





















![Data Filtering and Preprocessing
Filtering
● Value ranges
● String matching
● Regex
Setting Defaults
● Null checks
● Default function
● If-then-else function
define stream OrderStream
(custId string, item string, amount int);
from OrderStream[item!=“unknown”]
select default(custId, “internal”) as custId,
item,
ifThenElse(amount<0, 0, amount) as amount,
insert into CleansedOrderStream;](https://image.slidesharecdn.com/siddhi-cloud-nativestreamprocessor-200429101320/85/Siddhi-cloud-native-stream-processor-23-320.jpg)



















![Alert Based On Event Occurrence Order
Use pattern query to detect event occurrence order and non occurrence.
define stream OrderStream (custId string, orderId string, ...);
define stream PaymentStream (orderId string, ...);
from every (e1=OrderStream) ->
not PaymentStream[e1.orderId==orderId] for 15 min
select e1.custId, e1.orderId, ...
insert into PaymentDelayedStream;
Non occurrence of event](https://image.slidesharecdn.com/siddhi-cloud-nativestreamprocessor-200429101320/85/Siddhi-cloud-native-stream-processor-43-320.jpg)
















![@source(type = ‘HTTP’, …, @map(type = ‘json’))
define stream ProductionStream (name string, amount double, factoryId int);
@dist(parallel = ‘4’, execGroup = ‘gp1’)
from ProductionStream[amount > 100]
select *
insert into HighProductionStream ;
@dist(parallel = ‘2’, execGroup = ‘gp2’)
partition with (factoryId of HighProductionStream)
begin
from HighProductionStream#window.timeBatch(1 min)
select factoryId, sum(amount) as amount
group by factoryId
insert into ProdRateStream ;
end;
Filter
Source
FilterFilterFilter
PartitionPartition
Sample Distributed Siddhi App](https://image.slidesharecdn.com/siddhi-cloud-nativestreamprocessor-200429101320/85/Siddhi-cloud-native-stream-processor-62-320.jpg)

Siddhi - cloud-native stream processor
- 1. Cloud-native Stream Processor S. Suhothayan (Suho) Director WSO2 @suhothayan
- 2. Adaptation of Microservices for Stream Processing Organizations try to: 1. Port legacy big data solutions to the cloud. - Not designed to work in microservice architecture. - Massive (need 5 - 6 large nodes). - Needs multiple tools for integration and analytics. 2. Build microservices using on-premise solutions such as Siddhi or Esper library. - Do not support scalability and fault tolerance.
- 3. Introducing A Cloud Native Stream Processor ● Lightweight (low memory footprint and quick startup) ● 100% open source (no commercial features) with Apache License v2. ● Native support for Docker and Kubernetes. ● Support agile devops workflow and full CI/CD pipeline. ● Allow event processing logics to be written in SQL like query language and via graphical tool. ● Single tool for data collection, injection, processing, analyzing, integrating (with services and databases), and to manage notifications
- 4. Overview
- 5. Key features ● Native distributed deployment in Kubernetes ● Native CDC support for Oracle, MySQL, MSSQL, Postgres ● Long running aggregations from sec to years ● Complex pattern detection ● Online machine learning ● Synchronous decision making ● DB integration with caching ● Service integration with error handling ● Multiple built in connectors (file, Kafka, NATS, gRPC, ...)
- 6. Scenarios and Use Cases Supported by Siddhi 1. Realtime Policy Enforcement Engine 2. Notification Management 3. Streaming Data Integration 4. Fraud Detection 5. Stream Processing at Scale on Kubernetes 6. Embedded Decision Making 7. Monitoring and Time Series Data Analytics 8. IoT, Geo and Edge Analytics 9. Realtime Decision as a Service 10. Realtime Predictions With Machine Learning Find out more about the Supported Siddhi Scenarios here
- 7. Full size Image Area
- 8. Success Stories Experian makes real-time marketing channel decisions under 200 milliseconds using Siddhi. Eurecat built their next generation shopping experience by integrating iBeacons and IoT devices with WSO2. Cleveland Clinic and Hospital Corporation of America detects critical patient conditions and alert nurses and also automates decisions during emergencies. BNY Mellon uses Siddhi as a notification management engine.
- 9. Success Stories ... a TFL used WSO2 real time streaming to create next generation transport systems. Uber detected fraud in real time, processing over 400K events per second Use Siddhi as its APIM management throttling engine and as the policy manager for its Identify and Access Platform EBay and PayPal uses Siddhi as part of Apache Eagle to as a policy enforcement engine.
- 10. Image Area Working with Siddhi ● Develop apps using Siddhi Editor. ● CI/CD with build integration and Siddhi Test Framework. ● Running modes ○ Emadded in Java/Python apps. ○ Microservice in bare metal/VM. ○ Microservice in Docker. ○ Microservice in Kubernetes (distributed deployment with NATS)
- 11. Streaming SQL @app:name('Alert-Processor') @source(type='kafka', ..., @map(type='json')) define stream TemperatureStream (roomNo string, temp double); @info(name='AlertQuery') from TemperatureStream#window.time(5 min) select roomNo, avg(temp) as avgTemp group by roomNo insert into AvgTemperatureStream; Source/Sink & Streams Window Query with Rate Limiting
- 12. Web Based Source Editor
- 13. Web Based Graphical Editor
- 14. Siddhi Editor Introduction Video
- 15. Reference CI/CD Pipeline of Siddhi https://medium.com/siddhi-io/building-an-efficient-ci-cd-pipeline-for-siddhi-c33150721b5d
- 16. Full size Image Area with text Supported Data Processing Patterns
- 17. Supported Data Processing Patterns 1. Consume and publish events with various data formats. 2. Data filtering and preprocessing. 3. Date transformation. 4. Database integration and caching. 5. Service integration and error handling. 6. Data Summarization. 7. Rule processing. 8. Serving online and predefined ML models. 9. Scatter-gather and data pipelining. 10. Realtime decisions as a service (On-demand processing).
- 18. Image Area Scenario: Order Processing Customers place orders. Shipments are made. Customers pay for the order. Tasks: ● Process order fulfillment. ● Alerts sent on abnormal conditions. ● Send recommendations. ● Throttle order requests when limit exceeded. ● Provide order analytics over time.
- 19. Full size Image Area with text Consume and Publish Events With Various Data Formats
- 20. Consume and Publish Events With Various Data Formats Supported transports ● NATS, Kafka, RabbitMQ, JMS, IBMMQ, MQTT ● Amazon SQS, Google Pub/Sub ● HTTP, gRPC, TCP, Email, WebSocket, ● Change Data Capture (CDC) ● File, S3, Google Cloud Storage Supported data formats ● JSON, XML, Avro, Protobuf, Text, Binary, Key-value, CSV
- 21. Consume and Publish Events With Various Data Formats Default JSON mapping Custom JSON mapping @source(type = mqtt, …, @map(type = json)) define stream OrderStream(custId string, item string, amount int); @source(type = mqtt, …, @map(type = json, @attribute(“$.id”,"$.itm” “$.count”))) define stream OrderStream(custId string, item string, amount int); {“event”:{“custId”:“15”,“item”:“shirt”,“amount”:2}} {“id”:“15”,“itm”:“shirt”,“count”:2}
- 22. Full size Image Area with text Data Filtering and Preprocessing
- 23. Data Filtering and Preprocessing Filtering ● Value ranges ● String matching ● Regex Setting Defaults ● Null checks ● Default function ● If-then-else function define stream OrderStream (custId string, item string, amount int); from OrderStream[item!=“unknown”] select default(custId, “internal”) as custId, item, ifThenElse(amount<0, 0, amount) as amount, insert into CleansedOrderStream;
- 24. Full size Image Area with text Date Transformation
- 25. Date Transformation Data extraction ● JSON, Text Reconstruct messages ● JSON, Text Inline operations ● Math, Logical operations Inbuilt functions ● 60+ extensions Custom functions ● Java, JS json:getDouble(json,"$.amount") as amount str:concat(‘Hello ’,name) as greeting amount * price as cost time:extract('DAY', datetime) as day myFunction(item, price) as discount
- 26. Full size Image Area with text Database Integration and Caching
- 27. Database Integration and Caching Supported Databases: ● RDBMS (MySQL, Oracle, DB2, Postgre, H2), Redis, Hazelcast ● MongoDB, HBase, Cassandra, Solr, Elasticsearch
- 28. In-memory Table Joining stream with a table. define stream CleansedOrderStream (custId string, item string, amount int); @primaryKey(‘name’) @index(‘unitPrice’) define table ItemPriceTable (name string, unitPrice double); from CleansedOrderStream as O join ItemPriceTable as T on O.item == T.name select O.custId, O.item, O.amount * T.unitPrice as price insert into EnrichedOrderStream; In-memory Table Join Query
- 29. Database Integration Joining stream and table. define stream CleansedOrderStream (custId string, item string, amount int); @store(type=‘rdbms’, …,) @primaryKey(‘name’) @index(‘unitPrice’) define table ItemPriceTable(name string, unitPrice double); from CleansedOrderStream as O join ItemPriceTable as T on O.item == T.name select O.custId, O.item, O.amount * T.unitPrice as price insert into EnrichedOrderStream; Table backed with DB Join Query
- 30. Database Caching Joining table with cache (preloads data for high read performance). define stream CleansedOrderStream (custId string, item string, amount int); @store(type=‘rdbms’, …, @cache(cache.policy=‘LRU’, … )) @primaryKey(‘name’) @index(‘unitPrice’) define table ItemPriceTable(name string, unitPrice double); from CleansedOrderStream as O join ItemPriceTable as T on O.item == T.name select O.custId, O.item, O.amount * T.unitPrice as price insert into EnrichedOrderStream; Table with Cache Join Query
- 31. Full size Image Area with text Service Integration and Error Handling
- 32. Enriching data with HTTP and gRPC service Calls ● Non blocking ● Handle responses based on status codes Service Integration and Error Handling 200 4** Handle response based on status code
- 33. SQL for HTTP Service Integration Calling external HTTP service and consuming the response. @sink(type='http-call', publisher.url="http://mystore.com/discount", sink.id="discount", @map(type='json')) define stream EnrichedOrderStream (custId string, item string, price double); @source(type='http-call-response', http.status.code="200", sink.id="discount", @map(type='json', @attributes(custId ="trp:custId", ..., price="$.discountedPrice"))) define stream DiscountedOrderStream (custId string, item string, price double); Call service Consume Response
- 34. Error Handling Options Options when endpoint is not available. ● Log and drop the events ● Wait and back pressure until the service becomes available ● Divert events to another stream for error handling. In all cases system continuously retries for reconnection.
- 35. Events Diverted Into Error Stream @onError(action='stream') @sink(type='http', publisher.url = 'http://localhost:8080/logger', on.error='stream', @map(type = 'json')) define stream DiscountedOrderStream (custId string, item string, price double); from !DiscountedOrderStream select custId, item, price, _error insert into FailedEventsTable; Diverting connection failure events into table.
- 36. Full size Image Area with text Data Summarization
- 37. Data Summarization Type of data summarization ● Time based ○ Sliding time window ○ Tumbling time window ○ On time granularities (secs to years) ● Event count based ○ Sliding length window ○ Tumbling length window ● Session based ● Frequency based Type of aggregations ● Sum ● Count ● Avg ● Min ● Max ● DistinctCount ● StdDev
- 38. Summarizing Data Over Shorter Period Of Time Use window query to aggregate orders over time for each customer. define stream DiscountedOrderStream (custId string, item string, price double); from DiscountedOrderStream#window.time(10 min) select custId, sum(price) as totalPrice group by custId insert into AlertStream; Window query with aggregation and rate limiting
- 39. Aggregation Over Multiple Time Granularities Aggregation on every second, minute, hour, … , year Built using 𝝀 architecture ● In-memory real-time data ● RDBMs based historical data define aggregation OrderAggregation from OrderStream select custId, itemId, sum(price) as total, avg(price) as avgPrice group by custId, itemId aggregate every sec ... year; Query Speed Layer & Serving Layer Batch Layer
- 40. Data Retrieval from Aggregations Query to retrieve data for relevant time interval and granularity. Data being retrieved both from memory and DB with milliseconds accuracy. from OrderAggregation within "2019-10-06 00:00:00", "2019-10-30 00:00:00" per "days" select total as orders;
- 41. Full size Image Area with text Rule Processing
- 42. Rule Processing Type of predefined rules ● Rules on single event ○ Filter, If-then-else, Match, etc. ● Rules on collection of events ○ Summarization ○ Join with window or table ● Rules based on event occurrence order ○ Pattern detection ○ Trend (sequence) detection ○ Non-occurrence of event
- 43. Alert Based On Event Occurrence Order Use pattern query to detect event occurrence order and non occurrence. define stream OrderStream (custId string, orderId string, ...); define stream PaymentStream (orderId string, ...); from every (e1=OrderStream) -> not PaymentStream[e1.orderId==orderId] for 15 min select e1.custId, e1.orderId, ... insert into PaymentDelayedStream; Non occurrence of event
- 44. Full size Image Area with text Serving Online and Predefined ML Models
- 45. Serving Online and Predefined ML Models Type of Machine Learning and Artificial Intelligence processing ● Anomaly detection ○ Markov model ● Serving pre-created ML models ○ PMML (build from Python, R, Spark, H2O.ai, etc) ○ TensorFlow ● Online machine learning ○ Clustering ○ Classification ○ Regression from OrderStream #pmml:predict(“/home/user/ml.model”,custId, itemId) insert into RecommendationStream; Find recommendations
- 46. Full size Image Area with text Scatter-gather and Data Pipelining
- 47. Scatter-gather and Data Pipelining Divide into sub-elements, process each and combine the results Example : json:tokenize() -> process -> window.batch() -> json:group() str:tokenize() -> process -> window.batch() -> str:groupConcat() {x,x,x} {x},{x},{x} {y},{y},{y} {y,y,y}
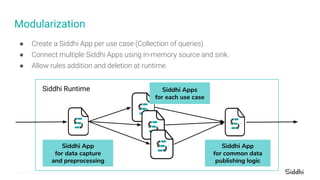
- 48. ● Create a Siddhi App per use case (Collection of queries). ● Connect multiple Siddhi Apps using in-memory source and sink. ● Allow rules addition and deletion at runtime. Modularization Siddhi Runtime Siddhi App for data capture and preprocessing Siddhi Apps for each use case Siddhi App for common data publishing logic
- 49. Periodically Trigger Events Periodic events can be generated to initialize data pipelines ● Time interval ● Cron expression ● At start define trigger FiveMinTrigger at every 5 min; define trigger WorkStartTrigger at '0 15 10 ? * MON-FRI'; define trigger InitTrigger at 'start';
- 50. Full size Image Area with text Realtime Decisions As A Service
- 51. Realtime Decisions As A Service Query Data Stores using REST APIs ● Database backed stores (RDBMS, NoSQL) ● Named aggregations ● In-memory windows & tables Call HTTP and gRPC service using REST APIs ● Use Service and Service-Response loopbacks ● Process Siddhi query chain and send response synchronously
- 52. Full size Image AreaScalable Deployment
- 53. Deployment of Scalable Stateful Apps ● Data kept in memory. ● Perform periodic state snapshots and replay data from NATS. ● Scalability is achieved partitioning data by key.
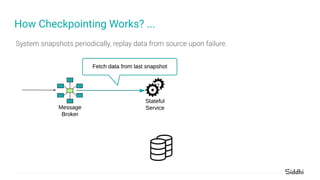
- 54. System snapshots periodically, replay data from source upon failure. How Checkpointing Works?
- 55. System snapshots periodically, replay data from source upon failure. How Checkpointing Works? ...
- 56. System snapshots periodically, replay data from source upon failure. How Checkpointing Works? ...
- 57. System snapshots periodically, replay data from source upon failure. How Checkpointing Works? ...
- 58. System snapshots periodically, replay data from source upon failure. How Checkpointing Works? ...
- 59. System snapshots periodically, replay data from source upon failure. How Checkpointing Works? ...
- 60. Full size Image Area with text Siddhi Deployment in Kubernetes
- 61. Kubernetes Deployment $ kubectl get siddhi NAME STATUS READY AGE Sample-app Running 2/2 5m
- 62. @source(type = ‘HTTP’, …, @map(type = ‘json’)) define stream ProductionStream (name string, amount double, factoryId int); @dist(parallel = ‘4’, execGroup = ‘gp1’) from ProductionStream[amount > 100] select * insert into HighProductionStream ; @dist(parallel = ‘2’, execGroup = ‘gp2’) partition with (factoryId of HighProductionStream) begin from HighProductionStream#window.timeBatch(1 min) select factoryId, sum(amount) as amount group by factoryId insert into ProdRateStream ; end; Filter Source FilterFilterFilter PartitionPartition Sample Distributed Siddhi App
- 63. Thank You For more information visit https://siddhi.io