Search Joins with the Web - ICDT2014 Invited Lecture
Download as PPTX, PDF4 likes3,553 views

The document presents an invited lecture on 'Search Joins with the Web' at the ICDT 2014 conference, highlighting methods to extend local tables using structured web data. It discusses the motivation and feasibility of search joins, providing an overview of the various data models and available structured data on the web. Key concepts include the operation of search joins, the role of linked data, and the challenges of integrating heterogeneous web tables.





































































Search Joins with the Web - ICDT2014 Invited Lecture
- 1. Slide 1 International Conference on Database Theory (ICDT 2014) Athens, Greece, 25.3.2014 Invited Lecture Search Joins with the Web Prof. Dr. Christian Bizer
- 2. Slide 2 Outline A Search Join is a join operation which extends a local table with additional attributes based on the large corpus of structured data that is published on the Web. 1. Motivation and Definition 2. Profile of the available Web Data 3. Feasibility of Search Joins 4. Table Relevance
- 3. Slide 3 Deluge of Structured Data on the Web
- 4. Slide 4 Relational HTML Tables In corpus of 14B raw tables, 154M are “good” relations (1.1%). • Cafarella, et al.: WebTables: Exploring the Power of Tables on the Web. VLDB 2008.
- 5. Slide 5 Data Consumers HTML-embedded Data on the Web Several million websites semantically markup the content of their HTML pages. Markup Syntaxes Microformats RDFa Microdata
- 6. Slide 6 Linked Data on the Web ~ 900 data sets (2014)
- 7. Slide 7 Data Portals Several 100.000 datasets are available via data portals.
- 8. Slide 8 Table Search Example: Google Table Search http://research.google.com/tables Problem: The user is left alone with the integration. using some tool doing cut@paste Given some keywords describing the user’s information need, generate ranked list of relevant tables. • Venetis, et al.: Table Search Using Recovered Semantics. VLDB, 2010. • Pimplikar, Sarawagi: Answering table queries on the web using column keywords. VLDB 2012.
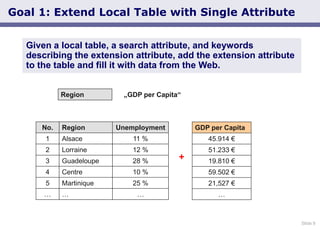
- 9. Slide 9 Goal 1: Extend Local Table with Single Attribute Given a local table, a search attribute, and keywords describing the extension attribute, add the extension attribute to the table and fill it with data from the Web. No. Region Unemployment 1 Alsace 11 % 2 Lorraine 12 % 3 Guadeloupe 28 % 4 Centre 10 % 5 Martinique 25 % … … … GDP per Capita 45.914 € 51.233 € 19.810 € 59.502 € 21,527 € … + Region „GDP per Capita“
- 10. Slide 10 Goal 2: Extend Local Table with Many Attributes Given a local table, a search attribute, add all attributes to the local table that can be filled beyond a density threshold. No. Region Unemp. Rate 1 Alsace 11 % 2 Lorraine 12 % 3 Guadeloupe 28 % 4 Centre 10 % 5 Martinique 25 % … … … GDP per Capita Population Growth Overseas departments … 45.914 € 0,16 % No … 51.233 € -0,05 % No … 19.810 € 1,34 % Yes … 59.502 € NULL NULL … NULL 2,64 % Yes … … … … + Region density >= 0.8
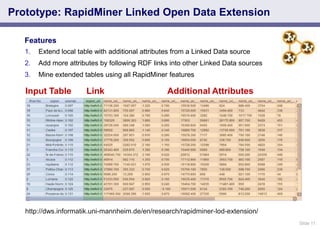
- 11. Slide 11 Features 1. Extend local table with additional attributes from a Linked Data source 2. Add more attributes by following RDF links into other Linked Data sources 3. Mine extended tables using all RapidMiner features http://dws.informatik.uni-mannheim.de/en/research/rapidminer-lod-extension/ Prototype: RapidMiner Linked Open Data Extension Input Table Link Additional Attributes
- 12. Slide 12 Resulting Correlations Overseas Department (positive) Population growth (positive) Fast food restaurants (positive) Police stations (positive) Hospital beds/inhabitants (negative) GDP (negative) Energy consumption (negative) Linked Data Sources used: Eurostat and DBpedia
- 13. Slide 13 Definition: Search Join Input: 1. Corpus of heterogeneous Web tables 2. Query table 3. Search attribute definition 4. Extension attribute(s) definition - Single attribute case: keyword describing extension attribute - Multiple attributes case: density threshold Output: Query table augmented with additional attribute(s) A Search Join is a join operation which extends a local table with additional attributes based on the large corpus of structured data that is published on the Web.
- 14. Slide 14 Search Joins in SQL SELECT city.*, web.population FROM city SEARCH JOIN web ON city.name; SELECT city.name, web.*(0.9) FROM city SEARCH JOIN web ON city.name;
- 15. Slide 15 Elements of a Search Join s() : Search operator determines the set of the top-k relevant Web tables. (Web tables which are beneficial join partners) m() : MultiJoin operator performs a series of left-outer joins between the query table and all tables in the input set. c() : Consolidation operator merges corresponding attributes and fuses attribute values in order to return a concise result table containing high-quality data.
- 16. Slide 16 The Search Operator Input TWeb = set of Web tables q = query table s = search attribute a = attribute description Output Tr = set of relevant Web Tables The Search operator determines the set of relevant Web tables.
- 17. Slide 17 Multi-Join Operator Input q = query table Tr = set of relevant Web tables Output te = extended query table The MultiJoin operator performs a series of left-outer joins between the query table and all tables in the input set. No. Region 1 Alsace 2 Lorraine 3 Guadeloupe 4 Centre Unemploy 11 % 12 % 28 % 10 % Unemploy NULL NULL NULL 9.4 % GDP 45.914 € 51.233 € NULL NULL GDP per C 45.000 € NULL 19.000 € 59.500 €
- 18. Slide 18 Consolidation Operator Input te = extended query table Output tr = result table Might employ various sources of attribute correspondences. Might employ various conflict resolution functions. The consolidation operator merges corresponding attributes and fuses attribute values in order to return a concise result table containing high-quality data. No Region Unemploy GDP 1 Alsace 11 % 45.914 € 2 Lorraine 12 % 51.233 € 3 Guadelo upe 28 % 19.000 € 4 Centre 10 % 59.500 €
- 19. Slide 19 Data Model for Representing Web Data Entity-Attributes-Tables One entity per row Subject Attribute name of the entity string, no number or other data type relatively unique values Rank Film Studio Director Length 1. Star Wars –Episode 1 Lucasfilm George Lucas 121 min 2. Alien Brandwine Ridley Scott 117 min 3. Black Moon NEF Louis Malle 100 min
- 20. Slide 20 Data Model Details Table Meta-Information Provenance: Source URL Table Context: Text around the table Attribute Headers Attribute name Unit of measurement Date Data types String, Number, Date, Geo Coordinates Lists URI Reference
- 21. Slide 21 2. Profile of the available Web Data
- 22. Slide 22 HTML Tables • Cafarella, et al.: WebTables: Exploring the Power of Tables on the Web. VLDB 2008. • Crestan, Pantel: Web-Scale Table Census and Classification. WSDM 2011. In corpus of 14B raw tables, 154M are “good” relations (1.1%). Cafarella (2008) Classification Precision: 70-80%
- 23. Slide 23 Subject Attribute and Header Detection Subject Attribute Detection (Ventis) Simple heuristic approach (Accuracy: 83%) - scan columns from left to right - take first column that is not a number or a date SVM Classifier (Accuracy: 94%) - fraction of cells with unique content - variance in the number of tokens in each cell - column index from the left - …. Header Detection (Pimplikar) one header row: 60% two or more header rows: 22% no header: 18% • Ventis, et al.: Recovering Semantics of Tables on the Web. VLDB 2011. • Pimplikar, Sarawagi: Answering table queries on the web using column keywords, VLDB 2012.
- 24. Slide 24 The Common Crawl
- 25. Slide 25 Web Data Commons – Web Tables Corpus Large corpus of relational Web tables for public download extracted from Common Crawl 2012 (3.3 billion pages) 147 million relational tables selected out of 11.2 B raw tables (1.3%) download includes the HTML pages of the tables (1TB zipped) Table Statistics Heterogeneity: Very high. • http://webdatacommons.org/webtables/ Min Max Avg Median Attributes 2 2,368 3.49 3 Data Rows 1 70,068 12.41 6
- 26. Slide 26 Attribute Statistics 28,000,000 different attribute labels Web Data Commons – Web Tables Corpus Attribute #Tables name 4,600,000 price 3,700,000 date 2,700,000 artist 2,100,000 location 1,200,000 year 1,000,000 manufacturer 375,000 counrty 340,000 isbn 99,000 area 95,000 population 86,000 Subject Attribute Values 1.74 billion rows 253,000,000 different subject labels Value #Rows usa 135,000 germany 91,000 greece 42,000 new york 59,000 london 37,000 athens 11,000 david beckham 3,000 ronaldinho 1,200 oliver kahn 710 twist shout 2,000 yellow submarine 1,400
- 27. Slide 27 HTML-embedded Data More and more Websites semantically markup the content of their HTML pages. Microformats Microdata RDFa
- 28. Slide 28 Schema.org ask site owners to embed data to enrich search results. 200+ Classes: Product, Review, LocalBusiness, Person, Place, Event, … Encoding: Microdata or RDFa
- 29. Slide 29 Usage of Schema.org Data @ Google Data snippets within search results Data snippets within info boxes
- 30. Slide 30 Websites containing Structured Data (2012) 2.29 million websites (PLDs) out of 40.6 million provide Microformat, Microdata or RDFa data (5.65%) 369 million of the 3 billion pages contain Microformat, Microdata or RDFa data (12.3%). Web Data Commons - Microformat, Microdata, RDFa Corpus 7 billion RDF triples from Common Crawl 2012 Winter 2013 release upcoming Google, October 2013: 15% of all websites provide structured data.
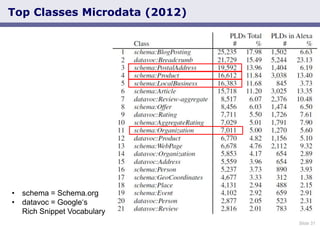
- 31. Slide 31 Top Classes Microdata (2012) • schema = Schema.org • datavoc = Google„s Rich Snippet Vocabulary
- 32. Slide 32 Example: Microdata Local Business
- 33. Slide 33 Looking Deeper into the E-Commerce Data Microdata Product (2012) Example Name: • Apple MacBook Air 11-in, Intel Core i5 1.60GHz, 64 GB, Lion 10.7 Example Description: • Configured with Intel Core 2 Duo processor, faster Flash Storage with 64 GB Solid State Drive and USB 3.0 …
- 34. Slide 34 Identity Resolution for Electronic Products We trained parser for product descriptions on data from Amazon. We analyzed 1.9 million product offers from 9200 e-shops • Petar Petrovski, et al.: Integrating Product Data from Websites offering Microdata Markup. DEOS workshop @ WWW 2014.
- 35. Slide 35 Representing HTML-embedded Data in Tabular Form Table Generation Represent each class per website as separate table. subject column: naming convention itemprop="name" Resulting tables several million tables mostly 2-10 attributes wide up to 100.000s of rows Heterogeneity low as data providers use vocabularies recommended by Google, Microsoft, Yahoo, and Facebook • Bizer, et al.: Deployment of RDFa, Microdata, and Microformats on the Web. ISWC 2013.
- 36. Slide 36 Linked Data B C RDF RDF link A D E RDF links RDF links RDF links RDF RDF RDF RDF RDF RDF RDF RDF RDF Extends the Web with a single global data graph 1. by using RDF to publish structured data on the Web 2. by setting links between data items within different data sources.
- 37. Slide 37 Data Graph including Integration Hints owl:sameAs dbo:populationTotal Richard Cyganiak dbpedia:Berlin foaf:name foaf:based_near foaf:Person rdf:type pd:cygri Data Providers set instance-level and schema-level RDF links reuse terms from common vocabularies freebase:Berlin owl:equivalentClass 3538652 yago:Berlin schema:Person
- 38. Slide 38 Effort Distribution between Publisher and Consumer Publisher reuses vocabularies Consumer calculates links and correspondences Effort Distribution Publisher or third party publishes links and correspondences
- 39. Slide 39 Linked Data on the Web ~ 900 data sets (2014) ~ 500 million RDF links (2011)
- 40. Slide 40 Wikipedia Data available as Linked Data
- 41. Slide 41 Representing Linked Data in Tabular Form Most Linked Data sources have a rather regular structure as they are generated from relational databases Table generation generate one table per class and data source use RDF property labels as attribute names subject attribute: naming convention rdfs:label, foaf:name Representation of RDF Links Add ID attribute containing original URI of each entity For each link predicate type add two attributes 1. URI reference to target entity 2. rdfs:label of target entity
- 42. Slide 42 Profile of the Resulting Tables Billion Triples Challenge 2012 Dataset 53,000 tables DBpedia as Tables 365 tables Min Max Avg Attributes 3 1,479 9 Data Rows 1 372,000 180 Min Max Avg Attributes 7 730 498 Data Rows 1 577,000 12,000 • http://km.aifb.kit.edu/projects/btc-2012/ • http://wiki.dbpedia.org/DBpediaAsTables Heterogeneity Low in some domains: People, Publications High in other domains: Life Science, eGovernment
- 43. Slide 43 datacatalogs.org lists 377 data portals world-wide open government data portals international organizations and NGOs scientific data portals Challenges syntax heterogeneity: Excel, CSV, XML, HTML, PDF data values are often time dependent table context understanding and header-unfolding necessary Profile of 7600 Tables from PublicData.eu Min Max Avg Median Attributes 2 488 8.88 9 Data Rows 1 5,600,000 3,160 66 • Ermilov, et al.: User-driven Semantic Mapping of Tabular Data. I-Semantics 2013. Data Portals
- 44. Slide 44 Wrap-up: Structured Data on the Web There is lots of data available that we can fit into our data model. use for search join experiments. A wide range of topics is covered. The size of the tables varies widely. Additional types of data sources not considered Web 2.0 APIs, Deep Web via HTML forms HTML Lists, Excel files somewhere on the Web • Elmeleegy, et al.: Harvesting Relational Tables from Lists on the Web. VLDB-J 2011. • Chen, Cafarella: Automatic Web Spreadsheet Data Extraction. WS Semantic Search 2013. • Furche: The Ontological Key: Automatically Understanding and Integrating Forms to access the Deep Web. VLDB-J 2013.
- 45. Slide 45 2. Feasibility of Search Joins
- 46. Slide 46 Search Join Systems • Cafarella, et al.: Data Integration for the Relational Web. VLDB 2009. • Yakout, et al.: InfoGather: Entity Augmentation and Attribute Discovery By Holistic Matching with Web Tables. SIGMOD 2012. • Bhagavatula, et al.: Methods for Exploring and Mining Tables on Wikipedia. KDD IDEA 2013. Octopus InfoGather WikiTables MSJ Engine Developer Google Research University Washington Microsoft Research Purdue University Northwestern University University of Mannheim Extend Operation Single Attribute Single Attribute Multiple Attributes Single Attribute Multiple Attributes Corpus Google Web crawl via Search API HTML tables from Bing Web crawl Tables from Wikipedia WDC Web Tables Linked Data Use Case Data Gathering Data Gathering Data Gathering Data Mining Data Gathering Data Mining
- 47. Slide 47 Infogather Prototype developed by Microsoft Research Operation: Extend with Singe Attribute Corpus: 573 million Web tables from Bing Crawl (2011) Split HTML Tables into Binary-Entity-Attribute Tables • Yakout, et al.: InfoGather: Entity Augmentation and Attribute Discovery By Holistic Matching with Web Tables. SIGMOD 2012. Region Unemployment Alsace 11 % Lorraine 12 % Guadeloupe 28 % Region GDP per Capita Alsace 45.914 € Lorraine 51.233 € Guadeloupe 19.810 € Subject Attribute Value Attribute
- 48. Slide 48 Matching Graph Pre-compute matching graph between BEA tables Features used for matching: 1. Attribute label similarity 2. Attribute values similarity 3. Key values overlap 4. Textual context around tables similarity 5. Table to context similarity 6. Table to table as bag of words similarity 7. URL similarity 8. column width similarity Accuracy of the resulting correspondences: Cameras and movies: 0.95 Governors and members of parliament: 0.5
- 49. Slide 49 Query Processing Input: Query table, extension attribute Web tables considered relevant for query share subject attribute value with query table and directly match extension attribute or are connected to directly matching tables via matching graph Matching score directly matching tables: entity overlap / min( l tq l , l tw l ) indirectly matching tables: propagate score along edges of matching graph Predict values cluster by value sum matching scores per cluster choose centroid of cluster with highest score or top-k centroids
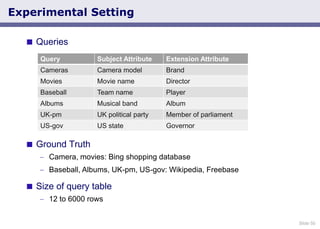
- 50. Slide 50 Queries Ground Truth Camera, movies: Bing shopping database Baseball, Albums, UK-pm, US-gov: Wikipedia, Freebase Size of query table 12 to 6000 rows Experimental Setting Query Subject Attribute Extension Attribute Cameras Camera model Brand Movies Movie name Director Baseball Team name Player Albums Musical band Album UK-pm UK political party Member of parliament US-gov US state Governor
- 51. Slide 51 Evaluation Results Query Subject attribute Extension Attribute Precision Coverage Cameras Camera model Brand 0.85 0.93 Movies Movie name Director 0.92 0.97 Baseball Team name Player 0.72 1.00 Albums Musical band Album 0.75 1.00 UK-pm UK political party Member of parliament 0.60 0.91 US-gov US state Governor 0.90 1.00 AVG 0.79 0.97 Response times: around 100 milliseconds
- 52. Slide 52 3. Table Relevance The Search operator determines the set of relevant Web tables.
- 53. Slide 53 Information Provision on the Web 1. Claims use different surface forms. entity name attribute labels data value 2. Claims refer to a specific point in time. 3. The trustworthiness of claims varies widely. Everything on the Web is a claim by somebody.
- 54. Slide 54 Dimensions of Table Relevance 1. Entity Coverage Web table should cover many entities in the query table. 2. Attribute Relevance Web table should contain relevant attributes. 3. Timeliness The data should refers to the desired point in time. 4. Trustworthiness The data should be trustworthy.
- 55. Slide 55 Dimension: Coverage Identity Resolution Approaches 1. Exact matching on subject attribute 2. Approximate matching on subject attribute 3. Matching using external knowledge about surface forms 4. Matching using multiple attributes from both tables 5. relying on owl:sameAs links Web table should cover many entities of the query table.
- 56. Slide 56 Exact Matching 20 country names 15 names of mayor cities 0 0.2 0.4 0.6 0.8 1 1 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 0 0.2 0.4 0.6 0.8 1 1 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 Exact matching of normalized values against WDC table corpus. Coverage Coverage
- 57. Slide 57 Collective Disambiguation City Country Munich Germany Berlin Germany Mannheim Germany Frankfurt Germany Karlsruhe Germany City Country Madison USA Berlin USA Chatham USA Fort Reed USA Sunville USA City Madison Berlin Chatham Perth Query Table Web Table 1 Web Table 2
- 58. Slide 58 Expansion with additional Surface Forms Examples of surface forms Berlin, 柏林, Berlijn, Berlín, Berlino, Берлин, Berlim, ベルリン FC Bayern München, Bayern Munich, FC Bayern, Bayern München Community-generated sources of surface forms Wikipedia - Redirects, Cross-Language Links - Easy accessible via DBpedia owl:sameAs Links - rdfs:labels of interlinked resources - 500 million links (2011)
- 59. Slide 59 Identity Resolution via owl:sameAs Links Query table: 20 country names 1. Names are matched to DBpedia 2. owl:sameAs links are followed from DBpedia 0 0.2 0.4 0.6 0.8 1 Coverage
- 60. Slide 60 Dimension: Attribute Relevance Attribute relevance depends on query type 1. Extend with single attribute 1. tables that have attribute directly matching the keywords 2. tables that have corresponding attributes 2. Extend with all attributes above density threshold 1. take all attributes 2. prefer attributes that are related to attributes in query table The Web table should contain relevant attributes.
- 61. Slide 61 Extend with Single Attribute Query table: 20 country names Query table: 15 names of mayor cities Search attribute: „population“ Search attribute: „country” 0 0.2 0.4 0.6 0.8 1 1 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 0 0.2 0.4 0.6 0.8 1 1 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 Coverage Coverage Median of values differs on average 4% from Wikipedia value. Simplest approach: Exact matching of normalized values.
- 62. Slide 62 Include Corresponding Attributes Approaches: 1. attributes having a synonymous name 2. attributes that correspond according to matching 1. tables with each other 2. tables against a mediated schema (knowledge base) Experimental Results: Yakout et al. Attribute Synonyms - Extension attribute value precision: 70 % Attributes corresponding via Schema Matching - Extension attribute value precision: 79 % • Yakout, et al.: InfoGather: Entity Augmentation and Attribute Discovery By Holistic Matching with Web Tables. SIGMOD 2012.
- 63. Slide 63 Mediated Schemata Cross-domain knowledge bases DBpedia - Classes: 259; attributes 1,373; entities: 4 million Freebase - Classes 1,450; attributes 3,500; entities: 15 million Advantage matching against large KBs is likely easier than matching small tables Zhang: Web tables against DBpedia matching accuracy: 85% Disadvantage Restricted to attributes contained in the knowledge base • Zhang, et al.: Mapping entity-attribute web tables to web-scale knowledge bases. In: Database Systems for Advanced Applications. Springer, 2013
- 64. Slide 64 Probase and Biperpedia Build comprehensive KBs using KBs like DBpedia and Freebase as seeds information extraction from Web text - taxonomy and instances: Hearst patterns „Y such as X“ - Attributes: Patterns „What is the A of I?” search engine query logs “New York City inhabitants” Probase (Microsoft) 2.7 million classes, a set of attributes for each class Biperpedia (Google) 10,000 classes and 67,000 attributes. table annotation accuracy: 51% • Wu, et al: Probase: a probabilistic taxonomy for text understanding. SIGMOD 2012. • Wang, et al.: Understanding tables on the Web. ER 2012. • Ventis, et al.: Recovering Semantics of Tables on the Web. VLDB 2011. • Gupta, et al.: Biperpedia: An Ontology for Search Applications. VLDB 2014.
- 65. Slide 65 Extend Table with Multiple Attributes Approaches 1. take all attributes 2. prefer attributes that are related to attributes in query table
- 66. Slide 66 Take all Attributes Query table: 20 country names WDC Web tables (Top 200 tables) 920 additional attributes 346 after attribute consolidation Linked Data (BTC dataset) 1131 additional attributes 403 after attribute consolidation Problem: Number of attributes might overwhelm the user (even if he only looks at correlating attributes)
- 67. Slide 67 Schema Complement What should be considered “consistent”? Answer: Combinations of local and Web attributes that often occur together on the Web. Approach Generate frequent item set database from Web table schema corpus. Retrieve frequency of all combinations of one local and Web attribute. Aggregate frequencies for Web attributes. • Das Sarma, et al.: Finding related tables. SIGMOD 2012. Add attributes while preserving “consistency” of the schema.
- 68. Slide 68 Dimension: Timeliness Requires meta-information about the intended point in time. HTML Tables Time reference in table - Problem: only present in a few tables Time reference on page - Problem: difficult to understand Linked Data W3C Data Cube Vocabulary The data in the Web tables should refers to the desired point in time. Region Unemployment (2013) Alsace 11 % Lorraine 12 % Guadeloupe 28 % The table below provides unemployment data for 2013. …
- 69. Slide 69 Label Propagation Approach: Infer time reference by matching to other tables that contain this information. Evaluation Results: Accuracy: 89% Recall: 50% • Zhang, Chakrabarti: InfoGather+: Semantic Matching and Annotation of Numeric and Time-varying attributes in Web Tables. SIGMOD 2013. Region Unemployment (2013) Alsace 11 % Lorraine 12 % Guadeloupe 28 % Region Unemployment Alsace 11.1 % Lorraine 11.8 % Guadeloupe 27.3 % Centre 10.1 % Martinique 24.7 % 2013
- 70. Slide 70 Dimension: Trustworthiness Not considered by Search Join systems yet. Approach exploiting only the data itself Consider value consistency between query table and Web table if the tables contain overlapping attributes Approaches exploiting external knowledge Put preference on specific sources - prefer data from .gov websites Exploit hyperlink structure of the Web The data in the Web table should be trustworthy.
- 71. Slide 71 Web Data Commons - Hyperlink Graph Covers 3.5 billion web pages and 128 billion hyperlinks Extracted from Common Crawl 2012 • http://webdatacommons.org/hyperlinkgraph/ • http://wwwranking.webdatacommons.org/
- 72. Slide 72 Wrap-up: Dimensions of Table Relevance 1. Entity Coverage Web table should cover many entities in the query table. 2. Attribute Relevance Web table should contain relevant attributes. 3. Timeliness The data should refers to the desired point in time. 4. Trustworthiness The data should be trustworthy.
- 73. Slide 73 Conclusion Simple queries are feasible with “acceptable”(?) precision. The Web is one application domain for search joins, corporate intranets are the other. Search Joins bring together Web Search and DB Joins via the concept of table relevance.