Recent Developments In SparkR For Advanced Analytics
8 likes3,031 views

Since its introduction in Spark 1.4, SparkR has received contributions from both the Spark community and the R community. In this talk, we will summarize recent community efforts on extending SparkR for scalable advanced analytics. We start with the computation of summary statistics on distributed datasets, including single-pass approximate algorithms. Then we demonstrate MLlib machine learning algorithms that have been ported to SparkR and compare them with existing solutions on R, e.g., generalized linear models, classification and clustering algorithms. We also show how to integrate existing R packages with SparkR to accelerate existing R workflows.











![Approximate Algorithms
• frequent items [Karp03]
df %>% freqItems(c(“title”, “gender”), support = 0.01)
• approximate quantiles [Greenwald01]
df %>% approxQuantile(“value”, c(0.1, 0.5, 0.9), relErr = 0.01)
• single pass with aggregate pattern
• trade-off between accuracy and space
12](https://image.slidesharecdn.com/recentdevelopmentinsparkrforadvancedanalytics-160608212456/85/Recent-Developments-In-SparkR-For-Advanced-Analytics-12-320.jpg)









![Implementation: Test against R
Besides normal tests, we also verify our implementation using R.
/*
df <- as.data.frame(cbind(A, b))
for (formula in c(b ~ . -1, b ~ .)) {
model <- lm(formula, data=df, weights=w)
print(as.vector(coef(model)))
}
[1] -3.727121 3.009983
[1] 18.08 6.08 -0.60
*/
val expected = Seq(Vectors.dense(0.0, -3.727121, 3.009983),
Vectors.dense(18.08, 6.08, -0.60))
23](https://image.slidesharecdn.com/recentdevelopmentinsparkrforadvancedanalytics-160608212456/85/Recent-Developments-In-SparkR-For-Advanced-Analytics-23-320.jpg)






































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Recent Developments In SparkR For Advanced Analytics (20)




















Ad
More from Databricks (20)




















Recently uploaded (20)




















Recent Developments In SparkR For Advanced Analytics
- 1. Recent Developments in SparkR for Advanced Analytics Xiangrui Meng [email protected] 2016/06/07 - Spark Summit 2016
- 2. About Me • Software Engineer at Databricks • tech lead of machine learning and data science • Committer and PMC member of Apache Spark • Ph.D. from Stanford in computational mathematics 2
- 3. Outline • Introduction to SparkR • Descriptive analytics in SparkR • Predictive analytics in SparkR • Future directions 3
- 4. Introduction to SparkR Bridging the gap between R and Big Data
- 5. SparkR • Introduced to Spark since 1.4 • Wrappers over DataFrames and DataFrame-based APIs • In SparkR, we make the APIs similar to existing ones in R (or R packages), rather than Python/Java/Scala APIs. • R is very convenient for analytics and users love it. • Scalability is the main issue, not the API. 5
- 6. DataFrame-based APIs • Storage: s3 / HDFS / local / … • Data sources: csv / parquet / json / … • DataFrame operations: • select / subset / groupBy / agg / collect / … • rand / sample / avg / var / … • Conversion to/from R data.frame 6
- 7. SparkR Architecture 7 Spark Driver R JVM RBackend JVM Worker JVM Worker DataSources
- 8. Data Conversion between R and SparkR 8 R JVM RBackend SparkR::collect() SparkR::createDataFrame()
- 9. Descriptive Analytics Big Data at a glimpse in SparkR
- 10. Summary Statistics 10 • count, min, max, mean, standard deviation, variance describe(df) df %>% groupBy(“dept”, avgAge = avg(df$age)) • covariance, correlation df %>% select(var_samp(df$x, df$y)) • skewness, kurtosis df %>% select(skewness(df$x), kurtosis(df$x))
- 11. Sampling Algorithms • Bernoulli sampling (without replacement) df %>% sample(FALSE, 0.01) • Poisson sampling (with replacement) df %>% sample(TRUE, 0.01) • stratified sampling df %>% sampleBy(“key”, c(positive = 1.0, negative = 0.1)) 11
- 12. Approximate Algorithms • frequent items [Karp03] df %>% freqItems(c(“title”, “gender”), support = 0.01) • approximate quantiles [Greenwald01] df %>% approxQuantile(“value”, c(0.1, 0.5, 0.9), relErr = 0.01) • single pass with aggregate pattern • trade-off between accuracy and space 12
- 13. Implementation: Aggregation Pattern split + aggregate + combine in a single pass • split data into multiple partitions • calculate partially aggregated result on each partition • combine partial results into final result 13
- 14. Implementation: High-Performance • new online update formulas of summary statistics • code generation to achieve high performance kurtosis of 1 billion values on a Macbook Pro (2 cores): 14 scipy.stats 250s octave 120s CRAN::moments 70s SparkR / Spark / PySpark 5.5s
- 15. Predictive Analytics Enabling large-scale machine learning in SparkR
- 16. MLlib + SparkR MLlib and SparkR integration started in Spark 1.5. API design choices: 1. mimic the methods implemented in R or R packages • no new method to learn • similar but not the same / shadows existing methods • inconsistent APIs 2. create a new set of APIs 16
- 17. Generalized Linear Models (GLMs) • Linear models are simple but extremely popular. • A GLM is specified by the following: • a distribution of the response (from the exponential family), • a link function g such that • maximizes the sum of log-likelihoods 17
- 18. Distributions and Link Functions SparkR supports all families supported by R in Spark 2.0. 18 Model Distribution Link linear least squares normal identity logistic regression binomial logit Poisson regression Poisson log gamma regression gamma inverse … … …
- 19. GLMs in SparkR # Create the DataFrame for training df <- read.df(sqlContext, “path/to/training”) # Fit a Gaussian linear model model <- glm(y ~ x1 + x2, data = df, family = “gaussian”) # mimic R model <- spark.glm(df, y ~ x1 + x2, family = “gaussian”) # Get the model summary summary(model) # Make predictions predict(model, newDF) 19
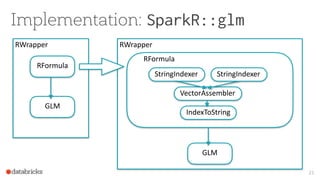
- 20. Implementation: SparkR::glm The `SparkR::glm` is a simple wrapper over an ML pipeline that consists of the following stages: • RFormula, which itself embeds an ML pipeline for feature preprocessing and encoding, • an estimator (GeneralizedLinearRegression). 20
- 22. Implementation: R Formula 22 • R provides model formula to express models. • We support the following R formula operators in SparkR: • `~` separate target and terms • `+` concat terms, "+ 0" means removing intercept • `-` remove a term, "- 1" means removing intercept • `:` interaction (multiplication for numeric values, or binarized categorical values) • `.` all columns except target • The implementation is in Scala.
- 23. Implementation: Test against R Besides normal tests, we also verify our implementation using R. /* df <- as.data.frame(cbind(A, b)) for (formula in c(b ~ . -1, b ~ .)) { model <- lm(formula, data=df, weights=w) print(as.vector(coef(model))) } [1] -3.727121 3.009983 [1] 18.08 6.08 -0.60 */ val expected = Seq(Vectors.dense(0.0, -3.727121, 3.009983), Vectors.dense(18.08, 6.08, -0.60)) 23
- 24. ML Models in SparkR • generalized linear models (GLMs) • glm / spark.glm (stats::glm) • accelerated failure time (AFT) model for survival analysis • spark.survreg (survival) • k-means clustering • spark.kmeans (stats:kmeans) • Bernoulli naive Bayes • spark.naiveBayes (e1071) 24
- 25. Model Persistence in SparkR • model persistence supported for all ML models in SparkR • thin wrappers over pipeline persistence from MLlib model <- spark.glm(df, x ~ y + z, family = “gaussian”) write.ml(model, path) model <- read.ml(path) summary(model) • feasible to pass saved models to Scala/Java engineers 25
- 26. Work with R Packages in SparkR • There are ~8500 community packages on CRAN. • It is impossible for SparkR to match all existing features. • Not every dataset is large. • Many people work with small/medium datasets. • SparkR helps in those scenarios by: • connecting to different data sources, • filtering or downsampling big datasets, • parallelizing training/tuning tasks. 26
- 27. Work with R Packages in SparkR df <- sqlContext %>% read.df(…) %>% collect() points <- data.matrix(df) run_kmeans <- function(k) { kmeans(points, centers=k) } kk <- 1:6 lapply(kk, run_kmeans) # R’s apply spark.lapply(sc, kk, run_kmeans) # parallelize the tasks 27
- 28. summary(this.talk) • SparkR enables big data analytics on R • descriptive analytics on top of DataFrames • predictive analytics from MLlib integration • SparkR works well with existing R packages Thanks to the Apache Spark community for developing and maintaining SparkR: Alteryx, Berkeley AMPLab, Databricks, Hortonworks, IBM, Intel, etc, and individual contributors!! 28
- 29. Future Directions • CRAN release of SparkR • more consistent APIs with existing R packages: dplyr, etc • better R formula support • more algorithms from MLlib: decision trees, ALS, etc • better integration with existing R packages: gapply / UDFs • integration with Spark packages: GraphFrames, CoreNLP, etc We’d greatly appreciate feedback from the R community! 29
- 30. Try Apache Spark with Databricks 30 http://databricks.com/try • Download a companion notebook of this talk at: http://dbricks.co/1rbujoD • Try latest version of Apache Spark and preview of Spark 2.0
- 31. Thank you. • SparkRuserguideonApacheSparkwebsite • MLlibroadmapforSpark2.1 • Officehours: • 2-3:30pmatExpoHallTheater;3:45-6pmatDatabricksbooth • DatabricksCommunityEditionandblogposts