Reproducible bioinformatics workflows with Nextflow and nf-core
0 likes261 views

Slides from my talk at a GenomeWeb webinar, I discuss how we use Nextflow at the SciLifeLab National Genomics Infrastructure and how this led to the founding of the nf-core community project.
1 of 24
Downloaded 10 times























Ad
Recommended
Reproducible Computational Pipelines with Docker and Nextflow
Reproducible Computational Pipelines with Docker and Nextflowinside-BigData.com This document summarizes a presentation about using Docker and Nextflow to create reproducible computational pipelines. It discusses two major challenges in computational biology being reproducibility and complexity. Containers like Docker help address these challenges by creating portable and standardized environments. Nextflow is introduced as a workflow framework that allows pipelines to run across platforms and isolates dependencies using containers, enabling fast prototyping. Examples are given of using Nextflow with Docker to run pipelines on different systems like HPC clusters in a scalable and reproducible way.
HOW TO RUN RSTUDIO SERVERS ANYWHERE WITH CONTAINERS - HPC, CLOUD, AND LOCALLY
HOW TO RUN RSTUDIO SERVERS ANYWHERE WITH CONTAINERS - HPC, CLOUD, AND LOCALLYWendy Wong SatRday talk on running Rstudio servers inside Docker and Singularity on HPC, Cloud and on local machine.
Trunk-Based Development and Toggling
Trunk-Based Development and TogglingBryan Liu - TBD & toggling
- what pre-push code review and test means for further automation
- Jenkins descriptive pipeline script & central libraries
CI/CD、自動化,你還沒準備好(GCPUG.TW Meetup #34)
CI/CD、自動化,你還沒準備好(GCPUG.TW Meetup #34)Chen Cheng-Wei 延續 2017 年 12 月於 Agile Tour Kaohsiung 2017 分享過相同主題,這次感謝 GCPUG.TW 的邀請,微調部分內容後,再次於台北分享此主題。
QNAP 錄影直播:
https://www.youtube.com/watch?v=Vr2SV26y7sw
Intro to Kubernetes & GitOps Workshop
Intro to Kubernetes & GitOps WorkshopWeaveworks For this info-packed and hands-on workshop we cover:
📍 Introduction to Kubernetes & GitOps talk:
We cover the most popular path that has brought success to many users already - GitOps as a natural evolution of Kubernetes. We'll give an overview of how you can benefit from Kubernetes and GitOps: greater security, reliability, velocity and more. Importantly, we cover definitions and principles standardized by the CNCF's OpenGitOps group and what it means for you.
📍 Get Started with GitOps:
You'll have GitOps up and running in about 30 mins using our free and open source tools! We'll give a brief vision of where you want to be with those security, reliability, and velocity benefits, and then we'll support you while go through the getting started steps. During the workshop, you'll also experience in action and see demos for:
- an opinionated repo structure to minimize decision fatigue
- disaster recovery using GitOps
- Helm charts example
- Multi-cluster example
- all with free and open source tools mostly in the CNCF (eg. Flux and Helm).
If you have questions before or after the workshop, talk to us at #weave-gitops http://bit.ly/WeaveGitOpsSlack (If you need to invite yourself to the Slack, visit https://slack.weave.works/)

WTF is GitOps and Why You Should Care?
WTF is GitOps and Why You Should Care?Weaveworks Slides from OpenSource101.com Talk (https://opensource101.com/sessions/wtf-is-gitops-why-should-you-care/)
If you’re interested in learning more about Cloud Native Computing or are already in the Kubernetes community you may have heard the term GitOps. It’s become a bit of a buzzword, but it’s so much more! The benefits of GitOps are real – they bring you security, reliability, velocity and more! And the project that started it all was Flux – a CNCF Incubating project developed and later donated by Weaveworks (the GitOps company who coined the term).
Pinky will share from personal experience why GitOps has been an essential part of achieving a best-in-class delivery and platform team. Pinky will give a brief overview of definitions, CNCF-based principles, and Flux’s capabilities: multi-tenancy, multi-cluster, (multi-everything!), for apps and infra, and more.
Pinky will cover a little of Flux’s microservices architecture and how the various components deliver this robust, secure, and trusted open source solution. Through the components of the Flux project, users today are enjoying compatibility with Helm, Jenkins, Terraform, Prometheus, and more as well as with cloud providers such as AWS, Azure, Google Cloud, and more.
Join us for this informative session and get all of your GitOps questions answered by an end user in the community!
Speaker: Priyanka (aka “Pinky”) is a Developer Experience Engineer at Weaveworks. She has worked on a multitude of topics including front end development, UI automation for testing and API development. Previously she was a software developer at State Farm where she was on the delivery engineering team working on GitOps enablement. She was instrumental in the multi-tenancy migration to utilize Flux for an internal Kubernetes offering. Outside of work, Priyanka enjoys hanging out with her husband and two rescue dogs as well as traveling around the globe.
How to write Ansible modules for A10 Thunder - A10 Networks' presentation at ...
How to write Ansible modules for A10 Thunder - A10 Networks' presentation at ...Kentaro Ishizuka Talk regarding A10 Ansible module at Ansible Night in Osaka on 28th Nov. 2018.
Prometheus Storage
Prometheus StorageFabian Reinartz This document discusses time series data storage and querying in Prometheus. It describes how Prometheus stores time series data as chunks on disk in a key-value store format, with compression to reduce storage needs. It also explains how Prometheus handles ingesting new time series data through appending to in-memory chunks before writing to disk, and how it handles querying time series data through iterators over chunk files on disk.
Scaling Uber
Scaling UberC4Media Video and slides synchronized, mp3 and slide download available at URL http://bit.ly/1ncT8iO.
From its simple roots as a PHP program, Uber has grown into a complex distributed system deployed across multiple datacenters using multiple databases and programming languages. Matt Ranney covers the evolution of Uber's architecture and some of the systems they built to handle the current scaling challenges. Filmed at qconsf.com.
Matt Ranney is the Chief Systems Architect at Uber. He has a computer science degree which has come in handy over a career of mostly network engineering, operations, and analytics.
Kubernetes a comprehensive overview
Kubernetes a comprehensive overviewGabriel Carro Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. It groups containers that make up an application into logical units for easy management and discovery called pods. Its main components include a master node that manages the cluster and worker nodes that run the applications. It uses labels to identify pods and services and selectors to group related pods. Common concepts include deployments for updating apps, services for network access, persistent volumes for storage, and roles/bindings for access control. The deployment process involves the API server, controllers, scheduler and kubelet to reconcile the desired state and place pods on nodes from images while providing discovery and load balancing.

CKA_1st.pptx
CKA_1st.pptxYIJHEHUANG The document provides an overview of Kubernetes concepts including pods, replica sets, deployments, services, and cluster architecture. It discusses Kubernetes' role in automatically maintaining services by deploying multiple containers across worker nodes. Key components like the master node, etcd cluster, scheduler, and kubelet are described at a high level. Examples are provided of imperative Kubernetes commands for creating pods, replica sets, deployments, and services.
Improve monitoring and observability for kubernetes with oss tools
Improve monitoring and observability for kubernetes with oss toolsNilesh Gule Slide deck from the ASEAN Cloud Summit meetup on 27 January 2022. The session cover the following topics
1 - Centralized Loggin with Elasticsearch, Fluentbit and Kibana
2 - Monitoring and Alerting with Prometheus and Grafana
3 - Exception aggregation with Sentry
The live demo showcased these aspects using Azure Kubernetes Service (AKS)
Orchestrating workflows Apache Airflow on GCP & AWS
Orchestrating workflows Apache Airflow on GCP & AWSDerrick Qin Working in a cloud or on-premises environment, we all somehow move data from A to B on-demand or on schedule. It is essential to have a tool that can automate recurring workflows. This can be anything from an ETL(Extract, Transform, and Load) job for a regular analytics report all the way to automatically re-training a machine learning model.
In this talk, we will introduce Apache Airflow and how it can help orchestrate your workflows. We will cover key concepts, features, and use cases of Apache Airflow, as well as how you can enjoy Apache Airflow on GCP and AWS by demo-ing a few practical workflows.
Fundamentals of DevOps and CI/CD
Fundamentals of DevOps and CI/CDBatyr Nuryyev The presentation about the fundamentals of DevOps workflow and CI/CD practices I presented at Centroida (https://centroida.ai/) as a back-end development intern.
How Azure DevOps can boost your organization's productivity
How Azure DevOps can boost your organization's productivityIvan Porta Azure DevOps can boost productivity through collaboration and automation. DevOps aims to continuously deliver value to users through practices like continuous integration, delivery, and deployment. Microsoft tools like Azure Boards, Pipelines, and Repos support the DevOps process. Azure Pipelines automates building, testing, and deploying code. Branching workflows and pull requests enable collaboration. Automation reduces errors and speeds up the release process. DevOps has helped organizations like Fidelity and Amica reduce costs and deployment times.
Why we chose Argo Workflow to scale DevOps at InVision
Why we chose Argo Workflow to scale DevOps at InVisionNebulaworks As the DevOps team grows in size and start to form a multi DevOps team structure, it starts to experience growing pains such as working in silos, decreased velocity, or lack of collaboration. The solution is to standardize tools for automation and provide the building blocks of commonly used patterns readily available. This is where workflows come into play. Adopting Workflows provides a common scalable platform for DevOps engineers to automate, trigger, and execute repetitive tasks and therefore leads to increased efficiency and innovation.
Gitlab, GitOps & ArgoCD
Gitlab, GitOps & ArgoCDHaggai Philip Zagury This document discusses improving the developer experience through GitOps and ArgoCD. It recommends building developer self-service tools for cloud resources and Kubernetes to reduce frustration. Example GitLab CI/CD pipelines are shown that handle releases, deployments to ECR, and patching apps in an ArgoCD repository to sync changes. The goal is to create faster feedback loops through Git operations and automation to motivate developers.
Prometheus - basics
Prometheus - basicsJuraj Hantak Prometheus is an open-source monitoring system that collects metrics from configured targets, stores time series data, and allows users to query and alert on that data. It is designed for dynamic cloud environments and has built-in service discovery integration. Core features include simplicity, efficiency, a dimensional data model, the PromQL query language, and service discovery.
Grafana Loki: like Prometheus, but for Logs
Grafana Loki: like Prometheus, but for LogsMarco Pracucci Loki is a horizontally-scalable, highly-available log aggregation system inspired by Prometheus. It is designed to be very cost-effective and easy to operate, as it does not index the contents of the logs, but rather labels for each log stream.
In this talk, we will introduce Loki, its architecture and the design trade-offs in an approachable way. We’ll both cover Loki and Promtail, the agent used to scrape local logs to push to Loki, including the Prometheus-style service discovery used to dynamically discover logs and attach metadata from applications running in a Kubernetes cluster.
Finally, we’ll show how to query logs with Grafana using LogQL - the Loki query language - and the latest Grafana features to easily build dashboards mixing metrics and logs.
Intro to GitOps & Flux.pdf
Intro to GitOps & Flux.pdfWeaveworks The document provides an introduction to GitOps and Flux. It discusses what GitOps is, how it utilizes version control as a single source of truth for continuous delivery. It then summarizes what Flux is and its key components like the source, kustomize, helm and notification controllers. The document highlights benefits of Flux like reducing developer burden and being extensible. It also briefly mentions new Flux features like OCI support and related tools like the terraform controller, flamingo and Weave GitOps.
Rootless Containers
Rootless ContainersAkihiro Suda In this talk we will discuss how to build and run containers without root privileges. As part of the discussion, we will introduce new programs like fuse-overlayfs and slirp4netns and explain how it is possible to do this using user namespaces. fuse-overlayfs allows to use the same storage model as "root" containers and use layered images. slirp4netns emulates a TCP/IP stack in userland and allows to use a network namespace from a container and let it access the outside world (with some limitations).
We will also introduce Usernetes, and how to run Kubernetes in an unprivileged user namespace
https://sched.co/Jcgg
Kubernetes GitOps featuring GitHub, Kustomize and ArgoCD
Kubernetes GitOps featuring GitHub, Kustomize and ArgoCDSunnyvale A brief dissertation about using GitOps paradigm to operate an application on multiple Kubernetes environments thanks to GitHub, ArgoCD and Kustomize. A talk about this matters has been taken at the event #CloudConf2020

Stream Processing using Apache Flink in Zalando's World of Microservices - Re...
Stream Processing using Apache Flink in Zalando's World of Microservices - Re...Zalando Technology In this talk we present Zalando's microservices architecture, introduce Saiki – our next generation data integration and distribution platform on AWS and show how we employ stream processing for near-real time business intelligence.
Zalando is one of the largest online fashion retailers in Europe. In order to secure our future growth and remain competitive in this dynamic market, we are transitioning from a monolithic to a microservices architecture and from a hierarchical to an agile organization.
We first have a look at how business intelligence processes have been working inside Zalando for the last years and present our current approach - Saiki. It is a scalable, cloud-based data integration and distribution infrastructure that makes data from our many microservices readily available for analytical teams.
We no longer live in a world of static data sets, but are instead confronted with an endless stream of events that constantly inform us about relevant happenings from all over the enterprise. The processing of these event streams enables us to do near-real time business intelligence. In this context we have evaluated Apache Flink vs. Apache Spark in order to choose the right stream processing framework. Given our requirements, we decided to use Flink as part of our technology stack, alongside with Kafka and Elasticsearch.
With these technologies we are currently working on two use cases: a near real-time business process monitoring solution and streaming ETL.
Monitoring our business processes enables us to check if technically the Zalando platform works. It also helps us analyze data streams on the fly, e.g. order velocities, delivery velocities and to control service level agreements.
On the other hand, streaming ETL is used to relinquish resources from our relational data warehouse, as it struggles with increasingly high loads. In addition to that, it also reduces the latency and facilitates the platform scalability.
Finally, we have an outlook on our future use cases, e.g. near-real time sales and price monitoring. Another aspect to be addressed is to lower the entry barrier of stream processing for our colleagues coming from a relational database background.
Infrastructure & System Monitoring using Prometheus
Infrastructure & System Monitoring using PrometheusMarco Pas The document introduces infrastructure and system monitoring using Prometheus. It discusses the importance of monitoring, common things to monitor like services, applications, and OS metrics. It provides an overview of Prometheus including its main components and data format. The document demonstrates setting up Prometheus, adding host metrics using Node Exporter, configuring Grafana, monitoring Docker containers using cAdvisor, configuring alerting in Prometheus and Alertmanager, instrumenting application code, and integrating Consul for service discovery. Live code demos are provided for key concepts.
twMVC 47_Elastic APM 的兩三事
twMVC 47_Elastic APM 的兩三事twMVC 講者:Roberson
一直以來,Elasticsearch 被廣泛地當作 Log 蒐集的首選平台之一,不過你知道 Elastic 家族還有一個 APM 產品嗎?除了開源之外,它提供了 10+ 以上的程式語言整合,可以將 Log / Trace / Error 通通收攏在一塊,讓我們可以輕易地在單一平台就完成操作,有效提升開發人員抓蟲的效率。而它的佈署模式也是相當地彈性,不管是上雲端還是下地端都能有很好的支援!本次議程除了介紹 .NET 如何與 Elastic APM 整合之外,也會分享一些佈署時需要注意的事項,以及實務上踩到的一些坑。
nf-core: A community-driven collection of omics portable pipelines
nf-core: A community-driven collection of omics portable pipelinesJose Espinosa-Carrasco nf-core is a community-driven collection of standardized omics analysis pipelines built using Nextflow. It contains over 30 pipelines for tasks like ATAC-seq, ChIP-seq, RNA-seq, and more. The pipelines are containerized, have consistent configurations, and come with helper tools to simplify their use. The nf-core community develops and maintains the pipelines according to shared guidelines.
Reproducible bioinformatics for everyone: Nextflow & nf-core
Reproducible bioinformatics for everyone: Nextflow & nf-corePhil Ewels Slides from my talk at the Karolinska Institute in Huddinge (Stockholm, Sweden). June 2022.
General introduction to Nextflow and nf-core, covering what they are and why you should use them!
Ad
More Related Content
What's hot (20)
Prometheus Storage
Prometheus StorageFabian Reinartz This document discusses time series data storage and querying in Prometheus. It describes how Prometheus stores time series data as chunks on disk in a key-value store format, with compression to reduce storage needs. It also explains how Prometheus handles ingesting new time series data through appending to in-memory chunks before writing to disk, and how it handles querying time series data through iterators over chunk files on disk.
Scaling Uber
Scaling UberC4Media Video and slides synchronized, mp3 and slide download available at URL http://bit.ly/1ncT8iO.
From its simple roots as a PHP program, Uber has grown into a complex distributed system deployed across multiple datacenters using multiple databases and programming languages. Matt Ranney covers the evolution of Uber's architecture and some of the systems they built to handle the current scaling challenges. Filmed at qconsf.com.
Matt Ranney is the Chief Systems Architect at Uber. He has a computer science degree which has come in handy over a career of mostly network engineering, operations, and analytics.
Kubernetes a comprehensive overview
Kubernetes a comprehensive overviewGabriel Carro Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. It groups containers that make up an application into logical units for easy management and discovery called pods. Its main components include a master node that manages the cluster and worker nodes that run the applications. It uses labels to identify pods and services and selectors to group related pods. Common concepts include deployments for updating apps, services for network access, persistent volumes for storage, and roles/bindings for access control. The deployment process involves the API server, controllers, scheduler and kubelet to reconcile the desired state and place pods on nodes from images while providing discovery and load balancing.
CKA_1st.pptx
CKA_1st.pptxYIJHEHUANG The document provides an overview of Kubernetes concepts including pods, replica sets, deployments, services, and cluster architecture. It discusses Kubernetes' role in automatically maintaining services by deploying multiple containers across worker nodes. Key components like the master node, etcd cluster, scheduler, and kubelet are described at a high level. Examples are provided of imperative Kubernetes commands for creating pods, replica sets, deployments, and services.
Improve monitoring and observability for kubernetes with oss tools
Improve monitoring and observability for kubernetes with oss toolsNilesh Gule Slide deck from the ASEAN Cloud Summit meetup on 27 January 2022. The session cover the following topics
1 - Centralized Loggin with Elasticsearch, Fluentbit and Kibana
2 - Monitoring and Alerting with Prometheus and Grafana
3 - Exception aggregation with Sentry
The live demo showcased these aspects using Azure Kubernetes Service (AKS)
Orchestrating workflows Apache Airflow on GCP & AWS
Orchestrating workflows Apache Airflow on GCP & AWSDerrick Qin Working in a cloud or on-premises environment, we all somehow move data from A to B on-demand or on schedule. It is essential to have a tool that can automate recurring workflows. This can be anything from an ETL(Extract, Transform, and Load) job for a regular analytics report all the way to automatically re-training a machine learning model.
In this talk, we will introduce Apache Airflow and how it can help orchestrate your workflows. We will cover key concepts, features, and use cases of Apache Airflow, as well as how you can enjoy Apache Airflow on GCP and AWS by demo-ing a few practical workflows.
Fundamentals of DevOps and CI/CD
Fundamentals of DevOps and CI/CDBatyr Nuryyev The presentation about the fundamentals of DevOps workflow and CI/CD practices I presented at Centroida (https://centroida.ai/) as a back-end development intern.
How Azure DevOps can boost your organization's productivity
How Azure DevOps can boost your organization's productivityIvan Porta Azure DevOps can boost productivity through collaboration and automation. DevOps aims to continuously deliver value to users through practices like continuous integration, delivery, and deployment. Microsoft tools like Azure Boards, Pipelines, and Repos support the DevOps process. Azure Pipelines automates building, testing, and deploying code. Branching workflows and pull requests enable collaboration. Automation reduces errors and speeds up the release process. DevOps has helped organizations like Fidelity and Amica reduce costs and deployment times.
Why we chose Argo Workflow to scale DevOps at InVision
Why we chose Argo Workflow to scale DevOps at InVisionNebulaworks As the DevOps team grows in size and start to form a multi DevOps team structure, it starts to experience growing pains such as working in silos, decreased velocity, or lack of collaboration. The solution is to standardize tools for automation and provide the building blocks of commonly used patterns readily available. This is where workflows come into play. Adopting Workflows provides a common scalable platform for DevOps engineers to automate, trigger, and execute repetitive tasks and therefore leads to increased efficiency and innovation.
Gitlab, GitOps & ArgoCD
Gitlab, GitOps & ArgoCDHaggai Philip Zagury This document discusses improving the developer experience through GitOps and ArgoCD. It recommends building developer self-service tools for cloud resources and Kubernetes to reduce frustration. Example GitLab CI/CD pipelines are shown that handle releases, deployments to ECR, and patching apps in an ArgoCD repository to sync changes. The goal is to create faster feedback loops through Git operations and automation to motivate developers.
Prometheus - basics
Prometheus - basicsJuraj Hantak Prometheus is an open-source monitoring system that collects metrics from configured targets, stores time series data, and allows users to query and alert on that data. It is designed for dynamic cloud environments and has built-in service discovery integration. Core features include simplicity, efficiency, a dimensional data model, the PromQL query language, and service discovery.
Grafana Loki: like Prometheus, but for Logs
Grafana Loki: like Prometheus, but for LogsMarco Pracucci Loki is a horizontally-scalable, highly-available log aggregation system inspired by Prometheus. It is designed to be very cost-effective and easy to operate, as it does not index the contents of the logs, but rather labels for each log stream.
In this talk, we will introduce Loki, its architecture and the design trade-offs in an approachable way. We’ll both cover Loki and Promtail, the agent used to scrape local logs to push to Loki, including the Prometheus-style service discovery used to dynamically discover logs and attach metadata from applications running in a Kubernetes cluster.
Finally, we’ll show how to query logs with Grafana using LogQL - the Loki query language - and the latest Grafana features to easily build dashboards mixing metrics and logs.
Intro to GitOps & Flux.pdf
Intro to GitOps & Flux.pdfWeaveworks The document provides an introduction to GitOps and Flux. It discusses what GitOps is, how it utilizes version control as a single source of truth for continuous delivery. It then summarizes what Flux is and its key components like the source, kustomize, helm and notification controllers. The document highlights benefits of Flux like reducing developer burden and being extensible. It also briefly mentions new Flux features like OCI support and related tools like the terraform controller, flamingo and Weave GitOps.
Rootless Containers
Rootless ContainersAkihiro Suda In this talk we will discuss how to build and run containers without root privileges. As part of the discussion, we will introduce new programs like fuse-overlayfs and slirp4netns and explain how it is possible to do this using user namespaces. fuse-overlayfs allows to use the same storage model as "root" containers and use layered images. slirp4netns emulates a TCP/IP stack in userland and allows to use a network namespace from a container and let it access the outside world (with some limitations).
We will also introduce Usernetes, and how to run Kubernetes in an unprivileged user namespace
https://sched.co/Jcgg
Kubernetes GitOps featuring GitHub, Kustomize and ArgoCD
Kubernetes GitOps featuring GitHub, Kustomize and ArgoCDSunnyvale A brief dissertation about using GitOps paradigm to operate an application on multiple Kubernetes environments thanks to GitHub, ArgoCD and Kustomize. A talk about this matters has been taken at the event #CloudConf2020
Stream Processing using Apache Flink in Zalando's World of Microservices - Re...
Stream Processing using Apache Flink in Zalando's World of Microservices - Re...Zalando Technology In this talk we present Zalando's microservices architecture, introduce Saiki – our next generation data integration and distribution platform on AWS and show how we employ stream processing for near-real time business intelligence.
Zalando is one of the largest online fashion retailers in Europe. In order to secure our future growth and remain competitive in this dynamic market, we are transitioning from a monolithic to a microservices architecture and from a hierarchical to an agile organization.
We first have a look at how business intelligence processes have been working inside Zalando for the last years and present our current approach - Saiki. It is a scalable, cloud-based data integration and distribution infrastructure that makes data from our many microservices readily available for analytical teams.
We no longer live in a world of static data sets, but are instead confronted with an endless stream of events that constantly inform us about relevant happenings from all over the enterprise. The processing of these event streams enables us to do near-real time business intelligence. In this context we have evaluated Apache Flink vs. Apache Spark in order to choose the right stream processing framework. Given our requirements, we decided to use Flink as part of our technology stack, alongside with Kafka and Elasticsearch.
With these technologies we are currently working on two use cases: a near real-time business process monitoring solution and streaming ETL.
Monitoring our business processes enables us to check if technically the Zalando platform works. It also helps us analyze data streams on the fly, e.g. order velocities, delivery velocities and to control service level agreements.
On the other hand, streaming ETL is used to relinquish resources from our relational data warehouse, as it struggles with increasingly high loads. In addition to that, it also reduces the latency and facilitates the platform scalability.
Finally, we have an outlook on our future use cases, e.g. near-real time sales and price monitoring. Another aspect to be addressed is to lower the entry barrier of stream processing for our colleagues coming from a relational database background.
Infrastructure & System Monitoring using Prometheus
Infrastructure & System Monitoring using PrometheusMarco Pas The document introduces infrastructure and system monitoring using Prometheus. It discusses the importance of monitoring, common things to monitor like services, applications, and OS metrics. It provides an overview of Prometheus including its main components and data format. The document demonstrates setting up Prometheus, adding host metrics using Node Exporter, configuring Grafana, monitoring Docker containers using cAdvisor, configuring alerting in Prometheus and Alertmanager, instrumenting application code, and integrating Consul for service discovery. Live code demos are provided for key concepts.
twMVC 47_Elastic APM 的兩三事
twMVC 47_Elastic APM 的兩三事twMVC 講者:Roberson
一直以來,Elasticsearch 被廣泛地當作 Log 蒐集的首選平台之一,不過你知道 Elastic 家族還有一個 APM 產品嗎?除了開源之外,它提供了 10+ 以上的程式語言整合,可以將 Log / Trace / Error 通通收攏在一塊,讓我們可以輕易地在單一平台就完成操作,有效提升開發人員抓蟲的效率。而它的佈署模式也是相當地彈性,不管是上雲端還是下地端都能有很好的支援!本次議程除了介紹 .NET 如何與 Elastic APM 整合之外,也會分享一些佈署時需要注意的事項,以及實務上踩到的一些坑。
Similar to Reproducible bioinformatics workflows with Nextflow and nf-core (20)
nf-core: A community-driven collection of omics portable pipelines
nf-core: A community-driven collection of omics portable pipelinesJose Espinosa-Carrasco nf-core is a community-driven collection of standardized omics analysis pipelines built using Nextflow. It contains over 30 pipelines for tasks like ATAC-seq, ChIP-seq, RNA-seq, and more. The pipelines are containerized, have consistent configurations, and come with helper tools to simplify their use. The nf-core community develops and maintains the pipelines according to shared guidelines.
Reproducible bioinformatics for everyone: Nextflow & nf-core
Reproducible bioinformatics for everyone: Nextflow & nf-corePhil Ewels Slides from my talk at the Karolinska Institute in Huddinge (Stockholm, Sweden). June 2022.
General introduction to Nextflow and nf-core, covering what they are and why you should use them!
Nextflow Camp 2019: nf-core tutorial (Updated Feb 2020)
Nextflow Camp 2019: nf-core tutorial (Updated Feb 2020)Phil Ewels The nf-core community provides a range of tools to help new users get to grips with nextflow - both by providing complete pipelines that can be used out of the box, and also by helping developers with best practices. Companion tools can create a bare-bones pipeline from a template scattered with TO-DO pointers and CI with linting tools check code quality. Guidelines and documentation help to get nextflow newbies on their feet in no time. Best of all, the nf-core community is always on hand to help.
In this tutorial we discuss the best-practice guidelines developed by the nf-core community, why they're important and give insight into the best tips and tricks for budding nextflow pipeline developers.
----
Updated Feb 2020 to switch TravisCI for GitHub Actions, plus a couple of other tweaks.
Nextflow Camp 2019: nf-core tutorial
Nextflow Camp 2019: nf-core tutorialPhil Ewels The nf-core community provides a range of tools to help new users get to grips with nextflow - both by providing complete pipelines that can be used out of the box, and also by helping developers with best practices. Companion tools can create a bare-bones pipeline from a template scattered with TO-DO pointers and CI with linting tools check code quality. Guidelines and documentation help to get nextflow newbies on their feet in no time. Best of all, the nf-core community is always on hand to help.
In this tutorial we discuss the best-practice guidelines developed by the nf-core community, why they're important and give insight into the best tips and tricks for budding nextflow pipeline developers.
Tutorial contributing to nf-core
Tutorial contributing to nf-coreGisela Gabernet The document provides an overview of contributing to nf-core, including documentation, code guidelines, helper tools, stable pipelines, downloading pipelines offline, listing and updating pipelines, and participation and development guidelines. Key points include contributing by adding new tools or features while avoiding duplication, developing with the community on Slack, and following contribution guidelines. Tutorial sections cover installation, creating pipelines, testing, modules, and releasing.
Introduction of eBPF
- 時下最夯的Linux Technology 
Introduction of eBPF
- 時下最夯的Linux Technology Jace Liang @ 2020/04/20 SDN x Cloud Native Meetup #27
隨著CNCF將Falco納入incubator project,eBPF這藏於Linux核心內的技術也開始受到矚目。
eBPF,一個從1992年就出現的技術,一路走來經過了甚麼樣的變化?
對於你我目前,或未來的工作又會有甚麼影響呢?
本次分享將會介紹eBPF的前世今生,帶各位了解何謂eBPF。並透過實際範例演示eBPF工具的特殊用法。
ELIXIR Proteomics Community - Connection with nf-core
ELIXIR Proteomics Community - Connection with nf-corePhil Ewels ELIXIR Proteomics Community and the Nextflow nf-core community - a meeting to discuss the joint efforton the standardization of analytical workflows.
Find out more at https://nf-co.re/
nf-core usage tutorial
nf-core usage tutorialGisela Gabernet This document provides an overview and instructions for using nf-core, an open source bioinformatics pipeline collection. It describes installing nf-core tools, listing available pipelines, running pipelines with test data, troubleshooting, and links to further documentation and tutorials. Exercises are included to familiarize users with installing nf-core, listing and filtering pipelines, running tests, and downloading pipelines for offline use. Support is available through the nf-core Slack workspace or reporting issues on GitHub.
Common design patterns (migang 16 May 2012)
Common design patterns (migang 16 May 2012)Steven Smith A discussion of six common design patterns, when to use them, how they are implemented, and when to avoid them.
ApacheCon 2021 - Apache NiFi Deep Dive 300
ApacheCon 2021 - Apache NiFi Deep Dive 300Timothy Spann 21-September-2021 - ApacheCon - Tuesday 17:10 UTC Apache NIFi Deep Dive 300
* https://github.com/tspannhw/EverythingApacheNiFi
* https://github.com/tspannhw/FLiP-ApacheCon2021
* https://www.datainmotion.dev/2020/06/no-more-spaghetti-flows.html
* https://github.com/tspannhw/FLiP-IoT
* https://github.com/tspannhw/FLiP-Energy
* https://github.com/tspannhw/FLiP-SOLR
* https://github.com/tspannhw/FLiP-EdgeAI
* https://github.com/tspannhw/FLiP-CloudQueries
* https://github.com/tspannhw/FLiP-Jetson
* https://www.linkedin.com/pulse/2021-schedule-tim-spann/
Tuesday 17:10 UTC
Apache NIFi Deep Dive 300
Timothy Spann
For Data Engineers who have flows already in production, I will dive deep into best practices, advanced use cases, performance optimizations, tips, tricks, edge cases, and interesting examples. This is a master class for those looking to learn quickly things I have picked up after years in the field with Apache NiFi in production.
This will be interactive and I encourage questions and discussions.
You will take away examples and tips in slides, github, and articles.
This talk will cover:
Load Balancing
Parameters and Parameter Contexts
Stateless vs Stateful NiFi
Reporting Tasks
NiFi CLI
NiFi REST Interface
DevOps
Advanced Record Processing
Schemas
RetryFlowFile
Lookup Services
RecordPath
Expression Language
Advanced Error Handling Techniques
Tim Spann is a Developer Advocate @ StreamNative where he works with Apache NiFi, Apache Pulsar, Apache Flink, Apache MXNet, TensorFlow, Apache Spark, big data, the IoT, machine learning, and deep learning. Tim has over a decade of experience with the IoT, big data, distributed computing, streaming technologies, and Java programming. Previously, he was a Principal Field Engineer at Cloudera, a senior solutions architect at AirisData and a senior field engineer at Pivotal. He blogs for DZone, where he is the Big Data Zone leader, and runs a popular meetup in Princeton on big data, the IoT, deep learning, streaming, NiFi, the blockchain, and Spark. Tim is a frequent speaker at conferences such as IoT Fusion, Strata, ApacheCon, Data Works Summit Berlin, DataWorks Summit Sydney, and Oracle Code NYC. He holds a BS and MS in computer science.
Practical virtual network functions with Snabb (SDN Barcelona VI)
Practical virtual network functions with Snabb (SDN Barcelona VI)Igalia By Andy Wingo.
SDN and Network Programmability Meetup in Barcelona (VI)
21 June 2017
https://www.meetup.com/es-ES/SDN-and-Network-Programmability-Meetup-in-Barcelona
/events/239667457/?eventId=239667457
The Next Chapter in the Sordid Love/Hate Relationship Between DBs and OSes by...
The Next Chapter in the Sordid Love/Hate Relationship Between DBs and OSes by...ScyllaDB DBMSs struggle with OS constraints, but new tech like eBPF can change the game. Join us to explore "user-bypass" designs for high-performance DBMSs with eBPF. Learn about BPF-DB, an embedded DBMS in the Linux kernel, providing ACID transactions and multi-versioned data. #databases #eBPF
AIDevWorldApacheNiFi101
AIDevWorldApacheNiFi101Timothy Spann AIDevWorld 23 Apache NiFi 101 Introduction and Best Practices
https://sched.co/1RoAO
Timothy Spann, Cloudera, Principal Developer Advocate
In this talk, we will walk step by step through Apache NiFi from the first load to first application. I will include slides, articles and examples to take away as a Quick Start to utilizing Apache NiFi in your real-time dataflows. I will help you get up and running locally on your laptop, Docker or in CDP Public Cloud.
Wednesday November 1, 2023 12:00pm - 12:25pm PDT
VIRTUAL AI DevWorld -- Main Stage https://app.hopin.com/events/api-world-2023-ai-devworld/stages
Retail & E-Commerce AI (Industry AI Conference)
Session Type OPEN TALK
Track or Conference Retail & E-Commerce AI (Industry AI Conference), Industry AI Conference, VIRTUAL, Tensorflow & PyTorch & Open Source Frameworks (AI/ML Engineering Conference), AI/ML Engineering Conference, AI DevWorld
In-Person/Virtual Virtual, Virtual Exclusive
apache nifi
Timothy Spann
Cloudera
Principal Developer Advocate for Data in Motion
Tim Spann is the Principal Developer Advocate for Data in Motion @ Cloudera where he works with Apache Kafka, Apache Flink, Apache NiFi, Apache Iceberg, TensorFlow, Apache Spark, big data, the IoT, machine learning, and deep learning. Tim has over a decade of experience with the IoT, big data, distributed computing, streaming technologies, and Java programming. Previously, he was a Developer Advocate at StreamNative, Principal Field Engineer at Cloudera, a Senior Solutions Architect at AirisData and a senior field engineer at Pivotal. He blogs for DZone, where he is the Big Data Zone leader, and runs a popular meetup in Princeton on big data, the IoT, deep learning, streaming, NiFi, the blockchain, and Spark. Tim is a frequent speaker at conferences such as IoT Fusion, Strata, ApacheCon, Data Works Summit Berlin, DataWorks Summit Sydney, and Oracle Code NYC. He holds a BS and MS in computer science.
cloudera dataflow
DEEP: a user success story
DEEP: a user success storyEOSC-hub project Valentin Kozlov from KIT-SCC demonstrates how developers can integrate their applications with DEEP components. DEEP is an EU-funded project that provides e-infrastructure for intensive data processing. Developers can run modules locally or on DEEP testbeds using Docker. More advanced users can use a data science template for version control and CI/CD pipelines. The presentation shows examples of plant classification and image recognition applications developed with DEEP.
ApacheCon 2021: Apache NiFi 101- introduction and best practices
ApacheCon 2021: Apache NiFi 101- introduction and best practicesTimothy Spann ApacheCon 2021: Apache NiFi 101- introduction and best practices
Thursday 14:10 UTC
Apache NiFi 101: Introduction and Best Practices
Timothy Spann
In this talk, we will walk step by step through Apache NiFi from the first load to first application. I will include slides, articles and examples to take away as a Quick Start to utilizing Apache NiFi in your real-time dataflows. I will help you get up and running locally on your laptop, Docker
DZone Zone Leader and Big Data MVB
@PaasDev
https://github.com/tspannhw https://www.datainmotion.dev/
https://github.com/tspannhw/SpeakerProfile
https://dev.to/tspannhw
https://sessionize.com/tspann/
https://www.slideshare.net/bunkertor

IGUANA: A Generic Framework for Benchmarking the Read-Write Performance of Tr...
IGUANA: A Generic Framework for Benchmarking the Read-Write Performance of Tr...Lixi Conrads Iguana is a framework for benchmarking the read-write performance of triple stores. It provides a realistic scenario by simulating multiple concurrent users querying and updating a triple store. Iguana executes benchmarks on different datasets and triple stores, measuring key performance indicators like queries per second. Results are stored in files and triple stores for analysis. The framework is extensible and can benchmark any dataset, SPARQL/update queries, and triple store configuration.
DIY Deep Learning with Caffe Workshop
DIY Deep Learning with Caffe Workshopodsc Caffe (Convolutional Architecture for Fast Feature Embedding) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors.
Caffe’s expressive architecture encourages application and innovation. Models and optimization are defined by configuration without hard-coding. Switch between CPU and GPU by setting a single flag to train on a GPU machine then deploy to commodity clusters or mobile devices.Caffe’s extensible code fosters active development. In Caffe’s first year, it has been forked by over 1,000 developers and had many significant changes contributed back. Thanks to these contributors the framework tracks the state-of-the-art in both code and models.Speed makes Caffe perfect for research experiments and industry deployment. Caffe can processover 60M images per day with a single NVIDIA K40 GPU*. That’s 1 ms/image for inference and 4 ms/image for learning. We believe that Caffe is the fastest convnet implementation available.Caffe already powers academic research projects, startup prototypes, and even large-scale industrial applications in vision, speech, and multimedia. Join our community of brewers on the caffe-users group and Github.
This tutorial is designed to equip researchers and developers with the tools and know-how needed to incorporate deep learning into their work. Both the ideas and implementation of state-of-the-art deep learning models will be presented. While deep learning and deep features have recently achieved strong results in many tasks, a common framework and shared models are needed to advance further research and applications and reduce the barrier to entry. To this end we present the Caffe framework, public reference models, and working examples for deep learning. Join our tour from the 1989 LeNet for digit recognition to today’s top ILSVRC14 vision models. Follow along with do-it-yourself code notebooks. While focusing on vision, general techniques are covered.
How we built a tools stack for the benchmarking AI and what happened next
How we built a tools stack for the benchmarking AI and what happened nextMichal Lukaszewski Origin story about testers team which transformed to a team of programmers writing custom software for ML and AI testing. How we started, what mistakes we did and how we solved them.
Microservices Application Tracing Standards and Simulators - Adrians at OSCON
Microservices Application Tracing Standards and Simulators - Adrians at OSCONAdrian Cockcroft This document discusses distributed tracing standards and microservices simulations. It introduces OpenZipkin and OpenTracing as open source distributed tracing projects. It also discusses Pivot Tracing and the OpenTracing initiative to standardize instrumentation. The document proposes using a microservices simulator called Spigo to generate test data and visualize traces. It provides an example of defining a LAMP stack architecture in JSON to simulate with Spigo.
Ad
More from Phil Ewels (14)
Coffee 'n code: Regexes
Coffee 'n code: RegexesPhil Ewels SciLifeLab Coffee & Code, Sept 25th 2020.
An introduction to regular expressions at the SciLifeLab / NGI Sweden "Coffee 'n code" talk. Aimed at people who sort-of-know what regexes are, but find them a bit terrifying..
Watch the talk on YouTube: https://youtu.be/2Yp6kvdUMxM
EpiChrom 2019 - Updates in Epigenomics at the NGI
EpiChrom 2019 - Updates in Epigenomics at the NGIPhil Ewels Slides from my talk at the SciLifeLab EpiChrom 2019 meeting: https://www.scilifelab.se/epichrom-2019/
# New epigenomics services at the National Genomics Infrastructure
A quick walkthrough of new library preparation methods on offer to study epigenetic signals at the National Genomics Infrastructure.
The future of genomics in the cloud
The future of genomics in the cloudPhil Ewels Slides from my talk given at the AWS Loft event in Stockholm, November 2018.
When genomic data is staged for analysis on Amazon S3, researchers have fast access to large volumes of data without needing to download and store their own copies. In this session, you will learn how a researcher at Sweden's SciLifeLab has made reference genome data available in the cloud as an AWS Public Dataset, and how this makes it easier for researchers to do large scale genomic analysis using tools like EMR and AWS Batch.
SciLifeLab NGI NovaSeq seminar
SciLifeLab NGI NovaSeq seminarPhil Ewels Talk from the SciLifeLab NGI NovaSeq seminar in September 2018. I describe how differences in illumina sequencing on the new NovaSeq 6000 can affect your sequencing, with illustrated examples from qcfail.com
Lecture: NGS at the National Genomics Infrastructure
Lecture: NGS at the National Genomics InfrastructurePhil Ewels Slides from my session on the SciLifeLab NBIS course "Introduction to Bioinformatics Using NGS Data". Held in Linköping, May 23 2018.
For more information about the course, see https://scilifelab.github.io/courses/ngsintro/1805/
SBW 2016: MultiQC Workshop
SBW 2016: MultiQC WorkshopPhil Ewels This document discusses NGS quality control using MultiQC. It provides background on the large volume of sequencing data processed in 2016 at NGI Stockholm, including different sequencing types and the challenges of manual quality control. It then introduces MultiQC as a tool that parses key metrics from analysis results/logs to create a single HTML report summarizing a project. It provides information on how MultiQC works, how to install and run it, and exercises for users. It also discusses customizing MultiQC reports and developing new modules.
Whole Genome Sequencing - Data Processing and QC at SciLifeLab NGI
Whole Genome Sequencing - Data Processing and QC at SciLifeLab NGIPhil Ewels Slides presented at the "Rare Disease Genomics" course held at the Centre for Molecular Medicine (Karolinska Institute, Stockholm, Sweden). Phil Ewels, 4th December 2017.
NBIS ChIP-seq course
NBIS ChIP-seq coursePhil Ewels Slides from my talk as part of the NBIS ChIP-seq tutorial course. I describe how we process ChIP-seq data at the Swedish National Genomics Infrastructure and how our NGI-ChIPseq analysis pipeline works. https://github.com/SciLifeLab/NGI-ChIPseq
NBIS RNA-seq course
NBIS RNA-seq coursePhil Ewels Slides from my talk as part of the NBIS RNA-seq tutorial course. I describe how we process RNA-seq data at the Swedish National Genomics Infrastructure and how our NGI-RNAseq analysis pipeline works. https://github.com/SciLifeLab/NGI-RNAseq
Developing Reliable QC at the Swedish National Genomics Infrastructure
Developing Reliable QC at the Swedish National Genomics InfrastructurePhil Ewels Good quality control procedures are essential for sequencing facilities. The SciLifeLab National Genomics Infrastructure is an accredited facility that processes thousands of samples every month, driving us to develop high-throughput QC procedures. We use a LIMS, a bespoke web system and most recently MultiQC - a tool that I have written to summarise analysis log files and produce reports that visualise key sample metrics.
In this talk I describe how our different systems integrate and how we use MultiQC results for both project level reporting and long term monitoring.
Standardising Swedish genomics analyses using nextflow
Standardising Swedish genomics analyses using nextflowPhil Ewels The SciLifeLab National Genomics Infrastructure is one of the largest sequencing facilities in Europe. We are an accredited facility providing library preparation, sequencing, basic analysis and quality control for Swedish research groups. Our sample throughput requires a highly automated and robust bioinformatics platform. Until recently, we had multiple analysis pipelines built with a range of different workflow tools for each data type. This made development work difficult and led to inevitable technical debt. In this talk I will describe how we have migrated to Nextflow for a range of our data types, the difficulties that we faced and how we hope to leverage Nextflow to migrate to the cloud in coming years.
Using visual aids effectively
Using visual aids effectivelyPhil Ewels Using effective visual aids is important for getting across your message when describing data. This can be in a presentation, poster or paper. This talk goes through some basic design tips that can help your visual aids look professional and work effectively.
Written for the Enabling Excellence ETN. https://eetraining.wordpress.com/
Analysis of ChIP-Seq Data
Analysis of ChIP-Seq DataPhil Ewels This document discusses the bioinformatics analysis of ChIP-seq data. It begins with an overview of ChIP-seq experiments and the major steps in processing and analyzing the sequencing data, including quality control, alignment, peak calling, and downstream analyses. Pipelines for automated analysis are described, such as Cluster Flow and Nextflow. The talk emphasizes that there is no single correct approach and the analysis depends on the biological question and experimental design.
Internet McMenemy
Internet McMenemyPhil Ewels The document discusses how the internet and websites work from a technical perspective. It covers how a web address is resolved to a server, the basic components of a webpage like HTML, CSS and images, how databases and templates allow dynamic content, and how cookies are used to store information on a user's browser. Real examples of code are provided to illustrate these concepts. Useful links are also included for hosting and creating websites.
Ad
Recently uploaded (20)


Volatile and Non Voloatile Memory in DFS.pptx
Volatile and Non Voloatile Memory in DFS.pptxNivya George Memory in computing is categorized into volatile and non-volatile types based on whether it retains data when power is lost.
Volatile memory is a type of temporary storage that requires continuous power to maintain the stored information. Once the system is turned off or restarted, all data in volatile memory is erased. It is primarily used for storing data that the CPU needs quick access to while performing tasks. The most common example is RAM (Random Access Memory), which provides fast, temporary storage for active processes and applications.
Non-volatile memory, on the other hand, retains data even when the power is turned off. It is used for long-term storage of programs, files, and system information. Examples include ROM (Read-Only Memory), hard drives, solid-state drives (SSDs), and USB flash drives. Non-volatile memory is essential for booting up the system and preserving data over time.
Together, volatile and non-volatile memory play crucial roles in the functionality and performance of computing devices, balancing speed and permanence.


Fungi Division: Deuteromycota (Fungi imperfecti)
Fungi Division: Deuteromycota (Fungi imperfecti)Elvis K. Goodridge The fungi imperfecti as known as Deuteromycota is a division under Fungi. A second class characterized by the non observance of a sexual phase in their lifecycle, although not much is known about the deuteromycetes, their contribution to fields like agricultural, medicine and botany has been astonishing to scientist.
DNA Profiling and STR Typing in Forensics: From Molecular Techniques to Real-...
DNA Profiling and STR Typing in Forensics: From Molecular Techniques to Real-...home This comprehensive assignment explores the pivotal role of DNA profiling and Short Tandem Repeat (STR) analysis in forensic science and genetic studies. The document begins by laying the molecular foundations of DNA, discussing its double helix structure, the significance of genetic variation, and how forensic science exploits these variations for human identification.
The historical journey of DNA fingerprinting is thoroughly examined, highlighting the revolutionary contributions of Dr. Alec Jeffreys, who first introduced the concept of using repetitive DNA regions for identification. Real-world forensic breakthroughs, such as the Colin Pitchfork case, illustrate the life-saving potential of this technology.
A detailed breakdown of traditional and modern DNA typing methods follows, including RFLP, VNTRs, AFLP, and especially PCR-based STR analysis, now considered the gold standard in forensic labs worldwide. The principles behind STR marker types, CODIS loci, Y-chromosome STRs, and the capillary electrophoresis (CZE) method are thoroughly explained. The steps of DNA profiling—from sample collection and amplification to allele detection using electropherograms (EPGs)—are presented in a clear and systematic manner.
Beyond crime-solving, the document explores the diverse applications of STR typing:
Monitoring cell line authenticity
Detecting genetic chimerism
Tracking bone marrow transplant engraftment
Studying population genetics
Investigating evolutionary history
Identifying lost individuals in mass disasters
Ethical considerations and potential misuse of DNA data are acknowledged, emphasizing the need for careful policy and regulation.
Whether you're a biotechnology student, a forensic professional, or a researcher, this document offers an in-depth look at how DNA and STRs transform science, law, and society.
AGENTS ACTING ON ENZYME HMG-CoA REDUCTASE M.PHARMA CHEMISTRY 2ND SEM (MPC203T...
AGENTS ACTING ON ENZYME HMG-CoA REDUCTASE M.PHARMA CHEMISTRY 2ND SEM (MPC203T...Pulkit Maheshwari M.PHARMA CHEMISTRY 2ND SEM
(MPC203T) COMPUTER AIDED DRUG DESIGN
AGENTS ACTING ON ENZYME HMG-CoA REDUCTASE
CONTENT-
1. INTRODUCTION
2. CLASSIFICATION
3. MECHANISM OF ACTION
4. SIDE EFFECTS
5. LIPID TRANSPORT
6. HMG-CoA REDUCTASE LOCATION , SYNTHESIS & ACTIVITY
7. CHOLESTROL SYNTHESIS
8. SOURCES OF STATINS
9. STRUCTURE OF STATINS
10. STRUCTURE OF TARGET PROTEIN
Nucleic Acids: Basics and Functions in cell
Nucleic Acids: Basics and Functions in cellNeetika Naudiyal This presentation contains the Basics of Nucleic Acids
Lipids: Classification, Functions, Metabolism, and Dietary Recommendations
Lipids: Classification, Functions, Metabolism, and Dietary RecommendationsSarumathi Murugesan This presentation offers a comprehensive overview of lipids, covering their classification, chemical composition, and vital roles in the human body and diet. It details the digestion, absorption, transport, and metabolism of fats, with special emphasis on essential fatty acids, sources, and recommended dietary allowances (RDA). The impact of dietary fat on coronary heart disease and current recommendations for healthy fat consumption are also discussed. Ideal for students and professionals in nutrition, dietetics, food science, and health sciences.
transitioning to quality approach .pptx
transitioning to quality approach .pptx091HarshikaModi what is quality ? or any other information can be provided.

whole ANATOMY OF EYE with eye ball .pptx
whole ANATOMY OF EYE with eye ball .pptxsimranjangra13 The human eye is a complex organ responsible for vision, composed of various structures working together to capture and process light into images. The key components include the sclera, cornea, iris, pupil, lens, retina, optic nerve, and various fluids like aqueous and vitreous humor. The eye is divided into three main layers: the fibrous layer (sclera and cornea), the vascular layer (uvea, including the choroid, ciliary body, and iris), and the neural layer (retina).
Here's a more detailed look at the eye's anatomy:
1. Outer Layer (Fibrous Layer):
Sclera:
The tough, white outer layer that provides shape and protection to the eye.
Cornea:
The transparent, clear front part of the eye that helps focus light entering the eye.
2. Middle Layer (Vascular Layer/Uvea):
Choroid:
A layer of blood vessels located between the retina and the sclera, providing oxygen and nourishment to the outer retina.
Ciliary Body:
A ring of tissue behind the iris that produces aqueous humor and controls the shape of the lens for focusing.
Iris:
The colored part of the eye that controls the size of the pupil, regulating the amount of light entering the eye.
Pupil:
The black opening in the center of the iris that allows light to enter the eye.
3. Inner Layer (Neural Layer):
Retina:
The light-sensitive layer at the back of the eye that converts light into electrical signals that are sent to the brain via the optic nerve.
Optic Nerve:
A bundle of nerve fibers that carries visual signals from the retina to the brain.
4. Other Important Structures:
Lens:
A transparent, flexible structure behind the iris that focuses light onto the retina.
Aqueous Humor:
A clear, watery fluid that fills the space between the cornea and the lens, providing nourishment and maintaining eye shape.
Vitreous Humor:
A clear, gel-like substance that fills the space between the lens and the retina, helping maintain eye shape.
Macula:
A small area in the center of the retina responsible for sharp, central vision.
Fovea:
The central part of the macula with the highest concentration of cone cells, providing the sharpest vision.
These structures work together to allow us to see, with the light entering the eye being focused by the cornea and lens onto the retina, where it is converted into electrical signals that are transmitted to the brain for interpretation.
he eye sits in a protective bony socket called the orbit. Six extraocular muscles in the orbit are attached to the eye. These muscles move the eye up and down, side to side, and rotate the eye.
The extraocular muscles are attached to the white part of the eye called the sclera. This is a strong layer of tissue that covers nearly the entire surface of the eyeball.he layers of the tear film keep the front of the eye lubricated.
Tears lubricate the eye and are made up of three layers. These three layers together are called the tear film. The mucous layer is made by the conjunctiva. The watery part of the tears is made by the lacrimal gland
Nutritional Diseases in poultry.........
Nutritional Diseases in poultry.........Bangladesh Agricultural University,Mymemsingh Poultry require at least 38 dietary nutrients inappropriate concentrations for a balanced diet. A nutritional deficiency may be due to a nutrient being omitted from the diet, adverse interaction between nutrients in otherwise apparently well-fortified diets, or the overriding effect of specific anti-nutritional factors.
Major components of foods are – Protein, Fats, Carbohydrates, Minerals, Vitamins
Vitamins are A- Fat soluble vitamins: A, D, E, and K ; B - Water soluble vitamins: Thiamin (B1), Riboflavin (B2), Nicotinic acid (niacin), Pantothenic acid (B5), Biotin, folic acid, pyriodxin and cholin.
Causes: Low levels of vitamin A in the feed. oxidation of vitamin A in the feed, errors in mixing and inter current disease, e.g. coccidiosis , worm infestation
Clinical signs: Lacrimation (ocular discharge), White cheesy exudates under the eyelids (conjunctivitis). Sticky of eyelids and (xerophthalmia). Keratoconjunctivitis.
Watery discharge from the nostrils. Sinusitis. Gasping and sneezing. Lack of yellow pigments,
Respiratory sings due to affection of epithelium of the respiratory tract.
Lesions:
Pseudo diphtheritic membrane in digestive and respiratory system (Keratinized epithelia).
Nutritional roup: respiratory sings due to affection of epithelium of the respiratory tract.
Pustule like nodules in the upper digestive tract (buccal cavity, pharynx, esophagus).
The urate deposits may be found on other visceral organs
Treatment:
Administer 3-5 times the recommended levels of vitamin A @ 10000 IU/ KG ration either through water or feed.
Lesions:
Pseudo diphtheritic membrane in digestive and respiratory system (Keratinized epithelia).
Nutritional roup: respiratory sings due to affection of epithelium of the respiratory tract.
Pustule like nodules in the upper digestive tract (buccal cavity, pharynx, esophagus).
The urate deposits may be found on other visceral organs
Treatment:
Administer 3-5 times the recommended levels of vitamin A @ 10000 IU/ KG ration either through water or feed.
Lesions:
Pseudo diphtheritic membrane in digestive and respiratory system (Keratinized epithelia).
Nutritional roup: respiratory sings due to affection of epithelium of the respiratory tract.
Pustule like nodules in the upper digestive tract (buccal cavity, pharynx, esophagus).
The urate deposits may be found on other visceral organs
Treatment:
Administer 3-5 times the recommended levels of vitamin A @ 10000 IU/ KG ration either through water or feed.
STR Analysis and DNA Typing in Forensic Science: Techniques, Steps & Applicat...
STR Analysis and DNA Typing in Forensic Science: Techniques, Steps & Applicat...home This presentation dives deep into the powerful world of DNA profiling and its essential role in modern forensic science. Beginning with the history of DNA fingerprinting, pioneered by Sir Alec Jeffreys in 1985, the presentation traces the evolution of forensic DNA analysis from the early days of RFLP (Restriction Fragment Length Polymorphism) to today's highly efficient STR (Short Tandem Repeat) typing methods.
You will learn about the key steps involved in STR analysis, including DNA extraction, amplification using PCR, capillary electrophoresis, and allele interpretation using electropherograms (EPGs). Detailed slides explain how STR markers, classified by repeat unit length and structure, are analyzed for human identification with remarkable precision—even from minute or degraded biological samples.
The presentation also introduces other DNA typing techniques such as Y-chromosome STR analysis, mitochondrial DNA (mtDNA) profiling, and SNP typing, alongside a comparative view of their strengths and limitations.
Real-world forensic applications are explored, from crime scene investigations, missing persons identification, and disaster victim recovery, to paternity testing and cold case resolution. Ethical considerations are addressed, emphasizing the need for informed consent, privacy protections, and responsible DNA database management.
Whether you're a forensic science student, a researcher, or simply curious about genetic identification methods, this presentation offers a comprehensive and clear overview of how STR typing works, its scientific basis, and its vital role in modern-day justice.
Introduction to Mobile Forensics Part 1.pptx
Introduction to Mobile Forensics Part 1.pptxNivya George Introduction to Mobile Forensics, Sim card crimes
Water analysis practical for ph, tds, hardness, acidity, conductivity, and ba...
Water analysis practical for ph, tds, hardness, acidity, conductivity, and ba...ss0077014 water analysis
2025 Insilicogen Company Korean Brochure
2025 Insilicogen Company Korean BrochureInsilico Gen Insilicogen is a company, specializes in Bioinformatics. Our company provides a platform to share and communicate various biological data analysis effectively.


Reproducible bioinformatics workflows with Nextflow and nf-core
- 1. Reproducible bioinformatics workflows with Nextflow and nf-core Phil Ewels [email protected] https://scilifelab.se https://ngisweden.scilifelab.se
- 2. 2020 62,789 samples 1112 projects 765.3 x1012 base pairs Human genome every 2 minutes 1X
- 5. A community effort to collect a curated set of analysis pipelines built using Nextflow. https://nf-co.re
- 7. Develop with the community Start from the template Collaborate, don’t duplicate https://nf-co.re
- 14. Running a pipeline nextflow run nf-core/<pipeline> -r <version> GitHub pipeline name Clones to ~/.nextflow Pipeline release tag Repository branch
- 15. Running a pipeline nextflow run nf-core/<pipeline> -r <version> --input my_samples.csv --genome GRCh38 Parsed as params.genome = 'GRCh38' Can be supplied in a file (config / YAML / JSON)
- 16. Running a pipeline nextflow run nf-core/<pipeline> -r <version> --input my_samples.csv --genome GRCh38 -profile docker Specifies a configuration profile Common setups bundled with pipelines, also shared institutional profiles available
- 17. Running a pipeline https://nf-co.re/rnaseq
- 18. Running a pipeline https://nf-co.re/launch
- 19. Running a pipeline nf-core launch --id 1637063024_d92e0f1632c2 nextflow run nf-core/rnaseq -params-file nf-params.json https://nf-co.re/launch
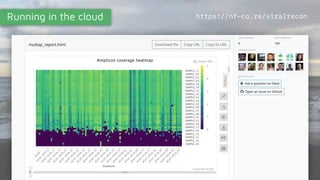
- 20. Running in the cloud
- 21. Running in the cloud https://github.com/nf-core/viralrecon
- 22. Running in the cloud https://nf-co.re/viralrecon
- 23. Running in the cloud https://nf-co.re/viralrecon
- 24. Phil Ewels Photos: Mattias Ormestad, unsplash.com @ewels @tallphil Ewels, P.A., Peltzer, A., et al. Nat Biotechnol 38, 276–278 (2020). https://doi.org/10.1038/s41587-020-0439-x https://www.nextflow.io https://tower.nf https://phil.ewels.co.uk [email protected] https://nf-co.re https://ngisweden.se https://scilifelab.se https://multiqc.info https://megaqc.info https://sra-explorer.info/