Real-World Machine Learning - Leverage the Features of MapR Converged Data Platform
1 like1,327 views

Examine the unique features of the MapR Converged Data Platform and how they can support production-grade enterprise machine learning - Ends with a live demo using H2O - Presented at Hadoop Summit Tokyo 2016


















![© 2014 MapR Technologies 21
MapR NFS and Volumes
[mapr@ip-10-0-0-110 mapr]$ pwd
/mapr/hadoopsummit/user/mapr](https://image.slidesharecdn.com/hadoopsummittokyo2016-161028021146/85/Real-World-Machine-Learning-Leverage-the-Features-of-MapR-Converged-Data-Platform-21-320.jpg)
![© 2014 MapR Technologies 22
MapR NFS and Volumes
[mapr@ip-10-0-0-110 mapr]$ pwd
/mapr/hadoopsummit/user/mapr](https://image.slidesharecdn.com/hadoopsummittokyo2016-161028021146/85/Real-World-Machine-Learning-Leverage-the-Features-of-MapR-Converged-Data-Platform-22-320.jpg)
![© 2014 MapR Technologies 23
MapR NFS and Volumes
[mapr@ip-10-0-0-110 mapr]$ pwd
/mapr/hadoopsummit/user/mapr](https://image.slidesharecdn.com/hadoopsummittokyo2016-161028021146/85/Real-World-Machine-Learning-Leverage-the-Features-of-MapR-Converged-Data-Platform-23-320.jpg)










![© 2014 MapR Technologies 34
Snapshots
[... mateusz]$ cd .snapshot
[... .snapshot]$ ll
total 1
drwxr-xr-x. 2 mapr mapr 1 Oct 14 10:56
mateusz.snap1](https://image.slidesharecdn.com/hadoopsummittokyo2016-161028021146/85/Real-World-Machine-Learning-Leverage-the-Features-of-MapR-Converged-Data-Platform-34-320.jpg)














































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Real-World Machine Learning - Leverage the Features of MapR Converged Data Platform (20)




















Ad
More from Mathieu Dumoulin (6)






Recently uploaded (20)




















Real-World Machine Learning - Leverage the Features of MapR Converged Data Platform
- 1. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential © 2016 MapR Technologies1 Real-World Machine Learning - Leverage the Features of MapR Converged Data Platform Mathieu Dumoulin ([email protected]) Mateusz Dymczyk ([email protected]) Hadoop Summit Tokyo 2016
- 2. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 2 Today’s goals • Machine Learning projects in the Enterprise have a LOT of requirements beyond training a good ML model • Current options are too complex • Need a Converged Data Platform • Introduce specific features useful for ML: – MapR-FS, Volumes, Mirrors and Topologies – MapR-DB and MapR Streams
- 3. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 3 Mathieu Dumoulin, Data Engineer • Master’s degree in text classification on Hadoop at Fujitsu Canada’s Innovation Lab • In Tokyo, I’ve worked as a Data Scientist, Search Engineer and Data Engineer • I like Scikit-Learn and H2O • 日本料理が大好き。とくに鍋としゃ ぶしゃぶです。
- 4. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 4 Mateusz Dymczyk, Software Engineer • M.Sc. in CS (Software and System Engineering) @ AGH UST, Poland • Ph.D. (Machine Learning) dropout • Software Engineer @ H2O.ai • Previously ML/NLP @ Fujitsu Laboratories and en-japan inc • I’m taking Sommelier classes
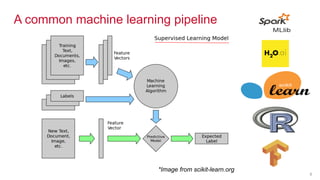
- 5. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 5 A common machine learning pipeline *Image from scikit-learn.org
- 6. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 6 … meets the real world (Enterprise IT)
- 7. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 7 … meets the real world Data comes from many sources maybe very large Data isn’t always labeled!
- 8. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 8 … meets the real world Data comes from many sources, maybe very large Needs ETL and cleaning Finding the best algorithm and parameters can use a lot of CPU Data isn’t always labeled!
- 9. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 9 … Meets the real world Data comes from many sources, maybe very large Needs ETL and cleaning Finding the best algorithm and parameters can use a lot of CPU Data isn’t always labeled! From production systems? Is it real time? What server will serve predictions? The predictions are used by another system...
- 10. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 10 Machine learning here...
- 11. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 11 Is not the same when you do it here
- 12. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 12 Enterprise machine learning matters Growing number of ML use cases at successful companies Anomaly Detection 異常検出 Customer 360 Fraud Detection 不正検出 Log Security Analysis ログ分析 Recommender Engines レコメンデーション Sensor Data Analysis (IoT) Personalized Offers 個人化 Ad Tech
- 13. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 13 …but it’s HARD Ref: http://advancedspark.com/ , https://github.com/fluxcapacitor/pipeline
- 14. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 14 There must be a better way...
- 15. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 15 Big data Enterprise IT infrastructure for ML • You can start simple and show value quickly • It just works. Easy configuration and administration. • Works with existing systems, and tools • Includes common basics (File storage, DB, Streams) • Strong ecosystem support (Apache projects) • Enterprise class (multi-tenancy, security, HA, support) An ideal platform for ML:
- 16. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential © 2016 MapR Technologies 16 MapR Converged Data Platform
- 17. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 17 MapR Converged Data Platform Open Source Engines & Tools Commercial Engines & Applications Utility-Grade Platform Services DataProcessing Enterprise Storage MapR-FS MapR-DB MapR Streams Database Event Streaming Global Namespace High Availability Data Protection Self-healing Unified Security Real-time Multi-tenancy Search & Others Cloud & Managed Services Custom Apps UnifiedManagementandMonitoring
- 18. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 18 MapR is great for Enterprise ML projects ●MapR-FS and NFS mount ●Volumes and Topologies ●Mirrors and Snapshots ●
- 19. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 19 MapR Filesystem •Native implementation in C/C++, it’s fast •Use it like your own local filesystem •Everything that can use files works as usual •Unique MapR technology •For more info watch on Youtube: •What is MapR-FS •MapR-FS vs. HDFS Working, battle-tested distributed read-write filesystem
- 20. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 20 NFS Mount Mount the cluster as a regular folder $> sudo mount -o hard,nolock ip-10-0-0-110:/mapr /mapr $> ll /mapr/hadoopsummit/ total 3 drwxr-xr-x. 3 mapr mapr 1 Oct 13 11:21 apps drwxr-xr-x. 2 mapr mapr 0 Oct 13 11:12 hbase drwxr-xr-x. 3 root root 1 Oct 13 11:21 installer drwxr-xr-x. 2 mapr mapr 0 Oct 13 11:14 opt drwxrwxrwx. 2 mapr mapr 1 Oct 14 10:41 tmp drwxr-xr-x. 6 mapr mapr 4 Oct 14 10:52 user drwxr-xr-x. 3 mapr mapr 1 Oct 13 11:13 var
- 21. © 2014 MapR Technologies 21 MapR NFS and Volumes [mapr@ip-10-0-0-110 mapr]$ pwd /mapr/hadoopsummit/user/mapr
- 22. © 2014 MapR Technologies 22 MapR NFS and Volumes [mapr@ip-10-0-0-110 mapr]$ pwd /mapr/hadoopsummit/user/mapr
- 23. © 2014 MapR Technologies 23 MapR NFS and Volumes [mapr@ip-10-0-0-110 mapr]$ pwd /mapr/hadoopsummit/user/mapr
- 24. © 2014 MapR Technologies 24 MapR-FS and NFS mount for ML • Get started quickly and simply • Use your favorite tool like... – Custom code (Scikit-learn, R) – SPSS, SAS, RapidMiner – Apache Spark, Drill, Flink • Super easy data import – Just save to file on MapR – Integrate with legacy servers and code – Use any ecosystem (Sqoop) it all works • Quick and scalable roundtrip during development – ETL/cleaning -> train/test -> predict – Don’t copy data (cluster to cluster, local to cluster) • Run in production direct from the cluster – no copying around
- 25. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 25 Volumes and Topologies - Managed in MCS
- 26. © 2014 MapR Technologies 26 Volumes and Topologies Volumes are just “regular” volumes
- 27. © 2014 MapR Technologies 27 Volumes and Topologies Volumes are just “regular” volumes Select what nodes for volume data = Topology
- 28. © 2014 MapR Technologies 28 Volumes and Topologies for ML • With YARN’s Node Labels, run tasks on nodes with guaranteed data locality – Special nodes with GPU, high memory or big CPU • Multi-Tenancy – Share cluster with business use cases in production – Data isolation guaranteed – Easy unified admin (Data scientists != Hadoop admin) – Bigger cluster, more reliable and faster
- 29. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 29 Snapshots and Mirrors
- 30. © 2014 MapR Technologies 30 Snapshots and Mirrors
- 31. © 2014 MapR Technologies 31 Snapshots and Mirrors
- 32. © 2014 MapR Technologies 32 Snapshots - Instant point in time save
- 33. © 2014 MapR Technologies 33 Mirrors - Physical copy
- 34. © 2014 MapR Technologies 34 Snapshots [... mateusz]$ cd .snapshot [... .snapshot]$ ll total 1 drwxr-xr-x. 2 mapr mapr 1 Oct 14 10:56 mateusz.snap1
- 35. © 2014 MapR Technologies 35 Snapshots and Mirrors for ML • Versioned data and models = Repeatable results – same model, same data guaranteed – Go back in time for free • Keep intermediate transformations – Quickly change your mind, don’t redo work • A/B Testing easy-mode
- 36. © 2014 MapR Technologies 36 Real-time events and DB for ML • Built-in, no config, it just works • Support next-gen use cases – hyper-personalization of web/store content – IoT Sensor data • easy to start small but grows with your data/use case
- 37. © 2014 MapR Technologies 37 MapR Converged Application Blueprint • Microservices connected by real-time streams – Ideal to serve predictions from ML models • Next-Generation large-scale architecture • Working example: https://www.mapr.com/appblueprint/ overview
- 38. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 38 Converged Data Platform 💖 Machine Learning • Features that work together to support all phases of ML • Supports your existing tools/code and the state of the art large scale frameworks • Easier to manage, more robust and secure. • MapR is made for the enterprise and great for ML!
- 39. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 39 Demo of H2O on MapR: Features in Action
- 40. Agenda • Why tooling matters in Machine Learning • What is H2O and Sparkling Water • Why MapR • Demo
- 41. ML project problems • Multiple data sources • Different formats • Large volumes of data to be read • System bootstrap time • Collaboration between data scientists • Comparing models • Deployment of the model • Versioning • Too many moving parts! • etc.etc.
- 42. Successful ML platform • Fast ingestion and manipulation of versatile data • Intuitive modeling UI/API • Easy model validation, visualisation and comparison • Easy model deployment w/ versioning for fast predictions
- 43. • Written in high performance Java - native Java API • Supports multiple file formats and data sources • ETL capabilities • Highly paralleled and distributed implementation • Fast in-memory computation on highly compressed data • Allows you to use all your data without sampling • Runs on top of most major Hadoop distributions ML platform Ingestions platform Big data platform What is H2O? • Open source platform • Exposes math and predictive algorithms • GLM, Random Forest, GBM, Deep Learning etc.
- 44. FlowUI • Notebook style open source interface for H2O • Code execution, mathematics, plots, and rich media
- 45. Why H2O? • Fast ingestion and manipulation of versatile data • Blazing fast data parsing, supports multiple formats and data sources • Intuitive modeling UI/API • FlowUI, R/Python/REST APIs • Easy model validation, visualisation and comparison • Cross-validation, FlowUI graphs, comparison via Steam • Easy model deployment /w versioning for fast predictions • Model export as POJO, deploy as service via Steam
- 46. What is Sparkling Water? • Framework integrating Spark and H2O • H2O instances on Spark executors • Allows to call Spark and H2O methods together
- 47. Why MapR? • H2O + MapR-FS = fast data ingestion made even faster • Data resilience • MapR snapshots + H2O modelling from checkpoints = continuous and versioned modelling
- 48. Demo
- 49. Airline delay classification Model predicting flight delays ETL Modelling Predictions Load data from CSVs Model using H2O’s GLM * https://github.com/h2oai/sparkling-water/tree/master/examples/scripts
- 50. © 2016 MapR Technologies© 2016 MapR TechnologiesMapR Confidential 50 Q & A @mapr [email protected] Engage with us! mapr-technologies