Solving Hadoop Replication Challenges with an Active-Active Paxos Algorithm
8 likes3,979 views

WANdisco Fusion is an active-active data replication solution that provides continuous replication of data across Hadoop distributions and storage located in different data centers connected over a LAN/WAN. It addresses key issues for organizations that require continuous data availability, share data across globally deployed Hadoop clusters, and want to ease administrative burdens around disaster recovery. WANdisco Fusion uses a distributed coordination engine and consensus algorithms to maintain a replicated virtual namespace and strict data consistency across locations, allowing multiple data centers to ingest and access data actively while supporting replication to any number of data centers globally.






























![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=560&fit=bounds)


























Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Solving Hadoop Replication Challenges with an Active-Active Paxos Algorithm (20)




















Ad
More from DataWorks Summit (20)



















Recently uploaded (20)




















Solving Hadoop Replication Challenges with an Active-Active Paxos Algorithm
- 1. WANdisco Fusion Active-active data replication solution for total data protection and availability across Hadoop distributions and storage Brett Rudenstein – Director of Product Management
- 2. 2 WD Fusion Non-Intrusive Provides Continuous Replication Across the LAN/WAN Active/Active
- 3. 3 Key Issue For Sharing Data Across Clusters LAN / WAN
- 4. 4 • Require Continuous Availability – SLA’s, Regulatory Compliance – Regional datacenter failure • Require Hadoop Deployed Globally – Share Data Between Data Centers – Data is Consistent and Not Eventual • Ease Administrative Burden – Reduce Operational Complexity – Simplify Disaster Recovery – Lower RTO/RPO • Allow Maximum Utilization of Resource – Within the Data Center – Across Data Centers Enterprise Ready Hadoop Characteristics of Mission Critical Applications
- 5. 5 Standby Datacenter • Idle Resource – Single Data Center Ingest – Disaster Recovery Only • One way synchronization – DistCp • Error Prone – Clusters can diverge over time • Difficult to scale > 2 Data Centers – Complexity of sharing data increases Active / Active • DR Resource Available – Ingest at all Data Centers – Run Jobs in both Data Centers • Replication is Multi-Directional – active/active • Absolute Consistency – Single Virtual NameSpace spans locations • ‘N’ Data Center support – Global Hadoop shared only appropriate data Active/Active vs. Active/Passive Data Centers What’s in a Data Center
- 6. Coordinated Replication of HCFS Namespace
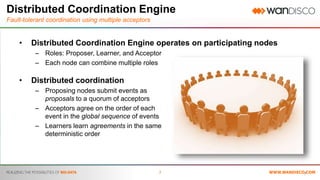
- 7. 7 Distributed Coordination Engine Fault-tolerant coordination using multiple acceptors • Distributed Coordination Engine operates on participating nodes – Roles: Proposer, Learner, and Acceptor – Each node can combine multiple roles • Distributed coordination – Proposing nodes submit events as proposals to a quorum of acceptors – Acceptors agree on the order of each event in the global sequence of events – Learners learn agreements in the same deterministic order 7
- 8. 8 Consensus Algorithms Consensus is the process of agreeing on one result among a group of participants • Coordination Engine guarantees the same state of the learners at a given GSN – Each agreement is assigned a unique Global Sequence Number (GSN) – GSNs form a monotonically increasing number series – the order of agreements – Learners have the same initial state, apply the same deterministic agreements in the same deterministic order – GSN represents “logical” time in coordinated systems • PAXOS is a consensus algorithm proven to tolerate a variety of failures – Quorum-based Consensus – Deterministic State Machine – Leslie Lamport: Part-Time Parliament (1990) 8
- 9. 9 Replicated Virtual Namespace Coordination Engine provides equivalence of multiple namespace replicas • Coordinated Virtual Namespace controlled by Fusion Node – Is a client that acts as a proxy to other client interactions – Reads are not coordinated – Writes (Open, Close, Append, etc…) are coordinated • The namespace events are consistent with each other – Each fusion server maintains a log of changes that would occur in the namespace – Any Fusion Node can initiate an update, which is propagated to all other Fusion Nodes • Coordination Engine establishes the global order of namespace updates – Fusion servers ensure deterministic updates in the same deterministic order to underlying file system – Systems, which start from the same state and apply the same updates, are equivalent 9
- 10. 10 Strict Consistency Model One-Copy Equivalence as known in replicated databases • Coordination Engine sequences file open and close proposals into the global sequence of agreements – Applied to individual replicated folder namespace in the order of their Global Sequence Number • Fusion Replicated Folders have identical states when they reach the same GSN • One-copy equivalence – Folders may have different states at a given moment of “clock” time as the rate of consuming agreements may vary – Provides same state in logical time 10 10
- 11. 11 Scaling Hadoop Across Data Centers Continuous Availability and Disaster Recovery over the WAN • The system should appear, act, and be operated as a single cluster – Instant and automatic replication of data and metadata • Parts of the cluster on different data centers should have equal roles – Data could be ingested or accessed through any of the centers • Data creation and access should typically be at LAN speed – Running time of a job executed on one data center as if there are no other centers • Failure scenarios: the system should provide service and remain consistent – Any Fusion node can fail and still provide replication – Fusion nodes can fail simultaneously on two or more data centers and still provide replication – WAN Partitioning does not cause a data center outage – RPO is as low as possible due to continuous replication as opposed to periodic 11
- 12. 12 • Majority Quorum – A fixed number of participants – The Majority must agree for change • Failure – Failed nodes are unavailable – Normal operation continue on nodes with quorum • Recovery / Self Healing – Nodes that rejoin stay in safe mode until they are caught up • Disaster Recovery – A complete loss can be brought back from another replica How DConE Works WANdisco Active/Active Replication TX id: 168 TX id: 169 TX id: 170 TX id: 171 TX id: 172 TX id: 173 TX id: 168 TX id: 169 TX id: 170 TX id: 171 TX id: 172 TX id: 173 TX id: 168 TX id: 169 TX id: 170 TX id: 171 TX id: 172 TX id: 173 Proposal 170 Agree 170 Agree 170 Proposal 171 Agree 172 Agree 173 Agree 171 Proposal 172 Proposal 173 B A CAgree 170 Agree 171 Agree 172 Agree 173
- 14. 14 Architecture Principles Strict consistency of metadata with fast data ingest 1. Synchronous replication of metadata between data centers – Using Coordination Engine – Provides strict consistency of the namespace 2. Asynchronous replication of data over the WAN – Data replicated in the background – Allows fast LAN-speed data creation 14
- 15. 15 How does it work? Coordinating writes
- 16. 17 Inter Hadoop Communication Service Uses HCFS API and communicates directly with Hadoop Compatible storage systems – Isilon – MAPR – HDFS – S3 NameNode and DataNode operations are unchanged
- 18. 19 Periodic Synchronization DistCp Parallel Data Ingest Load Balancer, Streaming Multi Data Center Hadoop Today What's wrong with the status quo
- 19. 20 Periodic Synchronization DistCp Multi Data Center Hadoop Today Hacks currently in use • Runs as Map reduce • DR Data Center is read only • Over time, Hadoop clusters become inconsistent • Manual and labor intensive process to reconcile differences • Inefficient us of the network • N to N datanode communication
- 20. 21 Parallel Data Ingest Load Balancer, Flume Multi Data Center Hadoop Today Hacks currently in use • Hiccups in either of the Hadoop cluster causes the two file systems to diverge • Potential to run out of buffer when WAN is down • Requires constant attention and sys-admin hours to keep running • Data created on the cluster is not replicated • Use of streaming technologies (like flume) for data redirection are only for streaming
- 21. 22 Use Cases
- 22. 23 • Data is as current as possible (no periodic synchs) • Virtually zero downtime to recover from regional data center failure • Meets or exceeds strict regulatory compliance around disaster recovery Disaster Recovery
- 23. 24 • Ingest and analyze anywhere • Analyze Everywhere – Fraud Detection – Equity Trading Information – New Business – Etc… • Backup Datacenter(s) can be used for work – No idle resource Multi Data-Center Ingest and multi-tenant workloads
- 24. 25 • Maximize Resource Utilization – No idle standby • Isolate Dev and Test Clusters – Share data not resource • Carve off hardware for a specific group – Prevents a bad map/reduce job from bringing down the cluster • Guarantee Consistency of data Zones
- 25. 26 • Mixed Hardware Profiles – Memory, Disk, CPU – Isolate memory-hungry processing (Storm/Spark) from regular jobs • Share data, not processing – Isolate lower priority (dev/test) work Heterogeneous Hardware (Zones) In memory analytics
- 26. 27 • Basel III – Consistency of Data • Data Privacy Directive – Data Sovereignty • data doesn’t leave country of origin Compliance Regulation Guidelines Regulatory Compliance
- 27. 28 • Fast network protocols can keep up with demanding network replication • Hadoop clusters do not require direct communication with each other. - No n x m communication among datanodes across datacenters - Reduced firewall / socks complexities • Reduced Attack Surface Use Case Security Between Data Centers
- 28. 30 Q & A Question and Answer Feel free to submit your questions
- 29. 31 Thank you
Editor's Notes
- #9: The core of a distributed CE are consensus algorithms
- #10: Double determinism is important for equivalent evolution of the systems
- #12: Unlike multi-cluster architecture, where clusters run independently on each data center mirroring data between them
- #16: Fusion service: 1 or more Fusion servers that act as a proxy for clients writing into HCFS and write replicated data into the local file system (Ref: Fusion technical paper) IHC service: 1 or more IHC servers that know how to read from the local underlying file system in order to send data to other clusters (Ref: Fusion technical paper) Although the diagram shows two data centers, there is no limit on how many data centers you can use – and you can have more than one cluster in a data center. The labels on the lines indicates the purpose and direction of data flow: IHC reads from the file system, Fusion writes into it, and there is coordination between Fusion servers. The color coding indicates coherent paths as one write comes into the HCFS and is replicated across to the other data center – but it shows functions, not an accurate timeline of events. For that, see the Fusion tech paper or the sequence diagram in the reference deck. It is important to stress that active-active replication provides single copy consistency: a user or application can use the data equally from either data center. Finally, note that there are few cross-cluster network connections, which simplifies network security and management.
- #25: Maximize Resource Utilization No idle standby Isolate Dev and Test Clusters Share data not resource Carve off hardware for a specific group Prevents a bad map/reduce job from bringing down the cluster Guarantee Consistency and availability of data Data is instantly available
- #27: Optimized hardware profiles for job specific tasks Batch Real-time NoSQL (HBASE) Set replication factors per sub-cluster Use at LAN or WAN scope Resilient to NameNode failures
- #29: Fusion can be set up to replicate data between the fusion servers without directly accessing DN across the WAN Unique over distcp Could be a large selling point as standard implementations using distcp requires all node to all node connectivity This model would only require the fusion servers to talk between data centers protecting direct node access