Server Monitoring from the Cloud
Download as PPTX, PDF3 likes2,219 views

Learn how to monitor your Windows/Linux server availability and performance from the cloud and gain insight into metrics that matter the most.



















































































![[Webinar] Site24x7 - The All-in-One Monitoring Solution for DevOps & IT](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-all-in-one-monitoring-for-devops-and-it-sep022015-150910064021-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)

Ad
More Related Content
What's hot (20)
Viewers also liked (20)
![[Webinar] AWS Monitoring with Site24x7](https://cdn.slidesharecdn.com/ss_thumbnails/site24x7-awsmonitoringwithsite24x704thnov2015-151105060402-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)
![[old] Network Performance Monitoring for DevOps and IT](https://cdn.slidesharecdn.com/ss_thumbnails/site24x7-networkmonitoringwebinar7cdec16th-151229132512-thumbnail.jpg?width=560&fit=bounds)

![[Webinar] End User Experience Monitoring with Site24x7](https://cdn.slidesharecdn.com/ss_thumbnails/enduserexperiencemonitoring07thoct2015-151008105654-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)














Ad
Similar to Server Monitoring from the Cloud (20)




















Ad
More from Site24x7 (12)







![[Old] Site24x7 Real Browser Monitoring](https://cdn.slidesharecdn.com/ss_thumbnails/site24x7-webapp-rbm-slideshare-150916105158-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)




Recently uploaded (20)




















Server Monitoring from the Cloud
- 1. Server Monitoring from the Cloud Windows / Linux Servers Site24x7 Webinar 21st, Oct 2015
- 2. • Introduction to Site24x7 • Server monitoring from the Cloud • Working principle and prerequisite • Windows & Linux Server monitoring • IIS, SQL, MS Exchange Server monitoring • VMware monitoring • Security • Upcoming Features Agenda
- 4. Windows & Linux Monitoring
- 5. For all our Site24x7 location servers - we do monitoring using Site24x7 Monitor your remote branch office servers using - Site24x7 Server Agent
- 6. Server monitoring from the Cloud
- 8. Prerequisites • Windows • RAM - 512 MB • Processor Speed - 1.0GHz • Disk Space - 30 MB • Windows version XP and above • Linux • glibc version - 2.5 • Debian, Ubuntu,CentOS, RedHat, Madriva, Fedora, Suse, Amazon Linux, Gentoo
- 9. > Windows - Metrics are captured with the help of Windows Management Instrumentation (WMI) and Windows API > Linux - Metrics are captured using the commands top, df, free, ps. Discovery
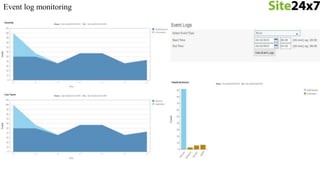
- 10. • CPU Utilization • by Processor, by Core, S/W and H/W Interrupts and Context switches • Memory Utilization • Used memory, Free Memory and Memory Pages(In/Out/Fault) • Disk Utilization • Individual Disk Utilization, Disk(I/O), Disk reads/writes • Processes & Services • CPU, Memory, Instances, Thread count, Handle count • Network • Speed, Packets, Data Transmitted & Received • Resources • Port, URL • Event logs/Syslogs • Analyze and view logs Metrics Monitored
- 11. Device snapshot
- 12. CPU dashboard
- 13. Memory dashboard
- 14. Disk dashboard
- 15. Services and process monitoring Resource monitoring
- 18. Server - Root Cause Analysis
- 20. IIS Monitoring
- 21. Microsoft IIS web server monitoring for unparalleled performance
- 22. • Windows Process Activation Services (WAS) • World Wide Web Publishing Service (W3svc) • Registry key query to confirm the IIS version • Requires IIS version 7.0 and above • Requires .Net version 3.0 and above. Discovery
- 23. Metrics monitored • Sites • Status & Binding • Application • Active Application Details • Session & Cache Details. • Application Pools • Active Application Pool Details • CLR Details
- 25. Sites on IIS server
- 29. Intelligent monitoring for top-notch SQL performance and availability
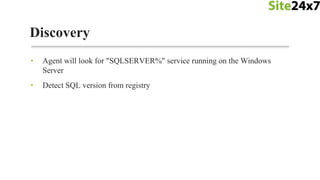
- 30. • Agent will look for "SQLSERVER%" service running on the Windows Server • Detect SQL version from registry Discovery
- 31. • Operations • MS SQL Agent & Browser Service • Active Connections • Errors • Transaction time • Capacity Planning • Memory & Buffer Management • DevOps • Lock & Latch Details • Database • Top Data Space Utilization & Log Space Utilization > Metrics
- 32. Operations
- 34. DevOps dashboard
- 35. Database
- 37. Discovery • Agent will look for MS Exchange service running on the Windows Server • Supports Exchange Server 2007 and 2010
- 38. MS Exchange Roles • Mailbox • Hub Transport • Client Access • Unified Messaging • Edge Transport
- 40. • On-Premise Poller • Monitor your internal network/resources behind the firewall • VMware vCenter • Auto discover your entire virtual infrastructure • VMware infrastructure • Data Centers, Clusters, Resource Pools, ESX/ESXi, VMs Discovery
- 42. • Visualize the vCenter infrastructure in a single view • Data center, Cluster, ESX/ESXi hosts • Performance Metrics • CPU, Memory, Datastore, Network & Disk Utilization • Hardware Metrics • Monitor disk failures and Voltage problems Metrics
- 47. VM dashboard
- 48. VM performance
- 49. Complement your IT Investments Monitor your core application servers from outside data center
- 50. Monitor ManageEngine's OpManager, ServiceDeskPlus and all ME applications Server via Site24x7 for free
- 51. The free Site24x7 monitoring service works with many of the most popular monitoring products: • ManageEngine • HP • Kaseya • Nagios • Solarwinds • Ipswitch to know more check out - https://www.site24x7.com/complement-your-it.html Free Site24x7 Server monitoring service
- 52. • Only outbound traffic no inbound traffic • Secured Shell Connection on https with latest TLSv1.2 (Port: 443) • Encrypted Connection (TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256, 128bit keys) Security
- 53. • Exchange 2013 • Log Monitoring • File Monitoring • Event Log Monitoring • Directory Monitoring • Biz Talk • Share point Upcoming Features
- 54. • Enable Auto Upgrade to be on the latest agent • Configure threshold on resource monitoring to get proactive notification. • Enable RCA to get to know about the top processes that are consuming CPU, memory, etc. • Bulk Installation for Linux is done via Chef services. • Bulk Installation for Windows is done in three ways • Remote Commands • Active Directory • Custom Scripts Best Practices
- 56. Knowledge Base : https://support.site24x7.com/portal/home Connect with us Phone USA : +1 408 352 9117 AUS : +61 280 662 895 UK : +44 203 564 7893 IND : +91 44 67447070 (Extn : 7273) Site24x7 Product Queries : [email protected] Site24x7 Sales Queries : [email protected] Chat with us : https://www.site24x7.com/chat Forums : https://forums.site24x7.com/ Email
- 57. Thanks!