 2
(1) Go to [Tools] [Documents] [Search Documents] in the menu
(2) Click [Browse] and open“code_1.txt” in the “tutorial-en” folder
(3) Double click any of the codes
(4) Double click a line to view
the whole paragraph](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-26-320.jpg)
![Characters in Each Chapter (1/2)
27
Step 2
(1) Go to [Tools] [Coding] [Crosstab] in the menu
(2) Click [Browse] and open“code_1.txt” in the “tutorial_en” folder
(5) Click
(4) Click(3) Select [Sentences]
and [chapter]](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-27-320.jpg)

![Characters and Verbs (1/2)
29
Step 2
(1) Go to [Tools] [Coding] [Co-occurrences Network] in the menu
(2) Click [Browse] and open “code_2.txt” in the tutorial folder
(3) Configure as shown in
this screen and Click [OK]](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-29-320.jpg)

![(1) Go to [Tools] [Words] [Word Association] in the menu
(2) Click [Browse] and open“code_3.txt”
(3) Click [*Marilla]
(4) Hold down [Ctrl]
key on the keyboard
and click [*01-07]
(5) Click
Change of Words Co-occurring with Marilla (1/3)
31
Step 2
* To search the words co-occurring
with Marilla in the following part "08-
19", repeat procedure (3) and then
click [*08-19] instead of [*01-07] in
procedure (4).](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-31-320.jpg)

![Change of Words Co-occurring with Marilla (3/3)
33
Step 2
Change of Marilla
1. Uncomfortable ignorance [01-07]
2. Calling Anne and Saying many things [08-28]
3. Exchanging feelings by words and eyes
with Anne [20-38]
The change is depicted throughout the story.](https://image.slidesharecdn.com/tutorialslides-190410192802/85/OUTDATED-Quick-Start-Tutorial-of-KH-Coder-3-33-320.jpg)
































Ad
More Related Content
Similar to [OUTDATED] Quick Start Tutorial of KH Coder 3 (20)
More from khcoder (8)






Ad
Recently uploaded (20)



![Share CONTROL OF BODY MOVEMENT[1]PHYSIO PRESENTATION.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/sharecontrolofbodymovement1physiopresentation-250504162954-915fb5e5-thumbnail.jpg?width=560&fit=bounds)






![Hardy_Weinbergs_law_and[1]. A simple Explanation](https://cdn.slidesharecdn.com/ss_thumbnails/hardyweinbergslawand1-250505160803-e672c3cf-thumbnail.jpg?width=560&fit=bounds)









Ad
[OUTDATED] Quick Start Tutorial of KH Coder 3
- 1. KH Coder Tutorial using Anne of Green Gables: A Two-Step Approach to Quantitative Content Analysis Koichi Higuchi 1
- 3. 3 Preface This presentation is a tutorial on how to use KH Coder. KH Coder is a free software for quantitative content analysis or text mining. It is also utilized for computational linguistics. Details and downloads: http://khcoder.net/en Introduction
- 4. Table of Contents 4 Introduction Data Purpose of Analysis Preparation Install KH Coder Configure Stopwords Create a Project and Run Pre-Processing Step 1 Word Frequency List The Context where a word is used Co-occurrence Network of Words Correspondence Analysis of Words Closing Remarks for Step 1 Step 2 Use Coding Rules to Count Concepts Retrieve Documents Assigned a Specific Code Characters in Each Chapter Characters and Verbs Change of Words Co-occurring with Marilla Conclusions Introduction
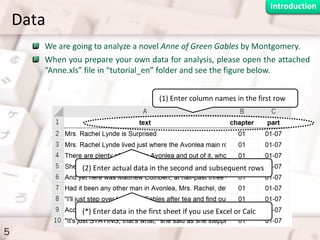
- 5. Data 5 We are going to analyze a novel Anne of Green Gables by Montgomery. When you prepare your own data for analysis, please open the attached “Anne.xls” file in “tutorial_en” folder and see the figure below. (1) Enter column names in the first row (2) Enter actual data in the second and subsequent rows (*) Enter data in the first sheet if you use Excel or Calc Introduction
- 6. Purpose of Analysis 6 To confirm whether the quantitative analysis can also illustrate the centrality of Marilla It has been pointed out that the heroine Anne’s foster mother Marilla plays an essential role in the novel and that Marilla is more central than Anne's best friend Diana, and Gilbert with whom Anne has a faint romance. To demonstrate a quantitative content analysis approach that comprises the following two steps: [Step 1] Extract words automatically from data and statistically analyze them to obtain a whole picture and explore the features of the data while avoiding the prejudices of the researcher. [Step 2] Specify coding rules, such as "if there is a particular expression, we regard it as an appearance of the concept A", and extract concepts from the data. Then, statistically analyze the concepts to deepen the analysis. Introduction
- 8. Install KH Coder 8 Preparation (1) Double click the downloaded file (2) Click (3) Click Now you are ready. The number of unzipped files may vary between versions.
- 9. Interface Language 9 Preparation (1) Double click the shortcut on your desktop to start KH Coder In case the menu is not displayed in your favorite language, please select it here We call this a “menu”. Interface translation is not completed. If you find a typo or if you have a suggestion, post it here: https://github.com/ko-ichi-h/khcoder/issues
- 10. Configure Stopwords 10 (2) Click (3) Open the “tutorial_en” folder,drag the file “stopwords_sample.txt” and drop here. (Alternatively, simply paste the content of the file here.) (4) Click (1) Go to [Project] [Settings] in the menu of KH Coder Preparation Black balloons indicate operations you have to perform.
- 11. Notes on Stopwords 11 You can specify any words as stopwords in KH Coder to exclude those words from your analysis. Stopwords will be given the special POS tag “OTHER”. “OTHER” is NOT checked by default, so that words with “OTHER” tag will be excluded from analyses. Preparation Green balloons and bare texts are notes. No operation needed.
- 12. Create a Project & Run Pre-Processing 12 If you get “could not find JAVA” error, please install JAVA. Next time you start KH Coder, go to [Project] [Open] in the menu and open the project you have created here. KH Coder “concentrates” on the task. So it may look frozen or “not responding”. But it is normal when it is busy. (1) Go to [Project] [New] in the menu of KH Coder (2) Click [Browse] and open “anne.xls” in the “tutorial_en” folder (3) Make sure [text] and [English] are selected (4) Click (5) Go to [Pre-Processing] [Run Pre-Processing] in the menu and click [OK] Preparation
- 13. 13 Step 1
- 14. Word Frequency List (1/2) 14 Go to [Tools] [Words] [Frequency List (Excel)] in the menu These numbers are counts of base forms / lemma Step 1
- 15. Word Frequency List (2/2) 15 The character name that most frequently appears next to the heroine “ANNE” is not her best friend “Diana” but “MARILLA”. In the novel, an orphan “girl” or “child” heroine gets adopted, finds a “home”, and goes to “school”. And she once had a inferiority complex about her “hair”. Words Freq Words Freq Words Freq ANNE 1138 little 283 want 149 say 952 girl 267 home 136 MARILLA 849 thing 260 child 134 think 486 tell 252 Barry 132 Diana 414 look 246 school 128 know 364 good 225 sit 126 Matthew 361 feel 215 night 117 just 358 time 208 really 116 come 353 eye 152 hair 114 make 286 Lynde 151 Gilbert 113 Step 1
- 16. The Context Where a Word is Used 16 Step 1 (1) Go to [Tools] [Words] [KWIC Concordance] in the menu (2) Type a word and hit the [Enter] key (3) Double click a line to view the whole paragraph
- 17. Co-Occurrence Network of Words (1/2) 17 Step 1 (1) Go to [Tools] [Words] [Co-Occurrence Network] in the menu (3) Select [Subgraph: modularity] here (2) Configure as shown in this screen and click [OK]
- 18. Co-Occurrence Network of Words (2/2) 18 girl time home school eye face evening boy night bed minister tea man woman ANNE thing MARILLA Diana Matthew people LyndeBarry Gilbert Avonlea Rachel GABLES GREEN Jane Ruby Allan Josie Stacy Blythe Gillis Andrews book Pye little good day old year window white glad world dress new hair red lovely course nice real just really life hard pretty right say think know come make big tell look feel way sure want sit like imagine place imagination suppose let try believelive away heart love worduse great grow read (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) “Diana”, “Marilla”, and “Matthew” are connected close to “Anne” “Gilbert” is in rather remote part and connected to “Anne” via “school” “Jane”, “Ruby”, “Josie”, and “Stacy” are also connected via “school” The figure is retouched with Illustrator Step 1
- 19. Methods for Exploring Co-Occurrences of Words 19 To explore co-occurrences of words, you can also use: hierarchical cluster analysis Multi-dimensional scaling By interpreting these result, you may find major themes of the text from groups of words which tend to appear together. KH Coder uses R as back end to execute these multivariate methods. Step 1 co-occurrence network cluster analysis MDS
- 20. Correspondence Analysis of Words (1/2) 20 Step 1 (1) Go to [Tools] [Words] [Correspondence Analysis] in the menu (3) Select [grayscale] here (2) Configure as shown in this screen and click [OK]
- 21. Correspondence Analysis of Words (2/2) 21 Step 1 −0.50 −0.25 0.00 0.25 0.50 −1.0 −0.5 0.0 0.5 Dimension 1 (0.1417, 54.59% ) Dimension2(0.07,26.97%) Frequency 300 600 900 01−07 08−19 20−28 29−38 Allan Diana Stacy ANNE Jane Josie minister Cuthbert child Matthew Ruby Rachel Gilbert imagine school boy Barry Pyeroad Gillis year old MARILLAlittle new Blythe evening heart place room bed walk hair friend want stay lifeimagination house night In the beginning [01-07], the “child” Anne was allowed to “stay” in “Cuthbert’s house”. Then in [08-19], she met a neighbor girl “Diana” and started going to “school”. At the school, she met “Gilbert”. In the latter half of the novel, Anne and Diana went separate ways, and Anne's schoolmates, such as “Josie”, “Jane”, and “Ruby”, become characteristic. Anne also learned a lot from adult women such as Mrs. “Allan” and Miss “Stacy”. We can understand the story flow throughout the novel by checking characteristic words of each part.
- 22. Characteristic Words of each Part Step 1 (1) Go to [Tools] [Variables & Headings] in the menu (2) Click “part” (3) Select “Sentences” (4) Select “catalogue: Excel” Top 10 characteristic words of each part are tabulated. It can be used as an alternative for correspondence analysis.
- 23. Closing Remarks for Step 1 23 Statistical analyses of automatically extracted words are suitable for gaining a whole picture of the data Main theme (word frequency list or co-occurrence network) Relations between characters or words (co-occurrence network) Story flow (correspondence analysis) About the centrality of Marilla Most frequently appears next to the heroine Anne Her relationship with Anne appears to be almost as strong as Diana’s Be present throughout all four parts of the story Step 1 We obtained overviews of entire data in this step. Next, we are going to put more focus on Marilla using coding rules.
- 24. 24 Step 2
- 25. Use Coding Rules to Count Concepts 25 In some cases, we have to count concepts, not words. To count concepts, you can compose “cording rules” like this: *Character_name_Gilbert Gilbert or Gil Indicates the name of this code: “Character_name_Gilbert” Not only the documents containing “Gilbert” but also those containing “Gil” are assigned this code. If a document is acceptable under multiple coding rules, multiple codes will be assigned to the document. Step 2
- 26. Retrieve Documents Assigned a Specific Code 26 Step 2 (1) Go to [Tools] [Documents] [Search Documents] in the menu (2) Click [Browse] and open“code_1.txt” in the “tutorial-en” folder (3) Double click any of the codes (4) Double click a line to view the whole paragraph
- 27. Characters in Each Chapter (1/2) 27 Step 2 (1) Go to [Tools] [Coding] [Crosstab] in the menu (2) Click [Browse] and open“code_1.txt” in the “tutorial_en” folder (5) Click (4) Click(3) Select [Sentences] and [chapter]
- 28. Characters in Each Chapter (2/2) 28 Step 2 Gilbert Diana Matthew Marilla ANNE 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 Pearson rsd. 5.0 2.5 0.0 −2.5 −5.0 Percent: 10 20 Marilla and Anne are present almost everywhere Although Marilla and Anne were apart in chapter 35, there was an emotional reunion in the following chapter 36. Anne won a scholarship and rejoiced saying “Oh, won’t Matthew and Marilla be pleased!”
- 29. Characters and Verbs (1/2) 29 Step 2 (1) Go to [Tools] [Coding] [Co-occurrences Network] in the menu (2) Click [Browse] and open “code_2.txt” in the tutorial folder (3) Configure as shown in this screen and Click [OK]
- 30. Characters and Verbs (2/2) 30 Step 2 .06 .04 .11 .06 .04 .06 .05 .04 .04 .03 .03 .03.04 .03 .05 .05 .04 Matthew Marilla ANNE Diana Gilbert think know tell look feel Anne often expresses what she “feels” to Marilla: “I do feel dreadfully sad, Marilla” (c21) Marilla and Anne often “look” at each other: Marilla looked at Anne and softened at sight of the child’s pale face… (c6) Anne looked at her with eyes limpid with sympathy (c20) Marilla looked at her with a tenderness that would never have been suffered to reveal itself in any clearer light… (c30) Marilla and Anne exchange their feelings by words, and also with their eyes, meaning that a close and intimate relationship is depicted between the two.
- 31. (1) Go to [Tools] [Words] [Word Association] in the menu (2) Click [Browse] and open“code_3.txt” (3) Click [*Marilla] (4) Hold down [Ctrl] key on the keyboard and click [*01-07] (5) Click Change of Words Co-occurring with Marilla (1/3) 31 Step 2 * To search the words co-occurring with Marilla in the following part "08- 19", repeat procedure (3) and then click [*08-19] instead of [*01-07] in procedure (4).
- 32. Change of Words Co-occurring with Marilla (2/3) 32 Step 2 01-07 08-19 20-28 29-38 Matthew .053 say .072 say .042 Matthew .041 mare .040 ANNE .059 think .034 look .040 Cuthbert .040 just .039 ANNE .032 sit .039 table .038 think .036 cake .030 ANNE .038 dish .037 brooch .031 make .028 say .038 child .033 tell .030 minister .028 face .031 bed .032 evening.025 Allan .026 girl .026 say .032 home .024 feel .025 think .024 uncomfortable .032 set .024 know .024 want .022 sorrel .032 let .023 time .023 lean .022 “Marilla really did not know how to talk to the child, and her uncomfortable ignorance made her crisp and...” (c4) The “child” is upgraded to “Anne” and implying that it is impossible to bring up a child without “saying” anything. The “feel” and “look”
- 33. Change of Words Co-occurring with Marilla (3/3) 33 Step 2 Change of Marilla 1. Uncomfortable ignorance [01-07] 2. Calling Anne and Saying many things [08-28] 3. Exchanging feelings by words and eyes with Anne [20-38] The change is depicted throughout the story.
- 34. Conclusions 34 Step 2 Results of step 2 showed that: Marilla is literally present almost everywhere A close and intimate relationship is depicted between Marilla and Anne Change of Marilla and growing relationship between Marilla and Anne is depicted throughout the story Our analysis supports the assertion that Marilla plays central roll in the story. Identifying keywords like “child”, “uncomfortable”, “look”, and “feel” through quantitative analysis is considered to be useful for extracting depiction which specifically describes Marilla’s roll and change in the story.
- 35. Web site of KH Coder http://khcoder.net/en For more details on this tutorial Part 1: http://www.ritsumei.ac.jp/file.jsp?id=325881 Part 2: http://www.ritsumei.ac.jp/file.jsp?id=346128 Questions or Comments? https://github.com/ko-ichi-h/khcoder/issues