Apache Avro vs Protocol Buffers
Download as PPTX, PDF5 likes6,337 views

In the first half, we give an introduction to modern serialization systems, Protocol Buffers, Apache Thrift and Apache Avro. Which one does meet your needs? In the second half, we show an example of data ingestion system architecture using Apache Avro.










![何故効率が良くなるのか (Avro)
Avroはさらに型, indexの値も排除しデータの内容のみ
11
0 0 0 0 1 0 1 0
wire type
string
field index
1
文字列長 文字列のUTF8
0 0 0 1 0 0 0 0
2 varint
整数の可変長表記
フィールド名でなく
indexの値でエンコード
{
"name": "Person", "type": "record”,
"fields": [
{"name":"userName","type":"string"},
{"name":"favouriteNumber","type":"long"}
]
}
SchemaSchema
Avroはindexも型も
データには入ってない](https://image.slidesharecdn.com/serialization-systems-170704150234/85/Apache-Avro-vs-Protocol-Buffers-11-320.jpg)


![Protocol Buffers vs Avro
Schemaからモデルクラスを
事前に生成
14
事前のコード生成不要
Schemaに基づくEncode/Decode
Schema
case class Person(
userName: String, favroriteNumber
) {
def toByteArray(): Array[Byte]
}
type Person struct {
…
}
person := &pb.Person{}
proto.unmarshall(person)
Encode
Decode
生成
val person = Person(“martin”, 23)
…
new SpecificDatumWriter[Person](Schema)
.write(person, encoder)
codec := goavro.NewCodec(schema)
…
person, _ := codec.Decode(reader)
Schema
Schema
Encode
Decode
生成したモデルクラスにByte配列との変換が
ストレートに定義されていてかなり簡単に使える](https://image.slidesharecdn.com/serialization-systems-170704150234/85/Apache-Avro-vs-Protocol-Buffers-14-320.jpg)
![Protocol Buffers vs Avro
Schemaからモデルクラスを
事前に生成
15
事前のコード生成不要
Schemaに基づくEncode/Decode
Schema
case class Person(
userName: String, favroriteNumber
) {
def toByteArray(): Array[Byte]
}
type Person struct {
…
}
person := &pb.Person{}
proto.unmarshall(person)
Encode
Decode
生成
val person = Person(“martin”, 23)
…
new SpecificDatumWriter[Person](Schema)
.write(person, encoder)
codec := goavro.NewCodec(schema)
…
person, _ := codec.Decode(reader)
Schema
Schema
Encode
Decode
Schemaを渡してエンコード/デコードを行う
クラスインスタンスを生成して使う](https://image.slidesharecdn.com/serialization-systems-170704150234/85/Apache-Avro-vs-Protocol-Buffers-15-320.jpg)







![AvroのSchema互換性
AvroではSchemaに定義されている全てのフィールドが
データから取り出せないと互換性がなくなってしまいます.
24
{
"name": "Person", "type": "record”,
"fields": [
{"name":"userName","type":"string"},
{"name":"favouriteNumber","type":"long"}
]
}
{
"name": "Person", "type": "record”,
"fields": [
{"name":"userName","type":"string"},
{"name":"favouriteNumber","type":"long"},
{"name":”age","type":”int"}
]
}
Martin
1337
フィールド追加
エンコード
user_name Martin
favorite_number 1337
age
値が決まらない!!
デコード
後方互換性なし](https://image.slidesharecdn.com/serialization-systems-170704150234/85/Apache-Avro-vs-Protocol-Buffers-24-320.jpg)

![どうすれば互換性を保てたのか…?
Avroでは各フィールドにデフォルト値を規定できる.
適切なデフォルト値とともにフィールドを追加することで互換性を維持できる.
26
{
"name": "Person", "type": "record”,
"fields": [
{"name":"userName","type":"string"},
{"name":"favouriteNumber","type":"long"}
]
}
{
"name": "Person", "type": "record”,
"fields": [
{"name":"userName","type":"string"},
{"name":"favouriteNumber","type":"long"},
{"name":”age","type":”int”,”default”: 0}
]
}
Martin
1337
フィールド追加
エンコード
user_name Martin
favorite_number 1337
age 0
値が決まる!!
デコード
後方互換性あり](https://image.slidesharecdn.com/serialization-systems-170704150234/85/Apache-Avro-vs-Protocol-Buffers-26-320.jpg)










![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=560&fit=bounds)


























Ad
More Related Content
What's hot (20)
Viewers also liked (6)




Ad
Similar to Apache Avro vs Protocol Buffers (20)







![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=560&fit=bounds)












Ad
More from Seiya Mizuno (7)







Apache Avro vs Protocol Buffers
- 1. データフォーマットいろいろ Seiya Mizuno @ Saint1991
- 2. おしながき Protocol Buffers vs Apache Avro vs Apache Thrift パフォーマンス比較 (Protocol Buffers vs Avro vs Thrift vs JSON vs CSV) 何が違うの? 結局どっちをつかえばいいの? Avroのデータ管理術 データのSchema互換性 データ取り込みのアーキテクチャ例 GCPならこんな感じ 2
- 3. Protocol Buffers, Avro, Thrift システム間で効率よくデータのやりとりをするためのシステム 3 Data user_name Martin favorite_number 1337 interests daydreaming syntax = "proto3"; message Person { string user_name = 1; int64 favourite_number = 2; repeated string interests = 3; } Schema 0a 06 4d 61 72 74 69 6e …. Schemaに基づいた データのEncode/Decode 効率のよいバイナリフォーマット 多言語間でのデータ交換
- 4. Protocol Buffers, Avro, Thrift 省リソース: 速い、通信路の帯域も節約できる. boilerplate削減: 各言語で別個にmodelクラスを書く必要がなくなる. ( Protocol Buffers & Thrift ) 破損安全性: 受信した時にデータが壊れている、というようなケースが減る. 4 Schemaに基づいたデータの Encode / Decode 効率のよいバイナリフォーマット 多言語間でのデータ交換
- 5. ベンチマーク 5 message Nobid { int32 adnw_id = 1; string app_name = 2; string auction_id = 3; string host = 4; string logged_at = 5; int32 m_id = 6; int32 nbr = 7; string page = 8; int32 res_time = 9; samples.Spot spot = 10; repeated string history = 11; map<string, string> tags = 12; }
- 6. ベンチマーク (Processing time) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 JSON Avro Protocol Buffers (proto3) Thrift (compact protocol) CSV Encoding time (sec) Decoding time (sec) 6 速すぎる… ※独自調べ
- 7. ベンチマーク (データサイズ) 7 0 0.5 1 1.5 2 2.5 3 3.5 JSON Avro Protocol Buffers (proto3) Thrift (compact protocol) CSV ※独自調べ JSON以外はまぁ優秀
- 8. ベンチマーク総評 JSONより圧倒的に速い データサイズもJSONの半分ぐらい サイズが一番小さくなるのは Avro ※ Protocol Buffersだけ異常に速いのは多分実装の問題 逆に言うと下手に書きようがないくらい簡単に使えるということでもある. 8
- 9. ベンチマーク総評 CSVは小さいし速いがそもそもフォーマットとしての表現力が乏しい ネストした構造が取れない 破損レコードも多いし紛れもないゴミフォーマット 9
- 10. 何故効率が良くなるのか (Protocol Buffers) フィールドのkeyがとるスペースの分効率がよくなる. 整数値が可変長エンコードになる. 10 message Person { string user_name = 1; int64 favourite_number = 2; … } Schema 0 0 0 0 1 0 1 0 wire type string field index 1 文字列長 文字列のUTF8 0 0 0 1 0 0 0 0 2 varint 整数の可変長表記 小さい数ほど少ない バイト数で表せるエンコード フィールド名でなく indexの値でエンコード 各フィールドに indexを振る Stringだとあまり 効率は上がらない…
- 11. 何故効率が良くなるのか (Avro) Avroはさらに型, indexの値も排除しデータの内容のみ 11 0 0 0 0 1 0 1 0 wire type string field index 1 文字列長 文字列のUTF8 0 0 0 1 0 0 0 0 2 varint 整数の可変長表記 フィールド名でなく indexの値でエンコード { "name": "Person", "type": "record”, "fields": [ {"name":"userName","type":"string"}, {"name":"favouriteNumber","type":"long"} ] } SchemaSchema Avroはindexも型も データには入ってない
- 14. Protocol Buffers vs Avro Schemaからモデルクラスを 事前に生成 14 事前のコード生成不要 Schemaに基づくEncode/Decode Schema case class Person( userName: String, favroriteNumber ) { def toByteArray(): Array[Byte] } type Person struct { … } person := &pb.Person{} proto.unmarshall(person) Encode Decode 生成 val person = Person(“martin”, 23) … new SpecificDatumWriter[Person](Schema) .write(person, encoder) codec := goavro.NewCodec(schema) … person, _ := codec.Decode(reader) Schema Schema Encode Decode 生成したモデルクラスにByte配列との変換が ストレートに定義されていてかなり簡単に使える
- 15. Protocol Buffers vs Avro Schemaからモデルクラスを 事前に生成 15 事前のコード生成不要 Schemaに基づくEncode/Decode Schema case class Person( userName: String, favroriteNumber ) { def toByteArray(): Array[Byte] } type Person struct { … } person := &pb.Person{} proto.unmarshall(person) Encode Decode 生成 val person = Person(“martin”, 23) … new SpecificDatumWriter[Person](Schema) .write(person, encoder) codec := goavro.NewCodec(schema) … person, _ := codec.Decode(reader) Schema Schema Encode Decode Schemaを渡してエンコード/デコードを行う クラスインスタンスを生成して使う
- 16. 使い方が簡単!! 遅くなりようがないほどにシンプル カラムの追加にリビルドが必要 16 使い方はやや難しい 何をするにもSchemaが付きまとう カラムを追加してもリビルド不要 データ生成元 データ利用 Martin 1337 Martin 1337 daydreaming カラム追加 Martin 1337 リビルド前 Martin 1337 daydreaming リビルド後 受信側で新しいフィールドを デコードするにはサーバを一旦止める必要がある Protocol Buffers vs Avro データ生成元 データ利用 Schema管理の仕組みを整えればサーバを 止めなくても新しいフィールドをデコード可能 Martin 1337 Schema Martin 1337 Schema Schema Martin 1337 daydreaming Schema Martin 1337 daydreaming
- 17. 使い方が簡単!! 遅くなりようがないほどにシンプル カラムの追加にリビルドが必要 17 使い方はやや難しい 何をするにもSchemaが付きまとう カラムを追加してもリビルド不要 データ生成元 データ利用 Martin 1337 Martin 1337 daydreaming カラム追加 Martin 1337 リビルド前 Martin 1337 daydreaming リビルド後 受信側で新しいフィールドを デコードするにはサーバを一旦止める必要がある Protocol Buffers vs Avro データ生成元 データ利用 Schemaさえあればサーバを止めなくても 新しいフィールドをデコード可能 Martin 1337 Schema Martin 1337 Schema Schema Martin 1337 daydreaming Schema Martin 1337 daydreaming
- 18. 結論 (あくまで個人の見解です Avroがオススメなケース とにかくデータを軽くしたい データ生成元のシステムとデータを使うシステムの開発の ライフサイクルが違う BigQueryで使いたい その他の場合はProtocol Buffers 圧倒的に書くのが楽なので… 18 ※後で軽くふれます
- 19. おしながき Protocol Buffers vs Apache Avro vs Apache Thrift パフォーマンス比較 (Protocol Buffers vs Avro vs Thrift vs JSON vs CSV) 何が違うの? 結局どっちをつかえばいいの? Avroのデータ管理術 データのSchema互換性 データ取り込みのアーキテクチャ例 GCPならこんな感じ 19
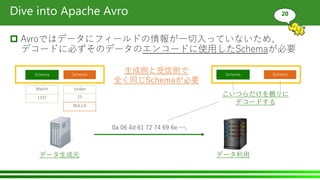
- 20. Dive into Apache Avro Avroではデータにフィールドの情報が一切入っていないため、 デコードに必ずそのデータのエンコードに使用したSchemaが必要 20 データ生成元 データ利用 Martin 1337 Schema 0a 06 4d 61 72 74 69 6e …. Schema こいつらだけを頼りに デコードする Jordan 23 BULLS Schema Schema 生成側と受信側で 全く同じSchemaが必要
- 21. Dive into Apache Avro Avroではデータにフィールドの情報が一切入っていないため、 デコードに必ずそのデータのエンコードに使用したSchemaが必要 21 データ生成元 データ利用 Martin 1337Schema 0a 06 4d 61 72 74 69 6e …. Schema Jordan 23 BULLS Schema Schema どうやって受信側はSchemaを取得するの? Schemaが違うデータが一緒に流れてるけど 一緒に保存して大丈夫だっけ…? こいつらだけを頼りに デコードする
- 23. 互換性 (Avroの場合) ※Avroの場合バイナリ配置に関する互換性ですが、 分析環境におけるデータの互換性にも通じるところがあります. というわけで、少しAvroのSchema互換性の話をします. 23
- 24. AvroのSchema互換性 AvroではSchemaに定義されている全てのフィールドが データから取り出せないと互換性がなくなってしまいます. 24 { "name": "Person", "type": "record”, "fields": [ {"name":"userName","type":"string"}, {"name":"favouriteNumber","type":"long"} ] } { "name": "Person", "type": "record”, "fields": [ {"name":"userName","type":"string"}, {"name":"favouriteNumber","type":"long"}, {"name":”age","type":”int"} ] } Martin 1337 フィールド追加 エンコード user_name Martin favorite_number 1337 age 値が決まらない!! デコード 後方互換性なし
- 26. どうすれば互換性を保てたのか…? Avroでは各フィールドにデフォルト値を規定できる. 適切なデフォルト値とともにフィールドを追加することで互換性を維持できる. 26 { "name": "Person", "type": "record”, "fields": [ {"name":"userName","type":"string"}, {"name":"favouriteNumber","type":"long"} ] } { "name": "Person", "type": "record”, "fields": [ {"name":"userName","type":"string"}, {"name":"favouriteNumber","type":"long"}, {"name":”age","type":”int”,”default”: 0} ] } Martin 1337 フィールド追加 エンコード user_name Martin favorite_number 1337 age 0 値が決まる!! デコード 後方互換性あり
- 27. Dive into Apache Avro Avroではデータにフィールドの情報が一切入っていないため、 デコードに必ずそのデータのエンコードに使用したSchemaが必要 27 データ生成元 データ利用 Martin 1337Schema 0a 06 4d 61 72 74 69 6e …. Schema Jordan 23 BULLS Schema Schema どうやって受信側はSchemaを取得するの? Schemaが違うデータが一緒に流れてるけど 一緒に保存して大丈夫だっけ…? こいつらだけを頼りに デコードする
- 28. TypeBook Schema Registryサーバ Schemaの中央管理 RESTful APIで登録や、検索ができる. 互換性ベースでSchemaをSemantic Versioning 28 v1 . 7 . 2 前方/後方互換が 維持された変更 後方互換のみが 維持された変更 後方互換が 崩れる変更 major versionが同じSchemaから生成されたデータは 最新のSchemaで読み出せることが保証される
- 29. GaneshaのAvro取り込み 29 TypeBook Schema hdfs://topic1/v1/parquet/… hdfs://topic1/v2/parquet/… schema_id: 1 Martin 1337 schema_id: 2 Jordan 23 18 1. データの前にSchema IDを 付与して送信 2. IDをもとにTypeBookから Schema(とそのversion)を 取得してデコード Schema データ生成元 3. versionから互換性が分かるので それに応じて適切なパスに配置
- 30. GCPでも… 30 TypeBook on GKE Schema Schema データ生成元 Pub/Sub Dataproc or Dataflow GCS Big Query gs://topic1/v1/parquet/… gs://topic1/v2/parquet/… 手軽にほぼ同じ構成が作れます!
- 31. BigQuery with Avro BigQueryはAvroを公式にサポートしている. Avroファイルの先頭にSchemaを書いておくと、自動でカラム名、型などを 抽出してくれます! 後方互換をもつファイルなら一括ロード可能なのは検証済み! 31
- 32. まとめ CSV, JSONで許されるのは個人開発まで! Protocol Buffers Avroを使いましょう!!! BigQueryを使うならAvroオススメです. TypeBookでSchemaの管理は楽できるのでぜひ!! 32
- 33. リファレンス ベンチマークなどなどに使ったサンプルコード Scalaから使うシンプルな例になってます. • Protocol Buffers >>>> Avro >> Thriftのシンプルさの違いが垣間見えるのでぜひ! ベンチマークへの不服はPRしていただけると嬉しいです. TypeBook (そのうちOSSにします) 公式以外の良リファレンス もはやこれのパクリ発表だったといっても過言ではない 33 https://github.com/Saint1991/samples/tree/master/scala/serialization https://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html https://github.com/CyberAgent/ganesha-schema-registry