淺談RESTful API認證 Token機制使用經驗分享
18 likes16,076 views

本文件探讨了 RESTful API 的认证机制,包括 JWT 与 Django REST Framework (DRF) 的令牌认证。指出 RESTful API 的无状态特性、缓存支持与可扩展性优势,以及使用 Djoser 进行用户认证的相关功能。最后,文档还提及了将 Django 和 AngularJS 结合用于开发单页应用的计划。





















淺談RESTful API認證 Token機制使用經驗分享
- 1. 淺談 RESTful API 認證 Token 機制使用經驗分享 RESTful API Authentication Cobalt Chang
- 2. Outline ❖HTTP Protocol ❖Stateless Connections ❖JWT v.s. DRF Token ❖Djoser ❖Atlas – NEXCOM Embedded System
- 3. ❖應用於 Web 服務 ➢ 符合 REST 設計風格的 Web API ➢ 直觀簡短的資源地址: URI ,比如: http://example.com/resources/ 。 ➢ 傳輸的資源: Web 服務接受與返回的網際網路媒體類型, JSON , XML , YAML 等。 ➢ 對資源的操作: Web 服務在該資源上所支持的一系列請求方法。 GET PUT POST DELETE 一組資源的 URI ,比如 http://api.example.com/resources/ 列出 URI ,以及該資 源組中每個資源的詳 細資訊。 使用給定的一組資源 替換當前整組資源。 創建 / 追加一個新的 資源。該操作往往返 回新資源的 URL 。 刪除整組資源。 單個資源的 URI ,比如 http://api.example.com/resources/ item17/ 獲取指定資源的詳細 資訊,格式可以是 XML 、 JSON 等。 替換 / 創建指定的資 源。 在指定的資源下創建 / 追加一個新的元 素。 刪除指定的元素。 HTTP Protocol
- 4. ❖REST, Representational State Transfer ( 具象狀態傳輸 ) ➢ Roy Thomas Fielding 博士於 2000 年在他的博士論文中提出來的一種軟體架構風格。 ➢ 應用程式的狀態跟功能拆成 resources ■ 每一個 resource 由一個 global identifier ( 即 URI) 所表示 ➢ 資源的表現形式則是 XML 或者 HTML ,取決於讀者是機器還是人,當然也可以是任何其 他的格式。 ➢ 所有 resources 共用一致的介面轉換狀態 ■ 一組有限的良好定義操作 well-defined operations RESTful API - REST
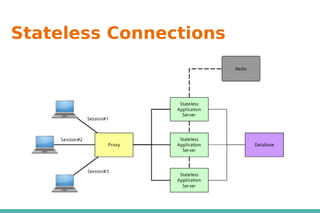
- 5. RESTful API - RESTful ❖REST 的要求: ➢ 使用者端 / 伺服器端 Client/Server ➢ 狀態無關 Stateless ➢ 可以快取 Cacheable ➢ 分層的 Layered ➢ 標準化的介面 Uniform interface ❖符合以上原則 (principles) 的系統稱做 RESTful 。
- 6. RESTful API - 有什麼優點 ❖支援快取 caching 將改善反應時間跟 server 的負載能力。 ❖因為不必維持連結狀態,大大改善 server 的 scalability 能力。這表示 不同 server 可以處理同一串 requests 。 ❖一個瀏覽器就可以存取任一應用程式跟資源, client 端不需使用別的軟 體。 ❖在 HTTP 之上不依存其他機制跟軟體。 ❖跟其他連結方式相比 ( 如 RPC) ,可以提供相等的功能。 ❖不需要其他的 discovery 機制,因為使用超連結了。
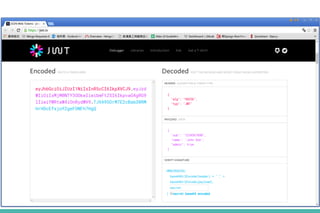
- 10. JSON Web Token (JWT)
- 12. JWT 特性 ❖無法真正「登出」 ➢ JWT 裡包含足夠的訊息可用來登入 ➢ 只能將 Client 的 Cookie 刪除 ❖維持連線 alive ➢ 有效時間內可拿舊 Token 換新 Token ➢ 設定長期間的 Token (14 天或 30 天 ) ➢ 自己實作定期換 Token
- 13. Django REST Framework ❖使用 django REST framework (DRF) 來開發 RESTful APIs ❖DRF 提供三種認證機制 ➢ BasicAuthentication ➢ SessionAuthentication ➢ TokenAuthentication
- 15. ❖Token 和 User 是一對一關係 ➢ 同一個 Client 在多台機器上登入都會使用同一個 Token ➢ 將 Client 「登出」會將 Token 刪除 ■ 其他機器的 Token 將無法再使用 ❖除非從 Database 裡刪除 Token ,否則永久存在。 DRF Token 特性
- 16. ❖使用 SSL 連線 ❖使用 SSL 連線 ❖使用 SSL 連線 安全性問題
- 17. ❖實作 Django 認證系統的 REST 套件 ❖利用 DRF 認證機制的第三方套件 ❖Supported authentication backends ➢ HTTP Basic Auth ( 預設 ) ➢ Token based authentication from Django Rest Framework ❖ 設定 ➢ 帳號是否需要 activate ➢ 密碼是否需要再次輸入 Introduction to Djoser
- 18. ❖提供的 APIs: ➢ /register/ 註冊 ➢ /login/ 登入 (token based authentication) ➢ /logout/ 登出 (token based authentication) ➢ /password/ 更換密碼 ➢ /password/reset/ 重設密碼 ( 發送 email) ➢ /password/reset/confirm/ 重設密碼 (email 裡的 link) Djoser APIs
- 19. 認證信功能 ❖要求輸入註冊時的 email 而不是帳號 ❖使用「加密」的 {uid} (base64 encode) 和 {token} (Django token) ➢ /password/reset/confirm/{uid}/{token} ➢ e.g. /password/reset/confirm/MQ/491-55796529106ab9437a42 ❖可修改 email 的 template ❖使用 Django 的 urls 和 view 來產生重設密碼的頁面
- 20. 我們正在打造的… ❖網通產品解決方案 ❖Web based desktop ➢ 使用 Django 作為 Backend ➢ 透過 RESTful APIs 串接 AngularJS ➢ Single page application (SPA) ❖以套件管理為基礎的作業系統 ❖跨平台的嵌入式系統
- 21. Single Page Application PythonJavascript DjangoAngularJS $resource ($http) Django REST framework RESTful API (JSON) HTML / CSS Database ORM Front-end Back-end Language Framework Module / App 21
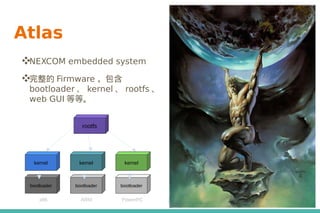
- 22. Atlas ❖NEXCOM embedded system ❖完整的 Firmware ,包含 bootloader 、 kernel 、 rootfs 、 web GUI 等等。 kernel bootloader kernel bootloader kernel bootloader x86 ARM PowerPC rootfs
- 23. DevOps
- 24. Thanks! 24