Simplifying training deep and serving learning models with big data in python using tensorflow - PyData Berlin
Download as PPTX, PDF2 likes78 views

This document discusses simplifying training and serving deep learning models with big data in Python using TensorFlow, Apache Beam, and Apache Flink. It covers using TF.Transform to preprocess data, running TensorFlow models on Spark using TensorFlowOnSpark, and the progress being made on non-JVM support in Apache Beam and TensorFlow on Flink. It also briefly discusses other big data systems and the challenges of interacting with them from outside the Java Virtual Machine.











![Defining a Transform processing function
def preprocessing_fn(inputs):
x = inputs['x']
y = inputs['y']
s = inputs['s']
x_centered = x - tft.mean(x)
y_normalized = tft.scale_to_0_1(y)
s_int = tft.string_to_int(s)
return { 'x_centered': x_centered,
'y_normalized': y_normalized, 's_int': s_int}](https://image.slidesharecdn.com/simplifyingtrainingdeepservinglearningmodelswithbigdatainpythonusingtensorflow-pydataberlin-180725012319/85/Simplifying-training-deep-and-serving-learning-models-with-big-data-in-python-using-tensorflow-PyData-Berlin-12-320.jpg)




![Ooor from the chicago taxi data...
for key in taxi.DENSE_FLOAT_FEATURE_KEYS:
# Preserve this feature as a dense float, setting nan's to
the mean.
outputs[key] = transform.scale_to_z_score(inputs[key])
for key in taxi.VOCAB_FEATURE_KEYS:
# Build a vocabulary for this feature.
outputs[key] = transform.string_to_int(
inputs[key], top_k=taxi.VOCAB_SIZE,
num_oov_buckets=taxi.OOV_SIZE)
for key in taxi.BUCKET_FEATURE_KEYS:
outputs[key] = transform.bucketize(inputs[key],](https://image.slidesharecdn.com/simplifyingtrainingdeepservinglearningmodelswithbigdatainpythonusingtensorflow-pydataberlin-180725012319/85/Simplifying-training-deep-and-serving-learning-models-with-big-data-in-python-using-tensorflow-PyData-Berlin-22-320.jpg)






![So how does that impact Py[X]
forall X in {Big Data}-{Native Python Big Data}
● Double serialization cost makes everything more
expensive
● Python worker startup takes a bit of extra time
● Python memory isn’t controlled by the JVM - easy to go
over container limits if deploying on YARN or similar
● Error messages make ~0 sense
● Dependency management makes limited sense
● features aren’t automatically exposed, but exposing
them is normally simple](https://image.slidesharecdn.com/simplifyingtrainingdeepservinglearningmodelswithbigdatainpythonusingtensorflow-pydataberlin-180725012319/85/Simplifying-training-deep-and-serving-learning-models-with-big-data-in-python-using-tensorflow-PyData-Berlin-31-320.jpg)







![Which becomes
train_func = TFSparkNode.train(self.cluster_info,
self.cluster_meta, qname)
@pandas_udf("int")
def do_train(inputSeries1, inputSeries2):
# Sad hack for now
modified_series = map(lambda x: (x[0], x[1]),
zip(inputSeries1, inputSeries2))
train_func(modified_series)
return pandas.Series([0] * len(inputSeries1))
ljmacphee](https://image.slidesharecdn.com/simplifyingtrainingdeepservinglearningmodelswithbigdatainpythonusingtensorflow-pydataberlin-180725012319/85/Simplifying-training-deep-and-serving-learning-models-with-big-data-in-python-using-tensorflow-PyData-Berlin-39-320.jpg)




































Ad
More Related Content
What's hot (20)
Similar to Simplifying training deep and serving learning models with big data in python using tensorflow - PyData Berlin (20)


















Ad
Recently uploaded (20)




















Ad
Simplifying training deep and serving learning models with big data in python using tensorflow - PyData Berlin
- 1. Simplifying Training & Serving Deep Learning with Big Data in Python w/ Tensorflow, Apache Beam, and Apache Flink + Possible Spark bonus @holdenkarau
- 2. Holden: ● My name is Holden Karau ● Prefered pronouns are she/her ● Developer Advocate at Google ● Apache Spark PMC, Beam contributor ● previously IBM, Alpine, Databricks, Google, Foursquare & Amazon ● co-author of Learning Spark & High Performance Spark ● Twitter: @holdenkarau ● Slide share http://www.slideshare.net/hkarau ● Code review livestreams: https://www.twitch.tv/holdenkarau / https://www.youtube.com/user/holdenkarau ● Spark Talk Videos http://bit.ly/holdenSparkVideos
- 4. Who I think you wonderful humans are? ● Nice enough people ● Don’t mind pictures of cats ● Probably pretty familiar with Spark ● Maybe somewhat familiar with Beam? Lori Erickson
- 5. What we did get to: ● TensorFlowOnSpark w/basic Apache Arrow ● Python & Go on Beam on Flink prototype (in random github branch, not finished) ○ Everyone loves wordcount right? right?.... ● New Beam architecture allowing for better portability & handling dependencies (like Tensorflow) ● TF Transform demo on Apache Flink via Apache Beam ● DO NOT non-JVM BEAM on Flink IN PRODUCTION Vladimir Pustovit
- 6. DO NOT USE THIS IN PRODUCTION TODAY ● I’m serious, I don’t want to die or cause the next financial meltdown with software I’m a part of ● By Today I mean June 8 2018, but it’s probably going to not be great for at least a “little while” Vladimir Pustovit PROTambako The Jaguar
- 7. What will be covered? Most likely: ● Where we are today in non-JVM support in Beam ● And why this matters for Tensorflow ● What the rest of Big Data ecosystem looks like going outside the JVM ● A partial TF Transform demo + TFMA links + possible system crash If there is time (e.g. demo runs quickly, wifi works, several other happy unlikely things): ● TensorFlowOnSpark ● Apache Arrow - How this changes “everything”*
- 8. So why do I need to power DL w/Big Data? ● Deep learning is most effective with large sample sets for training ● As much as some may say that no feature prep is required even if you’re looking at mnist.csv you probably have _some_ feature prep ● Since we need big data for training we need to to do our feature prep it ● Even if your just trying to raise some VC money it's going to go a lot better if you add some keywords about a large proprietary dataset
- 9. TensorFlow isn’t enough on its own ● Enter TFX & friends like Kubeflow ○ Current related TFX OSS components: TF.Transform TF.Serving (with more coming) ● Alternatives: piles of custom code re-created at serving time. ○ Yay job security? PROJennifer C.
- 10. How do I do feature prep? (old skool) ● Write custom preparation jobs in your favourite big data tool (mine is Apache Spark, but maybe yours is something else) ● Run it, train on the prepared data ● Rewrite your feature prep code to run at serving time ○ Error prone and sad
- 11. Enter: TF.Transform ● For pre-processing of your data ○ e.g. where you spend 90% of your dev time anyways ● Integrates into serving time :D ● OSS ● Runs on top of Apache Beam, but current release not yet outside of GCP ○ On master this can run on Flink, but probably has bugs currently. ○ Please don’t use this in production today unless your on GCP/Dataflow PROKathryn Yengel
- 12. Defining a Transform processing function def preprocessing_fn(inputs): x = inputs['x'] y = inputs['y'] s = inputs['s'] x_centered = x - tft.mean(x) y_normalized = tft.scale_to_0_1(y) s_int = tft.string_to_int(s) return { 'x_centered': x_centered, 'y_normalized': y_normalized, 's_int': s_int}
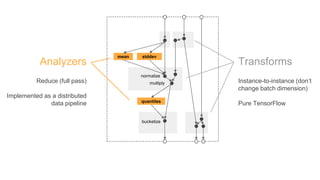
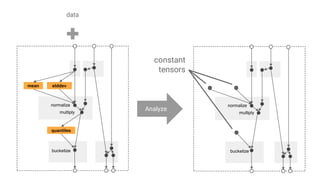
- 13. mean stddev normalize multiply quantiles bucketize Analyzers Reduce (full pass) Implemented as a distributed data pipeline Transforms Instance-to-instance (don’t change batch dimension) Pure TensorFlow
- 15. Scale to ... Bag of Words / N-Grams Bucketization Feature Crosses tft.ngrams tft.string_to_int tf.string_split tft.scale_to_z_score tft.apply_buckets tft.quantiles tft.string_to_int tf.string_join ... Some common use-cases...
- 16. BEAM Beyond the JVM: Current release ● Non JVM BEAM doesn’t work outside of Google’s environment yet ● tl;dr : uses grpc / protobuf ○ Similar to the common design but with more efficient representations (often) ● But exciting new plans to unify the runners and ease the support of different languages (called SDKS) ○ See https://beam.apache.org/contribute/portability/ ● If this is exciting, you can come join me on making BEAM work in Python3 ○ Yes we still don’t have that :( ○ But we're getting closer & you can come join us on BEAM-2874 :D Emma
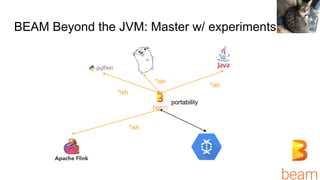
- 17. BEAM Beyond the JVM: Master + Experiments ● Common interface for setting up jobs ● Portability framework allows SDK harnesses in arbitrary to be kicked off ● Runners ship in their own docker containers (goodbye dependency hell, hello container hell) ○ Also for now rolling containers leaves something to be desired (e.g. edit docker file by hand) ● Hacked up Python SDK to sort of talk to the new interface ● Go SDK talks to the new interface, still missing some features ● Need permissions? Run on GKE or plumb through permissions file :( Nick
- 18. BEAM Beyond the JVM: Master w/ experiments *ish *ish *ish Nick portability *ish
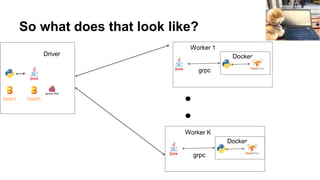
- 19. So what does that look like? Driver Worker 1 Docker grpc Worker K Docker grpc
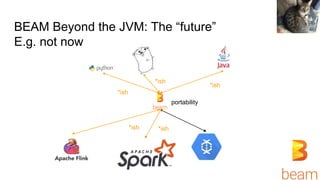
- 20. BEAM Beyond the JVM: The “future” E.g. not now *ish *ish *ish Nick portability *ish *ish
- 21. So how TF does this relate to TF? ● Tensorflow is in Python (kind of) ● Once we finish the Python SDK on Beam on Flink adventure you can use all sorts of cool libraries (like TFT/TFX) to do your tensorflow work ○ You can use them today too if your use case is on Dataflow ○ If you don’t mind bugs you can experiment with them on Flink too ● You will be able manage your dependencies ● You will be able to (in theory) re-use dataprep code at serving time ○ 80% less copy n’ paste code with slight mistakes that get out of date!** ● No that doesn’t work today ● Or tomorrow ● But… eventually ○ Standard OSS excuse “patches welcome” (sort of if you can find the branch :p) **Not a guarantee, see your vendor for details.
- 22. Ooor from the chicago taxi data... for key in taxi.DENSE_FLOAT_FEATURE_KEYS: # Preserve this feature as a dense float, setting nan's to the mean. outputs[key] = transform.scale_to_z_score(inputs[key]) for key in taxi.VOCAB_FEATURE_KEYS: # Build a vocabulary for this feature. outputs[key] = transform.string_to_int( inputs[key], top_k=taxi.VOCAB_SIZE, num_oov_buckets=taxi.OOV_SIZE) for key in taxi.BUCKET_FEATURE_KEYS: outputs[key] = transform.bucketize(inputs[key],
- 23. Beam Demo Time!!!!! ● TFT!!!!!! So amazing!!!!!!!!! ○ Want to move to SF and raise a series A? Pay attention :p ● Based on my testing on Saturday there is a 1 in 3 chance this will hard lock my computer ○ But that’s OK, we can reboot and take questions while I bounce :) ● That’s your friendly reminder not to run any of this in production (yet) ● The demo code is forked from axelmagn/model-analysis which is forked from tensorflow/model-analysis and runs on master of Apache Beam w/Flink ○ The example does something… possible questionable with the evaluation dataset currently, but #todofixmelater
- 24. Ok now what? ● Integrate this into your model serving pipeline of choice ○ Don’t have one or open to change? Checkout TFMA which can directly serve it ● There’s a guide (it doesn’t show Flink because not released yet) but steps are similar ○ But you’re not using this in production today anyways? ○ Right? Nick Perla
- 25. (Optional) Second Beam Demo Time!!!!! ● Word count!!!!!! So amazing!!!!!!!!! ● Based on my testing on Saturday there is a 2 in 3 chance this will hard lock my computer ● That’s your friendly reminder not to run any of this in production ● Demo shell script of fun (go only) & python + go
- 26. What do the rest of the systems do? ● Spoiler: mostly it’s not better ○ Although it tends to be more finished ○ Sometimes it's different ● Different tradeoffs, maybe better for your use case but all tradeoffs Kate Neilan
- 27. A quick detour into PySpark’s internals + + JSON TimOve
- 28. PySpark ● The Python interface to Spark ● Same general technique used as the bases for the C#, R, Julia, etc. interfaces to Spark ● Fairly mature, integrates well-ish into the ecosystem, less a Pythonrific API ● Has some serious performance hurdles from the design
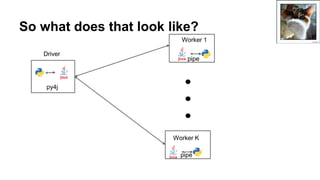
- 29. So what does that look like? Driver py4j Worker 1 Worker K pipe pipe
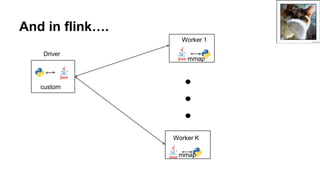
- 30. And in flink…. Driver custom Worker 1 Worker K mmap mmap
- 31. So how does that impact Py[X] forall X in {Big Data}-{Native Python Big Data} ● Double serialization cost makes everything more expensive ● Python worker startup takes a bit of extra time ● Python memory isn’t controlled by the JVM - easy to go over container limits if deploying on YARN or similar ● Error messages make ~0 sense ● Dependency management makes limited sense ● features aren’t automatically exposed, but exposing them is normally simple
- 32. TensorFlowOnSpark, everyone loves mnist! cluster = TFCluster.run(sc, mnist_dist_dataset.map_fun, args, args.cluster_size, num_ps, args.tensorboard, TFCluster.InputMode.SPARK) if args.mode == "train": cluster.train(dataRDD, args.epochs) Lida
- 33. The “future”*: faster interchange ● By future I mean availability today but running it in production is “adventurous” ● Unifying our cross-language experience ○ And not just “normal” languages, CUDA counts yo Tambako The Jaguar
- 34. Andrew Skudder *Arrow: Spark 2.3 and beyond & GPUs & R & Python & …. * *
- 35. What does the future look like?* *Source: https://databricks.com/blog/2017/10/30/introducing-vectorized-udfs-for-pyspark.html. *Vendor benchmark. Trust but verify.
- 36. Arrow (a poorly drawn big data view) Logos trademarks of their respective projects Juha Kettunen *ish
- 37. Rewriting your code because why not spark.catalog.registerFunction( "add", lambda x, y: x + y, IntegerType()) => add = pandas_udf(lambda x, y: x + y, IntegerType()) Jennifer C.
- 38. And we can do this in TFOnSpark*: unionRDD.foreachPartition(TFSparkNode.train(self.cluster_info, self.cluster_meta, qname)) Will Transform Into something magical (aka fast but unreliable) on the next slide! Delaina Haslam
- 39. Which becomes train_func = TFSparkNode.train(self.cluster_info, self.cluster_meta, qname) @pandas_udf("int") def do_train(inputSeries1, inputSeries2): # Sad hack for now modified_series = map(lambda x: (x[0], x[1]), zip(inputSeries1, inputSeries2)) train_func(modified_series) return pandas.Series([0] * len(inputSeries1)) ljmacphee
- 40. And this now looks like: Logos trademarks of their respective projects Juha Kettunen *ish
- 41. TFOnSpark Possible vNext+1? ● Avoid funneling the data through Python native types ○ For now the Spark Arrow UDFS aren’t perfect for this ○ But we can (and are) improving them ● mmapped Arrow? ● Skip Python on the workers handling data entirely (idk I’m lazy so probably not) Renars
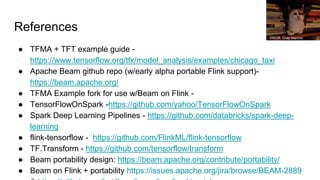
- 42. References ● TFMA + TFT example guide - https://www.tensorflow.org/tfx/model_analysis/examples/chicago_taxi ● Apache Beam github repo (w/early alpha portable Flink support)- https://beam.apache.org/ ● TFMA Example fork for use w/Beam on Flink - ● TensorFlowOnSpark -https://github.com/yahoo/TensorFlowOnSpark ● Spark Deep Learning Pipelines - https://github.com/databricks/spark-deep- learning ● flink-tensorflow - https://github.com/FlinkML/flink-tensorflow ● TF.Transform - https://github.com/tensorflow/transform ● Beam portability design: https://beam.apache.org/contribute/portability/ ● Beam on Flink + portability https://issues.apache.org/jira/browse/BEAM-2889 PROR. Crap Mariner
- 43. k thnx bye :) If you care about Spark testing and don’t hate surveys: http://bit.ly/holdenTestingSpark I need to give a testing talk next month, help a “friend” out. Will tweet results “eventually” @holdenkarau Do you want more realistic benchmarks? Share your UDFs! http://bit.ly/pySparkUDF Pssst: Have feedback on the presentation? Give me a shout ([email protected]) if you feel comfortable doing so :) Give feedback on this presentation http://bit.ly/holdenTalkFeedback
- 44. What’s the rest of big data outside the JVM look like? Most of the tools are built in the JVM, so how do we play together? ● Pickling, Strings, JSON, XML, oh my! ● Unix pipes ● Sockets What about if we don’t want to copy the data all the time? ● Or standalone “pure”* re-implementations of everything ○ Reasonable option for things like Kafka where you would have the I/O regardless. ○ Also cool projects like dask (pure python) -- but hard to talk to existing ecosystem David Brown
- 45. Hadoop “streaming” (Python/R) ● Unix pipes! ● Involves a data copy, formats get sad ● But the overhead of a Map/Reduce task is pretty high anyways... Lisa Larsson
- 46. Kafka: re-implement all the things ● Multiple options for connecting to Kafka from outside of the JVM (yay!) ● They implement the protocol to talk to Kafka (yay!) ● This involves duplicated client work, and sometimes the clients can be slow (solution, FFI bindings to C instead of Java) ● Buuuut -- we can’t access all of the cool Kafka business (like Kafka Streams) and features depend on client libraries implementing them (easy to slip below parity) Smokey Combs
- 47. Dask: a new beginning? ● Pure* python implementation ● Provides real enough DataFrame interface for distributed data ● Also your standard-ish distributed collections ● Multiple backends ● Primary challenge: interacting with the rest of the big data ecosystem ○ Arrow & friends might make this better with time too, buuut…. ● See https://dask.pydata.org/en/latest/ & http://dask.pydata.org/en/latest/spark.html Lisa Zins
Editor's Notes
- #5: Photo from https://www.flickr.com/photos/lorika/4148361363/in/photolist-7jzriM-9h3my2-9Qn7iD-bp55TS-7YCJ4G-4pVTXa-7AFKbm-bkBfKJ-9Qn6FH-aniTRF-9LmYvZ-HD6w6-4mBo3t-8sekvz-mgpFzD-5z6BRK-de513-8dVhBu-bBZ22n-4Vi2vS-3g13dh-e7aPKj-b6iHHi-4ThGzv-7NcFNK-aniTU6-Kzqxd-7LPmYs-4ok2qy-dLY9La-Nvhey-Kte6U-74B7Ma-6VfnBK-6VjrY7-58kAY9-7qUeDK-4eoSxM-6Vjs5A-9v5Pvb-26mja-4scwq3-GHzAL-672eVr-nFUomD-4s8u8F-5eiQmQ-bxXXCc-5P9cCT-5GX8no
- #6: introduce spark rdds, purple blog diagrams https://www.flickr.com/photos/pustovit/15867520885/in/photolist-qbac9i-9XLrR4-74scWq-bpnxfN-qYAD3D-e6u5Ej-oztsCu-qJMG4L-7b4y4a-gu8Wa-8MzgVR-b5gHki-djzdH3-82TowY-qJc99b-pC6yth-ifAkvP-mju1Ce-3ACPG6-F9aWR2-5QQL1U-4Hav3S-dGHvJj-jxQLth-djzdgd-dL24wn-8znjgb-aZxA6H-gDkWNo-djzcZF-22NYH5r-9amo58-apqLdG-fZhoSH-cDjpEQ-nLbBuK-6EuEN2-dAN5KN-asBjbL-Vx2zFR-djzdki-SRkhd1-djzcnF-Tc9FAf-qsduzQ-djzd4P-9wCiZT-8JALTP-eqbpop-R2S2FR
- #7: Remind people not to use this in production
- #10: https://www.flickr.com/photos/29638108@N06/26104346281/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #12: https://www.flickr.com/photos/29638108@N06/26104346281/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #13: https://www.flickr.com/photos/29638108@N06/26104346281/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #14: As just discussed, TFT provides utility functions that run analyzers as needed. These are data processing jobs that can be run in arbitrary environments using the Beam SDK.
- #15: What happens behind the scene is that the analyzers run as a distributed data processing graph, and the result is put into the output graph as constants.
- #16: Some of the common use cases: Just talked about ones on left: Scale scores Bucketize Text features: apply bag of words or n grams For Feature crosses: cross strings and generate vocabs of the result of those crosses As mentioned before, tf.Tranform is powerful in that you can chain these transformations.
- #20: SparkContext uses Py4J to launch a JVM and create a JavaSparkContext. On The executors, java subprocess launches a python subprocess via a pipe. The data is serialized using cpickle and sent ot the python subprocess
- #23: https://www.flickr.com/photos/29638108@N06/26104346281/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #28: https://www.flickr.com/photos/timove/2873619269/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #30: SparkContext uses Py4J to launch a JVM and create a JavaSparkContext. On The executors, java subprocess launches a python subprocess via a pipe. The data is serialized using cpickle and sent ot the python subprocess
- #32: What does python memory isn’t controlled by the JVM mean? Double serialization from lanague transform
- #37: https://www.flickr.com/photos/juhakettunen/17218305870/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #38: https://www.flickr.com/photos/29638108@N06/26104346281/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #39: https://www.flickr.com/photos/29638108@N06/26104346281/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #41: https://www.flickr.com/photos/juhakettunen/17218305870/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #42: https://www.flickr.com/photos/29638108@N06/26104346281/in/photolist-66Ky9n-5nW3TP-f4xVRt-sewjsA-BVmgy-FLKAFT-89kfzb-FSBrSp-puHhfg-xrXMpL-5fjZcs-G9DjaZ-eXvwfo-oUk4hz-7gmfLB-9s2gwi-bqRAKw-4CGf6X-5o24aR-25AijkV-njSsfw-4tYMke-FsvaQq-haUJv-6S2j5f-c19gY5-rdr7va-6qoirp-666Sgs-3bcTwj-7QoFUj-ayEq5k-2yduWy-Co2uwS-NKcKBY-eXvx2d-ZHnLQj-6Kk14A-rgBNGV-EXb2PG-dGg4Mk-23dGLzS-a7EshL-85r8fq-ix6nEM-6izGaR-9MT8Ee-oqhy96-CE4Sgs-5LKLdr/
- #46: Is debugging also really hard?
- #48: Or this one … also should we put these below python part?