RDB2RDF Tutorial (R2RML and Direct Mapping) at ISWC 2013
Download as PPTX, PDF18 likes17,418 views

The Relational Databases to RDF (RDB2RDF) Tutorial at the 2013 International Semantic Web Conference (ISWC2013)

































![Direct Mapping as R2RML
@prefix rr: <http://www.w3.org/ns/r2rml#> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/ID={ID}";
rr:class <http://www.ex.com/Person>
];
rr:predicateObjectMap [
rr:predicate <http://www.ex.com/Person#NAME> ;
rr:objectMap [rr:column ”NAME" ]
].
www.rdb2rdf.org - ISWC2013](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-34-320.jpg)
![Customized R2RML
@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
www.rdb2rdf.org - ISWC2013
.](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-35-320.jpg)
![<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName”Person" ];
rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person ];
rr:predicateObjectMap [
rr:predicate
foaf:based_near ;
rr:objectMap
[
rr:parentTripelMap <TripleMap2>;
rr:joinCondition [
rr:child “CID”;
rr:parent “CID”;
]
]
<TriplesMap2>
]
a rr:TriplesMap;
.
rr:logicalTable [ rr:tableName ”City" ];
rr:subjectMap [ rr:template "http://ex.com/City/{CID}";
rr:class ex:City ];
rr:predicateObjectMap [
rr:predicate
foaf:name;
rr:objectMap
[ rr:column ”TITLE" ]
]
.
www.rdb2rdf.org - ISWC2013](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-36-320.jpg)
![R2RML View
@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:sqlQuery
“””SELECT ID, NAME
FROM Person WHERE gender = “F” “””];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class <http://www.ex.com/Woman>
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
www.rdb2rdf.org - ISWC2013
.](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-37-320.jpg)































































![Direct Mapping as R2RML
@prefix rr: <http://www.w3.org/ns/r2rml#> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/ID={ID}";
rr:class <http://www.ex.com/Person>
];
rr:predicateObjectMap [
rr:predicate <http://www.ex.com/Person#NAME> ;
rr:objectMap [rr:column ”NAME" ]
].
101](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-101-320.jpg)
![Direct Mapping as R2RML
@prefix rr: <http://www.w3.org/ns/r2rml#> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”]; mapped?
Logical Table: What is being
rr:subjectMap [
rr:template "http://www.ex.com/Person/ID={ID}";
SubjectMap: How to generate the Subject?
rr:class <http://www.ex.com/Person>
];
rr:predicateObjectMap [
rr:predicate <http://www.ex.com/Person#NAME> ;
PredicateObjectMap: ”NAME" ]
rr:objectMap [rr:column How to generate the Predicate and Object?
].
102](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-102-320.jpg)
![Logical Table
@prefix rr: <http://www.w3.org/ns/r2rml#> .
<TriplesMap1>
a rr:TriplesMap;
What is being mapped?
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/ID={ID}";
rr:class <http://www.ex.com/Person>
];
rr:predicateObjectMap [
rr:predicate <http://www.ex.com/Person#NAME> ;
rr:objectMap [rr:column ”NAME" ]
]
.
103](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-103-320.jpg)
![Subject URI Template
@prefix rr: <http://www.w3.org/ns/r2rml#> .
<TriplesMap1>
a rr:TriplesMap;
Subject URI
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/ID={ID}";
rr:class <http://www.ex.com/Person>
];
rr:predicateObjectMap [
rr:predicate <http://www.ex.com/Person#NAME> ;
rr:objectMap [rr:column ”NAME" ]
]
<Subject URI> rdf:type <Class
.
URI>
104](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-104-320.jpg)
![Predicate URI Constant
@prefix rr: <http://www.w3.org/ns/r2rml#> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
Predicate URI
rr:subjectMap [
rr:template "http://www.ex.com/Person/ID={ID}";
rr:class <http://www.ex.com/Person>
];
rr:predicateObjectMap [
rr:predicate <http://www.ex.com/Person#NAME> ;
rr:objectMap [rr:column ”NAME" ]
]
.
105](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-105-320.jpg)
![Object Column Value
@prefix rr: <http://www.w3.org/ns/r2rml#> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/ID={ID}";
rr:class <http://www.ex.com/Person>
];
rr:predicateObjectMap [
rr:predicate <http://www.ex.com/Person#NAME> ;
rr:objectMap [rr:column ”NAME" ]
]
.
Object Literal
106](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-106-320.jpg)

![Customization
@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
Customized Subject URI
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
.
Customized Class
108](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-108-320.jpg)

![R2RML View
@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
Query instead of table
rr:logicalTable [ rr:sqlQuery
“””SELECT ID, NAME
FROM Person WHERE gender = “F” “””];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class <http://www.ex.com/Woman>
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
.
110](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-110-320.jpg)








![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
.
119](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-119-320.jpg)

![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
.
121](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-121-320.jpg)
![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:sqlQuery
“””SELECT ID, NAME
FROM Person WHERE gender = “F” “””];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class <http://www.ex.com/Woman>
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
.](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-122-320.jpg)





![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name ]
rr:objectMap [rr:column ”NAME" ]
]
.
129](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-129-320.jpg)

![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name ]
rr:objectMap [rr:column ”NAME" ]
]
.
131](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-131-320.jpg)

![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name ]
rr:objectMap [rr:column ”NAME" ]
]
.
133](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-133-320.jpg)


![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name ]
rr:objectMap [
rr:template ”{FIRST_NAME} {LAST_NAME}”;
rr:termType rr:Literal;
]
]
.
136](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-136-320.jpg)
![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template ”person{ID}";
rr:termType rr:BlankNode;
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name ]
rr:objectMap [rr:column ”NAME" ]
]
.
137](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-137-320.jpg)



![rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name ]
rr:objectMap [
rr:template ”{FIRST_NAME} {LAST_NAME}”;
rr:termType rr:Literal;
]
]
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name ]
rr:objectMap [
rr:template ”{FIRST_NAME} {LAST_NAME}”
]
]
rr:predicateObjectMap [
rr:predicateMap [rr:constant ex:role ]
rr:objectMap [
rr:template ”http://ex.com/role/{role}”
]
]
141](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-141-320.jpg)






![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
.
Optional
148](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-148-320.jpg)

![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name];
[rr:column ”NAME" ]
]
.
rr:objectMap
150](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-150-320.jpg)


![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name];
rr:objectMap [rr:column ”NAME" ]
]
.
153](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-153-320.jpg)
![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
Shortcut!
rr:predicateObjectMap [
rr:predicate foaf:name;
rr:objectMap [rr:column ”NAME" ]
]
.
154](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-154-320.jpg)
![Constant Shortcut Properties
• ?x rr:predicate ?y
• ?x rr:predicateMap [ rr:constant ?y ]
• ?x rr:subject ?y
• ?x rr:subjectMap [ rr:constant ?y ]
• ?x rr:object ?y
• ?x rr:objectMap [ rr:constant ?y ]](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-155-320.jpg)


![@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”Person”];
rr:subjectMap [
rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person
];
rr:predicateObjectMap [
rr:predicateMap [rr:constant foaf:name];
rr:objectMap [rr:column ”NAME" ]
]
.
158](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-158-320.jpg)


![Example 1
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://example.com/ns/>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName ”Student”];
rr:subjectMap [
rr:template "http://example.com/ns/{sid}";
rr:class ex:Student;
].
Logical Table is a Table Name
SubjectMap is a
Template-valued TermMap
And it has one Class IRI](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-161-320.jpg)

![Example 2
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://example.com/ns/>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName ”Student”];
rr:subjectMap [
rr:template "http://example.com/ns/{sid}";
rr:class ex:Student;
];
rr:predicateObjectMap [
rr:predicate ex:name;
rr:objectMap [ rr:column “name”];
].
PredicateMap which is a
Constant-valued TermMap
Logical Table is a Table Name
SubjectMap is a
Template-valued TermMap
And it has one Class IRI
PredicateObjectMap
ObjectMap which is a
Column-valued TermMap](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-163-320.jpg)

![Example 3
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://example.com/ns/>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName ”Student”];
rr:subjectMap [
rr:template "http://example.com/ns/{sid}";
rr:class ex:Student;
];
rr:predicateObjectMap [
rr:predicate ex:comment;
rr:objectMap [
rr:template “{name} is a Student”;
rr:termType rr:Literal;
];
].
PredicateMap which is a
Constant-valued TermMap
Logical Table is a Table Name
SubjectMap is a
Template-valued TermMap
And it has one Class IRI
PredicateObjectMap
ObjectMap which is a
Template-valued TermMap
TermType](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-165-320.jpg)

![Example 4
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://example.com/ns/>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName ”Student”];
rr:subjectMap [
rr:template "http://example.com/ns/{sid}";
rr:class ex:Student;
];
rr:predicateObjectMap [
rr:predicate ex:webpage;
rr:objectMap [
rr:template “http://ex.com/{name}”;
];
].
PredicateMap which is a
Constant-valued TermMap
Logical Table is a Table Name
SubjectMap is a
Template-valued TermMap
And it has one Class IRI
PredicateObjectMap
ObjectMap which is a
Template-valued TermMap
Note that there is not TermType](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-167-320.jpg)

![Example 6
@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://example.com/ns/>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName ”Student”];
rr:subjectMap [
rr:template "http://example.com/ns/{sid}";
rr:class ex:Student;
];
rr:predicateObjectMap [
rr:predicate ex:studentType;
rr:object ex:GradStudent ;
].
PredicateMap which is a
Constant-valued TermMap
Logical Table is a Table Name
SubjectMap is a
Template-valued TermMap
And it has one Class IRI
PredicateObjectMap
ObjectMap which is a
Constant-valued TermMap](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-169-320.jpg)

![<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName”Person" ];
rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person ];
rr:predicateObjectMap [
rr:predicate
foaf:based_near ;
rr:objectMap
[
rr:parentTripelMap <TripleMap2>;
rr:joinCondition [
rr:child “CID”;
rr:parent “CID”;
]
]
<TriplesMap2>
]
a rr:TriplesMap;
.
rr:logicalTable [ rr:tableName ”City" ];
RefObjectMap
rr:subjectMap [ rr:template "http://ex.com/City/{CID}";
rr:class ex:City ];
rr:predicateObjectMap [
rr:predicate
foaf:name;
rr:objectMap
[ rr:column ”TITLE" ]
]
.
171](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-171-320.jpg)
![ParentTripleMap
• The referencing TripleMap
• rr:parentTriplesMap
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName”Person" ];
rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person ];
rr:predicateObjectMap [
rr:predicate
foaf:based_near ;
rr:objectMap
[
rr:parentTripelMap <TripleMap2>;
rr:joinCondition [
rr:child “CID”;
rr:parent “CID”;
]
]
]
.
Parent TriplesMap](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-172-320.jpg)
![JoinCondition
• Join between child and parent attribuets
• rr:joinCondition
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName”Person" ];
rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person ];
rr:predicateObjectMap [
rr:predicate
foaf:based_near ;
rr:objectMap
[
rr:parentTripelMap <TripleMap2>;
rr:joinCondition [
rr:child “CID”;
rr:parent “CID”;
]
]
]
.
JoinCondition](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-173-320.jpg)
![<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName”Person" ];
rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}";
rr:class foaf:Person ];
rr:predicateObjectMap [
rr:predicate
foaf:based_near ;
rr:objectMap
[
rr:parentTripelMap <TripleMap2>;
rr:joinCondition [
rr:child “CID”;
rr:parent “CID”;
]
]
<TriplesMap2>
]
a rr:TriplesMap;
.
rr:logicalTable [ rr:tableName ”City" ];
RefObjectMap
Parent TriplesMap
JoinCondition
rr:subjectMap [ rr:template "http://ex.com/City/{CID}";
rr:class ex:City ];
rr:predicateObjectMap [
rr:predicate
foaf:name;
rr:objectMap
[ rr:column ”TITLE" ]
]
.
174](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-174-320.jpg)
![JoinCondition
• Child Column which must
be the column name that
exists in the logical table
of the TriplesMap that
contains the
RefObjectMap
• Parent Column which
must be the column name
that exists in the logical
table of the
RefObjectMap’s Parent
TriplesMap.
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName”Person" ];
...
rr:predicateObjectMap [
rr:predicate foaf:based_near ;
rr:objectMap [
rr:parentTripelMap <TripleMap2>;
rr:joinCondition [
rr:child “CID”;
rr:parent “CID”;]
]
].
<TriplesMap2>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”City" ];
...
.](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-175-320.jpg)
![JoinCondition
• Child Query
– The Child Query of a
RefObjectMap is the
LogicalTable of the
TriplesMap containing the
RefObjectMap
• Parent Query
– The ParentQuery of a
RefObjectMap is the
LogicalTable of the Parent
TriplesMap
• If the ChildQuery and
ParentQuery are not
identical, then a
JoinCondition must exist
<TriplesMap1>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName”Person" ];
...
rr:predicateObjectMap [
rr:predicate foaf:based_near ;
rr:objectMap [
rr:parentTripelMap <TripleMap2>;
rr:joinCondition [
rr:child “CID”;
rr:parent “CID”;]
]
].
<TriplesMap2>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”City" ];
...
.](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-176-320.jpg)

![@prefix rr: <http://www.w3.org/ns/r2rml#>.
@prefix ex: <http://example.com/ns/>.
<#TriplesMap1>
rr:logicalTable [ rr:tableName ”Student”];
rr:subjectMap [
rr:template "http://example.com/ns/{sid}";
rr:class ex:Student;
];
rr:predicateObjectMap [
rr:predicate ex:hasAdvisor;
RefObjectMap
rr:objectMap [
rr:parentTriplesMap <#TriplesMap2>;
Parent TriplesMap
rr:joinCondition [
rr:child “pid”;
JoinCondition
rr:parent “pid”;
]
]
<#TriplesMap2>
].
rr:logicalTable [ rr:tableName ”Professor”];
rr:subjectMap [
rr:template "http://example.com/ns/{pid}";
rr:class ex:Professor;
].](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-179-320.jpg)

![Languages
• TermMap with a TermType of rr:Literal may
have a language tag
• rr:language <#TriplesMap1>
rr:logicalTable [ rr:tableName ”Student”];
rr:subjectMap [
rr:template "http://example.com/ns/{sid}";
rr:class ex:Student;
];
rr:predicateObjectMap [
rr:predicate ex:comment;
rr:objectMap [
rr:column “comment”;
rr:language “en”;
];
].](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-181-320.jpg)



![Issue with Languages
• Mapping for each language
<#TripleMap_Countries_EN>
a rr:TriplesMap;
rr:logicalTable [ rr:sqlQuery """SELECT COUNTRY_ID, LABEL, LANG, FROM
COUNTRY WHERE LANG = ’en'""" ];
rr:subjectMap [
rr:template "http://example.com/country{COUNTRY_ID}"
];
rr:predicateObjectMap [
rr:predicate rdfs:label;
rr:objectMap [
rr:column “LABEL”;
rr:language “en”;
];
].](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-185-320.jpg)
![Language Extension
• Single mapping for all languages
<#TripleMap_Countries_EN>
a rr:TriplesMap;
rr:logicalTable [ rr:tableName ”COUNTRY" ];
rr:subjectMap [
rr:template "http://example.com/country{COUNTRY_ID}"
];
rr:predicateObjectMap [
rr:predicate rdfs:label;
rr:objectMap [
rr:column “LABEL”;
rrx:languageColumn “LANG”;
];
].
Column Value as Language](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-186-320.jpg)
![Datatypes
• TermMap with a TermType of rr:Literal
• TermMap does not have rr:language
<#TriplesMap1>
rr:logicalTable [ rr:tableName ”Student”];
rr:subjectMap [
rr:template "http://example.com/ns/{sid}";
rr:class ex:Student;
];
rr:predicateObjectMap [
rr:predicate ex:startDate;
rr:objectMap [
rr:column “start_date”;
rr:datatype xsd:date;
];
].](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-187-320.jpg)









![Scale
• MusicBrainz RDF derived via R2RML:
300M
Triples
lb:artist_member a rr:TriplesMap ;
rr:logicalTable [rr:sqlQuery
"""SELECT a1.gid, a2.gid AS band
FROM artist a1
INNER JOIN l_artist_artist ON a1.id =
l_artist_artist.entity0
INNER JOIN link ON l_artist_artist.link = link.id
INNER JOIN link_type ON link_type = link_type.id
INNER JOIN artist a2 on l_artist_artist.entity1 = a2.id
WHERE link_type.gid='5be4c609-9afa-4ea0-910b-12ffb71e3821'"""]
;
rr:subjectMap [rr:template "http://musicbrainz.org/artist/{gid}#_"]
;
rr:predicateObjectMap
[rr:predicate mo:member_of ;
rr:objectMap [rr:template
"http://musicbrainz.org/artist/{band}#_" ;
rr:termType rr:IRI]] .
197](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-197-320.jpg)


![R2RML Class Mapping
• Mapping tables to classes is ‘easy’:
lb:Artist a rr:TriplesMap ;
rr:logicalTable [rr:tableName "artist"] ;
rr:subjectMap
[rr:class mo:MusicArtist ;
rr:template
"http://musicbrainz.org/artist/{gid}#_"] ;
rr:predicateObjectMap
[rr:predicate mo:musicbrainz_guid ;
rr:objectMap [rr:column "gid" ;
rr:datatype xsd:string]] .
RDB2RDF
200](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-200-320.jpg)
![R2RML Property Mapping
• Mapping columns to properties can be easy:
lb:artist_name a rr:TriplesMap ;
rr:logicalTable [rr:sqlQuery
"""SELECT artist.gid, artist_name.name
FROM artist
INNER JOIN artist_name ON artist.name =
artist_name.id"""] ;
rr:subjectMap [rr:template
"http://musicbrainz.org/artist/{gid}#_"] ;
rr:predicateObjectMap
[rr:predicate foaf:name ;
rr:objectMap [rr:column "name"]] .
RDB2RDF
201](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-201-320.jpg)

![Advanced Relations Mapping
• Mapping advanced relationships (SQL joins):
lb:artist_member a rr:TriplesMap ;
rr:logicalTable [rr:sqlQuery
"""SELECT a1.gid, a2.gid AS band
FROM artist a1
INNER JOIN l_artist_artist ON a1.id = l_artist_artist.entity0
INNER JOIN link ON l_artist_artist.link = link.id
INNER JOIN link_type ON link_type = link_type.id
INNER JOIN artist a2 on l_artist_artist.entity1 = a2.id
WHERE link_type.gid='5be4c609-9afa-4ea0-910b-12ffb71e3821'"""] ;
rr:subjectMap [rr:template "http://musicbrainz.org/artist/{gid}#_"] ;
rr:predicateObjectMap
[rr:predicate mo:member_of ;
rr:objectMap [rr:template "http://musicbrainz.org/artist/{band}#_" ;
rr:termType rr:IRI]] .
RDB2RDF
203](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-203-320.jpg)
![Advanced Relations Mapping
• Mapping advanced relationships (SQL joins):
lb:artist_dbpedia a rr:TriplesMap ;
rr:logicalTable [rr:sqlQuery
"""SELECT artist.gid,
REPLACE(REPLACE(url, 'wikipedia.org/wiki',
'dbpedia.org/resource'),
'http://en.',
'http://')
AS url
FROM artist
INNER JOIN l_artist_url ON artist.id = l_artist_url.entity0
INNER JOIN link ON l_artist_url.link = link.id
INNER JOIN link_type ON link_type = link_type.id
INNER JOIN url on l_artist_url.entity1 = url.id
WHERE link_type.gid='29651736-fa6d-48e4-aadc-a557c6add1cb'
AND url SIMILAR TO
'http://(de|el|en|es|ko|pl|pt).wikipedia.org/wiki/%'"""] ;
rr:subjectMap lb:sm_artist ;
rr:predicateObjectMap
[rr:predicate owl:sameAs ;
rr:objectMap [rr:column "url"; rr:termType rr:IRI]] .
RDB2RDF
204](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-204-320.jpg)






![“Comparing the overall performance […] of
the fastest rewriter with the fastest
relational database shows an overhead for
query rewriting of 106%. This is an indicator
that there is still room for improving the
rewriting algorithms”
[Bizer and Schultz 2009]](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-211-320.jpg)


![Current rdb2rdf systems are not capable of
providing the query execution performance
required [...] it is likely that with more work
on query translation, suitable mechanisms
for translating queries could be developed.
These mechanisms should focus on
exploiting the underlying database system’s
capabilities to optimize queries and process
large quantities of structure data
[Gray et al. 2009]](https://image.slidesharecdn.com/rdb2rdftutorialiswc2013-131021011456-phpapp02/85/RDB2RDF-Tutorial-R2RML-and-Direct-Mapping-at-ISWC-2013-214-320.jpg)























































Ad
More Related Content
What's hot (20)
Similar to RDB2RDF Tutorial (R2RML and Direct Mapping) at ISWC 2013 (20)


















Ad
More from Juan Sequeda (20)




















Ad
Recently uploaded (20)




















RDB2RDF Tutorial (R2RML and Direct Mapping) at ISWC 2013
- 1. Relational Database to RDF (RDB2RDF) Tutorial International Semantic Web Conference ISWC2013 Juan F. Sequeda Daniel P. Miranker Barry Norton
- 2. RDB2RDF Tutorial Introduction Juan F. Sequeda Daniel P. Miranker Barry Norton
- 3. What is RDB2RDF? Alice Person ID NAME AGE CID 1 Alice 25 100 2 Bob NULL 100 foaf:name 25 Alice foaf:age <Person/1> foaf:name <Person/2> foaf:based_near City CID NAME 100 Austin 200 Madrid <City/100> <City/200> www.rdb2rdf.org - ISWC2013 foaf:name foaf:name Austin Madrid
- 4. Context RDF Data Management Relational Database to RDF (RDB2RDF) Wrapper Systems Extract-Transform-Load (ETL) Native Triplestores www.rdb2rdf.org - ISWC2013 Triplestores RDBMS-backed NoSQL Triplestores Triplestores
- 5. Outline • Historical Overview • 4 Scenarios • Overview W3C RDB2RDF Standards – Direct Mapping – R2RML www.rdb2rdf.org - ISWC2013
- 9. F2F Meeting ISWC 2008 March 2008 1. Recommendation to standardize a mapping language 2. RDB2RDF Survey October 2008 February 2009 (1) http://www.w3.org/2005/Incubator/rdb2rdf/XGR-rdb2rdf-20090126/ (2) http://www.w3.org/2005/Incubator/rdb2rdf/RDB2RDF_SurveyReport.pdf www.rdb2rdf.org - ISWC2013
- 10. Sept 2012 Sept 2009 www.rdb2rdf.org - ISWC2013
- 11. WD R2RML+DM FPWD DM FPWD R2RML 250 WD R2RML+DM Candidate Rec R2RML + DM Proposed Rec R2RML + DM WD R2RML + DM 200 150 100 50 First F2F @Semtech 2010 www.rdb2rdf.org - ISWC2013 Photo from cygri http://www.flickr.com/photos/cygri/4719458268/ Oct-12 Sep-12 Aug-12 Jul-12 Jun-12 May-12 Apr-12 Mar-12 Feb-12 Jan-12 Dec-11 Nov-11 Oct-11 Sep-11 Aug-11 Jul-11 Jun-11 May-11 Apr-11 Mar-11 Feb-11 Jan-11 Dec-10 Nov-10 Oct-10 Sep-10 Aug-10 Jul-10 Jun-10 May-10 Apr-10 Mar-10 Feb-10 Jan-10 Dec-09 Nov-09 Oct-09 Sep-09 0 Rec R2RML + DM
- 12. Statistics • 206 Actions • 78 Issues – 61 Closed – 17 Postponed • public-rdb2rdf-wg – 3393 emails (Sept 2009 – Oct 2012) • public-rdb2rdf-comments – 200 emails (Sept 2009 – March 2013) www.rdb2rdf.org - ISWC2013
- 13. Outline • Historical Overview • 4 Scenarios • Overview W3C RDB2RDF Standards – Direct Mapping – R2RML www.rdb2rdf.org - ISWC2013
- 14. How to include relational data in a semantic application? • Many architectural design choices. • Technology Development Fluid. • No established “best-of-breed” sol’n. www.rdb2rdf.org - ISWC2013
- 15. Feature Space of Design Choices • Scope of the application – Mash-up topic page – Heterogeneous Enterprise Data Application • Size of the (native) database – Data Model – Contents • Size of the useful (in application) database – Data Model – Contents • When to translate the data? – Wrapper – ETL www.rdb2rdf.org - ISWC2013
- 16. Reduction to 4 Scenario’s www.rdb2rdf.org - ISWC2013
- 17. Scenario 1: Direct Mapping Suppose: • Database of Chinese Herbal Medicine and Applicable Conditions – Database is static. – Herbs and conditions do not have representation in western medical ontologies. www.rdb2rdf.org - ISWC2013
- 18. Scenario 1: Direct Mapping Suppose: • Database of Chinese Herbal Medicine and Applicable Conditions – Database is static. – Herbs and conditions do not have representation in western medical ontologies. SPARQL Relational Database Extract Direct Mapping Engine Triplestore Transform www.rdb2rdf.org - ISWC2013 Load
- 19. Scenario 1: Direct Mapping Suppose: • Database of Chinese Herbal Medicine and Applicable Conditions SPARQL Relational Database Extract Direct Mapping Engine Triplestore Transform Load Then: • Existing table and column names are encoded into URIs • Data is translated into RDF and loaded into an existing, Internet accessible triplestore. www.rdb2rdf.org - ISWC2013
- 20. Scenario 2: R2RML Suppose: • Database of Chinese Herbal Medicine and Applicable Conditions + Clinical Records – Database is static. – Also have, patient names, demographics, outcomes www.rdb2rdf.org - ISWC2013
- 21. Scenario 2: R2RML Suppose: • Database of Chinese Herbal Medicine and Applicable Conditions + Clinical Records Domain Ontologies (e.g FOAF, etc) SPARQL R2RML Mapping Engine R2RML File Extract Triplestore Transform Relational Database www.rdb2rdf.org - ISWC2013 Load
- 22. Scenario 2: R2RML • Database of Chinese Herbal Medicine and Applicable Conditions + Clinical Records Domain Ontologies (e.g FOAF, etc) SPARQL R2RML Mapping Engine R2RML File Extract Triplestore Transform Load Relational Database • Then: – Developer says, “I know FOAF, I’ll write some R2RML and that data will have canonical URIs, and people will be able to use the data”. www.rdb2rdf.org - ISWC2013
- 23. Scenario 4: Automatic Mapping Suppose: • • • • Database of Electronic Medical Records Application, integration of all of a hospitals IT systems Database has 100 tables and a total of 7,000 columns Use of existing ontologies as a unifying data model – ICDE10 codes (> 12,000 concepts) – SNOMED vocabulary (> 40,000 concepts) www.rdb2rdf.org - ISWC2013
- 24. Scenario 4: Automatic Mapping Suppose: • 7,000 Columns • Use of existing ontologies as a unifying data model – ICDE10 codes (> 12,000 concepts) – SNOMED vocabulary (> 40,000 concepts) Then: • Convert the database schema and data to an ontology. SPARQL • Apply ontology alignment program RDF Automatic Mapping Domain Ontologies Source Putative Ontology Refined R2RML Direct Mapping as Ontology RDB2RDF Wrapper Relational Database www.rdb2rdf.org - ISWC2013
- 25. Scenario 4: Automatic Mapping Suppose: • 7,000 Columns • Use of existing ontologies as a unifying data model – ICDE10 codes (> 12,000 concepts) – SNOMED vocabulary (> 40,000 concepts) Then: • A semantic system implements the solution with no human labor SPARQL RDF Automatic Mapping Domain Ontologies Source Putative Ontology Refined R2RML Direct Mapping as Ontology RDB2RDF Wrapper Relational Database www.rdb2rdf.org - ISWC2013
- 26. Scenario 3: Semi-automatic Mapping Domain Ontologies SemiAutomatic Mapping Refined R2RML Source Putative Ontology Direct Mapping as Ontology SPARQL RDF RDB2RDF Wrapper Relational Database www.rdb2rdf.org - ISWC2013
- 27. Outline • Historical Overview • 4 Scenarios • Overview W3C RDB2RDF Standards – Direct Mapping – R2RML www.rdb2rdf.org - ISWC2013
- 28. W3C RDB2RDF Standards • Standards to map relational data to RDF • A Direct Mapping of Relational Data to RDF – Default automatic mapping of relational data to RDF • R2RML: RDB to RDF Mapping Language – Customizable language to map relational data to RDF www.rdb2rdf.org - ISWC2013
- 30. Direct Mapping Relational Database Direct Mapping Engine Input: Database (Schema and Data) Primary Keys Foreign Keys www.rdb2rdf.org - ISWC2013 RDF Output RDF graph
- 31. Direct Mapping Result 25 Alice Person ID NAME <Person#NAME> AGE Alice <Person#AGE> <Person#NAME> CID 1 Alice 25 100 2 Bob NULL 100 City <Person/ID=1> <Person/ID=2> <Person#ref-CID> CID NAME 100 Austin 200 Madrid <Person#ref-CID> <City/CID=100> <City/CID=200> www.rdb2rdf.org - ISWC2013 <Person#NAME> <Person#NAME> Austin Madrid
- 33. R2RML OWL Ontologies (e.g FOAF, etc) R2RML File R2RML Mapping Engine Relational Database www.rdb2rdf.org - ISWC2013 RDF
- 34. Direct Mapping as R2RML @prefix rr: <http://www.w3.org/ns/r2rml#> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/ID={ID}"; rr:class <http://www.ex.com/Person> ]; rr:predicateObjectMap [ rr:predicate <http://www.ex.com/Person#NAME> ; rr:objectMap [rr:column ”NAME" ] ]. www.rdb2rdf.org - ISWC2013
- 35. Customized R2RML @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] www.rdb2rdf.org - ISWC2013 .
- 36. <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName”Person" ]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:based_near ; rr:objectMap [ rr:parentTripelMap <TripleMap2>; rr:joinCondition [ rr:child “CID”; rr:parent “CID”; ] ] <TriplesMap2> ] a rr:TriplesMap; . rr:logicalTable [ rr:tableName ”City" ]; rr:subjectMap [ rr:template "http://ex.com/City/{CID}"; rr:class ex:City ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [ rr:column ”TITLE" ] ] . www.rdb2rdf.org - ISWC2013
- 37. R2RML View @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:sqlQuery “””SELECT ID, NAME FROM Person WHERE gender = “F” “””]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class <http://www.ex.com/Woman> ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] www.rdb2rdf.org - ISWC2013 .
- 39. RDB2RDF Tutorial Direct Mapping Juan F. Sequeda Daniel P. Miranker Barry Norton
- 41. W3C Direct Mapping • Input: – Database (Schema and Data) – Primary Keys – Foreign Keys • Output – RDF graph 41
- 42. What do we need to automatically generate? • Generate Identifiers – IRI – Blank Nodes • Generate Triples – Table – Literal – Reference
- 43. Generating Identifiers • Identifier for rows, tables, columns and foreign keys • If a table has a primary key, – then the row identifier will be an IRI, – otherwise a blank node • The identifiers for table, columns and foreign keys are IRIs • IRIs are generated by appending to a given base IRI • All strings are percent encoded
- 44. Row Node Base IRI “Table Name”/“PK attr”=“PK value” 1) <http://www.ex.com/Person/ID=1> Base IRI “Table Name”/“PK attr”=“PK value” 2) <http://www.ex.com/Person/ID=1;SID=123> 3) Fresh Blank Node
- 45. More IRI Base IRI “Table Name” 1) <http://www.ex.com/Person> Base IRI “Table Name”#“Attribute” 2) <http://www.ex.com/Person#NAME> Base IRI “Table Name”#ref-“Attribute” 3) <http://www.ex.com/Person#ref-CID>
- 49. Direct Mapping Result 25 Alice Person ID NAME <Person#NAME> AGE Alice <Person#AGE> <Person#NAME> CID 1 Alice 25 100 2 Bob NULL 100 City <Person/ID=1> <Person/ID=2> <Person#ref-CID> CID NAME 100 Austin 200 Madrid <Person#ref-CID> <City/CID=100> <City/CID=200> <Person#NAME> <Person#NAME> Austin Madrid 49
- 50. Summary: Direct Mapping • Default and Automatic Mapping • URIs are automatically generated – – – – <table> <table#attribute> <table#ref-attribute> <Table#pkAttr=pkValue> • RDF represents the same relational schema • RDF can be transformed by SPARQL CONSTRUCT – RDF represents the structure and ontology of mapping author’s choice 50
- 51. What else is missing? • Relational Schema to OWL is *not* in the W3C standard • NULL values • Many-to-Many relationships (binary tables) • “Ugly” IRIs 51
- 52. NULL “The direct mapping does not generate triples for NULL values. Note that it is not known how to relate the behavior of the obtained RDF graph with the standard SQL semantics of the NULL values of the source RDB.” A Direct Mapping of Relational Data to RDF. W3C Recommendation 52
- 53. Problem 1. How can a relational database schema and data, be automatically mapped to OWL and RDF? 2. How can we assure correctness of mapping? 53
- 54. Product ptID label prID 10 ACME Inc 4 11 FooBars String 5 String pt:Producer pt:label ex:Producer ex:Product String rdf:type rdf:type Producer prID title loc 4 Foo 5 Bar pt:label pr:title pt:Producer TX NULL FooBars Input • Relational Schema R • Set Σ of Primary Keys PK and Foreign Keys FK over R • Instance I of R ex:Product11 Mapping ex:Producer5 Bar Output • RDF graph • OWL ontology as a graph We need to be careful about two issues • Binary Relations • NULLs 54
- 55. NULLs • What should we do with NULLs? – Generate a Blank Node title loc 4 Bar prID Foo TX 5 Bar NULL ex:Producer5 _:a – Don’t generate a triple pr:title ex:Producer5 Bar How do we reconstruct the NULL? 55
- 56. Direct Mapping Properties • Fundamental Properties – Information Preserving: no information is lost – Query Preserving: no query is lost • Desirable Properties – Monotonicity – Semantics Preserving:
- 57. Information Preservation Direct Mapping RDB Inverse Direct Mapping 57
- 58. Query Preservation Result of Q RDB = Result of Q* Direct Mapping 58
- 60. Semantics Preservation RDB RDB Direct Mapping Direct Mapping 60
- 62. The Nugget • Defined a Direct Mapping DM • Formally defined semantics using Datalog • Considered RDBs that may contain NULL values • Studied DM wrt 4 properties – – – – Information Preservation Query Preservation Monotonicity Semantics Preservation Sequeda, Arenas & Miranker. On Directly Mapping Relational Databases to RDF and OWL. WWW 2012 Sequeda et. al. Survey of Directly Mapping SQL Databases to the Semantic Web. J KER 2011 62 Tirmizi, Sequeda & Miranker. Translating SQL Applications to the Semantic Web. DEXA 2008
- 63. Direct Mapping Input: A relational schema R a set of Σ of primary keys and foreign keys and a database instance I of this schema Output: An RDF Graph Definition: A direct mapping M is a total function from the set of all (R, Σ, I) to the set of all RDF graphs 63
- 64. The Direct Mapping DM • Relational Schema to OWL – S.H. Tirmizi, J.F. Sequeda and D.P. Miranker. Translating SQL Applications to the Semantic Web. DEXA 2008 • Relational Data to RDF – M. Arenas, A. Bertails, E. Prud’hommeaux and J.F. Sequeda. A Direct Mapping of Relational Data to RDF. W3C Recommendation. 27 September 2012 64
- 65. Direct Mapping RDB to RDF and OWL R, Σ I Predicates to store (R, Σ, I) Datalog Rules to generate O from R, Σ Predicates to Store Ontology O Datalog Rules to generate OWL from O Datalog Rules to generate RDF from O and I OWL RDF 65
- 66. Running Example Consider the following relational schema: – person(ssn, name, age) : ssn is the primary key – student(id, degree, ssn) : id is the primary key, ssn is a foreign key to ssn in person Consider the following instance: person student id degree ssn ssn name age 1 Math 789 123 Juan 26 2 EE 456 456 Marcelo 27 3 CS 123 789 Daniel NULL 66
- 67. Input: Relational Schema student • Rel(r) : – Rel(student) • Attr(a, r) : id degree ssn 1 Math 789 2 EE 456 3 CS 123 – Attr(degree, student) • PKn(a1, … , an, r) : – PK1(id, student) • FKn(a1, … , an, r, b1, … , bn, s) : – FK1(ssn, student, ssn, person) 67
- 68. Input: Instances student • Value(v, a, t, r) – – – – – – – – – Value( 1, id, t1, student) Value( Math, degree, t1, student) Value( 789, ssn, t1, student) Value( 2, id, t2, student) Value( EE, degree, t2, student) Value( 456, ssn, t2, student) Value( 3, id, t3, student) Value( CS, degree, t3, student) Value( 123, ssn, t3, student) id degree ssn 1 Math 789 2 EE 456 3 CS 123 68
- 69. Mapping to OWL Triple(http://ex.org/person, rdf:type, owl:Class) Triple(U,"rdf:type","owl:Class") ← Class(R), ClassIRI(R, U) ClassIRI(R, X) ← Class(R), Concat2(base, R, X) Class(X) ← Rel(X), ¬IsBinRel(X) IsBinRel(X) ← BinRel(X, A, B, S, C, T, D) BinRel(R, A, B, S, C, T, D) ← PK2(A, B, R), ¬ThreeAttr(R), FK1(A,R,C,S),R ≠ S, FK1(B,R,D,T),R ≠ T, ¬TwoFK(A, R), ¬TwoFK (B, R), ¬OneFK(A, B, R), ¬FKTo(R) 69
- 70. Mapping to RDF Table triples: for each relation, store the tuples that belongs to it Triple(http://ex.org/person#ssn=123, rdf:type, http://ex.org/person) 70
- 71. Mapping to RDF Table triples: for each relation, store the tuples that belongs to it Triple(http://ex.org/person#ssn=123 , rdf:type, http://ex.org/person ) Literal triples: for each tuple, store the values in each of its attributes Triple(http://ex.org/person#ssn=123 , http://ex.org/person#name , “Juan”) 71
- 72. Mapping to RDF Reference triples: store the references generated by the FKs Triple(http://ex.org/student#id=3 , http://ex.org/student,person#ssn,ssn , http://ex.org/person#ssn=123 ) 72
- 73. Mapping to RDF Triple(http://ex.org/person#ssn=123 , http://ex.org/person#name , “Juan”) Triple(U,V, W) ← DTP(A,R), Value(W, A, T, R), W != NULL. TupleID(T,R,U), DTP_IRI(A,R,V) DTP_IRI(A, R, X) ← DTP(A,R) , Concat4(base, R,”#”, A, X) DTP(A,R) Attr(A,R), ¬IsBinRel(X) TupleID(T, R, X) Class(R), PKn(A1, …, An, R), Value(V1, A1, T, R), …, Value(Vn, An, T, R), RowIRIn(V1, …, Vn, A1, …, An, T, R, X) 73
- 74. Information Preservation M(R, Σ, I) R, Σ I M- (M(R, Σ, I)) Theorem: The Direct Mapping is information preserving Proof: Provide a computable mapping M74
- 75. Relational Algebra tuples vs. SPARQL mappings person ssn 789 name Daniel age NULL t.ssn = 789 t.name = Daniel t.age = NULL Then, tr(t) = μ : • Domain of μ is {?ssn, ?name} • μ(?ssn) = 789 • μ(?name) = Daniel 75
- 76. Query Preservation tr(eval(Q, I)) R, Σ I = eval(Q*, M(R, Σ, I)) M(R, Σ, I) Theorem: The Direct Mapping is query preserving Proof: By induction on the structure of Q Bottom-up algorithm for translating Q into Q* 76
- 77. Example of Query Preservation πname, age( σdegree ≠ EE (student) person) person student id degree ssn ssn name age 1 CS 789 123 Juan 26 2 EE 456 456 Marcelo 27 3 Math 123 789 Daniel NULL 77
- 78. Example of Query Preservation πname, age( σdegree ≠ EE (student) person) SELECT ?id ?degree ?ssn WHERE { ?x rdf:type <…/student>. OPTIONAL{?x <…/student#id> ?id. } OPTIONAL{?x <…/student#degree> ?degree. } OPTIONAL{?x <…/student#ssn> ?ssn. } } student id degree ssn 1 CS 789 2 EE 456 3 Math 123 78
- 79. Example of Query Preservation πname, age( σdegree ≠ EE (student) person) SELECT ?id ?degree ?ssn WHERE { ?x rdf:type <…/student>. OPTIONAL{?x <…/student#id> ?id. } OPTIONAL{?x <…/student#degree> ?degree. } OPTIONAL{?x <…/student#ssn> ?ssn. } FILTER(?degree != “EE” && bound(?degree) ) } student id degree ssn 1 CS 789 2 EE 456 3 Math 123 79
- 80. Example of Query Preservation πname, age( σdegree ≠ EE(student) person) SELECT ?ssn ?name ?age WHERE { ?x rdf:type <…/person>. OPTIONAL{?x <…/person#ssn> ?ssn. } OPTIONAL{?x <…/person#name> ?name. } OPTIONAL{?x <…/person#age > ?age. } } person ssn name age 123 Juan 26 456 Marcelo 27 789 Daniel NULL 80
- 81. πname,age( σdegree ≠ EE(student) SELECT ?name ?age{ {SELECT ?id ?degree ?ssn WHERE { ?x rdf:type <…/student>. OPTIONAL{?x <…/student#id> ?id. } OPTIONAL{?x <…/student#degree> ?degree. } OPTIONAL{?x <…/student#ssn> ?ssn. } FILTER(?degree != “EE” && bound(?degree) ) FILTER(bound(?ssn)} } {SELECT ?ssn?name ?age WHERE { ?x rdf:type <…/person>. OPTIONAL{?x <…/person#ssn> ?ssn. } OPTIONAL{?x <…/person#name> ?name. } OPTIONAL{?x <…/person#age > ?age. } FILTER(bound(?ssn)} } } person) 81
- 82. Monotonicity R, Σ I2 I1 M(R, Σ, I2) I2 M(R, Σ, I1) R, Σ I1 M(R, Σ, I2) M(R, Σ, I1) Theorem: The Direct Mapping is monotone Proof: All negative atoms in the Datalog rules refer to the schema, where the schema is fixed. 82
- 83. Semantics Preservation Consistent under OWL semantics I satisfies Σ R, Σ I M(R, Σ, I) Not consistent under OWL semantics I does not satisfies Σ R, Σ I M(R, Σ, I) 83
- 84. DM is not Semantics Preserving person ssn Juan name 123 Juan 123 DM(R, Σ, I) 123 person#ssn #ssn=123 Marcelo Marcelo ssn is the PK I does not satisfy Σ however DM(R, Σ, I) is consistent under OWL semantics Theorem: No monotone direct mapping is semantics preserving Proof: By contradiction. 84
- 85. Extending DM for Semantics Preservation • Family of Datalog rules to determine violation – Primary Keys – Foreign Keys • Non-monotone direct mapping • Information Preserving • Query Preserving • Semantics Preserving 85
- 86. Summary • The Direct Mapping DM – Formally defined semantics using Datalog – Consider RDBs that may contain NULL values – Monotone, Information and Query Preserving • If you migrate your RDB to the Semantic Web using a monotone direct mapping, be prepared to experience consistency when what one would expect is inconsistency. 86
- 87. W3C Direct Mapping • Only maps Relational Data to RDF – Does not consider schema • Monotone • Not Information Preserving – Because it does not direct map the schema • Not Semantics Preserving 87
- 88. Questions? Next: From Direct Mapping to R2RML
- 89. Backup Slides 89
- 90. DM is not Semantics Preserving PREFIX ex: <http://ex.org/> PREFIX person: <http://ex.org/person#> ex:person rdf:type owl:Class . person:name rdf:type owl:DatatypeProperty ; rdfs:domain ex:person . person:ssn rdf:type owl:DatatypeProperty ; rdfs:domain ex:person . person ssn name 123 Juan 123 DM(R, Σ, I) Marcelo ssn is the PK Juan 123 person#ssn #ssn=123 Marcelo I does not satisfy Σ however DM(R, Σ, I) is consistent under OWL semantics 90
- 91. What about owl:hasKey student • Student/id=NULL, rdf:type Student • Student/id=1, degree, math id degree NULL Math • owl:hasKey can not make me have a value 91
- 92. owl:hasKey student • Tuple 1 – Student/id=1, student#id, 1 – Student/id=1, degree, math id degree 1 Math 1 EE • Tuple 2 – Student/id=1, student#id, 1 – Student/id=1, degree, EE • DM generate the same IRI Student/id=1 for two different tuples. This does not violate owl:hasKey 92
- 93. owl:hasKey student • Tuple 1 – Student/id=1, student#id, 1 – Student/id=1, degree, math id degree 1 Math 1 EE • Tuple 2 – Student/id=1, student#id, 1 – Student/id=1, degree, EE • However, UNA works: – Student/id=1 differentFrom Student/id=1 • However a new DM that generates IRIs based on tuple ids – Owl:hasKey would work 93
- 94. Semantics Preserving DMpk • Find violation of PK • Create artificial triple that will generate contradiction 94
- 95. Semantics Preserving DMpk+fk • Find violation of FK • Create artificial triple that will generate contradiction 95
- 96. RDB2RDF Tutorial From Direct Mapping to R2RML Juan F. Sequeda Daniel P. Miranker Barry Norton
- 98. W3C R2RML • Input – Database (schema and data) – Target Ontologies – Mappings between the Database and Target Ontologies in R2RML • Output – RDF graph 98
- 99. OWL Ontologies (e.g FOAF, etc) R2RML File R2RML Mapping Engine RDF Relational Database Direct Mapping helps to “bootstrap” 99
- 100. Direct Mapping as R2RML 25 Alice Person ID NAME <Person#NAME> AGE Alice <Person#AGE> <Person#NAME> CID 1 Alice 25 100 2 Bob NULL 100 City <Person/ID=1> <Person/ID=2> <Person#ref-CID> CID NAME 100 Austin 200 Madrid <Person#ref-CID> How can this be represented as R2RML? <City/CID=100> <City/CID=200> <Person#NAME> <Person#NAME> Austin Madrid 100
- 101. Direct Mapping as R2RML @prefix rr: <http://www.w3.org/ns/r2rml#> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/ID={ID}"; rr:class <http://www.ex.com/Person> ]; rr:predicateObjectMap [ rr:predicate <http://www.ex.com/Person#NAME> ; rr:objectMap [rr:column ”NAME" ] ]. 101
- 102. Direct Mapping as R2RML @prefix rr: <http://www.w3.org/ns/r2rml#> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; mapped? Logical Table: What is being rr:subjectMap [ rr:template "http://www.ex.com/Person/ID={ID}"; SubjectMap: How to generate the Subject? rr:class <http://www.ex.com/Person> ]; rr:predicateObjectMap [ rr:predicate <http://www.ex.com/Person#NAME> ; PredicateObjectMap: ”NAME" ] rr:objectMap [rr:column How to generate the Predicate and Object? ]. 102
- 103. Logical Table @prefix rr: <http://www.w3.org/ns/r2rml#> . <TriplesMap1> a rr:TriplesMap; What is being mapped? rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/ID={ID}"; rr:class <http://www.ex.com/Person> ]; rr:predicateObjectMap [ rr:predicate <http://www.ex.com/Person#NAME> ; rr:objectMap [rr:column ”NAME" ] ] . 103
- 104. Subject URI Template @prefix rr: <http://www.w3.org/ns/r2rml#> . <TriplesMap1> a rr:TriplesMap; Subject URI rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/ID={ID}"; rr:class <http://www.ex.com/Person> ]; rr:predicateObjectMap [ rr:predicate <http://www.ex.com/Person#NAME> ; rr:objectMap [rr:column ”NAME" ] ] <Subject URI> rdf:type <Class . URI> 104
- 105. Predicate URI Constant @prefix rr: <http://www.w3.org/ns/r2rml#> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; Predicate URI rr:subjectMap [ rr:template "http://www.ex.com/Person/ID={ID}"; rr:class <http://www.ex.com/Person> ]; rr:predicateObjectMap [ rr:predicate <http://www.ex.com/Person#NAME> ; rr:objectMap [rr:column ”NAME" ] ] . 105
- 106. Object Column Value @prefix rr: <http://www.w3.org/ns/r2rml#> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/ID={ID}"; rr:class <http://www.ex.com/Person> ]; rr:predicateObjectMap [ rr:predicate <http://www.ex.com/Person#NAME> ; rr:objectMap [rr:column ”NAME" ] ] . Object Literal 106
- 107. “Ugly” vs “Cool” URIs <http://www.ex.com/Person/ID=1> <http://www.ex.com/Person#NAME> <http://www.ex.com/Person> <http://www.ex.com/Person/1> foaf:name foaf:Person 107
- 108. Customization @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; Customized Subject URI rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] . Customized Class 108
- 109. What if … Person ID NAME GENDER 1 Alice F 2 Bob M <Woman> rdf:type <Person/1> foaf:name Alice R2RML View SELECT ID, NAME FROM Person WHERE GENDER = "F" 109
- 110. R2RML View @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; Query instead of table rr:logicalTable [ rr:sqlQuery “””SELECT ID, NAME FROM Person WHERE gender = “F” “””]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class <http://www.ex.com/Woman> ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] . 110
- 111. Quick Overview of R2RML • Manual and Customizable Language • Learning Curve • Direct Mapping bootstraps R2RML • RDF represents the structure and ontology of mapping author’s choice 111
- 113. RDB2RDF Tutorial R2RML Juan F. Sequeda Daniel P. Miranker Barry Norton
- 114. Outline • • • • • • Logical Tables: What is being mapped Term Maps: How to create RDF terms How to create Triples from a table How to create Triples between two tables Languages Datatypes
- 115. R2RML Mapping Input Database R2RML Mapping Logical Table Logical Table = base table or view or SQL query R2RML View = SQL Query
- 116. R2RML Mapping Student sid name pid 1 Juan 100 2 Martin 200 Professor pid name 100 Dan 200 Marcelo R2RML Mapping ex:Student1 rdf:type ex:Student . ex:Student2 rdf:type ex:Student . ex:Professor100 rdf:type ex:Professor . ex:Professor200 rdf:type ex:Professor . ex:Student1 foaf:name “Juan”. …
- 117. R2RML Mapping • A R2RML Mapping M consists of a finite set TM TripleMaps. • Each TM ∈TM consists of a tuple (LT, SM, POM) – LT: LogicalTable – SM: SubjectMap – POM: PredicateObjectMap • Each POM∈POM consists of a pair (PM, OM)* – PM: PredicateMap – OM: ObjectMap * For simplicity
- 118. R2RML Mapping • An R2RML Mapping is represented as an RDF Graph itself. • Associated RDFS schema – http://www.w3.org/ns/r2rml • Turtle is the recommended syntax
- 119. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] . 119
- 120. LogicalTable • Tabular SQL query result that is to be mapped to RDF – rr:logicalTable 1. SQL base table or view – rr:tableName 2. R2RML View – rr:sqlQuery
- 121. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] . 121
- 122. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:sqlQuery “””SELECT ID, NAME FROM Person WHERE gender = “F” “””]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class <http://www.ex.com/Woman> ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] .
- 124. How to create RDF terms that define S, P and O? • RDF term is either an IRI, a blank node, or a literal • Answer 1. Constant Value 2. Value in the database a. Raw Value in a Column b. Column Value applied to a template
- 125. TermMap • A TermMap is a function that generates an RDF Term from a logical table row. • RDF Term is either a IRI, or a Blank Node, or a Literal RDF Term TermMap Logical Table Row IRI Bnode Literal
- 126. TermMap • A TermMap must be exactly on of the following – Constant-valued TermMap – Column-valued TermMap – Template-valued TermMap • If TermMaps are used to create S, P, O, then – 3 ways to create a subject – 3 ways to create a predicate – 3 ways to create an object
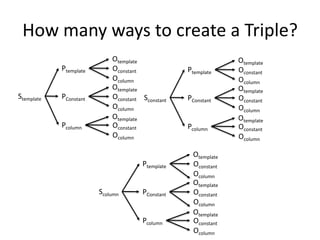
- 127. How many ways to create a Triple? Ptemplate Stemplate PConstant Pcolumn Otemplate Oconstant Ocolumn Otemplate Oconstant Sconstant Ocolumn Otemplate Oconstant Ocolumn Ptemplate Scolumn PConstant Pcolumn Ptemplate PConstant Pcolumn Otemplate Oconstant Ocolumn Otemplate Oconstant Ocolumn Otemplate Oconstant Ocolumn Otemplate Oconstant Ocolumn Otemplate Oconstant Ocolumn Otemplate Oconstant Ocolumn
- 128. Constant-valued TermMap • A TermMap that ignores the logical table row and always generates the same RDF term • rr:constant • Commonly used to generate constant IRIs as the predicate
- 129. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name ] rr:objectMap [rr:column ”NAME" ] ] . 129
- 130. Column-valued TermMap • A TermMap that maps a column value of a column name in a logical table row • rr:column • Commonly used to generate Literals as the object
- 131. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name ] rr:objectMap [rr:column ”NAME" ] ] . 131
- 132. Template-valued TermMap • A TermMap that maps the column values of a set of column names to a string template. • A string template is a format that can be used to build strings from multiple components. • rr:template • Commonly used to generate IRIs as the subject or concatenate different attributes
- 133. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name ] rr:objectMap [rr:column ”NAME" ] ] . 133
- 134. Commonly used… • … but any of these TermMaps can be used to create any RDF Term (s,p,o). Recall: – 3 ways to create a subject – 3 ways to create a predicate – 3 ways to create an object • Template-valued TermMap are commonly used to create an IRI for a subject, but can be used to create Literal for an object. • How to specify the term (IRI or Literal in this case)?
- 135. TermType • Specify the type of a term that a TermMap should generate • Force what the RDF term should be • Three types of TermType: – rr:IRI – rr:BlankNode – rr:Literal
- 136. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name ] rr:objectMap [ rr:template ”{FIRST_NAME} {LAST_NAME}”; rr:termType rr:Literal; ] ] . 136
- 137. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template ”person{ID}"; rr:termType rr:BlankNode; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name ] rr:objectMap [rr:column ”NAME" ] ] . 137
- 138. TermType (cont…) • Can only be applied to Template and Column valued TermMap • Applying to Constant-valued TermMap has no effect – i.e If the constant is an IRI, the term type is automatically an IRI
- 139. TermType Rules • If the Term Map is for a 1. Subject TermType = IRI or Blank Node 2. Predicate TermType = IRI 3. Object TermType = IRI or Blank Node or Literal
- 140. TermType is Optional • If a TermType is not specified then – Default = IRI – Unless it’s for an object being defined by a Column-based TermMap or has a language tag or specified datatype, then the TermType is a Literal • That’s why if there is a template in an ObjectMap, it will always generate an IRI, unless a TermType to Literal is specified.
- 141. rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name ] rr:objectMap [ rr:template ”{FIRST_NAME} {LAST_NAME}”; rr:termType rr:Literal; ] ] rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name ] rr:objectMap [ rr:template ”{FIRST_NAME} {LAST_NAME}” ] ] rr:predicateObjectMap [ rr:predicateMap [rr:constant ex:role ] rr:objectMap [ rr:template ”http://ex.com/role/{role}” ] ] 141
- 143. Now we have the elements to create Triples
- 144. Generating SPO • TermMap that specifies what RDF term should be for S, P, O – SubjectMap – PredicateMap – ObjectMap
- 145. SubjectMap • • • • SubjectMap is a TermMap rr:subjectMap Specifies what the subject of a triple should be 3 ways to create a subject – Template-valued Term Map – Column-valued Term Map – Constant-valued Term Map • Has to be an IRI or Blank Node
- 146. SubjectMap • SubjectMaps are usually Template-valued TermMap • Use-case for Column-valued TermMap – Use a column value to create a blank node – URI exist as a column value • Use-case for Constant-valued TermMap – For all tuples: <CompanyABC> <consistsOf> <Dep{id}>
- 147. SubjectMap • Optionally, a SubjectMap may have one or more Class IRIs associated – This will generate rdf:type triples • rr:class
- 148. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] . Optional 148
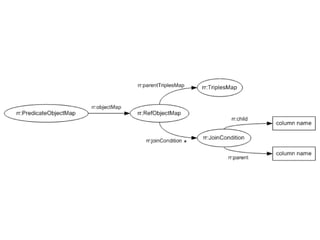
- 149. PredicateObjectMap • A function that creates one or more predicateobject pairs for each logical table row. • rr:predicateObjectMap • It is used in conjunction with a SubjectMap to generate RDF triples in a TriplesMap. • A predicate-object pair consists of* – One or more PredicateMaps – One or more ObjectMaps or ReferencingObjectMaps
- 150. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name]; [rr:column ”NAME" ] ] . rr:objectMap 150
- 151. PredicateMap • PredicateMap is a TermMap • rr:predicateMap • Specifies what the predicate of a triple should be • 3 ways to create a predicate – Template-valued Term Map – Column-valued Term Map – Constant-valued Term Map • Has to be an IRI
- 152. PredicateMap • PredicateMaps are usually Constant-valued TermMap • Use-case for Column-valued TermMap –… • Use-case for Template-valued TermMap –…
- 153. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name]; rr:objectMap [rr:column ”NAME" ] ] . 153
- 154. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; Shortcut! rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [rr:column ”NAME" ] ] . 154
- 155. Constant Shortcut Properties • ?x rr:predicate ?y • ?x rr:predicateMap [ rr:constant ?y ] • ?x rr:subject ?y • ?x rr:subjectMap [ rr:constant ?y ] • ?x rr:object ?y • ?x rr:objectMap [ rr:constant ?y ]
- 156. ObjectMap • • • • ObjectMap is a TermMap rr:objectMap Specifies what the object of a triple should be 3 ways to create a predicate – Template-valued Term Map – Column-valued Term Map – Constant-valued Term Map • Has to be an IRI or Literal or Blank Node
- 157. ObjectMap • ObjectMaps are usually Column-valued TermMap • Use-case for Template-valued TermMap – Concatenate values – Create IRIs • Use-case for Constant-valued TermMap – All rows in a table share a role
- 158. @prefix rr: <http://www.w3.org/ns/r2rml#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”Person”]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicateMap [rr:constant foaf:name]; rr:objectMap [rr:column ”NAME" ] ] . 158
- 160. Example 1 • We now have sufficient elements to create a mapping that will generate – A Subject IRI – rdf:Type triple(s) Student sid name pid 1 Juan 100 2 Martin 200 TripleMap @prefix ex: <http://example.com/ns/>. ex:Student1 rdf:type ex:Student . ex:Student2 rdf:type ex:Student .
- 161. Example 1 @prefix rr: <http://www.w3.org/ns/r2rml#>. @prefix ex: <http://example.com/ns/>. <#TriplesMap1> rr:logicalTable [ rr:tableName ”Student”]; rr:subjectMap [ rr:template "http://example.com/ns/{sid}"; rr:class ex:Student; ]. Logical Table is a Table Name SubjectMap is a Template-valued TermMap And it has one Class IRI
- 162. Example 2 Student sid name pid 1 Juan 100 2 Martin 200 TripleMap @prefix ex: <http://example.com/ns/>. ex:Student1 rdf:type ex:Student . ex:Student1 ex:name “Juan” . ex:Student2 rdf:type ex:Student . ex:Student2 ex:name “Martin” .
- 163. Example 2 @prefix rr: <http://www.w3.org/ns/r2rml#>. @prefix ex: <http://example.com/ns/>. <#TriplesMap1> rr:logicalTable [ rr:tableName ”Student”]; rr:subjectMap [ rr:template "http://example.com/ns/{sid}"; rr:class ex:Student; ]; rr:predicateObjectMap [ rr:predicate ex:name; rr:objectMap [ rr:column “name”]; ]. PredicateMap which is a Constant-valued TermMap Logical Table is a Table Name SubjectMap is a Template-valued TermMap And it has one Class IRI PredicateObjectMap ObjectMap which is a Column-valued TermMap
- 164. Example 3 Student sid name pid 1 Juan 100 2 Martin 200 TripleMap @prefix ex: <http://example.com/ns/>. ex:Student1 rdf:type ex:Student . ex:Student1 ex:comment “Juan is a Student” . ex:Student2 rdf:type ex:Student . ex:Student2 ex:comment “Martin is a Student” .
- 165. Example 3 @prefix rr: <http://www.w3.org/ns/r2rml#>. @prefix ex: <http://example.com/ns/>. <#TriplesMap1> rr:logicalTable [ rr:tableName ”Student”]; rr:subjectMap [ rr:template "http://example.com/ns/{sid}"; rr:class ex:Student; ]; rr:predicateObjectMap [ rr:predicate ex:comment; rr:objectMap [ rr:template “{name} is a Student”; rr:termType rr:Literal; ]; ]. PredicateMap which is a Constant-valued TermMap Logical Table is a Table Name SubjectMap is a Template-valued TermMap And it has one Class IRI PredicateObjectMap ObjectMap which is a Template-valued TermMap TermType
- 166. Example 4 Student sid name pid 1 Juan 100 2 Martin 200 TripleMap @prefix ex: <http://example.com/ns/>. ex:Student1 rdf:type ex:Student . ex:Student1 ex:webpage <http://ex.com/Juan>. ex:Student2 rdf:type ex:Student . ex:Student2 ex:webpage <http://ex.com/Martin>.
- 167. Example 4 @prefix rr: <http://www.w3.org/ns/r2rml#>. @prefix ex: <http://example.com/ns/>. <#TriplesMap1> rr:logicalTable [ rr:tableName ”Student”]; rr:subjectMap [ rr:template "http://example.com/ns/{sid}"; rr:class ex:Student; ]; rr:predicateObjectMap [ rr:predicate ex:webpage; rr:objectMap [ rr:template “http://ex.com/{name}”; ]; ]. PredicateMap which is a Constant-valued TermMap Logical Table is a Table Name SubjectMap is a Template-valued TermMap And it has one Class IRI PredicateObjectMap ObjectMap which is a Template-valued TermMap Note that there is not TermType
- 168. Example 5 Student sid name pid 1 Juan 100 2 Martin 200 TripleMap @prefix ex: <http://example.com/ns/>. ex:Student1 rdf:type ex:Student . ex:Student1 ex:studentType ex:GradStudent. ex:Student2 rdf:type ex:Student . ex:Student2 ex:studentType ex:GradStudent.
- 169. Example 6 @prefix rr: <http://www.w3.org/ns/r2rml#>. @prefix ex: <http://example.com/ns/>. <#TriplesMap1> rr:logicalTable [ rr:tableName ”Student”]; rr:subjectMap [ rr:template "http://example.com/ns/{sid}"; rr:class ex:Student; ]; rr:predicateObjectMap [ rr:predicate ex:studentType; rr:object ex:GradStudent ; ]. PredicateMap which is a Constant-valued TermMap Logical Table is a Table Name SubjectMap is a Template-valued TermMap And it has one Class IRI PredicateObjectMap ObjectMap which is a Constant-valued TermMap
- 170. RefObjectMap • A RefObjectMap (Referencing ObjectMap) allows using the subject of another TriplesMap as the object generated by a ObjectMap. • rr:objectMap • A RefObjectMap defined by – Exactly one ParentTripleMap, which must be a TripleMap – May have one or more JoinConditions
- 171. <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName”Person" ]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:based_near ; rr:objectMap [ rr:parentTripelMap <TripleMap2>; rr:joinCondition [ rr:child “CID”; rr:parent “CID”; ] ] <TriplesMap2> ] a rr:TriplesMap; . rr:logicalTable [ rr:tableName ”City" ]; RefObjectMap rr:subjectMap [ rr:template "http://ex.com/City/{CID}"; rr:class ex:City ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [ rr:column ”TITLE" ] ] . 171
- 172. ParentTripleMap • The referencing TripleMap • rr:parentTriplesMap <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName”Person" ]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:based_near ; rr:objectMap [ rr:parentTripelMap <TripleMap2>; rr:joinCondition [ rr:child “CID”; rr:parent “CID”; ] ] ] . Parent TriplesMap
- 173. JoinCondition • Join between child and parent attribuets • rr:joinCondition <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName”Person" ]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:based_near ; rr:objectMap [ rr:parentTripelMap <TripleMap2>; rr:joinCondition [ rr:child “CID”; rr:parent “CID”; ] ] ] . JoinCondition
- 174. <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName”Person" ]; rr:subjectMap [ rr:template "http://www.ex.com/Person/{ID}"; rr:class foaf:Person ]; rr:predicateObjectMap [ rr:predicate foaf:based_near ; rr:objectMap [ rr:parentTripelMap <TripleMap2>; rr:joinCondition [ rr:child “CID”; rr:parent “CID”; ] ] <TriplesMap2> ] a rr:TriplesMap; . rr:logicalTable [ rr:tableName ”City" ]; RefObjectMap Parent TriplesMap JoinCondition rr:subjectMap [ rr:template "http://ex.com/City/{CID}"; rr:class ex:City ]; rr:predicateObjectMap [ rr:predicate foaf:name; rr:objectMap [ rr:column ”TITLE" ] ] . 174
- 175. JoinCondition • Child Column which must be the column name that exists in the logical table of the TriplesMap that contains the RefObjectMap • Parent Column which must be the column name that exists in the logical table of the RefObjectMap’s Parent TriplesMap. <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName”Person" ]; ... rr:predicateObjectMap [ rr:predicate foaf:based_near ; rr:objectMap [ rr:parentTripelMap <TripleMap2>; rr:joinCondition [ rr:child “CID”; rr:parent “CID”;] ] ]. <TriplesMap2> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”City" ]; ... .
- 176. JoinCondition • Child Query – The Child Query of a RefObjectMap is the LogicalTable of the TriplesMap containing the RefObjectMap • Parent Query – The ParentQuery of a RefObjectMap is the LogicalTable of the Parent TriplesMap • If the ChildQuery and ParentQuery are not identical, then a JoinCondition must exist <TriplesMap1> a rr:TriplesMap; rr:logicalTable [ rr:tableName”Person" ]; ... rr:predicateObjectMap [ rr:predicate foaf:based_near ; rr:objectMap [ rr:parentTripelMap <TripleMap2>; rr:joinCondition [ rr:child “CID”; rr:parent “CID”;] ] ]. <TriplesMap2> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”City" ]; ... .
- 178. Example 7 Student sid name pid 1 Juan 100 2 Martin 200 Professor pid name 100 Dan 200 Marcelo R2RML Mapping ex:Student1 rdf:type ex:Student . ex:Student2 rdf:type ex:Student . ex:Professor100 rdf:type ex:Professor . ex:Professor200 rdf:type ex:Professor . ex:Student1 ex:hasAdvisor ex:Professor100 . ex:Student2 ex:hasAdvisor ex:Professor200
- 179. @prefix rr: <http://www.w3.org/ns/r2rml#>. @prefix ex: <http://example.com/ns/>. <#TriplesMap1> rr:logicalTable [ rr:tableName ”Student”]; rr:subjectMap [ rr:template "http://example.com/ns/{sid}"; rr:class ex:Student; ]; rr:predicateObjectMap [ rr:predicate ex:hasAdvisor; RefObjectMap rr:objectMap [ rr:parentTriplesMap <#TriplesMap2>; Parent TriplesMap rr:joinCondition [ rr:child “pid”; JoinCondition rr:parent “pid”; ] ] <#TriplesMap2> ]. rr:logicalTable [ rr:tableName ”Professor”]; rr:subjectMap [ rr:template "http://example.com/ns/{pid}"; rr:class ex:Professor; ].
- 180. Summary
- 181. Languages • TermMap with a TermType of rr:Literal may have a language tag • rr:language <#TriplesMap1> rr:logicalTable [ rr:tableName ”Student”]; rr:subjectMap [ rr:template "http://example.com/ns/{sid}"; rr:class ex:Student; ]; rr:predicateObjectMap [ rr:predicate ex:comment; rr:objectMap [ rr:column “comment”; rr:language “en”; ]; ].
- 182. Student sid name comment 1 Juan Excellent Student 2 Martin Wonderful student @prefix ex: <http://example.com/ns/>. ex:Student1 rdf:type ex:Student . ex:Student1 ex:comment “Excellent Student”@en . ex:Student2 rdf:type ex:Student . ex:Student2 ex:comment “Wonderful Student”@en .
- 183. Issue with Languages • What happens if language value is in the data? ID COUNTRY_ID LABEL LANG 1 1 United States en 2 1 Estados Unidos es 3 2 England en 4 2 Inglaterra es
- 184. ID COUNTRY_ID LABEL LANG 1 1 United States en 2 1 Estados Unidos es 3 2 England en 4 2 Inglaterra es ? @prefix ex: <http://example.com/ns/>. ex:country1 rdfs:label “United States”@en . ex:country1 rdfs:label “Estados Unidos”@es . ex:country2 rdfs:label “England”@en . ex:country2 rdfs:label “Inglaterra”@es .
- 185. Issue with Languages • Mapping for each language <#TripleMap_Countries_EN> a rr:TriplesMap; rr:logicalTable [ rr:sqlQuery """SELECT COUNTRY_ID, LABEL, LANG, FROM COUNTRY WHERE LANG = ’en'""" ]; rr:subjectMap [ rr:template "http://example.com/country{COUNTRY_ID}" ]; rr:predicateObjectMap [ rr:predicate rdfs:label; rr:objectMap [ rr:column “LABEL”; rr:language “en”; ]; ].
- 186. Language Extension • Single mapping for all languages <#TripleMap_Countries_EN> a rr:TriplesMap; rr:logicalTable [ rr:tableName ”COUNTRY" ]; rr:subjectMap [ rr:template "http://example.com/country{COUNTRY_ID}" ]; rr:predicateObjectMap [ rr:predicate rdfs:label; rr:objectMap [ rr:column “LABEL”; rrx:languageColumn “LANG”; ]; ]. Column Value as Language
- 187. Datatypes • TermMap with a TermType of rr:Literal • TermMap does not have rr:language <#TriplesMap1> rr:logicalTable [ rr:tableName ”Student”]; rr:subjectMap [ rr:template "http://example.com/ns/{sid}"; rr:class ex:Student; ]; rr:predicateObjectMap [ rr:predicate ex:startDate; rr:objectMap [ rr:column “start_date”; rr:datatype xsd:date; ]; ].
- 188. Summary of Terminology • • • • • • • • • • • • R2RML Mapping Logical Table Input Database R2RML View TriplesMap Logical Table Row TermMap TermType SubjectMap PredicateObjectMap PredicateMap ObjectMap • • • • • • • • • Constant-valued TermMap Column-valued TermMap Template-valued TermMap RefObjectMap JoinConditions ChildQuery ParentQuery Language Datatype
- 189. Questions? Next: ETL and Musicbrainz
- 190. RDB2RDF Tutorial ETL and Musicbrainz Juan F. Sequeda Daniel P. Miranker Barry Norton
- 191. Context RDF Data Management Relational Database to RDF (RDB2RDF) Wrapper Systems Extract-Transform-Load (ETL) Native Triplestores Triplestores RDBMS-backed NoSQL Triplestores Triplestores 191
- 192. Extract – Transform – Load (ETL) SPARQL Relational Database RDB2RDF Dump Triplestore
- 193. Analysis & Mining Module Visualization Module RDFa Data acquisition LD Dataset Access Application EUCLID Scenario SPARQL Endpoint Publishing Vocabulary Mapping Interlinking Physical Wrapper Integrated Dataset Cleansing LD Wrapper R2R Transf. LD Wrapper RDF/ XML Streaming providers Downloads Musical Content Metadata Other content 193
- 194. W3C RDB2RDF Data acquisition LD Dataset Access SPARQL Endpoint Publishing Integrated Data in Triplestore Vocabulary Mapping • Task: Integrate data from relational DBMS with Linked Data Interlinking • Approach: map from relational schema to semantic vocabulary with R2RML R2RML Engine Cleansing • Publishing: two alternatives – – Translate SPARQL into SQL on the fly – Batch transform data into RDF, index and provide SPARQL access in a triplestore Relational DBMS RDB2RDF 194
- 195. MusicBrainz Next Gen Schema • artist As pre-NGS, but further attributes • artist_credit Allows joint credit • release_group Cf. ‘album’ versus: • work • release • track • medium • tracklist • recording https://wiki.musicbrainz.org/Next_Generation_Schema RDB2RDF 195
- 196. Music Ontology • MusicArtist – ArtistEvent, member_of • SignalGroup ‘Album’ as per Release_Group • Release – ReleaseEvent • • • • Record Track Work Composition http://musicontology.com/ RDB2RDF 196
- 197. Scale • MusicBrainz RDF derived via R2RML: 300M Triples lb:artist_member a rr:TriplesMap ; rr:logicalTable [rr:sqlQuery """SELECT a1.gid, a2.gid AS band FROM artist a1 INNER JOIN l_artist_artist ON a1.id = l_artist_artist.entity0 INNER JOIN link ON l_artist_artist.link = link.id INNER JOIN link_type ON link_type = link_type.id INNER JOIN artist a2 on l_artist_artist.entity1 = a2.id WHERE link_type.gid='5be4c609-9afa-4ea0-910b-12ffb71e3821'"""] ; rr:subjectMap [rr:template "http://musicbrainz.org/artist/{gid}#_"] ; rr:predicateObjectMap [rr:predicate mo:member_of ; rr:objectMap [rr:template "http://musicbrainz.org/artist/{band}#_" ; rr:termType rr:IRI]] . 197
- 198. Musicbrainz • Musicbrainz Dumps: – http://mbsandbox.org/~barry/ • Musicbrainz R2RML Mappings – https://github.com/LinkedBrainz/MusicBrainz-R2RML • 30 mins to generate 150M triples with Ultrawrap – 8 Xeon cores, 16 GB Ram (2GB are usually free) – Should be less but server was overloaded – It use to be 8+ hours using D2RQ on a dedicated machine
- 199. Musicbrainz Dump Statistics (Lead) Table area artist dbpedia label medium recording release_group release track work Triples 59798 36868228 172017 201832 18069143 11400354 3050818 9764887 75506495 1728955 156822527 Time (s) 2 423 13 3 163 209 31 151 794 20 1809
- 200. R2RML Class Mapping • Mapping tables to classes is ‘easy’: lb:Artist a rr:TriplesMap ; rr:logicalTable [rr:tableName "artist"] ; rr:subjectMap [rr:class mo:MusicArtist ; rr:template "http://musicbrainz.org/artist/{gid}#_"] ; rr:predicateObjectMap [rr:predicate mo:musicbrainz_guid ; rr:objectMap [rr:column "gid" ; rr:datatype xsd:string]] . RDB2RDF 200
- 201. R2RML Property Mapping • Mapping columns to properties can be easy: lb:artist_name a rr:TriplesMap ; rr:logicalTable [rr:sqlQuery """SELECT artist.gid, artist_name.name FROM artist INNER JOIN artist_name ON artist.name = artist_name.id"""] ; rr:subjectMap [rr:template "http://musicbrainz.org/artist/{gid}#_"] ; rr:predicateObjectMap [rr:predicate foaf:name ; rr:objectMap [rr:column "name"]] . RDB2RDF 201
- 202. NGS Advanced Relations • Major entities (Artist, Release Group, Track, etc.) plus URL are paired (l_artist_artist) • Each pairing of instances refers to a Link • Links have types (cf. RDF properties) and attributes http://wiki.musicbrainz.org/Advanced_Relationship RDB2RDF 202
- 203. Advanced Relations Mapping • Mapping advanced relationships (SQL joins): lb:artist_member a rr:TriplesMap ; rr:logicalTable [rr:sqlQuery """SELECT a1.gid, a2.gid AS band FROM artist a1 INNER JOIN l_artist_artist ON a1.id = l_artist_artist.entity0 INNER JOIN link ON l_artist_artist.link = link.id INNER JOIN link_type ON link_type = link_type.id INNER JOIN artist a2 on l_artist_artist.entity1 = a2.id WHERE link_type.gid='5be4c609-9afa-4ea0-910b-12ffb71e3821'"""] ; rr:subjectMap [rr:template "http://musicbrainz.org/artist/{gid}#_"] ; rr:predicateObjectMap [rr:predicate mo:member_of ; rr:objectMap [rr:template "http://musicbrainz.org/artist/{band}#_" ; rr:termType rr:IRI]] . RDB2RDF 203
- 204. Advanced Relations Mapping • Mapping advanced relationships (SQL joins): lb:artist_dbpedia a rr:TriplesMap ; rr:logicalTable [rr:sqlQuery """SELECT artist.gid, REPLACE(REPLACE(url, 'wikipedia.org/wiki', 'dbpedia.org/resource'), 'http://en.', 'http://') AS url FROM artist INNER JOIN l_artist_url ON artist.id = l_artist_url.entity0 INNER JOIN link ON l_artist_url.link = link.id INNER JOIN link_type ON link_type = link_type.id INNER JOIN url on l_artist_url.entity1 = url.id WHERE link_type.gid='29651736-fa6d-48e4-aadc-a557c6add1cb' AND url SIMILAR TO 'http://(de|el|en|es|ko|pl|pt).wikipedia.org/wiki/%'"""] ; rr:subjectMap lb:sm_artist ; rr:predicateObjectMap [rr:predicate owl:sameAs ; rr:objectMap [rr:column "url"; rr:termType rr:IRI]] . RDB2RDF 204
- 205. SPARQL Example • SPARQL versus SQL ASK {dbp:Paul_McCartney mo:member dbp:The_Beatles} SELECT … INNER INNER INNER INNER INNER INNER INNER INNER INNER INNER INNER INNER WHERE JOIN JOIN JOIN JOIN JOIN JOIN JOIN JOIN JOIN JOIN JOIN JOIN AND … AND … AND … AND … RDB2RDF 205
- 206. For exercises, quiz and further material visit our website: http://www.euclid-project.eu Course eBook Other channels: @euclid_project EUCLID project EUCLIDproject 206
- 208. RDB2RDF Tutorial Wrappers Juan F. Sequeda Daniel P. Miranker Barry Norton
- 209. Context RDF Data Management Relational Database to RDF (RDB2RDF) Wrapper Systems Extract-Transform-Load (ETL) Native Triplestores Triplestores RDBMS-backed NoSQL Triplestores Triplestores 209
- 211. “Comparing the overall performance […] of the fastest rewriter with the fastest relational database shows an overhead for query rewriting of 106%. This is an indicator that there is still room for improving the rewriting algorithms” [Bizer and Schultz 2009]
- 212. Results of BSBM 2009 Larger numbers are better http://wifo5-03.informatik.uni-mannheim.de/bizer/berlinsparqlbenchmark/results/index.html
- 213. Results of BSBM 2009 100M Triple Dataset Larger numbers are better After March 2009, RDB2RDF systems have not been compared to RDBMS http://wifo5-03.informatik.uni-mannheim.de/bizer/berlinsparqlbenchmark/results/index.html
- 214. Current rdb2rdf systems are not capable of providing the query execution performance required [...] it is likely that with more work on query translation, suitable mechanisms for translating queries could be developed. These mechanisms should focus on exploiting the underlying database system’s capabilities to optimize queries and process large quantities of structure data [Gray et al. 2009]
- 217. Why is this happening if …
- 218. “SPARQL is equivalent, from an expressive point of you, to relational algebra” Angles & Gutierrez 2008
- 219. Problem • How can SPARQL queries be efficiently evaluated on a RDBMS? • Hypothesis: Existing commercial relational database already subsume optimizations for effective SPARQL execution on relationally stored data 219
- 220. Nugget 1. Defined architecture based on SQL Views which allows RDBMS to do the optimization. 2. Identified two important optimizations that already exist in commercial RDBMS. Sequeda & Miranker. Ultrawrap: SPARQL Execution on Relational Data. Journal Web Semantics 2013 220
- 221. Ultrawrap Compile Time 1. Translate SQL Schema to OWL and Mapping 2. Define RDF Triples, as a View Run Time 3. SPARQL to SQL translation 4. SQL Optimizer creates relational query plan 221
- 222. Creating Tripleview • For every ontology element (Class, Object Property and Datatype property), create a SQL SELECT query that outputs triples SELECT 'Product’+ptID as s, ‘label’ as p, label as o FROM Product WHERE label IS NOT NULL Product ptID label prID S P O 1 ACME Inc 4 Product1 label ACME Inc 2 Foo Bars Product2 label Foo Bars 5 222
- 223. Creating Tripleview SELECT ‘Product’+ptID as s, prID as s_id, ‘label’ as p, label as o, NULL as o_id FROM Product WHERE label IS NOT NULL Product ptID label prID S S_id P O O_id 1 ACME Inc 4 Product1 1 label ACME Inc NULL 2 Foo Bars Product2 2 label Foo Bars NULL 5 223
- 224. Class RDF Triples SELECT ‘Product’+ptID as s, prID as s_id, ‘rdf:type’ as p, ‘Product’ as o, NULL as o_id FROM Product S S_id P O O_id Product1 1 rdf:type Product NULL Product2 2 rdf:type Product NULL Object Property RDF Triples SELECT ‘Product’+ptID as s, ptID as s_id, ‘Product#Producer’ as p, ‘Producer’+prID as o, prID as o_id FROM Product S S_id P O O_id Product1 1 Product#Producer Producer4 4 Product2 2 Product#Producer Producer5 5
- 225. Creating Tripleview (…) • Create TripleViews (SQL View), which are unions of the SQL SELECT query that have the same datatype CREATE VIEW Tripleview_varchar AS SELECT ‘Product’+ptID as s, ptID as s_id, ‘label’ as p, label as o, NULL as o_id FROM Product UNION ALL SELECT ‘Producer’+prID as s, prID as s_id, ‘title’ as p, title as o, NULL as o_id FROM Producer UNION ALL … S S_id P O O_id Product1 1 label ACME Inc NULL Product2 2 label Foo Bars NULL Producer4 4 title Foo NULL Producer5 5 Ttitle Bars NULL 225
- 226. CREATE VIEW Tripleview_int AS SELECT ‘Product’+ptID as s, ptID as s_id, ‘pnum1’ as p, pnum1 as o, NULL as o_id FROM Product UNION ALL SELECT ‘Product’+ptID as s, ptID as s_id, ‘pnum2’ as p, pnum2 as o, NULL as o_id FROM Product S S_id P O O_id Product1 1 pnum1 1 NULL Product2 2 pnum1 3 NULL Product1 1 pnum2 2 NULL Product2 2 pnum2 3 NULL
- 227. SPARQL and SQL • Translating a SPARQL query to a semantically equivalent SQL query SELECT ?label ?pnum1 WHERE{ ?x label ?label. ?x pnum1 ?pnum1. } SQL on Tripleview SELECT label, pnum1 FROM product What is the Query Plan? SELECT t1.o AS label, t2.o AS pnum1 FROM tripleview_varchar t1, tripleview_int t2 WHERE t1.p = 'label' AND t2.p = 'pnum1' AND t1.s_id = t2.s_id 227
- 228. π t1.o AS label, t2.o AS pnum1 σp = ‘label’ Tripleview_varchar t1 σp = ‘pnum1’ Tripleview_int t2 CONTRADICTION CONTRADICTION U U π Product+’id’ AS s , ‘pnum2’ AS p, pnum2 AS o π Product+’id’ AS s , ‘pnum1’ AS p, pnum1 AS o π Producer+’id’ AS s , ‘title’ AS p, title AS o σpnum2 ≠ NULL π Product+’id’ AS s , ‘label’ AS p, label AS o σpnum1 ≠ NULL σtitle ≠ NULL Product σlabel ≠ NULL Product Product Producer 228
- 229. Detection of Unsatisfiable Conditions • Determine that the query result will be empty if the existence of another answer would violate some integrity constraint in the database. • This would imply that the answer to the query is null and therefore the database does not need to be accessed Chakravarthy, Grant and Minker. (1990) Logic-Based Approach to Semantic Query Optimization. 229
- 230. π t1.o AS label, t2.o AS pnum1 π Product+’id’ AS s , ‘label’ AS p, label AS o π Product+’id’ AS s , ‘pnum1’ AS p, pnum1 AS o σlabel ≠ NULL σpnum1 ≠ NULL Product Product Join on the same table? REDUNDANT 230
- 231. Self Join Elimination • If attributes from the same table are projected separately and then joined, then the join can be dropped Self Join Elimination of Projection SELECT p1.label, p2.pnum1 FROM product p1, product p2 WHERE p1.id = 1 and p1.id = p2.id SELECT label, pnum1 FROM product WHERE id = 1 Self Join Elimination of Selection SELECT p1.id FROM product p1, product p2 WHERE p1.pnum1 >100 and p2.pnum2 < 500 and p1.id = p2.id SELECT id FROM product WHERE pnum1 > 100 and pnum2 < 500 231
- 232. π label, pnum1 σlabel ≠ NULL AND pnum1 ≠ NULL Product 232
- 233. Evaluation • Use Benchmarks that stores data in relational databases, provides SPARQL queries and their semantically equivalent SQL queries • BSBM - 100 Million Triples • Barton – 45 million triples
- 235. Ultrawrap Experiment
- 236. Augmented Ultrawrap Experiment • Implemented DoUC – Hash predicate to SQL query – Few LOC
- 237. SPARQL as Fast as SQL Berlin Benchmark on 100 Million Triples on Oracle 11g using Ultrawrap 237
- 238. Discussion • Self join elimination • Push Selects and Join Predicates • Join Ordering • Left Outer Join
Editor's Notes
- #54: Goal of Slide: What is the Problem and My Contribution IP: No information is being lost. Ability of reconstructing the original database from the result of the direct mappingQP: No query is being lostEvery relational query over a RDB can be translated to a equivalent SPARQL query over directly mapped RDF.
- #55: Goal of Slide: Example of MappingIt seems easy… however, there are special issues
- #56: Goal of Slide: NULLs is an issue where this is not straightforward
- #58: Why is this hard and important because of NULLs. Need to be able to reconstruct the original database instance with nulls======The inverse direct mapping N : G -> I must be computable A mapping is computable if there exists an algorithm that, given G ∈ G, computes N (G).
- #59: Why is this hard and important because of NULLs.
- #60: Why is this hard and important adding new data won’t make you rerun the complete mapping
- #66: Goal of Slide: How does the Direct Mapping work?5 Predicates for RDB12 Rules for RDB -> Ontology3 Predicates for Ontology10 Rules for Ontology -> OWL10 Rules for Ontology + Instances -> RDFW3C Standard only has the 10 rules for Ontology + Instances -> RDF
- #70: R is a binary relation between two relations S and T if both S and T are different from R, R has exactly two attributes A and B, which form a primary key of R, A is the attribute of a foreign key in R that points to S, B is the attribute of a foreign key in R that points to T , A is not the attribute of two distinct foreign keys in R, B is not the attribute of two distinct foreign keys in R, A and B are not the attributes of a composite foreign key in R, and relation R does not have incoming foreign keys.
- #75: Goal of Slide: What is Information PreservationAbility of reconstructing the original database from the result of the direct mappingMapping is losslessNo information is being lostWhy is this hard and important because of NULLs. Need to be able to reconstruct the original database instance with nulls
- #77: Goal of Slide: What is Query PreservationEvery relational query over a RDB can be translated to a equivalent SPARQL query over directly mapped RDF. WHAT ABOUT SPARQL -> SQLopen issue is to prove that for any sparql query, there exist a relational algebra query. my future work aims at proving a more general result:for any mapping between any db and any ontologythis would be a corrollary.
- #83: Goal of Slide: What is MonotonicityDesired PropertyAssures that a re-computation of the entire mapping is not needed after any updates to the DB
- #84: Goal of Slide: What is Semantics PreservationSatisfaction of a set of integrity constraints are encoded in the mapping result
- #85: Goal of Slide: Monotone can’t be Semantics Preserving
- #91: Does this mean that our direct mapping is incorrect? What could we do to create a direct mapping that is semantics preserving?
- #153: Getty has a use case for Column-valued TermMap
- #213: These numbers are Query Mixes per Hour. Each query mix consists of 25 queries that represent ecommerce navigationThe reduced query mix takes out 2 types of queries (query 5 and 6) You can see the sparql and semantically equivalent sql here: http://www4.wiwiss.fu-berlin.de/bizer/BerlinSPARQLBenchmark/spec/ExploreUseCase/index.htmlThey were taken out because Q5: has “complex” FiltersQ6: has free text search
- #220: Goal of Slide: What is the Problem and My Contribution ----- Meeting Notes (5/8/13 18:03) -----assuming wrapper
- #223: A first implementation naively represented the relational data as RDF using only three columnsWe observe that the preconditions for applying optimizations were not being satisfied Indexes were not being exploited
- #224: With this refinement, the preconditions for applying optimizations were being satisfied Indexes were being exploited
- #226: Another precondition for applying optimization was the objects in the views need to be have the same datatype
- #228: Goal of the Slide = What is the SPARQL to SQL translationTV(X, ‘label’, Y) <- Product(X, Y, _)TV(X, ‘pnum1’, Z) <- Product(X, _, Z)Q(S,T) <-TV(X, ‘label’, S), TV(X, ‘pnum1’, T) Q(S,T) <-Product(X, S, _), Product(X, _, T)