Slide Presentasi EM Algorithm (Play Tennis & Brain Tissue Segmentation)
0 likes1,398 views

Slide Presentasi Machine Learning, EM-Algorithm (Kasus Play Tennis dan Brain tissue Segmentation pada citra MRI)
















![Implementasi EM
●
Inisialisasi
–
–
●
Menentukan probabilitas sense P(Sk) dari jumlah cluster yang ditentukan
– total P(Sk) adalah 1
Menentukan probabilitas P(Vj|Sk): angka random
Langkah E
–
●
Langkah M
–
●
Calculate the posterior probability that Sk generated Ci
re-estimate P(Vj|Sk) and P(Sk)
Perhitungan Konvergensi
–
Hitung model likelihood score: l(C|u) = Sum_I[Log_K(P(Ci|Sk)*P(Sk))]
–
Jika | model score baru – model score lama | < threshold, konvergen](https://image.slidesharecdn.com/slidepresentasitugasem-140129003803-phpapp02/85/Slide-Presentasi-EM-Algorithm-Play-Tennis-Brain-Tissue-Segmentation-18-320.jpg)






































Ad
More Related Content
More from Hendri Karisma (19)
Recently uploaded (20)

















Ad
Slide Presentasi EM Algorithm (Play Tennis & Brain Tissue Segmentation)
- 1. Expectation-Maximalization (EM) Algorithm Hendri Karisma 23512060 Luqman Abdul Mushawwir 23512146
- 2. Referensi ● Lecture Notes, Andrew Ng ● Machine Learning, Tom M. Mitchell ● ● Maximum Likelihood from Incomplete Data via the EM Algorithm, A. P. Dempster; N. M. Laird; D. B. Rubin; 1977 Dll
- 3. Konsep EM ● Maximum Likelihood Estimation (MLE) ● Mixtures of Gaussians ● Estimation-Maximization (EM) ● Rate of Convergence
- 4. Maximum Likelihood Estimation (MLE) ● ● ● Sebuah dataset dengan instans sebanyak m Parameter dari model p(x, z) akan disesuaikan dengan data, likelihood diberikan berupa Dengan Mixture of Gaussian
- 5. Maximum yang Digunakan Dalam EM-Algorithm
- 6. Formula Gaussian ● Gaussian Normal ● Gaussian Multivariet (extension) – Perbedaannya adalah penggunaan matrik covariant guna memperbaiki model yang dibangun.
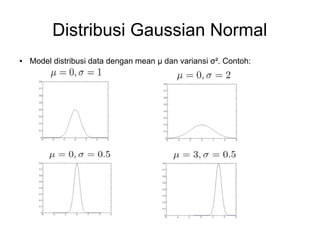
- 7. Distribusi Gaussian Normal ● Model distribusi data dengan mean μ dan variansi σ². Contoh:
- 8. Visualisasi Gaussian 3D dengan Mean & Variance yang Berbeda
- 9. Contoh Gaussian pada histogram
- 10. Contoh Distribusi Gaussian X1 dan X2 ● Contoh penerapan:
- 11. Visualisasi Gaussian 3D ● Contoh distribusi dan pemodelan dengan Gaussian
- 14. Mixture Gaussian
- 15. Estimation-Maximization (EM) ● Iterasi yang terdiri dari dua langkah: ● Step E (Estimation): mendekati z(i) ● Step M (Maximization): memperbaharui parameter
- 16. Fungsi E-M-Step ● ● Fungsi E-Step, melakukan estimasi gaussian awal dan akan di maksimalisasi oleh step M. Fungsi M-Step, atau Maximization step, melakukan perubahan parameter pada step estimasi, sehingga akan merubah posisi gaussian selanjutnya sehingga mencapai nilai maksimum.
- 18. Implementasi EM ● Inisialisasi – – ● Menentukan probabilitas sense P(Sk) dari jumlah cluster yang ditentukan – total P(Sk) adalah 1 Menentukan probabilitas P(Vj|Sk): angka random Langkah E – ● Langkah M – ● Calculate the posterior probability that Sk generated Ci re-estimate P(Vj|Sk) and P(Sk) Perhitungan Konvergensi – Hitung model likelihood score: l(C|u) = Sum_I[Log_K(P(Ci|Sk)*P(Sk))] – Jika | model score baru – model score lama | < threshold, konvergen
- 19. Pengujian dengan PlayTennis ● Pengujian dengan dataset 1 PlayTennis (14 instance)
- 20. Cont'd ● Representasi instance biner (0 dan 1), akurasi 57% ● Representasi instance index (0-2), akurasi 50%
- 21. EKSPERIMEN EM (Partial Volume Segmentation of Brain) ● Deskripsi Data ● Hasil Eksperimen ● Kesimpulan
- 22. Partial Volume Segmentation of Brain ● ● ● Dibagi menjadi 3 cluster utama + 3 irisan cluster. 3 Cluster : White Matter, Black Matter, CSF (Cerebrospinal Fluid) Data yang diambil adalah histogram dari MRI
- 23. Input Data
- 24. Hasil Eksperimen
- 26. Kesimpulan ● ● ● ● Dalam Algoritma Clustering Expectation Maximization Data harus didistribusikan dalam bentuk mixture gaussian, dan pada kasus eksplorasi kedua, mixture dapat memanfaatkan histogram citra MRI. Dalam Eksplorasi kedua terdapat perbedaan implementasi dengan paper pertama, dan hasilnya pun berbeda secara signifikan, tidak semua terdistribusi pada setiap cluster dan penyebab adalah data yang digunakan hanya 1 citra MRI pada eksplorasi sedangkan pada paper referensi utama 16 MRI. EM Algorithm untuk kasus segmentasi jaringan otak menghasilkan kompleksitas yang cukup tinggi. Belum dapat ditarik kesimpulan mengenai hasil dari eksplorasi karena dataset yang digunakan belum tepat digunakan dalam proses eksplorasi untuk mendapatkan akurasi dari implementasi em-algorithm dalam partial volume segmentation of human brain.