

























































![Event Receivers
You can use event receivers within sandboxed solutions to handle events on list items, lists, individual sites, and
features. The ExecutionModels.Sandboxed solution includes two event receivers that handle the
FeatureActivated event:
EstimateCTs.Ev entReceiver. This class programmatically creates the SOW and Estimation content
types when the EstimateCTs feature is activated.
EstimatesInstance.Ev entReceiver. This class associates the SOW and Estimation content types with
each instance of the Estimates library when the EstimatesInstance feature is activated.
The next sections describe these feature receiver classes.
EstimateCTs Event Receiver
The EstimateC Ts feature deploys site columns and document templates to the site collection. Because the SOW
and Estimation content types rely on these columns and templates, it makes sense to use a feature receiver to
create the content types when the feature is activated, because you can be certain that the prerequisites for the
content types are in place at this point. It is also easier to modify the content types in the case of an upgrade
when you use this approach. At a high level, the EstimateCTs.F eatureActivated method performs the
following actions for each content type:
1. It creates a new content type in the ContentTypes collection of the root SPWeb object.
2. It links the site columns to the content type.
3. It adds the document template to the content type.
4. It calls the Update method on the content type to persist changes to the database.
This process is illustrated by the following extract from the F eatureActivated method. The code has been
simplified for readability.
C#
SPSite site = properties.Feature.Parent as SPSite;
using (SPWeb web = site.RootWeb)
{
SPContentType sowContentType = web.ContentTypes[Constants.sowContentTypeId];
if (sowContentType == null)
{
sowContentType = new SPContentType(Constants.sowContentTypeId,
web.ContentTypes,
Constants.sowContentTypeName);
web.ContentTypes.Add(sowContentType);
}
sowContentType.DocumentTemplate = string.Concat(web.Url,
Constants.sowTemplatePath);
AddFieldsToContentType(web, sowContentType, fieldsToAdd);
sowContentType.Update(true);
}
The process is repeated for the Estimation content type. The AddF ieldsToContentType method links site
columns to the content type using the field ID values defined in the feature manifest for the site columns. For
more details, see the EstimateCTs.Ev entReceiver.cs class in the reference implementation.
There are various tradeoffs to consider when you choose whether to create content types declaratively or
programmatically. You cannot update a content type that has been created declaratively—all content types must
be upgraded programmatically. However, declarative approaches are simple; therefore, they are a better choice
if your content types are not expected to evolve or change.
EstimatesInstance Event Receiver
The EstimatesInstance feature creates an instance of the Estimates document library on every site in which the
feature is activated. The Estimates library exists solely to store documents based on the SOW and Estimation
content types. Because of this, it makes sense to use a feature receiver to associate the content types with each
Estimates library when the feature is activated. At a high level, the EstimatesInstance.F eatureActivated
method performs the following actions:
1. It locates the Estimates list in the current site.
2. It enables content types on the Estimates list.
Generated from CHM, not final book. Will be superseded in the future. Page 59](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-59-320.jpg)
![3. It adds the SOW and Estimation content types to the Estimates list.
4. It removes the Document content type from the Estimates list.
The F eatureActivated method uses a helper method to add the content types to the list, as shown in the
following code example.
C#
private static void AddContentTypeToList(SPContentTypeId spContentTypeId, SPList list,
SPWeb web)
{
var contentType = web.AvailableContentTypes[spContentTypeId];
if (contentType != null)
{
list.ContentTypesEnabled = true;
list.Update();
if (!ListContains(list, spContentTypeId))
{
list.ContentTypes.Add(contentType);
list.Update();
}
}
}
Before the method attempts to add a content type, it first makes sure that content types are enabled on the list.
If the ContentTypesEnabled property is false, any attempt to add content types to the list will fail. The method
then checks to see whether the list already contains the content type. ListContains is a simple helper method, as
shown in the following code example.
C#
static bool ListContains(SPList list, SPContentTypeId id)
{
var matchId = list.ContentTypes.BestMatch(id);
return matchId.IsChildOf(id);
}
Essentially, this method retrieves the content type ID from the list that is closest to the ID of the new content
type. It then checks to see whether the closest match is a child content type to the content type you are
attempting to add. This is necessary because of the way that SharePoint manages content type IDs. When you
copy a site content type to a list, SharePoint gives the list content type a new ID in the form site content type ID
+ "00" + 32-character hexadecimal GUID. If the closest match to your site content type ID in the Estimates list is
a "child" of your site content type, your content type has already been added to the list. For more information on
content type IDs, see C ontent Type IDs on MSDN.
Generated from CHM, not final book. Will be superseded in the future. Page 60](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-60-320.jpg)





![Exception Shielding
The ExecutionModels.Sandboxed solution demonstrates the use of an Exception Shielding pattern. This pattern is
designed to trap unhandled exceptions at the system boundary before they are propagated to the host
environment. In the case of Web Parts, unhandled exceptions that occur in the Web Part code are propagated to
the page that hosts the Web Part, where they can prevent the page from loading. By trapping unhandled
exceptions that occur at the Web Part boundary, you can make sure that problems in your Web Part do not cause
broader problems in the host environment. This approach also enables you to troubleshoot and diagnose error
messages more quickly and to provide users with a friendly error message.
Note:
The Developing SharePoint Applications release describes exception handling strategies in detail. This topic
provides a brief summary of how these strategies are used within the ExecutionModels.Sandboxed solution. For
more information about how to implement exception shielding strategies for SharePoint applications, see
Exception Management in SharePoint on MSDN.
In this case, the exception shielding functionality primarily consists of two key components:
The error visualizer is a Web control that adds itself to the child controls collection of the Web Part. It
renders error messages as HTML markup.
The view exception handler writes unhandled exception messages to the event log and sends the exception
message to the error visualizer. The view exception handler is invoked by the presenter class when the
presenter logic fails.
The rest of this topic describes how this works in the reference implementation. First, in the
CreateChildControls method, the AggregateView class creates a new instance of the ErrorVisualizer class,
passing a reference to itself as an argument.
C#
IErrorVisualizer errorVisualizer = new ErrorVisualizer(this);
presenter.ErrorVisualizer = errorVisualizer;
In the constructor, the ErrorVisualizer class adds itself to the Controls collection of the AggregateView Web
Part.
C#
public ErrorVisualizer(Control hostControl, params Control[] childControls)
{
Validation.ArgumentNotNull(hostControl, "hostControl");
hostControl.Controls.Add(this);
if (childControls == null)
return;
foreach (Control child in childControls)
this.Controls.Add(child);
}
Note:
Notice that the ErrorVisualizer constructor can also accept an array of child controls. Essentially, this enables
you to contain all your Web Part content in the ErrorVisualizer object. The advantage of doing this is that
the ErrorVisualizer will prevent this content from being rendered if an error occurs. However, the
ExecutionModels.Sandboxed solution does not use this approach.
In the AggregateViewPresenter class, the SetSiteData method includes a catch block that traps unhandled
exceptions. The catch block creates or retrieves an instance of ViewExceptionHandler, passing in the
unhandled exception and the ErrorVisualizer instance provided by the view.
C#
public IErrorVisualizer ErrorVisualizer { get; set; }
public ViewExceptionHandler ExceptionHandler { get; set; }
public void SetSiteData()
{
try
{
Generated from CHM, not final book. Will be superseded in the future. Page 66](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-66-320.jpg)








![The Proxy Operation Arguments Class
When you create a full-trust proxy, you need to provide developers with a way to pass arguments from their
sandboxed code to your full-trust logic. This must be carefully managed, because SharePoint needs to marshal
these arguments across process boundaries. Fortunately, the proxy operation arguments class handles these
issues for you.
Every call to a full-trust proxy must include an argument of type SPProxyOperationArgs. This is an abstract,
serializable class that you can find in the Microsoft.SharePoint.UserCode namespace. When you create a
full-trust proxy, you should create your own proxy operation arguments class that inherits from
SPProxyOperationArgs. Your class should define public properties for any arguments that you want to pass to
your full-trust logic.
Note:
A good practice is to define the assembly name and the type name of your proxy operations class as constants
in your proxy operation arguments class. The assembly name and type name are required when your full-trust
proxy is registered with SharePoint and every time the operation is invoked from sandbox code.
In the ExecutionModels.Sandboxed.Proxy solution, the proxy operation arguments class is named
AccountsPayableProxyArgs. This is shown in the following code example.
C#
[Serializable]
public class AccountsPayableProxyArgs : SPProxyOperationArgs
{
public static readonly string AssemblyName = "...";
public static readonly string TypeName =
"VendorSystemProxy.AccountsPayableProxyOps";
private string vendorName;
public string VendorName
{
get { return (this.vendorName); }
set { this.vendorName = value; }
}
public AccountsPayableProxyArgs(string vendorName)
{
this.vendorName = vendorName;
}
public AccountsPayableProxyArgs()
{
}
public string ProxyOpsAssemblyName
{
get { return AssemblyName; }
}
public string ProxyOpsTypeName
{
get { return TypeName; }
}
}
As you can see, the proxy operation arguments class is relatively straightforward. The class provides the
following functionality:
It defines a default constructor, which is required for serialization.
It defines a public string property to store and retrieve the vendor name.
It defines a constructor that accepts a string vendor name value.
It defines public read-only string properties to retrieve the assembly name and the type name of the proxy
operations class.
Generated from CHM, not final book. Will be superseded in the future. Page 75](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-75-320.jpg)




![Deploying Custom Pages to the Sandbox Environment
The ExecutionModels.Sandboxed.Proxy solution includes one new type of resource, in addition to the components
you have already seen in the Sandbox Reference Implementation (Sandbox RI). The VendorDetail.aspx file is a
custom Web Part page. It is used to display the VendorDetails Web Part in a Modal Dialog.
When you work with farm solutions, the most common way to make pages and scripts available in a SharePoint
environment is to deploy them to the TemplateLayouts folder in the SharePoint root on the server file system.
The Layouts folder is mapped to the _layouts virtual directory on each SharePoint site, so your files are always
available. However, you cannot use this approach in the sandbox environment because sandboxed solutions are
not permitted to deploy any files to the server file system. In the sandbox environment, you must deploy these
resources to an appropriate document library in the site collection or as inline script. The reference
implementation uses inline script instead of a separate JavaScript file, because it requires only a small amount of
JavaScript that is specific to the page.
The following code example shows the feature manifest for the VendorDetail.aspx file.
XML
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<Module Name="Pages" List="101" Url="Lists/Pages">
<File Url="VendorDetail.aspx" Type="GhostableInLibrary" >
<AllUsersWebPart WebPartZoneID="Left" WebPartOrder="1">
<![CDATA[<webParts>
<webPart xmlns="http://schemas.microsoft.com/WebPart/v3">
<metaData>…</metaData>
<data>…</data>
</webPart>
</webParts>]]>
</AllUsersWebPart>
</File>
</Module>
<CustomAction Location="ScriptLink" ScriptBlock ="
function ShowVendorDetailsDialog(url) {
var options = SP.UI.$create_DialogOptions();
options.url = url;
options.height = 300;
SP.UI.ModalDialog.showModalDialog(options);
}">
</CustomAction>
</Elements>
The preceding code uses a module to deploy the file to the Pages library in the site collection. In the F ile
element, the Type="GhostableInLibrary" attribute indicates that the deployment target is a type of document
library and that SharePoint should create a parent list item for the file. This also specifies that the file is stored in
the content database and not on the server file system.
You can also see that a CustomAction section is used to define a JavaScript function to inline. This approach to
script deployment is recommended if you have a relatively small amount of JavaScript, as opposed to deploying a
JavaScript file. SharePoint is able to optimize the script load performance more effectively when you use this
mechanism for a small amount of script. For information about the behavior of the JavaScript function, see
Launching a Modal Dialog within the Sandbox Environment.
Note:
If you require a large amount of JavaScript, it makes sense to deploy your script within a file. For more
information about this approach, see How to: Display a Page as a Modal Dialog.
Generated from CHM, not final book. Will be superseded in the future. Page 80](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-80-320.jpg)
![Launching a Modal Dialog in the Sandbox Environment
The ExecutionModels.Sandboxed.Proxy solution uses a modal dialog to display financial details when the user
clicks the name of a vendor. This dialog is actually a Web Part page (VendorDetail.aspx) that contains a Web Part
(VendorDetails.cs). To launch the modal dialog, the following three tasks must be performed:
C reate a JavaScript function that uses the SharePoint 2010 client object model to launch a specified page as
a modal dialog.
Deploy the JavaScript function to the sandbox environment. For more information, see Deploying C ustom
Pages to the Sandbox Environment.
Render vendor names as hyperlinks that call the JavaScript function when clicked.
The feature manifest for the Vendor Details page defines a function named ShowVendorDetailsDialog. This
function uses the SharePoint 2010 client object model to launch a page at a specified URL as a modal dialog, as
shown in the following code example.
Jav aScript
function ShowVendorDetailsDialog(url) {
var options = SP.UI.$create_DialogOptions();
options.url = url;
options.height = 300;
SP.UI.ModalDialog.showModalDialog(options);
}
In the AggregateView Web Part, you must render the vendor names as hyperlinks that call the JavaScript
function when clicked. To do this, handle the RowDataBound event for the grid view control. Within the grid
view, the contents of each vendor name cell is replaced with a HyperLink control, as shown in the following code
example.
C#
protected void GridView_RowDataBound(object sender, GridViewRowEventArgs e)
{
const int VendorNameCellIndex = 3;
const int EstimateValueCellIndex = 2;
DataControlRowType rowType = e.Row.RowType;
if (rowType == DataControlRowType.DataRow)
{
TableCell vendorNameCell = e.Row.Cells[VendorNameCellIndex];
HyperLink hlControl = new HyperLink();
hlControl.Text = vendorNameCell.Text;
hlControl.NavigateUrl = string.Concat(
"JavaScript: ShowVendorDetailsDialog('",
SPContext.Current.Site.RootWeb.Url,
"/Lists/Pages/VendorDetail.aspx?VendorName="
+ vendorNameCell.Text + "');"
);
vendorNameCell.Controls.Add(hlControl);
TableCell estimateValueCell = e.Row.Cells[EstimateValueCellIndex];
double currencyValue;
if(double.TryParse(estimateValueCell.Text, out currencyValue))
{
estimateValueCell.Text = String.Format("{0:C}", currencyValue);
}
}
}
This renders each vendor name as a hyperlink in the following format.
HTML
<a href="JavaScript: ShowVendorDetailsDialog('Page URL')>Vendor Name</a>
Generated from CHM, not final book. Will be superseded in the future. Page 81](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-81-320.jpg)


![VendorName property on the presenter. Next, it invokes the presenter logic by calling the SetVendorDetails
method.
C#
private VendorDetailsPresenter presenter;
protected override void CreateChildControls()
{
...
string vendorName = Page.Request.QueryString["VendorName"];
...
presenter = new VendorDetailsPresenter(this, new VendorService());
presenter.VendorName = vendorName;
presenter.ErrorVisualizer = errorVisualizer;
presenter.SetVendorDetails();
}
In the presenter class, the SetVendorDetails method constructs an instance of the proxy operation arguments
class, AccountsPayableProxyArgs. The presenter logic then calls the GetAccountsPayable method to
retrieve the outstanding balance from the model class, passing in the AccountsPayableProxyArgs instance as
an argument.
C#
public void SetVendorDetails()
{
try
{
AccountsPayableProxyArgs proxyArgs = new AccountsPayableProxyArgs();
proxyArgs.VendorName = vendorName;
string assemblyName = proxyArgs.ProxyOpsAssemblyName;
view.AccountsPayable = vendorService.GetVendorAccountsPayable(
proxyArgs, assemblyName);
}
catch (Exception ex)
{
// Exception shielding logic removed for clarity.
}
}
In the model class, VendorServ ice, the GetVendorAccountsPayable method invokes the proxy operation.
The return type is cast to a double and returned to the caller.
C#
public double GetVendorAccountsPayable(AccountsPayableProxyArgs proxyArgs, string
assemblyName)
{
var result = SPUtility.ExecuteRegisteredProxyOperation(
assemblyName,
proxyArgs.ProxyOpsTypeName,
proxyArgs);
if (result.GetType().IsSubclassOf(typeof(Exception)))
{
throw result as Exception;
}
double cred = (double) result;
return (cred);
}
Generated from CHM, not final book. Will be superseded in the future. Page 84](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-84-320.jpg)












![The Timer Job Configuration Page
The Approved Estimates timer job must retrieve various configuration settings to be able to function correctly. To
provide these settings, deploy a custom application page, TimerJobC onfig.aspx, to the C entral Administration
Web site.
The timer job configuration page
The timer job configuration page enables the farm administrator to provide the following settings:
The relative URL of the destination site collection
The name of the Approved Estimates list on the destination site collection
A semicolon-separated list of source site collections
It also enables the administrator to immediately run the job. When the user clicks Apply Changes, the
configuration settings are persisted to the property bag of the Approved Estimates timer job, as shown in the
following code example.
C#
protected void ApplyButton_Click(object sender, EventArgs e)
{
IEnumerable<SPJobDefinition> allJobs = GetTimerJobsByName(Constants.jobTitle);
foreach (SPJobDefinition selectedJob in allJobs)
{
if (!string.IsNullOrEmpty(ListNameTextBox.Text))
{
selectedJob.Properties[Constants.timerJobListNameAttribute] =
ListNameTextBox.Text;
}
if (!string.IsNullOrEmpty(SiteNamesTextBox.Text))
{
selectedJob.Properties[Constants.timerJobSiteNameAttribute] =
SiteNamesTextBox.Text;
}
if (!string.IsNullOrEmpty(DestinationSiteTextBox.Text))
{
selectedJob.Properties[Constants.timerJobDestinationSiteAttribute] =
DestinationSiteTextBox.Text;
}
selectedJob.Update();
}
}
Generated from CHM, not final book. Will be superseded in the future. Page 97](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-97-320.jpg)








![Activity Classes
The Workflow Activities Reference Implementation (Workflow Activities RI) includes three workflow activity
classes. Because CreateSubSiteActivity and CreateSiteCollectionActivity have many parameters in
common, they share a common base class, SiteCreationBaseActivity. All the activity classes ultimately derive
from the System.Workflow.ComponentModel.Activ ity base class, as shown in the following illustration.
Workflow activity classes
Each workflow activity class overrides the Execute method defined by the base Activ ity class. This method is
called by the workflow engine to invoke your activity logic.
C#
protected override ActivityExecutionStatus Execute(ActivityExecutionContext
executionContext) { }
A workflow activity class also typically defines a number of dependency properties that are used to pass
information to or from your workflow activity logic. Essentially, dependency properties allow you to define inputs
and outputs for your workflow activity, because the workflow engine and SharePoint Designer can bind values to
these properties in order to use your workflow logic. In other words, dependency properties allow you to bind the
output of one activity to the input of another activity.
Each full-trust workflow activity class in the Workflow Activities RI defines several dependency properties. For
example, the SiteExistsActiv ity class defines three dependency properties. The first dependency property,
SiteUrlProperty, allows you to provide your workflow logic with the URL of a site. Notice that the class also
defines a .NET Framework property wrapper, SiteUrl, which allows your activity logic to interact with the
managed property.
C#
public static DependencyProperty SiteUrlProperty = DependencyProperty.Register("SiteUrl",
typeof(string),typeof(SiteExistsActivity));
[Description("The absolute URL of the site or site collection to create")]
[Browsable(true)]
[Category("Patterns and Practices")]
[DesignerSerializationVisibility(DesignerSerializationVisibility.Visible)]
public string SiteUrl
{
Generated from CHM, not final book. Will be superseded in the future. Page 106](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-106-320.jpg)
![get { return ((string)base.GetValue(SiteUrlProperty)); }
set { base.SetValue(SiteUrlProperty, value); }
}
The second dependency property, ExistsProperty, enables your activity to provide a result that indicates
whether a specified site or site collection already exists. This result can be used by the workflow engine to
provide branching logic.
C#
public static DependencyProperty ExistsProperty = DependencyProperty.Register("Exists",
typeof(bool), typeof(SiteExistsActivity));
[Description("The result of the operation indicating whether the site exists")]
[Browsable(true)]
[Category("Patterns and Practices")]
[DesignerSerializationVisibility(DesignerSerializationVisibility.Visible)]
public bool Exists
{
get { return ((bool)base.GetValue(ExistsProperty)); }
set { base.SetValue(ExistsProperty, value); }
}
The final dependency property, ExceptionProperty, allows your activity to return an exception if problems
occur.
Note:
The workflow engine supports fault handlers that can capture exceptions and take action on them for coded
workflows. SharePoint Designer declarative workflows do not provide support for fault handlers, so when you
design activities for use with SharePoint Designer, it is sometimes necessary to return the exceptions as a
property.
C#
public static DependencyProperty ExceptionProperty =
DependencyProperty.Register("Exception",typeof(string),
typeof(SiteExistsActivity));
[Description("Exception generated while testing for the existence of the site")]
[Browsable(true)]
[Category("Patterns and Practices")]
[DesignerSerializationVisibility(DesignerSerializationVisibility.Visible)]
public string Exception
{
get { return ((string)base.GetValue(ExceptionProperty)); }
set { base.SetValue(ExceptionProperty, value); }
}
The following code example shows the Execute method of the SiteExistsActiv ity.
C#
protected override ActivityExecutionStatus Execute(ActivityExecutionContext
executionContext)
{
string exception;
Exists = DoesSiteExist(SiteUrl, out exception);
Exception = exception;
return base.Execute(executionContext);
}
In the preceding code example, the logic in the Execute method override does not use the
Activ ityExecutionContext argument or set a return value. It simply sets the value of the dependency
properties and then calls the base method implementation. The DoesSiteExist method is a simple helper method
that checks whether a site exists at the specified URL.
The SiteExistsActiv ity class includes an extra method named DoesSiteExistCondition that implements the
Generated from CHM, not final book. Will be superseded in the future. Page 107](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-107-320.jpg)

![Registering Workflow Activities for Declarative
Workflows
To be able to use a full-trust workflow activity in a declarative workflow, you must add an authorized type entry
for the activity class to the Web.config file. Typically, you should use a feature receiver class to add and remove
these entries when you deploy your workflow activities.
The Workflow Activities Reference Implementation (Workflow Activities RI) includes an empty farm-scoped
feature named SiteProv isioningActivity. The event receiver class for this feature adds authorized type entries
for the workflow activity classes when the feature is activated, and it removes the entries when the feature is
deactivated.
Note:
Farm-scoped features are automatically activated when the solution is deployed. Because of this, the
authorized type entry is automatically added to the Web.config file when the solution package is deployed to
the farm.
The SiteProv isioningActivity.Ev entReceiver class uses a helper method named GetConfigModification to
build the authorized type entry for the workflow activity classes as an SPWebConfigModification object, as
shown in the following code example.
C#
public SPWebConfigModification GetConfigModification()
{
string assemblyValue = typeof(CreateSubSiteActivity).Assembly.FullName;
string namespaceValue = typeof(CreateSubSiteActivity).Namespace;
SPWebConfigModification modification = new SPWebConfigModification(
string.Format(CultureInfo.CurrentCulture,
"authorizedType[@Assembly='{0}'][@Namespace='{1}'][@TypeName='*']
[@Authorized='True']", assemblyValue, namespaceValue),
"configuration/System.Workflow.ComponentModel.WorkflowCompiler/
authorizedTypes");
modification.Owner = "Patterns and Practices";
modification.Sequence = 0;
modification.Type =
SPWebConfigModification.SPWebConfigModificationType.EnsureChildNode;
modification.Value =
string.Format(CultureInfo.CurrentCulture,
"<authorizedType Assembly="{0}" Namespace="{1}"
TypeName="*" Authorized="True" />", assemblyValue,
namespaceValue);
Trace.TraceInformation("SPWebConfigModification value: {0}",modification.Value);
return modification;
}
For more information about the SPWebConfigModification class, see SPWebC onfigModification C lass on MSDN.
The F eatureActiv ated method uses the SPWebConfigModification object to add the authorized type entry to
the Web.config files of all Web applications on the farm, with the exception of the C entral Administration Web
application. This is shown in the following code example.
C#
public override void FeatureActivated(SPFeatureReceiverProperties properties)
{
try
{
SPWebService contentService = SPWebService.ContentService;
contentService.WebConfigModifications.Add(GetConfigModification());
// Serialize the Web application state and propagate changes across the farm.
Generated from CHM, not final book. Will be superseded in the future. Page 109](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-109-320.jpg)


![example. Each parameter maps to a dependency property in the activity class. The parameters are referenced by
the F ieldBind elements shown in the preceding code example. Some of the Parameter elements have been
removed from this example to aid readability.
XML
<Parameters>
<Parameter
Name="UseUniquePermissions"
Type="System.Boolean, mscorlib"
DisplayName="Use unique permissions"
Direction="In" />
<Parameter
Name="ConvertIfExists"
Type="System.Boolean, mscorlib"
DisplayName="Convert if exists"
Direction="In" />
<Parameter
Name="SiteUrl"
Type="System.String, mscorlib"
Direction="In" />
...
</Parameters>
The second Action element, which describes the CreateSiteCollectionActivity class, follows a similar pattern.
Defining Conditions
The ExecutionModels.actions file includes a single Condition element that describes the SiteExistsActivity
class.
XML
<Condition
Name="Site Exists"
FunctionName="DoesSiteExistCondition"
ClassName="ExecutionModels.Workflow.FullTrust.Activities.SiteExistsActivity"
Assembly="ExecutionModels.Workflow.FullTrust.Activities, ..."
AppliesTo="all"
UsesCurrentItem="True">
<RuleDesigner Sentence="The site %1 exists">
<FieldBind Id="1" Field="_1_" Text=""/>
</RuleDesigner>
<Parameters>
<Parameter Name="_1_" Type="System.String, mscorlib" Direction="In" />
</Parameters>
</Condition>
This Condition element has a few key differences from the Action elements described earlier. First, you must
provide a FunctionName attribute value to indicate that the condition logic is invoked through the
DoesSiteExistCondition method. Next, note the naming convention for parameters. The parameter that will
represent the site URL is named "_1_". This is because it is the first non-default argument that is provided to the
DoesSiteExistCondition method. Additional parameters should be named "_2_", "_3_", and so on. It is
essential to use this naming convention when you define a condition.
Deploying a Workflow Actions File
Workflow actions files are deployed to the TEMPLATE[Locale ID]Workflow folder in the SharePoint root folder
(for example, TEMPLATE1033Workflow). The best way to deploy files to the SharePoint root from a Visual Studio
2010 project is to add a SharePoint mapped folder to your project. This creates a folder within your project that
maps to a folder on the SharePoint file system. When you deploy your solution, any files in your mapped folder
are added to the corresponding location on the SharePoint file system.
Note:
Generated from CHM, not final book. Will be superseded in the future. Page 112](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-112-320.jpg)




![Notice how the method uses the hash table to return results. The method adds two entries to the hash table: a
string value that indicates success or failure and an integer value that indicates the number of files copied from
the source library to the target library.
C#
Hashtable results = new Hashtable();
...
int copiedFiles = CopyFolder(sourceLib.RootFolder, targetLib.RootFolder, true);
results["status"] = "success";
results["copiedFiles"] = copiedFiles;
return results;
If the source list does not exist, the method returns a status value of failure and a copied files count of zero.
C#
results["status"] = "failure";
results["copiedFiles"] = 0;
return (results);
For more information about returning values from a sandboxed workflow action, see How to: C reate a Sandboxed
Workflow Action.
Generated from CHM, not final book. Will be superseded in the future. Page 117](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-117-320.jpg)

















![Creating External Lists
External lists are SharePoint lists that are bound to a single external content type. Unlike external content types,
which apply to the Business Data C onnectivity (BDC ) service application, external lists are created within a
specific SharePoint site, just like regular SharePoint lists. You can create external lists in three ways:
Interactively, by selecting Create Lists & Form on the external content type settings page in SharePoint
Designer
Directly, by creating a new external list in the SharePoint site user interface, and then selecting the external
content type to which you want to bind
Programmatically, in a farm solution or a sandboxed solution
The external list reference implementation defines three external lists, which correspond to the external content
types described earlier:
The Vendors external list is bound to the Vendors external content type.
The Vendor Transactions external list is bound to the Vendor Transactions external content type.
The Vendor Transaction Types external list is bound to the Vendor Transaction Types external content
type.
C reating an external list is straightforward and requires no additional configuration. The external list is displayed
and managed in the same way as a regular SharePoint list. For example, the following illustration shows the
Vendors external list in the Web browser.
Vendors external list
You can also use SharePoint Designer to edit external lists. For example, you can add or remove columns, and
you can create views, forms, workflows, and custom actions for your external lists. For more information on how
to create external lists, see How to: C reate External Lists in SharePoint on MSDN.
You can use the SPList API to interact programmatically with external lists in exactly the same way that you
would interact with regular SharePoint lists. Because the SPList API is available within the sandbox environment,
you can interact with external lists from within your sandboxed solution code.
In the external list reference implementation, all the interaction with external lists takes place within the
VendorServ ice class. This class provides the data model for both the Vendor List Web Part and the Vendor
Transaction List Web Part. The presenter class for the Vendor List Web Part calls the
GetAllVendorsWithTransactionCount method to populate the Web Part, as shown in the following example.
C#
public DataTable GetAllVendorsWithTransactionCount()
{
var vendors = GetAllVendors();
vendors.Columns.Add("TransactionCount");
var columnIndex = vendors.Columns.Count - 1;
foreach (DataRow row in vendors.Rows)
{
int vendorId = int.Parse(row.ItemArray[0].ToString());
row[columnIndex] = GetTransactionCountByVendor(vendorId);
}
Generated from CHM, not final book. Will be superseded in the future. Page 135](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-135-320.jpg)
![return vendors;
}
As the example shows, the GetAllVendorsWithTransactionCount method relies on two helper methods. First,
the GetAllVendors method is used to retrieve all the data in the Vendors external list, as shown in the following
example.
C#
public DataTable GetAllVendors()
{
var web = SPContext.Current.Web;
string test = Constants.ectVendorListName;
var dt = web.Lists[Constants.ectVendorListName].Items.GetDataTable();
return dt;
}
Next, the GetTransactionCountByVendor method is used to get the number of transactions that are stored for
each vendor. This information is used to populate the TransactionCount column in the Vendor List Web Part.
The method builds a Collaborative Application Markup Language (C AML) query to count the number of
transactions in the Vendor Transactions external list that correspond to the specified vendor:
C#
public int GetTransactionCountByVendor(int vendorId)
{
var query = new SPQuery
{
ViewFields = "<FieldRef Name='ID' />",
Query = string.Format(
"<Where>
<Eq>
<FieldRef Name='VendorID' />
<Value Type='Counter'>{0}</Value>
</Eq>
</Where>",
vendorId.ToString())
};
return SPContext.Current.Web.Lists[Constants.ectVendorTransactionListName]
.GetItems(query).Count;
}
The presenter class for the Vendor Transaction List Web Part calls the GetTransactionByVendor method to
populate the Web Part, as shown in the following example.
C#
public DataTable GetTransactionByVendor(int vendorId)
{
var query = new SPQuery
{
ViewFields =
"<FieldRef Name='Name' />" +
"<FieldRef Name='TransactionType' />" +
"<FieldRef Name='Amount' />" +
"<FieldRef Name='Notes' />",
Query = string.Format(
"<Where>
<Eq>
<FieldRef Name='VendorID' />
<Value Type='Counter'>{0}</Value>
</Eq>
</Where>",
vendorId.ToString())
};
return
Generated from CHM, not final book. Will be superseded in the future. Page 136](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-136-320.jpg)
![SPContext.Current.Web.Lists[Constants.ectVendorTransactionListName]
.GetItems(query).GetDataTable();
}
In all of these code examples, the external lists are used in the same way as regular lists. The object model calls
and the query syntax are the same regardless of the type of list.
Generated from CHM, not final book. Will be superseded in the future. Page 137](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-137-320.jpg)








![C#
public Hashtable Log(SPUserCodeWorkflowContext context)
{
Hashtable results = new Hashtable();
results["Except"] = string.Empty;
try
{
using (SPSite site = new SPSite(context.CurrentWebUrl))
{
using (SPWeb web = site.OpenWeb())
{
SPWorkflow.CreateHistoryEvent(web, context.WorkflowInstanceId, 0,
web.CurrentUser, TimeSpan.Zero, "Information",
"Event from sandboxed activity", string.Empty);
}
}
}
catch (Exception ex)
{
results["Except"] = ex.ToString();
}
results["Status"] = "Success";
return (results);
}
Note:
Notice the use of the Except key to return an exception to the workflow.
Step 3: Create the Workflow Action Definition
This procedure creates a workflow action definition in a feature manifest file. This markup tells the SharePoint
workflow engine how to interact with your workflow action.
To create an action definition for a sandboxed workflow action
1. In Solution Explorer, right-click the project node, point to Add, and then click New Item.
2. In the Add New Item dialog box, in the Installed Templates pane, expand SharePoint, and then click
2010.
3. C lick Empty Element, type a name for the element in the Name text box, and then click Add. This
example uses the name LogDefinition for the element.
Generated from CHM, not final book. Will be superseded in the future. Page 146](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-146-320.jpg)




![3. Open the AssemblyInfo class file and add the AllowPartiallyTrustedCallers attribute to the class, as
shown here.
C#
[assembly: AllowPartiallyTrustedCallers]
Step 2: Create the Proxy Arguments Class
This procedure creates a proxy arguments class. This is a serializable type that you can use to pass data from
sandboxed code to the proxy operation class.
To create a proxy arguments class
1. Add a new class named SimpleProxyArgs to the project.
2. Add the following using statement to your class.
C#
using Microsoft.SharePoint.UserCode;
3. Add the public access modifier to your class.
4. Add the SerializableAttribute to your class.
5. Modify your class to inherit from the SPProxyOperationArgs class. Your class should resemble the
following code.
C#
[serializable]
public class SimpleProxyArgs : SPProxyOperationArgs { }
6. Add public properties for any arguments that you want to pass from the sandbox to the proxy.
C#
Generated from CHM, not final book. Will be superseded in the future. Page 151](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-151-320.jpg)






![required for the serialization and de-serialization of your timer job.
C#
public SimpleJobDefinition() : base() { }
8. Add a constructor that accepts an argument of type SPWebApplication, as shown in the following code.
This enables the base SPJobDefinition class to instantiate your timer job within a specific Web
application.
C#
public SimpleJobDefinition(SPWebApplication webApp) :
base(JobName, webApp, null, SPJobLockType.Job) { }
9.
Note:
The SPJobDefinition base constructor provides alternative overloads that you can use if you want to scope
your timer job to an SPService instance instead of a Web application. For more information, see
SPJobDefinition C lass on MSDN.
10. Within the constructor, give your timer job a title. This specifies how your timer job appears in the
SharePoint C entral Administration Web site.
C#
Title = "Simple Job Definition";
11. Within the SimpleJobDefinition class, override the Execute method. The method should accept an
argument of type Guid. In this case, the GUID represents the target Web application.
C#
public override void Execute(Guid targetInstanceId)
{
}
12. Add your timer job logic to the Execute method. This example simply adds an item to the task list on the
root site of the Web application. The job logic sets the title of the task to the current date and time.
C#
public override void Execute(Guid targetInstanceId)
{
// Execute the timer job logic.
SPWebApplication webApp = this.Parent as SPWebApplication;
SPList taskList = webApp.Sites[0].RootWeb.Lists["Tasks"];
SPListItem newTask = taskList.Items.Add();
newTask["Title"] = DateTime.Now.ToString();
newTask.Update();
}
Step 3: Create a Feature to Register the Job
This procedure describes how to use a feature receiver class to install the timer job in your SharePoint
environment.
To register a Web application-scoped timer job
1. In Solution Explorer, right-click the F eatures node, and then click Add F eature.
2. In Solution Explorer, right-click the new feature node, and then click Rename. This example uses the
name SimpleJobFeature for the feature.
3. Double-click the SimpleJobFeature node to open the feature designer window, and then set the scope of
the feature to WebApplication.
4. Add an event receiver to the SimpleJobFeature. To do this, right-click SimpleJobFeature in Solution
Explorer, and then click Add Ev ent Receiver.
5. In the SimpleJobF eatureEventReceiver class, add the following using statement.
C#
using Microsoft.SharePoint.Administration;
6. Add a method named DeleteJobs that accepts an argument of type SPJobDefinitionCollection. The
method should iterate through the job definition collection and delete any instances of
SimpleJobDefinition.
C#
private void DeleteJob(SPJobDefinitionCollection jobs)
Generated from CHM, not final book. Will be superseded in the future. Page 158](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-158-320.jpg)











![4. Expand the NavItem node and open the feature manifest file (Elements.xml). Delete the existing content,
and then add the following XML. You can also delete the Sample.txt file from Solution Explorer.
XML
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<CustomAction Id="[GUID]" GroupId="TimerJobs"
Location="Microsoft.SharePoint.Administration.Monitoring"
Sequence="10"
Title="Simple Page" Description="">
<UrlAction Url="_admin/ApplicationPage/SimplePage.aspx" />
</CustomAction>
</Elements>
Note:
This markup adds a custom action to the Timer Jobs action group on C entral Administration. In
practice, this adds a link to our custom application page under the Timer Jobs heading. For more
information about custom action locations, see Default C ustom Action Locations and IDs on MSDN.
If you reuse the code, replace [GUID] with a new GUID.
5. In Solution Explorer, expand F eatures, right-click F eature1, and then click Rename. This example uses
the name SimplePageF eature for the feature.
6. In Solution Explorer, double-click SimplePageF eature to open the Feature Designer. Notice that the
feature already contains your Nav Item module.
7. In the Feature Designer window, give the feature a friendly title. Leave the scope set to Web.
8. Press F5 to deploy and test your solution.
9. Browse to the C entral Administration Web site, and then click Monitoring. Notice that a Simple Page
link has been added under Timer Jobs.
Generated from CHM, not final book. Will be superseded in the future. Page 170](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-170-320.jpg)







![4. In the SharePoint C ustomization Wizard, under Which list do you want instantiate? [sic], click
Document Library.
5. Provide appropriate values for the display name, description, and relative URL, and then click F inish.
Generated from CHM, not final book. Will be superseded in the future. Page 178](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-178-320.jpg)










































![keyless association include when you need to navigate between entities that are related by an intermediate table.
The following are some examples:
You use an intermediate table to model a many-to-many relationship. For example, you might have a
many-to-many relationship between parts and machines—a machine contains many parts, and a part is
found in many machines.
A customer is related to an order, and an order is related to a line item. You want to show the customer in a
line item view.
For example, the following diagram illustrates a foreign keyless association between OrderLines and C ustomers.
The foreign keyless association would use a stored procedure to navigate back to C ustomers through the Orders
table.
Foreign keyless association between external content types
You can only create associations between entities in the same BDC model. For more information about creating
associations in Visual Studio 2010, see C reating an Association Between Entities, Authoring BDC Models, and
C reating External C ontent Types and Associations on MSDN. For more general information about creating
associations, see Association Element in MethodInstances, The Notion of Associations and the External Item
Picker, and Tooling Associations in SharePoint Designer 2010.
How Are Associations Defined in the BDC Model?
It can be instructive to take a look at how associations are represented in the underlying BDC model. For
example, SharePoint Designer created the following association method, which represents a foreign key
association between an Inv entoryLocations entity and a Parts entity. Notice the automatically generated
Transact-SQL in the RdbCommandText property. Defined on the InventoryLocations entity, the association
method allows you to navigate from a specific Parts instance to the related InventoryLocations instance by
providing a PartSKU parameter.
XML
<Method IsStatic="false" Name="InventoryLocationsNavigate Association">
<Properties>
<Property Name="BackEndObject" Type="System.String">InventoryLocations
</Property>
<Property Name="BackEndObjectType" Type="System.String">SqlServerTable
</Property>
<Property Name="RdbCommandText" Type="System.String">
SELECT [ID] , [PartSKU] , [BinNumber] , [Quantity]
FROM [dbo].[InventoryLocations]
WHERE [PartSKU] = @PartSKU
</Property>
<Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data,
Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">Text
</Property>
...
The method definition also defines every parameter, but these have been omitted for brevity. Within the method
definition, the method instance defines the specific logic that is actually invoked to traverse the association. Note
that the method instance has a Type attribute value of AssociationNav igator, which is common to all methods
Generated from CHM, not final book. Will be superseded in the future. Page 221](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-221-320.jpg)

![<Property Name="RdbCommandText" Type="System.String">
[dbo].[GetPartsByMachineID]
</Property>
<Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data,
Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">
StoredProcedure
</Property>
...
Again, the method definition also defines each parameter, but these have been omitted for brevity. Because the
relationship is not based on a foreign key, the method instance definition does not need to identify foreign key
mappings. Instead, it simply specifies the SourceEntity and the DestinationEntity.
XML
...
<MethodInstances>
<Association Name="GetPartsByMachineID"
Type="AssociationNavigator"
ReturnParameterName="GetPartsByMachineID"
DefaultDisplayName="Parts Read With Sproc">
<SourceEntity Namespace="DataModels.ExternalData.PartsManagement"
Name="Machines" />
<DestinationEntity Namespace="DataModels.ExternalData.PartsManagement"
Name="Parts" />
</Association>
</MethodInstances>
</Method>
To explore these entities and associations in more detail, see the External Data Models reference
implementation.
Generated from CHM, not final book. Will be superseded in the future. Page 223](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-223-320.jpg)









![Using Query Classes
Before the advent of LINQ to SharePoint, the SPQuery and SPSiteDataQuery classes were the predominant
approaches to performing data operations on SharePoint lists. There are still many scenarios in which these
classes provide the most effective approach—and, in some cases, the only viable approach—to data access.
Both the SPQuery class and the SPSiteDataQuery class allow you to construct a query using collaborative
application markup language (C AML). You can then use the SPList object model to execute your query against
one or more SharePoint lists. This topic explains when you should use each class and describes the considerations
that should guide your implementations.
Using SPQuery
The SPQuery class is used to retrieve data from a specific list. In most cases, you should use LINQ to SharePoint,
instead of the SPQuery class, to perform data operations on lists. However, there are still some circumstances in
which SPQuery is the most appropriate option—or the only option—for data access. Most notably, using the
SPQuery class is the only supported server object model approach for programmatically working with data in
external lists.
In SharePoint 2010, the SPQuery class has been extended to allow you to specify joins and projected fields. The
high-level process for using the SPQuery class is as follows:
C reate an SPQuery instance.
Set properties on the SPQuery instance to specify the C AML query, along with various additional query
parameters as required.
C all the GetItems method on an SPList instance, passing in the SPQuery instance as a parameter.
The following code example shows this.
C#
SPListItemCollection results;
var query = new SPQuery
{
Query = "[Your CAML query statement]",
ViewFields = "[Your CAML FieldRef elements]",
Joins = "[Your CAML Joins element]",
ProjectedFields = "[Your CAML ProjectsFields element]"
};
results = SPContext.Current.Web.Lists["ListInstance"].GetItems(query);
This chapter does not provide instructions on how to configure SPQuery instances, because this is well covered
by the product documentation. However, the following are brief summaries of the key properties of interest:
The Query property specifies the C AML query that you want to execute against the list instance.
The ViewFields property specifies the columns that you want your queries to return as C AML FieldRef
elements.
The Joins property specifies the join predicates for your query as a C AML Joins element.
The ProjectedFields property defines fields from foreign joined lists as a C AML ProjectedF ields element.
This allows you to reference these fields in your ViewF ields property and in your query statement.
Using SPQuery with Regular SharePoint Lists
You should consider using the SPQuery class, instead of LINQ to SharePoint, in the following scenarios:
When you hav e anonymous users on your site. LINQ to SharePoint does not support anonymous user
access.
Note:
This limitation exists at the time of publication. However, it may be resolved in future service packs or
cumulative updates.
When a lookup column in a list refers to a list in another site within the site collection. In this
situation, SPQuery allows you to use a join predicate that spans both sites. Although you can use LINQ to
SharePoint to query across sites with some additional configuration, the process required to generate entity
classes is more complex. By default, LINQ to SharePoint returns only the ID field from the target list, in
Generated from CHM, not final book. Will be superseded in the future. Page 233](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-233-320.jpg)




![new entity class for the list content type. If the list content type is identical to the corresponding site content
type, SPMetal will simply use the entity class for the site content type instead. Entities created from list
content types are named by preceding the content type name with the list name. For example, if you add a
StartDate column to the SOW content type in the Estimates list, an entity class named EstimatesSOW will
be generated to represent the list content type. C onversely, if you have not modified the SOW content type
in the Estimates list, an entity class named SOW will be generated to represent the site content type.
If a column is removed from a list content type, the corresponding property is made virtual in the entity
class that represents the site content type. The entity class that represents the list content type overrides
this method and will throw an Inv alidOperationException if you attempt to access the property. For
example, if you remove the VendorID column from the SOW content type in the Estimates list, the
VendorID property is made virtual in the SOW entity class, and the EstimatesSOW entity will throw an
exception if you attempt to access the property.
If a list contains a single content type, the EntityList<TEntity> class that represents that list in the data
context class will use that content type entity as its type parameter. For example, if the Estimates list
contained only documents based on the SOW content type, the list would be represented by an
EntityList<SOW> instance.
If a list contains more than one content type, the EntityList<TEntity> class that represents that list will
use the closest matching base content type as its type parameter. For example, the Estimates list actually
contains the SOW content type and the Estimate content type, which both inherit from the built-in
Document content type. In this case, the list is represented by an EntityList<Document> instance.
Because SOW entities and Estimate entities both inherit from the Document entity, the list can contain
entities of both types.
Modeling Associations in Entity Classes
When you use the SPMetal command-line tool to generate entity classes, it automatically detects relationships
between lists based on lookup columns, and it adds properties to the entity classes to enable you to navigate
these relationships. For example, in the SharePoint List Data Models ReferenceIimplementation, the Inventory
Locations list includes a lookup column named Part that retrieves values from the Parts list. In the
Inv entoryLocation class, this is reflected by the inclusion of a Part property that allows you to navigate to the
associated entity instance in the Parts list.
C#
private Microsoft.SharePoint.Linq.EntityRef<Part> _part;
[Microsoft.SharePoint.Linq.AssociationAttribute(Name="PartLookup",
Storage="_part",
MultivalueType=Microsoft.SharePoint.Linq.AssociationType.Single,
List="Parts")]
public Part Part
{
get { return this._part.GetEntity(); }
set { this._part.SetEntity(value); }
}
Note:
The InventoryLocation class also includes event handlers that ensure the Part reference remains up to date
if the associated entity instance is changed.
The SPMetal tool also adds properties to the Parts list that enable you to navigate to the Inventory Locations list.
This is known as a reverse lookup association. The Parts class includes an InventoryLocation property that
returns the set of inventory locations that are associated with a specific part—in other words, each
Inv entoryLocation instance that links to the specified part through its Part lookup column.
C#
private Microsoft.SharePoint.Linq.EntitySet<InventoryLocation> _inventoryLocation;
[Microsoft.SharePoint.Linq.AssociationAttribute(Name="PartLookup",
Storage="_inventoryLocation", ReadOnly=true,
MultivalueType=Microsoft.SharePoint.Linq.AssociationType.Backward,
List="Inventory Locations")]
public Microsoft.SharePoint.Linq.EntitySet<InventoryLocation> InventoryLocation
{
get { return this._inventoryLocation; }
Generated from CHM, not final book. Will be superseded in the future. Page 238](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-238-320.jpg)












![Each of the components in the programming model relates to a specific part of the BDC model, which was
described in Business Data C onnectivity Models. The BDC service application instance (BdcService) represents
the service instance that manages the metadata for the external systems you want to access. Remember that the
BDC service application instance you use is determined by the service application proxy group associated with
the current SharePoint Web application. Each BDC service application instance exposes a metadata catalog
(IMetadataC atalog) that you can use to navigate through the metadata definitions stored by the service.
Within the metadata catalog, the two primary concepts are the entity (IEntity) and the LOB system instance
(ILobSystemInstance). An entity represents an external content type and defines the stereotyped operations that
are used to interact with an external data entity. It can also define associations that allow you to navigate to
related entities and filters that enable you to constrain a result set. A LOB system instance represents a specific
instance, or installation, of the external system that the BDC model represents, and defines the connection and
authentication details required to connect to the system.
Note:
"LOB system instance" is a legacy term from Office SharePoint Server 2007. A LOB system is a
line-of-business application, such as customer relationship management (C RM) or enterprise resource planning
(ERP) software. Although the term "LOB system instance" is still used within the BDC object model, the broader
term "external system" is preferred in other cases.
Entities, or external content types, are common to all instances of a system. To access data from a specific
instance of an external system, you need to use an entity object in conjunction with a LOB system instance object
to retrieve an entity instance (IEntityInstance). The following code example illustrates this.
C#
public IEntityInstance GetMachineInstance(int machineId)
{
const string entityName = "Machines";
const string systemName = "PartsManagement";
const string nameSpace = "DataModels.ExternalData.PartsManagement";
BdcService bdcService = SPFarm.Local.Services.GetValue<BdcService>();
IMetadataCatalog catalog =
bdcService.GetDatabaseBackedMetadataCatalog(SPServiceContext.Current);
ILobSystemInstance lobSystemInstance =
catalog.GetLobSystem(systemName).GetLobSystemInstances()[systemName];
Generated from CHM, not final book. Will be superseded in the future. Page 251](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-251-320.jpg)
![Identity identity = new Identity(machineId);
IEntity entity = catalog.GetEntity(nameSpace, entityName);
IEntityInstance instance = entity.FindSpecific(identity, lobSystemInstance);
return instance;
}
When a method on an IEntity object takes an object of type ILobSystemInstance as a parameter—such as
the F indSpecific method shown here—usually, it is querying the external system for information. The IEntity
object defines the stereotyped operations that allow you to interact with a particular type of data entity on the
external system, while the ILobSystemInstance object defines the details required to actually connect to a
specific external system instance. Typically, you perform data operations on an IEntityInstance object or on a
collection of IEntityInstance objects. Each IEntityInstance object contains a set of fields and values that
correspond to the related data item in the external system. These fields can represent simple types or complex
types. For more information, see IEntityInstance Interface on MSDN.
Using Filters
IEntity objects can include filter definitions that allow you to constrain result sets when retrieving more than one
item. Filters can also provide contextual information to the external system, such as a trace identifier to use when
logging. The following code example shows how you can use filters to retrieve entity instances that match a
specified model number.
C#
public DataTable FindMachinesForMatchingModelNumber(string modelNumber)
{
const string entityName = "Machines";
const string systemName = "PartsManagement";
const string nameSpace = "DataModels.ExternalData.PartsManagement";
BdcService bdcService = SPFarm.Local.Services.GetValue<BdcService>();
IMetadataCatalog catalog =
bdcService.GetDatabaseBackedMetadataCatalog(SPServiceContext.Current);
ILobSystemInstance lobSystemInstance =
catalog.GetLobSystem(systemName).GetLobSystemInstances()[systemName];
IEntity entity = catalog.GetEntity(nameSpace, entityName);
IFilterCollection filters = entity.GetDefaultFinderFilters();
if (!string.IsNullOrEmpty(modelNumber))
{
WildcardFilter filter = (WildcardFilter)filters[0];
filter.Value = modelNumber;
}
IEntityInstanceEnumerator enumerator =
entity.FindFiltered(filters, lobSystemInstance);
return entity.Catalog.Helper.CreateDataTable(enumerator);
}
As you can see, the IEntity object includes a collection of filters that you can configure for use in queries. In this
case, a wildcard filter is used to perform a partial match against a machine model number.
Note:
The CreateDataTable method is a convenient new addition in SharePoint 2010 that automatically populates
a DataTable object with the query results.
Using Associations
At a conceptual level, associations between entities in the BDC model are similar to foreign key constraints in a
relational database or lookup columns in regular SharePoint lists. However, they work in a different way.
Associations are defined as methods within an entity that allow you to navigate from instances of that entity to
instances of a related entity. You cannot create joins across associations in a BDC model. Instead, you must
retrieve an entity instance and then use the association method to navigate to the related entity instances. This is
illustrated by the following code example, which retrieves the set of machine part entities that are associated with
Generated from CHM, not final book. Will be superseded in the future. Page 252](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-252-320.jpg)
![a machine entity.
C#
public DataTable GetPartsForMachine(int machineId)
{
const string entityName = "Machines";
const string systemName = "PartsManagement";
const string nameSpace = "DataModels.ExternalData.PartsManagement";
BdcService bdcService = SPFarm.Local.Services.GetValue<BdcService>();
IMetadataCatalog catalog =
bdcService.GetDatabaseBackedMetadataCatalog(SPServiceContext.Current);
ILobSystemInstance lobSystemInstance =
catalog.GetLobSystem(systemName).GetLobSystemInstances()[systemName];
IEntity entity = catalog.GetEntity(nameSpace, entityName);
// Retrieve the association method.
IAssociation association = (IAssociation)entity.GetMethodInstance(
"GetPartsByMachineID", MethodInstanceType.AssociationNavigator);
Identity identity = new Identity(machineId);
// Retrieve an entity instance.
IEntityInstance machineInstance =
entity.FindSpecific(identity, lobSystemInstance);
EntityInstanceCollection collection = new EntityInstanceCollection();
collection.Add(machineInstance);
// Navigate the association to get parts.
IEntityInstanceEnumerator associatedInstances = entity.FindAssociated(
collection, association, lobSystemInstance, OperationMode.Online);
return entity.Catalog.Helper.CreateDataTable(associatedInstances);
}
This approach is consistent with the way the BDC model works in general. You first retrieve definitions of entities
and associations from the model, and then you use these entities and associations in conjunction with a LOB
system instance to retrieve information from the external system. Although this may seem somewhat unnatural
at first, it allows you to decouple your applications from the implementation details of the backend service or
database.
Working with Database Views
In some scenarios, you may want to model external content types on composite views of entities in your external
system. For example, you might create an external content type from a database view or a specialized service
method instead of simply replicating database tables or other external entities. This approach is useful for read
operations in which you need to aggregate fields from multiple external tables or entities, especially when you are
working with large amounts of data. If you don't use a database view, you would need to traverse individual
entity associations in order to generate the composite view you require. This increases the load on the BDC
runtime and can lead to a poor user experience.
The drawback of binding external content types to database views is that create, update, and delete
operations become more complicated, because updating a view inevitably involves performing operations on
more than one table. There are two approaches you can use to enable updates to database views:
You can create an INSTEAD OF trigger on the SQL Server database to drive update operations. An INSTEAD
OF trigger defines the Transact-SQL commands that should be executed when a client attempts a particular
update operation. For example, you might define an INSTEAD OF INSERT routine that is executed when a
client attempts an INSERT operation.
You can develop stored procedures on the SQL Server database to perform the update operations and map
the relevant stereotyped operations for your external content type to these stored procedures.
Unless you are expert in creating Transact-SQL routines, using triggers can be somewhat cumbersome and
complex. You may find that creating stored procedures offers a more palatable approach.
Generated from CHM, not final book. Will be superseded in the future. Page 253](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-253-320.jpg)



![Using the Content Iterator
SharePoint Server provides a new API, C ontentIterator, to help with accessing more than 5,000 items in a large
list without hitting a list throttling limit and receiving an SPQueryThrottleException. C ontentIterator implements a
callback pattern for segmenting the query for processing a single item at a time. C onsider using this capability if
you need to process a large number of items that may exceed a throttling limit. The following trivial example
demonstrates the approach used with C ontentIterator tested with a list returning 20,001 items from the query.
C#
static int exceptions = 0;
static int items = 0;
protected void OnTestContentIterator(object sender, EventArgs args)
{
items = 0;
exceptions = 0;
string query1 = @"<View>
<Query>
<Where>
<And>
<BeginsWith>
<FieldRef Name='SKU' />
<Value Type='Text'>S</Value>
</BeginsWith>
</And>
</Where>
</Query>
</View>";
ContentIterator iterator = new ContentIterator();
SPQuery listQuery = new SPQuery();
listQuery.Query = query1;
SPList list = SPContext.Current.Web.Lists["Parts"];
iterator.ProcessListItems(list,
listQuery,
ProcessItem,
ProcessError
);
}
public bool ProcessError(SPListItem item, Exception e)
{
// process the error
exceptions++;
return true;
}
public void ProcessItem(SPListItem item)
{
items++;
//process the item.
}
C ontentIterator will run through each item in the list, invoking the callback provided for list item processing—in
this case, ProcessItem. If an error occurs while iterating the list, then the error function is invoked—in this
case, ProcessError. Using this approach the C ontentIterator processes the list in pieces and avoids any
excessively large queries. This functionality is provided as part of Enterprise C ontent Management (EC M) in
SharePoint Server 2010. C ontentIterator has additional functionality not described in this section, such as the
ability to order result sets. For more information see the C ontentIterator C lass.
Generated from CHM, not final book. Will be superseded in the future. Page 257](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-257-320.jpg)
























![In the same way that you can use foreign key constraints to specify delete behavior across tables in a relational
database, SharePoint 2010 allows you to specify delete behavior across list relationships. You can configure
lookup columns to manage deletions in two ways.
You can apply a cascade delete rule. In this case, if a user deletes an item from a parent list, related
items in the child list are also deleted. This helps to prevent orphaned items in the child list.
You can apply a restrict delete rule. In this case, users are prevented from deleting an item that is
referenced by items in a related list. This helps to prevent broken lookup links in the data model.
Because list relationships are formed between two specific list instances, you cannot declaratively specify delete
behavior when you define a lookup field as a site column. If you wanted to declaratively specify delete behavior,
you would need to define a custom schema.xml file for each list instance, which substantially increases the
complexity of the development process. In the SharePoint List Data Models reference implementation, we use a
feature receiver class to programmatically define the delete behavior for list relationships. The feature receiver
class is associated with the Initialize Model (CT2LI) feature, so that we set the delete behavior after we bind
each content type to its associated list. In the CT2LI.Ev entReceiver class, the F eatureActivated method
applies a restrict delete rule to lookup columns in several list instances, as shown by the following code
example.
C#
public override void FeatureActivated(SPFeatureReceiverProperties properties)
{
try
{
...
//Restrict deletion of list items that would create a broken lookup
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.InventoryLocations,
Constants.Fields.Guids.Part);
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.Machines,
Constants.Fields.Guids.Manufacturer);
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.Machines,
Constants.Fields.Guids.Category);
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.MachineDepartments,
Constants.Fields.Guids.Department);
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.MachineDepartments,
Constants.Fields.Guids.Machine);
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.MachineParts,
Constants.Fields.Guids.Machine);
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.MachineParts,
Constants.Fields.Guids.Part);
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.PartSuppliers,
Constants.Fields.Guids.Part);
RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.PartSuppliers,
Constants.Fields.Guids.Supplier);
...
}
catch (Exception e) { System.Diagnostics.Trace.WriteLine(e.ToString()); }
}
The RestrictDeleteOnLookupField helper method retrieves the SPF ield instance that represents the lookup
column, and then sets the RelationshipDeleteBehav ior property to the
SPRelationshipDeleteBehavior.Restrict enumeration value.
C#
private void RestrictDeleteOnLookupField(SPWeb web, string listUrl,
Guid fieldGuid)
{
SPList list = web.GetList(GetListUrl(web.ServerRelativeUrl, listUrl));
SPField field = list.Fields[fieldGuid];
SPFieldLookup fieldLookup = (SPFieldLookup)field;
fieldLookup.Indexed = true;
fieldLookup.RelationshipDeleteBehavior = SPRelationshipDeleteBehavior.Restrict;
fieldLookup.Update();
}
Generated from CHM, not final book. Will be superseded in the future. Page 282](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-282-320.jpg)

![Building Entity Classes for LINQ to SharePoint
The SharePoint List Data Models reference implementation makes extensive use of the LINQ to SharePoint
provider to perform data operations against SharePoint lists. Before you can use LINQ expressions to query
SharePoint lists, you must build a set of entity classes to represent the lists and list items in your SharePoint site.
SharePoint 2010 provides a command-line tool, SPMetal, which you can use to generate these classes
automatically. For more information on SPMetal, see Using LINQ to SharePoint.
In the DataModels.SharePointList.Model project, the PartsSite.cs file contains the entity classes that we
generated using the SPMetal tool. Within this file, the PartsSiteDataContext class sits at the top of the entity
hierarchy. This class inherits from the DataC ontext class and represents the SPWeb instance from which the
entity classes were generated—in this case, the root site of the SharePointList site collection. The data context
class provides the foundation for every LINQ to SharePoint query, as all LINQ to SharePoint expressions are
scoped to a DataContext instance. The class provides public read-only properties for each list on the SharePoint
site. For example, the following property provides the LINQ to SharePoint provider with access to the Parts list.
C#
[Microsoft.SharePoint.Linq.ListAttribute(Name="Parts")]
public Microsoft.SharePoint.Linq.EntityList<Part> Parts
{
get { return this.GetList<Part>("Parts"); }
}
As you can see, lists in LINQ to SharePoint expressions are represented by the generic EntityList<T> class,
which represents an enumerable collection of entities. If you take a look through the PartsSite.cs file, you can see
that SPMetal generates an entity class for each content type on the site. For example, the file includes a Part
class that contains fields, properties, and event handlers for the Part content type.
C#
[Microsoft.SharePoint.Linq.ContentTypeAttribute(Name="Part",
Id="0x01001966A9D6EDFEB845A8DD2DDA365BF5DC")]
public partial class Part : Item
{
...
}
This class provides a strongly typed representation of list items that use the Part content type. When you call the
GetList<Part>("Parts") method, you are requesting an enumerable collection of Part content type entity
instances from the Parts list instance.
Note:
For more information on building entity classes for LINQ to SharePoint, see Using LINQ to SharePoint.
Reverse Lookups in the Entity Model
When you use the SPMetal command-line tool to generate entity classes, it automatically detects relationships
based on lookup columns. For example, the Inventory Locations list includes a Part lookup column. As a result,
the InventoryLocation class includes a Part property that allows you to navigate to the associated Part entity.
C#
private Microsoft.SharePoint.Linq.EntityRef<Part> _part;
[Microsoft.SharePoint.Linq.AssociationAttribute(Name="PartLookup",
Storage="_part",
MultivalueType=Microsoft.SharePoint.Linq.AssociationType.Single,
List="Parts")]
public Part Part
{
get { return this._part.GetEntity(); }
set { this._part.SetEntity(value); }
}
The class also includes various event handlers to ensure that the Part reference remains up to date if the
associated Part entity is changed. What may be less obvious is that SPMetal also attempts to generate a reverse
lookup association for this relationship. In other words, SPMetal will add a property to the Part class that allows
Generated from CHM, not final book. Will be superseded in the future. Page 284](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-284-320.jpg)
![you to navigate from Parts to Inventory Locations, despite the fact that the Parts list includes no references to the
Inventory Locations list. The following code example shows the Inv entoryLocation property in the Parts class.
C#
private Microsoft.SharePoint.Linq.EntitySet<InventoryLocation> _inventoryLocation;
[Microsoft.SharePoint.Linq.AssociationAttribute(Name="PartLookup",
Storage="_inventoryLocation", ReadOnly=true,
MultivalueType=Microsoft.SharePoint.Linq.AssociationType.Backward,
List="Inventory Locations")]
public Microsoft.SharePoint.Linq.EntitySet<InventoryLocation> InventoryLocation
{
get { return this._inventoryLocation; }
set { this._inventoryLocation.Assign(value); }
}
As you can see from the code, each Part instance maintains a reference to a collection of Inv entoryLocation
instances; in other words, to every Inv entoryLocation instance that links to that Part instance through its Part
lookup column. Note that the Part instance does not actually store these Inv entoryLocation instances, and
navigating this relationship results in a call to the content database. As before, the class includes various event
handlers to ensure that the references remain up to date. However, the current version of SPMetal has an
important limitation when it comes to generating reverse lookup associations:
If a site lookup column is used by only one list or content type, SPMetal will generate a reverse lookup
association for the relationship.
However, if a site lookup column is used by more than one list or content type, SPMetal will not generate
reverse lookup associations for any of the relationships based on that lookup column.
As you can see from the following diagram, three lists—Part Suppliers, Machine Parts, and Inventory Locations—
all include a lookup column for the Parts list.
Lookup Relationships for the Parts List
If we had used the same site lookup column in each of these three lists, the Part class would not contain any
reverse lookup associations. However, the logic in our repository class requires that we are able to retrieve the
inventory locations associated with a specified part, which would be a somewhat unwieldy task without the
Generated from CHM, not final book. Will be superseded in the future. Page 285](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-285-320.jpg)













![Modeling Many-to-Many Relationships
First, let's look at how we navigate from parts to machines. We added a method named GetMachinesByPartSku
to the entity that defines the Parts external content type. Note that the RdbCommandText property identifies a
stored procedure named GetMachinesByPartSku.
XML
<Method IsStatic="false" Name="GetMachinesByPartSku">
<Properties>
<Property Name="BackEndObject" Type="System.String">GetMachinesByPartSku
</Property>
<Property Name="BackEndObjectType" Type="System.String">SqlServerRoutine
</Property>
<Property Name="RdbCommandText" Type="System.String">
[dbo].[GetMachinesByPartSku]
</Property>
<Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data,
Version=2.0.0.0, Culture=neutral,
PublicKeyToken=b77a5c561934e089">
StoredProcedure
</Property>
<Property Name="Schema" Type="System.String">dbo</Property>
</Properties>
<Parameters>
<Parameter Direction="In" Name="@partSku">
<TypeDescriptor TypeName="System.String" IdentifierName="SKU"
IdentifierEntityName="Parts"
IdentifierEntityNamespace="DataModels.ExternalData.PartsManagement"
ForeignIdentifierAssociationName="GetMachinesByPartSku" Name="@partSku" />
</Parameter>
...
<MethodInstances>
<Association Name="GetMachinesByPartSku"
Type="AssociationNavigator"
ReturnParameterName="GetMachinesByPartSku"
DefaultDisplayName="Machines Read With Sproc">
<SourceEntity Namespace="DataModels.ExternalData.PartsManagement"
Name="Parts" />
<DestinationEntity Namespace="DataModels.ExternalData.PartsManagement"
Name="Machines" />
</Association>
</MethodInstances>
</Method>
In the parts management database, we create a stored procedure named GetMachinesByPartSku that uses
join predicates across the MachineParts table to retrieve all the machines associated with a specified part SKU.
This is illustrated by the following code example.
Transact-SQL
SELECT Machines.* FROM Parts
INNER JOIN MachineParts ON Parts.SKU = MachineParts.PartSKU
INNER JOIN Machines ON MachineParts.MachineId = Machines.ID
WHERE Parts.SKU = @partSKU;
This arrangement allows us to use built-in business data Web Parts to view the machines associated with a
specified part. This is illustrated by the Machines By Part page, which uses a BusinessDataListWebPart to
represent parts and a BusinessDataAssociationWebPart to represent machines, as shown in the following
image.
The Machines By Part Page
Generated from CHM, not final book. Will be superseded in the future. Page 299](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-299-320.jpg)

![You may be tempted to change the ReadOnly attribute for the SKU return parameter to false, since you specify
the SKU in the C reate operation. However, the BDC model will then assume that the SKU can be updated after it
is created. The ReadOnly flag will not affect the C reate operation, but will affect the Update operation. If you
want to allow the SKU to be changed after creation, then set this flag to false. If not, leave it set to true. The
reference implementation treats the SKU as read-only once the Part entity instance is created.
If you choose to allow the identifier to be updateable then you should set the ReadOnly attribute to false for the
identifier field return value in the C reate operation. If you do this, you must amend the Update operation
definition by replacing the UpdaterField="true" attribute with a PreUpdaterField="true" attribute, as shown
by the following code. This tells the BDC runtime to use the original identifier to process the update. For example,
if a part SKU is changed from SKU123 to SKU345, then the Update operation will first locate the part with an SKU
value of SKU123, and then set the SKU value to SKU345.
XML
<Method Name="Update" DefaultDisplayName="Parts Update">
<Properties>
<Property Name="BackEndObject" Type="System.String">Parts</Property>
<Property Name="BackEndObjectType"
Type="System.String">SqlServerTable</Property>
<Property Name="RdbCommandText" Type="System.String">
UPDATE [dbo].[Parts] SET [Name] = @Name ,
[Description] = @Description WHERE [SKU] = @SKU</Property>
<Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data,
Version=2.0.0.0, Culture=neutral,
PublicKeyToken=b77a5c561934e089">Text</Property>
<Property Name="Schema" Type="System.String">dbo</Property>
</Properties>
<Parameters>
<Parameter Direction="In" Name="@SKU">
<TypeDescriptor TypeName="System.String" PreUpdaterField="true"
IdentifierName="SKU" Name="SKU">
<Properties>
<Property Name="Size" Type="System.Int32">255</Property>
</Properties>
<Interpretation>
<NormalizeString FromLOB="NormalizeToNull"
ToLOB="NormalizeToEmptyString" />
</Interpretation>
</TypeDescriptor>
</Parameter>
...
SharePoint Designer does not allow you to set the PreUpdaterField attribute. You must add the attribute by
manually editing the model XML. After doing this, you will no longer be able to open the model in SharePoint
Designer.
Generated from CHM, not final book. Will be superseded in the future. Page 301](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-301-320.jpg)



![public static BdcSupplier ConvertSupplier (Supplier.SampleService.Supplier supplier)
{
BdcSupplier bdcSupplier = new BdcSupplier();
bdcSupplier.DUNS = supplier.DUNS;
bdcSupplier.Name = supplier.Name;
bdcSupplier.Rating = supplier.Rating;
bdcSupplier.SupplierID = supplier.SupplierId.ToString();
return bdcSupplier;
}
However, you may also want to manipulate the external data before returning it, for example by flattening
complex types. The Conv ertContact method merges properties from an external Contact entity and its related
ContactAddresses entity into a single BdcContact entity, as shown in the following code example.
C#
private static BdcContact ConvertContact(Contact contact)
{
BdcContact bdcContact = new BdcContact();
bdcContact.Identifier1 = contact.ID.ToString();
bdcContact.SupplierID = contact.SupplierId.ToString();
bdcContact.DisplayName = contact.FirstName + " " + contact.LastName;
bdcContact.PrimaryPhone = contact.WorkPhone;
bdcContact.SecondaryPhone = contact.MobilePhone;
bdcContact.OtherPhone = contact.HomePhone;
bdcContact.Email = contact.Email;
bdcContact.Website = contact.Website;
if (contact.ContactAddresses != null &&
contact.ContactAddresses.Count() > 0)
{
bdcContact.Address1 = contact.ContactAddresses[0].Address1;
bdcContact.Address2 = contact.ContactAddresses[0].Address2;
bdcContact.City = contact.ContactAddresses[0].City;
bdcContact.PostalCode = contact.ContactAddresses[0].PostalCode;
bdcContact.State = contact.ContactAddresses[0].State;
bdcContact.Country = contact.ContactAddresses[0].Country;
}
return bdcContact;
}
Service classes in .NET connectivity assemblies can also include association methods. For example, the
BdcSupplierServ ice class includes a method named BdcSupplierToBdcContact that returns all the suppliers
associated with a specified contact ID. To do this, it calls a method named GetContactsBySupplierID on the
external service.
C#
public static IEnumerable<BdcContact> BdcSupplierToBdcContact(string supplierId)
{
using (Service svc = new Service())
{
List<Contact> contacts = svc.GetContactsBySupplierID(int.Parse(supplierId));
List<BdcContact> supplierContacts = new List<BdcContact>();
foreach (Contact contact in contacts)
{
supplierContacts.Add(ConvertContact(contact));
}
return supplierContacts;
}
}
Generated from CHM, not final book. Will be superseded in the future. Page 305](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-305-320.jpg)



![4. The repository returns the strongly typed list to the Web Part, which binds the list to a user interface
component.
For example, suppose the user searches for a supplier on the Manage Suppliers page. The ManageSuppliers
class calls the GetSuppliersByName method in the PartManagementRepository.
C#
void SearchSupplierNameButton_Click(object sender, EventArgs e)
{
var partManagementRepository = new PartManagementRepository();
SupplierGridView.DataSource =
partManagementRepository.GetSuppliersByName(searchSupplierNameTextBox.Text);
SupplierGridView.DataBind();
}
In the PartManagementRepository class, the GetSuppliersByName method queries the BDC service by
using the IEntity.F indFiltered method. The IEntityInstanceEnumerator interface represents a generic
collection of IEntityInstance objects.
C#
public List<BdcSupplier> GetSuppliersByName(string supplierName)
{
//Get the BDC entity
IEntity entity = catalog.GetEntity(Constants.BdcContactsEntityNameSpace,
"BdcSupplier");
//Get all filters for the entity
IFilterCollection filters = entity.GetDefaultFinderFilters();
//Set filter value
if (!string.IsNullOrEmpty(supplierName))
{
WildcardFilter filter = (WildcardFilter)filters[0];
filter.Value = supplierName;
}
//Get filtered items
IEntityInstanceEnumerator enumerator = entity.FindFiltered(filters,
lobSystemInstance);
return new ViewModel<BdcSupplier>
(entity.Catalog.Helper.CreateDataTable(enumerator)).Collection;
}
In order to convert the collection of IEntityInstance objects into a strongly typed collection of BdcSupplier
objects, we use the DataMapper class. We instantiate the DataMapper class by passing in a DataTable
instance, and then read the Collection property to return a strongly typed list to the view class. In this case, as
the DataMapper type parameter is BdcSupplier, we return a List<BdcSupplier> instance to the view class.
The following code example shows the DataMapper class.
C#
public class DataMapper<T>
{
private DataTable dataTable;
private int rowNumber;
public DataMapper(DataTable dataTable)
{
this.dataTable = dataTable;
this.rowNumber = 0;
}
private DataMapper(DataTable dataTable,int rowNumber)
{
this.dataTable = dataTable;
this.rowNumber = rowNumber;
}
Generated from CHM, not final book. Will be superseded in the future. Page 309](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-309-320.jpg)
![public T Instance
{
get
{
var dataMapperInstance = (T)Activator.CreateInstance(typeof(T));
PropertyInfo[] propertyInfos = typeof(T).GetProperties();
foreach (PropertyInfo propertyInfo in propertyInfos)
{
// Set the Properties on the instance
propertyInfo.SetValue(dataMapperInstance,
dataTable.Rows[rowNumber][propertyInfo.Name], null);
}
return dataMapperInstance;
}
}
public List<T> Collection
{
get
{
var dataMapperCollection = new List<T>();
int i = 0;
foreach (DataRow row in dataTable.Rows)
{
dataMapperCollection.Add(new ViewModel<T>(dataTable,i).Instance);
i++;
}
return dataMapperCollection;
}
}
}
The data mapper assumes that the names of the columns in the data table model match the names of the
properties of the strongly typed entities. In this example, the benefits of converting the entity instances returned
by the BDC service into a strongly typed collection may not be obvious. However, suppose you wanted to build a
testable business logic layer between the external supplier management system and the SharePoint user
interface, in order to perform tasks such as validation or consistency checks. The only way to achieve this
business logic layer is to return the "semi-typed" BDC entities as strongly typed business objects. The
DataMapper class illustrated in this reference implementation shows how you can manage this process without
significantly increasing the complexity of your application.
Generated from CHM, not final book. Will be superseded in the future. Page 310](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-310-320.jpg)

![In this case, a wildcard filter has been defined for the ModelNumber field on the Machines entity. This allows us
to search for machines with a model number that contains some specified text. To retrieve the set of machines
that match a filter, we call the F indFiltered method on the IEntity instance that represents machines, as shown
in the following code example.
C#
public DataTable GetMachinesByModelNumber(string modelNumber)
{
//Get the Machines entity (external content type) from the metadata catalog
IEntity entity = catalog.GetEntity(Constants.BdcEntityNameSpace, "Machines");
//Get the filters defined on the default Finder method for the entity
IFilterCollection filters = entity.GetDefaultFinderFilters();
//Set the WildCard filter value
if (!string.IsNullOrEmpty(modelNumber))
{
WildcardFilter filter = (WildcardFilter)filters[0];
filter.Value = modelNumber;
}
//Return the filtered list of items from the external data source
IEntityInstanceEnumerator enumerator = entity.FindFiltered(filters,
lobSystemInstance);
//Convert the filtered list of items to a DataTable and return it
return entity.Catalog.Helper.CreateDataTable(enumerator);
}
Note:
This example uses the IMetadataCatalog.Helper.CreateDataTable method to return the result set as a
DataTable instance. The CreateDataTable method is a new BC S method in SharePoint 2010 that allows you
to convert a result set from the BDC into a DataTable object with ease. For information on how to convert
the DataTable object into a strongly typed collection, see Web Part Patterns for BDC Logic.
The External Data Models reference implementation contains Finder methods that include three different types of
filter definitions:
LIMIT filters ensure that the number of results returned by the Read List operation does not exceed the
maximum allowed by the BC S. By default, this maximum value is set to 2,000 records. The use of LIMIT
filters is highly recommended to prevent performance degradation when you work with large amounts of
data.
WILDC ARD filters allow you to filter the results returned by the Read List operation based on partial search
matches. The user can constrain the result set by providing a few characters of text, including wildcard
characters as required. Including a WILDC ARD filter in your Finder methods enables the business data Web
Parts to use their built-in search functionality.
C OMPARISON filters allow you to constrain the results returned by the Read List operation to those with field
values that exactly match some search text. C omparison filters can be used to evaluate conditions such as
equals, not equals, less than, greater than, and so on. Including a C OMPARISON filter in your Finder
methods also enables exact match and condition-driven filtering in the business data Web Parts.
Querying Data by Using a SpecificFinder Method
A SpecificFinder method returns a single entity instance, where the identifier field value (or values) of the entity
instance matches the arguments supplied to the method. SpecificFinder methods are often referred to as Read
Item operations. To retrieve a machine with a specific identifier, we call the F indSpecific method on the IEntity
instance that represents machines, as shown by the following code example. Note that we must package the
identifier value in an Identity object before we pass it to the F indSpecific method.
C#
private IEntityInstance GetBdcEntityInstance(int identifier, string entityName)
{
//Create an identifier object to store the identifier value
Identity id = new Identity(identifier);
Generated from CHM, not final book. Will be superseded in the future. Page 312](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-312-320.jpg)




![XML
<Method Name="GetPartsForMachine" DefaultDisplayName="Get Parts For Machine">
<Properties>
<Property Name="BackEndObject" Type="System.String">GetPartsByMachineID</Property>
<Property Name="BackEndObjectType" Type="System.String">SqlServerRoutine</Property>
<Property Name="RdbCommandText"
Type="System.String">[dbo].[GetPartsByMachineID]</Property>
<Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data,
Version=2.0.0.0, Culture=neutral,
PublicKeyToken=b77a5c561934e089">StoredProcedure</Property>
<Property Name="Schema" Type="System.String">dbo</Property>
</Properties>
7. After the properties, specify the input and return parameter values in the Parameters element for the
method, as shown in the following example. The Parameters element is a child of the <Method> tag.
XML
<Parameters>
<Parameter Direction="In" Name="@machineId">
<TypeDescriptor TypeName="System.Nullable`1[[System.Int32, mscorlib, Version=2.0.0.0,
Culture=neutral, PublicKeyToken=b77a5c561934e089]]" IdentifierName="Id"
IdentifierEntityName="Machines"
IdentifierEntityNamespace="DataModels.ExternalData.PartsManagement" Name="@machineId">
<DefaultValues>
<DefaultValue MethodInstanceName="GetPartsByMachineID"
Type="System.Int32">1</DefaultValue>
</DefaultValues>
</TypeDescriptor>
</Parameter>
<Parameter Direction="Return" Name="GetPartsByMachineID">
<TypeDescriptor TypeName="System.Data.IDataReader, System.Data, Version=2.0.0.0,
Culture=neutral, PublicKeyToken=b77a5c561934e089" IsCollection="true"
Name="GetPartsByMachineID">
<TypeDescriptors>
<TypeDescriptor TypeName="System.Data.IDataRecord, System.Data, Version=2.0.0.0,
Culture=neutral, PublicKeyToken=b77a5c561934e089" Name="GetPartsByMachineIDElement">
<TypeDescriptors>
<TypeDescriptor TypeName="System.String" IdentifierName="SKU" Name="SKU">
<Properties>
<Property Name="Size" Type="System.Int32">255</Property>
</Properties>
<Interpretation>
<NormalizeString FromLOB="NormalizeToNull" ToLOB="NormalizeToEmptyString"
/>
</Interpretation>
</TypeDescriptor>
<TypeDescriptor TypeName="System.String" Name="Name">
<Properties>
<Property Name="ShowInPicker" Type="System.Boolean" >true</Property>
<Property Name="Size" Type="System.Int32" >255</Property>
</Properties>
<Interpretation>
<NormalizeString FromLOB="NormalizeToNull" ToLOB="NormalizeToNull" />
</Interpretation>
</TypeDescriptor>
<TypeDescriptor TypeName="System.String" Name="Description">
<Properties>
<Property Name="Size" Type="System.Int32" >255</Property>
</Properties>
<Interpretation>
<NormalizeString FromLOB="NormalizeToNull" ToLOB="NormalizeToNull" />
</Interpretation>
</TypeDescriptor>
</TypeDescriptors>
</TypeDescriptor>
Generated from CHM, not final book. Will be superseded in the future. Page 317](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-317-320.jpg)









![the ContentTypes collection for the Web, as shown in the following example.
C#
public static readonly SPContentTypeId myContentTypeId
= new SPContentTypeId("0x010100FA0963FA69A646AA916D2E41284FC9D9");
SPContentType myContentType = web.ContentTypes[myContentTypeId];
if (myContentType == null)
{
myContentType = new SPContentType(myContentTypeId,
web.ContentTypes, "My Content Type");
web.ContentTypes.Add(myContentType);
}
2. Retrieve the site column(s) created in step 1 from the Av ailableF ields collection of the Web. Add the
field to the content type by creating a SPFieldLink instance for the field, and then adding the field link to
the content type, as shown in the following example. Repeat this procedure for each column that you want
to add to your content type.
C#
SPField field = web.AvailableFields[MyFieldId];
SPFieldLink fieldLink = new SPFieldLink(field);
if (myContentType.FieldLinks[fieldLink.Id] == null)
{
myContentType.FieldLinks.Add(fieldLink);
}
3. C all the Update method on the new content type, as shown in the next example. Specify a parameter
value of true if you want to push down the changes to content types that inherit from the new content
type. For example, specify true if you are adding a column to a site content type that is already used in
lists.
C#
myContentType.Update(true);
Generated from CHM, not final book. Will be superseded in the future. Page 327](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-327-320.jpg)
![How to: Configure Business Data Web Parts to
Navigate ECT Associations
Overview
This how-to topic explains how to use Business Data Web Parts to navigate associations between external content
types (EC Ts).
Note:
Note: The how-totopic assumes that you have already created at least two EC Ts and configured associations
between them. For an explanation of how to configure associations between EC Ts, see How to: C onfigure an
Association Navigator by Using a Stored Procedure.
To use the Business Data Web Parts, you must be running Microsoft® SharePoint® Server 2010 Enterprise
edition.
This how-to topic uses two associated EC Ts—Vendors and VendorTransactions—to illustrate the process.
These EC Ts represent the corresponding tables in a vendor management database. The VendorTransactions
EC T includes an association that links the VendorID column in the VendorTransactions table to the ID column
in the Vendors table. The script required to create the database is contained in the following example.
SQL
CREATE TABLE [dbo].[Vendors](
[Id] [int] IDENTITY(1,1) NOT NULL,
[Name] [varchar](50) NULL,
[Address] [varchar](50) NULL,
[City] [varchar](50) NULL,
[State] [varchar](50) NULL,
[ZipCode] [varchar](50) NULL,
[Country] [varchar](50) NULL,
[Telephone] [varchar](50) NULL,
[Industry] [varchar](50) NULL,
[AccountsPayable] [bigint] NULL,
CONSTRAINT [PK_Clients] PRIMARY KEY CLUSTERED
(
[Id] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[VendorTransactions](
[ID] [int] IDENTITY(1,1) NOT NULL,
[VendorID] [int] NOT NULL,
[TransactionTypeId] [int] NOT NULL,
[Notes] [varchar](max) NULL,
[TransactionDate] [datetime] NULL,
[Amount] [money] NULL,
CONSTRAINT [PK_ClientActivity] PRIMARY KEY CLUSTERED
(
[ID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[VendorTransactions]
WITH CHECK ADD CONSTRAINT [FK_VendorTransactions_Vendors] FOREIGN KEY([VendorID])
REFERENCES [dbo].[Vendors] ([Id])
GO
ALTER TABLE [dbo].[VendorTransactions] CHECK CONSTRAINT [FK_VendorTransactions_Vendors]
GO
Summary of Steps
Generated from CHM, not final book. Will be superseded in the future. Page 328](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-328-320.jpg)








![How to: Programmatically Set the Delete Behavior on a
Lookup Field
Overview
Microsoft® SharePoint® Server 2010 lets you enforce a delete behavior between related lists. You can cascade
deletions, so that if a user deletes an item from one list, child items in a related list are also deleted. You can also
restrict deletions, so that users are prevented from deleting items in one list that are referenced by items in
another list. This how-to topic shows you how to programmatically define the delete behavior between related
lists.
For a practical example of programmatically defining the delete behavior between related lists, see Reference
Implementation: SharePoint List Data Models.
Note:
Note: This how-to topic assumes that you have created a project in Microsoft Visual Studio® 2010 by using the
Empty SharePoint Project template and that the project is a Farm Solution. This topic also assumes that you
have already created a feature that deploys a list instance with a lookup.
Summary of Steps
This procedure creates a feature receiver that programmatically sets the delete behavior on the lookup field. This
how-to topic includes the following steps:
Step 1: Create a F eature Receiv er. In this step, you create the feature receiver on the feature that
deploys a list instance containing a lookup column.
Step 2: Configure the Receiv er to Restrict Deletions. In this example, you set the delete behavior to
restrict deletions, which prevents users from deleting items from related lists that are referenced by the
lookup column. You could use the same approach to set the delete behavior to cascade deletions to the
related list.
Step 1: Create a Feature Receiver
To create a feature receiver that programmatically sets the delete behavior on a lookup field
1. In the Solution Explorer window, right-click the feature that deploys the list instance containing the lookup
column, and then click Add Event Receiver.
2. Open the corresponding <FeatureName>.EventReceiver.cs file that is generated.
3. Add the following method to the class.
C#
private string GetListUrl(string webRelativeUrl, string listUrl)
{
if (webRelativeUrl[webRelativeUrl.Length - 1] != '/') return
(webRelativeUrl + '/' + listUrl);
else return (webRelativeUrl + listUrl);
}
Note:
Note: This method accepts two arguments. The webRelativeUrl argument is the SPWeb.ServerRelativeUrl
property. The listUrl argument is the relative URL to the list.
Essentially this method ensures that the relative URL to the list is correct, regardless of whether the SPWeb
object represents a root site or a sub-site.
This method is called by other methods in the event receiver.
Step 2: Configure the Receiver to Restrict Deletions
1. Add the following method to the class that you created in step 1.
C#
private void RestrictDeleteOnLookupField(SPWeb web, string listUrl, Guid fieldGuid)
{
SPList list = web.GetList(GetListUrl(web.ServerRelativeUrl, listUrl));
Generated from CHM, not final book. Will be superseded in the future. Page 337](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-337-320.jpg)
![SPField field = list.Fields[fieldGuid];
SPFieldLookup fieldLookup = (SPFieldLookup)field;
fieldLookup.Indexed = true;
fieldLookup.RelationshipDeleteBehavior =
SPRelationshipDeleteBehavior.Restrict;
fieldLookup.Update();
}
Note:
Note: This method accepts three arguments. The Web argument is the SPWeb where the list resides. The
listUrl argument is the relative URL to the list that contains the lookup column. The fieldGuid argument
represents the ID of the lookup field to set the delete behavior on.
This method sets the delete behavior for a lookup field to SPRelationshipDeleteBehavior.Restrict. This
value turns on the restricted delete behavior for the lookup column and the lists it relates to. You could also set
the delete behavior to SPRelationshipDeleteBehavior.Cascade.
This method is called by other methods in the event receiver.
2. Remove the comment from the F eatureActivated method in the class.
3. Add the following code to the FeatureActiv ated method.
C#
try
{
SPSite thisSite = properties.Feature.Parent as SPSite;
SPWeb rootWeb = thisSite.RootWeb;
RestrictDeleteOnLookupField(rootWeb,
<ListUrl>,
<LookupFieldGUID>);
}
catch (Exception e)
{
System.Diagnostics.Trace.WriteLine(e.ToString());
}
Note:
Note: <ListUrl> is a placeholder for the relative URL to the list that contains the lookup column. <
LookupFieldGUID> is the ID for the lookup field on which to set the delete behavior.
Generated from CHM, not final book. Will be superseded in the future. Page 338](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-338-320.jpg)
![How to: Manually Generate LINQ to SharePoint Entity
Classes by Using SPMetal
Overview
Microsoft® SharePoint® 2010 gives developers the ability to use Language Integrated Query (LINQ) with
SharePoint lists. This allows developers to use strongly-typed entities to create, edit, view, and delete SharePoint
list and library data on a SharePoint site. To use LINQ with SharePoint, you must first create entity classes to
represent the lists on your SharePoint site. SharePoint 2010 includes a command-line tool named SPMetal that
you can use to automatically generate the data context and entity classes for the SharePoint site
Note:
Note: For an example of a project that uses LINQ to SharePoint classes that were generated by SPMetal, see
the SharePoint List Reference Implementation.
Summary of Steps
This how-to topic includes the following steps:
Step 1: Use SPMetal to Manually Create the SPLinq DataContext and Entity Class. In this step, you
use SPMetal to create the data context and entity class that LINQ will use to connect to your SharePoint site.
Step 2: Add the Data Context and Entity Class to Your Project. In this step, you use the Microsoft®
Visual Studio® development system to add the data context and entity class that you created in step 1 to
your project.
Step 1: Use SPMetal to Manually Create the SPLinq Data Context and Entity
Class
To create an SPLinq DataContext for an existing SharePoint site
1. Open a C ommand Prompt window.
2. C hange the current path to the SPMetal.exe file location (it is usually [DRIVE:]Program FilesC ommon
FilesMicrosoft Sharedweb server extensions14BIN).
3. Type the following command:
SPMetal /web:http://MyServ er/SiteName /code:SiteName.cs
where:
http://MyServer/SiteName is the fully-qualified URL of your site.
SiteName.cs is the output file for the generated code.
The following illustration is an example of this command.
Generated from CHM, not final book. Will be superseded in the future. Page 339](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-339-320.jpg)


![Before you can use the BC S to query an external system, you must connect to the BDC service, return the
metadata catalog, and then return the LobSystemInstance object.
The following line of code demonstrates how to connect to the BDC service application for the current server
farm.
bdcService = SPFarm.Local.Services.GetValue<BdcService>();
The following line of code demonstrates how the BDC service is used to connect to the metadata catalog.
catalog = bdcService.GetDatabaseBackedMetadataCatalog(SPServiceContext.Current);
The following line of code demonstrates how the lobSystemInstance object is retrieved from the metadata
catalog.
lobSystemInstance =
catalog.GetLobSystem("PartsManagement").GetLobSystemInstances()["ContactsSystem"];
Note:
Note: The Constants.LobSystemName string represents the name of the LobSystem to which you will be
connected.
Generated from CHM, not final book. Will be superseded in the future. Page 342](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-342-320.jpg)




























![}
private void ThreadCallback(object s)
{
var context = (ClientContext)s;
context.ExecuteQuery();
this.Dispatcher.BeginInvoke(DisplayParts);
}
In other words, if you don't use the ExecuteQueryAsync method, you must manually implement the
asynchronous logic. Both methods are functionally correct. However, the ExecuteQueryAsync method makes
your code easier to understand and is preferred from a stylistic perspective. The ExecuteQuery method is
useful in applications where a synchronous execution model is appropriate, such as a command-line application or
a PowerShell extension.
Accessing Binary Data
In some cases, you may want to either upload or download binary files, such as images or documents, from your
Rich Interactive Application (RIA) or managed client. You can use the C SOM to access binary data like
documents; however, there are varying levels of support, depending on the C SOM API that you use.
The managed version of the C SOM supports both binary file upload and download using F ile.OpenBinaryDirect
and F ile.SaveBinaryDirect. The following example shows how to retrieve and save a picture using these APIs
from a Windows Presentation Foundation (WPF) client. In this case, the method DisplayPix retrieves all the items
in the Pix picture library and displays them to a WPF control in the call to AddPix. Sav ePix saves the file stream
provided as an image to the Pix library, using the file name for the title.
C#
private void DisplayPix()
{
List pixList = clientContext.Web.Lists.GetByTitle("Pix");
CamlQuery camlQuery = new CamlQuery();
camlQuery.ViewXml = "<View/>";
pictureItems = pixList.GetItems(camlQuery);
clientContext.Load(pictureItems);
clientContext.ExecuteQuery();
foreach (ListItem pictureItem in pictureItems)
{
string fileRef = pictureItem["FileRef"].ToString();
FileInformation fileInfo = File.OpenBinaryDirect(clientContext, fileRef);
AddPix(fileInfo.Stream);
}
}
private void SavePix(string filename, Stream stream)
{
string url = "/sites/sharepointlist/Pix/" + filename;
File.SaveBinaryDirect(clientContext, url, stream, true);
}
For a detailed example of using this API with the managed C LOM, see Using the SharePoint Foundation 2010
Managed C lient Object Model with the Open XML SDK 2.0 on MSDN.
The Silverlight C SOM supports opening binary files from SharePoint with F ile.OpenBinaryDirect using the same
syntax as the managed C SOM but does not support saving binary files. The European C omputer Manufacturers
Association (EC MA) script (JavaScript) C SOM does not support either saving or reading binary files from
SharePoint.
Generated from CHM, not final book. Will be superseded in the future. Page 371](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-371-320.jpg)










































![$.each(noInventoryPartResults,
function bindNoInventory(index, partWithNoInventoryLocation) {
var bindingViewModel =
{
Id: partWithNoInventoryLocation.Id,
SKU: partWithNoInventoryLocation.SKU,
Title: partWithNoInventoryLocation.Title,
LocationBin: "unassigned",
InventoryQuantity: ""
};
bindingViewsModels.push(bindingViewModel);
});
buildTable(bindingViewsModels);
});
}
The mergePartsWithInv entoryLocations function first submits a new REST query to retrieve all the inventory
location instances that reference a part with the specified SKU. The function then performs the logical equivalent
of a left outer join between parts and inventory locations. Parts and inventory locations are merged into a
collection of bindingViewModel objects, which are essentially view projections that include selected fields from
both entities. Parts with no associated inventory locations are added to the collection with a LocationBin value of
unassigned and an empty Inv entoryQuantity value. Finally, the function calls the buildTable function, passing
in the bindingViewModels collection as an argument.
The buildTable function formats the collection of view models into an HTML table, and then inserts the table into
the C ontentDiv element on the web page.
Jav aScript
function buildTable(viewModels) {
returnTable =
'<table style="border: solid 1px black">
<tr style="font-weight:bold;font-style:underline">
<td>ID</td>
<td>Part Name</td>
<td>Part SKU</td>
<td>Bin #</td>
<td>Quantity</td>
<td>Inventory</td>
<td>Suppliers</td>
</tr>';
for (var i = 0; i < viewModels.length; i++) {
var item = viewModels[i];
buildRow(item);
}
returnTable = returnTable + '</table>';
$('#ContentDiv').html(returnTable);
}
The buildRow helper function converts each view model instance into a table row. As you can see, the
Inv entory and Suppliers fields are rendered as hyperlinks that call JavaScript functions when clicked.
Jav aScript
function buildRow(item) {
var sku = item["SKU"];
var partTitle = item["Title"];
var partId = item["Id"];
var bin = item["LocationBin"];
var quantity = item["InventoryQuantity"];
//id needs to be 0 if it doesn't exist
var id = '0';
if (item["InventoryLocationId"] !== undefined) {
Generated from CHM, not final book. Will be superseded in the future. Page 414](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-414-320.jpg)
![id = item["InventoryLocationId"]
}
returnTable = returnTable +
'<tr><td>' + id + '</td><td>' +
partTitle + '</td><td>' +
sku + '</td><td>' +
bin + '</td><td style="text-align:center">' +
quantity + '</td><td>
<a href="javascript:showLocation('' + id + '','' +
partId + '');">| Edit Inventory |</a></td><td>
<a href="javascript:showSuppliers('' +
partId + '');"> Suppliers |</a></td></tr>';
}
Updating Data with Ajax and REST
The Ajax REST interface in the C lient RI allows users to update inventory locations and quantities. Making updates
from JavaScript is a slightly more complex process than making updates using the Silverlight object model. When
the user clicks an Edit Inventory link in the UI, a modal dialog is launched that allows users to edit the bin number
and the quantity for the selected part.
The Inventory Locations dialog
When the user clicks Save, the savePartLocation method is called.
C#
var savePartLocation = function () {
var locationId = $('#hidLocationId').val();
var url = '/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations';
var beforeSendFunction;
var inventoryLocationModifications = {};
if (locationId == '0') {
//Insert a new Inventory Location
inventoryLocationModifications.PartId = $('#hidPartId').val();
beforeSendFunction = function () { };
Generated from CHM, not final book. Will be superseded in the future. Page 415](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-415-320.jpg)



![ShowField='PartsDescription' />
</ProjectedFields>
<Joins>
<Join Type='LEFT' ListAlias='PartLookup'>
<!--List Name: Parts-->
<Eq>
<FieldRef Name='PartLookup' RefType='ID' />
<FieldRef List='PartLookup' Name='ID' />
</Eq>
</Join>
</Joins>
</View>";
partListItems = partsList.GetItems(camlQueryPartsList);
inventoryLocationListItems =
inventoryLocationsList.GetItems(camlQueryInvLocationList);
clientContext.Load(partListItems);
clientContext.Load(inventoryLocationListItems);
clientContext.ExecuteQueryAsync(onQuerySucceeded, onQueryFailed);
Note:
partListItems and inv entoryLocationListItems are local variables of type ListItemCollection. The
clientContext object is instantiated with the site URL in the view model constructor.
In this example, the following actions are batched on the client:
The Parts list is retrieved by title.
The Inventory Locations list is retrieved by title.
A C AML query is executed against the Parts list.
A C AML query is executed against the Inventory Locations list. This query uses a left outer join across the
Inventory Locations list and the Parts list, and returns a view projection.
The results of both C AML queries are loaded into the client context object as list item collections.
However, none of these actions are sent to the server and executed until the call to ExecuteQueryAsync is
made at the bottom of the code example. When the server responds to the batched request, the partListItems
and inv entoryLocationListItems collections are populated with the query results. At this point, we can parse
these collections to update the user interface, as shown by the following code example.
C#
private void DisplayParts()
{
List<int> inventoryPartResults = new List<int>();
//Populate BindingViewsModels with Parts with InventoryLocations
foreach (ListItem inventoryLocationListItem in inventoryLocationListItems)
{
PartInventory view = new PartInventory();
view.InventoryItem.Id =
int.Parse(inventoryLocationListItem["ID"].ToString());
view.InventoryItem.Quantity =
int.Parse(inventoryLocationListItem["Quantity"].ToString());
view.InventoryItem.BinNumber =
inventoryLocationListItem["BinNumber"].ToString();
view.Part.SKU = ((FieldLookupValue)
inventoryLocationListItem["PartLookupSKU"]).LookupValue;
view.Part.Title = ((FieldLookupValue)
inventoryLocationListItem["PartLookupTitle"]).LookupValue;
view.Part.Id = ((FieldLookupValue)
inventoryLocationListItem["PartLookup"]).LookupId;
view.Part.Description = ((FieldLookupValue)
inventoryLocationListItem["PartLookupDescription"]).LookupValue;
Parts.Add(view);
inventoryPartResults.Add(view.Part.Id);
Generated from CHM, not final book. Will be superseded in the future. Page 419](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-419-320.jpg)

![throw Operation.Error;
}
if (Operation is QueryOperationResponse<InventoryLocationsItem>)
{
//Process Results
foreach (InventoryLocationsItem location in Operation as
QueryOperationResponse<InventoryLocationsItem>)
{
PartInventory partInventory = new PartInventory();
partInventory.Part = location.Part;
partInventory.InventoryItem = location;
Parts.Add(partInventory);
InventoryPartResults.Add(location.Part);
}
}
if (Operation is QueryOperationResponse<PartsItem>)
{
//Process Results
foreach (PartsItem part in Operation as
QueryOperationResponse<PartsItem>)
{
AllPartResults.Add(part);
}
}
}
foreach (var allPartResult in AllPartResults
.Where(allPartResult => !InventoryPartResults.Contains(allPartResult)))
{
NoInventoryPartResults.Add(allPartResult);
}
foreach (var part in NoInventoryPartResults)
{
PartInventory partInventory = new PartInventory();
partInventory.Part = part;
partInventory.InventoryItem = null;
Parts.Add(partInventory);
}
});
}
In this case, the callback method iterates through a set of query responses. It uses the type of each query
response to make a decision on how to process the result set.
Update Batching
When you use the C SOM or the REST interface, the context object manages change tracking for you. The
Client.CSOM.Silverlight and Client.REST.Silverlight projects take advantage of this behavior to support the
batching of updates. The following code shows a list update using the C SOM.
C#
public void UpdateInventoryLocation()
{
List inventoryLocationsList =
clientContext.Web.Lists.GetByTitle("Inventory Locations");
ListItem inventoryLocation = null;
inventoryLocation =
inventoryLocationsList.GetItemById(currentItem.InventoryItem.Id);
inventoryLocation["BinNumber"] = currentItem.InventoryItem.BinNumber;
inventoryLocation["Quantity"] = currentItem.InventoryItem.Quantity;
inventoryLocation.Update();
}
Generated from CHM, not final book. Will be superseded in the future. Page 421](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-421-320.jpg)







![How to: Construct and Process Batch Queries by Using
REST
Overview
This topic shows you how to submit batched queries to the Microsoft® SharePoint® Foundation representational
state transfer (REST) interface from a Microsoft Silverlight® application, and how to process the response from
the service.
Note:
This how-to topic assumes that you have an existing Microsoft Visual Studio® development system solution
that contains a Silverlight project. It also assumes that you have added a reference to the SharePoint
Foundation REST interface, as described in How to: C reate a REST Service Proxy.
This topic uses the Team Discussion list as an example. The Team Discussion list is created by default on
SharePoint 2010 team sites. If you created your SharePoint site from a different site definition, this list may not
be available.
Summary of Steps
This topic describes the following steps:
Step 1: Create Multiple REST Queries. In this step, you use your service reference to construct multiple
REST queries that will be sent to the server in a single batch.
Step 2: Create the Delegate Method and Process the Results. In this step you create the delegate
method that will process the batch results.
Step 1: Create Multiple REST Queries
This procedure creates several queries against the Team Discussion list, and submits them to the REST interface
as a batched request.
Note:
Typically, you add the code examples listed below to the code-behind file for your Silverlight control. In this
example, we use the click event handler of a button to create and submit the query.
To create and submit a batched request
1. Add a using statement that points to the REST service reference. Use the following format.
[Your.Silverlight.Project].[YourService.Namespace]
In the following example, Client.SilverlightSample is the Silverlight project namespace and
Sample.ServiceReference is the service namespace.
C#
using Client.SilverlightSample.Sample.ServiceReference;
2. Use the default constructor to instantiate the data context entity for the service, as shown in the following
example. The name of your data context class will take the form <sitename>DataContext, where
<sitename> is the name of your SharePoint site.
C#
private void button1_Click(object sender, RoutedEventArgs e)
{
DataDataContext context = new DataDataContext();
}
3. C reate your query objects. The following example creates three queries against the Team Discussion list.
C#
// Get anything with the word 'Business' in the Body
var query1 = context.TeamDiscussion
.Where(p => p.Body.Contains("Business"));
Generated from CHM, not final book. Will be superseded in the future. Page 429](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-429-320.jpg)


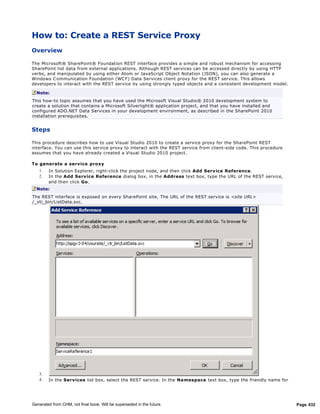




![</File>
</Module>
</Elements>
12. In the Elements.xml file, in the F ile element, add the following XML. This adds a Silverlight Web Part and
configures it to host your Silverlight control.
XML
<AllUsersWebPart WebPartOrder="1"
WebPartZoneID="Left"
ID="SilverlightExternalService">
<![CDATA[
<webParts>
<webPart xmlns="http://schemas.microsoft.com/WebPart/v3">
<metaData>
<type name="Microsoft.SharePoint.WebPartPages.SilverlightWebPart,
Microsoft.SharePoint, Version=14.0.0.0,
Culture=neutral, PublicKeyToken=71e9bce111e9429c" />
<importErrorMessage>Cannot import this WebPart.
</importErrorMessage>
</metaData>
<data>
<properties>
<property name="HelpUrl" type="string" />
<property name="AllowClose" type="bool">True</property>
<property name="ExportMode" type="exportmode">All</property>
<property name="Hidden" type="bool">False</property>
<property name="AllowEdit" type="bool">True</property>
<property name="Direction" type="direction">NotSet</property>
<property name="TitleIconImageUrl" type="string" />
<property name="AllowConnect" type="bool">True</property>
<property name="HelpMode" type="helpmode">Modal</property>
<property name="CustomProperties" type="string" null="true" />
<property name="AllowHide" type="bool">True</property>
<property name="Description" type="string">A web part to display
a Silverlight application.</property>
<property name="CatalogIconImageUrl" type="string" />
<property name="MinRuntimeVersion" type="string" null="true" />
<property name="ApplicationXml" type="string" />
<property name="AllowMinimize" type="bool">True</property>
<property name="AllowZoneChange" type="bool">True</property>
<property name="CustomInitParameters" type="string" null="true"/>
<property name="Height" type="unit">650px</property>
<property name="ChromeType" type="chrometype">Default</property>
<property name="Width" type="unit">800px</property>
<property name="Title" type="string">Silverlight Web
Part</property>
<property name="ChromeState" type="chromestate">Normal</property>
<property name="TitleUrl" type="string" />
<property name="Url" type="string">
~site/_catalogs/masterpage/SilverlightApp.xap</property>
<property name="WindowlessMode" type="bool">True</property>
</properties>
</data>
</webPart>
</webParts> ]]>
</AllUsersWebPart>
Note:
Pay particular attention to the Url property, which must point to the location of your .xap file in the master
page gallery. Make sure that the Height and Width properties match the dimensions of your Silverlight
application.
Step 3: Enable Silverlight Debugging
Generated from CHM, not final book. Will be superseded in the future. Page 438](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-438-320.jpg)
















![Using a Feature Receiver to Register a Type Mapping
Typical Goals
When you write a class that implements a particular interface, you can use the SharePoint Service Locator to
make your class available to callers who require an implementation of that interface. In this example, suppose
you have created a new implementation of the IPricingRepository interface named PriceRepUltimate. You
have also created a SharePoint feature to deploy the new component to a SharePoint environment.
Solution
In most cases, you should create a feature receiver class and override the F eatureActivated method to
register a new type mapping with the SharePoint Service Locator. By registering the type mapping within the
FeatureActivated method, you ensure that the type mapping is added when, and only when, your component is
made available to the SharePoint environment.
For more information on how to register type mappings, including how to create named type mappings and how
to specify that types should be instantiated as singleton services, see Adding Type Mappings.
For more information about using feature receivers, see Using Features on MSDN.
Registering a Service in a Feature Receiver Class
The following code shows how to use the RegisterTypeMapping method to retrieve the service instance. This
example assumes that you have added references to the Microsoft.Practices.SharePoint.Common.dll and
Microsoft.Practices.Serv iceLocation.dll assemblies.
C#
using Microsoft.SharePoint;
using Microsoft.Practices.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.ServiceLocation;
[Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")]
public class MyFeatureReceiver : SPFeatureReceiver
{
public override void FeatureActivated(SPFeatureReceiverProperties properties)
{
// Get the ServiceLocatorConfig service from the service locator.
IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent();
IServiceLocatorConfig typeMappings =
serviceLocator.GetInstance<IServiceLocatorConfig>();
typeMappings.RegisterTypeMapping<IPricingRepository, PriceRepUltimate>();
}
}
The F eatureInstalled method registers the PriceRepUltimate class as the configured implementation of the
IPricingRepository interface.
Usage Notes
Typically you should unregister the type mapping when the feature is uninstalled, because the assembly that
includes the implementation is made unavailable at this point. You can include this functionality in your
feature receiver class by overriding the F eatureDeactivating method, as illustrated by the following code.
public override void FeatureDeactivating(SPFeatureReceiverProperties properties)
{
// Get the ServiceLocatorConfig service from the service locator.
IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent();
IServiceLocatorConfig typeMappings =
Generated from CHM, not final book. Will be superseded in the future. Page 456](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-456-320.jpg)



![this.Messages.Add(message);
this.Message = message;
this.Category = category;
this.EventID = eventId;
this.Severity = severity;
}
}
class MockEventLogger : IEventLogLogger
{
public List<string> Messages = new List<string>();
public string Message;
public string Category;
public int EventID;
public EventLogEntryType Severity;
public void Log(string message, int eventId, EventLogEntryType severity,
string category)
{
this.Messages.Add(message);
this.Message = message;
this.Category = category;
this.EventID = eventId;
this.Severity = severity;
}
}
Configuring the Unit Test
At this point, we've created a testable SharePointLogger class and we've created some mock implementations
of ITraceLogger and IEventLogLogger for use in unit tests. The final stage is to create the test class itself.
The test method consists of three key sections:
Arrange. In this section we set up the SharePoint Service Locator. We replace the default current service
locator with a new instance of the Activ atingServiceLocator class. We register our mock classes as the
default implementations of ITraceLogger and IEventLogLogger. Finally we use the service locator to
instantiate our mock classes.
Act. In this section we perform the action that we want to test. We create a new instance of
SharePointLogger and we call the TraceToDeveloper method.
Assert. In this section we use various assert statements to verify that the SharePointLogger class
behaved as expected.
The following code example shows the relevant parts of the test class.
C#
[TestClass]
public class SharePointLoggerFixture
{
private MockTraceLogger traceLogger;
private MockEventLogger eventLogger;
[TestMethod]
public void TraceLogsOnlyToTraceLog()
{
//Arrange
ActivatingServiceLocator replaceLocator = new ActivatingServiceLocator();
SharePointServiceLocator.ReplaceCurrentServiceLocator(replaceLocator);
replaceLocator.RegisterTypeMapping<ITraceLogger, MockTraceLogger>
(InstantiationType.AsSingleton);
replaceLocator.RegisterTypeMapping<IEventLogLogger, MockEventLogger>
(InstantiationType.AsSingleton);
Generated from CHM, not final book. Will be superseded in the future. Page 460](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-460-320.jpg)

























![Using a Feature Receiver to Create a Configuration
Setting
Typical Goals
When you deploy an application to a SharePoint environment, you will often need to ensure that configuration
settings are both specified and available before your application is first run. For example, suppose that you have
developed a Web Part that provides a map view of customer locations, based on geo-coded data from a
SharePoint list. Before your Web Part can do its job, it needs to know where to find the customer location list.
Solution
The Application Setting Manager exposes an interface named IConfigManager. This interface defines methods
that you can use to add and update application settings. To ensure that the required settings are available before
the Web Part is added to a page, you can use a feature receiver class to add the configuration settings when the
Web Part feature is activated.
Using the IConfigManager Interface to Add Application Settings
The following code shows how to use the IConfigManager interface to add an application setting from within a
feature receiver class.
This example assumes that you have added a reference to the Microsoft.Practices.SharePoint.Common.dll
assembly, the Microsoft.Practices.ServiceLocation.dll assembly, and the Microsoft.SharePoint.dll
assembly.
C#
using Microsoft.SharePoint;
using Microsoft.Practices.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.Configuration;
[Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")]
public class MyFeatureReceiver : SPFeatureReceiver
{
public override void FeatureActivated(SPFeatureReceiverProperties properties)
{
IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent();
IConfigManager configManager =
serviceLocator.GetInstance<IConfigManager>();
SPSite mySite = properties.Feature.Parent as SPSite;
if(mySite != null)
{
configManager.SetWeb(mySite.RootWeb);
IPropertyBag bag = configManager.GetPropertyBag(
ConfigLevel.CurrentSPSite);
configManager.SetInPropertyBag(
"Contoso.Sales.Applications.CustomerLocationsListUrl",
"http://intranet.contoso.com/sites/sales/CustomerLocations",
bag);
}
}
}
Note:
The Parent property of a feature depends on the scope of the feature that is being activated. In this example,
the feature is scoped at the site collection level.
For more information about using the IConfigManager interface to add or update configuration settings, see
Generated from CHM, not final book. Will be superseded in the future. Page 486](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-486-320.jpg)

![Using a Feature Receiver to Remove a Configuration
Setting
Typical Goals
If you regularly use the Application Setting Manager to add and update configuration settings for your SharePoint
applications, you will also want to remove configuration settings that are no longer required. For example, if you
uninstall a Web Part, you should remove any configuration settings that are unique to that Web Part to prevent
your property bags from becoming unwieldy and to reduce the risk of duplicating key names for different
settings.
Solution
The IConfigManager interface defines a method named Remov eKeyFromPropertyBag that enables you to
remove configuration settings. This method takes two arguments: the key as a string and the IPropertyBag
instance from which you want to remove the setting. If you used a feature receiver class to add the configuration
setting when your feature was activated, good practice suggests that you should you use the same feature
receiver class to remove the configuration setting when it is no longer required.
Using the IConfigManager Interface to Remove Configuration Settings
The following code shows how to use the IConfigManager interface to remove a configuration setting from
within a feature receiver class.
This example assumes that you have added a reference to the Microsoft.Practices.SharePoint.Common.dll
assembly, the Microsoft.Practices.ServiceLocation.dll assembly, and the Microsoft.SharePoint.dll
assembly.
C#
using Microsoft.SharePoint;
using Microsoft.Practices.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.Configuration;
[Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")]
public class MyFeatureReceiver : SPFeatureReceiver
{
public override void FeatureDeactivating(SPFeatureReceiverProperties
properties)
{
IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent();
IConfigManager configManager =
serviceLocator.GetInstance<IConfigManager>();
SPSite mySite = properties.Feature.Parent as SPSite;
if(mySite != null)
{
configManager.SetWeb(mySite.RootWeb);
IPropertyBag bag = configManager.GetPropertyBag(
ConfigLevel.CurrentSPSite);
configManager.RemoveKeyFromPropertyBag(
"Contoso.Sales.Applications.CustomerLocationsListUrl", bag);
}
}
}
Note:
The Parent property of a feature depends on the scope of the feature that is being activated. In this example,
the feature is scoped at the site collection level.
Generated from CHM, not final book. Will be superseded in the future. Page 488](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-488-320.jpg)

![Reading Configuration Data in a SharePoint Web Part
Typical Goals
Your application may need to retrieve configuration settings at various points in its execution. To determine where
your application should be deployed, a deployment package might need to retrieve global configuration settings
as part of the installation process. A Web Part or an application page might need to retrieve configuration settings
as part of the page load life cycle, or in other words, whenever a user requests the page. If your application
contains more complex logic, it might need to retrieve configuration settings regularly in response to user
interface events.
In any of these situations, it is useful to have a consistent, type-safe approach to the retrieval of configuration
data.
Solution
This scenario continues to use the example of a Web Part that provides a map view of customer locations, based
on geo-coded data from a SharePoint list. Every time the Web Part loads, it must retrieve the URL of the
customer location list from the configuration settings for the SharePoint environment.
The IHierarchicalConfig interface defines a generic method named GetByKey that you can use to retrieve
configuration settings from any level of the SharePoint hierarchy. When you use the GetByKey method, the
HierarchicalConfig class will first look for the setting in the current SPWeb object. If the specified key cannot
be found at the SPWeb level, the HierarchicalConfig class will next look in the root web of the current SPSite
object (as the SPSite object does not include a property bag), then in the current SPWebApplication, and
finally in the SPF arm object.
Using the GetByKey Method
The following code example shows how to use the IHierarchicalConfig interface to retrieve a configuration
setting from within a Web Part class.
This example assumes that you have added a reference to the Microsoft.Practices.SharePoint.Common.dll
assembly, the Microsoft.Practices.ServiceLocation.dll assembly, the Microsoft.SharePoint.dll assembly,
and the System.Web.dll assembly.
C#
using System.Web;
using Microsoft.SharePoint;
using Microsoft.Practices.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.Configuration;
[Guid("70ACDCFF-A253-4133-9064-25DB28F17514")]
public class CustomerLocationsWebPart : System.Web.UI.WebControls.WebParts.WebPart
{
protected override void OnLoad(EventArgs e)
{
IServiceLocator serviceLocator =
SharePointServiceLocator.GetCurrent();
IHierarchicalConfig config =
serviceLocator.GetInstance<IHierarchicalConfig>();
string locationsListUrl;
if(config.ContainsKey("Contoso.Sales.CustomerLocationsListUrl"))
{
locationsListUrl = config.GetByKey<string>
("Contoso.Sales.CustomerLocationsListUrl");
}
}
Generated from CHM, not final book. Will be superseded in the future. Page 490](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-490-320.jpg)

















![If you used the default constructor to create your DiagnosticsAreaCollection object, an
Inv alidOperationException will be thrown if you call the Sav eConfiguration method. This is because the
DiagnosticsAreaCollection needs a reference to the C onfiguration Manager in order to persist areas and
categories as configuration data.
If you attempt to add an area that already exists, an Inv alidOperationException will be thrown. A safer
approach is to check that areas or categories do not already exist before you add them.
C#
foreach (DiagnosticsArea newArea in MyAreas)
{
var existingArea = configuredAreas[newArea.Name];
if (existingArea == null)
{
configuredAreas.Add(newArea);
}
else
{
foreach (DiagnosticsCategory c in newArea.DiagnosticsCategories)
{
var existingCategory = existingArea.DiagnosticsCategories[c.Name];
if (existingCategory == null)
{
existingArea.DiagnosticsCategories.Add(c);
}
}
}
}
When you create a new diagnostic category, you can specify default throttling values for event severity and trace
severity in addition to a category name. For example, if you set the event severity value to Information, any
events in this category will only be reported to the event log if they have a severity value equal to or higher than
Information. The system administrator can change these throttling settings at any time through the C entral
Administration Web site.
C#
DiagnosticsCategory newCategory = new DiagnosticsCategory("Projects",
EventSeverity.Information, TraceSeverity.Medium);
If you do not specify an event severity or a trace severity, by default, the category uses an event severity of
Warning and a trace severity of Medium.
Removing Custom Areas and Categories
The process for removing areas and categories is similar to the process for adding areas and categories. First,
you must construct the DiagnosticsAreaCollection object by using the constructor that takes an argument of
type IConfigManager. Next, use the Remove method to remove individual areas. Finally, call the
SaveConfiguration method to persist your changes.
C#
IConfigManager configMgr =
SharePointServiceLocator.GetCurrent().GetInstance<IConfigManager>();
DiagnosticsAreaCollection configuredAreas = new
DiagnosticsAreaCollection(configMgr);
foreach (DiagnosticsArea area in MyAreas)
{
DiagnosticsArea areaToRemove = configuredAreas[area.Name];
if (areaToRemove != null)
{
configuredAreas.Remove(areaToRemove);
}
}
Generated from CHM, not final book. Will be superseded in the future. Page 508](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-508-320.jpg)
![configuredAreas.SaveConfiguration();
Take care when removing areas, because other users may have added categories for applications that are still
deployed. The safest way to remove your logging configuration is to remove all your own categories, and then if
no categories remain, remove the area.
C#
foreach (DiagnosticsArea area in MyAreas)
{
DiagnosticsArea areaToRemove = configuredAreas[area.Name];
if (areaToRemove != null)
{
foreach (DiagnosticsCategory c in area.DiagnosticsCategories)
{
var existingCat = areaToRemove.DiagnosticsCategories[c.Name];
if (existingCat != null)
{
areaToRemove.DiagnosticsCategories.Remove(existingCat);
}
}
if (areaToRemove.DiagnosticsCategories.Count == 0)
{
configuredAreas.Remove(areaToRemove);
}
}
}
}
Generated from CHM, not final book. Will be superseded in the future. Page 509](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-509-320.jpg)









![Using Feature Receivers to Configure Diagnostic Areas
and Categories
Typical Goals
SharePoint 2010 provides a default set of diagnostic areas and categories that relate to different features and
aspects of the product. Typically, system administrators use these areas and categories to restrict what gets
written to the event log and the trace log. For example, the administrator might choose to allow verbose logging
for categories that are of particular concern, while restricting logging for other areas to only high severity items.
It is strongly recommended that you do not use the built-in areas and categories to log events from your custom
applications. Instead, you should create your own areas and categories to enable system administrators to
manage diagnostic logging from your application alongside the log entries generated by SharePoint itself.
Solution
C reate a farm-scoped feature and add a feature receiver class. Within the feature receiver class, override the
FeatureActivated and FeatureDeactivating methods. Use the DiagnosticsAreaCollection class to create
and register your custom areas and categories.
Note:
Why should you use a farm-scoped feature to configure diagnostic areas and categories for your solution?
Suppose your solution consists of features that are scoped to site collection level or the Web application level.
An administrator can deploy and retract these features to multiple site collections or Web applications across
the server farm. By using a farm-scoped feature to configure areas and categories, you ensure that your
areas and categories are available to any feature after your solution is activated, and that the configured areas
and categories are not removed until the solution is retracted. A farm-scoped feature automatically activates
when the solution is deployed, and it deactivates when the solution is retracted.
After you configure your diagnostic areas and categories, you can use these values in your code when you write
to the event log or the trace log. System administrators can also throttle logging by severity for each of your
areas and categories.
Configuring Diagnostic Areas and Categories
The following code shows an example of how to configure an area and some categories in a feature receiver
class. Suppose you are deploying a Web Part that enables your users to interact with a C ustomer Relationship
Management (C RM) system. This example registers a new area named C RM. The area contains two categories,
LostSale and TransactionError. The feature receiver class is split into three areas for readability.
First, the class includes a helper property to build the collection of areas and categories. This is used both when
the feature is activated and when the feature is deactivated.
C#
using Microsoft.Practices.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.Logging;
[Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")]
public class MyFeatureReceiver : SPFeatureReceiver
{
// This helper property builds a collection of areas and categories.
DiagnosticsAreaCollection _myAreas = null;
DiagnosticsAreaCollection MyAreas
{
get
{
if (_myAreas == null)
{
_myAreas = new DiagnosticsAreaCollection();
DiagnosticsArea crmArea = new DiagnosticsArea("CRM");
Generated from CHM, not final book. Will be superseded in the future. Page 519](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-519-320.jpg)
![crmArea.DiagnosticsCategories.Add(new DiagnosticsCategory(
"LostSale", EventSeverity.Warning, TraceSeverity.Medium));
crmArea.DiagnosticsCategories.Add(new DiagnosticsCategory(
"TransactionError", EventSeverity.Error, TraceSeverity.Medium));
_myAreas.Add(crmArea);
}
return _myAreas;
}
}
Next, the FeatureActiv ated method retrieves the collection of areas and categories and writes the collection to
configuration settings.
// Use the FeatureActivated method to save areas and categories
// to configuration settings.
public override void FeatureActivated(SPFeatureReceiverProperties properties)
{
IConfigManager configMgr =
SharePointServiceLocator.GetCurrent().GetInstance<IConfigManager>();
DiagnosticsAreaCollection configuredAreas =
new DiagnosticsAreaCollection(configMgr);
foreach (DiagnosticsArea newArea in MyAreas)
{
var existingArea = configuredAreas[newArea.Name];
if (existingArea == null)
{
configuredAreas.Add(newArea);
}
else
{
foreach (DiagnosticsCategory c in newArea.DiagnosticsCategories)
{
var existingCategory = existingArea.DiagnosticsCategories[c.Name];
if (existingCategory == null)
{
existingArea.DiagnosticsCategories.Add(c);
}
}
}
}
configuredAreas.SaveConfiguration();
}
Finally, the F eatureDeactiv ating method retrieves the collection of areas and categories and removes them
from the configuration settings.
// Use the FeatureDeactivating method to remove areas and categories
// from configuration settings.
public override void FeatureDeactivating(SPFeatureReceiverProperties properties)
{
IConfigManager configMgr =
SharePointServiceLocator.GetCurrent().GetInstance<IConfigManager>();
DiagnosticsAreaCollection configuredAreas =
new DiagnosticsAreaCollection(configMgr);
foreach (DiagnosticsArea area in MyAreas)
{
Generated from CHM, not final book. Will be superseded in the future. Page 520](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-520-320.jpg)
![DiagnosticsArea areaToRemove = configuredAreas[area.Name];
if (areaToRemove != null)
{
foreach (DiagnosticsCategory c in area.DiagnosticsCategories)
{
var existingCat = areaToRemove.DiagnosticsCategories[c.Name];
if (existingCat != null)
{
areaToRemove.DiagnosticsCategories.Remove(existingCat);
}
}
if (areaToRemove.DiagnosticsCategories.Count == 0)
{
configuredAreas.Remove(areaToRemove);
}
}
}
configuredAreas.SaveConfiguration();
}
}
Note:
In some circumstances, different solutions may create duplicate categories. In the preceding code example,
there is a risk that you will remove a category that is still in use by another application in the
FeatureDeactiv ating method, because any duplicated categories will be removed. To prevent problems with
duplicate categories, you may instead choose to throw an exception if a duplicate category is found during
installation.
For more information about how to manage diagnostic areas and categories, see Managing C ustom Areas and
C ategories.
Registering Event Sources for Diagnostic Areas
When you use the SharePoint Logger to create new diagnostic areas, you must create a corresponding event
source for each diagnostic area on each WFE server in your farm (or on any other server where your code will
execute). This allows you to specify the new diagnostic areas when you write to the Windows event log.
Event sources are defined in the local registry of each computer. Because you must write to the registry to create
new event sources, this procedure requires an account with high privileges. There are two principal approaches
that you can use to register event sources:
You can manually run a batch file or PowerShell script on each WFE server.
You can create a timer job that executes on each WFE server.
The SharePoint Logger provides a convenience method to help register event sources. The static
DiagnosticsAreaEv entSource.EnsureAreasRegisteredAsEventSource method iterates through all the
diagnostic areas in configuration settings, checks to see whether each diagnostic area is already registered as an
event source, and registers a new event source if required. You can call this method from your PowerShell script
or your timer job, as required.
Usage Notes
SharePoint 2010 allows you to create your own custom categories under built-in areas. However, this is not a
recommended approach. You should create custom areas for your custom code.
Generated from CHM, not final book. Will be superseded in the future. Page 521](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-521-320.jpg)


![Customizing the Logger for Unit Testing
Typical Goals
To effectively unit test your classes, you may want to bypass the default logging and tracing behavior of the
SharePoint Logger and instead write all logging and tracing information to a mock ILogger implementation.
Depending on the primary motivation for your test, the mock logger might write to the Windows event log and the
ULS trace log as normal, write to a test-specific file stream, or simply set a public property that show that the
logger was invoked as expected.
Solution
To configure the SharePoint Logger for unit testing, you need to replace the default SharePoint Logger
instantiation with your mock ILogger implementation when you initialize the unit test. To do this, you must first
create a new, test-specific instance of the SharePoint Service Locator. You can then register your mock ILogger
implementation with the service locator instance for the duration of the test.
This approach ensures that you do not have to modify the code that you are testing. Your code can continue to
use the LogToOperations and TraceToDeveloper methods that are defined by the ILogger interface. Behind
the scenes, the SharePoint Service Locator simply switches the default ILogger implementation with your mock
ILogger implementation.
You need to be familiar with the SharePoint Service Locator to understand how and why this solution works. For
more information, see The SharePoint Service Locator.
Providing a Mock ILogger Implementation
Your first step should be to develop the mock implementation of ILogger. The following code shows an example
implementation.
C#
public class MockLogger : ILogger
{
// Define a public property for the message.
// Your unit tests can query this property
// to validate that the method was called.
public string LogToOperationsCalledWithMessage {get; set;};
public void LogToOperations (string message)
{
LogToOperationsCalledWithMessage = message;
}
}
Your next step is to register your mock implementation with the SharePoint Service Locator for the duration of
your unit test. The registration takes place in the test initialization method.
C#
public class MyFixture
{
[TestMethod]
public void TestMyWidgetThatUsesLogging()
{
// Arrange
ActivatingServiceLocator locator = new ActivatingServiceLocator();
locator.RegisterTypeMapping<ILogger, MockLogger>
(InstantiationType.AsSingleton);
SharePointServiceLocator.ReplaceCurrentServiceLocator(locator);
Generated from CHM, not final book. Will be superseded in the future. Page 524](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-524-320.jpg)

![Customizing the Logger in an Application
Typical Goals
In some circumstances, you may want to customize how the SharePoint Logger behaves in your production
environment. For example, you might want to update the logger so that calls to LogToOperations copy
messages to a third-party repository.
Solution
By default, the SharePointLogger class implements two key interfaces that define the logging and tracing
functionality of the SharePoint Logger:
The IEventLogLogger interface defines logging functionality.
The ITraceLogger interface defines tracing functionality.
To customize the behavior of the SharePoint Logger, you can create your own implementations of these
interfaces. You can then register your custom implementations with the SharePoint Service Locator, so any code
that calls the SharePoint Logger automatically uses the updated functionality. In most cases, you should aim to
register your custom implementations with the service locator at the same time as you deploy them to the
SharePoint environment. A common approach is to use a feature receiver class to update the service locator type
mappings.
This scenario focuses on how to register your implementations with the SharePoint Service Locator. For
information about how to implement the IEv entLogLogger interface and the ITraceLogger interface, see
C reating C ustom Logger C lasses.
Updating Type Mappings for the Logger Interfaces
The following code shows how to register custom implementations of the IEv entLogLogger interface and the
ITraceLogger interface from within a feature receiver class. This example assumes that you have created
classes named MyEv entLogLogger and MyTraceLogger that implement the IEventLogLogger and
ITraceLogger interfaces, respectively.
The example also assumes that you have added a reference to the
Microsoft.Practices.SharePoint.Common.dll assembly, the Microsoft.Practices.Serv iceLocation.dll
assembly, and the Microsoft.SharePoint.dll assembly.
C#
using Microsoft.Practices.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.ServiceLocation;
using Microsoft.Practices.SharePoint.Common.Logging;
[CLSCompliant(false)]
[Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")]
public class MyFeatureReceiver : SPFeatureReceiver
{
// ...
[SharePointPermission(SecurityAction.LinkDemand, ObjectModel = true)]
public override void FeatureInstalled(SPFeatureReceiverProperties properties)
{
IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent();
IServiceLocatorConfig typeMappings =
serviceLocator.GetInstance<IServiceLocatorConfig>();
typeMappings.RegisterTypeMapping<IEventLogLogger, MyEventLogLogger>();
typeMappings.RegisterTypeMapping<ITraceLogger, MyTraceLogger>();
}
}
Generated from CHM, not final book. Will be superseded in the future. Page 526](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-526-320.jpg)
















![Using Stubs
When you use a stub, the Moles framework generates stub implementations of dependency methods and classes
for unit testing. This functionality is similar to that of many conventional isolation frameworks such as Moq,
NMock2, and Rhino Mocks. The stub types are automatically generated classes that run very quickly at execution
and are simple to use. However, stubs lack many of the capabilities of the conventional mocking frameworks and
may require some additional coding. Moles can automatically generate stub types for both for your own code and
for third-party assemblies you are using, including assemblies in the .NET Framework or SharePoint. By default,
stubs are generated for all interfaces and abstract classes, although you can also configure Moles to generate
stubs for non-abstract classes that expose virtual methods. You can configure stub generation through a stub
configuration file. The following code example shows the stub configuration file for the
Microsoft.Practices.SharePoint.Common assembly.
XML
<?xml version="1.0" encoding="utf-8" ?>
<Moles xmlns="http://schemas.microsoft.com/moles/2010/" Verbosity="Noisy">
<Assembly Name="Microsoft.Practices.SharePoint.Common"/>
<StubGeneration>
<TypeFilter NonSealedClasses="true" Namespace="Microsoft*" />
</StubGeneration>
<MoleGeneration Disable="false" />
<Compilation Disable="true" />
</Moles>
This configuration file instructs the Moles framework to generate stub implementations for all non-sealed classes
in namespaces that begin with "Microsoft" within the Microsoft.Practices.SharePoint.Common assembly. Note
that in some cases, it may be easier to manually implement mocks or stubs for your own code instead of using
the stub class generated by the Moles framework.
The following example shows how to consume a stub object generated by the Moles framework within a test
class. In this example, we want to test the Serv iceLocatorConfig class, a key component of the SharePoint
Service Locator. The Serv iceLocatorConfig class depends on implementations of the IConfigManager
interface to manage the storage of configuration settings. In this case, the IConfigManager instance is provided
by a stub implementation named SIConfigManager.
C#
[TestMethod]
public void SetSiteCacheInterval_WithValidValue_UpdatesConfiguration()
{
// Arrange
int expected = 30;
string expectedKey =
"Microsoft.Practices.SharePoint.Common.SiteLocatorCacheInterval";
var bag = new BIPropertyBag();
int target = -1;
var cfgMgr = new SIConfigManager();
cfgMgr.SetInPropertyBagStringObjectIPropertyBag =
(key, value, propBag) =>
{
if(key == expectedKey)
target = (int) value;
};
cfgMgr.GetPropertyBagConfigLevel = (configlevel) => bag;
var config = new ServiceLocatorConfig(cfgMgr);
// Act
config.SetSiteCacheInterval(expected);
// Assert
Assert.AreEqual(expected, target);
}
Generated from CHM, not final book. Will be superseded in the future. Page 543](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-543-320.jpg)


![Using Moles
Moles is a detouring framework. It uses the powerful profiling features of the C LR's just-in-time compiler to
redirect method calls to custom delegates.
A common problem that demonstrates the need for a detouring framework such as Moles is when you want to run
unit tests on code that depends on the DateTime.Now static property. You cannot use DateTime.Now to test
specific conditions, because the value always returns the current date and time from your system clock. You also
cannot directly override the DateTime.Now property to return a specific value. In this situation, you can use the
Moles framework to detour the DateTime.Now property getter to your own custom delegate. This custom
delegate is known as a mole.
Note:
For an example of how to detour the DateTime.Now property to a custom delegate, see Moles – Detours for
.NET on the Microsoft Research Web site.
When execution enters a method, such as the DateTime.Now property getter, the Moles framework checks to
see whether the test class has defined a detour for that method. If a detour is defined, the framework redirects
the call to the detour delegate. If a detour is not defined, the call is directed to the real implementation of the
method. Alternatively, you can configure Moles to throw an exception if a detour is not defined or return a default
value. For example, if a detour for the DateTime.Now property getter is defined, the method call returns the
result of the detour expression. Otherwise, it uses the real implementation of the property getter to return the
current date and time.
The following code example shows a test method that uses Moles to create a detour for the SPF arm.Local static
property. This is a unit test for the SharePointServ iceLocator class. The goal of this test is to verify that calls
to SharePointServiceLocator.GetCurrent() fail if a SharePoint context is unavailable.
C#
[TestMethod]
[HostType("Moles")]
public void GetCurrent_CallWithoutSharePoint_ThrowsNoSharePointContextException()
{
// Arrange
MSPFarm.LocalGet = () => null;
bool expectedExceptionThrown = false;
// Act
try
{
IServiceLocator target = SharePointServiceLocator.GetCurrent();
}
catch(NoSharePointContextException)
{
expectedExceptionThrown = true;
}
// Assert
Assert.IsTrue(expectedExceptionThrown);
}
This section describes the key points of interest in this test method. First, note that a HostType attribute has
been added to the method. This instructs the test runtime to execute this test within the Moles environment, which
runs in a separate process. This attribute is necessary only when you use a mole, because moles rely on the
profiler to detour method calls. Stubs do not involve detours, so they can run in the standard test environment.
In this test method, MSPF arm defines a mole for the SPF arm class. The naming convention for a mole is to
prefix the name of the class with the letter "M". Just like stubs, moles are created in a sub-namespace, .Moles, of
the namespace that contains the class we are detouring. In this case, the MSPF arm mole is defined in the
Microsoft.SharePoint.Administration.Moles namespace.
In this case, the test creates a delegate for the SPF arm.Local property getter. The delegate signature,
LocalGet, indicates that you are overriding the property getter for the Local property. If you could set the Local
property, the mole would also have a LocalSet delegate. Because SPF arm.Local is a read-only property, the
LocalSet delegate is not defined. The lambda expression, () => null, specifies that detoured calls to the
SPFarm.Local property getter will return null.
Generated from CHM, not final book. Will be superseded in the future. Page 546](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-546-320.jpg)

![Behavioral Models
When you start using a framework such as Moles or TypeMock for unit testing, you may find that your unit tests
often break when you change the way your logic is implemented. When your unit test dictates a specific response
for each method call to a mock object, your unit test must reflect the state and behavior of the types that you are
substituting. If you edit the code under test to use alternative methods, or even to call the same methods in a
different order, you may find that your unit test no longer provides an accurate snapshot of the behavior of the
dependency class—even though the functionality remains outwardly unchanged. Your unit tests become
susceptible to frequent breaking changes, and risk becoming a reflection of the implementation details instead of
a pure test of output conditions.
One approach to mitigating this problem is to implementbehaved typesthat provide a more general representation
of the class that you are faking. This allows you factor the behavior logic for dependency types out of your
individual unit tests and into a single behaved type definition that you can reuse in multiple unit tests. For
example, suppose you edit the way your code under test retrieves a list item—instead of using the GetItems
method, you use the list indexer. Instead of updating every unit test to mock this new behavior, you would simply
edit the behaved type for the list to ensure it supports the new retrieval method. If a behaved type doesn’t have
the functionality required for your test, you can simply update the behaved type once and all future tests will
benefit from the updated functionality.
Behaved types support the concept of state-based testing. In your unit tests, you assign values to the behaved
type—for example, you might add a list item to a behaved type that represents a list. The behaved type will
always return the same item, regardless of whether the code under test uses an indexer or a query to retrieve
the item. This breaks the dependency between the overall functionality of the test code and the underlying
implementation details of the test code. In other words, your unit tests simply set the state of the fake object,
while the underlying behavior of the fake object is encapsulated within the behaved type. The use of behaved
types leads to simpler and more resilient unit tests, and it's preferable to use behaved types instead of moles
wherever possible.
The Moles installer includes many behaved type implementations for SharePoint and.NET Framework classes. The
following example shows a test method that uses the behaved type implementations of the SPWeb, SPList,
SPListItem, and SPF ield classes—BSPWeb, BSPList, BSPListItem, and BSPField respectively—which are
provided by the Moles framework. The example tests the presenter class logic in a simple Web Part that
implements the Model-View-Presenter (MVP) pattern.
C#
[TestMethod]
[HostType("Moles")]
public void DoMagic_WithOneAnswer_ReturnsAnswer()
{
//Arrange
string answer = null;
string error = null;
// First, set up a stub class to represent the view passed to the presenter.
var view = new SIMagicEightBallView();
view.DisplayAnswerString = (s) => answer = s;
view.DisplayErrorString = (e) => error = e;
//Setup a behaved type for a web, add a list, and add an item to the list.
BSPWeb web = new BSPWeb();
BSPList list = web.Lists.SetOne();
BSPListItem item = list.Items.SetOne();
item.ID = 0;
list.Title = MagicEightBallConstants.EightBallListName;
item.Values.SetOne("answer.123");
// add the field that will be used to the list fields.
BSPField field = new BSPField();
field.Id = MagicEightBallConstants.AnswerFieldId;
list.Fields.SetOne(field);
//Act
var presenter = new MagicEightBallPresenter(view, web);
presenter.DoMagic("Ask a question");
Generated from CHM, not final book. Will be superseded in the future. Page 548](https://image.slidesharecdn.com/sharepointguidance2010-110310005519-phpapp01/85/Share-pointguidance2010-548-320.jpg)


































More Related Content
What's hot (20)
Similar to Share pointguidance2010 (20)


















Recently uploaded (20)




















Share pointguidance2010
- 1. D E V E L O P I N G A P P L I C AT I O N S FOR MICROSOFT ® S H A R E P O I N T 2010 ® Design Patterns for Decomposition, Coordination and Scalable Sharing • • • • • • • • • • • • • • • • • • • • • • • • • • Feedback http://spg.codeplex.com
- 2. Introduction Microsoft SharePoint® 2010 includes many new areas of functionality that extend the capabilities of the platform and provide exciting new opportunities for developers. The Developing Applications for SharePoint 2010 release provides technical insight and best practice guidance for architects and developers who want to design and develop applications for SharePoint 2010. This introductory section includes the following topics: Overview. This topic provides a brief description of the Developing Applications for SharePoint 2010 release. It identifies the scope of the guidance and describes the different types of components included in the release. Intended Audience. This topic describes the prerequisites for understanding the contents of this release, and identifies the people who will benefit most from the guidance within. Getting Started. This topic describes how to get started with the various components that comprise the Developing Applications for SharePoint 2010 release. C opyright and Terms of Use. This topic explains the terms under which you may use the components in the Developing Applications for SharePoint 2010 release. Generated from CHM, not final book. Will be superseded in the future. Page 2
- 3. Overview SharePoint 2010 introduces new ways of developing applications for the SharePoint platform. With SharePoint 2010, you can build multi-tenant, hosted applications on an infrastructure that is scalable, secure, and stable, while taking advantage of modern browser capabilities for an improved user experience. SharePoint 2010 also introduces improved tools and APIs that address many of the application development and configuration challenges of SharePoint 2007. The new features, operational models, and tooling introduce new design possibilities for developers and architects. This guidance will help you understand the key decisions you face, and to learn how best to take advantage of the new capabilities that SharePoint 2010 provides. The Developing Applications for SharePoint 2010 release includes three different types of resources: Guidance documentation that provides deep technical insight into different aspects of application development with SharePoint 2010. Reusable components that can help you implement best practice design patterns in your own applications. Reference implementations that illustrate how best to work with particular areas of SharePoint functionality. The guide itself is divided into four broad areas of design and development for SharePoint 2010 applications: execution models, data models, client-side development, and application foundations. Each represents a key area of architectural decision making for SharePoint developers, as shown in the following illustration. Key architectural decision drivers in SharePoint 2010 Execution Models provides insight into how different types of SharePoint solutions are managed and executed. It describes how you can develop effective applications in different operating environments and under a variety of constraints. In particular, it provides deep technical insight into the new sandboxed solution model, and it explains the different ways in which you can extend the sandbox environment with various types of full-trust functionality. Execution model decision points Generated from CHM, not final book. Will be superseded in the future. Page 3
- 4. Data Models addresses the challenges involved in consuming and manipulating data in SharePoint applications. SharePoint 2010 includes a great deal of new functionality in the data area, particularly with the introduction of external content types, external lists, and the ability to build relationships and constraints between SharePoint lists. This section of the documentation provides insights that can help you choose between standard SharePoint lists and external data sources as a platform for your SharePoint applications, and it offers approaches and patterns that you can use to mitigate the performance degradation associated with large lists. It also provides detailed insights into data access techniques, including the new LINQ to SharePoint capability. Data model decision points Client Application Models shows how you can make effective use of the new client-side development features Generated from CHM, not final book. Will be superseded in the future. Page 4
- 5. in SharePoint 2010. These features include several new mechanisms for data access, such as client-side APIs for JavaScript, Silverlight, and managed clients, as well as a Representational State Transfer (REST) interface. The SharePoint 2010 platform also provides more out-of-the-box support for rich Internet application (RIA) technologies such as Ajax and Silverlight®. Client-side development decision points Application F oundations shows how best to meet common development challenges in SharePoint applications, such as providing effective isolation of classes and services, managing configuration settings, logging events and trace information, and performing unit testing and integration testing. Addressing these challenges enables you to build flexible, robust, and modular solutions that are easy to maintain as your applications evolve. The concepts described in this section of the documentation should underpin everything you do in the areas of execution models, data models, and client-side development. The scope of technical material that falls under the umbrella of SharePoint development grows increasingly broad with every release, and so several decisions were needed to constrain the scope of this guidance. In the client section, the guidance concentrates on new opportunities for building RIA user interfaces with Silverlight and Ajax. Office client development also includes many new areas of functionality, but this area is worthy of its own book and is too broad a topic to include here. In the data section, the guidance concentrates on lists and libraries, external data, and data access. While site structure is also an important component of an effective SharePoint deployment, in many ways it’s more of an operational issue than a development issue and as such it's not included in the guidance. The new service application model in SharePoint is powerful, but as most organizations will not need to build their own service applications the guidance does not address this area. Note: TheDeveloping Applications for SharePoint 2010 release has an associated community site on C odePlex. You can use this site to post questions, participate in discussions, provide feedback, and download interim releases. Generated from CHM, not final book. Will be superseded in the future. Page 5
- 6. Intended Audience The Developing Applications for SharePoint 2010 release is intended primarily for software architects and experienced developers with some prior experience with SharePoint products and technologies. It offers technical insights, guidance, and design patterns for developers who know the basics and want to extend their skills to the design of robust, enterprise-scale applications. Although the release is not intended to provide an introduction to SharePoint development, experienced developers will benefit from many areas of the guidance even if they are new to SharePoint. To get the greatest benefit from this guidance, you should have some experience with or an understanding of the following technologies: Microsoft® Office® SharePoint Server 2007 or Windows® SharePoint Services 3.0 Microsoft .NET Framework 3.5 Microsoft Visual C #® Microsoft ASP.NET 3.5 The release does not assume that you are already familiar with all the new functionality in SharePoint 2010. Links to the product documentation are provided where appropriate. Generated from CHM, not final book. Will be superseded in the future. Page 6
- 7. Getting Started As described previously, the Developing Applications for SharePoint 2010 release includes three different types of resources—guidance documentation, reusable class libraries, and reference implementations. These resources span the key areas covered by this release, as shown in the following table. Component Description Key Areas Guidance The guidance documentation associated with this release includes Application documentation detailed technical insights and design patterns for developers in key Foundations functional areas. It also includes accompanying documentation for each of the reference implementations, together with how-to topics that can Execution help you meet specific technical challenges. For more information on Models the guidance documentation, see Documentation Overview. Data Models C lient-Side Development Reusable class The SharePoint Guidance Library is a downloadable collection of class Application libraries libraries that you can compile and deploy with your own SharePoint Foundations solutions. The SharePoint Guidance Library includes three components (SharePoint —the SharePoint Service Locator, the C onfiguration Manager, and the Guidance Library) SharePoint Logger—that are designed to help you address common development challenges in SharePoint applications. For information on how to download and compile the SharePoint Guidance Library, see The SharePoint Guidance Library. Reference The Developing Applications for SharePoint 2010 release includes eight Execution implementations reference implementations that illustrate how best to work with Models different areas of functionality in SharePoint 2010. Each reference implementation is a fully functional SharePoint solution, consisting of Data Models source code, supporting resources, and an installation script, that you C lient Models can deploy to a test environment and explore at your leisure. The guidance documentation includes a walkthrough of each reference implementation that explains each aspect of the design and implementation. For more information on how to use the reference implementations, see Reference Implementations. The best way to get started with the Developing Applications for SharePoint 2010 release is to allow the documentation to guide you through the other resources. For example, the documentation explains how and why you should use the components in the SharePoint Guidance Library, and the reference implementations reinforce the execution and data concepts introduced in the documentation. Generated from CHM, not final book. Will be superseded in the future. Page 7
- 8. Documentation Overview The guidance documentation for the Developing Applications for SharePoint 2010 release is organized into four chapters. These chapters map to the four key areas of SharePoint 2010 design and development that are targeted by this release. Application Foundations for SharePoint 2010 provides guidance on how to build your SharePoint applications on solid foundations. In particular, it explains how to address the challenges of testability, flexibility, configuration, logging and exception handling, and maintainability. This chapter introduces the reusable components in the SharePoint Guidance Library and provides in-depth guidance on how to use them in your own applications. Execution Models in SharePoint 2010 provides guidance on how to meet the challenges of different execution environments. It provides deep technical insights into the mechanics of the full-trust execution environment, the sandbox execution environment, and various hybrid approaches to the execution of logic on the SharePoint 2010 platform. The chapter includes accompanying documentation for each of the reference implementations in the execution area. It also includes several how-to topics on how to meet various execution-related challenges in SharePoint 2010 development. Data Models in SharePoint 2010 provides guidance on how to meet common challenges in working with data on SharePoint 2010. It explains key design decision points that can help you to choose between standard SharePoint lists and external lists, and it describes techniques that you can use to mitigate performance degradation when you work with large lists. It also introduces application patterns for data aggregation with SharePoint lists. The chapter includes accompanying documentation for each of the reference implementations in the data area. C lient Application Models in SharePoint 2010 provides guidance on how best to use the new client-side development features in SharePoint 2010, such as the client data access object model, the REST-based service architecture, and the support for RIA technologies such as Silverlight and Ajax. In addition to these Web pages, the guidance documentation is included as a C HM file in the download associated with this release. Generated from CHM, not final book. Will be superseded in the future. Page 8
- 9. The SharePoint Guidance Library The SharePoint Guidance Library is a collection of reusable code-based utilities that address common challenges in application development for the SharePoint platform. You can use these components in your own SharePoint applications to help you improve your development speed and follow best practice guidance. The SharePoint Guidance Library consists of three key components: The SharePoint Service Locator provides a simple implementation of the service location pattern for SharePoint applications. This enables you to isolate your code from dependencies on external types, which makes your code more modular, easier to test, and easier to maintain. The Application Setting Manager provides a robust and consistent mechanism for storing and retrieving configuration settings at each level of the SharePoint hierarchy, from individual sites (SPWeb) to the entire server farm (SPF arm). The SharePoint Logger provides easy-to-use utility methods that you can employ to write information to the Windows event log and the SharePoint Unified Logging Service (ULS) trace log. It also enables you to create custom diagnostic areas and categories for logging. To get started with the SharePoint Guidance Library, we recommend that you read Application Foundations for SharePoint 2010. It puts each component in the SharePoint Guidance Library into context and provides detailed information on using each component. Deploying the SharePoint Guidance Library The SharePoint Guidance Library is distributed as source code. To build and install the library, you must open and build the Microsoft.Practices.SharePoint solution in Microsoft Visual Studio® 2010. This will create the Microsoft.Practices.SharePoint.Common assembly, which includes all three library components. To use the SharePoint Service Locator, you must also deploy the Microsoft.Practices.Serv iceLocation assembly to the global assembly cache. This assembly defines the common service locator interfaces on which the SharePoint Service Locator is developed. The Microsoft.Practices.Serv iceLocation assembly is included in this release as a compiled assembly. The end user license agreement for the Developing Applications for SharePoint 2010 release permits you to include and distribute these assemblies within your SharePoint solutions. System Requirements To build the SharePoint Guidance Library, your development environment must include Visual Studio 2010 Professional Edition or higher and any version of SharePoint 2010, including SharePoint Foundation 2010. The SharePoint Guidance Library is compatible with all versions of SharePoint 2010, including SharePoint Foundation 2010. Using the SharePoint Guidance Library in Sandboxed Solutions SharePoint 2010 introduces a new restricted execution environment—known as the sandbox—that allows you to run partially trusted solutions in a strictly controlled environment within the scope of an individual site collection. The sandbox environment limits the APIs that can be used by code contained in a sandboxed solution, and restricts a sandboxed solution to the resources of the site collection where it is deployed. Wherever possible, the SharePoint Guidance Library components include enhancements that enable them to run within the sandbox environment. C ertain capabilities, such as logging and tracing, are not possible within sandboxed solutions as the security restrictions of the environment do not permit these activities. For these scenarios, the SharePoint Guidance Library provides full trust proxies—which must be installed by a farm administrator—to deliver the capability. The SharePoint Guidance Library also provides several extensibility points where the existing logic can be replaced by an approach that can be used within the sandbox—for example, by logging events to a list within the site collection, rather than through the SharePoint APIs. You will find more details on the capabilities and limitations of the SharePoint Guidance library within the sandbox environment in the chapter Application Foundations for SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 9
- 10. Reference Implementations The Developing Applications for SharePoint 2010 release includes several reference implementations that illustrate different execution models and data models in SharePoint 2010 solutions. Each reference implementation contains a complete working solution, including source code, template files, and other resources, together with an installation script. Deploying a reference implementation to your SharePoint 2010 test environment enables you to explore and debug best practice implementations at your leisure. The following table provides an overview of the reference implementations in the Developing Applications for SharePoint 2010 release, together with the key points illustrated by each implementation. Reference Implementation Key Points Sandboxed Solution Effective use of feature partitioning for reliable solution deployment. List aggregation within a site collection Using query objects to retrieve data from multiple lists. Using the model-view-presenter pattern in a Web Part to isolate business logic from the presentation layer and the underlying data source. Using constructor injection patterns to isolate business logic from dependencies. Using an exception shielding pattern to stop unhandled Web Part errors from preventing the host page from loading. Sandboxed Solution with Full Trust Proxy C reating, deploying, and registering a full-trust proxy. List aggregation with supplemental data from a C onsuming a full-trust proxy from sandboxed code. CRM system Deploying pages and client-side scripts to the sandbox environment. Launching pages as modal dialogs from the sandbox environment. Sandboxed Solution with External List C reating and consuming external lists from a sandboxed solution. Interaction with external data from sandboxed Web Parts C reating and managing external content types in the Business Data C onnectivity (BDC ) service application. C onfiguring the Secure Store Service (SSS) to enable sandboxed code to impersonate credentials for external data sources. Sandboxed Solution with C ustom Workflow C reating and deploying full-trust workflow activities. Actions C reating and deploying sandboxed workflow actions. Deployment of declarative workflows with custom full-trust activities and custom C onsuming custom activities and sandboxed actions from a sandboxed actions declarative workflow. Farm Solution C reating, deploying, and registering a timer job. Aggregation of data from multiple site Managing configuration data for timer jobs. collections using a timer job Deploying custom application pages to the central administration Web site. SharePoint List Data Models Modeling data with lists, including many-to-many relationships. Modeling application data with standard SharePoint Lists Using Lookup fields and list relationships. Using LINQ to SharePoint for list access. External Data Models C onnecting to a database with Business C onnectivity Services (BC S). Modeling application data with an external data source and consuming the data in SharePoint Modeling many-to-many relationships with BC S. Generated from CHM, not final book. Will be superseded in the future. Page 10
- 11. Using the BC S API to access external data. Using the Business Data Web Parts to access external data. Representing associations between entities using stored procedures. Integrating to external data sources using a .NET C onnectivity Assembly. C lient Application Models Using the C lient-Side Object Model (C SOM) from Silverlight and JavaScript. Using rich internet application (RIA) with SharePoint Using REST Services from Silverlight and JavaScript. Using the Model-View-ViewModel pattern with Silverlight. Accessing non-SharePoint services using Silverlight. Accessing binary data with Silverlight. Accessing SharePoint Web Services from Silverlight. System Requirements To deploy the reference implementations, you need a functional SharePoint 2010 test deployment with Visual Studio 2010 Professional Edition or higher. The supported editions of SharePoint 2010 vary according to the features used by each individual reference implementation. The following table shows the editions of SharePoint 2010 required for each reference implementation. Reference Implementation SharePoint 2010 Version Requirements Sandboxed Solution SharePoint Foundation 2010 Sandboxed Solution with Full Trust Proxy SharePoint Foundation 2010 Sandboxed Solution with External List SharePoint Server 2010* Sandboxed Solution with C ustom Workflow Actions SharePoint Server 2010** Farm Solution: Timer Job SharePoint Foundation 2010 SharePoint List Data Models SharePoint Foundation 2010 External List Data Models SharePoint Server 2010*** C lient SharePoint Foundation 2010 * Uses the Secure Store Service which is only available in SharePoint Server 2010. ** Workflows must be deployed to the same SharePoint edition used to create them. This workflow is built using SharePoint Server 2010. You can build the workflow for SharePoint Foundation 2010. *** Uses Business Data Web Parts which is only available in SharePoint Server 2010. Generated from CHM, not final book. Will be superseded in the future. Page 11
- 12. Copyright and Terms of Use This document is provided “as-is”. Information and views expressed in this document, including URL and other Internet Web site references, may change without notice. You bear the risk of using it. Some examples depicted herein are provided for illustration only and are fictitious. No real association or connection is intended or should be inferred. This document does not provide you with any legal rights to any intellectual property in any Microsoft product. You may copy and use this document for your internal, reference purposes. You may modify this document for your internal, reference purposes. Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property. © 2010 Microsoft C orporation. All rights reserved. Microsoft, Active Directory, IntelliSense, MSDN, SharePoint, Silverlight, TechNet, Visual C #, Visual Basic, Visual Studio, Windows, and Windows Server are trademarks of the Microsoft group of companies. All other trademarks are property of their respective owners. Generated from CHM, not final book. Will be superseded in the future. Page 12
- 13. Execution Models in SharePoint 2010 SharePoint solution development encompasses many different types of applications. These applications are deployed to different locations, are loaded by different processes, and are subject to different execution conditions and constraints. The topics in this section are designed to give you an understanding of your execution options when you develop solutions for SharePoint 2010. When you plan how you want your code to execute, the factors driving your decisions fall into two broad areas: Execution environment. This is the security and processing boundary that contains your running code. If you have worked with earlier versions of SharePoint, you are familiar with the full trust execution model and the bin/code access security (commonly known as bin/C AS) execution model. SharePoint 2010 provides new options in this area with the introduction of the restricted, site collection-scoped sandbox execution model. Execution logic. This is the means by which your code actually gets invoked. For example, execution logic defines whether your code runs synchronously or asynchronously, whether it is invoked by a timer job or a workflow or a Web page, and whether it impersonates the current user or runs using the identity of the process account. The following illustration shows some of the options available to you in each of these areas. Execution considerations for SharePoint 2010 applications Execution environment and execution logic are heavily interrelated. Some of the choices you make under execution logic prescribe the use of a particular execution environment model. For example, if you develop a timer job, you must deploy it as a full-trust application. Likewise, if you want to run your code with elevated permissions, you cannot use a sandboxed application. Some execution logic patterns can also be used to bridge the divide between different execution environments, as described later in this section. This guidance is largely structured around the capabilities and constraints of each execution environment model. However, in each topic, the guidance is informed by the options and constraints imposed by the various different approaches to execution logic in SharePoint applications. Generated from CHM, not final book. Will be superseded in the future. Page 13
- 14. This section includes the following topics that will help you to understand execution in SharePoint 2010: Understanding SharePoint Execution Models. This section introduces the different execution and deployment models that are available to you when you develop solutions for SharePoint 2010. It provides an overview of each execution model, explains the benefits and limitations of each approach, and describes when it may be appropriate to use a particular model. Farm Solutions. This topic provides a detailed insight into how farm solution code is executed by the SharePoint environment. It describes what you can do with farm solutions, and it identifies the core issues that you should consider when you write farm solution code. Sandboxed Solutions. This topic provides a similar insight into the sandbox execution environment. In addition, it aims to give you a detailed understanding of how sandboxed solutions are monitored and managed by the SharePoint environment. Hybrid Approaches. This topic provides a detailed review of execution models that enable you to combine sandboxed solutions with full trust functionality. It explains how each of these execution models works, and it identifies issues specific to the deployment and execution of hybrid solutions. This documentation uses the term "execution model" to describe the different approaches that are available to you in the execution environment area. Generated from CHM, not final book. Will be superseded in the future. Page 14
- 15. Understanding SharePoint Execution Models In earlier versions of SharePoint, there were limited options for deploying custom solutions to a SharePoint environment. You would deploy assemblies either to the global assembly cache or to the Web application's bin folder within the Internet Information Services (IIS) file structure. You would deploy other resources, such as images, configuration files, user controls, and SharePoint features, to the SharePoint file structure (commonly referred to as the "SharePoint root") on each server. In order to manage the installation, deployment, and retraction of these assemblies and resources over multiple servers, you would use a SharePoint solution package (WSP). The solution package would have to be placed on a file system available to a SharePoint server in the farm, installed using the stsadm command line tool, and then deployed to one or more Web applications from either the command line or the SharePoint C entral Administration Web site. This approach works well, as long as you meet the following criteria: You have server-side access to the SharePoint farm. You are a member of the Farm Administrators group. You have the confidence of the IT team. This is increasingly unlikely to be the case. Many large companies provide a single, centrally-managed SharePoint platform and simply provision site collections for disparate divisions, departments, and teams as required. Many smaller companies look to hosting companies to provide a SharePoint environment, which is also typically provided on a per-site collection basis. In both cases, developers who are looking to provide custom solutions are unlikely to have the server-side access they need to deploy their solutions. Hosting companies in particular may be understandably reluctant to permit anyone to deploy code that may jeopardize the performance, stability, or security of the SharePoint farm and, therefore, their other tenants. In response to the market need to allow developers to create code that can be run in shared environments, SharePoint 2010 supports an additional deployment and execution model: the sandboxed solution. This model allows users who do not have access to the server file system to deploy managed code applications into individual site collections. Sandboxed solutions are deployed using a SharePoint solution package to a specialized gallery (document library) in the root site of the site collection. These applications run in an environment of reduced trust—the sandbox—and are executed within an isolated process that uses a low-trust account. When you develop solutions that target the sandbox execution model, you are restricted to using a subset of the SharePoint APIs and your code must observe more stringent code access security policies for the rest of the .NET Framework base class libraries. These constraints offer additional safeguards to the IT team, because the inherently lower trust environment reduces the risk of a security exploit by the sandboxed application. In return, the sandbox execution model offers developers the opportunity to customize and extend the functionality of their SharePoint sites in circumstances where the deployment of custom code would otherwise be prohibited, such as hosted solutions or large, regulated corporate deployments. In order to balance this newfound freedom to deploy managed code without the involvement of the IT team, SharePoint 2010 includes various safeguards against inefficient or resource intensive sandboxed applications. In addition to the restrictions on the APIs that are available to the developer, the sandboxed solution framework monitors the execution of sandboxed applications and can terminate code that runs for too long or consumes too many resources. This contributes to the overall stability of the system. Administrators may configure a points-based system to throttle the system resources that are made available to sandboxed applications. This section provides an overview of each execution model, from the familiar full-trust approach to the new sandbox option. It identifies the benefits and drawbacks of each approach, and it examines when it is appropriate to use a particular model. The remainder of the chapter then provides a detailed technical insight into the workings of each execution model. Note: This documentation focuses on server-side execution models. You can also interact with a SharePoint environment from client platforms such as Silverlight or Windows Presentation Foundation (WPF) through the new SharePoint client object model. For more information about the client object model, see C lient Application Models. Generated from CHM, not final book. Will be superseded in the future. Page 15
- 16. What Are the SharePoint Execution Models? In terms of execution models, there are two principal types of solution in SharePoint 2010: farm solutions and sandboxed solutions. Within each type of solution, there are various execution models available to you. Farm solutions can include components that run in a full-trust environment or components that run under code access security policy restrictions. Sandboxed solutions can include components that run entirely within the sandbox environment as well as hybrid approaches that can include various full-trust components. This topic introduces these execution models and describes the key concepts behind each approach. Farm Solutions A farm solution is a collection of resources that you deploy through the server-side file system in your SharePoint environment. These resources execute within the same process space as the SharePoint application, which means that your code can use the full SharePoint object model and has access to all the same resources as SharePoint itself. When you deploy a farm solution, you can choose from two different execution models: the full trust execution model and the bin folder/code access security (bin/C AS) execution model. These models will already be familiar to you if you have worked with Office SharePoint Server 2007 and Windows SharePoint Services 3.0. The Full Trust Execution Model When you use the full-trust execution model, you deploy your assemblies to the global assembly cache on each Web front-end server and application server in the server farm. The SharePoint Web application process loads the assembly from the global assembly cache and your code runs with full trust—in other words, it runs without any code access security restrictions. The full trust execution model Because the assemblies are deployed to the global assembly cache, you can make your solution available to any Web application on the server farm. For more information about the full-trust execution model, see Farm Solutions. The Bin/CAS Execution Model The bin/C AS approach is a partial trust execution model. When you use the bin/C AS execution model, you deploy your assemblies to the bin directory associated with a SharePoint Web application. The worker process associated with the SharePoint Web application loads the assembly from the bin directory. However, the operations your code may perform are restricted by the code access security policies that are applied in the Web.config file to assemblies in the bin directory. The bin/CAS execution model Generated from CHM, not final book. Will be superseded in the future. Page 16
- 17. Because the assemblies are deployed to the bin folder of a specific Web application, your solution is, by definition, scoped to that Web application instead of to the farm as a whole. In terms of deployment, the only differences between the full-trust execution model and the bin/C AS execution model are the location where you deploy your assemblies and the code access security policies associated with that location. In both cases, any non-compiled items, such as ASP.NET markup files, XML files, or resource files, are typically deployed to the SharePoint root on each Web front-end server. If you want to deploy a farm solution using either of the farm solution execution models, you must have access to the server file system and be a member of the Farm Administrators security group. For more information about the bin/C AS execution model, see Farm Solutions. Sandboxed Solutions Sandboxed solutions are new to SharePoint 2010. A sandboxed solution is a collection of resources that you deploy directly to a specialized gallery (library) in the root site of a site collection. This library is referred to as the Solutions Gallery. Just like a farm solution, you package a sandboxed solution as a SharePoint solution package (WSP). However, you can deploy a sandboxed solution without physical access to the server file system and without the involvement of the IT team by directly uploading the WSP through the Web user interface (UI). Instead, the site collection administrator determines who has permissions to add sandboxed solutions to his or her site collection. To counterbalance this newfound freedom to deploy solutions without the explicit approval of the IT team, SharePoint includes several constraints that restrict what you can do with a sandboxed solution. The following are some examples: Your code has access to a limited, "safe" subset of the SharePoint object model. Your assemblies are loaded by an isolated process that uses a low-privilege identity. The solution framework terminates your code if it does not respond to requests within a specified duration. The IT team allocates a resource quota to each site collection that defines the boundaries within which the sandboxed solution must operate. The solution framework shuts down all sandboxed solutions within a site collection if the site collection uses up its daily resource quota for sandboxed solutions. Within an individual site collection, administrators can review the resources consumed by individual sandboxed solutions from the site collection user interface. There are two approaches to execution using the sandboxed solution environment. You can deploy a solution that runs entirely within the sandbox environment, which is referred to as the sandbox execution model. However, the sandbox environment also allows you call out to full-trust components under certain conditions. For example, you can consume specially developed, fully trusted, global assembly cache–deployed classes from your sandboxed solutions via a full trust proxy. These approaches are referred to as hybrid execution models. Note: It is important to draw a distinction between components that you can deploy within a sandbox solution and components that actually execute in the sandbox environment. For example, you can deploy a declarative workflow in a sandbox solution. However, all workflow logic actually executes with full trust. Any calls to the SharePoint object model actually execute with full trust. These concepts are explained in greater detail in the topics that follow. The Sandbox Execution Model When a SharePoint Web application process receives a request that invokes your sandboxed solution, the Web application process does not directly load your assembly. Instead, the Web application process loads an execution Generated from CHM, not final book. Will be superseded in the future. Page 17
- 18. wrapper that loads your assembly into an isolated sandbox process. The sandbox execution model When you use the sandbox execution model, your solution is limited in scope to the site collection in which it is deployed. In addition to the constraints outlined previously, the solution cannot access content or resources from other site collections. For more information about the sandbox execution model, see Sandboxed Solutions. Hybrid Execution Models There are times when the benefits of the sandbox approach are appealing to an organization, but the limitations of the sandbox environment prevent you from creating a complete solution. In these cases, a hybrid approach may offer an attractive solution. Sandboxed solutions can access full trust components through various mechanisms. For example, sandboxed solutions can do the following: They can use a full trust proxy to access logic that runs with full trust, such as calls to APIs that are not permitted in the sandbox or calls to external services. They can use a declarative workflow to access a code-based custom workflow activity. They can use an external list to access external data through Business C onnectivity Services (BC S). These full-trust components could be developed in parallel with the sandboxed functionality, or they might be developed and deployed by the IT team to make additional functionality available to sandboxed solution developers. For example, the SharePoint Guidance Library includes a full-trust proxy that you can use to enable sandbox developers to log events and trace information from their sandboxed solutions. In the first hybrid approach described in this topic, you can execute global access control–deployed, full-trust code from a sandboxed solution by using a full trust proxy. The full-trust proxy is a controlled exit point that allows your sandboxed code to make a synchronous call out to logic that executes outside of the sandbox process. Hybrid execution using a full-trust proxy It is important to understand that the full-trust proxy is implemented by the fully trusted component, instead of by the sandboxed solution. If sandboxed solution developers could use a proxy to run any global assembly cache– deployed code, this would subvert the restrictions placed on the sandbox environment. In order to provide services to sandboxed solutions, your fully trusted classes must inherit from the SPProxyOperation abstract class. After your full-trust proxies are deployed to the global assembly cache, they can be consumed from any sandboxed solution in the SharePoint farm. C reating a full-trust proxy should be carefully considered and managed, because it increases the scope for sandboxed applications to cause security or performance issues. Generally speaking, you should aim to keep the Generated from CHM, not final book. Will be superseded in the future. Page 18
- 19. functionality that you expose to sandboxed applications through a full-trust proxy to the minimum required. In the second hybrid approach described in this topic, the full-trust component is a custom workflow activity that is deployed to the global assembly cache. You can consume the custom workflow activity in a declarative workflow from your sandboxed solution. Hybrid execution using a declarative workflow Using this approach, the fully trusted logic in the custom workflow activity is invoked asynchronously when the sandbox process executes the declarative workflow. In final hybrid approach described in this topic, the full-trust component is an external content type defined in the BC S. The sandboxed solution includes an external list that connects to the external content type. As a result, the sandboxed solution can access data from other applications through the external list, even though the sandbox is prohibited from directly making external connection. Hybrid execution using an external list Note: The external content type is a new SharePoint 2010 feature that enables you to define a connection to an external data source. External content types can also define a set of C RUD (C reate, Retrieve, Update, and Delete) operations that allow you to manipulate that external data from your SharePoint environment. External lists connect to external content types and provide a SharePoint list wrapper around external data, so that you can access and manipulate that external data from the familiar format of a SharePoint list. For more information about external lists and external content types, see Business C onnectivity Services Fundamentals on MSDN. For more information about hybrid execution models, see Hybrid Approaches. Generated from CHM, not final book. Will be superseded in the future. Page 19
- 20. Examples and Scenarios Before you take a detailed look at the functionality and constraints of each execution model, it is worth taking some time to review some high-level examples that illustrate when each model might be appropriate. There are several factors that should influence your choice of execution model. In some cases, the decision may be made for you. If your code will be deployed to a shared or hosted environment, you may well be limited to the deployment of sandboxed solutions. If you are designing a third-party application, targeting the sandbox environment could make your product viable to a wider audience. In other cases, despite the inherent benefits to the overall stability, security, and performance of the farm as a whole, sandboxed solutions may not allow you to do everything you need to. The intended scope of your solution is another important factor—sandboxed solutions are constrained to a single site collection, bin/C AS solutions are restricted in scope to a single Web application, and full-trust solutions are available to the entire server farm. Typical Scenarios for Farm Solutions You can use the full trust farm solution approach to deploy absolutely any combination of functionality and resources from the entire spectrum of SharePoint development. However, that does not mean that the full-trust model is always the best choice. When you deploy a solution that uses the full-trust execution model, you lose all the safeguards that are offered by the sandbox and hybrid approaches. Typically, you might choose to deploy a full-trust farm solution when the functionality you need is not available in the sandbox environment and the additional effort of building a hybrid solution is not justified. You might also consider full-trust solutions for high volume, public-facing sites where the performance impact of using a sandboxed solution is unacceptable. When you consider a bin/C AS deployment, remember that code access security policies can be difficult to get right and difficult to maintain. With the introduction of the sandbox environment, the combination of sandboxed solutions with full-trust components where necessary is preferred to the use of the bin/C AS approach in most cases. However, there are still some circumstances where you may want to consider using the bin/C AS execution model. For example, if you have a high volume site and you want to take advantage of granular security for your application, the bin/C AS model might meet your requirements. If you invest a great deal of time in Web Part development, and the lack of support for Visual Web Parts within the sandbox causes an unacceptable decrease in productivity, the bin/C AS model could offer an alternative solution. The bin/C AS approach cannot be used to run feature receivers, coded workflow activities, timer jobs, or service applications. These components must be deployed to the global assembly cache. C ommon scenarios for full-trust farm solutions include the following: Asynchronous timer jobs for large, regular batch operations. For example, you might want to aggregate data from lists and sites on different site collections. Alternatively, you might want to run a bulk import or export of external data on a daily or weekly basis. Fully coded workflows or activities. You can model many business processes by creating your own custom workflow activities and consuming these activities from declarative workflows. However, in some cases, only a fully coded workflow will provide the functionality you need, particularly if you require complex or parallel branching logic. For example, suppose you implement a process to create swipe cards for secure access. The workflow must connect to an external security system to create the user record and request card production. You might use a fully coded workflow to support a parallel approval process with the Human Resources department and the security team. Typical Scenarios for Sandboxed Solutions In many cases, the sandbox execution model may be the only option available to you. This is particularly likely if you want to deploy a solution to a highly regulated environment, such as a shared or hosted deployment, or if your organization cannot justify the management costs of an environment that allows full-trust solutions. However, there are also many scenarios in which the sandbox execution model might be your preferred approach, regardless of the options available to you. In addition to the farm-wide benefits of stability, security, performance, and monitoring, sandboxed solutions offer benefits to solution developers. For example, you can upload your sandboxed solutions through a Web interface and without the involvement of the IT team; this enables hassle-free deployments and faster development iterations. If the capabilities of the sandbox environment meet the requirements of your application, the sandbox execution model will often be an attractive choice. C ommon scenarios for sandboxed solutions include the following: Data aggregation. For example, you might want create a Web Part or a Silverlight control that shows a summary of all tasks assigned to the current user from across the site collection or that aggregates sales data from individual team sites. Data capture. For example, suppose you are responsible for organizing and posting job vacancies at your Generated from CHM, not final book. Will be superseded in the future. Page 20
- 21. organization. You might deploy a content type and an InfoPath form to collect and organize the information. You could also include a declarative workflow to manage the process through the received, approved, and posted phases. Document management. For example, suppose you need to create a document repository for resumes. You might create a solution package that includes a document template and a content type. You deploy the document template to a document library and you include feature receivers classes to register the content type with the library. Typical Scenarios for Hybrid Solutions Hybrid approaches can offer an attractive choice when the sandbox execution model alone does not provide all the capabilities that you need. You can use a hybrid approach to minimize the amount of full-trust code in your solution, both to maximize the performance and stability benefits you gain from the sandbox environment and to limit the management and review costs associated with the deployment of full-trust code. Hybrid approaches also enable you to make additional functionality available to sandboxed solution developers across your organization. For example, you could develop and deploy a full-trust proxy that provides logging functionality. Other developers can use your full-trust proxy in sandboxed solutions, from any site collection, without exceeding the limitations of the sandbox environment. C ommon scenarios for hybrid approaches include the following: Interaction with external services. For example, suppose you create a sandboxed solution that tracks help desk requests from external customers. Your solution might use a full-trust proxy to submit each customer's location details to a geo-coding service. The geo-coding service returns a latitude and longitude, which your sandboxed solution can use to calculate the nearest available engineer for each customer. Full trust workflow activ ities. For example, suppose you want to extend the job postings data capture example from the sandbox scenarios. You might create and deploy a full-trust workflow activity that takes the data from a posting form and then uses a Web service to publish the information to an external job board Web site. You can consume this workflow activity from the declarative workflow within your sandboxed solution. Extension of sandbox capabilities. For example, suppose you want to allow sandboxed solution developers to use personalization. You might create a full-trust proxy to expose properties from the profile store. Similarly, you might create proxies to enable sandboxed solution developers to use logging functionality or read configuration settings from the farm-scoped property bag. Integration with business data. For example, suppose you want to show a list of custom activities from your C RM system alongside a proposal workspace in SharePoint 2010. You could create an external content type to enable SharePoint solutions to interact with the C RM data. External content types are full-trust components. Within the sandboxed solution, you could create an external list that binds to the C RM external content type and enables you to query customer data. How Does My Execution Logic Affect My Choice of Model? Before you make design decisions about how to build a SharePoint application, it is important to understand how various SharePoint components execute their logic. First, knowing where your logic will execute can provide a useful context when you choose an implementation strategy. The following table maps different approaches to execution logic to the actual processes in which they execute. SharePoint Components and Where Execution Happens IIS worker Sandbox worker Timer job Serv ice application process processes process processes Declarative components Web Parts * Web pages Event receivers * C oded workflow ** activities Generated from CHM, not final book. Will be superseded in the future. Page 21
- 22. Full-trust assemblies Fully coded workflows Timer jobs Service applications *Restrictions apply; see text for details. **SharePoint 2010 provides a wrapper activity that can call custom code in the sandbox. See text for details. Note: Typically, workflows run in the IIS worker process when they are first initiated. After rehydration, they execute within the same process as the event that triggered the rehydration. For example, if there is a timed delay in the workflow, the workflow will be restarted from the timer process when the timer fires. If an approval causes the workflow to rehydrate, the workflow runs in the IIS worker process where the approval was received from the user. In some circumstances, workflow activities may also run in the sandbox worker proxy process (for example, if the sandbox code creates an item in a list that causes a workflow to run). In addition to understanding where logic executes, it is important to know which execution logic patterns are supported by each execution model. The following table shows which execution models you can use with different execution logic patterns. SharePoint Components and Supported Execution Models Sandboxed solution Hybrid solution F ull-trust farm solution Declarative components Web Parts * C ontent pages Application pages Event receivers * C oded workflow activities * Full-trust assemblies Fully coded workflows Timer jobs Service applications *Restrictions apply; see text for details. Some of these execution logic patterns are subject to restrictions when they run within a sandboxed solution. Visual Web Parts cannot be used in the sandbox without employing a workaround, because this would require the deployment of .ascx files to the SharePoint root on the server. Web Parts that run within the sandbox cannot use user controls for the same reason. Event receivers that run within the sandbox are limited to events that occur within the boundaries of the site collection, and they can only be registered declaratively. Full-trust coded workflow activities can only be used within sandboxed solutions when they are consumed by a declarative workflow. You can also create sandbox code that is invoked by a wrapper workflow activity provided by SharePoint. For more information, see Sandboxed Solutions. Generated from CHM, not final book. Will be superseded in the future. Page 22
- 23. Farm Solutions Typically, farm solutions are packaged as SharePoint solution package (WSP) files that contain assemblies, other non-compiled components, and an XML manifest file. A farm administrator uses Windows PowerShell, the STSADM command-line tool, or the SharePoint C entral Administration Web site to install solution packages to the server environment. After a solution package is installed, the farm administrator can activate the solution to a specific Web application (or multiple Web applications, if you use the full-trust model). As described in other topics in this section, you can configure your farm solutions to use a full-trust execution model or a bin/C AS execution model. When you use the full-trust approach, the solution package deploys your assembly to the global assembly cache on each Web server. When you use the bin/C AS approach, the solution package deploys your assembly to the bin folder of a specific Web application in the Internet Information Services (IIS) file structure on each Web server. In both cases, the solution package can deploy other components such as resource files, ASC X user controls, and ASPX Web pages to the SharePoint directory structure on each Web server (commonly referred to as the "SharePoint root"). This topic explains the technical details behind the execution models for farm solutions, and it identifies some of the key execution issues that you should consider when you work with farm solutions. The topic largely focuses on the full-trust execution model, because the bin/C AS model is no longer considered a recommended approach. How Does the Full-Trust Execution Model Work? The precise details of a how full-trust solution executes vary slightly, depending on the type of SharePoint component that you have deployed. For example, Web Part assemblies and event receivers are loaded by an IIS worker process (W3wp.exe), while timer jobs are loaded by the SharePoint timer job process (Owstimer.exe). However, the concepts remain broadly the same (although the timer process typically runs under an account with higher permission levels than the IIS worker process). In this case, this example assumes you have deployed a Web Part. A request that invokes your Web Part logic is directed to the IIS worker process that manages the Web application associated with the request. The IIS worker process loads the appropriate assembly from the global assembly cache. Because the assembly is located in the global assembly cache and as such is not subject to code access security policies, it has unrestricted access to the SharePoint object model and to any other APIs that are accessible from the worker process. The assembly is also able to access remote resources such as databases, Web services, and Windows C ommunication Foundation (WC F) services. The following illustration shows the various components of full-trust execution. The full-trust execution model Generated from CHM, not final book. Will be superseded in the future. Page 23
- 24. How Does the Bin/CAS Execution Model Work? When you deploy a farm solution using the bin/C AS execution model, the assembly is added to the bin folder in the IIS file structure for your SharePoint Web application. As a result, the assembly can be loaded only by the IIS worker process associated with that Web application (in contrast to the full-trust execution model, where your global assembly cache–deployed assemblies can be loaded by any process). This difference precludes the use of bin/C AS solutions to deploy various SharePoint components, such as timer jobs, event receivers, service applications, and workflows, which require your assemblies to be available to other processes. Requests that invoke your code are directed to the IIS worker process that runs the Web application associated with the request. The IIS worker process loads the appropriate assembly from the Web application's bin folder in the IIS file system. Because the assembly is located in the bin folder, it is subject to the code access security policies defined in the configuration file for the Web application. These policies define the degree to which your assembly can use the SharePoint object model as well as other APIs, databases, and services. The following illustration shows the various components of bin/C AS execution. The bin/CAS execution model What Can I Do with Farm Solutions? Full-trust farm solutions have no limitations in terms of functionality or scope. You can deploy every type of SharePoint component with a full-trust solution, and you can make your components available to site collections across the server farm. Bin/C AS solutions are more limited. Scope is restricted to the target Web application, and functionality is constrained by the code access security policies that are applied to the Web application. Bin/C AS solutions are also unsuitable for the deployment of timer jobs, event receivers, service applications, and workflows. These components require assemblies to be deployed to the global assembly cache, as explained earlier in this topic. What Are the Core Issues for Farm Solutions? Each execution model creates a different set of challenges for the developer. Farm solution development creates particular issues for consideration in the areas of deployment, capabilities, stability, and security. The next sections describe each of these. Generated from CHM, not final book. Will be superseded in the future. Page 24
- 25. Deployment When you create a full-trust farm solution, there are no limits to the types of resources that you can deploy. Nor are there restrictions on the locations within the server file system to which you can add these resources. However, your organization may limit or prohibit the deployment of farm solutions due to security or performance concerns. In many cases, your application may also have to undergo a formal code review before you can deploy the solution to the server environment. Capabilities Full-trust farm solutions execute without any code access security restrictions and run using the same process identity as the code that invokes your solution. Typically, your code will run in the IIS worker process (W3wp.exe), the SharePoint Timer process (Owstimer.exe), or a service application process, depending on your execution logic. As a result, your code executes without any restrictions—in other words, your code can do whatever the SharePoint platform itself can do. In cases where security or stability are not significant issues, or where the application undergoes a high level of functional and scale testing, a farm solution is an appropriate choice. Otherwise, consider running only the components that specifically require a farm solution deployment within a farm solution. C omponents that can run within the sandbox environment should be deployed in a sandboxed solution. Stability Farm solutions are not subject to any monitoring or resource allocation throttling. Poorly written code in a farm solution can jeopardize the performance and stability of the server farm as a whole. To prevent these issues, you should carefully review your farm solution code to identify issues that could cause memory leaks or process timeouts. For example, developers often encounter the following pitfalls that can adversely affect performance: The developer could fail to dispose of SPSite and SPWeb objects after use. The developer could iterate through items in large lists instead of executing queries on the lists. The developer could use for or foreach loops to aggregate data, instead of using SPSiteDataQuery or other recommended data aggregation methods. The developer could use recursive method calls to iterate through information in every site within a site collection. The developer could fail to close connections to external systems after use. The developer could fail to trap timeouts when connecting to external systems. The developer could overuse, or improperly use, session state. This is not an exhaustive list instead, it simply illustrates that there are many different ways in which you can unnecessarily slow your SharePoint environment. To minimize risks to farm stability, you should review your solution code against all best practice guidance in the relevant functional areas. Security Farm solution code runs in the same process space as SharePoint itself. These processes run using privileged accounts. Both of these factors increase the scope for harm if your code is compromised or exploited. Even if you deploy your code using the bin/C AS approach and apply restrictive code access security policies, the risk of a damaging security exploit is substantially higher than you would encounter through a sandboxed solution. You should take care to review your code for security vulnerabilities before your deploy your solution. Generated from CHM, not final book. Will be superseded in the future. Page 25
- 26. Sandboxed Solutions Sandboxed solutions are packaged as SharePoint solution package (WSP) files that contain assemblies, other non-compiled components, and an XML manifest file. A site collection administrator, or another user with sufficient permissions, uploads the solution package to a specialized library—the solution gallery—in the root site of the site collection. Every sandboxed solution is executed in a unique application domain. Because the application domain is unique to your solution, SharePoint is able to monitor your solution for performance issues and resource use, and it can terminate your code if it exceeds the boundaries set by the IT team. The application domain runs within an isolated process, using an account with a lower set of permissions than the Web application service account, and is subject to various restrictions on functionality and scope. The remainder of this topic explains the technical details behind the execution model for sandboxed solutions. It describes in detail what you can and cannot do in the sandbox environment, and it explains how IT professionals can manage, configure, and constrain the execution of sandboxed solutions. It also identifies some of the key execution issues that you should consider when you work with sandboxed solutions. How Does the Sandbox Execution Model Work? When your solution runs within the sandbox environment, requests that invoke your code are first directed to the Internet Information Services (IIS) worker process that runs the Web application associated with the request. The request is handled by the Execution Manager, a component that runs in the same application pool as the Web application. The Execution Manager routes the request to a server that runs the SharePoint User C ode Service (SPUC HostService.exe). Depending on your farm configuration, this could be a Web front-end server or it could be a dedicated application server. When the user code service receives a request, it will either start a new sandbox worker process (SPUC WorkerProcess.exe) or route the request to an existing sandbox worker process. More specifically, the execution manager routes the request to a specific sandbox worker process if that process is already hosting an application domain for the solution in question. If no loaded application domain is found, the execution manager will route the request to the sandbox worker process that is under least load. The worker process then creates a new application domain and loads the solution assembly. If the worker process has reached the maximum number of application domains it is configured to host, it unloads an existing application domain before it creates a new one. After the sandbox worker process loads the solution assembly into an application domain, it executes your code. Because the assembly runs in the context of the sandbox worker process, it has a limited set of permissions to use the SharePoint object model and it is prevented from interacting with any other APIs, services, or resources. The code access security policies that limit access to the SharePoint object model are described by the configuration file associated with the sandbox worker process. When your sandboxed code makes calls into the permitted subset of the SharePoint API, the sandbox worker process forwards these requests to a proxy process (SPUC WorkerProcessProxy.exe) that executes the SharePoint object model code. A sandbox worker process and a sandbox proxy process always work as a pair. The following illustration shows the different components of the sandbox execution architecture. The sandbox execution model Generated from CHM, not final book. Will be superseded in the future. Page 26
- 27. The following are the three key processes that drive the execution of sandboxed solutions: User Code Service (SPUC HostService.exe). This is responsible for creating the sandbox worker processes that execute individual sandboxed solutions and for allocating requests to these processes. You must start this service through the SharePoint C entral Administration Web site on each server that will host sandboxed solutions. Sandbox Worker Process (SPUC WorkerProcess.exe). This is the process in which any custom code in your sandboxed solution executes. When a sandbox worker process receives a request that invokes a particular solution, it loads an application domain for that solution (unless it is already loaded). If the worker process reaches the limit on the number of application domains that it can host, it will unload one of the application domains for another solution and load the application domain required to serve the current request. The sandbox worker process throttles the resources accessed by your solution and destroys processes that take too long to execute. Each sandbox worker process is monitored by the SharePoint environment against the criteria specified by the IT team. Sandbox Worker Process Proxy (SPUC WorkerProcessProxy.exe). This provides a full-trust environment that hosts the SharePoint API. This enables sandboxed solutions to make calls into the subset of the SharePoint object model that is accessible to sandboxed solutions. These calls are actually executed in the proxy process. Note: Generated from CHM, not final book. Will be superseded in the future. Page 27
- 28. The executable files that drive sandboxed solutions are stored in the folder 14Usercode on each SharePoint server. What Can I Do with Sandboxed Solutions? When you develop solutions that target the sandbox execution model, you need to understand the constraints that apply to the sandbox environment. This section reviews some common SharePoint development scenarios for their compatibility with the sandbox execution model. The following table shows several common development scenarios together with the execution models that are available to you in each case. This is not an exhaustive list; however, it serves to give you a feel for the types of scenarios that you can implement with a sandboxed solution. Scenario Sandbox Hybrid F ull-Tru st C reate a Web Part that aggregates data from multiple SharePoint lists within the same site collection. * C reate a Web Part that aggregates data from multiple SharePoint lists from different site collections within the same SharePoint farm. C reate a Web Part that aggregates data from multiple SharePoint lists from different site collections from different SharePoint farms. C reate a Web Part that displays data from an external list. C reate a Web Part that interacts with a Web service or a Windows C ommunication Foundation (WC F) service. C reate a workflow in SharePoint designer. C reate a sandbox workflow action (a method call). C reate a full-trust workflow activity. C reate a workflow in SharePoint designer that uses a full-trust custom coded workflow activity. C reate a fully coded workflow. Deploy a new list definition. Deploy a new list definition with list item event receivers. Deploy a list definition with list event receivers. Deploy a site definition. C reate a content type. C reate an external content type.** C reate a new ribbon element. C reate a new Site Actions menu item. C reate an instance of a SharePoint list. Programmatically create a SharePoint subsite. Bind a content type to the home page of a SharePoint subsite. Deploy a new application page. C reate a timer job. C reate a service application. Generated from CHM, not final book. Will be superseded in the future. Page 28
- 29. *The Visual Web Part supplied with Visual Studio 2010 will not run in the sandbox. You must use the Visual Studio Power Tool in the sandbox. **External content types are typically created by using the External C ontent Type Designer in SharePoint Designer 2010. However, they must be deployed using a farm solution or through the C entral Administration Web site. Note: The standard Visual Web Part is not supported in the sandbox environment. The reason for this is because Visual Web Parts effectively host an ASC X user control within the Web Part control. The ASC X file is deployed to the _controltemplates virtual directory in the physical file system on each Web front-end server. The sandbox environment does not allow you to deploy physical files to the SharePoint root, so you cannot use a sandboxed solution to deploy a Visual Web Part based on the Visual Studio 2010 Visual Web Part project template. A Visual Studio Power Tool is available that addresses this issue. A Power Tool is a plug in for Visual Studio. The tool will generate and compile code representing the user control (.ascx) as part of the assembly. This avoids the file deployment issue. You can download a Power Tool for Visual Studio 2010 that supports Visual Web Parts in the sandbox from Visual Studio 2010 SharePoint Power Tools on MSDN. Code Access Security Restrictions The execution of sandboxed solutions is governed by a restrictive code access security policy. This limits sandboxed solutions to the use of a specific subset of the Microsoft.SharePoint namespace. The code access security policy also prevents sandboxed solution code from accessing external resources or systems. The directory 14Usercode contains the Web.config file that specifies the C AS policies that apply to sandboxed solutions as a trust level. For a complete list of the namespaces and classes that are available in the sandbox environment, together with details of the code access security policies that apply to sandboxed solutions, see the following articles in the SharePoint Foundation SDK: Sandboxed Solutions Architecture Namespaces and Types in Sandboxed Solutions Note: If you attempt to use a SharePoint method that is not permitted in the sandbox environment, the method call will throw a MissingMethod exception. This occurs for all methods in the blocked namespacesThe Visual Studio 2010 SharePoint Power Tools has a Sandbox C ompilation extension that generates build errors when the sandbox solution project uses types that are not permitted. There are various nuances that apply to these API restrictions: Within the sandbox, you can use an assembly that includes blocked types and methods, as long as those blocked types and methods are not used within the sandbox environment. Any methods that are called from the sandbox must not include any blocked types or methods, even if those blocked types or methods are not actually invoked when the method is called from the sandbox environment. Permission Restrictions In addition to code access security policy restrictions, the sandbox worker process uses an account with a limited permission set. Using a low-privileged account further limits the amount of harm that a compromised sandboxed solution can do within the production environment. This further restricts the actions that you can perform from sandboxed code. Because sandboxed code is executed in a partial trust environment, any assembly that contains code that will be called from the sandbox must include the AllowPartiallyTrustedC allersAttribute. Retrieving User Identity Within your sandboxed solutions, you can programmatically retrieve the SPUser object associated with the current request. However, you cannot access the underlying authentication token for the current user. In most cases, this is not a problem, because the restrictions of the sandbox environment generally prevent you from performing operations in which the underlying identity is required, such as impersonating a user in order to access an external system. Using Event Receivers You can create event receiver classes within sandboxed solutions for events that fire on list items, lists, and Generated from CHM, not final book. Will be superseded in the future. Page 29
- 30. individual sites—in other words, events that fire within the boundaries of a site collection. Specifically, you can only create event receivers that derive from the following classes: SPItemEventReceiver SPListEventReceiver SPWebEventReceiver You cannot use the object model to register event receivers within sandboxed solutions. For example, you cannot use a feature receiver class to register an event receiver on feature activation. However, you can register event receivers declaratively in your feature elements file. For more information about how to register an event receiver declaratively, see Registering an Event Handler on MSDN. Note: To determine whether your application code is running in the sandbox process, check whether the application domain name contains the text "Sandbox". You can use the following code to accomplish this: if(System.AppDomain.CurrentDomain.FriendlyName.Contains(“Sandbox”)) { // Your code is running in the sandbox. } In the SharePoint Guidance Library, the SharePointEnvironment class contains a static method named InSandbox that returns true if this condition is met. Accessing External Data Broadly speaking, there are two main approaches that you can use to access external data in SharePoint 2010 solutions: Business Data Connectivity Object Model (BDC OM). You can use this to work with external content types and external lists. SharePoint Object Model. You can use this, namely the SPList API, to work with external lists. You can use both the BDC OM and the SPList API to access data from external lists. In fact, the SPList API actually uses the BDC OM to perform C RUD (C reate, Read, Update, and Delete) operations on external list data. However, the SPList API is available in the sandbox environment, whereas the BDC OM is not. The SPList API performs well when the external list contains simple field types and when the built-in BDC formatter is able to "flatten" (serialize) more complex types. However, there are certain scenarios in which the SPList API will not work; for example, it will not work when you need to retrieve custom data types or binary large objects, when a list has bi-directional associations, or when they back-end system uses non-integer identifier fields. For a complete list of these scenarios, see Using the SharePoint List Object Model and the SharePoint C lient Object Model with External Lists. In these cases, you must use the BDC OM. The BDC OM is not directly available within the sandbox environment; instead, you need to create a full-trust solution or a hybrid solution that uses a full-trust proxy to access the BDC APIs. For more information about this approach, see Hybrid Approaches. Note: The BDC OM is present in SharePoint Foundation 2010, SharePoint Server 2010, and Office 2010. For more information, see Business C onnectivity Services Object Model Reference on MSDN. Using Workflows You can use sandboxed solutions to deploy declarative workflows that were created in SharePoint Designer. These declarative workflows are stored in the content database. Like with any declarative logic, declarative workflows execute with full trust, regardless of whether you define them in a sandboxed solution or a farm solution. However, you cannot deploy coded workflows to the sandbox environment. As you probably already know, you can define custom-coded workflow activities that run in the full-trust execution environment. You can also create sandboxed code that is invoked by a workflow action. Note: Workflow activities and workflow actions are related concepts. A workflow activity is any class that derives from System.Workflow.ComponentModel.Activ ity. A workflow action is a SharePoint Designer concept that describes any activity or group of activities that can be composed into a human-readable sentence in the SharePoint workflow engine. A workflow action is represented by an Action element in a feature manifest file or an .actions file, as you will see in the code examples that follow. Technically, you cannot create a workflow activity that runs in the sandbox. However, you can create a Generated from CHM, not final book. Will be superseded in the future. Page 30
- 31. sandboxed method that is packaged as a workflow action. In the case of sandboxed workflow logic, the workflow activity is the SharePoint-provided wrapper class that calls your sandboxed code. For the sake of readability and simplicity, this topic refers to sandboxed code that is invoked by a workflow action as a sandboxed workflow action. To create a sandboxed workflow action, you must create a class with a method that accepts a SPUserCodeWorkflowContext as the first parameter. You can also have additional parameters, which will be defined in the Elements.xml file for the solution. The following example is taken from the workflow reference implementation. C# public Hashtable CopyLibraryAction(SPUserCodeWorkflowContext context, string libraryName, string targetSiteUrl) { // This is the logic to copy a library to a target site. } The action is then defined in the Elements.xml file, which tells SharePoint about the action and the implementing class. It also enables SharePoint Designer to use the activity in a declarative workflow for the site collection. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <WorkflowActions> <Action Name="Copy Library" SandboxedFunction="true" Assembly="..." ClassName="..." FunctionName="CopyLibraryAction" AppliesTo="list" UsesCurrentItem="true" Category="Patterns and Practices Sandbox"> <RuleDesigner Sentence="Copy all items from library %1 to site %2"> <FieldBind Field="libraryName" Text="Library Name" Id="1" DesignerType="TextBox" /> <FieldBind Field="targetSiteUrl" Text="Target Site" Id="2" DesignerType="TextBox" /> </RuleDesigner> <Parameters> <Parameter Name="__Context" Type="Microsoft.SharePoint.WorkflowActions.WorkflowContext, Microsoft.SharePoint.WorkflowActions" Direction="In" DesignerType="Hide" /> <Parameter Name="libraryName" Type="System.String, mscorlib" Direction="In" DesignerType="TextBox" Description="The library to copy" /> <Parameter Name="targetSiteUrl" Type="System.String, mscorlib" Direction="In" DesignerType="TextBox" Description="The URL of the target site" /> </Parameters> </Action> </WorkflowActions> </Elements> The workflow execution environment calls the method specified in the Action element to launch your sandboxed workflow action. Suppose that you have deployed a declarative workflow and a sandboxed workflow action to the sandbox environment. SharePoint executes the declarative workflow with full trust, because all the actual run-time code invoked by the workflow is deployed with full trust; therefore, it is considered safe. SharePoint defines a sandboxed activity wrapper that executes with full trust and provides a wrapper for all sandboxed actions. The sandbox activity wrapper makes the method call into your sandboxed method. The method defined in the sandboxed solution—CopyLibraryAction in the previous example—actually executes within a sandbox worker process. The following illustration shows this, where the details of the user code service processes have been omitted for brevity. Generated from CHM, not final book. Will be superseded in the future. Page 31
- 32. Using a sandboxed workflow action from a declarative workflow When you create the declarative workflow, SharePoint Designer hides the relationship between the sandbox activity wrapper and the sandboxed action implementation. SharePoint Designer also enables you to define parameters and field bindings as inputs to the custom sandbox action. Sandboxed workflow actions offer advantages in many scenarios, particularly because you can deploy these actions as sandboxed solutions without access to the server environment. However, there are limitations on the tasks that a sandboxed workflow action can perform. Declarative workflows can also use certain approved full-trust workflow activities. For information about how to add custom full trust workflow activities that can be consumed by a declarative workflow, see Hybrid Approaches. How Do I Manage Sandboxed Solutions? Farm administrators can customize many aspects of how sandboxed solutions are executed, validated, and monitored. As a solution architect or a senior developer, it is important to have an awareness of these features because they can impact how your solutions behave and perform. Understanding Operational Modes The IT team can configure the SharePoint farm to execute sandboxed solutions in one of two operational modes. The operational mode determines where the sandbox worker process that executes each sandboxed solution Generated from CHM, not final book. Will be superseded in the future. Page 32
- 33. actually resides: When the farm is configured in local mode, each sandboxed solution executes on the Web front-end server that receives the request. When the farm is configured in remote mode, sandboxed solutions can execute on servers other than the server that receives the request. When you configure the farm to run sandboxed solutions in remote mode, you can use dedicated application servers to run sandboxed solutions. Alternatively, the server farm can use load balancing to distribute the execution of sandboxed solutions across Web front-end servers. You must start the user code service on each Web front-end server that will run sandboxed solutions. The following illustration shows the difference between these approaches. When your farm is configured in local mode, sandboxed solution code executes on the Web front-end server that receives the request. The Web front-end server will spin up a new sandbox worker process and load the solution, unless a process already exists for that solution's unique application domain. Sandbox execution in local mode When your farm is configured in remote mode with dedicated sandbox servers, the Web front-end server that receives the request will first establish whether any of the sandbox servers are already running a sandbox worker process for the required solution. If this is the case, the Web front-end server will route the request to that sandbox server. This is known as solution affinity. If the process is not running on any of the sandbox servers, the Web front-end server will route the request to the sandbox server currently experiencing least load. This sandbox server will spin up a sandbox worker process and load the solution. Sandbox execution in remote mode with dedicated sandbox servers Generated from CHM, not final book. Will be superseded in the future. Page 33
- 34. When your farm is configured in remote mode, and the user code service is running on more than one Web front-end server, the Web front-end servers will distribute requests that invoke sandboxed solutions according to server load. If one of the Web front-end servers is already running a sandbox worker process that has loaded the required solution into an application domain, the request is routed to that server. If the solution is not loaded on any of the Web front-end servers, the request is routed to the Web front-end server currently experiencing least load. This server will spin up a new application domain in the sandbox worker process and load the solution. Remote mode with Web front-end servers hosting the user code service The IT team should use capacity planning to select the best operational mode for a particular SharePoint environment. In general, it is recommended to use remote mode. However, if you expect a small number of sandboxed solutions, and response latency is a major concern, local mode may be preferable. This is because there is a minor latency cost in cases where the request is received on one server and the sandbox processes run on a different server. As your server farm grows larger, or the expected number of sandboxed solutions increases, remote mode can become increasingly advantageous. When more than one server runs the user code service, load balancing and solution affinity mean that each server needs to host only a subset of the deployed sandboxed solutions. This is important because every server that runs the user code service can host only a finite number of sandbox worker processes and application domains. When a server hits these limits, what happens when it receives a request for a sandboxed solution that is not already loaded? To serve the request, it must recycle an existing application domain to be able to load the new application domain. This results in requests queuing for a free application Generated from CHM, not final book. Will be superseded in the future. Page 34
- 35. domain and increased recycling of application domains. In addition, it becomes increasingly unlikely that there will be an already loaded ("warm") application domain for particular solutions. These factors can substantially impact server performance and response times. Using remote mode to distribute application domains across multiple servers clearly mitigates these issues. In addition to simply setting the operational mode to local or remote, the IT team can make various configuration changes that will impact on the performance issues described here. For example, farm administrators can configure the number of sandbox worker processes and application domains that can be hosted on each server that runs the user code service. They can also constrain the number of connections allowed per process. Finally, the user code service includes a flag named AlwaysRecycleAppDomains. By default, this is set to false. When it is set to true, the user code service recycles application domains after every request. This reduces the response time of the server as a "warm" application domain is never available, but it can reduce the risk of data crossover in poorly designed sandboxed solutions. Deploying and Upgrading Solutions Sandboxed solutions are deployed as SharePoint solution package (WSP) files to the solutions gallery, a specialized library in the root site of each site collection. You can find the solutions gallery at the site relative URL _catalog/solutions. The site collection administrator can activate and deactivate the solutions within the gallery. If you need to deploy a sandboxed solution to multiple site collections, you must upload it to each site collection gallery separately. Alternatively, you could create a central repository for sandboxed solutions and register a custom solution provider with the solution galleries on each site collection. Site collection administrators can then choose which centrally-available solutions they want to activate on their individual site collection. The custom provider approach essentially allows you to upload and manage a solution in a single location while making it available to multiple site collections. You can upgrade sandboxed solution packages through the user interface. If you upload a solution package with a new file name but the same solution ID as an existing solution, SharePoint will prompt you to upgrade the existing solution. Alternatively, you can use the Update-SPUserSolution command in Windows PowerShell to upgrade your solutions. However, this requires access to the server environment, which is not necessarily available to sandboxed solution developers or site collection administrators. For more information about managing sandboxed solutions in the solutions gallery, see Sandboxed Solutions Architecture in the SharePoint Foundation SDK. Understanding Solution Monitoring SharePoint 2010 monitors the performance and resource use of your sandboxed solutions through a system of resource points. Farm administrators can set limits on the number of resource points that a site collection containing sandboxed solutions may consume daily. Because these limits are set on a per-site collection basis, the available resources are effectively shared between every sandboxed solution in the site collection. Site collection administrators can monitor the resource points used by individual solutions from the site collection solution gallery. If the solutions in a site collection exceed the daily resource point allocation for that site collection, SharePoint will take every sandboxed solution in the site collection offline for the rest of the day. Resource points are calculated according to 14 different measurements known as resource measures, including C PU execution time, memory consumption, and unhandled exceptions. Each resource measure defines a property named Resources per Point. This is the quantity of that particular resource that constitutes an individual resource point. For example, suppose you deploy a solution named C ontoso Project Management to the sandbox environment. The following table shows a hypothetical example of the resources it consumes across two sample resource measures. Resource measure Resources per Point Used by Contoso Points consumed Project Management solution in one day SharePointDatabaseQuery 20 queries 300 queries 15 C ount SharePointDatabaseQuery 120 seconds cumulative 240 seconds cumulative 2 Time SharePoint counts the most expensive resource measure toward the total for the solution, instead of the sum of all measures. In this example, because the number of database queries represents the highest resource point usage, the C ontoso Project Management solution consumes 15 resource points from the total allocated to the site Generated from CHM, not final book. Will be superseded in the future. Page 35
- 36. collection. To prevent rogue sandboxed solutions from causing instability SharePoint also monitors individual sandboxed solutions per request. Each of the 14 resource measures includes an AbsoluteLimit property that defines a hard limit of the resources that a sandboxed solution can consume in a single request. If an absolute limit is exceeded, SharePoint terminates the request by stopping and restarting the Sandbox worker process. For example, the C PU execution time resource measure has a default absolute limit of 60 seconds. If a single request takes more than 60 seconds to execute, the user code service will stop and restart the sandbox worker process that is executing the request. Individual solutions will not be disabled for violating an absolute limit, although the utilization will count toward the resource points for the site collection; therefore, they will be expensive. In addition, the user code service includes a property named WorkerProcessExecutionTimeout with a default value of 30 seconds. If this time limit is exceeded during a single request, the user code service will recycle the application domain in question and the request will return an error. These two settings are measured independently by different parts of the system but they effectively measure the same thing. In general, setting the WorkerProcessExecutionTimeout is preferred over the absolute limit because it will only recycle the application pool instead of the entire process. Exceeding an absolute limit will result in a worker process recycle. When a worker process is recycled, any requests running within the process will fail. In production installations, it is likely that multiple solutions will be running within multiple application domains within one process, so a single rogue solution can disrupt users of more benign solutions. For more information about configuring sandbox environments for resiliency in a production environment, see the Performance and capacity management (SharePoint Server 2010) on TechNet. Farm administrators can use Windows PowerShell to change the Resources Per Point for a Resource Measure . However, the default measurement weightings were carefully chosen, and understanding the impact of adjustments to these weightings can be complex. You should carefully consider the impact of changing these weightings before you make any modifications. You can also use Windows PowerShell to investigate how many resource points are being used by specific individual solutions. Resource point consumption depends on the capacity of your server farm and on how you configure measurement weightings, so it is hard to provide an absolute recommendation on where to cap resource point allocations for sandboxed solutions. Instead, you should determine limits by testing against a representative production environment. For full details of the measurements used to calculate resource points, see Developing, Deploying, and Monitoring Sandboxed Solutions in SharePoint 2010 andPlan sandboxed solutions (SharePoint Server 2010 on MSDN. On a final note, farm administrators use the C entral Administration Web site to block poorly performing or otherwise undesirable sandboxed solutions. This ensures that the solution in question cannot be deployed to any site collection in the farm. Understanding Solution Validation In SharePoint 2010, farm administrators can install solution validators to provide additional verification of sandboxed solutions. SharePoint 2010 runs these solution validators when you attempt to activate a sandboxed solution package. Each solution validator can run various validation checks on the solution package and can block activation if your solution fails any of these checks. By default, SharePoint 2010 includes a single default solution validator that simply sets the Valid property of each solution to true. To create your own custom solution validator, you must create a class that inherits from the SPSolutionValidator abstract class. This class includes two key methods: ValidateSolution. This method validates the solution package and its contents. This method has access to the name of the solution package and any files that the package contains. ValidateAssembly. This method validates each assembly in the solution package. Both methods enable you to set an error message, together with an error URL to which the user should be directed if validation fails. To register a solution validator with the SharePoint farm, you can use a feature receiver to add your class to the SolutionValidators collection in the local SPUserCodeService object. What Are the Core Issues for Sandboxed Solutions? Sandboxed solutions introduce a fresh set of challenges for SharePoint developers. When you develop a Generated from CHM, not final book. Will be superseded in the future. Page 36
- 37. sandboxed solution, you should pay particular attention to the areas described in the following sections. Scope and Capabilities Sandboxed solutions can only interact with resources within the site collection in which they reside. If your application must access data in multiple site collections, you can rule out a sandboxed solution at an early stage in the design process. Similarly, the restricted capabilities of the sandbox environment may prohibit the use of a sandboxed solution. Security (Authentication) Sandboxed solutions do not maintain the full identity of the user originating the request, and they cannot impersonate a different user account or provide credentials to authenticate to other systems. The SPUser object is maintained, but the related security tokens are not. With this in mind, you should consider whether a sandboxed solution is capable of accessing the data or resources that your application requires. In particular, the constraints on authentication prevent you from executing your code with elevated permissions. In farm solutions, developers will often use the SPSecurity.RunWithElevatedPrivileges method to execute a method with full control privileges, even if the user has a lesser set of permissions. However, you should consider carefully whether elevated permissions are really necessary before you reject a sandboxed approach altogether. Although there are scenarios in which you need to elevate permissions, there are also many cases where proper management of user groups and permission sets within the SharePoint site allow your logic to execute from the sandbox environment. Performance (Throughput) If a sandbox worker process runs for more than 30 seconds, the user code service will terminate the process. If you need to use long-running processes to deliver your functionality, a sandboxed solution is unlikely to be the best choice. However, in these circumstances, you should probably be using an asynchronous execution mechanism instead. For example, use a timer job, a workflow, or a service application to execute your logic as a background task within a farm solution. Executing code within the sandbox environment also incurs a small amount of performance overhead. This is only likely to have a noticeable impact in high volume applications, such as in Internet-facing portal environments. In these cases, you may want to consider deploying your code within a farm solution. Logging Logging functionality is unavailable within the sandbox environment. Sandboxed solutions cannot write entries to the Windows Event log or the Unified Logging Service (ULS) trace log, nor can they create or retrieve diagnostic areas or categories. This should not come as too much of a surprise—writing to the Windows Event log has always required a relatively permissive code access security policy, and creating diagnostic areas requires access to the Windows registry. Exposing logging functionality to sandboxed solutions is a good example of a scenario in which you might consider creating a full-trust proxy. For example, the SharePoint Logger component includes a full-trust proxy to enable developers of sandboxed solutions to use the full range of logging features in SharePoint 2010. Configuration Settings Your ability to read and write configuration settings is somewhat restricted in the sandbox environment. The following are some examples: You cannot read configuration settings from or write configuration settings to the Web.config file. You can store and retrieve settings in the SPWeb.AllProperties hash table, but you cannot use property bags at any level of the SharePoint hierarchy. You cannot read or write settings to the hierarchical object store, because you do not have access to an SPWebApplication object or an SPF arm object. You can read or write settings to a SharePoint list within the same site collection as your sandboxed solution. Deployment Sandboxed solutions are deployed and activated to a single site collection. If you need to deploy a solution to multiple site collections, the sandbox approach can be less convenient. You can either manually distribute solution packages to individual site collection administrators, or you could implement a custom centralized solutions Generated from CHM, not final book. Will be superseded in the future. Page 37
- 38. gallery to make solutions available to individual site collection administrators. When you use a sandboxed solution to deploy document templates, you cannot deploy the document templates to the file system. The sandboxed environment does not permit you to deploy any files to the server file system. To solve this issue, use a Module element with a Type attribute value of Ghostable or GhostableInLibrary to deploy your templates. This indicates that the templates are deployed to the content database instead of to the server file system. Similarly, you cannot deploy JavaScript files or modal dialog Web pages to the server file system. Instead, you might choose to deploy Web pages to the Pages document library and scripts to a subfolder within the Master Page Gallery. By deploying JavaScript files to the Master Page Gallery, you ensure that all users, even anonymous users, have the permissions required to access the file at run time. This approach is especially useful in Internet-facing deployments where anonymous users have read access to the site. Generated from CHM, not final book. Will be superseded in the future. Page 38
- 39. Hybrid Approaches When describing execution models, the term hybrid approaches refers to applications that run in the sandbox yet can call out to full-trust code through various mechanisms. In other words, hybrid approaches combine components that execute in the sandbox environment with components that run with full trust and are deployed with multiple solutions. Essentially, you can think of a hybrid approach as two (or more) distinct, loosely coupled components. The sandboxed component is deployed in a SharePoint solution package (WSP) to a site collection solutions gallery, and the full trust component is deployed in a WSP to the server farm. These components are typically developed in isolation, often at different times, and a single full-trust component can be consumed by multiple sandboxed applications. In many environments, the full-trust components are built or validated by the central IT team in order to make them available to multiple sandboxed solutions. Because a hybrid approach involves creating a sandboxed solution and a full trust solution, it is important to fully understand the sandbox execution model and the full-trust execution model before you start to work with hybrid approaches. To recap, there are three different types of full trust components that you can consume from within a sandboxed solution: Full trust proxies. You can implement your full-trust functionality in classes that derive from the SPProxyOperation abstract class and deploy the assembly to the global assembly cache. These classes expose a full-trust proxy that you can call from within the sandbox environment. External content types. You can use an external content type to retrieve data from line-of-business (LOB) applications and other external sources through Business C onnectivity Services (BC S). External content types must be deployed as full-trust solutions. However, you can create external lists from within the sandbox environment that use these external content types to retrieve data. Custom workflow activities. You can create custom, code-based workflow activities and deploy these activities as full-trust assemblies to the global assembly cache. You can then consume these activities in declarative workflows from within the sandbox environment. This topic explains the technical details behind each of these hybrid execution models. It explains in detail how you can use each model, and it identifies some of the key execution issues that you should consider when you work with hybrid solutions. How Do Hybrid Execution Models Work? When you use a hybrid approach to solution deployment, the execution process varies, according to the type of full-trust component you use. Hybrid Execution with a Full Trust Proxy When you use a full trust proxy from the sandbox environment, requests follow the normal execution path of sandboxed solutions. The code access security policy for the sandbox environment allows sandboxed code to make calls to full-trust proxy assemblies, providing that the proxy assembly is registered with the server farm. You can programmatically register a proxy assembly from a feature receiver or by using Windows PowerShell. Your sandboxed code must use the SPProxyOperationsArgs class to structure the arguments that you want to pass to the full-trust proxy. When you call the SPUtility.ExecuteRegisteredProxyOperation method, the sandbox worker process invokes the full-trust proxy and passes in your arguments. The proxy code executes with full trust in a proxy process. The full-trust proxy then passes any return arguments back to the sandboxed solution, and normal execution within the sandbox environment resumes. Note: The SharePoint context (SPContext) is not available within the proxy operation class. If you require contextual information in the proxy operation class, you will need to pass the information required to recreate the context to the proxy. For example, if you need to access a site within the proxy, you would pass the site ID as a property on the proxy arguments passed into the proxy operation. The proxy would then recreate the site using the site ID. You can then access the SPUser in the sandbox through site.RootWeb.CurrentUser. The following illustration shows the key components of hybrid execution with a full trust proxy. Hybrid execution with a full-trust proxy Generated from CHM, not final book. Will be superseded in the future. Page 39
- 40. The following describes the three key code components behind full-trust proxies: SPProxyOperation. This class provides an abstract base class for full-trust proxies. The class includes a method named Execute, within which you can define your full trust functionality. Your full-trust proxy classes must be deployed to the global assembly cache and registered with the SharePoint server farm, either programmatically or by using Windows PowerShell. SPProxyOperationArgs. This class provides an abstract base class for the parameter that you pass to the full-trust proxy. To pass arguments to the full-trust proxy, you must create a serializable class that derives from SPProxyOperationArgs. Add properties within this class to get and set your arguments. SPUtility.ExecuteRegisteredProxyOperation. This static method enables you to invoke the full-trust proxy from your sandboxed code. This method requires a string assembly name, a string type name, and an SPProxyOperationArgs object. The method returns an argument of type Object to the caller. Generated from CHM, not final book. Will be superseded in the future. Page 40
- 41. Note: Any types you include in the proxy arguments class must be marked as serializable. Similarly, the type returned by the proxy operation must be marked as serializable. This is because arguments and return values are serialized when they are passed between processes. Both the proxy operation class and the proxy argument class must be deployed to the global assembly cache. You cannot pass any types defined in the sandboxed code into the proxy, because the proxy will not have access to load the sandboxed assembly; therefore, it will not be able to load the passed-in type. Hybrid Execution with External Content Types When you want to use external content types with sandboxed solutions, deployment constraints alone mean you must use a hybrid approach. External content types must be defined in a farm-scoped feature; therefore, they cannot be deployed as part of a sandboxed solution. You do not need to deploy any fully trusted code to the server. Instead, you can create external content types from the External C ontent Type Designer in SharePoint Designer 2010 or from the Business C onnectivity Services Model Designer in Visual Studio 2010. After the external content types are in place, you can define an external list from within your sandboxed solution to access the external data. For an example of this scenario, see the external list reference implementation. Hybrid Execution with external content types Generated from CHM, not final book. Will be superseded in the future. Page 41
- 42. The only means to access external data from custom code in a sandbox solution is through an external list, by using the SPList object model. You cannot use the BC S runtime APIs directly in sandboxed code. There are special considerations for securing services for access in the sandbox. When your access external data from the sandbox, it is important to understand how credentials must be configured and used. When code in the sandbox requests access to external data through the external list, the external list implementation calls the BC S runtime. Because this code is part of the internal SharePoint implementation, it will execute within the user code Generated from CHM, not final book. Will be superseded in the future. Page 42
- 43. proxy service. For security reasons SharePoint removes the authentication tokens for the user from the context when it enters the sandbox worker process. As a result, the Windows identity associated with the user is not available in either the sandbox worker process or the sandbox proxy process. Because a Windows identity is not available, the managed account for the sandbox proxy process must be used as the basis for securing calls to an external service or a database through the BC S. All users will authenticate to the service based upon the managed account that runs the user code proxy service. This is an example of the trusted subsystem model. When the BDC runtime receives a request for external data, it determines if the Secure Store Service (SSS) is used to manage credentials to access the service. If the SSS is being used, then the identity of the user associated with the request is typically provided to the SSS, which maps the user (or a group or role to which the user belongs) to a credential that can be used to access the service. Because the user authentication token is not available in this case, the BDC uses impersonation mode, which results in the identity of the managed account that runs the user code proxy service being passed to the SSS rather than the identity of the user. In the SSS, the credentials of the managed account are mapped to the credentials that you want to use to access the external system. The SSS returns the mapped credentials to the BDC runtime, which then uses the credentials to authenticate to the external system. Because the BDC runtime does not receive the credentials of individual users, you cannot constrain access to the external system to specific user accounts when the request originates from the sandbox environment. The following illustration shows this process, using the example of an external vendor management system from the external list reference implementation. Identity flow and external service access The following describes the numbered steps in the preceding illustration: 1. C ustom user code, executing in the sandbox environment, uses the SPList object model (OM) to request data from an external list. The user authentication tokens for the user submitting the request have been removed from the context. 2. The SPList OM call is delegated to the user code proxy service. The user code proxy service passes the request to the BDC runtime, which also runs within the user code proxy service process. 3. The BDC runtime calls the Secure Store Service (SSS). The identity associated with the request is that of the managed account that runs the user code proxy service. The SSS returns the vendor management system credentials that are mapped to the identity of the user code proxy service. 4. The BDC runtime retrieves the external content type metadata from the BDC metadata cache. If the metadata is not already in the cache, the BDC runtime retrieves the external content type metadata from the BDC service. The external content type metadata provides the information the BDC runtime needs to be able to interact with the external vendor management system. 5. The BDC runtime uses the vendor management logon credentials retrieved from the SSS to authenticate Generated from CHM, not final book. Will be superseded in the future. Page 43
- 44. to the service and access data from the external vendor management system. The SharePoint user (SPUser) context is available within the sandbox environment. As such, the credentials of the user are used to control access to SharePoint resources within the sandbox. Note: For more information about creating external content types, see How to: C reate External C ontent Types on MSDN. Hybrid Execution with Custom Workflow Activities Workflow logic is not executed synchronously in response to a user request. Instead, it is executed asynchronously by the workflow engine. This results in a significantly different execution model. Within the sandbox environment, you can deploy a declarative workflow that defines connections between individual workflow activities. Many commonly used workflow activities are provided out-of-the-box by SharePoint 2010. The IT team can make additional workflow activities available to your declarative workflow by deploying custom, code-based workflow activities to the global assembly cache as full-trust solutions. In order to make a full-trust workflow activity available to declarative workflows, the IT team must add an authorizedType entry to the Web.config file for the content Web application. This gives your custom activity the same status as the built-in workflow activities that come with SharePoint 2010. The following code example shows the format of an authorizedType entry. XML <configuration> <System.Workflow.ComponentModel.WorkflowCompiler> <authorizedType Assembly="…" Namespace="…" TypeName="*" Authorized="True" /> </System.Workflow.ComponentModel.WorkflowCompiler> </system.web> When you add an authorized type, set the Assembly attribute to the strong name of your assembly and set the Namespace attribute to the fully qualified namespace of your activity class. For an example of how to use a feature receiver class to add an authorized type entry for a custom workflow activity, see the Workflow Activities Reference Implementation. Note: As described earlier, you can also create and deploy custom sandboxed workflow actions. These actions run within the constraints of the sandbox environment. If you need to take advantage of capabilities outside the sandbox, you must deploy your custom workflow activities as full-trust solutions. The workflow engine itself always runs in full trust, regardless of whether you deploy your workflow as a sandboxed solution or a full-trust solution. When you deploy a declarative workflow to the sandbox environment, it simply specifies the rules that determine how execution will proceed through the full-trust activities in the workflow. This following illustration shows the key components involved in workflow execution. The declarative workflow is loaded from a sandbox solution, whereas custom full-trust workflow activities are loaded from the global assembly cache. However, the workflow is executed entirely in a full-trust environment. Hybrid execution with a custom workflow activity Generated from CHM, not final book. Will be superseded in the future. Page 44
- 45. Note: The declarative workflow is defined as part of the sandbox solution, but it always executes in a full-trust process such as Owstimer.exe, W3wp.exe, or in the user code proxy process. Generally, the process in which the workflow is determined by where the workflow is initiated or where an action is taken that causes the workflow to be "rehydrated" from the database. There are some performance mechanisms that can push execution into the timer process under high load conditions. A full-trust custom activity included in the declarative workflow also runs in a full-trust process. Declarative workflows cannot be moved between SharePoint Foundation and SharePoint Server. In general, you can create equivalent workflows for each environment, although there are, of course, more activities available for SharePoint Server. Declarative workflows are managed slightly differently on each platform, and the workflow is packaged and deployed with the expectation that the server version is the same. You must develop the workflows on the same SharePoint version that you expect them to run on in production. Generated from CHM, not final book. Will be superseded in the future. Page 45
- 46. What Can I Do with Hybrid Solutions? Hybrid approaches enable you to bypass the code access security policies and the limited permission set of the sandbox environment. When you create a full-trust proxy or a custom workflow activity, your code runs with full trust and there are no restrictions on what it can do. Any resources consumed by the full-trust code are not counted against the sandbox resource limits of the site collection. However, by definition, hybrid approaches require that your full-trust code is invoked from the sandbox environment. Because sandboxed logic can only run in the context of pages, event receivers, or workflows, hybrid approaches are inherently inappropriate for other application types such as timer jobs or service applications. In these cases, you must look to a full-trust solution. How Do I Manage Hybrid Solutions? When you design a SharePoint application to use a hybrid execution model, you will use two or more solution packages to deploy the components to the SharePoint environment. C omponents that target the sandbox are deployed as sandboxed solutions to a site collection solution gallery, and components that run with full trust are deployed as farm solutions to the server environment. For example, suppose your solution includes a Web Part that uses an external list to query a LOB application. Behind the scenes, the external list relies on an external content type to provide an interaction with the LOB data source. The following illustration shows an example where the Web Part is deployed in a sandboxed solution, while the external content type is deployed as a farm solution. Hybrid approach with a Web Part and an external content type Alternatively, suppose your Web Part uses a full trust proxy to access parts of the object model that are inaccessible to sandboxed code. The following illustration shows an example where the Web Part is deployed in a sandboxed solution, while the full trust proxy is deployed as a farm solution. Hybrid approach with a Web Part and a full trust proxy From an administrative perspective, these types of deployment are managed as two separate solutions. The sandboxed solution is subject to the monitoring, resource throttling, and permission limitations of the sandbox environment, while the farm solution is subject to any organizational constraints on the deployment of full trust code. What Are the Core Issues for Hybrid Solutions Generated from CHM, not final book. Will be superseded in the future. Page 46
- 47. When you design your applications to use a hybrid execution model, you will deploy components in both sandboxed solutions and full-trust solutions. As such, you need to consider the issues that relate to each individual solution type in addition to those issues that apply specifically to hybrid approaches. When you develop a hybrid solution, you should pay particular attention to the areas described in the following sections. Security Hybrid solutions expose a smaller surface area of full-trust code compared to farm solutions. This can reduce the amount of security review time that you require before deploying your solution. Because some of your solution code runs in full trust, you can impersonate the application pool (in other words, elevate permissions) if necessary. However, the boundaries of the sandbox environment were carefully designed when SharePoint 2010 was developed. You should consider the impact of any full-trust functionality that you expose to the sandbox, because this code runs without the security restrictions that apply to the sandbox environment. Deployment If you want to use a hybrid approach, your organization must permit you to deploy farm solutions to your SharePoint environment. If you do not have permission to deploy assemblies and other resources to the server environment, you cannot deploy a hybrid solution. Organizations may be more permissive to external content types, as you can create an external content type from SharePoint Designer without deploying any managed code. Capabilities It is important to understand which components of your solutions can run within the sandbox environment and which components require a full-trust proxy. The full-trust proxy should only include those elements that need to execute with full trust—the other elements should remain within the sandboxed solution. This helps to minimize the surface area of code that you expose to performance or security vulnerabilities. It can also help to reduce the time required for code review, as described in the preceding paragraphs. Logging and Configuration Full-trust proxies can provide a useful way to expose logging and configuration functionality to sandboxed applications. For example, the SharePoint Logger component includes a full-trust proxy that enables sandboxed applications to write events to the Windows Event log and the Unified Logging Service (ULS) trace log. Similarly, a full-trust proxy can provide a sandboxed application with access to configuration settings that would otherwise be unavailable. Full-trust proxies can read and write to any data within the Web application and can read data stored in the SPF arm object. However, if you create a full-trust proxy to expose additional configuration functionality to sandboxed solutions, take care to include safeguards against improper use of that functionality. For example, developers risk corrupting the content or configuration database if they attempt to persist a non-serializable object to a property bag. In this case, it would be wise to include functionality within the full-trust proxy to verify that the object can be serialized before you proceed with the operation. Stability Because full-trust proxies are deployed to the global assembly cache, they are not subject to the resource throttling and monitoring constraints that are applied to sandboxed solutions. It is important to verify that the code in your full-trust proxy performs to a high standard. For example, ensure that your code does not cause excessive memory use or process timeouts, just as you would for code in a farm solution. This can help to ensure that your full-trust proxy does not jeopardize the stability of the farm as a whole. Performance (Throughput) Like with sandboxed solutions, there is a marginal reduction in performance when you use a hybrid solution instead of a farm solution. This is because of the marshaling of data across application domains. Generated from CHM, not final book. Will be superseded in the future. Page 47
- 48. Conclusion This section reviewed the different ways you can deploy and run your custom solutions in SharePoint 2010. It described two key aspects of logic execution in SharePoint 2010: the execution environment and the execution logic. The execution environment is the security and processing boundary that contains your running code, while the execution logic is the means by which your code actually gets invoked. Together, the decisions you make about execution environment and execution logic form the execution model for your solution. Execution models in SharePoint 2010 fall into three categories: farm solutions, sandboxed solutions, and hybrid approaches. This section provided a detailed insight into each of these models, including their advantages, limitations, functionality, and manageability. The SharePoint Guidance Library includes several reference implementations that illustrate different execution models. It is recommended that you deploy these implementations in order to explore practical examples of the concepts described in this section. Generated from CHM, not final book. Will be superseded in the future. Page 48
- 49. Reference Implementation: The Sandbox Execution Model Many rich SharePoint applications can run within the confines of the sandbox. One of the most common scenarios for custom development in a SharePoint environment is the aggregation of data from several different lists within the same site collection. The Sandbox Reference Implementation (Sandbox RI) uses this scenario to illustrate a reasonably complex application that can run as a sandboxed solution. The implementation highlights techniques and best practices in the following areas: It demonstrates effective use of feature partitioning for reliable solution deployment. It demonstrates the use of query objects to retrieve data from multiple lists. It demonstrates the use of the Model-View-Presenter (MVP) pattern in a Web Part to isolate business logic from the presentation layer and the underlying data source. It demonstrates the use of the C onstructor Injection pattern to isolate business logic from dependencies. It demonstrates the use of an Exception Shielding pattern to stop unhandled Web Part errors that prevent the host page from loading. Solution Scenario In this example, suppose you are providing consultancy services to a pharmaceutical company named C ontoso Inc. C ontoso has production plants in several locations, each of which has several departments, including Design, Maintenance, and C onstruction. Each department has a separate team site on your SharePoint 2010 intranet portal within the production plant site collection. Among other things, each department uses its individual team sites to keep records of statements of work (SOWs) and cost estimates provided to clients tracked against a central list of projects for the plant. Each project can have one or more SOWs associated with it. The general manager for the Springfield production plant, Janet Schorr, wants to be able to monitor the progress of SOWs and estimates across all departments within the plant. However, the central IT team at C ontoso headquarters is reluctant to permit farm solution deployments. To meet Janet's requirements, you implement a sandboxed solution that retrieves details of SOWs and estimates from each team site. The solution presents key details of these SOWs and estimates in a Web Part on the landing page of the Manufacturing site collection, as shown in the following illustration. The Aggregate View Web Part Deploying the Sandbox RI The Sandbox Reference Implementation (Sandbox RI) includes an automated installation script that creates a site collection, deploys the reference implementation components, and adds sample data. After running the installation script, browse to the new Manufacturing site collection at http://<Hostname>/sites/Manufacturing. You can open and run the solution in Visual Studio, but this does not create a site collection or add sample data. To see the system fully functioning, you must run the installation script. The following table summarizes how to get started with the Sandbox RI. Note: The Auto-retract after debugging property is disabled for this Visual Studio project. This prevents Visual Studio from retracting the solution if you choose to step through the code. For more information about auto-retract, see Developing SharePoint Solutions. Question Answer Generated from CHM, not final book. Will be superseded in the future. Page 49
- 50. Where can I find the <install location>SourceExecutionModelSandboxed Sandbox RI? What is the name of the ExecutionModels.Sandboxed.sln solution file? What are the system SharePoint Foundation 2010 requirements? What preconditions are You must be a member of SharePoint Farm Admin. required for installation? You must be a memberof the Windows admin group. SharePoint must be installed at http://<Hostname:80>. If you want to install to a different location you can edit these settings in the Settings.xml file located in the Setup directory for the solution. SharePoint 2010 Administration service must be running. By default, this service is set to a manual start. To start the service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 Administration serv ice, and then click Start. How do I Install the Follow the instructions in the readme file located in the project folder. Sandbox RI? What is the default http://<Hostname>/sites/ Manufacturing installation location? (This location can be altered by changing the Settings.xml in the Setup directory.) How do I download the The Sandbox RI is included in the download Developing Applications for Sandbox RI? SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 50
- 51. Solution Overview This topic provides a high-level overview of the various components that make up the Sandbox Reference Implementation (Sandbox RI). It does not examine the design of the solution or the implementation details of the Web Part, both of which are described later in this guidance. Instead, it illustrates how the reference implementation works at a conceptual level. The Sandbox RI consists of various components, as shown in the following illustration. Conceptual overview of the Sandbox RI The next sections describe each of these components in more detail. Libraries and Content Types Each team site includes a document library named Estimates with two assigned content types: SOW (statement of work). This content type includes a Microsoft Word document template that defines a standardized format for a statement of work, together with various site column references for the SOW. Estimation. This content type includes a Microsoft Excel document template that facilitates budget calculations, together with various site column references for the estimate. The root site for the plant site collection includes a list named Projects. Every SOW and estimation must be linked to a project record. Site Columns The SOW and Estimation content types both include the following site columns: SOW Status. This is used to indicate the progress of the SOW and the estimation through the sales process. This is a choice field with the values Draft, Submitted, and Approved. Estimate Value. This is a currency field that represents the estimated value of the proposal to the organization. Projects Lookup. This is a lookup field that is used to link the SOW or estimation to a project record in the Projects list. The lookup returns the Title field of the project record. Client Name. This is a text field that is used to record the name of the client. Client ID. This is a text field that represents a unique identifier for the client. Generated from CHM, not final book. Will be superseded in the future. Page 51
- 52. Web Part The AggregateView Web Part uses the SPSiteDataQuery class to retrieve data from the Estimates library in each team site. The Web Part uses an ASP.NET GridView control to present the data. This enables the user to view a tabular summary of SOWs and estimations. Note: The AggregateView Web Part uses the ASP.NET GridView control because the SharePoint equivalent, SPGridView, is not available in the sandbox environment. Generated from CHM, not final book. Will be superseded in the future. Page 52
- 53. Solution Design To implement the solution as described in Solution Overview, the solution package needs to perform various deployment tasks. The following diagram shows these deployment tasks together with the order in which they must be performed. Deployment tasks and task ordering The dependencies between these tasks are fairly intuitive: The site columns include a lookup field that retrieves metadata from the Projects list, so you must deploy the Projects list before you can deploy the site columns. The SOW and Estimation content types include site columns and document templates, so you must deploy the site columns and the document templates before you can create the content types. To associate the content types with the Estimates libraries, you must first create both the content types and the libraries. Note: The deployment of the Web Part does not directly depend on the deployment of any other components. Although the Web Part will not do anything useful until these components are in place, there is nothing to prevent you from deploying it up front. In order to manage these tasks and dependencies, the ExecutionModels.Sandboxed solution consists of three features, as shown in the following diagram. The arrows represent feature activation dependencies. For more information about feature activation dependencies, see Activation Dependencies and Scope on MSDN. Solution design for the Sandbox RI Generated from CHM, not final book. Will be superseded in the future. Page 53
- 54. Note: When you use Visual Studio 2010 SharePoint tools to package a solution, be aware that features are installed in the order in which they appear in the Package Designer. If your features include activation dependencies, make sure that you order your features correctly. In this solution, the ProjectsList feature appears at the top of the list, followed by the EstimateC Ts feature, followed by the EstimatesInstance feature. For more information about feature ordering, see How to: C hange Deployment Order. These three features perform the following actions: ProjectsList. This feature creates an instance of the Projects list on the root site of the site collection. It also adds the AggregateView Web Part to the Web Part gallery on the site collection. EstimateCTs. This feature deploys the document templates and the new site columns to the site collection. When the feature is activated, the event receiver class uses the document templates and the site columns to create the SOW and Estimation content types. Programmatic creation of content types is new in SharePoint 2010. EstimatesInstance. This feature creates an instance of the Estimates document library on each subsite. When the feature is activated, the event receiver class associates the SOW and Estimation content types with each Estimates library. The next topics in this section describe these components in more detail. Generated from CHM, not final book. Will be superseded in the future. Page 54
- 55. Web Part Deployment You can deploy Web Parts within sandboxed solution packages using the same approach that you would use for full-trust Web Part deployment. Note that the SharePoint tools in Visual Studio 2010 actually automatically create the XML artifacts described in this topic. However, it is useful to understand what happens behind the scenes. If you are an advanced user, you may also choose to manually edit these XML artifacts to fine tune your solution. First, note that the solution includes a .webpart file that defines how the Web Part is listed in the Web Part gallery. The following code example shows the contents of the Sandbox-AggregateView.webpart file. XML <webParts> <webPart xmlns="http://schemas.microsoft.com/WebPart/v3"> <metaData> <type name="ExecutionModels.Sandboxed.AggregateView.AggregateView, $SharePoint.Project.AssemblyFullName$" /> <importErrorMessage>$Resources:core,ImportErrorMessage;</importErrorMessage> </metaData> <data> <properties> <property name="Title" type="string">P&P SPG V3 - Execution Models Sandbox Aggregate View</property> <property name="Description" type="string">AggregateView Web Part - Sandbox Execution Model. This web part shows aggregating multiple lists in the same site collection.</property> </properties> </data> </webPart> </webParts> Essentially, the .webpart file points to the type and assembly of the Web Part and provides a title and description to display within the gallery. Next, the solution includes a feature manifest to deploy the .webpart file to the Web Part gallery in your site collection. The following code example shows the contents of the Elements.xml file for the AggregateView Web Part. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/" > <Module Name="AggregateView" List="113" Url="_catalogs/wp"> <File Path="AggregateViewSandbox-AggregateView.webpart" Url="Sandbox-AggregateView.webpart" Type="GhostableInLibrary"> <Property Name="Group" Value="P&P SPG V3" /> </File> </Module> </Elements> In feature manifest files, modules are used to deploy one or more files to a specified location. In the Module element, the List="113" attribute value identifies the deployment target as a Web Part gallery, and the Url=" _catalogs/wp" attribute value is the site-relative URL of the Web Part gallery. The Module element contains a File element for the .webpart file. In the F ile element, the Path attribute specifies the physical location of the file within your feature, and the Url attribute specifies a virtual path for the file. The Type="GhostableInLibrary" attribute indicates that the deployment target is a type of document library and that SharePoint should create a parent list item for the file. Using this approach, the file is stored in the content database. Note: For more information about the Module element schema, see Modules on MSDN. Although the feature manifest for a sandboxed module is no different to the manifest for any other module, SharePoint processes feature manifests in sandboxed solutions differently. In contrast to a farm solution deployment, feature files in sandboxed solutions are not deployed to the TEMPLATEFEATURES folder in the SharePoint root on each Web Front End server. Instead, they remain in the solution package and are retrieved from the content database when required. Generated from CHM, not final book. Will be superseded in the future. Page 55
- 56. Finally, you must ensure your Web Part assembly is included in the solution manifest file. The following code example shows the contents of the solution manifest for the ExecutionModels.Sandboxed solution, edited for readability. XML <Solution xmlns="..." SolutionId="..." SharePointProductVersion="14.0"> <Assemblies> <Assembly Location="ExecutionModels.Common.dll" DeploymentTarget="GlobalAssemblyCache" /> <Assembly Location="ExecutionModels.Sandboxed.dll" DeploymentTarget="GlobalAssemblyCache"> <SafeControls> <SafeControl Assembly="ExecutionModels.Sandboxed, ..." Namespace="ExecutionModels.Sandboxed.AggregateView" TypeName="*" /> </SafeControls> </Assembly> </Assemblies> <FeatureManifests> <FeatureManifest Location="...ProjectsListFeature.xml" /> <FeatureManifest Location="...EstimateCTsFeature.xml" /> <FeatureManifest Location="...EstimatesInstanceFeature.xml" /> </FeatureManifests> </Solution> As you can see, the solution manifest file looks broadly the same as the manifest for a farm solution. There are two key points to note in this example: The manifest specifies that the assemblies should be deployed to the global assembly cache. Sandboxed assemblies are not deployed to the global assembly cache, but the Assembly elements must specify DeploymentTarget="GlobalAssemblyCache" regardless. Sandboxed assemblies are actually stored in the content database within the SharePoint solution package (WSP) and are loaded as required by the user code worker process. The manifest includes a SafeControl entry for the Web Part type. When you deploy a sandboxed solution, safe control entries are not added to the Web.config file. However, SharePoint verifies these entries behind the scenes when your sandboxed solution is loaded. If you do not include a SafeControl entry for your Web Part type, the Web Part will fail to load. Note: If you used the Visual Studio 2010 SharePoint tools to build your solution, the solution manifest is automatically generated by default. Generated from CHM, not final book. Will be superseded in the future. Page 56
- 57. List Instances The ExecutionModels.Sandboxed solution deploys two list instances: the Projects list and the Estimates library. The Projects list is based on the custom list template, which by default includes a single field named Title. The Estimates library is a standard document library. You can deploy list instances by creating a ListInstance element within a feature manifest file. The SharePoint tools in Visual Studio 2010 will automatically generate the feature manifest file for you, but it is useful to understand how it works behind the scenes. The following code example shows the feature manifest for the Projects list. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <ListInstance Id="{877CD3C2-DDE1-4EF3-82BA-4367D2FC079B}" Title="Projects" OnQuickLaunch="TRUE" TemplateType="100" FeatureId="00bfea71-de22-43b2-a848-c05709900100" Url="Lists/Projects" Description=""> </ListInstance> </Elements> The following code example shows the feature manifest for the Estimates list. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <ListInstance Title="Estimates" OnQuickLaunch="TRUE" TemplateType="101" FeatureId="00bfea71-e717-4e80-aa17-d0c71b360101" Url="Lists/Estimates" Description=""> </ListInstance> </Elements> Note that the schema for list instances is the same regardless of whether you are deploying a sandboxed solution or a farm solution. The Projects list instance is deployed by a site-scoped feature; because of this, the Projects list is created in the root site of the site collection. The Estimates list instance is deployed by a Web-scoped feature; because of this, the Estimates library is created on every site in the site collection where the feature is activated. The key point of interest in the feature manifest files is the TemplateType element. A template type of 100 indicates that SharePoint should create a custom list, and a template type of 101 indicates that SharePoint should create a document library. Note: You can also declaratively associate content types with a list instance within the feature manifest file. However, this implementation demonstrates programmatic creation of content types in the feature receiver class, because this functionality is new to SharePoint 2010. For more information about the ListInstance element schema, see ListInstance Element on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 57
- 58. Site Columns The ExecutionModels.Sandboxed solution deploys five site columns for use by the SOW content type and the Estimation content type. Site columns are defined by F ield elements within a feature manifest file. As with all feature manifests, the contents of the manifest file remain the same regardless of whether you target a sandboxed solution or a farm solution. For example, the following code shows the definition of the SOW Status site column. This is taken from the Elements.xml file for the SiteC olumns project item. XML <Field ID="{91EBB5B9-D8C5-43C5-98A2-BCB1400438B7}" Name="SOWStatus" DisplayName="SOW Status" StaticName="SOWStatus" DisplaceOnUpgrade="TRUE" Group="SiteColumns" Type="Choice" Format="Dropdown"> <CHOICES> <CHOICE>Draft</CHOICE> <CHOICE>Submitted</CHOICE> <CHOICE>Approved</CHOICE> </CHOICES> </Field> The site columns include a column named Projects Lookup that retrieves data from the Projects list, as shown in the following code example. Because this column retrieves data from the Projects list, you must make sure that the Projects list is in place before you deploy the lookup column. This is achieved through the feature activation dependencies described in Solution Design. XML <Field ID="{F52FAC8A-7028-4BE1-B5C7-2A316AB1B88E}" Name="ProjectsLookup" DisplayName="Projects Lookup" StaticName="ProjectsLookup" Group="SiteColumns" DisplaceOnUpgrade="TRUE" Type="Lookup" ShowField="Title" WebId="" List="Lists/Projects"> </Field> The ability to create lookup fields declaratively is a new feature in SharePoint 2010. For more information about the F ield element schema, see Field Definition Schema on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 58
- 59. Event Receivers You can use event receivers within sandboxed solutions to handle events on list items, lists, individual sites, and features. The ExecutionModels.Sandboxed solution includes two event receivers that handle the FeatureActivated event: EstimateCTs.Ev entReceiver. This class programmatically creates the SOW and Estimation content types when the EstimateCTs feature is activated. EstimatesInstance.Ev entReceiver. This class associates the SOW and Estimation content types with each instance of the Estimates library when the EstimatesInstance feature is activated. The next sections describe these feature receiver classes. EstimateCTs Event Receiver The EstimateC Ts feature deploys site columns and document templates to the site collection. Because the SOW and Estimation content types rely on these columns and templates, it makes sense to use a feature receiver to create the content types when the feature is activated, because you can be certain that the prerequisites for the content types are in place at this point. It is also easier to modify the content types in the case of an upgrade when you use this approach. At a high level, the EstimateCTs.F eatureActivated method performs the following actions for each content type: 1. It creates a new content type in the ContentTypes collection of the root SPWeb object. 2. It links the site columns to the content type. 3. It adds the document template to the content type. 4. It calls the Update method on the content type to persist changes to the database. This process is illustrated by the following extract from the F eatureActivated method. The code has been simplified for readability. C# SPSite site = properties.Feature.Parent as SPSite; using (SPWeb web = site.RootWeb) { SPContentType sowContentType = web.ContentTypes[Constants.sowContentTypeId]; if (sowContentType == null) { sowContentType = new SPContentType(Constants.sowContentTypeId, web.ContentTypes, Constants.sowContentTypeName); web.ContentTypes.Add(sowContentType); } sowContentType.DocumentTemplate = string.Concat(web.Url, Constants.sowTemplatePath); AddFieldsToContentType(web, sowContentType, fieldsToAdd); sowContentType.Update(true); } The process is repeated for the Estimation content type. The AddF ieldsToContentType method links site columns to the content type using the field ID values defined in the feature manifest for the site columns. For more details, see the EstimateCTs.Ev entReceiver.cs class in the reference implementation. There are various tradeoffs to consider when you choose whether to create content types declaratively or programmatically. You cannot update a content type that has been created declaratively—all content types must be upgraded programmatically. However, declarative approaches are simple; therefore, they are a better choice if your content types are not expected to evolve or change. EstimatesInstance Event Receiver The EstimatesInstance feature creates an instance of the Estimates document library on every site in which the feature is activated. The Estimates library exists solely to store documents based on the SOW and Estimation content types. Because of this, it makes sense to use a feature receiver to associate the content types with each Estimates library when the feature is activated. At a high level, the EstimatesInstance.F eatureActivated method performs the following actions: 1. It locates the Estimates list in the current site. 2. It enables content types on the Estimates list. Generated from CHM, not final book. Will be superseded in the future. Page 59
- 60. 3. It adds the SOW and Estimation content types to the Estimates list. 4. It removes the Document content type from the Estimates list. The F eatureActivated method uses a helper method to add the content types to the list, as shown in the following code example. C# private static void AddContentTypeToList(SPContentTypeId spContentTypeId, SPList list, SPWeb web) { var contentType = web.AvailableContentTypes[spContentTypeId]; if (contentType != null) { list.ContentTypesEnabled = true; list.Update(); if (!ListContains(list, spContentTypeId)) { list.ContentTypes.Add(contentType); list.Update(); } } } Before the method attempts to add a content type, it first makes sure that content types are enabled on the list. If the ContentTypesEnabled property is false, any attempt to add content types to the list will fail. The method then checks to see whether the list already contains the content type. ListContains is a simple helper method, as shown in the following code example. C# static bool ListContains(SPList list, SPContentTypeId id) { var matchId = list.ContentTypes.BestMatch(id); return matchId.IsChildOf(id); } Essentially, this method retrieves the content type ID from the list that is closest to the ID of the new content type. It then checks to see whether the closest match is a child content type to the content type you are attempting to add. This is necessary because of the way that SharePoint manages content type IDs. When you copy a site content type to a list, SharePoint gives the list content type a new ID in the form site content type ID + "00" + 32-character hexadecimal GUID. If the closest match to your site content type ID in the Estimates list is a "child" of your site content type, your content type has already been added to the list. For more information on content type IDs, see C ontent Type IDs on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 60
- 61. Web Part Design The ExecutionModels.Sandboxed solution illustrates various best practices for the design of sandboxed Web Parts in SharePoint 2010. The following class diagram shows the structure of the AggregateView Web Part. This design is an example of the Model-View-Presenter (MVP) pattern, which is designed to isolate your business logic from the details of your user interface (UI). Class diagram for the Sandbox RI The AggregateViewPresenter class represents the Presenter component in the MVP pattern. This class performs the following tasks: It retrieves a DataTable from the model represented by the IEstimatesService. It sets the DataTable as the data source in the view represented by IAggregateView. The AggregateView class represents the View component in the MVP pattern. This class is the actual Web Part. This class performs the following tasks: It instantiates the Presenter object represented by the AggregateViewPresenter. To do this, it creates an instance of the Model represented by EstimatesServ ice, and then it constructs the AggregrateViewPresenter, passing in itself as the View and the EstimatesServ ice as the Model. This is an example of constructor injection. It renders the data supplied by the presenter to the UI. Finally, the EstimatesServ ice class represents the Model component in the MVP pattern. This class performs the following tasks: It executes a query to retrieve data from the Estimates list on each subsite. It returns the data to the caller in a DataTable. The use of the MVP pattern increases modularity, flexibility, and testability of the application. If you want to display the data differently, you can modify or replace the view, without changing any of the business logic, by providing an alternative implementation of IAggregateView. In other words, you can create a view that displays the data in any way you want, as long as it exposes a public write-only property of type DataTable named SetSiteData. Similarly, if you change the way you store your SOWs and estimations, you can provide an alternative implementation of IEstimatesService without editing the view or the presenter. Finally, the design makes it easy to test your presenter logic by providing mock implementations of IEstimatesService and IAggregateView. The following illustration shows how execution passes between the view, model, and presenter classes. Generated from CHM, not final book. Will be superseded in the future. Page 61
- 62. Flow of execution in the Sandbox RI It is important to note that the view is relatively passive and is entirely driven by the presenter logic. The view class simply provides a forward-only property setter that the presenter can use to set the data source for the view. Generated from CHM, not final book. Will be superseded in the future. Page 62
- 63. View Classes In terms of contracts, the sole responsibility of a view class is to expose a public property that enables a presenter class to insert data into the view. What the view class does with the data is of no concern to the presenter. Because of this, the interface that underpins the view class in the Sandbox Reference Implementation (Sandbox RI) simply defines a write-only property of type DataTable. C# public interface IAggregateView { DataTable SetSiteData { set; } } In this case, the view class should be a Web Part. In addition to implementing the IAggregateView interface, the AggregateView class must inherit from the abstract WebPart class. This class provides the functionality that enables the AggregateView class to plug into the SharePoint Web Part framework. C# public class AggregateView : WebPart, IAggregateView Because the Web Part provides the entry point for the application, the AggregateView class must instantiate the Presenter class. You can do this in the CreateChildControls method, which is called early in the page life cycle before the Web Part is rendered. You can then call the SetSiteData method on the Presenter object, which invokes the presenter logic. C# private AggregateViewPresenter presenter; protected override void CreateChildControls() { base.CreateChildControls(); // Configure the grid view. presenter = new AggregateViewPresenter(this, new EstimatesService()); presenter.SetSiteData(); Controls.Add(gridView); IErrorVisualizer errorVisualizer = new ErrorVisualizer(this); presenter.ErrorVisualizer = errorVisualizer; } Note: The ErrorVisualizer class is a Web control that the presenter class uses to display exception information if an unhandled exception is caught. This is part of an exception shielding strategy that stops unhandled Web Part exceptions that prevent the host page from loading. For more information, see Exception Shielding. The AggregateView class provides an implementation of the SetSiteData property setter that performs two tasks: It extracts column names from the passed-in data table and creates corresponding data columns in the grid view. It binds the grid view to the passed-in data table. This property setter is used by the presenter class to provide the view with a data source. The following code example shows the SetSiteData implementation in the AggregateView class. C# public DataTable SetSiteData { set { PresenterUtilities.FormatGridDisplay(gridView, value); gridView.DataSource = value; Generated from CHM, not final book. Will be superseded in the future. Page 63
- 64. gridView.DataBind(); } Note: IsNotSystemColumn is a helper method that ensures column headers are not added for hidden system columns such as index values. Finally, it is worth noting that the Presenter class simply requires a view object that implements IAggregateView. In unit testing scenarios, you can instantiate the presenter class using a mock implementation of IAggregateView, such as the MockAggregateView class shown in the following code example. C# class MockAggregateView : IAggregateView { public DataTable Data { get; set; } public DataTable SetSiteData { set { this.Data = value; } } } This ability to substitute a fake view class allows you to test your presenter logic in isolation, without any dependencies on the SharePoint environment or the implementation details of the user interface (UI). In the assert phase of your unit test, you can simply read the Data property of the MockAggregateView object to verify that the presenter class is sending valid data to the view. Generated from CHM, not final book. Will be superseded in the future. Page 64
- 65. Presenter Classes Presenter classes have one primary task: to retrieve data from the model and to send that data to the view. When you create a presenter class, you must pass in a view object and a model object. The following code example shows the constructor of the AggregateViewPresenter class. C# private IAggregateView view; private IEstimatesService estimatesService; public AggregateViewPresenter(IAggregateView view, IEstimatesService estimatesService) { this.view = view; this.estimatesService = estimatesService; } The AggregateViewPresenter class has no knowledge of how the view class and the model class are implemented; it simply requires that they implement the specified interfaces: IAggregateView. This interface defines a single write-only property named SetSiteData that requires an object of type DataTable. IEstimatesService. This interface defines a single method named GetSiteData that returns an object of type DataTable. In the AggregateViewPresenter class, the presenter logic is contained in a method named SetSiteData. In the reference implementation, this method is invoked by the view class. However, you could just as easily invoke this method from a unit test. C# public void SetSiteData() { try { view.SetSiteData = estimatesService.GetSiteData(); } catch (Exception ex) { // The Exception shielding logic is removed from here for simplicity. } } As you can see, the presenter logic itself is extremely straightforward and consists of a single line of code. However, in many real world examples, the presenter class will include substantial business logic and is likely to be larger and more complex. Generated from CHM, not final book. Will be superseded in the future. Page 65
- 66. Exception Shielding The ExecutionModels.Sandboxed solution demonstrates the use of an Exception Shielding pattern. This pattern is designed to trap unhandled exceptions at the system boundary before they are propagated to the host environment. In the case of Web Parts, unhandled exceptions that occur in the Web Part code are propagated to the page that hosts the Web Part, where they can prevent the page from loading. By trapping unhandled exceptions that occur at the Web Part boundary, you can make sure that problems in your Web Part do not cause broader problems in the host environment. This approach also enables you to troubleshoot and diagnose error messages more quickly and to provide users with a friendly error message. Note: The Developing SharePoint Applications release describes exception handling strategies in detail. This topic provides a brief summary of how these strategies are used within the ExecutionModels.Sandboxed solution. For more information about how to implement exception shielding strategies for SharePoint applications, see Exception Management in SharePoint on MSDN. In this case, the exception shielding functionality primarily consists of two key components: The error visualizer is a Web control that adds itself to the child controls collection of the Web Part. It renders error messages as HTML markup. The view exception handler writes unhandled exception messages to the event log and sends the exception message to the error visualizer. The view exception handler is invoked by the presenter class when the presenter logic fails. The rest of this topic describes how this works in the reference implementation. First, in the CreateChildControls method, the AggregateView class creates a new instance of the ErrorVisualizer class, passing a reference to itself as an argument. C# IErrorVisualizer errorVisualizer = new ErrorVisualizer(this); presenter.ErrorVisualizer = errorVisualizer; In the constructor, the ErrorVisualizer class adds itself to the Controls collection of the AggregateView Web Part. C# public ErrorVisualizer(Control hostControl, params Control[] childControls) { Validation.ArgumentNotNull(hostControl, "hostControl"); hostControl.Controls.Add(this); if (childControls == null) return; foreach (Control child in childControls) this.Controls.Add(child); } Note: Notice that the ErrorVisualizer constructor can also accept an array of child controls. Essentially, this enables you to contain all your Web Part content in the ErrorVisualizer object. The advantage of doing this is that the ErrorVisualizer will prevent this content from being rendered if an error occurs. However, the ExecutionModels.Sandboxed solution does not use this approach. In the AggregateViewPresenter class, the SetSiteData method includes a catch block that traps unhandled exceptions. The catch block creates or retrieves an instance of ViewExceptionHandler, passing in the unhandled exception and the ErrorVisualizer instance provided by the view. C# public IErrorVisualizer ErrorVisualizer { get; set; } public ViewExceptionHandler ExceptionHandler { get; set; } public void SetSiteData() { try { Generated from CHM, not final book. Will be superseded in the future. Page 66
- 67. view.SetSiteData = estimatesService.GetSiteData(); } catch (Exception ex) { ViewExceptionHandler viewExceptionHandler = this.ExceptionHandler ?? new ViewExceptionHandler(); viewExceptionHandler.HandleViewException(ex, this.ErrorVisualizer); } } In the ViewExceptionHandler class, the HandleViewException method writes the exception message to the event log and instructs the ErrorVisualizer instance to render the error message. C# ILogger logger = GetLogger(exception); logger.LogToOperations(exception, eventId, EventSeverity.Error, null); EnsureErrorVisualizer(errorVisualizer, exception); errorVisualizer.ShowDefaultErrorMessage(); In the ErrorVisualizer class, the ShowDefaultErrorMessage method simply sets the value of a property named ErrorMessage to the exception message. When the Web Part renders its child controls, the Render method of the ErrorVisualizer instance is invoked. If an error message is present, the ErrorVisualizer renders the message. By omitting the call base.Render, this also ensures that any child controls that were passed to the ErrorVisualizer are not rendered. C# protected override void Render(HtmlTextWriter writer) { if (string.IsNullOrEmpty(ErrorMessage)) { base.Render(writer); } else { RenderErrorMessage(writer, this.ErrorMessage); } } Generated from CHM, not final book. Will be superseded in the future. Page 67
- 68. Data Models and Service Classes The responsibility of a Model class is to interact with the underlying data source and to hide the details of that interaction from the presenter. The interface that underpins the Model class in the sandbox reference implementation defines a single method that returns a DataTable object. The interface that underpins the View class in the Sandbox RI simply defines a write-only property of type DataTable. C# public interface IEstimatesService { DataTable GetSiteData(); } The interface specifies nothing of the location or format of the data, so you can easily provide alternative implementations of IEstimatesService that retrieve data in different formats or from alternative locations. Also, you can easily create mock implementations of IEstimatesService to test the presenter logic. In the Sandbox RI, the EstimatesServ ice class provides a simple implementation of IEstimatesService. When the EstimatesServ ice class is instantiated, it builds an SPSiteDataQuery object. The implementation of the GetSiteData method simply runs the query. C# public class EstimatesService : IEstimatesService { private SPSiteDataQuery query; public EstimatesService() { query = new SPSiteDataQuery(); query.Lists = "<Lists BaseType='1' />"; query.ViewFields = "<FieldRef Name='SOWStatus' />" + "<FieldRef Name='EstimateValue' />"; query.Query = "<OrderBy><FieldRef Name='EstimateValue' /></OrderBy>"; query.Webs = "<Webs Scope='SiteCollection' />"; } public System.Data.DataTable GetSiteData() { SPWeb web = SPContext.Current.Web; return web.GetSiteData(query); } } Note: The SPSiteDataQuery object uses the C ollaborative Application Markup Language (C AML) query syntax. For more information about the C AML query syntax, see C ollaborative Application Markup Language C ore Schemas on MSDN. There are also several community and third-party tools that you can use to automatically generate C AML code. Generated from CHM, not final book. Will be superseded in the future. Page 68
- 69. Conclusion The Sandbox Reference Implementation (Sandbox RI) demonstrates best practice approaches to various aspects of sandboxed solution development. The key points illustrated by the Sandbox RI include the following: List instances, site columns, content types, document templates, and Web Parts are deployed to the sandbox environment. Use feature receiver classes within the sandbox environment and organize your feature dependencies. Use SPSiteDataQuery object to aggregate data from multiple lists, which obviates the need to enumerate sites and lists. Use of various patterns and techniques, including Model-View-Presenter (MVP), C onstructor Injection, and exception shielding, to improve the reliability, modularity, and testability of your code. We recommend deploying the reference implementation and exploring the different components and code in the ExecutionModels.Sandboxed solution. For more information about the sandbox execution environment, see Execution Models in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 69
- 70. Reference Implementation: Full-Trust Proxies for Sandboxed Solutions Full-trust proxies allow you to expose additional functionality to your SharePoint applications while maintaining many of the benefits of the sandbox environment. The Sandbox Reference Implementation (Sandbox RI) includes a sandboxed solution that retrieves statement of work (SOW) documents and estimations from multiple lists in a site collection. The solution includes a Web Part that displays a summary of the aggregated content in a central location. The Full-Trust Proxy Reference Implementation (Full-Trust Proxy RI) extends the list aggregation scenario to supplement the aggregated data with accounts payable information from a vendor system. The solution uses a full-trust proxy that connects to an Enterprise resource planning (ERP) Web service and retrieves information about the current vendor. The Full-Trust Proxy RI highlights details and best practices in the following areas: C reating, deploying, and registering a full-trust proxy C onsuming a full trust proxy from sandboxed code Deploying pages and client-side scripts to the sandbox environment Launching pages as modal dialogs from the sandbox environment Note: This solution builds on the Sandbox Reference Implementation. The documentation for the Sandbox RI describes many issues—such as feature partitioning, exception shielding, and the use of various design patterns—that are not repeated in this topic. We recommend that you familiarize yourself with the documentation for the Sandbox RI before you review this topic. Solution Scenario In this example, suppose you are a SharePoint consultant working for a pharmaceutical company named C ontoso Inc. You have already designed and implemented a sandboxed solution that aggregates list data from across the site collection for the Springfield manufacturing plant, as described in the Sandbox Reference Implementation. The solution includes a Web Part that displays an approval status and an estimated value for work items from various departments within the Springfield plant. The head of the Springfield plant, Janet Schorr, now wants you to extend this solution. In addition to a summary of approval status and estimated value, Janet wants to be able to view details of the vendor associated with each work item. In particular, Janet wants to be able to view the amount owed (accounts payable) to the vendor to make sure the plant is balancing work across preferred vendors. At present, this vendor information is stored in C ontoso's ERP system. The ERP system exposes various Web services that allow external systems to retrieve and interact with financial data, including the retrieval financial information related to vendors. To meet Janet’s requirements, you implement a full-trust proxy that interacts with the ERP Web services for vendor data. You then modify your sandboxed solution to use this full-trust proxy to retrieve and display client details. The user can click the name of a vendor to launch a modal dialog that displays the amount currently owed to the vendor, as shown in the following illustrations. Full Trust Proxy RI user interface Generated from CHM, not final book. Will be superseded in the future. Page 70
- 71. Deploying the Full-Trust Proxy RI The Full-Trust Proxy RI includes an automated installation script that creates a site collection, deploys the reference implementation components, and adds sample data. After running the installation script, browse to the new SpringfieldProxy site collection at http://<Hostname>/sites/SpringfieldProxy. You can open and run the project in Visual Studio, but this does not create a site collection or add sample data. To see the system fully functioning, you must run the installation script. The following table summarizes how to get started with the Full-Trust Proxy RI. Question Answer Where can I find the <install location>SourceExecutionModelProxy Full-Trust Proxy RI? What is the name of ExecutionModels.Sandboxed.Proxy.sln the solution file? What are the system SharePoint Foundation 2010 requirements? What preconditions You must be a member of SharePoint Farm Admin. are required for installation? You must be a memberof the Windows admin group. SharePoint must be installed at http://<Hostname:80>. If you want to install to a different location you can edit these settings in the Settings.xml file located in the Setup directory for the solution. SharePoint 2010 Administration service must be running. By default, this service is set to a manual start. To start the service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 Administration serv ice, and then click Start. How do I Install the Follow the instructions in the Readme.txt file located in the project folder. Full-Trust Proxy RI? What is the default http://<Hostname>/sites/SpringfieldProxy installation location? (This location can be altered by changing the Settings.xml in the Setup directory.) Generated from CHM, not final book. Will be superseded in the future. Page 71
- 72. How do I download The Full-Trust Proxy RI is included in the download Developing Applications for the Full-Trust Proxy SharePoint 2010. RI? Generated from CHM, not final book. Will be superseded in the future. Page 72
- 73. Solution Overview This topic provides a high-level conceptual overview of the Full-Trust Proxy Reference Implementation (Full-Trust Proxy RI). The solution consists of various sandboxed components and various full-trust components, as shown in the following illustration. Conceptual overview of the Full-Trust Proxy RI The Full-Trust Proxy RI consists of two solution packages, one for the sandboxed components and one for the full-trust proxy. The sandboxed components are deployed to the site collection solution gallery through the user interface (UI), while the full-trust proxy is deployed as a full-trust solution to the server environment. The implementation also includes a simple Windows C ommunication Foundation (WC F) service named VendorServices. In the sandboxed solution, the Aggregate View Web Part renders vendor names as hyperlinks. When a user clicks a vendor name, a client-side JavaScript function launches the Vendor Details page within a modal dialog. The JavaScript function passes the vendor name to the details page as a query string parameter. The Vendor Details page is a Web Part page that hosts the Vendor Details Web Part. The Vendor Details Web Part loads the vendor name from the page query string. The Web Part makes a call to the full-trust proxy to request the accounts payable associated with the current vendor name. The full-trust proxy calls the appropriate Vendor Web service method and then returns the outstanding balance to the Vendor Details Web Part. Note: Why does the Full-Trust Proxy RI use a Web Part within a Web Part page to display vendor details within a modal dialog? It might seem more straightforward to use a simple ASC X user control. However, deployment constraints prevent the Full-Trust Proxy RI from deploying application pages or user controls to the sandbox environment. The WC F service, VendorServices, is a simple proof-of-concept Web service that exposes a single method named GetAccountsPayable. This method accepts a string vendor name and returns a random double to represent what is owed to the vendor. Generated from CHM, not final book. Will be superseded in the future. Page 73
- 74. Proxy Components The ExecutionModels.Sandboxed.Proxy solution illustrates everything you need to know to create and deploy a full-trust proxy. At a high level, you must complete three key tasks to make a full-trust proxy available to sandboxed solutions: C reate a proxy operation arguments class that represents the data that you want to pass to your full-trust proxy. This class should inherit from the SPProxyOperationArgs base class. The proxy operation arguments class is essentially a serializable collection of user-defined public properties. C reate a proxy operations class that implements your full-trust logic. This class should inherit from the SPProxyOperations base class. The base class defines a single method named Execute that requires a single argument of type SPProxyOperationsArgs and returns a value of type Object. Register your full-trust proxy with the user code service. This is best accomplished through the use of a feature receiver class. The registration process makes your proxy operation arguments class available in the sandbox environment, and it enables you to invoke your proxy logic through the SPUtility.ExecuteRegisteredProxyOperation method. Generated from CHM, not final book. Will be superseded in the future. Page 74
- 75. The Proxy Operation Arguments Class When you create a full-trust proxy, you need to provide developers with a way to pass arguments from their sandboxed code to your full-trust logic. This must be carefully managed, because SharePoint needs to marshal these arguments across process boundaries. Fortunately, the proxy operation arguments class handles these issues for you. Every call to a full-trust proxy must include an argument of type SPProxyOperationArgs. This is an abstract, serializable class that you can find in the Microsoft.SharePoint.UserCode namespace. When you create a full-trust proxy, you should create your own proxy operation arguments class that inherits from SPProxyOperationArgs. Your class should define public properties for any arguments that you want to pass to your full-trust logic. Note: A good practice is to define the assembly name and the type name of your proxy operations class as constants in your proxy operation arguments class. The assembly name and type name are required when your full-trust proxy is registered with SharePoint and every time the operation is invoked from sandbox code. In the ExecutionModels.Sandboxed.Proxy solution, the proxy operation arguments class is named AccountsPayableProxyArgs. This is shown in the following code example. C# [Serializable] public class AccountsPayableProxyArgs : SPProxyOperationArgs { public static readonly string AssemblyName = "..."; public static readonly string TypeName = "VendorSystemProxy.AccountsPayableProxyOps"; private string vendorName; public string VendorName { get { return (this.vendorName); } set { this.vendorName = value; } } public AccountsPayableProxyArgs(string vendorName) { this.vendorName = vendorName; } public AccountsPayableProxyArgs() { } public string ProxyOpsAssemblyName { get { return AssemblyName; } } public string ProxyOpsTypeName { get { return TypeName; } } } As you can see, the proxy operation arguments class is relatively straightforward. The class provides the following functionality: It defines a default constructor, which is required for serialization. It defines a public string property to store and retrieve the vendor name. It defines a constructor that accepts a string vendor name value. It defines public read-only string properties to retrieve the assembly name and the type name of the proxy operations class. Generated from CHM, not final book. Will be superseded in the future. Page 75
- 76. Generated from CHM, not final book. Will be superseded in the future. Page 76
- 77. The Proxy Operations Class The proxy operations class contains the logic that gets executed when you invoke your full-trust proxy from a sandboxed solution. The proxy operations class does not expose methods directly to the sandbox environment. Instead, the logic in the Execute method is invoked when the sandboxed code calls the SPUtility.ExecuteRegisteredProxyOperation method. In the proxy operations class, the Execute method must do the following: Take a single argument of type SPProxyOperationArgs. Return a serializable value as an object. In the Full-Trust Proxy Reference Implementation (Full-Trust Proxy RI), the proxy operations class is named AccountsPayableProxyOps. This is shown in the following code example. C# public class AccountsPayableProxyOps : SPProxyOperation { private const string address = Vendor.Services.Implementation.VendorServices.DeploymentLocation; public override object Execute(SPProxyOperationArgs args) { // Perform error checking. try { AccountsPayableProxyArgs proxyArgs = args as AccountsPayableProxyArgs; string vendorName = proxyArgs.VendorName; double accountsPayable = 0.0; WSHttpBinding binding = new WSHttpBinding(); EndpointAddress endpointAddress = new EndpointAddress(address); using (ChannelFactory<IVendorServices> factory = new ChannelFactory<IVendorServices>(binding, endpointAddress)) { IVendorServices proxy = factory.CreateChannel(); accountsPayable = proxy.GetAccountsPayable(vendorName); factory.Close(); } return accountsPayable; } catch (Exception ex) { return ex; } } } Essentially, the Execute method in the AccountsPayableProxyOps class performs three tasks: It retrieves the vendor name value from the AccountsPayableProxyArgs instance. It calls the Web service's GetAccountsPayable method, passing in the vendor name. It returns the outstanding account balance for the vendor to the caller. If an exception occurs, it is caught and returned. This gives the calling code more information about what failed. Because the proxy operations class, AccountsPayableProxyOps, is deployed in a farm solution and runs with full trust, there are no limitations on the actions that you can perform within the Execute method. Generated from CHM, not final book. Will be superseded in the future. Page 77
- 78. Registering a Full-Trust Proxy To enable sandboxed solution developers to use your full-trust proxy, you must register your proxy operations class and assembly with the user code service. The best way to do this is to create a farm-scoped feature with an event receiver class that inherits from SPF eatureActivated. You can register the full-trust proxy in the FeatureActivated method of the event receiver. The following code example shows the F eatureActiv ated method from the RegisterVendorFullTrustProxyEv entReceiver class. C# public override void FeatureActivated(SPFeatureReceiverProperties properties) { SPUserCodeService userCodeService = SPUserCodeService.Local; SPProxyOperationType vendorPayablesOperation = new SPProxyOperationType( AccountsPayableProxyArgs.AssemblyName, AccountsPayableProxyArgs.TypeName); userCodeService.ProxyOperationTypes.Add(vendorPayablesOperation); userCodeService.Update(); } Essentially, the proxy registration code performs the following actions: It creates a new SPProxyOperationType from the proxy operations type name and assembly name. It adds the SPProxyOperationType to the local user code service's ProxyOperationTypes collection. It calls the Update method to persist the changes to the user code service. For information about how to invoke a proxy operation from the sandbox environment, see C onsuming a Full-Trust Proxy. Generated from CHM, not final book. Will be superseded in the future. Page 78
- 79. Sandboxed Components Primarily, the sandboxed components in the ExecutionModels.Sandboxed.Proxy solution are designed to show you how to consume a full-trust proxy from sandboxed code. However, these components also demonstrate approaches to various other challenges that you may face when you work with sandboxed applications. Essentially, the sandboxed components consist of two Web Parts: AggregateView. This Web Part displays aggregated list data from across the site collection. This is largely unchanged from the sandbox reference implementation. VendorDetails. This Web Part displays the name, ID, and current accounts payable balance for an individual vendor. It uses the full-trust proxy to retrieve the outstanding balance from the Vendors service exposed by the Enterprise resource planning (ERP) system. This Web Part is embedded in a Web Part page named VendorDetails.aspx, which is displayed as a modal dialog when the user clicks the name of a vendor in the AggregateView Web Part. The following illustration shows how these Web Parts interact at a conceptual level. Conceptual overview of Web Part interaction To make this approach work, you need to perform various tasks: Deploy a custom Web Part page to the sandbox environment. C reate a JavaScript function to launch the custom Web Part page as a modal dialog and to provide the Web Part with a vendor name. Modify the AggregateView Web Part to call the JavaScript function when the user clicks a vendor name. Program the VendorDetails Web Part to call the full-trust proxy. Generated from CHM, not final book. Will be superseded in the future. Page 79
- 80. Deploying Custom Pages to the Sandbox Environment The ExecutionModels.Sandboxed.Proxy solution includes one new type of resource, in addition to the components you have already seen in the Sandbox Reference Implementation (Sandbox RI). The VendorDetail.aspx file is a custom Web Part page. It is used to display the VendorDetails Web Part in a Modal Dialog. When you work with farm solutions, the most common way to make pages and scripts available in a SharePoint environment is to deploy them to the TemplateLayouts folder in the SharePoint root on the server file system. The Layouts folder is mapped to the _layouts virtual directory on each SharePoint site, so your files are always available. However, you cannot use this approach in the sandbox environment because sandboxed solutions are not permitted to deploy any files to the server file system. In the sandbox environment, you must deploy these resources to an appropriate document library in the site collection or as inline script. The reference implementation uses inline script instead of a separate JavaScript file, because it requires only a small amount of JavaScript that is specific to the page. The following code example shows the feature manifest for the VendorDetail.aspx file. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Pages" List="101" Url="Lists/Pages"> <File Url="VendorDetail.aspx" Type="GhostableInLibrary" > <AllUsersWebPart WebPartZoneID="Left" WebPartOrder="1"> <![CDATA[<webParts> <webPart xmlns="http://schemas.microsoft.com/WebPart/v3"> <metaData>…</metaData> <data>…</data> </webPart> </webParts>]]> </AllUsersWebPart> </File> </Module> <CustomAction Location="ScriptLink" ScriptBlock =" function ShowVendorDetailsDialog(url) { var options = SP.UI.$create_DialogOptions(); options.url = url; options.height = 300; SP.UI.ModalDialog.showModalDialog(options); }"> </CustomAction> </Elements> The preceding code uses a module to deploy the file to the Pages library in the site collection. In the F ile element, the Type="GhostableInLibrary" attribute indicates that the deployment target is a type of document library and that SharePoint should create a parent list item for the file. This also specifies that the file is stored in the content database and not on the server file system. You can also see that a CustomAction section is used to define a JavaScript function to inline. This approach to script deployment is recommended if you have a relatively small amount of JavaScript, as opposed to deploying a JavaScript file. SharePoint is able to optimize the script load performance more effectively when you use this mechanism for a small amount of script. For information about the behavior of the JavaScript function, see Launching a Modal Dialog within the Sandbox Environment. Note: If you require a large amount of JavaScript, it makes sense to deploy your script within a file. For more information about this approach, see How to: Display a Page as a Modal Dialog. Generated from CHM, not final book. Will be superseded in the future. Page 80
- 81. Launching a Modal Dialog in the Sandbox Environment The ExecutionModels.Sandboxed.Proxy solution uses a modal dialog to display financial details when the user clicks the name of a vendor. This dialog is actually a Web Part page (VendorDetail.aspx) that contains a Web Part (VendorDetails.cs). To launch the modal dialog, the following three tasks must be performed: C reate a JavaScript function that uses the SharePoint 2010 client object model to launch a specified page as a modal dialog. Deploy the JavaScript function to the sandbox environment. For more information, see Deploying C ustom Pages to the Sandbox Environment. Render vendor names as hyperlinks that call the JavaScript function when clicked. The feature manifest for the Vendor Details page defines a function named ShowVendorDetailsDialog. This function uses the SharePoint 2010 client object model to launch a page at a specified URL as a modal dialog, as shown in the following code example. Jav aScript function ShowVendorDetailsDialog(url) { var options = SP.UI.$create_DialogOptions(); options.url = url; options.height = 300; SP.UI.ModalDialog.showModalDialog(options); } In the AggregateView Web Part, you must render the vendor names as hyperlinks that call the JavaScript function when clicked. To do this, handle the RowDataBound event for the grid view control. Within the grid view, the contents of each vendor name cell is replaced with a HyperLink control, as shown in the following code example. C# protected void GridView_RowDataBound(object sender, GridViewRowEventArgs e) { const int VendorNameCellIndex = 3; const int EstimateValueCellIndex = 2; DataControlRowType rowType = e.Row.RowType; if (rowType == DataControlRowType.DataRow) { TableCell vendorNameCell = e.Row.Cells[VendorNameCellIndex]; HyperLink hlControl = new HyperLink(); hlControl.Text = vendorNameCell.Text; hlControl.NavigateUrl = string.Concat( "JavaScript: ShowVendorDetailsDialog('", SPContext.Current.Site.RootWeb.Url, "/Lists/Pages/VendorDetail.aspx?VendorName=" + vendorNameCell.Text + "');" ); vendorNameCell.Controls.Add(hlControl); TableCell estimateValueCell = e.Row.Cells[EstimateValueCellIndex]; double currencyValue; if(double.TryParse(estimateValueCell.Text, out currencyValue)) { estimateValueCell.Text = String.Format("{0:C}", currencyValue); } } } This renders each vendor name as a hyperlink in the following format. HTML <a href="JavaScript: ShowVendorDetailsDialog('Page URL')>Vendor Name</a> Generated from CHM, not final book. Will be superseded in the future. Page 81
- 82. Note that the URL that is passed to the ShowVendorDetailsDialog function includes a query string values for VendorName. This is retrieved by the VendorDetails Web Part and is used in the proxy operation call. Generated from CHM, not final book. Will be superseded in the future. Page 82
- 83. Consuming a Full-Trust Proxy Essentially, consuming a full-trust proxy from sandboxed code consists of two steps. First, you must create an instance of your proxy operation arguments class and provide values for any properties. C# AccountsPayableProxyArgs proxyArgs = new AccountsPayableProxyArgs(); proxyArgs.VendorName = VendorName; Next, you must call the SPUtility.ExecuteRegisteredProxyOperation method, passing in the assembly name of the proxy operations class, the type name of the proxy operations class, and the proxy operation arguments instance. C# var result = SPUtility.ExecuteRegisteredProxyOperation( proxyArgs.ProxyOpsAssemblyName, proxyArgs.ProxyOpsTypeName, proxyArgs); The VendorDetails Web Part uses the Model-View-Presenter (MVP) pattern, as shown in the following illustration. The VendorDetails Web Part For more information about how the MVP pattern works in practice, see Sandbox Reference Implementation. The remainder of this topic focuses on how to consume a full-trust proxy within the context of the MVP pattern. First, note that the presenter class, VendorDetailsPresenter, includes a public property for the vendor name. C# private string vendorName; public string VendorName { get { return (vendorName); } set { vendorName = value; } } The VendorDetails Web Part (the v iew class) is responsible for instantiating the presenter class. In the CreateChildControls method, the Web Part retrieves the vendor name from the page query string and sets the Generated from CHM, not final book. Will be superseded in the future. Page 83
- 84. VendorName property on the presenter. Next, it invokes the presenter logic by calling the SetVendorDetails method. C# private VendorDetailsPresenter presenter; protected override void CreateChildControls() { ... string vendorName = Page.Request.QueryString["VendorName"]; ... presenter = new VendorDetailsPresenter(this, new VendorService()); presenter.VendorName = vendorName; presenter.ErrorVisualizer = errorVisualizer; presenter.SetVendorDetails(); } In the presenter class, the SetVendorDetails method constructs an instance of the proxy operation arguments class, AccountsPayableProxyArgs. The presenter logic then calls the GetAccountsPayable method to retrieve the outstanding balance from the model class, passing in the AccountsPayableProxyArgs instance as an argument. C# public void SetVendorDetails() { try { AccountsPayableProxyArgs proxyArgs = new AccountsPayableProxyArgs(); proxyArgs.VendorName = vendorName; string assemblyName = proxyArgs.ProxyOpsAssemblyName; view.AccountsPayable = vendorService.GetVendorAccountsPayable( proxyArgs, assemblyName); } catch (Exception ex) { // Exception shielding logic removed for clarity. } } In the model class, VendorServ ice, the GetVendorAccountsPayable method invokes the proxy operation. The return type is cast to a double and returned to the caller. C# public double GetVendorAccountsPayable(AccountsPayableProxyArgs proxyArgs, string assemblyName) { var result = SPUtility.ExecuteRegisteredProxyOperation( assemblyName, proxyArgs.ProxyOpsTypeName, proxyArgs); if (result.GetType().IsSubclassOf(typeof(Exception))) { throw result as Exception; } double cred = (double) result; return (cred); } Generated from CHM, not final book. Will be superseded in the future. Page 84
- 85. Finally, the presenter class sets the accounts payable balance on the view instance. To facilitate this, the VendorDetails class provides a simple write-only property named AccountsPayable that sets the Text property of a label to the value supplied by the presenter. C# public double AccountsPayable { set { PayablesValueLabel.Text = string.Format("{0:C}", value); } } Generated from CHM, not final book. Will be superseded in the future. Page 85
- 86. Vendor Service Security Configuration Because the Vendor Service exposes sensitive accounts payable data, the service must be secured. The reference implementation uses a trusted subsystem model to authenticate to the service. Because the sandbox runtime removes any security tokens associated with the user, many of the standard authentication mechanisms will not work because the user credentials are unavailable. Using a trusted subsystem model in which credentials of the process account are used to authenticate to the service avoids this issue, but it provides only coarse granularity for performing authorization. In this reference implementation, the service is secured using Windows authentication with transport-level security, which provides a balance between security and complexity. Because this is designed for a test environment, an unencrypted HTTP connection is used for the service. In a production environment, this would provide an insufficient level of security, so you should use a Secure Socket Layer (SSL) connection. To use transport-level security with Windows and Internet Information Services (IIS), you must enable Windows authentication for the Web site that hosts the service, and you must configure IIS to support URL authorization. URL authorization is configured by default in Windows Server 2008, but if you are using Windows 7, you will need to manually configure it. To do this, in the Turn Windows features on or off dialog box, expand Internet Information Serv ices, expand World Wide Web Services, expand Security, and then ensure the URL Authorization check box is selected, as shown in the following illustration. Enabling URL Authorization in Windows 7 The service is installed to the C ontoso Web site in IIS. You must use IIS Manager to configure authentication for the site. Ensure that Windows authentication is configured for the Web site that hosts the service, as shown in the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 86
- 87. Authentication settings in IIS Manager When the Full-Trust Proxy RI deploys the VendorService service, it also adds an authorization policy to the Web site that hosts the service. The installer achieves this by adding the following code to the Web.config file for the C ontoso Web site. XML <system.webServer> <security> <authorization> <remove users="*" roles="" verbs="" /> <add accessType="Allow" roles="ContosoUsers" /> <add accessType="Deny" users="?" /> <add accessType="Allow" users="SandboxSvcAcct" /> </authorization> </security> </system.webServer> As you can see, the policy allows members of the C ontosoUsers role and the SandboxSvcAcct user to access the service. SandboxSvcAcct is a managed account that the installer creates to run the Microsoft SharePoint Foundation Sandboxed C ode Service, and this is the identity that is provided when you access the service from the sandbox environment. The C ontosoUsers role is added to support the C lient Reference Implementation, which uses client-side code to access the same service. The full-trust proxy programmatically configures the service binding in a way that the Windows identity of the sandbox proxy process is provided to the service. This causes the SandboxSvcAcct identity to be used, as shown by the following code. C# BasicHttpBinding binding = new BasicHttpBinding(); binding.Security.Transport.ClientCredentialType = HttpClientCredentialType.Windows; binding.Security.Mode = BasicHttpSecurityMode.TransportCredentialOnly; EndpointAddress endpointAddress = new EndpointAddress(address); using (ChannelFactory<IVendorServices> factory = new ChannelFactory<IVendorServices>(binding, endpointAddress)) { IVendorServices proxy = factory.CreateChannel(); accountsPayable = proxy.GetAccountsPayable(vendorName); factory.Close(); } For more sophisticated approaches to security, you could consider using a Trusted Façade pattern, which combines using the trusted subsystem model and providing the name of the user. You can obtain the name of the Generated from CHM, not final book. Will be superseded in the future. Page 87
- 88. user, but not the user's security token, from the SPUser instance in the SPContext object. Generated from CHM, not final book. Will be superseded in the future. Page 88
- 89. Conclusion The Full-Trust Proxy Reference Implementation (Full-Trust Proxy RI) demonstrates proven practice approaches to creating and consuming full-trust proxies for sandboxed solutions. The key points of interest include the following: The creation and deployment of full-trust proxies. The registration process for full-trust proxy assemblies. The consumption of full-trust proxies from sandboxed code. The deployment of pages and scripts to the sandbox environment. The use of the SharePoint 2010 client object model to launch modal dialogs from the sandbox environment. We recommend you deploy the Full-Trust Proxy RI and to explore the different components and code within the ExecutionModels.Sandboxed.Proxy solution. For more information about full-trust proxies, see Execution Models in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 89
- 90. Reference Implementation: Farm Solutions Although you can use sandboxed solutions and hybrid approaches to deploy a wide variety of SharePoint applications, there are some components, such as timer jobs, that must be deployed as full-trust farm solutions. This reference implementation illustrates the use of a timer job to aggregate data across multiple site collections. The Sandbox Reference Implementation includes a sandboxed solution that retrieves statement of work (SOW) documents and estimations from multiple lists in a site collection. The solution includes a Web Part that displays a summary of the aggregated content on the site collection root site. The Full-Trust Proxy Reference Implementation extends the list aggregation scenario to supplement the aggregated data with accounts payable details from a vendor system. The solution uses a full-trust proxy that connects to an ERP Web service and retrieves information about the current vendor. This reference implementation further extends these scenarios by using a timer job to aggregate content from multiple site collections. The reference implementation highlights details and best practices in the following areas: C reating, deploying, and registering a timer job Managing configuration data for timer jobs Deploying custom application pages to the C entral Administration Web site Note: This solution builds on the Sandbox Reference Implementation and the Full-Trust Proxy Reference Implementation. To fully understand the concepts in this solution, we recommend you first familiarize yourself with the documentation for these implementations before you study the Full-Trust Reference Implementation (Full-Trust RI). Solution Scenario In this example, suppose you are a SharePoint consultant working for a pharmaceutical company named C ontoso Inc. The Northwest division of C ontoso currently includes manufacturing plants at Blue Bell and New Brunswick. The construction and maintenance teams in each plant all have their own sites on the corporate intranet portal, which they use to track statements of work (SOWs) and corresponding budget estimates in the team. The general manager of the Northwest division, Phyllis Harris, now wants you to extend this solution. Phyllis wants to be able to view a rollup of all open estimates to gain an understanding of the potential uncommitted work in the division. To meet Phyllis 's requirements, you implement a timer job that retrieves approved estimates from each site collection in the division. The timer job then populates an Approved Estimates library on the divisional site collection, as shown in the following illustration. The Approved Estimates library Deploying the Farm Solution RI The Farm Solution RI includes an automated installation script that creates a site collection, deploys the reference implementation components, and adds sample data. After running the installation script, browse to the new Headquarters site collection at http://<Hostname>/sites/HeadQuarters. You can open and run the solution in Visual Studio, but this does not create a site collection or add sample data. To see the system fully functioning, you must run the installation script. The following table summarizes how to get started with the Farm Solution RI. Generated from CHM, not final book. Will be superseded in the future. Page 90
- 91. Question Answer Where can I find the <install location>SourceExecutionModelFullTrust Farm Solution RI? What is the name of ExecutionModels.FarmSolution.sln the solution file? What are the system SharePoint Foundation 2010 requirements? What preconditions You must be a member of SharePoint Farm Admin. are required for installation? You must be a member of the Windows admin group. SharePoint must be installed at http://<Hostname:80>. If you want to install to a different location, you can edit these settings in the Settings.xml file located in the Setup directory for the solution. SharePoint 2010 Administration service must be running. By default, this service is set to a manual start. To start the service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 Administration serv ice, and then click Start. The timer service must be running. To start the timer service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click on SharePoint 2010 timer, and then click Start. How do I Install the Follow the instructions in the readme file located in the project folder. Farm Solution RI? What is the default http://<Hostname>/sites/HeadQuarters installation location? (This location can be altered by changing the Settings.xml file in the Setup directory.) How do I download The Sandbox Farm Solution RI is included in the download Developing Applications for the Sandbox Farm SharePoint 2010. Solution RI? Generated from CHM, not final book. Will be superseded in the future. Page 91
- 92. Solution Overview This topic provides a high-level conceptual overview of the Full-Trust Reference Implementation (Full-Trust RI). The key component of the solution is a timer job, as shown in the following illustration. Conceptual overview of the Full-Trust RI The timer job relies on a custom application page to provide a list of site collections from which to retrieve approved estimates. This application page is deployed to the C entral Administration Web site, where a custom action is used to create a navigation link to the page under the Timer Jobs heading. Configuration link and application page in Central Administration After it retrieves the list of site collections, the timer job looks for an Estimates list in all of the subsites in each site collection. It then copies any approved estimates in these lists to a central Approved Estimates list on the divisional headquarters site collection. The Full-Trust Proxy RI consists of two solution packages: Generated from CHM, not final book. Will be superseded in the future. Page 92
- 93. ExecutionModels.FarmSolution.Jobs. This solution package deploys the timer job to the SharePoint server environment, and it uses a feature receiver class to register the timer job. It also deploys the Approved Estimates list to the divisional headquarters site collection. ExecutionModels.FarSolution. This solution package deploys the custom application page to the C entral Administration Web site, together with the custom action that creates the navigation link. Generated from CHM, not final book. Will be superseded in the future. Page 93
- 94. The Approved Estimates Timer Job Essentially, a timer job definition class exposes full-trust logic that can be invoked by the SharePoint timer service (owstimer.exe) on a scheduled basis. A SharePoint 2010 timer job can be associated with either a SharePoint Web application or a SharePoint service application. In the Full-Trust Reference Implementation (Full-Trust RI), the timer job class is named ApprovedEstimatesJob and targets the Web application scope. To make its logic available to the timer service, the timer job class must meet certain requirements. The class must be public and must implement the SPJobDefinition base class. It must also have a default constructor, so that it can be serialized by the timer service. In the Full-Trust RI, the timer job is scoped at the Web application level, so it must also define a constructor that accepts an argument of type SPWebApplication. This allows you to target a specific Web application when you register the timer job. The following code example shows the class definition and the constructors for the ApprovedEstimatesJob class. C# public class ApprovedEstimatesJob : SPJobDefinition { public const string JobName = "ApprovedEstimatesJob"; ... public ApprovedEstimatesJob() : base() { } public ApprovedEstimatesJob(SPWebApplication webApplication) : base(JobName, webApplication, null, SPJobLockType.Job) { Title = Constants.jobTitle; } ... The timer job definition overrides a method named Execute. This method is called by the SharePoint timer service when the timer job is run. C# public override void Execute(Guid targetInstanceId) { ... } Essentially, the Execute method performs the following actions: It retrieves the source sites and the destination site from configuration settings. It runs a query on each source site to retrieve any approved estimate items. It adds the approved estimate items to the Approved Estimates list on the destination site. The logic that retrieves approved estimates from each site collection is provided by a helper method named GetAllApprov edEstimatesF romSiteCollection. This method uses an SPSiteDataQuery object to retrieve estimate documents that have a SOWStatus value of Approved. C# private static SPSiteDataQuery GetAllApprovedEstimatesFromSiteCollection() { var query = new SPSiteDataQuery(); query.Lists = "<Lists BaseType='1' />"; query.ViewFields = "<FieldRef Name='Title' Nullable='TRUE' />" + "<FieldRef Name='FileRef' Nullable='TRUE' />"; query.Query = "<Where>" + "<Eq>" + "<FieldRef Name='SOWStatus' />" + "<Value Type='Choice'>Approved</Value>" + Generated from CHM, not final book. Will be superseded in the future. Page 94
- 95. "</Eq>" + "</Where>"; query.Webs = "<Webs Scope='SiteCollection' />"; return query; } As you can see, the query retrieves the value of the Title field and the F ileRef field for each approved estimate. The Execute method uses the FileRef to access the estimate document and create a copy on the Approved Estimates list. Note: For step-by-step guidance on how to implement a timer job, see How to: C reate a Web Application-Scoped Timer Job. Generated from CHM, not final book. Will be superseded in the future. Page 95
- 96. Registering the Timer Job To be able to use a timer job class, you must register it with the SharePoint timer service (Owstimer.exe). To be able to register the timer job at the point of deployment, you create a farm-scoped feature—the Approved Estimates Job feature—and use a feature receiver class to perform the registration. Note that the Approved Estimates Job feature contains no feature manifests; it exists solely to register the timer job on feature activation. The timer job registration process consists of three steps: The timer job definition is instantiated, and the current Web application is passed to the constructor as an argument. A schedule is created and then associated with the timer job instance. The timer job instance is updated. The following code example shows this process. C# public override void FeatureActivated(SPFeatureReceiverProperties properties) { SPWebApplication webApplication = properties.Feature.Parent as SPWebApplication; DeleteJob(webApplication.JobDefinitions); ApprovedEstimatesJob estimatesJob = new ApprovedEstimatesJob(webApplication); SPMinuteSchedule schedule = new SPMinuteSchedule(); schedule.BeginSecond = 0; schedule.EndSecond = 59; schedule.Interval = 5; estimatesJob.Schedule = schedule; estimatesJob.Update(); } Note that the F eatureActiv ated method calls a helper method named DeleteJob. This removes the timer job from the collection of job definitions in the current Web application. This method is also used to remove the timer job when the feature is deactivated. C# private void DeleteJob(SPJobDefinitionCollection jobs) { foreach (SPJobDefinition job in jobs) { if (job.Name.Equals(ApprovedEstimatesJob.JobName, StringComparison.OrdinalIgnoreCase)) { job.Delete(); } } } When the feature is deactivated, the F eatureDeactivating method simply calls the DeleteJob method to delete the job definition from the current Web application. public override void FeatureDeactivating(SPFeatureReceiverProperties properties) { SPWebApplication webApplication = properties.Feature.Parent as SPWebApplication; DeleteJob(webApplication.JobDefinitions); } Generated from CHM, not final book. Will be superseded in the future. Page 96
- 97. The Timer Job Configuration Page The Approved Estimates timer job must retrieve various configuration settings to be able to function correctly. To provide these settings, deploy a custom application page, TimerJobC onfig.aspx, to the C entral Administration Web site. The timer job configuration page The timer job configuration page enables the farm administrator to provide the following settings: The relative URL of the destination site collection The name of the Approved Estimates list on the destination site collection A semicolon-separated list of source site collections It also enables the administrator to immediately run the job. When the user clicks Apply Changes, the configuration settings are persisted to the property bag of the Approved Estimates timer job, as shown in the following code example. C# protected void ApplyButton_Click(object sender, EventArgs e) { IEnumerable<SPJobDefinition> allJobs = GetTimerJobsByName(Constants.jobTitle); foreach (SPJobDefinition selectedJob in allJobs) { if (!string.IsNullOrEmpty(ListNameTextBox.Text)) { selectedJob.Properties[Constants.timerJobListNameAttribute] = ListNameTextBox.Text; } if (!string.IsNullOrEmpty(SiteNamesTextBox.Text)) { selectedJob.Properties[Constants.timerJobSiteNameAttribute] = SiteNamesTextBox.Text; } if (!string.IsNullOrEmpty(DestinationSiteTextBox.Text)) { selectedJob.Properties[Constants.timerJobDestinationSiteAttribute] = DestinationSiteTextBox.Text; } selectedJob.Update(); } } Generated from CHM, not final book. Will be superseded in the future. Page 97
- 98. The click event handler uses the GetTimerJobsByName helper method to retrieve all instances of the Approved Estimates job from the server farm. This is necessary because several instances of the job could be associated with different service applications or Web applications. C# private List<SPJobDefinition> GetTimerJobsByName(string displayName) { List<SPJobDefinition> AllJobs = new List<SPJobDefinition>(); // For all servers in the farm (the servers could be different). foreach (SPServer server in farm.Servers) { // For each service instance on the server. foreach (SPServiceInstance svc in server.ServiceInstances) { if (svc.Service.JobDefinitions.Count > 0) { // If it is a Web Service, then get the Web application from // the Web Service entity. if (svc.Service is SPWebService) { SPWebService websvc = (SPWebService) svc.Service; AllJobs.AddRange(from webapp in websvc.WebApplications from def in webapp.JobDefinitions where def.DisplayName.ToLower() == displayName.ToLower() select def); } else { //Otherwise Get it directly from the Service AllJobs.AddRange(svc.Service.JobDefinitions.Where(def => def.DisplayName.ToLower() == displayName.ToLower())); } } } } return AllJobs; } To make the timer job configuration page available to farm administrators, it is deployed to the C entral Administration Web site. Generated from CHM, not final book. Will be superseded in the future. Page 98
- 99. Deploying the Configuration Page to Central Administration In most cases, when you add custom application pages to a SharePoint environment, you deploy your pages to a subfolder in the TemplateLayouts folder in the SharePoint root. This makes your page available under the _layouts virtual directory on every site. However, in this case, you do not want to expose the timer job configuration page on every SharePoint site—it should be available only on the C entral Administration site. To achieve this, deploy the page to the TemplateAdmin folder in the SharePoint root. This makes the page available under the _admin virtual directory on the C entral Administration Web site. The _admin virtual directory is not made available to any Web application except for C entral Administration. To deploy the page to the TemplateAdmin folder, a SharePoint Mapped Folder was added to the solution, as shown in the following illustration. This makes the timer job configuration page available at a relative URL of _admin/TimerJobAdmin/TimerJobC onfig.aspx within the C entral Administration Web site. Using a SharePoint Mapped Folder After you deploy the page to the correct location, add a navigation link to enable farm administrators to find the page. To achieve this, create a feature manifest that defines a CustomAction element. This is deployed to the C entral Administration Web site in a Web-scoped feature named Admin Forms Navigation. Note: For more information about how to add actions to the SharePoint user interface, see Default C ustom Action Locations and IDs and How to: Add Actions to the User Interface on MSDN. The following code example shows the feature manifest for the Admin Forms Navigation feature. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <CustomAction Id="DCA50F3D-D38F-41D9-8120-25BD7F930FDE" GroupId="TimerJobs" Location="Microsoft.SharePoint.Administration.Monitoring" Sequence="10" Title="Configure Approved Estimates Aggregation Timer Job" Description=""> <UrlAction Url="_admin/TimerJobAdmin/TimerJobConfig.aspx" /> Generated from CHM, not final book. Will be superseded in the future. Page 99
- 100. </CustomAction> </Elements> Essentially, this code adds a link to the timer job configuration page to the Monitoring page on the C entral Administration Web site. The link is added to the Timer Jobs group, as shown in the following illustration. Using a custom action to add a link Note: For step-by-step guidance on how to deploy an application page to the C entral Administration Web site, see How to: Deploy an Application Page to C entral Administration. Generated from CHM, not final book. Will be superseded in the future. Page 100
- 101. Conclusion The Full-Trust Reference Implementation (Full-Trust RI) demonstrates best practice approaches to the deployment of various full-trust components to the SharePoint environment. The key points of interest include the following: The creation and deployment of timer job definitions The registration process for timer jobs The management of configuration data for timer jobs The deployment of custom application pages to the C entral Administration Web site We recommend you deploy the Full-Trust RI and to explore the different components and code within the ExecutionModels.FarmSolution solution. For more information about full-trust components, see Execution Models in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 101
- 102. Reference Implementation: Workflow Activities In SharePoint 2010, site users can create powerful workflows in SharePoint Designer by connecting and configuring workflow actions. These workflows are known as declarative workflows, because the logic that connects the individual workflow actions is defined entirely in declarative markup and does not require custom code. SharePoint 2010 includes many built-in workflow actions for common tasks and activities. As a developer, you can also make additional actions available to workflow creators in two ways: You can create a full-trust workflow activity class and deploy it as a farm solution. To use these activities in SharePoint Designer, you must create and deploy a workflow actions file to package your activity, and you must add an authorized type entry for your activity class to the Web.config file. You can create a sandboxed workflow action class and deploy it as a sandboxed solution. To be able to package your workflow action, you must create a feature with a workflow actions element in an element manifest file. Both approaches make additional workflow actions available to users in SharePoint Designer. The full-trust approach allows developers to expose specialized functionality to workflow creators, such as connecting to external systems and services or performing actions across site collection boundaries. The sandboxed approach allows developers to introduce custom workflow logic to site collections in hosted environments or in other environments in which the deployment of farm solutions is prohibited. Sandboxed workflow action logic must observe the constraints of the sandbox environment—for example, sandboxed workflow actions cannot access external systems or services and are limited to a subset of the SharePoint API. Note: We recommend that you review Execution Models in SharePoint 2010 prior to studying the Workflow Activities Reference Implementation (Workflow Activities RI). It provides a more detailed explanation of many of the concepts described in this topic. This implementation highlights details and best practices in the following areas: C reating and deploying full-trust workflow activities C reating and deploying sandboxed workflow actions C onsuming custom activities and sandboxed actions from a declarative workflow. Solution Scenario In this example, suppose you are a SharePoint consultant working for a pharmaceutical company named C ontoso Inc. You have already designed and implemented a system that tracks the progress of statements of work (SOWs) and budget estimations, as described in Sandbox Reference Implementation. As a result, each team site on the C ontoso intranet portal includes an Estimates list that contains SOWs and budget estimations. The Estimates list includes a field that indicates the approval status of each work item. The IT manager at C ontoso, C ristian Petculescu now wants you to extend this solution. C ristian wants you to automate the creation of project sites, so that when the approval status of a work item is set to Approved, a new project site is created and configured for that work item. To meet Gerhard's requirements, you first create various workflow activities: You create a full-trust workflow activity to create a new site. You create a full-trust workflow activity to determine whether the new site already exists. You create a sandboxed workflow action to copy a document library from one site to another. Note: You could actually use a sandboxed workflow action to create a site, because this process takes place within the boundaries of the site collection. However, in the Workflow Activities RI, the CreateSiteCollection and CreateSite derive from a common base class, and you cannot create a site collection within a sandboxed workflow action. Next, you use SharePoint Designer to create a declarative workflow that incorporates these activities. This workflow runs on each item in the Estimates list. When the approval status of the item is set to Approved, the workflow attempts to create a new project site for the work item. It then uses the sandboxed workflow action to copy the Templates document library to the new project site. Deploying the Workflow Activities RI The Workflow Activities RI includes an automated installation script that creates various site collections, deploys the reference implementation components, and adds sample data. After running the installation script, browse to Generated from CHM, not final book. Will be superseded in the future. Page 102
- 103. the new ManufacturingWF site collection at http://<Hostname>/sites/ManufacturingWF. You can open and run the project in Visual Studio, but this does not create a site collection or add sample data. To see the system fully functioning, you must run the installation script. The following table summarizes how to get started with the Workflow Activities RI. Question Answer Where can I find the <install location>SourceExecutionModelWorkflow Workflow Activities RI? What is the name of ExecutionModels.Workflow.sln the solution file? What are the system SharePoint Server 2010 Server Standard or Enterprise requirements? What preconditions You must be a member of SharePoint Farm Admin. are required for installation? You must be a member of the Windows admin group. SharePoint must be installed at http://<Hostname:80>. If you want to install to a different location, you can edit these settings in the Settings.xml file located in the Setup directory for the solution. SharePoint 2010 Administration service must be running. By default, this service is set to a manual start. To start the service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 Administration serv ice, and then click Start. How do I Install the Follow the instructions in the readme file located in the project folder. Workflow Activities RI? What is the default http://<Hostname>/sites/ManufacturingWF installation location? (This location can be altered by changing the Settings.xml file in the Setup directory.) How do I download The Workflow Activities RI is included in the download Developing Applications for the Workflow SharePoint 2010. Activities RI? Note: The workflow contained in this project could also be implemented for SharePoint Foundation. However workflows must be authored on the same server version to which they are deployed. SharePoint Foundation 2010 workflows cannot be deployed to SharePoint Server 2010, and vice versa. Generated from CHM, not final book. Will be superseded in the future. Page 103
- 104. Solution Overview This topic provides a high-level conceptual overview of the Workflow Activities Reference Implementation (Workflow Activities RI). Essentially, the solution consists of a declarative workflow that includes built-in SharePoint workflow actions, custom full-trust activities, and sandboxed workflow actions. The following illustration shows the workflow logic. The Workflow Activities RI Note: The preceding illustration was originally created using the new Export to Visio option in SharePoint Designer 2010. The annotations were manually added. When you deploy the Workflow Activities RI, a workflow instance is created every time a work item with a content type of Estimate is added to the Estimates library. When a work item is approved, the workflow proceeds through the actions shown in the preceding illustration. The custom full-trust activities and sandboxed actions are called at the appropriate points in the workflow execution. The Workflow Activities RI consists of three solution packages—one for the full-trust workflow activities, one for the sandboxed workflow action, and one for the declarative workflow definition. Generated from CHM, not final book. Will be superseded in the future. Page 104
- 105. Full-Trust Activities C reating and deploying a custom full-trust workflow activity to a SharePoint 2010 environment involves the following three key steps: C reate an activity class that derives from the System.Workflow.ComponentModel.Activ ity base class and overrides the Execute() method. Add an authorizedType entry to the Web.config file for each activity class. C reate a workflow actions file that defines how the workflow engine and the SharePoint Designer user interface will interact with your activity classes. The Workflow Activities Reference Implementation (Workflow Activities RI) includes three workflow activities. CreateSiteCollectionActivity creates a new site collection, using parameters supplied by the workflow. CreateSubSiteActivity creates a new site in a site collection, using parameters supplied by the workflow. SiteExistsActiv ity returns a Boolean value to indicate whether a specified site or site collection already exists at the specified URL. Within the workflow actions file required for SharePoint Designer support, workflow activities are packaged as actions. You can also define conditions in the workflow actions file. In this solution, CreateSiteCollectionActivity and CreateSubSiteActivity are packaged as actions, and SiteExistsActivity is packaged as a condition. Unlike actions, conditions are not required to derive from System.Workflow.ComponentModel.Activ ity. A condition class must declare a method that does the following: Returns a Boolean value Takes an object of type Microsoft.SharePoint.WorkflowActions.WorkflowContext as its first parameter Takes a string, which represents the GUID of the parent list, as its second parameter Takes an integer, which is the ID of the parent list item, as its third parameter Note: In the case of the SiteExistsActiv ity, it was decided to implement this as an activity so that the code could be leveraged easily within a full-trust coded workflow as well as a declarative workflow. Generated from CHM, not final book. Will be superseded in the future. Page 105
- 106. Activity Classes The Workflow Activities Reference Implementation (Workflow Activities RI) includes three workflow activity classes. Because CreateSubSiteActivity and CreateSiteCollectionActivity have many parameters in common, they share a common base class, SiteCreationBaseActivity. All the activity classes ultimately derive from the System.Workflow.ComponentModel.Activ ity base class, as shown in the following illustration. Workflow activity classes Each workflow activity class overrides the Execute method defined by the base Activ ity class. This method is called by the workflow engine to invoke your activity logic. C# protected override ActivityExecutionStatus Execute(ActivityExecutionContext executionContext) { } A workflow activity class also typically defines a number of dependency properties that are used to pass information to or from your workflow activity logic. Essentially, dependency properties allow you to define inputs and outputs for your workflow activity, because the workflow engine and SharePoint Designer can bind values to these properties in order to use your workflow logic. In other words, dependency properties allow you to bind the output of one activity to the input of another activity. Each full-trust workflow activity class in the Workflow Activities RI defines several dependency properties. For example, the SiteExistsActiv ity class defines three dependency properties. The first dependency property, SiteUrlProperty, allows you to provide your workflow logic with the URL of a site. Notice that the class also defines a .NET Framework property wrapper, SiteUrl, which allows your activity logic to interact with the managed property. C# public static DependencyProperty SiteUrlProperty = DependencyProperty.Register("SiteUrl", typeof(string),typeof(SiteExistsActivity)); [Description("The absolute URL of the site or site collection to create")] [Browsable(true)] [Category("Patterns and Practices")] [DesignerSerializationVisibility(DesignerSerializationVisibility.Visible)] public string SiteUrl { Generated from CHM, not final book. Will be superseded in the future. Page 106
- 107. get { return ((string)base.GetValue(SiteUrlProperty)); } set { base.SetValue(SiteUrlProperty, value); } } The second dependency property, ExistsProperty, enables your activity to provide a result that indicates whether a specified site or site collection already exists. This result can be used by the workflow engine to provide branching logic. C# public static DependencyProperty ExistsProperty = DependencyProperty.Register("Exists", typeof(bool), typeof(SiteExistsActivity)); [Description("The result of the operation indicating whether the site exists")] [Browsable(true)] [Category("Patterns and Practices")] [DesignerSerializationVisibility(DesignerSerializationVisibility.Visible)] public bool Exists { get { return ((bool)base.GetValue(ExistsProperty)); } set { base.SetValue(ExistsProperty, value); } } The final dependency property, ExceptionProperty, allows your activity to return an exception if problems occur. Note: The workflow engine supports fault handlers that can capture exceptions and take action on them for coded workflows. SharePoint Designer declarative workflows do not provide support for fault handlers, so when you design activities for use with SharePoint Designer, it is sometimes necessary to return the exceptions as a property. C# public static DependencyProperty ExceptionProperty = DependencyProperty.Register("Exception",typeof(string), typeof(SiteExistsActivity)); [Description("Exception generated while testing for the existence of the site")] [Browsable(true)] [Category("Patterns and Practices")] [DesignerSerializationVisibility(DesignerSerializationVisibility.Visible)] public string Exception { get { return ((string)base.GetValue(ExceptionProperty)); } set { base.SetValue(ExceptionProperty, value); } } The following code example shows the Execute method of the SiteExistsActiv ity. C# protected override ActivityExecutionStatus Execute(ActivityExecutionContext executionContext) { string exception; Exists = DoesSiteExist(SiteUrl, out exception); Exception = exception; return base.Execute(executionContext); } In the preceding code example, the logic in the Execute method override does not use the Activ ityExecutionContext argument or set a return value. It simply sets the value of the dependency properties and then calls the base method implementation. The DoesSiteExist method is a simple helper method that checks whether a site exists at the specified URL. The SiteExistsActiv ity class includes an extra method named DoesSiteExistCondition that implements the Generated from CHM, not final book. Will be superseded in the future. Page 107
- 108. signature required for SharePoint Designer. Specifically, it returns a Boolean value and accepts parameters that represent the workflow context, the parent list, and the parent list item, as shown in the following code example. C# public static bool DoesSiteExistCondition(WorkflowContext workflowContext, string listId, int itemId, string siteUrl) { string exception; return (DoesSiteExist(siteUrl, out exception)); } Generated from CHM, not final book. Will be superseded in the future. Page 108
- 109. Registering Workflow Activities for Declarative Workflows To be able to use a full-trust workflow activity in a declarative workflow, you must add an authorized type entry for the activity class to the Web.config file. Typically, you should use a feature receiver class to add and remove these entries when you deploy your workflow activities. The Workflow Activities Reference Implementation (Workflow Activities RI) includes an empty farm-scoped feature named SiteProv isioningActivity. The event receiver class for this feature adds authorized type entries for the workflow activity classes when the feature is activated, and it removes the entries when the feature is deactivated. Note: Farm-scoped features are automatically activated when the solution is deployed. Because of this, the authorized type entry is automatically added to the Web.config file when the solution package is deployed to the farm. The SiteProv isioningActivity.Ev entReceiver class uses a helper method named GetConfigModification to build the authorized type entry for the workflow activity classes as an SPWebConfigModification object, as shown in the following code example. C# public SPWebConfigModification GetConfigModification() { string assemblyValue = typeof(CreateSubSiteActivity).Assembly.FullName; string namespaceValue = typeof(CreateSubSiteActivity).Namespace; SPWebConfigModification modification = new SPWebConfigModification( string.Format(CultureInfo.CurrentCulture, "authorizedType[@Assembly='{0}'][@Namespace='{1}'][@TypeName='*'] [@Authorized='True']", assemblyValue, namespaceValue), "configuration/System.Workflow.ComponentModel.WorkflowCompiler/ authorizedTypes"); modification.Owner = "Patterns and Practices"; modification.Sequence = 0; modification.Type = SPWebConfigModification.SPWebConfigModificationType.EnsureChildNode; modification.Value = string.Format(CultureInfo.CurrentCulture, "<authorizedType Assembly="{0}" Namespace="{1}" TypeName="*" Authorized="True" />", assemblyValue, namespaceValue); Trace.TraceInformation("SPWebConfigModification value: {0}",modification.Value); return modification; } For more information about the SPWebConfigModification class, see SPWebC onfigModification C lass on MSDN. The F eatureActiv ated method uses the SPWebConfigModification object to add the authorized type entry to the Web.config files of all Web applications on the farm, with the exception of the C entral Administration Web application. This is shown in the following code example. C# public override void FeatureActivated(SPFeatureReceiverProperties properties) { try { SPWebService contentService = SPWebService.ContentService; contentService.WebConfigModifications.Add(GetConfigModification()); // Serialize the Web application state and propagate changes across the farm. Generated from CHM, not final book. Will be superseded in the future. Page 109
- 110. contentService.Update(); // Save Web.config changes. contentService.ApplyWebConfigModifications(); } catch (Exception e) { Console.WriteLine(e.ToString()); throw; } } This adds the following entry as a child of the AuthorizedTypes element in the Web.config file. XML <authorizedType Assembly="ExecutionModels.Workflow.FullTrust.Activities, ..." Namespace="ExecutionModels.Workflow.FullTrust.Activities" TypeName="*" Authorized="True" /> The F eatureDeactiv ating method also uses the helper method; this time, it is used to remove the authorized type entry from the Web.config file, as shown in the following code example. C# public override void FeatureDeactivating(SPFeatureReceiverProperties properties) { try { SPWebService contentService = SPWebService.ContentService; contentService.WebConfigModifications.Remove(GetConfigModification()); // Serialize the Web application state and propagate changes across the farm. contentService.Update(); // Save Web.config changes. contentService.ApplyWebConfigModifications(); } catch (Exception e) { Console.WriteLine(e.ToString()); throw; } } Generated from CHM, not final book. Will be superseded in the future. Page 110
- 111. Workflow Actions Files A workflow actions file (.actions) is an XML file that describes how SharePoint Designer should interact with your workflow activities. Primarily, this file provides a human-readable sentence structure that is wrapped around the mechanics of your activity. The workflow actions file consists of a parent WorkflowInfo element that can contain conditions and actions. XML <WorkflowInfo> <Conditions And="and" Or="or" Not="not" When="If" Else="Else if"> ... </Conditions> <Actions Sequential="then" Parallel="and"> ... </Actions> </WorkflowInfo> In the Conditions and Actions elements, the attribute values specify the sentence constructs that SharePoint Designer should use to describe the workflow when your activities are used in a particular way. For example, if two activities are used sequentially, SharePoint Designer will describe the workflow as activity Athenactivity B. If two activities are used in parallel, the resulting sentence will be activity Aandactivity B. In the Workflow Activities Reference Implementation (Workflow Activities RI), the workflow actions file is named ExecutionModels.actions. Defining Actions The Action element describes the CreateSubSiteActivity class. First, the Action element identifies the class name and assembly name for the workflow activity. XML <Action Name="Create a Sub-Site" ClassName="ExecutionModels.Workflow.FullTrust.Activities.CreateSubSiteActivity" Assembly="ExecutionModels.Workflow.FullTrust.Activities, ..." AppliesTo="all" Category="Patterns and Practices"> Next, a RuleDesigner element defines a sentence that will represent the workflow activity in SharePoint Designer. The sentence includes placeholders that are filled by parameters (which are defined in the next part of the Action element). The FieldBind child elements are used to map parameters to the placeholders in the rule designer sentence, as shown in the following code example. Some of the FieldBind elements have been removed from this example to aid readability. XML <RuleDesigner Sentence="Create subsite at %3 using the site template %4 using the title %5 and description %6 and locale of %7. The site will be converted if exists? %2 The site will use unique permissions? %1"> <FieldBind Field="UseUniquePermissions" DesignerType="Boolean" Text="Use unique permissions for the sub-site" Id="1"/> <FieldBind Field="ConvertIfExists" DesignerType="Boolean" Text="Convert the sub-site to the template if it already exists" Id="2"/> <FieldBind Field="SiteUrl" DesignerType="Hyperlink" Text="The full URL of the site" Id="3"/> ... </RuleDesigner> Next, a Parameters element defines the inputs and outputs for the activity class, as shown in the following code Generated from CHM, not final book. Will be superseded in the future. Page 111
- 112. example. Each parameter maps to a dependency property in the activity class. The parameters are referenced by the F ieldBind elements shown in the preceding code example. Some of the Parameter elements have been removed from this example to aid readability. XML <Parameters> <Parameter Name="UseUniquePermissions" Type="System.Boolean, mscorlib" DisplayName="Use unique permissions" Direction="In" /> <Parameter Name="ConvertIfExists" Type="System.Boolean, mscorlib" DisplayName="Convert if exists" Direction="In" /> <Parameter Name="SiteUrl" Type="System.String, mscorlib" Direction="In" /> ... </Parameters> The second Action element, which describes the CreateSiteCollectionActivity class, follows a similar pattern. Defining Conditions The ExecutionModels.actions file includes a single Condition element that describes the SiteExistsActivity class. XML <Condition Name="Site Exists" FunctionName="DoesSiteExistCondition" ClassName="ExecutionModels.Workflow.FullTrust.Activities.SiteExistsActivity" Assembly="ExecutionModels.Workflow.FullTrust.Activities, ..." AppliesTo="all" UsesCurrentItem="True"> <RuleDesigner Sentence="The site %1 exists"> <FieldBind Id="1" Field="_1_" Text=""/> </RuleDesigner> <Parameters> <Parameter Name="_1_" Type="System.String, mscorlib" Direction="In" /> </Parameters> </Condition> This Condition element has a few key differences from the Action elements described earlier. First, you must provide a FunctionName attribute value to indicate that the condition logic is invoked through the DoesSiteExistCondition method. Next, note the naming convention for parameters. The parameter that will represent the site URL is named "_1_". This is because it is the first non-default argument that is provided to the DoesSiteExistCondition method. Additional parameters should be named "_2_", "_3_", and so on. It is essential to use this naming convention when you define a condition. Deploying a Workflow Actions File Workflow actions files are deployed to the TEMPLATE[Locale ID]Workflow folder in the SharePoint root folder (for example, TEMPLATE1033Workflow). The best way to deploy files to the SharePoint root from a Visual Studio 2010 project is to add a SharePoint mapped folder to your project. This creates a folder within your project that maps to a folder on the SharePoint file system. When you deploy your solution, any files in your mapped folder are added to the corresponding location on the SharePoint file system. Note: Generated from CHM, not final book. Will be superseded in the future. Page 112
- 113. To add a SharePoint mapped folder, right-click the project node in Solution Explorer, point to Add, and then click SharePoint Mapped F older. This launches a dialog box that lets you browse the SharePoint file system and select a folder to map. In the Workflow Activities RI, a SharePoint mapped folder maps to the SharePoint root folder on the file system. Within the mapped folder, there is the TEMPLATE1033Workflow subfolder and the ExecutionModels.actions file, as shown in the following illustration. Using SharePoint mapped folders to deploy a workflow actions file When you deploy your workflow actions file to this location, SharePoint automatically detects the new actions, and they are made available in SharePoint Designer for use in declarative workflows. Note: In the Workflow Activities RI, there could also have been a mapped folder for the TEMPLATE1033Workflow folder directly. The reason for mapping the SharePoint root folder is to better illustrate the target folder structure on the server file system, and to allow for the addition of workflow action files for other locales at a later time. Generated from CHM, not final book. Will be superseded in the future. Page 113
- 114. Sandboxed Workflow Actions In SharePoint 2010, you can create coded workflow actions that run in the sandbox environment. You can consume these workflow actions from declarative workflows in your site collection. One of the key advantages to creating sandboxed workflow actions is that you do not need to add authorized type entries to the Web.config file. The workflow action itself can be packaged and deployed as a sandboxed solution, and the declarative workflow can be created in SharePoint Designer by site users with sufficient permissions. This enables the users of a site collection to create and deploy their own custom workflow functionality without the involvement of the IT team. C reating and deploying a sandboxed workflow action to a SharePoint 2010 environment involves two key steps: C reate a class that defines the logic for your workflow action. C reate a feature element manifest that contains the workflow actions markup that describes your workflow action. The Workflow Activities Reference Implementation (Workflow Activities RI) includes a sandboxed workflow action class named, together with a feature manifest that provides the markup for the workflow action, CopyLibrary. Generated from CHM, not final book. Will be superseded in the future. Page 114
- 115. Creating Sandboxed Actions In the Workflow Activities Reference Implementation (Workflow Activities RI), the CopyLibrary class is a sandboxed workflow action class that copies a document library from the current site to a target site in the same site collection. When you create a sandboxed workflow action class, the class must include a public method that meets the following criteria: The method must accept an argument of type SPUserCodeWorkflowContext, plus any arguments required by your activity logic. The method must return an object of type Hashtable. The CopyLibrary class provides a method named CopyLibraryActiv ity that meets the criteria in the following code example. C# public Hashtable CopyLibraryActivity(SPUserCodeWorkflowContext context, string libraryName, string targetSiteUrl) { return (CopyLibrary(context.WebUrl, libraryName, targetSiteUrl)); } This method calls a second method named CopyLibrary that contains the workflow action logic. This performs the actual work and is used because it is easier to test than the signature required by SharePoint Designer. This method performs the actions shown in the following illustration. The Copy Library workflow action Generated from CHM, not final book. Will be superseded in the future. Page 115
- 116. Note: CopyLibraryActiv ity calls CopyLibrary instead of having overloads because SharePoint is not capable of determining which overload to use. Methods that are referenced for sandboxed workflow actions cannot be overloaded. Generated from CHM, not final book. Will be superseded in the future. Page 116
- 117. Notice how the method uses the hash table to return results. The method adds two entries to the hash table: a string value that indicates success or failure and an integer value that indicates the number of files copied from the source library to the target library. C# Hashtable results = new Hashtable(); ... int copiedFiles = CopyFolder(sourceLib.RootFolder, targetLib.RootFolder, true); results["status"] = "success"; results["copiedFiles"] = copiedFiles; return results; If the source list does not exist, the method returns a status value of failure and a copied files count of zero. C# results["status"] = "failure"; results["copiedFiles"] = 0; return (results); For more information about returning values from a sandboxed workflow action, see How to: C reate a Sandboxed Workflow Action. Generated from CHM, not final book. Will be superseded in the future. Page 117
- 118. Packaging and Deploying Sandboxed Actions When you work with sandboxed solutions, you cannot deploy a workflow actions file to the server file system. Instead, you can use a feature manifest file to deploy your workflow actions markup to the sandbox environment. The Workflow Activities Reference Implementation (Workflow Actions RI) includes a site-scoped feature named CopyLibraryFeature. This feature deploys a component named CopyLibraryModule that consists of the following feature manifest. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <WorkflowActions> <Action Name="Copy Library" SandboxedFunction="true" Assembly="$SharePoint.Project.AssemblyFullName$" ClassName="ExecutionModels.Workflow.SandboxActivity.CopyLibrary" FunctionName="CopyLibraryActivity" AppliesTo="list" UsesCurrentItem="true" Category="Patterns and Practices Sandbox"> <RuleDesigner Sentence="Copy all items from library %1 to site %2"> <FieldBind Field="libraryName" Text="Library Name" Id="1" DesignerType="TextBox" /> <FieldBind Field="targetSiteUrl" Text="Target Site" Id="2" DesignerType="TextBox" /> </RuleDesigner> <Parameters> <Parameter Name="__Context" Type="Microsoft.SharePoint.WorkflowActions.WorkflowContext, Microsoft.SharePoint.WorkflowActions" Direction="In" DesignerType="Hide" /> <Parameter Name="libraryName" Type="System.String, mscorlib" Direction="In" DesignerType="TextBox" Description="The library to copy" /> <Parameter Name="targetSiteUrl" Type="System.String, mscorlib" Direction="In" DesignerType="TextBox" Description="The URL of the target site" /> </Parameters> </Action> </WorkflowActions> </Elements> In the WorkflowActions element, the Action element is defined in exactly the same way as actions in workflow actions files. Note that the Action element includes a SandboxedF unction="true" attribute. Also note that a FunctionName attribute is specified to indicate the method that contains the activity logic, because sandboxed workflow actions cannot inherit from the base Activ ity class or implement the standard Activ ity.Execute method. Finally, note the naming convention for the parameter that represents the SPUserCodeWorkflowContext argument to the sandboxed action method. The parameter must be named __Context. Take care to include the double-underscore prefix when you create your own sandboxed actions. This enables the SharePoint workflow engine to provide a wrapper for your sandboxed action, which allows you to use the action in declarative workflows. When you deploy and activate a feature that includes this manifest, the sandboxed workflow action is automatically made available in SharePoint Designer for use in declarative workflows within the site collection scope. Generated from CHM, not final book. Will be superseded in the future. Page 118
- 119. Consuming Custom Components from a Declarative Workflow The Workflow Activities Reference Implementation includes a declarative workflow named C reate Project Site. The workflow is associated with the Estimate content type, which was created by the Sandbox Reference Implementation. The Estimate content type defines several fields, as shown in the following illustration. Estimate content type fields The C reate Project Site workflow uses the values of the SOW Status field and the Projects Lookup field on each estimate item during workflow execution. The workflow also defines two local variables, ProjectName and ProjectSiteUrl, to manage the information that is passed to individual workflow actions. The following illustration shows the sentence designer for the C reate Project Site workflow in SharePoint Designer. Note: In the illustration, the line that begins "C reate subsite…" has been cut down because of width restrictions. Workflow designer for the Create Project Site workflow Generated from CHM, not final book. Will be superseded in the future. Page 119
- 120. As you can see, the workflow begins with a Wait for Field Change in Current Item action. This pauses the execution of the workflow until the SOW Status field of the current item is set to Approved. The remaining workflow actions are then contained within an Impersonation Step, because, in most cases, elevated permissions are required to create a new site. An Impersonation Step runs as the identity of the user that associated the workflow with a list or library. This allows the workflow to perform actions that the user would not normally be allowed to perform, such as creating a subsite for the project. The workflow then sets the values of the local variables: ProjectName. This variable is set to the value of the Projects Lookup field in the current work item. ProjectSiteUrl. This variable is set to a concatenation of the current site collection URL and the ProjectName variable. These variables are used as inputs to the actions that follow. Notice how the custom workflow actions are included in the workflow designer: The sentence "The site _ exists" is provided by the Site Exists condition defined in the ExecutionModels.actions file. The sentence "Create subsite at _ using the site template _ using the title _ ..." is provided by the Create a Sub-Site action defined in the ExecutionModels.actions file. The sentence "Copy all items from library _ to site _" is provided by the Copy Library action defined the C opyLibraryModule feature manifest. No additional configuration is required to use these custom actions in SharePoint Designer. The actions automatically become available when you deploy the ExecutionModels.actions file (for full-trust activities) and the C opyLibraryModule feature manifest (for the sandboxed workflow action) to the SharePoint environment. Generated from CHM, not final book. Will be superseded in the future. Page 120
- 121. Conclusion The Workflow Activities Reference Implementation (Workflow Activities RI) demonstrates best practice approaches to creating and deploying full-trust workflow activities and sandboxed workflow actions. The key points of interest include the following: The creation and deployment of full-trust workflow activities The creation and deployment of sandboxed workflow actions The consumption of custom workflow actions from a declarative workflow We recommend you deploy the Workflow Activities RI and to explore the different components and code within the ExecutionModels.Workflow solution. For more information about workflow activities, see Execution Models in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 121
- 122. Reference Implementation: External Lists External lists enable you to view and manipulate external data in the same way that you can view and manipulate data stored in regular SharePoint lists. In this reference implementation, we deploy a sandboxed solution that includes external lists. The solution demonstrates how sandboxed Web Parts can query and present the data provided by the external lists. External lists rely on external content types to interact with external data sources. You can view an external content type as a bridge between the external list and the external data source. Unlike external lists, external content types cannot be defined or used directly within sandboxed solutions. Instead, they are typically created dynamically in SharePoint Designer or in Visual Studio 2010 if they are more complex. They are then managed by the Business Data C onnectivity (BDC ) service application, which runs with full trust. This use of an external list in a sandboxed solution is an example of a hybrid approach to execution. It allows you to manipulate external data from within the sandbox environment, which would not otherwise be permitted. Note: Note: We recommend that you review Execution Models in SharePoint 2010 before studying this reference implementation. The Execution Models chapter provides a more detailed explanation of many of the concepts described here. This implementation demonstrates the details and best practices for the following areas: C reating and consuming external lists from a sandboxed solution C reating and managing external content types in the BDC service application C onfiguring the Secure Store Service (SSS) to enable sandboxed code to impersonate credentials for external data sources Note: Note: This reference implementation makes use of many design and implementation techniques that were the focus of the preceding reference implementations. These techniques include exception shielding, the use of various design patterns, and the use of the client object model to launch modal dialog pages. For a detailed discussion of these approaches, see the sandbox reference implementation and the full trust proxy reference implementation. Solution Scenario In this example, suppose you are a SharePoint consultant working for a pharmaceutical company named C ontoso, Inc. The procurement manager at C ontoso, Jim Hance, wants to be able to view a summary of financial transactions with vendor organizations. At present, vendor transactions are recorded in C ontoso's vendor management system, a proprietary database application based on SQL Server. To meet Jim's requirements, you first create a set of external content types that map to different tables in the vendor management database. Next, you create a set of external lists to surface the data from the external content types. Finally, you create a Web Part that shows a list of vendors. Jane can click a vendor name to start a modal dialog that displays a list of transactions for that vendor, as illustrated in the following illustrations. Vendor list of transactions Vendor transaction details Generated from CHM, not final book. Will be superseded in the future. Page 122
- 123. Deploying the External Lists RI The External Lists RI includes an automated installation script that creates various site collections, deploys the RI components, and adds sample data. After running the installation script, browse to the Headquarters site collection at http://<Hostname>/sites/ Headquarters. You can open and run the project in Visual Studio, but this does not create a site collection or add sample data. To see the fully functioning system, you must run the installation script. The following table answers questions you might have about how to get started with the External Lists RI. Question Answer Where can I find the <install location>SourceExecutionModelExternalList External Lists RI? Which file is the ExecutionModels.Sandbox.ExternalList.sln solution file? What are the system SharePoint Server 2010 Standard or Enterprise Edition (for Secure Store Service) requirements? What preconditions are You must be a member of the SharePoint Farm administrator group. required for installation? You must be a member of the Windows administrator group. SharePoint must be installed at http://<Hostname:80>. If you want to install SharePoint in a different location, you can edit the location settings in the Settings.xml file located in the Setup directory for the solution. SharePoint 2010 Administration service must be running. By default, this service is set to a manual start. To start the service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 Administration serv ice, and then click Start. The timer service must be running. To start the timer service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 timer, and then click Start. How do I Install the Follow the instructions in the Readme.txt file located in the project folder. External List RI? Generated from CHM, not final book. Will be superseded in the future. Page 123
- 124. What is the default http://<Hostname>/sites/Headquarters installation location for the External List RI? You can change this location by changing the Settings.xml in the Setup directory. How do I download the The External List RI is included in the download Developing Applications for External List RI? SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 124
- 125. Solution Overview This topic provides a high-level conceptual overview of the external list reference implementation. The solution consists of both sandboxed and full trust components, as illustrated in following illustration. Conceptual overview of the External List Reference Implementation The Vendor List Web Part displays a list of vendors, together with basic information about each vendor, such as address, telephone details, and the number of transactions. The number of transactions is rendered as a hyperlink. When the user clicks the hyperlink, a client-side JavaScript function opens the Transaction Details page within a modal dialog box. The JavaScript function passes the vendor ID to the details page as a query string parameter. The Transaction Details page is a Web Part page that hosts the Transaction List Web Part. The Transaction List Web Part loads the vendor ID from the page query string, and then retrieves and displays a list of transactions. Note: Note: The application pattern in which one Web Part starts another Web Part within a modal dialog box is described in detail in the full trust proxy reference implementation. Both the Vendor List Web Part and the Transaction List Web Part obtain their data by running queries against external lists. These external lists are created on a specific site and can be considered sandboxed components. Each external list is associated with an external content type, which maps to a table or a view in an external database and defines a series of operations for the external data. The external content types are managed by the Business Data C onnectivity (BDC ) service application. While you cannot directly interact with the BDC APIs from sandboxed code, you can interact with external lists. In this way, external lists provide a mechanism for viewing and manipulating external data from within the sandbox environment. The BDC service uses impersonation to access the vendor management database. Because the requests to the BDC originate from the sandbox environment, the credentials used to access the database are mapped to the identity of the user code service account, rather than to the identity of individual users. Generated from CHM, not final book. Will be superseded in the future. Page 125
- 126. Environment Configuration Before configuring the SharePoint environment to access external data, you first need to understand how credentials are managed and passed between the different components in your solution. The following diagram summarizes the process. Accessing external data from a sandboxed solution The following numbered steps correspond to the numbers shown in the diagram: 1. A Web Part within a sandboxed solution uses the SPList object model to request data from an external list. 2. The SPList object model call is sent to the user code proxy service. The user code proxy service passes the request to the Business Data C onnectivity service (BDC ) runtime, which also runs within the user code proxy service process. The identity associated with the request is the managed account that runs the user code proxy service. 3. The BDC runtime calls the Secure Store Service (SSS). The SSS returns the external credentials that are mapped to the identity of the user code proxy service. 4. The BDC runtime retrieves the external content type metadata from the BDC metadata cache. If the metadata is not already in the cache, the BDC runtime retrieves it from the BDC Service. The external content type metadata provides the information that the BDC runtime needs to interact with the Vendor Management system. 5. The BDC runtime uses impersonation and the external credentials retrieved from the SSS to retrieve data from the Vendor Management system. For a more detailed explanation of this process, see the Hybrid Approaches topic. The key point to understand is that the external credentials used to access the Vendor Management system must be mapped to the identity of the user code proxy service, rather than to the identity of the actual user. To enable your SharePoint environment to support this approach, you must complete three tasks: C onfiguring the Secure Store Service. You must configure the SSS to map the identity of the user code proxy service to the external credentials required by the Vendor Management system. C reating the External C ontent Types. You must add the external content types to the BDC service. You can either create external content types in SharePoint Designer or import a BDC model (.bdcm) file in the C entral Administration Web site. C onfiguring Business Data C onnectivity Service Permissions Within the BDC , you must configure permissions on each individual external content type. Generated from CHM, not final book. Will be superseded in the future. Page 126
- 127. Generated from CHM, not final book. Will be superseded in the future. Page 127
- 128. Configuring the Secure Store Service The Secure Store Service (SSS) maintains an encrypted database that maps the identities of SharePoint users, groups, or process accounts to the external credentials required to access external systems. When the Business Data C atalog (BDC ) needs to impersonate external credentials to access a data source, it passes the identity of the caller to the SSS. The SSS then returns the external credentials that are mapped to the identity of the caller. Within the SSS, credentials mappings are organized by target applications. A target application represents an external system or data source, and includes a unique target application ID. When the BDC requests a set of credentials from the SSS, it specifies the target application ID so that the SSS knows which credential mapping to retrieve. In the external list reference implementation, we created a target application to represent the Vendor Management system. Within this target application, we mapped the identity of the user code proxy service to the external credentials required to access the Vendor Management system. To enable users to access the external lists from outside a sandboxed application, we also mapped individual user identities to the external credentials required to access the Vendor Management system. This is illustrated by the following diagram. Configuring a target application in the Secure Store Service In the external list reference implementation, the install script configures the SSS and creates a target application that you can use. If you want to create your own target application, you can use the following procedure. To create a target application in the Secure Store Service 1. In the C entral Administration Web site, click Application Management, and then click Manage Serv ice Applications. 2. On the Manage Service Applications page, click Secure Store Serv ice. 3. On the ribbon, in the Manage Target Applications section, click New. 4. On the C reate New Secure Store Target Application page: a. Set the Target Application ID to SPGVM. b. Set the Display Name to SPG Vendor Management Application. c. Provide a contact e-mail address. d. Under Target Application Type, select Group as shown in the following illustration. C lick Next. Generated from CHM, not final book. Will be superseded in the future. Page 128
- 129. Note: Note: A target application type of Group indicates that you want to map multiple identities to a single set of credentials. 5. On the next page, leave the credential fields set to Windows User Name and Windows Password, and then click Next. 6. On the next page, in the Target Application Administrators text box, add your administrative account. 7. In the Members text box, add the user code proxy service account and any user accounts or groups that require access to the external system, and then click OK. See the following illustration. 8. On the Secure Store Service page, on the SPGVM drop-down list, click Set Credentials, as shown in the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 129
- 130. 9. On the Set C redentials for Secure Store Target Application page, provide the credentials that are required to access the external system, and then click OK. Generated from CHM, not final book. Will be superseded in the future. Page 130
- 131. Creating the External Content Types External content types are stored and managed by the Business Data C onnectivity (BDC ) service application. You can create external content types by using interactive tools in SharePoint Designer 2010. Alternatively, you can import predefined external content types by uploading a Business Data C onnectivity Model (.bdcm) file to the C entral Administration Web site. Note: Note: The install script for the external list reference implementation uses a .bdcm file to create the external content types required by the solution. You can export your external content types as a .bdcm file from SharePoint Designer 2010 or the SharePoint C entral Administration web site. Essentially, an external content type consists of two components: a connection to an external data source, and a series of operation definitions (commonly referred to as stereotyped operations) on the external data. When you create a connection, you first identify the type of data source—.NET type, SQL Server, or Windows C ommunication Foundation (WC F) Service. For a SQL Server data source, you must specify the database server, the database name, and the type of impersonation. SQL Server connections can use the following different types of impersonation: Connect with user's identity. The BDC uses the identity of the SharePoint user who requested the external data to authenticate with the data source. Connect with impersonated Windows identity. The BDC sends the identity of the caller to the Secure Store Service (SSS). The SSS supplies the Windows credentials that are mapped to the identity of the caller. The BDC uses the mapped Windows credentials to authenticate with the data source. Connection with impersonated custom identity. The BDC sends the identity of the caller to the Secure Store Service (SSS). The SSS supplies a set of custom credentials—such as a Forms authentication username and password—that are mapped to the identity of the caller. The BDC uses the mapped custom credentials to authenticate with the data source. Note: Note: If you want to use an impersonated Windows identity or an impersonated custom identity, you must specify the target application ID when you configure the connection. The SSS uses the target application ID to organize credential mappings. The external list reference implementation could not use the connect with user's identity approach because the requests for external data originate from the sandbox. When the BDC receives a request that originates from the sandbox, the request is made using the identity of the user code proxy service, rather than the identity of the user. Instead, we used the connect with impersonated Windows identity approach to authenticate to the Vendor Management database. The following image shows the connection properties for the external content types in the external list reference implementation. Vendor Management Connection Properties Once you have configured the SQL Server connection, the next step is to define a set of operations on a table, view, or stored procedure in the target database. The external list reference implementation includes three external content types with the following operation definitions: The Vendors external content type defines create, read item, update, delete, and readlist operations on the Vendors table in the Vendor Management database. The Vendor Transactions external content type defines read item and read list operations on the VendorTransactionView view in the Vendor Management database. The Vendor Transaction Types external content type defines create, read item, update, delete, and read list operations on the TransactionTypes table in the Vendor Management database. For more information about creating EC Ts, see How to: C reate External C ontent Types and How to: C reate an External C ontent Type Based on a SQL Server Table on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 131
- 132. Configuring Business Data Connectivity Service Permissions When you have deployed your external content types to the Business Data C onnectivity (BDC ) service application, you must configure permissions on each individual external content type. You can assign the following permissions to users or groups on each external content type: Edit. This permission enables the user or group to edit the external content type definition. Execute. This permission enables the user or group to use the operations defined by the external content type, such as create, readitem, update, delete, and read list. Selectable in clients. This permission enables the user or group to create an external list from the external content type. It also enables users to use the external content type Picker control. Set Permissions. This permission enables the user or group to manage permissions on the external content type. The following illustration shows an example. Setting permissions on an external content type The key thing to remember is that your external content type might need to support requests from both inside and outside the sandbox environment. If you want to support requests for external data from sandboxed solutions, you must assign Execute permissions to the user code proxy service account. If you want to support requests for external data from non-sandboxed components, you must assign Execute permissions to the site users or groups who require access to the data. For more information about setting permissions on external content types, see Manage external content types (SharePoint Server 2010) on TechNet. Generated from CHM, not final book. Will be superseded in the future. Page 132
- 133. Sandboxed Components The external list reference implementation includes two Web Parts that are configured to provide a master-details user experience. The Vendor List Web Part displays a list of vendors with summary information for each individual vendor as shown in the following illustration. Vendor List Web Part When a user clicks an item in the TransactionCount column, a JavaScript function launches a Web Part page as a modal dialog box. This Web Part page contains the Vendor Transaction List Web Part, which displays a list of the transactions that correspond to the selected vendor. Vendor Transaction List Web Part Note: For a detailed explanation of this application pattern, in which the master Web Part uses a JavaScript function to launch the details Web Part as a modal dialog, see Reference Implementation: Full Trust Proxies for Sandboxed Solutions. Both the Vendor List Web Part and the Vendor Transaction List Web Part are implemented by using the Model-View-Presenter (MVP) pattern. In this case, the model class is shared by both Web Parts, as shown by the following class diagram. Class structure of the Vendor List Web Part Generated from CHM, not final book. Will be superseded in the future. Page 133
- 134. Class structure of the Vendor Transaction List Web Part Note: Note: For a detailed explanation of how to implement the MVP pattern in a Web Part, see Reference Implementation: The Sandbox Execution Model. Many elements of this solution, such as the master-details Web Parts and the MVP pattern, are described in the documentation for the preceding reference implementations. For information about how to create and interact with external lists, see C reating External Lists. The retrieval of data from external lists takes place entirely within the VendorServ ice class. Generated from CHM, not final book. Will be superseded in the future. Page 134
- 135. Creating External Lists External lists are SharePoint lists that are bound to a single external content type. Unlike external content types, which apply to the Business Data C onnectivity (BDC ) service application, external lists are created within a specific SharePoint site, just like regular SharePoint lists. You can create external lists in three ways: Interactively, by selecting Create Lists & Form on the external content type settings page in SharePoint Designer Directly, by creating a new external list in the SharePoint site user interface, and then selecting the external content type to which you want to bind Programmatically, in a farm solution or a sandboxed solution The external list reference implementation defines three external lists, which correspond to the external content types described earlier: The Vendors external list is bound to the Vendors external content type. The Vendor Transactions external list is bound to the Vendor Transactions external content type. The Vendor Transaction Types external list is bound to the Vendor Transaction Types external content type. C reating an external list is straightforward and requires no additional configuration. The external list is displayed and managed in the same way as a regular SharePoint list. For example, the following illustration shows the Vendors external list in the Web browser. Vendors external list You can also use SharePoint Designer to edit external lists. For example, you can add or remove columns, and you can create views, forms, workflows, and custom actions for your external lists. For more information on how to create external lists, see How to: C reate External Lists in SharePoint on MSDN. You can use the SPList API to interact programmatically with external lists in exactly the same way that you would interact with regular SharePoint lists. Because the SPList API is available within the sandbox environment, you can interact with external lists from within your sandboxed solution code. In the external list reference implementation, all the interaction with external lists takes place within the VendorServ ice class. This class provides the data model for both the Vendor List Web Part and the Vendor Transaction List Web Part. The presenter class for the Vendor List Web Part calls the GetAllVendorsWithTransactionCount method to populate the Web Part, as shown in the following example. C# public DataTable GetAllVendorsWithTransactionCount() { var vendors = GetAllVendors(); vendors.Columns.Add("TransactionCount"); var columnIndex = vendors.Columns.Count - 1; foreach (DataRow row in vendors.Rows) { int vendorId = int.Parse(row.ItemArray[0].ToString()); row[columnIndex] = GetTransactionCountByVendor(vendorId); } Generated from CHM, not final book. Will be superseded in the future. Page 135
- 136. return vendors; } As the example shows, the GetAllVendorsWithTransactionCount method relies on two helper methods. First, the GetAllVendors method is used to retrieve all the data in the Vendors external list, as shown in the following example. C# public DataTable GetAllVendors() { var web = SPContext.Current.Web; string test = Constants.ectVendorListName; var dt = web.Lists[Constants.ectVendorListName].Items.GetDataTable(); return dt; } Next, the GetTransactionCountByVendor method is used to get the number of transactions that are stored for each vendor. This information is used to populate the TransactionCount column in the Vendor List Web Part. The method builds a Collaborative Application Markup Language (C AML) query to count the number of transactions in the Vendor Transactions external list that correspond to the specified vendor: C# public int GetTransactionCountByVendor(int vendorId) { var query = new SPQuery { ViewFields = "<FieldRef Name='ID' />", Query = string.Format( "<Where> <Eq> <FieldRef Name='VendorID' /> <Value Type='Counter'>{0}</Value> </Eq> </Where>", vendorId.ToString()) }; return SPContext.Current.Web.Lists[Constants.ectVendorTransactionListName] .GetItems(query).Count; } The presenter class for the Vendor Transaction List Web Part calls the GetTransactionByVendor method to populate the Web Part, as shown in the following example. C# public DataTable GetTransactionByVendor(int vendorId) { var query = new SPQuery { ViewFields = "<FieldRef Name='Name' />" + "<FieldRef Name='TransactionType' />" + "<FieldRef Name='Amount' />" + "<FieldRef Name='Notes' />", Query = string.Format( "<Where> <Eq> <FieldRef Name='VendorID' /> <Value Type='Counter'>{0}</Value> </Eq> </Where>", vendorId.ToString()) }; return Generated from CHM, not final book. Will be superseded in the future. Page 136
- 137. SPContext.Current.Web.Lists[Constants.ectVendorTransactionListName] .GetItems(query).GetDataTable(); } In all of these code examples, the external lists are used in the same way as regular lists. The object model calls and the query syntax are the same regardless of the type of list. Generated from CHM, not final book. Will be superseded in the future. Page 137
- 138. Conclusion The external list reference implementation demonstrates best practice approaches to consuming external data from within sandboxed solutions. After reviewing the reference implementation, you should understand the following: The configuration of the Secure Store Service to support external data access from the sandbox environment The creation and configuration of external content types for a SQL Server data source The consumption of external data from the sandbox environment via an external list We encourage you to deploy the reference implementation and to explore the different components and code in the ExecutionModels.Sandboxed.ExternalList solution. For more information on using external lists within the sandbox environment, see Execution Models in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 138
- 139. Execution Models: How-to Topics When the execution models reference implementations were developed, several tasks proved challenging to accomplish. In some cases the procedures were simple but hard to find, in other cases they were somewhat complicated. The following topics address these issues and provide step-by-step instructions on how to complete the tasks. How to: Set the Deployment Order for a Project How to: C reate a Sandboxed Workflow Action How to: C reate and Register a Sandbox Proxy How to: C reate a Web Application-Scoped Timer Job How to: Debug a Feature Receiver How to: Debug a Timer Job How to: Deploy an Application Page to C entral Administration How to: Deploy a Document Template in a Sandboxed Solution How to: Deploy a Web Part Page in a Sandboxed Solution How to: Display a Page as a Modal Dialog Box How to: Log to the History List from a Workflow Activity How to: Import and Package a Declarative Workflow in Visual Studio Generated from CHM, not final book. Will be superseded in the future. Page 139
- 140. How to: Set the Deployment Order for a Project Overview When you create large Microsoft® SharePoint® solutions in Microsoft Visual Studio® 2010 development system, your solutions will often contain several features. Additionally, these features will often include dependencies on other features within the solution package. In this situation, you must configure the solution to deploy your features in the correct order to prevent Visual Studio from attempting to activate a feature before its dependencies are in place. This how-to topic describes how to set the deployment order for features in a Visual Studio 2010 SharePoint solution. Note: This topic uses the ExecutionModels.Sandboxed solution as an example of a project with feature dependencies. Steps To change the project deployment order 1. Open a Visual Studio 2010 solution based on one of the SharePoint project templates. 2. In Solution Explorer, double-click the Package node. The Package Designer window opens. Generated from CHM, not final book. Will be superseded in the future. Page 140
- 141. 3. Select an item in the Package Designer window, and use the up and down arrow buttons on the right side to change the deployment order. Generated from CHM, not final book. Will be superseded in the future. Page 141
- 142. Note: Features at the top of the Package Designer window are deployed first. If a feature includes activation dependencies, make sure that the feature appears beneath its dependencies in the Package Designer window. 4. Repeat this procedure until you achieve the desired order. Generated from CHM, not final book. Will be superseded in the future. Page 142
- 143. How to: Create a Sandboxed Workflow Action Overview Microsoft® SharePoint® 2010 enables you to create and deploy custom workflow actions as sandboxed solutions. You can then consume these workflow actions within declarative workflows in SharePoint Designer. This how-to topic describes how to create and deploy a sandboxed workflow action. For a practical example of the deployment of a sandboxed workflow action, see the workflow activities reference implementation. Summary of Steps This how-to topic includes the following steps: Step 1: Create the SharePoint Project. In this step, you create a Visual Studio 2010 project that you can use to deploy and test your sandbox proxy. Step 2: Create the Workflow Action Class. In this step, you create a class that contains your sandboxed logic. Step 3: Create the Workflow Action Definition. In this step, you create a feature manifest file. This contains the markup that references your class and defines your workflow action. Step 1: Create the SharePoint Project This procedure creates a SharePoint project in the Microsoft Visual Studio® 2010 development system. You can use this project to build and deploy your sandboxed workflow action. To create a project 1. Start Visual Studio 2010 and create a new Empty SharePoint Project, as shown in the following illustration. Name the project SimpleAction. Generated from CHM, not final book. Will be superseded in the future. Page 143
- 144. 2. In the SharePoint C ustomization Wizard, specify a valid local site for debugging, select Deploy as a sandboxed solution, and then click Finish. Generated from CHM, not final book. Will be superseded in the future. Page 144
- 145. Step 2: Create the Workflow Action This procedure creates a sandboxed workflow action class. It contains a method that defines the workflow action logic, and it shows you how to return values to the workflow. To create a sandboxed workflow action class 1. Add a new class named SandboxActiv ityLog to the project. 2. Add the following using statements to your class. C# using System.Collections; using Microsoft.SharePoint; using Microsoft.SharePoint.UserCode; using Microsoft.SharePoint.Workflow; 3. Add the public access modifier to your class. 4. Within the class, add a public method that accepts an argument of type SPUserCodeWorkflowContext and returns a value of type Hashtable. This method defines the workflow action. C# public class SandboxActivityLog { public Hashtable Log(SPUserCodeWorkflowContext context) { } } 5. Within your method, implement your action logic. You can return values from your method by adding key/value pairs to a Hashtable object. Generated from CHM, not final book. Will be superseded in the future. Page 145
- 146. C# public Hashtable Log(SPUserCodeWorkflowContext context) { Hashtable results = new Hashtable(); results["Except"] = string.Empty; try { using (SPSite site = new SPSite(context.CurrentWebUrl)) { using (SPWeb web = site.OpenWeb()) { SPWorkflow.CreateHistoryEvent(web, context.WorkflowInstanceId, 0, web.CurrentUser, TimeSpan.Zero, "Information", "Event from sandboxed activity", string.Empty); } } } catch (Exception ex) { results["Except"] = ex.ToString(); } results["Status"] = "Success"; return (results); } Note: Notice the use of the Except key to return an exception to the workflow. Step 3: Create the Workflow Action Definition This procedure creates a workflow action definition in a feature manifest file. This markup tells the SharePoint workflow engine how to interact with your workflow action. To create an action definition for a sandboxed workflow action 1. In Solution Explorer, right-click the project node, point to Add, and then click New Item. 2. In the Add New Item dialog box, in the Installed Templates pane, expand SharePoint, and then click 2010. 3. C lick Empty Element, type a name for the element in the Name text box, and then click Add. This example uses the name LogDefinition for the element. Generated from CHM, not final book. Will be superseded in the future. Page 146
- 147. 4. Expand the LogDefinition node and open the feature manifest file (Elements.xml). 5. Add a WorkflowActions element to the feature manifest. 6. Within the WorkflowActions element, add an Action element. This should do the following: a. Provide a friendly name for your workflow action. b. Specify that the action runs in the sandbox. c. Identify the assembly name and class name of your action. d. Identify the method that provides the action's functionality. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <WorkflowActions> <Action Name="Log Testing" SandboxedFunction="true" Assembly="$SharePoint.Project.AssemblyFullName$" ClassName="SimpleAction.SandboxActivityLog" FunctionName="Log" AppliesTo="all" Category="patterns and practices sandbox"> </Action> </WorkflowActions> </Elements> 7. Within the Action element, add a RuleDesigner element. This specifies the sentence that your workflow action will display in SharePoint Designer. It also binds the Except argument returns by your action to a variable named Exception. XML <RuleDesigner Sentence="Log Activity (Exception to %1)"> <FieldBind Field="Except" Text="Exception" Id="1" Generated from CHM, not final book. Will be superseded in the future. Page 147
- 148. DesignerType="ParameterNames" /> </RuleDesigner> 8. Within the Action element, add a Parameters element. This should define the arguments passed to your workflow action method and the types returned by your workflow action method. XML <Parameters> <Parameter Name="__Context" Type="Microsoft.SharePoint.WorkflowActions.WorkflowContext, Microsoft.SharePoint.WorkflowActions" Direction="In" DesignerType="Hide"/> <Parameter Name="Except" Type="System.String, mscorlib" Direction="Out" DesignerType="ParameterNames" Description="Exception encountered"/> </Parameters> Note: The context argument must be preceded by a double underscore, as shown (__Context). 9. When you added the empty element to your project, Visual Studio created a feature named F eature 1. In Solution Explorer, right-click Feature 1, and then click Rename. This example uses the name SimpleActionF eature for the feature. 10. Double-click SimpleActionFeature to open the feature designer, and then change the scope of the feature to Site. 11. Press F5 to deploy and test your sandboxed workflow action. 12. To verify that your sandboxed workflow action deployed successfully, open SharePoint Designer and create a new workflow. You should find that the Log Testing action has been added to the list of available actions. Generated from CHM, not final book. Will be superseded in the future. Page 148
- 149. How to: Create and Register a Sandbox Proxy Overview Sandbox proxies are components that enable you to make full-trust functionality available to sandboxed solutions. This how-to topic describes how to create a sandbox proxy in the Microsoft® Visual Studio® 2010 development system. For more information about sandbox proxies, see Execution Models in SharePoint 2010. For an example of sandbox proxies in action, see the Sandbox Proxy Reference Implementation. Summary of Steps This how-to topic includes the following steps: Step 1: Create the SharePoint Project. In this step, you create a Visual Studio 2010 project that you can use to deploy and test your sandbox proxy. Step 2: Create the Proxy Arguments Class. In this step, you create a serializable type that you can use to pass arguments from the sandbox to the sandbox proxy. Step 3: Create the Proxy Operation Class. In this step, you create a class that contains the full-trust logic that you want to expose to sandboxed solutions. Step 4: Register the Proxy Operation. In this step, you register your proxy operation with the user code service in order to make your operation available to sandboxed callers. Step 5: Use the Proxy Operation from the Sandbox. In this step, you call your proxy operation from a sandboxed solution. Step 1: Create the SharePoint Project This procedure creates a Microsoft® SharePoint® project in Visual Studio 2010. You can use this project to build and deploy your sandbox proxy assembly. To create a sandbox proxy project 1. Start Visual Studio 2010, and create a new Empty SharePoint Project, as shown in the following illustration. Name the project SimpleProxy. Generated from CHM, not final book. Will be superseded in the future. Page 149
- 150. 2. In the SharePoint C ustomization Wizard, specify a valid local site for debugging, select Deploy as a farm solution, and then click Finish. Generated from CHM, not final book. Will be superseded in the future. Page 150
- 151. 3. Open the AssemblyInfo class file and add the AllowPartiallyTrustedCallers attribute to the class, as shown here. C# [assembly: AllowPartiallyTrustedCallers] Step 2: Create the Proxy Arguments Class This procedure creates a proxy arguments class. This is a serializable type that you can use to pass data from sandboxed code to the proxy operation class. To create a proxy arguments class 1. Add a new class named SimpleProxyArgs to the project. 2. Add the following using statement to your class. C# using Microsoft.SharePoint.UserCode; 3. Add the public access modifier to your class. 4. Add the SerializableAttribute to your class. 5. Modify your class to inherit from the SPProxyOperationArgs class. Your class should resemble the following code. C# [serializable] public class SimpleProxyArgs : SPProxyOperationArgs { } 6. Add public properties for any arguments that you want to pass from the sandbox to the proxy. C# Generated from CHM, not final book. Will be superseded in the future. Page 151
- 152. public string clientName { get; set; } public int clientID {get; set; } Note: Ensure that any properties you create use serializable types. 7. As a good practice, you might also want to add read-only properties for the type name and assembly name of your proxy operations class (which you will create in the next step). These are required when you register your proxy operation and when you invoke the operation from sandboxed code. By adding these properties to the proxy arguments class, you ensure that they are available from all locations when required. 8. (Optional) Add read-only properties for the type name and assembly name of your proxy operations class. The type name should be fully qualified and the assembly name should be the four-part strong name of your assembly. C# public static string ProxyOperationTypeName { get { return "SimpleProxy.SimpleProxyOps"; } } public static string ProxyAssemblyName { get { return "SimpleProxy, Version=1.0.0.0, Culture=neutral, PublicKeyToken=2dfe43bced7458f6"; } } Step 3: Create the Proxy Operations Class This procedure describes how to create a proxy operations class that exposes full-trust logic to the sandbox environment. To create a proxy operations class 1. Add a new class named SimpleProxyOps to the project. 2. Add the following using statement to your class. C# using Microsoft.SharePoint.UserCode; 3. Add the public access modifier to your class. 4. Modify your class to inherit from the SPProxyOperation class. Your class should resemble the following code. C# public class SimpleProxyOps : SPProxyOperation { } 5. Within the SimpleProxyOps class, override the Execute method. The method should accept an argument of type SPProxyOperationArgs and return an Object. C# public override object Execute (SPProxyOperationArgs args) { } 6. Within the Execute method, cast the SPProxyOperationsArgs parameter to your proxy operations argument type, which in this case is SimpleProxyArgs. C# var proxyArgs = args as SimpleProxyArgs; 7. Retrieve your arguments from the proxy arguments class, perform any full-trust logic, and return an object to the caller. In this example, assume that your class includes a helper method named GetAvailableCredit that calls a Windows C ommunication Foundation (WC F) service and returns a double value. Generated from CHM, not final book. Will be superseded in the future. Page 152
- 153. C# // Retrieve arguments from the proxy arguments class. string clientName = proxyArgs.ClientName; int clientID = proxyArgs.ClientID; // Perform full-trust logic; for example, call a WCF service. double availableCredit = GetAvailableCredit(clientName, clientID); // Return an object to the caller. return availableCredit; Note: Exception handling has been omitted for brevity. You should validate the incoming arguments and trap exceptions that occur within your logic. Step 4: Register the Proxy Operation This procedure describes how to create a feature receiver class to register your proxy operation with the user code service. This makes your proxy operation available to callers in the sandbox environment. To register a proxy operation 1. Add a new feature named SimpleProxyFeature to the project. To do this, right-click F eatures in Solution Explorer, and then click Add F eature. To rename the feature, right-click the new feature name, and then click Rename. 2. In the Feature Designer window, in the Scope drop-down list box, click Farm. 3. Add an event receiver to the SimpleProxyFeature. To do this, right-click SimpleProxyF eature in Solution Explorer, and then click Add Ev ent Receiver. 4. Add the following using statements to the SimpleProxyF eature.EventReceiver class. C# using Microsoft.SharePoint.Administration; using Microsoft.SharePoint.UserCode; 5. Uncomment the FeatureActiv ated method. 6. In the FeatureActiv ated method, add the following code to retrieve the local user code service. C# SPUserCodeService userCodeService = SPUserCodeService.Local; 7. Add the following code to create a new proxy operation type, based on your proxy operation class. C# var simpleOperation = new SPProxyOperationType( SimpleProxyArgs.ProxyAssemblyName, SimpleProxyArgs.ProxyOperationTypeName); 8. Add the following code to register your proxy operation type with the local user code service. C# userCodeService.ProxyOperationTypes.Add(simpleOperation); userCodeService.Update(); 9. Press F5 to deploy your sandbox proxy to the test environment. Step 5: Use the Proxy Operation from the Sandbox This procedure describes how to call a registered proxy operation from sandboxed code. To use a sandbox proxy 1. In your sandboxed solution, add a reference to the sandbox proxy assembly. 2. C reate an instance of the proxy arguments class and set any property values. C# var proxyArgs = new SimpleProxyArgs(); proxyArgs.ClientName = "Adventure Works"; proxyArgs.ClientID = 1; 3. C all the SPUtility.ExecuteRegisteredProxyOperation method, passing in the assembly name of the Generated from CHM, not final book. Will be superseded in the future. Page 153
- 154. proxy operation, the type name of the proxy operations class, and the proxy arguments instance. In this case, the assembly name and the type name are provided by static properties of the proxy arguments class, as described in step 2. C# var result = SPUtility.ExecuteRegisteredProxyOperation( SimpleProxyArgs.ProxyAssemblyName, SimpleProxyArgs.ProxyOperationTypeName, proxyArgs); 4. C ast the returned value to the expected return type of the proxy operation. C# double availableCredit = (double) result; Generated from CHM, not final book. Will be superseded in the future. Page 154
- 155. How to: Create a Web Application-Scoped Timer Job Overview In Microsoft® SharePoint® 2010, you can associate a timer job with a Web application (SPWebApplication) or a shared service (SPService). This how-to topic describes how to create a timer job and scope it to a Web application. For a practical example of the creation and deployment of a timer job, see the Farm Solution Reference Implementation. Note: This how-to topic assumes that your test site includes a Tasks list. The Tasks list is created by default if you use the Team Site template. If you used the Blank Site template to create your site, you will need to add a Tasks list manually. Summary of Steps This how-to topic includes the following steps: Step 1: Create the SharePoint Project. In this step, you create a Microsoft Visual Studio® 2010 project that you can use to deploy and test your timer job. Step 2: Create the Job Definition Class. In this step, you create a job definition class that contains your timer job logic. Step 3: Create a F eature to Register the Job. In this step, you use a feature receiver class to install the timer job in your SharePoint environment. Step 1: Create the SharePoint Project This procedure creates a SharePoint project in Visual Studio 2010. You can use this project to build and deploy your timer job assembly. To create a sandbox proxy project 1. Start Visual Studio 2010, and then create a new Empty SharePoint Project, as shown in the following illustration. Name the project SimpleTimerJob. Generated from CHM, not final book. Will be superseded in the future. Page 155
- 156. 2. In the SharePoint C ustomization Wizard, specify a valid local site for debugging, select Deploy as a farm solution, and then click Finish. Generated from CHM, not final book. Will be superseded in the future. Page 156
- 157. Step 2: Create the Job Definition Class This procedure describes how to create a job definition class. The job definition class encapsulates your timer job logic. To create a job definition class 1. Add a new class named SimpleJobDefinition to the project. 2. Add the following using statement to the class. C# using Microsoft.SharePoint; using Microsoft.SharePoint.Administration; 3. Add the public access modifier to the class. 4. Modify the class to inherit from the SPJobDefinition class. Your class should resemble the following code. C# public class SimpleJobDefinition : SPJobDefinition { } 5. Within the SimpleJobDefinition class, add a public constant string named JobName. C# public const string JobName = "SimpleJobDefinition"; 6. Note: Note: You must provide a job name when you add or remove a job definition. By defining the job name as a constant in the job definition class, you ensure that it is always available and remains unchanged. 7. Add a default constructor to the class that inherits from the default constructor of the base class. This is Generated from CHM, not final book. Will be superseded in the future. Page 157
- 158. required for the serialization and de-serialization of your timer job. C# public SimpleJobDefinition() : base() { } 8. Add a constructor that accepts an argument of type SPWebApplication, as shown in the following code. This enables the base SPJobDefinition class to instantiate your timer job within a specific Web application. C# public SimpleJobDefinition(SPWebApplication webApp) : base(JobName, webApp, null, SPJobLockType.Job) { } 9. Note: The SPJobDefinition base constructor provides alternative overloads that you can use if you want to scope your timer job to an SPService instance instead of a Web application. For more information, see SPJobDefinition C lass on MSDN. 10. Within the constructor, give your timer job a title. This specifies how your timer job appears in the SharePoint C entral Administration Web site. C# Title = "Simple Job Definition"; 11. Within the SimpleJobDefinition class, override the Execute method. The method should accept an argument of type Guid. In this case, the GUID represents the target Web application. C# public override void Execute(Guid targetInstanceId) { } 12. Add your timer job logic to the Execute method. This example simply adds an item to the task list on the root site of the Web application. The job logic sets the title of the task to the current date and time. C# public override void Execute(Guid targetInstanceId) { // Execute the timer job logic. SPWebApplication webApp = this.Parent as SPWebApplication; SPList taskList = webApp.Sites[0].RootWeb.Lists["Tasks"]; SPListItem newTask = taskList.Items.Add(); newTask["Title"] = DateTime.Now.ToString(); newTask.Update(); } Step 3: Create a Feature to Register the Job This procedure describes how to use a feature receiver class to install the timer job in your SharePoint environment. To register a Web application-scoped timer job 1. In Solution Explorer, right-click the F eatures node, and then click Add F eature. 2. In Solution Explorer, right-click the new feature node, and then click Rename. This example uses the name SimpleJobFeature for the feature. 3. Double-click the SimpleJobFeature node to open the feature designer window, and then set the scope of the feature to WebApplication. 4. Add an event receiver to the SimpleJobFeature. To do this, right-click SimpleJobFeature in Solution Explorer, and then click Add Ev ent Receiver. 5. In the SimpleJobF eatureEventReceiver class, add the following using statement. C# using Microsoft.SharePoint.Administration; 6. Add a method named DeleteJobs that accepts an argument of type SPJobDefinitionCollection. The method should iterate through the job definition collection and delete any instances of SimpleJobDefinition. C# private void DeleteJob(SPJobDefinitionCollection jobs) Generated from CHM, not final book. Will be superseded in the future. Page 158
- 159. { foreach(SPJobDefinition job in jobs) { if(job.Name.Equals(SimpleJobDefinition.JobName, StringComparison.OrdinalIgnoreCase)) { job.Delete(); } } } 7. Uncomment the FeatureActiv ated method. 8. In the FeatureActiv ated method, add the following code to register the job definition, and set the job schedule to run once every minute. C# SPWebApplication webApp = properties.Feature.Parent as SPWebApplication; DeleteJob(webApp.JobDefinitions); SimpleJobDefinition simpleJob = new SimpleJobDefinition(webApp); SPMinuteSchedule schedule = new SPMinuteSchedule(); schedule.BeginSecond = 0; schedule.EndSecond = 59; schedule.Interval = 1; simpleJob.Schedule = schedule; simpleJob.Update(); 9. Uncomment the FeatureDeactivating method. 10. In the FeatureDeactiv ating method, add the following code to remove the job definition from the Web application. C# SPWebApplication webApp = properties.Feature.Parent as SPWebApplication; DeleteJob(webApp.JobDefinitions); 11. Press F5 to debug your timer job. After a few minutes, browse to the task list on your root site and verify that the timer job has added a task once in every one minute period. Generated from CHM, not final book. Will be superseded in the future. Page 159
- 160. How to: Debug a Feature Receiver Overview One of the new features in the Microsoft® Visual Studio® 2010 development system is the ability to press F5 to debug Microsoft SharePoint® components, such as feature receivers. However, to debug a feature receiver class, you must configure your SharePoint project to use the No Activation deployment configuration. This means that Visual Studio 2010 will install your features, but you must manually activate them through the user interface. This how-to topic describes how to change your deployment configuration and debug a feature receiver class. Note: This how-to topic uses the ExecutionModels.Sandboxed solution as an example of a project with feature receiver classes. Steps To debug a feature receiv er in Visual Studio 2010 1. Open the Visual Studio 2010 project that contains your feature. 2. In Solution Explorer, right-click the project node, and then click Properties. 3. On the SharePoint tab, in the Activ e Deployment Configuration drop-down list, click No Activ ation. 4. Open the feature receiver class that you want to debug, and then insert a breakpoint. Generated from CHM, not final book. Will be superseded in the future. Page 160
- 161. 5. Press F5 to deploy and debug your solution. In the Attach Security Warning dialog box, click OK. 6. Activate your feature through the browser user interface. 7. Verify that the debugger stops at your breakpoint. Generated from CHM, not final book. Will be superseded in the future. Page 161
- 162. How to: Debug a Timer Job Overview When you create a timer job for Microsoft® SharePoint® 2010, you cannot directly press F5 to debug your code. Instead, you must attach the debugger to the SharePoint 2010 Timer process (Owstimer.exe). This how-to topic describes how to debug a timer job by attaching the Visual Studio debugger to the timer process. Note: This how-to topic uses the simple timer job described in How To: C reate a Web Application-Scoped Timer Job as an example. Steps To debug a timer job in Visual Studio 2010 1. On the Start menu, point to Administrative Tools, and then click Serv ices. 2. In the Services window, make sure the SharePoint 2010 Timer service is started. 3. Open the Visual Studio 2010 project that contains your timer job. Note: Make sure that the code has not changed since you deployed the timer job; otherwise, the debugger will not match your source code to the deployed assembly. 4. Set a breakpoint in the Execute method of your job definition class. 5. On the Debug menu, click Attach to Process. 6. In the Attach to Process dialog box, click OWSTIMER.EXE, and then click Attach. Generated from CHM, not final book. Will be superseded in the future. Page 162
- 163. 7. If the Attach Security Warning dialog box is displayed, click Attach. 8. In the SharePoint C entral Administration Web site, click Monitoring, and then click Review job definitions. 9. C lick the name of your job, and then click Run Now on the Edit Timer Job page. 10. Verify that the Visual Studio 2010 debugger stops execution on your breakpoint. Generated from CHM, not final book. Will be superseded in the future. Page 163
- 164. How to: Deploy an Application Page to Central Administration Overview In some situations, you might want to deploy an application page to the C entral Administration Web site. For example, you might deploy a page that allows administrators to configure a timer job. This topic describes the steps you must perform to deploy the page to C entral Administration. For a practical example of the deployment of a custom application page to C entral Administration, see the Farm Solution Reference Implementation. This uses a custom application page to configure a timer job. Summary of Steps This how-to topic includes the following steps: Step 1: Create the SharePoint Project. In this step, you use the Microsoft® Visual Studio® development system to create a project that you can use to deploy and test your application page. Step 2: Create a Mapped F older. In this step, you create a SharePoint Mapped Folder that enables you to deploy your files to the correct location on the server file system. Step 3: Add an Application Page. In this step, you add a simple application page to the mapped folder that you created. Step 4: Create a Custom Action to Launch the Page. In this step, you create a feature manifest that defines a custom action. The custom action adds a navigation item to the C entral Administration Web site. Step 1: Create the SharePoint Project This procedure creates a Microsoft SharePoint® project in Visual Studio 2010. You can use this project to build and deploy your application page. To create a project 1. Start Visual Studio 2010, and then create a new Empty SharePoint Project, as shown in the following illustration. Name the projectApplicationPage. Generated from CHM, not final book. Will be superseded in the future. Page 164
- 165. 2. In the SharePoint C ustomization Wizard, specify a valid local site for debugging, select Deploy as a farm solution, and then click Finish. Note: If you want Visual Studio 2010 to automatically activate your feature on the C entral Administration Web site, set the local site to the URL of your C entral Administration Web site. Generated from CHM, not final book. Will be superseded in the future. Page 165
- 166. 3. Step 2: Create a Mapped Folder This procedure creates a SharePoint Mapped Folder. This makes it easy for you to deploy your files to a specific location on the server file system. To create a mapped folder 1. In Solution Explorer, right-click the project node, point to Add, and then click SharePoint Mapped Folder. 2. In the Add SharePoint Mapped F older dialog box, select the {SharePointRoot}TEMPLATEADMIN folder, and then click OK. Generated from CHM, not final book. Will be superseded in the future. Page 166
- 167. Notice that Visual Studio has added an ADMIN node to Solution Explorer. Generated from CHM, not final book. Will be superseded in the future. Page 167
- 168. Step 3: Add an Application Page This procedure creates a new application page and adds it to the ADMIN mapped folder. To add an application page 1. In Solution Explorer, right-click the ADMIN node, point to Add, and then click New Item. 2. In the Add New Item dialog box, expand SharePoint in the Installed Templates pane, and then click 2010. 3. C lick Application Page, type a name for the page in the Name text box, and then click Add. This example uses the name SimplePage.aspx for the page. Note: In Solution Explorer, notice that Visual Studio has actually created a Layouts mapped folder and added the new page to that. This is the default behavior for application pages, and you must manually move the page to the desired location. Generated from CHM, not final book. Will be superseded in the future. Page 168
- 169. 4. In Solution Explorer, drag the ApplicationPage folder from the Layouts mapped folder to the ADMIN mapped folder. You can now delete the Layouts mapped folder. 5. Add some content to your application page. This example uses some HTML to verify that the page was deployed successfully. HTML <asp:Content ID="Main" ContentPlaceHolderID="PlaceHolderMain" runat="server"> <p>This is a simple application page</p></asp:Content> Step 4: Create a Custom Action to Launch the Page This procedure creates a feature manifest that defines a CustomAction element. The custom action adds a navigation item that enables administrators to launch your page from the C entral Administration Web site. To add a navigation item to Central Administration 1. In Solution Explorer, right-click the project node, point to Add, and then click New Item. 2. In the Add New Item dialog box, expand SharePoint in the Installed Templates pane, and then click 2010. 3. C lick Module, type a name for the module in the Name text box, and then click Add. This example uses the name NavItem for the module. Generated from CHM, not final book. Will be superseded in the future. Page 169
- 170. 4. Expand the NavItem node and open the feature manifest file (Elements.xml). Delete the existing content, and then add the following XML. You can also delete the Sample.txt file from Solution Explorer. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <CustomAction Id="[GUID]" GroupId="TimerJobs" Location="Microsoft.SharePoint.Administration.Monitoring" Sequence="10" Title="Simple Page" Description=""> <UrlAction Url="_admin/ApplicationPage/SimplePage.aspx" /> </CustomAction> </Elements> Note: This markup adds a custom action to the Timer Jobs action group on C entral Administration. In practice, this adds a link to our custom application page under the Timer Jobs heading. For more information about custom action locations, see Default C ustom Action Locations and IDs on MSDN. If you reuse the code, replace [GUID] with a new GUID. 5. In Solution Explorer, expand F eatures, right-click F eature1, and then click Rename. This example uses the name SimplePageF eature for the feature. 6. In Solution Explorer, double-click SimplePageF eature to open the Feature Designer. Notice that the feature already contains your Nav Item module. 7. In the Feature Designer window, give the feature a friendly title. Leave the scope set to Web. 8. Press F5 to deploy and test your solution. 9. Browse to the C entral Administration Web site, and then click Monitoring. Notice that a Simple Page link has been added under Timer Jobs. Generated from CHM, not final book. Will be superseded in the future. Page 170
- 171. 10. C lick Simple Page, and then verify that your custom application page is displayed. Generated from CHM, not final book. Will be superseded in the future. Page 171
- 172. How to: Deploy a Document Template in a Sandboxed Solution Overview In previous versions of Microsoft® SharePoint®, resources such as document templates, application pages, and JavaScript files were deployed to the SharePoint root on the server file system, typically within the _layouts virtual directory. In SharePoint 2010, you cannot deploy any resources to the server file system from a sandboxed solution. Instead, your deployment must target the content database. This how-to topic describes how to manage the deployment of files and documents in a sandboxed solution. For a practical example of the deployment of files and documents to the sandbox environment, see the Sandbox Proxy Reference Implementation. Summary of Steps This how-to topic includes the following steps: Step 1: Create and Configure a Module. In this step, you create a feature manifest file that contains a Module element. This specifies which files to deploy and where to deploy them. Step 2: Add the Module to a F eature. In this step, you create a feature and add your feature manifest file to the feature. This enables you to deploy the module to the SharePoint environment. Note: This how-to topic assumes that you have used the Microsoft Visual Studio® 2010 development system and one of the SharePoint 2010 templates to create a project. Step 1: Create and Configure a Module This procedure creates a feature manifest that contains a Module element. The module is configured to add files to the content database, which enables you to deploy it within a sandboxed solution. To create a Module element 1. In Solution Explorer, right-click the project node, point to Add, and then click New Item. 2. In the Add New Item dialog box, in the Installed Templates pane, expand SharePoint, and then click 2010. 3. C lick Module, type a name for the module in the Name text box, and then click Add. This example uses the name Templates for the module. Generated from CHM, not final book. Will be superseded in the future. Page 172
- 173. In Solution Explorer, notice that Visual Studio has added a Templates node to represent your module. Generated from CHM, not final book. Will be superseded in the future. Page 173
- 174. 4. Expand the Templates node, and then open the feature manifest file (Elements.xml). By default, the feature manifest includes a Module element with a placeholder File child element, as shown in the following XML. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Templates"> <File Path="TemplatesSample.txt" Url="Templates/Sample.txt" /> </Module> </Elements> 5. In the Elements.xml file, delete the placeholder F ile element. You can also delete the Sample.txt file from Solution Explorer. 6. In Solution Explorer, right-click the Templates node, point to Add, and then click Existing Item. 7. Browse to the file or files you want to deploy, and then click Add. 8. Notice that Visual Studio adds a F ile element for each file that you add, as shown in the following XML. This example adds an Excel template named Estimate.xltx. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Templates"> <File Path="Templatesestimate.xltx" Url="Templates/estimate.xltx" /> </Module> </Elements> 9. In the Module element, add a Url attribute to specify the destination for the files. In this example, a document template for a content type is being deployed, so a value of _cts/Estimate is specified. Note: In SharePoint 2010, like in earlier versions of SharePoint, content types and document templates are stored as subfolders in the _cts virtual directory. 10. Make the following changes to the F ile element: a. Leave the Path attribute value as Templatesestimate.xltx. This tells the feature where to find the file in your Visual Studio project. b. C hange the Url attribute value to estimate.xltx. This specifies the virtual path to the file, within the virtual directory specified by the Module element. c. Add a Type="Ghostable" attribute value. This indicates that the file will be stored in the content database. Note: Visual Studio 2010 does not always automatically pick up the feature manifest schema. If you see schema Generated from CHM, not final book. Will be superseded in the future. Page 174
- 175. errors or you lack IntelliSense support when you edit a feature manifest, check the properties of the XML document in the Properties window. The Schemas property should be set to 14TEMPLATEXMLwss.xsd. 11. The feature manifest should resemble the following. C# <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Templates" Url="_cts/Estimate"> <File Path="Templatesestimate.xltx" Url="estimate.xltx" Type="Ghostable" /> </Module> </Elements> Note: For sandboxed deployments, you can use Type attribute values of Ghostable or GhostableInLibrary. Use GhostableInLibrary if your deployment target is a document library and you want SharePoint to create a parent list item for your file. Step 2: Add the Module to a Feature This procedure adds the module to a feature, which provides the mechanism to deploy your files to the SharePoint environment. To add a module to a feature 1. In Solution Explorer, right-click the F eatures node, and then click Add F eature. Note: Visual Studio 2010 may have already added an empty feature when you added other SharePoint components. In this case, you can either rename the empty feature or delete it and create a new one. 2. In Solution Explorer, right-click the new feature node, and then click Rename. This example uses the name TemplatesF eature for the feature. 3. If the Feature Designer is not already open, double-click the TemplatesFeature node to open the designer. 4. In the Feature Designer, select an appropriate scope. You can use a feature scope value of Web or Site within a sandboxed solution. 5. In the Items in the Solution pane, click the Templates module. 6. C lick the right arrow button to add the module to the feature. This moves the Templates module to the Items in the Feature pane. Generated from CHM, not final book. Will be superseded in the future. Page 175
- 176. 7. To deploy the feature, right-click the project node in Solution Explorer, and then click Deploy. Note: This example deploys the document template to the _cts virtual directory. This location is not directly accessible to end users. You can use steps 8–11 to verify that the file was deployed successfully. 8. Open your site in SharePoint Designer. 9. In the Site Objects pane, click All F iles. 10. In the main window, click _cts. 11. C lick the Estimate folder, and verify that the folder contains the file Estimate.xltx. For more information about provisioning files into SharePoint sites, see How to: Provision a File and How to: Include Files by Using a Module on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 176
- 177. How to: Deploy a Web Part Page in a Sandboxed Solution Overview Many Microsoft® SharePoint® applications require customized Web Part pages, either to provision additional Web Part zones or to provide alternative layouts. This how-to topic describes how to deploy a custom Web Part page in a sandboxed solution. For a practical example of the deployment of a Web Part page to the sandbox environment, see the Sandbox Proxy Reference Implementation. The reference implementation displays a custom Web Part page as a modal dialog box. Summary of Steps This how-to topic includes the following steps: Step 1: Create and Configure a List Instance. In this step, you create a feature manifest file that provisions a new document library in which to store your Web Part page. Step 2: Create and Configure a Module. In this step, you create a feature manifest file that contains a Module element. This specifies which files to deploy and where to deploy them. Step 3: Add the Module to a F eature. In this step, you create a feature and add your feature manifest files to the feature. This enables you to provision the list instance and deploy the module to the SharePoint environment. Note: This how-to topic assumes that you have used the Microsoft Visual Studio 2010 development system and one of the SharePoint 2010 templates to create a project. It also assumes that you have a custom Web Part page ready to deploy. Step 1: Create and Configure a List Instance This procedure creates a feature manifest that provisions a new document library named Pages on your SharePoint site. You will use this library to store your custom Web Part page. Note: If you are deploying a page to a site that has the Publishing feature activated, you do not need to complete step 1. Instead, you can deploy your page to the Pages library that is automatically created by the Publishing feature. However, if you are using SharePoint Foundation 2010, the Publishing feature is unavailable and you must manually create a Pages library as described in this step. To create a list instance 1. In Solution Explorer, right-click the project node, point to Add, and then click New Item. 2. In the Add New Item dialog box, expand SharePoint in the Installed Templates pane, and then click 2010. 3. C lick List Instance, type a name for the list instance in the Name text box, and then click Add. This example uses the name PagesLibrary for the module. Generated from CHM, not final book. Will be superseded in the future. Page 177
- 178. 4. In the SharePoint C ustomization Wizard, under Which list do you want instantiate? [sic], click Document Library. 5. Provide appropriate values for the display name, description, and relative URL, and then click F inish. Generated from CHM, not final book. Will be superseded in the future. Page 178
- 179. Notice that Visual Studio creates and displays a feature manifest file based on the settings that you provided. Your feature manifest should resemble the following code. C# <Elements xmlns="http://schemas.microsoft.com/sharepoint"/> <ListInstance Title="Custom Pages" OnQuickLaunch="TRUE" TemplateType="101" FeatureId="00bfea71-e717-4e80-aa17-d0c71b360101" Url="Lists/CustomPages" Description=""> </ListInstance> </Elements> Step 2: Create and Configure a Module This procedure creates a feature manifest that contains a Module element. The module is configured to add files to the content database, which enables you to deploy it within a sandboxed solution. To create a Module element 1. In Solution Explorer, right-click the project node, point to Add, and then click New Item. 2. In the Add New Item dialog box, expand SharePoint in the Installed Templates pane, and then click 2010. 3. C lick Module, type a name for the module in the Name text box, and then click Add. This example uses the name Pages for the module. Generated from CHM, not final book. Will be superseded in the future. Page 179
- 180. In Solution Explorer, notice that Visual Studio has added a Pages node to represent your module. Generated from CHM, not final book. Will be superseded in the future. Page 180
- 181. 4. Expand the Pages node and open the feature manifest file (Elements.xml). By default, the feature manifest includes a Module element with a placeholder File child element, as shown in the following code. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Pages"> <File Path="PagesSample.txt" Url="Pages/Sample.txt" /> </Module> </Elements> 5. In the Elements.xml file, delete the placeholder F ile element. You can also delete the Sample.txt file in Solution Explorer. 6. In Solution Explorer, right-click the Pages node, point to Add, and then click Existing Item. 7. Browse to the Web Part page that you want to deploy, and then click Add. 8. Notice that Visual Studio adds a F ile element for the Web Part page, as shown in the following code. This example uses a Web Part page named SimplePage.aspx. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Pages"> <File Path="PagesSimplePage.aspx" Url="Pages/SimplePage.aspx" /> </Module> </Elements> 9. In the Module element, add a Url attribute to specify the destination for the files. This should be the relative URL of the target list instance, which in this case is Lists/CustomPages. 10. In the Module element, add a List attribute to indicate the type of list to which you are deploying your files. Because this example deploys files to a document library, the attribute value should be List="101". 11. Make the following changes to the F ile element: a. Leave the Path attribute value as PagesSimplePage.aspx. This tells the feature where to find the file within your Visual Studio project. b. C hange the Url attribute value to SimplePage.aspx. This specifies the virtual path to the file, within the virtual directory specified by the Module element. c. Add a Type="GhostableInLibrary" attribute value. This indicates that the file will be stored in the content database and that it should support library operations, such as check-in and check-out. Note: Visual Studio 2010 does not always automatically pick up the feature manifest schema. If you see schema errors or you lack Microsoft IntelliSense® support when you edit a feature manifest, check the properties of the XML document in the Properties window. The Schemas property should be set to Generated from CHM, not final book. Will be superseded in the future. Page 181
- 182. 14TEMPLATEXMLwss.xsd. 12. The feature manifest should resemble the following. C# <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Pages" Url="Lists/CustomPages" List="101"> <File Path="PagesSimplePage.aspx" Url="SimplePage.aspx" Type="GhostableInLibrary" /> </Module> </Elements> Step 3: Add the List Instance and the Module to a Feature This procedure adds the list instance and module to a feature, which provides the mechanism to provision your Pages library and deploy your files to the SharePoint environment. To add items to a feature 1. In Solution Explorer, right-click the F eatures node, and then click Add F eature. Note: Visual Studio 2010 may have already added an empty feature when you added other SharePoint components. In this case, you can either rename the empty feature or delete it and create a new one. 2. In Solution Explorer, right-click the new feature node, and then click Rename. This example uses the name PagesFeature for the feature. 3. If the Feature Designer is not already open, double-click the PagesFeature node to open the designer. 4. In the Feature Designer, select an appropriate scope. You can use a feature scope value of Web or Site in a sandboxed solution. 5. Use the arrow buttons to add both items to the feature. 6. To deploy the feature, right-click the project node in Solution Explorer, and then click Deploy. 7. You can verify the deployment by browsing to the C ustom Pages library on your test site. The library should contain your Web Part page. For more information about provisioning files into SharePoint sites, see How to: Provision a File and How to: Include Files by Using a Module on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 182
- 183. Generated from CHM, not final book. Will be superseded in the future. Page 183
- 184. How to: Display a Page as a Modal Dialog Box Overview The Microsoft® SharePoint® 2010 user interface makes extensive use of modal dialog boxes, which helps to improve the user experience by reducing the number of postbacks. You can use this functionality in your own applications through the use of the SharePoint client object model. This how-to topic describes how to use the SharePoint EC MAScript object model to launch a page as a modal dialog box. For a practical example of the deployment and use of pages for modal dialog boxes, including how to pass information to the modal dialog box, see the Full-Trust Proxy Reference Implementation. For more information about using the SharePoint client object model in JavaScript, see EC MAScript Object Model Reference on MSDN. Note: These steps are designed for sandboxed solution deployment. However, you can use the same approach to deploy JavaScript functions within farm solutions. Summary of Steps This how-to topic includes the following steps: Step 1: Create and Configure a Module. In this step, you create a feature manifest file that contains a Module element. This specifies which files to deploy and where to deploy them. Step 2: Create the Jav aScript Function. In this step, you create a JavaScript file and add it to the module. The file contains a function that accepts a page URL and displays the page as a modal dialog box. Step 3: Add the Module to a F eature. In this step, you create a feature and add the feature manifest file to the feature. This enables you to deploy your JavaScript function to the SharePoint environment. Step 4: Inv oke the Jav aScript Function. In this step, you use the JavaScript function to launch the site calendar as a modal dialog box. Note: This how-to topic assumes that you have used the Microsoft Visual Studio® 2010 development system and one of the SharePoint 2010 templates to create a project. Step 1: Create and Configure a Module This procedure creates a feature manifest that contains a Module element. You will use the module to deploy the JavaScript file. The module is configured to add files to the content database, which enables you to deploy it within a sandboxed solution. To create a Module element 1. In Solution Explorer, right-click the project node, point to Add, and then click New Item. 2. In the Add New Item dialog box, expand SharePoint in the Installed Templates pane, and then click 2010. 3. C lick Module, type a name for the module in the Name text box, and then click Add. This example uses the name Scripts for the module. Generated from CHM, not final book. Will be superseded in the future. Page 184
- 185. In Solution Explorer, notice that Visual Studio has added a Scripts node to represent your module. Generated from CHM, not final book. Will be superseded in the future. Page 185
- 186. 4. In Solution Explorer, right-click the Scripts node, point to Add, and then click New Item. 5. In the Add New Item dialog box, click Web in the Installed Templates pane, and then click the Jscript File template. 6. In the Name text box, type jsFunctions.js, and then click Add. 7. Open the Elements.xml file in the Script module. Notice that Visual Studio has added a File element for the jsFunctions.js file. XML <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Scripts"> <File Path="ScriptsSample.txt" Url="Scripts/Sample.txt" /> <File Path="ScriptsjsFunctions.js" Url="Scripts/jsFunctions.js" /> </Module> </Elements> 8. In the Module element, add a Url ="_catalogs/masterpage" attribute value. This tells the feature to deploy the JavaScript file to the site's master page gallery. Note: In a sandboxed solution, you are not permitted to deploy any files to the server-side file system. Instead, you can deploy the JavaScript file to the site's master page gallery. This ensures that it is available to all users who can view the site. 9. In the Module element, add a List="116" attribute value. This indicates that the destination is a library of type master page gallery. 10. Delete the File element for the Sample.txt file. You can also delete the Sample.txt file from Solution Explorer. 11. Make the following changes to the F ile element for the jsFunctions.js file: a. Leave the Path attribute value as ScriptsjsF unctions.js. This tells the feature where to find the file in your Visual Studio project. b. C hange the Url attribute value to jsFunctions.js. This specifies the virtual path to the file in the virtual directory specified by the Module element. c. Add a Type="GhostableInLibrary" attribute value. This indicates that the file will be stored as a document library item in the content database. Note: Visual Studio 2010 does not always automatically pick up the feature manifest schema. If you see schema errors or you lack IntelliSense support when you edit a feature manifest, check the properties of the XML document in the Properties window. The Schemas property should be set to 14TEMPLATEXMLwss.xsd. 12. The feature manifest should resemble the following code example. C# <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Scripts" List="116" Url="_catalogs/masterpage"> <File Path="ScriptsjsFunctions.js" Url="jsFunctions.js" Type="GhostableInLibrary"/> </Module> </Elements> Note: For sandboxed deployments, you can use Type attribute values of Ghostable or GhostableInLibrary. Use GhostableInLibrary if your deployment target is a document library and you want SharePoint to create a parent list item for your file. Step 2: Create the JavaScript Function This procedure creates a JavaScript function. The function accepts a single argument that represents the URL of a Web page. The function then uses the SharePoint EC MAScript object model to launch the specified page as a modal dialog box. To create a JavaScript function that launches a modal dialog box 1. In Solution Explorer, double-click jsF unctions.js to open the file. 2. Add a function named ShowDialog that takes a single argument named url. Jav aScript function ShowDialog(url) { } 3. Add the following code to the ShowDialog function. Generated from CHM, not final book. Will be superseded in the future. Page 186
- 187. Jav aScript var options = SP.UI.$create_DialogOptions(); options.url = url; options.height = 300; SP.UI.ModalDialog.showModalDialog(options); 4. When invoked, this JavaScript function launches the specified page as a modal dialog box with a height of 300 pixels. Step 3: Add the Module to a Feature This procedure adds the module to a feature, which provides the mechanism to deploy your JavaScript file to the SharePoint environment. To add a module to a feature 1. In Solution Explorer, right-click the F eatures node, and then click Add F eature. Note: Visual Studio 2010 may have already added an empty feature when you added the module. In this case, you can either rename the empty feature or delete it and create a new one. 2. In Solution Explorer, right-click the new feature node, and then click Rename. Type a name for the feature. This example uses the name ScriptsF eature. 3. Double-click the ScriptsF eature node to open the Feature Designer. 4. In the Feature Designer, set the feature scope to Site. 5. In the Items in the Solution pane, click the Scripts module. 6. C lick the right arrow button to add the module to the feature. This moves the feature to the Items in the Feature pane. Step 4: Invoke the JavaScript Function You can use your JavaScript function in several different ways. This procedure provides a simple demonstration that uses the JavaScript function to display the site calendar as a modal dialog box page. Generated from CHM, not final book. Will be superseded in the future. Page 187
- 188. To inv oke the Jav aScript function 1. In Solution Explorer, right-click the project node, point to Add, and then click New Item. 2. In the Add New Item dialog box, expand SharePoint in the Installed Templates pane, and then click 2010. 3. C lick Web Part, type a name for the module in the Name text box, and then click Add. This example uses the name DialogDemo for the Web Part. 4. Add the following using statement to the DialogDemo class. C# using System.Web.UI.HtmlControls; 5. Add the following constant string to the DialogDemo class. This indicates the site-relative location of the JavaScript file. C# const string jsScriptURL = "/_catalogs/masterpage/jsFunctions.js"; 6. Add the following code to the CreateChildControls method. This renders an HTML script element that loads the JavaScript file. C# HtmlGenericControl scriptInclude = new HtmlGenericControl("script"); scriptInclude.Attributes.Add("src", SPContext.Current.Site.RootWeb.Url + jsScriptURL); Controls.Add(scriptInclude); 7. Add the following code to the CreateChildControls method. This renders a hyperlink that calls the ShowDialog function, passing in the relative URL of the site calendar. C# HyperLink link = new HyperLink(); link.Text = "View Calendar"; Generated from CHM, not final book. Will be superseded in the future. Page 188
- 189. link.NavigateUrl = string.Concat("javascript: ShowDialog('", SPContext.Current.Site.RootWeb.Url, "/Lists/Calendar/calendar.aspx')"); this.Controls.Add(link); 8. In Solution Explorer, double-click the ScriptsF eature node to open the Feature Designer. Make sure that the DialogDemo Web Part is added to the feature. 9. In Solution Explorer, right-click the project node, and then click Deploy. 10. Browse to your test site, add the DialogDemo Web Part to a page, and then click the View Calendar link. Note: By default, the DialogDemo Web Part is added to the C ustom C ategories Web Part group. 11. 12. The site calendar is displayed in a modal dialog box. Generated from CHM, not final book. Will be superseded in the future. Page 189
- 190. How to: Log to the History List from a Workflow Activity Overview When you create custom full-trust workflow activities for Microsoft® SharePoint® solutions, you might often want to add entries to the Workflow History list on your SharePoint site. This how-to topic describes how to log to the History list from a workflow activity class. Note: This how-to topic assumes that you have already created a workflow activity class that derives from the System.Workflow.ComponentModel.Activ ity base class. For more information about creating a custom workflow activity, see the Workflow Activities reference implementation. Steps To log to the history list from a workflow activity 1. Locate the Execute method in your workflow activity class. C# protected override ActivityExecutionStatus Execute(ActivityExecutionContext executionContext) { // The activity logic goes here. return base.Execute(executionContext); } 2. In the Execute method, retrieve an implementation of the ISharePointService interface from the execution context object. C# ISharePointService wfService = executionContext.GetService<ISharePointService>(); 3. On the ISharePointServ ice implementation, call the LogToHistoryList method. C# wfService.LogToHistoryList(executionContext.ContextGuid, SPWorkflowHistoryEventType.WorkflowComment, 0, TimeSpan.Zero, "Information", "Logged via ISharePointService", string.Empty); 4. The LogToHistoryList method will create an entry in the Workflow History list that corresponds to the execution context of the workflow. Generated from CHM, not final book. Will be superseded in the future. Page 190
- 191. How to: Import and Package a Declarative Workflow in Visual Studio Overview When you create a declarative workflow in Microsoft® SharePoint® Designer 2010, you can save the workflow as a template in a SharePoint solution package (.wsp) file. In some circumstances, you may need to import your workflow template into the Microsoft Visual Studio® 2010 development system, and repackage it as a Visual Studio project—for example, if you want to create a solution package that contains both a declarative workflow and custom-coded workflow activities. This how-to topic describes how to import and package a workflow template in Visual Studio 2010. Note: This how-to topic assumes that you have already created a declarative workflow in SharePoint Designer 2010 and saved it as a .wsp file. Steps To import a declarativ e workflow into Visual Studio 1. In Visual Studio 2010, create a new project by using the Import SharePoint Solution Package template. Note: It is important to use the Import SharePoint Solution Package template instead of the Import Reusable Workflow template. 2. In the SharePoint C ustomization Wizard, provide a valid local site URL for debugging, and then click Next. 3. Browse to the location of your solution package, and then click Next. Generated from CHM, not final book. Will be superseded in the future. Page 191
- 192. 4. On the Select items to import page, click F inish. Generated from CHM, not final book. Will be superseded in the future. Page 192
- 193. 5. When the solution import completes, use the Replace in Files tool to replace all instances of "workflows/" with "_catalogs/wfpub/" throughout the solution. Note: _catalogs/wfpub/ is the virtual directory in which declarative workflow files are stored on each site collection. 6. Open the .xoml.wfconfig.xml file, and then make the following changes: a. In the Template element, change the value of the Visibility attribute to RootPublic from either Public or DraftPublic. b. In the Template element, change the value of the DocLibURL attribute to _catalogs/wfpub. 7. In Solution Explorer, expand the PropertyBags node, and then open the Elements.xml file within the PropertyBags node. Generated from CHM, not final book. Will be superseded in the future. Page 193
- 194. 8. Locate the PropertyBags node for the .xoml.config.xml file, and then change the value of the NoCodeVisibility property to RootPublic from either Public or DraftPublic. 9. Press F5 to build and deploy your solution. You can use SharePoint Designer to verify that the workflow was added to your target site. Generated from CHM, not final book. Will be superseded in the future. Page 194
- 195. Data Models in SharePoint 2010 Every custom SharePoint application is driven by data in one way or another. Because the SharePoint platform is geared toward managing the flow of information, it's hard to think of a solution development task that doesn't involve either displaying data, aggregating data, sorting data, filtering data, manipulating data, or creating data. SharePoint 2010 includes functionality that provides SharePoint developers with new ways to work with both internal and external data. For example, you can create relationships between SharePoint lists, in the same way that you might create a foreign key relationship between database tables. You can query across these relationships to support moderately complex data aggregation scenarios. You can use new measures designed to protect the performance of data-driven SharePoint solutions, such as throttling list queries to restrict the number of items returned by the query. You can interactively create external content types that define a set of stereotyped operations on external databases and services. A stereotyped operation is a data access method that conforms to a common and well-recognized signature, such as create, retrieve, update, and delete operations. You can create external lists, which effectively map a SharePoint list to an external content type. This allows users to interact with external data in the same way as they interact with standard SharePoint list data. Finally, you can use LINQ to SharePoint to query SharePoint list data using the Language Integrated Query (LINQ) syntax. This enables you to build sophisticated queries, including the use of joins. This plethora of new features brings with it many new design options and tradeoffs for the SharePoint application developer. There are three core approaches to defining data models for SharePoint applications: You can define a data model using SharePoint data structures such as lists and content types. You can define a data model in an external data source, such as a relational database, and then create a set of external content types to expose the data to SharePoint through the Business C onnectivity Services (BC S) component. Alternatively, you could create a Web service to wrap the data source and create your external content types from the Web service. You can create a set of external content types to model and integrate an existing data source, such as a database, a Windows C ommunication Foundation (WC F) service, or a .NET type, to expose the data to SharePoint through the BC S. This chapter is designed to guide you on key decision points and best practices for working with data in SharePoint 2010. The chapter includes the following sections and topics: Understanding Data in SharePoint 2010. This section covers the key concepts behind the storage and management of data in SharePoint 2010. It describes the core building blocks for SharePoint data models, including lists, columns, and content types. It explains how list relationships work in SharePoint 2010, and it provides an insight into managing the impact of query throttling and indexing functionality. External Data in SharePoint 2010. This section examines aspects of how you can use Business C onnectivity Services to work with external data in SharePoint 2010. It describes options for modeling complex types and entity associations in a Business Data C onnectivity (BDC ) model, it explains how filtering and throttling works in the BDC runtime, and it maps common external data scenarios to different approaches to data modeling. Data Access in SharePoint 2010. This section provides insights into the three main approaches to data access in SharePoint 2010—query classes, LINQ to SharePoint, and the BDC object model. It examines the benefits and limitations of each approach from the perspectives of usability, efficiency, and performance. List Patterns. This section describes different design options to deal with common challenges faced with lists, including managing large lists and aggregating data across lists. It describes the benefits and consequences of each approach. What's Not Covered in This Document? Data in SharePoint 2010 encompasses a broad range of material, and there are some topics that are beyond the scope of this topic. The following subjects are not covered: The Metadata Management Service, which manages the taxonomy and folksonomy data used in tagging. Access Services and Excel Services, which allow users to publish Access databases and Excel workbooks on the SharePoint platform and use them through a Web browser. Access Services is a new feature in SharePoint 2010 that enables non-developers to assemble data-centric applications in Microsoft Access and then publish those applications to SharePoint. When published to SharePoint, the application is converted into a native SharePoint application based upon SharePoint lists. Access Services applications can be synchronized with the Access client for offline access to data and for report generation. For more information, see the Access Team Blog. Business intelligence capabilities, which is a rich and important area, but it is not typically developer focused. InfoPath-based solutions for custom user interfaces and data capture. Generated from CHM, not final book. Will be superseded in the future. Page 195
- 196. Understanding Data in SharePoint 2010 Whenever you design a data-driven application, regardless of the platform, you need to consider how your data is stored and managed. The data model addresses various aspects of data storage and management, including how and where your data is stored, how the relationships between different pieces of information are defined and managed, and how you will access your data. When you work with SharePoint 2010, one of the first things you should consider is whether you can map your data storage requirements to the built-in data structures provided by the SharePoint platform. SharePoint defines a wide range of lists that can be used without modification or extended according to your needs by creating list templates, defining list instances, or associating content types you create to a list. The following are some examples: If you want to store a list of projects, together with descriptive information about each project, you can use a basic list. If you want to store statements of work (Word documents) and bid information (Excel workbooks) related to a project, you can use a document library with content types. If you want to store image resources for a particular project, you can use a picture library with content types. This sounds intuitive, but one of the basic challenges of SharePoint development is to understand what SharePoint provides in order to avoid recreating existing functionality. Spend time exploring the list types and content types that are provided by SharePoint 2010, and consider how these components can meet your needs during the data modeling process. This section provides an overview of the data-driven components in SharePoint 2010 and examines how they relate to the concepts of data modeling in general. The section includes the following topics: SharePoint Data Models in Broader C ontext . This topic provides a high-level discussion of how SharePoint 2010 relates to broader issues of data storage and data modeling. SharePoint C olumns, Lists, and C ontent Types . This topic provides an overview of the main components of data storage and data modeling in SharePoint 2010. List Relationships in SharePoint 2010 . This topic describes how you can create list relationships and execute queries using these relationships between lists in SharePoint 2010. It examines the key similarities and differences between list relationships in SharePoint and foreign key constraints in relational databases. Query Throttling and Indexing . This topic describes the concept of query throttling in SharePoint 2010 and explains how an effective indexing strategy can mitigate performance issues in general and query throttling in particular. Generated from CHM, not final book. Will be superseded in the future. Page 196
- 197. SharePoint Data Models in Broader Context Before you look at the specifics of working with data in SharePoint 2010, it can be instructive to consider the SharePoint platform in the broader context of data modeling and data storage. This topic discusses common high-level aspects of data modeling in relation to SharePoint 2010. Green Field and Brown Field Scenarios When it comes to designing data-driven applications, solution architects can find themselves in one of two situations. In one situation, they don't have to worry about anything that exists already and they can start the design process with a blank piece of paper. In the other situation, they have to design the solution around an existing environment, which could include legacy systems and different types of data repository. Most architects would agree that not having to deal with legacy systems and preexisting data stores is more fun. This situation is known as green field development. You can design the application the way you want it without working around constraints imposed by other systems. On the other hand, brown field development describes scenarios in which you are enhancing an operational system, or integrating with existing systems, such as line-of-business applications, proprietary software, and legacy data stores. As the data management requirements of most organizations evolve continuously over time, you're generally more likely to encounter brown field development scenarios. Whether your application needs to integrate with other systems and data stores will clearly have a major bearing on the design process. SharePoint 2010 excels as a platform for brown field development scenarios because of its ability to connect to and interact with almost any kind of external system. Although most guidance necessarily ignores the sticky details around integrating existing systems into a solution design, this topic devotes much of its content to the opportunities for integrating with external systems and working with external data. Structured vs. Unstructured Data When it comes to data models for the SharePoint platform, the discussion often leads quickly to structured and unstructured data. Structured data is typically highly organized and tabular, such as the information in a SharePoint list or a database table. Unstructured data contains information but lacks a rigorous schema, such as the content of a document or an image. For example, the content of this topic is unstructured data. It contains information, but the information doesn't fall into neat categories of rows and columns. C onversely, structured tables may contain columns for notes, videos, or other unstructured information. At a basic level, you typically use a SharePoint list to store structured data and a SharePoint document library to store unstructured data. However, one of the key benefits of the SharePoint platform is that it allows users to associate some structured data with fundamentally unstructured content. For example, a document will typically have a title and an author, as well as purpose-specific information such as the name of a customer, the due date for an invoice, or the final effective date for a contract. You can add these fields to a SharePoint document library in the same way that you would add them to a SharePoint list, and the SharePoint platform includes features such as property promotion that enable you to automatically extract this information from the document in many cases. This blurring between traditional definitions of structured and unstructured data occurs because conceptually, a document library is simply a list where each item has one—and only one—attachment. SharePoint document libraries include all the same functionality as SharePoint lists, such as the ability to add columns and create different views. This allows users to sort, query, and filter libraries of files and documents in the same way that they would work with regular structured data. Database Models vs. SharePoint Data Models A data model describes the real-world pieces of information that your application will work with, together with the relationship between these pieces of information. In the case of a relational data model, this is often represented as an entity-relationship diagram. The following illustration shows an example of an entity-relationship diagram for a machine parts inventory database. Entity-relationship diagram for machine parts inventory database Generated from CHM, not final book. Will be superseded in the future. Page 197
- 198. Today, most developers are familiar with relational databases. In a relational database, the data model is realized using the following constructs: A database contains one or more tables. Typically, each table models a logical entity, such as a person, an organization, or a manufactured item. For example, the machine parts inventory database contains tables for machines, parts, suppliers, and other entities. Each table contains one or more columns, or fields. Each column represents a single item of information about the entity modeled by the table. For example, the table named Machines includes fields named Name , ModelNumber, and ManufacturerId. Each field has a specific type, such as a string or an integer. A table row represents a single entry in the table. For example, the Machines table will include a single row for each machine defined in the table. Each table includes a primary key. This is a field value, or a combination of field values, that uniquely identifies each entry in the table. You can create relationships between tables by linking the primary key of one table to the same field (the foreign key) in another table. This is known as a foreign key relationship. For example, the Id field is the primary key for the Machines table, while MachineId represents the same field in the MachineDepartment table. As such, a foreign key relationship can be defined between the two tables. Most database engines, such as Microsoft SQL Server, also allow tables to execute some programming logic when certain events, known as triggers, occur. You might invoke your logic when a row is added, updated, or removed from the table. You can use trigger logic to enforce rules that ensure consistency in the data or to drive updates to applications such as cache refreshes. Typically, database engines use a data definition language (DDL) to represent the data model internally. In Microsoft SQL Server, the DDL is a subset of SQL statements that are used to create the tables and relationships. The database engine stores DDL metadata that describes these structures in a system database. When you query a database, the database engine uses this metadata to determine how to interact with the database in question. SharePoint allows you to construct data models using constructs that are conceptually similar to those found in a SQL database: Generated from CHM, not final book. Will be superseded in the future. Page 198
- 199. SharePoint lists (and by association, document libraries) are conceptually similar to database tables. SharePoint columns are conceptually similar to database table columns. SharePoint content types provide an additional layer of abstraction to support reuse and can be compared to the schema for a database table. You can create relationships between SharePoint lists using lookup columns that are conceptually similar to the foreign key relationships between database tables. However, the way in which the data model is stored and implemented differs substantially between SharePoint and a SQL database. Although SharePoint uses SQL Server as its underlying data store, it introduces a level of abstraction between the data structures you define and the data store. One key advantage of this additional abstraction is that SharePoint users with sufficient permissions can define and manage their own data structures without the intervention of a database administrator. SharePoint stores the metadata that defines columns, lists, and content types in its content databases, in much the same way that the SQL Server database engine stores data model metadata in its system databases. Generated from CHM, not final book. Will be superseded in the future. Page 199
- 200. SharePoint Columns, Lists, and Content Types Data models in SharePoint 2010 are implemented using columns, lists, and content types. A full understanding of these constructs underpins every effective data model in SharePoint 2010. SharePoint Columns The column, or field, is the core data construct in SharePoint 2010. In the context of the SharePoint platform and SharePoint applications, the terms "column" and "field" are used interchangeably: "C olumn" is preferred in product documentation and is used in the SharePoint user interface. "Field" is often used when referring to declarative markup or object model code. For example, columns are represented as F ield elements in site or list definitions, as F ieldRef elements in content type definitions, and by the SPField class in the SharePoint object model. Note: A FieldRef in a C ontentType is a reference to an existing site column, instead of a column definition. C olumns can exist at two different scopes. You can create a list column, which exists only within a specific SharePoint list. You can also create a site column, which is defined at the site collection level and is made available for use in lists and content types across the site collection, including all subsites. Each site collection includes a site column gallery in which built-in and user-defined site columns are listed. When you create a column, you can define the following information: C ore details, including the column name and the data type Group details, which can help you organize and find your columns within a site collection Logical details, such as whether a value is required, whether the value must be unique, the maximum length of the value, and a default value, if appropriate Validation details, including a validation formula and an error message Note: For more information about columns and fields in SharePoint 2010, see Building Block: C olumns and Field Types and C olumns on MSDN. You can also define columns at any site level, although the common practice is to define all site columns in the root site to maximize reuse within the site collection. The ability to enforce unique column values is new to SharePoint 2010. The unique value constraint applies only at the list instance level. Uniqueness can be defined at the site column level, but it is enforced within each list. Because of the way the unique value constraint works, you must index any columns that enforce uniqueness. You can only apply unique value constraints to columns with certain data types, because some data types cannot be indexed. You can apply the unique value constraint to a column in three ways—interactively through the user interface, declaratively by setting the EnforceUniqueValues attribute in the column definition, or programmatically through the SPF ield class. Note: For more information about the unique value constraint for SharePoint columns and a list of column types that can be indexed, see Enforcing Uniqueness in C olumn Values on MSDN. SharePoint Lists Lists are the storage mechanism in the SharePoint platform. In some ways, lists are conceptually similar to a SQL database table, in that they are comprised of columns (or fields) and rows (or list items), and that you can create relationships between lists. SharePoint lists additionally provide a user interface including forms for interacting with the data. Unlike a database table, which typically has a constant predefined set of columns, the SharePoint list also allows users with sufficient permissions to add or remove columns at will. Although it is possible to define a data model using only lists, the recommended approach is to use content types to define your key data entities. SharePoint Content Types C ontent types were introduced in SharePoint 2007 products and technologies. A content type defines the metadata and behavior for a particular data entity—usually, a business document or item of some kind. Each content type contains references to one or more site columns. You can also associate workflows, information management policies, and document templates with content types. For example, suppose you defined a content Generated from CHM, not final book. Will be superseded in the future. Page 200
- 201. type named C ontract. This content type might include the following: C olumns named C ustomer, Amount, and Final Effective Date An approval workflow A retention policy linked to the F inal Effective Date field A Word template for a contract document C ontent types can be created in three ways. Site collection administrators can create content types interactively through the user interface without developer involvement. Developers can create content types declaratively by using collaborative application markup language (C AML) or programmatically through the SPContentType object model. C ontent types are defined and managed at the site level, but they are typically defined at the root site in a site collection. In order to use a content type, you must associate it with a list or a document library. You can associate a content type with multiple lists or libraries, and each list or library can host multiple content types. This is useful in scenarios where different types of document share similar metadata—for example, you might store invoices and sales orders in the same document library, because both share similar fields but might differ in terms of approval processes or retention requirements. The ability to associate behaviors with a content type, such as workflows and event receivers, is comparable to the concept of triggers on a database table. However, because the content type can be applied to multiple locations, you can use content types to define a contract, purchase order, or invoice that has the same metadata—and the same behavior—across the entire organization. When you associate a content type with a list or library, the content type is attached to the list, together with the site columns, workflows, and policies for that content type. These policies and workflows will apply to any item of that content type in the list. The following illustration shows this. Associating content types with lists and libraries C ontent types follow the concepts of inheritance, because many data entities will share common metadata and behaviors. For example, an Invoice content type would inherit from the Document base content type, because an invoice is a type of document and shares certain characteristics with other types of documents. Ultimately, all content types inherit from the Item base content type. For more information about content type inheritance, see Base C ontent Type Hierarchy on MSDN. When you associate a content type with a list, the site content type is actually copied to the list and is given a new ID value that identifies it as a child of the site content type. The list content type is then said to inherit from the site content type. As a result, changes to a site content type are not reflected in individual lists and libraries unless you explicitly propagate, or "push down," the changes. If you update the content type programmatically, you can use the SPContentType.Update(true) method to propagate your changes—the Boolean argument to the Update method indicates that your changes should be applied to all child site and list content types. If you update the content type through the site collection user interface, you can select whether your updates should be applied to child content types. For more information, see Updating C ontent Types and on MSDN. Note: You cannot update a content type by changing the declarative (C AML) content type definition. Where possible, you should use content types to define data models in SharePoint 2010 instead of using lists directly. C ontent types enable you to define data structures that can be reused across lists, sites, site collections, Generated from CHM, not final book. Will be superseded in the future. Page 201
- 202. and even between farms. This allows you to apply a consistent and identifiable data schema across your entire organization. Note: Sharing content types across site collection boundaries is new to SharePoint 2010 and requires you to configure the managed metadata service application. For more information, see Managed metadata service application overview on TechNet. For more information about content types, see the product documentation. In particular, we recommend you refer to C ontent Types and Building Block: C ontent Types on MSDN and to C ontent type and workflow planning and Plan to share terminology and content types on TechNet. Because the fundamentals of designing content types remain unchanged, several articles about planning, designing, and using content types for the SharePoint 2007 product and technologies release are still relevant. For more information, see Best Practices: Developing C ontent Types in SharePoint Server 2007 and Windows SharePoint Services 3.0 and Managing Enterprise Metadata with C ontent Types. Generated from CHM, not final book. Will be superseded in the future. Page 202
- 203. List Relationships in SharePoint 2010 SharePoint 2010 allows you to create relationships between lists in the same site collection. List instances are related through lookup columns (as known as lookup fields). The real benefit of this functionality is that SharePoint 2010 allows you to use join statements, in LINQ to SharePoint or in collaborative application markup language (C AML), to query across lists where lookup column relationships are defined. By default, SharePoint permits a maximum of eight joins per query, although administrators can change this limit through the C entral Administration Web site or by using PowerShell. However, queries that contain large numbers of join statements are resource-intensive, and exceeding eight joins per query is likely to have a significant detrimental effect on performance. Although this newly introduced ability to query across lists brings the capabilities of SharePoint data models closer to those of relational databases, SharePoint support join predicates only where a lookup column relationship exists between the lists. In this regard, the join functionality in SharePoint is less powerful than the JOIN predicate in SQL. Lookup Columns Explained Suppose you use a relational database to manage goods orders received from your customers. The database might include a table named Orders, which stores the orders you've received, and a table named OrderLines, which stores the individual items that comprise an order. Unrelated database tables To relate the tables, you could add an OrderID column to the OrderLines table, and use this column to define a foreign key relationship between the tables. Database tables linked by foreign key constraint (primary key) Alternatively, you could add an OrderNo column to the OrderLines table, and use this column to define the foreign key relationship (providing that the OrderNo column in the Orders table is subject to a unique values constraint). Database tables linked by foreign key constraint Generated from CHM, not final book. Will be superseded in the future. Page 203
- 204. Defining the foreign key relationship helps to ensure referential integrity—in the first example, the OrderID column of the OrderLines table can only contain values that are found in the ID column in the Orders table. You can also impose further conditions on the foreign key relationship. For example, when an item is deleted from the Orders table, you can force the database engine to remove corresponding rows from the OrderLines table. C onversely, you can prohibit the deletion of OrderLines items that are linked to an active row in the Orders table. Lookup column relationships in SharePoint are conceptually similar to foreign key constraints in relational databases, but there are key differences. Suppose you want to implement the previous example in a SharePoint data model. First, you create the Orders list. Next, you define a site lookup column that retrieves values from the Orders list. Finally, you create the OrderLines list and you add the lookup column that retrieves values from Orders. When a user enters a new order line to the OrderLines list, they would select the associated order using the lookup column. You don't get to choose which columns in the Orders or OrderLines lists drive the foreign key constraint—in SharePoint lists, you can view the built in ID column as a permanent, unchangeable primary key; and this is the value that drives the relationship. Instead, you choose the column in the target list that you want to display in the source list, by setting the ShowF ield attribute. When a user adds data to the source list, he or she can select from a list of values in the column you selected on the target list. The following illustration shows this. Lookup column relationship between SharePoint lists Another key difference is that in a relational database, you can apply a foreign key constraint to existing data. This is not always good practice, and you would need to take care to remedy any existing data rows that violate the constraint. However, in SharePoint, you do not have this option—you cannot convert an existing column to a lookup column. You must create the lookup column first, and then the user must populate the data by selecting values from the target list. Note that a lookup column definition in itself does not define a relationship until you add it to a list. For example, you can create a lookup field as a site column. The lookup column definition effectively defines one half of the relationship. Lookup Column Definition Generated from CHM, not final book. Will be superseded in the future. Page 204
- 205. Whenever you add the site column to a list, you effectively create a unique foreign key relationship between the source list and the target list. In the case of lookup columns, the relationship between lists is managed by SharePoint, not by the underlying database. You can also leave a lookup column blank unless it is marked as a required field, whereas a foreign key constraint always requires a value. If you want to model a many-to-many relationship using SharePoint lists, you must create an intermediate list to normalize the relationship. This is conceptually similar to the normalization process in database design, where you would also use an intermediate table to model a many-to-many relationship. For example, suppose you want to model the relationship between parts and machines. A part can be found in many machines, and a machine can contain many parts. To normalize the relationship, you would create an intermediate list named PartMachine, as shown in the following illustration. Using an intermediate list to model a many-to-many relationship Generated from CHM, not final book. Will be superseded in the future. Page 205
- 206. In this example, the intermediate list, PartMachine, contains lookup columns that link to both lists. To create a relationship between a part and a machine, you would need to create an entry in the PartMachine list. To navigate from a part to a machine, or vice versa, you would have to browse through the PartMachine list. From a user experience point of view, this is less than ideal, so at this point, you would probably add custom logic and custom user interface components to maintain associations between parts and machines. Relationships between SharePoint lists can be navigated programmatically using either C AML or LINQ to SharePoint. For more information, see Data Access in SharePoint 2010. Creating and Using Lookup Columns You can create lookup columns in three different ways—interactively through the SharePoint site settings user interface (UI), programmatically through the SPF ieldLookup class or declaratively through C AML. For example, the following C AML code declaratively defines a lookup column named Projects Lookup that returns items from a list named Projects. XML <Field ID="{3F55B8CF-3537-4488-B250-02914EE6B4A8}" Name="ProjectsLookup" DisplayName="Projects Lookup" StaticName="ProjectsLookup" DisplaceOnUpgrade="TRUE" Group="SiteColumns" ShowField="Title" WebId="" List="Lists/Projects" Type="Lookup" Required="TRUE"> </Field> The attributes of interest for a lookup column are as follows: The value of the Type attribute must be set to Lookup. The WebId attribute specifies the internal name of the site that contains the target list. If the attribute is omitted or set to an empty string, SharePoint will assume that the list is on the root site of the site collection. The List attribute specifies the site-relative URL of the target list. This list instance must exist before the field is defined. The ShowField attribute specifies the column in the target list that contains the values that you want to display in the lookup column. Note: C onsider picking a meaningful ShowField value for the lookup column that is unlikely to change. For example, choosing a product SKU or a model number is a better foundation for a relationship than a description field. List Columns, Site Columns, and Content Types You can define a lookup column as a site column or a list column. If you define a lookup column declaratively or programmatically, you must take care to ensure that the target list (in other words, the list that the column refers to) is in place at the appropriate point in the column provisioning process. Regardless of whether you define a lookup column as a site column or a list column, the target list must already exist at the point at which the column is created—otherwise, the column will be unusable. Similarly, if you define a lookup column as part of a list definition, the target list must already exist at the point at which you provision the list containing the lookup column. Because a lookup column defines a relationship between two list instances, it can often make sense to define your lookup columns at the list level. There are some circumstances where it makes sense to use site columns and content types. For example, if many similar lists within the same site collection will include a relationship to a list on the root site, you can define a site column for the lookup, include it in a content type, and provision the content type to multiple lists within the site collection. Projected Fields In addition to the column you identify in the ShowF ield attribute, SharePoint 2010 enables you to display additional columns from the target list in the view of the list that contains the lookup column. These additional Generated from CHM, not final book. Will be superseded in the future. Page 206
- 207. columns are known as projected fields. For example, suppose you use SharePoint lists to model the relationship between employees and their departments. You create a Department lookup column for the Employees list. You might also want to display the name of the department manager in the list of employees, as shown in the following illustration. Projected fields in SharePoint lists Note: This is a somewhat contrived example, because, in reality, the department manager may not be the employee's manager, and the department manager would also be a member of the employees table. However, it serves to illustrate the concept of projected fields. Enforcing List Relationships SharePoint 2010 can help you to maintain referential integrity in your data model by enforcing the relationships defined by lookup columns. Just like foreign key constraints in a relational database, SharePoint allows you to configure restrict delete and cascade delete rules on lookup column relationships: C ascade delete rules automatically delete items that reference a record when you delete that record. This rule is typically used to enforce parent-child relationships. Restrict delete rules prevent you from deleting a record that is referenced by a lookup column in another list. This rule is typically used to enforce peer-to-peer relationships. Parent-Child Relationships and Cascade Delete Rules In a parent-child relationship, some records are children of other records. The child records are meaningless without a valid parent record. For example, an invoicing system might model a relationship between invoices and invoice line items. The invoice line items, which describe the product purchased, quantity ordered, and unit cost, are child records of the invoice item, which describes the customer, the shipping address, the total cost, and so on. To create the relationship between invoices and invoice line items, you would add a lookup column to the InvoiceLineItems list that retrieves an invoice number from the Invoices list. Because an invoice line item is meaningless without a parent invoice, it would be appropriate to configure the lookup column to cascade deletes. This ensures that when a user deletes an invoice, SharePoint will delete the corresponding line items. C hild items without a valid parent are often referred to as orphans. C ascade delete behavior is designed to prevent orphans from occurring. Peer-to-Peer Relationships and Restrict Delete Rules In a peer-to-peer relationship, there is no clear hierarchy between the related entities. For example, in our invoice line items list, you might want to include a lookup column that retrieves an item from a list of products. In this case, the product is neither child to nor parent of the invoice line item—the product lookup simply provides additional information on the invoice line. Generated from CHM, not final book. Will be superseded in the future. Page 207
- 208. Suppose you delete a product record because you no longer sell that product. This damages the referential integrity of your data model, because historical invoice line items will now reference product records that do not exist. A better approach is to mark the product record as inactive if it is no longer available for distribution. In this case, it would be appropriate to configure the product lookup column in the InvoiceLineItem list to restrict deletes. This ensures that a product record cannot be deleted if it has been referenced in an invoice line item. Making a record inactive while ensuring that it is still accessible for consistency with historical records is often referred to as a soft delete. You can configure list relationship behavior interactively through the user interface or programmatically in a feature receiver class. Because list relationship behavior is specific to individual list instances, you cannot configure this behavior declaratively in column definitions or content types. For details of how to configure cascade delete and restrict delete rules programmatically, see How to: Programmatically Set the Delete Behavior on a Lookup Field. Generated from CHM, not final book. Will be superseded in the future. Page 208
- 209. Query Throttling and Indexing A familiar challenge when you work with SharePoint lists is how to address the performance degradation that can occur when your list contains a large number of items. However, SharePoint is capable of managing extremely large lists containing millions of rows. The often-quoted limit of 2,000 items per list, actually refers to the maximum number of items that you should retrieve in a single query or view in order to avoid performance degradation. Effective indexing and query throttling strategies can help you to improve the performance of large lists. Note: For more information about working with large lists, see List Patterns, "Designing Large Lists and Maximizing Performance" from Performance and capacity test results and recommendations on TechNet and Handling Large Folders and Lists on MSDN. What Is Indexing? SharePoint enables you to index columns in a list. This is conceptually similar to indexing columns in a database table; however, in the case of SharePoint lists data, the index is maintained by SharePoint instead of SQL Server. Indexing columns in a list can substantially improve the performance of various query operations, such as queries that use the indexed column, join operations, and ordering operations such as sorting. In any list, you can either index a single column or define a composite index on two columns. C omposite indexes can enable you to speed up queries across related values. However, like with database indices, list indexing does incur a performance overhead. Maintaining the index adds processing to creating, updating, or deleting items from a list, and the index itself requires storage space. A list instance supports a maximum of 20 indices. Some SharePoint features require indices and cannot be enabled on a list where there is no index slot remaining. You should choose your indexed columns carefully to maximize query performance while avoiding unnecessary overhead. Note: Not all column data types can be indexed. For a list of column types that can be indexed, see Enforcing Uniqueness in C olumn Values on MSDN. Also note that you cannot include text fields in a composite index. What Is Query Throttling? Query throttling is a new administrative feature in SharePoint 2010. It allows farm administrators to mitigate the performance issues associated with large lists by restricting the number of items that can be accessed when you execute a query (known as the list view threshold). By default, this limit is set to 5,000 items for regular users and 20,000 items for users in an administrator role. If a query exceeds this limit, an exception is thrown and no results are returned to the calling code. Out-of-the-box, SharePoint list views manage throttled results by returning a subset of the query results, together with a warning message that some results were not retrieved. Farm administrators can use the C entral Administration Web site to configure query throttling for each Web application in various ways. For example, farm administrators can do the following: C hange the list view threshold, both for users and for site administrators. Specify whether developers can use the object model to programmatically override the list view threshold. Specify a daily time window when queries that exceed the list view threshold are permitted. This enables organizations to schedule resource-intensive maintenance operations, which would typically violate the list view threshold, during off peak hours. Limit the number of lookup, person, or workflow status fields that can be included in a single database query. If the farm administrator has enabled object model overrides, you can also change list view thresholds programmatically. For example, you can do the following: C hange the global list view threshold for a Web application by setting the SPWebApplication.MaxItemsPerThrottledOperation property. Override the list view threshold for an individual list by setting the SPList.EnableThrottling property to false. Override the query throttling settings on a specific query by using the SPQueryThrottleOption enumeration. Query throttling is designed to prevent performance degradation, so you should only programmatically suspend throttling as a temporary measure and as a last resort. Ensure that you restrict the scope of any throttling overrides to a minimum. We recommend against changing the query throttling thresholds. The default limit of 5,000 items was chosen to match the default point at which SQL Server will escalate from row-level locks to a table-level lock, which has a markedly detrimental effect on overall throughput. Generated from CHM, not final book. Will be superseded in the future. Page 209
- 210. List-based throttling applies to other operations as well as read operations. In addition to query operations, throttling also applies to the following scenarios: Deleting a list or folder that contains more than 5,000 items Deleting a site that contains more than 5,000 items in total across the site C reating an index on a list that contains more than 5,000 items Note: For detailed information about the behavior and impact of indexing and query throttling, download the white paper Designing Large Lists and Maximizing Performancefrom Performance and capacity test results and recommendations on TechNet. How Does Indexing Affect Throttling? The list view threshold does not apply simply to the number of results returned by your query. Instead, it restricts the numbers of database rows that can be accessed in order to complete execution of the query at the row level in the content database. For example, suppose you are working with a list that contains 10,000 items. If you were to build a query that returns the first 100 items sorted by the ID field, the query would execute without issue because the ID column is always indexed. However, if you were to build a query that returns the first 100 items sorted by a non-indexed Title field, the query would have to scan all 10,000 rows in the content database in order to determine the sort order by title before returning the first 100 items. Because of this, the query would be throttled, and rightly so—this is a resource-intensive operation. In this case, you could avoid the issue by indexing the Title field. This would enable SharePoint to determine the top 100 items sorted by title from the index without scanning all 10,000 list items in the database. The same concepts that apply to sort operations also apply to where clauses and join predicates in list queries. C areful use of column indexing can mitigate many large list performance issues and help you to avoid query throttling limits. Generated from CHM, not final book. Will be superseded in the future. Page 210
- 211. External Data in SharePoint 2010 In SharePoint 2010, the functionality that enables you to work with external data is provided by Business C onnectivity Services (BC S). BC S is an umbrella term—much like Enterprise C ontent Management (EC M) in SharePoint 2007—that encompasses a broad range of components and services. Introducing Business Connectivity Services Each of these components and services provide functionality relating to the modeling, access, and management of external data. The following illustration shows the key components of the BC S. SharePoint Server includes all components that are part of SharePoint Foundation. Business Connectivity Services in SharePoint 2010 The Business Data C onnectivity (BDC ) service application and the BDC runtime are the core components of the BC S when it comes to modeling, managing, and accessing external data. The Secure Store Service (SSS) supports access to external data by allowing you to map the credentials of SharePoint users or groups to external system credentials. Other BC S components enable users to interact with external data in various ways. For more information about how these components relate from an execution perspective, see Hybrid Approaches. Note: The Business Data C onnectivity service should not be confused with the Business Data C atalog (also referred to as the BDC ) in Office SharePoint Server 2007, which was the predecessor to the BC S. In this documentation, BDC refers to the Business Data C onnectivity service application. Service Proxy Groups Note: Generated from CHM, not final book. Will be superseded in the future. Page 211
- 212. The service application framework is a complex topic in its own right. This section discusses service applications and service application proxies with regard to specific issues in working with external data. For more information about the service application framework, see Service applications and service management on TechNet. SharePoint 2010 introduces a new service application framework. This replaces the shared service provider found in Office SharePoint Server 2007 and enables third parties to build new service applications for the SharePoint platform. Instead of using a shared service provider to provide collections of services to SharePoint farms and Web applications, each service in SharePoint 2010 is architected as an individual service application. In BC S, both the SSS and the BDC are examples of service applications. Administrators can create multiple instances of particular service applications. For example, you might configure one BDC instance for an intranet portal and another for a public-facing internet site. In order to use a service application, you must create a service application proxy. Where the service application provides a service, the service application proxy consumes a service. A default configuration of SharePoint 2010 largely contains pairs of service applications and service application proxies, as shown in the following illustration. Service applications and proxies in the Central Administration Web site Each Web application is associated with an application proxy group that contains a collection of service application proxies. This model supports a flexible approach to application proxy management—for example, an administrator may want different Web applications to use different subsets of the available application proxies. You can add a single service application proxy to multiple application proxy groups. Likewise, you can add multiple service application proxies of the same type to an application proxy group. However, the application proxy group will only use one of the proxies, and the proxy instance you want to use must be marked as the default instance of that proxy type for the application proxy group. Having more than one proxy instance for the same service type is an administrative convenience that enables you to easily switch between two instances by changing which is marked as default. This arrangement can lead to confusion for developers who are not familiar with the service application framework. For example, if you add a new instance of the SSS application, and you want to use that SSS application instance in your Web application, you must ensure the following: The service application proxy for the service instance is in the application proxy group mapped to your Web application. The service application proxy is the default SSS proxy instance in the application proxy group. Generated from CHM, not final book. Will be superseded in the future. Page 212
- 213. Failure to configure application proxy groups correctly can lead to bugs that are hard to diagnose. For more information about application proxy groups, see SharePoint 2010 Shared Service Architecture Part 1 on MSDN Blogs. More Information The following topics help you to understand external data models in SharePoint 2010: Business Data C onnectivity Models. This topic introduces business data connectivity models and describes how BDC models relate to external content types, external lists, and indexing external data for search. Modeling C omplex Types in External Data. This topic describes various options for mapping complex types to a BDC model, including the use of .NET connectivity assemblies. Modeling Associations in External Data. This topic explains the concepts behind associations, which enable you to build relationships between external content types in a BDC model. Filters and Throttling in the BDC . This topic describes how you can use filtering to constrain the result set returned by a BDC operation and explains how the BDC uses throttling to limit the impact of BDC operations on the performance. BDC Models and C ommon Scenarios. This topic explains how the different approaches to creating BDC models map to common application development scenarios. Generated from CHM, not final book. Will be superseded in the future. Page 213
- 214. Business Data Connectivity Models When you design a SharePoint application around external data, the metadata for your data model is stored and managed by the BDC service application. This is known as a Business Data C onnectivity model, or BDC model. You can interactively create a BDC model in SharePoint Designer 2010, or programmatically in Visual Studio 2010 for more complex scenarios. In a BDC model, data entities are represented by external content types. An external content type models an external data entity, such as a database table or view or a Web service method, and defines a set of stereotyped operations on that data entity. In addition to external content types, a BDC model typically includes an external data source definition, connection and security details for the external data source, and associations that describe the relationship between individual data entities. Other BC S components, such as external lists and external data search, enable end users to interact with the external data provided by the BDC model. Note: A stereotyped operation is a data access method that conforms to a common and well-recognized signature, such as create, retriev e, update, and delete operations. C reating BDC models for your external data sources offers many benefits. First, the BDC model enables you to centrally maintain all the information you need to interact with an external data source. This ensures that the external data source is accessed consistently by applications across your environment. After creating the BDC model, you can work with the external data in several ways without writing any code. The following are some examples: You can surface the external data through the out-of-the-box Business Data Web Parts. You can interact with the external data through external lists. You can crawl and index the external data for search. The following illustration shows the basic overall structure of a BDC model. Conceptual illustration of a BDC model As you can see, each model defines one or more external systems or services. These are sometimes known as LOB systems (line-of-business systems) for historical reasons, and are represented by LobSystem elements in the BDC model schema. This represents a general view of an external system, its data entities, and its operations. For example, it might represent a particular type of C ustomer Relationship Management (C RM) system. Within each external system definition, you must define one or more system instances. These represent a specific, individual implementation of the external system, such as a particular installation of a C RM system. The system instance definition defines the connection and authentication information that the BDC service application requires in order to communicate with the external system instance. The other key component of an external system definition is a set of entities, represented by external content types (EC Ts). These are described later in this topic. The metadata that comprises a BDC model is stored as XML. You can import, export, and manually edit BDC models as .bdcm files. For a good introduction to the BDC model schema, see BDC Model Infrastructure on MSDN. BDC models are stored by the BDC metadata store, a central component of the BDC service application. When a SharePoint client application requests external data, the BDC runtime component on the Web front-end server requests the metadata that defines the BDC model from the BDC metadata store. The BDC runtime then uses the Generated from CHM, not final book. Will be superseded in the future. Page 214
- 215. metadata provided to perform data operations directly on the external system. The BDC runtime also caches BDC model metadata on the Web front-end server. In the case of client computers that use Microsoft Office 2010 to access external systems, the metadata for an application is packaged on the server and deployed with the application for use by the BDC client runtime. The BDC client runtime uses the metadata provided to perform operations directly on the external system instead of going through SharePoint. The BDC client runtime caches both BDC model metadata and the external data itself for offline use. This is illustrated by the following diagram. Metadata and data access in BDC models For more information about this process, see Mechanics of Using Business C onnectivity Services on MSDN. You can also download the Microsoft Business C onnectivity Services Model poster from the Microsoft Web site. External Content Types An external content type (EC T) is conceptually similar to a regular SharePoint content type (although unrelated in terms of implementation). Just like a regular content type, an EC T is a collection of metadata that models a data entity. External data sources describe data schemas in different ways. For example, Web services describe their data entities and operations using the Web Service Description Language (WSDL), while relational databases describe their data entities and operations using a database schema. When you create a BDC model in SharePoint Designer, these data definitions are translated into EC Ts. Note: Visual Studio 2010 also provides tooling for defining BDC models for .NET C onnectivity Assemblies. Each EC T definition includes the following components: One or more identifiers that uniquely identify instances of the data entity One or more methods (known as "operations" in SharePoint Designer) that define a particular operation, Generated from CHM, not final book. Will be superseded in the future. Page 215
- 216. such as create, read items, update, or delete, on the data entity The methods are the central component of any EC T, and the BDC service application infers the structure of your data entity from the return types of these methods. The methods that make up an EC T are known as stereotyped operations, because they map the external service methods or database queries to standardized data operations that the BC S user interface components can use to display and manipulate the external data. For example, the BDC model supports stereotyped operations that perform the following actions: C reate an item. Retrieve all items. Retrieve an individual item. Update an item. Delete an item. Stream an item. Note: For more information about stereotyped operations, see Designing a Business Data C onnectivity Model on MSDN. Stereotyped operations offer many advantages, such as enabling SharePoint to crawl and index external data for search and allowing users to manipulate external data through built-in Business Data Web Parts without requiring custom-coded components. External Lists External lists are not part of the BDC model, but they are briefly described here because of their close relationship with EC Ts. An external list is a BC S component that provides a SharePoint list wrapper for data entities modeled by an EC T. Unlike SharePoint lists and content types, each external list is mapped to a single EC T. The external list enables users to view, sort and filter, create, update, and delete external data entities in the same way that they would work with data in a regular SharePoint list. An EC T must implement F inder and SpecificFinder methods to be exposed as an external list. As a developer, you can also use the SPList object model to programmatically interact with data through the external list (with some restrictions). However, because external lists don't "own" the external data, they cannot receive events when items are added, updated, or deleted. As such, you can't associate workflows or event receivers with external lists. However, logic in workflows and event receivers can access items in external lists. Note: For more information about using the SPList object model with external lists, see Hybrid Approaches. For more information about F inder and SpecificF inder methods in the BC S, see Stereotyped Operations Supported by BDC on MSDN. External Data and Search The SharePoint search service uses EC Ts to crawl external data sources for search. To support search crawls, the EC T must include the following types of stereotyped operations: An IdEnumerator method. This type of method returns the identity values for each instance of an EC T entity. You can support incremental indexing by configuring the IdEnumerator method to return a field that represents the last modified date and time, because this enables the search service to establish whether an item has been modified since the last search crawl. A SpecificFinder method. This type of method returns a single entity instance when provided with the unique identifier for that item. Generated from CHM, not final book. Will be superseded in the future. Page 216
- 217. Modeling Complex Types in External Data When your external system contains tabular data structures, it's straightforward to build a representative Business Data C onnectivity (BDC ) model. SharePoint Designer 2010 will discover the data structures for you, and tabular entities map well to SharePoint lists. However, advanced scenarios require more complex handling. How do you create a BDC model that aggregates data from multiple sources? How do you create your data entities when your external system contains complex, nested data structures? This topic describes some of the options that can help you to address these issues. Creating and Using .NET Connectivity Assemblies When you create a new connection for a BDC model in SharePoint Designer 2010, you've probably noticed that you're presented with three options for the type of connection—SQL Server, WC F Service, or .NET type. This last option, the .NET type, is designed to allow you to use a .NET connectivity assembly (variously referred to as a . NET shim, a BC S shim, or a shim assembly) to drive your BDC model. C reating a .NET connectivity assembly allows you to write custom code to define the stereotyped operations for your BDC model. For example, you could create a F inder method, using the recommended method signature for that operation and include custom logic that queries and concatenates data from multiple entities. Typical scenarios in which you should consider using a .NET connectivity assembly include the following: You want to aggregate data from multiple services and expose a single data model to SharePoint. You want to access data that is not accessible through a SQL Server database connection or a WC F Web service. You want to convert proprietary data types returned by an external system into .NET data types that are understood by the BDC runtime. You want to "flatten" complex data entities into fields that are compatible with the user interface (UI) components provided by the BC S. Visual Studio provides tooling for modeling and building .NET connectivity assemblies. For more information on building .NET connectivity assemblies for BDC models, see Integrating Business Data into SharePoint on MSDN. Where possible, you should aim to make your .NET connectivity assembly methods conform to the recommended signatures for stereotyped operations, because this will enable you to maximize functionality without writing custom code. For more information, see Stereotyped Operations Supported by BDC and Recommended Method Signatures for Stereotyped Operations on MSDN. For a practical example of a .NET connectivity assembly, see the External Data Models reference implementation. Note: In the BDC model overview discussed in Business Data C onnectivity Models, the .NET connectivity assembly maps to the external system level (LobSystem in the BDC schema). Because of this, the .NET connectivity assembly must provide classes and methods for all the entities in your model–you can't mix and match with other connection types. Flattening Nested Complex Types In an XML data structure, a complex type refers to an element that has child elements. A complex type that contains only one level of descendants can be represented as a tabular data structure. However, if a complex type contains more than one level of descendants—in other words, the parent node has grandchildren as well as children—the type can no longer be represented as a table or a list. In this situation, you must take additional action if you want to use built-in data constructs, such as external lists and Business Data Web Parts, to provide an interface for your external data. Flattening describes the process whereby a complex, nested type is converted into a flat two-dimensional structure that can be managed more easily by the out-of-the-box BC S components. In general, there are two approaches you can use to manage nested complex types in SharePoint data models: You can flatten the nested complex types into one or more simple types. You can build a custom user interface that is able to represent the complex structure, such as through the use of custom fields or custom Web Parts. If you choose to flatten the nested complex types, there are various options available to you. C onsider the following example of a Customer entity, returned by a Web service, which includes a nested Address element. XML <Customer> Generated from CHM, not final book. Will be superseded in the future. Page 217
- 218. <Name>Contoso</Name> <Address> <Street>1 Microsoft Way</Street> <City>Redmond</City> <StateProvince>WA</StateProvince> <PostalCode>98052</PostalCode> </Address> </Customer> One approach would be to modify the Web service to return a flattened data structure that maps well to external lists and Business Data Web Parts: XML <Customer> <Name>Contoso</Name> <AddressStreet>1 Microsoft Way</AddressStreet> <AddressCity>Redmond</AddressCity> <AddressStateProvince>WA</AddressStateProvince> <AddressPostalCode>98052</AddressPostalCode> </Customer> Although this approach certainly solves the problem, in many cases, you will not want, or will not be able, to modify the Web service. An alternative approach is to include a format string in the BDC model, so that the data entity is displayed as a flattened structure. In this case, the customer address is "flattened" and displayed as a single string. XML <TypeDescriptor TypeName="CustomerAddress" IsCollection="false" Name="CustomerAddresses" > <TypeDescriptors> <Properties> <Property Name="ComplexFormatting" Type="System.String" /> </Properties><TypeDescriptor TypeName="CustomerAddress" Name="CustomerAddress" > <Properties> <Property Name="FormatString" Type="System.String">{0}, {1}, {2} {3}</Property> </Properties> <TypeDescriptors> <TypeDescriptor TypeName="System.String" Name="Street"/> <TypeDescriptor TypeName="System.String" Name="City" /> <TypeDescriptor TypeName="System.String" Name="StateProvince" /> <TypeDescriptor TypeName="System.String" Name="PostalCode" /> </TypeDescriptors> </TypeDescriptor> </TypeDescriptors> </TypeDescriptor> In this example, the format string tells the BDC runtime how to render the address entity as a single string, in the order that the child elements are listed in the TypeDescriptors collection. If you apply the sample data to this BDC model, the address is formatted on a single line as 1 Microsoft Way, Redmond, WA 98052. You can programmatically retrieve the formatted data by using the EntityInstance.GetFormatted("FieldName") method. However, this approach has several limitations. First, the approach is only viable if the data entity can be represented effectively as a single string. Second, this formatting only handles the display of data. If you need to update the external data, you must add programming logic or custom forms to parse the new values and update the data source. Unfortunately, you can only use format strings with Business Data Web Parts. This approach will not work with external lists. A third option is to use a custom renderer. A custom renderer is a .NET class containing a static method that takes in an array of objects and returns a string. The runtime calls this renderer to format the objects into a string. To use this approach, in the TypeDescriptor element, you would use the RendererDefinition attribute to identify the method, class, and assembly of the custom renderer. Using a custom renderer is an expensive operation, because the renderer must be called on a per-item basis; because of this, you should generally only use a custom renderer when no other options are available. Just like format strings, custom renderers can only be used with Business Data Web Parts and will not work with external lists. Another option is to create a custom field type. A custom field type defines a data type for a SharePoint list column, and provides a useful way of storing complex list data in a manageable way. You can also create custom field controls that interpret the data in the custom field type and render it in a user-friendly way. For example, you could create a custom field type that stores nested address data, together with a custom field control that displays the data in a flattened, list-friendly format. C ustom field controls typically define two interfaces—one that presents the data, and one that allows the user to edit the data—so that the control works in both list view forms and list edit forms. . In the edit view, you can provide a user interface that allows the user to provide the field data in its nested format, thereby preserving the integrity of the underlying data. C ustom field types and field controls offer the most flexible approach to working with complex data, and you can build in sophisticated behavior such as sorting and filtering. However, creating field types and field controls involves creating several Generated from CHM, not final book. Will be superseded in the future. Page 218
- 219. classes and definition files, which makes them somewhat complicated to implement. For examples of how to create custom field types and field controls, see C reating C ustom SharePoint Server 2010 Field Types and Field C ontrols with Visual Studio 2010 and Silverlight 3 on MSDN. Finally, you can use a .NET connectivity assembly to manage the conversion between complex types and flat types. This is a powerful approach, because you can specify exactly how your data is flattened and unflattened for each stereotyped operation. The .NET connectivity assembly bridges the gap between the external system and the BDC model—the external system sees nested complex types, while the BDC model sees flattened data structures. For more information about these approaches, see Working with C omplex Data Types on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 219
- 220. Modeling Associations in External Data A Business Data C onnectivity (BDC ) model can include associations between external content types (EC Ts). An association is a relationship that allows the BDC runtime to navigate between external content types. You can create two different types of association between external content types: Foreign key association. This type of association maps a field in one external content type EC T (the foreign key) to an identifier in another EC T. Foreign keyless association. This type of association uses custom logic to relate one EC T to another EC T. For example, suppose you create an EC T named C ustomers, with an identifier of C ustomerID. You also create an EC T named Orders, which includes a CustomerID field. You create a foreign key association from the Orders EC T to the C ustomers EC T, as shown in the following diagram. Note that the field types must be the same on both sides of the association. Foreign key association between external content types This association allows you to create rich user interfaces using built-in BC S components. For example, you can create a profile page for a customer that automatically shows all of their orders in a Business Data Related List. The association would also allow you to use external item picker controls to select a customer when you create an order. Note: Associations in a BDC model do not enforce referential integrity. For example, the cascade delete and restrict delete functionality found in regular SharePoint list relationships do not apply to BDC associations. However, the underlying database or service may enforce referential integrity. Just like the stereotyped operations that define an EC T, associations are created as methods in the BDC model. Each association includes an input parameter, which must be an identifier on the destination EC T, and a set of return parameters. In the previous example, CustomerID is the input parameter and OrderID and Amount are likely choices for return parameters. The association method could be expressed as "Get me all the orders where the CustomerID is equal to the specified value." SharePoint Designer enables you to interactively create the following types of associations: One-to-one foreign key associations. One item in the destination table relates to one item in the source table. For example, you could use a one-to-one association to model the relationship between an employee and a department. One-to-many foreign key associations. One item in the destination table relates to many items in the source table. For example, you could use a one-to-many association to model the relationship between a customer and their orders. Self-referential foreign key associations. One item in the source table relates to other items in the source table. For example, you could use a self-referential association to model relationships between people. All of these associations are expressed declaratively as non-static methods in the BDC model. However, in the following cases, you will need to edit the BDC model XML directly: One-to-one, one-to-many, or many-to-many foreign keyless associations. This refers to any association that cannot be modeled directly by a foreign key relationship. Multiple ECT associations. This refers to any association that returns fields from more than one EC T. Non-integer primary keys. This refers to any entity that has a primary key that is not an integer. In each of these cases, it's worth using SharePoint Designer to take the model as far as you can, before you export the .bdcm file and manually edit the XML. Foreign keyless associations always require custom logic to define the relationship between the EC Ts. This custom logic could be a stored procedure in a database, a Web service, or a method in a .NET connectivity assembly. Typical scenarios in which you might require a foreign Generated from CHM, not final book. Will be superseded in the future. Page 220
- 221. keyless association include when you need to navigate between entities that are related by an intermediate table. The following are some examples: You use an intermediate table to model a many-to-many relationship. For example, you might have a many-to-many relationship between parts and machines—a machine contains many parts, and a part is found in many machines. A customer is related to an order, and an order is related to a line item. You want to show the customer in a line item view. For example, the following diagram illustrates a foreign keyless association between OrderLines and C ustomers. The foreign keyless association would use a stored procedure to navigate back to C ustomers through the Orders table. Foreign keyless association between external content types You can only create associations between entities in the same BDC model. For more information about creating associations in Visual Studio 2010, see C reating an Association Between Entities, Authoring BDC Models, and C reating External C ontent Types and Associations on MSDN. For more general information about creating associations, see Association Element in MethodInstances, The Notion of Associations and the External Item Picker, and Tooling Associations in SharePoint Designer 2010. How Are Associations Defined in the BDC Model? It can be instructive to take a look at how associations are represented in the underlying BDC model. For example, SharePoint Designer created the following association method, which represents a foreign key association between an Inv entoryLocations entity and a Parts entity. Notice the automatically generated Transact-SQL in the RdbCommandText property. Defined on the InventoryLocations entity, the association method allows you to navigate from a specific Parts instance to the related InventoryLocations instance by providing a PartSKU parameter. XML <Method IsStatic="false" Name="InventoryLocationsNavigate Association"> <Properties> <Property Name="BackEndObject" Type="System.String">InventoryLocations </Property> <Property Name="BackEndObjectType" Type="System.String">SqlServerTable </Property> <Property Name="RdbCommandText" Type="System.String"> SELECT [ID] , [PartSKU] , [BinNumber] , [Quantity] FROM [dbo].[InventoryLocations] WHERE [PartSKU] = @PartSKU </Property> <Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">Text </Property> ... The method definition also defines every parameter, but these have been omitted for brevity. Within the method definition, the method instance defines the specific logic that is actually invoked to traverse the association. Note that the method instance has a Type attribute value of AssociationNav igator, which is common to all methods Generated from CHM, not final book. Will be superseded in the future. Page 221
- 222. that navigate an association. Also note the SourceEntity and DestinationEntity elements that actually define the association. A single method definition could contain multiple method instances, each defining an association between InventoryLocations and another entity (providing that all the associations are based on the PartSKU field). Note: The Association class derives from the MethodInstance class. In terms of the object model, an Association is one specific type of MethodInstance. XML ... <MethodInstances> <Association Name="InventoryLocationsNavigate Association" Type="AssociationNavigator" ReturnParameterName="InventoryLocationsNavigate Association" DefaultDisplayName="InventoryLocations Navigate Association"> <Properties> <Property Name="ForeignFieldMappings" Type="System.String"> <?xml version="1.0" encoding="utf-16"?> <ForeignFieldMappings xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <ForeignFieldMappingsList> <ForeignFieldMapping ForeignIdentifierName="SKU" ForeignIdentifierEntityName="Parts" ForeignIdentifierEntityNamespace="DataModels.ExternalData.PartsManagement" FieldName="PartSKU" /> </ForeignFieldMappingsList> </ForeignFieldMappings> </Property> </Properties> <SourceEntity Namespace="DataModels.ExternalData.PartsManagement" Name="Parts" /> <DestinationEntity Namespace="DataModels.ExternalData.PartsManagement" Name="InventoryLocations" /> </Association> </MethodInstances> </Method> The encoded XML within the F oreignFieldMappings element can be hard to read. Essentially, this identifies the foreign key—in other words, the field in the Parts entity that provides the PartSKU parameter. Decoded and simplified, the field value resembles the following. XML <ForeignFieldMappings> <ForeignFieldMappingsList> <ForeignFieldMapping ForeignIdentifierName="SKU" ForeignIdentifierEntityName="Parts" ForeignIdentifierEntityNamespace= "DataModels.ExternalData.PartsManagement" FieldName="PartSKU" /> </ForeignFieldMappingsList> </ForeignFieldMappings> C ompare this association to a manually-defined foreign keyless association. The following association method defines an association between a Machines entity and a Parts entity. Because this is a many-to-many relationship, you need to specify a stored procedure to navigate the association. In this case, the RdbCommandText property identifies the stored procedure to call. XML <Method IsStatic="false" Name="GetPartsByMachineID"> <Properties> <Property Name="BackEndObject" Type="System.String">GetPartsByMachineID </Property> <Property Name="BackEndObjectType" Type="System.String">SqlServerRoutine </Property> Generated from CHM, not final book. Will be superseded in the future. Page 222
- 223. <Property Name="RdbCommandText" Type="System.String"> [dbo].[GetPartsByMachineID] </Property> <Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"> StoredProcedure </Property> ... Again, the method definition also defines each parameter, but these have been omitted for brevity. Because the relationship is not based on a foreign key, the method instance definition does not need to identify foreign key mappings. Instead, it simply specifies the SourceEntity and the DestinationEntity. XML ... <MethodInstances> <Association Name="GetPartsByMachineID" Type="AssociationNavigator" ReturnParameterName="GetPartsByMachineID" DefaultDisplayName="Parts Read With Sproc"> <SourceEntity Namespace="DataModels.ExternalData.PartsManagement" Name="Machines" /> <DestinationEntity Namespace="DataModels.ExternalData.PartsManagement" Name="Parts" /> </Association> </MethodInstances> </Method> To explore these entities and associations in more detail, see the External Data Models reference implementation. Generated from CHM, not final book. Will be superseded in the future. Page 223
- 224. Filters and Throttling in the BDC The Business Data C onnectivity (BDC ) runtime includes configurable filtering and throttling functionality. Administrators can use this functionality to control both the load that BDC operations put on SharePoint and the load that the operations put on the external systems that you connect to. Filters constrain the result set by restricting the scope of the query, such as by including wildcard queries or paging sets. Throttling prevents BDC operations from using excessive system resources by terminating requests that exceed the resource thresholds set by the administrator. The following diagram illustrates the filtering and throttling process. Filtering and throttling in the BDC runtime Filters encompass a wide range of information that the BDC can pass to the external system in order to constrain the result set. The types of filter you can use depend on the types of filter that are supported by the external system. The BDC allows you to use two key types of filters: system filters and user filters. System filters provide context information to the external system. For example, system filters can include a UserContext value that securely provides the identity of the caller to the external system and an Activ ityId value that represents the current operation context for diagnostic purposes. C onversely, user filters enable end users or application logic to refine a query. For example, user filters can include Wildcard and Comparison filters for pattern matching and a PageNumber value to support data retrieval on a page-by-page basis. For more information about filters, see Types of Filters Supported by the BDC and How to: Add Filter Parameters to Operations to Limit Instances from the External System on MSDN. C onceptually, throttling in the BDC is similar to the query throttling for regular lists found in SharePoint 2010. The BDC runtime throttles external data requests based on various criteria, including maximum acceptable response times, maximum permissible response sizes in data rows or bytes, and the total number of concurrent connections to databases or services. Each throttling rule can be associated with one of four scopes: Web services, WC F services, databases, or global. The default threshold values are as follows: 2000 rows for a database query 3,000,000 bytes for a Windows C ommunication Foundation (WC F) service or Web service response 180 seconds response time for a WC F service or a database request 200 total connections across databases, Web services, and WC F services The throttling criteria that are available to the administrator depend on the scope of the rule. The following table shows the criteria that apply to each of the four possible scopes. Global Database Web Service WCF Serv ice Items Size C onnections Generated from CHM, not final book. Will be superseded in the future. Page 224
- 225. Timeout For more information about BDC throttling criteria and about how to change the threshold values, see the blog post BC S PowerShell: Introduction and Throttle Management. Generated from CHM, not final book. Will be superseded in the future. Page 225
- 226. BDC Models and Common Scenarios Depending on your requirements, there are three basic approaches you can take to creating a Business Data C onnectivity (BDC ) model for an external system: You can create a purely declarative BDC model. You can create a declarative BDC model and create additional database stored procedures or additional Web service logic to support foreign keyless associations or type flattening. You can create a .NET connectivity assembly to connect to the external system and perform data operations, and then build your BDC model around the .NET connectivity assembly. The following table lists which of these approaches is typically used in various common scenarios. Note: The table does not prescribe specific approaches to specific scenarios. Your own application scenarios may merit a different approach. Scenario Declarative Declarative BDC model with .NET connectivity BDC model additional stored procedures or assembly serv ice logic Single entity One-to-one relationships One-to-many relationships Many-to-many relationships Non-integer–based foreign key relationships C omplex data types* Blob storage Unsupported data types Proprietary protocol for accessing external system Aggregating data into a single entity from multiple data sources *C omplex data types are limited to read operations in Business Data Web Parts. There are also various scenarios in which declarative BDC models created in SharePoint Designer require manual edits to the model XML. After you make these edits, you can no longer use SharePoint Designer to work on the BDC model. These scenarios include the following: When the user can modify the identifier field. In this case, you must add a PreUpdaterField="true" attribute value to the type descriptor for the relevant parameter in the Update method. For example, if you were using SKU as your identifier field, and you allowed the user to change the SKU when updating a part, you must set this field to true. This capability is not supported by the BDC client runtime for offline data updates. When you create a method of type AssociationNav igator. This type of stereotyped operation represents a foreign keyless association and uses a stored procedure or a Web service method to navigate between entities. Note: The PreUpdaterField is discussed in more detail in the External Data Models reference implementation. Generated from CHM, not final book. Will be superseded in the future. Page 226
- 227. Security and Identity Business C onnectivity Services (BC S) in SharePoint 2010 supports two different security modes for accessing services and databases—PassThrough authentication and RevertToSelf authentication: PassThrough authentication. This uses the credentials of the logged-on user to authenticate to the Web service or the database. RevertToSelf authentication. This uses the credentials of the process running the application to authenticate to the Web service or the database. This is known as a trusted subsystem model. By default, RevertToSelf authentication is disabled because it poses a potential security risk and is not permitted in hosting environments. If you enable RevertToSelf authentication in the BC S, a malicious developer or designer could point the service endpoint back to SharePoint and use the elevated privileges of the application pool account to circumvent security restrictions. The Secure Store Service (SSS) is a BC S component that is licensed with SharePoint Server 2010. The SSS provides additional options for authenticating to external services and databases. The SSS maps SharePoint user identities to other external credentials and supports claims-based approaches to authentication. The SSS provides an impersonation model that provides a trusted subsystem approach in a safer way than RevertToSelf authentication, because the SSS does not use the application pool account to access the external service. For more information, see Business C onnectivity Services security overview on TechNet. For more information about the security risk of RevertToSelf authentication, see the blog post Authenticating to Your External System. Meeting security requirements can become more complex when you use the BC D through the runtime APIs or through external lists. The user security token is not available in every context. Without the security token, PassThrough security will not work. Additionally, you will be unable to use the SSS to map the identity of the user to external credentials. The following are two common scenarios in which the user security token is unavailable: Sandboxed solutions. In the sandbox environment, the SPUser object is available, but the security tokens are stripped from the user context. Workflows. Because a workflow runs asynchronously, the security tokens for the user will not be available. You can create an SPUser context by using impersonation in a workflow, but this will not create an identity token for the impersonated account. In these situations, you need to work around the lack of an identity token and use a trusted subsystem model where all users will use the same account to access the services or database. The External Lists reference implementation demonstrates how to use the SSS with impersonation to access an external list in the sandbox. In this case, the managed account that runs the user code proxy service (SPUC WorkerProcessProxy.exe) is mapped to the external credentials. A similar approach can be used for workflow, although the workflow scenario is a little more complicated. Workflow can run in the context of several processes, including the application pool identity of the Web application hosting the application (W3wp.exe), the timer job identity (Owstimer.exe), or the user code proxy service (SPUC WorkerProcessProxy.exe). Typically, a workflow runs in the context of the content Web application when it is initiated (although under heavy load it may instead be started by the timer service) and in the OWSTimer process if it is triggered by a timed event, such as a timeout or a timer job. It can also run in the sandbox proxy process if the workflow is triggered by an action that is initiated by sandboxed code, such as programmatically adding an item to a list. In order to use BC S in workflow you will need to map each of the managed accounts for these three processes to the single account used to impersonate to the service or database. You can also use RevertToSelf under these circumstances as long as you are aware of and accept the risks described previously. If you use ReverToSelf, then the service or database must accept the credentials of the three managed accounts. Generated from CHM, not final book. Will be superseded in the future. Page 227
- 228. SharePoint Lists vs. External Databases When you design data-driven applications for the SharePoint platform, you will often need to decide where to store your data. At a high level, you have two choices: you can store your data in the SharePoint content database or you can use an external data source and connect to it through Business C onnectivity Services (BC S). In some cases, the decision is easy. For example, SharePoint has an extensive functionality set devoted to document management, so it makes sense to store documents in the SharePoint content database. Likewise, if your application consumes data from line-of-business (LOB) applications or other existing repositories of any kind, there are very few circumstances in which there will be benefit in replicating large amounts of data to the SharePoint content database. In most cases, you will want to access existing data where it resides, through the BC S. Note: There are some circumstances in which you might want to replicate data from an external data source— typically when you want to cache data for performance reasons. Although you could use the SharePoint content database to cache external data, you should also consider building an intermediate service façade with responsibility for caching. This may be more efficient than adding the caching logic to a SharePoint application. There are two high level scenarios in which the choice may be less clear. You are building a new data-driven application with no legacy code or pre-existing data (a green field development scenario). In this case, you could either use list-based SharePoint data structures as a data store or you could develop an external data source such as a relational database and connect to it through the BC S. The factors that drive your decision are likely to include the ease of implementing the data model, the performance of the application, and the ease of programming against the data model. You are porting an existing data-driven application to SharePoint (a quasi-brown field development scenario). In this case, you can continue to use the existing data store and connect through the BC S or you can implement a SharePoint list–based data model and migrate your data to the SharePoint content database. Your decision may be influenced by any design constraints in the existing data model. Note that this option only applies to complete migration scenarios. In other words, if you move the data to SharePoint, you can destroy the existing data store and there are no ongoing synchronization costs. This topic focuses on a comparison between implementing a data model in a SharePoint list and using an external database with the BC S. Of course, there are other data modeling options. You could implement a model that uses a combination of external database tables and SharePoint lists—for example, if you want to extend the data model provided by an existing database, you could continue to use the external database tables and develop SharePoint lists to extend the model. In support of this scenario, SharePoint 2010 allows you to look up data in an external list from a SharePoint list. However, you cannot look up data in a SharePoint list from an external list, because the external list represents external data that is unaware of the SharePoint implementation. For more complex business logic requirements, you should also consider building a service tier between an external database and your SharePoint application. In this case, you would build your Business Data C onnectivity (BDC ) model entities against service methods instead of against database tables. However, these scenarios are beyond the scope of this topic. In most cases, experience shows that implementing a data model using SharePoint lists can reduce development time, providing that the capabilities of SharePoint lists meet the needs of your data model and fulfill any non-functional requirements. The following table describes the development complexity and other issues for various data modeling scenarios when you use SharePoint lists or an external database with the BC S. Note: In the following table, an entity can be considered to represent a SharePoint list or a table in a relational database. Modeling scenario SharePoint lists External database with BCS One-to-one relationships Straightforward Straightforward One-to-many relationships Straightforward Straightforward Many-to-many relationships Straightforward C omplex Requires manual customization of the BDC model Default external list forms do Generated from CHM, not final book. Will be superseded in the future. Page 228
- 229. not support all create, update, and delete operations Picker controls do not work for all create, update, and delete operations Relationships with Not applicable C omplex non-integer-based primary keys You cannot specify the field on which to build Requires manual a list relationship. In a SharePoint list, the customization of the BDC built-in ID field is effectively always the model primary key Event handling on item added, Straightforward Limited updated, or deleted You can use stored procedure triggers for events within the database, but any SharePoint logic will remain unaware of the event Alerts Straightforward Not supported RSS feeds Straightforward Not supported Workflow for item added, Straightforward Not supported updated, or deleted Transactions Not supported Moderate to complex Requires additional entity classes to model the aggregated entities for update Requires stored procedures to manage the transaction A Web service layer or a .NET connectivity assembly could be used instead of stored procedures Aggregate calculations Straightforward but inefficient Moderate to complex You can aggregate data using LINQ to Requires additional entity SharePoint, but the resulting query will classes to represent retrieve all items and the aggregation will be aggregated data performed as a post-query operation on the client Right outer joins and cross Not supported Moderate joins Requires additional entity classes to model composite entities Distinct queries Not supported Straightforward Item-level security Moderate Not supported Field-level security Not supported Not supported Storing binary large object Straightforward Straightforward (BLOB) data Use the Business Data Item Web Part with StreamAccessors Nested queries Not supported Straightforward to moderate, Generated from CHM, not final book. Will be superseded in the future. Page 229
- 230. depending on whether you need to create additional entity classes C omplex business intelligence Limited support using the C hart Web Part, Full database capabilities requirements Excel Services, and Performance Point Simple user input validation Straightforward Not supported Requires custom user interface development or a .NET connectivity assembly C omplex user input validation Moderate Not supported Requires custom user interface development or a .NET connectivity assembly C ompatibility with sandbox Straightforward Depends on security requirements No security: Straightforward Trusted subsystem model: Moderate (requires access to the Secure Store Service, which is not available in SharePoint Foundation 2010) Other security models: C omplex (requires ability to install full-trust proxies) Requires access to C entral Administration or Tenant Administration Web sites to install external content types For more information about approaches to data access for SharePoint lists and for external data, see Data Access in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 230
- 231. Data Access in SharePoint 2010 SharePoint 2010 introduces several new ways in which you can programmatically interact with your data. Most notably, the introduction of LINQ to SharePoint allows you to build complex list queries with the user-friendly language integrated query (LINQ) syntax instead of constructing queries with the somewhat cumbersome C ollaborative Application Markup Language (C AML). Both LINQ to SharePoint and C AML now support join predicates in queries, which moves the SharePoint list-based data model a step closer to the power and flexibility of a relational database. One of the major evolutions in the latest version of SharePoint is the blurring of the distinction, from the user's perspective, between internal and external data. The introduction of external lists in SharePoint2010 means that you can use many of the same techniques to query data, regardless of whether that data resides in a SharePoint content database or an external system. The introduction of new options for data access brings new challenges and best practices for developers. This chapter provides an overview of each approach to server-side data access and provides guidance on the benefits and potential pitfalls of each approach. Note: C lient data access techniques, such as the new client object model and REST services, are not covered in this chapter. These techniques cover a large area of functionality and merit a chapter of their own. For more information, see Data Access for C lient Applications. SharePoint 2010 offers three key approaches that you can use to query data: C AML queries (SPQuery and SPSiteDataQuery). The SPQuery and SPSiteDataQuery classes allow you to construct and submit C AML queries to perform data operations. C AML suffers from a number of shortcomings, including quirky syntax, lack of tooling support, and difficult debugging. However, C AML remains the core engine for data operations and is still the most appropriate choice in some scenarios. The C AML schema has been expanded in SharePoint 2010 to include support for join predicates. You can also use the SPQuery class to query external lists. Note that the results returned by C AML queries are non-typed items. LINQ to SharePoint. SharePoint 2010 allows you to use LINQ queries to perform data operations on SharePoint lists, including support for join predicates. LINQ to SharePoint operates against strongly-typed entities that represent the items in your lists, and SharePoint 2010 includes a command-line tool named SPMetal that you can use to generate these entities. Internally, the LINQ to SharePoint provider generates the underlying C AML queries that perform the data operations. The Business C onnectivity Services (BC S) object model. SharePoint 2010 includes new BC S APIs that enable you to interact with external data. The BDC Object Model allows you to programmatically navigate the data entities and associations in your Business Data C onnectivity (BDC ) models and to invoke the stereotyped operations defined on these entities. The following table provides a summary of the different scenarios in which you can use each of these approaches to data access. Scenario LINQ to SPQuery SPSiteDataQuery BDC object SharePoint model Querying SharePoint list data within a site Using joins on SharePoint lists within a site Using joins on SharePoint list data across sites within a site collection Aggregating list data across multiple sites within a site collection Querying external list data within a site Navigating associations between entities in a BDC model (external data) Accessing binary streams from external data Accessing external data from a sandboxed application (requires the use of external lists) Querying external data that returns complex types Generated from CHM, not final book. Will be superseded in the future. Page 231
- 232. Querying external data that uses a non-integer, or 64-bit integer, ID field Navigating bidirectional associations between entities in a BDC model (external data) Locating an entity by specifying a field other than the ID field (external data) Querying entities that include fields that do not map to an SPF ieldType (external data) Perform bulk operations on external data Note: For information about how to use LINQ to SharePoint and C AML queries, see Querying from Server-side C ode on MSDN. This section includes the following topics that will help you to understand the key details, performance issues, and best practices behind the different approaches to data access in SharePoint 2010: Using Query C lasses . This topic identifies scenarios in which you should consider using the C AML-based query classes—SPQuery and SPSiteDataQuery—for data access. Using LINQ to SharePoint . This topic examines the use of the new LINQ to SharePoint provider, and identifies key efficiency issues and potential stumbling blocks. Using the BDC Object Model . This topic identifies scenarios in which you must use the BDC object model for data access and provides insight about how you can use the BDC object model to accomplish various common tasks. Out of Scope Topics There are a number of additional approaches to data access that are beyond the scope of this documentation. You may want to consider the following components for more specialized scenarios: The C ontentIterator class. This class is new in SharePoint Server 2010. It enables you to iterate sites, lists, and list items in chunks, in order to avoid violating query throttling thresholds. This class is useful in circumstances where you cannot avoid iterating large lists. If you think a list is likely to grow large, consider using the ContentIterator class to access the list from the start. For more information, see Large Lists. The C ontentByQueryWebPart class. This class is part of the publishing infrastructure in SharePoint Server 2010. It allows you to submit a C AML query across sites and lists within a site collection and then format the HTML output by specifying an XSL transform. The ContentByQueryWebPart class makes extensive use of caching to provide an efficient means of data retrieval. The PortalSiteMapProvider class. This class is also part of the publishing infrastructure in SharePoint 2010. It provides an efficient mechanism that you can use to query and access cached objects within a site collection. The PortalSiteMapProvider class offers a useful alternative to the ContentByQueryWebPart class when you require programmatic access to the objects you are retrieving and is capable of caching query results from SPQuery or SPSiteDataQuery. Like the ContentByQueryWebPart class, the PortalSiteMapProvider makes extensive use of caching for reasons of performance and efficiency. Generated from CHM, not final book. Will be superseded in the future. Page 232
- 233. Using Query Classes Before the advent of LINQ to SharePoint, the SPQuery and SPSiteDataQuery classes were the predominant approaches to performing data operations on SharePoint lists. There are still many scenarios in which these classes provide the most effective approach—and, in some cases, the only viable approach—to data access. Both the SPQuery class and the SPSiteDataQuery class allow you to construct a query using collaborative application markup language (C AML). You can then use the SPList object model to execute your query against one or more SharePoint lists. This topic explains when you should use each class and describes the considerations that should guide your implementations. Using SPQuery The SPQuery class is used to retrieve data from a specific list. In most cases, you should use LINQ to SharePoint, instead of the SPQuery class, to perform data operations on lists. However, there are still some circumstances in which SPQuery is the most appropriate option—or the only option—for data access. Most notably, using the SPQuery class is the only supported server object model approach for programmatically working with data in external lists. In SharePoint 2010, the SPQuery class has been extended to allow you to specify joins and projected fields. The high-level process for using the SPQuery class is as follows: C reate an SPQuery instance. Set properties on the SPQuery instance to specify the C AML query, along with various additional query parameters as required. C all the GetItems method on an SPList instance, passing in the SPQuery instance as a parameter. The following code example shows this. C# SPListItemCollection results; var query = new SPQuery { Query = "[Your CAML query statement]", ViewFields = "[Your CAML FieldRef elements]", Joins = "[Your CAML Joins element]", ProjectedFields = "[Your CAML ProjectsFields element]" }; results = SPContext.Current.Web.Lists["ListInstance"].GetItems(query); This chapter does not provide instructions on how to configure SPQuery instances, because this is well covered by the product documentation. However, the following are brief summaries of the key properties of interest: The Query property specifies the C AML query that you want to execute against the list instance. The ViewFields property specifies the columns that you want your queries to return as C AML FieldRef elements. The Joins property specifies the join predicates for your query as a C AML Joins element. The ProjectedFields property defines fields from foreign joined lists as a C AML ProjectedF ields element. This allows you to reference these fields in your ViewF ields property and in your query statement. Using SPQuery with Regular SharePoint Lists You should consider using the SPQuery class, instead of LINQ to SharePoint, in the following scenarios: When you hav e anonymous users on your site. LINQ to SharePoint does not support anonymous user access. Note: This limitation exists at the time of publication. However, it may be resolved in future service packs or cumulative updates. When a lookup column in a list refers to a list in another site within the site collection. In this situation, SPQuery allows you to use a join predicate that spans both sites. Although you can use LINQ to SharePoint to query across sites with some additional configuration, the process required to generate entity classes is more complex. By default, LINQ to SharePoint returns only the ID field from the target list, in Generated from CHM, not final book. Will be superseded in the future. Page 233
- 234. which case, you would need to run additional queries to retrieve relevant field values from the target list. For more information about generating LINQ classes that work across site boundaries, see the section, "Using List Joins across Sites," in Using LINQ to SharePoint. When performance is paramount. Using LINQ to SharePoint incurs some additional overhead, because the LINQ query must be dynamically converted to C AML at run time. If you are running a time-sensitive operation and performance is critical, you may want to consider creating the C AML yourself and using SPQuery to execute the query directly. Generally speaking, this approach is only required in extreme cases. Using SPQuery with External Lists Using the SPQuery class is the only supported way to query external lists. Using this approach, you can query an external list in exactly the same way that you would query a regular SharePoint list. However, there are some additional considerations when you access data from an external list: You cannot join across external lists, even if you have defined entity associations in the BDC model. You can specify authorization rules by assigning permissions to the external content type. Most Web services and databases will also implement authentication and authorization. You will need to implement a security scheme either by using the Secure Store Service or by configuring your own security mechanisms. Throttling mechanisms and limits differ from those that apply to regular SharePoint lists. When you query an external list, the throttling settings for the BDC runtime apply. If you want to access external data from a sandboxed application, without using a full-trust proxy, you must use an external list. Using the BDC Object Model or directly accessing external systems is prohibited in the sandbox environment. As a result, using the SPQuery class and the SPList object model with external lists is the only option for external data access if you want your solution to run in the sandbox. Note: For security reasons, the identity token for the current user is removed from the sandbox worker process. If you need to access external lists from within the sandbox environment, you must use the Secure Store Service to map the managed account that runs the User C ode Proxy Service to the credentials required by the external system. For more information, see Hybrid Approaches in the Execution Models section of this documentation. Using SPSiteDataQuery The SPSiteDataQuery class is used to query data from multiple lists across different sites in a site collection. SPSiteDataQuery is commonly used in list aggregation scenarios, where list data from team sites or other subsites is collated and presented in a single interface. Unlike the SPQuery class, you cannot use join predicates or projected fields with the SPSiteDataQuery class. The SPSiteDataQuery will only aggregate data from SharePoint lists and will ignore data from external lists. Note: Because of a bug in SharePoint 2010, an SPException (hr=0x80004005) is thrown if you execute an SPSiteDataQuery on a site that contains an external list with a column named Id. This may be fixed in a future service pack or cumulative update. The high-level process for using the SPSiteDataQuery class is as follows: C reate an SPSiteDataQuery instance. Set properties on the SPSiteDataQuery instance to specify the lists or list types to include in the query, the individual sites to include in the query, and the C AML query itself. C all the GetSiteData method on an SPWeb instance, passing in the SPSiteDataQuery instance as a parameter. The GetSiteData method returns a DataTable. The following code example, which was adapted from the sandbox reference implementation, shows this. C# SPSiteDataQuery query = new SPSiteDataQuery(); query.Lists = "<Lists BaseType='1' />"; query.ViewFields = "<FieldRef Name='SOWStatus' />" + "<FieldRef Name='EstimateValue' />"; query.Query = "<OrderBy><FieldRef Name='EstimateValue' /></OrderBy>"; query.Webs = "<Webs Scope='SiteCollection' />"; SPWeb web = SPContext.Current.Web; DataTable results = web.GetSiteData(query); Generated from CHM, not final book. Will be superseded in the future. Page 234
- 235. In terms of efficiency, the SPSiteDataQuery class provides an optimal approach to data access in the following scenarios: When you need to query multiple lists within the same site collection for the same content When you need to query across two or more lists that are not related by lookup columns You should avoid using LINQ to SharePoint to aggregate list data across sites. LINQ to SharePoint is designed to aggregate data across list relationships defined by lookup columns. Attempting cross-site operations in LINQ to SharePoint typically requires a post-query join operation in memory, which is a resource intensive process. In contrast, the SPSiteDataQuery class is optimized for querying list data across multiple sites in a site collection and across multiple lists within a single site. Note: The SPSiteDataQuery class is available in SharePoint Foundation 2010. SharePoint Server 2010 includes additional built-in components that are appropriate for certain list aggregation scenarios. These components include the C ontent Query Web Part and the Portal Site Map Navigation Provider. Generated from CHM, not final book. Will be superseded in the future. Page 235
- 236. Using LINQ to SharePoint The LINQ to SharePoint provider is a new feature in SharePoint 2010 that allows you to use a strongly-typed entity model and the language integrated query (LINQ) query syntax to query list data. Essentially, LINQ to SharePoint hides the complexity of developing C AML queries from developers, which can reduce development time and make code more readable. The LINQ to SharePoint provider converts the LINQ expressions into C AML queries at run time. Using LINQ to SharePoint in your own solutions consists of three main steps: Generate the entity classes. Before you can start writing LINQ queries against your SharePoint lists, you must create or generate the strongly-typed entity classes that represent your list data and lookup column relationships. Dev elop the solution. After you add the entity classes to your Visual Studio 2010 project, you can write LINQ queries against the strongly-typed entities that represent your data model. Run the solution. At run time, the LINQ to SharePoint provider dynamically converts your LINQ expressions into C AML queries, executes the C AML, and then maps the returned items to your strongly-typed data entities. The LINQ to SharePoint Process Although you can manually develop your entity classes, in most cases, you will want to use the SPMetal command line tool. This is included in SharePoint Foundation 2010 and can be found in the BIN folder in the SharePoint root. The SPMetal tool targets an individual SharePoint site and, by default, generates the following code resources: A data context class that deriv es from DataContext. This is the top-level entity class. It represents the content of your site and provides methods that allow you to retrieve list entities. The data context class uses the EntityList<TEntity> class to represent the lists in your site, where TEntity is a class that represents a content type. Classes that represent content types. These are marked with the ContentTypeAttribute. C ontent type classes are generated for implicit content types as well as content types that are explicitly defined on the site. For example, if a user adds a column to an existing list, the user is creating an implicit content type and a representative class will be generated. Classes and properties that represent relationships between lists. SPMetal can detect relationships based on lookup columns. Within the entity class that represents a content type, SPMetal uses the EntityRef<TEntity> class to represent the singleton side of a one-to-many relationship and the EntitySet<TEntity> class to represent the "many" side of one-to-many or many-to-many relationships (known as a reverse lookup). Properties that are mapped to a field in a related list are decorated with the AssociationAttribute. Note: You can configure the SPMetal tool to generate entity classes for specific lists, instead of for all the content in your site, by creating a parameters file. For more information, see Overriding SPMetal Defaults with a Parameters XML File on MSDN. After the entity classes are generated, you can write LINQ queries against strongly-typed entities instead of creating C AML queries. Under the covers, the LINQ to SharePoint provider converts your LINQ queries into C AML at run time and executes the C AML against your SharePoint lists. For more information about the entity classes of the LINQ to SharePoint provider, see Entity C lasses on MSDN. The following code example, adapted from the sandbox reference implementation, illustrates some of the key aspects of using LINQ with entity classes. C# using (ManufacturingSiteDataContext context = new ManufacturingSiteDataContext(SPContext.Current.Web.Url)) { string sponsor = "David Pelton"; var results = from projectItem in context.PriorityProjects where projectItem.ExecutiveSponsor == sponsor select projectItem; foreach (var proj in results) { output.AppendFormat("Title: {0} Sponsor: {1} Leader: {2} n", Generated from CHM, not final book. Will be superseded in the future. Page 236
- 237. proj.Title, proj.ExecutiveSponsor, proj.Project.Leader); } } All the entity classes in this example were generated by the SPMetal tool. The example illustrates the following key points: The query uses a data context class. The ManufacturingSiteDataContext class inherits from the DataContext class and includes strongly-typed properties for each list on the manufacturing site, such as the PriorityProjects list. The content type class that represents the entities within the list includes strongly-typed properties for each column value, such as Title and Executiv eSponsor. The entity classes understand the relationships defined by lookup columns—the Project.Leader property retrieves a Leader column value from a related Project entity. You should always dispose of the data context instance after use. The DataContext base class implements the IDisposable interface, and thereby ensures that the data context instance is released when execution passes beyond the scope of the using statement. For more information about using LINQ to SharePoint, see Managing Data with LINQ to SharePoint on MSDN. Note: You can extend the entity classes produced by the SPMetal command-line tool in order to expose additional functionality to the LINQ to SharePoint provider, for example, to handle custom field data types. This guidance does not explore this area. For more information, see Extending the Object-Relational Mapping on MSDN. Execution of LINQ to SharePoint Queries LINQ to SharePoint uses deferred loading—commonly known as lazy loading—of result sets to improve query efficiency. If you create a query that returns a collection of entities, the query won't actually execute until you commence an action that uses the result set—such as iterating over the results or converting the result set to an array. In the preceding code example, the LINQ query is only converted to C AML and executed when the foreach statement starts enumerating the result set. LINQ to SharePoint also uses the deferred loading approach for related entities. Any related entities are only loaded when the entity is actually accessed, in order to reduce unnecessary calls to the content database. In the preceding code example, the Project entity is only loaded when the foreach statement reads the Project.Leader property. When a query is executed in the context of an HTTP request, LINQ to SharePoint uses the SPContext.Current property to load the data context. This makes the process of loading the data context relatively efficient. However, if you use a LINQ query outside the context of an HTTP request, such as in a command line application or a PowerShell script, the LINQ to SharePoint provider must construct context objects, such as the SPWeb and the SPSite, in order to build the data context instance. In this case, the process becomes more resource intensive. Any create, update, or delete operations within your LINQ queries are automatically batched by the data context instance and applied when the DataContext.SubmitChanges method is called by your code. For more information, see How to: Write to C ontent Databases Using LINQ to SharePoint. Generating Entities for Content Types The SPMetal command line tool generates entity classes for the content types defined in a SharePoint site. C ontent types have various characteristics that can make this process difficult to understand: C ontent types support inheritance. C ontent types can be defined at the site level or at the list level. When a content type is added to a list, SharePoint creates a local copy of the content type which can be modified. A list can have multiple content types associated with it. SPMetal uses the following rules when it generates content types: An entity class is generated for every content type on the site (SPWeb). If a content type inherits from another content type, the entity class that represents the child content type will inherit from the entity class that represents the parent content type. For example, in the sandbox reference implementation, the SOW content type inherits from the built-in Document content type, which in turn inherits from the built-in Item content type. SPMetal generates entity classes for SOW, Document, and Item, and builds an inheritance relationship between the classes. If a list content type has been modified from the corresponding site content type, SPMetal will generate a Generated from CHM, not final book. Will be superseded in the future. Page 237
- 238. new entity class for the list content type. If the list content type is identical to the corresponding site content type, SPMetal will simply use the entity class for the site content type instead. Entities created from list content types are named by preceding the content type name with the list name. For example, if you add a StartDate column to the SOW content type in the Estimates list, an entity class named EstimatesSOW will be generated to represent the list content type. C onversely, if you have not modified the SOW content type in the Estimates list, an entity class named SOW will be generated to represent the site content type. If a column is removed from a list content type, the corresponding property is made virtual in the entity class that represents the site content type. The entity class that represents the list content type overrides this method and will throw an Inv alidOperationException if you attempt to access the property. For example, if you remove the VendorID column from the SOW content type in the Estimates list, the VendorID property is made virtual in the SOW entity class, and the EstimatesSOW entity will throw an exception if you attempt to access the property. If a list contains a single content type, the EntityList<TEntity> class that represents that list in the data context class will use that content type entity as its type parameter. For example, if the Estimates list contained only documents based on the SOW content type, the list would be represented by an EntityList<SOW> instance. If a list contains more than one content type, the EntityList<TEntity> class that represents that list will use the closest matching base content type as its type parameter. For example, the Estimates list actually contains the SOW content type and the Estimate content type, which both inherit from the built-in Document content type. In this case, the list is represented by an EntityList<Document> instance. Because SOW entities and Estimate entities both inherit from the Document entity, the list can contain entities of both types. Modeling Associations in Entity Classes When you use the SPMetal command-line tool to generate entity classes, it automatically detects relationships between lists based on lookup columns, and it adds properties to the entity classes to enable you to navigate these relationships. For example, in the SharePoint List Data Models ReferenceIimplementation, the Inventory Locations list includes a lookup column named Part that retrieves values from the Parts list. In the Inv entoryLocation class, this is reflected by the inclusion of a Part property that allows you to navigate to the associated entity instance in the Parts list. C# private Microsoft.SharePoint.Linq.EntityRef<Part> _part; [Microsoft.SharePoint.Linq.AssociationAttribute(Name="PartLookup", Storage="_part", MultivalueType=Microsoft.SharePoint.Linq.AssociationType.Single, List="Parts")] public Part Part { get { return this._part.GetEntity(); } set { this._part.SetEntity(value); } } Note: The InventoryLocation class also includes event handlers that ensure the Part reference remains up to date if the associated entity instance is changed. The SPMetal tool also adds properties to the Parts list that enable you to navigate to the Inventory Locations list. This is known as a reverse lookup association. The Parts class includes an InventoryLocation property that returns the set of inventory locations that are associated with a specific part—in other words, each Inv entoryLocation instance that links to the specified part through its Part lookup column. C# private Microsoft.SharePoint.Linq.EntitySet<InventoryLocation> _inventoryLocation; [Microsoft.SharePoint.Linq.AssociationAttribute(Name="PartLookup", Storage="_inventoryLocation", ReadOnly=true, MultivalueType=Microsoft.SharePoint.Linq.AssociationType.Backward, List="Inventory Locations")] public Microsoft.SharePoint.Linq.EntitySet<InventoryLocation> InventoryLocation { get { return this._inventoryLocation; } Generated from CHM, not final book. Will be superseded in the future. Page 238
- 239. set { this._inventoryLocation.Assign(value); } } Note: The Part class also includes event handlers that ensure the Inv entoryLocation references remain up to date if the associated entity instance is changed. However, there is a limitation in the way the current version of SPMetal builds reverse lookups: If a site lookup column is used by one list, SPMetal will generate a reverse lookup association for the relationship. If a site lookup column is used by more than one list, SPMetal will not generate reverse lookup associations for any of the relationships based on that lookup column. In many scenarios, you will want to use a lookup column in more than one list. For example, in the reference implementation, there are three lists that use lookup columns to retrieve values from the Parts list. In some cases, depending on how you intend to query your data, you may not require reverse lookup associations. However, if you do need to traverse the relationship in the reverse direction, your LINQ to SharePoint queries will be far less efficient if you proceed without a reverse lookup association in place. C onsider the relationship between Parts and Inventory Locations. If you need to find all the inventory locations associated with a specified part, you would need to retrieve every inventory location instance, check the value of the Part lookup column, and build a collection of inventory locations. In this case, the reverse lookup association simplifies the LINQ expressions and reduces the processing overhead. There are various approaches you can use to work around this limitation of SPMetal, each of which has drawbacks: 1. C reate a new site column for each list that requires a lookup column for a particular list. This results in multiple site columns that retrieve information from the same list—the columns are duplicates in everything but name. This has several negative consequences: If a developer uses a site lookup column that is already in use, reverse lookups will not be generated for that column the next time you use SPMetal, and some existing code will break. Site administrators will need to manage multiple site columns for the same value, which will be confusing. This drawback can be mitigated by hiding the duplicate lookup fields. The site columns are not really reusable, which is the main purpose of using site columns in the first place. 2. C reate lookup columns at the list level. This eliminates the problems associated with duplicate site columns. This has the following negative consequences: Your content types will no longer represent your data model, because the lookup columns are now pushed into individual lists. This makes information management more challenging. It also reduces the effectiveness of search and queries that retrieve items from different lists, because the information from the lookup column is not included in the content type. 3. C reate duplicate site columns and use them in content types or list definitions to generate the entity classes with SPMetal, as in option 1. After you generate the entity classes, delete the duplicate site lookup columns and manually edit the entity classes to use a single lookup column. This keeps your data model clean because you do not need to maintain duplicate site columns, and it avoids the problems associated with option 2 because the lookup column is included in the relevant content types. This is the preferred approach in most scenarios. However, it has the following negative consequences: Extra effort is required to create the duplicate site columns, create the content type definitions, remove the duplicate site columns, and edit the entity classes. Manual editing of the entity classes can be error-prone and difficult to debug. However, the edit should only involve straightforward renaming of properties. 4. Avoid using reverse lookup associations in cases where more than one list or content type uses a particular site lookup column. Although this approach is simple, you will need to use more complex and less efficient LINQ queries if you need to navigate the association in the reverse direction without reverse lookup properties. Query Efficiency with LINQ to SharePoint Although LINQ to SharePoint makes it quick and easy to query SharePoint lists, you still need to consider whether your LINQ expressions will translate into efficient C AML queries. If your LINQ code translates into efficient C AML queries, the performance overhead of the LINQ to SharePoint provider can be considered negligible in all but the most extreme cases—in fact, you may actually see better performance with LINQ to SharePoint because it can be difficult to manually create efficient C AML queries. This section describes how nuances in your LINQ expressions can have substantial effects on the efficiency of the generated queries. In some cases, LINQ to SharePoint prevents you from executing queries that contain certain inefficiencies. The Generated from CHM, not final book. Will be superseded in the future. Page 239
- 240. LINQ to SharePoint provider is not always able to convert a LINQ expression into a single C AML query—for example, if you use a join predicate to query across two lists that are not connected by a lookup column, the LINQ to SharePoint provider would actually need to submit two queries in order to return a result set. In cases like this where LINQ to SharePoint cannot perform an operation using a single C AML query, the runtime will throw a NotSupportedException. In other cases, the LINQ to SharePoint provider cannot translate the entire LINQ code into an efficient C AML query. In these cases the provider will first execute a C AML query to retrieve items from the list and then perform a LINQ to Objects query on the list item collection results to satisfy the portions of the LINQ query that could not be translated to C AML. For more information see Unsupported LINQ Queries and Two-stage Queries. As an example, suppose you want to review orders for every customer. You might use the following LINQ expression. C# dataContext.Customers.Select(c=>c.Orders).ToArray(); In this example, the LINQ to SharePoint provider would need to submit an additional query for every customer in order to retrieve their orders. As a result, the runtime would throw an exception. Similarly, suppose you want to aggregate data from two different lists of customers. You might use the following LINQ expression. C# dataContext.Customers.Union(dataContext.MoreCustomers).ToArray(); In this case, the LINQ to SharePoint provider would need to submit two queries—one for each list. Again, the runtime would throw an exception. The remainder of this section describes ways in which you can perform this type of query and other common operations without compromising on efficiency. Reviewing the CAML Output In many cases, it can be useful to review the C AML output that is generated by your LINQ queries. The DataContext class includes a Log property that exposes a TextWriter object. You can use this property to log the generated C AML query to a text file or to the user interface. For example, the following code shows how you can modify the previous example to view the generated C AML query. In this example, the C AML query is appended to the query results in a Literal control named displayArea. C# using (ManufacturingSiteDataContext context = new ManufacturingSiteDataContext(SPContext.Current.Web.Url)) { var sb = new StringBuilder(); var writer = new StringWriter(sb); context.Log = writer; string sponsor = "David Pelton"; var results = from projectItem in context.PriorityProjects where projectItem.ExecutiveSponsor == sponsor select projectItem; foreach (var proj in results) { output.AppendFormat("Title: {0} Sponsor: {1} Leader: {2}", proj.Title, proj.ExecutiveSponsor, proj.ProjectsLookup.Leader); } output.Append("n Query: " + sb.ToString()); displayArea.Mode = LiteralMode.Encode; displayArea.Text = output.ToString(); } After you set the Log property to a TextWriter implementation, the DataContext class will write the C AML query to the underlying stream or string as the LINQ expression is executed. You can then view the C AML query that is generated by the LINQ to SharePoint provider. XML <View> <Query> Generated from CHM, not final book. Will be superseded in the future. Page 240
- 241. <Where> <And> <BeginsWith> <FieldRef Name="ContentTypeId" /> <Value Type="ContentTypeId">0x0100</Value> </BeginsWith> <Eq> <FieldRef Name="Executive_x0020_Sponsor" /> <Value Type="Text">David Pelton</Value> </Eq> </And> </Where> </Query> <ViewFields> <FieldRef Name="Executive_x0020_Sponsor" /> <FieldRef Name="ProjectsLookup" LookupId="TRUE" /> <FieldRef Name="ID" /> <FieldRef Name="owshiddenversion" /> <FieldRef Name="FileDirRef" /> <FieldRef Name="Title" /> </ViewFields> <RowLimit Paged="TRUE">2147483647</RowLimit> </View> There are several interesting observations about the automatically generated C AML query: Notice the BeginsWith element in the Where clause. This stipulates that the content type ID of the items returned must begin with 0x0100. Effectively, this means that the content type of the items returned must be a custom content type that inherits from the built-in Item content type—which is true of the Project content type. The LINQ to SharePoint provider includes this provision in addition to the where clause specified by the LINQ query. The C AML query returns a view that contains all the fields in the PriorityProjects list, including fields that aren't required by the LINQ expression. The query returns a lookup field for the Projects list, instead of an entity. The LookupId attribute indicates that the referenced item in the Projects list will be retrieved by its internal ID value. During the development process, you should take time to examine the C AML that is generated by your LINQ queries, in order to proactively identify poorly performing queries. This is especially important when you query lists that you expect to be sizeable. For example, you should take care to catch the obviously offending cases where the LINQ to SharePoint provider is unable to translate some or all of the query into C AML and must resort to LINQ to Objects. In the preceding example, PriorityProjects is a simple list, and returning the complete set of fields causes little adverse effect on performance. As the number of items returned increases and the items grow in complexity, the performance overheads can become more substantial. For more information about how to constrain the view fields returned by a query, see the section, "Using Anonymous Types." Where Clause Efficiency When you create a LINQ expression, you typically use operators within a where clause to constrain your result set. However, the LINQ to SharePoint provider is unable to translate every LINQ operator into C AML. For example, the Equals operator and the HasValue operator have no C AML equivalent. The LINQ to SharePoint provider will translate as many where clause operators as possible into C AML, and then it will use LINQ to Objects to fulfill the remaining criteria. The following table shows the operators that are supported by the LINQ to SharePoint provider and their equivalent expressions in C AML. LINQ Operator CAML Translation && And || Or == Eq >= Geq Generated from CHM, not final book. Will be superseded in the future. Page 241
- 242. > Gt <= Leq < Lt != Neq == null IsNull != null IsNotNull String.C ontains C ontains String.StartsWith BeginsWith You should avoid using operators that are not listed in this table in your LINQ to SharePoint queries. Using unsupported operators causes the LINQ to SharePoint provider to return a larger result set and then process the outstanding where clauses on the client by using LINQ to Objects. This can create substantial performance overheads. For example, consider the following LINQ expression. The where clause includes an Equals operator and a StartsWith operator. C# var results = from projectItem in context.PriorityProjects where projectItem.ExecutiveSponsor.Equals(sponsor) && projectItem.Title.StartsWith("Over") select projectItem; The resulting C AML query includes a Where clause that reflects the StartsWith operator. However, it makes no mention of the unsupported Equals operator. XML <View> <Query> <Where> <And> <BeginsWith> <FieldRef Name="ContentTypeId" /> <Value Type="ContentTypeId">0x0100</Value> </BeginsWith> <BeginsWith> <FieldRef Name="Title" /> <Value Type="Text">Over</Value> </BeginsWith> </And> </Where> </Query> <ViewFields> … </ViewFields> <RowLimit Paged="TRUE">2147483647</RowLimit> </View> In this case, the LINQ to SharePoint provider would return a results set that includes project items with a Title field that begins with "Over," as defined by the C AML query. It would then use LINQ to Objects on the client to query the results set for project items with a matching ExecutiveSponsor field, as defined by the unsupported Equals operator. The following XML shows what it looks like if you rewrite the LINQ expression to use the supported == operator instead of the unsupported Equals operator. XML var results = from projectItem in context.PriorityProjects where projectItem.ExecutiveSponsor == sponsor && projectItem.Title.StartsWith("Over") select projectItem; Generated from CHM, not final book. Will be superseded in the future. Page 242
- 243. This time, the resulting C AML query reflects the LINQ expression in its entirety. XML <View> <Query> <Where> <And> <BeginsWith> <FieldRef Name="ContentTypeId" /> <Value Type="ContentTypeId">0x0100</Value> </BeginsWith> <And> <Eq> <FieldRef Name="Executive_x0020_Sponsor" /> <Value Type="Text">David Pelton</Value> </Eq> <BeginsWith> <FieldRef Name="Title" /> <Value Type="Text">Over</Value> </BeginsWith> </And> </And> </Where> </Query> <ViewFields> … </ViewFields> In this case, the LINQ to SharePoint provider returns only relevant results to the client; no post-processing steps are required. Using View Projections In many cases, you can substantially improve query efficiency by using view projections. A view projection queries a specific set of fields from one or more entities. When you want to retrieve a read-only view of a set of data, using a view projection restricts the number of fields returned by the query and ensures that joins are added to the C AML query instead of performed as a post-processing step. You can create a view projection in various ways: You can select a single field, such as projectItem.Title. You can build an anonymous type by selecting a specific set of fields from one or more entities. You can instantiate a known type and set the property values in your LINQ expression. View projections are limited to certain field types. Valid field types for projections are Text (single line of text only), DateTime, Counter (internal Ids), Number, and ContentTypeId. All remaining field types are not supported; an Inv alidOperationException will be thrown if a column of that field type is used in the projection. For a list of all field types, see SPFieldType. In the following example, the new keyword in the LINQ expression creates an anonymous type that contains fields named Title, Executiv eSponsor, and Leader. C# using (ManufacturingSiteDataContext context = new ManufacturingSiteDataContext(SPContext.Current.Web.Url)) { string sponsor = "David Pelton"; var results = from projectItem in context.PriorityProjects where projectItem.ExecutiveSponsor == sponsor select new { projectItem.Title, projectItem.ExecutiveSponsor, projectItem.Project.Leader }; foreach (var proj in results) { Generated from CHM, not final book. Will be superseded in the future. Page 243
- 244. output.AppendFormat("Title: {0} Sponsor: {1} Leader: {2}", proj.Title, proj.ExecutiveSponsor, proj.Leader); } } In this case, the LINQ to SharePoint provider creates a view that contains only the columns that correspond to the fields in the anonymous type. <View> <Query> <Where> <And> <BeginsWith> <FieldRef Name="ContentTypeId" /> <Value Type="ContentTypeId">0x0100</Value> </BeginsWith> <Eq> <FieldRef Name="Executive_x0020_Sponsor" /> <Value Type="Text">David Pelton</Value> </Eq> </And> </Where> </Query> <ViewFields> <FieldRef Name="Title" /> <FieldRef Name="Executive_x0020_Sponsor" /> <FieldRef Name="ProjectLeader" /> </ViewFields> <ProjectedFields> <Field Name="ProjectLeader" Type="Lookup" List="Project" ShowField="Leader" /> </ProjectedFields> <Joins> <Join Type="LEFT" ListAlias="Project"> <!--List Name: Projects--> <Eq> <FieldRef Name="Project" RefType="ID" /> <FieldRef List="Project" Name="ID" /> </Eq> </Join> </Joins> <RowLimit Paged="TRUE">2147483647</RowLimit> </View> The alternative approach, in which you instantiate a known type and set property value in your LINQ expression, is illustrated by the following example. C# public class PriorityProjectView { public string Title { get; set; } public string ExecutiveSponsor { get; set; } public string Leader { get; set; } } using (ManufacturingSiteDataContext context = new ManufacturingSiteDataContext(SPContext.Current.Web.Url)) { IEnumerable<PriorityProjectView> proirityProjects = from projectItem in context.PriorityProjects where projectItem.ExecutiveSponsor == sponsor select new PriorityProjectView { Title = projectItem.Title, ExecutiveSponsor = projectItem.ExecutiveSponsor, Generated from CHM, not final book. Will be superseded in the future. Page 244
- 245. Leader = projectItem.Project.Leader }; } ... Retrieving only the columns that you actually require will clearly improve the efficiency of your queries; in this regard, the use of view projections can provide a significant performance boost. This example also illustrates how the use of view projections forces the LINQ to SharePoint provider to perform the list join within the C AML query instead of retrieving a lookup column and using the deferred loading approach described earlier. The LINQ to SharePoint provider will only generate C AML joins when you use view projections. This is a more efficient approach when you know in advance that you will need to display data from two or more entities, because it reduces the number of round trips to the content database. Note: View projections cannot be used for create, update, or delete operations. You must retrieve the full entity instances if you want use LINQ to SharePoint to perform create, update, or delete operations. LINQ to SharePoint can only generate C AML joins from join projections for a limited number of data types. An Inv alidOperationException will be thrown if the projection contains a disallowed data type. The permitted data types are Text, Number, DateTime, Count, and Content Type ID. All remaining field types cannot be projected, including Boolean, multi-line text, choice, currency, and calculated fields. On a final note for view projections, recall that the LINQ to SharePoint provider will block certain LINQ expressions because they cannot be translated into a single C AML query. For example, the following LINQ expression attempts to retrieve a collection of orders for each customer. However, LINQ to SharePoint is unable to translate the LINQ expression into a single C AML query. C# dataContext.Customers.Select(c=>c.Orders).ToArray(); Suppose you modify the expression to use anonymous types, as shown in the following example. C# var results = dataContext.Customers.Select(c => new { Description = c.Order.Description, CustomerId = c.Order.CustomerId }).ToArray(); In this case, the LINQ to SharePoint provider is able to translate the expression into a single C AML query, and the runtime will not throw an exception. As you can see, view projections can provide a valuable resource when you develop LINQ to SharePoint expressions. Using List Joins across Sites In many common SharePoint scenarios, a list will include a lookup column that retrieves data from another list in a parent site within the site collection. However, the SPMetal command-line tool generates entity classes for a single site, and LINQ to SharePoint expressions operate within a data context that represents a single site. By default, when a list includes a lookup column that refers to a list on another site, SPMetal will generate an ID value for the item in the related list instead of constructing the related entity itself. If you were to write queries against this data model, you would need to retrieve the related entity yourself in a post-processing step. As a result, if you want to use LINQ to SharePoint to query cross-site list relationships effectively, you must perform some additional steps: 1. Temporarily move every list onto a single site before you run the SPMetal tool, so that SPMetal generates a full set of entity classes. 2. When you create a LINQ expression, use the DataContext.RegisterList method to inform the runtime of the location of lists that are not on the current site. C onsider the earlier example of a PriorityProjects list. The list includes a lookup column that retrieves information from a central Projects list on a parent site, as shown in the following illustration. Lookup column relationship across sites in a site collection Generated from CHM, not final book. Will be superseded in the future. Page 245
- 246. In order to generate entities for both lists using the SPMetal tool, you should create a copy of the PriorityProjects list on the root site, as shown in the following illustration. Temporary list to build entity classes SPMetal will now build a full set of entities and entity relationships. After you finish building entity classes, you can remove the duplicate lists from the site. When you run a query in the context of the C onstruction team site, you must use the RegisterList method to tell the runtime where to find the Projects list. The following code example shows this. C# using (ManufacturingSiteDataContext context = new ManufacturingSiteDataContext("http://localhost/sites/manufacturing/construction")) { context.RegisterList<Construction.ProjectsItem>("Projects", "/sites/Manufacturing", "Projects"); var results = from projectItem in context.PriorityProjects select new { projectItem.Title, projectItem.ExecutiveSponsor, projectItem.Project.Leader }; foreach (var item in results) { output.AppendFormat("Title: {0} Sponsor: {1} Leader: {2}", item.Title, item.ExecutiveSponsor, item.Leader); } } There are various ways in which you could approach setting up your lists for entity generation. In most cases, you will want to generate your entity classes from the site that contains any lists that are referenced by lookup columns, because lookup columns reference a specific list on a specific site. In other words, if a lookup column retrieves data from a list on the root site, you should move all your lists onto the root site and build the entity model from there. If you build an entity model that uses a lookup column to retrieve data from a list on one site and then move that list to another site, you will need to manually update your entity classes. The key options for building your entity model are as follows: Generated from CHM, not final book. Will be superseded in the future. Page 246
- 247. C reate copies of all your lists on the root site, and use SPMetal to build a single, comprehensive entity model from the root site. This approach is recommended for most scenarios, because it is usually the simplest and does not require you to modify the entity classes after creation. Use SPMetal with a parameters file to build a specialized entity model for one specific entity relationship. For example, suppose you have a lookup column that retrieves data from a specific team site instead of the root site. In this case, you should consider replicating all related lists on that specific team site and building your entity model from there, in order to avoid having to manually edit the lookup relationship in your entity classes. You might also consider this approach if you have a large number of lists in your site collection, because it may not be worth the extra effort involves in replicating and maintaining every single list on the root site. When you have a list on a subsite that includes a lookup column that retrieves values from a list on the root site, you may be tempted to reproduce the root site list on the subsite and generate entity classes from there. However, this approach should generally be avoided. First, you would need to generate temporary lookup columns, because the actual lookup columns you want to use are associated with the specific list instance on the root site. Second, you would need to manually edit the associations in the entity classes in order to use the actual lookup columns instead of the temporary lookup columns. Finally, remember that the SPQuery class supports C AML-based list joins. LINQ to SharePoint is primarily designed to expedite the development process. If the time it takes to set up and maintain copies of lists in order to build a representative entity model outweighs the time savings you derive from writing LINQ expressions instead of C AML queries, you might want to consider whether SPQuery is a better choice for your application scenario. Additional Performance Considerations LINQ expressions define a generic IEnumerable<T> collection of objects. The Enumerable class provides a set of extension methods that you can use to query and manipulate this collection. These methods have varying efficiency when you use them in your LINQ to SharePoint expressions. The following table briefly describes some of the performance issues for the operations that have not already been described. Operations that are marked as efficient are translated into C AML and do not require post-processing steps after the list data is retrieved. Operation Performance and behavior Contains Efficient OrderBy Efficient OrderByDescending Efficient ThenBy Efficient ThenByDescending Efficient GroupBy Efficient when used in conjunction with OrderBy Sum Returns all elements that satisfy the where clause and then uses LINQ to Objects to compute the sum of the elements Aggregate Returns all elements that satisfy the where clause and then uses LINQ to Objects to apply an accumulator function to the elements Av erage Returns all elements that satisfy the where clause and then uses LINQ to Objects to calculate the average value Max Returns all elements that satisfy the where clause and uses LINQ to Objects to calculate the maximum value Min Returns all elements that satisfy the where clause and then uses LINQ to Objects to calculate the minimum value Skip Returns all elements that satisfy the where clause and then uses LINQ to Objects to perform the Skip operation Generated from CHM, not final book. Will be superseded in the future. Page 247
- 248. SkipWhile Returns all elements that satisfy the where clause and then uses LINQ to Objects to perform the SkipWhile operation ElementAt Unsupported; use the Take method instead ElementAtOrDefault Unsupported; use the Take method instead Last Returns all items that satisfy the where clause, and then gets the last LastOrDefault Returns all items that satisfy the where clause, and then gets the last or returns default if no items All Returns all elements that satisfy the where clause, and then uses LINQ to Objects to evaluate the condition Any Returns all elements that satisfy the where clause, and then uses LINQ to Objects to evaluate the condition AsQueryable Efficient Cast Efficient Concat Efficient DefaultIfEmpty Efficient Distinct Performed across two collections; returns all elements that satisfy the where clause and then uses LINQ to Objects to filter out duplicates Except Performed across two collections; returns all elements that satisfy the where clause and then uses LINQ to Objects to calculate the set difference First Efficient FirstOrDefault Efficient GroupJoin Efficient Intersect Performed across two collections; returns all elements that satisfy the where clause and then uses LINQ to Objects to calculate the set intersection OfType Efficient Reverse Returns all elements that satisfy the where clause, and then uses LINQ to Objects to reverse the order of the sequence SelectMany Efficient SequenceEqual Performed across two collections; returns all elements that satisfy the where clause and then uses LINQ to Objects to calculate whether the two sets are equal Single Efficient SingleOrDefault Efficient Take Efficient TakeWhile Efficient Generated from CHM, not final book. Will be superseded in the future. Page 248
- 249. Union Efficient The Repository Pattern and LINQ to SharePoint The Repository pattern is an application design pattern that provides a centralized, isolated data access layer. The repository retrieves and updates data from an underlying data source and maps the data to your entity model. This approach allows you to separate your data access logic from your business logic. In some ways, the advent of LINQ to SharePoint may appear to obviate the need for repositories. However, there are many good reasons to continue to use the Repository pattern with LINQ to SharePoint: Query optimization. LINQ to SharePoint substantially reduces the effort involved in developing queries, when compared to creating C AML queries directly. However, it is still easy to write LINQ to SharePoint queries that perform poorly, as described earlier in this topic. Developing your queries in a central repository means that there are fewer queries to optimize and there is one place to look if you do encounter issues. Maintainability. If you use LINQ to SharePoint directly from your business logic, you will need to update your code in multiple places if your data model changes. The Repository pattern decouples the consumer of the data from the provider of the data, which means you can update your queries in response to data model changes without impacting business logic throughout your code. Testability. The repository provides a substitution point at which you can insert fake objects for unit testing. Flexibility. The repository pattern promotes layering and decoupling, which leads to more flexible, reusable code. In practice, you will encounter tradeoffs between the advantages of the Repository pattern and the practicalities of implementing a solution. In the SharePoint Guidance reference implementations, the following practices were established: Encapsulate all LINQ to SharePoint queries in a repository. This provides a central point of management for the queries. C onfigure the repository class to return the entity types generated by the SPMetal command-line tool. This avoids the additional overhead of creating custom business entities and mapping them to the SPMetal entity classes, which would be the purist approach to implementing the Repository pattern. However, on the negative side, this results in a tighter coupling between the data model and the data consumers. Add view objects to the repository in order to return composite projections of entities. A view object combines fields from more than one entity, and using view projections can make LINQ to SharePoint queries across multiple entities more efficient, as described earlier in this topic. This approach was used in the reference implementations, even though it deviates from the Repository pattern, because the views are relatively simple and the entities that are represented in the views are all owned by the same repository. If the views were more complex, or the entities involved spanned multiple repositories, the developers would have implemented a separate class to manage views to provide a cleaner division of responsibilities. To view this repository implementation in action, see the SharePoint List Data Models Reference Implementation. Generated from CHM, not final book. Will be superseded in the future. Page 249
- 250. Using the BDC Object Model Scenarios for access to external data vary widely in complexity, from simply displaying a list of information from an external source to providing heavily customized interactivity. For many basic scenarios, using the built-in Business Data Web Parts or using the SPList API to query external lists provide straightforward and effective approaches to meeting your application requirements. However, for more complex scenarios, you will need to use the BDC object model for full control of how you interact with your external data entities. The BDC object model is not available in sandboxed solutions. The following table summarizes the scenarios where external lists or Business Data Web Parts may meet your requirements and the scenarios where you must use the BDC object model. External data scenario External Business Data Web BCS API list Parts Access two-dimensional (flat) data from a sandboxed solution Access two-dimensional (flat) data from a farm solution Access data with non-integer identifiers Navigate one-to-one associations between entities Navigate one-to-many associations between entities Navigate many-to-many associations between entities Read entities with complex types that can be flattened using a format string Read entities with complex types that cannot be flattened using a format string C reate, update, or delete entities with complex types Perform paging or chunking of data Stream binary objects Access two-dimensional (flat) data from client logic* Navigate associations between entities from client logic* *The BDC provides a client API and a server API that offer the same functionality. However, the client API is only available in full .NET applications; it cannot be used from Silverlight or JavaScript. The BDC runtime API allows you to programmatically navigate a BDC model, and to interact with an external system through the model, without using intermediary components such as external lists or Business Data Web Parts. The following diagram illustrates the key components of the BDC programming model. Key components of the BDC programming model Generated from CHM, not final book. Will be superseded in the future. Page 250
- 251. Each of the components in the programming model relates to a specific part of the BDC model, which was described in Business Data C onnectivity Models. The BDC service application instance (BdcService) represents the service instance that manages the metadata for the external systems you want to access. Remember that the BDC service application instance you use is determined by the service application proxy group associated with the current SharePoint Web application. Each BDC service application instance exposes a metadata catalog (IMetadataC atalog) that you can use to navigate through the metadata definitions stored by the service. Within the metadata catalog, the two primary concepts are the entity (IEntity) and the LOB system instance (ILobSystemInstance). An entity represents an external content type and defines the stereotyped operations that are used to interact with an external data entity. It can also define associations that allow you to navigate to related entities and filters that enable you to constrain a result set. A LOB system instance represents a specific instance, or installation, of the external system that the BDC model represents, and defines the connection and authentication details required to connect to the system. Note: "LOB system instance" is a legacy term from Office SharePoint Server 2007. A LOB system is a line-of-business application, such as customer relationship management (C RM) or enterprise resource planning (ERP) software. Although the term "LOB system instance" is still used within the BDC object model, the broader term "external system" is preferred in other cases. Entities, or external content types, are common to all instances of a system. To access data from a specific instance of an external system, you need to use an entity object in conjunction with a LOB system instance object to retrieve an entity instance (IEntityInstance). The following code example illustrates this. C# public IEntityInstance GetMachineInstance(int machineId) { const string entityName = "Machines"; const string systemName = "PartsManagement"; const string nameSpace = "DataModels.ExternalData.PartsManagement"; BdcService bdcService = SPFarm.Local.Services.GetValue<BdcService>(); IMetadataCatalog catalog = bdcService.GetDatabaseBackedMetadataCatalog(SPServiceContext.Current); ILobSystemInstance lobSystemInstance = catalog.GetLobSystem(systemName).GetLobSystemInstances()[systemName]; Generated from CHM, not final book. Will be superseded in the future. Page 251
- 252. Identity identity = new Identity(machineId); IEntity entity = catalog.GetEntity(nameSpace, entityName); IEntityInstance instance = entity.FindSpecific(identity, lobSystemInstance); return instance; } When a method on an IEntity object takes an object of type ILobSystemInstance as a parameter—such as the F indSpecific method shown here—usually, it is querying the external system for information. The IEntity object defines the stereotyped operations that allow you to interact with a particular type of data entity on the external system, while the ILobSystemInstance object defines the details required to actually connect to a specific external system instance. Typically, you perform data operations on an IEntityInstance object or on a collection of IEntityInstance objects. Each IEntityInstance object contains a set of fields and values that correspond to the related data item in the external system. These fields can represent simple types or complex types. For more information, see IEntityInstance Interface on MSDN. Using Filters IEntity objects can include filter definitions that allow you to constrain result sets when retrieving more than one item. Filters can also provide contextual information to the external system, such as a trace identifier to use when logging. The following code example shows how you can use filters to retrieve entity instances that match a specified model number. C# public DataTable FindMachinesForMatchingModelNumber(string modelNumber) { const string entityName = "Machines"; const string systemName = "PartsManagement"; const string nameSpace = "DataModels.ExternalData.PartsManagement"; BdcService bdcService = SPFarm.Local.Services.GetValue<BdcService>(); IMetadataCatalog catalog = bdcService.GetDatabaseBackedMetadataCatalog(SPServiceContext.Current); ILobSystemInstance lobSystemInstance = catalog.GetLobSystem(systemName).GetLobSystemInstances()[systemName]; IEntity entity = catalog.GetEntity(nameSpace, entityName); IFilterCollection filters = entity.GetDefaultFinderFilters(); if (!string.IsNullOrEmpty(modelNumber)) { WildcardFilter filter = (WildcardFilter)filters[0]; filter.Value = modelNumber; } IEntityInstanceEnumerator enumerator = entity.FindFiltered(filters, lobSystemInstance); return entity.Catalog.Helper.CreateDataTable(enumerator); } As you can see, the IEntity object includes a collection of filters that you can configure for use in queries. In this case, a wildcard filter is used to perform a partial match against a machine model number. Note: The CreateDataTable method is a convenient new addition in SharePoint 2010 that automatically populates a DataTable object with the query results. Using Associations At a conceptual level, associations between entities in the BDC model are similar to foreign key constraints in a relational database or lookup columns in regular SharePoint lists. However, they work in a different way. Associations are defined as methods within an entity that allow you to navigate from instances of that entity to instances of a related entity. You cannot create joins across associations in a BDC model. Instead, you must retrieve an entity instance and then use the association method to navigate to the related entity instances. This is illustrated by the following code example, which retrieves the set of machine part entities that are associated with Generated from CHM, not final book. Will be superseded in the future. Page 252
- 253. a machine entity. C# public DataTable GetPartsForMachine(int machineId) { const string entityName = "Machines"; const string systemName = "PartsManagement"; const string nameSpace = "DataModels.ExternalData.PartsManagement"; BdcService bdcService = SPFarm.Local.Services.GetValue<BdcService>(); IMetadataCatalog catalog = bdcService.GetDatabaseBackedMetadataCatalog(SPServiceContext.Current); ILobSystemInstance lobSystemInstance = catalog.GetLobSystem(systemName).GetLobSystemInstances()[systemName]; IEntity entity = catalog.GetEntity(nameSpace, entityName); // Retrieve the association method. IAssociation association = (IAssociation)entity.GetMethodInstance( "GetPartsByMachineID", MethodInstanceType.AssociationNavigator); Identity identity = new Identity(machineId); // Retrieve an entity instance. IEntityInstance machineInstance = entity.FindSpecific(identity, lobSystemInstance); EntityInstanceCollection collection = new EntityInstanceCollection(); collection.Add(machineInstance); // Navigate the association to get parts. IEntityInstanceEnumerator associatedInstances = entity.FindAssociated( collection, association, lobSystemInstance, OperationMode.Online); return entity.Catalog.Helper.CreateDataTable(associatedInstances); } This approach is consistent with the way the BDC model works in general. You first retrieve definitions of entities and associations from the model, and then you use these entities and associations in conjunction with a LOB system instance to retrieve information from the external system. Although this may seem somewhat unnatural at first, it allows you to decouple your applications from the implementation details of the backend service or database. Working with Database Views In some scenarios, you may want to model external content types on composite views of entities in your external system. For example, you might create an external content type from a database view or a specialized service method instead of simply replicating database tables or other external entities. This approach is useful for read operations in which you need to aggregate fields from multiple external tables or entities, especially when you are working with large amounts of data. If you don't use a database view, you would need to traverse individual entity associations in order to generate the composite view you require. This increases the load on the BDC runtime and can lead to a poor user experience. The drawback of binding external content types to database views is that create, update, and delete operations become more complicated, because updating a view inevitably involves performing operations on more than one table. There are two approaches you can use to enable updates to database views: You can create an INSTEAD OF trigger on the SQL Server database to drive update operations. An INSTEAD OF trigger defines the Transact-SQL commands that should be executed when a client attempts a particular update operation. For example, you might define an INSTEAD OF INSERT routine that is executed when a client attempts an INSERT operation. You can develop stored procedures on the SQL Server database to perform the update operations and map the relevant stereotyped operations for your external content type to these stored procedures. Unless you are expert in creating Transact-SQL routines, using triggers can be somewhat cumbersome and complex. You may find that creating stored procedures offers a more palatable approach. Generated from CHM, not final book. Will be superseded in the future. Page 253
- 254. You might think that binding external content types to database views is more trouble than it's worth; especially if you must create stored procedures to support update operations. However, if you took the alternative approach of modeling database tables directly, one update to your user interface view would require updates to multiple external content types in the BDC model. To accomplish these updates in a single operation, you would need to write code using the BDC object model. By putting the multiple update logic in a stored procedure on the database, you reduce the load on the BDC runtime. From an efficiency perspective, the stored procedure approach requires only a single round trip to the database server, because the database view represents a single entity to the BDC runtime. In contrast, managing updates to multiple entities through the BDC object model requires multiple round trips to the database server; therefore, it is a more expensive operation. Other Scenarios That Require the Use of the BDC Object Model In addition to the operations described in this topic, there are several other scenarios for external data access in which you must write custom code using the BDC object model instead of using simpler mechanisms such as external lists or Business Data Web Parts. These include the following: You want to perform bulk write-back operations where you write multiple rows of data to the same entity in an external system. For example, you might need to add multiple line items to an order created by a user. You want to update multiple entities concurrently. For example, to submit an order, you might need to update order entities, order line item entities, and carrier entities simultaneously. You want to use a GenericInvoker stereotyped operation. A GenericInvoker method is used to invoke logic on the external system, and can call methods with arbitrary parameters and return types. Generated from CHM, not final book. Will be superseded in the future. Page 254
- 255. List Patterns Many topics covered in the data section discuss how to build models in lists and how to query the lists, how to achieve efficient data access through optimized queries and indexing, and the consequences of inefficient access techniques such as list throttling. List patterns, which we discuss next, can help you address common challenges encountered with lists. The following diagram represents the list patterns we will consider here. Generated from CHM, not final book. Will be superseded in the future. Page 255
- 256. Large Lists As lists become larger, they can reduce the ability of Microsoft® SharePoint® 2010 to operate efficiently and perform well. For example, viewing more than 2,000 items at a time from a list will impact performance, as will list queries that touch more than 5,000 items in the SQL Server content database during execution (for more information, see Query Throttling and Indexing). Performance will always benefit when you minimize the amount of list data retrieved, limiting it to only the data the user needs to perform his tasks. Generally it’s not realistic to display several thousand items at once, although in some situations it is reasonable to query many items, as you must when downloading data to a spreadsheet. Large lists are not necessarily bad, and when properly managed, SharePoint can handle millions of items of data in a single list. However, large lists require proactive developer and IT pro engagement to ensure that they work smoothly on your site. You may need to use large lists if you: Have organic growth that pushes list capacity. Have a high estimated list growth rate. Are migrating from a large document store. For detailed information on dealing with large lists from an access perspective, see Designing Large Lists and Maximizing List Performance. Generated from CHM, not final book. Will be superseded in the future. Page 256
- 257. Using the Content Iterator SharePoint Server provides a new API, C ontentIterator, to help with accessing more than 5,000 items in a large list without hitting a list throttling limit and receiving an SPQueryThrottleException. C ontentIterator implements a callback pattern for segmenting the query for processing a single item at a time. C onsider using this capability if you need to process a large number of items that may exceed a throttling limit. The following trivial example demonstrates the approach used with C ontentIterator tested with a list returning 20,001 items from the query. C# static int exceptions = 0; static int items = 0; protected void OnTestContentIterator(object sender, EventArgs args) { items = 0; exceptions = 0; string query1 = @"<View> <Query> <Where> <And> <BeginsWith> <FieldRef Name='SKU' /> <Value Type='Text'>S</Value> </BeginsWith> </And> </Where> </Query> </View>"; ContentIterator iterator = new ContentIterator(); SPQuery listQuery = new SPQuery(); listQuery.Query = query1; SPList list = SPContext.Current.Web.Lists["Parts"]; iterator.ProcessListItems(list, listQuery, ProcessItem, ProcessError ); } public bool ProcessError(SPListItem item, Exception e) { // process the error exceptions++; return true; } public void ProcessItem(SPListItem item) { items++; //process the item. } C ontentIterator will run through each item in the list, invoking the callback provided for list item processing—in this case, ProcessItem. If an error occurs while iterating the list, then the error function is invoked—in this case, ProcessError. Using this approach the C ontentIterator processes the list in pieces and avoids any excessively large queries. This functionality is provided as part of Enterprise C ontent Management (EC M) in SharePoint Server 2010. C ontentIterator has additional functionality not described in this section, such as the ability to order result sets. For more information see the C ontentIterator C lass. Generated from CHM, not final book. Will be superseded in the future. Page 257
- 258. Partitioned View Description View partitioning leaves the data in a single large list, but allows for access to the data in small segments through targeted views. Often data can be segmented naturally—for example, by region, by status, by date range, or by department. This approach also efficiently supports multiple types of views on the same list because all data is in one place; thus, you could have a view by date range and by region for the same list. In order for partitioning to be effective, the fields being used to partition the view must be indexed. Approaches to Implementation 1. Remove default views. 2. Determine the field you want to partition on. 3. C reate views for the partition. View options include: Using Metadata Navigation and Filtering C reating custom views based on filtered columns. C reating custom views with folders. C reating custom Web Parts. Using C ontent Query Web Parts. Considerations Performance. With proper indexing and reasonable view sizes, view portioning will perform well. If views are introduced that miss the indices, performance will degrade and it is likely that a list throttling limit will be reached for lists containing more than 5,000 items. Lists with high growth rates need to be monitored to ensure that views remain reasonably sized. For extensive analysis of the performance of the different approaches to view partitioning, see the Designing Large Lists and Maximizing List Performance whitepaper. Staleness. List data is pulled in real time, thus stale data is avoided. Storage. No information is duplicated, so there is no additional storage cost. Security. Item security permissions are enforced. For very large lists, there are performance implications to applying item-level permissions. Performance is affected by both the number of unique permissions on the list, Generated from CHM, not final book. Will be superseded in the future. Page 258
- 259. and the number of items in the list. You should minimize the number of unique security permissions applied on a large list. There is no hard and fast rule about query performance and unique permissions in a list. A small set of unique permission scopes in a list will have a low impact on performance, and as the number of unique permissions grows, performance will degrade. Performance will significantly degrade with more than 5,000 unique permissions, and there is a hard limit of 50,000 unique permissions per list. If a list is performing poorly because of many unique permission scopes, then segmentation of the list into multiple lists may significantly reduce the number of permissions required and improve performance. In these cases aggregation, which is also an expensive operation, may still be less expensive than the cost of filtering for permissions. Related Patterns Aggregate View Union Aggregated List Examples The reference implementation for SharePoint Lists includes a large list of machine parts. We chose to segment the list by building custom Web Parts to search and display list information. Generated from CHM, not final book. Will be superseded in the future. Page 259
- 260. Partitioned List with Aggregate View Description Using the Partitioned List with Aggregate View pattern breaks the same type of data into individual lists. Typical usage of the list is through the default list views, but for specific cases items are aggregated across the lists into a central view. In this case you need to choose your segmentation strategy carefully because once you have segmented the data, segmenting a different field will require cross-list querying and filtering, which becomes more and more costly from a performance perspective as the number of lists grows. In order to do the aggregation you will need to define custom views to roll up data across lists. There needs to be a natural segmentation of data for this approach to work well. In order for partitioning to be effective, the fields being used to partition the view must be indexed; this will improve performance for aggregation. Approaches to Implementation 1. Determine the criteria you want to partition on. 2. Partition the data into separate lists based upon the criteria. All lists use the same content type. 3. C reate aggregate views for the list. The most common aggregate view options are: C ontent Query Web Part C ustom Web Parts using SPSiteDataQuery Considerations Performance. Individual lists scale well because they are relatively small. If your lists grow at different rates, then some lists could become a problem, and further segmentation may be difficult to achieve because additional dimensions must be used. Since the segmented lists are smaller than a single large list, you will more easily avoid throttling limits, except on aggregate queries. The throttling limits are higher on aggregate queries than on a single list, which by default will allow 20,000 items to be touched in the SQL Server content database when generating the view. C ross-list queries are expensive, so you should consider caching aggregate views. Staleness. List data is pulled in real time. C aching aggregate result sets will result in staleness. Storage. No information is duplicated, so there is no additional storage cost. Security. Item security permissions are enforced. Since the lists are smaller, the performance cost of item Generated from CHM, not final book. Will be superseded in the future. Page 260
- 261. security is mitigated. Additionally, by segmenting the lists you may be able to avoid item-level permissions. For example, consider a single large list where item permissions are applied based upon department. If that list is segmented by department into individual lists, you can apply list-level security for each department list rather than using item-level security. Related Patterns Search-Aggregated View Aggregate View Examples The reference implementation for the sandbox includes a library containing statement of work and estimate documents on departmental sub-sites. The status information is aggregated on the root site of the estimates. Generated from CHM, not final book. Will be superseded in the future. Page 261
- 262. List Aggregation Patterns Aggregating data from multiple lists is one of the most common requests that SharePoint developers receive. Fortunately SharePoint provides a number of mechanisms to solve aggregating list data. Many of these approaches fall into different list aggregation patterns that have different tradeoffs for server load, timeliness of data, and security. This section examines the approaches and tradeoffs of the following patterns for aggregating list data: Aggregated View Search-Aggregated View List of Lists List of Sites Union List Aggregation Denormalized List Aggregation Generated from CHM, not final book. Will be superseded in the future. Page 262
- 263. Aggregated View Description An aggregate view uses the SharePoint APIs to query data from several sources and aggregate it into a single view. This approach can return results from lists in the same site collection. Approaches to Implementation 1. Determine what data you need to aggregate. 2. C reate a custom Web Part and use the SharePoint APIs (SPSiteDataQuery, SPPortalSiteMapProvider) to query the data. Considerations Performance. Performance will vary depending on how many items you aggregate. To improve performance and reduce the load on the server, you may use SPPortalSiteMapProvider to cache queries performed with SPSiteDataQuery. You should index columns on the lists you are aggregating to improve performance and avoid list throttling. In addition, to further avoid list throttling, construct your queries such that you limit the number of items aggregated to only what is required by your scenario. Also remember that caching query results will increase memory utilization. Staleness. List data is pulled in real time. Keep in mind that caching aggregate result sets may result in stale or outdated data. As the cache interval increases, the likelihood of staleness increases. For this reason, you should only cache results if it is acceptable to display results that will occasionally not be synchronized with changes in list data. Storage. No additional storage is needed because the data is queried dynamically at run time. Security. Item security permissions are enforced when using SPSiteDataQuery and SPPortalSiteMapProvider. Related Patterns Partitioned List with Aggregate View Search-Aggregated View Examples The reference implementation for the sandbox includes a library containing statement of work and estimate documents on departmental sub-sites. The status information is aggregated on the root site of the estimates using SPSiteDataQuery. Generated from CHM, not final book. Will be superseded in the future. Page 263
- 264. Search-Aggregated View Description A search-aggregated view uses the SharePoint search service to query data from several sources and aggregate it into a single view. This approach can return results from multiple site collections in the same farm. Approaches to Implementation 1. C reate content sources pertaining to the data you wish to aggregate. 2. Perform full crawls on the content sources and set up incremental crawls. 3. C reate search scopes containing the content sources. 4. Update the search scopes. 5. Use the Search service web services or APIs to query the search scopes. Considerations Performance. This approach performs very well, especially when aggregating data across several sites or site collections. This is the best-performing option you can use for large volumes of data that span site collections. Staleness. The search engine periodically indexes (or crawls) the data sources being searched. However, the search results will be stale if data in the content sources changes between indexing operations. Therefore, you should consider performing incremental indexing operations to reduce staleness. Storage. This approach does not duplicate the list; however, the search index contains information from the list and does take up space. Security. The Search service respects permissions set on SharePoint list items and documents stored in SharePoint. Security trimming ensures that only the items to which a user has permission are displayed in results. Security trimming is performed automatically by the search engine. Keep in mind that the content access account that the search service uses to crawl the data must be granted access to the data sources to be crawled. Related Patterns Partitioned List with Aggregate View Aggregate View Generated from CHM, not final book. Will be superseded in the future. Page 264
- 265. Examples The reference implementations for this release do not show search-based aggregation. The previous release, Developing SharePoint Applications, showed how to perform search-based aggregation and included details in the section Using Search to Aggregate Data. Generated from CHM, not final book. Will be superseded in the future. Page 265
- 266. List of Lists Description A list of lists contains links to other lists. These lists are usually centrally accessible. Lists of lists appear in many different scenarios including lists of lists in the same site collection, multiple site collections, the same web application, multiple web applications, the same farm, and multiple farms. Many times you will find that these lists are used to provide easy navigation to lists in many sites or across site collections, web applications, or SharePoint Server farms. It is also common to see lists of lists queried by custom navigation controls such as Microsoft Silverlight® menus. These lists are frequently populated by workflows. Approaches to Implementation 1. Determine the lists you want to provide links to. 2. C reate the list to hold the links. (This is the list of lists) 3. C reate the links to the other lists in the list of lists. Considerations Performance. Usually lists of lists do not contain many records because their purpose is to consolidate links to other lists to improve navigation. Since this is the case, performance is not usually an issue. Staleness. There is no automatic mechanism that keeps track of other lists, so the data may be inaccurate. This can lead to broken navigation connections. To circumvent this, you can create an automated process to check for link accuracy. This would usually be implemented in the form of a timer job. Storage. Minimal storage is needed for a list of this type because the number of items in the list is usually small, as are the number of columns. Security. Out of the box, links in the list are not security trimmed at run time. It is possible that a user could see a link to a list in another site collection, web application, or server farm, that they may not have permission to access. It is possible to set permissions on list items to work around this. Related Patterns List of sites Examples A typical example is a workflow that makes project team sites. The workflow creates links to the calendar lists in the project team sites it provisions. The centralized list of lists, which holds all of the project team site calendars, makes it easy for project managers to quickly browse to the various calendars associated with many projects. The list of calendars is displayed on a dashboard page that project managers use to track projects. The ListOf Reference Implementation in the Data section shows an implementation of this pattern using a workflow. Generated from CHM, not final book. Will be superseded in the future. Page 266
- 267. List of Sites Description A list of sites stores links to other SharePoint sites, or other web sites. These lists are usually centrally accessible. Lists of sites appear in many different scenarios including in lists of sites in the same site collection, multiple site collections, the same web application, multiple web applications, the same farm, and multiple farms. Often you will find that these lists are used to provide easy navigation to sites across site collections, web applications, or SharePoint Server farms. It is also common to see lists of sites queried by custom navigation controls such as Silverlight menus. These lists are frequently populated by workflows. Approaches to Implementation 1. Determine the sites you want to provide links to. 2. C reate the list to hold the links. (This is the list of sites.) 3. C reate the links to the other sites in the list of sites. Considerations Performance. Usually, lists of sites do not contain many records because their purpose is to consolidate links to other sites to improve navigation. Since this is the case, performance is not usually an issue. Staleness. There is no automatic mechanism that keeps track of other sites, so the data may be inaccurate; this can lead to broken navigation connections. To avoid this, you can create an automated process to check for link accuracy. This would usually be implemented in the form of a timer job. Storage. Minimal storage is needed for a list of this type because the number of items in the list is usually small, as is the number of columns. Security. Out of the box, links in the list are not security trimmed at run time. It is possible that a user could see a link to a site in another site collection, web application, or server farm, that they may not have permission to access. It is possible to set permissions on list items to work around this. Related Patterns List of lists NOTE: In prior versions of SharePoint, this functionality was provided by the Site Directory site template. This site template created a SharePoint site that included a list named Sites. This list was used to store links to SharePoint sites. This functionality has been removed from SharePoint 2010. The template still exists on the file system, but it is hidden and does not appear in the site templates list box in the create site page. It is considered deprecated and should not be used. Examples A typical example is a workflow that makes project team sites. The workflow creates links to the project team sites it provisions. The centralized list of sites, which holds all of the project team sites, makes it easy for project managers to quickly browse to the various project team sites. The list of sites is displayed on a dashboard page that project managers use to track projects. The Data Models ListOf reference implementation demonstrates how to create a central list of project sites when the project sites are provisioned. Generated from CHM, not final book. Will be superseded in the future. Page 267
- 268. Union List Aggregation Description A union-aggregated list stores information from several lists or data sources. Usually this type of list is centrally accessible. These lists are easy to maintain because they allow users to manage information from many sources in a single location. Union-aggregated lists contain data from data sources that share the same columns of data. Approaches to Implementation This type of list typically uses custom code to load the union-aggregated list with data. Timer jobs and asynchronous processes usually perform this task. C reating custom views to filter the data improves performance and usability. You should configure indexed columns and folders (as applicable) to enhance query performance. Finally, it is typical to use a static set of views to ensure that the lists, which may have lookups into the large list, do not break. In general, you should choose search-aggregated view over union-aggregated view if it meets your needs because search maintains the central index for you. Some examples of when you should consider this approach rather than search include: When search is not available. When you need to perform transformations or calculations on list data. When you want to use lookup columns. When you want to be able to perform sorting, grouping, or filtering on the entire aggregated data set. When you want to be able to use list capabilities such as workflow on the aggregated list. Considerations Performance. Use views to query the data and return only the columns needed to increase query performance. Staleness. Data may be stale because the list items originate from other sources and are loaded periodically. Storage. Additional database storage will be needed to consolidate the lists into a central list. This will increase your storage, and counts towards the storage permitted by your site collection content database quota. Security. Item-level security is honored; however, the item-level security must be set on the items in the list. Generated from CHM, not final book. Will be superseded in the future. Page 268
- 269. Put another way, the items in the list do not inherit the security from list items that were copied from another list or data source. Item-level security offers better performance than running queries to dynamically query data from multiple sources when there are a small number of unique security scopes (or permissions). For example, if you have a permission defined for each of four different departments, the impact will be low. As the number of unique security scopes increases, the performance benefit will degrade, and eventually it could become more expensive to perform this query on the union list than it would be to perform an aggregate query. A common cause of this situation is a large list with workflow attached to each item, where each item on the list is permissioned for an individual employee to operate on that item by the workflow. If you have 8,000 distinct employees working on the list, then the performance will likely be poor. Having many security permissions typically makes this type of list harder to manage from a security point of view as well. Related Patterns Large-list segmented view. A denormalized aggregated list is an expansion of a union aggregation. Search-aggregrated view Examples The full trust reference implementation is an example of a union-aggregated list. Union-aggregated lists can make security settings easier to manage on the various lists they aggregate (when compared to large lists) because you can set the permissions on the list level for the individual lists. Then you can set permissions on the aggregated list to only allow people who should see the entire roll up list of aggregated data. This keeps permissions defined at the list level which perform better and are easier to manage. For example, if you aggregated lists of Statements of Work (SOWs) from the HR, IT, and Finance departments you could set permissions on the lists holding the SOWs in each of the departmental lists to ensure that only people in that department could view the data in the lists. Then, on the aggregated list you could set permissions to allow executives to view the aggregated data for SOWs across the organization. Generated from CHM, not final book. Will be superseded in the future. Page 269
- 270. Denormalized List Aggregation Description A denormalized aggregated list stores information from several lists or data sources using the same sort of process described in union-aggregated lists to perform the aggregation. Usually, this type of list is centrally accessible. These lists are easy to maintain because they allow users to manage information from many sources in a single location. Denormalized aggregated lists contain data from data sources whose columns differ. This type of list is similar to a view in a database. Approaches to Implementation The data is denormalized and the aggregated data contains different columns from several data sources. This approach uses custom code to load the denormalized aggregated list with data. Timer jobs or other asynchronous processes typically load this data. You should configure indexed columns and folders (as applicable) to enhance query performance. C ustom views may be used to filter the data to improve performance and usability. Finally, it is typical to use a static set of views to ensure that the lists, which may have lookups into the large list, do not break. You should use list joins when available. In the following circumstances you may well use denormalized aggregation: No lookup relationship exists between established lists. The data is coming from an external source. The lists reside in different site collections. Considerations Performance. Use views and indexed columns to query the data and return only the columns needed to increase query performance. Because the data loads are performed in an asynchronous fashion, they are not a performance concern. Staleness. Data may be stale because the list items originate from other sources and are loaded periodically. Storage. Additional database storage is needed because data is duplicated or rolled up from other lists or data sources. All data is stored within a single site collection and impacts the storage available within the site collection content database quota for the site. Generated from CHM, not final book. Will be superseded in the future. Page 270
- 271. Security. Item-level security is honored; however, the item-level security must be set on the items in the list. Put another way, the items in the list do not inherit the security from list items that were copied from another list or data source. This makes this type of list harder to manage from a security point of view when item-level security is required, especially if the security rights differ between items merged between the two lists being denormalized since a row of data from each list forms one row in the aggregate view. This approach has the same performance impact with item-level security as described in the Union Aggregation pattern. . Related Patterns Large list segmented view. Large list dynamic view. A denormalized aggregated list is an expansion of a union aggregation. Examples A typical scenario where this list pattern is used is when you need to create a list containing information from multiple lists that are not identical, but contain related/complementary data. For example, if you have a customers list and an orders list you may want to display information about a customer and their orders in the same list. Generated from CHM, not final book. Will be superseded in the future. Page 271
- 272. Reference Implementation: SharePoint List Data Models Microsoft® SharePoint® 2010 introduces new functionality that makes it easier to implement real-world data models using SharePoint lists. In particular, the ability to build relationships between SharePoint lists and the ability to impose behavioral constraints on these relationships, such as cascading deletions and restricting deletions, brings the capabilities of SharePoint lists closer to those of a relational database and boosts the credentials of SharePoint as a platform for data-driven applications. The introduction of the LINQ to SharePoint provider makes it easier to query data in SharePoint lists without constructing complex C ollaborative Application Markup Language (C AML) queries. The SharePoint List Data Models reference implementation demonstrates how you can use these new features to implement a relatively complex data model on the SharePoint platform, and how you can use that data model to power a fairly sophisticated data-driven application. The implementation highlights techniques and best practices in the following areas: Using SharePoint lists to implement a data model. Modeling many-to-many relationships with SharePoint lists. Building entity classes for use with the LINQ to SharePoint provider. Using LINQ expressions to query SharePoint lists. Using ViewModel classes with LINQ to SharePoint in order to simplify user interface logic. Solution Scenario In this example, suppose you are providing consultancy services to a pharmaceutical company named C ontoso Inc. C ontoso has production plants in several locations that operate an extensive range of manufacturing machinery. Every machine requires parts to be replaced on a regular basis due to wear and tear in the course of everyday operations. Different types of machines consume a wide variety of parts, which means the manufacturing team at C ontoso must manage large amounts of information relating to machines, parts, and suppliers. C urrently, the Springfield production plant uses a desktop application built on FoxPro to track part inventories for machine maintenance and repair. This application is used by the warehouse manager to track how many parts are in inventory and where the parts are located. The data model for the parts management system is relatively complex, and includes one-to-many relationships, many-to-many relationships, and foreign key constraints that restrict the deletion of rows that have dependencies in other tables. Whenever employees need a spare part for maintenance or repair, they must contact the warehouse manager to see if the part is available, slowing down both the warehouse manager and the employees. The user interface for the current parts management system allows the warehouse manager to search for items using wildcard filters, and allows him to create, update, and delete items. The user can also browse associated data; for example, users can browse the parts associated with a specified machine. Imagine now that as part of an infrastructure consolidation and employee efficiency exercise, the C ontoso manufacturing team wants you to migrate this functionality to the C ontoso SharePoint 2010 intranet portal. To accomplish this, you create a SharePoint solution that implements the part management data model using SharePoint lists. The solution includes several custom Web Parts and Web Part pages that allow employees to create, retrieve, update, delete, and query entities in the parts management system from a centrally managed site. Deploying the SharePoint List Data Models RI The SharePoint List Data Models RI includes an automated installation script that creates various site collections, deploys the RI components, and adds sample data. After running the installation script, browse to the new SharePointList site collection at http://<Hostname>/sites/sharepointlist. You can open and run the project in Visual Studio, but this does not create a site collection or add sample data. To see the system fully functioning, you must run the installation script. The following table summarizes how to get started with the SharePoint List Data Models RI. Question Answer Where can I find the <install location>SourceDataModelsDataModels.SharePointList Workflow Activities RI? What is the name of DataModels.SharePointList.sln the solution file? Generated from CHM, not final book. Will be superseded in the future. Page 272
- 273. What are the system SharePoint Foundation 2010 requirements? What preconditions You must be a member of SharePoint Farm Admin. are required for installation? You must be a member of the Windows admin group. SharePoint must be installed at http://<Hostname:80>. If you want to install to a different location, you can edit these settings in the Settings.xml file located in the Setup directory for the solution. SharePoint 2010 Administration service must be running. By default, this service is set to a manual start. To start the service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 Administration serv ice, and then click Start. How Do I Install the Follow the instructions in the readme file located in the project folder. SharePoint List Data Models RI? What is the default http://<Hostname>/sites/ SharePointList installation location? (This location can be altered by changing the Settings.xml file in the Setup directory.) How do I download The SharePoint List Data Models RI is included in the download Developing Applications the SharePoint List for SharePoint 2010. Data Models RI? Generated from CHM, not final book. Will be superseded in the future. Page 273
- 274. Solution Overview This topic provides a high-level overview of the various components that make up the SharePoint List Data Models reference implementation. It does not examine the design of the solution or the implementation details of specific features, as these are described later in this guidance. Instead, it illustrates how the reference implementation works at a conceptual level. Data Model Components The data model in this implementation is based on the parts management database described in the External Data Models reference implementation. It illustrates how you can use SharePoint lists to provide similar functionality to that of a relational database. The following image shows the entity-relationship diagram for the parts management data model. The Parts Management Data Model The reference implementation uses various SharePoint data and logic constructs to implement this data model. It uses: List instances to represent each physical table in the data model. Site columns to represent the fields in the data model. These include lookup columns, which form the basis of relationships between lists. Content types to represent the entities in the data model. C ontent type bindings are used to associate each content type with its eponymous list. Feature event receivers to programmatically set the delete behavior on list relationships. List item ev ent receivers to programmatically ensure that new or updated items are unique. Entity classes that represent the lists and list items in the data model. These were generated by the SPMetal command-line tool and enable you to use the LINQ to SharePoint provider to query SharePoint list Generated from CHM, not final book. Will be superseded in the future. Page 274
- 275. data. User Interface Components The SharePoint List Data Models reference implementation includes several custom Visual Web Parts that allow you to query and manipulate the parts management data. These Web Parts rely on a central data repository class that uses LINQ to SharePoint to perform operations on the underlying SharePoint list data. The use of a centralized repository class consolidates all of the data operations into one place for ease of maintenance, and reduces the amount of code duplication across the solution. As the focus of this implementation is on how to access and manipulate SharePoint list data, it is also beneficial to abstract out this data access logic from the user interface implementation details of the Web Parts. When you deploy the SharePoint List Data Models reference implementation, the installer creates a new site collection named SharePointList and deploys and activates all the features within the solution. One of these features, the Web-scoped Navigation feature, adds a number of links to the site Quick Launch bar, as shown in the following diagram. Navigating the SharePoint List Data Models reference implementation You can use these links to explore the pages in the reference implementation. Each page includes a Visual Web Part that interacts with the underlying data store in a different way. The Manage Categories, Manage Departments, Manage Parts, Manage Machines, Manage Manufacturers, Manage Suppliers, and Manage Inv entory pages allow you to search for each type of data entity, view detailed records, browse related items, create new items, and edit or delete existing items. The Search Administration page provides more sophisticated functionality for finding parts. You can search by machine model number or part SKU, or you can browse for parts by category, department, or manufacturer. Generated from CHM, not final book. Will be superseded in the future. Page 275
- 276. The functionality contained within these Web Parts and the data repository class is discussed in more detail as we take a look at specific areas of functionality in the topics that follow. Browsing the Visual Studio Solution The Microsoft Visual Studio® 2010 solution for the SharePoint List Data Model reference implementation contains two projects. The DataModels.SharePointList.Model project contains the components that implement the parts management data model, and include SharePoint lists, site columns, content types, and event receivers. The DataModels.SharePointList.PartsMgmnt project contains the components that allow users to interact with the data model, and include Visual Web Parts together with supporting components such as ViewModel classes and a LINQ to SharePoint repository class. The following diagram shows the structure of the DataModels.SharePointList.Model project in Solution Explorer. The DataModels.SharePointList.Model Project The key components of this project are as follows: The SharePointListLIs node contains a feature manifest file that provisions a list instance for each entity in the data model. These are standard custom lists and do not define any columns. The SharePointListCTs node contains a feature manifest file that defines columns and content types. It defines a column for each field in the data model and a content type for each entity in the data model. The content types that represent join tables in the model—Machine Department, Machine Part, and Part Supplier—register the UniqueListItemEv entReceiver class for ItemAdding and ItemUpdating events. This ensures that all items in these join lists are unique. The SharePointListCT2LI node contains a feature manifest file that binds each content type to its respective list. The ListEvntReceiv ers node contains the UniqueListItemEventReceiver class. As described above, this ensures that new or updated items in lists that represent join tables are unique. The methods in the UniqueListItemEventReceiver class use the ListItemValidator class to verify uniqueness when items are added or updated. The PartsSite.cs file contains entity classes that provide a strongly-typed representation of the SharePoint lists and list items in the data model. These classes are used to define LINQ to SharePoint queries that perform data operations against the SharePoint lists. The classes were generated automatically by the SPMetal command-line tool. Generated from CHM, not final book. Will be superseded in the future. Page 276
- 277. The following diagram shows the structure of the DataModels.SharePointList.PartsMgmnt project in Solution Explorer. The DataModels.SharePointList.PartsMgmnt Project The key components of this project are as follows: The Images node is a SharePoint mapped folder that deploys the banner image used on the custom user interface pages within the solution. The project includes several feature manifest nodes that deploy individual Visual Web Parts. Each Visual Web Part provides a custom user interface that allows you to interact with a particular part of the data model. The Pages node contains the feature manifest for a single Web Part page, PartsMgmnt.aspx, which defines the page layout for our custom user interface pages. The accompanying Elements.xml file includes multiple File elements for this page, all with different Web Part-based content for the page. These elements define the pages that you see when you browse the deployed reference implementation. The PartsMgmntNavigation node contains a feature manifest that adds navigation links for each custom user interface page to the Quick Launch bar on the left-hand navigation panel. The ViewModels node contains ViewModel classes that represent views of the entities in the data model. Generated from CHM, not final book. Will be superseded in the future. Page 277
- 278. For example, the PartInv entoryViewModel class represents a data view that contains fields from the Parts content type and the InventoryLocations content type. The PartManagementRepository class is a central repository that contains all the LINQ to SharePoint-based data operations that are used within the project. This class implements an interface, IPartManagementRepository, which enables us to use service location to replace the repository class with a fake implementation for the purposes of unit testing. In the remainder of this documentation, we will take a closer look at the key points of interest in these components. Generated from CHM, not final book. Will be superseded in the future. Page 278
- 279. Solution Design The SharePoint List Data Models reference implementation consists of two solution packages, each of which contains several features. The solution package for the DataModels.SharePointList.Model project implements the parts management data model on a SharePoint site, through the following features: List Instances (LI). This is a site-scoped feature that provisions a list instance for each entity in the data model. Site Columns and Content Types (CT). This is a site-scoped feature that provisions the site columns and content types. Initialize Model (CT2LI). This is a site-scoped feature that binds each content type to its respective list instance. The feature includes activation dependencies on the List Instances feature and the Site Columns and Content Types feature. The feature includes a feature activation class that removes default content types from each list instance and sets the delete behavior for list relationships. The solution also deploys the project assembly, DataModels.SharePointList.Model, which includes the feature receiver classes, the event receiver classes, and the data context class. The solution package for the DataModels.SharePointList.PartsMgmnt project implements the custom user interface components of the reference implementation, through the following features: Nav igation. This is a Web-scoped feature that provisions navigation links for the custom pages in the solution. A feature receiver class adds the links to the Quick Launch navigation menu on the SharePoint site. Pages. This is a Web-scoped feature that deploys the custom Web Part pages to the SharePoint site. As described in Solution Overview, the feature contains a single physical Web Part page named PartsMgmnt.aspx. The feature manifest contains multiple File elements that deploy the page to multiple URLs with different Web Parts. Serv ices. This is a farm-scoped feature that contains a feature receiver class. The feature receiver registers a type mapping for the IPartManagementRepository interface with the SharePoint Service Locator when the feature is activated. As this is a farm-scoped feature, activation takes place automatically when the feature is installed. Web Parts. This is a site-scoped feature that deploys the Visual Web Parts to the SharePoint site. The feature includes an activation dependency on the Serv ices feature. Generated from CHM, not final book. Will be superseded in the future. Page 279
- 280. Implementing Relationships between SharePoint Lists In SharePoint 2010, lookup columns form the basis for relationships between lists. In the SharePoint List Data Models reference implementation, the Site Columns and Content Types feature manifest defines several lookup columns as site columns. For example, the following code defines a lookup field on the Machines list. XML <Field Type="Lookup" DisplayName="Machine" Required="TRUE" EnforceUniqueValues="FALSE" List="Lists/Machines" WebId="" ShowField="Title" UnlimitedLengthInDocumentLibrary="FALSE" Group="Parts Database Columns" ID="{322e5c46-da10-4948-b3ab-dc657bc51a4a}" Name="MachineLookup" Overwrite="TRUE" /> C learly the site column alone will not define a relationship until you add it to a list. If you refer to the entity-relationship diagram in Solution Overview, you can see that both the MachineParts list and the MachineDepartments list use this lookup column to relate to the Machines list. When you define a lookup field as a site column, the list that the column refers to—the Machines list in this case—must already exist at the point at which you add the lookup column to the site collection. This can be confusing, as although the list exists, it will contain only the default Title field as we have yet to create and deploy the content types that define the fields of interest. For this reason, the order in which you deploy the data model components is important: 1. Provision the list instances. At this point, all list instances will contain only the default Title field. 2. Provision the site columns. 3. Provision the content types that reference the site columns. 4. Bind the content types to the appropriate lists. Modeling Many-to-Many Relationships You can use lookup columns to model one-to-many relationships or one-to-one relationships between lists. However, if you require a many-to-many relationship between entities in your data model, lookup columns alone are insufficient for defining the relationship. While you could use custom user interface components to manage the relationship, a better approach is to normalize the data model. Just as you would add a join table to normalize a many-to-many relationship in a relational database, you can add a join list to normalize a many-to-many relationship between SharePoint lists. For example, in our parts management data model, there is a many-to-many relationship between Parts and Machines. A part can be found in many machines, and a machine contains many parts. To normalize the relationship, we add a join list, MachineParts, which links the two tables through one-to-many relationships. The MachineParts list does not represent a physical entity—it exists purely to link items in the Parts list to items in the Machines list, by providing lookup columns to both lists. The following code sample shows how these lookup columns are referenced in the Machine Part content type. XML <ContentType ID="0x0100220B06426A421E41A0CA50F1FA1F421F" Name="Machine Part" Group="Parts Database" Overwrite="TRUE" xmlns="http://schemas.microsoft.com/sharepoint/"> <Folder TargetName="_cts/Machine Part" /> <FieldRefs> <FieldRef ID="{c042a256-787d-4a6f-8a8a-cf6ab767f12d}" Name="ContentType" /> <FieldRef ID="{fa564e0f-0c70-4ab9-b863-0177e6ddd247}" Name="Title" Hidden="TRUE" ShowInNewForm="TRUE" ShowInEditForm="TRUE" ReadOnly="FALSE" PITarget="" PrimaryPITarget="" PIAttribute="" PrimaryPIAttribute="" Aggregation="" Node="" /> <FieldRef ID="{322e5c46-da10-4948-b3ab-dc657bc51a4a}" Name="MachineLookup" Generated from CHM, not final book. Will be superseded in the future. Page 280
- 281. Required="TRUE" Hidden="FALSE" ReadOnly="FALSE" PITarget="" PrimaryPITarget="" PIAttribute="" PrimaryPIAttribute="" Aggregation="" Node="" /> <FieldRef ID="{4962bb01-d4a4-409d-895c-fd412baa8293}" Name="PartSKULookup" Required="TRUE" Hidden="FALSE" ReadOnly="FALSE" PITarget="" PrimaryPITarget="" PIAttribute="" PrimaryPIAttribute="" Aggregation="" Node="" /> </FieldRefs> ... </ContentType> Note: While you could allow end users to define relationships between parts and machines by manually populating the MachineParts list, this approach provides a poor user experience. A better approach is to develop custom user interface components, which we describe in more detail later in this documentation. Each entry in the MachineParts list represents a relationship between a specific part and a specific machine. To maintain the integrity of these relationships, each entry in the MachineParts list must be unique. As such, the Machine Part content type registers a list event receiver class for the ItemAdding and ItemUpdating events, which ensures that new or updated list items are unique. The following code example shows the relevant part of the content type definition. XML <XmlDocument NamespaceURI="http://schemas.microsoft.com/sharepoint/events"> <spe:Receivers xmlns:spe="http://schemas.microsoft.com/sharepoint/events"> <Receiver> <Name>List Item Adding</Name> <Type>ItemAdding</Type> <SequenceNumber>1</SequenceNumber> <Assembly>DataModels.SharePointList.Model, Version=1.0.0.0, Culture=neutral, PublicKeyToken=acb84d90d3a9b0ad</Assembly> <Class>DataModels.SharePointList.Model.ListEventReceivers .UniqueListItemEventReceiver</Class> <Data>MachineLookup;PartLookup</Data> <Filter /> </Receiver> <Receiver> <Name>List Item Updating</Name> <Type>ItemUpdating</Type> <SequenceNumber>1</SequenceNumber> <Assembly>DataModels.SharePointList.Model, Version=1.0.0.0, Culture=neutral, PublicKeyToken=acb84d90d3a9b0ad</Assembly> <Class>DataModels.SharePointList.Model.ListEventReceivers .UniqueListItemEventReceiver</Class> <Data>MachineLookup;PartLookup</Data> <Filter /> </Receiver> </spe:Receivers> </XmlDocument> When you work with a database, you can impose a uniqueness constraint on a composite key. This constraint is applied automatically if the composite key is the primary key for the table. However, SharePoint lists have no equivalent notion of a uniqueness constraint on a composite key. To ensure that duplicate entries are not made between the machine and parts table, the UniqueListItemEventReceiver class ensures that the composite key of the new or amended MachineParts list item—in other words, a concatenation of the part SKU and the machine ID—does not already exist in the list. If it does, the event receiver will cancel the operation and return an error message. Note: For more information on modeling relationships between SharePoint lists, see List Relationships in SharePoint 2010. Maintaining Referential Integrity in a SharePoint List Data Model Generated from CHM, not final book. Will be superseded in the future. Page 281
- 282. In the same way that you can use foreign key constraints to specify delete behavior across tables in a relational database, SharePoint 2010 allows you to specify delete behavior across list relationships. You can configure lookup columns to manage deletions in two ways. You can apply a cascade delete rule. In this case, if a user deletes an item from a parent list, related items in the child list are also deleted. This helps to prevent orphaned items in the child list. You can apply a restrict delete rule. In this case, users are prevented from deleting an item that is referenced by items in a related list. This helps to prevent broken lookup links in the data model. Because list relationships are formed between two specific list instances, you cannot declaratively specify delete behavior when you define a lookup field as a site column. If you wanted to declaratively specify delete behavior, you would need to define a custom schema.xml file for each list instance, which substantially increases the complexity of the development process. In the SharePoint List Data Models reference implementation, we use a feature receiver class to programmatically define the delete behavior for list relationships. The feature receiver class is associated with the Initialize Model (CT2LI) feature, so that we set the delete behavior after we bind each content type to its associated list. In the CT2LI.Ev entReceiver class, the F eatureActivated method applies a restrict delete rule to lookup columns in several list instances, as shown by the following code example. C# public override void FeatureActivated(SPFeatureReceiverProperties properties) { try { ... //Restrict deletion of list items that would create a broken lookup RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.InventoryLocations, Constants.Fields.Guids.Part); RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.Machines, Constants.Fields.Guids.Manufacturer); RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.Machines, Constants.Fields.Guids.Category); RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.MachineDepartments, Constants.Fields.Guids.Department); RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.MachineDepartments, Constants.Fields.Guids.Machine); RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.MachineParts, Constants.Fields.Guids.Machine); RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.MachineParts, Constants.Fields.Guids.Part); RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.PartSuppliers, Constants.Fields.Guids.Part); RestrictDeleteOnLookupField(rootWeb, Constants.ListUrls.PartSuppliers, Constants.Fields.Guids.Supplier); ... } catch (Exception e) { System.Diagnostics.Trace.WriteLine(e.ToString()); } } The RestrictDeleteOnLookupField helper method retrieves the SPF ield instance that represents the lookup column, and then sets the RelationshipDeleteBehav ior property to the SPRelationshipDeleteBehavior.Restrict enumeration value. C# private void RestrictDeleteOnLookupField(SPWeb web, string listUrl, Guid fieldGuid) { SPList list = web.GetList(GetListUrl(web.ServerRelativeUrl, listUrl)); SPField field = list.Fields[fieldGuid]; SPFieldLookup fieldLookup = (SPFieldLookup)field; fieldLookup.Indexed = true; fieldLookup.RelationshipDeleteBehavior = SPRelationshipDeleteBehavior.Restrict; fieldLookup.Update(); } Generated from CHM, not final book. Will be superseded in the future. Page 282
- 283. Note: The SPRelationshipDeleteBehavior enumeration provides three values—None, Cascade, and Restrict. The default value is None. For more information on specifying delete rules, see List Relationships in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 283
- 284. Building Entity Classes for LINQ to SharePoint The SharePoint List Data Models reference implementation makes extensive use of the LINQ to SharePoint provider to perform data operations against SharePoint lists. Before you can use LINQ expressions to query SharePoint lists, you must build a set of entity classes to represent the lists and list items in your SharePoint site. SharePoint 2010 provides a command-line tool, SPMetal, which you can use to generate these classes automatically. For more information on SPMetal, see Using LINQ to SharePoint. In the DataModels.SharePointList.Model project, the PartsSite.cs file contains the entity classes that we generated using the SPMetal tool. Within this file, the PartsSiteDataContext class sits at the top of the entity hierarchy. This class inherits from the DataC ontext class and represents the SPWeb instance from which the entity classes were generated—in this case, the root site of the SharePointList site collection. The data context class provides the foundation for every LINQ to SharePoint query, as all LINQ to SharePoint expressions are scoped to a DataContext instance. The class provides public read-only properties for each list on the SharePoint site. For example, the following property provides the LINQ to SharePoint provider with access to the Parts list. C# [Microsoft.SharePoint.Linq.ListAttribute(Name="Parts")] public Microsoft.SharePoint.Linq.EntityList<Part> Parts { get { return this.GetList<Part>("Parts"); } } As you can see, lists in LINQ to SharePoint expressions are represented by the generic EntityList<T> class, which represents an enumerable collection of entities. If you take a look through the PartsSite.cs file, you can see that SPMetal generates an entity class for each content type on the site. For example, the file includes a Part class that contains fields, properties, and event handlers for the Part content type. C# [Microsoft.SharePoint.Linq.ContentTypeAttribute(Name="Part", Id="0x01001966A9D6EDFEB845A8DD2DDA365BF5DC")] public partial class Part : Item { ... } This class provides a strongly typed representation of list items that use the Part content type. When you call the GetList<Part>("Parts") method, you are requesting an enumerable collection of Part content type entity instances from the Parts list instance. Note: For more information on building entity classes for LINQ to SharePoint, see Using LINQ to SharePoint. Reverse Lookups in the Entity Model When you use the SPMetal command-line tool to generate entity classes, it automatically detects relationships based on lookup columns. For example, the Inventory Locations list includes a Part lookup column. As a result, the InventoryLocation class includes a Part property that allows you to navigate to the associated Part entity. C# private Microsoft.SharePoint.Linq.EntityRef<Part> _part; [Microsoft.SharePoint.Linq.AssociationAttribute(Name="PartLookup", Storage="_part", MultivalueType=Microsoft.SharePoint.Linq.AssociationType.Single, List="Parts")] public Part Part { get { return this._part.GetEntity(); } set { this._part.SetEntity(value); } } The class also includes various event handlers to ensure that the Part reference remains up to date if the associated Part entity is changed. What may be less obvious is that SPMetal also attempts to generate a reverse lookup association for this relationship. In other words, SPMetal will add a property to the Part class that allows Generated from CHM, not final book. Will be superseded in the future. Page 284
- 285. you to navigate from Parts to Inventory Locations, despite the fact that the Parts list includes no references to the Inventory Locations list. The following code example shows the Inv entoryLocation property in the Parts class. C# private Microsoft.SharePoint.Linq.EntitySet<InventoryLocation> _inventoryLocation; [Microsoft.SharePoint.Linq.AssociationAttribute(Name="PartLookup", Storage="_inventoryLocation", ReadOnly=true, MultivalueType=Microsoft.SharePoint.Linq.AssociationType.Backward, List="Inventory Locations")] public Microsoft.SharePoint.Linq.EntitySet<InventoryLocation> InventoryLocation { get { return this._inventoryLocation; } set { this._inventoryLocation.Assign(value); } } As you can see from the code, each Part instance maintains a reference to a collection of Inv entoryLocation instances; in other words, to every Inv entoryLocation instance that links to that Part instance through its Part lookup column. Note that the Part instance does not actually store these Inv entoryLocation instances, and navigating this relationship results in a call to the content database. As before, the class includes various event handlers to ensure that the references remain up to date. However, the current version of SPMetal has an important limitation when it comes to generating reverse lookup associations: If a site lookup column is used by only one list or content type, SPMetal will generate a reverse lookup association for the relationship. However, if a site lookup column is used by more than one list or content type, SPMetal will not generate reverse lookup associations for any of the relationships based on that lookup column. As you can see from the following diagram, three lists—Part Suppliers, Machine Parts, and Inventory Locations— all include a lookup column for the Parts list. Lookup Relationships for the Parts List If we had used the same site lookup column in each of these three lists, the Part class would not contain any reverse lookup associations. However, the logic in our repository class requires that we are able to retrieve the inventory locations associated with a specified part, which would be a somewhat unwieldy task without the Generated from CHM, not final book. Will be superseded in the future. Page 285
- 286. reverse lookup association for Inventory Locations. There are several possible approaches to resolve this issue, as described in Using LINQ to SharePoint. To work around the limitation, we temporarily created two site columns —PartLookup and PartDUPELookup—that reference the Parts list. These columns are identical in everything but name, as shown by the following code example. XML <Field Type="Lookup" DisplayName="Part" Required="TRUE" EnforceUniqueValues="FALSE" List="Lists/Parts" WebId="" ShowField="Title" UnlimitedLengthInDocumentLibrary="FALSE" Group="Parts Database Columns" ID="{4962bb01-d4a4-409d-895c-fd412baa8293}" Name="PartLookup" Overwrite="TRUE" /> <Field Type="Lookup" DisplayName="PartDUPE" Required="TRUE" EnforceUniqueValues="FALSE" List="Lists/Parts" WebId="" ShowField="Title" UnlimitedLengthInDocumentLibrary="FALSE" Group="Parts Database Columns" ID="{299E6CC0-0DEF-49CB-AB38-D371CC98EFCE}" Name="PartDUPELookup" Overwrite="TRUE" /> After generating the model using SPMetal, we removed the PartDUPELookup column and updated the generated code in PartsSite.cs by finding and replacing all instances of PartDUPELookup with PartLookup. Using this approach kept the information model clean at the cost of a straightforward manual edit. However, this would not be a viable approach if you were automatically generating the entity classes as part of your build process. Since we do not require reverse lookup associations from the Parts list to the Part Suppliers list or the Machine Parts list, the entity classes for these lists were both generated using the PartLookup site column. As a result, the Parts list does not contain reverse lookup associations for Part Suppliers or Machine Parts. In contrast, since we do require a reverse lookup association from the Parts list to the Inventory Locations list, the Inventory Locations list alone used the PartDUPELookup site column during the SPMetal generation process. As this column is not used by any other lists, SPMetal generates the reverse lookup association for Inventory Locations in the Parts class. We expect that future product releases may address this limitation. However, for the time being it's important to understand where the limitation applies and how you can address it. Generated from CHM, not final book. Will be superseded in the future. Page 286
- 287. Using LINQ to SharePoint The SharePoint List Data Models reference implementation includes a repository class, PartManagementRepository, which contains all the data operations used by the Visual Web Parts in the solution. The functionality that is implemented in the repository class is defined by the IPartManagementRepository interface. C reating the repository class as an implementation of an interface makes the solution easier to unit test, since we can use the SharePoint Service Locator to substitute a fake implementation of IPartManagementRepository for testing purposes. All the data operations in the repository class use LINQ to SharePoint expressions, in order to demonstrate the capabilities of the new LINQ to SharePoint provider in SharePoint 2010. These expressions use the entity classes that we generated using the SPMetal command-line tool, as described in Building Entity C lasses for LINQ to SharePoint. When you review the PartManagementRepository class, the first thing to note is that the constructor instantiates a data context object, as shown by the following code example. C# public class PartManagementRepository : IPartManagementRepository { private PartsSiteDataContext dataContext { get; set; } public PartManagementRepository() { dataContext = new PartsSiteDataContext(SPContext.Current.Web.Url); } ... } Every LINQ expression in the repository class uses this data context object as the foundation for the data operation. The PartsSiteDataContext class exposes properties for each list in the site. These properties return a generic EntityList<T> object, which represents an enumerable collection of strongly typed list item entities. For example, the LINQ expression in the following method returns a subset of Machine instances from an EntityList<Machine> collection on the basis of a partial model number. C# public IEnumerable<Machine> GetMachinesByPartialModelNumber(string modelNumber) { return from machine in dataContext.Machines where machine.ModelNumber.StartsWith(modelNumber) select machine; } You can browse the PartManagementRepository class to see examples of LINQ to SharePoint expressions with varying levels of complexity. Using ViewModel Classes with LINQ Expressions The SharePoint List Data Models reference implementation includes several ViewModel classes. These consist of properties that represent field values from more than one list. For example, the PartInv entoryViewModel class includes fields from the Parts list and the InventoryLocations list. C# public class PartInventoryViewModel { public int PartId{ get; set; } public string PartName { get; set; } public string Sku { get; set; } public int InventoryLocationId { get; set; } public string LocationBin { get; set; } public double InventoryQuantity { get; set; } } The use of ViewModel classes allows us to simplify the data binding logic for the user interface. For example, if we want to show a grid view that displays parts together with their inventory locations, we would typically need to: 1. Submit a query to retrieve a list of parts. Generated from CHM, not final book. Will be superseded in the future. Page 287
- 288. 2. Submit another query for each part to determine the inventory location. 3. Merge the results into a single collection and bind the grid view to the collection. By creating queries that return a collection of PartInv entoryViewModel objects, we can submit a single query and bind the grid view to the query result. For example, the following method returns an enumerable collection of PartInv entoryViewModel objects for parts that are associated with a specified machine ID. C# public IEnumerable<PartInventoryViewModel> GetPartsByMachineId(int machineId) { //get all matching parts. var partResults = (from machinePart in dataContext.MachineParts where machinePart.Machine.Id == machineId select new PartResult { PartId = machinePart.PartSKU.Id, Title = machinePart.PartSKU.Title, SKU = machinePart.PartSKU.SKU }); IEnumerable<int?> partIds = (from part in partResults where part.PartId != null select part.PartId); //Get all matching parts that have inventory. List<InvResult> inventoryResults = GetInventoryListForParts(partIds); return MergePartInventory(partResults, inventoryResults); } The PartResult and InvResult classes are simple collections of fields that help us to merge results. The use of these classes in LINQ expressions is an example of view projection, which can result in more efficient queries. This is because the query returns only the fields of interest, rather than every field from the lists being queried. After building a collection of part IDs for the parts that match the specified machine ID, the method calls the GetInventoryListForParts method, passing in the collection of part IDs as a parameter. C# List<InvResult> GetInventoryListForParts(IEnumerable<int?> partIds) { List<InvResult> inventoryResults = new List<InvResult>(); foreach (int? partId in partIds) { if (partId != null) { var locations = from location in dataContext.InventoryLocations where location.Part.Id == partId select new InvResult { PartId = location.Part.Id, LocationId = location.Id, BinNumber = location.BinNumber, Quantity = location.Quantity }; foreach (var loc in locations) { inventoryResults.Add(loc); } } } return inventoryResults; } Finally, the GetPartsByMachineId method calls the MergePartInv entory method. This method uses a LINQ join predicate to merge the inventory query results with the part query results, and then uses a view projection to Generated from CHM, not final book. Will be superseded in the future. Page 288
- 289. return an enumerable collection of PartInv entoryViewModel objects. C# IEnumerable<PartInventoryViewModel> MergePartInventory(IEnumerable<PartResult> partResults, IEnumerable<InvResult> inventoryResults) { // do a left outer join between the two result sets // This associates the parts with inventory info and includes the parts // that have no inventory info (inv == null). var results = from part in partResults join inv in inventoryResults on part.PartId equals inv.PartId into gj from subInv in gj.DefaultIfEmpty() select new PartInventoryViewModel { PartId = part.PartId.HasValue ? part.PartId.Value : 0, Sku = part.SKU, PartName = part.Title, InventoryLocationId = (subInv != null && subInv.LocationId.HasValue ? subInv.LocationId.Value : 0), InventoryQuantity = (subInv != null && subInv.Quantity.HasValue ? subInv.Quantity.Value : 0), LocationBin = (subInv != null ? subInv.BinNumber : "") }; return results.ToArray(); } To see an example of how the GetPartsByMachineId method is used, look at the code-behind file for the ManageMachines.ascx control in the ManageMachines Visual Web Part. When the user clicks a Show Parts link on the user interface, the event handler calls the GetPartsByMachineId method, passing in the selected machine ID as a parameter. C# ShowParts(partManagementRepository.GetPartsByMachineId(selectedMachineId)); The ShowParts method then simply binds the returned collection of PartInv entoryViewModel objects to a GridView control. C# public void ShowParts(IEnumerable<PartInventoryViewModel> partResultsViewModels) { PartResultsGridView.EmptyDataText = Constants.EmptyData.MachinePartResults; PartResultsGridView.DataSource = partResultsViewModels; PartResultsGridView.DataBind(); PartResultUpdatePanel.Update(); PartResultsGridView.EmptyDataText = string.Empty; As you can see, the ViewModel approach substantially simplifies what would otherwise be complex user interface logic. The PartManagementRepository class includes many examples of LINQ expressions that return enumerable collections of ViewModel objects. Efficiency of LINQ to SharePoint Expressions When you use a LINQ expression to query a SharePoint list, the LINQ to SharePoint provider dynamically converts the LINQ expression into a C ollaborative Application Markup Language (C AML) query at run time. The efficiency of the generated C AML queries varies widely according to how you construct your LINQ expressions, and it's important to review the C AML output that your LINQ expressions produce. For information on the efficiency of different LINQ constructs, and for details on how to review the C AML output for a LINQ to SharePoint expression, see Using LINQ to SharePoint. Generated from CHM, not final book. Will be superseded in the future. Page 289
- 290. The SharePoint List Sandbox Implementation The guidance download includes an additional project, DataModels.SharePointList.Sandbox, which implements the scenario addressed by this reference implementation as a sandboxed solution. This implementation demonstrates the use of a sandbox-compatible Visual Web Part that is available from the Visual Studio Gallery. The feature manifest (elements.xml) under the Pages node is also updated to import the sandbox-compatible Visual Web Parts onto the page. The standard Visual Web Part is not supported in the sandbox environment because Visual Web Parts effectively host an ASC X user control within the Web Part control. The ASC X file is deployed to the _controltemplates virtual directory in the physical file system on each Web front-end server. The sandbox environment does not allow you to deploy physical files to the SharePoint root, so you cannot use a sandboxed solution to deploy a Visual Web Part based on the Visual Studio 2010 Visual Web Part project template. The sandbox-compatible Visual Web Part gets around this limitation by generating and compiling the code that represents the ASC X user control as part of the assembly, thereby obviating the need to deploy any files to the server. C ertain types of LINQ to SharePoint queries will fail and throw a security exception in the sandbox environment. One of the operations that cause this failure is the StartsWith method. In order to avoid this limitation, the sandbox version performs an exact match rather than a partial match when searching. This limitation is likely to be fixed in a future update. Generated from CHM, not final book. Will be superseded in the future. Page 290
- 291. Conclusion The SharePoint List Data Models reference implementation demonstrates good practice approaches to implementing and querying a data model using SharePoint lists. The key points of interest include the following: The implementation of data models using SharePoint lists. The effective management of many-to-many relationships between SharePoint lists. The generation of entity classes for use with the LINQ to SharePoint provider, and how to mitigate some of the limitations of the SPMetal command-line tool. The use of LINQ expressions with varying degrees of complexity to query SharePoint lists. The use of ViewModel classes in conjunction with LINQ expressions to simplify the logic behind the user interface. We encourage you to deploy the reference implementation and to explore the different components and code within the DataModels.SharePointList solution. For more information on data models for SharePoint lists, see Data Models in SharePoint 2010. For more information on choosing between SharePoint lists and an external database as a data source, see SharePoint Lists versus External Databases. Generated from CHM, not final book. Will be superseded in the future. Page 291
- 292. Reference Implementation: External Data Models Microsoft® SharePoint® 2010 includes many new and enhanced areas of functionality for modeling and accessing external data, including external lists, external content types, business data Web Parts, and tooling in SharePoint Designer 2010 and Visual Studio® 2010. The External Data Models Reference Implementation uses a business integration scenario to illustrate how you can work with these areas of functionality in real-world applications. The implementation highlights techniques and best practices in the following areas: C reating Business Data C onnectivity (BDC ) models for Microsoft SQL Server® databases and external services. C ustomizing BDC models to support many-to-many relationships and non-integer primary keys. Using stored procedures and other custom logic to navigate foreign-keyless relationships in a BDC model. C reating .NET connectivity assemblies to flatten complex data from an external service. Using external lists and built-in business data Web Parts to interact with BDC models. Developing custom code to interact with external data by using the BDC object model. This solution uses the same scenario as the SharePoint List Data Models reference implementation. Together, these reference implementations are designed to help you compare and contrast the use of SharePoint lists and external databases as the data platform for moderately complex, data-driven SharePoint applications. Solution Scenario In this example, suppose you are providing consultancy services to a pharmaceutical company named C ontoso Inc. C ontoso has production plants in several locations that operate an extensive range of manufacturing machinery. Every machine requires parts to be replaced on a regular basis due to wear and tear incurred in the course of everyday operations. Different types of machines consume a wide variety of parts, which means the manufacturing team at C ontoso must manage large amounts of information relating to machines, parts, and suppliers. C urrently, the Springfield production plant uses a desktop application built on FoxPro to track part inventories for machine maintenance and repair. This application is used by the warehouse manager to track how many parts are in inventory and where the parts are located. The data model for the parts management system is relatively complex, and includes one-to-many relationships, many-to-many relationships, and foreign key constraints that restrict the deletion of rows that have dependencies in other tables. Whenever employees need a spare part for maintenance or repair, they must contact the warehouse manager to see if the part is available, slowing down both the warehouse manager and the employees. The user interface for the current parts management system allows the warehouse manager to search for items using wildcard filters, and allows him to create, update, and delete items. The user can also browse associated data; for example, users can browse the parts associated with a specified machine. The plant also uses a proprietary supplier management system to manage suppliers and their contact details. The manufacturing team would like to be able to view and manage key aspects of this information on the C ontoso SharePoint 2010 intranet portal. In particular, they would like to be able to: Search for machines and view a list of parts associated with the specified machine. Search for parts and view a list of machines that require the specified part. Search for suppliers by name and view all contacts at the specified supplier. To meet these requirements, you implement a SharePoint solution that uses a wide variety of business connectivity services (BC S) functionality, together with a SQL Server database for storing and managing the parts and inventory locations data. This solution includes: A business data connectivity (BDC ) model that maps to the SQL Server database for the parts management system. A .NET connectivity assembly to connect to the supplier management system, together with a BDC model that maps to the .NET connectivity assembly. Parts management and supplier management pages that use a combination of external lists, built-in business data Web Parts, and custom-coded Web Parts to allow users to interact with the external data. Note: The project template for creating a .NET connectivity assembly in Visual Studio 2010 is called Business Data Connectivity Model. When you create a .NET connectivity assembly, Visual Studio provides support both for developing the connectivity assembly code and creating the declarative model that is deployed to the BDC . SharePoint Designer can be used to create a declarative BDC model against a database or a Web service, where there is no .NET connectivity assembly involved. Visual Studio 2010 does not provide interactive support for creating or editing a declarative BDC model. Generated from CHM, not final book. Will be superseded in the future. Page 292
- 293. Deploying the External Data Models RI The External Data Models RI includes an automated installation script that creates various site collections, deploys the RI components, and adds sample data. After running the installation script, browse to the new PartsManagement site collection at http://<Hostname>/sites/PartsManagement. You can open and run the project in Visual Studio, but this does not create a site collection or add sample data. To see the system fully functioning, you must run the installation script. The following table summarizes the steps to get started with the External Data Models RI. Question Answer Where can I find the <install location>SourceDataModelsDataModels.ExternalData External Data Models RI? What is the name of DataModels.ExternalData.sln the solution file? What are the SharePoint Server 2010 Enterprise Edition (required for Business Data Web Parts) system requirements? What preconditions You must be a member of SharePoint Farm Admin. are required for installation? You must be a member of the Windows admin group. SharePoint must be installed at http://<Hostname:80>. If you want to install to a different location, you can edit these settings in the Settings.xml file located in the Setup directory for the solution. SharePoint 2010 Administration service must be running. By default, this service is set to a manual start. To start the service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 Administration serv ice, and then click Start. How Do I Install the Follow the instructions in the readme file located in the project folder. External Data Models RI? What is the default http://<Hostname>/sites/ PartsManagement installation location? (This location can be altered by changing the Settings.xml file in the Setup directory.) How do I download The External Data Models RI is included in the download Developing Applications for the External Data SharePoint 2010. Models RI? Note: The reference implementation uses a SQL Server database. The installation script assumes that there is a SQL Server instance named SharePoint. If you do not have a SQL Server Data instance named SharePoint, or you do not want to install the test data in that database, you need to update the installation files. Edit the database instance name in PartsManagement_SqlInstall.bat and PartsManagement_Sqluninstall.bat, replacing SharePoint with your database instance name. Open the PartsManagement.bdcm file (located in the PartsManagement subdirectory) in Visual Studio, and replace the database name in the RdbConnection Data Source property, as shown by the following code. <Property Name="RdbC onnection Data Source" Type="System.String">.SHAREPOINT</Property> Generated from CHM, not final book. Will be superseded in the future. Page 293
- 294. Solution Overview This topic provides a high-level overview of the various components that make up the External Data Models Reference Implementation. It does not examine the design of the solution or the implementation details of the .NET connectivity assembly, the BDC models, or the user interface components, all of which are described later in this guidance. Instead, it illustrates how the reference implementation works at a conceptual level. The External Data Models RI consists of various components, as shown in the following illustration. Conceptual Overview of the External Data Models RI The parts management system is underpinned by a SQL Server database. As such, we can interact directly with the data store using an entirely declarative BDC model. We allow the user to interact with the BDC model, and thereby interact with the parts management system, through a combination of external lists, built-in business data Web Parts, and custom-coded Web Parts that uses the BDC object model to provide more sophisticated functionality. In contrast, the supplier management system is a proprietary system, represented in this case by a simple custom .NET class library. The services exposed by the system use complex, nested entities that cannot be mapped to out-of-the-box UI elements such as external lists or business data Web Parts. To address this issue, we build a .NET connectivity assembly to programmatically define stereotyped operations on the external supplier management system. The connectivity assembly flattens the nested address data returned by the supplier management system into two-dimensional table-like entities, in order to make it more amenable to display within a SharePoint site. Alongside the connectivity assembly, we create a declarative BDC model that tells the BDC runtime how to interact with the connectivity assembly. A combination of built-in business data Web Parts and custom-coded Web Parts allow users to interact with the external data. Browsing the Visual Studio Solution The Visual Studio 2010 solution for the External Data Model reference implementation (RI) is large, and it can be useful to know what each component does before you start browsing the code. This section explains the purpose of each component in the DataModels.ExternalData solution. The following diagram shows the solution structure in Solution Explorer. Generated from CHM, not final book. Will be superseded in the future. Page 294
- 295. The DataModels.ExternalData Solution The roles of these components are as follows: The ContactsSystem node contains the .NET connectivity assembly classes and the BDC model for the supplier management system. The ListInstances node contains feature manifest files for the external lists that map to parts management entities. The ManageMachines node contains the files for the ManageMachines Web Part, which uses the BDC object model to interact with the parts management system. The ManageSuppliers node contains the files for the ManageSuppliers Web Part, which uses the BDC object model to interact with the supplier management system. The Pages node contains the feature manifest for a single Web Part page, PartsManagement.aspx, which defines the page layout for our custom user interface pages. The accompanying Elements.xml file includes multiple F ile elements for this page, all with different Web Part-based content for the page. These elements define the pages that you see when you browse the deployed reference implementation. This feature also includes a feature receiver class to provision the navigation links for each parts management page to the Quick Launch navigation panel. The PartsManagement node contains the BDC model for the parts management system. The ViewModels node contains some business entity classes. The custom Web Parts use these classes to return BDC data as a strongly typed collection of business objects. The DataMapper class is a simple utility that maps a data table of results to the business entity classes contained in the ViewModels node. The PartManagementRepository class provides a data access layer for the solution. It implements data Generated from CHM, not final book. Will be superseded in the future. Page 295
- 296. operations against the BDC runtime and maps the strongly typed business entity classes to the underlying BDC types. The DataModels.ExternalData.Schema project contains resources that are used to build and populate the parts management database in SQL Server. The Supplier.SampleServ ice project is a class library that represents the external supplier management system for the purposes of the RI. Browsing the Deployed Components When you deploy the External Data Models reference implementation, the installer creates a new site collection named PartsManagement and deploys and activates all the features within the solution. Navigating the External Data Models reference implementation You can use these links to explore the pages in the reference implementation. The pages include various combinations of built-in business data Web Parts and custom Web Parts to demonstrate specific aspects of working with external data. The Manage Machines page contains a custom Web Part that allows you to search for machines by model number. When you select a machine from the search result, the Web Part displays a list of parts associated with the machine. The Web Part demonstrates how you can use the BDC object model to search for entity instances, retrieve specific entity instances, and navigate associations between entities. It also illustrates various design patterns that are especially relevant when you work with BDC data. The Manage Suppliers page contains a custom Web Part that allows you to search for suppliers by name, with the aid of a wildcard filter. When the user selects a supplier, he is redirected to the Supplier Details page, which uses business data Web Parts to display more information about the selected supplier together with the contacts associated with that supplier. The Web Part demonstrates how you can programmatically use wildcard filters to constrain search results, and how to pass information to business data Web Parts. The Machines By Part page and the Parts By Machine page contain business data Web Parts. They allow you to navigate the many-to-many relationship between parts and machines by viewing the parts associated with a specified machine or the machines associated with a specified part. These pages demonstrate how the built-in business data Web Parts can automatically navigate foreign-keyless associations based on stored procedures or other custom logic. They also show how business data Web Parts can automatically utilize the filters that you define in the BDC model. These pages are discussed in more detail as we take a look at specific areas of functionality in the topics that follow. Generated from CHM, not final book. Will be superseded in the future. Page 296
- 297. Solution Design The components of the External Data Model reference implementation are packaged into six features. BDC Model. This is a farm-scoped feature that deploys the BDC model for the parts management system (PartsManagement.bdcm). Connector. This is a farm-scoped feature that deploys the BDC model for the supplier management system (C ontactSystem.bdcm) together with the .NET connectivity assembly for the supplier management system (DataModels.ExternalData.PartsManagement.dll). External List Instances. This is a Web-scoped feature that provisions external lists for the external content types defined in the parts management BDC model. This feature includes an activation dependency on the BDC Model feature. Pages. This is a Web-scoped feature that provisions the custom Web Part pages to the SharePoint site. As described in Solution Overview, the feature contains a single physical Web Part page named PartsManagement.aspx. The feature manifest contains multiple File elements that deploy the page to multiple URLs with different Web Parts. This feature includes an activation dependency on the WebParts feature. A feature receiver provisions the custom navigation links to the left hand (Quick Link) navigation. WebParts. This is a site-scoped feature that deploys the custom Web Parts. The External Data Model reference implementation makes use of the Business Data C onnectivity Model project template in Visual Studio 2010. This template creates a farm-scoped feature that deploys the declarative BDC M file, together with any other resources you create such as a .NET connectivity assembly. The feature uses a built-in feature receiver class, ImportModelReceiv er, to import and install the BDC model into the BDC service application in your SharePoint environment. You can also specify a SiteUrl property in the feature file. SharePoint uses this property to determine which BDC service application instance the BDC model should be deployed to. To do this, it looks up the service application group that is associated with the Web application that owns the specified site. For example, the following code shows the feature file for the BDC Model feature. XML <Feature xmlns="http://schemas.microsoft.com/sharepoint/" Title="... BDC Model" Description="..." Id="1d7ad3d0-1fe5-4b10-8cdf-858291174817" ReceiverAssembly="Microsoft.Office.SharePoint.ClientExtensions, Version=14.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c" ReceiverClass= "Microsoft.Office.SharePoint.ClientExtensions.Deployment.ImportModelReceiver" Scope="Farm"> <ElementManifests> <ElementFile Location="PartsManagementPartsManagement.bdcm" /> <ElementFile Location="BdcAssembliesDataModels.ExternalData.PartsManagement.dll" /> </ElementManifests> <Properties> <Property Key="IncrementalUpdate" Value="true" /> <Property Key="ModelFileName" Value="PartsManagementPartsManagement.bdcm" /> <Property Key="SiteUrl" Value="http://localhost/" /> </Properties> </Feature> Generated from CHM, not final book. Will be superseded in the future. Page 297
- 298. Modeling a SQL Server Database In the External Data Models reference implementation, the parts management system is represented by a SQL Server database. The following illustration shows the entity-relationship diagram for the parts management database. The Parts Management Database As you can see, the parts management database includes a number of many-to-many relationships that have been normalized through the creation of join tables. Suppliers and Parts are related by the PartSuppliers table, Parts and Machines are related through the MachineParts table, and Machines and Departments and related through the MachineDepartments table. These join tables do not correspond to any real-world entities; they exist solely to allow clients to navigate between entities with complex relationships. As a starting point, we used SharePoint Designer 2010 to build a business data connectivity model (BDC model) for the parts management database. We were able to define an external content type for each table in the parts management database, and we were able to create foreign key associations between our external content types based on the foreign key constraints defined between the tables in the database. However, there are two key requirements that required manual edits to the BDC model: Users must be able to view a list of machines associated with a particular part, and a list of parts associated with a particular machine. This requires that we navigate a many-to-many relationship across a join table. To do this, we had to manually edit the BDC model to create a foreign keyless association between parts and machines. The Parts table has a non-integer primary key named SKU. To support this entity in the BDC model, we had to manually add a PreUpdaterField="true" attribute to the type descriptor for the @SKU parameter in the Create method for the Parts entity. The remainder of this topic describes these manual edits in more detail. Generated from CHM, not final book. Will be superseded in the future. Page 298
- 299. Modeling Many-to-Many Relationships First, let's look at how we navigate from parts to machines. We added a method named GetMachinesByPartSku to the entity that defines the Parts external content type. Note that the RdbCommandText property identifies a stored procedure named GetMachinesByPartSku. XML <Method IsStatic="false" Name="GetMachinesByPartSku"> <Properties> <Property Name="BackEndObject" Type="System.String">GetMachinesByPartSku </Property> <Property Name="BackEndObjectType" Type="System.String">SqlServerRoutine </Property> <Property Name="RdbCommandText" Type="System.String"> [dbo].[GetMachinesByPartSku] </Property> <Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"> StoredProcedure </Property> <Property Name="Schema" Type="System.String">dbo</Property> </Properties> <Parameters> <Parameter Direction="In" Name="@partSku"> <TypeDescriptor TypeName="System.String" IdentifierName="SKU" IdentifierEntityName="Parts" IdentifierEntityNamespace="DataModels.ExternalData.PartsManagement" ForeignIdentifierAssociationName="GetMachinesByPartSku" Name="@partSku" /> </Parameter> ... <MethodInstances> <Association Name="GetMachinesByPartSku" Type="AssociationNavigator" ReturnParameterName="GetMachinesByPartSku" DefaultDisplayName="Machines Read With Sproc"> <SourceEntity Namespace="DataModels.ExternalData.PartsManagement" Name="Parts" /> <DestinationEntity Namespace="DataModels.ExternalData.PartsManagement" Name="Machines" /> </Association> </MethodInstances> </Method> In the parts management database, we create a stored procedure named GetMachinesByPartSku that uses join predicates across the MachineParts table to retrieve all the machines associated with a specified part SKU. This is illustrated by the following code example. Transact-SQL SELECT Machines.* FROM Parts INNER JOIN MachineParts ON Parts.SKU = MachineParts.PartSKU INNER JOIN Machines ON MachineParts.MachineId = Machines.ID WHERE Parts.SKU = @partSKU; This arrangement allows us to use built-in business data Web Parts to view the machines associated with a specified part. This is illustrated by the Machines By Part page, which uses a BusinessDataListWebPart to represent parts and a BusinessDataAssociationWebPart to represent machines, as shown in the following image. The Machines By Part Page Generated from CHM, not final book. Will be superseded in the future. Page 299
- 300. The BusinessDataListWebPart allows users to search for parts by part SKU. When the user selects a part from the search results, the BusinessDataAssociationWebPart displays a list of machines that use the selected part. The business data Web Parts are automatically able to understand and navigate the many-to-many relationship we defined between parts and machines. We used a similar approach to facilitate navigation from machines to parts. The Machines entity includes a custom method named GetPartsByMachineID, which uses a stored procedure by the same name to retrieve a collection of parts associated with a specified machine ID. This relationship is illustrated by the Parts By Machine page. Non-Integer Primary Keys and the PreUpdaterField Attribute When you add an entity with a non-integer identifier to your BDC model, the field will be added as read-only. For example, in this reference implementation the Part entity has a non-integer identifier. As you can see from the following code, the C reate method for the Part entity returns a SKU parameter that is read-only as part of the operation definition. XML <Parameter Direction="Return" Name="Create"> <TypeDescriptor TypeName="System.Data.IDataReader…Name="Create"> <TypeDescriptors> <TypeDescriptor TypeName="System.Data.IDataRecord…Name="CreateElement"> <TypeDescriptors> <TypeDescriptor TypeName="System.String" ReadOnly="true" IdentifierName="SKU" Name="SKU"> <Properties> <Property Name="Size" Type="System.Int32">255</Property> </Properties> … </TypeDescriptor> </TypeDescriptors> </TypeDescriptor> </TypeDescriptors> </TypeDescriptor> </Parameter> Generated from CHM, not final book. Will be superseded in the future. Page 300
- 301. You may be tempted to change the ReadOnly attribute for the SKU return parameter to false, since you specify the SKU in the C reate operation. However, the BDC model will then assume that the SKU can be updated after it is created. The ReadOnly flag will not affect the C reate operation, but will affect the Update operation. If you want to allow the SKU to be changed after creation, then set this flag to false. If not, leave it set to true. The reference implementation treats the SKU as read-only once the Part entity instance is created. If you choose to allow the identifier to be updateable then you should set the ReadOnly attribute to false for the identifier field return value in the C reate operation. If you do this, you must amend the Update operation definition by replacing the UpdaterField="true" attribute with a PreUpdaterField="true" attribute, as shown by the following code. This tells the BDC runtime to use the original identifier to process the update. For example, if a part SKU is changed from SKU123 to SKU345, then the Update operation will first locate the part with an SKU value of SKU123, and then set the SKU value to SKU345. XML <Method Name="Update" DefaultDisplayName="Parts Update"> <Properties> <Property Name="BackEndObject" Type="System.String">Parts</Property> <Property Name="BackEndObjectType" Type="System.String">SqlServerTable</Property> <Property Name="RdbCommandText" Type="System.String"> UPDATE [dbo].[Parts] SET [Name] = @Name , [Description] = @Description WHERE [SKU] = @SKU</Property> <Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">Text</Property> <Property Name="Schema" Type="System.String">dbo</Property> </Properties> <Parameters> <Parameter Direction="In" Name="@SKU"> <TypeDescriptor TypeName="System.String" PreUpdaterField="true" IdentifierName="SKU" Name="SKU"> <Properties> <Property Name="Size" Type="System.Int32">255</Property> </Properties> <Interpretation> <NormalizeString FromLOB="NormalizeToNull" ToLOB="NormalizeToEmptyString" /> </Interpretation> </TypeDescriptor> </Parameter> ... SharePoint Designer does not allow you to set the PreUpdaterField attribute. You must add the attribute by manually editing the model XML. After doing this, you will no longer be able to open the model in SharePoint Designer. Generated from CHM, not final book. Will be superseded in the future. Page 301
- 302. Creating a .NET Connectivity Assembly In the External Data Models reference implementation, the supplier management system is represented by a simple class library that is designed to simulate an external service. You can find this class library in the Supplier.SampleServ ice project in the DataModels.ExternalData Visual Studio 2010 solution. This part of the reference implementation is designed to illustrate how to model complex data types that include nested data structures. The connectivity assembly consumes data from the service, flattens the nested data, and applies formatting to the data before providing it to the BDC model. The following entity-relationship diagram shows the schema for the supplier management service. As you can see, a supplier organization can have multiple contacts associated with it. The address details for each contact are stored as a separate, nested entity. The Supplier Management Service Schema One of the primary roles of our .NET connectivity assembly is to flatten the address data for contacts. In other words, we want to merge the address details of a contact into the entity that represents the contact, rather than maintaining address details in a separate entity. Making this change allows us to use out-of-the-box user interface components such as external lists and business data Web Parts with the entities exposed by the supplier management service. Visual Studio 2010 includes a project template named Business Data Connectivity Model that you can use to build a.NET connectivity assembly together with a declarative BDC model. The BDC Designer in Visual Studio enables you to create entities, assign identifiers, define methods (stereotyped operations), and build associations. We used this approach to build the connectivity assembly and the BDC model for the supplier management system. You can find these components in the ContactSystem folder within the DataModels.ExternalData solution, as shown in the following image. The .NET Connectivity Assembly Classes Generated from CHM, not final book. Will be superseded in the future. Page 302
- 303. When you create an entity with the BDC Designer, Visual Studio performs three actions: It creates a class to represent the entity. The entity class defines the data structure of the entity, and typically consists of a simple collection of properties. It creates a serv ice class for the entity. The service class defines the stereotyped operations that the entity should support, including data operations and associations. It adds an entity definition to the BDCM file. The entity definition references the entity class and the methods within the service class. Note: For more information about the BDC model designer in Visual Studio 2010, see BDC Model Design Tools Overview on MSDN. The connectivity assembly contains two classes that represent entities—BdcSupplier and BdcContact. These classes are simply collections of properties. The BdcSupplier class maps directly to the Supplier entity in the preceding entity-relationship diagram, as illustrated by the following code example. C# public partial class BdcSupplier { public BdcSupplier() {} Generated from CHM, not final book. Will be superseded in the future. Page 303
- 304. public string SupplierID { get; set; } public string DUNS { get; set; } public string Name { get; set; } public int Rating { get; set; } } The BdcContact class contains properties that represent both a contact and the contact’s address details, as shown in the following code example. C# public partial class BdcContact { public BdcContact() {} public string Identifier1 { get; set; } public string SupplierID { get; set; } public string DisplayName { get; set; } public string Address1 { get; set; } public string Address2 { get; set; } public string City { get; set; } public string State { get; set; } public string PostalCode { get; set; } public string Country { get; set; } public string PrimaryPhone { get; set; } public string SecondaryPhone { get; set; } public string OtherPhone { get; set; } public string Email { get; set; } public string Website { get; set; } } Each entity class has a corresponding service class—BdcSupplierServ ice and BdcContactService in this example—that implement the stereotyped operations that are required for each entity. For example, the BdcSupplierServ ice class includes a ReadList method, as shown in the following code example. C# public static IEnumerable<BdcSupplier> ReadList() { using (Service svc = new Service()) { List<BdcSupplier> bdcSuppliers = new List<BdcSupplier>(); List<Supplier.SampleService.Supplier> suppliers = svc.GetAllSuppliers(); foreach (var supplier in suppliers) { bdcSuppliers.Add(ConvertSupplier(supplier)); } return bdcSuppliers.AsEnumerable(); } } This method illustrates various key points about implementing stereotyped operations in a .NET connectivity assembly: The method returns an enumerable collection of BdcSupplier entities. This matches the recommended method signature for Finder operations. The method calls an external service, processes the returned data, and builds a collection of entities, thereby hiding the implementation details of the external service from the BDC model. Note: For more information on implementing stereotyped operations, see Recommended Method Signatures for Stereotyped Operations on MSDN. The ReadList method uses a simple utility method, Conv ertSupplier, to parse each entity returned by the external service. In this case the method simply needs to map the properties of the external entity to the properties of our BdcSupplier entity. Generated from CHM, not final book. Will be superseded in the future. Page 304
- 305. public static BdcSupplier ConvertSupplier (Supplier.SampleService.Supplier supplier) { BdcSupplier bdcSupplier = new BdcSupplier(); bdcSupplier.DUNS = supplier.DUNS; bdcSupplier.Name = supplier.Name; bdcSupplier.Rating = supplier.Rating; bdcSupplier.SupplierID = supplier.SupplierId.ToString(); return bdcSupplier; } However, you may also want to manipulate the external data before returning it, for example by flattening complex types. The Conv ertContact method merges properties from an external Contact entity and its related ContactAddresses entity into a single BdcContact entity, as shown in the following code example. C# private static BdcContact ConvertContact(Contact contact) { BdcContact bdcContact = new BdcContact(); bdcContact.Identifier1 = contact.ID.ToString(); bdcContact.SupplierID = contact.SupplierId.ToString(); bdcContact.DisplayName = contact.FirstName + " " + contact.LastName; bdcContact.PrimaryPhone = contact.WorkPhone; bdcContact.SecondaryPhone = contact.MobilePhone; bdcContact.OtherPhone = contact.HomePhone; bdcContact.Email = contact.Email; bdcContact.Website = contact.Website; if (contact.ContactAddresses != null && contact.ContactAddresses.Count() > 0) { bdcContact.Address1 = contact.ContactAddresses[0].Address1; bdcContact.Address2 = contact.ContactAddresses[0].Address2; bdcContact.City = contact.ContactAddresses[0].City; bdcContact.PostalCode = contact.ContactAddresses[0].PostalCode; bdcContact.State = contact.ContactAddresses[0].State; bdcContact.Country = contact.ContactAddresses[0].Country; } return bdcContact; } Service classes in .NET connectivity assemblies can also include association methods. For example, the BdcSupplierServ ice class includes a method named BdcSupplierToBdcContact that returns all the suppliers associated with a specified contact ID. To do this, it calls a method named GetContactsBySupplierID on the external service. C# public static IEnumerable<BdcContact> BdcSupplierToBdcContact(string supplierId) { using (Service svc = new Service()) { List<Contact> contacts = svc.GetContactsBySupplierID(int.Parse(supplierId)); List<BdcContact> supplierContacts = new List<BdcContact>(); foreach (Contact contact in contacts) { supplierContacts.Add(ConvertContact(contact)); } return supplierContacts; } } Generated from CHM, not final book. Will be superseded in the future. Page 305
- 306. In the BDC M file, the BDC Designer creates the declarative components that consume your entity classes and service class. The following illustrations show the resulting BDC model in the BDC Explorer window and in the BDC Designer. It's worth taking time to explore the markup in the C ontactSystem.bdcm file to gain an understanding of how the BDC model and the connectivity assembly work under the covers. The Supplier Management BDC Model Generated from CHM, not final book. Will be superseded in the future. Page 306
- 307. Web Part Patterns for BDC Logic The External Data Models reference implementation includes two custom Web Parts that demonstrate how you can use the BDC object model to work with external data. On the Manage Machines page, the ManageMachines Web Part allows you to search for machines by model. When the user selects a machine from the search results, a second GridView control displays a list of the parts associated with the selected machine, as shown in the following image. The Manage Machines Web Part On the Manage Suppliers page, the ManageSuppliers Web Part allows you to search for suppliers by name, as illustrated by the following image. The Manage Suppliers Web Part When the user clicks View Details, the Web Part redirects the request to the Supplier Details page and passes the ID of the selected supplier as a query string value. The Supplier Details page uses the following built-in Generated from CHM, not final book. Will be superseded in the future. Page 307
- 308. business data Web Parts to display further information about the supplier: A BDC Item Builder Web Part uses parameters in the query string to retrieve a BDC item, in this case a BdcSupplier entity, and make the item available to other Web Parts on the page. The BDC Item Builder is only visible when the page is in design view. A Business Data Details Web Part retrieves the BdcSupplier entity from the BDC Item Builder and displays all its property values. A Business Data Association Web Part displays all the BdcContact entities associated with the BdcSupplier entity that the business data details Web Part displays. The following diagram shows the Supplier Details page. The Supplier Details Page The reference implementation uses a repository pattern approach to data access. Both the ManageMachines Web Part and the ManageSuppliers Web Part use the PartManagementRepository class to retrieve data. The PartManagementRepository uses the DataMapper<T> class to convert the collection of entity instances returned by the BDC service into a strongly typed collection of business objects. This approach simplifies the development process; rather than calling the BDC to retrieve loosely -typed data tables, the PartManagementRepository can query the BDC service and then use the DataMapper<T> class with an appropriate type parameter to convert the result set into a strongly typed collection. This approach frees Web Part developers to concentrate on building great user interfaces. Before we take a look at the underlying code, let's briefly examine the role of each of these classes. When the user submits a request, the flow of execution is as follows. 1. When a user interface event occurs, the Web Part invokes a method on the repository to request data. The Web Part passes relevant arguments, such as the contents of a search box on the user interface, to the repository method. 2. The repository uses the arguments provided by the Web Part to query the BDC service. It uses BDC object model methods to build a data table that contains the filtered results returned by the BDC service. It then instantiates the DataMapper class with an appropriate type parameter, passing in the data table as an argument to the DataMapper constructor. 3. The DataMapper class parses the data table and exposes a strongly typed list of business objects to the repository. Generated from CHM, not final book. Will be superseded in the future. Page 308
- 309. 4. The repository returns the strongly typed list to the Web Part, which binds the list to a user interface component. For example, suppose the user searches for a supplier on the Manage Suppliers page. The ManageSuppliers class calls the GetSuppliersByName method in the PartManagementRepository. C# void SearchSupplierNameButton_Click(object sender, EventArgs e) { var partManagementRepository = new PartManagementRepository(); SupplierGridView.DataSource = partManagementRepository.GetSuppliersByName(searchSupplierNameTextBox.Text); SupplierGridView.DataBind(); } In the PartManagementRepository class, the GetSuppliersByName method queries the BDC service by using the IEntity.F indFiltered method. The IEntityInstanceEnumerator interface represents a generic collection of IEntityInstance objects. C# public List<BdcSupplier> GetSuppliersByName(string supplierName) { //Get the BDC entity IEntity entity = catalog.GetEntity(Constants.BdcContactsEntityNameSpace, "BdcSupplier"); //Get all filters for the entity IFilterCollection filters = entity.GetDefaultFinderFilters(); //Set filter value if (!string.IsNullOrEmpty(supplierName)) { WildcardFilter filter = (WildcardFilter)filters[0]; filter.Value = supplierName; } //Get filtered items IEntityInstanceEnumerator enumerator = entity.FindFiltered(filters, lobSystemInstance); return new ViewModel<BdcSupplier> (entity.Catalog.Helper.CreateDataTable(enumerator)).Collection; } In order to convert the collection of IEntityInstance objects into a strongly typed collection of BdcSupplier objects, we use the DataMapper class. We instantiate the DataMapper class by passing in a DataTable instance, and then read the Collection property to return a strongly typed list to the view class. In this case, as the DataMapper type parameter is BdcSupplier, we return a List<BdcSupplier> instance to the view class. The following code example shows the DataMapper class. C# public class DataMapper<T> { private DataTable dataTable; private int rowNumber; public DataMapper(DataTable dataTable) { this.dataTable = dataTable; this.rowNumber = 0; } private DataMapper(DataTable dataTable,int rowNumber) { this.dataTable = dataTable; this.rowNumber = rowNumber; } Generated from CHM, not final book. Will be superseded in the future. Page 309
- 310. public T Instance { get { var dataMapperInstance = (T)Activator.CreateInstance(typeof(T)); PropertyInfo[] propertyInfos = typeof(T).GetProperties(); foreach (PropertyInfo propertyInfo in propertyInfos) { // Set the Properties on the instance propertyInfo.SetValue(dataMapperInstance, dataTable.Rows[rowNumber][propertyInfo.Name], null); } return dataMapperInstance; } } public List<T> Collection { get { var dataMapperCollection = new List<T>(); int i = 0; foreach (DataRow row in dataTable.Rows) { dataMapperCollection.Add(new ViewModel<T>(dataTable,i).Instance); i++; } return dataMapperCollection; } } } The data mapper assumes that the names of the columns in the data table model match the names of the properties of the strongly typed entities. In this example, the benefits of converting the entity instances returned by the BDC service into a strongly typed collection may not be obvious. However, suppose you wanted to build a testable business logic layer between the external supplier management system and the SharePoint user interface, in order to perform tasks such as validation or consistency checks. The only way to achieve this business logic layer is to return the "semi-typed" BDC entities as strongly typed business objects. The DataMapper class illustrated in this reference implementation shows how you can manage this process without significantly increasing the complexity of your application. Generated from CHM, not final book. Will be superseded in the future. Page 310
- 311. Building Queries with the BDC Object Model The Manage Suppliers Web Part and the Manage Machines Web Part illustrate how you can use the BDC object model to query external data by invoking the stereotyped operations that we defined in our BDC models. In particular, the custom Web Parts demonstrate how you can consume the following types of stereotyped operations: Finder methods. These are methods that return multiple entity instances, typically by applying filtering criteria to the set of entity instances for a particular entity on the BDC . SpecificFinder methods. These are methods that return a single entity instance, when provided with its identifier. AssociationNavigator methods. These are methods that return entity instances that are related to a specified entity instance by an association in the BDC model. This topic highlights examples of the use of each of these stereotypes. In each case, the approach is broadly similar: Retrieve an IEntity object from the metadata catalog that represents the entity (external content type) of interest. C all a method on the IEntity instance to invoke the operation, passing in a LobSystemInstance object and other relevant parameters such as filters or identifier values. Note: It's important to understand the difference between entities and entity instances. The IEntity class represents an entity in the BDC model, which corresponds to an external content type. Instances of that entity, which you can think of as list items or rows of data, are represented by the IEntityInstance class. Methods that query multiple entity instances typically return an IEntityInstanceEnumerator object, which represents an enumerable collection of IEntityInstance objects. The examples that follow are taken from the ManageMachinesPresenter class in the reference implementation. Querying Data by Using a Finder Method A Finder method returns all of the entity instances for a specified entity, subject to any filtering criteria. Finder methods typically include one or more filter descriptors in the BDC model. When you invoke a Finder method, you can retrieve and use these filters to constrain your result set. Finder methods are often referred to as Read List operations. For example, in the PartsManagement BDC model, in the Machines entity definition, the Read List method—a method that conforms to the Finder stereotype—defines the following filter descriptors: XML <FilterDescriptors> <FilterDescriptor Type="Wildcard" FilterField="ModelNumber" Name="ModelNumberWildcardFilter"> <Properties> <Property Name="CaseSensitive" Type="System.Boolean">false</Property> <Property Name="DontCareValue" Type="System.String"></Property> <Property Name="IsDefault" Type="System.Boolean">false</Property> <Property Name="UsedForDisambiguation" Type="System.Boolean">false</Property> <Property Name="UseValueAsDontCare" Type="System.Boolean">true</Property> </Properties> </FilterDescriptor> <FilterDescriptor Type="Limit" FilterField="ID" Name="Filter"> <Properties> <Property Name="CaseSensitive" Type="System.Boolean">false</Property> <Property Name="IsDefault" Type="System.Boolean">false</Property> <Property Name="UsedForDisambiguation" Type="System.Boolean">false</Property> </Properties> </FilterDescriptor> </FilterDescriptors> Generated from CHM, not final book. Will be superseded in the future. Page 311
- 312. In this case, a wildcard filter has been defined for the ModelNumber field on the Machines entity. This allows us to search for machines with a model number that contains some specified text. To retrieve the set of machines that match a filter, we call the F indFiltered method on the IEntity instance that represents machines, as shown in the following code example. C# public DataTable GetMachinesByModelNumber(string modelNumber) { //Get the Machines entity (external content type) from the metadata catalog IEntity entity = catalog.GetEntity(Constants.BdcEntityNameSpace, "Machines"); //Get the filters defined on the default Finder method for the entity IFilterCollection filters = entity.GetDefaultFinderFilters(); //Set the WildCard filter value if (!string.IsNullOrEmpty(modelNumber)) { WildcardFilter filter = (WildcardFilter)filters[0]; filter.Value = modelNumber; } //Return the filtered list of items from the external data source IEntityInstanceEnumerator enumerator = entity.FindFiltered(filters, lobSystemInstance); //Convert the filtered list of items to a DataTable and return it return entity.Catalog.Helper.CreateDataTable(enumerator); } Note: This example uses the IMetadataCatalog.Helper.CreateDataTable method to return the result set as a DataTable instance. The CreateDataTable method is a new BC S method in SharePoint 2010 that allows you to convert a result set from the BDC into a DataTable object with ease. For information on how to convert the DataTable object into a strongly typed collection, see Web Part Patterns for BDC Logic. The External Data Models reference implementation contains Finder methods that include three different types of filter definitions: LIMIT filters ensure that the number of results returned by the Read List operation does not exceed the maximum allowed by the BC S. By default, this maximum value is set to 2,000 records. The use of LIMIT filters is highly recommended to prevent performance degradation when you work with large amounts of data. WILDC ARD filters allow you to filter the results returned by the Read List operation based on partial search matches. The user can constrain the result set by providing a few characters of text, including wildcard characters as required. Including a WILDC ARD filter in your Finder methods enables the business data Web Parts to use their built-in search functionality. C OMPARISON filters allow you to constrain the results returned by the Read List operation to those with field values that exactly match some search text. C omparison filters can be used to evaluate conditions such as equals, not equals, less than, greater than, and so on. Including a C OMPARISON filter in your Finder methods also enables exact match and condition-driven filtering in the business data Web Parts. Querying Data by Using a SpecificFinder Method A SpecificFinder method returns a single entity instance, where the identifier field value (or values) of the entity instance matches the arguments supplied to the method. SpecificFinder methods are often referred to as Read Item operations. To retrieve a machine with a specific identifier, we call the F indSpecific method on the IEntity instance that represents machines, as shown by the following code example. Note that we must package the identifier value in an Identity object before we pass it to the F indSpecific method. C# private IEntityInstance GetBdcEntityInstance(int identifier, string entityName) { //Create an identifier object to store the identifier value Identity id = new Identity(identifier); Generated from CHM, not final book. Will be superseded in the future. Page 312
- 313. //Return the entity on which to execute the SpecificFinder method IEntity entity = catalog.GetEntity(Constants.BdcEntityNameSpace, "Machines"); //Invoke the SpecificFinder method to return the entity instance IEntityInstance instance = entity.FindSpecific(id, lobSystemInstance); return instance; } Querying Data by Using an AssociationNavigator Method An AssociationNav igator method returns a set of entity instances that are related to a specified entity instance (or instances) through a specified association. To retrieve the set of parts that are associated with a specified machine, we call the FindAssociated method on the IEntity object that represents machines. The FindAssociated method requires four parameters: An EntityInstanceCollection object. This contains the entity instance, or entity instances, for which you want to find related entity instances. In this case, our EntityInstanceCollection contains a single entity instance, which represents a machine with a specified machine ID. An IAssociation object. This contains the association navigator method instance. We retrieve this from the entity definition that represents machines. A LobSystemInstance object. This represents a specific instance of an external system in the BDC model. An OperationMode enumeration value. A value of Online indicates that data should be retrieved from the external system, while a value of Offline indicates that data should be retrieved from the local cache. This is illustrated by the following code example, which retrieves a set of parts based on a specified machine ID. C# public DataTable GetPartsByMachineId(int machineId) { //Return the Parts entity - this entity is the destination entity as modeled //in the Association method IEntity entity = catalog.GetEntity(Constants.BdcEntityNameSpace, "Parts"); //Return the association defined on the Parts entity which associates the //Parts entity with the Machines entity IAssociation association = (IAssociation)entity.GetMethodInstance("GetPartsByMachineID", MethodInstanceType.AssociationNavigator); //Return the Machine entity instance for a given Machine ID - this entity is //the source entity as modeled in the Association method IEntityInstance machineInstance = GetBdcEntityInstance(machineId, "Machines"); //Create an EntityInstanceCollection to hold the Machine entity instance EntityInstanceCollection collection = new EntityInstanceCollection(); //Add the Machine entity instance to the EntityInstanceCollection collection.Add(machineInstance); //Execute the association method on the destination entity (Parts) to //return all the parts for a given machine IEntityInstanceEnumerator associatedInstances = entity.FindAssociated(collection, association, lobSystemInstance, OperationMode.Online); //Convert the associated list of items to a DataTable and return it return entity.Catalog.Helper.CreateDataTable(associatedInstances); } Generated from CHM, not final book. Will be superseded in the future. Page 313
- 314. Conclusion The External Data Models reference implementation demonstrates best practice approaches to various aspects of modeling and querying external systems through the business data connectivity (BDC ) service application. The key points of interest include the following: C reating BDC models for SQL Server databases and external services, and the challenges you may encounter while doing so. C ustomizing BDC models to include functionality not supported by SharePoint Designer, such as navigating many-to-many relationships and updating primary key fields. Using stored procedures and other custom logic to navigate foreign-keyless relationships between entities in a BDC model. Using .NET connectivity assemblies to flatten complex data from external services. Using external lists and built-in business data Web Parts to interact with BDC models. Using the BDC object model to develop custom components that interact with external systems. We encourage you to deploy the reference implementation and to explore the different components and code within the DataModels.ExternalData solution. For more information on data models and working with external data, see Data Models in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 314
- 315. Data Models: How-to Topics When the data models reference implementations were developed, several tasks proved challenging to accomplish. In some cases the procedures were simple but hard to find, in other cases they were somewhat complicated. The following topics address these issues and provide step-by-step instructions on how to complete the tasks. How to: C onfigure an Association Navigator Using a Stored Procedure How to: C reate and Export a BDC Model Using SharePoint Designer How to: Deploy a Declarative BDC Model with a Feature How to: Programmatically C reate C ontent Types How to: C onfigure Business Data Web Parts to Navigate EC T Associations How to: Programmatically Set the Delete Behavior on a Lookup Field How to: Manually Generate SPLINQ Entity C lasses by Using SPMetal How to: Use the BDC Runtime APIs to Access BC S Data How To: View C AML Generated by LINQ to SharePoint Generated from CHM, not final book. Will be superseded in the future. Page 315
- 316. How to: Configure an Association Navigator Using a Stored Procedure Overview Microsoft® SharePoint® Designer 2010 provides only the ability to create one-to-many associations between external content types (EC Ts). However, a line-of-business (LOB) application might require many-to-many relationships as well. To support many-to-many associations, you must edit the Business Data C atalog (BDC ) Model file to include an association navigator. Note: Note: This how-to topic assumes that you have an existing BDC Model (.bdcm) file with EC Ts and a many-to-many relationship that needs to be modeled correctly. To create the BDC Model file used in this topic, see How to: C reate and Export a BDC Model Using SharePoint Designer. Steps To configure an association nav igator by using a stored procedure 1. Open the database that you created when you created the BDC Model. 2. Add a Microsoft SQL Server® stored procedure that will go through the MachineParts table named GetPartsByMachineID, and return the parts for a given machine ID. See the following example. C# -- ------------------------------------------------- ------------------------------------------------- -- Author: <Author,,Name> -- Create date: <Create Date,,> -- Description: <Description,,> -- -------------------------------------------------- -------------------------------------------------- CREATE PROCEDURE GetPartsByMachineId -- Add the parameters for the stored procedure here @machineId int AS BEGIN -- SET NOCOUNT ON added to prevent extra result sets from -- interfering with SELECT statements. SET NOCOUNT ON; -- Insert statements for procedure here SELECT Parts.* FROM Machines INNER JOIN MachineParts ON Machines.ID=MachineParts.MachineId INNER JOIN Parts ON MachineParts.PartSKU=Parts.SKU WHERE Machines.ID=@machineId; END 3. Open the BDC Model file in an XML editor, and find the <Entity> tag for the Parts EC T. 4. For each entity element in the file, modify the namespace in <Entity Namespace=”<your name space> ” to <Entity Namespace="DataModels.ExternalData.PartsManagement". 5. In the <Methods> element, add a new <Method> that defines a method for navigating the many-to-many relationship to retrieve parts for the computer, as shown in the following example. This method is called an association navigator. XML <Method Name="GetPartsForMachine" DefaultDisplayName="Get Parts For Machine"> Note: Note: The <Method> tag must conform to the BDC Model Schema definition. You can find the BdcMetadata.XSD file in the TEMPLATE directory of your Microsoft Office SharePoint Server 2007 installation, typically at <Root>Program FilesMicrosoft Office Server14TEMPLATEXMLBDC MetaData.xsd. 6. Add the following child properties for the method that you created in step 4. These properties describe the stored procedure. Generated from CHM, not final book. Will be superseded in the future. Page 316
- 317. XML <Method Name="GetPartsForMachine" DefaultDisplayName="Get Parts For Machine"> <Properties> <Property Name="BackEndObject" Type="System.String">GetPartsByMachineID</Property> <Property Name="BackEndObjectType" Type="System.String">SqlServerRoutine</Property> <Property Name="RdbCommandText" Type="System.String">[dbo].[GetPartsByMachineID]</Property> <Property Name="RdbCommandType" Type="System.Data.CommandType, System.Data, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">StoredProcedure</Property> <Property Name="Schema" Type="System.String">dbo</Property> </Properties> 7. After the properties, specify the input and return parameter values in the Parameters element for the method, as shown in the following example. The Parameters element is a child of the <Method> tag. XML <Parameters> <Parameter Direction="In" Name="@machineId"> <TypeDescriptor TypeName="System.Nullable`1[[System.Int32, mscorlib, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089]]" IdentifierName="Id" IdentifierEntityName="Machines" IdentifierEntityNamespace="DataModels.ExternalData.PartsManagement" Name="@machineId"> <DefaultValues> <DefaultValue MethodInstanceName="GetPartsByMachineID" Type="System.Int32">1</DefaultValue> </DefaultValues> </TypeDescriptor> </Parameter> <Parameter Direction="Return" Name="GetPartsByMachineID"> <TypeDescriptor TypeName="System.Data.IDataReader, System.Data, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" IsCollection="true" Name="GetPartsByMachineID"> <TypeDescriptors> <TypeDescriptor TypeName="System.Data.IDataRecord, System.Data, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" Name="GetPartsByMachineIDElement"> <TypeDescriptors> <TypeDescriptor TypeName="System.String" IdentifierName="SKU" Name="SKU"> <Properties> <Property Name="Size" Type="System.Int32">255</Property> </Properties> <Interpretation> <NormalizeString FromLOB="NormalizeToNull" ToLOB="NormalizeToEmptyString" /> </Interpretation> </TypeDescriptor> <TypeDescriptor TypeName="System.String" Name="Name"> <Properties> <Property Name="ShowInPicker" Type="System.Boolean" >true</Property> <Property Name="Size" Type="System.Int32" >255</Property> </Properties> <Interpretation> <NormalizeString FromLOB="NormalizeToNull" ToLOB="NormalizeToNull" /> </Interpretation> </TypeDescriptor> <TypeDescriptor TypeName="System.String" Name="Description"> <Properties> <Property Name="Size" Type="System.Int32" >255</Property> </Properties> <Interpretation> <NormalizeString FromLOB="NormalizeToNull" ToLOB="NormalizeToNull" /> </Interpretation> </TypeDescriptor> </TypeDescriptors> </TypeDescriptor> Generated from CHM, not final book. Will be superseded in the future. Page 317
- 318. </TypeDescriptors> </TypeDescriptor> </Parameter> </Parameters> 8. Define the method instance as a child of the method element, which describes this method as an association navigator type. See the following example. XML <MethodInstances> <Association Name="GetPartsByMachineID" Type="AssociationNavigator" ReturnParameterName="GetPartsByMachineID" DefaultDisplayName="Parts Read with Sproc"> <SourceEntity Namespace="DataModels.ExternalData.PartsManagement" Name="Machines" /> <DestinationEntity Namespace="DataModels.ExternalData.PartsManagement" Name="Parts"/> </Association> </MethodInstances> </Method> 9. Define an AssociationGroup for the new association. The AssociationGroup must be located after the closing tag for the Methods (</Methods>). See the following example. XML </Methods> <AssociationGroups> <AssociationGroup Name="PartAssociationGroup"> <AssociationReference AssociationName="GetPartsByMachineID" Reverse="false" EntityNamespace="DataModels.ExternalData.PartsManagement" EntityName="Parts" /> </AssociationGroup> </AssociationGroups> </Entity> 10. Save the new .bdcm file. 11. Use the SharePoint C entral Administration Web page to import the updated .bdcm file. To do this: a. Open C entral Administration, and browse to Application Management. b. C lick Application Management, click Manage Serv ice Applications, and then select Business Data Connectiv ity Service. c. Because the EC T’s were already created, they will appear in the list of EC T’s. You must delete the Machines, Parts, and MachineParts external content types before you import the .bdcm file. Select them individually, and then, on the ribbon, click Delete. d. On the ribbon, click Import, and then browse to the .bdcm file that you created. C lick OK. e. C onfirm that the file was imported successfully (there should not be any import errors. You should see the following Warnings screen. You can ignore the warnings. Generated from CHM, not final book. Will be superseded in the future. Page 318
- 319. How to: Create and Export a BDC Model Using SharePoint Designer Overview Microsoft® SharePoint® Designer 2010 enables you to quickly and easily create external content types (EC Ts) for any external data source. However, there are limitations in the tooling that SharePoint Designer 2010 provides. Note: This how-to topic assumes that your external line-of-business (LOB) system uses a Microsoft SQL Server® database and is connected as a SQL Server data store. This document models the many-to-many relationship shown in the following illustration. Steps To create your initial BDC model file 1. C reate a new empty SQL Server database, and name it PartsManagement. 2. C reate new SQL Server tables as shown in the preceding illustration (Machines, MachineParts, and Parts). 3. Start SharePoint Designer 2010 and connect to your SharePoint site. 4. Select External Content Types from the left pane. 5. C lick the new External Content Type button located in the New group of the Ribbon. a. Type the EC T name in the Name and Display Name text boxes. b. Select the Click here to discov er external data sources and define operations link. c. Select the Add Connection button. d. Select SQL Serv er for the data source type, and click OK. The following SQL Server dialog box will appear. Generated from CHM, not final book. Will be superseded in the future. Page 319
- 320. e. Type the connection information to connect to the SQL Server database, and then click OK. The data source explorer will now contain the database you specified. Note: For simplicity, select Connect with User’s Identity to use pass-through authentication. f. C lick the Data Source Explorer tab, and find the Parts table. Select the table, right-click, and then select Create All Operations. g. C omplete the wizard by accepting all default settings. h. Save the EC T. 6. Repeat Step 4 to create external content types for the Machines and MachineParts tables. 7. After you configure all of the EC Ts, select External Content Types from the left pane. A list of all EC Ts will appear. 8. Select all the EC Ts by pressing the C trl key while you click each EC T name. Right-click the selection, and select Export BDC Model. 9. Enter the model name and location, and then click OK. 10. Select the save location, and then click Sav e. Generated from CHM, not final book. Will be superseded in the future. Page 320
- 321. Generated from CHM, not final book. Will be superseded in the future. Page 321
- 322. How to: Deploy a Declarative BDC Model with a Feature Overview Another new feature of Microsoft® SharePoint® Server 2010 is the ability to build a Business Data C onnectivity (BDC ) model file that defines the connections, operations, and associations of an external line-of-business (LOB) system. You can deploy the BDC model as a SharePoint feature and package the feature as part of a SharePoint solution. The Microsoft Visual Studio® 2010 development system provides tooling to help you construct and deploy BDC models that use a .NET connectivity assembly. If you create a Visual Studio project by using the Business Data C onnectivity Model project template, Visual Studio builds the BDC model definition with the classes required for the .NET connectivity assembly. It will also create a deployment package for these components. However, in many cases you will not require a .NET connectivity assembly. A purely declarative BDC model will suffice for many common scenarios that access data in relational databases or from Web services that map to the stereotyped operations supported by the BDC . Typically, you will use SharePoint Designer 2010 to build the BDC model in these cases, because the Visual Studio Designer only supports building the BDC model for a .NET connectivity assembly. When you use SharePoint Designer to create a BDC model, you need to take some additional steps to import your BDC model (.bdcm) file into Visual Studio so that you can deploy and install the model as part of a SharePoint solution. Note: For a practical example that uses this approach, see the External Data Reference Implementation. Steps This procedure imports an existing .bdcm file into Visual Studio and deploys it as part of a SharePoint solution package. The procedure assumes that you have created a declarative BDC model, either by using SharePoint Designer 2010 or an XML editor, and saved it locally as a .bdcm file. To create a feature to deploy a declarative BDC model by using Visual Studio 2010 1. Open the Visual Studio 2010 project that contains your feature. 2. In Solution Explorer, right-click the project node, point to Add, and then click New. 3. In the Add New Item dialog box, under Installed Templates, click the SharePoint 2010 template type, and then click Business Data Connectiv ity Model in the middle pane. In the Name box, type a friendly name for the item, and then click Add. Generated from CHM, not final book. Will be superseded in the future. Page 322
- 323. By default, the Business Data C onnectivity Model item will add a new <projectname>.bdcm file and associated entity classes. 4. Delete the default <projectname >.bdcm file and entity classes. 5. Right-click the Business Data Connectivity Model project item, point to Add, and then click Existing Item. 6. Browse to your existing model file, and then click Add to add the existing model. 7. Since the model file being added was generated using SharePoint Designer, you will receive a message asking if you want to add a .NET assembly LobSystem to the model. Select No, and then click OK. Generated from CHM, not final book. Will be superseded in the future. Page 323
- 324. 8. Right-click the Business Data Connectivity Model project item, and then click Properties. 9. C lick the F eature Properties ellipsis button (…) in the Properties dialog box. 10. In the Feature Properties window, find the F eature Property with the name of the original BDC model item added when the solution was created. Select it, and then click Remov e to remove it from the Property collection. Generated from CHM, not final book. Will be superseded in the future. Page 324
- 325. 11. Add a new farm-scoped feature to the Visual Studio project by right-clicking the F eatures item in the project, and then clicking Add F eature. 12. Use the Properties dialog box to change the folder name for the feature. Make sure that the feature is farm scoped. 13. Add your BDC model item to the feature. 14. Right-click the Visual Studio project, and then click Deploy. Your BDC model should now be packaged and deployed successfully to your SharePoint farm. Generated from CHM, not final book. Will be superseded in the future. Page 325
- 326. How to: Programmatically Create Content Types Overview In Microsoft® SharePoint® 2010, you can declare content types in a feature or you can create them programmatically. In SharePoint 2007, it was not possible to programmatically create a content type with a fixed content type ID. Programmatically created content types are more flexible and provide more granular control over how and when updates to the content type are made during upgrades. In contrast, you cannot change the declarative definition of a content type that was created by using C ollaborative Application Markup Language (C AML) after the content type is activated—instead, you must update the content type programmatically. Note: Note: You can declaratively add columns to a content type in SharePoint 2010 by using the AddC ontentTypeField feature element. Summary of Steps C reating a content type is composed of two basic actions: Step 1: Create the Site Columns. In this step, you create the site columns that the content type will use. Typically, site columns are created declaratively rather than programmatically. However, to provide a complete example, this how-to topic creates a site column programmatically. Step 2: Create the Content Type Programmatically. In this step, you first confirm that the content type does not already exist, and then you create the new content type. Note: Note: In most cases, you should use a feature receiver class to programmatically create content types when the feature is activated. C ontent types are typically created on the root Web of a site collection to maximize reuse. In this case, you should use a site-scoped feature. Step 1: Create the Site Columns To create the site columns C reate the site columns as required. The following example uses the AddF ieldAsXml method to programmatically create a site column from an XML field definition. Note that to avoid errors, the code first checks whether the column already exists. C# public static readonly Guid MyFieldId = new Guid("{891B57CF-B826-4B0C-9EDF-8948C824D96F}"); public static readonly string MyFieldDefXml = "<Field ID="{CC1E421C-29BE-4373-81D0-55D5D64B2E3D}"" + " Name="MyFieldName" StaticName="MyFieldName"" + " Type="Text" DisplayName="My Field Name"" + " Group="My Columns" DisplaceOnUpgrade="TRUE" />"; if (web.AvailableFields.Contains(MyFieldId) == false) { web.Fields.AddFieldAsXml(MyFieldDefXml); } Note: Note: In this example, the web variable is an SPWeb instance that represents the root Web of a site collection. Step 2: Create the Content Type Programmatically To programmatically create a content type 1. C heck whether the content type already exists. If it does not exist, create the content type and add it to Generated from CHM, not final book. Will be superseded in the future. Page 326
- 327. the ContentTypes collection for the Web, as shown in the following example. C# public static readonly SPContentTypeId myContentTypeId = new SPContentTypeId("0x010100FA0963FA69A646AA916D2E41284FC9D9"); SPContentType myContentType = web.ContentTypes[myContentTypeId]; if (myContentType == null) { myContentType = new SPContentType(myContentTypeId, web.ContentTypes, "My Content Type"); web.ContentTypes.Add(myContentType); } 2. Retrieve the site column(s) created in step 1 from the Av ailableF ields collection of the Web. Add the field to the content type by creating a SPFieldLink instance for the field, and then adding the field link to the content type, as shown in the following example. Repeat this procedure for each column that you want to add to your content type. C# SPField field = web.AvailableFields[MyFieldId]; SPFieldLink fieldLink = new SPFieldLink(field); if (myContentType.FieldLinks[fieldLink.Id] == null) { myContentType.FieldLinks.Add(fieldLink); } 3. C all the Update method on the new content type, as shown in the next example. Specify a parameter value of true if you want to push down the changes to content types that inherit from the new content type. For example, specify true if you are adding a column to a site content type that is already used in lists. C# myContentType.Update(true); Generated from CHM, not final book. Will be superseded in the future. Page 327
- 328. How to: Configure Business Data Web Parts to Navigate ECT Associations Overview This how-to topic explains how to use Business Data Web Parts to navigate associations between external content types (EC Ts). Note: Note: The how-totopic assumes that you have already created at least two EC Ts and configured associations between them. For an explanation of how to configure associations between EC Ts, see How to: C onfigure an Association Navigator by Using a Stored Procedure. To use the Business Data Web Parts, you must be running Microsoft® SharePoint® Server 2010 Enterprise edition. This how-to topic uses two associated EC Ts—Vendors and VendorTransactions—to illustrate the process. These EC Ts represent the corresponding tables in a vendor management database. The VendorTransactions EC T includes an association that links the VendorID column in the VendorTransactions table to the ID column in the Vendors table. The script required to create the database is contained in the following example. SQL CREATE TABLE [dbo].[Vendors]( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [varchar](50) NULL, [Address] [varchar](50) NULL, [City] [varchar](50) NULL, [State] [varchar](50) NULL, [ZipCode] [varchar](50) NULL, [Country] [varchar](50) NULL, [Telephone] [varchar](50) NULL, [Industry] [varchar](50) NULL, [AccountsPayable] [bigint] NULL, CONSTRAINT [PK_Clients] PRIMARY KEY CLUSTERED ( [Id] ASC ) ON [PRIMARY] ) ON [PRIMARY] GO CREATE TABLE [dbo].[VendorTransactions]( [ID] [int] IDENTITY(1,1) NOT NULL, [VendorID] [int] NOT NULL, [TransactionTypeId] [int] NOT NULL, [Notes] [varchar](max) NULL, [TransactionDate] [datetime] NULL, [Amount] [money] NULL, CONSTRAINT [PK_ClientActivity] PRIMARY KEY CLUSTERED ( [ID] ASC ) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[VendorTransactions] WITH CHECK ADD CONSTRAINT [FK_VendorTransactions_Vendors] FOREIGN KEY([VendorID]) REFERENCES [dbo].[Vendors] ([Id]) GO ALTER TABLE [dbo].[VendorTransactions] CHECK CONSTRAINT [FK_VendorTransactions_Vendors] GO Summary of Steps Generated from CHM, not final book. Will be superseded in the future. Page 328
- 329. This how-to topic includes the following steps: Step 1: Configure a Business Data List Web Part. In this step, you add a Business Data List Web Part to a SharePoint page, and then configure it to display data from an EC T that contains an association definition. Step 2: Configure a Business Data Related List Web Part. In this step, you add a Business Data Related List Web Part to a SharePoint page, and then configure it to display data from an EC T that contains an association definition. Step 3: Connect the Business Data Web Parts. In this step, you connect the two Business Data Web Parts. This enables you to navigate the associated data. Step 1: Configure a Business Data List Web Part This procedure adds a Business Data List Web Part to a SharePoint page, and then configures it to display data from an EC T. This EC T should represent the parent entity in your association. Note: Note: Business Data Web Parts ship with SharePoint Server 2010 Enterprise edition. To configure a Business Data List Web Part 1. On a SharePoint Web Part page, on the Page tab in the ribbon, click Edit. 2. C lick in a rich content zone on the page, click the Insert tab on the ribbon, and then click Web Part, as shown in the following illustration. 3. In the Categories list box, select Business Data, and then in the Web Parts list box, select Business Data List. After you make these selections, your page should resemble the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 329
- 330. 4. C lick Add. 5. In the Business Data List Web Part, click Open the tool pane. 6. In the tool pane, click the Select External Content Type button. 7. In the External Content Type Picker dialog box, select the EC T that represents the parent entity of the association. In this example, we selected the Vendors EC T. 8. C lick OK. 9. In the Web Part tool pane, click OK. Note: Steps 10-14 are optional. They configure the Web Part to improve the usability and presentation of the data. 10. In the Business Data List Web Part, on the drop-down menu, click Edit Web Part, as shown in the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 330
- 331. 11. In the top right corner of the Web Part, click Edit View. (See the highlighted text in the following illustration.) 12. In the Columns section, select the columns that you want to display, as shown in the following illustration. 13. In the Pages section, choose how many items you want to display on a page. In the example, we indicated 5 items. 14. C lick OK. The Business Data List Web Part is now configured. In this example, it displays vendor data from the data source associated with the Vendors EC T. Generated from CHM, not final book. Will be superseded in the future. Page 331
- 332. Step 2: Configure a Business Data Related List Web Part This procedure adds a Business Data Related List Web Part to a SharePoint page, and then configures it to display data from an EC T. This EC T should represent the child entity in your association. Note: Note: Business Data Web Parts ship with SharePoint Server 2010 Enterprise edition. To configure a Business Data Related List Web Part 1. On your SharePoint Web Part page, on the Page tab in the ribbon, click Edit. 2. C lick below the Business Data List Web Part in the rich content zone on the page, and then on the Insert tab on the ribbon, click Web Part, as shown in the following illustration. 3. In the Categories list box, select Business Data, and then in the Web Parts list box, select Business Data Related List, as shown in the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 332
- 333. 4. C lick Add. 5. In the Business Data Related List Web Part, click Open the tool pane. 6. In the Web Part tool pane, click Select External Content Type. 7. In the External Content Type Picker dialog box, select the EC T that represents the child entity in your association. In this example, we selected the Vendor Transactions EC T. Note: When you configure a Business Data Related List Web Part, the External C ontent Type Picker only displays EC Ts that have associations defined for them. 8. C lick OK. 9. In the Relationship drop-down list, select the relationship that the Business Data Related List Web Part should use to query and display associated data. See the following example. Generated from CHM, not final book. Will be superseded in the future. Page 333
- 334. 10. In the Web Part tool pane, click OK. Note: Steps 11-13 are optional. They configure the Web Part to improve the usability and presentation of the data. 11. In the Business Data Related List Web Part, on the drop-down menu, click Edit Web Part. 12. In the top right corner of the Web Part, click Edit View. 13. In the Columns section, select the columns that you want to display, and then click OK. See the following example. The Business Data Related List Web Part is now configured. However, you must connect the Web Parts before you can browse related data. The connection process is described in Step◦3. Step 3: Connect the Business Data Web Parts This procedure connects the Business Data List Web Part to the Business Data Related List Web Part. To connect the Business Data Web Parts 1. In the BusinessData Related List Web Part, on the drop-down menu, select Edit Web Part. 2. In the Business Data Related List Web Part, on the drop-down menu, point to Connections, point to Get Related Item F rom, and select the name of your Business Data List Web Part. In this example, our Business Data List Web Part is named Vendors List. Generated from CHM, not final book. Will be superseded in the future. Page 334
- 335. The page refreshes and the Web Parts indicate that they are connected, as shown in the following illustration. 3. In the Web Part tool pane, click OK. 4. In the Business Data List Web Part, click the diagonal arrow next to a row of data, as shown in the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 335
- 336. Notice that the page refreshes and the Business Data Related List Web Part displays the associated data for the selected item, as shown in the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 336
- 337. How to: Programmatically Set the Delete Behavior on a Lookup Field Overview Microsoft® SharePoint® Server 2010 lets you enforce a delete behavior between related lists. You can cascade deletions, so that if a user deletes an item from one list, child items in a related list are also deleted. You can also restrict deletions, so that users are prevented from deleting items in one list that are referenced by items in another list. This how-to topic shows you how to programmatically define the delete behavior between related lists. For a practical example of programmatically defining the delete behavior between related lists, see Reference Implementation: SharePoint List Data Models. Note: Note: This how-to topic assumes that you have created a project in Microsoft Visual Studio® 2010 by using the Empty SharePoint Project template and that the project is a Farm Solution. This topic also assumes that you have already created a feature that deploys a list instance with a lookup. Summary of Steps This procedure creates a feature receiver that programmatically sets the delete behavior on the lookup field. This how-to topic includes the following steps: Step 1: Create a F eature Receiv er. In this step, you create the feature receiver on the feature that deploys a list instance containing a lookup column. Step 2: Configure the Receiv er to Restrict Deletions. In this example, you set the delete behavior to restrict deletions, which prevents users from deleting items from related lists that are referenced by the lookup column. You could use the same approach to set the delete behavior to cascade deletions to the related list. Step 1: Create a Feature Receiver To create a feature receiver that programmatically sets the delete behavior on a lookup field 1. In the Solution Explorer window, right-click the feature that deploys the list instance containing the lookup column, and then click Add Event Receiver. 2. Open the corresponding <FeatureName>.EventReceiver.cs file that is generated. 3. Add the following method to the class. C# private string GetListUrl(string webRelativeUrl, string listUrl) { if (webRelativeUrl[webRelativeUrl.Length - 1] != '/') return (webRelativeUrl + '/' + listUrl); else return (webRelativeUrl + listUrl); } Note: Note: This method accepts two arguments. The webRelativeUrl argument is the SPWeb.ServerRelativeUrl property. The listUrl argument is the relative URL to the list. Essentially this method ensures that the relative URL to the list is correct, regardless of whether the SPWeb object represents a root site or a sub-site. This method is called by other methods in the event receiver. Step 2: Configure the Receiver to Restrict Deletions 1. Add the following method to the class that you created in step 1. C# private void RestrictDeleteOnLookupField(SPWeb web, string listUrl, Guid fieldGuid) { SPList list = web.GetList(GetListUrl(web.ServerRelativeUrl, listUrl)); Generated from CHM, not final book. Will be superseded in the future. Page 337
- 338. SPField field = list.Fields[fieldGuid]; SPFieldLookup fieldLookup = (SPFieldLookup)field; fieldLookup.Indexed = true; fieldLookup.RelationshipDeleteBehavior = SPRelationshipDeleteBehavior.Restrict; fieldLookup.Update(); } Note: Note: This method accepts three arguments. The Web argument is the SPWeb where the list resides. The listUrl argument is the relative URL to the list that contains the lookup column. The fieldGuid argument represents the ID of the lookup field to set the delete behavior on. This method sets the delete behavior for a lookup field to SPRelationshipDeleteBehavior.Restrict. This value turns on the restricted delete behavior for the lookup column and the lists it relates to. You could also set the delete behavior to SPRelationshipDeleteBehavior.Cascade. This method is called by other methods in the event receiver. 2. Remove the comment from the F eatureActivated method in the class. 3. Add the following code to the FeatureActiv ated method. C# try { SPSite thisSite = properties.Feature.Parent as SPSite; SPWeb rootWeb = thisSite.RootWeb; RestrictDeleteOnLookupField(rootWeb, <ListUrl>, <LookupFieldGUID>); } catch (Exception e) { System.Diagnostics.Trace.WriteLine(e.ToString()); } Note: Note: <ListUrl> is a placeholder for the relative URL to the list that contains the lookup column. < LookupFieldGUID> is the ID for the lookup field on which to set the delete behavior. Generated from CHM, not final book. Will be superseded in the future. Page 338
- 339. How to: Manually Generate LINQ to SharePoint Entity Classes by Using SPMetal Overview Microsoft® SharePoint® 2010 gives developers the ability to use Language Integrated Query (LINQ) with SharePoint lists. This allows developers to use strongly-typed entities to create, edit, view, and delete SharePoint list and library data on a SharePoint site. To use LINQ with SharePoint, you must first create entity classes to represent the lists on your SharePoint site. SharePoint 2010 includes a command-line tool named SPMetal that you can use to automatically generate the data context and entity classes for the SharePoint site Note: Note: For an example of a project that uses LINQ to SharePoint classes that were generated by SPMetal, see the SharePoint List Reference Implementation. Summary of Steps This how-to topic includes the following steps: Step 1: Use SPMetal to Manually Create the SPLinq DataContext and Entity Class. In this step, you use SPMetal to create the data context and entity class that LINQ will use to connect to your SharePoint site. Step 2: Add the Data Context and Entity Class to Your Project. In this step, you use the Microsoft® Visual Studio® development system to add the data context and entity class that you created in step 1 to your project. Step 1: Use SPMetal to Manually Create the SPLinq Data Context and Entity Class To create an SPLinq DataContext for an existing SharePoint site 1. Open a C ommand Prompt window. 2. C hange the current path to the SPMetal.exe file location (it is usually [DRIVE:]Program FilesC ommon FilesMicrosoft Sharedweb server extensions14BIN). 3. Type the following command: SPMetal /web:http://MyServ er/SiteName /code:SiteName.cs where: http://MyServer/SiteName is the fully-qualified URL of your site. SiteName.cs is the output file for the generated code. The following illustration is an example of this command. Generated from CHM, not final book. Will be superseded in the future. Page 339
- 340. Step 2: Add the Data Context and Entity Class to Your Project To create an SPLinq DataContext for an existing SharePoint site 1. Start the Microsoft Visual Studio® development system. 2. Add the file to your Visual Studio project by right-clicking the project file and then selecting Add Existing Item. 3. Browse to the SPMetal source directory, find your newly generated class, and then select it. C lick OK to add the class to your project. Note: For information about configuring SPMetal to automatically generate the classes as a pre-build step, see How to: Use SPMetal on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 340
- 341. How to: Use the BDC Runtime APIs to Access BCS Data Overview The Business Data C atalog (BDC ) runtime APIs can be used to query and perform operations on data from external systems. The BDC runtime APIs provide richer functionality than the SPList API does, and can be used to create custom solutions that extend the out-of-the-box capabilities that external lists and Business Data Web Parts offer. This how-to topic explains how you can use the BDC runtime APIs to access Business C onnectivity Services (BC S) data. For a practical example of querying data with the BDC runtime APIs, see the External List Reference Implementation. The reference implementation uses the BDC runtime APIs in a custom Web Part to query data. It uses the Finder, SpecificF inder, and Association methods to find the data and then display it in the Web Part. Summary of Steps This how-to topic describes the following steps: Step 1: Add References to the Assemblies that Contain the BDC Runtime APIs. In this step, you add the Microsoft.SharePoint.dll and the Microsoft.BusinessData.dll assemblies to your project so that you can use the BDC runtime APIs. Step 2: Connect to the BDC Service, Metadata Catalog, and lobSystemInstance Object. In this step, you connect to the BDC service, return the metadata catalog, and then return the LobSystemInstance so that you can use the BC S to query an external system. Step 1: Add References to the Assemblies that Contain the BDC Runtime APIs The Microsoft.SharePoint.dll and the Microsoft.BusinessData.dll assemblies contain the namespaces that are required before you can use the BDC runtime APIs to query the BC S. These assemblies must be added as references to a project to make the BDC runtime APIs available. Note: Note: The Microsoft Visual Studio® 2010 development system SharePoint project templates automatically add a reference to the Microsoft.SharePoint.dll assembly. The only reference that needs to be added when you use one of the Visual Studio 2010 SharePoint project templates is the Microsoft.BusinessData.dll assembly. The Microsoft.BusinessData.dll assembly is located in the C :Program FilesC ommon FilesMicrosoft SharedWeb Server Extensions14ISAPI directory. After you add the assembly references to your project, the BDC runtime APIs are available. The following namespaces are typically used to access BC S data: Microsoft.BusinessData.MetadataModel Microsoft.BusinessData.Runtime Microsoft.SharePoint Microsoft.SharePoint.Administration Microsoft.SharePoint.BusinessData.Runtime Microsoft.SharePoint.BusinessData.SharedService The following using statements are typically added to classes which need to access BC S data. using Microsoft.BusinessData.MetadataModel; using Microsoft.BusinessData.Runtime; using Microsoft.SharePoint; using Microsoft.SharePoint.Administration; using Microsoft.SharePoint.BusinessData.Runtime; using Microsoft.SharePoint.BusinessData.SharedService; Step 2: Connect to the BDC Service, Metadata Catalog, and lobSystemInstance Object Generated from CHM, not final book. Will be superseded in the future. Page 341
- 342. Before you can use the BC S to query an external system, you must connect to the BDC service, return the metadata catalog, and then return the LobSystemInstance object. The following line of code demonstrates how to connect to the BDC service application for the current server farm. bdcService = SPFarm.Local.Services.GetValue<BdcService>(); The following line of code demonstrates how the BDC service is used to connect to the metadata catalog. catalog = bdcService.GetDatabaseBackedMetadataCatalog(SPServiceContext.Current); The following line of code demonstrates how the lobSystemInstance object is retrieved from the metadata catalog. lobSystemInstance = catalog.GetLobSystem("PartsManagement").GetLobSystemInstances()["ContactsSystem"]; Note: Note: The Constants.LobSystemName string represents the name of the LobSystem to which you will be connected. Generated from CHM, not final book. Will be superseded in the future. Page 342
- 343. How to: View CAML Generated by LINQ to SharePoint Overview Microsoft® SharePoint® Server 2010 lets you use LINQ to SharePoint to take advantage of the LINQ framework and LINQ to Entities against SharePoint lists. The LINQ framework will convert LINQ to SharePoint statements into collaborative application markup language (C AML), and then execute the C AML against the SharePoint object model or Web Services. To ensure optimization of C AML queries, it is essential that you are able to inspect the C AML generated by the LINQ framework. This how-to topic explains how you can inspect the C AML. Note: This how-to topic uses the SharePoint List RI as an example of a project with generated SPLinq classes. It assumes that you have already generated LINQ to SharePoint DataContext and Entity classes. For more information about how to create these references, see How to: Manually Generate LINQ to SharePoint Entity Classes by Using SPMetal. Steps To view the CAML generated by LINQ to SharePoint 1. C reate a new using() block that defines a new DataContext for the LINQ query, as shown in the following example. using (var dataContext = new YourDataContext(@"http://yourdomain/sites/yoursite")) { } Note: In your code, replace YourDataContext, yourdomain, and yoursite with the appropriate information for your environment. 2. Instantiate a new StringBuilder object, as shown here. StringBuilder stringBuilder = new StringBuilder(); 3. Instantiate a new TextWriter object, as shown here. TextWriter textWriter = new StringWriter(stringBuilder); 4. Set the .Log Property of the DataContext to the TextWriter, as shown here. dataContext.Log = textWriter; 5. Write a LINQ query or LINQ Entity operation against the DataContext, as shown here. Note: The queries shown are dependent on a specific DataContext, and most likely will not function as shown if your DataContext differs. var departments = from department in dataContext.Departments where department.Title.StartsWith("deptname1") select department; 6. or var departments = dataContext.Department.Where(d => d.Title.StartsWith ("deptname2")) 7. Inspect the C AML by inspecting value of the StringBuilder. string queryLog = stringBuilder.ToString(); Generated from CHM, not final book. Will be superseded in the future. Page 343
- 344. For reference, the following is an example of the complete implementation. C# using (var dataContext = new PartsSiteDataContext(@http://localhost/sites/parts)) { StringBuilder stringBuilder = new StringBuilder(); TextWriter textWriter = new StringWriter(stringBuilder); dataContext.Log = textWriter; var departments = from department in dataContext.Departments where department.Title.StartsWith("deptname1") select department; Assert.True(departments.Count() > -1); string queryLog = stringBuilder.ToString(); } Generated from CHM, not final book. Will be superseded in the future. Page 344
- 345. Client Application Models in SharePoint 2010 One of the most significant additions to Microsoft® SharePoint® 2010 is new and enhanced client-side functionality. The increasing prevalence of rich Internet application (RIA) technologies that run in the browser to deliver an enriched user experience, such as Ajax and Microsoft Silverlight®, means that traditional server-side development techniques are no longer sufficient for meeting the expectations of today's users. Users increasingly expect seamless access to data regardless of platform, whether from a browser window, a Microsoft Office® client application, or a custom solution. To meet these evolving needs, SharePoint 2010 introduces native support for RIA technologies and several new mechanisms for client-side, or remote, data access. So what do we mean when we speak of a client application? In the context of SharePoint development, we mean any logic that interacts with SharePoint data from an external computer. This includes logic that executes in the browser, such as JavaScript or Silverlight applications, as well as Office applications and stand-alone solutions. This also includes applications that run on mobile devices, but that is beyond the scope of this document. Typically, there are three main reasons for developing client-side logic that interacts with a SharePoint environment: You want to provide a richer user experience on a SharePoint web page. You want to perform actions that are unavailable to server-side code running in the sandbox environment, such as accessing information from multiple site collections or retrieving data from an external service. You want to access and manipulate SharePoint data from another application, such as an Office client application or a custom solution. When you design a client application for SharePoint 2010, the factors driving your decisions fall into two broad areas: User experience. This describes the platform that your users will use to interact with SharePoint and the technologies on which you will build your application. Data access. This is the mechanism by which your application will communicate with the SharePoint server in order to retrieve and manipulate data. The following illustration shows some of the options available to you in each of these areas. Client application considerations for SharePoint 2010 In many cases, a particular approach to user experience will lend itself to a particular data access mechanism. For example, the EC MAScript client object model will clearly lend itself to Ajax clients, the Silverlight client object model is designed for Silverlight clients, and the REST interface will be the best approach for accessing Generated from CHM, not final book. Will be superseded in the future. Page 345
- 346. SharePoint data from clients that are not based on Microsoft Windows®. However, there are scenarios in which the choice is not so clear cut. This documentation identifies some of the nuances, advantages, and drawbacks to the different approaches to building a user experience and accessing data from client-side logic. The C lient reference implementation that accompanies this section also provides a side-by-side comparison of each approach to client-side data access. This documentation includes the following sections and topics that will help you to understand the key issues around client application development for SharePoint 2010: Overview of User Experience Approaches. This topic describes the different approaches you can take to building a rich user experience for SharePoint clients. It explains the core functionality behind each approach and describes how client-server communication works in each case. RIA Technologies: Benefits, Tradeoffs, and C onsiderations. This topic focuses on the use of Ajax and Silverlight to build SharePoint clients. It examines the advantages and disadvantages of each approach, and compares it to a traditional thin-client page model. The topic focuses on performance considerations, including initial load time, caching strategies, and responsiveness. Data Access for C lient Applications. This section provides detailed insights into the use of the client-side object model and the REST interface, and examines how you can optimize the performance of client applications when you use these data access mechanisms. What's Not Covered in This Documentation? Building user experiences for SharePoint could constitute a whole book in itself. This guidance focuses primarily on rich Internet applications (RIAs) and the underlying data access mechanisms that support these approaches. The following topics are out of scope: The Business C onnectivity Services (BC S) client runtime and Office client integration are not included. These features certainly introduce many new capabilities to SharePoint and Office, and really change the way you should view Office clients, allowing them to serve as a vehicle for extending line of business (LOB) applications. However the scope of the technology is quite broad, and consequently we were unable to fit it into this release. For a conceptual overview of the BC S client runtime, see Understanding Business C onnectivity Services and Microsoft Business C onnectivity Services Model. For examples of how to work with the BC S client runtime, see Business C onnectivity Services: How-tos and Walkthroughs and Business C onnectivity Services: Sample XML and C ode Examples. The majority of server-side approaches to user experience, including branding, master pages, delegate controls, publishing page layouts, and related concepts, are not included. These are all very important topics to SharePoint, but they are enhanced, not new, in this release. The scope of this topic is also very broad. We highlight some of the new server-side concepts for user experience such as Visual Web Parts, the ribbon, and dialogs, but only when the context requires it; thus, the coverage is not complete. No tutorial or in-depth coverage of Ajax, JavaScript, or Silverlight programming is included. We describe how these approaches apply to client-side SharePoint development, but the programming techniques for each technology are well documented elsewhere. Generated from CHM, not final book. Will be superseded in the future. Page 346
- 347. Overview of User Experience Approaches If you've worked with previous releases of SharePoint products and technologies, you're probably familiar with the traditional server-side controls approach to building a web-based user experience. Typically, your server-side toolbox would include master pages, application pages, themes, cascading style sheets (C SS), Web Parts, delegate controls, navigation controls and providers, and so on. SharePoint uses these resources to construct an ASP.NET page dynamically. This is then converted into HTML, packaged into an HTTP response, and sent to the web browser on the client. When you use this approach, all the logic in your application executes on the server. In order to update any of the content on the web page—to apply a filter or view the details associated with a list item, for example—the browser must send an HTTP GET request to the server. The server processes the request, regenerates the HTML, and sends a new HTTP response to the web browser on the client, which must render the entire page from scratch. This is known as a full-page postback. The process is illustrated by the following diagram. Web page with server-side controls While this approach provides a robust, functional approach to web application development, it can lead to a frustrating user experience. Interactivity is limited, as users must wait for the page to reload in response to any changes they make on the user interface. As a result, web developers increasingly rely on RIA technologies, such as Ajax, Silverlight, and Flash, to provide a more engaging user experience. These technologies allow you to execute some logic on the browser, rather than relying entirely on server-side execution. RIA technologies typically use asynchronous communication to send and receive data from the server without reloading the entire page. With an asynchronous programming model, the request communication is disconnected from the response mechanism. This results in more responsive applications and an increased ability to perform work in the background or in parallel. The result is web pages with multiple, relatively isolated regions that can be updated independently, and user interfaces that continue to respond to the user while data is being retrieved from the server. RIA technologies are not mutually exclusive. It's common to see SharePoint web pages that contain a mixture of server-side controls, Ajax-enabled regions, and Silverlight applications. In the remainder of this topic we provide an overview of the key approaches to building a client-side user experience for SharePoint applications. Note: Generated from CHM, not final book. Will be superseded in the future. Page 347
- 348. There is some debate within the technical community as to whether or not Ajax qualifies as an RIA technology. However, in this documentation we view Ajax as an RIA technology, as you can use it to provide a more interactive user experience through client-side logic. Ajax User Interface In the broadest sense of the term, Ajax refers to a set of technologies that allow you to retrieve data asynchronously from the server, and manipulate that data in the client browser, without disrupting the display or behavior of the current web page. Ajax was originally an acronym for Asynchronous JavaScript and XML, as Ajax applications would traditionally rely on the JavaScript XMLHttpRequest API to send asynchronous requests to a web server and to return the response to the calling script. The script could then use the response to alter the document object model (DOM) of the current page—for example, by updating the values in a table—without refreshing the entire page. However, Ajax has evolved to encompass a broader set of technologies in which scripts running in a browser window can use a variety of asynchronous communication channels to retrieve and manipulate data from a server. Today, the term Ajax has become synonymous with a web application style in which user interactions are managed predominantly by the browser, rather than the web server. The use of Ajax-style technologies in a web page is rarely an all-or-nothing approach. At one end of the scale, you might use a little bit of JavaScript to display dialog boxes, concatenate strings, or validate user input. You might add Ajax-enabled regions, which make use of partial postbacks to provide users with access to constantly changing data without reloading the entire page. Depending on your requirements and your target audience, you might move to a pure Ajax approach, in which the page is loaded once, all further interactivity takes place on the client, and all further client-server communication takes place asynchronously in the background. However, you will still need to design a server-side page to host your Ajax components, you'll typically still require Web Parts to host the Ajax-enabled content, and the browser will still need to retrieve your page from the server at least once. Your web page will typically use a combination of full-page postbacks and asynchronous communication to communicate with the server, depending on the extent to which you implement Ajax features of your user interface. This is illustrated by the following diagram. Web page with Ajax components Note: C lient-side data access mechanisms include the client-side object model (C SOM), the REST interface, and the Generated from CHM, not final book. Will be superseded in the future. Page 348
- 349. ASP.NET (ASMX) web services. These are described in Data Access for C lient Applications. Ajax functionality is supported by virtually all web browsers, with some minor differences in how scripting functionality is interpreted. Popular JavaScript frameworks such as jQuery help to manage the complexity of variations between browsers, and improved debugging support for JavaScript has made Ajax more accessible. The Ajax approach delivers a more responsive user experience for several reasons: It only loads part of the page at a time. This reduces the amount of data that is passed between the client and server, and largely eliminates entire page refreshes. Only data is sent between the server and the client on asynchronous requests; no HTML markup is included. It handles more events on the client without requiring a postback to the server. It caches information on the client between user interactions. This is more efficient than the full-page postback approach in which state information is typically passed between the client and the server on every request. SharePoint 2010 makes extensive use of Ajax principles in the out-of-the-box user interface, and client-side APIs in the 2010 release make it easier for you to use Ajax approaches when you develop SharePoint applications. Silverlight User Interface Silverlight is a development platform that enables you to create rich, engaging applications that run in web browsers and on other devices. Silverlight developers use a specialized, lightweight version of the Microsoft .NET Framework to create applications. Alongside the benefits of a familiar .NET development experience, Silverlight offers capabilities in areas such as graphics, animation, and multimedia that go well beyond what you can achieve with Ajax. Silverlight applications can run on a variety of platforms—in fact the latest release, Silverlight 4.0, allows you to build applications that can be taken offline and started from the desktop. However, in this documentation we focus on the use of Silverlight as an RIA technology. In the case of web pages, compiled Silverlight applications (XAP files) are hosted within HTML object elements, which can either be embedded in the page or generated dynamically through JavaScript. In the case of a SharePoint web page, Silverlight applications are typically hosted within a Web Part. SharePoint 2010 includes a Silverlight Web Part that is specifically designed for hosting XAPs within a SharePoint page. Just like web pages that contain Ajax-enabled components, the browser must use a traditional synchronous page load at least once in order to render the page and download associated resources, such as the Silverlight XAP and any JavaScript files. The Silverlight application can then use a variety of data access mechanisms to communicate asynchronously with the SharePoint server. This is illustrated by the following diagram. Web page with Silverlight components Generated from CHM, not final book. Will be superseded in the future. Page 349
- 350. Silverlight applications can also interact directly with Ajax elements on a page. It's increasingly common to use a combination of Silverlight applications, Ajax elements, and traditional server-side controls together to provide a full range of functionality for SharePoint users. Note: SharePoint 2010 includes a new SilverlightWebPart class. This provides a Web Part that you can use to host Silverlight applications within SharePoint web pages. Office Clients and Managed Code Clients Managed code clients are typically stand-alone applications that use the full capabilities of the .NET Framework. Managed code clients include Office clients, rich stand-alone clients built on Windows Presentation Foundation (WPF) and Windows Forms applications, and administrative applications built as console applications or Windows PowerShell extensions. A Silverlight application in offline mode could also be considered a rich client application. Rich clients usually provide a full UI and often integrate data and functionality from multiple sources into one composite application. These applications can use the SharePoint client APIs synchronously or asynchronously, in order to access and manipulate data on the SharePoint server. This is illustrated by the following diagram. Rich client application Generated from CHM, not final book. Will be superseded in the future. Page 350
- 351. Office client applications, such as Microsoft Word, Microsoft Excel®, Microsoft Access®, and SharePoint Workspace, have their own development framework in Visual Studio Tools for Office (VSTO) as well as more advanced out-of-the-box integration with SharePoint. Office client applications can also use the Business C onnectivity Services (BC S) client object model, which installs with Office and is licensed with SharePoint Enterprise. This capability enables Office clients to connect directly to external services through a Business Data C onnectivity (BDC ) model defined on the SharePoint server. Portions of the BDC model can be deployed to the client as part of an application, and the client application uses the model to connect directly to external services through the client BC S runtime. The client application can also use the Secure Store Service on the SharePoint server to authenticate to the external services that it accesses. The BC S client includes offline caching capabilities and an API for developers. The API is accessible outside of Office when the Office client is installed. However, its use is not supported outside the context of an Office client. Development for Office clients is a specialized area that differs substantially from other approaches to client-side development for SharePoint. For this reason, this documentation does not cover Office client development in any detail. Note: For more information on working with the BC S, see External Data in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 351
- 352. RIA Technologies: Benefits, Tradeoffs, and Considerations For the most part, developing Ajax or Silverlight components for the SharePoint platform is no different from developing Ajax or Silverlight components for any other platform. In this topic we look at some of the criteria that will help you decide whether Ajax, Silverlight, or traditional server-side controls best meet your requirements in a variety of scenarios. We also examine specific aspects of the SharePoint platform that can have a bearing on the suitability of each approach. Reach Considerations When you design and build a user experience, you need to think about whether all your end users have an environment that supports your chosen approach. Users in a tightly controlled environment may not be able to download or use the plug-ins required to support technologies such as Silverlight or Flash. Older web browsers, or browsers with high security settings, may prevent web pages from executing script. Older web browsers, in particular, may provide a more idiosyncratic interpretation of cascading style sheet (C SS) files and non-standardized HTML constructs. Essentially, web UI technologies present a tradeoff between reach and capability, as illustrated by the following diagram. Web UI technologies—reach versus capability C learly, plain HTML has the broadest reach of all web UI technologies. As such, the use of traditional server-side controls, which render web content as HTML, will have the most pervasive reach of all our approaches to user experience. Ajax-style programming has also gained broad acceptance, especially as browser implementations of JavaScript and C SS become increasingly consistent. Popular JavaScript libraries, such as the open source jQuery library, can provide a level of abstraction that isolates browser idiosyncrasies from user code. Just like plain HTML, JavaScript is interpreted by the web browser and does not require the user to download and install any additional plug-ins. Like other similar multimedia technologies, users must install a plug-in—the Silverlight runtime—in order to view Generated from CHM, not final book. Will be superseded in the future. Page 352
- 353. Silverlight content. The installed base of Silverlight has grown quickly, so you can increasingly depend on it already being installed on client machines. However, as described previously, users in some environments may be unable or unwilling to download and install a plug-in in order to view your content. A common solution is to provide alternative HTML content, within the object tag that hosts the Silverlight control, for users who have not installed the Silverlight runtime. This content can either point users to the download location for the Silverlight plug-in, or provide a plain HTML alternative rendering of the Silverlight content. If your applications increasingly rely on multimedia content, or you need to perform increasingly complex logic with large datasets, you may find that Silverlight is the right solution. Performance Considerations Performance is an important consideration when you design a web-based UI, as users quickly lose patience with web pages that are slow to load or slow to update. Each approach to user experience has benefits and drawbacks for particular aspects of performance. However, there are also various strategies—such as caching, delayed loading, predictive loading, and minifying—that you can use to mitigate some of the potential performance issues associated with each technology. The sections that follow examine these aspects of UI design in more detail. Initial Load Time In classic thin-client approaches, where all the logic executes on the server and the browser simply renders HTML, there is little difference between initial load time and subsequent load times. Since HTTP is a stateless protocol, each request to the server results in a response that includes the entire page. The biggest issue that hampers initial load time concerns resources such as C SS files, images, and JavaScript files that must be downloaded by the browser. These resources are typically cached by the browser on initial load and do not need to be reloaded for subsequent responses. In terms of browser loading and rendering, Ajax clients are broadly similar to thin clients, although they typically contain significantly more JavaScript that will slow the initial load time if not already cached by the browser. C ommon JavaScript libraries that are used by many applications, such as jQuery, are typically downloaded and cached once by the browser and do not need to be reloaded for different applications. Ajax clients will often retrieve data related to a page on first load, which can also impact initial load times. However, to some degree this is the price you pay for the additional functionality that Ajax provides, and subsequent user interactions will be significantly faster than those of a traditional thin client. A typical Ajax client has substantially more functionality on a single page than a traditional server-driven web page, and it therefore requires less frequent page loads. You can improve the initial load times for Ajax clients through careful management of your JavaScript resources. First of all, you need to decide whether to use inline script (JavaScript functions embedded into the HTML of your web page) or include a separate JavaScript file with your application. In most non-trivial solutions, you will want to include a JavaScript file. However, if you have a small amount of JavaScript—say less than 10KB—and you're not reusing JavaScript functions across controls or Web Parts, it may be preferable to use the inline scripting approach, especially if the JavaScript file will not be cached. Another important consideration is the number of JavaScript files in your application. Browsers can only open a limited number of connections to the web server at any one time. Historically, this limit was two connections, as mandated by the HTTP 1.1 specification, although more recent browser versions have relaxed this behavior and now support up to eight connections. However, a rich web page includes many resources, such as images, that require a download connection. When the connection limit to a domain is reached, resources will begin downloading sequentially. Having many JavaScript files will result in more concurrent connections, and potentially sequential downloads if a connection limit is reached, both of which can impact performance. By consolidating JavaScript functions that are frequently used together into a single file, you can minimize the impact of this limitation on your page load times. You can also reduce JavaScript load times by minifying your JavaScript files. Minifying compresses JavaScript files by removing all unnecessary characters, such as white space, without altering the functionality of the file. There are various open source tools available that you can use to minify JavaScript files, such as the Microsoft Ajax Minifier. You can dynamically minify and combine scripts in an HTTP handler and cache the results, or you can perform similar actions as part of a build process. If you use reusable JavaScript libraries in your Ajax clients, be sure to reference the minified versions of the libraries in your production code. For more information on these approaches, and more advanced techniques for improving load time—such as delayed loading or on-demand loading of script files—see Developing Web Apps: Building Responsive Modular Web Applications. Note: You can also minify C SS files. Silverlight applications are compiled into a XAP (pronounced zap) file that includes compiled code as well as other resources, such as XAML files and images. This file must be downloaded to the browser, parsed by the Silverlight Generated from CHM, not final book. Will be superseded in the future. Page 353
- 354. runtime, and loaded into memory. Not surprisingly, the load time corresponds to the size of the XAP file. While XAP files can be cached like other web resources, there is still a performance penalty on page load as the XAP file still needs to be parsed. As a result, initial load times are typically higher for Silverlight clients than for other client approaches. As with JavaScript, there are techniques you can use to minimize the initial load time for Silverlight clients. For example, you can split a solution into multiple XAP files, and you can delay the loading of some of the resources and assemblies. Caching JavaScript and Silverlight XAP Files One of the easiest ways to reduce the initial load time for Ajax and Silverlight clients is to enable caching of the related JavaScript and XAP files, both on the client browser and on the SharePoint Web front-end server. There are two main options for caching in a SharePoint environment. Put the Jav aScript or XAP files in a subfolder of the layouts folder in the SharePoint root. SharePoint Web front-end servers cache the contents of the layouts folder to reduce the time required to retrieve the content in response to client requests. When Internet Information Services (IIS) creates the _layouts virtual directory, it applies an expiration policy to the content within the folder. This means that client browsers can also cache content from the layouts folder. However, you cannot deploy files to the layouts folder—or any other folder on the server file system—from a sandboxed solution. Note: By default, IIS specifies that content in the _layouts virtual directory will expire after 365 days. This is configurable, but we do not recommend that you change this value. The preferred approach to retrieve JavaScript or XAP files that are subject to frequent change is to add query strings to the URLs you use to retrieve the files. Although the query strings themselves are ignored, adding a new query string to each request will prevent the browser from matching the requested URL to the cached resources. As a result, the browser will download the latest files from the server. Put the Jav aScript or XAP files in a SharePoint library, and enable binary large object (BLOB) caching. BLOB caching instructs SharePoint to cache BLOB content, such as JavaScript and XAP files, on the SharePoint Web front-end servers. It also enables client browsers to cache the content. If BLOB caching is not enabled, the HTTP header that returns the JavaScript or XAP resources to the client will instruct the browser not to cache the files. It does this by including a cache-control: priv ate directive and by setting an expiration time in the past. As a result, neither the client browser nor the web front-end server will cache the content, which instead will be retrieved from the content database on every request. BLOB caching is a SharePoint Server 2010 feature and must be enabled in the configuration files for the SharePoint web applications, so to some degree you are at the mercy of the farm administrator. For more information on BLOB caching, see Disk-Based C aching for Binary Large Objects. If you are creating a sandboxed solution, you must deploy your resources to a SharePoint library as you do not have access to the file system on the server. You may also have to manage without BLOB caching, depending on administrative policy and whether you are able to request changes. Note: C onsider deploying JavaScript and XAP files to the master page gallery for Internet-facing sites. The master page gallery is preconfigured to allow access by anonymous users. By deploying resources to this location, you avoid the need to manage permissions on a custom library containing your JavaScript and XAP files. You should aim to package, consolidate, and divide your JavaScript and XAP files to maximize the sharing of resources across controls, applications, and pages. That way, when one page has caused the browser to download and cache a particular resource, other pages can benefit from the cached content until it reaches its expiration time. In the case of Ajax clients, you can maximize browser caching of resources by referencing JavaScript library files in a central location. For example, large cloud providers, such as Microsoft's C ontent Delivery Network (C DN), host many publicly available JavaScript libraries. By referencing the libraries in these locations, you increase the chance that the file will already be cached on the browser from its use in other applications. When you work with Silverlight, you can use application library caching to improve load times on pages hosting multiple Silverlight applications and for subsequent visits to your web page. When you enable application library caching for a Silverlight project in Visual Studio, library assemblies (such as System.Xml.Linq.dll) are packaged separately from your application assemblies, which are included in the XAP file. Each library is packaged as a zip file—for example System.Xml.Linq.zip—in the output directory of your project. This approach allows client browsers to cache system libraries separately from your XAP files. As library assemblies such as these are often used by multiple Silverlight controls, application library caching can substantially reduce total download sizes. For example, in the C lient reference implementation, removing the shared resources reduced the size of the XAP file by over 97 percent, from 500KB to 11KB once SharePoint libraries were included. Visual Studio determines whether or not to separate out an individual assembly based on an external mapping file, which is unique to a particular assembly. The SharePoint client assemblies—Microsoft.SharePoint.C lient.Silverlight.dll and Microsoft.SharePoint.C lient.Silverlight.Runtime.dll—do not have an external mapping file. In order to separate Generated from CHM, not final book. Will be superseded in the future. Page 354
- 355. these assemblies from your XAP file, you need to add an external mapping file for each assembly to the C lientBin folder within the SharePoint root folder on your server file system. The naming convention for the external mapping file is the assembly name with an .extmap.xml extension, such as Microsoft.SharePoint.C lient.Silverlight.extmap.xml. The following example shows the external mapping file that instructs the compiler to separate out Microsoft.SharePoint.C lient.Silverlight.dll into a zip file if application library caching is configured for a project that uses the assembly. XML <?xml version="1.0"?> <manifest xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <assembly> <name>Microsoft.SharePoint.Client.Silverlight</name> <version>14.0.4762.1000</version> <publickeytoken>71e9bce111e9429c</publickeytoken> <relpath>Microsoft.SharePoint.Client.Silverlight.dll</relpath> <extension downloadUri="Microsoft.SharePoint.Client.Silverlight.zip" /> </assembly> </manifest> A similar file is also then defined for Microsoft.SharePoint.C lient.Silverlight.Runtime.dll. To use application library caching for a SharePoint Silverlight client, you would do the following: 1. C onfigure your Silverlight project to use application library caching. To do this, select Reduce XAP size by using application library caching on the properties page of your project. 2. Rebuild the application. Once you rebuild your solution, you will see zip files in the output directory for each system assembly. If you also added the external mapping files for the SharePoint client assemblies, you will see a zip file for those assemblies. You should also notice that the size of your XAP file has been reduced substantially. The application manifest embedded in the XAP file instructs the Silverlight runtime to download these assemblies separately. For example, the following code shows the application manifest contained in the C lient.C SOM.Silverlight.xap file, from the C lient reference implementation, after rebuilding the solution with application library caching turned on. XML <Deployment xmlns="http://schemas.microsoft.com/client/2007/deployment" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" EntryPointAssembly="Client.CSOM.Silverlight" EntryPointType="Client.CSOM.Silverlight.App" RuntimeVersion="4.0.50401.0"> <Deployment.Parts> <AssemblyPart x:Name="Client.CSOM.Silverlight" Source="Client.CSOM.Silverlight.dll" /> </Deployment.Parts> <Deployment.ExternalParts> <ExtensionPart Source="Microsoft.SharePoint.Client.Silverlight.zip" /> <ExtensionPart Source="Microsoft.SharePoint.Client.Silverlight.Runtime.zip" /> <ExtensionPart Source="System.ComponentModel.DataAnnotations.zip" /> <ExtensionPart Source="System.Data.Services.Client.zip" /> <ExtensionPart Source="System.Windows.Controls.Data.zip" /> <ExtensionPart Source="System.Windows.Controls.Data.Input.zip" /> <ExtensionPart Source="System.Windows.Data.zip" /> <ExtensionPart Source="System.Xml.Linq.zip" /> </Deployment.ExternalParts> </Deployment> Once this is completed, you will need to deploy these zip files alongside the XAP file to your SharePoint environment. The zip files and the XAP file must be in the same location, regardless of whether that location is a physical folder on the server or a document library. If you deploy all of the Silverlight applications on your site collection to the same library, then you only need to include a single zip file for a particular assembly, even though multiple Silverlight applications use the assembly. If BLOB caching is enabled, each zip file will only be downloaded once. This significantly reduces download times and bandwidth utilization. An alternative to deploying the zip files alongside the XAP files is to deploy the zip files to one central location. In this case, you must define the URL of this location in the external mapping file for each assembly, as illustrated by the following example. The extension element indicates the location of the zip file. Generated from CHM, not final book. Will be superseded in the future. Page 355
- 356. XML <?xml version="1.0"?> <manifest xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <assembly> <name>Microsoft.SharePoint.Client.Silverlight</name> <version>14.0.4762.1000</version> <publickeytoken>71e9bce111e9429c</publickeytoken> <relpath>Microsoft.SharePoint.Client.Silverlight.dll</relpath> <extension downloadUri="http://contoso/XAP/Microsoft.SharePoint.Client.Silverlight.zip" /> </assembly> </manifest> As a result, the application manifest will include a reference to the full URL from which to download the zip file. The following code shows the resulting application manifest file after we updated the external mapping file for the Microsoft.SharePoint.C lient.Silverlight assembly. As you can see, the assembly is now referenced by a fully qualified URL. XML <Deployment xmlns="http://schemas.microsoft.com/client/2007/deployment" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" EntryPointAssembly="Client.CSOM.Silverlight" EntryPointType="Client.CSOM.Silverlight.App" RuntimeVersion="4.0.50401.0"> <Deployment.Parts> <AssemblyPart x:Name="Client.CSOM.Silverlight" Source="Client.CSOM.Silverlight.dll" /> </Deployment.Parts> <Deployment.ExternalParts> <ExtensionPart Source="http://contoso/_layouts/XAP/Microsoft.SharePoint.Client.Silverlight.zip" /> <ExtensionPart Source="Microsoft.SharePoint.Client.Silverlight.Runtime.zip" /> <ExtensionPart Source="System.ComponentModel.DataAnnotations.zip" /> <ExtensionPart Source="System.Data.Services.Client.zip" /> <ExtensionPart Source="System.Windows.Controls.Data.zip" /> <ExtensionPart Source="System.Windows.Controls.Data.Input.zip" /> <ExtensionPart Source="System.Windows.Data.zip" /> <ExtensionPart Source="System.Xml.Linq.zip" /> </Deployment.ExternalParts> </Deployment> One of the drawbacks of this approach is that you must modify the external mapping files for the system assemblies, which by default are located at C :Program Files (x86)Microsoft SDKsSilverlightv4.0LibrariesC lient. Since these URLs are embedded in the application manifest files, you will likely need to rebuild your Silverlight applications for production environments. As such you would need to implement a policy for building XAPs for specific environments, or configure development and test environments to mimic production URLs. The advantage of this approach is that you can define a single download location for your entire organization. As a result, the assemblies are cached by browsers for all of the Silverlight applications built with application library caching within your organization. Note: For more information on application library caching, see How to: Use Application Library C aching on MSDN. Responsiveness Ajax and Silverlight clients offer many inherent benefits over traditional thin clients in the area of responsiveness. A thorough understanding of these benefits can help you to take maximum advantage and provide a slick, responsive user experience. Asynchronous Execution Model Ajax and Silverlight clients typically have a higher initial load cost compared to traditional thin client approaches. However, in most cases you will more than compensate for that load cost through enhanced UI responsiveness. Since the UI is controlled from the client, in many cases the client can react locally to user interaction without communicating with the server. When the client needs to send or retrieve information from the server, the communication takes place asynchronously and the UI remains responsive. The ability to build more capable UIs Generated from CHM, not final book. Will be superseded in the future. Page 356
- 357. that run on the client also means that you can include more functionality on a single page. This compensates for the slower initial page load time, as pages typically need to be loaded far less frequently. Local Processing Power In almost all web UI models, the operations that take the most time are those that require communication with the server. Both Ajax and Silverlight allow you to take advantage of client-side processing, which reduces the number of round-trips to the server. When communication with the server is required, the data exchange is restricted to only what is necessary for the operation. This contrasts with the traditional server controls approach, in which every request from the client results in the server building and resending the entire page—even if many areas of the page remain unchanged. This increases the load on the server, increases the volume of network traffic—the average page size is several orders of magnitude larger than the average asynchronous data request —and results in a somewhat disjointed user experience. If your application requires substantial computation on the client, such as calculations or the processing of many rows of data, Silverlight will generally outperform Ajax approaches. This is because in these circumstances JavaScript incurs a certain amount of interpretation overhead due to the untyped nature of the language. Client-side Data Caching RIA clients such as Ajax and Silverlight can maintain state information on the client. This contrasts with traditional thin client approaches, where state must be maintained on the server and tracked through cookies or posted back and forth with every request through view state. Data retrieved from the server can be retained in memory and reused across different operations. For example, suppose a manager must approve 20 orders once a day. With a thin client (server control) model, the manager navigates into an order, reviews the line items, and approves the order. Each time the manager approves an order, he or she is redirected back to the order list. The remaining orders are reloaded on the server, which rebuilds the page and sends it back to the browser. With an RIA approach, the orders are retrieved once and stored on the client. As the manager navigates into each order, the line item details are retrieved asynchronously from the server, and approvals are sent asynchronously back to the server. In this case the orders have only been retrieved once, and the client is far more responsive since it can cache the information in memory and avoid unnecessary round-trips to the server. Predictive Loading Predictive loading approaches anticipate the actions of a user to make the client seem even more responsive. Building on the previous example, you could assume that managers will work through approvals in the order in which they are listed in the UI. The client might then anticipate that the order which appears after the order being currently viewed will be viewed next. As such, the client could retrieve the details of the next order in advance, in order to avoid any delay in retrieving the information from the server. However, if the manager chooses to view a different order next, they will incur the usual delay while the data is retrieved asynchronously from the server. The disadvantage of this approach is that you are performing additional server-side processing that may not be used. As such, you should use this approach when you can predict the actions of the user to a fairly high degree of accuracy. For more details on these concepts, see patterns & practices Web C lient Developer Guidance. Security Considerations In traditional, server control-based user interfaces for SharePoint applications, security concerns were largely managed for you by the server environment. Authentication was managed by IIS (for Windows credentials) or by an ASP.NET authentication provider (for forms-based authentication). The SharePoint environment would then apply authorization rules to the authenticated credentials for each server resource. When you move to a client-based, RIA user interface, there are some additional aspects to managing security that you will need to consider. Authentication Each of the client-side programming models provided by SharePoint 2010 is underpinned by a secure web service. The JavaScript, Silverlight, and managed client object models use the client.svc Windows C ommunication Foundation (WC F) service under the covers. The REST interface is provided by the listdata.svc WC F service. Backward-compatible client-side access to various resources is provided by ASP.NET (ASMX) web services. Generated from CHM, not final book. Will be superseded in the future. Page 357
- 358. When you develop Ajax and Silverlight clients that run within a SharePoint web page, the client-side object model and the REST interface will by default inherit the security credentials that were used to authenticate the browser session. In this way, Ajax and Silverlight will support any mechanism with which you can authenticate a browser session, including Windows authentication, forms-based authentication, and claims-based authentication. When you use the managed client API for stand-alone clients, you can specify the authentication mode and other security details through the ClientContext instance. For example, the following code example configured the ClientContext instance to use forms-based authentication and specifies a user name and password. C# ClientContext context = new ClientContext("http://contoso/sites/manufacturing"); context.AuthenticationMode = ClientAuthenticationMode.FormsAuthentication; context.FormsAuthenticationLoginInfo = new FormsAuthenticationLoginInfo(myUsername, myPassword); Note: The ClientContext class is discussed in more detail in Data Access for C lient Applications. You can also use claims-based approaches to authentication from a stand-alone client, although this is more complex and is not within the scope of our guidance. For more information on security for the .NET managed client API, see Authentication in the Managed C lient Object Models on MSDN. For more information on using claims-based authentication with a stand-alone client, see the blog post Using the C lient Object Model with a C laims Based Auth Site in SharePoint 2010. When you access SharePoint ASP.NET web services that are secured with forms-based authentication from a Silverlight client, you must call the Authentication web service and provide your credentials. The Authentication web service returns a cookie, which you can supply to the other SharePoint web services in order to authenticate your requests. For more information, see Authentication Web Service on MSDN®. Cross-Domain Data Access and Client Access Policy Both Ajax and Silverlight clients are subject to certain restrictions and caveats when it comes to accessing data from a different domain. C ross-site scripting (XSS) attacks were one of the most prevalent threats to web applications, so modern browsers now prevent scripts from making calls across domain boundaries. As a result, Ajax clients have traditionally been unable to access resources on a different domain. Developers often worked around this limitation by including a proxy on the web server that retrieves data from external services. However, emerging standards allow script calls across domain boundaries if those calls are explicitly permitted by the server hosting the web page. This is based on the W3C draft specification C ross-Origin Resource Sharing (C ORS). The most recent versions of the major browsers support C ORS, although not in entirely consistent ways. Implementing C ORS is beyond the scope of this guidance. For more information, see AJAX - Introducing C ross-domain Request (XDR) on MSDN. In the case of Silverlight clients for SharePoint 2010, there are two key cross-domain data access scenarios that you need to consider: 1. When a Silverlight application on a SharePoint page needs to access data from an external (non-SharePoint) service on another domain. 2. When a Silverlight application on any page, SharePoint or otherwise, needs to access data from a SharePoint web application on another domain. Note: Silverlight considers different ports, different protocols, and different sub-domains to represent different domains. For example, https://services.contoso.com, http://services.constoso.com, http://www.constoso.com, and http://services.contoso.com:8080 are all considered different domains. In the first scenario, the fact that the Silverlight application is hosted on a SharePoint page is irrelevant. Silverlight looks for a client access policy file (clientaccesspolicy.xml) on the external domain to determine whether it is allowed cross-domain access to resources on that domain. The client access policy should be located at the root of the site you are attempting to access on the external domain. Silverlight can also use an Adobe Flash cross-domain policy file (crossdomain.xml) if the client access policy is not present. This scenario is illustrated by the following diagram. Cross-domain access to non-SharePoint resources Generated from CHM, not final book. Will be superseded in the future. Page 358
- 359. Essentially, the service owner modifies the client access policy to specify which domains are allowed cross-domain access to which resources. For more information, see Making a Service Available Across Domain Boundaries and HTTP C ommunication and Security with Silverlight on MSDN. The C lient.ExtService.Silverlight project in the client reference implementation also demonstrates how to use a client access policy to permit access to cross-domain resources from a Silverlight application. In the second scenario, a Silverlight application needs to access SharePoint data on a different domain. This could be a Silverlight application running in a standard web page, running as a stand-alone application, or running in a SharePoint web page from a different web application. In this case you need to take a different approach, as modifying the client access policy in a SharePoint environment is not supported. Instead, SharePoint 2010 provides a framework named Silverlight C ross-Domain Data Access, or Silverlight C DA, that allows farm administrators to manage access to resources from clients on other domains. This scenario is illustrated in the following diagram. Cross-domain access to SharePoint resources C onfiguring Silverlight C DA is beyond the scope of this guidance. However, you can find detailed guidance at Web Parts that Host External Applications Such As Silverlight on MSDN. For more information on cross-domain data access, see What's New: Silverlight Integration and C ross-Domain Data Access on MSDN. For more information on Silverlight security in general, see Silverlight Security, Silverlight Security Overview, and Security Guidance for Writing and Deploying Silverlight Applications. Generated from CHM, not final book. Will be superseded in the future. Page 359
- 360. Overcoming Sandbox Restrictions As described in Execution Models in SharePoint 2010, SharePoint 2010 restricts the functionality of solutions that are deployed to the sandbox environment within a site collection. One way to address the limitations of sandboxed solutions is to implement the restricted functionality in your client-side logic. Sandboxed solutions can include both Ajax and Silverlight components that run in the client browser. Scenarios in which you might choose to implement functionality in client logic include the following: When you need to access data from an external service. The sandbox environment does not permit server-side code to call external services. However, an Ajax component or a Silverlight application can call an external service and retrieve data directly from the client. When you need to access data across site collection boundaries. The sandbox environment does not allow you to access data from outside the site collection in which the solution is running. However, an Ajax component or a Silverlight application can use the client data access mechanisms to access data from any site collection where the user has sufficient permissions. When you need to access more advanced capabilities, such as the user profile service, that are not available with the sandbox environment. However, you can use the SharePoint ASP.NET Web Services to access these capabilities. When you access SharePoint data, each client-side data access mechanism is secured by the SharePoint environment. As such, users can only access resources on which they have the necessary permissions, and security is maintained. A more important consideration is the processing load that you place on the client. The sandbox environment prevents you from performing expensive, process-intensive operations in server-side code in order to maintain the performance of the server as a whole, so circumventing these safeguards by moving process-intensive operations to the client is likely to result in a poor user experience. For example, aggregation across site collection boundaries is an expensive operation and should be used judiciously from client-side code. In more complex scenarios, you can use Ajax and Silverlight to build composite client UIs that bridge SharePoint data and external data. For example, you might retrieve a list of statements of work from a SharePoint document library. When the user selects a statement of work in the user interface, an Ajax or Silverlight client can then retrieve information for that vendor from a vendor management system. In this way, the client is bridging the SharePoint environment and the external service to provide a composite data application. C learly, when you bridge services in this way you need to consider how to authenticate to each service. The C lient reference implementation demonstrates how to bridge services using Windows authentication. The use of other authentication techniques, such as claims-based authentication, is beyond the scope of this guidance. For an example of how to use claims-based authentication with Silverlight, see the Silverlight and Identity Hands-on Lab in the Identity Developer Training Kit. Generated from CHM, not final book. Will be superseded in the future. Page 360
- 361. Data Access for Client Applications In the previous version of SharePoint products and technologies, your options for accessing data from client applications were largely limited to the SharePoint ASP.NET Web services. The lack of a strongly-typed object model and the need to construct complex C ollaborative Application Markup Language (C AML) queries in order to perform simple data operations made the development of SharePoint client applications challenging and somewhat limited. SharePoint 2010 introduces several new data access mechanisms that make it easier to build rich Internet applications (RIAs) that consume and manipulate data stored in SharePoint. There are now three principal approaches to accessing SharePoint data from client applications: The client-side object model. The client-side object model (C SOM) consists of three separate APIs that provide a subset of the server-side object model for use in client applications. The EC MAScript object model is designed for use by JavaScript or JScript that runs in a Web page, the Silverlight client object model provides similar support for Silverlight applications, and the .NET managed client object model is designed for use in .NET client applications such as WPF solutions. The SharePoint Foundation REST interface. The SharePoint Foundation Representational State Transfer (REST) interface uses WC F Data Services (formerly ADO.NET Data Services) to expose SharePoint lists and list items as addressable resources that can be accessed through HTTP requests. In keeping with the standard for RESTful Web services, the REST interface maps read, create, update, and delete operations to GET, POST, PUT, and DELETE HTTP verbs respectively. The REST interface can be used by any application that can send and retrieve HTTP requests and responses. The ASP.NET Web Services. SharePoint 2010 continues to expose the ASMX Web services that were available in SharePoint 2007. Although these are likely to be less widely used with the advent of the C SOM and the REST interface, there are still some scenarios in which these Web services provide the only mechanism for client-side data access. For future compatibility, use C SOM and REST where possible. Note: In addition to these options, you can develop custom Windows C ommunication Foundation (WC F) services to expose SharePoint functionality that is unavailable through the existing access mechanisms. For more information about this approach, see WC F Services in SharePoint Foundation 2010 on MSDN. The product documentation for SharePoint 2010 includes extensive details about each of these approaches, together with examples and walkthroughs describing approaches to common client-side data access requirements. This documentation focuses on the merits and performance implications of each approach for different real-world scenarios, and it presents some guidance about how to maximize the efficiency of your data access operations in each case. Before you start, you need a broad awareness of the capabilities of each approach. The following table shows what you can do in terms of data access with the C SOM, the REST interface, and the ASP.NET Web services. CSOM REST interface Web serv ices List queries List join queries * External list queries View projections Request batching Synchronous operations (except EC MA) Asynchronous operations SharePoint Foundation object model access Access to SharePoint Server functionality (beyond SharePoint Foundation) Support non-Windows clients (EC MA only) Support strongly-typed LINQ queries (objects only, no list (with proxy, lists queries) only) Generated from CHM, not final book. Will be superseded in the future. Page 361
- 362. *The REST interface will perform implicit list joins, but only to satisfy where clause evaluation. This section includes the following topics: Using the C lient Object Model. This topic describes the capabilities, performance, and limitations of accessing data using the C SOM. Using the REST Interface. This topic describes the capabilities, performance, and limitations of accessing data using the SharePoint REST interface. Because the ASP.NET Web services exposed by SharePoint 2010 work in the same way as the previous release, they are not covered in detail here. Generally speaking, you should prefer the use of the C SOM or the REST interface over the ASP.NET Web services when they meet your needs. However, the Web services expose some advanced data, such as organization profiles, published links, search data, social data, and user profiles, which is unavailable through the C SOM or the REST interface. For more information about the ASP.NET Web services exposed by SharePoint 2010, see SharePoint 2010 Web Services on MSDN. Note: There are also scenarios in which you may want to use the client-side APIs to access data from server-side code. Although the C SOM, the REST interface, and the SharePoint ASP.NET Web services are all available when you develop server-side code, the use of these APIs in server-side code is only recommended for accessing data from another farm. Using the server-side object model is more efficient than using any of the client-side APIs. Generated from CHM, not final book. Will be superseded in the future. Page 362
- 363. Using the Client Object Model The client-side object model (C SOM) provides client-side applications with access to a subset of the SharePoint Foundation server object model, including core objects such as site collections, sites, lists, and list items. As described in Data Access for C lient Applications, the C SOM actually consists of three distinct APIs—the EC MAScript object model, the Silverlight client object model, and the .NET managed client object model—that target distinct client platforms. The EC MAScript object model and the Silverlight client object model provide a smaller subset of functionality. This is designed to enhance the user experience, because it minimize the time it takes Silverlight applications or JavaScript functions running in a Web page to load the files required for operation. The .NET managed client object model provides a larger subset of functionality for standalone client applications. However, these APIs provide a broadly similar developer experience and work in a similar way. Note: For more information about the C SOM, see Managed C lient Object Model on MSDN. For examples of how to perform common tasks with the C SOM, see C ommon Programming Tasks on MSDN. Of the three principal approaches to client-side data access, using the C SOM APIs is the only approach that provides the kind of hierarchical, strongly-typed representation of SharePoint objects, such as sites and Webs, that compares to server-side development. The C SOM is the only approach for any client-side data access scenarios beyond list queries. The C SOM allows you to query SharePoint lists by creating C AML queries. This is the most efficient way to query lists, although it requires that developers revert to creating C AML queries. Specific cases where you should favor the use of the C SOM include the following: You need to perform advanced list operations, such as complicated joins or paging. You can also perform joins through REST requests, although this is subject to various limitations. You need to manipulate SharePoint objects, such as sites or Webs. You need client-side access to other areas of SharePoint functionality, such as security. Query Efficiency and the Client Object Model Although the C SOM APIs mirror the server APIs in terms of functionality, the way C SOM actually works necessitates some changes to the way in which you approach your development tasks. The C SOM uses a set of specialized Windows C ommunication Foundation (WC F) services to communicate with the SharePoint server. Each API is optimized to work efficiently with remote clients and with the asynchronous loading model used by the Ajax and Silverlight frameworks. This section describes how these efficiency mechanisms work and how you can use them to best effect in your client-side SharePoint applications. Request Batching All the C SOM APIs include a C lientC ontext class that manages the interaction between client-side application code and the SharePoint server. Before you perform any operations in client-side code, you must instantiate a ClientContext object with the URL of a SharePoint site, as shown by the following code example. C# ClientContext clientContext = new ClientContext(webUrl); The clientContext instance provides programmatic access to the objects within your site, such as the current Web object, the parent Site object, and a Lists collection. C ommunication with the server occurs when you call the ExecuteQuery method, or the ExecuteQueryAsync method, on the ClientContext instance. C onsider the following example, which was adapted from the C lient Reference Implementation. Notice that the class names in the C SOM differ from their server-side counterparts in that they no longer have the SP prefix, like SPList or SPWeb—instead, they are simply List and Web. C# private void GetParts(string searchSku) { Parts.Clear(); List partsList = clientContext.Web.Lists.GetByTitle("Parts"); List inventoryLocationsList = clientContext.Web.Lists.GetByTitle("Inventory Locations"); CamlQuery camlQueryPartsList = new CamlQuery(); camlQueryPartsList.ViewXml = @"<View> <Query> Generated from CHM, not final book. Will be superseded in the future. Page 363
- 364. <Where> <BeginsWith> <FieldRef Name='SKU' /> <Value Type='Text'>" + searchSku + @"</Value> </BeginsWith> </Where> </Query> </View>"; CamlQuery camlQueryInvLocationList = new CamlQuery(); camlQueryInvLocationList.ViewXml = @"<View> <Query> <Where> <BeginsWith> <FieldRef Name='PartLookupSKU' /> <Value Type='Lookup'>" + searchSku + @"</Value> </BeginsWith> </Where> <OrderBy Override='TRUE'> <FieldRef Name='PartLookupSKU' /> </OrderBy> </Query> <ViewFields> <FieldRef Name='PartLookup' LookupId='TRUE' /> <FieldRef Name='PartLookupSKU' /> <FieldRef Name='PartLookupTitle' /> <FieldRef Name='PartLookupDescription' /> <FieldRef Name='BinNumber' /> <FieldRef Name='Quantity' /> </ViewFields> <ProjectedFields> <Field Name='PartLookupSKU' Type='Lookup' List='PartLookup' ShowField='SKU' /> <Field Name='PartLookupTitle' Type='Lookup' List='PartLookup' ShowField='Title' /> <Field Name='PartLookupDescription' Type='Lookup' List='PartLookup' ShowField='PartsDescription' /> </ProjectedFields> <Joins> <Join Type='LEFT' ListAlias='PartLookup'> <!--List Name: Parts--> <Eq> <FieldRef Name='PartLookup' RefType='ID' /> <FieldRef List='PartLookup' Name='ID' /> </Eq> </Join> </Joins> </View>"; partListItems = partsList.GetItems(camlQueryPartsList); inventoryLocationListItems = inventoryLocationsList.GetItems(camlQueryInvLocationList); clientContext.Load(partListItems); clientContext.Load(inventoryLocationListItems); clientContext.ExecuteQueryAsync(onQuerySucceeded, onQueryFailed); } The following actions take place within this code example: 1. The client-side code uses the ClientContext class to define a series of operations to execute against a SharePoint site. In this example, the operations are the following: a. Retrieve the Parts list. b. Retrieve the Inventory Locations list. Generated from CHM, not final book. Will be superseded in the future. Page 364
- 365. c. Build a query for the Parts list. d. Build a query for the Inventory Locations list. e. Execute the query against the Parts list. f. Execute the query against the Inventory Locations list. g. Load the Parts query results (which causes them to be returned to the client). h. Load the Inventory Locations query results. 2. The client code calls the ClientContext.ExecuteQueryAsync method. This instructs the C SOM to send a request containing all operations to the server. 3. The SharePoint server executes the series of operations in order and returns the results to the client. 4. The C SOM notifies the client-side code of the results by invoking the callback method associated with the onQuerySucceed delegate. This following illustration shows this process. Client object model request batching This request batching process helps to improve performance and reduce network traffic in two ways. First, fewer Web service calls occur between the client and the SharePoint server, which reduces the "chattiness" of the client-server interface. For example, you can perform two list queries in a single request. Second, as a set of operations occur on the server in a single request, the data being acted on doesn't need to be moved between the client and the server for the intermediate operations—only the list of operations and the final result set are passed between the client and the server. Request batching requires a different mindset when you create queries from client-side code. First, be aware that you do not have access to any results until you call ExecuteQueryAsync (or ExecuteQuery) and receive the call back with the results. If you need to implement conditional logic in the client-side code that can't be expressed in the command list that you send to the server, you will need to execute multiple queries. Second, you should aim to group your operations to minimize the number of service calls. This means you may need to think about how you sequence your logic in order to take full advantage of request batching. List Queries with CAML As you can see from the preceding code example, the C SOM supports querying list data using C AML. The C SOM allows you to submit any C AML queries that you could use with the SPQuery class, including the use of join statements and view projections. In fact, the C SOM is the only client-side data access mechanism that supports the use of joins with view projections that executes as a single list query. Note: The REST interface provides partial support for joins, when you specify implicit joins as part of the filter criteria. For more information, see Using the REST Interface. For an explanation of list joins and projections, see Data Access in SharePoint 2010. The ability to use join statements and view projections in list queries leads to more efficient queries and reduces the number of queries required. The following example, which was adapted from the C lient Reference Implementation, includes a C AML query that uses list joins and view projections. The query performs a left join between the Part Suppliers list and the Suppliers list. These lists are related by lookup columns, as shown in the following illustration. Entity-relationship diagram Generated from CHM, not final book. Will be superseded in the future. Page 365
- 366. The query then uses a view projection to select the supplier name, DUNS, and rating that match a specified part SKU from the join table. C# private void GetPartSuppliers() { if (currentItem != null) { List partSuppliersList = clientContext.Web.Lists.GetByTitle("Part Suppliers"); CamlQuery camlQuery = new CamlQuery(); camlQuery.ViewXml = @"<View> <Query> <Where> <Eq> <FieldRef Name='PartLookup' LookupId='TRUE' /> <Value Type='Lookup'>" + currentItem.Part.Id + @"</Value> </Eq> </Where> </Query> <ViewFields> <FieldRef Name='SupplierLookupTitle' /> <FieldRef Name='SupplierLookupDUNS' /> Generated from CHM, not final book. Will be superseded in the future. Page 366
- 367. <FieldRef Name='SupplierLookupRating' /> </ViewFields> <ProjectedFields> <Field Name='SupplierLookupTitle' Type='Lookup' List='SupplierLookup' ShowField='Title' /> <Field Name='SupplierLookupDUNS' Type='Lookup' List='SupplierLookup' ShowField='DUNS' /> <Field Name='SupplierLookupRating' Type='Lookup' List='SupplierLookup' ShowField='Rating' /> </ProjectedFields> <Joins> <Join Type='LEFT' ListAlias='SupplierLookup'> <!--List Name: Suppliers--> <Eq> <FieldRef Name='SupplierLookup' RefType='ID' /> <FieldRef List='SupplierLookup' Name='ID' /> </Eq> </Join> </Joins> </View>"; partSuppliersListItems = partSuppliersList.GetItems(camlQuery); clientContext.Load(partSuppliersListItems); //Get Supplier Data clientContext.ExecuteQueryAsync(onPartSupplierQuerySucceeded, onQueryFailed); } } In this example, the use of a list join dramatically improves the efficiency of the query and reduces network traffic. Without the list join, you would need to issue more queries and perform the join logic in your application code. The use of a view projection reduces the amount of data returned by the query, because it returns only a subset of field values that are relevant to your requirements. In the case of client-side data access, the benefits of this approach are even more pronounced. The ability to join lists in client-side data queries reduces the load on the server, reduces the number of round trips required between the client and the server, and reduces the overall amount of data transmitted between the client and the server. The C SOM does not provide a mechanism for querying data across multiple lists that are not associated by a lookup field. In other words, there is no client-side functional equivalent of the SPSiteDataQuery class. If you need to perform a cross-list query from client-side code, consider creating a list view on the server that performs the list aggregation. You can then query the aggregated data from your client-side code. Using LINQ for Objects When you use the C SOM, you can write LINQ queries against client-side objects, such as lists and Webs, and then use the ClientContext class to submit these queries to the server. It's important to understand that when you take this approach, you are using LINQ to Objects to query SharePoint objects, not LINQ to SharePoint. This means that your LINQ expressions are not converted to C AML and you will not see the performance benefits that are associated with C AML conversion. Note: The LINQ to SharePoint provider is not supported by any of the client-side data access mechanisms. Submitting a LINQ to Objects expression to the server reduces network traffic between the client and the server and alleviates some of the processing burden on the client platform. This is because you use the LINQ expression to narrow down the objects returned through server-side processing, instead of retrieving all objects in a collection, such as all Webs on a site and iterating through the collection on the client. LINQ to Objects makes it easy to specify fairly complex criteria with which to narrow down your result set. For example, you could use the following code to retrieve all non-hidden lists that have been created since March 20, 2010. C# private IEnumerable<List> newLists; var dt = new DateTime(2010, 3, 20); var query = from list in clientContext.Web.Lists Generated from CHM, not final book. Will be superseded in the future. Page 367
- 368. where list.Created > dt && list.Hidden == false select list; newLists = clientContext.LoadQuery(query); clientContext.ExecuteQueryAsync(onPartQuerySucceeded, onPartQueryFailed); In-Place Load and Queryable Load The client object model provides two different mechanisms for data retrieval—in-place load and queryable load. In-place load. This loads an entire collection into the client context. To perform an in-place load, you use the ClientContext.Load method. Queryable load. This returns an enumerable collection of results. To perform a queryable load, you use the ClientContext.LoadQuery method. For example, the following code uses an in-place load to load the collection of lists in the context site into the client context object. C# clientContext.Load(clientContext.Web.Lists); clientContext.ExecuteQueryAsync(onQuerySucceeded, onQueryFailed); After executing the query, you can access the list collection through the clientContext.Web.Lists property. When you perform an in-place load, the client context manages object identity for you. If you modify a setting such as the title of a list, and then you perform a second query that loads the same list, the client context understands that the returned items refer to the same list and it preserves the changes. The following code uses an equivalent queryable load to load the collection of lists in the context site. C# private IEnumerable<List> allLists; var query = from list in clientContext.WebLists select list; this.allLists = clientContext.LoadQuery(query); clientContext.ExecuteQueryAsync(onQuerySucceeded, on QueryFailed); When you use a queryable load, you are not loading items into the client context. Instead, you are loading items into a results array—in this case, the allLists field. In this case, object identity is not managed by the client context. If you were to repeat the query, the client context would simply repopulate the allLists field from server-side data and would overwrite any changes you had made on the client in the meantime. In terms of performance, there are no advantages or disadvantages to either approach. Because you can only use an in-place load to load one collection of objects at a time, there are circumstances in which you may want to use a queryable load to simultaneously load an alternative view of the data on your site. For example, suppose you would like to add the completion date for every project within your organization into all the calendars on your SharePoint site. The projects are distributed across several custom lists. In this scenario, you would use the in-place load for the collection of calendar lists, because these are the objects that you want to update. You would use the queryable load for the collection of project lists, because these will not be updated. Note: For more information about using the C SOM to load object collections and query lists, see Data Retrieval Overview on MSDN. Synchronous and Asynchronous Operations As described earlier in this topic, the C SOM batches your client-side operations and sends them to the server for execution. The C SOM provides both a synchronous model and an asynchronous model for invoking this server-side execution. If you use the .NET managed client API or the Silverlight client API, you can use either approach. If you use the EC MAScript API, you must use the asynchronous approach. This prevents service calls from causing the Web browser to block user interaction for the duration of the call. For example, suppose you are using the .NET managed client API or the Silverlight client API to retrieve data from the server: If you call the ClientContext.ExecuteQuery method, your operation will be invoked synchronously. The Generated from CHM, not final book. Will be superseded in the future. Page 368
- 369. thread that executes your code will wait for the server to respond before continuing. If you call the ClientContext.ExecuteQueryAsync method, your operation will be invoked asynchronously. In this case, you specify callback methods to handle the server response, and the current thread remains unblocked. Although the Silverlight client API supports the synchronous ExecuteQuery method, in most cases you will want to use ExecuteQueryAsync to submit your operation set. The following example, taken from the C lient Reference Implementation, illustrates how you can use the ExecuteQueryAsync method with the Silverlight client API. The PartSearchButton_Click method executes when the user clicks a button in the Silverlight application. C# private void PartSearchButton_Click(object sender, RoutedEventArgs e) { bindingViewsModels.Clear(); List partsList = clientContext.Web.Lists.GetByTitle("Parts"); CamlQuery camlQueryPartsList = new CamlQuery(); camlQueryPartsList.ViewXml = @" <View> <Query> <Where> <BeginsWith> <FieldRef Name='SKU' /> <Value Type='Text'>" + PartSkuTextBox.Text + @"</Value> </BeginsWith> </Where> </Query> </View>"; partListItems = partsList.GetItems(camlQueryPartsList); clientContext.Load(partListItems); clientContext.ExecuteQueryAsync(onQuerySucceeded, onQueryFailed); } The ExecuteQueryAsync method accepts two arguments—a delegate for a method that is called if the server-side operation succeeds and a delegate for a method that is called if the server-side operation fails. If the operation is successful, the onQuerySucceeded method is called. C# private void onQuerySucceeded(object sender, ClientRequestSucceededEventArgs args) { this.Dispatcher.BeginInvoke(DisplayParts); } As you can see, this method also makes an asynchronous method call. The Dispatcher.BeginInv oke method invokes the DisplayParts method on the user interface (UI) thread. This is a mandatory approach when you work with Silverlight, because you must use the UI thread to execute logic that updates the UI. The DisplayParts method simply binds the query results to the appropriate UI controls. The following illustration shows this overall process. Asynchronous execution with the Silverlight client API Generated from CHM, not final book. Will be superseded in the future. Page 369
- 370. In the previous example, what would happen if you called ExecuteQuery instead of ExecuteQueryAsync? Silverlight would throw an InvalidOperationException with the following message: The method or property that is called may block the UI thread and it is not allowed. Please use background thread to invoke the method or property, for example, using System.Threading.ThreadPool.QueueUserWorkItem method to invoke the method or property. In other words, Silverlight will not allow you to block the UI thread. To avoid this exception, you would need to execute the query on a background thread, as shown in the following code example. C# private void PartSearchButton_Click(object sender, RoutedEventArgs e) { bindingViewsModels.Clear(); List partsList = clientContext.Web.Lists.GetByTitle("Parts"); List inventoryLocationsList = clientContext.Web.Lists.GetByTitle("Inventory Locations"); CamlQuery camlQueryPartsList = new CamlQuery(); camlQueryPartsList.ViewXml = @" <View> <Query> <Where> <BeginsWith> <FieldRef Name='SKU' /> <Value Type='Text'>" + PartSkuTextBox.Text + @"</Value> </BeginsWith> </Where> </Query> </View>"; partListItems = partsList.GetItems(camlQueryPartsList); clientContext.Load(partListItems); System.Threading.ThreadPool.QueueUserWorkItem( new WaitCallback(ThreadCallback), clientContext); Generated from CHM, not final book. Will be superseded in the future. Page 370
- 371. } private void ThreadCallback(object s) { var context = (ClientContext)s; context.ExecuteQuery(); this.Dispatcher.BeginInvoke(DisplayParts); } In other words, if you don't use the ExecuteQueryAsync method, you must manually implement the asynchronous logic. Both methods are functionally correct. However, the ExecuteQueryAsync method makes your code easier to understand and is preferred from a stylistic perspective. The ExecuteQuery method is useful in applications where a synchronous execution model is appropriate, such as a command-line application or a PowerShell extension. Accessing Binary Data In some cases, you may want to either upload or download binary files, such as images or documents, from your Rich Interactive Application (RIA) or managed client. You can use the C SOM to access binary data like documents; however, there are varying levels of support, depending on the C SOM API that you use. The managed version of the C SOM supports both binary file upload and download using F ile.OpenBinaryDirect and F ile.SaveBinaryDirect. The following example shows how to retrieve and save a picture using these APIs from a Windows Presentation Foundation (WPF) client. In this case, the method DisplayPix retrieves all the items in the Pix picture library and displays them to a WPF control in the call to AddPix. Sav ePix saves the file stream provided as an image to the Pix library, using the file name for the title. C# private void DisplayPix() { List pixList = clientContext.Web.Lists.GetByTitle("Pix"); CamlQuery camlQuery = new CamlQuery(); camlQuery.ViewXml = "<View/>"; pictureItems = pixList.GetItems(camlQuery); clientContext.Load(pictureItems); clientContext.ExecuteQuery(); foreach (ListItem pictureItem in pictureItems) { string fileRef = pictureItem["FileRef"].ToString(); FileInformation fileInfo = File.OpenBinaryDirect(clientContext, fileRef); AddPix(fileInfo.Stream); } } private void SavePix(string filename, Stream stream) { string url = "/sites/sharepointlist/Pix/" + filename; File.SaveBinaryDirect(clientContext, url, stream, true); } For a detailed example of using this API with the managed C LOM, see Using the SharePoint Foundation 2010 Managed C lient Object Model with the Open XML SDK 2.0 on MSDN. The Silverlight C SOM supports opening binary files from SharePoint with F ile.OpenBinaryDirect using the same syntax as the managed C SOM but does not support saving binary files. The European C omputer Manufacturers Association (EC MA) script (JavaScript) C SOM does not support either saving or reading binary files from SharePoint. Generated from CHM, not final book. Will be superseded in the future. Page 371
- 372. Using the REST Interface The SharePoint 2010 Representational State Transfer (REST) interface is a WC F Data Service that allows you to use construct HTTP requests to query SharePoint list data. Like all RESTful Web services, the SharePoint REST interface maps HTTP verbs to data operations, as shown in the following table. HTTP v erb Data operation GET Retrieve POST C reate PUT Update (update all fields and use default values for any undefined fields) DELETE Delete MERGE Update (update only the fields that are specified and changed from current version) Note: In practice, many firewalls and other network intermediaries block HTTP verbs other than GET and POST. To work around this issue, WC F Data Services (and the OData standard) support a technique known as "verb tunneling." In this technique, PUT, DELETE, and MERGE requests are submitted as a POST request, and an X-HTTP-Method header specifies the actual verb that the recipient should apply to the request. For more information, see X-HTTP-Method on MSDN and OData: Operations (the Method Tunneling through POST section) on the OData Web site. A RESTful service models data entities, in this case SharePoint lists, as HTTP resources that can be addressed by a URL. You can append query strings to the URLs in order to specify filter criteria or query logic. The following examples show some URLs that correspond to simple REST operations. http://localhost/_vti_bin/listdata.svc/Parts The preceding URL returns the contents of the Parts list in XML format as an Atom feed. http://localhost/_vti_bin/listdata.svc/Parts(3) The preceding URL returns the Parts list item with an ID value of 3 as an Atom feed. http://localhost/_vti_bin/listdata.svc/Parts?$orderby=Name The preceding URL returns the Parts list as an Atom feed, ordered by the Name field. However, you don't need to manually construct HTTP requests in order to use the SharePoint REST interface. When you use Visual Studio 2010 to create a SharePoint client application, Visual Studio will generate a WC F Data Services Framework service proxy when you add a reference to the service. The service proxy provides strongly-typed entity classes and enables you to use LINQ expressions to build queries. Behind the scenes, the service proxy manages the details of building and submitting requests to the service. The SharePoint REST interface is based on the REST-based Open Data protocol (OData) for Web-based data services, which extends the Atom and AtomPub syndication formats to exchange XML data over HTTP. Because OData is a platform-independent open standard, the SharePoint REST interface is a great way to access SharePoint list data from platforms on which the C SOM may be unavailable to you, such as from non-Windows– based operating systems. However, the REST interface only provides access to list data—if you need to manipulate other data on your SharePoint site, you will need to use the C SOM. The REST implementation can also return the output in JavaScript Object Notation (JSON) format as an alternative to an ATOM feed. JSON is a compact representation of the returned results that can be easily parsed by JavaScript clients. Note: For background information about Windows C ommunication Foundation (WC F)–based REST services, see Overview of REST in WC F on MSDN. For product documentation for the SharePoint REST interface, see SharePoint Foundation REST Interface on MSDN. For more information about creating a service proxy for the REST interface, see Query SharePoint Foundation with ADO.NET Data Services on MSDN. For more information about OData, Atom, and REST, see Open Data Protocol by Example on MSDN and the Open Data Protocol Web Generated from CHM, not final book. Will be superseded in the future. Page 372
- 373. site. ADO.NET Data Services and WC F Data Services are the same thing—WC F Data Services is now the official name. Using the Service Proxy The WC F Data Services service proxy for the SharePoint REST interface includes classes that provide strongly-typed representations of the lists and content types in your SharePoint site. At the top level in the service proxy object model, a data context class that inherits from DataServiceC ontext provides the starting point for all your service calls. In this way, it performs a similar role to the data context class that you use with the LINQ to SharePoint provider. When you want to perform a data operation using the REST interface, your first step is always to instantiate the data context class to the WC F service endpoint for your SharePoint site. For example, in the C lient Reference Implementation, the data context class is named PartsDataContext. C# PartsDataContext context = new PartsDataContext( new Uri("http://localhost/sites/sharepointlist/_vti_bin/listdata.svc")); The data context class allows you to specify contextual information for the operations, such as user credentials, and it provides methods that you can use to build and execute REST queries. Your code runs in a browser—using either JavaScript or Silverlight—the calls to SharePoint will use the security context already established by the browser session. You can use the LINQ query syntax to build query expressions. For example, the following method, which was taken from the C lient Reference Implementation, retrieves parts that start with the SKU search string. C# var partsQuery = (DataServiceQuery<PartsItem>) context.Parts.Where(p => p.SKU.StartsWith(SearchSku)) .Select(p => new PartsItem { Title = p.Title, SKU = p.SKU, Id = p.Id, Description = p.Description }); // Execute query. query.BeginExecute(DisplayParts, query); The preceding example demonstrates various key points of submitting queries to the REST interface by using the service proxy: It creates a LINQ expression from the data context object. The LINQ expression returns a query in the form of a DataServiceQuery<TElement> instance. This is a WC F Data Services class that represents a query request to a service, where the query returns a collection of TElement instances. The DataServiceQuery<TElement> class implements the IQueryable interface, which allows you to use the LINQ extension methods provided by the Queryable class to query the result set. In the preceding example, TElement is PartsItem. The DataServiceQuery.BeginExecute method is used to send the query to the REST service asynchronously, passing in the callback delegate and the query object as arguments. The results of the query in partsQuery are not available until the callback delegate, DisplayParts, is invoked. The proxy generates a REST statement from the LINQ expression and submits it to the REST service, as shown here. http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/Parts() ?$filter=startswith(SKU,'sku') &$select=Title,SKU,Id,Description Note: You can also use the CreateQuery method to create the query object explicitly from the data context. In the previous example, where a LINQ statement was specified without calling CreateQuery, the WC F Data Services proxy created the query object implicitly when the results of the LINQ statement were cast to a DataServiceQuery<PartsItem> instance. For example, the following statement is functionally equivalent to the previous code example: context.CreateQuery<PartsItem>("Parts").Where(p Generated from CHM, not final book. Will be superseded in the future. Page 373
- 374. => p.SKU.StartsWith(SearchSku)).Select(p => new PartsItem { Title = p.Title, SKU = p.SKU, Id = p.Id, Description = p.Description }); In general, the implicit approach is preferred for readability and simplicity. The callback method iterates through the query results and adds each item to the Parts observable collection. The Parts collection is bound to a UI control that renders the results in a grid. Because this is a Silverlight application, you must use the Dispatcher.BeginInv oke method to execute the data binding logic asynchronously on the UI thread. C# Dispatcher.BeginInvoke( () => { Parts.Clear(); DataServiceQuery<PartsItem> query = (DataServiceQuery<PartsItem>) result.AsyncState; var partResults = query.EndExecute(result); foreach (var part in partResults) { Parts.Add(part); } }); Although the queries themselves will vary, the pattern of use remains broadly the same for all REST interface queries. How Does the REST Interface Work? When you create a WC F Data Services service proxy for the REST interface, you can use it to send a query to the REST interface in one of three ways: You can use the data context class to create a DataServiceQuery<TElement> instance, as seen in the preceding code examples. When you use this approach, you submit a LINQ expression to the service proxy. The service proxy converts the LINQ expression into a URL-based REST request and submits it to the REST interface. You can use view projection, in which case the DataServiceQuery<TElement> is created implicitly. This approach is described in more detail in the next section. You can use the data context class to submit a URL-based REST request directly, as shown by the following code example. C# context.Execute<PartsItem>(new uri("http://contoso/_vti_bin/listdata.svc/Parts() ?$filter=startswith(SKU,'Sku2') &$select=Title,SKU,Id,Description")); The LINQ expression used on the client is specific to the WC F Data Services proxy, which converts the LINQ expression into a REST statement. On the SharePoint server, the REST service implementation translates the REST statement into a LINQ to SharePoint expression. This translation process is not visible to the developer. The important thing to note is that the LINQ expressions you submit to the service proxy on the client are completely independent of the LINQ to SharePoint expressions that the REST service implementation generates in order to fulfill the request. The LINQ to SharePoint provider converts the server-generated LINQ expressions into C AML, and then it executes the C AML queries against your SharePoint lists. The REST interface returns the results to the service proxy in JSON format or as an Atom feed, using the OData protocol. The service proxy then converts the response into strongly-typed entity instances and returns the results to the caller. The following illustration shows this process. The SharePoint REST interface Generated from CHM, not final book. Will be superseded in the future. Page 374
- 375. It can be instructive to see how LINQ expressions are translated into REST queries, and how these REST queries translate into the HTTP requests and responses that are exchanged between the client and the server. Using the preceding LINQ expression as an example, the process is as follows: 1. The proxy forms a REST query from the LINQ expression. http://localhost/sites/sharepointlist/_vti_bin/listdata.svc/Parts() ?$filter=startswith(SKU,'sku') &$select=Title,SKU,Id,Description 2. The proxy submits the REST query to the server as an HTTP GET request. HTTP Request GET http://localhost/sites/sharepointlist/_vti_bin/listdata.svc/Parts()?$filter=startswith(SKU, 'sku1')&$select=Title,SKU,Id,Description HTTP/1.1 Accept: application/atom+xml,application/xml Accept-Language: en-US Referer: file:///C:/spg3/Trunk/Source/Client/Client.REST/Client.REST.Silverlight/Bin/Debug/Client.RE ST.Silverlight.xap Accept-Encoding: identity DataServiceVersion: 2.0;NetFx MaxDataServiceVersion: 2.0;NetFx User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; Generated from CHM, not final book. Will be superseded in the future. Page 375
- 376. .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; MS-RTC LM 8; .NET4.0C; .NET4.0E) Host: contoso Connection: Keep-Alive 3. The server responds with an OData-formatted result set. (The HTTP headers have been omitted for brevity.) HTTP Response <?xml version="1.0" encoding="utf-8" standalone="yes"?> <feed xml:base="http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/" xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices" xmlns:m= "http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns="http://www.w3.org/2005/Atom"> <title type="text">Parts</title> <id>http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/Parts</id> <updated>2010-05-30T14:20:47Z</updated> <link rel="self" title="Parts" href="Parts" /> <entry m:ETag="W/"2""> <id>http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/Parts(2) </id> <title type="text">SHAFT - PUMP 1</title> <updated>2010-05-21T14:06:12-04:00</updated> <author> <name /> </author> <link rel="edit" title="PartsItem" href="Parts(2)" /> <category term="Microsoft.SharePoint.DataService.PartsItem" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" /> <content type="application/xml"> <m:properties> <d:Title>SHAFT - PUMP 1</d:Title> <d:SKU>SKU1</d:SKU> <d:Description m:null="true" /> <d:Id m:type="Edm.Int32">2</d:Id> </m:properties> </content> </entry> </feed> 4. The WC F Data Services proxy invokes the DisplayParts delegate and provides the results from the request as a strongly-typed collection of PartsItem instances. Query Efficiency with the REST Interface In order to understand the performance implications of using the REST interface, you need to understand what happens when you request data from the service: 1. You submit a LINQ expression to the service proxy. 2. The service proxy converts your LINQ expression into a URL-based REST request, and then submits the request to the REST interface on the server. 3. The REST interface converts the REST request into a LINQ to SharePoint expression. 4. The LINQ to SharePoint provider converts the LINQ expression into a C AML query. Joins You have some control over whether the REST interface generates LINQ expressions with efficient syntax. You can gain an insight into the performance of REST-based queries by understanding how some specific REST constructs are implemented by the service. The REST interface does not support explicit list joins. You can use the Expand method to navigate from one entity to a related entity. Although this appears similar to a join, it actually results in the execution of additional list queries on the server. If required, the REST provider performs an implicit join to satisfy the where clause. However, for each item in the result set, the Expand method causes an additional list query to retrieve the related entity instance that corresponds to the value in a lookup column. For example, consider the following query that retrieves a list of inventory locations ordered by Part.SKU. Generated from CHM, not final book. Will be superseded in the future. Page 376
- 377. C# var query = (DataServiceQuery<InventoryLocationsItem>) context.InventoryLocations .Expand("Part") .Where(p => p.Part.SKU.StartsWith(SearchSku)) .OrderBy(p => p.Part.SKU); The Expand method in our LINQ query is translated to an &expand="Part" query string in the REST request URL, as shown here. http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations() ?$filter=startswith(Part/SKU,'sku') &$orderby=Part/SKU &$expand=Part In this case, the following actions take place in order to execute the query on the server: 1. A list join is performed between the Inventory Locations list and the Parts list, in order to satisfy the where clause match on the part SKU. From the REST statement, the implicit join occurs because Part/SKU in the startswith statement follows a lookup field relationship. 2. The inventory location items are ordered by part SKU. 3. For each inventory item in the result set, a query is executed on the server to retrieve the related part to satisfy the expand clause. 4. The results are formatted using the OData protocol and returned to the caller. As you can see, this operation is going to be less efficient than submitting a C AML query with a join predicate where all values can be retrieved in a single list query. However, the C SOM is the only data access mechanism that supports explicit joins. The C SOM allows you to submit a C AML query that specifies a list join and a view projection directly from your client-side logic. Projections The REST interface supports view projections. As described in Data Access in SharePoint 2010, view projections improve query efficiency by limiting the field values returned to only those fields that are of interest. For example, the following query uses a view projection to select parts, based on a partial part SKU match. C# context.Parts.Where(p => p.SKU.StartsWith(SearchSku)) .Select(p => new PartsItem { Title = p.Title, SKU = p.SKU, Id = p.Id, Description = p.Description }); The service proxy translates this query into the following REST request URL, and then it parses the response feed into a collection of PartsItem instances. http://contoso/_vti_bin/listdata.svc/Parts() ?$filter=startswith(SKU,'SKU2') &$select=Title,SKU,Id,Description You can also perform query projections explicitly on the query object. This can be useful as a concise way to query multiple related entities. C# var query = (DataServiceQuery<InventoryLocationsItem>)context. CreateQuery<InventoryLocationsItem>("InventoryLocations") .Expand("Part") .AddQueryOption("$select", "BinNumber,Quantity,Title,Id,PartId,Part/SKU,Part/Title") .Where(p => p.Part.SKU.StartsWith(SearchSku)).OrderBy(p => p.Part.SKU); In this case, only the BinNumber, Quantity, Title, ID, and PartId values are retrieved from each inventory location item, and only SKU and Title are retrieved from each part item. If you use view projections, you need to be aware that the result set will include null values for the fields that you have omitted. For example, if you Generated from CHM, not final book. Will be superseded in the future. Page 377
- 378. attempt to access inv entoryItem.Part.Description from a returned result, the value will always be null because your query excluded the Part.Description property. The expression results in the following REST query. http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations() ?$filter=startswith(Part/SKU,'sku') &$orderby=Part/SKU &$expand=Part &$select=BinNumber,Quantity,Title,Id,PartId,Part/SKU,Part/Title In addition to projecting fields from related entities onto a target entity—such as projecting Part fields onto an Inventory Location entity, as illustrated in the preceding example—you can also create a new view entity that combines the fields of interest. The following query populates a PartInv View instance that contains fields from the Inventory Locations list and the Parts list. C# var query = (DataServiceQuery<PartInvView>)context.InventoryLocations .Where(p => p.Part.SKU.StartsWith(SearchSku)) .OrderBy(p => p.Part.SKU) .Select((i) => new PartInvView { BinNumber = i.BinNumber, Quantity=i.Quantity, InvTitle=i.Title, InvId=i.Id, PartId=i.PartId, SKU=i.Part.SKU, PartTitle=i.Part.Title }); This projection produces the same REST query as the previous example. The only difference is that the service proxy will use the results to populate a collection of PartInv View instances, instead of a collection of Inv entoryLocationsItem instances. http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations() ?$filter=startswith(Part/SKU,'sku') &$orderby=Part/SKU &$expand=Part &$select=BinNumber,Quantity,Title,Id,PartId,Part/SKU,Part/Title You should consider using view projections whenever you are retrieving lists of items, in order to reduce network traffic and improve query efficiency. Concurrency Management By default, the REST implementation supports optimistic concurrency. This means that no locks are placed on the underlying database tables between the time you read an item and the time you write an update to the item. This is a standard approach to service development that prevents clients from controlling precious database resources and impacting other clients. To detect whether an underlying entity has changed between a read operation and an update operation, the REST interface records information about the version of the entity you originally retrieved. If this version information has changed when you perform the update operation, the REST interface will return the following error. XML <?xml version="1.0" encoding="utf-8" standalone="yes"?><error xmlns="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata"> <code></code> <message xml:lang="en-US"> Since entity type 'Microsoft.SharePoint.DataService.PartsItem' has one or more ETag properties, If-Match HTTP header must be specified for DELETE/PUT operations on this type. </message></error> Generated from CHM, not final book. Will be superseded in the future. Page 378
- 379. The OData standard used by the REST interface uses ETags to perform this concurrency control. ETags are a mechanism defined by the HTTP protocol for efficient cache control between a client browser and a Web server. An ETag consists of a unique value that the Web server specifies to identify a particular version of a resource. When you update an entity, the service proxy will automatically add an ETag to the HTTP request. The ETag value matches the value provided by the service when you retrieved the data that you want to update. However, if the server-side data changes between the point at which you retrieve it and the point at which you persist an update, the ETag values will not match, and the server will detect a conflict. In this case, you receive the error described earlier. This error may also occur within your code if you have more than one data context retrieving the same entity, or if you create a new data context to save an item that was previously retrieved. If you want to persist your changes regardless of whether the underlying entity has changed, you can use the following code to force the service to apply your updates. C# context.MergeOption = MergeOption.OverwriteChanges;context.AttachTo("Parts", currentItem, "*"); The DataServiceC ontext.AttachTo method instructs the context object to track the object that you intend to update. By specifying an ETag value of *, you are telling the service to overwrite the object, regardless of the ETag value. Note: For more information, see Section 3.1, "C oncurrency control and ETags," in OData: Operations. PUT and MERGE Operations The WC F Data Services proxy uses two different HTTP verbs for different update operations: A PUT request is used to update an entire entity. If no values are specified for fields in the entity, the fields will be set to default values. A MERGE request is used to update only those field values that have changed. Any fields that are not specified by the operation will remain set to their current value. Because the service proxy and the DataServiceContext class manage the creation of HTTP requests, you generally do not need to worry about these details when you use the REST interface from managed code. However, when you use JavaScript, you must manually create the HTTP requests and, as such, you need to understand this distinction. The next section provides more details about using the REST interface from JavaScript. Using the REST Interface from JavaScript Using the REST interface from JavaScript requires some extra work, because you can't generate a service proxy to build requests and handle responses. In order to use the REST interface to create entities from JavaScript, you must perform the following actions: C reate an HTTP request using the POST verb. Use the service URL of the list to which you want to add an entity as the target for the POST. Set the content type to application/json. Serialize the JSON objects that represent your new list items as a string, and add this value to the request body. This is illustrated by the following code, which creates a new inventory location item. This simplified example was taken from the RestScripts.js file in the C lient Reference Implementation. Jav aScript var url = 'http://localhost/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations'; var inventoryLocation = {}; // Insert a new Part location. inventoryLocation.PartId = $('#hidPartId').val(); inventoryLocation.BinNumber = $('#binText').val(); inventoryLocation.Quantity = $('#quantityText').val(); var body = Sys.Serialization.JavaScriptSerializer.serialize(inventoryLocation); Generated from CHM, not final book. Will be superseded in the future. Page 379
- 380. $.ajax({ type: 'POST', url: url, contentType: 'application/json', processData: false, data: body, success: function () { alert('Inventory Location Saved.'); } }); Updating an existing entity is a little more complex. If you've worked with REST services before, you might be tempted to use an HTTP PUT operation to update the entity. However, this approach can be problematic. Even if you load the entire entity, keep the entity in memory, and use the entity in a PUT operation, you may still experience problems with field values. Experience with this approach has shown issues with date time conversion and the population of lookup fields. This is because the OData protocol assumes that a PUT operation will update the entire entity, and any fields that are not explicitly specified are reset to their default values, most of which are a null value. A better approach is to use the HTTP MERGE operation, which updates only the fields that have changed. This approach also improves performance, because you don't need to initially retrieve a full representation of the entity just to send it back to the server to update it. To use this approach to update an existing entity, you must perform the following actions: C reate an HTTP request using the POST verb. Add an X-HTTP-Method header with a value of MERGE. Use the service URL of the list item you want to update as the target for the POST—for example, _vti_bin/listdata.sv c/Inv entoryLocations(XXX), where XXX is the ID of the list item. Add an If-Match header with a value of the entity's original ETag. This is illustrated by the following code, which updates an existing inventory location item. This simplified example was taken from the RestScripts.js file in the C lient Reference Implementation. C# var locationId = $('#hidLocationId').val(); var url = 'http://localhost/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations'; var beforeSendFunction; var inventoryLocationModifications = {}; // Update the existing Part location. url = url + "(" + locationId + ")"; beforeSendFunction = function (xhr) { xhr.setRequestHeader("If-Match", inventoryLocation.__metadata.ETag); // Using MERGE so that the entire entity doesn't need to be sent over the wire. xhr.setRequestHeader("X-HTTP-Method", 'MERGE'); } inventoryLocationModifications.BinNumber = $('#binText').val(); inventoryLocationModifications.Quantity = $('#quantityText').val(); var body = Sys.Serialization.JavaScriptSerializer.serialize(inventoryLocationModifications); $.ajax({ type: 'POST', url: url, contentType: 'application/json', processData: false, beforeSend: beforeSendFunction, data: body, success: function () { alert('Inventory Location Saved.'); } }); Generated from CHM, not final book. Will be superseded in the future. Page 380
- 381. For more information about update and merge operations, see Section 2.6, "Updating Entries," in OData: Operations. Batching The OData protocol used by WC F Data Services supports the batching of multiple REST queries into a single HTTP request. Using batching reduces chattiness, uses network bandwidth more efficiently, and improves the responsiveness of your applications. In order to use batching, you simply submit multiple queries at the same time using the DataServiceContext.BeginExecuteBatch method. C# context.BeginExecuteBatch(DisplayParts, context, invQuery, partsQuery); In this example, two queries are submitted: inv Query and partsQuery. The list of queries submitted is variable, so while this example shows two queries, additional queries could be added. When the server finishes executing a batch of requests, it returns a collection of results to the client. This is illustrated by the following code example. C# // Get the batch response. DataServiceResponse Response = context.EndExecuteBatch(result); // Loop through each operation. foreach (QueryOperationResponse operation in Response) { if (operation.Error != null) { throw operation.Error; } if (oOperation is QueryOperationResponse<InventoryLocationsItem>) { ProcessInventoryLocation(operation); } if (operation is QueryOperationResponse<PartsItem>) { ProcessParts(operation); } } The service proxy sends batch requests in a multi-part message (MIME) format to the REST service. Notice that the message contains two GET requests, one for Inventory Locations and one for Parts. HTTP Request POST http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/$batch HTTP/1.1 Content-Type: multipart/mixed; boundary=batch_16c7085d-ad1e-4962-b5e3-e7c83452b95a Accept-Language: en-US Referer: file:///C:/spg3/Trunk/Source/Client/Client.REST/Client.REST.Silverlight/Bin/Debug/Client.RE ST.Silverlight.xap Authorization: Negotiate oXcwdaADCgEBoloEWE5UTE1TU1AAAwAAAAAAAABYAAAAAAAAAFgAAAAAAAAAWAAAAAAAAABYAAAAAAAAAFgAAAAAAAA AWAAAABXCiOIGAbAdAAAAD4N0FBUwhwapfSA5hPbF5jGjEgQQAQAAAPUXp1AtIpqEAAAAAA== Accept-Encoding: identity DataServiceVersion: 1.0;NetFx MaxDataServiceVersion: 2.0;NetFx Accept: application/atom+xml,application/xml User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; MS-RTC LM 8; .NET4.0C; .NET4.0E) Host: contoso Connection: Keep-Alive Pragma: no-cache Content-Length: 717 Generated from CHM, not final book. Will be superseded in the future. Page 381
- 382. --batch_16c7085d-ad1e-4962-b5e3-e7c83452b95a Content-Type: application/http Content-Transfer-Encoding: binary GET http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations()?$filter=star tswith(Part/SKU,'sku11')&$orderby=Part/SKU&$expand=Part&$select=BinNumber,Quantity,Title,Id ,PartId,Part/SKU,Part/Title HTTP/1.1 DataServiceVersion: 2.0;NetFx --batch_16c7085d-ad1e-4962-b5e3-e7c83452b95a Content-Type: application/http Content-Transfer-Encoding: binary GET http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/Parts()?$filter=startswith(SKU,'s ku11')&$select=Title,SKU,Id,Description HTTP/1.1 DataServiceVersion: 2.0;NetFx --batch_16c7085d-ad1e-4962-b5e3-e7c83452b95a-- The response to the batch execution also uses MIME formatting, and it contains two HTTP responses, one for each query submitted. Http Response HTTP/1.1 202 Accepted Cache-Control: no-cache Content-Type: multipart/mixed; boundary=batchresponse_8ad6352b-ac02-4946-afc5-1df735bb7f55 Server: Microsoft-IIS/7.5 SPRequestGuid: 5f0f516c-78cf-4ffe-b37e-1c9e7168ef18 Set-Cookie: WSS_KeepSessionAuthenticated={0a9aa553-ad9a-401f-862a-2566fe4c94f4}; path=/ X-SharePointHealthScore: 0 DataServiceVersion: 1.0; X-AspNet-Version: 2.0.50727 WWW-Authenticate: Negotiate oRswGaADCgEAoxIEEAEAAABDh+CIwTbjqQAAAAA= Persistent-Auth: true X-Powered-By: ASP.NET MicrosoftSharePointTeamServices: 14.0.0.4762 Date: Sun, 30 May 2010 16:34:19 GMT Content-Length: 4204 --batchresponse_8ad6352b-ac02-4946-afc5-1df735bb7f55 Content-Type: application/http Content-Transfer-Encoding: binary HTTP/1.1 200 OK Cache-Control: no-cache DataServiceVersion: 2.0; Content-Type: application/atom+xml;charset=utf-8 <?xml version="1.0" encoding="utf-8" standalone="yes"?> <feed xml:base="http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/" xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices" xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns="http://www.w3.org/2005/Atom"> <title type="text">InventoryLocations</title> <id>http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations</id> <updated>2010-05-30T16:34:19Z</updated> <link rel="self" title="InventoryLocations" href="InventoryLocations" /> <entry m:ETag="W/"1""> <id>http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations(18)</id> <title type="text"></title> <updated>2010-05-21T14:06:13-04:00</updated> <author> Generated from CHM, not final book. Will be superseded in the future. Page 382
- 383. <name /> </author> <link rel="edit" title="InventoryLocationsItem" href="InventoryLocations(18)" /> <link rel="http://schemas.microsoft.com/ado/2007/08/dataservices/related/Part" type="application/atom+xml;type=entry" title="Part" href="InventoryLocations(18)/Part"> <m:inline> <entry m:ETag="W/"2""> <id>http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/Parts(12)</id> <title type="text">LOCK WASHERS, 1/2 11</title> <updated>2010-05-21T14:06:13-04:00</updated> <author> <name /> </author> <link rel="edit" title="PartsItem" href="Parts(12)" /> <category term="Microsoft.SharePoint.DataService.PartsItem" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" /> <content type="application/xml"> <m:properties> <d:Title>LOCK WASHERS, 1/2 11</d:Title> <d:SKU>SKU11</d:SKU> </m:properties> </content> </entry> </m:inline> </link> <category term="Microsoft.SharePoint.DataService.InventoryLocationsItem" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" /> <content type="application/xml"> <m:properties> <d:Title m:null="true" /> <d:PartId m:type="Edm.Int32">12</d:PartId> <d:BinNumber>Bin 0.5.17</d:BinNumber> <d:Quantity m:type="Edm.Double">9</d:Quantity> <d:Id m:type="Edm.Int32">18</d:Id> </m:properties> </content> </entry> </feed> --batchresponse_8ad6352b-ac02-4946-afc5-1df735bb7f55 Content-Type: application/http Content-Transfer-Encoding: binary HTTP/1.1 200 OK Cache-Control: no-cache DataServiceVersion: 2.0; Content-Type: application/atom+xml;charset=utf-8 <?xml version="1.0" encoding="utf-8" standalone="yes"?> <feed xml:base="http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/" xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices" xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns="http://www.w3.org/2005/Atom"> <title type="text">Parts</title> <id>http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/Parts</id> <updated>2010-05-30T16:34:19Z</updated> <link rel="self" title="Parts" href="Parts" /> <entry m:ETag="W/"2""> <id>http://contoso/sites/sharepointlist/_vti_bin/listdata.svc/Parts(12)</id> <title type="text">LOCK WASHERS, 1/2 11</title> <updated>2010-05-21T14:06:13-04:00</updated> <author> <name /> </author> <link rel="edit" title="PartsItem" href="Parts(12)" /> Generated from CHM, not final book. Will be superseded in the future. Page 383
- 384. <category term="Microsoft.SharePoint.DataService.PartsItem" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" /> <content type="application/xml"> <m:properties> <d:Title>LOCK WASHERS, 1/2 11</d:Title> <d:SKU>SKU11</d:SKU> <d:Description m:null="true" /> <d:Id m:type="Edm.Int32">12</d:Id> </m:properties> </content> </entry> </feed> --batchresponse_8ad6352b-ac02-4946-afc5-1df735bb7f55-- Note: For more information about how the OData protocol implements batching, see OData: Batch Processing. Synchronous and Asynchronous Operations The service proxy for the SharePoint REST interface supports synchronous and asynchronous calls to the service. The approach to managing asynchronous operations is almost identical to the C SOM experience. As described in the section, "Using the Service Proxy," earlier in this topic, the DataServ iceQuery<TElement> class provides a BeginExecute method that you can use to asynchronously invoke a REST query. You should use the asynchronous approach in applications where you need to avoid blocking the UI thread. You cannot make a synchronous call to the REST interface from Silverlight or from JavaScript. Generated from CHM, not final book. Will be superseded in the future. Page 384
- 385. Reference Implementation: Client Microsoft® SharePoint® 2010 includes new areas of functionality that simplify the development of rich Internet applications (RIAs) for the SharePoint platform. The C lient Application Models chapter described many of these areas, which include a client-side object model (C SOM) for JavaScript, Microsoft Silverlight®, and managed .NET clients, a Representational State Transfer (REST) interface, enhanced tooling, and improved native support for Ajax and Silverlight components. The C lient Reference Implementation (C lient RI) demonstrates how you can use these technologies in real-world scenarios. The reference implementation uses the same basic manufacturing scenario as all our previous reference implementations—in short, a data-driven application that allows users to manage related entities such as machines, parts, and inventory locations. The key idea behind this reference implementation is that it shows you how to implement the same user interface using different client data access technologies and different approaches to user experience. For example, it demonstrates how to implement the user interface using Silverlight with the C SOM, Silverlight with the REST interface, JavaScript with the C SOM, JavaScript with the REST interface, and Silverlight with ASP.NET Web services. This allows you to compare and contrast each implementation approach. In addition, the C lient RI demonstrates the following key aspects of client-side development for SharePoint applications: It demonstrates how to use client-side logic to overcome the limitations of the sandbox execution environment. It demonstrates how to use RIA technologies and asynchronous execution to build a highly functional user experience without the associated server load. It demonstrates the use of the Model-View-ViewModel (MVVM) pattern in Silverlight applications to isolate business logic from the presentation layer and the underlying data source. It provides equivalent non-MVVM implementations of the Silverlight applications, in order to help developers who are unfamiliar with the pattern to understand the application logic. Deploying the Client RI The C lient RI includes an automated installation script that creates various site collections, deploys the RI components, and adds sample data. After running the installation script, browse to the new C lient site collection at http://<Hostname>/sites/ SharePointList/client. You can open and run the project in Visual Studio, but this does not create a site collection or add sample data. To see the system fully functioning, you must run the installation script. The following table summarizes how to get started with the C lient RI. Question Answer Where can I find the <install location>SourceC lient C lient RI? What is the name of C lient.sln the solution file? What are the system SharePoint Foundation 2010 requirements? What preconditions You must be a member of SharePoint Farm Admin. are required for installation? You must be a member of the Windows admin group. SharePoint must be installed at http://<Hostname:80>. If you want to install to a different location, you can edit these settings in the Settings.xml file located in the Setup directory for the solution. SharePoint 2010 Administration service must be running. By default, this service is set to a manual start. To start the service, click Start on the taskbar, point to Administrative Tools, click Serv ices, double-click SharePoint 2010 Administration serv ice, and then click Start. You must install Silverlight 4 from here. You must install ADO.NET Data Services from here. How Do I Install the Follow the instructions in the readme file located in the project folder. C lient RI? Generated from CHM, not final book. Will be superseded in the future. Page 385
- 386. What is the default http://<Hostname>/sites/SharePointList/ C lient installation location? (This location can be altered by changing the Settings.xml file in the Setup directory.) How do I download The C lient RI is included in the download Developing Applications for SharePoint 2010. the C lient RI? Generated from CHM, not final book. Will be superseded in the future. Page 386
- 387. Solution Overview This topic provides a high-level overview of the various components that make up the C lient Reference Implementation (C lient RI). It does not examine the design of the solution or the implementation details of specific features, as these are described later in this guidance. Instead, it illustrates how the reference implementation works at a conceptual level. The C lient RI uses SharePoint lists as its underlying data source. The data model was implemented in the same way as the SharePoint List Data Models reference implementation, and is not described again here. Instead, this documentation focuses on the implementation of user interfaces and data access mechanisms in client-side logic. The C lient RI includes eight different client implementations that demonstrate various approaches to client-side SharePoint development. The following image shows a Silverlight implementation that uses the client-side object model (C SOM) as its data access mechanism. This builds on the SharePoint List Data Models RI scenario of managing inventory locations and suppliers for machine parts. The Client RI user interface As you can see from the C lient RI user interface in the image above, the solution adds links to all eight implementations to the Quick Launch bar on the left-hand side of the page. Each implementation explores a different approach to a similar scenario. Each illustrates how you can use client-side logic to provide a richer user experience and to avoid some of the limitations of the sandbox execution environment. Not all of the interfaces look identical, even where they implement the same scenario, as they rely on different UI technologies. The following list provides a summary of each implementation: The Silverlight CSOM, Silverlight REST, Ajax CSOM, and Ajax REST interfaces all implement the machine parts inventory management scenario described by the SharePoint List Data Models RI, which must be installed as a prerequisite for the C lient RI. This allows you to compare and contrast the use of Ajax and Silverlight as a platform for user experience, and the use of the C SOM and the REST interface as client-side data access mechanisms. The Silverlight SP Service interface implements a subset of the machine parts inventory management scenario, using the SharePoint ASP.NET (ASMX) Web services as the client-side data access mechanism. This allows you to compare the ASP.NET Web services found in the previous version of SharePoint to the new C SOM and the REST interface. The SharePoint ASP.NET Web services are useful as they provide backwards compatibility for SharePoint 2007 applications, and they expose some functionality—such as the user profile service—that is unavailable through the C SOM or the REST interface. However, you should favor the use of the C SOM or the REST interface wherever possible. The Silverlight REST Alt interface demonstrates an alternative approach to the machine parts inventory management scenario. This approach retrieves inventory locations on demand to improve the overall efficiency of the implementation. Generated from CHM, not final book. Will be superseded in the future. Page 387
- 388. The Silverlight REST Alt No MVVM interface demonstrates an approach to the machine parts inventory management scenario that does not use the Model-View-ViewModel (MVVM) pattern. Every other Silverlight interface uses the MVVM pattern, which takes maximum advantage of Silverlight's binding and eventing capabilities while maintaining the testability of the code. This implementation is included to help developers understand how to translate between an MVVM and a non-MVVM pattern. The Silverlight External Service interface uses the same approach as the Silverlight C SOM interface to retrieve suppliers, and then retrieves the accounts payable for that supplier from an external Web service. This is the same scenario as the Full-Trust Proxies for Sandboxed Solutions (Proxy RI) reference implementation. However, where the Proxy RI required a full trust proxy to call the external Web service from the server, this interface circumvents the limitations of the sandbox environment by calling the external Web service directly from the client. This allows you to deploy the interface using solely sandboxed solution components. Browsing the Visual Studio Solution The Microsoft Visual Studio® solution for the client reference implementation contains seven projects, as shown in the following image. The Client solution Six of the seven projects are Silverlight applications that correspond to the interfaces described in the previous topic. They are: The Client.CSOM.Silverlight project is the Silverlight application that provides the Silverlight CSOM interface. The Client.ExtService.Silverlight project is the Silverlight application that provides the Silverlight External Service interface. The Client.REST.Silv erlight project is the Silverlight application that provides the Silverlight REST interface. The Client.ExtService.Silverlight.Alt project is the Silverlight application that provides the Silverlight REST Alt interface. The Client.ExtService.Silverlight.Alt.NoMVVM project is the Silverlight application that provides the Silverlight REST Alt No MVVM interface. The Client.ExtService.Silverlight project is the Silverlight application that provides the Silverlight External Service interface. The C lient.SharePoint project is somewhat more complex. This is a SharePoint project that contains the features that deploy all the solution components—such as libraries, pages, images, scripts, and Silverlight XAP files—to the SharePoint environment. These components include the pages and scripts that define the Ajax C SOM and Ajax REST interfaces. This project is described in more detail in the Solution Design topic. Anatomy of a Silverlight Project Each of the Silverlight projects contains a similar structure, based around an implementation of the MVVM pattern. Generated from CHM, not final book. Will be superseded in the future. Page 388
- 389. For example, the following image shows the structure of the Client.CSOM.Silverlight project. Silverlight project structure for a Model-View-ViewModel implementation The key components of this project structure are as follows: The Entities node contains classes that provide a strongly typed representation of business entities such as parts and suppliers. The ViewModels node contains the view model classes for the application, as part of the MVVM pattern implementation. For more information on the role of the view model class, see Implementing the Model-View-ViewModel Pattern. The XAML files provide the declarative component of the Silverlight controls used in the application. The C lient.ExtService.Silverlight project has an additional node, Service References, which contains the components required to interact with the external vendor service. The C lient.ExtService.Silverlight.Alt.NoMVVM project contains no nodes, as all the logic is in the code-behind files for the Silverlight controls. This project provides a non-MVVM implementation of the C lient.ExtService.Silverlight project. This implementation requires more code, as it doesn't take advantage of the Silverlight binding infrastructure in the same way that an MVVM implementation does. However, the implementation is easier to follow for developers who are unfamiliar with the MVVM pattern, and it enables developers to compare the two approaches side by side. Generated from CHM, not final book. Will be superseded in the future. Page 389
- 390. Solution Design In the Client Visual Studio solution, the Client.SharePoint project packages and deploys all of the solution components to the SharePoint environment. This project contains four features: Libraries. This feature provisions two document libraries to the target SharePoint site. The C ustomScripts library is provisioned to store the JavaScript files required by the Ajax implementations, and the SilverlightApps library is provisioned to store the XAP files required by the Silverlight implementations. Both libraries are based on the standard document library list definition. Pages. This feature provisions ASPX pages to host the Ajax components and Silverlight controls required by each user interface. The C ustomPage.aspx file is deployed to several different virtual URLs, with a Silverlight Web Part configured differently in each case, for each of the Silverlight user interfaces. The JavascriptWithC SOM.aspx file and the JavascriptWithREST.aspx file host the corresponding Ajax user interfaces. The pages themselves can be found in the C ustomPages module. Jav aScript Files. This feature provisions the JavaScript files required by the Ajax user interfaces to the CustomScripts library. The JavaScript files themselves can be found in the Scripts module. Silv erlight Apps. This feature provisions the XAP files required by the Silverlight user interfaces to the SilverlightApps library. Each XAP file represents the compiled output of one of the Silverlight projects in the solution. The XAP files are referenced in the Silverlight module. The JavaScript Files feature and the Silverlight Apps feature include dependencies on the Libraries feature, as the document libraries must be in place before the JavaScript files and XAP files can be deployed. This is illustrated by the following diagram. Feature activation dependencies for the Client RI If you want to follow the execution of a Silverlight application, you can debug the application from within the Client solution. To do this, on the Properties page for the C lient.SharePoint project, on the SharePoint tab, select EnableSilv erlight debugging (instead of Script debugging), as shown in the following image. Enabling Silverlight debugging Generated from CHM, not final book. Will be superseded in the future. Page 390
- 391. Generated from CHM, not final book. Will be superseded in the future. Page 391
- 392. Using Client Logic to Reduce Server Load When you create an application in client-side code, you often need to consider alternative ways of implementing your data operations in order to maximize efficiency. For example, in the SharePoint List Data Models reference implementation, we used a view to display a list of parts together with their inventory locations. Now suppose that you want to implement a similar interface using client-side logic. Parts and inventory locations are stored in two different lists. Since parts can be in more than one inventory location, there may be more than one entry for a part. In other cases a part may be out of stock, and therefore not have any inventory locations. In the SharePoint List Data Models RI, we used a left outer join between the Parts list and the Inventory Locations list. However REST doesn’t support this approach. To replicate this user interface on the client using REST, we would need to submit multiple queries and merge the results. In the Silverlight REST Alt and Silverlight REST Alt No MVVM interfaces, we demonstrate a more efficient alternative approach for client-side logic that meets the same overall requirements. Instead of merging parts data with inventory locations data, we initially simply retrieve a list of parts. When the user selects a part, we retrieve the inventory locations associated with that part. In this case, the application uses the asynchronous communication model associated with RIA technologies to its advantage. The service only retrieves the specific inventory locations data it requires, so the actual request is small and fast. Since the client works asynchronously, the interface remains responsive while the data is retrieved. C learly this approach would be less desirable if we used a traditional thin client model that required a full page postback to retrieve the inventory locations data. In the remainder of this topic, we walk through this approach for the Silverlight REST Alt No MVVM interface. The Silverlight REST Alt interface demonstrates the same approach using the Model-View-ViewModel (MVVM) pattern, which we discuss in the next topic. Our user interface is provided by the MainPage.xaml Silverlight control. The following image shows a screen capture of the MainPage.xaml control in design view, with the main data-bound components labeled. The MainPage.xaml control Generated from CHM, not final book. Will be superseded in the future. Page 392
- 393. PartsDataGrid and SuppliersGrid are standard Silverlight DataGrid controls. The partsLocation1 control is a custom user control that is displayed as a dialog when required. When the MainPage control is loaded, the constructor performs some initialization tasks, including creating a data context object that will be used in all subsequent interactions. This illustrates one of the key differences between traditional thin client approaches and newer RIA approaches—when you build a user interface using an RIA technology, you no longer have to recreate every item on each request. Instead, it is common to create and store objects that you will reuse over the lifetime of the page. This page lifetime is typically much longer than that of a traditional server-driven Web page. The following code shows the constructor for the MainPage control. C# public partial class MainPage : UserControl { private readonly string partsSiteURL = "/sites/sharepointlist/"; private readonly string listService = "_vti_bin/listdata.svc"; private PartsItem currentPart; private readonly ObservableCollection<PartsItem> parts = new ObservableCollection<PartsItem>(); private readonly ObservableCollection<SuppliersItem> currentPartSuppliers = new ObservableCollection<SuppliersItem>(); public MainPage() { InitializeComponent(); Uri appSource = App.Current.Host.Source; string fullPartsSiteUrl = string.Format("{0}://{1}:{2}{3}{4}", appSource.Scheme, appSource.Host, appSource.Port, partsSiteURL, listService); this.DataContext = new PartsDataContext(new Uri(fullPartsSiteUrl)); PartsDataGrid.ItemsSource = parts; SuppliersGrid.ItemsSource = currentPartSuppliers; } ... The MainPage constructor takes the following actions: It calls the InitializeComponent method. This is an automatically generated class, common to all Silverlight applications, that creates and initializes the controls defined in the corresponding MainPage.xaml file. It builds the URL of the site that hosts the Silverlight application. It instantiates a data context object of type PartsDataContext, using the site URL, and assigns it to the DataContext property of the MainPage control. The PartsDataContext class was generated by Windows® C ommunication Foundation (WC F) Data Services and contains strongly typed entities that represent lists and list items on our site. The partLocation1 user control contained within the MainPage user control will inherit this context. It assigns the ItemsSource property of the PartsDataGrid and the SuppliersGrid controls to observable collections of PartsItem and SuppliersItem, respectively. PartsItem and SuppliersItem are entity classes, defined by the data context, that represent items in the Parts list and the Suppliers list. An Observ ableCollection implements two key interfaces that support dynamic data binding. The INotifyC ollectionC hanged interface specifies that the class provides notifications whenever the collection has changed. The INotifyPropertyC hanged interface specifies that the class provides notifications, in the form of a PropertyChanged event, when an item within the collection is added, removed, or altered. As a result of this mechanism, when you bind an ObservableCollection to a DataGrid control, the user interface and the underlying collection will automatically remain synchronized. To find parts, the user types some text into the search box and then clicks Search. In the MainPage code-behind class, the PartSearchButton_Click method handles this event. The event handler calls the GetParts method, which builds a query and submits it to the REST interface. C# private void PartSearchButton_Click(object sender, RoutedEventArgs e) { GetParts(PartSkuTextBox.Text); Generated from CHM, not final book. Will be superseded in the future. Page 393
- 394. partLocations1.CurrentLocation = null; partLocations1.ResetPart(); } public void GetParts(string Sku) { parts.Clear(); var context = (PartsDataContext)this.DataContext; //Define Query var query = (DataServiceQuery<PartsItem>)context.Parts .Where(p => p.SKU.StartsWith(Sku)) .Select(p => new PartsItem { Title = p.Title, SKU = p.SKU, Id = p.Id, Description = p.Description }); //Execute Query query.BeginExecute(DisplayParts, query); } The key points to note in this example are as follows: The query uses the same data context object that we created in the constructor. View projection is used to select only four of the available fields for each PartsItem entity. View projections select a subset of available fields in the query, which reduces bandwidth consumption and processing overhead. However, any PartsItem properties that were not retrieved will have invalid values. The BeginExecute method is called on the query, which causes the query to be executed asynchronously. The DisplayParts delegate will be invoked once the query has completed. At this point, control is returned to the user interface while the data is being retrieved, which means that the user interface remains responsive. When the query results are returned, the DisplayParts method is invoked. C# private void DisplayParts(IAsyncResult result) { Dispatcher.BeginInvoke(() => { DataServiceQuery<PartsItem> query = (DataServiceQuery<PartsItem>)result.AsyncState; var partResults = query.EndExecute(result); foreach (var part in partResults) { parts.Add(part); } }); } In this method, the call to Dispatcher.BeginInvoke uses a lambda expression to execute an anonymous method asynchronously on the UI thread. Dispatcher.BeginInv oke ensures that the logic executes on the same thread as the UI, which is compulsory for logic that interacts with the UI in all Silverlight applications. If you don’t take this action, you will receive an exception or a cross-threading violation. Because we maintain our parts list in an Observ ableCollection, we simply need to update the collection. Any controls that are data-bound to the collection are updated automatically, as shown by the following image. Part SKU search results Generated from CHM, not final book. Will be superseded in the future. Page 394
- 395. When the user selects a row, the PartsDataGrid_SelectionChanged method handles the event. This method must perform two key actions—it must retrieve the suppliers for the selected part, and it must retrieve the locations of the selected part. C# private void PartsDataGrid_SelectionChanged(object sender, SelectionChangedEventArgs e) { currentPart = PartsDataGrid.SelectedItem as PartsItem; GetPartSuppliers(); partLocations1.GetLocations(currentPart.Id); } In this topic we focus on retrieving the part locations. The event handler calls the GetLocations method on the partLocations1 control, passing in the part ID from the currentPart local variable as an argument. This is shown by the following code example. C# public void GetLocations(int partId) { var context = (PartsDataContext)this.DataContext; inventoryLocations.Clear(); this.currentPartId = partId; var query = (DataServiceQuery<InventoryLocationsItem>)context.InventoryLocations .Where(p => p.PartId == partId) .Select(p => new InventoryLocationsItem { BinNumber = p.BinNumber, Id = p.Id, Quantity = p.Quantity, Title = p.Title, PartId = p.PartId }); //Execute Query query.BeginExecute(DisplayLocations, query); } As before, the callback method—DisplayLocations in this case—uses a call to Dispatcher.BeginInv oke to update an observable collection. The inventoryLocations local variable is an observable collection of type Inv entoryLocationsItem. Generated from CHM, not final book. Will be superseded in the future. Page 395
- 396. C# private void DisplayLocations(IAsyncResult asyncResult) { Dispatcher.BeginInvoke(() => { DataServiceQuery<InventoryLocationsItem> query = (DataServiceQuery<InventoryLocationsItem>)asyncResult.AsyncState; var partLocations = query.EndExecute(asyncResult); foreach (var location in partLocations) { inventoryLocations.Add(location); } }); } Because the inv entoryLocations observable collection is data-bound to the locationsDataGrid control, the user interface automatically updates to show the locations associated with the selected part. Location data for selected part As you can see, this approach provides an efficient, responsive user interface without increasing server load or performing heavy duty processing on the client. Generated from CHM, not final book. Will be superseded in the future. Page 396
- 397. Implementing the Model-View-ViewModel Pattern The Model-View-ViewModel (MVVM) pattern is an application pattern that isolates the user interface from the underlying business logic. MVVM belongs to a class of patterns called Separated Presentation. These patterns provide a clean separation between the UI and the rest of the application. This improves the testability of the application and allows the application and its UI to evolve more easily and independently. The MVVM pattern consists of the following parts: The Model, which provides a view-independent representation of your business entities. The design of the model is optimized for the logical relationships and operations between your business entities, regardless of how the data is presented in the user interface. The View class which is the user interface. It displays information to the user and fires events in response to user interactions. The ViewModel class, which is the bridge between the view and the model. Each View class has a corresponding ViewModel class. The ViewModel retrieves data from the Model and manipulates it into the format required by the View. It notifies the View if the underlying data in the model is changed, and it updates the data in the Model in response to UI events from the View. The following diagram illustrates the relationship between the View, the ViewModel, and the Model. The MVVM pattern In some ways the MVVM pattern is similar to the Model-View-Presenter (MVP) pattern described in The Sandbox Execution Model reference implementation—both patterns are variants of the Model-View-C ontroller (MVC ) pattern, both are Separated Presentation patterns, and both are designed to isolate the details of the user interface from the underlying business logic in order to enhance manageability and testability. However, whereas the MVP pattern is best suited to traditional server-rendered Web pages and the request/response paradigm, the MVVM pattern is optimized for stateful rich client applications where client-side business logic and application state is maintained through user or service interactions. The pattern enables you to maximize the benefits of Windows Presentation Foundation (WPF) and Silverlight capabilities such as two-way data-binding functionality, events, and stateful behavior provided by these frameworks. For example, you can use declarative data binding to connect the View to the ViewModel, rather than writing code to glue the two together. Implementations of the MVVM pattern have the following characteristics: The View class generates events in response to user interactions, and these events are handled by the corresponding ViewModel class. The View class has no knowledge of how the events are handled, or what impact the events will have on the Model. The ViewModel class determines whether a user action requires modification of the data in the Model, and acts on the Model if required. For example, if a user presses a button to update the inventory quantity for a part, the View simply notifies the ViewModel that this event occurred. The ViewModel retrieves the new inventory amount from the View and updates the Model. This decouples the View from the Model, and consolidates the business logic into the ViewModel and the Model where it can be tested. The Model notifies the ViewModel if the data in the underlying data store has changed. Generally, when you work with a stateless request/response model, you don't need to worry about whether data has changed while the request is being processed, since the window of time is small. With rich Internet application (RIA) approaches, the Model data typically stays in memory for longer, and multiple active Views may share the Model data. A user may make changes in one View that affects a different View within the application. The Model fires events to notify any active ViewModels of data changes. Generated from CHM, not final book. Will be superseded in the future. Page 397
- 398. The ViewModel notifies the View when information has changed. This is typically automated through the two-way binding infrastructure described previously. In the previous topic, Using C lient Logic to Reduce Server Load, we looked at a Silverlight implementation of an interface that allows users to view parts, suppliers, and inventory locations. To help you to understand the MVVM pattern, let's take a look at an implementation of the same scenario using MVVM. This is taken from the Silverlight REST Alt interface in the reference implementation. As before, the user interface is defined by the MainPage.xaml Silverlight control that displays parts and suppliers. A second Silverlight user control, PartLocations.xaml, displays the inventory locations for the selected part. These two controls represent the View components of our MVVM implementation. Both views use declarative data binding to connect to the information provided by the corresponding ViewModels. For example, the following code from the MainPage.xaml control shows the extensible application markup language (XAML) that defines the grid that displays parts. XAML <data:DataGrid AutoGenerateColumns="False" Height="247" HorizontalAlignment="Left" Margin="12,41,0,0" Name="PartsDataGrid" VerticalAlignment="Top" Width="550" ItemsSource="{Binding Parts}" SelectedItem="{Binding CurrentPart, Mode=TwoWay}" > <data:DataGrid.Columns> <data:DataGridTextColumn CanUserReorder="True" CanUserResize="True" CanUserSort="True" Width="Auto" Binding="{Binding Id}" /> <data:DataGridTextColumn CanUserReorder="True" CanUserResize="True" CanUserSort="True" Width="Auto" Binding="{Binding SKU}" /> <data:DataGridTextColumn CanUserReorder="True" CanUserResize="True" CanUserSort="True" Width="Auto" Binding="{Binding Title}" /> </data:DataGrid.Columns> </data:DataGrid> Notice that the ItemsSource property data-binds the grid to the Parts property, which is an observable collection defined by the ViewModel class. Note also that the SelectedItem property is data-bound to CurrentPart property, and that this is a two-way data binding. This means that the view gets updated if the source changes, and the source gets updated if the view changes. This allows us to use the selected item to drive other views, such as the suppliers and the inventory locations for the selected part. The code-behind file for the MainPage.xaml file contains only the minimal logic required to perform the initial wire-up between the View and the ViewModel. C# public partial class MainPage : UserControl { private PartInventoryViewModel viewModel; public MainPage() { InitializeComponent(); viewModel = new PartInventoryViewModel(); this.DataContext = viewModel; } private void PartSearchButton_Click(object sender, RoutedEventArgs e) { viewModel.GetParts(); } } This code performs the following actions: It instantiates the ViewModel class, PartInv entoryViewModel. It sets the DataContext of the MainPage control to the ViewModel instance. Any controls contained within the MainPage control, such as the PartLocations control, will inherit this data context. Generated from CHM, not final book. Will be superseded in the future. Page 398
- 399. It notifies the ViewModel instance when the user clicks the PartSearchButton. By setting the DataContext property, we are instructing the View to data-bind properties within the View to the specified ViewModel instance. For example, when the runtime resolves the binding expression ItemsSource="{Binding Parts}" in the View, it will attempt to find the Parts property in the specified ViewModel instance. So far, the interactions between the View and the ViewModel shown in the following illustration have been described: View interactions The ViewModel contains the majority of the application logic. In this implementation, we chose not to implement a separate data repository. As such the Model component of the application is provided by the entities contained in the data context, PartsDataContext, which was generated by WC F Data Services for our SharePoint list data. In more complex applications, a separate data repository would make sense in order to centralize the queries used to access data. To understand the role of the ViewModel, let's examine what happens when the user searches for a part by typing a full or partial SKU and clicking the PartSearchButton. As you can see from the previous example, the event handler in the View calls the GetParts method on the ViewModel. The SearchSku property, which contains the search text for the query, was set through two-way data binding to the PartSkuTextBox text box. The GetParts method clears the Parts collection and then queries the Model asynchronously, as shown by the following code example. C# public void GetParts() { Parts.Clear(); CurrentPart = null; //Define Query var query = (DataServiceQuery<PartsItem>) context.Parts .Where(p => p.SKU.StartsWith(SearchSku)) .Select(p => new PartsItem { Title = p.Title, SKU = p.SKU, Id = p.Id, Description = p.Description Generated from CHM, not final book. Will be superseded in the future. Page 399
- 400. }); //Execute Query query.BeginExecute(DisplayParts, query); } The Parts property represents an ObservableCollection of PartsItem entities. As described in the previous topic, Using C lient Logic to Reduce Server Load, an ObservableCollection fires a PropertyChanged event when the collection is changed. Because the collection is bound to a grid in the MainPage View, this event notifies the grid that it needs to update its data. As such, when we clear the collection, the user interface will update accordingly. This is illustrated by the following diagram. Note: Since updating the Parts collection will update the UI, it's important to ensure that we only update the collection from the UI thread. However, because the GetParts method is invoked as a result of a UI event, we know it is executing on the UI thread. Therefore, we do not need to use Dispatcher.BeginInv oke to update the collection. View interactions and PropertyChanged notifications When the query returns, the callback delegate invokes the DisplayParts method in the ViewModel. C# private void DisplayParts(IAsyncResult result) { Deployment.Current.Dispatcher.BeginInvoke(() => { DataServiceQuery<PartsItem> query = (DataServiceQuery<PartsItem>)result.AsyncState; var parts = query.EndExecute(result); foreach (var part in parts) { Parts.Add(part); } }); } The callback method must update the Parts observable collection, which will in turn automatically update the View. It calls Deployment.Current.Dispatcher.BeginInvoke in order to ensure that the update takes place on the UI thread. The application now includes all the logic required for part search, as shown in the following Generated from CHM, not final book. Will be superseded in the future. Page 400
- 401. diagram. MVVM implementation for part search As you saw earlier, when the user selects a part, the CurrentPart property is updated in the ViewModel because we defined a two-way data binding in the View. The following code shows the CurrentPart property in the ViewModel. C# private PartsItem currentPart = null; public PartsItem CurrentPart { get { return currentPart; } set { if (value == currentPart) return; currentPart = value; GetPartSuppliers(); GetLocations(); OnPropertyChanged("CurrentPart"); } } As you can see from the code, if the current part is unchanged, the property setter will take no action. This is a recommended practice to avoid unnecessary service calls. If the current part has changed, the property setter will retrieve the suppliers and the inventory locations for the new part. The data grids that display suppliers and inventory locations are also bound to observable collections, so the Views will update automatically as before when the ViewModel is updated. The aspect of the MVVM that we have yet to see is how the ViewModel updates the data in the Model. When a part is selected, the PartsLocation control allows you to select an inventory location and update the inventory quantities for that part. You can also add a new inventory location by clicking Add New Location. The PartsLocation control Generated from CHM, not final book. Will be superseded in the future. Page 401
- 402. The PartsLocation user interface uses declarative data binding to track changes to the bin number and quantity fields in the ViewModel. The following code example shows the markup for the parts location data grid. As you can see, there is a two-way data binding between the SelectedItem property in the data grid and the CurrentLocation property in the ViewModel. XAML <sdk:DataGrid AutoGenerateColumns="False" Height="120" HorizontalAlignment="Left" Margin="12,12,0,0" Name="locationsDataGrid" VerticalAlignment="Top" Width="348" ItemsSource="{Binding CurrentInventoryLocations}" SelectedItem="{Binding CurrentLocation, Mode=TwoWay}"> The Bin Number and Quantity text boxes are also data-bound to the CurrentLocation property, as shown by the following code. XAML <Button Content="Save" Height="23" HorizontalAlignment="Left" Margin="271,192,0,0" Name="saveButton" VerticalAlignment="Top" Width="83" Click="saveButton_Click" /> <TextBox Height="23" HorizontalAlignment="Left" Margin="84,147,0,0" Name="binTextBox" VerticalAlignment="Top" DataContext="{Binding CurrentLocation}" Width="120" Text="{Binding BinNumber, Mode=TwoWay}" /> <TextBox Height="23" HorizontalAlignment="Left" Margin="268,147,0,0" Name="quantityTextBox" DataContext="{Binding CurrentLocation}" VerticalAlignment="Top" Width="86" Text="{Binding Quantity, Mode=TwoWay, ValidatesOnExceptions=True}" /> If the user elects to add a new inventory location, the ViewModel simply sets the value of the CurrentLocation property to a new Inv entoryLocationItem instance. It also tracks the new instance in the private newLocation field. Two-way data binding ensures that the corresponding controls in the UI are cleared. C# public void SetNewLocation() { if (newLocation == null) { newLocation = new InventoryLocationsItem(); } else { newLocation.BinNumber = string.Empty; newLocation.Quantity = null; Generated from CHM, not final book. Will be superseded in the future. Page 402
- 403. } CurrentLocation = newLocation; } When the user clicks the Sav e button, the code-behind for the PartsLocation control calls the Inv entoryLocationSav ed method in the ViewModel. C# private void saveButton_Click(object sender, RoutedEventArgs e) { PartInventoryViewModel viewModel = (PartInventoryViewModel)this.DataContext; string error = viewModel.InventoryLocationSaved(); if(error != null) MessageBox.Show(error); } This method simply forwards the command to the ViewModel by calling the Inv entoryLocationSav ed method. Thanks to the two-way data binding in the control XAML, the new or updated values are already available in the ViewModel. The objects that populate the observable collections are the same objects that populate the data context, so the ViewModel can use a call to context.UpdateObject to let the Model know that an item has changed. To commit the changes in the model, the ViewModel calls the context.BeginSaveChanges method. C# public string InventoryLocationSaved() { string error = ValidateSaveInputs(currentLocation.BinNumber, currentLocation.Quantity); if (error == null) { if (CurrentLocation != newLocation) { //CurrentLocation represents an object that is already in the data context //and observable collection. We just need to update the values. context.UpdateObject(CurrentLocation); } else { newLocation.PartId = CurrentPart.Id; //Add the new part to the data context. context.AddToInventoryLocations(newLocation); //Add the new part to the observable collection. this.currentInventoryLocations.Add(newLocation); this.CurrentLocation = newLocation; newLocation = null; } context.BeginSaveChanges(SaveChangesOptions.Batch, OnSaveChanges, null); } return error; } The callback method simply displays a message indicating that the updates were successfully applied. C# private void OnSaveChanges(IAsyncResult result) { Deployment.Current.Dispatcher.BeginInvoke(() => { context.EndSaveChanges(result); MessageBox.Show("Inventory Changes Saved Successfully"); Generated from CHM, not final book. Will be superseded in the future. Page 403
- 404. }); } At this point, you've seen how each leg of the MVVM pattern works in this implementation. In this case the model does not generate change events, so that aspect of the pattern is omitted. Complete MVVM implementation for the Silverlight REST Alt interface Data Binding to the Model The one point that may be unclear in all of this is exactly how the changes happen. The same entity object instances are being used in a number of different cases, which may feel unnatural to Web developers who are used to stateless user interfaces driven by requests and responses. In this case, the data context object first retrieves the entities by querying the SharePoint server. These entities are then added to observable collections to enable tight data binding to the View. This is a common approach in MVVM implementations—entities from the data model can be bound directly to the View, providing that they don’t need to undergo any transformations to match the View. The entity instances added to the observable collections are the same entity instances in the data context. When a user selects an item, such as an inventory location, the CurrentLocation property is set by two-way data binding, and the entity instance that is in the CurrentLocation is also in the observable collection and the data context. As a result, if you update the inventory location in the user interface, the two-way data binding updates the object in the C urrentLocation property, which in turn means that the object in the observable collection and the data context is updated. The code simply needs to call context.UpdateObject to let the data context know that the value has changed. This all works because the same entity instances that were initially retrieved from the SharePoint server remain in memory and are used throughout the application. Additional Considerations The Silverlight REST Alt interface is a relatively simple implementation of the MVVM pattern in order to provide a straightforward demonstration. Two additional areas that are not covered in depth are commands and validation. C ommands are used to represent actions that require more sophisticated coordination between the View, the ViewModel, and the Model. C ommands can be implemented as methods in the ViewModel class, or encapsulated in separate classes that implement the IC ommand interface. In both approaches, the ViewModel exposes the command to the View, so that the View can invoke the command in response to user interactions. If the command is implemented as a method on the ViewModel class, you can invoke the command in the code-behind class for the View. For example, the View class in this implementation calls the PartInv entoryViewModel.GetParts method when the user clicks the part search button. If the command is implemented as an ICommand instance, the View can bind directly to it, removing the need for any code in the View’s code-behind. C ommands can also be directed from the ViewModel to the View. For example, the ViewModel can disable a button on the View if the data provided by the user is not valid. The ViewModel and the Model validate the data that they encapsulate. Data validation is fully integrated into the WPF and Silverlight data-binding mechanism. This enables the ViewModel or the Model to validate data as the user updates it in the View, and enables the View to automatically inform the user that invalid data has been entered. The C lient RI includes only minimal validation. Generated from CHM, not final book. Will be superseded in the future. Page 404
- 405. For more detailed insights into the MVVM pattern, see WPF Apps With The Model-View-ViewModel Design Pattern and Introduction to Model/View/ViewModel pattern for building WPF apps on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 405
- 406. Using the Client to Bridge to External Services SharePoint 2010 does not permit solutions running in the sandbox execution environment to communicate with external services. If you want to call an external service from server-side code, you need to deploy either a farm solution that runs with full trust or deploy a full-trust proxy that communicates with the service on behalf of sandboxed solutions. However, the client-side data access mechanisms in SharePoint do provide an alternative solution. You can deploy to the sandbox environment a solution that uses client-side, rather than server-side, logic to call services that reside in other domains. Service Calls Across Domain Boundaries When you implement your client-side logic in a Silverlight application, there are two approaches you can use to access services in other domains from the client. The first approach is to deploy a service facade, or proxy, to the domain that hosts your SharePoint server. This allows your Silverlight application to access the service within its own domain and avoids any cross-domain issues. Using a services façade for cross-domain access You can also use this approach for JavaScript clients. The principal advantage is that the services facade can reuse the credentials associated with the browser session in order to authenticate the consumer of the service. However, there are various disadvantages. The approach adds an additional "hop" to the service interactions. It can be complicated to preserve the identity of a user across a double hop to the service; for example, NTLM authentication cannot be used over a double hop. This approach also requires that you develop and deploy a services facade. If you are constrained to the sandbox execution environment, you may also be unable to deploy Generated from CHM, not final book. Will be superseded in the future. Page 406
- 407. this kind of server-side component. Therefore, the reference implementation does not demonstrate this approach. The second approach is to use the Silverlight application to access the external service directly. As described in RIA Technologies: Benefits, Tradeoffs, and C onsiderations, the domain that hosts the service must define a client access policy (clientaccesspolicy.xml) file that permits access from Silverlight clients across domain boundaries. The Silverlight External Service interface in the reference implementation demonstrates this by deploying a service to a different port (which constitutes a different domain) on the SharePoint server. Cross-domain service calls from a Silverlight client The client access policy must be located at the root of the Web site that hosts the service. In the reference implementation, this is the localhost:81 site. The following code example shows the client access policy for the VendorService in the reference implementation. XML <?xml version="1.0" encoding="utf-8" ?> <access-policy> <cross-domain-access> <policy> <allow-from http-request-headers="SOAPAction"> <domain uri="http://*"/> </allow-from> <grant-to> <resource include-subpaths="true" path="/Vendor/"/> </grant-to> </policy> </cross-domain-access> </access-policy> Generated from CHM, not final book. Will be superseded in the future. Page 407
- 408. The client access policy stipulates who is allowed access and which resources they are allowed access to. In this example, callers are only permitted to access the Vendor subpath that hosts the service. It's good practice to limit the resources that you expose to cross-domain access. Securing the Service In the reference implementation, the VendorService service is secured using Windows authentication with transport-level security, which provides a balance between security and complexity. Because this is designed for a test environment, we use an unencrypted HTTP connection for the service. In a production environment this would provide an insufficient level of security and you should use an SSL connection. VendorService is installed by the Full-Trust Proxies for Sandboxed Solutions reference implementation, which is a prerequisite for the C lient RI. The installer for the C lient RI will automatically deploy the Full-Trust Proxies RI to your test environment. In order to use transport-level security with Windows and Internet Information Services (IIS), you must enable Windows authentication for the web site that hosts the service, and you must configure Microsoft Internet Information Services (IIS) to support URL authorization. URL authorization is configured by default in Windows Server® 2008, but if you are using Windows 7 you will need to configure it manually. To do this, in the Turn Windows features on or off dialog, expand Internet Information Serv ices, expand World Wide Web Serv ices, expand Security, and then ensure URL Authorization is checked, as illustrated by the following image. Enabling URL Authorization in Windows 7 The service is installed to the C ontoso Web site in IIS. You must use IIS Manager to configure authentication for Generated from CHM, not final book. Will be superseded in the future. Page 408
- 409. the site. Ensure that Windows authentication is configured for the web site that hosts the service, as shown in the following image. Authentication settings in IIS Manager When the Full-Trust Proxies RI deploys the VendorService service, it also adds an authorization policy to the Web site that hosts the service. The installer achieves this by adding the following code to the Web.config file for the C ontoso web site. XML <system.webServer> <security> <authorization> <remove users="*" roles="" verbs="" /> <add accessType="Allow" roles="Administrators" /> <add accessType="Deny" users="?" /> <add accessType="Allow" users="SandboxSvcAcct" /> </authorization> </security> </system.webServer> Note: SandboxSvcAcct is a managed account that runs the Microsoft SharePoint Foundation Sandboxed C ode Service. This was configured in the Full-Trust Proxies RI, as this is the identity provided by the full-trust proxy when a sandboxed solution uses a full-trust proxy to call the service. This account is not relevant to the C lient RI. As you can see, the policy allows members of the Administrators role and the SandboxSvcAcct user to access the service. In the C lient RI, it's assumed that you will use a member of the Administrators group to browse the Silverlight External Service interface and therefore to access the service. However, you can amend the security policy to grant access to other groups or specific users, or to experiment with alternative authorization rules. The WC F service proxy for the vendor service was generated by Visual Studio, by adding a service reference to the service at http://localhost:81/Vendor/Service.svc. Because the service was configured for transport authentication when we created the proxy, adding the service reference automatically creates the correct security policy. The following example shows the client configuration file for the vendor service. XML <configuration> <system.serviceModel> <bindings> <basicHttpBinding> <binding name="BasicHttpBinding_IVendorServices" maxBufferSize="2147483647" Generated from CHM, not final book. Will be superseded in the future. Page 409
- 410. maxReceivedMessageSize="2147483647"> <security mode="TransportCredentialOnly" /> </binding> </basicHttpBinding> </bindings> <client> <endpoint address="http://localhost:81/Vendor/Service.svc" binding="basicHttpBinding" bindingConfiguration="BasicHttpBinding_IVendorServices" contract="VendorService.IVendorServices" name="BasicHttpBinding_IVendorServices" /> </client> </system.serviceModel> </configuration> The service binding defines the security mode as TransportC redentialOnly. This instructs the WC F service to accept credentials over an unsecured HTTP connection. It should be emphasized that this approach is not appropriate for anything other than test environments. If you want to use transport-level security in a production environment, you should secure the transport with SSL encryption. Because the host web site is configured to use Windows authentication, the service will authenticate Windows credentials over the unsecured HTTP connection. With these settings in place, the service is secured for access directly from the client (in the C lient RI) and access through a full-trust proxy (in the Full-Trust Proxy RI). The C lient RI approach passes the credentials of the current user to the service, which allows for more granular authorization rules. The Full-Trust Proxy RI instead uses a trusted subsystem model—the sandbox environment removes the identity of the current user, and the identity of the managed account that runs the Sandboxed C ode Service is provided instead. Generated from CHM, not final book. Will be superseded in the future. Page 410
- 411. Using the REST Interface from JavaScript In the C lient RI, the Ajax REST interface demonstrates how to use the REST interface from an Ajax client. The interface provides a part search facility, as shown by the following diagram. The user can view the suppliers associated with each part and edit the inventory locations for each part in modal dialog boxes, by clicking the links in each row. The AJAX REST interface The JavaScript files that provide this functionality are contained within the Scripts node of the C lient.SharePoint project. The project includes three JavaScript files: clientCommon.js. This file contains the functions that are used by both the Ajax REST interface and the Ajax C SOM interface. These functions are primarily used for managing user interface elements. CsomScripts.js. This file contains data access functions that use the client-side object model (C SOM) to implement the scenario. These functions are used by the Ajax C SOM interface. RestScripts.js. This file contains data access functions that use the SharePoint REST interface to implement the scenario. These functions are used by the Ajax REST interface. Note: The Internet Explorer Developer Toolbar is a useful tool for debugging JavaScript on a Web page. To show the developer toolbar in Internet Explorer 8, press F12. The Ajax REST interface is provided by the JavascriptWithREST.aspx page. The page itself is a straightforward Web Part page that loads the JavaScript files. Within the page, the Ajax REST interface is defined by the following HTML. HTML <table> <tr> <td> <input id="skuTextBox" type="text" /> </td> <td style="text-align:left"> <input id="Button1" type="button" value="Find Parts" /> </td> </tr> <tr> <td colspan="2"> <div id="ContentDiv"> </div> </td> </tr> <tr> <td colspan="2"> <div id="divSuppliers"> <div id="divSupplierResults"> </div> </div> </td> </tr> <tr> <td colspan="2"> <div id="divLocations"> <div id="divPartLocations"> </div> <div id="divLocationAdd" style="display:none"> <input id="hidLocationId" type="hidden" /> <input id="hidPartId" type="hidden" /> <table> <tr> <td>Bin #</td> <td><input id="binText" type="text"/></td> </tr> <tr> Generated from CHM, not final book. Will be superseded in the future. Page 411
- 412. <td>Quantity</td> <td><input id="quantityText" type="text" /></td> </tr> <tr> <td> <input id="buttonSave" type="button" value="Save" onclick="savePartLocation();" /> </td> </tr> </table> </div> <input id="buttonNew" type="button" value="New Location" onclick="showLocation('0','0');" style="display:none" /> </div> </td> </tr> </table> As you can see from the code, there are many named div elements with no content. This is a common pattern in Ajax-style applications, as the div tags act as placeholders for data that will be retrieved asynchronously from the server and inserted into the page by client-side JavaScript logic. Note: SharePoint includes a ScriptLink control that you can use to register JavaScript files on an ASPX page. This control offers a number of advantages, such as on-demand loading of the required files. However, the ScriptLink control is not available in the sandbox environment, and as such it is not used in this implementation. Retrieving Data with Ajax and REST To gain an understanding of how the application works, consider what happens when the user searches for a part by SKU. The search is triggered when the user clicks the Find Parts button, defined near the top of the preceding code example: HTML <input id="Button1" type="button" value="Find Parts" /> As you can see, the button isn't declaratively wired to a JavaScript function. This implementation uses a technique known as Unobtrusive JavaScript, which aims to separate markup from script. HTML controls are wired to JavaScript event handlers when the JavaScript file loads. The following function, which is taken from the RestScripts.js file, defines an event handler function named OnButtonC lick and associates it with the client-side click event of the Find Parts button. Jav aScript $(function AssociateButtonClickWithJSONCall() { $('#Button1').click(function OnButtonClick(){ $('#ContentDiv').html(""); $('#divSupplierResults').html(""); var sku = $('#skuTextBox').val(); $.getJSON("/sites/sharepointlist/_vti_bin/listdata.svc/Parts() ?$filter=startswith(SKU,'" + sku + "') &$select=Title,SKU,Id,Description", {}, function ClearDivsAndMerge(data, status) { var parts = data.d.results; mergePartsWithInventoryLocations(sku, parts); } ); }); }); The dollar symbol ($) is shorthand for the global jQuery object and can be used to execute functions, retrieve objects or collections, and perform actions on retrieved objects or collections. In this example, the dollar symbol is used in various key ways: If you enclose a JavaScript function within parentheses preceded by a dollar symbol, jQuery will execute the Generated from CHM, not final book. Will be superseded in the future. Page 412
- 413. function when the JavaScript file is loaded. For example, the AssociateButtonClickWithJSONCall function is executed when the browser loads the RestScripts.js file. The jQuery object is used to retrieve named elements from the Web page Document Object Model (DOM). For example, $('#C ontentDiv') retrieves the div element with an ID of C ontentDiv. This is functionally similar to document.getElementById('ContentDiv ') in classic JavaScript. When the JavaScript file is loaded, jQuery immediately executes the AssociateButtonClickWithJSONCall function. This uses the jQuery click function to wire the OnButtonClick handler to the client-side click event of the Find Parts button (Button1). When the button is clicked, the OnButtonClick method performs the following actions: C lears the ContentDiv element. C lears the div SupplierResults element. Retrieves the search text from the skuTextBox element. C alls the jQuery getJSON method, which uses an HTTP GET request to retrieve JSON-encoded data from the server. The method takes a URL (which in this case corresponds to a REST query), a data object (which in this case is empty), and a callback function that is executed asynchronously if the request succeeds. Note: You don't have to name the callback function you supply to the getJSON method. However, naming the function improves the debugging experience. The function name will show up in the stack trace during debugging, and the debugging stack can become confused when anonymous functions are used. Tools that minify the JavaScript code for production will typically strip out function names in these scenarios in order to reduce the file size. The callback function, ClearDivsAndMerge, first retrieves the query results from the data returned by the REST service. It then passes these results, together with the original part SKU search text, to the mergePartsWithInventoryLocations function. Jav aScript function mergePartsWithInventoryLocations(sku, parts) { $.getJSON( "/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations() ?$filter=startswith(Part/SKU,'" + sku + "') &$orderby=Part/SKU &$expand=Part &$select=Id,BinNumber,Quantity,Part/Title,Part/SKU,Part/Id", {}, function mergePartsAndInventory(data) { var inventoryLocations = data.d.results; var bindingViewsModels = new Array(); var inventoryPartResults = new Array(); var noInventoryPartResults = new Array(); $.each(inventoryLocations, function bindViewModel(index, inventoryLocation) { var bindingViewModel = { Id: inventoryLocation.Part.Id, SKU: inventoryLocation.Part.SKU, Title: inventoryLocation.Part.Title, InventoryLocationId: inventoryLocation.Id, LocationBin: inventoryLocation.BinNumber, InventoryQuantity: inventoryLocation.Quantity }; bindingViewsModels.push(bindingViewModel); inventoryPartResults.push(inventoryLocation.Part.Id); }); //Determine parts with no inventory location $.each(parts, function addIfNoInventory(index, part) { if (arrayContainsValue(inventoryPartResults, part.Id) != true) { noInventoryPartResults.push(part); }; }); Generated from CHM, not final book. Will be superseded in the future. Page 413
- 414. $.each(noInventoryPartResults, function bindNoInventory(index, partWithNoInventoryLocation) { var bindingViewModel = { Id: partWithNoInventoryLocation.Id, SKU: partWithNoInventoryLocation.SKU, Title: partWithNoInventoryLocation.Title, LocationBin: "unassigned", InventoryQuantity: "" }; bindingViewsModels.push(bindingViewModel); }); buildTable(bindingViewsModels); }); } The mergePartsWithInv entoryLocations function first submits a new REST query to retrieve all the inventory location instances that reference a part with the specified SKU. The function then performs the logical equivalent of a left outer join between parts and inventory locations. Parts and inventory locations are merged into a collection of bindingViewModel objects, which are essentially view projections that include selected fields from both entities. Parts with no associated inventory locations are added to the collection with a LocationBin value of unassigned and an empty Inv entoryQuantity value. Finally, the function calls the buildTable function, passing in the bindingViewModels collection as an argument. The buildTable function formats the collection of view models into an HTML table, and then inserts the table into the C ontentDiv element on the web page. Jav aScript function buildTable(viewModels) { returnTable = '<table style="border: solid 1px black"> <tr style="font-weight:bold;font-style:underline"> <td>ID</td> <td>Part Name</td> <td>Part SKU</td> <td>Bin #</td> <td>Quantity</td> <td>Inventory</td> <td>Suppliers</td> </tr>'; for (var i = 0; i < viewModels.length; i++) { var item = viewModels[i]; buildRow(item); } returnTable = returnTable + '</table>'; $('#ContentDiv').html(returnTable); } The buildRow helper function converts each view model instance into a table row. As you can see, the Inv entory and Suppliers fields are rendered as hyperlinks that call JavaScript functions when clicked. Jav aScript function buildRow(item) { var sku = item["SKU"]; var partTitle = item["Title"]; var partId = item["Id"]; var bin = item["LocationBin"]; var quantity = item["InventoryQuantity"]; //id needs to be 0 if it doesn't exist var id = '0'; if (item["InventoryLocationId"] !== undefined) { Generated from CHM, not final book. Will be superseded in the future. Page 414
- 415. id = item["InventoryLocationId"] } returnTable = returnTable + '<tr><td>' + id + '</td><td>' + partTitle + '</td><td>' + sku + '</td><td>' + bin + '</td><td style="text-align:center">' + quantity + '</td><td> <a href="javascript:showLocation('' + id + '','' + partId + '');">| Edit Inventory |</a></td><td> <a href="javascript:showSuppliers('' + partId + '');"> Suppliers |</a></td></tr>'; } Updating Data with Ajax and REST The Ajax REST interface in the C lient RI allows users to update inventory locations and quantities. Making updates from JavaScript is a slightly more complex process than making updates using the Silverlight object model. When the user clicks an Edit Inventory link in the UI, a modal dialog is launched that allows users to edit the bin number and the quantity for the selected part. The Inventory Locations dialog When the user clicks Save, the savePartLocation method is called. C# var savePartLocation = function () { var locationId = $('#hidLocationId').val(); var url = '/sites/sharepointlist/_vti_bin/listdata.svc/InventoryLocations'; var beforeSendFunction; var inventoryLocationModifications = {}; if (locationId == '0') { //Insert a new Inventory Location inventoryLocationModifications.PartId = $('#hidPartId').val(); beforeSendFunction = function () { }; Generated from CHM, not final book. Will be superseded in the future. Page 415
- 416. } else { //Update Existing Inventory Location url = url + "(" + locationId + ")"; beforeSendFunction = function (xhr) { xhr.setRequestHeader("If-Match", inventoryLocation.__metadata.etag); //Using an HTTP MERGE so that the entire entity doesn't need to be sent to //the server. xhr.setRequestHeader("X-HTTP-Method", 'MERGE'); } } inventoryLocationModifications.BinNumber = $('#binText').val(); inventoryLocationModifications.Quantity = $('#quantityText').val(); var body = Sys.Serialization.JavaScriptSerializer.serialize(inventoryLocationModifications); $.ajax({ type: 'POST', url: url, contentType: 'application/json', processData: false, beforeSend: beforeSendFunction, data: body, success: function () { alert('Inventory Location Saved.'); } }); hideLocationDialogue(); } There are various points of interest in the update operation. First, note that we add an If-Match header that specifies an etag value to the request: Jav aScript xhr.setRequestHeader("If-Match", inventoryLocation.__metadata.etag); In this case, inv entoryLocation is a local variable in the RestScripts.js file. The variable is assigned when the inventory location was originally retrieved from the server, so the __metadata.etag value indicates the current version of the item on the server when the item was retrieved. The REST interface uses etags for concurrency control – if it detects that the server version has changed between the client retrieving the item and the client updating the item, the service will reject the update. Second, note that we add a header that instructs the service to use an HTTP MERGE method to update the item. Jav aScript xhr.setRequestHeader("X-HTTP-Method", 'MERGE'); The use of the MERGE verb indicates that the REST service should only update the fields that are specified in the request. However, this is sent to the server as a POST verb, as firewall rules often block HTTP requests that use extended verbs such as MERGE. CSOM Cross-Site Collection Limitation When you use the client-side object model from JavaScript, you can only access sites and objects within the site collection from which the page originated. Attempting to access a different site collection causes an Invalid Form Digest Error, which will typically result in a dialog box warning as shown in the following image. Invalid Form Digest Error Generated from CHM, not final book. Will be superseded in the future. Page 416
- 417. This limitation may be addressed in future releases of SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 417
- 418. Implementing Request Batching As described in Data Access for C lient Applications, request batching is a useful way of minimizing the number of messages that are passed between the client and the server. This reduces network traffic and provides a smoother, less chatty user interface. Both the client-side object model (C SOM) and the SharePoint REST interface support batched requests, although they implement batching in very different ways. The C lient Reference Implementation (C lient RI) demonstrates request batching with both the C SOM and the REST interface. Request Batching with the CSOM The C SOM programming model is built around request batching. When you work with the C SOM, you can perform a series of data operations on the C lientC ontext object. These operations are submitted to the server in a single request when you call the ClientContext.BeginExecuteQuery method. You can also use the ClientContext.Load method to tell the client context object what to return when it executes a batched request. The following code example, taken from the PartInv entoryViewModel class in the Silverlight C SOM interface, shows a set of batched C SOM operations using the Silverlight client API. C# List partsList = clientContext.Web.Lists.GetByTitle("Parts"); List inventoryLocationsList = clientContext.Web.Lists .GetByTitle("Inventory Locations"); CamlQuery camlQueryPartsList = new CamlQuery(); camlQueryPartsList.ViewXml = @"<View> <Query> <Where> <BeginsWith> <FieldRef Name='SKU' /> <Value Type='Text'>" + SearchSku + @"</Value> </BeginsWith> </Where> </Query> </View>"; CamlQuery camlQueryInvLocationList = new CamlQuery(); camlQueryInvLocationList.ViewXml = @"<View> <Query> <Where> <BeginsWith> <FieldRef Name='PartLookupSKU' /> <Value Type='Lookup'>" + SearchSku + @"</Value> </BeginsWith> </Where> <OrderBy Override='TRUE'> <FieldRef Name='PartLookupSKU' /> </OrderBy> </Query> <ViewFields> <FieldRef Name='PartLookup' LookupId='TRUE' /> <FieldRef Name='PartLookupSKU' /> <FieldRef Name='PartLookupTitle' /> <FieldRef Name='PartLookupDescription' /> <FieldRef Name='BinNumber' /> <FieldRef Name='Quantity' /> </ViewFields> <ProjectedFields> <Field Name='PartLookupSKU' Type='Lookup' List='PartLookup' ShowField='SKU' /> <Field Name='PartLookupTitle' Type='Lookup' List='PartLookup' ShowField='Title' /> <Field Name='PartLookupDescription' Type='Lookup' List='PartLookup' Generated from CHM, not final book. Will be superseded in the future. Page 418
- 419. ShowField='PartsDescription' /> </ProjectedFields> <Joins> <Join Type='LEFT' ListAlias='PartLookup'> <!--List Name: Parts--> <Eq> <FieldRef Name='PartLookup' RefType='ID' /> <FieldRef List='PartLookup' Name='ID' /> </Eq> </Join> </Joins> </View>"; partListItems = partsList.GetItems(camlQueryPartsList); inventoryLocationListItems = inventoryLocationsList.GetItems(camlQueryInvLocationList); clientContext.Load(partListItems); clientContext.Load(inventoryLocationListItems); clientContext.ExecuteQueryAsync(onQuerySucceeded, onQueryFailed); Note: partListItems and inv entoryLocationListItems are local variables of type ListItemCollection. The clientContext object is instantiated with the site URL in the view model constructor. In this example, the following actions are batched on the client: The Parts list is retrieved by title. The Inventory Locations list is retrieved by title. A C AML query is executed against the Parts list. A C AML query is executed against the Inventory Locations list. This query uses a left outer join across the Inventory Locations list and the Parts list, and returns a view projection. The results of both C AML queries are loaded into the client context object as list item collections. However, none of these actions are sent to the server and executed until the call to ExecuteQueryAsync is made at the bottom of the code example. When the server responds to the batched request, the partListItems and inv entoryLocationListItems collections are populated with the query results. At this point, we can parse these collections to update the user interface, as shown by the following code example. C# private void DisplayParts() { List<int> inventoryPartResults = new List<int>(); //Populate BindingViewsModels with Parts with InventoryLocations foreach (ListItem inventoryLocationListItem in inventoryLocationListItems) { PartInventory view = new PartInventory(); view.InventoryItem.Id = int.Parse(inventoryLocationListItem["ID"].ToString()); view.InventoryItem.Quantity = int.Parse(inventoryLocationListItem["Quantity"].ToString()); view.InventoryItem.BinNumber = inventoryLocationListItem["BinNumber"].ToString(); view.Part.SKU = ((FieldLookupValue) inventoryLocationListItem["PartLookupSKU"]).LookupValue; view.Part.Title = ((FieldLookupValue) inventoryLocationListItem["PartLookupTitle"]).LookupValue; view.Part.Id = ((FieldLookupValue) inventoryLocationListItem["PartLookup"]).LookupId; view.Part.Description = ((FieldLookupValue) inventoryLocationListItem["PartLookupDescription"]).LookupValue; Parts.Add(view); inventoryPartResults.Add(view.Part.Id); Generated from CHM, not final book. Will be superseded in the future. Page 419
- 420. } ... Request Batching with REST You can also batch requests to the SharePoint REST interface. REST is underpinned by the OData protocol, which allows you to batch requests by creating a multi-part MIME format request. The DataServiceC ontext class provides a method, BeginExecuteBatch, which you can use to submit multiple queries to the REST service. The following code example, taken from the PartInv entoryViewModel class in the Silverlight REST interface, shows a set of batched REST operations using the Silverlight client API. C# public void RefreshSearchSku(string Sku) { SearchSku = Sku; var inventoryLocationsQuery = (DataServiceQuery<InventoryLocationsItem>)context.InventoryLocations .Expand("Part") .AddQueryOption("$select", "BinNumber,Quantity,Title,Id,PartId,Part/SKU,Part/Title,Part/Id") .Where(p => p.Part.SKU.StartsWith(SearchSku)) .OrderBy(p => p.Part.SKU); var partsQuery = (DataServiceQuery<PartsItem>)context.Parts .Where(p => p.SKU.StartsWith(SearchSku)) .Select(p => new PartsItem { Title = p.Title, SKU = p.SKU, Id = p.Id, Description = p.Description }); //Execute Query as a Batch context.BeginExecuteBatch(DisplayParts, context, inventoryLocationsQuery, partsQuery); } The BeginExecuteBatch method accepts a params array of DataServiceRequest objects, so you can submit as many simultaneous queries as you want. However, unlike the C SOM approach, you must manually parse the response in order to retrieve the query results. The following code shows the DisplayParts callback method for the batched request. C# private void DisplayParts(IAsyncResult result) { Dispatcher.BeginInvoke(() => { Parts.Clear(); List<PartsItem> AllPartResults = new List<PartsItem>(); List<PartsItem> NoInventoryPartResults = new List<PartsItem>(); //Get the Batch Response DataServiceResponse Response = context.EndExecuteBatch(result); //Loop through each operation foreach (QueryOperationResponse Operation in Response) { if (Operation.Error != null) { Generated from CHM, not final book. Will be superseded in the future. Page 420
- 421. throw Operation.Error; } if (Operation is QueryOperationResponse<InventoryLocationsItem>) { //Process Results foreach (InventoryLocationsItem location in Operation as QueryOperationResponse<InventoryLocationsItem>) { PartInventory partInventory = new PartInventory(); partInventory.Part = location.Part; partInventory.InventoryItem = location; Parts.Add(partInventory); InventoryPartResults.Add(location.Part); } } if (Operation is QueryOperationResponse<PartsItem>) { //Process Results foreach (PartsItem part in Operation as QueryOperationResponse<PartsItem>) { AllPartResults.Add(part); } } } foreach (var allPartResult in AllPartResults .Where(allPartResult => !InventoryPartResults.Contains(allPartResult))) { NoInventoryPartResults.Add(allPartResult); } foreach (var part in NoInventoryPartResults) { PartInventory partInventory = new PartInventory(); partInventory.Part = part; partInventory.InventoryItem = null; Parts.Add(partInventory); } }); } In this case, the callback method iterates through a set of query responses. It uses the type of each query response to make a decision on how to process the result set. Update Batching When you use the C SOM or the REST interface, the context object manages change tracking for you. The Client.CSOM.Silverlight and Client.REST.Silverlight projects take advantage of this behavior to support the batching of updates. The following code shows a list update using the C SOM. C# public void UpdateInventoryLocation() { List inventoryLocationsList = clientContext.Web.Lists.GetByTitle("Inventory Locations"); ListItem inventoryLocation = null; inventoryLocation = inventoryLocationsList.GetItemById(currentItem.InventoryItem.Id); inventoryLocation["BinNumber"] = currentItem.InventoryItem.BinNumber; inventoryLocation["Quantity"] = currentItem.InventoryItem.Quantity; inventoryLocation.Update(); } Generated from CHM, not final book. Will be superseded in the future. Page 421
- 422. Notice that the BeginExecute method is not called on the client context object. Therefore, these updates remain in memory on the client and are not immediately sent to the server. The user can update many items through the user interface without causing a request to be sent to the server. When the user clicks the Sav e Changes button in the user interface, all of the pending changes are committed to SharePoint simultaneously. C# public void Update() { clientContext.ExecuteQueryAsync(onUpdatePartLocationSuccess, onQueryFailed); } The REST implementation works in a similar way, although in this case the REST service proxy, PartsDataContext, tracks the changes. C# public void UpdateInventoryLocation() { context.UpdateObject(CurrentItem.InventoryItem); } When the user clicks Save Changes, the code commits all the pending changes to SharePoint by calling the BeginSav eChanges on the context object. Notice that the SaveC hangesOptions.Batch argument is added to indicate that this is a batch update. C# public void Update() { context.BeginSaveChanges(SaveChangesOptions.Batch, OnSaveChanges, null); } In general, batched operations provide a better user experience and make more efficient use of network bandwidth and server resources. Generated from CHM, not final book. Will be superseded in the future. Page 422
- 423. Conclusion The C lient Reference Implementation (C lient RI) demonstrates best practice approaches to various aspects of client-side solution development for SharePoint 2010. The key points illustrated by the C lient RI include the following: Side-by-side comparisons of the client-side object model (C SOM) and the REST interface, both from a Silverlight UI and an Ajax UI. The use of the Model-View-ViewModel (MVVM) pattern with the SharePoint Silverlight client API. The use of client-side logic to access external services. The use of request batching, both with the C SOM and the REST interface, for improved efficiency and user experience. We recommend deploying the reference implementation and exploring the different components and code in the client solution. For more information about client-side solution development for SharePoint 2010, see C lient Application Models. Generated from CHM, not final book. Will be superseded in the future. Page 423
- 424. Client Models: How-to Topics When the client models reference implementations were developed, several tasks proved challenging to accomplish. In some cases the procedures were simple but hard to find, in other cases they were somewhat complicated. The following topics address these issues and provide step-by-step instructions on how to complete the tasks. How to: Enable EC MA C lient Object Model IntelliSense in Visual Studio 2010 How to: C onstruct and Process Batch Queries by Using REST How to: C reate a REST Service Proxy How To: Use a SharePoint Project to Deploy a Silverlight Application Generated from CHM, not final book. Will be superseded in the future. Page 424
- 425. How to: Enable ECMA Client Object Model IntelliSense in Visual Studio 2010 Overview The Microsoft® SharePoint® 2010 EC MA C lient Object Model allows developers to interact with SharePoint from JavaScript code running in a Web browser. This topic shows you how to enable Microsoft IntelliSense® for the EC MA C lient Object Model in the Microsoft Visual Studio® 2010 development system. This how-to topic describes the following procedures: Enabling EC MA C lient Object Model IntelliSense for an application page Enabling EC MA C lient Object Model IntelliSense for a Visual Web Part Enabling EC MA C lient Object Model IntelliSense for a standalone JavaScript file Note: This how-to topic assumes that you have created a project in Visual Studio 2010 by using the Empty SharePoint Project template. Enabling ECMA Client Object Model IntelliSense for an Application Page This procedure registers script tags in an application page. This allows Visual Studio 2010 to provide EC MA C lient Object Model IntelliSense for the application page. To enable ECMA Client Object Model IntelliSense for an application page 1. In the Solution Explorer window, right-click the project node, point to Add, and then click New Item. 2. In the New Item dialog box, in the Installed Templates pane, expand Visual C#, expand SharePoint , and then click 2010. 3. To the right of the Installed Templates pane, click Application Page. 4. In the Name box, type the name that you want to use for your application page. 5. C lick Add. 6. On the application page, in the PageHead content placeholder, add the following code. HTML <% #if SOME_UNDEFINED_CONSTANT %> <script type="text/javascript" SRC="C:ABCTemp_layouts/SP.debug.js" ></script> <% #endif %> Note: Note: by using an undefined constant, Visual Studio will provide Intellisense while the <script> element is omitted from the actual page rendering 7. Notice that the Visual Studio 2010 status bar indicates that it is updating the JavaScript IntelliSense for your page, as shown by the following illustration. 8. 9. On the application page, in the PageHead content placeholder, use the following code to add another script tag and create a JavaScript function. HTML <script type="text/javascript" language="javascript"> ExecuteOrDelayUntilScriptLoaded(test, "sp.js"); function test() { this.ClientContext = SP.ClientContext.get_current(); } </script> 10. Notice the IntelliSense is available for the EC MA C lient Object Model, as shown by the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 425
- 426. 11. Note: Depending on the portions of the object model that you are working with, you might need to add script tags that reference other SharePoint C lient Object Model .js files. These files can be found in the _layouts virtual directory. Enabling ECMA Client Object Model IntelliSense for a Visual Web Part This procedure registers script tags in a Visual Web Part. This allows Visual Studio 2010 to provide EC MA C lient Object Model IntelliSense for a Visual Web Part. To enable ECMA Client Object Model IntelliSense for a Visual Web Part 1. In the Solution Explorer window, right-click the project node, point to Add, and then click New Item. 2. In the New Item dialog box, in the Installed Templates pane, expand Visual C#, expand SharePoint , and then click 2010. 3. To the right of the Installed Templates pane, click Visual Web Part. 4. In the Name box, type the name that you want to use for your Visual Web Part. 5. C lick Add. 6. In the Visual Web Part .ascx file, add the following code. HTML <% #if SOME_UNDEFINED_CONSTANT %> <script type="text/javascript" SRC="C:ABCTemp_layouts/MicrosoftAjax.js" ></script> <script type="text/javascript" SRC="C:ABCTemp_layouts/SP.debug.js"></script> <% #endif %> 7. Notice that the Visual Studio 2010 status bar indicates that it is updating the JavaScript IntelliSense for your page, as shown by the following illustration. 8. 9. In the Visual Web Part ASCX file, use the following code to add another script tag and create a JavaScript function. HTML <script type="text/javascript" language="javascript"> ExecuteOrDelayUntilScriptLoaded(test, "sp.js"); function test() { this.ClientContext = SP.ClientContext.get_current(); } Generated from CHM, not final book. Will be superseded in the future. Page 426
- 427. </script> 10. Notice that IntelliSense is now available for the EC MA C lient Object Model, as shown by the following illustration. 11. Note: Note: Depending on the portions of the object model that you are working with, you might need to add tags that reference other SharePoint C lient Object Model .js files. These files can be found in the _layouts virtual directory. You should remove the references to the .js files that enable IntelliSense when you deploy the Visual Web Part in a production environment. Enabling ECMA Client Object Model IntelliSense for a Standalone JavaScript File This procedure registers script tags in a standalone JavaScript file. This allows Visual Studio 2010 to provide EC MA C lient Object Model IntelliSense for a standalone JavaScript file. To enable ECMA Client Object Model IntelliSense for a standalone Jav aScript file 1. In the Solution Explorer window, right-click the project node, point to Add, and then click New Item. 2. In the New Item dialog box, in the Installed Templates pane, expand Visual C#, and then click Web. 3. To the right of the Installed Templates pane, click Jscript F ile. 4. In the Name box, type the name that you want to use for your JavaScript file. 5. C lick Add. 6. In the JavaScript file, add the following code. Jav aScript /// <reference path="C:Program FilesCommon FilesMicrosoft SharedWeb Server Extensions14TEMPLATELAYOUTSMicrosoftAjax.js" /> /// <reference path="C:Program FilesCommon FilesMicrosoft SharedWeb Server Extensions14TEMPLATELAYOUTSSP.debug.js" /> 7. Notice that the Visual Studio 2010 status bar indicates that it is updating the JavaScript IntelliSense for your page, as shown by the following illustration. 8. 9. In the JavaScript file, add the following code. Jav aScript ExecuteOrDelayUntilScriptLoaded(test, "sp.js"); function test() { this.ClientContext = SP.ClientContext.get_current(); } 10. Notice that IntelliSense is now available for the EC MA C lient Object Model, as shown by the following illustration. Generated from CHM, not final book. Will be superseded in the future. Page 427
- 428. 11. Note: Note: Depending on the portions of the object model that you are working with, you might need to add tags that reference other SharePoint C lient Object Model .js files. These files can be found in the _layouts virtual directory. You should remove the references to the .js files that enable IntelliSense when you deploy the standalone JavaScript file in a production environment. Generated from CHM, not final book. Will be superseded in the future. Page 428
- 429. How to: Construct and Process Batch Queries by Using REST Overview This topic shows you how to submit batched queries to the Microsoft® SharePoint® Foundation representational state transfer (REST) interface from a Microsoft Silverlight® application, and how to process the response from the service. Note: This how-to topic assumes that you have an existing Microsoft Visual Studio® development system solution that contains a Silverlight project. It also assumes that you have added a reference to the SharePoint Foundation REST interface, as described in How to: C reate a REST Service Proxy. This topic uses the Team Discussion list as an example. The Team Discussion list is created by default on SharePoint 2010 team sites. If you created your SharePoint site from a different site definition, this list may not be available. Summary of Steps This topic describes the following steps: Step 1: Create Multiple REST Queries. In this step, you use your service reference to construct multiple REST queries that will be sent to the server in a single batch. Step 2: Create the Delegate Method and Process the Results. In this step you create the delegate method that will process the batch results. Step 1: Create Multiple REST Queries This procedure creates several queries against the Team Discussion list, and submits them to the REST interface as a batched request. Note: Typically, you add the code examples listed below to the code-behind file for your Silverlight control. In this example, we use the click event handler of a button to create and submit the query. To create and submit a batched request 1. Add a using statement that points to the REST service reference. Use the following format. [Your.Silverlight.Project].[YourService.Namespace] In the following example, Client.SilverlightSample is the Silverlight project namespace and Sample.ServiceReference is the service namespace. C# using Client.SilverlightSample.Sample.ServiceReference; 2. Use the default constructor to instantiate the data context entity for the service, as shown in the following example. The name of your data context class will take the form <sitename>DataContext, where <sitename> is the name of your SharePoint site. C# private void button1_Click(object sender, RoutedEventArgs e) { DataDataContext context = new DataDataContext(); } 3. C reate your query objects. The following example creates three queries against the Team Discussion list. C# // Get anything with the word 'Business' in the Body var query1 = context.TeamDiscussion .Where(p => p.Body.Contains("Business")); Generated from CHM, not final book. Will be superseded in the future. Page 429
- 430. // Get anything that was created within the previous 14 days var query2 = context.TeamDiscussion .Where(p => p.Created.Value > DateTime.Now.AddDays(-14)); // Get anything with an attachment var query3 = context.TeamDiscussion .Where(p => p.Attachments != null && p.Attachments.Count > 0); 4. C all the BeginExecuteBatch method on the data context to submit your queries as a batched request. Supply the following objects as arguments to the BeginExecuteBatch method. a. A callback delegate that points to the method you want to invoke when the query returns. In this case, we will create a callback method named DisplayDiscussions in step 2. b. A state object, which in this case is the data context instance. c. Each of your query objects. The method accepts a parameter array of query objects; therefore, you can submit as many queries as required. C# context.BeginExecuteBatch(DisplayDiscussions, context, query1, query2, query3); Step 2: Create the Delegate Method and Processing the Results This procedure creates a callback method to process the results of the batch query. In this example, we create a method named DisplayDiscussions to match the delegate used in the last task of step 1. To process the batched results 1. C reate a new private method named DisplayDiscussions that accepts a single parameter of type IAsyncResult. C# private void DisplayDiscussions (IAsyncResult result) { } 2. In the DisplayDiscussions method, add a call to the Dispatcher.BeginInv oke() method. This is used to process the results on the UI thread. C# private void DisplayDiscussions (IAsyncResult result) { Dispatcher.BeginInvoke(() => { //Process results here }); } Note: The results are processed on the UI thread because, typically, Silverlight applications maintain results in ObservableCollection instances, which are tightly data-bound to the UI. Updating the observable collection will also update the UI. All UI updates must be performed on the UI thread. 3. Add code to retrieve the response from the data service and process each response operation. For each response operation, check the following before you process the results. a. C heck that the operation is error free. b. C heck that the operation is of the expected type. C# private void DisplayParts(IAsyncResult result) { Dispatcher.BeginInvoke(() => { //Get the Batch Response DataServiceResponse Response = context.EndExecuteBatch(result); //Loop through each operation foreach (QueryOperationResponse Operation in Response) { if (Operation.Error != null) Generated from CHM, not final book. Will be superseded in the future. Page 430
- 431. { throw Operation.Error; } //Check the Operation is of the expected type if (Operation is QueryOperationResponse<TeamDiscussionItem>) { //TODO: Process your results } } }); } 4. Note: Note: This is a simple example in which each query returns a result of the same type (TeamDiscussionItem in this case). If you are processing results of varying types, you must check the type of each OperationResponse before processing it. For more information, see Using the REST Interface in the C lient Reference Implementation. Generated from CHM, not final book. Will be superseded in the future. Page 431
- 432. How to: Create a REST Service Proxy Overview The Microsoft® SharePoint® Foundation REST interface provides a simple and robust mechanism for accessing SharePoint list data from external applications. Although REST services can be accessed directly by using HTTP verbs, and manipulated by using either Atom or JavaScript Object Notation (JSON), you can also generate a Windows C ommunication Foundation (WC F) Data Services client proxy for the REST service. This allows developers to interact with the REST service by using strongly typed objects and a consistent development model. Note: This how-to topic assumes that you have used the Microsoft Visual Studio® 2010 development system to create a solution that contains a Microsoft Silverlight® application project, and that you have installed and configured ADO.NET Data Services in your development environment, as described in the SharePoint 2010 installation prerequisites. Steps This procedure describes how to use Visual Studio 2010 to create a service proxy for the SharePoint REST interface. You can use this service proxy to interact with the REST service from client-side code. This procedure assumes that you have already created a Visual Studio 2010 project. To generate a serv ice proxy 1. In Solution Explorer, right-click the project node, and then click Add Serv ice Reference. 2. In the Add Serv ice Reference dialog box, in the Address text box, type the URL of the REST service, and then click Go. Note: The REST interface is exposed on every SharePoint site. The URL of the REST service is <site URL> /_vti_bin/ListData.svc. 3. 4. In the Serv ices list box, select the REST service. In the Namespace text box, type the friendly name for Generated from CHM, not final book. Will be superseded in the future. Page 432
- 433. the service, and then click OK. Note: The REST service will always be named <sitename>DataContext, where <sitename> is the name of the SharePoint site. 5. 6. When you click OK, Visual Studio creates the service proxy classes. You can now use the service proxy to interact with the REST interface from your code. 7. In the code-behind for your Silverlight control, instantiate the data context class, using the fully qualified URL of the REST service. Note: You should declare and instantiate the data context at the class level so that it is available to all the methods on your control. C# PartsDataContext context = new PartsDataContext(new Uri("http://localhost/sites/sharepointlist/_vti_bin/listdata.svc")); You can now use the data context to create and submit queries to the REST interface. For more information about using the service proxy with the REST interface, see the C lient Reference Implementation. Generated from CHM, not final book. Will be superseded in the future. Page 433
- 434. How to: Use a SharePoint Project to Deploy a Silverlight Application Overview In many client-side development scenarios, you will want to use a Microsoft® SharePoint® project created in the Microsoft Visual Studio® 2010 development system to deploy a Microsoft Silverlight® application to a SharePoint environment. This topic shows you how to deploy a Silverlight application to the master page gallery in a SharePoint site. It also demonstrates how to provision a page that hosts the Silverlight control. Note: This how-to topic assumes that you have an existing Visual Studio solution that contains a Silverlight application project, and that you have an existing SharePoint environment that has a team site provisioned. It is not appropriate to deploy a Silverlight application to the master page gallery in every scenario. For more information, see C lient Application Models. Summary of Steps This how-to topic includes the following steps: Step 1: Create the SharePoint project. In this step, you add a SharePoint project to your Visual Studio solution. You also add modules to provision the Silverlight application and the Web Part page. Step 2: Configure the SharePoint project. In this step, you configure the SharePoint project to deploy the output of the Silverlight project. You also configure feature manifest files to add a Silverlight Web Part that hosts your Silverlight application to the Web Part page. Step 3: Enable Silv erlight debugging. In this step, you configure the SharePoint project to enable Silverlight debugging. This allows you to debug Silverlight code running on a SharePoint Web Part page in a browser window. Step 1: Create the SharePoint Project This procedure adds a SharePoint project to a Visual Studio 2010 solution. To add a SharePoint project 1. In Solution Explorer, right-click the solution node, point to Add, and then click New Project. 2. In the New Project dialog box, select the Empty SharePoint Project template, provide a name for the project, and then click OK. Generated from CHM, not final book. Will be superseded in the future. Page 434
- 435. 3. On the SharePoint C ustomization Wizard page, provide the URL of your local SharePoint site, select Deploy as a farm solution, and then click Finish. Generated from CHM, not final book. Will be superseded in the future. Page 435
- 436. 4. Add the following SharePoint 2010 project items to the project: a. A module named Silv erlight. Delete the Sample.txt file that is added automatically. b. A module named Pages. Delete the Sample.txt file that is added automatically. Step 2: Configure the SharePoint Project This procedure configures the SharePoint project to deploy the .xap file generated by your Silverlight project. It also configures the project to deploy a Web Part page that hosts your Silverlight control in a Silverlight Web Part. To configure the SharePoint project 1. In Solution Explorer, right-click the Silv erlight node, and then click Properties. 2. In the Properties window, click Project Output References, and then click the ellipsis (…) button. 3. In the Project Output References window, click Add. 4. In the properties pane for the new project output reference, perform the following actions: a. In the Deployment Type drop-down list, select ElementF ile. b. In the Project Name drop-down list, select the name of your Silverlight application project, and then click OK. Generated from CHM, not final book. Will be superseded in the future. Page 436
- 437. 5. In Solution Explorer, expand the Silverlight node, and then open the Elements.xml file. 6. Modify the Elements.xml file to resemble the following code. Note: In the File element, change the value of the Path attribute to the build location of your .xap file in the Visual Studio solution. C hange the value of the Url attribute to the file name of your .xap file. XML <?xml version="1.0" encoding="utf-8"?> <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Silverlight" Url="_catalogs/masterpage"> <File Path="SilverlightSilverlightApp.xap" Url="SilverlightApp.xap" Type="GhostableInLibrary" /> </Module> </Elements> 7. At this point, you have configured the SharePoint project to deploy the Silverlight .xap file to the master page gallery. Next, you will add and configure a Web Part page to host the Silverlight control. 8. In Solution Explorer, right-click the Pages node, point to Add, and then click Existing Item. 9. In the Add Existing Item dialog box, browse to 14TEMPLATESiteTemplatesstsdefault.aspx in the SharePoint root, and then click Add. Note: This adds a copy of the default.aspx file to the Pages node. You could also use a page from any other site template or create your own page. 10. In Solution Explorer, expand the Pages node, and then open the Elements.xml file. 11. Modify the Elements.xml file to resemble the following code. Note: In the File element, change the value of the Url attribute to the relative URL you want to use for the Web Part page. XML <?xml version="1.0" encoding="utf-8"?> <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Module Name="Pages" Url="SitePages"> <File Path="Pagesdefault.aspx" Url="SilverlightTest.aspx" Type="GhostableInLibrary"> Generated from CHM, not final book. Will be superseded in the future. Page 437
- 438. </File> </Module> </Elements> 12. In the Elements.xml file, in the F ile element, add the following XML. This adds a Silverlight Web Part and configures it to host your Silverlight control. XML <AllUsersWebPart WebPartOrder="1" WebPartZoneID="Left" ID="SilverlightExternalService"> <![CDATA[ <webParts> <webPart xmlns="http://schemas.microsoft.com/WebPart/v3"> <metaData> <type name="Microsoft.SharePoint.WebPartPages.SilverlightWebPart, Microsoft.SharePoint, Version=14.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c" /> <importErrorMessage>Cannot import this WebPart. </importErrorMessage> </metaData> <data> <properties> <property name="HelpUrl" type="string" /> <property name="AllowClose" type="bool">True</property> <property name="ExportMode" type="exportmode">All</property> <property name="Hidden" type="bool">False</property> <property name="AllowEdit" type="bool">True</property> <property name="Direction" type="direction">NotSet</property> <property name="TitleIconImageUrl" type="string" /> <property name="AllowConnect" type="bool">True</property> <property name="HelpMode" type="helpmode">Modal</property> <property name="CustomProperties" type="string" null="true" /> <property name="AllowHide" type="bool">True</property> <property name="Description" type="string">A web part to display a Silverlight application.</property> <property name="CatalogIconImageUrl" type="string" /> <property name="MinRuntimeVersion" type="string" null="true" /> <property name="ApplicationXml" type="string" /> <property name="AllowMinimize" type="bool">True</property> <property name="AllowZoneChange" type="bool">True</property> <property name="CustomInitParameters" type="string" null="true"/> <property name="Height" type="unit">650px</property> <property name="ChromeType" type="chrometype">Default</property> <property name="Width" type="unit">800px</property> <property name="Title" type="string">Silverlight Web Part</property> <property name="ChromeState" type="chromestate">Normal</property> <property name="TitleUrl" type="string" /> <property name="Url" type="string"> ~site/_catalogs/masterpage/SilverlightApp.xap</property> <property name="WindowlessMode" type="bool">True</property> </properties> </data> </webPart> </webParts> ]]> </AllUsersWebPart> Note: Pay particular attention to the Url property, which must point to the location of your .xap file in the master page gallery. Make sure that the Height and Width properties match the dimensions of your Silverlight application. Step 3: Enable Silverlight Debugging Generated from CHM, not final book. Will be superseded in the future. Page 438
- 439. This procedure configures the SharePoint project to allow Silverlight debugging. To enable Silv erlight debugging 1. In the Solution Explorer, right-click the SharePoint project node, and then click Properties. 2. On the Properties page, on the SharePoint tab, select Enable Silv erlight debugging (instead of Script debugging). 3. In Solution Explorer, select the SharePoint project, and then press F 5 to build and run the solution with the debugger attached. You can add breakpoints to the Silverlight application and step through your code as required. Generated from CHM, not final book. Will be superseded in the future. Page 439
- 440. Application Foundations for SharePoint 2010 There is a world of difference between simply making your code work and writing production-quality applications. Before you look at specific areas of SharePoint functionality in greater detail, it's important to ensure that your solutions are built on solid foundations. This chapter looks at how you can improve the quality of your code across the entire spectrum of SharePoint functional areas. It also introduces some of the reusable components that are included in the SharePoint Guidance Library to help you develop better solutions. So what makes good code? Performance and stability are obviously at the top of the list. However, when you develop code for enterprise-scale applications, other concerns become increasingly important: Testability. C an you test your classes in isolation? If your code is tightly coupled to a user interface, or relies on specific types, this can be challenging. Flexibility. C an you update or replace dependencies without editing and recompiling your code? Configuration. How do you manage configuration settings for your solution? Will your approach scale out to an enterprise-scale deployment environment? Logging and exception handling. How do you log exceptions and trace information in the enterprise environment? Is your approach consistent with that of other developers on the team? Are you providing system administrators with reliable information that they can use to diagnose problems effectively? Maintainability. How easy is it to maintain your code in a code base that is constantly evolving? Do you have to rewrite your code if a dependent class is updated or replaced? This topic is designed to provide you with guidance on how to address these challenges when you develop enterprise-scale solutions for SharePoint 2010. The content does not provide an introduction to SharePoint development—if you're looking for guidance on getting started, visit the SharePoint Developer C enter on MSDN. This content is for developers with some experience with the SharePoint product suite who want to improve the quality and robustness of their SharePoint applications through best practice use of design patterns. The SharePoint Guidance Library includes reusable components and utility classes that can help you to address each of these challenges: The SharePoint Service Locator can help you to develop testable, modular code, by enabling you to decouple your code from dependencies on external types. The Application Setting Manager can help you to manage configuration settings, by providing a robust, consistent mechanism that you can use to store and retrieve configuration settings at each level of the SharePoint hierarchy. The SharePoint Logger can help you to log exceptions and trace information in a consistent, informative way, by providing easy-to-use utility methods that write to the Windows Event log and the ULS (SharePoint Unified Logging Service) trace log. Note: The August 2009 Developing SharePoint Applications release, which targets the SharePoint 2007 platform, covers many areas related to quality and supportability in greater depth. You can review this guidance in C onsiderations for Enterprise Scale Applications on MSDN. This release focuses on a subset of fundamentals for managing testability, flexibility, application configuration, and logging in SharePoint 2010, together with the reusable components that can help you in these areas. Testability and Flexibility When you write a unit test, you are aiming to isolate a piece of code in order to test it with known inputs. You typically need to substitute dependencies—such as external code, data sources, and the user interface—with fake implementations that provide the specific conditions that you want to test. These fake implementations are referred to by various names, but most often, they are known as mocks or stubs. When you write flexible, modular code, you are also aiming to isolate your code from the implementation details of external classes, data sources, and the user interface. Ideally, you should be able to amend or replace dependencies without editing and recompiling your code. As such, testability and flexibility go hand in hand. To write fully testable code is to write flexible, pluggable code. You can use a combination of design patterns to isolate your code in this way. The Service Locator pattern allows you to request an implementation of an interface without knowing the details of the implementation. As such, you can replace dependencies with alternative implementations or mock implementations without editing or recompiling your code. The Model-View-Presenter (MVP) pattern allows you to isolate the business logic in your application from the user interface. As such, you can test the business logic in isolation. You can also make the business logic Generated from CHM, not final book. Will be superseded in the future. Page 440
- 441. easier to understand and maintain by removing user interface–specific implementation details. The Repository pattern allows you to isolate the data access code in your application from the business logic. You can use the Repository pattern to wrap any data source, such as a database or a SharePoint list. This allows you to test the data access code in isolation and to substitute the data access implementation to unit test your business logic. The Service Locator pattern is particularly valuable in enterprise-scale applications because it decouples your code from all its dependencies. The advantages go beyond facilitating unit tests. This pattern makes the entire solution more modular and more flexible, because you can update and replace individual components without having to edit and recompile consumer classes. Just like the previous releases of the SharePoint Guidance Library, this release includes a SharePoint-specific implementation of the Service Locator pattern that you can use in your own solutions. For more information, see The SharePoint Service Locator. When you start writing code for SharePoint applications with testing in mind, it is important to understand the difference between unit tests and integration tests. Unit tests isolate your code from all its dependencies and should run outside the SharePoint execution environment. Unit tests typically execute very quickly, allowing rapid iterations. They also allow you to test error conditions that would be hard to reproduce with actual SharePoint logic, such as a disk or database running out of space. On the other hand, integration tests follow later and test whether your code functions as expected in its target execution environment. In this case, integration tests run against the SharePoint 2010 APIs. For more information about unit testing and integration testing, see Testing SharePoint Solutions. This release describes how to use a test framework named Moles, which is scheduled to ship with the next release of Visual Studio Power Tools. The Moles framework allows you to create mock objects for use in unit tests. For example, you can create mock SharePoint objects that allow you to run unit tests from outside the SharePoint execution environment. It also allows you to run integration tests directly against the SharePoint execution environment. For more information, see The Moles Framework. Note: Previous releases of the SharePoint Guidance Library demonstrated the use of another third-party mocking product named TypeMock Isolator. TypeMock Isolator provides similar functionality using a behavior-driven approach. TypeMock also has a specific version of Isolator that targets the SharePoint APIs. Configuration Almost every application needs to store and retrieve configuration data of some kind, such as the location of lists that are shared between applications and other environment-specific variables. However, when you develop solutions for a platform like SharePoint 2010, it's not always obvious where you should store your configuration settings. The first complicating factor is the hierarchical logical architecture of SharePoint. When you deploy a SharePoint application, you will typically scope your application to one of these logical levels—the server farm, the Web application, the site collection, or the site. At each of these levels, different mechanisms are available for the storage and retrieval of configuration settings. Other factors such as payload size, serialization, and security constraints will also affect your choice of storage mechanism. You can use the following mechanisms to manage configuration information within the SharePoint environment: Web.config. You can add configuration data to the configuration file either declaratively or programmatically. This effectively confines your configuration settings to the Web application scope. Hierarchical object store. You can use the SPPersistedObject class to persist strongly-typed data at any level of the SharePoint hierarchy. Property bags. Each level of the SharePoint hierarchy exposes property bags, albeit with slightly different access mechanisms. Lists. You can persist configuration data to a SharePoint list. This effectively confines your configuration settings to the site collection scope or the site scope. For more information about each of these storage mechanisms, together with the advantages and disadvantages of each approach, see the following resources on MSDN: Managing Application C onfiguration Managing C ustom C onfiguration Options for a SharePoint Application Because of the complexities in choosing and implementing an appropriate strategy for the storage of configuration data, the SharePoint Guidance team has developed a reusable component named the C onfiguration Manager. The C onfiguration Manager provides a consistent, strongly-typed mechanism that you can use to store and retrieve configuration settings in property bags at any level of the SharePoint hierarchy. The C onfiguration Generated from CHM, not final book. Will be superseded in the future. Page 441
- 442. Manager also provides a hierarchical storage model, which allows you to override settings at different levels of the hierarchy. For example, if you have defined a configuration setting at the site collection level, you can override this setting for a specific site by adding the same configuration key at the site level. For more information, see the Application Setting Manager. Logging and Exception Handling When you develop an application for any platform, you must ensure that your application provides information about run-time issues to system administrators. In many cases, you will also want to record trace information so that developers can follow the execution of your application through key points in the logic. For general guidance on using event logs and trace logs for SharePoint applications, see Providing Application Diagnostics. SharePoint 2010 includes enhanced functionality for logging and tracing. You can now throttle reporting to the Windows Event Log and the Office Server Unified Logging Service (ULS) trace logs by area and by category. Areas represent broad regions of SharePoint functionality, such as Access Services, Business C onnectivity Services, and Document Management Server. Within each area, categories define more specific aspects of functionality. For example, the Document Management Server area includes categories named Document Management, Information Policy Management, and Records C enter. In addition to areas and categories, SharePoint 2010 makes substantial improvements to event correlation. Every trace log entry now includes a correlation ID that identifies all the events that correspond to a particular action, such as a user uploading a document. Administrators can use tools such as the ULS Viewer to filter the trace logs by correlation ID. The platform also provides a centralized logging database that allows you to consolidate diagnostic information and generate reports. SharePoint 2010 also includes a Health Analyzer tool that administrators can configure to actively monitor the system for error conditions and to address them where possible. For more information about these features, see C onfiguring Monitoring on TechNet. The SharePoint Guidance Library includes a reusable logging component, the SharePoint Logger, that you can use in your SharePoint applications to write to the Windows Event log and the ULS trace logs. The latest release of the SharePoint Logger features support for the extended SharePoint 2010 logging functionality. For example, you can select areas and categories when you write to the event log or the trace logs, and you can create your own areas and categories for use in your applications. For more information, see The SharePoint Logger. Using the Library in the Sandbox The introduction of the sandbox execution environment in SharePoint 2010 posed some interesting challenges for the developers behind the SharePoint Guidance Library, because the sandbox environment imposes restrictions on many of the key functional areas. The latest release of the SharePoint Guidance Library includes enhancements that enable the library to run in the sandbox environment. Not all of the functionality will work in the sandbox, because there are certain limitations imposed by the environment that are unavoidable. The guidance library provides full-trust proxies that you can optionally install to enable configuration management and logging from sandboxed code. Full-trust proxy assemblies are deployed to the global assembly cache and expose full-trust functionality to sandboxed code that would otherwise be unavailable. There are three possible configurations you can use to access the guidance library functionality from sandboxed applications: Deploy the guidance library assemblies—Microsoft.Practices.ServiceLocation.dll, Microsoft.Practices.SharePoint.C ommon.dll, and Microsoft.Practices.SharePoint.C ommon.XmlSerializers.dll— within your sandboxed application. In this case, the functionality of the assemblies will be restricted by the security settings of the sandbox environment. Deploy the guidance library assemblies to the global assembly cache. In this case, the functionality of the assemblies will be restricted by the security settings of the sandbox environment. However, the assemblies will be available to any sandboxed solutions across the server farm. Deploy the guidance library assemblies to the global assembly cache, and install the full-trust proxies for configuration management and logging. In this case, the extended functionality exposed by the full-trust proxy is made available to your sandboxed solution, bypassing the security restrictions of the sandbox environment. If you are deploying a sandboxed solution to a hosted or strictly controlled environment, you may find that the first option is your only option, because you can't add assemblies to the global assembly cache if you don't have permission to deploy farm solutions. The sandbox environment imposes limitations on each of the guidance library components as follows: SharePoint Serv ice Locator. The service locator will function in the sandbox, but you can only register type mappings at the site collection level from a sandboxed application. The service locator can read type mappings from the farm level if the application settings manager full-trust proxy is installed. For more Generated from CHM, not final book. Will be superseded in the future. Page 442
- 443. information about storing type mappings at the site collection level, see The SharePoint Service Locator. Application Settings Manager. The application settings manager relies on XML serialization, which creates temporary assemblies by default. This requires write access to the file system, which is not permitted in the sandbox environment. To store complex types, you must pre-generate the serialization assembly for the application settings manager and deploy it with your solution. Simple types such as strings, integers, and enumerations are generally not serialized—they are simply converted to and from strings. When you configure the application settings manager to pre-generate a serialization assembly, the assembly is named Microsoft.Practices.SharePoint.Common.XmlSerializers.dll. You can only read and write settings at the site (SPWeb) and site collection (SPSite) levels from a sandboxed application. You can read settings from Web application and farm-level settings if the full-trust proxies are installed. For more information, see The Application Setting Manager. SharePoint Logger. Logging to event logs or trace files requires fully trusted code. Because of this, you can only use the SharePoint Logger from sandboxed applications if the logging full-trust proxy is installed. If the full-trust proxy is not installed and you attempt to log from the sandbox, the SharePoint Logger will simply discard the logged information. The SharePointLogger class includes two virtual methods, WriteToOperationsLogSandbox and WriteSandboxTrace, which you can override to provide functionality to write to another location such as a SharePoint list if you are unable to install the full-trust proxy for logging. The following table summarizes these constraints. Deployment Application Settings SharePoint Serv ice SharePoint Logger configuration Manager Locator Assemblies deployed Must pre-generate C an only read and write Must provide a custom with the sandbox serialization assemblies. site collection–level implementation of solution C annot read application type mappings. SharePointLogger and settings at the Web override the type mapping for application and farm ILogger. levels. Assemblies deployed Must pre-generate C an only read and write Must provide a custom to the global assembly serialization assemblies. site collection–level implementation of cache C annot read application type mappings SharePointLogger and settings at the Web override the type mapping for application and farm ILogger. levels. Assemblies deployed Must pre-generate C an read and write site C an write to the trace and to the global assembly serialization assemblies. collection-level type event log. cache and full-trust C an read, but not write, mappings. C an read, proxies installed application settings at the but not write, farm level Web application and farm type mappings. levels. To deploy the assemblies with your sandbox application, you will need to add them to the solution package for your application in Visual Studio 2010. You only need to deploy the assemblies with your solution if you cannot put the library assemblies into the global assembly cache. For more information, see The Application Setting Manager. Next Steps This topic introduced some of the challenges that you will face when you develop production-quality solutions for SharePoint 2010. The rest of the topics in this section take a closer look at the SharePoint Guidance components that you can use in your own solutions to help address these challenges. Generated from CHM, not final book. Will be superseded in the future. Page 443
- 444. The SharePoint Service Locator What do we mean by servicewhen we say Service Locator? We don't necessarily mean a Web service. In this context, a service is any class that provides a service to other classes. The services provided by each class are defined by the interfaces that the class implements. Note: This documentation makes frequent references to implementations and implementation classes. These terms are used to refer to classes that implement an interface required by the caller. Service location takes this decoupling process to the next level. When you use a service location pattern, your code can create and use an instance of a class that supports a desired interface without knowing the name or any details of the class that implements the interface. This removes the dependency between the consumer class and the implementation class. For more information on the service locator pattern, see The Service Locator Pattern on MSDN. The SharePoint Service Locator is a reusable component that provides a simple implementation of the service locator pattern. You can use it in your own SharePoint applications to decouple the consumers of an interface from the implementations of that interface. Instead of creating an object by invoking the constructor of a class, you request an object with a specified interface from the service locator. The service implementation can now be replaced or updated without altering the consuming class implementation. So why is it a good idea to remove explicit dependencies on other classes from your code? As your code base becomes more complex and abstracted, it can be difficult to manage references and assembly dependencies that are scattered throughout various projects and solutions. These dependencies often make it challenging to maintain code over time—if you modify one class, you must recompile every project that references that class. This also makes unit testing code in isolation much more complicated. In short, decoupling your code from specific types makes your code more modular, easier to manage, and easier to test. This section includes the following topics that will help you to understand and use the SharePoint Service Locator: What Does the SharePoint Service Locator Do? This section provides a brief overview of the SharePoint Service Locator, the concepts behind it, and the features that it incorporates. It also provides a simple example of how you can programmatically interact with the SharePoint Service Locator. When Should I Use the SharePoint Service Locator? This section can help you to decide whether the SharePoint Service Locator is suitable for your requirements. It identifies key scenarios in which the SharePoint Service Locator may be useful to you, and it explains the benefits and limitations of using the SharePoint Service Locator. Developing Applications Using the SharePoint Service Locator. This section describes how to approach the key development tasks that you will encounter when you use the SharePoint Service Locator, such as adding the right references to your solution, getting a service instance, and adding or removing type mappings. Key Scenarios. This section provides some examples of the SharePoint Service Locator at work in the context of broader SharePoint operations. Design of the SharePoint Service Locator. This section explains how the SharePoint Service Locator works in more detail, including the background and rationale behind the component. Developer How-To Topics. This section provides step-by-step, end-to-end procedural guidance on how to perform the most common developer tasks with the SharePoint Service Locator. Generated from CHM, not final book. Will be superseded in the future. Page 444
- 445. What Does the SharePoint Service Locator Do? Modular, test-driven code is central to the successful development of enterprise-scale applications. If you want to write code that is modular, pluggable, and fully compatible with automated unit testing, you need to employ a design pattern that enables you to remove dependencies on concrete types from your code. The Service Locator pattern is one such approach. Essentially, it maps interfaces to their implementations. Rather than using the concrete implementation directly in your code, you can simply request an implementation of an interface from the service locator, thereby decoupling your code from its dependencies. For more information on the Service Locator pattern, see The Service Locator Pattern. Note: Service location is a specialized subset of the dependency injection pattern. For more information on dependency injection, see Unity Application Block on MSDN. The SharePoint Service Locator is a simple, easy-to-use implementation of the Service Locator pattern. At the core of the SharePoint Service Locator is a dictionary of type mappings. Each dictionary entry maps an interface and an optional key string to the name of a class that implements the specified interface. The following table illustrates this. These type mappings are included by default to support other components in the SharePoint Guidance library. Interface Registered implementation class ILogger SharePointLogger IHierarchicalC onfig HierarchicalC onfig IC onfigManager C onfigManager When you need to use an external service in your code, rather than creating an object by invoking the constructor of a class, you can request an object with a specified interface from the service locator. The service locator looks up the interface in the dictionary, locates the corresponding implementation class, and returns an instantiated object to the caller. For example, suppose that your class needs an implementation of the ILogger interface. You could instantiate a specific implementation of the ILogger interface in your code, as shown in the following diagram and code example: Class with a direct dependency on a service C# using Microsoft.Practices.SharePoint.Common.Logging; SharePointLogger logger = new SharePointLogger(); This approach has several drawbacks. For example, let’s say that your corporate policy changes and you need to enhance your logging functionality to take additional action on critical errors, beyond the default behavior of writing to the event log. If you want to replace the SharePointLogger class with an enhanced implementation of the ILogger interface, you must edit and recompile your consumer class. Also, as your consumer classes reference SharePointLogger directly, it's difficult to replace it with a mock object or a stub implementation of the ILogger interface for testing. Finally, you must ensure that the correct version of SharePointLogger is available at compile time. In contrast, the service locator approach allows you to simply request the registered implementation of the ILogger interface. You do not need to know the details of the implementation. As a result, you can replace all the direct service dependencies in your class with a dependency on the service locator. The following diagram and code example illustrates this. Generated from CHM, not final book. Will be superseded in the future. Page 445
- 446. Class using the SharePoint Service Locator to retrieve a service C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); ILogger logger = serviceLocator.GetInstance<ILogger>(); As you can see from the preceding code example, the SharePointServ iceLocator class includes a static GetCurrent method that provides access to a service locator instance. The service locator allows you to define type mappings at the SPF arm and SPSite configuration levels. You can therefore override the farm-level type mappings within a site collection if you want to provide a different behavior. For example, you may have a high security site collection where you want to save logged information out to a specialized auditing database as well. In this case, you could register a new logging service for the site collection, and provide an implementation that adds the additional auditing logic. Note: You can use the service locator within sandboxed solutions. In this case, the service locator will only load type mappings from the site collection configuration level. However, the SharePoint Guidance library also includes a full trust proxy that allows sandboxed solutions to read configuration from the farm level. If this proxy is installed in the farm, the service locator will load type mappings from both the farm level and site collection level regardless of whether or not it is running in the sandbox. Generated from CHM, not final book. Will be superseded in the future. Page 446
- 447. When Should I Use the SharePoint Service Locator? You can use the SharePoint Service Locator within server-side code that runs in your SharePoint environment. The SharePoint Service Locator is particularly useful when: You want to develop modular, flexible classes that do not need to be edited and recompiled if an internal or external dependency is updated or replaced. You want to be able to unit test your classes using mock objects or stubs. The Service Locator allows you to substitute the real implementation of a dependency with a test implementation. You want to remove repetitive logic that creates, locates, and manages dependent objects from your classes. You want to develop code that relies on interfaces whose concrete implementation is not known, or not yet developed, at compile time. You can use the SharePoint Service Locator in most SharePoint development scenarios. To use the SharePoint Service Locator, your code must either: Run in the SharePoint context (for example Web Parts). Have access to the local SPF arm object (for example timer jobs, feature receivers, console applications running on a Web front end server, and other types of full trust farm solutions). Note: What do we mean by code that runs in the SharePoint context? When your code is invoked synchronously by a user action, such as clicking a button on a Web Part or selecting an item on the Site Actions menu, you have access to an SPContext object. This represents the context of the current HTTP request, and provides information about the current user, the current site, and so on. SharePoint solutions that are not invoked synchronously by a user action, such as timer jobs, service applications, and feature receivers, are not associated with an HTTP request and as such do not have access to an SPContext object. These solutions are said to run outside the SharePoint context. Benefits of the SharePoint Service Locator The SharePoint Service Locator provides the following benefits: It makes a codebase less fragile by compartmentalizing dependencies, because classes consume interface implementations without requiring knowledge of the implementing classes. It creates a pluggable architecture that allows you to replace interface implementations with updated or alternative versions, without requiring you to edit and recompile consumer classes. It allows your code to use different implementations of the same interface, based upon selection logic. This allows you to change the behavior of your solution, based on the execution context. It centralizes dependency management in the service locator. This allows developers to replace multiple direct dependencies on specific classes with a single dependency on the service locator. It ensures that interface implementations are used consistently across an application, by removing the need for dependencies on specific classes. It supports more modular applications where portions of the codebase can independently grow and evolve as business needs change. It allows services to be replaced with mock objects or stub implementations for unit testing. Disadvantages of the SharePoint Service Locator While using the SharePoint Service Locator in your solutions is generally beneficial, you should be aware of the following consequences: There are more solution elements to manage initially. However, as your codebase grows you should benefit from less code redundancy and improved organizational structure. You must write additional code that adds service references to the service locator before your objects can use it, and you must implement interfaces on your services. You may be using configuration data to define run-time relationships. If the configuration data is corrupted, your run-time relationships will break. If the service locator does not find the definition for an interface, it will throw a NotRegisteredException. Generated from CHM, not final book. Will be superseded in the future. Page 447
- 448. Developing Applications Using the SharePoint Service Locator This section describes how you can use the SharePoint Service Locator in your SharePoint applications. The first topic, Getting a Service Locator Instance, describes how to get started with the SharePoint Service Locator by obtaining a reference to the local service locator instance. The remaining topics build on this by providing guidance and reference material on common development tasks. The topics in this section are as follows: Getting a Service Locator Instance C reating a New Service Locator Instance Retrieving Service Instances Adding Type Mappings Removing Type Mappings Note: Before you can use the SharePoint Service Locator in your SharePoint applications, you must add assembly references to Microsoft.Practices.SharePoint.Common.dll and Microsoft.Practices.Serv iceLocation.dll. For broader, contextual guidance on specific scenarios, see Key Scenarios. For step by step guidance on the most common end-to-end tasks, see Developer How-To Topics. Generated from CHM, not final book. Will be superseded in the future. Page 448
- 449. Getting a Service Locator Instance The SharePoint Service Locator makes a single IServ iceLocator implementation available to all callers within the farm or the site collection, depending on your execution context. Regardless of whether you want to register a service or consume a service, your first step is to get a reference to a service locator instance. The SharePointServ iceLocator class provides various static methods that you can use to retrieve a service locator instance. All of these methods return an implementation of IServ iceLocator—the only difference is the scope of the type mappings that are loaded into the service locator instance. If you are running in a context where an SPContext object is available, then the GetCurrent() static method will automatically load the type mappings defined at the site collection scope and the farm scope, and return a service locator that includes these mappings. If a type mapping for a particular interface is defined at both the site collection scope and the farm scope, then the site collection mapping will take precedence. If an SPContext object is not available—in a timer job, for example—then the GetCurrent() method will return a service locator that loads farm-only type mappings. A second overload, GetCurrent(SPSite), will load type mappings from the specified site collection and merge them with the farm-scoped type mappings. This method overload is useful when an SPContext object is not available but you want to use type mappings defined in a particular site collection. A third method, GetCurrentF armLocator(),will return a service locator instance that contains only farm-scoped type mappings. You can use this method if you do not want to use any site collection-scoped type mappings. An instance of the farm-level service locator is shared by all application components throughout the farm, whereas an instance of a site collection-level service locator is shared by all components within a site collection. The following code shows you how you can get a reference to the current service locator instance. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); If an SPContext object is unavailable, but you want to load the type mappings defined for a particular site collection, you can provide an SPSite argument to the GetCurrent method: C# IServiceLocator locator = SharePointServiceLocator.GetCurrent(properties.Web.Site); Note: The SharePoint Service Locator depends upon the Application Setting Manager component to load type mappings from configuration. Type mappings are stored in configuration settings at the site collection level and at the farm level. In order to retrieve these settings, the SPF arm.Local property must return a valid SPFarm instance. This is only possible when your code runs on a server that can access the SharePoint object model, such as a Web Front End (WFE) server. If a SharePoint context is available (SPContext), then the service locator will also load the site collection-scoped configuration data. The service locator instances for the site collection level and the farm level are cached. The site collection-level service locator instances are periodically refreshed to pick up any new type mappings. You can configure this interval by using the SetSiteCacheInterval method in the IServiceLocatorConfig interface. By default, the site collection-level service locator instances are refreshed every 60 seconds. At this point, the configuration settings are checked for changes by comparing timestamps with the cached values. If the configuration settings have changed, the service locator instance is reloaded with the new settings. In unit testing scenarios you should create a new service locator instance rather than using the current instance, as the current instance requires a SharePoint context in order to get a reference to the local SPF arm object. For more information, see C reating a New Service Locator Instance. Generated from CHM, not final book. Will be superseded in the future. Page 449
- 450. Creating a New Service Locator Instance In unit testing scenarios, you must replace the current SharePoint Service Locator instance with a new service locator instance. The reason for this is that the default service locator instance requires access to the SharePoint object model in order to retrieve type mappings, which are stored as farm and site collection scoped configuration settings. By replacing the current service locator before you evaluate the SharePointServ iceLocator.GetCurrent() method, you can avoid a run-time dependency on the SharePoint environment. By default, the IServ iceLocator interface is implemented by the Activ atingServiceLocator class. When the SharePoint Service Locator creates an instance of Activ atingServiceLocator, it retrieves type mappings from farm level configuration and adds these to the service locator instance. When you create a new instance of Activ atingServ iceLocator manually, you bypass the retrieval of configured type mappings. As such, the service locator doesn't require access to farm-scoped configuration settings and can execute outside the SharePoint environment. Since an SPContext object is unavailable when your code runs outside the SharePoint environment, the service locator will not attempt to load site collection-scoped type mappings. The following code shows you how to replace the current service locator instance with a new instance of Activ atingServ iceLocator for unit testing purposes. C# // Create a new service locator instance for unit testing purposes ActivatingServiceLocator serviceLocator = new ActivatingServiceLocator(); // Replace the current service locator with the new instance SharePointServiceLocator.ReplaceCurrentServiceLocator(serviceLocator); When you create a new instance of the Activ atingServiceLocator class, your service locator instance will not contain any of the default type mappings, such as ILogger. You should also be aware that any types you register in this way will not be persisted to the property bag and will therefore be lost if Internet Information Services (IIS) is restarted. For this reason, you should only create a new instance of Activ atingServiceLocator for unit test scenarios. After each unit test you can reset the service locator to its original state by calling the Reset method. It is recommended that you call the Reset method as part of the unit test's cleanup step. This puts the service locator back into its original state and prevents tests from interfering with each other. C# SharePointServiceLocator.Reset(); Note: Failing to reset the service locator often causes other tests within your test suite to fail. If you have a test that succeeds in isolation but fails when run in the suite, there is a good chance you forgot to reset the service locator in one of your tests. Each SharePoint Web application runs in its own application domain. C alling the ReplaceCurrentServ iceLocator and Reset methods only affects the SharePointServiceLocator.Current instance in the current application domain. These methods do not have an effect in other application domains. Therefore, the ReplaceCurrentServ iceLocator and Reset methods should only be used within unit tests. If you want to change the type of service locator for your application, you should register a custom IServiceLocatorF actory interface. See Using a C ustom Service Locator for more information. For more information on the Activ atingServiceLocator class, see Adding Type Mappings and Design of the SharePoint Service Locator. For more information on using the SharePoint Service Locator in unit testing scenarios, see the scenario-based topic Testing C lasses in Isolation. Generated from CHM, not final book. Will be superseded in the future. Page 450
- 451. Retrieving Service Instances When you use the SharePoint Service Locator, your most common task will be to retrieve a service instance. The SharePoint Service Locator lets you retrieve service instances in several different ways. The most common way to retrieve a service instance is by calling the generic GetInstance method that corresponds to the required interface type. If more than one implementing class is registered to the specified interface type, the GetInstance method will return the implementing class that was most recently registered. C# IService1 service1 = serviceLocator.GetInstance<IService1>(); When you register a service with the SharePoint Service Locator, you can optionally include a key string in each type mapping. This is useful if you have registered more than one implementing class against an interface, as it allows you to request a service by name as well as by interface. To do this, pass in the key string as a parameter to the GetInstance method. C# IService2 service2 = serviceLocator.GetInstance<IService2>("alternate"); You may not always be able to use a strongly-typed GetInstance method if type mappings are not available at compile time—for example, if no implementations of a particular interface have been registered when you develop your code. The GetInstance method provides overloads that allow you to specify interface types at run time. C# IService3 service3 = (IService3)serviceLocator.GetInstance(typeof(IService3)); You can also use this approach to retrieve named mappings at run time. C# IService4 service4 = (IService4)serviceLocator.GetInstance(typeof(IService4), "alternate"); Finally, you can retrieve a collection of all the services registered for an interface type. The SharePoint Service Locator will instantiate each service and return an IEnumerable collection containing each object. C# IEnumerable<IService5> services5 = serviceLocator.GetAllInstances<IService5>(); Similarly, you can retrieve a collection of all the services registered for an interface type by specifying the interface type at run time. C# IEnumerable<object> services6 = serviceLocator.GetAllInstances(typeof(IService6)); Generated from CHM, not final book. Will be superseded in the future. Page 451
- 452. Adding Type Mappings To register a service with the SharePoint Service Locator, you must add a type mapping. To add a type mapping to the current service locator instance, you should use the SharePoint Service Locator to get a reference to a Microsoft.Practices.SharePoint.Common.Serv iceLocation.IServ iceLocatorConfig interface, and then call the RegisterTypeMapping method on the IServ iceLocatorConfig object. The following code shows how you can register a class named Serv ice1 as an implementation of the IService1 interface (as a farm-scoped type mapping). C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); typeMappings.RegisterTypeMapping<IService1, Service1>(); If you want to register or change a type mapping for a site collection, you must first set the Site property on the IServiceLocatorConfig instance. This approach of setting context for the service locator configuration class is an example of property injection. The following code shows how you can register a type mapping at the site collection level. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); typeMappings.Site = SPContext.Current.Site; typeMappings.RegisterTypeMapping<IService1, Service1>(); If you want to add a name to the type mapping, you can include a key string as a parameter to the RegisterTypeMapping method. C# typeMappings.RegisterTypeMapping<IService1, AltService1>("alternate"); For more information on retrieving services by name, see Retrieving Service Instances. Note: The RegisterTypeMapping method stores type mappings in the farm-level property bag. SharePoint 2010 does not allow you to write to the farm-level property bag from content Web applications—the entire Microsoft.SharePoint.Administration is blocked for security reasons. Instead, you must perform this operation from a feature receiver, a command line application, or the C entral Administration Web application. Typically, you would add type mappings from within a feature receiver class. When the feature containing your interface implementation is activated, the type mapping is added to the SharePoint Service Locator. For more information, see the scenario topic Using a Feature Receiver to Register a Type Mapping. The SharePoint Service Locator can instantiate services in two different ways. By default, it creates a new service instance for each request. However, you can also configure type mappings such that the service locator will create a singleton service—in other words, that service will be instantiated once, and that service instance will be shared by all callers. When you use the IServ iceLocatorConfig.RegisterTypeMapping method to add a type mapping, the SharePoint Service Locator will always create a new service instance every time that the service is requested. You cannot change this behavior. This is because in most circumstances you should not use the service locator to register types as singletons. Registering a service as a singleton requires the service to be thread-safe. Unless you have designed your service to be thread safe, you should not share a single instance of your object across all application threads. In certain scenarios, such as unit testing, you may need to register a service as a singleton. In this case, you must use the ActivatingServiceLocator class directly. The Activ atingServiceLocator class extends the IServiceLocator interface in two important ways: It allows you to register type mappings directly, rather than through an IServ iceLocatorConfig implementation. It allows you to specify whether types should be instantiated as singleton services. Generated from CHM, not final book. Will be superseded in the future. Page 452
- 453. To register a type as a singleton service, first cast the current service locator instance to the Activ atingServ iceLocator type. Next, call the RegisterTypeMapping method and pass in an InstantiationType.AsSingleton enumeration value as a parameter. C# ActivatingServiceLocator serviceLocator = (ActivatingServiceLocator)SharePointServiceLocator.GetCurrent(); serviceLocator.RegisterTypeMapping<IService2, Service2>(InstantiationType.AsSingleton); You can also add a name to the type mapping by including a key string parameter. C# serviceLocator.RegisterTypeMapping<IService2, AltService2> ("alternate", InstantiationType.AsSingleton); For more information on the Activ atingServiceLocator class, see Design of the SharePoint Service Locator. Generated from CHM, not final book. Will be superseded in the future. Page 453
- 454. Removing Type Mappings You can remove redundant type mappings in two ways. You can either overwrite the type mapping with a new entry, or you can explicitly remove the type mapping programmatically. Note: Existing type mappings will only be overwritten if both the interface name and the key string of the new mapping match those of the existing mapping. If the key string is null (not specified), the new type mapping will replace any existing type mapping with a matching interface name and a null key string. To remove a type mapping from the current service locator instance, you should first use the SharePoint Service Locator to get a reference to a Microsoft.Practices.SharePoint.Common.Serv iceLocation.IServ iceLocatorConfig interface. The IServiceLocatorConfig object provides two methods that you can use to remove type mappings. The Remov eTypeMapping method allows you to remove specific type mappings from the service locator. To remove a type mapping that was created without a key string, you must pass a null value as a parameter to the RemoveTypeMapping method. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); typeMappings.RemoveTypeMapping<IService1>(null); If the type mapping you want to remove includes a key string, pass the key string as a parameter to the RemoveTypeMapping method. C# typeMappings.RemoveTypeMapping<IService1>("alternate"); Alternatively, you may wish to remove every type mapping associated with a particular interface name. In this case, you can use the RemoveTypeMappings method. C# typeMappings.RemoveTypeMappings<IService1>(); Generated from CHM, not final book. Will be superseded in the future. Page 454
- 455. Key Scenarios This section describes the most common situations in which you might use the SharePoint Service Locator. Each topic in this section describes a realistic scenario, identifies the solution, and provides code to demonstrate how to use the SharePoint Service Locator to complete the task. Each topic also includes usage notes and hints where applicable. The scenarios are as follows: Using a Feature Receiver to Register a Type Mapping. This scenario illustrates how you can use a SharePoint feature receiver class to register a type mapping with the SharePoint Service Locator. Testing C lasses in Isolation. This scenario illustrates how you can configure the SharePoint Service Locator for use in unit testing, by mapping interfaces to mock objects. Providing a C ustom Service Locator Implementation in a SharePoint Environment. This scenario illustrates how you can create a factory class to provide an alternative service locator implementation through the SharePoint Service Locator. Generated from CHM, not final book. Will be superseded in the future. Page 455
- 456. Using a Feature Receiver to Register a Type Mapping Typical Goals When you write a class that implements a particular interface, you can use the SharePoint Service Locator to make your class available to callers who require an implementation of that interface. In this example, suppose you have created a new implementation of the IPricingRepository interface named PriceRepUltimate. You have also created a SharePoint feature to deploy the new component to a SharePoint environment. Solution In most cases, you should create a feature receiver class and override the F eatureActivated method to register a new type mapping with the SharePoint Service Locator. By registering the type mapping within the FeatureActivated method, you ensure that the type mapping is added when, and only when, your component is made available to the SharePoint environment. For more information on how to register type mappings, including how to create named type mappings and how to specify that types should be instantiated as singleton services, see Adding Type Mappings. For more information about using feature receivers, see Using Features on MSDN. Registering a Service in a Feature Receiver Class The following code shows how to use the RegisterTypeMapping method to retrieve the service instance. This example assumes that you have added references to the Microsoft.Practices.SharePoint.Common.dll and Microsoft.Practices.Serv iceLocation.dll assemblies. C# using Microsoft.SharePoint; using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; [Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")] public class MyFeatureReceiver : SPFeatureReceiver { public override void FeatureActivated(SPFeatureReceiverProperties properties) { // Get the ServiceLocatorConfig service from the service locator. IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); typeMappings.RegisterTypeMapping<IPricingRepository, PriceRepUltimate>(); } } The F eatureInstalled method registers the PriceRepUltimate class as the configured implementation of the IPricingRepository interface. Usage Notes Typically you should unregister the type mapping when the feature is uninstalled, because the assembly that includes the implementation is made unavailable at this point. You can include this functionality in your feature receiver class by overriding the F eatureDeactivating method, as illustrated by the following code. public override void FeatureDeactivating(SPFeatureReceiverProperties properties) { // Get the ServiceLocatorConfig service from the service locator. IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IServiceLocatorConfig typeMappings = Generated from CHM, not final book. Will be superseded in the future. Page 456
- 457. serviceLocator.GetInstance<IServiceLocatorConfig>(); typeMappings.RemoveTypeMapping<IPricingRepository>(null); } For more information on how to remove type mappings, see Removing Type Mappings. Generated from CHM, not final book. Will be superseded in the future. Page 457
- 458. Testing Classes in Isolation Typical Goals When you want to run unit tests on your code, dependencies on internal or external classes can introduce problems. At best, including these service implementations will introduce a degree of complexity to the test process. At worst, the external code may not function as expected or may not even have been developed yet. The easiest way to support unit testing is to use the service locator to remove direct dependencies from your classes. Assuming that you designed your classes to use the service locator in this way, you can use the following approach to replace your dependencies with mock objects or stub implementations and test specific behaviors of your class in isolation. Solution To isolate your code, you can configure the SharePoint Service Locator to return mock objects for specified interfaces instead of full implementations. To do this, you must create a new service locator instance, configure your type mappings, and then replace the current service locator instance with your new service locator instance. It is possible to create your own mock service locator that implements the IServ iceLocator interface, but it is generally easier to use an existing service locator implementation such as the Activ atingServiceLocator class. The reason you should create a new service locator instance, rather than simply using the current instance, is that instantiating the default service locator requires your code to run in a SharePoint environment. This is because the SharePoint Service Locator attempts to retrieve type mappings from the local SPF arm and SPSite objects when you call SharePointServiceLocator.GetCurrent(). The SharePoint object model is unavailable if you perform an isolated unit test. In unit testing scenarios you should configure the service locator to instantiate your mock objects as singleton services, so that every request to the service locator returns the same object. For more information on using the Activ atingServ iceLocator class, see C reating a New Service Locator Instance and Adding Type Mappings. Using the SharePoint Service Locator for Unit Tests The following examples are taken from the SharePoint Logger, a component in the SharePoint Guidance library that you can use to log information to the Windows event log and the Unified Logging Service (ULS) trace log. The examples have been simplified to distill the key points of interest for unit testing. You can read about the SharePoint Logger in more detail in the SharePoint Logger chapter. Creating Testable Classes At a basic level, the SharePointLogger class relies on implementations of two key interfaces: ITraceLogger and IEventLogLogger. The default implementations of these classes log information to the ULS trace log and the Windows Event log, respectively. In order to unit test the SharePointLogger class, we need to be able to substitute mock implementations of ITraceLogger and IEventLogLogger without editing and recompiling the SharePointLogger class. To support this approach, rather than referencing implementations of ITraceLogger and IEventLogLogger directly, the SharePointLogger class uses the SharePoint Service Locator to retrieve the registered implementations. In this case we're interested in what happens when you call the TraceToDeveloper method. Our unit test verifies that this method writes trace information but does not write event log information. The following code example shows the relevant excerpts from the SharePointLogger class and its base class, BaseLogger. When you call the TraceToDeveloper method: The TraceToDeveloper method builds a trace message and calls the WriteToDev eloperTrace method. The WriteToDev eloperTrace method uses the SharePoint Service Locator to retrieve an instance of ITraceLogger, and then calls the ITraceLogger.Trace method. C# public abstract class BaseLogger : ILogger { public void TraceToDeveloper(string message, int eventId, TraceSeverity severity, string category) { Generated from CHM, not final book. Will be superseded in the future. Page 458
- 459. WriteToDeveloperTrace( BuildTraceMessage(message, eventId, severity, category), eventId, severity, category); } protected abstract void WriteToDeveloperTrace(string message, int eventId, TraceSeverity severity, string category); } public class SharePointLogger : BaseLogger { private ITraceLogger traceLogger; public ITraceLogger TraceLogger { get { if (traceLogger == null) { traceLogger = SharePointServiceLocator.GetCurrent().GetInstance<ITraceLogger>(); } return traceLogger; } } protected override void WriteToDeveloperTrace(string message, int eventId, TraceSeverity severity, string category) { try { TraceLogger.Trace(message, eventId, severity, category); } catch (Exception ex) { AttemptToWriteTraceExceptionToEventLog(ex, message); } } } Notice that at no point in the previous code example were specific implementations of ITraceLogger referenced directly. This means that you can provide alternative implementations of ITraceLogger without editing your original methods. Creating Mock Objects At this point, we've used the SharePoint Service Locator to decouple the SharePointLogger class from specific implementations of ITraceLogger and IEventLogLogger. The next stage is to create mock implementations of ITraceLogger and IEventLogLogger that we can supply to the SharePointLogger class for the purposes of unit testing. In this case, our mock implementations simply build a generic list that we can interrogate from our test class. The following code example shows the mock implementations of ITraceLogger and IEv entLogLogger. C# class MockTraceLogger : ITraceLogger { public List<string> Messages = new List<string>(); public string Message; public string Category; public int EventID; public TraceSeverity Severity; public void Trace(string message, int eventId, TraceSeverity severity, string category) { Generated from CHM, not final book. Will be superseded in the future. Page 459
- 460. this.Messages.Add(message); this.Message = message; this.Category = category; this.EventID = eventId; this.Severity = severity; } } class MockEventLogger : IEventLogLogger { public List<string> Messages = new List<string>(); public string Message; public string Category; public int EventID; public EventLogEntryType Severity; public void Log(string message, int eventId, EventLogEntryType severity, string category) { this.Messages.Add(message); this.Message = message; this.Category = category; this.EventID = eventId; this.Severity = severity; } } Configuring the Unit Test At this point, we've created a testable SharePointLogger class and we've created some mock implementations of ITraceLogger and IEventLogLogger for use in unit tests. The final stage is to create the test class itself. The test method consists of three key sections: Arrange. In this section we set up the SharePoint Service Locator. We replace the default current service locator with a new instance of the Activ atingServiceLocator class. We register our mock classes as the default implementations of ITraceLogger and IEventLogLogger. Finally we use the service locator to instantiate our mock classes. Act. In this section we perform the action that we want to test. We create a new instance of SharePointLogger and we call the TraceToDeveloper method. Assert. In this section we use various assert statements to verify that the SharePointLogger class behaved as expected. The following code example shows the relevant parts of the test class. C# [TestClass] public class SharePointLoggerFixture { private MockTraceLogger traceLogger; private MockEventLogger eventLogger; [TestMethod] public void TraceLogsOnlyToTraceLog() { //Arrange ActivatingServiceLocator replaceLocator = new ActivatingServiceLocator(); SharePointServiceLocator.ReplaceCurrentServiceLocator(replaceLocator); replaceLocator.RegisterTypeMapping<ITraceLogger, MockTraceLogger> (InstantiationType.AsSingleton); replaceLocator.RegisterTypeMapping<IEventLogLogger, MockEventLogger> (InstantiationType.AsSingleton); Generated from CHM, not final book. Will be superseded in the future. Page 460
- 461. traceLogger = SharePointServiceLocator.GetCurrent() .GetInstance<ITraceLogger>() as MockTraceLogger; eventLogger = SharePointServiceLocator.GetCurrent() .GetInstance<IEventLogLogger>() as MockEventLogger; //Act SharePointLogger target = new SharePointLogger(); target.TraceToDeveloper("Message", 99, TraceSeverity.High, "Category1"); //Assert Assert.IsNull((target.EventLogLogger as MockEventLogger).Message); AssertLogData(target.TraceLogger as MockTraceLogger, TraceSeverity.High); //Cleanup SharePointServiceLocator.Reset(); } } Because we designed the SharePointLogger class for testability and decoupled the class from its dependencies, this entire test process can be conducted without editing or recompiling the SharePointLogger class itself. Usage Notes After your test completes, call the SharePointServ iceLocator.Reset method. This ensures that the next call to the SharePointServiceLocator.GetCurrent() property creates a new service locator instance. It is recommended that you use the Reset method to return the service locator to its original state as part of the cleanup step for your unit test. This prevents tests from interfering with each other. Generated from CHM, not final book. Will be superseded in the future. Page 461
- 462. Providing a Custom Service Locator Implementation Typical Goals In some circumstances, you might require a service locator implementation that provides more sophisticated features than those offered by the SharePoint Service Locator's default implementation. For example, you want to develop a service locator that automatically selects the most appropriate implementation of an interface according to run-time conditions. Alternatively, you might require a service locator implementation that employs a dependency injection pattern. Solution The SharePoint Service Locator allows you to substitute the default service locator implementation with other IServiceLocator implementations. You can use the following high-level steps to do this. 1. C reate a class that implements the IServ iceLocatorF actory interface. 2. In the Create method, instantiate and return your custom service locator instance. 3. In the LoadTypeMappings method, add the passed-in type mappings to the passed-in service locator instance. 4. In the Current service locator instance provided by the SharePoint Service Locator, add a type mapping that associated your implementation with the IServiceLocatorF actory interface. In Visual Studio, add a reference to the SharePoint Guidance Library, Microsoft.Practices.SharePoint.Common.dll, and to Microsoft.Practices.ServiceLocation.dll. C reate a class that implements the IServiceLocatorFactory interface and creates the custom service locator instance. Register your new class factory using the IServ iceLocatorConfig interface. Using a Custom Service Locator The following code shows how you can create a new implementation of the IServ iceLocatorF actory implementation. The code assumes that you have created a custom service locator named MyServ iceLocator that implements the IServ iceLocator interface. C# class MyServiceLocatorFactory : IServiceLocatorFactory { public IServiceLocator Create() { return new MyServiceLocator(); } public void LoadTypeMappings(IServiceLocator serviceLocator, IEnumerable<TypeMapping> typeMappings) { if (serviceLocator == null) { throw new ArgumentNullException("serviceLocator"); } MyServiceLocator myServiceLocator = serviceLocator as MyServiceLocator; if (typeMappings == null) { return; } foreach(TypeMapping typeMapping in typeMappings) { // ... invoke custom methods of MyServiceLocator to establish type //mappings } Generated from CHM, not final book. Will be superseded in the future. Page 462
- 463. } } Now that you have created your IServ iceLocatorF actory implementation, you must register this implementation with the SharePoint Service Locator. The following code shows you how to do this. Typically, you should include this code in a feature receiver class. The following code example shows how to configure the SharePoint Service Locator to use your custom service locator factory. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); typeMappings.RegisterTypeMapping<IServiceLocatorFactory, MyServiceLocatorFactory>(); SharePointServiceLocator.Reset(); Usage Notes The IServ iceLocatorF actory.Create method must return an instance of a class that implements the IServiceLocator interface. The IServiceLocator interface is defined by the C ommon Service Locator library, which is available on C odePlex. The LoadTypeMappings method initializes the service locator instance that is returned by the Create method with application-specific type mappings that are provided as arguments. The LoadTypeMapping method must add each type mapping to your service locator's table of type mappings. In some circumstances the LoadTypeMappings method can be invoked more than once. In the current version of the SharePoint Guidance Library, this method is invoked once for the default type mappings for the SharePoint Guidance Library and once for type mappings that are stored in farm configuration for the farm level service locator. For the combined site and farm-scoped service locator, LoadTypeMappings is invoked one additional time for the type mappings that are stored in site collection configuration settings. Your implementation of the LoadTypeMappings method must be able to overwrite any previous type mappings and ensure that the most recent type mapping takes precedence. Generated from CHM, not final book. Will be superseded in the future. Page 463
- 464. Design of the SharePoint Service Locator The SharePoint Service Locator provides a lightweight, easy-to-use implementation of the service locator pattern. It is designed to do the following: It allows developers of consumer classes to decouple their classes from concrete implementations of interfaces. It allows developers of provider classes to register their classes as implementations of an interface, and to make these classes available to consumer classes across the application. It makes a single service locator implementation available throughout the farm or the site collection, which ensures that interface implementations are used consistently. It allows developers to substitute mock objects for dependencies, which facilitates isolated unit testing of classes. It allows developers to substitute alternative service locator implementations into the SharePoint Service Locator. Design Highlights The following class diagram illustrates the interrelationships between the key classes in the SharePoint Service Locator. The SharePoint Service Locator The main entry point to the service locator is the SharePointServ iceLocator static class. This class creates and initializes instances of IServ iceLocator, and exposes these service locator instances through the GetCurrent() method. The SharePoint Service Locator relies on an IServ iceLocatorF actory implementation to instantiate an IServiceLocator implementation. The SharePoint Service Locator also relies on the Serv iceLocatorConfig class to store type mappings at both the farm and site collection levels. Service providers can use the RegisterTypeMapping method to register Generated from CHM, not final book. Will be superseded in the future. Page 464
- 465. their service with the service locator. The Serv iceLocatorConfig class persists these type mappings as site collection-level configuration settings if the Site property is set, or as farm-level configuration settings if it is not. Note: The IConfigManager and IHierarchicalConfig interfaces shown in the diagram are part of the Application Settings Manager component. For more information on the Application Settings Manager, see the Application Setting Manager chapter in this guidance. The IServ iceLocator and IServ iceLocatorF actory interfaces are defined by the C ommon Service Locator library, as described in the following section. Design Details This section describes the design and functionality of the SharePoint Service Locator in more detail, including how the SharePoint Service Locator relates to the C ommon Service Locator project, which type mappings are registered by default, and how the SharePoint Service Locator actually creates service locator instances. Relationship to the Common Service Locator The IServ iceLocator and IServ iceLocatorFactory interfaces are defined by the C ommon Service Locator library, which is available on C odePlex. The goal of the C ommon Service Locator is to provide shared interfaces with binary compatibility for inversion of control (IOC ) containers and service locators. The SharePoint Guidance team has not tested the use of any other service locator or IoC containers. By default, the SharePoint Service Locator uses an IServ iceLocatorF actory implementation named Activ atingServ iceLocatorFactory. This class instantiates an IServiceLocator implementation named Activ atingServ iceLocator. This relationship is illustrated by the following table. Common Serv ice Locator interface SharePoint Serv ice Locator implementation IServiceLocator ActivatingServiceLocator IServiceLocatorFactory ActivatingServiceLocatorFactory While the SharePoint Service Locator includes specific implementations of the C ommon Service Locator interfaces, you can substitute alternative implementations of these interfaces according to your application requirements. For more information on how to create your own IServ iceLocatorF actory implementation to instantiate an alternative service locator, see Using a C ustom Service Locator. Note: You cannot use the ServiceLocator class from the C ommon Service Locator project in a SharePoint environment. The ServiceLocator class is designed to work with environments that expose a bootstrapping event when the application starts, such as the events within global.asax in an ASP.NET Web application. Because SharePoint does not expose similar events, the SharePoint Service Locator performs this initial bootstrapping when you call SharePointServ iceLocator.GetCurrent(). If you attempt to set the SharePoint Service Locator instance using the ServiceLocator class, the SharePoint Service Locator will throw a NotSupportedException. Creation of the Service Locator Instances The IServ iceLocator instances are created through the GetCurrent(), GetCurrent(SPSite), and GetCurrentFarmLocator static methods of the SharePointServ iceLocator class. The service locator calls into an IServiceLocatorF actory implementation that creates and configures instances of IServ iceLocator. This process works as follows: 1. The SharePointServ iceLocator class constructs the ServiceLocatorConfig object to retrieve the type mappings that are persisted to the configuration database in SharePoint property bags. Farm-scoped type mappings are retrieved only once and then cached. 2. If applicable, the SharePointServ iceLocator class also loads site collection-scoped type mappings. To do this, it constructs another Serv iceLocatorConfig object and sets the Site property to the relevant SPSite object. 3. To create an IServiceLocator instance, the SharePointServ iceLocator class looks for the registered implementation of the IServ iceLocatorF actory interface. 4. If no custom IServ iceLocatorFactory implementation is registered, the Generated from CHM, not final book. Will be superseded in the future. Page 465
- 466. Activ atingServ iceLocatorFactory class creates the IServiceLocator instance. 5. If a custom IServ iceLocatorFactory implementation is registered with the SharePoint Service Locator, the custom IServ iceLocatorFactory implementation creates a new IServiceLocator instance. The IServiceLocatorFactory instance also populates the new service locator instance with the type mappings supplied by the Serv iceLocatorConfig class. The service locator instances are cached by the SharePointServiceLocator static class to improve performance. The farm-level service locator is loaded only once and cached. It only needs to be loaded once because deploying a farm level feature will cause the application domains to reload. As you update farm-scoped type mappings through a farm-scoped feature receiver, the application domain will be recycled and the new settings will be picked up when the service locator instance is reconstructed. As a result, it is safe to assume that the type mappings don’t change during the lifetime of the cached farm-level service locator instance. However, this will not be the case for site collection-scoped type mappings, as these are deployed by site collection-scoped features. As a result the cached instances of the combined site collection and farm-level locators must be periodically refreshed. The configuration settings are checked periodically to see if any type mappings have been updated, and if necessary the service locator instance is refreshed with new type mappings. Finally, the SharePoint service locator must also account for type mappings that are registered at runtime. When a farm-scoped type mapping is registered at runtime, the service locator receives an event. The service locator then updates each cached site collection service locator instance with the new type mapping. Default Type Mappings When you start to use the SharePoint Service Locator, you may notice that certain type mappings are already registered. In keeping with broader aspects of the SharePoint Guidance project, the service locator includes default type mappings for logging and configuration management. The following type mappings are registered by default: Logging. The ILogger interface is mapped to the SharePointLogger class. This logging implementation logs to the event log and to the Unified Logging Service (ULS), but this behavior can also be overwritten by registering custom type mappings for the IEv entLogLogger or ITraceLogger interfaces. Configuration management. The IConfigManager and IHierarchicalConfig interfaces are mapped to the HierarchicalConfig class. As with any type mappings, these default mappings can be overwritten by registering custom type mappings using the Serv iceLocatorConfig class. Error Handling The SharePoint service locator raises an exception of type Activ ationException if an error occurs during the process of service location. It may also raise .NET Framework exceptions for assembly and class load errors and exceptions of type NoSharePointContextException when a SharePoint context is required but not present. Generated from CHM, not final book. Will be superseded in the future. Page 466
- 467. Developer How-To Topics This section includes step-by-step guidance for the most common tasks that you will undertake when you work with the SharePoint Service Locator. Each how-to topic provides all the steps you need to complete each task without referring to other topics. However, for more detailed information and best practice guidance you are urged to consult the rest of the documentation. This section includes the following how-to topics: How to: Register a Service How to: Remove a Type Mapping How to: Retrieve an Interface Implementation Generated from CHM, not final book. Will be superseded in the future. Page 467
- 468. How to: Register a Service The following procedure demonstrates how you can use the SharePoint Service Locator to register a class as the implementation of an interface. To register a serv ice with the SharePoint Serv ice Locator 1. Add assembly references to Microsoft.Practices.SharePoint.Common.dll and Microsoft.Practices.Serv iceLocation.dll. 2. Add the following using statements to the top of your source code file. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; 3. Declare an object of type IServ iceLocator and set it to the value of the SharePointServ iceLocator.Current property. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); 4. Use the service locator to request an implementation of the IServ iceLocatorConfig interface. The returned object contains the type mappings that are managed by the service locator. Note: If you want to scope your type mapping to a site collection, you must also set the Site property on the IServiceLocatorConfig instance. C# IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); 5. C all the IServ iceLocator.RegisterTypeMapping method. The first type parameter is the interface that you are implementing, and the second type parameter is your implementation class. C# typeMappings.RegisterTypeMapping<IService1, Service1>(); Generated from CHM, not final book. Will be superseded in the future. Page 468
- 469. How to: Remove a Type Mapping The following procedure demonstrates how to remove a type mapping from the SharePoint Service Locator. To remove a type mapping from the SharePoint Service Locator 1. Add assembly references Microsoft.Practices.SharePoint.Common.dll and Microsoft.Practices.Serv iceLocation.dll. 2. Add the following using statements to the top of your source code file. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; 3. Declare an object of type IServ iceLocator and set it to the value of the SharePointServ iceLocator.Current property. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); 4. Use the service locator to request an implementation of the IServ iceLocatorConfig interface. The returned object contains the type mappings that are managed by the service locator. Note: To remove a site collection-scoped type mapping, you must also set the Site property on the IServiceLocatorConfig instance. C# IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); 5. C all the IServ iceLocator.Remov eTypeMapping method. The type parameter is the interface that your mapped class implements. Pass a null argument to remove a default unnamed mapping, or a string key to remove a named mapping. C# typeMappings.RemoveTypeMapping<IService1>(null); Generated from CHM, not final book. Will be superseded in the future. Page 469
- 470. How to: Retrieve an Interface Implementation The following procedure demonstrates how to retrieve an implementation of a specified interface from the SharePoint Service Locator. To retrieve an interface implementation from the SharePoint Serv ice Locator 1. Add assembly references to Microsoft.Practices.SharePoint.Common.dll and Microsoft.Practices.Serv iceLocation.dll. 2. Add the following using statements to the top of your source code file. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; 3. Declare an object of type IServ iceLocator and set it to the value of the SharePointServ iceLocator.GetCurrent() method. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); 4. C all the IServ iceLocator.GetInstance method. Set the type parameter to the interface for which you want to retrieve the registered implementation. C# IService1 service1 = serviceLocator.GetInstance<IService1>(); Generated from CHM, not final book. Will be superseded in the future. Page 470
- 471. The Application Setting Manager All enterprise-scale applications use configuration settings to some extent. Application configuration data provides the information that an application requires to be able to run in a specific deployment environment. For example, configuration data might include a connection string for a database, the location of a dependent SharePoint library or list, or information about the security context of the environment. Managing application settings in a SharePoint environment introduces challenges beyond those encountered by developers who are familiar with ASP.NET and other platforms. First, the SharePoint environment employs a unique hierarchy that enables configuration at each logical level of its architecture—farm, Web application, site collection, site, and list. Second, developers need to account for the dynamic nature of SharePoint. Users can drop your Web Parts into many different pages and instantiate your templates in many different locations. This can have a major bearing on how you manage configuration options for your solutions. There are also several different storage mechanisms for configuration settings, including the hierarchical object store, configuration files, property bags, and SharePoint lists. Each mechanism has advantages, disadvantages, and sometimes risks—for example, SharePoint property bags provide an easy-to-use storage mechanism, but developers risk corrupting the configuration database or the content database if they attempt to persist non-serializable types. Note: For more information about the advantages and disadvantages of each storage mechanism, see Managing Application C onfiguration on MSDN. Although this content was developed for a previous version of SharePoint, the guidance is still valid for SharePoint 2010. To help you to address these challenges, the SharePoint Guidance Library includes a reusable component named the Application Setting Manager. You can use the Application Setting Manager in your SharePoint applications to provide an easy, consistent, and type-safe means of storing and retrieving configuration data at any level of the SharePoint hierarchy. This section includes the following topics that will help you to understand and use the Application Setting Manager: What Does the Application Setting Manager Do? This topic provides a brief overview of the Application Setting Manager, the concepts behind it, and the features that it incorporates. It also provides a simple example of how you can programmatically interact with the Application Setting Manager. When Should I Use the Application Setting Manager? This topic can help you to decide whether the Application Setting Manager is suitable for your requirements. It identifies key scenarios in which the setting manager may be useful to you, and it explains the benefits and limitations of using the setting manager. Developing Applications Using the Application Setting Manager. This section describes how to approach the key development tasks that you will encounter when using the Application Setting Manager, such as adding, removing, and retrieving application settings. Key Scenarios. This section shows you how to use the Application Setting Manager in the most common end-to-end scenarios. Design of the Application Setting Manager. This topic explains in more detail how the setting manager works, including the background and rationale behind the component. Developer How-to Topics. This section provides step-by-step, end-to-end procedural guidance on how to perform the most common developer tasks with the Application Setting Manager. Note: The SharePoint Guidance Library's Application Setting Manager provides an API to read and write configuration settings. It does not provide a user interface (UI) to read and write these configuration settings at run time. To do this, you either can create a custom UI for the Application Setting Manager or you can use a general purpose property bag editor. For example, on C odePlex, there is a community-driven effort to create a property bag editor that allows you to change the raw property bag values. Generated from CHM, not final book. Will be superseded in the future. Page 471
- 472. What Does the Application Setting Manager Do? The Application Setting Manager is a set of utility classes that you can use to store and retrieve configuration settings for your SharePoint applications. The Application Setting Manager provides a uniform, type-safe approach for managing configuration settings at the following levels of the SharePoint hierarchy: Farm (SPFarm class) Web application (SPWebApplication class) Site collection (SPSite class) Site (SPWeb class) You can use the Application Setting Manager to store simple types, such as integers or strings, as well as more complex types that can be serialized to XML. The Application Setting Manager manages the serialization and deserialization of data types to and from XML. The Application Setting Manager provides a hierarchical model for the storage and retrieval of configuration settings. This enables you to create an application setting at a broad scope (such as the farm level) and override that setting at a narrower scope (such as the site level). When you retrieve a setting, using a key string, the Application Setting Manager will first look for that key at the site (SPWeb) level of the current execution context. If the configuration key is not found, the Application Setting Manager will look for the configuration setting at a progressively broader scope, up to and including the farm level. For example, you could use the following code to locate a configuration setting of type DateTime, without knowing the level in the SharePoint hierarchy at which the setting is stored. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); var config = serviceLocator.GetInstance<IHierarchicalConfig>(); DateTime timeApproved; if (config.ContainsKey("approvedTime")) timeApproved = config.GetByKey<DateTime>("approvedTime"); Note: As illustrated by the code example, you are encouraged to use the SharePoint Service Locator to retrieve and instantiate instances of the interfaces provided by the Application Setting Manager. For more information about the SharePoint Service Locator, see The SharePoint Service Locator. Understanding the SharePoint Hierarchy All the components of the Application Setting Manager rely on building a hierarchy of SharePoint objects, from SPWeb to SPFarm, in which to store and retrieve application settings. For example, if you tell the Application Setting Manager to store an application setting at the site collection level, it needs to know which site collection is relevant to your solution. In most cases, the key element of this hierarchy is the SPWeb object—if you provide the Application Setting Manager with a relevant SPWeb object, it can deduce the current SPSite, SPWebApplication, and SPF arm objects by walking up the hierarchy. This is shown in the following illustration. Building a SharePoint hierarchy Generated from CHM, not final book. Will be superseded in the future. Page 472
- 473. The Application Setting Manager components allow you to identify the relevant hierarchy of SharePoint objects in two ways: You can allow the component to build the current hierarchy from the current SharePoint context (the SPContext.Current property). You can provide the component with an SPWeb object from which to build a SharePoint hierarchy. The component will deduce the relevant SPSite, SPWebApplication, and SPF arm objects from the SPWeb object you provide. This approach is useful in scenarios where the SharePoint context is unavailable, such as in command-line applications or test classes, feature receivers, or when you want to manage application settings for SharePoint objects that are external to your current context. Note: What does "code that runs in the SharePoint context" mean? It means that when your code is invoked synchronously by a user action, such as clicking a button on a Web Part or selecting an item on the Site Actions menu, you have access to an object of type SPContext using the SPContext.Current property. This represents the context of the current HTTP request, and provides information about the current user, the current site, and so on. SharePoint solutions that are not invoked synchronously by a user action, such as timer jobs, service applications, and feature receivers, are not associated with an HTTP request; therefore, they do not have access to an SPContext object. These solutions are said to run outside the SharePoint context. If you use an Application Setting Manager component without providing a starting SPWeb object, it will automatically attempt to build a hierarchy from the current SharePoint context. Generated from CHM, not final book. Will be superseded in the future. Page 473
- 474. When Should I Use the Application Setting Manager? You should consider using the Application Setting Manager whenever you need to store and retrieve configuration settings for your SharePoint applications. You can use the Application Setting Manager in server-side code to retrieve application configuration settings from any level in the SharePoint hierarchy. Benefits of the Application Setting Manager The Application Setting Manager provides the following benefits: It provides a mechanism for managing application configuration settings that is consistent across all levels of the SharePoint hierarchy. It provides a type-safe way to read and write application configuration settings. It automatically manages the serialization and deserialization of configuration data. It prevents developers from attempting to store nonserializable objects, which can corrupt SharePoint databases. It enables you to structure application settings in a hierarchical way, such that a configuration key at a more specific level (such as the individual site) can override the same configuration key at a broader level (such as the Web application). It provides a mechanism for reading and writing application settings that is integrated into SharePoint (as opposed to using some other configuration storage and retrieval mechanism such as a custom database or a configuration file). Limitations and Considerations for the Application Setting Manager You should consider the following limitations before you use the Application Setting Manager: Because it uses property bags as its underlying storage mechanism, the Application Setting Manager is not suitable for storing large payloads. If you need to store data exceeding 4kilobytes (KB) in size, you should choose an alternative approach to storage. For example, you can configure the Application Setting Manager to use list-based property bags. There are also certain configuration settings that must be stored in the Web.config file. These include configuration information for HTTP modules, HTTP handlers, and Windows C ommunication Foundation (WC F) endpoints. However, settings should be stored in the Web.config file only when SharePoint, Internet Information Services (IIS), or ASP.NET needs access to these settings to be able to operate. Settings that are specific to your solution should not be stored in the Web.config file. Like with all approaches to managing application configuration settings, the security settings of the sandbox environment restrict what you can do with the Application Setting Manager. In a sandboxed solution, you can store and retrieve configuration settings at only the site level and the site collection level. However, the Application Setting Manager includes a full-trust proxy that enables you to read configuration settings from the Web application level and the farm level. The Application Setting Manager automatically detects whether this proxy is installed and uses it as appropriate. The Application Setting Manager relies on XML serialization to store complex types as application settings. By default, the XML serialization process generates and compiles temporary assemblies. These operations are not permitted in the sandbox environment. You will need to take additional steps to be able to store complex types in application settings for sandboxed solutions. The Application Setting Manager is designed to allow you to programmatically manage your configuration data. It does not include a user interface for administering configuration settings. Generated from CHM, not final book. Will be superseded in the future. Page 474
- 475. Developing Applications Using the Application Setting Manager This section describes how you can use the Application Setting Manager in your SharePoint applications. The first topic, Using the Application Setting Manager Interfaces, introduces the two key interfaces provided by the Application Setting Manager and shows you how to get started. The remaining topics build on this by providing guidance and reference material on common development tasks. This section describes how to accomplish the key development tasks that you will encounter when you use the Application Manager. It includes the following topics: Using the Application Setting Manager Interfaces Adding and Updating C onfiguration Settings Removing C onfiguration Settings Retrieving C onfiguration Settings Using the Application Setting Manager in Sandboxed Solutions For broader, contextual guidance on specific scenarios, see Key Scenarios. For step-by-step guidance on the most common end-to-end tasks, see Developer How-to Topics. Generated from CHM, not final book. Will be superseded in the future. Page 475
- 476. Using the Application Setting Manager Interfaces The Application Setting Manager exposes two interfaces that you can use in your SharePoint applications to store and retrieve configuration data: IHierarchicalConfig. Implementations of this interface allow you to retrieve configuration setting data, regardless of the location of that data in the SharePoint hierarchy. By default, this interface is implemented by the HierarchicalConfig class. IConfigManager. Implementations of this interface allow you to store, update, and delete configuration data. You can also retrieve settings from specific levels in the SharePoint hierarchy. By default, this interface is implemented by the ConfigManager class. To use these interfaces and their default implementations in your solutions, add a reference to the Microsoft.Practices.SharePoint.Common.dll assembly and the Microsoft.Practices.ServiceLocation.dll assembly. Using the IHierarchicalConfig Interface Implementations of the IHierarchicalConfig interface retrieve application configuration settings from a hierarchical structure of storage, starting at the SPWeb level and culminating at the SPF arm level. The default implementation of the IHierarchicalConfig interface—the HierarchicalConfig class—can retrieve and build up this hierarchical storage structure in two ways. By default, the HierarchicalConfig class uses the SPContext.Current property to retrieve the current SPWeb object. The remaining hierarchy structure—the local SPSite, SPWebApplication, and SPF arm objects—can be inferred from the SPWeb object. Alternatively, the HierarchicalConfig class includes a method named SetWeb that you can use to specify an SPWeb object for the hierarchy structure. The HierarchicalConfig class then builds a hierarchical structure from the SPWeb object you provided. This approach is useful if a SharePoint context is unavailable or if you want to read from a hierarchy that differs from your current SharePoint context. Note: If you do not specify an SPWeb object, and the HierarchicalConfig class is unable to retrieve a valid SharePoint context, calls to the IHierarchicalConfig interface will throw an exception. You can also create an instance of the HierarchicalConfig and provide an SPWeb object as an argument to the constructor. You should use this approach or the SetWeb method in command-line applications, feature receivers, and test classes where the SharePoint context is unavailable. When you use the HierarchicalConfig class to retrieve a configuration setting—regardless of how you instantiated it—the class first looks for the specified setting in the property bag of the SPWeb object. If it finds the setting at the SPWeb level, it uses it and stops searching. If a setting is not found at the SPWeb level, it next looks for the setting at the site collection level. If the setting is not found at the site collection level, it looks in the current SPWebApplication object, and then it looks in the current SPFarm object. For example, you could use the following code to retrieve a string-based configuration setting, regardless of the level in the SharePoint hierarchy at which it is stored. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; using Microsoft.Practices.SharePoint.Common.ServiceLocation; IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); var config = serviceLocator.GetInstance<IHierarchicalConfig>(); string myValue; if (config.ContainsKey("testKey")) myValue = config.GetByKey<string>("testKey"); As described earlier, if you are retrieving configuration settings when the context is not available, you must first provide an SPWeb object to the HierarchicalConfig class. The following example shows how to provide an SPWeb object from the properties passed into an event receiver. This must be done prior to retrieving a value from configuration; otherwise, the class will throw a NoSharePointContextException. C# var config = serviceLocator.GetInstance<IHierarchicalConfig>(); Generated from CHM, not final book. Will be superseded in the future. Page 476
- 477. config.SetWeb(properties.Web); For more information about how to use the IHierarchicalConfig interface, see Retrieving C onfiguration Settings. Using the IConfigManager Interface The IConfigManager interface reads and writes configuration settings at specific locations in the hierarchy. Unlike the IHierarchicalConfig interface, the methods in this interface do not traverse the hierarchy—instead, you specify the level of the hierarchy that you want to work with. By default, the IConfigManager interface is implemented by the ConfigManager class. Like the HierarchicalConfig class, you can provide context for the ConfigManager class in three ways: You can allow the ConfigManager class to build the hierarchical storage structure from the SPContext.Current property. You can call the ConfigManager.SetWeb method to provide the ConfigManager class with the starting point for the storage hierarchy. You can manually instantiate the ConfigManager class and provide an SPWeb object as an argument to the constructor. You should use one of the latter two approaches when your code runs outside the SharePoint context, such as in command-line applications, feature receivers, and test classes. The Application Setting Manager stores application settings in purpose-built property bags. When you use the ConfigManager class to read or write application settings, you must first call the GetPropertyBag method to obtain an IPropertyBag instance from the current configuration hierarchy. This method accepts an argument of type ConfigLevel, which provides an enumeration of storage levels. After you have a property bag instance, you can store application settings by providing the ConfigManager instance with a key, a value, and the target property bag. The key must be a string. The value can be any object that can be serialized to XML. The following example shows how to use the ConfigManager class without a SharePoint context. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; using Microsoft.Practices.SharePoint.Common.ServiceLocation; IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IConfigManager configManager = serviceLocator.GetInstance<IConfigManager>(); // Retrieve a site collection by URL. using(SPSite site = new SPSite("http://intranet.contoso.com/sites/testzone")) { // Store a configuration setting at the site collection level. configManager.SetWeb(site.RootWeb); IPropertyBag bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPSite); configManager.SetInPropertyBag("testKey", "Test Value", bag); } Note: Under some circumstances, the GetPropertyBag method may throw an exception. For example, if you attempt to retrieve a farm-level property bag from a sandboxed solution, the method will throw a ConfigurationException because you are not permitted to access farm-level configuration settings from the sandbox. You can also use IConfigManager to retrieve configuration settings from specific levels in the SharePoint hierarchy. This can be useful if you need to retrieve configuration settings in scenarios where the SharePoint context is unavailable, or if you need to retrieve settings from Web applications, site collections, or sites that are not in the current context. For more information about how to use the IConfigManager interface, see Adding and Updating C onfiguration Settings and Removing C onfiguration Settings. Generated from CHM, not final book. Will be superseded in the future. Page 477
- 478. Adding and Updating Configuration Settings The IConfigManager interface defines a single method named SetInPropertyBag that you can use to store configuration data at any level of the SharePoint hierarchy. The following code shows how to use the SetInPropertyBag method to add or update a configuration setting. It is important to note that items stored as configuration settings can be read by all users that have permissions on the object containing the property bag, such as the SPWeb or the SPFarm objects. As such, you should not store sensitive or personal information as configuration settings without first encrypting them. Note: SharePoint 2010 does not allow you to write to the farm-level configuration from a content Web application. If you want to use the Application Setting Manager to store farm-level settings, your code must run from a feature receiver, the command line, or the C entral Administration Web application. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.SharePoint.Administration; using Microsoft.SharePoint; IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IConfigManager configManager = serviceLocator.GetInstance<IConfigManager>(); IPropertyBag bag; // Store configuration data at the SPWeb level. bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPWeb); configManager.SetInPropertyBag("MyApplications.WorkgroupName", "Customer Service", bag); // Store configuration data at the SPSite level. bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPSite); configManager.SetInPropertyBag("MyApplications.DivisionName", "Pharmaceuticals", bag); // Store configuration data at the SPWebApplication level. bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPWebApplication); configManager.SetInPropertyBag("MyApplications.CompanyName", "Contoso", bag); // Store configuration data at the SPFarm level. // Note that you cannot do this from a content Web application. bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPFarm); configManager.SetInPropertyBag("MyApplications.FarmLocation", "Redmond", bag); Before you use the SetInPropertyBag method, you must retrieve the property bag in which you want to store your application setting. The ConfigManager class provides a method named GetPropertyBag that returns an IPropertyBag instance. The GetPropertyBag method accepts an argument of type ConfigLevel. This is an enumeration that allows you to specify the level in the SharePoint hierarchy that you want to target. The GetPropertyBag method returns the property bag at the appropriate level in the current hierarchy. Note: Typically, the ConfigManager class builds a hierarchy of SharePoint objects from the SPContext.Current property. Alternatively, you can manually specify an SPWeb object as a starting point for the hierarchy, if the SharePoint context is unavailable. For more information, see Using the Application Setting Manager Interfaces. The first argument to the SetInPropertyBag method is the key that defines the configuration setting. If this is a null string, an exception is thrown. Because there might be name collisions with properties that were set by other applications or by SharePoint itself, it is recommended that you fully qualify the key for each configuration setting with the namespace of the code that defines the setting. Generated from CHM, not final book. Will be superseded in the future. Page 478
- 479. The second argument to the SetInPropertyBag method is the new value of the configuration setting. This value must be an object that is serializable to XML. If a key already exists at the specified location, the existing value is overwritten. Otherwise, a new key/value pair is added to the property bag. Finally, the third argument is the property bag in which you want to store your application setting. Remember that if the SharePoint context is unavailable, you must provide the ConfigManager class with an SPWeb object as the starting point for the current SharePoint hierarchy (SPWeb, SPSite, SPWebApplication, and SPF arm). To do this, call the ConfigManager.SetWeb method. The following code example shows how you could use this approach to store configuration data at the SPSite level. C# using(SPSite remoteSite = new SPSite ("http://intranet.contoso.com/sites/pharm")) { configManager.SetWeb(remoteSite.RootWeb); IPropertyBag bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPSite); configManager.SetInPropertyBag("MyApplications.DivisionName", "Pharmaceuticals", bag); } Note: Various key namespaces and suffixes are reserved for use by the Application Setting Manager. The Application Setting Manager will throw an exception if you attempt to set a property that starts with the reserved key namespace (PnP.Config.Key). The library provides a full-trust proxy that allows sandbox applications to read Web application–level settings and farm-level settings when installed. The prefix ensures that the sandbox code will only read settings created through the Application Setting Manager. The Application Setting Manager will also throw an exception if you attempt to set a property that ends with the suffix that distinguishes a site collection setting (._Site_). This suffix is used internally to distinguish between site collection settings and site settings in the SPWeb property bag at the root of a site collection. The following table shows SharePoint groups and the default permission levels that apply when adding and updating configuration settings, where site name is the actual name of the site. Group (default Can set site Can set site Can set Web Can set farm permission lev el) configuration collection application configuration configuration configuration Site name Visitors No No No No (Read) Site name Members No No No No (C ontribute) Site nameOwners Yes Yes No No (Full C ontrol) Farm Administrators Policy dependent Policy dependent Yes Yes (Full C ontrol) Note: Site name Owners is a SharePoint group that is created by default with the site collection. The Site name Owners group has Full C ontrol permissions. The site administrator is a member of this group. For more information about SharePoint permissions, see Permission Levels and Permissions on the Microsoft Office Online Web site. Note: Note: Members of the Farm Administrators group may or may not have automatic rights to manage site configuration data and site collection configuration data, depending on the policy configuration in your SharePoint environment. C hanges to farm configuration are not allowed from content Web applications. Generated from CHM, not final book. Will be superseded in the future. Page 479
- 480. Removing Configuration Settings The IConfigManager interface defines a single method named Remov eKeyFromPropertyBag that you can use to remove configuration data from any level of the SharePoint hierarchy. The following code shows how to use the Remov eKeyFromPropertyBag method to remove a configuration setting. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.SharePoint; //for the SPContext object IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IConfigManager configManager = serviceLocator.GetInstance<IConfigManager>(); // Remove configuration data at the SPWeb level IPropertyBag bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPWeb); configManager.RemoveKeyFromPropertyBag("Contoso.Applications.WorkgroupName", bag); // Remove configuration data at the SPSite level. bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPSite); configManager.RemoveKeyFromPropertyBag("Contoso.Applications.DivisionName", bag); // Remove configuration data at the SPWebApplication level. bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPWebApplication); configManager.RemoveKeyFromPropertyBag("Contoso.Applications.CompanyName", bag); // Remove configuration data at the SPFarm level. // Note that you cannot do this from a content Web application. bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPFarm); configManager.RemoveKeyFromPropertyBag("Contoso.Applications.FarmLocation", bag); The first argument to the RemoveKeyFromPropertyBag method is the key of the configuration setting to be deleted. This should be a string that was previously used in a corresponding invocation of the SetInPropertyBag method. The RemoveKeyFromPropertyBag method does not fail if the key cannot be found, so this method can be safely called to ensure that the key is removed. The second argument to the Remov eKeyFromPropertyBag is an object of type IPropertyBag that represents the property bag in which the configuration data is stored. You can use the GetPropertyBag method to retrieve the property bag instance from the ConfigManager class. If the SharePoint context is unavailable, you must provide the ConfigManager class with an SPWeb object as the starting point for the current SharePoint hierarchy (SPWeb, SPSite, SPWebApplication, and SPF arm) before you delete any settings. To do this, call the ConfigManager.SetWeb method. The following example shows how you could use this approach to remove an application setting at the SPSite level. C# using(SPSite remoteSite = new SPSite ("http://intranet.contoso.com/sites/pharm")) { configManager.SetWeb(remoteSite.RootWeb); IPropertyBag bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPSite); configManager.RemoveKeyFromPropertyBag("MyApplications.DivisionName", bag); } The permissions for removing items from the property bags are the same as the permissions for update and create defined in the previous section. Generated from CHM, not final book. Will be superseded in the future. Page 480
- 481. Retrieving Configuration Settings The Application Setting Manager provides two different models you can use to retrieve configuration settings: IHierarchicalConfig. This interface allows you to retrieve configuration settings from any level of the SharePoint hierarchy, without knowing the level at which your setting is stored. If the same configuration key is defined at more than one level of the hierarchy, the IHierarchicalConfig implementation will return the value defined at the most specific level. IConfigManager. This interface allows you to retrieve configuration settings at a specific level in the SharePoint hierarchy. For example, you can retrieve an application setting from a specified SPWeb object or a specified SPFarm. The following sections describe how to use each of these approaches to retrieve configuration settings. Note: Both of these interfaces rely on a hierarchy of SharePoint objects (from SPWeb to SPFarm) in order to manage configuration settings. You can either allow the interface implementations to use the hierarchy current SharePoint context via the SPContext.Current property, or you can provide an SPWeb object as the starting point for the hierarchy. For more information, see Using the Application Setting Manager Interfaces. Using IHierarchicalConfig to Retrieve Configuration Settings The IHierarchicalConfig interface defines methods that you can use to retrieve configuration settings from any level of the SharePoint hierarchy in which your code is running. The GetByKey generic method provides a strongly typed way to retrieve a configuration setting. Because this method throws an exception if the key cannot be found, you should first use the ContainsKey method to verify that the key exists. The following code shows how to retrieve a configuration setting using the ContainsKey and GetByKey methods. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IHierarchicalConfig config = serviceLocator.GetInstance<IHierarchicalConfig>(); string workgroupName; if(config.ContainsKey("Contoso.Applications.WorkgroupName")) workgroupName = config.GetByKey<string>("Contoso.Applications.WorkgroupName"); The ContainsKey method and the GetByKey method take a single argument that contains the key string of the setting you want to retrieve. This should be a string that was previously used in a corresponding invocation of the SetInPropertyBag method, as described in Adding and Updating C onfiguration Settings. You can also specify the level in the SharePoint hierarchy at which the ContainsKey method and the GetByKey method should start looking for a property key. To do this, pass a member of the ConfigLevel enumeration as a second argument to the ContainsKey method or the GetByKey method. The ConfigLevel enumeration defines the following values: ConfigLevel.CurrentSPWeb. This value indicates that properties of the current site, site collection, Web application, and farm are searched. ConfigLevel.CurrentSPSite. This value indicates that properties of the current site collection, Web application, and farm are searched. ConfigLevel.CurrentSPWebApplication. This value indicates that properties of the current Web application and farm are searched. ConfigLevel.CurrentSPF arm. This value indicates that properties of the current farm are searched. For example, you could use the following code to look for and retrieve a property that could be defined at the Web application level or the farm level. C# bool isInternetFacing; if(config.ContainsKey("Contoso.Applications.IsInternetFacing", ConfigLevel.CurrentSPWebApplication)) { isInternetFacing = config.GetByKey<bool> ("Contoso.Applications.IsInternetFacing", ConfigLevel.CurrentSPWebApplication); } Generated from CHM, not final book. Will be superseded in the future. Page 481
- 482. If you do not provide a ConfigLevel argument to the ContainsKey method or the GetByKey method, the ConfigLevel.CurrentSPWeb value is used and the HierarchicalConfig class will start searching at the SPWeb level. Note: In some circumstances, such as in a timer job, the local SPF arm object is the only available SharePoint context unless the application code sets the SPWeb instance to use with the SetWeb method. In this case, the HierarchicalConfig class will search only the farm-scoped property bag. Using IConfigManager to Retrieve Application Settings If you do not want to search up the SharePoint hierarchy, you can use the IConfigManager interface to retrieve configuration settings. The ContainsKeyInPropertyBag method enables you to check for a key value at a specific level of the SharePoint hierarchy. The generic GetF romPropertyBag method enables you to retrieve a strongly typed object from a specific level of the SharePoint hierarchy. Both methods take the following two arguments: The string key under which the configuration setting was stored The IPropertyBag instance in which the setting was stored For example, you could use the following code to retrieve a configuration setting from a specific site collection. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IConfigManager configManager = serviceLocator.GetInstance<IConfigManager>(); double bonusMultiplier; using(SPSite mySite = new SPSite("http://intranet.contoso.com/sites/sales")) { configManager.SetWeb(mySite.RootWeb); IPropertyBag bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPSite); if(configManager.ContainsKeyInPropertyBag ("Contoso.Applications.BonusMultiplier", bag)) { bonusMultiplier = configManager.GetFromPropertyBag<double> ("Contoso.Applications.BonusMultiplier", bag); } } Generated from CHM, not final book. Will be superseded in the future. Page 482
- 483. Using the Application Setting Manager in Sandboxed Solutions In many SharePoint 2010 development scenarios, you will need to create solutions that run in the sandbox environment. This places certain limitations on how you can use the Application Setting Manager. This topic identifies these limitations and describes the actions you can take to mitigate them. The security restrictions on the sandbox environment prevent sandboxed code from reading or writing configuration data at the Web application level or the farm level, and the Application Setting Manager is no exception. The Application Setting Manager will automatically detect whether it is running in the sandbox. If this is the case, it builds a reduced storage hierarchy that consists of the current SPWeb object and the current SPSite object. The HierarchicalConfig class will not search for settings beyond the SPSite level, and the ConfigManager class will not permit you to store settings beyond the SPSite level—any attempts to retrieve a Web application–scoped or farm-scoped property bag will return null. Reading Farm-Level and Web Application-Level Configuration Data The Application Setting Manager includes various full-trust proxies that allow you to read farm-level and Web application–level application settings from a sandboxed solution. These full-trust proxies will only allow you to retrieve settings that are managed by the Application Setting Manager, in order to avoid subverting the security restrictions of the sandbox environment. Furthermore, the proxies do not allow you to write any settings to Web application–level or farm-level storage. The project Microsoft.Practices.SharePoint.C ommon.C onfigProxy defines the following full-trust proxy classes: ContainsKeyOperation. This proxy allows you to check for a Web application or farm-scoped configuration setting from sandboxed code. ReadConfigurationOperation. This proxy allows you to retrieve a Web application or farm-scoped configuration setting from sandboxed code. The ConfigProxy project is scoped as a farm solution. If you deploy this solution to your server farm, both proxies are made available to the sandbox environment. The Application Setting Manager automatically detects whether the proxy is installed and will use it when appropriate—you can use the same code to interact with application settings that you would use in the full-trust environment. Note: The SharePoint Guidance Library includes a static utility method, SharePointEnvironment.CanAccessF armConfig, which you can use to determine whether your code has access to Web application–level or farm-level application settings. Storing Complex Types from Sandboxed Solutions The Application Setting Manager uses different techniques to store different types of data: Simple types, such as strings, enumerations, and primitive values, are converted to strings if required and stored directly in the relevant property bag. More complex types are serialized and stored as XML in the relevant property bag. This can create difficulties when you attempt to store complex types from the sandbox environment. The Application Setting Manager uses the XmlSerializer class to serialize and deserialize complex types. By default, the XMLSerializer class dynamically generates assemblies to serialize and deserialize these types. When this occurs during sandbox execution, an error is raised because writing files and running the compiler is prohibited in the sandbox environment. To work around this problem in the sandbox environment, you can configure your projects to automatically pre-generate serialization assemblies for specific types when the project builds. You can use the following procedure to pre-generate serialization assemblies for a Visual Studio 2010 project. To pre-generate serialization assemblies 1. In Visual Studio 2010, in Solution Explorer, right-click the project for which you want to generate serialization assemblies, and then click Unload Project. 2. In Solution Explorer, right-click the project for which you want to generate serialization assemblies, and then click Edit <Project Name>.csproj. 3. In the <Project Name>.csproj file, immediately after the Generated from CHM, not final book. Will be superseded in the future. Page 483
- 484. <TargetFrameworkVersion>v 3.5</TargetF rameworkVersion> element, add the following element. XML <SGenUseProxyTypes>false</SGenUseProxyTypes> 4. Save and close the <Project Name>.csproj file. 5. In Solution Explorer, right-click the project for which you want to generate serialization assemblies, and then click Reload Project. 6. Open the properties page for the project, and then click the Build tab. 7. In the Generate serialization assembly drop-down list box, click On. This procedure generates an additional assembly named <Project Name>.xmlSerializers.dll in your bindebug folder. You will need to deploy this assembly with your solution. Occasionally, you may need to constrain the types that are added to the serialization assembly. This should only be necessary for assemblies that run both in full trust and in the sandbox and for assemblies that use types that are not permitted in the sandbox. If you include types in the serialization assembly that are not permitted in the sandbox environment, an exception will occur in the sandbox when the assembly is loaded. To constrain the types that are added to the serialization assembly, add an SGenSerializationTypes element to the PropertyGroup node in your .csproj file. For example, the Microsoft.Practices.SharePoint.C ommon project includes the following element, which specifies that a serialization assembly is only pre-generated for the Serv iceLocationConfigData type. XML <SGenSerializationTypes> Microsoft.Practices.SharePoint.Common.ServiceLocation.ServiceLocationConfigData </SGenSerializationTypes> To add multiple entries to the SGenSerializationTypes element, use semicolons to delineate your type names. Note: If you are deploying your assembly to the global assembly cache, you must first remove any existing versions of your assembly and the pre-generated serialization assembly from the global assembly cache in a pre-build step. If you do not remove the assemblies, the serialization assembly will be generated to your project directory instead of to the bindebug folder, and subsequent compiles will fail. Assembly Deployment To use the Application Setting Manager in a sandboxed solution, you will need to deploy the following SharePoint Guidance Library assemblies within your sandboxed solution package (assuming that they have not already been deployed to the global assembly cache): Microsoft.Practices.SharePoint.Common.dll Microsoft.Practices.SharePoint.Common.XmlSerializers.dll Microsoft.Practices.Serv iceLocation.dll If you pre-generated XML serialization assemblies for your own projects, be sure to deploy the <Project Name >.XmlSerializers.dll assembly with your solution. To deploy the assemblies with your project, click the Package node in your project, click the Adv anced tab, click Add, and then click Add Existing Assembly. Select the deploy target as the global assembly cache (even though the assemblies won't actually be deployed there for a sandboxed solution). Generated from CHM, not final book. Will be superseded in the future. Page 484
- 485. Key Scenarios This section describes the most common situations in which you might use the Application Setting Manager. Each topic in this section describes a realistic scenario, identifies the solution, and provides code to demonstrate how to use the Application Setting Manager to complete the task. Each topic also includes usage notes and hints where applicable. The scenarios are as follows: Using a Feature Receiver to C reate a C onfiguration Setting. This scenario illustrates how you can use the Application Setting Manager to add a configuration setting from within a feature receiver class. Using a Feature Receiver to Remove a C onfiguration Setting. This scenario illustrates how you can use the Application Setting Manager to remove a configuration setting from within a feature receiver class, to provide a cleanup operation when your application or component is uninstalled. Reading C onfiguration Data in a SharePoint Web Part. This scenario illustrates how you can use the Application Setting Manager to retrieve configuration settings from code running within the SharePoint context. Generated from CHM, not final book. Will be superseded in the future. Page 485
- 486. Using a Feature Receiver to Create a Configuration Setting Typical Goals When you deploy an application to a SharePoint environment, you will often need to ensure that configuration settings are both specified and available before your application is first run. For example, suppose that you have developed a Web Part that provides a map view of customer locations, based on geo-coded data from a SharePoint list. Before your Web Part can do its job, it needs to know where to find the customer location list. Solution The Application Setting Manager exposes an interface named IConfigManager. This interface defines methods that you can use to add and update application settings. To ensure that the required settings are available before the Web Part is added to a page, you can use a feature receiver class to add the configuration settings when the Web Part feature is activated. Using the IConfigManager Interface to Add Application Settings The following code shows how to use the IConfigManager interface to add an application setting from within a feature receiver class. This example assumes that you have added a reference to the Microsoft.Practices.SharePoint.Common.dll assembly, the Microsoft.Practices.ServiceLocation.dll assembly, and the Microsoft.SharePoint.dll assembly. C# using Microsoft.SharePoint; using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; [Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")] public class MyFeatureReceiver : SPFeatureReceiver { public override void FeatureActivated(SPFeatureReceiverProperties properties) { IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IConfigManager configManager = serviceLocator.GetInstance<IConfigManager>(); SPSite mySite = properties.Feature.Parent as SPSite; if(mySite != null) { configManager.SetWeb(mySite.RootWeb); IPropertyBag bag = configManager.GetPropertyBag( ConfigLevel.CurrentSPSite); configManager.SetInPropertyBag( "Contoso.Sales.Applications.CustomerLocationsListUrl", "http://intranet.contoso.com/sites/sales/CustomerLocations", bag); } } } Note: The Parent property of a feature depends on the scope of the feature that is being activated. In this example, the feature is scoped at the site collection level. For more information about using the IConfigManager interface to add or update configuration settings, see Generated from CHM, not final book. Will be superseded in the future. Page 486
- 487. Adding and Updating Application Settings. Usage Notes As a good practice, consider removing any related application settings from the SharePoint environment when you deactivate a feature. You can do this by overriding the F eatureDeactivating method in a feature receiver class. However, remove configuration settings only if you are certain that no other features are using the configuration data, and take care to avoid removing settings that other instances of the activated feature may rely on. C reating the application settings at the same scope as the application feature will typically avoid this situation. Adding, updating, and removing configuration settings can lead to contention issues, because only one process can write to a property bag at any one time. If SharePoint is unable to write to a property bag because of contention, it will throw an SPUpdatedConcurrencyException. The SPF arm and SPWebApplication property bag implementations will automatically retry the operation in this situation, but the retry limit may be exceeded in heavy contention situations. In this case, the ConfigManager class will throw a ConfigurationException, and the inner exception will be an SPUpdatedConcurrencyException. Generated from CHM, not final book. Will be superseded in the future. Page 487
- 488. Using a Feature Receiver to Remove a Configuration Setting Typical Goals If you regularly use the Application Setting Manager to add and update configuration settings for your SharePoint applications, you will also want to remove configuration settings that are no longer required. For example, if you uninstall a Web Part, you should remove any configuration settings that are unique to that Web Part to prevent your property bags from becoming unwieldy and to reduce the risk of duplicating key names for different settings. Solution The IConfigManager interface defines a method named Remov eKeyFromPropertyBag that enables you to remove configuration settings. This method takes two arguments: the key as a string and the IPropertyBag instance from which you want to remove the setting. If you used a feature receiver class to add the configuration setting when your feature was activated, good practice suggests that you should you use the same feature receiver class to remove the configuration setting when it is no longer required. Using the IConfigManager Interface to Remove Configuration Settings The following code shows how to use the IConfigManager interface to remove a configuration setting from within a feature receiver class. This example assumes that you have added a reference to the Microsoft.Practices.SharePoint.Common.dll assembly, the Microsoft.Practices.ServiceLocation.dll assembly, and the Microsoft.SharePoint.dll assembly. C# using Microsoft.SharePoint; using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; [Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")] public class MyFeatureReceiver : SPFeatureReceiver { public override void FeatureDeactivating(SPFeatureReceiverProperties properties) { IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IConfigManager configManager = serviceLocator.GetInstance<IConfigManager>(); SPSite mySite = properties.Feature.Parent as SPSite; if(mySite != null) { configManager.SetWeb(mySite.RootWeb); IPropertyBag bag = configManager.GetPropertyBag( ConfigLevel.CurrentSPSite); configManager.RemoveKeyFromPropertyBag( "Contoso.Sales.Applications.CustomerLocationsListUrl", bag); } } } Note: The Parent property of a feature depends on the scope of the feature that is being activated. In this example, the feature is scoped at the site collection level. Generated from CHM, not final book. Will be superseded in the future. Page 488
- 489. For more information about using the IConfigManager interface to remove configuration settings, see Removing C onfiguration Settings. Generated from CHM, not final book. Will be superseded in the future. Page 489
- 490. Reading Configuration Data in a SharePoint Web Part Typical Goals Your application may need to retrieve configuration settings at various points in its execution. To determine where your application should be deployed, a deployment package might need to retrieve global configuration settings as part of the installation process. A Web Part or an application page might need to retrieve configuration settings as part of the page load life cycle, or in other words, whenever a user requests the page. If your application contains more complex logic, it might need to retrieve configuration settings regularly in response to user interface events. In any of these situations, it is useful to have a consistent, type-safe approach to the retrieval of configuration data. Solution This scenario continues to use the example of a Web Part that provides a map view of customer locations, based on geo-coded data from a SharePoint list. Every time the Web Part loads, it must retrieve the URL of the customer location list from the configuration settings for the SharePoint environment. The IHierarchicalConfig interface defines a generic method named GetByKey that you can use to retrieve configuration settings from any level of the SharePoint hierarchy. When you use the GetByKey method, the HierarchicalConfig class will first look for the setting in the current SPWeb object. If the specified key cannot be found at the SPWeb level, the HierarchicalConfig class will next look in the root web of the current SPSite object (as the SPSite object does not include a property bag), then in the current SPWebApplication, and finally in the SPF arm object. Using the GetByKey Method The following code example shows how to use the IHierarchicalConfig interface to retrieve a configuration setting from within a Web Part class. This example assumes that you have added a reference to the Microsoft.Practices.SharePoint.Common.dll assembly, the Microsoft.Practices.ServiceLocation.dll assembly, the Microsoft.SharePoint.dll assembly, and the System.Web.dll assembly. C# using System.Web; using Microsoft.SharePoint; using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; [Guid("70ACDCFF-A253-4133-9064-25DB28F17514")] public class CustomerLocationsWebPart : System.Web.UI.WebControls.WebParts.WebPart { protected override void OnLoad(EventArgs e) { IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IHierarchicalConfig config = serviceLocator.GetInstance<IHierarchicalConfig>(); string locationsListUrl; if(config.ContainsKey("Contoso.Sales.CustomerLocationsListUrl")) { locationsListUrl = config.GetByKey<string> ("Contoso.Sales.CustomerLocationsListUrl"); } } Generated from CHM, not final book. Will be superseded in the future. Page 490
- 491. } You can also retrieve hierarchical configuration settings from outside a SharePoint context. In this case, you must provide the HierarchicalConfig instance with an SPWeb object from which to build the configuration hierarchy. C# using(SPSite mySite = new SPSite("http://intranet.contoso.com/sites/sales")) { IHierarchicalConfig config = serviceLocator.GetInstance<IHierarchicalConfig>(); config.SetWeb(mySite.RootWeb); locationsListUrl = config.GetByKey<string>(“Contoso.Sales.CustomerLocationListUrl”); } Usage Notes Beyond simple developer convenience, there are sound design reasons to use an application settings manager that searches up the SharePoint hierarchy for specific configuration keys. In the customer locations example, the URL of the customer locations list was initially stored at the site collection level. Suppose a specialized sales team wanted to use the same Web Part within their own individual site. However, they want to use a different customer locations list to drive the Web Part. By adding a configuration setting with the same key at the SPWeb level, their Web Part will use the customized local list, while any other instances of the Web Part within the site collection will be unaffected. The use of generics in the GetByKey method forces you to retrieve configuration values as strongly-typed objects. You will receive a ConfigurationException at run time if you attempt to read a configuration setting with the wrong type. For example, if you read a configuration setting as type Int32, but it was stored as type DateTime, an exception would be raised. For more information about how to retrieve configuration settings, including how to retrieve settings from outside the SharePoint context, see Retrieving C onfiguration Settings. Generated from CHM, not final book. Will be superseded in the future. Page 491
- 492. Design of the Application Setting Manager The Application Setting Manager includes the following features: It provides a uniform interface for reading and writing application settings into the property bags associated with each level of the SharePoint hierarchy. It provides a type-safe way to read configuration settings. It provides automatic serialization of complex data types. It provides the ability to read configuration settings in a hierarchical way. Settings defined at a lower or more specific level can override settings at a higher or more general level. Design Highlights The following class diagram illustrates the design of the Application Setting Manager. The Application Setting Manager Generated from CHM, not final book. Will be superseded in the future. Page 492
- 493. The functionality of the Application Settings Manager is exposed through two key interfaces: IHierarchicalConfig. This interface consumes configuration settings. Generated from CHM, not final book. Will be superseded in the future. Page 493
- 494. IConfigManager. This interface manages and can consume configuration settings. In most cases, you should locate and instantiate these interfaces through the SharePoint Service Locator. The SharePoint Service Locator includes a default type mapping that maps the IHierarchicalConfig interface and the IConfigManager interface to their default implementations—the HierarchicalConfig class and the ConfigManager class, respectively. Design Details To store and retrieve application settings, the Application Settings Manager must build a hierarchy of storage levels. At each level of the hierarchy, the configuration store is represented by an implementation of IPropertyBag. This interface defines a collection of key-value pairs. The Application Setting Manager defines the following implementations of the IPropertyBag interface. IPropertyBag Description implementation SPWebPropertyBag The property bag that stores settings at the site (SPWeb) level. This implementation uses the property bag of the underlying SPWeb object to store application settings. This property bag is accessible from sandboxed code. SPSitePropertyBag The property bag that stores settings at the site collection (SPSite) level. This implementation uses the property bag of the root Web ( SPSite.RootWeb) to store application settings, because the SPSite object does not include a property bag. Site collection–scoped keys have the suffix _Site_ appended to the key name internally to differentiate them from similarly-named Web-scoped keys in the root Web. An exception is thrown if you attempt to set a property that has the _Site_ suffix in its key string. This property bag is accessible from sandboxed code. SPWebAppPropertyBag The property bag that stores settings at the Web application level. This implementation uses a custom configuration object, WebAppSettingStore , to store settings. This store derives from SPPersistedObject and is stored as a child object of the SPWebApplication instance. This property bag is not accessible from sandboxed code. SPFarmPropertyBag The property bag that stores settings at the farm level. This implementation uses a custom configuration object, F armAppSettingStore, to store settings. This store derives from SPPersistedObject and is stored as a child object of the SPFarm instance. This property bag is not accessible from sandboxed code. SandboxWebAppPropertyBa A read-only property bag that enables you to read Web application-scoped g application settings from sandboxed code. This implementation requires that you install the full-trust proxy for reading Web application-scoped settings from the sandbox environment. SandboxFarmPropertyBag A read-only property bag that enables you to read farm-scoped application settings from sandboxed code. This implementation requires that you install the full-trust proxy for reading farm-scoped settings from the sandbox environment. SPListBackedPropertyBag A property bag that enables you to store application settings in a SharePoint list. The configuration list is stored at the root web level and can store values scoped to any level in the hierarchy. Internally, values stored in the list are retrieved based upon the key and a unique context ID that represents the hierarchy level, such as the ID property for an SPWeb object. This class is provided to help developers build list-based property bags as an alternate approach to the storage of application settings. This property bag is accessible from sandboxed code. SPListBackedUrlPropertyBag A property bag that enables you to store application settings in a SharePoint list. This class is intended for managing settings at the Web application and farm level, where settings must be stored in a central list. The class sets AllowUnsafeUpdates=true when updating or deleting a value, because the list may reside on a site collection outside the current Generated from CHM, not final book. Will be superseded in the future. Page 494
- 495. context. Because of this, this property bag cannot be used from sandboxed code. The Application Setting Manager must build a hierarchy of property bags to suit your execution context. The IPropertyBagHierarchy interface represents an ordered collection of property bags. The Application Setting Manager includes the following implementations of IPropertyBagHierarchy, each of which is targeted to a different execution context. IPropertyBagHierarchy implementation Description PropertyBagHierarchy Provides the base functionality for all property bag hierarchy implementations. FarmPropertyBagHierarchy Provides a property bag hierarchy when only farm configuration is available, such as when your code runs in a timer job. C ontains an SPF armPropertyBag. FullTrustPropertyBagHierarchy Provides a property bag hierarchy for full-trust solutions. C ontains an SPWebPropertyBag, an SPSitePropertyBag, an SPWebAppPropertyBag, and an SPF armPropertyBag. SandboxPropertyBagHierarchy Provides a property bag hierarchy for sandboxed solutions. C ontains an SPWebPropertyBag and an SPSitePropertyBag. SandboxWithProxyPropertyBagHierarc Provides a property bag hierarchy for sandboxed solutions hy when the full-trust proxy for reading Web application–scoped and farm-scoped settings is installed. C ontains an SPWebPropertyBag, an SPSitePropertyBag, a SandboxWebAppPropertyBag, and a SandboxF armPropertyBag. The HierarchyBuilder class is responsible for selecting the right IPropertyBagHierarchy implementation for a particular execution context. Both the HierarchicalConfig class and the ConfigManager class rely on the HierarchyBuilder class to select and populate a suitable implementation of IPropertyBagHierarchy. The ConfigSettingSerializer class implements the IConfigSettingSerializer interface. This class enables the HierarchicalConfig class and the ConfigManager class to serialize and deserialize application settings. Simple values, such as enumerations, strings, and primitive types, are converted to strings if necessary and stored directly. More complex objects are serialized and stored as XML representations. Both the IConfigManager interface and the IHierarchicalConfig interface expose a SetWeb method that enables you to provide an SPWeb object from which to derive the storage hierarchy. This is an example of a method injection pattern. The default implementing classes, ConfigManager and HierarchicalConfig, also support a constructor injection pattern whereby you can pass an SPWeb object to the class constructor. Use the method injection approach if you are using service location to load the Application Setting Manager classes and you are running in an environment where the SharePoint context is unavailable, such as in a feature receiver or a timer job. The constructor injection approach provides an additional alternative if you want to directly instantiate the Application Setting Manager classes instead of by using service location. Reserved Key Terms Various key prefixes and suffixes are reserved for internal use by the Application Setting Manager: All keys are prefixed with PnP.Config.Key. This distinguishes configuration settings that are managed by the Application Setting Manager from other configuration data in the SharePoint property bags. All keys for site collection-scoped settings include a _Site_ suffix. This distinguishes site collection–scoped settings from Web-scoped settings in the root Web property bag. If you attempt to use a key that includes a reserved prefix or suffix, the Application Setting Manager throws a configuration exception. Generated from CHM, not final book. Will be superseded in the future. Page 495
- 496. Developer How-to Topics This section includes step-by-step guidance for the most common tasks that you will undertake when you work with the Application Setting Manager. Each how-to topic provides all the steps you need to complete each task without referring to other topics. However, for more detailed information and best practice guidance, you are urged to consult the rest of the documentation. This section includes the following how-to topics: How to: Add a C onfiguration Setting How to: Retrieve a C onfiguration Setting How to: Remove a C onfiguration Setting Generated from CHM, not final book. Will be superseded in the future. Page 496
- 497. How to: Add a Configuration Setting The following procedure demonstrates how you can use the Application Setting Manager to store a configuration setting. In this example, the configuration setting is stored at the Web application level. However, you can use the same procedure to store data at the site level, the site collection level, or the farm level. Note: To store settings at the farm level, your code must run in a context that has permissions to write to the farm— for example, in a console application, a feature receiver installed event, the C entral Administration Web site, or a farm-scoped feature receiver class. You cannot write to farm-level configuration from standard SharePoint Web applications. To add a configuration setting 1. Add a reference to the SharePoint Guidance Library assembly. In Visual Studio, right-click your project node in Solution Explorer, and then click Add References. C lick the Browse tab, and then navigate to the location of the Microsoft.Practices.SharePoint.Common.dll assembly. 2. Using the same procedure, add a reference to the Microsoft.Practices.Serv iceLocation.dll assembly. 3. Add the following using statements to the top of your source code file. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; using Microsoft.Practices.SharePoint.Common.ServiceLocation; 4. Use the SharePointServiceLocator.GetCurrent method to get a reference to the current service locator instance. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); 5. Use the service locator to request an implementation of the IConfigManager interface. C# IConfigManager configManager = serviceLocator.GetInstance<IConfigManager>(); 6. (Optional) If your code is running in an environment where the SPContext.Current property is not available, call the SetWeb method and pass in an SPWeb object from which to build the storage hierarchy. If a SharePoint context exists, you can skip this step. C# configManager.SetWeb(web); 7. Retrieve the IPropertyBag instance in which you want to store your application setting. C# IPropertyBag bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPWebApplication); 8. C all the IConfigManager.SetInPropertyBag method. The first parameter is the key string with which you want to identify your configuration data. The second parameter is the object that you want to store as configuration data, which in this case is an object of type DateTime. The third parameter is the IPropertyBag in which you want to store your configuration setting. C# configManager.SetInPropertyBag("MyApplication.LastUpdate", DateTime.Now, bag); Generated from CHM, not final book. Will be superseded in the future. Page 497
- 498. How to: Retrieve a Configuration Setting The following procedure demonstrates how you can retrieve a configuration setting that you created through the Application Setting Manager. To retrieve a configuration setting 1. Add a reference to the SharePoint Guidance Library assembly. In Visual Studio, right-click your project node in Solution Explorer, and then click Add References. C lick the Browse tab, and then navigate to the location of the Microsoft.Practices.SharePoint.Common.dll assembly. 2. Using the same procedure, add a reference to the Microsoft.Practices.Serv iceLocation.dll assembly. 3. Add the following using statements to the top of your source code file. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; using Microsoft.Practices.SharePoint.Common.ServiceLocation; 4. Use the SharePointServiceLocator.GetCurrent() property to get a reference to the current service locator instance. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); 5. Use the service locator to request an implementation of the IHierarchicalConfig interface. C# IHierarchicalConfig config = serviceLocator.GetInstance<IHierarchicalConfig>(); 6. C reate an object of the same type as the stored configuration data. You will use this to store the object you retrieve. C# DateTime lastUpdate; 7. (Optional) If your code is running in an environment where the SPContext.Current property is not available, call the SetWeb method and pass in an SPWeb object from which to build the storage hierarchy. If a SharePoint context exists, you can skip this step. C# config.SetWeb(web); 8. C all the IHierarchicalConfig.ContainsKey method to verify that your configuration data exists. C# if(config.ContainsKey("MyApplication.LastUpdate")) 9. If the ContainsKey method returns true, call the IHierarchicalConfig.GetByKey method to retrieve the configuration data. Set the type parameter to the type of the object you want to retrieve. C# lastUpdate = config.GetByKey<DateTime>("MyApplication.LastUpdate"); Generated from CHM, not final book. Will be superseded in the future. Page 498
- 499. How to: Remove a Configuration Setting The following procedure demonstrates how you can remove a configuration setting that you created through the Application Setting Manager. To remove a configuration setting 1. Add a reference to the SharePoint Guidance Library assembly. In Visual Studio, right-click your project node in Solution Explorer, and then click Add References. C lick the Browse tab, and then navigate to the location of the Microsoft.Practices.SharePoint.Common.dll assembly. 2. Using the same procedure, add a reference to the Microsoft.Practices.Serv iceLocation.dll assembly. 3. Add the following using statements to the top of your source code file. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Configuration; using Microsoft.Practices.SharePoint.Common.ServiceLocation; 4. Use the SharePointServiceLocator.GetCurrent() method to get a reference to the current service locator instance. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); 5. Use the service locator to request an implementation of the IConfigManager interface. C# IConfigManager configManager = serviceLocator.GetInstance<IConfigManager>(); 6. (Optional) If your code is running in an environment where the SPContext.Current property is not available, call the SetWeb method and pass in an SPWeb object from which to build the storage hierarchy. If a SharePoint context exists, you can skip this step. C# configManager.SetWeb(web); 7. Retrieve the IPropertyBag instance from which you want to remove your application setting. C# IPropertyBag bag = configManager.GetPropertyBag(ConfigLevel.CurrentSPWebApplication); 8. C all the IConfigManager.RemoveKeyF romPropertyBag method. The first parameter is the key string that you originally used to identify your configuration data. The second parameter is the IPropertyBag object in which the configuration setting is stored. C# configManager.RemoveKeyFromPropertyBag("MyApplication.LastUpdate", bag); 9. Generated from CHM, not final book. Will be superseded in the future. Page 499
- 500. The SharePoint Logger When you develop business-critical solutions, it is essential to ensure that you make diagnostic information about your application available to administrators and other developers. Providing and consuming diagnostic information involves two distinct activities: logging and tracing. Logging is primarily directed toward system administrators, who typically rely on the Windows event logs to monitor deployed applications. They often use automated tools such as the System C enter Operations Manager (SC OM) to monitor the event logs. Tracing, on the other hand, is primarily directed toward developers and field engineers. Trace logs record more detailed information about action taken and problems encountered during the execution of an application, and are typically used by people who are familiar with the implementation details of the application to monitor behavior and diagnose problems. Like previous versions of SharePoint Products and Technologies, SharePoint 2010 uses both the Windows event logs and the SharePoint Unified Logging Service (ULS) trace log to record information and exceptions. Using the same approach in your own SharePoint applications offers many benefits. For example, logging your custom application traces to the ULS trace log allows you to view them in the larger context of Windows SharePoint Services operations without having to correlate multiple trace logs. However, implementing logging and tracing functionality can be complex and unwieldy. To simplify these issues, the SharePoint Guidance Library includes a reusable component named the SharePoint Logger. You can use the SharePoint Logger in your own SharePoint applications to write to both the event log and the ULS trace log in a simple, consistent manner. This section includes the following topics that will help you to understand and use the SharePoint Logger: What Does the SharePoint Logger Do? This topic provides a brief overview of the SharePoint Logger, the concepts behind it, and the features that it incorporates. It also provides a simple example of how you can programmatically interact with the SharePoint Logger. When Should I Use the SharePoint Logger? This topic can help you to decide whether the SharePoint Logger is suitable for your requirements. It identifies key scenarios in which the SharePoint Logger may be useful to you, and it explains the benefits and limitations of using the SharePoint Logger. Developing Applications Using the SharePoint Logger. This section describes how to approach the key development tasks that you will encounter when you use the SharePoint Logger, such as adding the right references to your solution, getting a logger instance, and writing to the event log or the trace log. Key Scenarios. This section provides some examples of the SharePoint Logger at work in the context of broader SharePoint operations. Design of the SharePoint Logger. This topic explains how the SharePoint Logger works in more detail, including the background and rationale behind the component. Developer How-to Topics. This section provides step-by-step, end-to-end procedural guidance on how to perform the most common developer tasks with the SharePoint Logger. Generated from CHM, not final book. Will be superseded in the future. Page 500
- 501. What Does the SharePoint Logger Do? The SharePoint Logger is a reusable component that you can use to write messages to the Windows event logs and the ULS trace log. The SharePoint Logger works by exposing and implementing a simple interface named ILogger. This interface defines the two key methods listed in the following table. ILogger method Description LogToOperations This method writes a message to the Windows event logs and the ULS trace log. Overloads allow you to specify identifiers, categories, severities, and exception details. TraceToDevelope This method writes a message to the ULS trace log. Overloads allow you to specify r identifiers, categories, severities, and exception details. Note: At this stage, you might be wondering why the LogToOperations method writes to both the Windows event logs and the ULS trace log. Generally speaking, the trace log contains much more information than the event logs. If something is worth writing to the event logs, it is also worth writing to the trace log. In other words, the event logs should contain a subset of the information that you write to the trace log. When you write a message to either log, the SharePoint Logger adds contextual information, such as the current URL and the name of the currently logged-on user, which can help the reader to diagnose the problem. The SharePoint Logger also provides a high level of robustness in case the logging fails. For example, if a message cannot be written to the event log, a LoggingException is thrown that contains both the original message and the reason for the logging failure. The following code shows a simple example of how you can use the SharePoint Logger to write a message to the ULS trace log. C# ILogger logger = SharePointServiceLocator.GetCurrent().GetInstance<ILogger>(); logger.TraceToDeveloper("Unexpected condition"); Notice how the SharePoint Service Locator is used to retrieve an implementation of the ILogger interface. Using this approach ensures that your code will still work if the current ILogger implementation is updated or replaced, and it allows you to plug in different logging implementations. For more information about the SharePoint service locator, see The SharePoint Service Locator. SharePoint 2010 introduces new functionality that can help administrators to manage diagnostic information. You can now configure diagnostic logging by area and by category: Areas correspond to broad areas of SharePoint functionality, such as Access Services, Business C onnectivity Services, and Document Management Server. The area is used as the event source name in the Windows event logs. Each area contains one or more categories, which correspond to more specific areas of functionality. For example, the Document Management Server area includes categories named C ontent Organizer, Information Policy Management, and Records C enter. For each category, you can specify the least critical event to report to the event log and the trace log. In other words, this sets the default event throttling threshold for that category. These values are also used as the default severity for a trace or log if no severity level is specified. Note: Event sources for Windows event logs must be added to the registry on the local machine. To enable SharePoint to use a custom diagnostic area as a Windows event source, you must register the event sources on each Web front end server. For more information, see Using Feature Receivers to C onfigure Diagnostic Areas and C ategories. The SharePoint Logger allows you to create and register custom areas and categories for use by your own SharePoint applications. This allows administrators to throttle diagnostic logging from your application, along with all the built-in areas and categories, through the SharePoint C entral Administration Web site. Note: Avoid using the built-in areas and categories to log events and traces from your custom solutions. Instead, you should create your own custom areas and categories when you deploy a solution. This enables administrators to set event throttling thresholds that are specific to your solution without affecting other SharePoint functionality. Generated from CHM, not final book. Will be superseded in the future. Page 501
- 502. When Should I Use the SharePoint Logger? Generally, when your solutions are migrated from a test environment to a production environment, you lose control over how the execution environment is configured and what resources are available to your solution. Applications can fail in production environments for a variety of reasons, such as firewall issues, permission restrictions, or database configuration. In these circumstances, it is essential that your application can report on any issues it encounters that prevent it from doing its job, in a language that a human can read and understand. To help developers who are working with your components, you should go further still. It is useful to log trace messages at significant points in the execution of your code, such as the following: When you attempt to connect to databases or other external resources When you attempt to query a database When you attempt to call external code When you commence long-running or resource-intensive procedures When you call a method that persists data You should use the SharePoint Logger whenever you want to write messages to the Windows event logs or the ULS trace log from your SharePoint applications. You can use the SharePoint Logger in any full-trust server–side code that runs in your SharePoint environment. Note: You cannot use the SharePoint Logger from the sandbox environment without a full trust sandbox proxy. This is because the logger derives from a SharePoint base class, SPDiagnosticsServ iceBase, which is located in the administrative namespace, is not accessible from the sandbox. The SharePoint Guidance Library includes a full trust proxy that enables you to use the SharePoint Logger within the sandbox environment. It is important to ensure that you create appropriate areas and categories for your logging messages and that you choose suitable trace and event severity levels for the logged information. Typically, administrators set up message filtering according to severity levels. If you set your severity levels too low, important information could be missed. On the other hand, if you set your severity levels too high, it could cause performance issues as large amounts of details information are written to the logs. For best practice guidance on how to configure logging in a SharePoint environment see C onfigure diagnostic logging on TechNet. Benefits of the SharePoint Logger The SharePoint Logger provides the following benefits: It allows you to write messages and exceptions to the Windows event logs and the ULS trace log in a simple, consistent manner. It adds contextual information to each message, such as the name of the logged-on user and the URL of the current request, to help the reader to identify the problem. It provides a robust logging mechanism that throws a LoggingException with details of the problem if it is unable to write to the event log. It offers a pluggable architecture that enables you to substitute your own custom logging components. It allows you to manage logging through configuration, instead of by creating your own logger from the SPDiagnosticsServ iceBase base class. It allows you to use logging and tracing from sandboxed code, through the use of the logging proxy. Limitations of the SharePoint Logger By default, the SharePoint Logger can write messages to two locations: the Windows event logs and the ULS trace log. Some organizations prefer to use other repositories for diagnostic logging. For example, you might want log events in a third-party database or use a dedicated trace log for your custom applications. In these scenarios, you will need to customize various components of the SharePoint Logger. These customizations can range from providing simple alternative implementations of the SharePoint Logger interfaces to developing an entirely new logging framework. For more information about how the SharePoint Logger provides opportunities for customization, see Design of the SharePoint Logger. Using the Logger in the Sandbox Environment The SharePoint Logger is built on the SPDiagnosticsServ iceBase class. This is a SharePoint base class that Generated from CHM, not final book. Will be superseded in the future. Page 502
- 503. exposes core logging functionality. However, you cannot use this class in sandboxed code. As a result, you cannot use the SharePoint Logger within the sandbox without taking additional action. The Application Design for SharePoint 2010 release includes a full-trust proxy that you can install to enable sandboxed solutions to use logging and tracing functionality. The proxy is installed by a farm scoped feature contained in a farm solution, which is also provided as part of the proxy implementation. When you call the SharePoint Logger from your application code, the logger will automatically detect whether it is running in the sandbox environment. If it finds that it is running in the sandbox, it will then check whether the full-trust proxy is installed. If the proxy is installed, the logger will use it. If the proxy is not installed, the logger will drop any log or trace messages. If you are unable to install the full trust proxy in your environment, then you can derive from the SharePointLogger. For more information about how to deploy the logging proxy and how to define your own logger, see Using the SharePoint Logger from Sandboxed C ode. For more information about full-trust proxies in general, see Execution Models in SharePoint 2010. Generated from CHM, not final book. Will be superseded in the future. Page 503
- 504. Developing Applications Using the SharePoint Logger This section describes how you can use the SharePoint Logger in your SharePoint applications. The first topic, C reating a Logger Object, shows how to instantiate the ILogger interface. The remaining topics build on this by providing guidance and reference material for common development tasks. This section includes the following topics: C reating a Logger Object Managing C ustom Areas and C ategories C reating Log Entries C reating Trace Messages Using C ustom Logger C lasses C reating C ustom Logger C lasses For broader, contextual guidance on specific scenarios, see Key Scenarios. For step-by-step guidance on the most common end-to-end tasks, see Developer How-to Topics. Generated from CHM, not final book. Will be superseded in the future. Page 504
- 505. Creating a Logger Object Before you can write messages to the Windows event logs or the ULS trace log, you must create an object that implements the ILogger interface. The SharePoint Logger provides a default implementation of this interface in a class named SharePointLogger. You can directly instantiate the SharePointLogger class although it is typically a good practice to use the SharePoint Service Locator to request an implementation of the ILogger interface. This keeps your code decoupled from the SharePointLogger implementation. Before you can use the SharePoint Logger in your custom solutions, you must add references to the Microsoft.Practices.SharePoint.Common.dll assembly and the Microsoft.Practices.ServiceLocation.dll assembly. The following code shows how you can get an implementation of the ILogger interface from the SharePoint Service Locator. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); ILogger logger = serviceLocator.GetInstance<ILogger>(); For brevity, you can reduce the ILogger instantiation to a single line of code, as follows. C# ILogger logger = SharePointServiceLocator.GetCurrent().GetInstance<ILogger>(); At this point, you can start to use the ILogger object to write messages to the Windows event log and the ULS trace log. Note: If you want to use the SharePoint Logger from sandboxed code, you must first register the logger proxy. The SharePoint Logger automatically detects whether it is running in a sandbox environment and will use the proxy when appropriate—the developer experience is unchanged. For more information about how to register the logger proxy, see Using the SharePoint Logger from Sandboxed C ode. Generated from CHM, not final book. Will be superseded in the future. Page 505
- 506. Managing Custom Areas and Categories The latest release of the SharePoint Logger allows you to create custom diagnostic areas and categories for your SharePoint applications. This enables system administrators to apply event throttling rules to your applications in the same way that they configure logging and reporting from the SharePoint application itself. The SharePoint Logger includes a class named DiagnosticsAreaCollection that is responsible for loading and saving your diagnostic areas and categories. The DiagnosticsAreaCollection class extends a generic collection of DiagnosticsArea objects that represent your custom areas. Each DiagnosticsArea object contains a DiagnosticsCategoryCollection object. This consists of a collection of DiagnosticsCategory objects that represent the custom categories within each area. The following illustration shows this relationship. Diagnostic areas and categories Typically, you should use a feature receiver class to configure your custom areas and categories when you install your application. Because your solution may contain several features that use the areas and categories you define, a recommended practice is to define your areas and categories within a farm-scoped feature in your solution. This ensures that your areas and categories are available when the solution is deployed, and will remain available until the solution is retracted. If you add any new areas, you will also need to create corresponding event sources on each Web front-end (WFE) server in your farm, because event sources are specific to individual computers. For more information about this scenario, see Using Feature Receivers to C onfigure Diagnostic Areas and C ategories. Note: Although you can add your own custom categories to the built-in diagnostic areas in SharePoint 2010, this is considered bad practice. Instead, you should create your own custom areas and categories for your SharePoint applications. Adding Custom Areas and Categories Whenever you work with custom areas and categories, your first task will always be to construct an object of type DiagnosticsAreaCollection. The DiagnosticsAreaCollection class provides two constructors: A default constructor. This creates an empty collection. A constructor that takes an argument of type IConfigManager. This creates a collection and populates it with the custom diagnostic areas and categories that have already been configured in the current server farm. Generated from CHM, not final book. Will be superseded in the future. Page 506
- 507. The IConfigManager interface is provided by the The Application Setting Manager component. The SharePoint Logger uses the C onfiguration Manager to persist and retrieve custom areas and categories. Because of this, if you plan to persist additions, updates or deletions to the areas or categories, or if you want to retrieve the areas and categories that are already configured, you must include an IConfigManager argument when you instantiate a DiagnosticsAreaCollection object. The default constructor is useful if you want to build a collection of areas and categories before you persist them to the SharePoint environment. For example, you might use a property to build your collection using the default DiagnosticsAreaCollection constructor. C# public class ConfigureLogging { DiagnosticsAreaCollection _myAreas = null; DiagnosticsAreaCollection MyAreas { get { if (_myAreas == null) { _myAreas = new DiagnosticsAreaCollection(); DiagnosticsArea newArea = new DiagnosticsArea("HelpDesk"); newArea.DiagnosticsCategories.Add(new DiagnosticsCategory( "Execution", EventSeverity.Warning, TraceSeverity.Medium)); newArea.DiagnosticsCategories.Add(new DiagnosticsCategory( "Data", EventSeverity.Error, TraceSeverity.Medium)); DiagnosticsArea newArea1 = new DiagnosticsArea("CRM"); newArea1.DiagnosticsCategories.Add(new DiagnosticsCategory( "LostSale", EventSeverity.Warning, TraceSeverity.Medium)); newArea1.DiagnosticsCategories.Add(new DiagnosticsCategory( "TransactionError", EventSeverity.Error, TraceSeverity.Medium)); _myAreas.Add(newArea); _myAreas.Add(newArea1); } return _myAreas; } } When you want to persist your collection of areas and categories to the SharePoint environment, you use the constructor that takes an argument of type IConfigManager. This creates a definitive collection that contains all the custom areas and categories that have already been configured. C# public void AddAreasToConfiguration() { IConfigManager configMgr = SharePointServiceLocator.GetCurrent().GetInstance<IConfigManager>(); DiagnosticsAreaCollection configuredAreas = new DiagnosticsAreaCollection(configMgr); After you create the pre-populated DiagnosticsAreaCollection object, you can add your new areas and categories to the collection. After you finish adding your areas, call the Sav eConfiguration method to persist your areas (and any categories that you created within your areas) to the SharePoint environment. C# foreach (DiagnosticsArea newArea in MyAreas) { configuredAreas.Add(newArea); } configuredAreas.SaveConfiguration(); } Note: Generated from CHM, not final book. Will be superseded in the future. Page 507
- 508. If you used the default constructor to create your DiagnosticsAreaCollection object, an Inv alidOperationException will be thrown if you call the Sav eConfiguration method. This is because the DiagnosticsAreaCollection needs a reference to the C onfiguration Manager in order to persist areas and categories as configuration data. If you attempt to add an area that already exists, an Inv alidOperationException will be thrown. A safer approach is to check that areas or categories do not already exist before you add them. C# foreach (DiagnosticsArea newArea in MyAreas) { var existingArea = configuredAreas[newArea.Name]; if (existingArea == null) { configuredAreas.Add(newArea); } else { foreach (DiagnosticsCategory c in newArea.DiagnosticsCategories) { var existingCategory = existingArea.DiagnosticsCategories[c.Name]; if (existingCategory == null) { existingArea.DiagnosticsCategories.Add(c); } } } } When you create a new diagnostic category, you can specify default throttling values for event severity and trace severity in addition to a category name. For example, if you set the event severity value to Information, any events in this category will only be reported to the event log if they have a severity value equal to or higher than Information. The system administrator can change these throttling settings at any time through the C entral Administration Web site. C# DiagnosticsCategory newCategory = new DiagnosticsCategory("Projects", EventSeverity.Information, TraceSeverity.Medium); If you do not specify an event severity or a trace severity, by default, the category uses an event severity of Warning and a trace severity of Medium. Removing Custom Areas and Categories The process for removing areas and categories is similar to the process for adding areas and categories. First, you must construct the DiagnosticsAreaCollection object by using the constructor that takes an argument of type IConfigManager. Next, use the Remove method to remove individual areas. Finally, call the SaveConfiguration method to persist your changes. C# IConfigManager configMgr = SharePointServiceLocator.GetCurrent().GetInstance<IConfigManager>(); DiagnosticsAreaCollection configuredAreas = new DiagnosticsAreaCollection(configMgr); foreach (DiagnosticsArea area in MyAreas) { DiagnosticsArea areaToRemove = configuredAreas[area.Name]; if (areaToRemove != null) { configuredAreas.Remove(areaToRemove); } } Generated from CHM, not final book. Will be superseded in the future. Page 508
- 509. configuredAreas.SaveConfiguration(); Take care when removing areas, because other users may have added categories for applications that are still deployed. The safest way to remove your logging configuration is to remove all your own categories, and then if no categories remain, remove the area. C# foreach (DiagnosticsArea area in MyAreas) { DiagnosticsArea areaToRemove = configuredAreas[area.Name]; if (areaToRemove != null) { foreach (DiagnosticsCategory c in area.DiagnosticsCategories) { var existingCat = areaToRemove.DiagnosticsCategories[c.Name]; if (existingCat != null) { areaToRemove.DiagnosticsCategories.Remove(existingCat); } } if (areaToRemove.DiagnosticsCategories.Count == 0) { configuredAreas.Remove(areaToRemove); } } } } Generated from CHM, not final book. Will be superseded in the future. Page 509
- 510. Creating Log Entries The ILogger interface defines a method named LogToOperations. Operations is another term for administrators and the tools that they use to monitor applications. When you log an event to operations, you should provide information that can help IT professionals understand how to remedy the problem. The information should be valuable and comprehensible to a systems administrator, even if the message is simply that the system behaved in an unexpected way that requires advanced debugging. The default implementation of the LogToOperations method writes a message to both the Windows event log and the ULS trace log. The method provides several overloads that you can use to specify an event identifier, a severity, and a diagnostic area and category along with your message. All method overloads also append contextual information to the log entry, such as the user identity and the current URL, where applicable. To log a message without specifying any additional information, simply pass in your message string as a parameter to the LogToOperations method. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); ILogger logger = serviceLocator.GetInstance<ILogger>(); // Log an event with a message. string msg = "The current user does not have a valid PartnerID"; logger.LogToOperations(msg); When you log an event, you may want to include an integer event ID with the event message. This can help system administrators to reference the issue and locate other instances of the same problem. It is good practice to use enumerated values or constants for event IDs in each solution that you develop. The following example assumes that you have created an enumeration of integer values named Ev entLogEv entId. C# // Log an event with a message and an event ID. logger.LogToOperations(msg, (int)EventLogEventId.MissingPartnerID); You may also want to specify a severity level. To do this, you can use the Ev entSev erity enumeration. This defines the severity levels used by SharePoint for the event log: ErrorCritical, Error, Warning, Information, and Verbose. The Ev entSev erity enumeration also contains various deprecated values that you should not use. Note: The logger has several method overloads that accept a SandboxEventSev erity argument instead of an EventSev erity argument. Because the Ev entSev erity enumeration is not permitted in the sandbox, the SandboxEv entSev erity provides a parallel enumeration structure that you can use within sandboxed code. If you use the SandboxEv entSev erity enumeration, logging will succeed, regardless of whether your code runs inside or outside the sandbox. C# // Log an event with a message and a severity level. logger.LogToOperations(msg, EventSeverity.Error); // Log an event with a message, an event ID, and a severity level. logger.LogToOperations(msg, (int) EventLogEventId.MissingPartnerID, EventSeverity.Error); Specifying a severity level enables system administrators to filter the Windows event log. For example, an administrator might want to view all messages with severity level Error without scrolling through many more trivial messages. Note: The previous release of the SharePoint Guidance Library used Ev entLogEntryType instead of EventSev erity enumeration for events. This was because SharePoint 2007 did not expose any methods that write to the Windows event log, so the logger wrote to the event log using standard .NET Framework methods and enumerations. In this release, the SharePoint object model includes methods that you can use to directly Generated from CHM, not final book. Will be superseded in the future. Page 510
- 511. write to the Windows event log. Because of this, the interface was changed to be consistent with the severity levels used by SharePoint 2010. It is important to carefully choose the EventSeverity value, because SharePoint administrators will usually apply "event throttling" settings that limit what appears in the Windows event logs by severity and by category. For more information about the Ev entSev erity enumeration, see EventSeverity Enumeration on MSDN. Finally, in most cases, you should include values for diagnostic area and category when you log an event. Again, this can help system administrators to filter the event log to find only those events that are relevant to the issue under investigation. In the Windows event log, the area corresponds to the event source name and the category corresponds to the task category. To specify an area and category, you must pass a string parameter with the format "area/category" to the LogToOperations method. C# // Log an event with a message, an event ID, a severity level, and a category. string area = "Custom Area" string category = "Execution"; string areaCategory = string.Format("{0}/{1}", area, category); logger.LogToOperations(msg, (int) EventLogEventId.MissingPartnerID, EventSeverity.Error, areaCategory); If you do not specify a value for the diagnostic area and category when you log an event, the SharePoint Logger will set the area value to Patterns and Practices and the category value to SharePoint Guidance. Note: You can also pass an exception directly to the LogToOperations method. For a scenario-based example of exception logging, see Logging an Unhandled Exception. For more information about the Ev entSev erity enumeration, see EventSeverity Enumeration on MSDN. Generated from CHM, not final book. Will be superseded in the future. Page 511
- 512. Creating Trace Messages The ILogger interface defines a method named TraceToDeveloper. The default implementation of this method writes a message to the ULS trace log. Like the LogToOperations method, the TraceToDeveloper method provides several overloads that accept exceptions, integer event identifiers, severity levels, and diagnostic areas and categories along with your messages. However, while the LogToOperations method is aimed at system administrators, the TraceToDeveloper method is aimed at developers or advanced administrators who cannot attach a debugger to a production environment and therefore must rely on trace logs to identify the sources of problems. Note: The ULS trace logs are located in the LOGS folder in the SharePoint installation root directory. The SharePoint installation root directory, also known as the "SharePoint root", is by default located at C :Program FilesC ommon FilesMicrosoft SharedWeb Server Extensions14. The following code examples show how you can use different overloads of the TraceToDeveloper method. To log a message without specifying any additional information, simply pass in your message string as a parameter to the TraceToDeveloper method. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); ILogger logger = serviceLocator.GetInstance<ILogger>(); // Create a simple trace message. string msg = "The current user does not have a valid PartnerID"; logger.TraceToDeveloper(msg); If you are reporting an event to the trace log, you may want to include an integer event ID with your trace message. This can help developers who are searching for instances of a particular issue in the trace logs. The best practice approach is to use enumerated values or constants for event IDs in your solutions. The following example assumes that you have created an enumeration of integer values named TraceLogEv entId. C# // Create a trace message with an event ID. logger.TraceToDeveloper(msg, (int) TraceLogEventId.MissingPartnerID); If you want to specify a severity level in your trace message, use the TraceSev erity enumeration. This is a SharePoint-specific enumeration that is defined in the Microsoft.SharePoint.Administration namespace. Note: The logger has several method overloads that accept a SandboxTraceSev erity argument instead of a TraceSev erity argument. Because the TraceSev erity enumeration is not permitted in the sandbox, the SandboxTraceSev erity provides a parallel enumeration structure that you can use within sandboxed code. If you use the SandboxTraceSev erity enumeration, logging will succeed, regardless of whether your code runs inside or outside the sandbox. // Create a trace message with a trace severity level. logger.TraceToDeveloper(msg, TraceSeverity.High); Note: It is important to carefully choose the TraceSev erity value, because SharePoint administrators will usually apply "event throttling" settings that limit what appears in the ULS trace logs by severity and by category. For more information about the TraceSev erity enumeration, see TraceSeverity Enumeration on MSDN. You can also specify values for diagnostic area and category when you create a trace message. To specify an area and category, pass a string parameter with the format "area/category" to the TraceToDeveloper method. // Create a trace message with a diagnostic area and category. string area = "Custom Area" string category = "Data"; Generated from CHM, not final book. Will be superseded in the future. Page 512
- 513. string areaCategory = string.Format("{0}/{1}", area, category); Logger.TraceToDeveloper(msg, areaCategory); Note: If you are going to specify a category value, you must pass in a string in the format "area/category". The SharePoint Logger will throw an exception if the value is not in this format. Other overloads of the TraceToDev eloper method allow you to specify various combinations of these properties. Like the LogToOperations method, the TraceToDeveloper method provides several overloads that you can use to handle exceptions, as shown in the following code example. Exception ex = … // Trace an exception. logger.TraceToDeveloper(ex); // Trace an exception with an additional error message. logger.TraceToDeveloper(ex, msg); // Trace an exception with an additional error message and // an application-defined event ID. logger.TraceToDeveloper(ex, msg, (int) EventLogEventId.SkuNotFound); // Trace an exception with an additional error message, an event ID, // a trace severity level, and an area/category string. logger.TraceToDeveloper(ex, msg, (int) EventLogEventId.SkuNotFound, TraceSeverity.High, areaCategory); // Trace an exception with an event ID, a trace severity level, and // an area/category string. logger.TraceToDeveloper(ex, (int) EventLogEventId.SkuNotFound, TraceSeverity.Verbose, areaCategory); Generated from CHM, not final book. Will be superseded in the future. Page 513
- 514. Using Custom Logger Classes By default, when you use the SharePoint Service Locator to request an ILogger implementation, the SharePoint Service Locator returns an object of type SharePointLogger. In certain scenarios, you may need to substitute the SharePointLogger class with a different implementation of the ILogger interface. For example, you might want to use a mock object for unit testing, or you might want to develop a custom logging provider to meet your organization-specific logging requirements. Suppose that you have developed a class named MyLogger that provides an alternative implementation of the ILogger interface. To replace the default SharePoint Logger functionality, all you need to do is to register the MyLogger class with the SharePoint Service Locator as the default implementation of the ILogger interface. Any code that uses the SharePoint Logger will not need to be updated or recompiled, because calling classes simply request an implementation of ILogger instead of a specific type. The following code example shows how you can register the MyLogger class with the SharePoint Service Locator as an ILogger implementation. C# IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); typeMappings.RegisterTypeMapping<ILogger, MyLogger>(); If you are substituting a mock ILogger implementation for unit testing, you should register your implementation with the SharePoint Service Locator as a singleton service. For more information about customizing the logger for unit testing, see C ustomizing the Logger for Unit Testing. For details of how to create custom logger classes, see C reating C ustom Logger C lasses. Generated from CHM, not final book. Will be superseded in the future. Page 514
- 515. Creating Custom Logger Classes The SharePointLogger class implements two key interfaces named IEv entLogLogger and ITraceLogger that define how events and traces are logged. You can change the behavior of the SharePoint Logger by providing alternative implementations of these interfaces: To change the behavior of the ILogger.LogToOperations method, create a class that implements the IEv entLogLogger interface. To change the behavior of the ILogger.TraceToDeveloper method, create a class that implements the ITraceLogger interface. For example, you might want to customize the SharePoint Logger so that the LogToOperations method writes a message to a database instead of to the Windows event log. Alternatively, you might want to modify the behavior of the TraceToDev eloper method, so that trace messages are written to a dedicated location instead of to the ULS trace logs that also contain many other SharePoint-related trace messages. The following code example shows how you can override the IEv entLogLogger interface to provide your own event logger implementation. Notice that the interface requires you to implement a single method named Log. public class MyEventLogLogger : IEventLogLogger { public void Log(string message, int eventId, EventSeverity severity, string category) { // Custom code to handle event logging request… } } The following code shows how you can override the ITraceLogger interface to provide your own trace logger implementation. This interface defines a single method named Trace. C# public class MyTraceLogger : ITraceLogger { public void Trace(string message, int eventId, TraceSeverity severity, string category) { // Custom code to handle tracing request… } } After you develop and deploy your custom logging and tracing classes, you must register these classes with the SharePoint Service Locator as implementations of IEv entLogLogger and ITraceLogger respectively. Typically, you should use a feature receiver class to register your implementations at the point of deployment. For more information, see C ustomizing the Logger in an Application. For more information about the ITraceLogger interface and the IEv entLogger interface, see Design of the SharePoint Logger. Generated from CHM, not final book. Will be superseded in the future. Page 515
- 516. Key Scenarios This section describes the most common situations in which you might use the SharePoint Logger. Each topic in this section describes a realistic scenario, identifies the solution, and provides code to demonstrate how to use the SharePoint Logger to complete the task. Each topic also includes usage notes and hints, where applicable. The scenarios are as follows: Logging an Unhandled Exception. This scenario illustrates how you can use the SharePoint Logger to report an unhandled exception to the event log and the trace log. Using Feature Receivers to C onfigure Diagnostic Areas and C ategories. This scenario illustrates how you can use a SharePoint feature receiver class to create and register custom diagnostic areas and categories for your own SharePoint solutions. Using the SharePoint Logger from Sandboxed C ode. This scenario illustrates how you can register the logging proxy to enable logging for applications in the sandbox. C ustomizing the Logger for Unit Testing. This scenario illustrates how you can create a mock logger implementation to use in your unit tests. C ustomizing the Logger in an Application. This scenario illustrates how you can override the default functionality of the SharePoint Logger to meet any custom logging requirements. Generated from CHM, not final book. Will be superseded in the future. Page 516
- 517. Logging an Unhandled Exception Typical Goals If your SharePoint solution encounters an unhandled exception, it is important to let the system administrator know about it. No matter how robustly your code performs during testing, the production environment can introduce variables that are beyond the control of your application. For example, lists and databases can be moved or deleted, disks can run out of space, and dependent assemblies can be removed or replaced. Writing an informative message to the event log can help the system administrator to resolve the problem. Solution The ILogger interface defines a method named LogToOperations that you can use to log unhandled exceptions directly to the Windows event log and the ULS trace log. This method provides several overloads that allow you to specify an integer identifier, a severity, a category, and a custom message in addition to the actual exception object. To log an unhandled exception, use the LogToOperations method in a catch block within your application logic. Using the LogToOperations Method to Log Exceptions The following code shows how to use the LogToOperations method to log an exception from within a catch block. This example assumes that you have added a reference to the Microsoft.Practices.SharePoint.Common.dll assembly, the Microsoft.Practices.Serv iceLocation.dll assembly, and the Microsoft.SharePoint.dll assembly. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; using Microsoft.SharePoint; // ... ILogger logger = SharePointServiceLocator.GetCurrent().GetInstance<ILogger>(); try { // Attempt a SharePoint operation. } catch (SPException ex) { // Define your exception properties. string msg = "An error occurred while trying to retrieve the customer list"; string category = @"SalesTool/Data"; int eventID = 0; EventLogEntryType severity = EventSeverity.Error; // Log the exception. logger.LogToOperations(ex, msg, eventID, severity, category); } For more information about how to use the LogToOperations method, see C reating Log Entries. Usage Notes Logging unhandled exceptions is probably the most common scenario for using the SharePoint Logger. Although it is valuable for a system administrator to know that there are problems with a certain component, exception messages alone rarely suggest a clear course of action. You can provide additional text when logging exceptions. Try to provide information that can help the Generated from CHM, not final book. Will be superseded in the future. Page 517
- 518. administrator to identify what happened when the exception occurred. For example, the message "An unknown exception occurred while trying to retrieve product information from the product service. The exception message was: A time-out occurred." is much more helpful than "A time-out occurred." Finally, to avoid flooding the event log, be selective about the exceptions that you log. For best practice guidance on managing exceptions, see Exception Management in SharePoint. Generated from CHM, not final book. Will be superseded in the future. Page 518
- 519. Using Feature Receivers to Configure Diagnostic Areas and Categories Typical Goals SharePoint 2010 provides a default set of diagnostic areas and categories that relate to different features and aspects of the product. Typically, system administrators use these areas and categories to restrict what gets written to the event log and the trace log. For example, the administrator might choose to allow verbose logging for categories that are of particular concern, while restricting logging for other areas to only high severity items. It is strongly recommended that you do not use the built-in areas and categories to log events from your custom applications. Instead, you should create your own areas and categories to enable system administrators to manage diagnostic logging from your application alongside the log entries generated by SharePoint itself. Solution C reate a farm-scoped feature and add a feature receiver class. Within the feature receiver class, override the FeatureActivated and FeatureDeactivating methods. Use the DiagnosticsAreaCollection class to create and register your custom areas and categories. Note: Why should you use a farm-scoped feature to configure diagnostic areas and categories for your solution? Suppose your solution consists of features that are scoped to site collection level or the Web application level. An administrator can deploy and retract these features to multiple site collections or Web applications across the server farm. By using a farm-scoped feature to configure areas and categories, you ensure that your areas and categories are available to any feature after your solution is activated, and that the configured areas and categories are not removed until the solution is retracted. A farm-scoped feature automatically activates when the solution is deployed, and it deactivates when the solution is retracted. After you configure your diagnostic areas and categories, you can use these values in your code when you write to the event log or the trace log. System administrators can also throttle logging by severity for each of your areas and categories. Configuring Diagnostic Areas and Categories The following code shows an example of how to configure an area and some categories in a feature receiver class. Suppose you are deploying a Web Part that enables your users to interact with a C ustomer Relationship Management (C RM) system. This example registers a new area named C RM. The area contains two categories, LostSale and TransactionError. The feature receiver class is split into three areas for readability. First, the class includes a helper property to build the collection of areas and categories. This is used both when the feature is activated and when the feature is deactivated. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; [Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")] public class MyFeatureReceiver : SPFeatureReceiver { // This helper property builds a collection of areas and categories. DiagnosticsAreaCollection _myAreas = null; DiagnosticsAreaCollection MyAreas { get { if (_myAreas == null) { _myAreas = new DiagnosticsAreaCollection(); DiagnosticsArea crmArea = new DiagnosticsArea("CRM"); Generated from CHM, not final book. Will be superseded in the future. Page 519
- 520. crmArea.DiagnosticsCategories.Add(new DiagnosticsCategory( "LostSale", EventSeverity.Warning, TraceSeverity.Medium)); crmArea.DiagnosticsCategories.Add(new DiagnosticsCategory( "TransactionError", EventSeverity.Error, TraceSeverity.Medium)); _myAreas.Add(crmArea); } return _myAreas; } } Next, the FeatureActiv ated method retrieves the collection of areas and categories and writes the collection to configuration settings. // Use the FeatureActivated method to save areas and categories // to configuration settings. public override void FeatureActivated(SPFeatureReceiverProperties properties) { IConfigManager configMgr = SharePointServiceLocator.GetCurrent().GetInstance<IConfigManager>(); DiagnosticsAreaCollection configuredAreas = new DiagnosticsAreaCollection(configMgr); foreach (DiagnosticsArea newArea in MyAreas) { var existingArea = configuredAreas[newArea.Name]; if (existingArea == null) { configuredAreas.Add(newArea); } else { foreach (DiagnosticsCategory c in newArea.DiagnosticsCategories) { var existingCategory = existingArea.DiagnosticsCategories[c.Name]; if (existingCategory == null) { existingArea.DiagnosticsCategories.Add(c); } } } } configuredAreas.SaveConfiguration(); } Finally, the F eatureDeactiv ating method retrieves the collection of areas and categories and removes them from the configuration settings. // Use the FeatureDeactivating method to remove areas and categories // from configuration settings. public override void FeatureDeactivating(SPFeatureReceiverProperties properties) { IConfigManager configMgr = SharePointServiceLocator.GetCurrent().GetInstance<IConfigManager>(); DiagnosticsAreaCollection configuredAreas = new DiagnosticsAreaCollection(configMgr); foreach (DiagnosticsArea area in MyAreas) { Generated from CHM, not final book. Will be superseded in the future. Page 520
- 521. DiagnosticsArea areaToRemove = configuredAreas[area.Name]; if (areaToRemove != null) { foreach (DiagnosticsCategory c in area.DiagnosticsCategories) { var existingCat = areaToRemove.DiagnosticsCategories[c.Name]; if (existingCat != null) { areaToRemove.DiagnosticsCategories.Remove(existingCat); } } if (areaToRemove.DiagnosticsCategories.Count == 0) { configuredAreas.Remove(areaToRemove); } } } configuredAreas.SaveConfiguration(); } } Note: In some circumstances, different solutions may create duplicate categories. In the preceding code example, there is a risk that you will remove a category that is still in use by another application in the FeatureDeactiv ating method, because any duplicated categories will be removed. To prevent problems with duplicate categories, you may instead choose to throw an exception if a duplicate category is found during installation. For more information about how to manage diagnostic areas and categories, see Managing C ustom Areas and C ategories. Registering Event Sources for Diagnostic Areas When you use the SharePoint Logger to create new diagnostic areas, you must create a corresponding event source for each diagnostic area on each WFE server in your farm (or on any other server where your code will execute). This allows you to specify the new diagnostic areas when you write to the Windows event log. Event sources are defined in the local registry of each computer. Because you must write to the registry to create new event sources, this procedure requires an account with high privileges. There are two principal approaches that you can use to register event sources: You can manually run a batch file or PowerShell script on each WFE server. You can create a timer job that executes on each WFE server. The SharePoint Logger provides a convenience method to help register event sources. The static DiagnosticsAreaEv entSource.EnsureAreasRegisteredAsEventSource method iterates through all the diagnostic areas in configuration settings, checks to see whether each diagnostic area is already registered as an event source, and registers a new event source if required. You can call this method from your PowerShell script or your timer job, as required. Usage Notes SharePoint 2010 allows you to create your own custom categories under built-in areas. However, this is not a recommended approach. You should create custom areas for your custom code. Generated from CHM, not final book. Will be superseded in the future. Page 521
- 522. Using the SharePoint Logger from Sandboxed Code Typical Goals In many cases, you may want to give your sandboxed solution developers the ability to use the SharePoint Logger from within sandboxed code. However, the SharePoint logging framework relies on APIs that are not available within the sandbox. Solution The SharePoint Logger includes a full-trust proxy that makes logging and tracing functionality available to sandboxed code. After you install and register the logging proxy, the SharePoint Logger automatically uses the proxy when it detects that it is running in the sandbox environment. As a result, the developer can use the SharePoint Logger in the same way regardless of whether he or she is writing full-trust code or sandboxed code— the developer experience is unchanged. If a developer attempts to use the SharePoint Logger in the sandbox environment, and the proxy is not installed and registered, any log or trace messages are dropped. To install the logger proxy assemblies and register the proxy operations, you will need to deploy the solution package provided in Microsoft.Practices.SharePoint.Common.LoggerProxy. This package deploys a farm-scoped feature with a feature receiver class that registers the proxy operations. After it is deployed, the logger will function in the sandbox. Because the logger proxy is deployed at the farm scope, the proxy operations are available to all site collections within the farm. Note: If your code will log or trace within the sandbox environment, and you want to specify a severity level, you must use the method overloads that accept SandboxEv entSev erity and SandboxTraceSeverity values, respectively, because the Ev entSeverity and TraceSeverity enumerations are not available within the sandbox. You can also use any logging or tracing operation that does not specify a severity level. Any code that uses SandboxEv entSev erity or SandboxTraceSeverity values will work both within and outside the sandbox. You cannot register diagnostic areas or categories from the sandbox environment, because areas and categories must be persisted to farm-level configuration settings. If you want to create diagnostic areas and categories for sandboxed solutions, you must create them from outside the sandbox environment. You may not be able to install the full-trust proxy for logging to your environment. Another alternative is to implement your own custom logger and write the event and trace messages to an alternative location such as a list. The following code example shows the methods that you must override. C# public class MyLogger : SharePointLogger { protected override void WriteToOperationsLogSandbox(string message, int eventId, SandboxEventSeverity? severity, string category) { WriteToOperationList(message, eventId, severity, category); } protected override void WriteToTraceSandbox(string message, int eventId, SandboxTraceSeverity? severity, string category) { WriteToTraceList(message, eventId, severity, category); } } You should then register your logger with the Service Locator in a site-scoped feature receiver. C# ServiceLocatorConfig cfg = new ServiceLocatorConfig(); cfg.Site = SPContext.Current.Site; cfg.RegisterTypeMapping<ILogger, MyLogger>(); Users need to have access to the lists to which the messages are written because the messages are logged from the context of the accessing user. Generated from CHM, not final book. Will be superseded in the future. Page 522
- 523. Generated from CHM, not final book. Will be superseded in the future. Page 523
- 524. Customizing the Logger for Unit Testing Typical Goals To effectively unit test your classes, you may want to bypass the default logging and tracing behavior of the SharePoint Logger and instead write all logging and tracing information to a mock ILogger implementation. Depending on the primary motivation for your test, the mock logger might write to the Windows event log and the ULS trace log as normal, write to a test-specific file stream, or simply set a public property that show that the logger was invoked as expected. Solution To configure the SharePoint Logger for unit testing, you need to replace the default SharePoint Logger instantiation with your mock ILogger implementation when you initialize the unit test. To do this, you must first create a new, test-specific instance of the SharePoint Service Locator. You can then register your mock ILogger implementation with the service locator instance for the duration of the test. This approach ensures that you do not have to modify the code that you are testing. Your code can continue to use the LogToOperations and TraceToDeveloper methods that are defined by the ILogger interface. Behind the scenes, the SharePoint Service Locator simply switches the default ILogger implementation with your mock ILogger implementation. You need to be familiar with the SharePoint Service Locator to understand how and why this solution works. For more information, see The SharePoint Service Locator. Providing a Mock ILogger Implementation Your first step should be to develop the mock implementation of ILogger. The following code shows an example implementation. C# public class MockLogger : ILogger { // Define a public property for the message. // Your unit tests can query this property // to validate that the method was called. public string LogToOperationsCalledWithMessage {get; set;}; public void LogToOperations (string message) { LogToOperationsCalledWithMessage = message; } } Your next step is to register your mock implementation with the SharePoint Service Locator for the duration of your unit test. The registration takes place in the test initialization method. C# public class MyFixture { [TestMethod] public void TestMyWidgetThatUsesLogging() { // Arrange ActivatingServiceLocator locator = new ActivatingServiceLocator(); locator.RegisterTypeMapping<ILogger, MockLogger> (InstantiationType.AsSingleton); SharePointServiceLocator.ReplaceCurrentServiceLocator(locator); Generated from CHM, not final book. Will be superseded in the future. Page 524
- 525. var logger = SharePointServiceLocator.GetCurrent().GetInstance<ILogger>() as MockLogger; string expectedMessage = “some message you expect your logic to log”; // Act … run your logic that uses logging //Assert Assert.AreEqual(expectedMessage, logger.LogToOperationsCalledWithMessage); } // ... } For more information about how to use alternative ILogger implementations, see Using C ustom Logger C lasses. For more information about how to use the SharePoint Service Locator to isolate code for unit tests, see Testing C lasses in Isolation. Usage Notes In the preceding code example, notice how the mock ILogger implementation is registered as a singleton service. This ensures that every call to the service locator returns the same object, which can help to provide consistency for your unit test. Generated from CHM, not final book. Will be superseded in the future. Page 525
- 526. Customizing the Logger in an Application Typical Goals In some circumstances, you may want to customize how the SharePoint Logger behaves in your production environment. For example, you might want to update the logger so that calls to LogToOperations copy messages to a third-party repository. Solution By default, the SharePointLogger class implements two key interfaces that define the logging and tracing functionality of the SharePoint Logger: The IEventLogLogger interface defines logging functionality. The ITraceLogger interface defines tracing functionality. To customize the behavior of the SharePoint Logger, you can create your own implementations of these interfaces. You can then register your custom implementations with the SharePoint Service Locator, so any code that calls the SharePoint Logger automatically uses the updated functionality. In most cases, you should aim to register your custom implementations with the service locator at the same time as you deploy them to the SharePoint environment. A common approach is to use a feature receiver class to update the service locator type mappings. This scenario focuses on how to register your implementations with the SharePoint Service Locator. For information about how to implement the IEv entLogLogger interface and the ITraceLogger interface, see C reating C ustom Logger C lasses. Updating Type Mappings for the Logger Interfaces The following code shows how to register custom implementations of the IEv entLogLogger interface and the ITraceLogger interface from within a feature receiver class. This example assumes that you have created classes named MyEv entLogLogger and MyTraceLogger that implement the IEventLogLogger and ITraceLogger interfaces, respectively. The example also assumes that you have added a reference to the Microsoft.Practices.SharePoint.Common.dll assembly, the Microsoft.Practices.Serv iceLocation.dll assembly, and the Microsoft.SharePoint.dll assembly. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; [CLSCompliant(false)] [Guid("8b0f085e-72a0-4d9f-ac74-0038dc0f6dd5")] public class MyFeatureReceiver : SPFeatureReceiver { // ... [SharePointPermission(SecurityAction.LinkDemand, ObjectModel = true)] public override void FeatureInstalled(SPFeatureReceiverProperties properties) { IServiceLocator serviceLocator = SharePointServiceLocator.GetCurrent(); IServiceLocatorConfig typeMappings = serviceLocator.GetInstance<IServiceLocatorConfig>(); typeMappings.RegisterTypeMapping<IEventLogLogger, MyEventLogLogger>(); typeMappings.RegisterTypeMapping<ITraceLogger, MyTraceLogger>(); } } Generated from CHM, not final book. Will be superseded in the future. Page 526
- 527. Design of the SharePoint Logger The SharePoint Logger provides a reusable set of classes that developers can use to log diagnostic information from SharePoint applications. It is designed to do the following: It provides a consistent mechanism that developers can use to write messages to the Windows event log and the ULS trace log. It enables developers to create and manage custom diagnostic areas and categories. It supports substitution of mock logger implementations for unit testing. It provides an extensible architecture that developers can customize to their own requirements, if required. Design Highlights The ILogger interface and the SharePointLogger class are at the heart of the SharePoint Logger. The ILogger interface is designed to accommodate most logging scenarios and to help developers target their messages to either system administrators or developers. It does this by defining two key methods: LogToOperations and TraceToDeveloper. C onsumers use the SharePoint Service Locator to request an implementation of the ILogger interface. The default implementation is the SharePointLogger class, although developers can register alternative implementations if required. The SharePointLogger class is a straightforward implementation of the ILogger interface. The class is comprised of two replaceable components that implement the IEv entLogLogger interface and the ITraceLogger interface. These interfaces define the following functionality: IEv entLogLogger. C lasses that implement this interface record events that are meant for system administrators. The default implementation of this interface is the Ev entLogLogger class, which uses the DiagnosticsServ ice class to write messages to the Windows event log. ITraceLogger. C lasses that implement this interface record trace information for application developers. The default implementation of this interface is the TraceLogger class, which uses the DiagnosticsServ ice class to write messages to the ULS trace log. The following class diagram illustrates the relationship between the key classes in the SharePoint Logger. The SharePoint Logger Generated from CHM, not final book. Will be superseded in the future. Page 527
- 528. Generated from CHM, not final book. Will be superseded in the future. Page 528
- 529. Design Details This section describes the design and functionality of the SharePoint Logger in more detail, including the roles and responsibilities of the key classes and the points at which the SharePoint Logger can be customized. The SharePointLogger Class The SharePointLogger class has the following responsibilities: Forward the log messages to the appropriate logger. Messages targeted at operations are sent to both the class that implements the IEv entLogLogger interface and the class that implements the ITraceLogger interface. Messages targeted solely at developers are only sent to the class that implements the ITraceLogger. Enrich the log message with contextual information. Relevant information, such as the current URL and the name of the currently logged-on user, is added to each log message. Format exceptions into a human readable message. Exception messages are sent to the log files in a format that is readable by humans. Provide a high lev el of robustness in case the logging fails. If a message cannot be written to the event logger implementation, a LoggingException is thrown that contains both the original log message and the reason for the logging failure. Note: An exception is not thrown if a message cannot be written to the trace logger implementation. Instead, the SharePointLogger class attempts to write a message to the event logger implementation to indicate that the trace has failed. The SharePointLogger class is not responsible for actually writing messages to the logs. This functionality is the responsibility of the classes that implement the ITraceLogger interface and the IEv entLogLogger interface. This provides a more flexible design. For example, you could develop an alternative implementation of IEv entLogLogger that writes messages to a database instead of the Windows event log. The SharePointLogger class would remain unaffected by this change and would simply send the same logging information to the new IEv entLogLogger implementation. The TraceLogger and EventLogLogger Classes The TraceLogger class is the default implementation of the ITraceLogger interface. This implementation simply receives trace messages from the SharePointLogger class and passes them to the DiagnosticsService class for logging to the ULS trace log. Similarly, the Ev entLogLogger class is the default implementation of the IEv entLogLogger interface. This class receives event messages from the SharePointLogger class and passes them to the DiagnosticsService class for logging to the Windows event log. The DiagnosticsService Class The SharePoint 2010 API includes an abstract class named SPDiagnosticsServ iceBase that defines the core functionality required to manage diagnostic areas and categories in a SharePoint environment. In the SharePoint Logger, the DiagnosticsServ ice class inherits from SPDiagnosticsServ iceBase to provide several key features: It manages the collection of custom diagnostic areas and categories. It registers new diagnostic areas as event sources in the Windows registry. It writes received messages to the Windows event log and the ULS trace log. The DiagnosticsServ ice class uses the SharePoint The Application Setting Manager to persist custom areas and categories to the farm-scoped property bag. For more information about the SPDiagnosticsServ iceBase class, see SPDiagnosticsServiceBase C lass on MSDN. Registering the SharePoint Logger Because the SharePoint Logger enables users to make changes to the built-in diagnostic areas and categories, it must be registered with the SharePoint farm before you can use it. SharePoint automatically registers the logger when you first use a class that requires the logger. Generated from CHM, not final book. Will be superseded in the future. Page 529
- 530. When the logger requires an instance of DiagnosticsServ ice, it retrieves the instance from the static DiagnosticsServ ice.Local property. In turn, the property getter calls the SPDiagnosticsServ iceBase.GetLocal<DiagnosticsServ ice> method in the SharePoint API to create the instance. The GetLocal first checks to see whether DiagnosticsServ ice is registered; if it is not already registered, it registers it. Because of this, no action is actually required to register the logger. The SharePoint Logger provides a Register method for symmetry, but generally you should not have to use it. If you want to remove the SharePoint Logger from your environment, you should use the DiagnosticsServ ice.Unregister method. This calls a SharePoint API to delete the logger from the configuration database. The best way to manage this is to use include a farm-scoped feature in the solution package that you use to deploy the SharePoint Logger. In the feature receiver class, override the F eatureDeactivating method and call the DiagnosticsServ ice.Unregister method. This ensures that the SharePoint Logger is unregistered when you retract the solution. Customizing the SharePoint Logger The SharePoint Logger is designed to work with the SharePoint Service Locator. With service location, you can replace the default logging and tracing components if you need more flexibility or if you want to reuse an existing logging or tracing component. For example, during unit testing, you can customize logging so that the logging information becomes part of the unit test's output, as shown in C ustomizing the Logger for Unit Testing. For more information about the SharePoint service locator, see The SharePoint Service Locator. Service location occurs at three points of the logger's design: IEv entLogLogger. By default, this interface is mapped to the Ev entLogLogger class. ITraceLogger. By default, this interface is mapped to the TraceLogger class. ILogger. By default, this interface is mapped to the SharePointLogger class. You can customize logging and tracing by reconfiguring any of these type mappings: If you want to change the way event logging is handled, replace the Ev entLogLogger class with a new class that implements the IEventLogLogger interface. For example, you could log events to a central database instead of to the Windows event log. If you want to change the way trace logging is handled, replace the TraceLogger class with a new class that implements the ITraceLogger interface. For example, you can log trace messages to the ASP.NET trace log. If you want to make minor changes to the way the SharePointLogger class handles logging, you can create a class that derives from it. The SharePointLogger class uses virtual methods for most operations, so you can override much of its behavior. If you want full control over how logging and tracing are handled, replace the SharePointLogger class with a new class that derives from the BaseLogger class or that directly implements the ILogger interface. If you want to create your own logging infrastructure, you must derive from the SPDiagnosticsServ iceBase class in the SharePoint API. You can review the DiagnosticsServ ice class in the SharePoint Logger for an example of how to approach this. Use the IServiceLocatorConfig interface to configure your application to use your new custom logger. For an example of how to use the SharePoint Service Locator to replace a service, see Using a Feature Receiver to Register a Type Mapping. Extending Logging Functionality to the Sandbox Environment The SharePoint Logger includes a full-trust proxy that you can use to enable logging from sandboxed solutions. However, if you are unable to deploy the logging proxy, you can extend the SharePoint Logger to support logging to an alternative location within the sandbox environment, such as a SharePoint list. The SharePointLogger class includes two virtual methods named WriteToOperationsLogSandbox and WriteSandboxTrace. When the logger detects that it is running in the sandbox, it calls these methods to write log messages and trace messages, respectively. By default, these methods first check whether the logging proxy is installed. If the logging proxy is available, the methods use it to write to the event logs or the trace files. If the proxy is unavailable, the methods simply drop any log messages. By overriding these methods, you can customize the logger to take alternative actions when it is running in the sandbox environment. To do this, you should use the following high-level steps: 1. C reate a class that derives from the SharePointLogger class. 2. Override the WriteToOperationsLogSandbox method and the WriteSandboxTrace method to Generated from CHM, not final book. Will be superseded in the future. Page 530
- 531. implement your custom handling of logging and tracing messages within the sandbox environment. 3. Use the SharePoint Service Locator to register your logger class as the default implementation of the ILogger interface. For more information about how to do this, see Using C ustom Logger C lasses and Adding Type Mappings. You should use a feature receiver class to register your type mapping at the site collection level when your application is installed. Generated from CHM, not final book. Will be superseded in the future. Page 531
- 532. Developer How-to Topics This section includes step-by-step guidance for the most common tasks that you will undertake when you work with the SharePoint Logger. Each how-to topic provides all the steps you need to complete each task without referring to other topics. However, for more detailed information and best practice guidance, you are urged to consult the rest of the documentation. This section includes the following how-to topics: How to: Log an Event Message How to: Log a Trace Message Generated from CHM, not final book. Will be superseded in the future. Page 532
- 533. How to: Log an Event Message The following procedure demonstrates how you can use the SharePoint Logger to write an event message to the Windows event log and the ULS trace log. To log an event message 1. Add a reference to the SharePoint Guidance Library assembly. In Visual Studio, right-click your project node in Solution Explorer, and then click Add References. C lick the Browse tab, and then navigate to the location of the Microsoft.Practices.SharePoint.Common.dll assembly. 2. Using the same procedure, add a reference to the Microsoft.Practices.Serv iceLocation.dll assembly. This assembly contains the SharePoint Service Locator, which you will use to retrieve a logger instance. 3. Add the following using statements to the top of your source code file. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; using System.Diagnostics; 4. Define an event message, an area/category string, and an integer event ID as required. C# string msg = "Your Message"; string areaCategory = @"Your Area/Your Category"; int eventID = (int)YourEnumeration.YourEventID; 5. If you want to specify a severity, use a value defined by the Ev entSev erity enumeration. C# EventSeverity severity = EventLogEntryType.Error; 6. Use the SharePoint Service Locator to request an implementation of the ILogger interface. C# ILogger logger = SharePointServiceLocator.GetCurrent().GetInstance<ILogger>(); 7. C all the ILogger.LogToOperations method, passing in your message, area/category string, integer ID, and severity as parameters. C# logger.LogToOperations(msg, eventID, severity, areaCategory); For more information about how to use the LogToOperations method, see C reating Log Entries. Generated from CHM, not final book. Will be superseded in the future. Page 533
- 534. How to: Log a Trace Message The following procedure demonstrates how you can use the SharePoint Logger to write a trace message to the ULS trace log. To log a trace message 1. Add a reference to the SharePoint Guidance Library assembly. In Visual Studio, right-click your project node in Solution Explorer, and then click Add References. C lick the Browse tab, and then navigate to the location of the Microsoft.Practices.SharePoint.Common.dll assembly. 2. Using the same procedure, add a reference to the Microsoft.Practices.Serv iceLocation.dll assembly. This assembly contains the SharePoint Service Locator, which you will use to retrieve a logger instance. 3. Add the following using statements to the top of your source code file. C# using Microsoft.Practices.ServiceLocation; using Microsoft.Practices.SharePoint.Common.ServiceLocation; using Microsoft.Practices.SharePoint.Common.Logging; using Microsoft.SharePoint.Administration; 4. Define a trace message, an area/category string, and an integer event ID as required. C# string msg = "Your Trace Message"; string areaCategory = @"Your Area/Your Category"; int eventID = (int)YourEnumeration.YourEventID; 5. If you want to specify a severity, use a value defined by the TraceSev erity enumeration. C# TraceSeverity severity = TraceSeverity.High; 6. Use the SharePoint Service Locator to request an implementation of the ILogger interface. C# ILogger logger = SharePointServiceLocator.GetCurrent().GetInstance<ILogger>(); 7. C all the ILogger.TraceToDeveloper method, passing in your message, area/category string, integer ID, and severity as parameters. C# logger.TraceToDeveloper(msg, eventID, severity, areaCategory); For more information about how to use the TraceToDeveloper method, see C reating Trace Messages. Generated from CHM, not final book. Will be superseded in the future. Page 534
- 535. Testing SharePoint Solutions Automated, robust testing is an increasingly essential part of enterprise-scale SharePoint development. This section provides a brief overview of the different types of testing that you are likely to encounter when you work on enterprise-scale applications and provides information about unit testing for SharePoint applications. In particular, it demonstrates the use of a new isolation framework, Moles, for unit testing SharePoint solutions. The section includes the following topics: Testing C oncepts and Phases Unit Testing for SharePoint Applications Stubs and Mocks The Moles Framework Using Stubs Using Moles Best Practices for Stubs and Moles Behavioral Models Generated from CHM, not final book. Will be superseded in the future. Page 535
- 536. Testing Concepts and Phases This section provides a conceptual overview of the most common approaches to code testing. It introduces some of the key terminology and identifies the scenarios in which each type of test may be appropriate. Unit Testing Unit tests are automated procedures that verify whether an isolated piece of code behaves as expected in response to a specific input. Unit tests are usually created by developers and are typically written against public methods and interfaces. Each unit test should focus on testing a single aspect of the code under test; therefore, it should generally not contain any branching logic. In test-driven development scenarios, developers create unit tests before they code a particular method. The developer can run the unit tests repeatedly as they add code to the method. The developer's task is complete when their code passes all of its unit tests. A unit test isolates the code under test from all external dependencies, such as external APIs, systems, and services. There are various patterns and tools you can use to ensure that your classes and methods can be isolated in this way—these are discussed later in this section. Unit tests should verify that the code under test responds as expected to both normal and exceptional conditions. Unit tests can also provide a way to test responses to error conditions that are hard to generate on demand in real systems, such as hardware failures and out-of-memory exceptions. Because unit tests are isolated from external dependencies, they run very quickly—it is typical for a large suite consisting of hundreds of unit tests to run in a matter of seconds. The speed of execution is critical when you are using an iterative approach to development, because the developer should run the test suite on a regular basis during the development process. Unit tests make it easier to exercise all code paths in branching logic. They do this by simulating conditions that are difficult to produce on real systems in order to drive all paths through the code. This leads to fewer production bugs, which are often costly to the business in terms of the resulting downtime, instability, and the effort required to create, test, and apply production patches. Integration Testing While unit tests verify the functionality of a piece of code in isolation, integration tests verify the functionality of a piece of code against a target system or platform. Just like unit tests, integration tests are automated procedures that run within a testing framework. Although comprehensive unit testing verifies that your code behaves as expected in isolation, you still need to ensure that your code behaves as expected in its target environment, and that the external systems on which your code depends behave as anticipated. That is where integration testing comes in. Unlike a unit test, an integration test executes all code in the call path for each method under test—regardless of whether that code is within the class you are testing or is part of an external API. Because of this, it takes much longer to set up the test conditions for an integration test. For example, you may need to create users and groups or add lists and list items. Integration tests also take considerably longer to run. However, unlike unit tests, integration tests do not rely on assumptions about the behavior of external systems and services. As a result, integration tests may detect bugs that are missed by unit tests. Developers often use integration tests to verify that external dependencies, such as Web services, behave as expected, or to test code with a heavy reliance on external dependencies that cannot be factored out. Testers often also develop and use integration tests for more diverse scenarios, such as security testing and stress testing. In many cases, organizations do not distinguish between integration and unit testing, because both types of tests are typically driven by unit testing frameworks such as nUnit, xUnit, and Visual Studio Unit Test. Typically, organizations that use agile development practices make this distinction, because the two types of tests have different purposes within the agile process. Note: In the Visual Studio 2010 release, there is a limitation that prevents you from testing a SharePoint assembly using Visual Studio Unit Test. Unit tests created for Visual Studio Unit Test must be developed using .NET Framework 4.0 in Visual Studio 2010; whereas, SharePoint 2010 assemblies are based on .NET Framework 3.5. In many cases, this is not an issue—because, generally, .NET Framework 4.0 assemblies are compatible with .NET Framework 3.5 assemblies, so you can run a .NET Framework 4.0 test against a .NET Framework 3.5 assembly. However, the way in which SharePoint loads the .NET common language runtime (C LR) prevents the Generated from CHM, not final book. Will be superseded in the future. Page 536
- 537. runtime from properly loading and running the tests within Visual Studio Unit Test. This limitation prevents you from running integration tests with SharePoint within Visual Studio Unit Test. Integration tests execute real SharePoint API logic instead of substituting the logic with a test implementation. Two isolation tools discussed in the following sections, TypeMock and Moles, will continue to work because they intercept calls to the SharePoint API before the actual SharePoint logic is invoked. You can execute integration tests using a third-party framework such as xUnit or nUnit. C oded user interface (UI) tests against SharePoint applications will run without any issues from within Visual Studio 2010. Continuous Integration Testing C ontinuous integration (C I) is a process that provides a continual verification of code as it is checked into the source repository. This process ensures that the quality of checked in code is always high, because developers do not want to be responsible for breaking the team build. It also ensures that any problems are quickly identified and addressed—in many agile teams, development stops if the C I server is "red" until the issue is resolved. Typically, development teams run C I in response to a check-in event when code is added or changed, although it may also run periodically at a regular interval such as every couple of hours. The C I process builds the code and runs all of the unit tests. The C I process can also run additional checks, such as static analysis. For example, when you work with SharePoint solutions, a recommended practice is to run the SPDisposeC heck utility to check for leaky disposal of SharePoint objects. Typically, C I servers use a commercial tool, such as Team Foundation Build, or an open source tool, such as C ruise C ontrol, to help automate the build and test process. These tools simplify the setup and execution of the C I process and provide reporting on build and test results. For information on setting up Team Foundation Build for C I with SharePoint 2010 see How to Build SharePoint Projects with TFS Team Build. Web Testing Web testing simulates the interaction between a user and a Web-based user interface. The Web test sends HTTP requests to your solution and verifies that the HTTP response it receives is as you expect. Even with sophisticated tools, writing a robust, repeatable Web test can be challenging and time consuming for complex user interfaces. Within Visual Studio, Web tests are known as coded UI tests. Stress Testing Stress tests run an isolated component under excessive load conditions. The purpose of a stress test is to drive the component beyond its normal operating conditions to ensure that it degrades gracefully. Usually, you will use integration tests to conduct stress testing, although you can also use coded UI tests. Stress tests are a useful way to detect certain classes of problems, including memory leaks due to improper disposal and threading-related issues, such as deadlocks or resource contention. When you conduct stress testing, you need to make sure that you stay within the limits of the underlying hardware and operating system, because, inevitably, failures will arise as you exceed the capacity of the infrastructure. Functional Testing Functional testing refers to any procedure that tests the functionality of an application from the perspective of a user. Functional tests can include manual tests, Web tests, and integration tests. Integration tests are included in functional testing because systems often expose APIs for extensibility or for programmatic use. In this case, the target user is a developer. Build Verification Testing Build verification tests (BVTs) work in a similar way to continuous integration, and typically use the same tools. However, while continuous integration ensures that code builds successfully and passes unit tests, BVTs are used to determine whether code satisfies a representative subset of the functionality expected by end users. Typically, BVTs use a combination of integration tests and coded UI tests. A BVT process builds, installs, deploys, and tests an application on a regular basis. BVTs must often perform extensive scripted configuration of the deployment environment before running intensive test processes; because of this, they can take tens of minutes to complete. BVTs provide a baseline measure of confidence in the quality of a build against a real system before it is deployed more widely into other testing environments. BVTs should be conducted in addition to rather than Generated from CHM, not final book. Will be superseded in the future. Page 537
- 538. instead of unit testing, because unit tests do not catch bugs related to the behavior of a system at run time. A build can be "green" on the C I server but still may not function in the production environment. Load or Scale Testing Load or scale testing measures the performance of a solution against a specific set of resources. Ideally, you should run load or scale testing on a test farm that replicates the conditions of your production environment. The idea is to ensure that your system behaves well under normal high-end load conditions and to understand how your application scales as load increases. Load or scale testing uses coded UI tests, often with multiple computers running client test agents to simulate requests and measure responses. Preparing and running load or scale tests is a time-consuming and resource-intensive process. User Acceptance Testing User acceptance testing is any process that tests your solution from the user's perspective, such as load testing and functional testing procedures. In many agile development methodologies, the business owner for the system is also required to test the solution to ensure that business needs are being met. Functional testing by business owners is considered to be a part of user acceptance testing. Generated from CHM, not final book. Will be superseded in the future. Page 538
- 539. Unit Testing for SharePoint Applications The introduction to the Application Foundations chapter identifies several reasons why you should avoid writing classes that have direct dependencies on other services. It introduces various patterns that you can use to avoid direct dependencies in your code and provides links to more information about these patterns. One of the key reasons for removing direct dependencies is to make your classes suitable for unit testing. The previous section describes how unit testing involves isolating specific components of your code, usually individual methods, to be able to verify that the code under test provides expected outputs in response to known inputs. This section describes how unit testing actually works for SharePoint applications. Suppose you want to design a Web Part that enables users to view and query product details from a catalog. In a rough, proof-of-concept approach, you might create a Visual Web Part and put all your logic in the code-behind file for the user control. However, this makes it almost impossible to unit test your business logic. Your code is tightly coupled to the user interface, the SharePoint environment, and the data source. To make your logic testable, there are several design changes you can introduce: Use the Model-View-Presenter (MVP) pattern to isolate your business logic from the user interface and the data source. You create a view class to render your user interface and a repository, or model, class to interact with your data source. All your business logic goes in the presenter class. Implement interfaces for your view classes and your services (such as repository classes). This enables you to replace the real classes with a fake class, typically known as stub classesormock classes. Later sections describe these concepts in more detail. Use the Service Locator pattern to decouple your presenter class from specific implementations of the services that your presenter uses (such as your repository class). This provides an "interception" point where you can replace the real implementation that your presenter depends on with a fake implementation during test execution. The following diagram illustrates this approach. You can view this test in the Partner Portal reference implementation in the Developing SharePoint Applications release. Designing Web Parts for ease of testing Let's review what happens when you unit test the ProductDetailsPresenter class. First, you develop two fake classes, the MockProductDetailsView and the MockProductCatalogRepository. The first class, MockProductDetailsView, implements the view interface. The test creates an instance of the MockProductDetailsView class. The view class instantiates the presenter class, and then it passes itself as the argument to the constructor for the presenter class. This approach is known as constructor injection. However, the test still needs to replace the actual repository class with the mock repository class. To achieve this, the test configures the service locator to return the test implementation to the presenter. The end result is that the presenter executes its logic without ever knowing that it is using fake implementations of the view and the repository. Generated from CHM, not final book. Will be superseded in the future. Page 539
- 540. The MVP pattern is a variation of the well known Model-View-C ontroller (MVC ) pattern. In the client reference implementation, we use another variation of MVC called Model-View-ViewModel (MVVM). MVVM provides a similar isolation of user interface from business logic, but more closely fits the way that Silverlight and Windows Presentation Framework (WPF) work. It's also designed to take advantage of the rich binding capabilities and asynchronous eventing mechanisms available with these technologies. For more information, see the C lient reference implementation. Note: For a more detailed end-to-end view on how to apply unit testing to SharePoint, together with guidance on the design patterns that you can use to isolate code, see the section, Improving Application Quality Through Testing, in the Developing SharePoint Applications release. The Developing SharePoint Applications release was produced for Microsoft Office SharePoint Server 2007, but the patterns and testing approaches described are equally relevant to SharePoint Server 2010. Generated from CHM, not final book. Will be superseded in the future. Page 540
- 541. Stubs and Mocks So what do the terms stub classesand mock classes mean? In a unit test, you test one specific piece of code. If your code makes calls to other classes and external assemblies, you introduce complexity and uncertainty into the test—you do not know whether your code is failing the test or whether the dependency classes are behaving in an unexpected way. To remove this uncertainty, you replace the dependency classes with fake implementations. These fake implementations are known as fakes, mocks, and stubs. The nuanced differences between fakes, mocks, and stubs are not very important to this section, vary according to who you ask, and often evolve into complex discussions around topics such as behavioral and state-based testing. As your approach to testing becomes more sophisticated, these variations are good to understand. Mock has become a popular term and is often used today to represent any type of test class substituted for a real implementation. Fake is a more generic term in increasingly common use and has less controversy surrounding it, so the remainder of this section refers to these substitute test implementations as fakes. Substituting classes that are required by the code under test is challenging. For example, your presenter class calls into your repository class. How do replace the repository implementation with a fake class without editing the presenter class? This is where service location (or a more sophisticated dependency injection approach) comes in. Your presenter class uses service location to get a repository implementation, and when you run the test, you configure the service locator to return your fake implementation instead. Service location is driven by interfaces and interface implementations. To use service location, you must design your dependency classes to implement relevant interfaces. For example, by defining the IProductCatalogRepository interface as the basis for your repository class, and by calling IProductCatalogRepository methods from your presenter class, you make it possible to supply fake implementations of IProductCatalogRepository without editing your presenter logic. Note: Service location is an important concept for unit testing and for modular, flexible code in general. The SharePoint Guidance Library includes a SharePoint-specific implementation of the Service Location pattern that you can use in your own solutions. For more information, see The SharePoint Service Locator. Using fake classes is straightforward if you create the dependency classes yourself, because you have full control over how they are implemented. It can be more challenging if you need to provide substitutes for external classes. The SharePoint object model is a case in point. SharePoint integration is problematic in unit tests for the following reasons: Most classes in the SharePoint object model do not implement interfaces or virtual methods that you can override to create substitute implementations. Many SharePoint classes are sealed with private constructors, so you cannot derive from them or even create them directly. This makes these classes impossible to substitute with conventional mocking techniques. Providing substitute implementations of SharePoint classes for unit testing requires a more sophisticated toolset. The Developing SharePoint Applications release demonstrated the use of a third-party product named TypeMock. This overcomes the limitations of conventional mocking by intercepting calls to SharePoint APIs and redirecting the calls to mock implementations. TypeMock continues to be a great choice for mocking functionality when you work with SharePoint Server 2010. This release adds another approach that can be used to overcome these limitations through the use of a framework named Moles. Generated from CHM, not final book. Will be superseded in the future. Page 541
- 542. The Moles Framework The Moles framework emerged as part of a larger Microsoft Research project named Pex, which aims to provide a systematic, automated approach to unit testing. Pex provides comprehensive test automation based on parameterized unit tests, and is not covered in this brief overview. Moles also includes many features that are beyond the scope of this document. Moles is a Visual Studio Power Tool—it's available as a free download from Visual Studio Gallery, and supports both Visual Studio 2010 and Visual Studio 2008. Pex is available for MSDN subscribers as a subscriber download. For more information about Pex and Moles, see the Pex project site. The Moles framework actually supports two different kinds of substitution class—stub types and mole types. These two approaches allow you to create substitute classes for code dependencies under different circumstances: Stub types provide a lightweight isolation framework that generates fake stub implementations of virtual methods and interfaces for unit testing. Mole types use a powerful detouring framework that uses code profiler APIs to intercept calls to dependency classes and redirects the calls to a fake object. Generally speaking, you should use stubs (or an alternative mocking framework) to create substitute implementations for your own code and for any third-party code that exposes virtual methods and interfaces that you can override. When it is not possible to create stubs for third-party code, such as when the code uses sealed classes or static, non-virtual methods, you should use moles to redirect calls to the code. Later sections provide more guidance on when it is appropriate to use stubs and moles. First, the next sections describe how you can use these two components. Generated from CHM, not final book. Will be superseded in the future. Page 542
- 543. Using Stubs When you use a stub, the Moles framework generates stub implementations of dependency methods and classes for unit testing. This functionality is similar to that of many conventional isolation frameworks such as Moq, NMock2, and Rhino Mocks. The stub types are automatically generated classes that run very quickly at execution and are simple to use. However, stubs lack many of the capabilities of the conventional mocking frameworks and may require some additional coding. Moles can automatically generate stub types for both for your own code and for third-party assemblies you are using, including assemblies in the .NET Framework or SharePoint. By default, stubs are generated for all interfaces and abstract classes, although you can also configure Moles to generate stubs for non-abstract classes that expose virtual methods. You can configure stub generation through a stub configuration file. The following code example shows the stub configuration file for the Microsoft.Practices.SharePoint.Common assembly. XML <?xml version="1.0" encoding="utf-8" ?> <Moles xmlns="http://schemas.microsoft.com/moles/2010/" Verbosity="Noisy"> <Assembly Name="Microsoft.Practices.SharePoint.Common"/> <StubGeneration> <TypeFilter NonSealedClasses="true" Namespace="Microsoft*" /> </StubGeneration> <MoleGeneration Disable="false" /> <Compilation Disable="true" /> </Moles> This configuration file instructs the Moles framework to generate stub implementations for all non-sealed classes in namespaces that begin with "Microsoft" within the Microsoft.Practices.SharePoint.Common assembly. Note that in some cases, it may be easier to manually implement mocks or stubs for your own code instead of using the stub class generated by the Moles framework. The following example shows how to consume a stub object generated by the Moles framework within a test class. In this example, we want to test the Serv iceLocatorConfig class, a key component of the SharePoint Service Locator. The Serv iceLocatorConfig class depends on implementations of the IConfigManager interface to manage the storage of configuration settings. In this case, the IConfigManager instance is provided by a stub implementation named SIConfigManager. C# [TestMethod] public void SetSiteCacheInterval_WithValidValue_UpdatesConfiguration() { // Arrange int expected = 30; string expectedKey = "Microsoft.Practices.SharePoint.Common.SiteLocatorCacheInterval"; var bag = new BIPropertyBag(); int target = -1; var cfgMgr = new SIConfigManager(); cfgMgr.SetInPropertyBagStringObjectIPropertyBag = (key, value, propBag) => { if(key == expectedKey) target = (int) value; }; cfgMgr.GetPropertyBagConfigLevel = (configlevel) => bag; var config = new ServiceLocatorConfig(cfgMgr); // Act config.SetSiteCacheInterval(expected); // Assert Assert.AreEqual(expected, target); } Generated from CHM, not final book. Will be superseded in the future. Page 543
- 544. There are a few key points you need to be aware of to fully understand this test method. First, the following describes the naming conventions used for the generated stubs. The generated stub class, SIConfigManager, provides stubs for the interface IConfigManager. The naming convention precedes the name of the interface or abstract class with the letter "S". The stub class is created in the Microsoft.Practices.SharePoint.Common.Configuration.Moles namespace. Stub classes are created in a sub-namespace, .Moles, of the namespace that contains the interface or abstract class being stubbed. In this case, the interface in question, IConfigManager, is in the Microsoft.Practices.SharePoint.Common.Configuration namespace. The Arrange section of the code example is the setup phase of the test. You can see that the stub object is passed in to the constructor of the class under test, Serv iceLocatorConfig, which requires an argument of type IConfigManager. This is an example of constructor injection, which is a type of dependency injection. Whenever you use a fake object, you need a way to provide the fake object to the code under test, and you typically do this by using some form of dependency injection. So how do we make our stub object instance simulate the behavior we require for the unit test? One of the key tenets of the Moles framework is that you can override virtual methods or interface methods in a flexible way, by attaching delegates to the corresponding method in the stub class. When the object under test calls interface methods on the stub object, the stub object will invoke our delegate. In the Arrange section, you can see that lambda expressions are used to specify implementations for two delegates, SetInPropertyBagStringObjectIPropertyBag, and GetPropertyBagConfigLevel. The following conventions and approaches are used when defining delegate test implementations for a stub class: The name of each delegate on the stub class indicates the name of the method on the interface, together with the parameters that it takes. This naming convention is intended to make the name of the delegate unique—a method may have multiple overloads, so adding parameter types makes the delegate name specific to an individual method overload. In the first example, the method name is SetInPropertyBag and the parameter types are String, Object, and IPropertyBag. Hence the delegate is named SetInPropertyBagStringObjectIPropertyBag. Each lambda expression defines an anonymous method that will be invoked by our delegate. The stub class invokes this delegate when the code under test calls the corresponding actual method on the interface. The following code shows the first delegate implementation for the SIConfigManager stub class: C# cfgMgr.SetInPropertyBagStringObjectIPropertyBag = (key, value, propBag) => { if(key == expectedKey) target = (int) value; }; This example specifies the logic to invoke when the IConfigManager.SetInPropertyBag(string, object, IPropertyBag) method is called. If the provided key matches the expected key, then the value is saved in the local integer variable named target. If the provided key does not match the expected key, no action is taken. Reading and writing local variables within our lambda expressions provides a convenient way to record what occurs during the test, and allows us to check the values during the Assertphase of the test. The following code shows the second delegate implementation for the SIConfigManager stub class: C# cfgMgr.GetPropertyBagConfigLevel = (configlevel) => bag; This example specifices the behavior for the method GetPropertyBag(ConfigLev el) and will always return a reference to the local variable named bag. A common mistake is to return a new value every time a lambda expression is evaluated. Often the code under test will expect the same value to be returned, and by defining a local variable you can ensure that the object is created once and the same value returned each time the test code is invoked. Note: The bag local variable is a instance of BIPropertyBag, which is an example of another type of fake object known as a behaved type. For more information on behaved types, see Behavioral Models. You can configure the Moles framework to respond in various ways if the code under test calls a stub method for which a test implementation has not been defined. By default, the framework will throw an exception indicating that the method has not been defined: Generated from CHM, not final book. Will be superseded in the future. Page 544
- 545. Microsoft.Moles.Framework.Behaviors.BehaviorNotImplementedException: SIConfigManager.global::Microsoft.Practices.SharePoint.Common.Configuration.IConfigManager.GetPropertyBag(C onfigLevel) was not stubbed. A common approach to discovering which methods you need to stub for your test is to run the test, see if the exception is thrown for a missing stub method, then implement the stub method. The Moles framework also supports a BehaveAsDefault approach, in which case any stub methods that you have not implemented will return a default value for the return type of the method. The remainder of the test class uses the same approach as any other unit test. The Act section performs one more action on the code that you want to test. The Assert section verifies that the code under test behaved as expected. Generated from CHM, not final book. Will be superseded in the future. Page 545
- 546. Using Moles Moles is a detouring framework. It uses the powerful profiling features of the C LR's just-in-time compiler to redirect method calls to custom delegates. A common problem that demonstrates the need for a detouring framework such as Moles is when you want to run unit tests on code that depends on the DateTime.Now static property. You cannot use DateTime.Now to test specific conditions, because the value always returns the current date and time from your system clock. You also cannot directly override the DateTime.Now property to return a specific value. In this situation, you can use the Moles framework to detour the DateTime.Now property getter to your own custom delegate. This custom delegate is known as a mole. Note: For an example of how to detour the DateTime.Now property to a custom delegate, see Moles – Detours for .NET on the Microsoft Research Web site. When execution enters a method, such as the DateTime.Now property getter, the Moles framework checks to see whether the test class has defined a detour for that method. If a detour is defined, the framework redirects the call to the detour delegate. If a detour is not defined, the call is directed to the real implementation of the method. Alternatively, you can configure Moles to throw an exception if a detour is not defined or return a default value. For example, if a detour for the DateTime.Now property getter is defined, the method call returns the result of the detour expression. Otherwise, it uses the real implementation of the property getter to return the current date and time. The following code example shows a test method that uses Moles to create a detour for the SPF arm.Local static property. This is a unit test for the SharePointServ iceLocator class. The goal of this test is to verify that calls to SharePointServiceLocator.GetCurrent() fail if a SharePoint context is unavailable. C# [TestMethod] [HostType("Moles")] public void GetCurrent_CallWithoutSharePoint_ThrowsNoSharePointContextException() { // Arrange MSPFarm.LocalGet = () => null; bool expectedExceptionThrown = false; // Act try { IServiceLocator target = SharePointServiceLocator.GetCurrent(); } catch(NoSharePointContextException) { expectedExceptionThrown = true; } // Assert Assert.IsTrue(expectedExceptionThrown); } This section describes the key points of interest in this test method. First, note that a HostType attribute has been added to the method. This instructs the test runtime to execute this test within the Moles environment, which runs in a separate process. This attribute is necessary only when you use a mole, because moles rely on the profiler to detour method calls. Stubs do not involve detours, so they can run in the standard test environment. In this test method, MSPF arm defines a mole for the SPF arm class. The naming convention for a mole is to prefix the name of the class with the letter "M". Just like stubs, moles are created in a sub-namespace, .Moles, of the namespace that contains the class we are detouring. In this case, the MSPF arm mole is defined in the Microsoft.SharePoint.Administration.Moles namespace. In this case, the test creates a delegate for the SPF arm.Local property getter. The delegate signature, LocalGet, indicates that you are overriding the property getter for the Local property. If you could set the Local property, the mole would also have a LocalSet delegate. Because SPF arm.Local is a read-only property, the LocalSet delegate is not defined. The lambda expression, () => null, specifies that detoured calls to the SPFarm.Local property getter will return null. Generated from CHM, not final book. Will be superseded in the future. Page 546
- 547. Best Practices for Stubs and Moles When you work with the Moles framework, it is important to understand when you should use stub types and when you should use mole types. The following guidelines apply to the majority of test scenarios: Use stub types (or an alternative mocking framework) and hand-coded mock classes for replacing components you control. Use mole types (or an alternative detouring framework) for mocking static methods and classes that you do not control, such as SharePoint classes. Do not use mole types to implement interfaces, abstract classes, or virtual methods that you can easily mock using stub types. Structure your unit tests into areas of Arrange, Act, and Assert for clarity: Put the setup and configuration tasks for your test in the Arrange section. Perform the actions that you want to test in the Act section. Verify the results of your actions in the Assert section. Test a single behavior in your unit test. If you have branching logic in your unit test, it is often a good indicator that you should have more tests. Assert multiple results when it makes sense to do so. Often, a single behavior can result in multiple changes in state. Use the SharePoint Service Locator, or an alternative implementation of the service location pattern, to decouple your classes from dependencies and to substitute interface implementations for unit testing. Undoubtedly, you will encounter scenarios in which these guidelines do not apply. For example, suppose you create a class that derives from a base class that you do not own. In this case, it may be difficult to get full test coverage through the use of only simple mocking techniques. You can sometimes avoid this problem by adding virtual methods that you can override in a test implementation, but in other cases, you will need to create detours for your own methods through Moles or TypeMock. There are many more sophisticated examples that illustrate the use of stub types, manual mocks, and mole types in the SharePoint Guidance Library and the accompanying reference implementations. Generated from CHM, not final book. Will be superseded in the future. Page 547
- 548. Behavioral Models When you start using a framework such as Moles or TypeMock for unit testing, you may find that your unit tests often break when you change the way your logic is implemented. When your unit test dictates a specific response for each method call to a mock object, your unit test must reflect the state and behavior of the types that you are substituting. If you edit the code under test to use alternative methods, or even to call the same methods in a different order, you may find that your unit test no longer provides an accurate snapshot of the behavior of the dependency class—even though the functionality remains outwardly unchanged. Your unit tests become susceptible to frequent breaking changes, and risk becoming a reflection of the implementation details instead of a pure test of output conditions. One approach to mitigating this problem is to implementbehaved typesthat provide a more general representation of the class that you are faking. This allows you factor the behavior logic for dependency types out of your individual unit tests and into a single behaved type definition that you can reuse in multiple unit tests. For example, suppose you edit the way your code under test retrieves a list item—instead of using the GetItems method, you use the list indexer. Instead of updating every unit test to mock this new behavior, you would simply edit the behaved type for the list to ensure it supports the new retrieval method. If a behaved type doesn’t have the functionality required for your test, you can simply update the behaved type once and all future tests will benefit from the updated functionality. Behaved types support the concept of state-based testing. In your unit tests, you assign values to the behaved type—for example, you might add a list item to a behaved type that represents a list. The behaved type will always return the same item, regardless of whether the code under test uses an indexer or a query to retrieve the item. This breaks the dependency between the overall functionality of the test code and the underlying implementation details of the test code. In other words, your unit tests simply set the state of the fake object, while the underlying behavior of the fake object is encapsulated within the behaved type. The use of behaved types leads to simpler and more resilient unit tests, and it's preferable to use behaved types instead of moles wherever possible. The Moles installer includes many behaved type implementations for SharePoint and.NET Framework classes. The following example shows a test method that uses the behaved type implementations of the SPWeb, SPList, SPListItem, and SPF ield classes—BSPWeb, BSPList, BSPListItem, and BSPField respectively—which are provided by the Moles framework. The example tests the presenter class logic in a simple Web Part that implements the Model-View-Presenter (MVP) pattern. C# [TestMethod] [HostType("Moles")] public void DoMagic_WithOneAnswer_ReturnsAnswer() { //Arrange string answer = null; string error = null; // First, set up a stub class to represent the view passed to the presenter. var view = new SIMagicEightBallView(); view.DisplayAnswerString = (s) => answer = s; view.DisplayErrorString = (e) => error = e; //Setup a behaved type for a web, add a list, and add an item to the list. BSPWeb web = new BSPWeb(); BSPList list = web.Lists.SetOne(); BSPListItem item = list.Items.SetOne(); item.ID = 0; list.Title = MagicEightBallConstants.EightBallListName; item.Values.SetOne("answer.123"); // add the field that will be used to the list fields. BSPField field = new BSPField(); field.Id = MagicEightBallConstants.AnswerFieldId; list.Fields.SetOne(field); //Act var presenter = new MagicEightBallPresenter(view, web); presenter.DoMagic("Ask a question"); Generated from CHM, not final book. Will be superseded in the future. Page 548
- 549. //Assert Assert.IsTrue(answer != null); Assert.IsTrue(error == null); Assert.IsTrue(answer == "answer.123"); } As you can see from the example, the use of behaved types simplifies the test method and makes it easier to read and understand. In many cases it also obviates the need for the developer to create moles for SharePoint types, which is beneficial as mole types can be complex to develop. The naming convention for a behaved type is to prefix the name of the class with the letter "B". This test performs the following actions: It instantiates a behaved type to represent an SPWeb instance. It creates a single list for the Web by calling the web.Lists.SetOne() method. It adds a single item to the list by calling the list.Items.SetOne() method. It assign values for the ID field, the Title field, and a custom answer field to the list item. This allows us to test the logic of the presenter class—in short, we are able to verify that the presenter class returns the expected answer when we ask it a question. It's worth taking time to explore some of the built-in behaved type implementations. Behaved types typically contain moles that define the functionality of the type. For example, the constructor of the BSPList class instantiate a new mole, of type MSPList, to represent the SPList class. Just like any other mole class implementation, the behaved type attaches several delegates to the mole class to define the behavior of particular methods. For more advanced scenarios, you can override the behavior of a behaved type by wrapping it with an additional mole. For example the following example overrides the behavior that the BSPWeb behaved type defines for the SPWeb.CurrentUser property getter. C# BSPWeb web = new BSPWeb(); MSPUser testUser = new MSPUser(); testUser.NameGet = () => "test name"; MSPWeb web1 = new MSPWeb((SPWeb)web); web1.CurrentUserGet = () => testUser; In general, you can build up the functionality in your behaved types progressively over time, as additional unit tests call for additional behavior definitions. However, you should avoid making the behaved type overly specialized or complex. If a particular unit test requires highly specialized behavior, you can still use the behaved type and override particular behaviors from within your unit test set up phase. For more information about using Pex and Moles to test SharePoint applications, including more details on behaved types, see Unit Testing SharePoint Services with Pex and Moles. Note: The Moles Start Menu includes an option to build the behaved types using Visual Studio 2010. Selecting this option builds the behaved types to your user directory. You must perform this action before running the Moles-based tests provided with the SharePoint Guidance Library. The use of behaved types in the SharePoint Guidance Library is limited, as the Moles framework was still under development when the SharePoint Guidance Library components were implemented. Generated from CHM, not final book. Will be superseded in the future. Page 549
- 550. List-Backed Configuration Quick Start Overview In some environments, developers and IT professionals might prefer to manage configuration settings through lists rather than through property bags and persisted objects. (The SharePoint Guidance Library implements property bags and persisted objects by default.). The 2010 release of Designing SharePoint Applications enables you to manage application setting configurations. It also provides several classes that you can use to implement a list-backed approach for storing configuration settings. This quick start explains how to create and register a list-backed application settings manager and provides a sample implementation. To understand this quick start, you should first review the chapter on the Application Setting Manager. The example implementation stores configuration settings in two lists. Site collection (SPSite) and site settings (SPWeb) are stored in a list at the root Web site of the site collection in which they are located. Farm and Web application settings apply across site collections, and therefore these settings need to be located in a single central site collection. Implementation Details To manage settings at specific levels, a custom application settings manager must replace the property bags with a list-backed property bag. The collection of property bags are managed by a configuration hierarchy. To move to a list-backed implementation you will: 1. C reate a configuration hierarchy that uses list-backed property bags. 2. Derive a configuration manager to use this hierarchy. 3. Derive a hierarchical configuration to use this hierarchy. 4. Register the configuration manager and hierarchical configuration implementations with the service locator. The SharePoint Guidance Library provides most of the implementation code required to implement a list-backed solution, including: ListBackedPropertyBag – This class implements a property bag that stores configuration in a list. The implementation assumes that the list for storing settings is located in the root Web site of the site collection which contains the site. This property bag can be used within a sandbox as well. ListBackedUrlPropertyBag – This class implements a property bag that stores configuration in a list. The implementation assumes that the list for storing settings is located at the root Web site of a site collection identified by the URL provided. Updating the settings for a list in a different site collection requires enabling unsafe updates. This class cannot be used in the sandbox because sandboxed solutions cannot perform unsafe updates. ConfigurationList – This class implements the logic for creating the list that will contain the settings. It also contains the logic for looking up and storing values in that list. The ConfigurationList contains a context ID (for example, the Site.ID that uniquely identifies a site), a key, and a value. When a value is looked up, both the context ID and the key identify the value to retrieve. PropertyBagHierarchy – This class provides the base implementation for a property bag hierarchy. It contains the collection of property bags to use in the hierarchy, and implements the interface expected by the configuration manager and hierarchical manager for any property bag. HierarchicalConfig – This class provides the logic for performing a hierarchical lookup of application settings. ConfigManager – This class provides the logic for reading and writing settings for a specific property bag. The quick start implements the following classes to realize list-backed application settings management: ListBackedConfigHierarchy – This class derives from the PropertyBagHierarchy class. The implementation creates list-backed property bags for the Web, site, Web application, and farm, and then adds these property bags to the collection managed by the base class. ListBackedHierarchicalConfig – This class overrides the method for creating the configuration hierarchy, and returns the ListBackedConfigHierarchy in place of the default implementation. ListBackedConfigManager – This class overrides the method for creating the configuration hierarchy, and returns the ListBackedConfigHierarchy in place of the default implementation. CentralSiteConfig – This class manages the configuration setting for the URL location of the site that contains the list for storing Web application and farm settings. Generated from CHM, not final book. Will be superseded in the future. Page 550
- 551. Packaging and Deployment The quick start is packaged as a site-scoped feature. The feature implements a feature event receiver, which takes the following actions: FeatureInstalled – This action creates the central list for storing configuration settings for the farm and Web application level the list does not already exist. The ConfigurationList implementation contains a method, called EnsureConfigurationList, that creates the site columns, content type, and list at the central location if they do not already exist. It uses the CentralSiteConfig class to store the URL for the central site. FeatureActivated – This action uses the EnsureConfigurationMethod to create the list for managing the site and Web–level settings. It creates the list at the root Web site of the site collection, if it does not already exist. It uses the service locator to register the implementations for the IHierarchicalConfig and IConfigManager interfaces as ListBackedHierarchicalConfig and ListBackedConfigManager, respectiv ely. These classes are at the site level. FeatureDeactivated – This action removes the registration of the ListBackedHierarchicalConfig and ListBackedConfigManager from the service locator. Demonstration This quick start includes a simple visual Web Part—named ListBackedC onfigurationTests—that demonstrates how to implement a list-backed approach for managing configuration settings. This Web Part demonstrates running through settings and getting values at different levels when a button is pushed. It then displays the results, as shown by the following diagram. Demonstration of list-backed implementation results Generated from CHM, not final book. Will be superseded in the future. Page 551
- 552. Generated from CHM, not final book. Will be superseded in the future. Page 552