Scylla Summit 2016: Outbrain Case Study - Lowering Latency While Doing 20X IOPS of Cassandra
5 likes3,441 views

Outbrain is the world's largest content discovery program. Learn about their use case with Scylla where they lowered latency while doing 20X IOPS of Cassandra.







































































Ad
More Related Content
What's hot (20)
Similar to Scylla Summit 2016: Outbrain Case Study - Lowering Latency While Doing 20X IOPS of Cassandra (20)


















Ad
More from ScyllaDB (20)




















Ad
Recently uploaded (20)




















Scylla Summit 2016: Outbrain Case Study - Lowering Latency While Doing 20X IOPS of Cassandra
- 1. Case Study Shalom Yerushalmy - Production Engineer @ Outbrain Shlomi Livne - VP R&D @ ScyllaDB
- 2. Lowering Latency While Doing 20X IOPS of Cassandra
- 3. About Me • Production Engineer @ Outbrain, Recommendations Group. • Data Operations team. Was in charge of Cassandra, ES, MySQL, Redis, Memcache. • Past was a DevOps Engineer @ EverythingMe. ETL, chef, monitoring.
- 4. About Outbrain • Outbrain is the world’s largest content discovery platform. • Over 557 million unique visitors from across the globe. • 250 billion personalized content recommendations every month. • Outbrain platform include: ESPN, CNN, Le Monde, Fox News, The Guardian, Slate, The Telegraph, New York Post, India.com, Sky News and Time Inc.
- 6. Infrastructure at Outbrain • 3 Data Centers. • 7000 Servers. • 2000 Data servers. (Hadoop, Cassandra, ES, Scylla, etc.) • Peta bytes of data. • Real hardcore opensource devops shop. https://github.com/outbrain
- 7. Cassandra at Outbrain • 16 C* Clusters. ~400 nodes. • Documents Services cassandra node spec: ▪ Memory - 64GB. ▪ Disk - Two HDDs for system (Mirror). ▪ One 500GB ssd for data. ▪ 2*1G ETH links. ▪ DSE 4.8.X (Cassandra 2.1.X)
- 8. Use Case
- 9. Specific use case • Documents (articles) data column family ▪ Holds data in key/value manner ▪ ~2 billion records ▪ 10 nodes in each DC, 3 DCs. ▪ RF: 3, local quorum for writes and reads • Usage: Serving our documents (articles) data to different flows. ▪ ~50K writes per minute, ~2-3M reads per minute per DC and growing… ▪ SLA - single requests in 10 ms and multi requests in 200 ms in the 99%ile. ▪ Same cluster for offline and serving use-cases ▪ Microservices: reads are done using a microservice and not directly
- 10. Cassandra only no memcache Performance • Scales up to ~1.5M RPM with local quorum. • Quick writes (99%ile up to 5 ms), slower reads (up to 50ms in 99%ile) Cassandra deployment V1 Read Microservice Write Process
- 11. Issues we had with V1 • Consistency vs. performance (local one vs. local quorum) • Growing vs. performance
- 12. Cassandra deployment V2 Cassandra + Memcache • Memcached DC-local cluster over C* with 15 minutes TTL. • First read from memcached, go to C* on misses. • Reads volume from C* ~500K RPM. • Reads are now within SLA (5 ms in 99%ile) Read Microservice Write Process
- 13. Issues we had/have with v2 • Stale data from cache • Complex solution • Cold cache -> C* gets full volume
- 14. Scylla & Cassandra + Memcache • Writes are written in parallel to C* and Scylla • Two reads are done in parallel: ▪ First: Memcached + Cassandra ▪ Second: Scylla Scylla/Cassandra side by side deployment Read Microservice Write Process
- 15. Replicating the data 1. Scylla cluster initialized with C* token ownership: a. System tables from C* have been copied over to Scylla: assuring one-to- one node relationship (maintaining token ownership of nodes) 2. Dual Writes: a. Writes to C* are written to Scylla 3. Snapshot upload: a. Snapshots from C* have been copied over to Scylla following one-to-one matching b. Snapshot uploaded with nodetool refresh. 4. Comparing the data on reads a. Reads from C* (not found in Memcache) are also read from Scylla b. Comparing the data returned from C* and Scylla - diff writing to ELK
- 16. Things we have Learnt Along the Way
- 17. • The cluster is running on 1 Gb network • Using the metrics collected on servers at 1 minute interval it is impossible to detect issues in networking (the cluster is using ~10 MB/s) • Viewing this locally on servers in a more fine grained manner (quickstats) ▪ Burst of traffic for sub second intervals saturating the network (every 5 minute interval) Bursty clients
- 18. Compressed Block Size • Queries return a full partition • Nodetool cfstats provides info on partition size (4K) • Using the default 64KB chunk_size is can be wasteful • Tune accordingly (ALTER TABLE … WITH compression = { 'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 4 };)
- 19. Queries with CL=LOCAL_QUORUM are not local • Running with read_repair_chance > 0 adds nodes outside of the local dc. • In case the first returned responses (local ones) do not match (by digest) ▪ wait for all the responses (including the non local ones) to compute the query result ▪ This is especially problematic in cases of read after write • Scylla 1.3 includes scylla-1250 that provides a solution in case of LOCAL_* to detect a potential read after write and downgrade global read_repair to local read_repair.
- 20. Global read_repair when local data is the same DC1 DC2 Client
- 21. Global read_repair when local data is the same DC1 DC2 Client
- 22. Global read_repair when local data is the same DC1 DC2 Client Data is the same
- 23. Global read_repair when local data is the same DC1 DC2 Client
- 24. Global read_repair when local data is different DC1 DC2 Client
- 25. Global read_repair when local data is different DC1 DC2 Client
- 26. Global read_repair when local data is different DC1 DC2 Client Data is different
- 27. Global read_repair when local data is different DC1 DC2 Client Compute Res & Diff
- 28. Global read_repair when local data is different DC1 DC2 Client
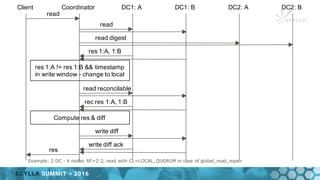
- 29. Client Coordinator DC1: A DC1: B DC2: A DC2: B read read read digest res 1:A, 1:B res 1:A != res 1:B Compute res & diff res read reconcilable rec res 1:A, 1:B, 2:A, 2:B write diff write diff ack Example: 2 DC - 4 nodes RF=2:2, read with CL=LOCAL_QUORUM in case of global_read_repair
- 30. Client Coordinator DC1: A DC1: B DC2: A DC2: B read read read digest res 1:A, 1:B res 1:A != res 1:B && timestamp in write window - change to local Compute res & diff res read reconcilable rec res 1:A, 1:B write diff write diff ack Example: 2 DC - 4 nodes RF=2:2, read with CL=LOCAL_QUORUM in case of global_read_repair
- 31. Cold cache • Restarting a node forces all requests to be served from disk (in peak traffic we are bottlenecked by the disk) • DynamicSnitch in C* tries to address this - yet it assumes that all queries are the same. • We are looking into using the cache hit ratio scylla-1455 and allowing a more fine grained evaluation
- 32. Performance
- 33. Scylla vs Cassandra + Memcached - CL:LOCAL_QUORUM Scylla Cassandra RPM 12M 500K AVG Latency 4 ms 8 ms Max RPM 1.7 RPM Max Latency 8 ms 35 ms
- 34. Lowering Latency While Doing 20X IOPS of Cassandra
- 35. Scylla vs Cassandra - CL:LOCAL_ONE Scylla and Cassandra handling the full load (peak of ~12M RPM) 80 6
- 36. Scylla vs Cassandra - CL:LOCAL_QUORUM * Cassandra has ~500 Timeouts (1 second) per minute in peak hours Scylla and Cassandra handling the full load (peak of ~12M RPM) 200 10
- 37. So ...
- 38. Summary • Scylla handles all the traffic with better latencies • Current bottleneck is network • Scylla nodes are almost idle
- 39. Next steps • A new cluster: ▪ 3 nodes ▪ 10 Gb network ▪ Larger disks ▪ More memory • Move to production
- 40. Visibility ● Outbrain’s Cassandra Grafana dashbords. ● https://github.com/outbrain/Cassibility You are more than welcome to use this and optimize for ScyllaDB use.
- 41. Analytics ● Redash - ● http://redash.io/ ● https://github.com/getredash/redash/pull/1236 Available now on github, will be part of version 0.12.
- 42. Thank You! Shalom Yerushalmy <[email protected]> Shlomi Livne <[email protected]> @slivne