Serverless Framework Workshop - Tyler Hendrickson, Chicago/burbs
2 likes387 views

AWS Community Day | Midwest 2018 Track 1 Serverless Framework Workshop - Tyler Hendrickson, Chicago/burbs






























![STEP 3: WRITE HANDLER CODE
# handlers.py
import json
from urllib.parse import unquote
def put_product__http(event, context):
payload = json.loads(event['body'])
product = {
'name': unquote(event['pathParameters']['name']),
'price': payload['price'],
'description': payload['description']
}
print('Saving product {}'.format(product['name']))
return {
'statusCode': '200',
'body': json.dumps(product),
'headers': {
'Content-Type': 'application/json'
}
}
Standard (event, context)
signature for our handler function.
The event argument is a dict
containing information about the
request.](https://image.slidesharecdn.com/awscommunityday-serverlessframeworkworkshop1-180611141450/85/Serverless-Framework-Workshop-Tyler-Hendrickson-Chicago-burbs-32-320.jpg)
![STEP 3: WRITE HANDLER CODE
# handlers.py
import json
from urllib.parse import unquote
def put_product__http(event, context):
payload = json.loads(event['body'])
product = {
'name': unquote(event['pathParameters']['name']),
'price': payload['price'],
'description': payload['description']
}
print('Saving product {}'.format(product['name']))
return {
'statusCode': '200',
'body': json.dumps(product),
'headers': {
'Content-Type': 'application/json'
}
}
We’ll add database interactions here,
but just log something for now.
API Gateway expects response data
in this format.](https://image.slidesharecdn.com/awscommunityday-serverlessframeworkworkshop1-180611141450/85/Serverless-Framework-Workshop-Tyler-Hendrickson-Chicago-burbs-33-320.jpg)







![iamRoleStatements:
-
Effect: Allow
Action:
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource:
-
Fn::GetAtt: [ "ProductDynamoDBTable", "Arn" ]
We add the IAM permissions
our Lambda functions will
require in order to interact
with our DynamoDB table.
This statement will be added
to the existing execution role.
We can use CloudFormation
intrinsic functions in our
serverless.yml file too!
STEP 6: ADD A DYNAMODB TABLE](https://image.slidesharecdn.com/awscommunityday-serverlessframeworkworkshop1-180611141450/85/Serverless-Framework-Workshop-Tyler-Hendrickson-Chicago-burbs-41-320.jpg)

![STEP 6: ADD A DYNAMODB TABLE
# handlers.py
import json
import os
from urllib.parse import unquote
import boto3
def put_product__http(event, context):
payload = json.loads(event['body'])
product = {
'name': unquote(event['pathParameters']['name']),
'price': payload['price'],
'description': payload['description']
}
db = boto3.resource('dynamodb')
table = db.Table(name=os.getenv('PRODUCT_TABLE_NAME'))
table.put_item(Item=product)
print('Saved product {}'.format(product['name']))
return {
'statusCode': '200',
'body': json.dumps(product),
'headers': {
'Content-Type': 'application/json'
Lambda provides the boto3
library automatically.
Save the product to the
DynamoDB table!](https://image.slidesharecdn.com/awscommunityday-serverlessframeworkworkshop1-180611141450/85/Serverless-Framework-Workshop-Tyler-Hendrickson-Chicago-burbs-43-320.jpg)





































Ad
More Related Content
What's hot (14)
Similar to Serverless Framework Workshop - Tyler Hendrickson, Chicago/burbs (13)





Ad
More from AWS Chicago (20)




















Ad
Recently uploaded (20)




















Serverless Framework Workshop - Tyler Hendrickson, Chicago/burbs
- 1. USING THE SERVERLESS FRAMEWORK Presented by: Tyler Hendrickson [email protected]
- 2. WHAT IS “SERVERLESS”? (The Concept) • No servers! • Infrastructure-as-Code • More time focusing on features that matter to your users
- 3. WHY SERVERLESS? (The Framework) • Easy to get started
- 4. WHY SERVERLESS? (The Framework) • Easy to get started • Simple templating
- 5. WHY SERVERLESS? (The Framework) • Easy to get started • Simple templating • Language-agnostic
- 6. WHY SERVERLESS? (The Framework) • Easy to get started • Simple templating • Language-agnostic • Active community
- 7. WHY SERVERLESS? (The Framework) • Easy to get started • Simple templating • Language-agnostic • Active community • Good support for common event sources
- 8. WHY SERVERLESS? (The Framework) • Easy to get started • Simple templating • Language-agnostic • Active community • Good support for common event sources • Supports various aspects of the development lifecycle
- 9. WHAT ARE MY ALTERNATIVES? SAM (Serverless Application Model) Chalice ?
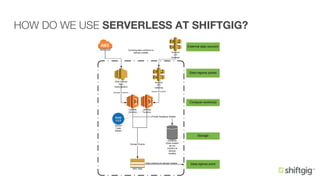
- 10. HOW DO WE USE SERVERLESS AT SHIFTGIG? • A few notes about Shiftgig architecture: + Microservices! + Microservice = Codebase = CloudFormation stack = Serverless application + Lambda functions as the main compute resource of choice + Avoid HTTP(S)-based communication between microservices and prefer asynchronous messaging instead + Microservice stacks are self-contained with little to no overlapping resources + Domain models
- 11. HOW DO WE USE SERVERLESS AT SHIFTGIG?
- 12. WAIT… ISN’T THIS SUPPOSED TO BE A WORKSHOP?
- 13. GETTING STARTED: PREREQUISITES • Development requirements: + Serverless: • Node JS • NPM • npm install -g serverless + Development: • Python 3.6 (not strictly necessary, but the examples will conform to this) • Also: Pipenv or pip + virtualenv • Project directory/workspace
- 14. GETTING STARTED: PREREQUISITES • AWS authentication + Serverless will authenticate with AWS automatically using your environment-sourced AWS credentials. + Check for ~/.aws/config and ~/.aws/credentials files + If you use an AWS config file, make sure you set this environment variable to instruct the Node JS AWS SDK (used internally by Serverless) to load the config file: $ export AWS_SDK_LOAD_CONFIG=1
- 15. GETTING STARTED: PREREQUISITES • Deployment requirements: + AWS account (full permissions are ideal) + AWS services we will use • Lambda • API Gateway • DynamoDB • CloudWatch • CloudFormation • S3
- 16. STEP 0: GOALS • We will create a simple cloud-native service in AWS as a CloudFormation stack • Our service will… + Execute custom logic defined as code run within Lambda functions + Store data in a DynamoDB table + Provide a web API with API Gateway + Log execution data to CloudWatch • But what will my application do?
- 17. • Navigate to your project directory and set up your development workspace + $ cd ~/your/projects $ git clone [email protected]:shiftgig/aws-serverless-workshop.git + Using Python with Pipenv? $ pipenv shell --python 3.6 to set up your virtual environment + Initialize Node JS in the current directory: $ npm init -f to create a package.json file $ npm install to install plugin dependencies + Open in your editor: serverless.yml STEP 1: CONFIGURE SERVERLESS
- 18. STEP 1: CONFIGURE SERVERLESS service: candystore plugins: - serverless-python-requirements # Python only custom: foo: bar Name your service. This is used to name your AWS resources. Define array of Serverless plugins
- 19. STEP 1: CONFIGURE SERVERLESS custom: foo: bar pythonRequirements: # Python only usePipenv: true dockerizePip: true dockerImage: lambci/lambda:build-python3.6 dockerSsh: true The custom section lets you define arbitrary variables that you can reference in other parts of your Serverless config file. This section is also often used to configure your installed Serverless plugins. These docker* values tell Serverless to use a Docker image that matches the Lambda Python 3.6 runtime to install dependencies.
- 20. STEP 1: CONFIGURE SERVERLESS provider: name: aws stage: ${opt:stage} region: ${opt:region} logRetentionInDays: 7 stackTags: SERVICE: ${self:service} iamRoleStatements: environment: FOO_VALUE: ${self:custom.foo} The provider section configures values specific to your vendor.
- 21. STEP 1: CONFIGURE SERVERLESS Our vendor is AWS. provider: name: aws stage: ${opt:stage} region: ${opt:region} logRetentionInDays: 7 stackTags: SERVICE: ${self:service} iamRoleStatements: environment: FOO_VALUE: ${self:custom.foo}
- 22. STEP 1: CONFIGURE SERVERLESS The stage value is used (along with the service name) to name resources. provider: name: aws stage: ${opt:stage} region: ${opt:region} logRetentionInDays: 7 stackTags: SERVICE: ${self:service} iamRoleStatements: environment: FOO_VALUE: ${self:custom.foo}
- 23. STEP 1: CONFIGURE SERVERLESS These are variables: ${source:variable} There are several variable sources. The opt: source retrieves variables from command line flags (e.g. --region us-east-1 ). The self: source references variables from within this YAML file. provider: name: aws stage: ${opt:stage} region: ${opt:region} logRetentionInDays: 7 stackTags: SERVICE: ${self:service} iamRoleStatements: environment: FOO_VALUE: ${self:custom.foo}
- 24. STEP 1: CONFIGURE SERVERLESS Tagging resources comes in handy when trying to control and manage costs in AWS. provider: name: aws stage: ${opt:stage} region: ${opt:region} logRetentionInDays: 7 stackTags: SERVICE: ${self:service} iamRoleStatements: environment: FOO_VALUE: ${self:custom.foo}
- 25. STEP 1: CONFIGURE SERVERLESS iamRoleStatements is an array of IAM permissions used to create your Lambda functions’ execution role. For now, we’ll leave it blank. provider: name: aws stage: ${opt:stage} region: ${opt:region} logRetentionInDays: 7 stackTags: SERVICE: ${self:service} iamRoleStatements: environment: FOO_VALUE: ${self:custom.foo}
- 26. STEP 1: CONFIGURE SERVERLESS The environment section is for defining environment variables available to your Lambda functions at runtime. We’ll add more useful items to this section later. provider: name: aws stage: ${opt:stage} region: ${opt:region} logRetentionInDays: 7 stackTags: SERVICE: ${self:service} iamRoleStatements: environment: FOO_VALUE: ${self:custom.foo}
- 27. STEP 2: ADD FUNCTIONS functions: PutProduct: description: Creates and updates products memorySize: 128 runtime: python3.6 handler: handlers.put_product__http events: - http: method: put path: "/product/{name}" request: parameters: paths: name: true The functions section of your Serverless configuration defines the various Lambda functions for your service.
- 28. STEP 2: ADD FUNCTIONS Your Lambda function’s memory allocation, in megabytes. functions: PutProduct: description: Creates and updates products memorySize: 128 runtime: python3.6 handler: handlers.put_product__http events: - http: method: put path: "/product/{name}" request: parameters: paths: name: true
- 29. STEP 2: ADD FUNCTIONS functions: PutProduct: description: Creates and updates products memorySize: 128 runtime: python3.6 handler: handlers.put_product__http events: - http: method: put path: "/product/{name}" request: parameters: paths: name: true Any supported Lambda runtime
- 30. STEP 2: ADD FUNCTIONS functions: PutProduct: description: Creates and updates products memorySize: 128 runtime: python3.6 handler: handlers.put_product__http events: - http: method: put path: "/product/{name}" request: parameters: paths: name: true The handler string defines the function in your source code that should be called by your Lambda function when it is invoked.
- 31. STEP 2: ADD FUNCTIONS The events array defines various triggers for your Lambda function. Here, we are defining API Gateway triggers to expose this functionality within a web API. This marks the name segment of the URL as required. functions: PutProduct: description: Creates and updates products memorySize: 128 runtime: python3.6 handler: handlers.put_product__http events: - http: method: put path: "/product/{name}" request: parameters: paths: name: true
- 32. STEP 3: WRITE HANDLER CODE # handlers.py import json from urllib.parse import unquote def put_product__http(event, context): payload = json.loads(event['body']) product = { 'name': unquote(event['pathParameters']['name']), 'price': payload['price'], 'description': payload['description'] } print('Saving product {}'.format(product['name'])) return { 'statusCode': '200', 'body': json.dumps(product), 'headers': { 'Content-Type': 'application/json' } } Standard (event, context) signature for our handler function. The event argument is a dict containing information about the request.
- 33. STEP 3: WRITE HANDLER CODE # handlers.py import json from urllib.parse import unquote def put_product__http(event, context): payload = json.loads(event['body']) product = { 'name': unquote(event['pathParameters']['name']), 'price': payload['price'], 'description': payload['description'] } print('Saving product {}'.format(product['name'])) return { 'statusCode': '200', 'body': json.dumps(product), 'headers': { 'Content-Type': 'application/json' } } We’ll add database interactions here, but just log something for now. API Gateway expects response data in this format.
- 34. STEP 4: DEPLOY! $ export SLS_DEBUG=* $ serverless deploy --region us-east-1 --aws-profile myprofile --stage dev --verbose Makes our output nice and verbose! Specify the AWS region your deployment should target If you use IAM role-assumption to authenticate with multiple AWS accounts, specify your profile name here Sensible and consistent stage values help keep things organized. It is used to name your CloudFormation stack and its resources. Even more verbose!
- 35. STEP 4: DEPLOY! CloudFormation - UPDATE_IN_PROGRESS - AWS::CloudFormation::Stack - candystore-dev CloudFormation - CREATE_IN_PROGRESS - AWS::IAM::Role - IamRoleLambdaExecution CloudFormation - CREATE_IN_PROGRESS - AWS::Logs::LogGroup - PutProductLogGroup CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::RestApi - ApiGatewayRestApi CloudFormation - CREATE_IN_PROGRESS - AWS::IAM::Role - IamRoleLambdaExecution CloudFormation - CREATE_IN_PROGRESS - AWS::Logs::LogGroup - PutProductLogGroup CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::RestApi - ApiGatewayRestApi CloudFormation - CREATE_COMPLETE - AWS::ApiGateway::RestApi - ApiGatewayRestApi CloudFormation - CREATE_COMPLETE - AWS::Logs::LogGroup - PutProductLogGroup CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::Resource - ApiGatewayResourceProduct CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::Resource - ApiGatewayResourceProduct CloudFormation - CREATE_COMPLETE - AWS::ApiGateway::Resource - ApiGatewayResourceProduct CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::Resource - ApiGatewayResourceProductNameVar CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::Resource - ApiGatewayResourceProductNameVar CloudFormation - CREATE_COMPLETE - AWS::ApiGateway::Resource - ApiGatewayResourceProductNameVar CloudFormation - CREATE_COMPLETE - AWS::IAM::Role - IamRoleLambdaExecution CloudFormation - CREATE_IN_PROGRESS - AWS::Lambda::Function - PutProductLambdaFunction CloudFormation - CREATE_IN_PROGRESS - AWS::Lambda::Function - PutProductLambdaFunction CloudFormation - CREATE_COMPLETE - AWS::Lambda::Function - PutProductLambdaFunction CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::Method - ApiGatewayMethodProductNameVarPut CloudFormation - CREATE_IN_PROGRESS - AWS::Lambda::Version - PutProductLambdaVersionI17kp6Q9rcYZSzgFOR8MgEqWaxZpBDZjz94X6WavEcD Look at all that CloudFormation you didn’t have to write!
- 36. STEP 4: DEPLOY! Serverless: Stack update finished... Service Information service: candystore stage: dev region: us-east-1 stack: candystore-dev api keys: None endpoints: PUT - https://fv907pkjxg.execute-api.us-east-1.amazonaws.com/dev/product/{name} functions: PutProduct: candystore-dev-PutProduct Stack Outputs PutProductLambdaFunctionQualifiedArn: arn:aws:lambda:us-east-1:123456789876:function:candystore-dev-PutProduct:1 ServiceEndpoint: https://fv907pkjxg.execute-api.us-east-1.amazonaws.com/dev ServerlessDeploymentBucketName: candystore-dev-serverlessdeploymentbucket-1s7wgv4xc93h6 Useful information printed at the end! Includes our API Gateway endpoints
- 37. STEP 5: TEST $ curl -X PUT https://fv907pkjxg.execute-api.us-east-1.amazonaws.com/dev/product/skittles -H 'Content-Type: application/json' -d '{ "description": "Taste the rainbow", "price": "2.55" }' -w 'n' {"name": "skittles", "price": "2.55", "description": "Taste the rainbow"}
- 38. STEP 5: TEST $ serverless logs --function PutProduct --region us-east-1 --aws-profile poc --stage dev --verbose --tail START RequestId: ff3ff102-692f-11e8-801f-cde97c6f36e8 Version: $LATEST Saving product skittles END RequestId: ff3ff102-692f-11e8-801f-cde97c6f36e8 REPORT RequestId: ff3ff102-692f-11e8-801f-cde97c6f36e8 Duration: 1.72 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 22 MB
- 39. STEP 6: ADD A DYNAMODB TABLE custom: foo: bar pythonRequirements: # Python only usePipenv: true dockerizePip: true dockerImage: lambci/lambda:build-python3.6 dockerSsh: true product_table_name: ${self:service}-${self:provider.stage}-product We centrally define the name of our DynamoDB table in custom so we can reference it elsewhere.
- 40. resources: Resources: ProductDynamoDBTable: Type: "AWS::DynamoDB::Table" Properties: AttributeDefinitions: - AttributeName: name AttributeType: S KeySchema: - AttributeName: name KeyType: HASH TableName: ${self:custom.product_table_name} ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1 The resources section is reserved for CloudFormation syntax. In the Resources subsection, you define AWS resources for your stack that aren’t implicitly created for you in the functions section. Use the variable defined in custom to name the table STEP 6: ADD A DYNAMODB TABLE
- 41. iamRoleStatements: - Effect: Allow Action: - dynamodb:GetItem - dynamodb:PutItem - dynamodb:UpdateItem - dynamodb:DeleteItem Resource: - Fn::GetAtt: [ "ProductDynamoDBTable", "Arn" ] We add the IAM permissions our Lambda functions will require in order to interact with our DynamoDB table. This statement will be added to the existing execution role. We can use CloudFormation intrinsic functions in our serverless.yml file too! STEP 6: ADD A DYNAMODB TABLE
- 42. environment: FOO_VALUE: ${self:custom.foo} PRODUCT_TABLE_NAME: ${self:custom.product_table_name} We’ll also add an environment variable to make our table’s name available to our Lambda functions STEP 6: ADD A DYNAMODB TABLE
- 43. STEP 6: ADD A DYNAMODB TABLE # handlers.py import json import os from urllib.parse import unquote import boto3 def put_product__http(event, context): payload = json.loads(event['body']) product = { 'name': unquote(event['pathParameters']['name']), 'price': payload['price'], 'description': payload['description'] } db = boto3.resource('dynamodb') table = db.Table(name=os.getenv('PRODUCT_TABLE_NAME')) table.put_item(Item=product) print('Saved product {}'.format(product['name'])) return { 'statusCode': '200', 'body': json.dumps(product), 'headers': { 'Content-Type': 'application/json' Lambda provides the boto3 library automatically. Save the product to the DynamoDB table!
- 44. STEP 7: DEPLOY CHANGES AND TEST (AGAIN) $ serverless deploy --region us-east-1 --aws-profile myprofile --stage dev --verbose
- 45. STEP 7: DEPLOY CHANGES AND TEST (AGAIN) $ curl -X PUT https://fv907pkjxg.execute-api.us-east-1.amazonaws.com/dev/product/snickers -H 'Content-Type: application/json' -d '{ "description": "Hungry? Grab a Snickers!", "price": "2.55" }' -w 'n' {"name": "snickers", "price": "1.25", "description": "Hungry? Grab a Snickers!"}
- 46. STEP 7: DEPLOY CHANGES AND TEST (AGAIN) $ serverless logs --function PutProduct --region us-east-1 --aws-profile poc --stage dev --verbose --tail --startTime 5m START RequestId: b7ebe0b5-76b0-4b31-bfe9-334892d57674 Version: $LATEST Saved product snickers END RequestId: b7ebe0b5-76b0-4b31-bfe9-334892d57674 REPORT RequestId: b7ebe0b5-76b0-4b31-bfe9-334892d57674 Duration: 464.11 ms Billed Duration: 500 ms Memory Size: 128 MB Max Memory Used: 32 MB
- 47. NEXT STEPS: MORE FEATURES • Respond to GET requests • Respond to DELETE requests • Bonus: Restrict access to your API with a usage plan in under 5 minutes!
- 48. RECAP
- 49. FINAL NOTES: LINKS • Shiftgig is hiring! + https://www.shiftgig.com/careers • Example code used today: + https://github.com/shiftgig/aws-serverless-workshop
- 50. Q & A