Scaling Multinomial Logistic Regression via Hybrid Parallelism
0 likes93 views

The document discusses the challenges in scaling multinomial logistic regression through hybrid parallelism techniques to optimize parameter estimation. It outlines issues in traditional distributed machine learning, such as storage limitations and inefficiencies in synchronous communication, and introduces a hybrid-parallel method that allows independent updates and decentralization. Through reformulating models into a doubly-separable form, the approach aims to enhance parallel computation efficiency and overcome synchronization bottlenecks.













![Outline
1 Introduction
2 Distributed Parameter Estimation
3 Scaling Multinomial Logistic Regression [Raman et al., KDD 2019]
4 Conclusion and Future Directions
7 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-14-320.jpg)














![Outline
1 Introduction
2 Distributed Parameter Estimation
3 Scaling Multinomial Logistic Regression [Raman et al., KDD 2019]
4 Conclusion and Future Directions
12 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-29-320.jpg)


![Distributed Parameter Estimation
Data parallel
N
D
X
Data
D
K
θ
Model
e.g. L-BFGS
Model parallel
N
D
X
Data
D
K
θ
Model
e.g. LC [Gopal et al., 2013]
13 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-32-320.jpg)






















![Direct Double-Separability
e.g. Matrix Factorization
L(w1, w2, . . . , wN, h1, h2, . . . , hM) =
1
2
N
i=1
M
j=1
(Xij − wi , hj )2
Objective function is trivially doubly-separable! [Yun et al 2014]
29 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-55-320.jpg)


![Outline
1 Introduction
2 Distributed Parameter Estimation
3 Scaling Multinomial Logistic Regression [Raman et al., KDD 2019]
4 Conclusion and Future Directions
32 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-58-320.jpg)






![Reformulation into Doubly-Separable form
Log-concavity bound [Bouchard07]
log(γ) ≤ a · γ − log(a) − 1, ∀γ, a > 0,
where a is a variational parameter. This bound is tight when a = 1
γ .
37 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-65-320.jpg)











![Parallelization: Synchronous DSGD [Gemulla et al., 2011]
X and local parameters A are partitioned horizontally (1, . . . , N)
45 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-77-320.jpg)
![Parallelization: Synchronous DSGD [Gemulla et al., 2011]
X and local parameters A are partitioned horizontally (1, . . . , N)
Global model parameters W are partitioned vertically (1, . . . , K)
45 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-78-320.jpg)
![Parallelization: Synchronous DSGD [Gemulla et al., 2011]
X and local parameters A are partitioned horizontally (1, . . . , N)
Global model parameters W are partitioned vertically (1, . . . , K)
P = 4 workers work on mutually-exclusive blocks of A and W
45 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-79-320.jpg)
![Parallelization: Asynchronous NOMAD [Yun et al., 2014]
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
A
W
46 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-80-320.jpg)
![Parallelization: Asynchronous NOMAD [Yun et al 2014]
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
A
W
47 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-81-320.jpg)
![Parallelization: Asynchronous NOMAD [Yun et al 2014]
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
A
W
48 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-82-320.jpg)
![Parallelization: Asynchronous NOMAD [Yun et al 2014]
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
A
W
49 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-83-320.jpg)






![Outline
1 Introduction
2 Distributed Parameter Estimation
3 Scaling Multinomial Logistic Regression [Raman et al., KDD 2019]
4 Conclusion and Future Directions
57 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-91-320.jpg)










![Ongoing Work: Other Matrix Parameterized Models
Factorization Machines
Infinite Mixture Models
DP Mixture Model [BleiJordan2006]
60 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-102-320.jpg)
![Ongoing Work: Other Matrix Parameterized Models
Factorization Machines
Infinite Mixture Models
DP Mixture Model [BleiJordan2006]
Pittman-Yor Mixture Model [Dubey et al., 2014]
60 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-103-320.jpg)
![Ongoing Work: Other Matrix Parameterized Models
Factorization Machines
Infinite Mixture Models
DP Mixture Model [BleiJordan2006]
Pittman-Yor Mixture Model [Dubey et al., 2014]
Stochastic Mixed-Membership Block Models [Airoldi et al., 2008]
60 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-104-320.jpg)
![Ongoing Work: Other Matrix Parameterized Models
Factorization Machines
Infinite Mixture Models
DP Mixture Model [BleiJordan2006]
Pittman-Yor Mixture Model [Dubey et al., 2014]
Stochastic Mixed-Membership Block Models [Airoldi et al., 2008]
Deep Neural Networks [Wang et al., 2014]
60 / 62](https://image.slidesharecdn.com/parameswaranramanamazontechtalk-200316214329/85/Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-105-320.jpg)


Scaling Multinomial Logistic Regression via Hybrid Parallelism
- 1. Scaling Multinomial Logistic Regression via Hybrid Parallelism Parameswaran Raman Ph.D. Candidate University of California Santa Cruz Tech Talk: Amazon March 17 2020 1 / 62
- 3. Motivation Data and Model grow hand in hand 2 / 62
- 4. Data and Model grow hand in hand e.g. Extreme Multi-class classification 3 / 62
- 5. Data and Model grow hand in hand e.g. Extreme Multi-label classification http://manikvarma.org/downloads/XC/XMLRepository.html 4 / 62
- 6. Data and Model grow hand in hand e.g. Extreme Clustering 5 / 62
- 7. Challenges in Parameter Estimation 6 / 62
- 8. Challenges in Parameter Estimation 1 Storage limitations of Data and Model 6 / 62
- 9. Challenges in Parameter Estimation 1 Storage limitations of Data and Model 2 Interdependence in parameter updates 6 / 62
- 10. Challenges in Parameter Estimation 1 Storage limitations of Data and Model 2 Interdependence in parameter updates 3 Bulk-Synchronization is expensive 6 / 62
- 11. Challenges in Parameter Estimation 1 Storage limitations of Data and Model 2 Interdependence in parameter updates 3 Bulk-Synchronization is expensive 4 Synchronous communication is inefficient 6 / 62
- 12. Challenges in Parameter Estimation 1 Storage limitations of Data and Model 2 Interdependence in parameter updates 3 Bulk-Synchronization is expensive 4 Synchronous communication is inefficient Traditional distributed machine learning approaches fall short. 6 / 62
- 13. Challenges in Parameter Estimation 1 Storage limitations of Data and Model 2 Interdependence in parameter updates 3 Bulk-Synchronization is expensive 4 Synchronous communication is inefficient Traditional distributed machine learning approaches fall short. Hybrid-Parallel algorithms for parameter estimation! 6 / 62
- 14. Outline 1 Introduction 2 Distributed Parameter Estimation 3 Scaling Multinomial Logistic Regression [Raman et al., KDD 2019] 4 Conclusion and Future Directions 7 / 62
- 15. Regularized Risk Minimization Goals in machine learning 8 / 62
- 16. Regularized Risk Minimization Goals in machine learning We want to build a model using observed (training) data 8 / 62
- 17. Regularized Risk Minimization Goals in machine learning We want to build a model using observed (training) data Our model must generalize to unseen (test) data 8 / 62
- 18. Regularized Risk Minimization Goals in machine learning We want to build a model using observed (training) data Our model must generalize to unseen (test) data min θ L (θ) = λ R (θ) regularizer + 1 N N i=1 loss (xi , yi , θ) empirical risk 8 / 62
- 19. Regularized Risk Minimization Goals in machine learning We want to build a model using observed (training) data Our model must generalize to unseen (test) data min θ L (θ) = λ R (θ) regularizer + 1 N N i=1 loss (xi , yi , θ) empirical risk X = {x1, . . . , xN}, y = {y1, . . . , yN} is the observed training data θ are the model parameters 8 / 62
- 20. Regularized Risk Minimization Goals in machine learning We want to build a model using observed (training) data Our model must generalize to unseen (test) data min θ L (θ) = λ R (θ) regularizer + 1 N N i=1 loss (xi , yi , θ) empirical risk X = {x1, . . . , xN}, y = {y1, . . . , yN} is the observed training data θ are the model parameters loss (·) to quantify model’s performance 8 / 62
- 21. Regularized Risk Minimization Goals in machine learning We want to build a model using observed (training) data Our model must generalize to unseen (test) data min θ L (θ) = λ R (θ) regularizer + 1 N N i=1 loss (xi , yi , θ) empirical risk X = {x1, . . . , xN}, y = {y1, . . . , yN} is the observed training data θ are the model parameters loss (·) to quantify model’s performance regularizer R (θ) to avoid over-fitting (penalizes complex models) 8 / 62
- 22. Frequentist Models 9 / 62
- 23. Frequentist Models Binary Classification/Regression Multinomial Logistic Regression Matrix Factorization Latent Collaborative Retrieval Polynomial Regression, Factorization Machines 9 / 62
- 24. Bayesian Models 10 / 62
- 25. Bayesian Models p(θ|X) posterior = likelihood p(X|θ) · prior p(θ) p(X, θ)dθ marginal likelihood (model evidence) prior plays the role of regularizer R (θ) likelihood plays the role of empirical risk 10 / 62
- 26. Bayesian Models Gaussian Mixture Models (GMM) Latent Dirichlet Allocation (LDA) p(θ|X) posterior = likelihood p(X|θ) · prior p(θ) p(X, θ)dθ marginal likelihood (model evidence) prior plays the role of regularizer R (θ) likelihood plays the role of empirical risk 10 / 62
- 27. Focus on Matrix Parameterized Models N D X Data D K θ Model 11 / 62
- 28. Focus on Matrix Parameterized Models N D X Data D K θ Model What if these matrices do not fit in memory? 11 / 62
- 29. Outline 1 Introduction 2 Distributed Parameter Estimation 3 Scaling Multinomial Logistic Regression [Raman et al., KDD 2019] 4 Conclusion and Future Directions 12 / 62
- 30. Distributed Parameter Estimation 13 / 62
- 31. Distributed Parameter Estimation Data parallel N D X Data D K θ Model e.g. L-BFGS 13 / 62
- 32. Distributed Parameter Estimation Data parallel N D X Data D K θ Model e.g. L-BFGS Model parallel N D X Data D K θ Model e.g. LC [Gopal et al., 2013] 13 / 62
- 33. Distributed Parameter Estimation Good Easy to implement using map-reduce Scales as long as Data or Model fits in memory 14 / 62
- 34. Distributed Parameter Estimation Good Easy to implement using map-reduce Scales as long as Data or Model fits in memory Bad Either Data or the Model is replicated on each worker. 14 / 62
- 35. Distributed Parameter Estimation Good Easy to implement using map-reduce Scales as long as Data or Model fits in memory Bad Either Data or the Model is replicated on each worker. Data Parallel: Each worker requires O N×D P + O (K × D) bottleneck 14 / 62
- 36. Distributed Parameter Estimation Good Easy to implement using map-reduce Scales as long as Data or Model fits in memory Bad Either Data or the Model is replicated on each worker. Data Parallel: Each worker requires O N×D P + O (K × D) bottleneck Model Parallel: Each worker requires requires O (N × D) bottleneck +O K×D P 14 / 62
- 37. Distributed Parameter Estimation Question Can we get the best of both worlds? 15 / 62
- 39. Hybrid-Parallelism 1 One versatile method for all regimes of data and model parallelism 17 / 62
- 40. Why Hybrid Parallelism? 18 / 62
- 41. Why Hybrid Parallelism? 19 / 62
- 42. Why Hybrid Parallelism? 20 / 62
- 43. Why Hybrid Parallelism? 21 / 62
- 44. Why Hybrid Parallelism? LSHTC1-small LSHTC1-large ODP Youtube8M-Video Reddit-Full 101 102 103 104 105 106 max memory of commodity machine SizeinMB(log-scale) data size (MB) parameters size (MB) 22 / 62
- 45. Hybrid-Parallelism 1 One versatile method for all regimes of data and model parallelism 2 Independent parameter updates on each worker 23 / 62
- 46. Hybrid-Parallelism 1 One versatile method for all regimes of data and model parallelism 2 Independent parameter updates on each worker 3 Fully de-centralized and asynchronous optimization algorithms 24 / 62
- 47. How do we achieve Hybrid Parallelism in machine learning models? 25 / 62
- 49. Double-Separability Definition A function f in two sets of parameters θ and θ is doubly separable if it can be decomposed into sub-functions fij such that: f (θ1, θ2, . . . , θm, θ1, θ2, . . . , θm ) = m i=1 m j=1 fij (θi , θj ) 27 / 62
- 50. Double-Separability f (θ1, θ2, . . . , θm, θ1, θ2, . . . , θm ) = m i=1 m j=1 fij (θi , θj ) 28 / 62
- 51. Double-Separability f (θ1, θ2, . . . , θm, θ1, θ2, . . . , θm ) = m i=1 m j=1 fij (θi , θj ) x x x x x x x x x x x x x m m fij (θi , θj ) 28 / 62
- 52. Double-Separability f (θ1, θ2, . . . , θm, θ1, θ2, . . . , θm ) = m i=1 m j=1 fij (θi , θj ) x x x x x x x x x x x x x m m fij (θi , θj ) fij corresponding to highlighted diagonal blocks can be computed independently and in parallel 28 / 62
- 53. Direct Double-Separability e.g. Matrix Factorization 29 / 62
- 54. Direct Double-Separability e.g. Matrix Factorization L(w1, w2, . . . , wN, h1, h2, . . . , hM) = 1 2 N i=1 M j=1 (Xij − wi , hj )2 29 / 62
- 55. Direct Double-Separability e.g. Matrix Factorization L(w1, w2, . . . , wN, h1, h2, . . . , hM) = 1 2 N i=1 M j=1 (Xij − wi , hj )2 Objective function is trivially doubly-separable! [Yun et al 2014] 29 / 62
- 56. Others require Reformulations 30 / 62
- 57. Doubly-Separable Multinomial Logistic Regression (DS-MLR) min W λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yikwT k xi + 1 N N i=1 log K k=1 exp(wT k xi ) makes model parallelism hard Doubly-Separable form min W ,A N i=1 K k=1 λ wk 2 2N − yik wT k xi N − log ai NK + exp(wT k xi + log ai ) N − 1 NK 31 / 62
- 58. Outline 1 Introduction 2 Distributed Parameter Estimation 3 Scaling Multinomial Logistic Regression [Raman et al., KDD 2019] 4 Conclusion and Future Directions 32 / 62
- 59. Multinomial Logistic Regression (MLR) Given: Training data (xi , yi )i=1,...,N, xi ∈ RD Labels yi ∈ {1, 2, . . . , K} N D X Data y 33 / 62
- 60. Multinomial Logistic Regression (MLR) Given: Training data (xi , yi )i=1,...,N, xi ∈ RD Labels yi ∈ {1, 2, . . . , K} N D X Data y Goal: Learn a model W Predict labels for the test data points using W D K W Model 33 / 62
- 61. Multinomial Logistic Regression (MLR) Given: Training data (xi , yi )i=1,...,N, xi ∈ RD Labels yi ∈ {1, 2, . . . , K} N D X Data y Goal: Learn a model W Predict labels for the test data points using W D K W Model Assume: N, D and K are large (N >>> D >> K) 33 / 62
- 62. Multinomial Logistic Regression (MLR) The probability that xi belongs to class k is given by: p(yi = k|xi , W ) = exp(wk T xi ) K j=1 exp(wj T xi ) where W = {w1, w2, . . . , wK } denotes the parameter for the model. 34 / 62
- 63. Multinomial Logistic Regression (MLR) The corresponding l2 regularized negative log-likelihood loss: min W λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yikwk T xi + 1 N N i=1 log K k=1 exp(wk T xi ) where λ is the regularization hyper-parameter. 35 / 62
- 64. Multinomial Logistic Regression (MLR) The corresponding l2 regularized negative log-likelihood loss: min W λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yikwk T xi + 1 N N i=1 log K k=1 exp(wk T xi ) makes model parallelism hard where λ is the regularization hyper-parameter. 36 / 62
- 65. Reformulation into Doubly-Separable form Log-concavity bound [Bouchard07] log(γ) ≤ a · γ − log(a) − 1, ∀γ, a > 0, where a is a variational parameter. This bound is tight when a = 1 γ . 37 / 62
- 66. Reformulating the objective of MLR min W ,A λ 2 K k=1 wk 2 + 1 N N i=1 − K k=1 yik wk T xi + ai K k=1 exp(wk T xi ) − log(ai ) − 1 where ai can be computed in closed form as: ai = 1 K k=1 exp(wk T xi ) 38 / 62
- 67. Doubly-Separable Multinomial Logistic Regression (DS-MLR) Doubly-Separable form min W ,A N i=1 K k=1 λ wk 2 2N − yik wk T xi N − log ai NK + exp(wk T xi + log ai ) N − 1 NK 39 / 62
- 68. Doubly-Separable Multinomial Logistic Regression (DS-MLR) Stochastic Gradient Updates Each term in stochastic update depends on only data point i and class k. 40 / 62
- 69. Doubly-Separable Multinomial Logistic Regression (DS-MLR) Stochastic Gradient Updates Each term in stochastic update depends on only data point i and class k. wk t+1 ← wk t − ηtK λxi − yikxi + exp wk T xi + log ai xi 40 / 62
- 70. Doubly-Separable Multinomial Logistic Regression (DS-MLR) Stochastic Gradient Updates Each term in stochastic update depends on only data point i and class k. wk t+1 ← wk t − ηtK λxi − yikxi + exp wk T xi + log ai xi log ai t+1 ← log ai t − ηtK exp(wk T xi + log ai ) − 1 K 40 / 62
- 71. Access Pattern of updates: Stoch wk, Stoch ai X W A (a) Updating wk only requires computing ai X W A (b) Updating ai only requires accessing wk and xi . 41 / 62
- 72. Updating ai: Closed form instead of Stoch update Closed-form update for ai ai = 1 K k=1 exp(wk T xi ) 42 / 62
- 73. Access Pattern of updates: Stoch wk, Exact ai X W A (a) Updating wk only requires computing ai X W A (b) Updating ai requires accessing entire W. Synchronization bottleneck! 43 / 62
- 74. Updating ai: Avoiding bulk-synchronization Closed-form update for ai ai = 1 K k=1 exp(wk T xi ) 44 / 62
- 75. Updating ai: Avoiding bulk-synchronization Closed-form update for ai ai = 1 K k=1 exp(wk T xi ) Each worker computes partial sum using the wk it owns. 44 / 62
- 76. Updating ai: Avoiding bulk-synchronization Closed-form update for ai ai = 1 K k=1 exp(wk T xi ) Each worker computes partial sum using the wk it owns. P workers: After P rounds the global sum is available 44 / 62
- 77. Parallelization: Synchronous DSGD [Gemulla et al., 2011] X and local parameters A are partitioned horizontally (1, . . . , N) 45 / 62
- 78. Parallelization: Synchronous DSGD [Gemulla et al., 2011] X and local parameters A are partitioned horizontally (1, . . . , N) Global model parameters W are partitioned vertically (1, . . . , K) 45 / 62
- 79. Parallelization: Synchronous DSGD [Gemulla et al., 2011] X and local parameters A are partitioned horizontally (1, . . . , N) Global model parameters W are partitioned vertically (1, . . . , K) P = 4 workers work on mutually-exclusive blocks of A and W 45 / 62
- 80. Parallelization: Asynchronous NOMAD [Yun et al., 2014] x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx A W 46 / 62
- 81. Parallelization: Asynchronous NOMAD [Yun et al 2014] x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx A W 47 / 62
- 82. Parallelization: Asynchronous NOMAD [Yun et al 2014] x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx A W 48 / 62
- 83. Parallelization: Asynchronous NOMAD [Yun et al 2014] x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx A W 49 / 62
- 84. Experiments: Datasets 50 / 62
- 85. Experiments: Single Machine NEWS20, Data=35 MB, Model=9.79 MB 100 101 102 103 1.45 1.5 1.55 1.6 1.65 time (secs) objective DS-MLR L-BFGS LC 51 / 62
- 86. Experiments: Single Machine LSHTC1-small, Data=15 MB, Model=465 MB 101 102 103 104 0 0.2 0.4 0.6 0.8 1 time (secs) objective DS-MLR L-BFGS LC 52 / 62
- 87. Experiments: Multi Machine LSHTC1-large, Data=356 MB, Model=34 GB, machines=4, threads=12 103 104 0.5 0.6 0.7 0.8 time (secs) objective DS-MLR LC 53 / 62
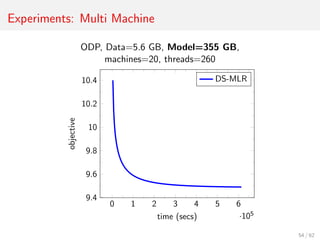
- 88. Experiments: Multi Machine ODP, Data=5.6 GB, Model=355 GB, machines=20, threads=260 0 1 2 3 4 5 6 ·105 9.4 9.6 9.8 10 10.2 10.4 time (secs) objective DS-MLR 54 / 62
- 89. Experiments: Multi Machine Dense Dataset YouTube-Video, Data=76 GB, Model=43 MB, machines=4, threads=260 0 1 2 3 ·105 0 20 40 60 time (secs) objective DS-MLR 55 / 62
- 90. Experiments: Multi Machine (Nothing fits in memory!) Reddit-Full, Data=228 GB, Model=358 GB, machines=40, threads=250 0 2 4 6 ·105 10 10.2 10.4 time (secs) objective DS-MLR 211 million examples, 44 billion parameters (# features × # classes) 56 / 62
- 91. Outline 1 Introduction 2 Distributed Parameter Estimation 3 Scaling Multinomial Logistic Regression [Raman et al., KDD 2019] 4 Conclusion and Future Directions 57 / 62
- 92. Conclusion and Key Takeaways Data and Model grow hand in hand. 58 / 62
- 93. Conclusion and Key Takeaways Data and Model grow hand in hand. Challenges in Parameter Estimation. 58 / 62
- 94. Conclusion and Key Takeaways Data and Model grow hand in hand. Challenges in Parameter Estimation. I have developed: 58 / 62
- 95. Conclusion and Key Takeaways Data and Model grow hand in hand. Challenges in Parameter Estimation. I have developed: Hybrid-Parallel formulations 58 / 62
- 96. Conclusion and Key Takeaways Data and Model grow hand in hand. Challenges in Parameter Estimation. I have developed: Hybrid-Parallel formulations Distributed, Asynchronous Algorithms 58 / 62
- 97. Conclusion and Key Takeaways Data and Model grow hand in hand. Challenges in Parameter Estimation. I have developed: Hybrid-Parallel formulations Distributed, Asynchronous Algorithms Applied them to several machine learning tasks: Classification (e.g. Multinomial Logistic Regression) Clustering (e.g. Mixture Models) Ranking 58 / 62
- 98. Summary: Other Hybrid-Parallel formulations 59 / 62
- 99. Ongoing Work: Other Matrix Parameterized Models 60 / 62
- 100. Ongoing Work: Other Matrix Parameterized Models Factorization Machines 60 / 62
- 101. Ongoing Work: Other Matrix Parameterized Models Factorization Machines Infinite Mixture Models 60 / 62
- 102. Ongoing Work: Other Matrix Parameterized Models Factorization Machines Infinite Mixture Models DP Mixture Model [BleiJordan2006] 60 / 62
- 103. Ongoing Work: Other Matrix Parameterized Models Factorization Machines Infinite Mixture Models DP Mixture Model [BleiJordan2006] Pittman-Yor Mixture Model [Dubey et al., 2014] 60 / 62
- 104. Ongoing Work: Other Matrix Parameterized Models Factorization Machines Infinite Mixture Models DP Mixture Model [BleiJordan2006] Pittman-Yor Mixture Model [Dubey et al., 2014] Stochastic Mixed-Membership Block Models [Airoldi et al., 2008] 60 / 62
- 105. Ongoing Work: Other Matrix Parameterized Models Factorization Machines Infinite Mixture Models DP Mixture Model [BleiJordan2006] Pittman-Yor Mixture Model [Dubey et al., 2014] Stochastic Mixed-Membership Block Models [Airoldi et al., 2008] Deep Neural Networks [Wang et al., 2014] 60 / 62
- 106. Acknowledgements Thanks to all my collaborators. 61 / 62
- 107. References Parameswaran Raman, Sriram Srinivasan, Shin Matsushima, Xinhua Zhang, Hyokun Yun, S.V.N. Vishwanathan. Scaling Multinomial Logistic Regression via Hybrid Parallelism. KDD 2019. Parameswaran Raman∗ , Jiong Zhang∗ , Shihao Ji, Hsiang-Fu Yu, S.V.N. Vishwanathan, Inderjit S. Dhillon. Extreme Stochastic Variational Inference: Distributed and Asynchronous. AISTATS 2019. Hyokun Yun, Parameswaran Raman, S.V.N. Vishwanathan. Ranking via Robust Binary Classification. NIPS 2014. Source Code: DS-MLR: https://bitbucket.org/params/dsmlr ESVI: https://bitbucket.org/params/dmixmodels RoBiRank: https://bitbucket.org/d ijk stra/robirank 62 / 62