RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
61 likes60,325 views

2016/05/25 de:code2016での、渡部の講演資料になります

![自己紹介
{"ID" :"fetaro"
"名前" :"渡部 徹太郎"
"所属" :株式会社リクルートテクノロジーズ
"研究" :"東京工業大学でデータベースと情報検索の研究
(@日本データベース学会)"
"仕事" :["証券会社のオンライントレードシステムのWeb基盤",
"オープンソースなら何でも。主にMongoDB",
"リクルート各種サービスを横断的分析する基盤。主にHadoop"]
"エディタ":"emacs派"
"趣味":"自宅サーバ"
"属性" : ["ギーク","スーツ"]}
fetaro
RDB技術者のためのNoSQLガイド 2](https://image.slidesharecdn.com/20160525watanabe-160602065426/85/RDB-NoSQL-NoSQL-2-320.jpg)


![背景:3つのVの増加
• Volume(データ量)の増加
• Googleは1日に24ペタバイトのデー
タを処理している
• facebookの写真は1.5ペタバイト
スケールアップ スケールアウト
コントローラ
性能限界
高コスト+構造上の限界限界有り
CPU↑
メモリ↑
ディスク↑ RDB
RDB技術者のためのNoSQLガイド 5
• Velocity(処理速度)の増加
• orange(大規模Web)サービス秒間11万アクセス
• マウスの軌跡を解析→秒間万単位の書き込み
• twitter 「バルス」で秒間14万つぶやき
[課題] RDBではビッグデータの扱いが困難](https://image.slidesharecdn.com/20160525watanabe-160602065426/85/RDB-NoSQL-NoSQL-5-320.jpg)
![背景: 3つのVの増加
• Variety(多様性)の増加
社内 社外
非リレー
ショナル
データ
非構造
半構造
リレーショ
ナルデータ
構造化
オフィス文章
システムロ
グ
テキスト・音声
(顧客対応履
歴)電子メール
経理・財務・
人事
営業・CRM
センサー
情報 位置・地
図
SNS
マルチメ
ディア
他社が保
有する
データ
気象・交
通
健康・医
療
各種統計 行政 金融取引
商品・在庫
決済・残高
口コミ文
章
RDB技術者のためのNoSQLガイド 6
[課題] 半構造データはRDBでは格納が困難
Schema on Write < Schema on Read](https://image.slidesharecdn.com/20160525watanabe-160602065426/85/RDB-NoSQL-NoSQL-6-320.jpg)
![RDBだと厳しい身近なケース
• 「Twitterのデータを分析して商品評判を知りたい。プロトを3日で作ってくれ」
TwitterのAPIが返却するデータ(JSON)
• この状況でこのデータをRDBMSにいれますか??
{
"_id" : ObjectId("55b93f4bb427f0c12e080473"),
"created_at" : "Wed Jul 29 20:57:42 +0000 2015",
"id" : 626496848031690800,
"text" : "@mchris4duke and certainly not concious, for a f
moment, of their prejudices",
"source" : "<a href=¥"http://twitter.com¥" rel=¥"nofollow
Web Client</a>",
"truncated" : false,
"in_reply_to_status_id" : 626496667957751800,
"in_reply_to_screen_name" : "mchris4duke",
"user" : {
"id" : 772136,
"id_str" : "772136",
"name" : "Greg Smith",
"place" : null,
"contributors" : null,"retweet_count" : 0,
"favorite_count" : 0,
"entities" : {
"hashtags" : [ ],
"trends" : [ ],
"urls" : [ ],
"user_mentions" : [
{
"screen_name" : "mchris4duke",
"name" : "Chris Bourg",
"id" : 14093339,
"id_str" : "14093339",
"indices" : [0,12]
ここは一対多
これは何桁ある
んだろう?
なんか、前と変
わってるような ここも一対多
テーブルは3つに分けて、
JOINを2回するしかない
RDB技術者のためのNoSQLガイド 7](https://image.slidesharecdn.com/20160525watanabe-160602065426/85/RDB-NoSQL-NoSQL-7-320.jpg)





















![データモデル JSON
{
ID : 12345 ,
name :"渡部”,
address : {
City :"東京”,
ZipNo :"045-3356”,
}
friendID : [ 3134 , 10231 , 10974 , 11165 ] ,
hobbies :
[
{ name :"自宅サーバ","year": 6 } ,
{ name :"プログラミング","year": 10 } ,
配列
サブドキュメントの配
列
キーと値
サブドキュメント](https://image.slidesharecdn.com/20160525watanabe-160602065426/85/RDB-NoSQL-NoSQL-30-320.jpg)
![データモデル リレーショナルとの比較
{
id: 10
name: "マトリクス"
tag : ["SF", "キアヌ", "ハリウッド"]
}
id name
10 "マトリクス"
11 "天空の城ラピュタ"
JSON
id movie_id value
1 10 "SF"
2 10 "キアヌ"
3 10 "ハリウッド"
4 11 "ファンタジー"
5 11 "宮崎駿"
6 11 "ジブリ"
リレーショナル
movieテーブル
tagテーブル
・全貌が分からない
・データ構造を事前に定
義する必要がある
・読みやすい
・全貌がわかる
・データ変更に対応できる
{
Id: 11
name: "天空の城ラピュタ"
tag : ["ファンタジー", "宮崎駿","ジブリ"]
}](https://image.slidesharecdn.com/20160525watanabe-160602065426/85/RDB-NoSQL-NoSQL-31-320.jpg)
![データモデル キーバリューとの比較
{
id: 10
name: "マトリクス"
tag : ["SF", "キアヌ", "ハリウッド"]
}
JSON
・読みやすい
・全貌がわかる
・データ変更に対応できる
{
Id: 11
name: "天空の城ラピュタ"
tag : ["ファンタジー", "宮崎駿","ジブリ"]
}
キーバリュー
・複雑なデータ構造だと
扱いが困難
key value
10-name "マトリクス"
10-tag-0 "SF"
10-tag-1 "キアヌ"
10-tag-2 "ハリウッド"
11-name "天空の城ラピュ
タ"
11-tag-0 "ファンタジー"
11-tag-1 "宮崎駿"
11-tag-2 "ジブリ"](https://image.slidesharecdn.com/20160525watanabe-160602065426/85/RDB-NoSQL-NoSQL-32-320.jpg)










































Ad
More Related Content
What's hot (20)
Viewers also liked (7)





Ad
Similar to RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ (20)








![[db tech showcase OSS 2017] A14: IoT時代のデータストア--躍進するNoSQL、拡張するRDB by OSSコンソーシア...](https://cdn.slidesharecdn.com/ss_thumbnails/20170616dbtechshowcaseossyoshida-170621081930-thumbnail.jpg?width=560&fit=bounds)











Ad
More from Recruit Technologies (20)




















RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
- 2. 自己紹介 {"ID" :"fetaro" "名前" :"渡部 徹太郎" "所属" :株式会社リクルートテクノロジーズ "研究" :"東京工業大学でデータベースと情報検索の研究 (@日本データベース学会)" "仕事" :["証券会社のオンライントレードシステムのWeb基盤", "オープンソースなら何でも。主にMongoDB", "リクルート各種サービスを横断的分析する基盤。主にHadoop"] "エディタ":"emacs派" "趣味":"自宅サーバ" "属性" : ["ギーク","スーツ"]} fetaro RDB技術者のためのNoSQLガイド 2
- 3. 書籍について • ギーク向けではなく、一般のRDB技術者向け • NoSQLの位置づけを明確化 (Hadoop, DWHとの違い) • エンタープライズの課題を解決する視点 • NoSQL界のスペシャリスト達による最新情報 • 評価良好!4.3点→ RDB技術者のためのNoSQLガイド 3
- 5. 背景:3つのVの増加 • Volume(データ量)の増加 • Googleは1日に24ペタバイトのデー タを処理している • facebookの写真は1.5ペタバイト スケールアップ スケールアウト コントローラ 性能限界 高コスト+構造上の限界限界有り CPU↑ メモリ↑ ディスク↑ RDB RDB技術者のためのNoSQLガイド 5 • Velocity(処理速度)の増加 • orange(大規模Web)サービス秒間11万アクセス • マウスの軌跡を解析→秒間万単位の書き込み • twitter 「バルス」で秒間14万つぶやき [課題] RDBではビッグデータの扱いが困難
- 6. 背景: 3つのVの増加 • Variety(多様性)の増加 社内 社外 非リレー ショナル データ 非構造 半構造 リレーショ ナルデータ 構造化 オフィス文章 システムロ グ テキスト・音声 (顧客対応履 歴)電子メール 経理・財務・ 人事 営業・CRM センサー 情報 位置・地 図 SNS マルチメ ディア 他社が保 有する データ 気象・交 通 健康・医 療 各種統計 行政 金融取引 商品・在庫 決済・残高 口コミ文 章 RDB技術者のためのNoSQLガイド 6 [課題] 半構造データはRDBでは格納が困難 Schema on Write < Schema on Read
- 7. RDBだと厳しい身近なケース • 「Twitterのデータを分析して商品評判を知りたい。プロトを3日で作ってくれ」 TwitterのAPIが返却するデータ(JSON) • この状況でこのデータをRDBMSにいれますか?? { "_id" : ObjectId("55b93f4bb427f0c12e080473"), "created_at" : "Wed Jul 29 20:57:42 +0000 2015", "id" : 626496848031690800, "text" : "@mchris4duke and certainly not concious, for a f moment, of their prejudices", "source" : "<a href=¥"http://twitter.com¥" rel=¥"nofollow Web Client</a>", "truncated" : false, "in_reply_to_status_id" : 626496667957751800, "in_reply_to_screen_name" : "mchris4duke", "user" : { "id" : 772136, "id_str" : "772136", "name" : "Greg Smith", "place" : null, "contributors" : null,"retweet_count" : 0, "favorite_count" : 0, "entities" : { "hashtags" : [ ], "trends" : [ ], "urls" : [ ], "user_mentions" : [ { "screen_name" : "mchris4duke", "name" : "Chris Bourg", "id" : 14093339, "id_str" : "14093339", "indices" : [0,12] ここは一対多 これは何桁ある んだろう? なんか、前と変 わってるような ここも一対多 テーブルは3つに分けて、 JOINを2回するしかない RDB技術者のためのNoSQLガイド 7
- 8. RDBの課題の一部を解決するDBが登場 RDB技術者のためのNoSQLガイド 8 スケールアウト アプリ 性能限界 水平分散で性能向上 アプリ 大量データ処理 高速データ処理 半構造 データ処理 KVS/ ドキュメント データベース グラフ データベース 課題 解決するDB 事前に構造を定義する必要がない 「スキーマ・オン・リード」 CREATE TABLE ALTER TABLEJSONが格納できる RDB
- 9. RDBの課題の一部を解決するDBが登場 RDB技術者のためのNoSQLガイド 9 スケールアウト アプリ 性能限界 水平分散で性能向上 アプリ 大量データ処理 高速データ処理 半構造 データ処理 KVS/ ドキュメント データベース グラフ データベース 課題 解決するDB 事前に構造を定義する必要がない 「スキーマ・オン・リード」 CREATE TABLE ALTER TABLEJSONが格納できる RDB
- 11. DBを重視する性能で分類 • レスポンスを重視 →主にオペレーション用途 • スループットを重視 →主に分析用途 11 アプリケーションサーバ オペレーション 用途 データベース登録画面 リクエスト 参照 更新 挿入 参照画面 編集画面 即時応答 マスタ データベース BIツール 集計 バッチで ロード 分析用途 データベース レポート生成ジョ ブ 抽出 CSV バッチで ロード レポート 20分で全件集計 10秒で全件取得 RDB技術者のためのNoSQLガイド
- 12. NoSQLの位置づけ 凡例 レスポンス重視 (オペレーション用途) スループット重視 (分析用途) スケールアウトできる Hadoop (HDFS+MapReduce) ・Cloudera ・MapR ・Hortonworks RDB(OLTP) ・Oracle ・SQL Server ・MySQL グラフDB ・Neo4j RDB(DWH) ・Oracle Exadata ・Netezza ・RedShift 登場順 KVS ・Cassandra ・Redis ドキュメントDB ・MongoDB ・Couchbase NoSQL
- 13. RDB(OLTP)とKVS/ドキュメントDBの違い • RDB(OLTP)とは違い、 以下の3つによりスケーラビリティを獲得 1. トランザクションを提供しない 2. 分散しやすいデータモデルと、分散しやすいクエリだけを提供 する 3. 「強い整合性」を犠牲にして、複製に対して読み書きを行う 「結果整合性」を採用
- 14. RDB(OLTP)とKVS/ドキュメントDBの違い アプリケーション アプリケーション スケールアウト構成 整合性は 保証される ②準備OK ④コミット ②準備OK ④コミット ②準備OK ④コミット ①コミット準備の確認 ③コミット指示 アプリケーション アプリケーション 待たされる A B C 分散トランザクションで ABCを一括更新 アプリケーション 待たされる待たされる
- 15. RDB(OLTP)とKVS/ドキュメントDBの違い アプリケーション スケールアウト構成 更新 一括更新はできないので A→B→C の順番で更新 A B C 更新 アプリケーション アプリケーション アプリケーション アプリケーション 更新 更新 更新 待たない 更新 更新 割り込まれて 整合性が 崩れる 可能性あり
- 16. KVS/ドキュメントDBとHadoopとの違い RDB技術者のためのNoSQLガイド 16 分散ファイルシステム (HDFS等) 分散処理フレームワーク (MapReduce, Spark等) ABC A B C クライアント 計算 ノード 計算 ノード 計算 ノード コーディネータ ①データの配布 ②提出 ③計算 計算 結果 プログラム プログラム クライアント プログラムプログラム KVS/ ドキュメントDB シャード シャード シャード A クエリルータ B C アプリアプリ クエリ クエリ
- 17. データベースは互いの領域に進出している RDB技術者のためのNoSQLガイド 17 レスポンス重視 (オペレーション用途) スループット重視 (分析用途) スケールアップするしかない スケールアウトできるKVS/ドキュメントDB RDB(OLTP) RDB(DWH) Hadoop 分析もできる KVS/ドキュメントDB ・MongoDB ・Cassandra JSONを格納する RDB(OLTP) ・MySQL ・PostgreSQL ・IBM DB2 オペレーション もできるDWH ・SAP HANA 応答が速くて SQLが使えるHadoop ・Impala ・Presto ・Hive on Tez スケールアウトも できるDWH ・Oracle Exadata ・Teradata ・Neteeza ・Greenplum ・Vertica SQLが使える KVS/ドキュメントDB ・DocumentDB ・Cassandra
- 19. NoSQLの分類 RDB技術者のためのNoSQLガイド 19 NoSQL ー NoSQL プロダ クト KVS(キーバリューストア) ドキュメントDB RDB グラフDB データ モデル キーバリュー ワイドカラム ドキュメント(JSON) リレーショナ ルモデル グラフ データ 構造 キー 値 キー 値 array hash 階層構造 ノード リレー ション ノード ノード リレー ション データの複雑度 大小 処理の分散がしやすい 複雑なデータ処理が可能 キー 列
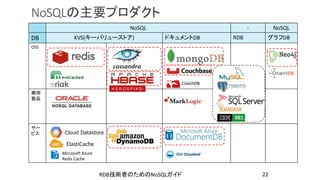
- 22. NoSQL - NoSQL DB KVS(キーバリューストア) ドキュメントDB RDB グラフDB OSS 商用 製品 サー ビス NoSQLの主要プロダクト RDB技術者のためのNoSQLガイド 22 ElastiCache Microsoft Azure Redis Cache
- 23. DB ENGINESによるランキング 23 以下の指標を総合的に判断 ・ウェブでのシステム名称の登場回数 (Google, Bing) ・一般的な人気度 (Google Trends) ・技術的なディスカッションの頻度 (Stack Overflowなど) ・求人サイトにおける募集スキル (Indeed, Simply Hired) ・プロフィール登場回数 (LinkedIn) (出所)DB ENGINES http://db-engines.com/en/ranking RDB技術者のためのNoSQLガイド
- 26. その他本書で紹介していること • 統一した観点で、代表プロダクトの最新情報を説明 • 想定されるユースケース(多数掲載) • RDBの課題を解決するNoSQLプロダクトの選び方 RDB技術者のためのNoSQLガイド 26 • データモデル • API • 性能拡張 • 高可用 • 運用 • セキュリティ • 出来ないこと • 主要バージョンと特徴 • 国内サポート体制
- 28. 目次
- 30. データモデル JSON { ID : 12345 , name :"渡部”, address : { City :"東京”, ZipNo :"045-3356”, } friendID : [ 3134 , 10231 , 10974 , 11165 ] , hobbies : [ { name :"自宅サーバ","year": 6 } , { name :"プログラミング","year": 10 } , 配列 サブドキュメントの配 列 キーと値 サブドキュメント
- 31. データモデル リレーショナルとの比較 { id: 10 name: "マトリクス" tag : ["SF", "キアヌ", "ハリウッド"] } id name 10 "マトリクス" 11 "天空の城ラピュタ" JSON id movie_id value 1 10 "SF" 2 10 "キアヌ" 3 10 "ハリウッド" 4 11 "ファンタジー" 5 11 "宮崎駿" 6 11 "ジブリ" リレーショナル movieテーブル tagテーブル ・全貌が分からない ・データ構造を事前に定 義する必要がある ・読みやすい ・全貌がわかる ・データ変更に対応できる { Id: 11 name: "天空の城ラピュタ" tag : ["ファンタジー", "宮崎駿","ジブリ"] }
- 32. データモデル キーバリューとの比較 { id: 10 name: "マトリクス" tag : ["SF", "キアヌ", "ハリウッド"] } JSON ・読みやすい ・全貌がわかる ・データ変更に対応できる { Id: 11 name: "天空の城ラピュタ" tag : ["ファンタジー", "宮崎駿","ジブリ"] } キーバリュー ・複雑なデータ構造だと 扱いが困難 key value 10-name "マトリクス" 10-tag-0 "SF" 10-tag-1 "キアヌ" 10-tag-2 "ハリウッド" 11-name "天空の城ラピュ タ" 11-tag-0 "ファンタジー" 11-tag-1 "宮崎駿" 11-tag-2 "ジブリ"
- 33. API • • 表現力豊かなクエリ • 強力なインデックス • セカンダリインデックス:主キー以外でインデックスを作成可能 • 複合キーインデックス:複数のキーでインデックスを作成可能 • マルチキーインデックス:配列の要素に対してインデックス作成可能 • 集計できる(集計中はJOINもできる) • データバリデーションできる db.person.find( {"name":"watanabe","age": 30 } ).limit(3)
- 34. 性能拡張 x ドキュメント チャンク シャードキーに基 づいて ルーティング シャードキー 範囲 0-9 範囲10-19 範囲20- アプリケーション mongosルータ 1 4 9 11 16 20 27 MongoDB ドライバ 23 23 mongod mongod mongod シャードキー で分散 自動的に 再配置
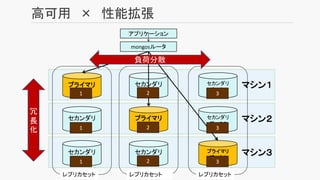
- 35. 高可用 • 仮想IPなどを用意しなくてもフェイルオーバが可能 (≒クラスタソフトウェアが不要) アプリケーション プライマリ 1 4 9 セカンダリ 1 4 9 セカンダリ 1 4 MongoDBドライバ 9 書き レプリカセット 読み 非同期 で複製 読み プライマリ 1 4 9 プライマリ 1 4 9 セカンダリ 1 4 9 アプリケーション MongoDBドライバ 書き 読み読み 自動フェイル オーバ レプリカセット 書き込み はプライマ リのみ
- 39. 運用
- 41. できないこと • • • • • • ⇒ver 3.0で解決 • • ⇒ ver 3.2で解決 ユーザ1 取引1 取引2 ユーザ1 取引1 取引2 ドキュ メント 参照 制約 結合 トランザクション
- 42. ユースケース Webアプリ・オンラインゲーム • KVSでは扱えないデータの複雑さ • ユーザが一気に増えた時に、 RDBでは性能の拡張が難しい • そもそもデータ量が多すぎて RDBでは現実的なコストで扱えない app Mongo Mongoapp Mongo app Mongo Mongo Mongo Mongo Mongo Mongo 急なユーザ増加にも、水 平分散で簡単に対応で きる 課題 選定理由・解決策 結果 •MySQLがスケーラビリティの上限に達して性能要 件を達成できなくなった •RBMSでは非定型なメタデータの管理が困難 •性能とスケーラビリティに期待しMongoDBを導入 •60億におよぶ属性情報データの代わりに、1コン テンツを1ドキュメントにする構造を導入 •秒間11万件以上のクエリに対応 •3年で200万ドル以上のコスト削減 •新規機能の導入のスピードが著しく早くなった •新規プロジェクトでは全てMongoDBを利用する方 針となった 活用事例: orange(Webサービス事業) 700万ユーザを超えるWebサービスのバックグラウンドDB
- 43. ユースケース ログ管理 • フォーマットが違っても、JSON で吸収 • インデックスを貼って高速に検 索 • レプリケーションしておけばロス トする心配もない • FluentdならばFluentdのタグが そのままMongoDBのコレクショ ン名になる • 台数が増えたらスケールアウト すれば良い • 高度なトランザクションは不要
- 44. ユースケース カタログ管理 • RDBでは列の定義が膨大になる • エンジニアでなくてもデータの全貌 がわかる • データ追加項目が容易 Mongo app カタログ (JSON) 課金情報等 (リレーショナル) 既存 新規 トランザクションが必要な課金は 従来通りRDBMSで一貫性を担保 読みやすい。 項目追加も簡単。 カタログ管理 RDBMS 課題 選定理由・解決策 結果 •RDBMSベースの旧システムでは商品カタログの アップデートに12時間かかった •JSONがスキーマレスでかつ複雑なデータ構造を 格納できるので、商品データを入れるのには最 適だった •カタログのアップデートに要する時間が12時間か ら15分になり、ビジネス環境の変化に応じて迅速 にカタログを変更できるようになった 活用事例: OTTO 毎日200万人が利用する大手Eコマースサイトの商品カタログを管理
- 45. ユースケース アジャイル • スキーマの変更不要 • 直観的にデータを表現できるため、データの扱 いが簡単 • ORマッパーを使う必要なし • アプリ開発をサポートする機能が充実 • ハッカソンでは常連DB • 近年のWeb開発フレームワークに採用されてい る 機能 ユースケース GridFS 大容量ファイルの管理 地理空間インデッ クス 地図アプリ 集計機能 データの集計 旧データ自動削除 ログ保管