Serverless ML Workshop with Hopsworks at PyData Seattle
1 like488 views

1. The document discusses building a minimal viable prediction service (MVP) to predict air quality using only Python and free serverless services in 90 minutes. 2. It describes creating feature, training, and inference pipelines to build an air quality prediction service using Hopsworks, Modal, and Streamlit/Gradio. 3. The pipelines would extract features from weather and air quality data, train a model, and deploy an inference pipeline to make predictions on new data.
























![// Write Weather Pandas DataFrame to Hopsworks
weather_df = # 1. read today’s data in as a Pandas DataFrame
# 2. create features for in Pandas DataFrame
weather_fg = fs.get_or_create_feature_group(name="weather",
version=1,
description="Weather Daily Updates",
primary_key=['city'],
event_time=‘date’
)
weather_fg.insert(weather_df) # 3. write Pandas DataFrame to Feature Group
# …](https://image.slidesharecdn.com/serverlessmlwithhopsworkspydataseattle-230426181121-d4aa1020/85/Serverless-ML-Workshop-with-Hopsworks-at-PyData-Seattle-28-320.jpg)
![air_quality_df = # 1. read the most recent air quality observations
# 2. create features for in Pandas DataFrame
air_quality_fg = fs.get_or_create_feature_group(name="air_quality",
version=1,
description="City Air Quality Data",
primary_key=['city'],
expectation_suite=expectation_suite,
event_time='date'
)
air_quality_fg.insert(air_quality_df) # 3. write DataFrame to Feature Group
# …
// Write Air Quality Pandas DataFrame to Hopsworks](https://image.slidesharecdn.com/serverlessmlwithhopsworkspydataseattle-230426181121-d4aa1020/85/Serverless-ML-Workshop-with-Hopsworks-at-PyData-Seattle-29-320.jpg)
![// Feature Functions in a Python module
def moving_average(df, window=7):
df[f'mean_{window}_days'] = df.groupby('city_name')['pm2_5']
.rolling(window=window).mean().reset_index(0,drop=True).shift(1)
features/air_quality.py
One Python module per Feature Group](https://image.slidesharecdn.com/serverlessmlwithhopsworkspydataseattle-230426181121-d4aa1020/85/Serverless-ML-Workshop-with-Hopsworks-at-PyData-Seattle-30-320.jpg)
![stub = modal.Stub("air_quality_daily")
image = modal.Image.debian_slim().pip_install(["hopsworks"])
@stub.function(image=image, schedule=modal.Period(days=1),
secret=modal.Secret.from_name("jim-hopsworks-ai"))
def g():
…
if __name__ == "__main__":
stub.deploy("air_quality_daily")
with stub.run():
g()
// Schedule your Feature Pipeline with Modal
Define program
dependencies
and program
schedule, env
variables
Deploy main()
function as a
scheduled
program on
modal](https://image.slidesharecdn.com/serverlessmlwithhopsworkspydataseattle-230426181121-d4aa1020/85/Serverless-ML-Workshop-with-Hopsworks-at-PyData-Seattle-31-320.jpg)








![select features
(wind_speed_max,wind_speed_dir, …)
air_quality_fv
FeatureView
filter (city_name == “Seattle”)
transform = { “wind_speed_max” : min_max_scaler }
label = [“pm2_5”]
weather
Feature Group
air_quality
Feature Group
Training Data Inference Data
Optional Steps
join on
city, date
// Building a Feature View from existing Features](https://image.slidesharecdn.com/serverlessmlwithhopsworkspydataseattle-230426181121-d4aa1020/85/Serverless-ML-Workshop-with-Hopsworks-at-PyData-Seattle-40-320.jpg)
![// Select Features and create a Feature View
select
features
from
feature
groups
create
feature
view from
selected
features
fg_air_quality = fs.get_feature_group(name="air_quality", version=1)
fg_weather = fs.get_feature_group(name="weather", version=1)
selected = fg_air_quality.select(['pm2_5').join(fg_weather.select_all())
fv = fs.create_feature_view(name="air_quality_fv",
version=1,
description="Weather and Air Quality",
labels=['pm2_5'],
query=selected
)](https://image.slidesharecdn.com/serverlessmlwithhopsworkspydataseattle-230426181121-d4aa1020/85/Serverless-ML-Workshop-with-Hopsworks-at-PyData-Seattle-41-320.jpg)



![X_train, X_test, y_train, y_test = fv.train_test_split(test_size=0.2)
categorical_transformer=Pipeline(steps=[("encoder",
OneHotEncoder(handle_unknown="ignore"))])
preprocessor = ColumnTransformer(transformers=[
("cat", categorical_transformer, categorical_feature_ids)])
clf = Pipeline(steps=[("preprocessor", preprocessor), ("regressor", XGBRegressor())])
clf.fit(X_train, y_train)
// Model Training with Feature Views
get train &
test set
model-dependent
feature encoding
The pipeline
encodes features,
then train model](https://image.slidesharecdn.com/serverlessmlwithhopsworkspydataseattle-230426181121-d4aa1020/85/Serverless-ML-Workshop-with-Hopsworks-at-PyData-Seattle-45-320.jpg)














![● In Hopsworks, you can make non-breaking schema changes that do not require
updating the schema version.
● Appending features with a default value is a non-breaking schema change
● Breaking schema changes require updating the schema version for a Feature Group.
fg1 = fs.create_feature_group(name=”example”, version=1)
df = fg1.read()
fg2 = fs.create_feature_group(name=”example”, version=2, features=new_features, …)
fg2.insert(df) #backfill the new feature group with data from the prev version
from hsfs.feature import Feature
features = [
Feature(name="id",type="int",online_type="int"),
Feature(name="name",type="string",online_type="varchar(20)")]
fg = fs.get_feature_group(name="example", version=1)
fg.append_features(features)
// Schema Versioning](https://image.slidesharecdn.com/serverlessmlwithhopsworkspydataseattle-230426181121-d4aa1020/85/Serverless-ML-Workshop-with-Hopsworks-at-PyData-Seattle-61-320.jpg)

































Ad
More Related Content
What's hot (20)
Similar to Serverless ML Workshop with Hopsworks at PyData Seattle (20)


















Ad
More from Jim Dowling (20)
![ARVC and flecainide case report[EI] Jim.docx.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/finalarvcandflecainidecasereporteijim-230918192356-cebc27e5-thumbnail.jpg?width=560&fit=bounds)



















Ad
Recently uploaded (20)




















Serverless ML Workshop with Hopsworks at PyData Seattle
- 1. Create a MVPS (minimal viable prediction service) in 90 mins Jim Dowling @jim_dowling CEO, Hopsworks WORKSHOP Build a production ML system with only Python on free serverless services
- 2. Jim Dowling - CEO & Co-Founder of Hopsworks and an Associate Professor at KTH Royal Institute of Technology. Co-inventor of the open-source Hopsworks platform. Presenter; https://www.serverless-ml.org - Free Online Course Serverless ML Community Discord
- 3. Register on app.hopsworks.ai Register on modal.ai Register on huggingface.co - create a new “space” SLIDES:
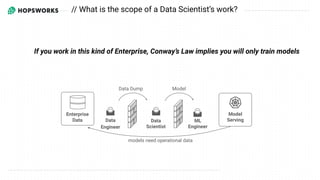
- 4. 1 The scope of Data Scientist’s work has expanded to build Prediction Services It’s not enough to just train models anymore
- 5. Data Engineer Data Scientist ML Engineer Data Dump Model Enterprise Data Model Serving models need operational data If you work in this kind of Enterprise, Conway’s Law implies you will only train models // What is the scope of a Data Scientist’s work?
- 6. Business Value Real-Time Data Real time prediction services Personalized search / recommendations High Business Value Batch Prediction Services Demand forecasting, risk estimation, financial planning Good Business Value Batch Data Static Data One-off Reports Medium Business Value // Increase Business Value with more up-to-date Data
- 7. 1. Train a Model on a static dataset and produce an Evaluation Report OR 2. Build a Minimal Viable Prediction Service to show your stakeholders how/where your model will be used // What is the scope of a Data Scientist’s work?
- 8. https://id2223kth.github.io/assignments/project/ServerlessMLProjectsID22232023.html // Build Minimal Viable Prediction Services
- 9. AI Powered Product & Services Monitoring & Compliance New Data Historical Data Output Source data data Models 1. Feature engineering 3. Inference 2. Model Training data data data logs models data models Model Registry ML Pipelines & MLOps data // ML System = Feature + Training + Inference Pipelines Feature Store
- 10. 2 Write Feature, Training, Inference pipelines to build an Air Quality Prediction Service Hopsworks, Modal, Streamlit/Gradio
- 11. 1. Feature Pipeline => Features/Labels 2. Training Pipeline => Model 3. Inference Pipeline => Predictions Data => Features/Labels => Model/Features => // ML Systems should have 3 independent Machine Learning Pipelines
- 12. Prediction Problem with Business KPIs & Data Sources Prediction Consumer // Minimal Viable Prediction service - Iteratively Develop it MVPs (Minimal Viable Prediction service) Feature Pipeline Inference Pipeline Training Pipeline
- 13. feature-pipeline.py batch-inference- pipeline.py training-pipeline.ipynb Interactive UI (app.py) Weather Data Air Quality Data // Today’s Serverless ML Air Quality Prediction Service Dashboard (Github Pages)
- 14. User Interface with Maps Predictions Data features model Model Registry features,labels models data predict data Feature View Feature Group Feature Group Feature Group Hopsworks Feature View Streaming Data event bus Batch Data databases & warehouse Feature Pipeline Online Inference Pipeline Training Pipeline ML Pipelines & MLOps Hopsworks: write to Feature Groups, read from Feature Views features
- 15. Data Sources: Open-Meteo and AQPA https://open-meteo.com/en/docs/air-quality-api https://aqicn.org/api/
- 16. city_name date wind_speed_max wind_direction_dominant wind_gusts_max temp_max <entity_id> <event_time> <numerical feature> <categorical feature> <numerical feature> <numerical feature> string datetime double string double double berlin 2022-01-01 14.3 ne 22.4 22.7 dublin 2022-04-01 9.3 n 18.2 25.4 seattle 2022-07-01 11.1 nw 15.2 20.8 tacoma 2022-10-01 1.3 w 2.5 28.4 Row Feature value. Store unencoded to maximize reuse over many models. Feature vector. Set of feature values with the same primary key. Feature Types Feature Group - weather entity_id and event_time uniquely identify each row. They are not features.
- 17. city_name date pm2_5 <entity_id> <event_time> <numerical feature> string datetime double berlin 2022-01-01 5.3 dublin 2022-04-01 2.3 seattle 2022-07-01 3.1 tacoma 2022-10-01 4.3 Feature Group - air_quality Possible Label Column could be a target for a prediction problem
- 18. 3 Get started Create an account on Hopsworks
- 19. ● Use Conda or virtual environments to manage your python dependencies on your laptop. See more info on how to manage your Python environment here. ● git clone https://github.com/jimdowling/air_quality.git cd air_quality conda create -n serverlessml python=3.9 conda activate serverlessml pip install -r requirements.txt // Getting Started…
- 20. 1. First, create an account on https://app.hopsworks.ai 2. Click on “User Settings” 3. Create and Save an “API Key” Register on app.hopsworks.ai
- 21. Add HOPSWORKS_API_KEY as a Environment variable secret Create an account on Modal (might need some time to be approved) // modal.ai
- 22. 1. Create an account on Hugging Face 2. Create a “Space” 3. Create a Streamlit App // huggingface.ai
- 23. 1. Add your HOPSWORKS_API_KEY as a Repo Secret
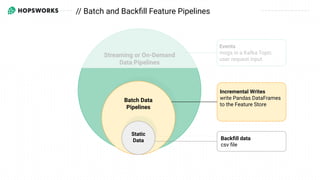
- 25. Streaming or On-Demand Data Pipelines Backfill data csv file Events msgs in a Kafka Topic user request input Incremental Writes write Pandas DataFrames to the Feature Store Batch Data Pipelines Static Data // Batch and Backfill Feature Pipelines
- 26. // What features are computed in a feature pipeline? ● Grouped Aggregations ● Binning ● Filtering ● Rolling/lag features ● Combining data from multiple tables using a common join key. ● Mapping: Transforming values using a user-defined function (UDF). ● Stream mapping: transforming values from using a UDF and accumulated state. ● Time series analysis: Analyzing or aggregating data over time, such as identifying trends, patterns, or anomalies. ● NLP - classifying text and outputting features (e.g., sentiment) ● Clustering, dimensionality reduction, etc Generally, features are not encoded in Feature Pipelines as it prevents reuse of features across models and slows down writes.
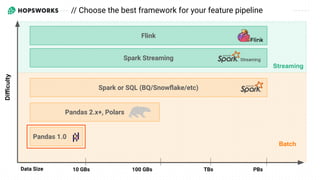
- 27. Pandas 1.0 10 GBs 100 GBs TBs PBs Data Size Pandas 2.x+, Polars Spark or SQL (BQ/Snowflake/etc) Spark Streaming Batch Streaming Flink // Choose the best framework for your feature pipeline Difficulty
- 28. // Write Weather Pandas DataFrame to Hopsworks weather_df = # 1. read today’s data in as a Pandas DataFrame # 2. create features for in Pandas DataFrame weather_fg = fs.get_or_create_feature_group(name="weather", version=1, description="Weather Daily Updates", primary_key=['city'], event_time=‘date’ ) weather_fg.insert(weather_df) # 3. write Pandas DataFrame to Feature Group # …
- 29. air_quality_df = # 1. read the most recent air quality observations # 2. create features for in Pandas DataFrame air_quality_fg = fs.get_or_create_feature_group(name="air_quality", version=1, description="City Air Quality Data", primary_key=['city'], expectation_suite=expectation_suite, event_time='date' ) air_quality_fg.insert(air_quality_df) # 3. write DataFrame to Feature Group # … // Write Air Quality Pandas DataFrame to Hopsworks
- 30. // Feature Functions in a Python module def moving_average(df, window=7): df[f'mean_{window}_days'] = df.groupby('city_name')['pm2_5'] .rolling(window=window).mean().reset_index(0,drop=True).shift(1) features/air_quality.py One Python module per Feature Group
- 31. stub = modal.Stub("air_quality_daily") image = modal.Image.debian_slim().pip_install(["hopsworks"]) @stub.function(image=image, schedule=modal.Period(days=1), secret=modal.Secret.from_name("jim-hopsworks-ai")) def g(): … if __name__ == "__main__": stub.deploy("air_quality_daily") with stub.run(): g() // Schedule your Feature Pipeline with Modal Define program dependencies and program schedule, env variables Deploy main() function as a scheduled program on modal
- 32. schedule: - cron: '0 14 * * *' .. steps: - name: checkout repo content uses: actions/checkout@v3 - name: setup python uses: actions/setup-python@v3 with: python-version: '3.9' working-directory: . - name: install python packages run: pip install -r requirements.txt - name: execute Feature Pipeline env: HOPSWORKS_API_KEY: ${{ secrets.HOPSWORKS_API_KEY }} CONTINENT: "Seattle" run: jupyter nbconvert --to notebook --execute 2_feature_pipeline.ipynb // Schedule Notebooks with Github Actions
- 33. // Create Data Validation Rules in Great Expectations from great_expectations.core import ExpectationSuite, ExpectationConfiguration expectation_suite = ExpectationSuite( expectation_suite_name="transaction_suite") expectation_suite.add_expectation( ExpectationConfiguration( expectation_type="expect_column_values_to_be_between", kwargs={ "column":"pm2_5", "min_value":"0.0", "max_value":"1000.0", } ) )
- 34. Feature Pipeline Data Sources Data warehouse Applications - Services Validate Data Unstructured Data Great Expectations Expectation Suite Feature 1 Expectation Suite Feature 2 Validation Reports Feature 1 Validation Reports Feature 2 Feature Group 1 Data Feature Group 2 Data Monitor Search Alert // Data Validation with Great Expectations https://www.hopsworks.ai/post/data-validation-for-enterprise-ai-using-great-expectations-with-hopsworks
- 35. https://docs.hopsworks.ai/3.1/user_guides/fs/feature_group/data_validation/ // Great Expectations in Hopsworks
- 37. Redundant Feature Irrelevant Feature A similar feature is already selected The feature has no predictive power Prohibited Feature Feature cannot be used. May be context dependent Useful Feature It has predictive power for my prediction problem Infeasible Feature Useful feature that can’t be computed for some reason // Feature Selection
- 38. FEATURE VIEW Select and Join Features city_name date wind_speed_max wind_direction_dominant wind_gusts_max temp_max <entity_id> <event_time> <numerical feature> <categorical feature> <numerical feature> <numerical feature> string datetime double string double double berlin 2022-01-01 14.3 ne 22.4 22.7 dublin 2022-04-01 9.3 n 18.2 25.4 seattle 2022-07-01 11.1 nw 15.2 20.8 tacoma 2022-10-01 1.3 w 2.5 28.4 city_name date pm2_5 <entity_id> <event_time> <numerical feature> string datetime double berlin 2022-01-01 5.3 dublin 2022-04-01 2.3 seattle 2022-07-01 3.1 tacoma 2022-10-01 4.3 // Select Features and Create a Feature View
- 39. Label ts Feature ts // Data Modelling: Training Data is a Fact/Dimension Model Feature ts Feature ts Feature ts Feature ts ts=TimeStamp Join Features to Labels with Entity IDs
- 40. select features (wind_speed_max,wind_speed_dir, …) air_quality_fv FeatureView filter (city_name == “Seattle”) transform = { “wind_speed_max” : min_max_scaler } label = [“pm2_5”] weather Feature Group air_quality Feature Group Training Data Inference Data Optional Steps join on city, date // Building a Feature View from existing Features
- 41. // Select Features and create a Feature View select features from feature groups create feature view from selected features fg_air_quality = fs.get_feature_group(name="air_quality", version=1) fg_weather = fs.get_feature_group(name="weather", version=1) selected = fg_air_quality.select(['pm2_5').join(fg_weather.select_all()) fv = fs.create_feature_view(name="air_quality_fv", version=1, description="Weather and Air Quality", labels=['pm2_5'], query=selected )
- 42. Time city date max_temp wind_direction_dominant … pm2_5 <entity_id> <event_time> min_max_scaler ordinal_encoder … min_max_scaler string datetime double string … double Amsterdam 2022-01-01 21.4 w … 11.0 Berlin 2022-04-01 25.3 nw … 10.2 Seattle 2022-07-01 12.1 n … 1.4 Dublin 2022-10-01 15.3 ne … 2.2 Dehli 2022-11-01 33.9 n … 38.2 New York 2022-12-01 5.1 e … 19.2 Portland 2023-01-01 -2.4 ssw … 3.2 Training Data-v2 Batch Inference Data Feature View - air_quality_fv Feature vector Training Data-v1 // Feature Views - Create Data Snapshots for Training or Inference
- 43. // Feature Views - Create Data Snapshots for Training or Inference
- 44. city date max_temp wind_direction_dominant … pm2_5 <entity_id> <event_time> min_max_scaler ordinal_encoder … min_max_scaler string datetime double string … double FeatureView for Model-FeedForwardNet city date max_temp wind_direction_dominant … pm2_5 <entity_id> <event_time> label_encoder … string datetime double string … double FeatureView for Model-XGBoost city date max_temp wind_direction_dominant … pm2_5 <entity_id> <event_time> min_max_scaler ordinal_encoder … min_max_scaler string datetime double string … double FeatureView for Model-LogisticRegression Model-Dependent Transformations // Feature Views - Model-Dependent Transformations Model-Dependent Transformations Model-Dependent Transformations
- 45. X_train, X_test, y_train, y_test = fv.train_test_split(test_size=0.2) categorical_transformer=Pipeline(steps=[("encoder", OneHotEncoder(handle_unknown="ignore"))]) preprocessor = ColumnTransformer(transformers=[ ("cat", categorical_transformer, categorical_feature_ids)]) clf = Pipeline(steps=[("preprocessor", preprocessor), ("regressor", XGBRegressor())]) clf.fit(X_train, y_train) // Model Training with Feature Views get train & test set model-dependent feature encoding The pipeline encodes features, then train model
- 46. joblib.dump(clf, 'air_quality_model/xgboost_pipeline.pkl') input_schema = Schema(X_test) output_schema = Schema(y_test) aq_model = mr.sklearn.create_model("air_quality_model", metrics={'accuracy': accuracy}, input_example=X_test.sample().to_numpy(), model_schema=ModelSchema(input_schema=input_schema, output_schema=output_schema)) fraud_model.save('air_quality_model') // Store the trained Model in a Model Registry serialize model package up model and upload to model registry get model schema from DFs
- 48. fv = fs.get_feature_view(name="air_quality_fv", version=1) df = feature_view.get_batch_data(start_time=today) mr = project.get_model_registry() model = mr.get_model("lending_model", version=1) model_dir = model.download() model = joblib.load(model_dir + "/air_quality_model.pkl") predictions_df = model.predict(df) // Batch Inference Pipeline - predict air quality on latest features download inference data download model make predictions
- 49. fv = fs.get_feature_view(name="air_quality_fv", version=1) mr = project.get_model_registry() model = mr.get_model("air_quality_model", version=1) model_dir = model.download() model = joblib.load(model_dir + "/air_quality_model.pkl") def air_quality(city_name): arr = fv.get_feature_vector({"city_name": city_name}, passed_features={}) y_pred = model.predict(np.asarray(arr).reshape(1, -1)) get feature view & download model make a prediction with precomputed and user-supplied features // Online Inference Pipeline - interactive prediction service
- 50. fv = fs.get_feature_view(name="air_quality_fv", version=1) mr = project.get_model_registry() model = mr.get_model("air_quality", version=1) model_dir = model.download() model = joblib.load(model_dir + "/air_quality_model.pkl") # FLINK CALLS THE METHOD BELOW FOR EVERY EVENT def air_quality(city_name): arr = fv.get_feature_vector({"city_name": city_name}, passed_features={}) y_pred = model.predict(np.asarray(arr).reshape(1, -1)) get feature view & download model make a prediction with precomputed and user-supplied features // Streaming Inference Pipeline
- 51. 5 Principles of MLOps WORKSHOP
- 52. ● ML-enabled products evolve over time ○ The available input data (features) change over time ○ The target you are trying to predict changes over time ● Automate the testing and deployment of ML-enabled Products ○ Safe incremental updates and a tighter iteration loop ● To this end, features and models must be tested ○ Tests should run automatically as part of a CI/CD workflow // MLOps Principles
- 53. // MLOps according to Hopsworks (1) Automated Testing Untrusted Raw Data ● ML-Apps build-on models tested with A/B tests ● Models tested with model validation tests ● Features tested with data validation and unit tests and corrected with imputation/encoding Tested Features Tested Models Tested ML-Apps
- 54. air_quality_v1 air_quality_v1 air_quality_v2 air_quality_v2 // MLOps according to Hopsworks (2) Versioning of Features, Models Models Rollback Upgrade weather_v1 air_quality_v1 Features weather_v1 air_quality_v2 air_quality_v1 Models air_quality_v2 Features
- 55. // MLOps according to Hopsworks (2) Versioning of Features, Models Models air_quality_v2 Rollback Upgrade weather_v1 air_quality_v1 air_quality_v2 Features air_quality_v1 weather_v1 air_quality_v2 air_quality_v1 Models air_quality_v1 air_quality_v2 Features
- 56. // MLOps according to Hopsworks (2) Versioning of Features, Models Models air_quality_v2 Rollback Upgrade weather_v1 air_quality_v1 air_quality_v2 Features air_quality_v1 weather_v1 air_quality_v2 air_quality_v1 Models air_quality_v1 air_quality_v2 Features
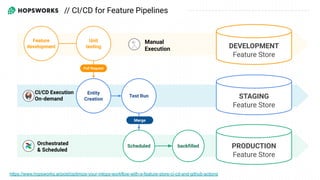
- 57. DEVELOPMENT Feature Store PRODUCTION Feature Store Test Run Unit testing Feature development Entity Creation STAGING Feature Store Scheduled Pull Request Manual Execution CI/CD Execution On-demand Orchestrated & Scheduled Merge backfilled // CI/CD for Feature Pipelines https://www.hopsworks.ai/post/optimize-your-mlops-workflow-with-a-feature-store-ci-cd-and-github-actions
- 58. Evaluate and Validate Model Training Data Evaluation Sets (for Bias) Main Branch Jenkins PyTest Pull Request Trigger bias,behaviour, performance tests deployment-test Model Training // CI/CD for Model Training STAGING Model Registry PyTest Manual Trigger Development Branch Evaluate and Validate Model Training Data Evaluation Sets (for Bias) bias,behaviour, performance tests deployment-test Model Training DEVELOPMENT Model Registry
- 59. HTTPS client KServe Blue: model-A1 Green: model-A2 Network Endpoint (Istio) Hopsworks deploy model-A2 with 10% of traffic read pre-computed features 10% traffic (mirrored) 100% traffic // CI/CD for Deployed Models PRODUCTION Feature Store
- 60. weather_v1 air_quality_v1 air_quality_v1 air_quality_v1 training_data_v1 Feature Groups Training Data Models Connector BQ Connector Snowflake Connector S3 Connector Redshift air_quality Model Deployments Feature View Source Data // Lineage for Features and Models
- 61. ● In Hopsworks, you can make non-breaking schema changes that do not require updating the schema version. ● Appending features with a default value is a non-breaking schema change ● Breaking schema changes require updating the schema version for a Feature Group. fg1 = fs.create_feature_group(name=”example”, version=1) df = fg1.read() fg2 = fs.create_feature_group(name=”example”, version=2, features=new_features, …) fg2.insert(df) #backfill the new feature group with data from the prev version from hsfs.feature import Feature features = [ Feature(name="id",type="int",online_type="int"), Feature(name="name",type="string",online_type="varchar(20)")] fg = fs.get_feature_group(name="example", version=1) fg.append_features(features) // Schema Versioning
- 62. 6 Ideas for Serverless ML Systems? WORKSHOP
- 63. ChatGPT / GPT-4 (model of world) 1. History, Context Personalized Prompt Feature Store Prompt 2.Hand-crafted Prompts Vector DB (model of user) embedding Personalized ChatGPT You have 10,000 customers and 8.7% churn annually. This is a relative high amount churn, so you should estimate churn at a fine granularity using this specific churn model: …. ChatGPT A churn model helps predict the probability of a customer leaving you within a given time period. Here is a code snippet in Python for estimating customer churn: ….. Help me design a churn model for my customers! // IDEA FOR SERVERLESS ML SYSTEM - Personalized GPT-4
- 64. Show love with a star! SERVERLESS MACHINE LEARNING www.serverless-ml.org https://github.com/featurestoreorg/serverless-ml-course ⭐