Recurrent Neural Networks (RNN) | RNN LSTM | Deep Learning Tutorial | Tensorflow Tutorial | Edureka
14 likes4,243 views

This document discusses recurrent neural networks (RNNs) and their advantages over feedforward networks, particularly in handling sequential data and maintaining context over time. It highlights the issues of vanishing and exploding gradients during training and introduces long short-term memory units (LSTMs) as a solution. The document also includes a use-case for LSTMs in predicting sequences from text data.



































Recurrent Neural Networks (RNN) | RNN LSTM | Deep Learning Tutorial | Tensorflow Tutorial | Edureka
- 1. Agenda ▪ Why Not Feedforward Networks? ▪ What Is Recurrent Neural Network? ▪ Issues With Recurrent Neural Networks ▪ Vanishing And Exploding Gradient ▪ How To Overcome These Challenges? ▪ Long Short Term Memory Units ▪ LSTM Use-Case
- 2. Agenda ▪ Why Not Feedforward Networks? ▪ What Is Recurrent Neural Network? ▪ Issues With Recurrent Neural Networks ▪ Vanishing And Exploding Gradient ▪ How To Overcome These Challenges? ▪ Long Short Term Memory Units ▪ LSTM Use-Case
- 3. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Why Not Feedforward Network? Let’s begin by understanding few limitations with feedforward networks
- 4. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Why Not Feedforward Networks? A trained feedforward network can be exposed to any random collection of photographs, and the first photograph it is exposed to will not necessarily alter how it classifies the second Seeing photograph of a dog will not lead the net to perceive an elephant next Output at ‘t’ Output at ‘t-1’ No Relation
- 5. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Why Not Feedforward Networks? When you read a book, you understand it based on your understanding of previous words I cannot predict the next word in a sentence if I use feedforward nets Input at ‘t+1’ Output at ‘t+1’ Output at ‘t-2’ Output at ‘t-1’ Output at ‘t’ Independent of the previous outputs
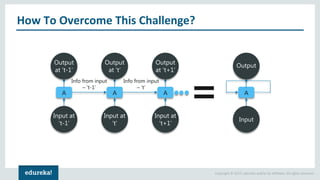
- 6. Copyright © 2017, edureka and/or its affiliates. All rights reserved. How To Overcome This Challenge? Let’s understand how RNN solves this problem
- 7. Copyright © 2017, edureka and/or its affiliates. All rights reserved. How To Overcome This Challenge? Input at ‘t-1’ A Output at ‘t-1’ Input at ‘t’ A Output at ‘t’ Input at ‘t+1’ A Output at ‘t+1’ Input A Output Info from input – ‘t-1’ Info from input – ‘t’
- 8. Copyright © 2017, edureka and/or its affiliates. All rights reserved. What Is Recurrent Neural Network? Now, is the correct time to understand what is RNN
- 9. Copyright © 2017, edureka and/or its affiliates. All rights reserved. What Is Recurrent Neural Network? Suppose your gym trainer has made a schedule for you. The exercises are repeated after every third day. Recurrent Networks are a type of artificial neural network designed to recognize patterns in sequences of data, such as text, genomes, handwriting, the spoken word, or numerical times series data emanating from sensors, stock markets and government agencies.
- 10. Copyright © 2017, edureka and/or its affiliates. All rights reserved. What Is Recurrent Neural Network? First Day Second Day Third Day Shoulder Exercises Biceps Exercises Cardio Exercises Predicting the type of exercise Using Feedforward Net Day of the week Month of the year Health Status Shoulder Exercises Biceps Exercises Cardio Exercises
- 11. Copyright © 2017, edureka and/or its affiliates. All rights reserved. What Is Recurrent Neural Network? First Day Second Day Third Day Shoulder Exercises Biceps Exercises Cardio Exercises Predicting the type of exercise Shoulder Yesterday Biceps Yesterday Cardio Yesterday Shoulder Exercises Biceps Exercises Cardio Exercises Using Recurrent Net
- 12. Copyright © 2017, edureka and/or its affiliates. All rights reserved. What Is Recurrent Neural Network? First Day Second Day Third Day Shoulder Exercises Biceps Exercises Cardio Exercises Predicting the type of exercise Using Recurrent Net
- 13. Copyright © 2017, edureka and/or its affiliates. All rights reserved. What Is Recurrent Neural Network? Predicting the type of exercise Using Recurrent Net Information from prediction at time ‘t-1’ New Information Prediction at time ‘t’ Vector 1 Vector 2 Vector 3
- 14. Copyright © 2017, edureka and/or its affiliates. All rights reserved. What Is Recurrent Neural Network? Predicting the type of exercise Using Recurrent Net Vector 1 Vector 2 Vector 3 Prediction New Information
- 15. Copyright © 2017, edureka and/or its affiliates. All rights reserved. What Is Recurrent Neural Network? 𝑥0 ℎ0 𝑦0 𝑤 𝑅 𝑤𝑖 𝑤 𝑦 𝑥1 ℎ1 𝑦1 𝑤 𝑅 𝑤𝑖 𝑤 𝑦 𝑥2 ℎ2 𝑦2 𝑤 𝑅 𝑤𝑖 𝑤 𝑦 ℎ(𝑡) = 𝑔ℎ (𝑤𝑖 𝑥(𝑡) + 𝑤 𝑅ℎ(𝑡−1) + 𝑏ℎ) 𝑦(𝑡) = 𝑔 𝑦 (𝑤 𝑦ℎ(𝑡) + 𝑏 𝑦)
- 16. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Training A Recurrent Neural Network Let’s see how we train a Recurrent Neural Network
- 17. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Training A Recurrent Neural Network Recurrent Neural Nets uses backpropagation algorithm, but it is applied for every time stamp. It is commonly known as Backpropagation Through Time (BTT).
- 18. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Training A Recurrent Neural Network Recurrent Neural Nets uses backpropagation algorithm, but it is applied for every time stamp. It is commonly known as Backpropagation Through Time (BTT). Vanishing Gradient Exploding Gradient Let’s look at the issues with Backpropagation
- 19. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Vanishing And Exploding Gradient Problem Let’s understand the issues with Recurrent Neural Networks
- 20. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Vanishing Gradient 𝑤 = 𝑤 + ∆𝑤 ∆𝑤 = 𝑛 𝑑𝑒 𝑑𝑤 𝑒 = (𝐴𝑐𝑡𝑢𝑎𝑙 𝑂𝑢𝑡𝑝𝑢𝑡 − 𝑀𝑜𝑑𝑒𝑙 𝑂𝑢𝑡𝑝𝑢𝑡)^2 𝑖𝑓 𝑑𝑒 𝑑𝑤 ≪≪1 ∆𝑤 <<<<<<1 𝑤 ≪≪≪ 1 Backpropagation
- 21. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Exploding Gradient 𝑤 = 𝑤 + ∆𝑤 ∆𝑤 = 𝑛 𝑑𝑒 𝑑𝑤 𝑒 = (𝐴𝑐𝑡𝑢𝑎𝑙 𝑂𝑢𝑡𝑝𝑢𝑡 − 𝑀𝑜𝑑𝑒𝑙 𝑂𝑢𝑡𝑝𝑢𝑡)^2 𝑖𝑓 𝑑𝑒 𝑑𝑤 ≫≫1 ∆𝑤 >>>>>>1 𝑤 ≫≫≫ 1 Backpropagation
- 22. Copyright © 2017, edureka and/or its affiliates. All rights reserved. How To Overcome These Challenge? Now, let’s understand how we can overcome Vanishing and Exploding Gradient
- 23. Copyright © 2017, edureka and/or its affiliates. All rights reserved. How To Overcome These Challenges? ▪ Truncated BTT Instead of starting backpropagation at the last time stamp, we can choose a smaller time stamp like 10 (we will lose the temporal context after 10 time stamps) ▪ Clip gradients at threshold Clip the gradient when it goes higher than a threshold ▪ RMSprop to adjust learning rate Exploding gradients ▪ ReLU activation function We can use activation functions like ReLU, which gives output one while calculating gradient ▪ RMSprop Clip the gradient when it goes higher than a threshold ▪ LSTM, GRUs Different network architectures that has been specially designed can be used to combat this problem Vanishing gradients
- 24. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks ✓ Long Short Term Memory networks – usually just called “LSTMs” – are a special kind of RNN. ✓ They are capable of learning long-term dependencies. The repeating module in a standard RNN contains a single layer
- 25. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks
- 26. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks 𝑓𝑡 = σ(𝑤𝑓 ℎ 𝑡−1, 𝑥𝑡 + 𝑏𝑓) Step-1 The first step in the LSTM is to identify those information that are not required and will be thrown away from the cell state. This decision is made by a sigmoid layer called as forget gate layer. 𝑤𝑓 = 𝑊𝑒𝑖𝑔ℎ𝑡 ℎ 𝑡−1 = 𝑂𝑢𝑡𝑝𝑢𝑡 𝑓𝑟𝑜𝑚 𝑡ℎ𝑒 𝑝𝑟𝑒𝑣𝑖𝑜𝑢𝑠 𝑡𝑖𝑚𝑒 𝑠𝑡𝑎𝑚𝑝 𝑥𝑡 = 𝑁𝑒𝑤 𝑖𝑛𝑝𝑢𝑡 𝑏𝑓 = 𝐵𝑖𝑎𝑠
- 27. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks Step-2 The next step is to decide, what new information we’re going to store in the cell state. This whole process comprises of following steps. A sigmoid layer called the “input gate layer” decides which values will be updated. Next, a tanh layer creates a vector of new candidate values, that could be added to the state. 𝑖 𝑡 = σ(𝑤𝑖 ℎ 𝑡−1, 𝑥𝑡 + 𝑏𝑖) 𝑐˜ 𝑡 = 𝑡𝑎𝑛ℎ(𝑤𝑐 ℎ 𝑡−1, 𝑥𝑡 + 𝑏 𝑐) In the next step, we’ll combine these two to update the state.
- 28. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks Step-3 Now, we will update the old cell state, Ct−1, into the new cell state Ct. First, we multiply the old state (Ct−1) by ft , forgetting the things we decided to forget earlier. Then, we add 𝑖 𝑡* 𝑐˜ 𝑡. This is the new candidate values, scaled by how much we decided to update each state value. 𝑐𝑡 = 𝑓𝑡 ∗ 𝑐𝑡−1 + 𝑖 𝑡* 𝑐˜ 𝑡
- 29. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks Step-4 We will run a sigmoid layer which decides what parts of the cell state we’re going to output. Then, we put the cell state through tanh (push the values to be between −1 and 1) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to. 𝑜𝑡 = σ(𝑤𝑜 ℎ 𝑡−1, 𝑥𝑡 + 𝑏 𝑜) ℎ 𝑡 = 𝑜𝑡*tanh(𝑐𝑡)
- 30. Copyright © 2017, edureka and/or its affiliates. All rights reserved. LSTM Use-Case Let’s look at a use-case where we will be using TensorFlow
- 31. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks Use-Case We will feed a LSTM with correct sequences from the text of 3 symbols as inputs and 1 labeled symbol, eventually the neural network will learn to predict the next symbol correctly had a general LSTM cell Council Prediction label vs inputs LSTM cell with three inputs and 1 output.
- 32. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks Use-Case long ago , the mice had a general council to consider what measures they could take to outwit their common enemy , the cat . some said this , and some said that but at last a young mouse got up and said he had a proposal to make , which he thought would meet the case . you will all agree , said he , that our chief danger consists in the sly and treacherous manner in which the enemy approaches us . now , if we could receive some signal of her approach , we could easily escape from her . i venture , therefore , to propose that a small bell be procured , and attached by a ribbon round the neck of the cat . by this means we should always know when she was about , and could easily retire while she was in the neighborhood . this proposal met with general applause , until an old mouse got up and said that is all very well , but who is to bell the cat ? the mice looked at one another and nobody spoke . then the old mouse said it is easy to propose impossible remedies . How to train the network? A short story from Aesop’s Fables with 112 unique symbols
- 33. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Long Short Term Memory Networks Use-Case A unique integer value is assigned to each symbol because LSTM inputs can only understand real numbers. 20 6 33 LSTM cell LSTM cell with three inputs and 1 output. had a general .01 .02 .6 .00 37 37 vs Council Council 112-element vector Recurrent Neural Network
- 34. Copyright © 2017, edureka and/or its affiliates. All rights reserved. Session In A Minute Why Not Feedforward Network What Is Recurrent Neural Network? Vanishing Gradient Exploding Gradient LSTMs LSTM Use-Case Recurrent Neural Network Tutorial
- 35. Copyright © 2017, edureka and/or its affiliates. All rights reserved.