Self-serve analytics journey at Celtra: Snowflake, Spark, and Databricks

Celtra provides a platform for streamlined ad creation and campaign management used by customers including Porsche, Taco Bell, and Fox to create, track, and analyze their digital display advertising. Celtra’s platform processes billions of ad events daily to give analysts fast and easy access to reports and ad hoc analytics. Celtra’s Grega Kešpret leads a technical dive into Celtra’s data-pipeline challenges and explains how it solved them by combining Snowflake’s cloud data warehouse with Spark to get the best of both. Topics include: - Why Celtra changed its pipeline, materializing session representations to eliminate the need to rerun its pipeline - How and why it decided to use Snowflake rather than an alternative data warehouse or a home-grown custom solution - How Snowflake complemented the existing Spark environment with the ability to store and analyze deeply nested data with full consistency - How Snowflake + Spark enables production and ad hoc analytics on a single repository of data







































![Getting Data OUT of Snowflake
val sessions: RDD[Session] = sc.textFile(s"s3a://...").map(deserialize)
• Copy to S3 (Snowflake cluster)
• Read from S3 and apply schema (Spark cluster)
OLAP
cubes
Applications
Client-facing
dashboards
MySQL
ETL
Sessions](https://image.slidesharecdn.com/whyceltraadoptedsnowflakeintoitsadeventsparkpipelinev1-160401222230/85/Self-serve-analytics-journey-at-Celtra-Snowflake-Spark-and-Databricks-41-320.jpg)
![Combining Spark and Snowflake
Parallel
unload
InputFormat
RDD[Array[String]]
DataFrame
Parallel
consumption
AWS S3](https://image.slidesharecdn.com/whyceltraadoptedsnowflakeintoitsadeventsparkpipelinev1-160401222230/85/Self-serve-analytics-journey-at-Celtra-Snowflake-Spark-and-Databricks-42-320.jpg)






























More Related Content
What's hot (18)
Viewers also liked (10)






Similar to Self-serve analytics journey at Celtra: Snowflake, Spark, and Databricks (20)




















Recently uploaded (20)

















![PRE-NATAL GRnnnmnnnnmmOWTH seminar[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pre-natalgrowthseminar1-250427093235-de04befc-thumbnail.jpg?width=560&fit=bounds)


Self-serve analytics journey at Celtra: Snowflake, Spark, and Databricks
- 2. Self-serve Analytics Journey at Celtra: Snowflake, Spark and Databricks Grega Kespret Director of Engineering, Analytics @ Matthew J. Glickman Vice President of Product @
- 3. • Where we started (aggregate fact tables) • Why we needed data warehouse • Requirements and evaluations • Snowflake adoption • How Celtra handles schema evolution and data rewrites • Snowflake architecture • Next steps Story (Agenda)
- 6. 188,000+ Ads Built 15,000+ Campaigns 5000+ Brands 2bn+ Analytics Events / Day 1TB+ New Data / Day
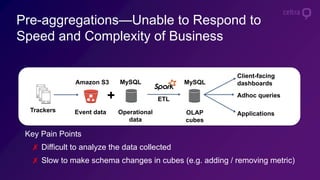
- 7. Key Pain Points ✗ Difficult to analyze the data collected ✗ Slow to make schema changes in cubes (e.g. adding / removing metric) Pre-aggregations—Unable to Respond to Speed and Complexity of Business OLAP cubes Operational data + Event dataTrackers Adhoc queries Applications Client-facing dashboardsMySQLAmazon S3 MySQL ETL
- 8. • Point in time facts about what happened • Bread and butter of our analytics data • JSON records • Very sparse • Complex relationships between events • Sessionization: Combine discrete events into sessions Event Data
- 9. • Patterns more interesting than sums and counts of events • Easier to troubleshoot/debug with context • Able to check for/enforce causality (if X happened, Y must also have happened) • De-duplication possible (no skewed rates because of outliers) • Later events reveal information about earlier arriving events (e.g. session duration, attribution, identity, etc.) Sessionization: Why We Do It Sessionization Events Sessions
- 10. Spark for Complex ETL on Events • Complex ETL: de-duplicate, sessionize, clean, validate, emit facts • Production hourly runs • Get full expressive power of Scala for ETL • Shuffle needed for sessionization • Seamless integration with S3
- 11. • Needed flexibility, not provided by precomputed aggregates (unique counting, order statistics, outliers, etc.) • Needed answers to questions that existing data model did not support • Wanted short development cycles and faster experimentation • Visualizations ✗ Difficult to Analyze the Data Collected For example: • Analyzing effects of placement position on engagement rates • Troubleshooting 95th percentile of ad loading time performance
- 12. Key Pain Points Now able to analyze the data collected ✗ Slow to make schema changes in cubes (e.g. adding / removing metric) Better with Databricks + SparkSQL OLAP cubes Trackers Adhoc queries Applications Client-facing dashboardsMySQL ETL Operational dataEvent data MySQLAmazon S3 + SQL
- 13. Key Pain Points Now able to analyze the data collected ✗ Slow to make schema changes in cubes (e.g. adding / removing metric) ✗ Complex ETL repeated in adhoc queries (slow, error-prone) But a New Problem Emerged OLAP cubes Trackers Adhoc queries Applications Client-facing dashboardsMySQL ETL Operational dataEvent data MySQLAmazon S3 + SQL
- 14. Idea: Split ETL, Materialize Sessions OLAP cubes Event data + Operational dataTrackers Adhoc queries Applications Client-facing dashboards Amazon S3 MySQL MySQL ETL ETL Sessions ??? deduplication, sessionization, cleaning, validation, external dependencies aggregating across different dimensions Part 1: Complex Part 2: Simple SQL
- 15. Requirements • Fully managed service • Columnar storage format • Support for complex nested structures • Schema evolution possible • Data rewrites possible • Scale compute resources separately from storage Needed Data Warehouse to Store Intermediate Results Nice-to-Haves • Transactions • Partitioning • Skipping • Access control • Appropriate for OLAP use case
- 16. Operational tasks for self-service installation: • Replace failed node • Refresh projection • Restart database with one node down • Remove dead node from DNS • Ensure enough (at least 2x) disk space available for rewrites • Backup data • Archive data Why We Wanted a Managed Service We did not want to deal with these tasks
- 17. 1. Denormalize everything ✓ Speed (aggregations without joins) ✗ Expensive storage 2. Normalize everything ✗ Speed (joins) ✓ Cheap storage 3. Nested objects: pre-group the data on each grain ✓ Speed (a "join" between parent and child is essentially free) ✓ Cheap storage 3 Choices for How to Model Sessions Session Unit views Page views 0 N 1 N Creative 1 N Campaign 1 N Interactions 0 N
- 18. Complex Nested Structures Session Unit views Page views 0 N 1 N Creative 1 N Campaign 1 N Interactions 0 N Unit views Session Page views Interactions Creative Campaign 1 N 1 N Flat Data in Relational Tables Nested Data
- 19. Flat + Normalized Nested Find top 10 pages on creative units with most interactions on average Flat vs. Nested Queries SELECT creativeId, uv.name unitName, pv.name pageName, AVG(COUNT(*)) avgInteractions FROM sessions s JOIN unitViews uv ON uv.id = s.id JOIN pageViews pv ON pv.uvid = uv.id JOIN interactions i ON i.pvid = pv.id GROUP BY 1, 2, 3 ORDER BY avgInteractions DESC LIMIT 10 Distributed join turned into local joinRequires unique ID at every grain Joins SELECT creativeId, unitViews.value:name unitName, pageViews.value:name pageName, AVG(ARRAY_SIZE(pageViews.value:interactions)) avgInteractions FROM sessions, LATERAL FLATTEN(json:unitViews) unitViews, LATERAL FLATTEN(unitViews.value:pageViews) pageViews GROUP BY 1, 2, 3 ORDER BY avgInteractions DESC LIMIT 10
- 21. • Evaluated Spark + HCatalog + Parquet + S3 solution • Too many small files problem => file stitching • No consistency guarantees over set of files on S3 => secondary index | convention • Liked one layer vs. separate Query layer (Spark), Metadata layer (HCatalog), Storage format layer (Parquet), Data layer (S3) Work with Data, Not Files We really wanted a database-like abstraction with transactions, not a file format!
- 22. We Chose Snowflake as Our Managed Data Warehouse (DWaaS) Pain Points Now able to analyze the data collected Data processed once & consumed many times ETL'd data acts as a single source of truth ✗ Slow to make schema changes in cubes (e.g. adding / removing metric) OLAP cubes Trackers Adhoc queries Applications Client-facing dashboards MySQL ETL ETL SessionsEvent data + Operational data Amazon S3 MySQL SQL
- 23. Snowflake Adoption • Backfilling / recomputing sessions of the last 2 years (from January 2014) 28TB of data (compressed) • "Soft deploy", period of mirrored writes Soon switch completely in production • Each developer/analyst has its own database • Separate roles and data warehouses for: production, developers, analysts • Analysts & data scientists already using Snowflake through Databricks daily
- 24. • Session schema Known, well defined (by Session Scala model) and enforced • Latest Session model Authoritative source for sessions schema • Historical sessions conform to the latest Session model Can de-serialize any historical session • Readers should ignore fields not in Session model We do not guarantee to preserve this data • Computing facts (metrics, dimensions) from Session model is time-invariant Computed 2 months ago or today, numbers must be the same How Celtra Handles Data Structure Evolution
- 25. Schema Evolution Change in Session model Top level / scalar column Nested / VARIANT column Rename field ALTER TABLE tbl RENAME COLUMN col1 TO col2; data rewrite (!) Remove field ALTER TABLE tbl DROP COLUMN col; batch together in next rewrite Add field, no historical values ALTER TABLE tbl ADD COLUMN col type; no change necessary Also considered views for VARIANT schema evolution For complex scenarios have to use Javascript UDF => lose benefits of columnar access Not good for practical use
- 26. • They are sometimes necessary • We have the ability to do data rewrites • Rewrites of ~35TB (compressed) are not fun • Complex and time consuming, so we fully automate them • Costly, so we batch multiple changes together • Rewrite must maintain sort order fast access (note: UPDATE breaks it!) • Javascript UDFs are our default approach for rewrites of data in VARIANT Data Rewrites
- 27. • Expressive power of Javascript (vs. SQL) • Run on the whole VARIANT record • (Almost) constant performance • More readable and understandable • For changing a single field, OBJECT_INSERT/OBJECT_DELETE are preferred Inline Rewrites with Javascript UDFs CREATE OR REPLACE FUNCTION transform("json" variant) RETURNS VARIANT LANGUAGE JAVASCRIPT AS ' // modify json return json; '; SELECT transform(json) FROM sessions;
- 28. Snowflake Spark Connector • Implements Spark Data Sources API • Access data in Snowflake through Spark SQL (via Databricks) • Currently available in Beta, soon to be open-source Operational data + Event data Adhoc queries MySQL Amazon S3 ETL Sessions SQL
- 29. Snowflake Data Warehouse as a Service Centralized storage Instant, automatic scalability & elasticity Single service Scalable, resilient cloud services layer coordinates access & management Elastically scalable compute Multiple “virtual warehouse” compute clusters scale horsepower & concurrency Database Storage Python
- 30. • Data Warehouse as a Service: No infrastructure, knobs or tuning • Infinite & Independent Scalability: Scale storage and compute layers independently • One Place for All Data: Native support for structured & semi- structured data • Instant Cloning: Isolate prod/dev • Highly Available: 11 9’s durability, 4 9’s availability Snowflake’s Multi-cluster, Shared Data Service Logical Databases Virtual Warehouse Virtual Warehouse ETL & Data Loading Virtual Warehouse Finance Virtual Warehouse Dev, Test, QA Dashboards Virtual Warehouse Marketing Clone Data Science
- 31. Apple 101.12 250 FIH-2316 Pear 56.22 202 IHO-6912 Orange 98.21 600 WHQ-6090 Native Support for Structured + Semi-structured Data Any hierarchical, nested data type (e.g. JSON, Avro) Optimized VARIANT data type, no fixed schema or transformation required Full benefit of database optimizations – pruning, filtering, etc. Structured data { "firstName": "John", "lastName": "Smith", "height_cm": 167.64, "address": { "streetAddress": "21 2nd Street", "city": "New York", "state": "NY”, … .. .. . { "firstName": "John", "lastName": "Smith", "height_cm": 167.64, "address": { "streetAddress": "21 2nd Street", "city": "New York", "state": "NY", "postalCode": "10021-3100" }, Semi-Structured Data Stored Natively Queried using SQL Semi-structured data
- 32. Next Stage: Snowflake Also for Aggregates OLAP cubes Trackers Adhoc queries Applications Client-facing dashboards MySQL ETL ETL SessionsEvent data + Operational data Amazon S3 MySQL SQL
- 33. End Goal Pain Points Now able to analyze the data collected Data processed once & consumed many times ETL'd data acts as a single source of truth Fast schema changes in cubes (e.g. adding / removing metric) + Trackers ETL Sessions & OLAP cubes Adhoc queries Applications Client-facing dashboards Event data + Amazon S3 MySQL Operational data
- 34. Thank You. Grega Kespret Director of Engineering, Analytics @ @gregakespret github.com/gregakespret slideshare.net/gregak linkedin.com/in/gregakespret Matthew J. Glickman Vice President of Product, @matthewglickman linkedin.com/in/matthewglickman
- 35. Appendix
- 36. Snowflake Query Performance • There are no indexes or projections • Sort the data on ingest to maintain query performance • 3 "tiers" • Query cache • File cache • S3 storage
- 37. • Save sessions to S3 in parallel (Spark cluster) Getting Data INTO Snowflake Operational data + Event data Adhoc queries MySQL Amazon S3 ETL SQL Sessions sessions.map(serializeJson).saveAsTextFile("s3a://...")
- 38. • Save sessions to S3 in parallel (Spark cluster) • Copy from S3 to temporary table (Snowflake cluster) Getting Data INTO Snowflake Operational data + Event data Adhoc queries MySQL Amazon S3 ETL Sessions CREATE TEMPORARY TABLE sessions-import (json VARIANT NOT NULL); COPY INTO sessions-import FROM s3://... FILE_FORMAT = (FORMAT_NAME = 'session_gzip_json') CREDENTIALS = (AWS_KEY_ID = '...' AWS_SECRET_KEY = '...') REGION = 'external-1'; SQL
- 39. • Save sessions to S3 in parallel (Spark cluster) • Copy from S3 to temporary table (Snowflake cluster) • Sort and insert into main table (Snowflake cluster) Getting Data INTO Snowflake INSERT INTO sessions SELECT TO_TIMESTAMP_NTZ(json:adRequestServerTimestamp::int, 3)::date, json:accountId AS accountId, json:campaignId AS campaignId, HOUR(TO_TIMESTAMP_NTZ(json:adRequestServerTimestamp::int, 3)), json:creativeId AS creativeId, json:placementId AS placementId, TO_TIMESTAMP_NTZ(json:adRequestServerTimestamp::int, 3), json FROM sessions-import ORDER BY utcDate ASC, accountId ASC, campaignId ASC, utcHour ASC, creativeId ASC, placementId ASC; Operational data + Event data Adhoc queries MySQL Amazon S3 ETL Sessions SQL
- 40. Getting Data OUT of Snowflake COPY INTO s3://... FROM (SELECT json FROM sessions WHERE ...) FILE_FORMAT = (FORMAT_NAME = 'session_gzip_json') REGION = 'external-1' CREDENTIALS = (AWS_KEY_ID = '...' AWS_SECRET_KEY = '...'); • Copy to S3 (Snowflake cluster) OLAP cubes Applications Client-facing dashboards MySQL ETL Sessions
- 41. Getting Data OUT of Snowflake val sessions: RDD[Session] = sc.textFile(s"s3a://...").map(deserialize) • Copy to S3 (Snowflake cluster) • Read from S3 and apply schema (Spark cluster) OLAP cubes Applications Client-facing dashboards MySQL ETL Sessions
- 42. Combining Spark and Snowflake Parallel unload InputFormat RDD[Array[String]] DataFrame Parallel consumption AWS S3