Apache® Spark™ MLlib: From Quick Start to Scikit-Learn
45 likes11,399 views

These are the slides to support the Apache® Spark™ MLlib: From Quick Start to Scikit-Learn webinar. In this webcast, Joseph Bradley from Databricks will be speaking about Apache Spark’s distributed Machine Learning Library - MLlib. We will start off with a quick primer on machine learning, Spark MLlib, and a quick overview of some Spark machine learning use cases. We will continue with multiple Spark MLlib quick start demos. Afterwards, the talk will transition toward the integration of common data science tools like Python pandas, scikit-learn, and R with MLlib














![Scatterplot
import numpy as np
import matplotlib.pyplot as plt
x = data.map(lambda p:
(p.features[0])).collect()
y = data.map(lambda p:
(p.label)).collect()
from pandas import *
from ggplot import *
pydf = DataFrame({'pop':x,'price':y})
p = ggplot(pydf, aes('pop','price')) +
geom_point(color='blue')
display(p)](https://image.slidesharecdn.com/spark-mllibfrom-quickstart-to-scikit-learn-160224225718/85/Apache-Spark-MLlib-From-Quick-Start-to-Scikit-Learn-16-320.jpg)











![Our ML workflow
29
Text
This scarf I
bought is
very strange.
When I ...
Label
Rating = 3.0
Tokenizer
Words
[This,
scarf,
I,
bought,
...]
Hashing
Term-Freq
Features
[2.0,
0.0,
3.0,
...]
Linear
Regression
Prediction
Rating = 2.7](https://image.slidesharecdn.com/spark-mllibfrom-quickstart-to-scikit-learn-160224225718/85/Apache-Spark-MLlib-From-Quick-Start-to-Scikit-Learn-29-320.jpg)









































Ad
More Related Content
Similar to Apache® Spark™ MLlib: From Quick Start to Scikit-Learn (20)
More from Databricks (20)


















Ad
Recently uploaded (20)




















Ad
Apache® Spark™ MLlib: From Quick Start to Scikit-Learn
- 1. Apache® Spark™ MLlib: From Quick Start to Scikit-Learn Joseph K. Bradley February 24th, 2016
- 2. About the speaker: Joseph Bradley Joseph Bradley is a Software Engineerand Apache Spark Committer working on MLlib at Databricks. Previously,he was a postdoc at UC Berkeley after receiving hisPh.D. in Machine Learning from Carnegie Mellon U. in 2013.Hisresearch included probabilistic graphical models,parallel sparse regression,and aggregation mechanismsfor peer grading in MOOCs. 2
- 3. About the moderator: Denny Lee Denny Lee is a Technology Evangelistwith Databricks; he is a hands-on data sciencesengineer with more than 15 years of experience developing internet-scale infrastructure, data platforms, and distributed systems for both on-premisesand cloud. Prior to joining Databricks, Denny worked as a SeniorDirector of Data SciencesEngineering at Concur and was part of the incubation teamthat builtHadoop on Windowsand Azure (currently known as HDInsight). 3
- 4. We are Databricks, the company behind Apache Spark Founded by the creators of Apache Spark in 2013 Share of Spark code contributed by Databricks in 2014 75% 4 Data Value Created Databricks on top of Spark to make big data simple.
- 5. … Apache Spark Engine Spark Core Spark Streaming Spark SQL MLlib GraphX Unified engineacross diverse workloads & environments Scale out, fault tolerant Python, Java, Scala, and R APIs Standard libraries
- 7. NOTABL E USERS THAT PRESENTED AT SPARK SUMMIT 2 0 1 5 SAN F RANCISCO Source: Slide5ofSparkCommunityUpdate
- 8. Machine Learning: What and Why? What: ML usesdata to identify patterns and make decisions. Why: Thecore value of ML is automated decision making. • Especially important when dealing with TB or PB of data Many use cases, including: • Marketing and advertising optimization • Security monitoring /fraud detection • Operational optimizations
- 9. Why Spark MLlib Provide generalpurposeML algorithms on top of Spark • Hide complexity of distributing data & queries,and scaling • Leverage Spark improvements(DataFrames, Tungsten, Datasets) Advantages of MLlib’s design: • Simplicity • Scalability • Streamlined end-to-end • Compatibility
- 10. Spark scales well Largest cluster: 8000 Nodes (Tencent) Largest single job: 1 PB (Alibaba, Databricks) Top Streaming Intake: 1 TB/hour (HHMI Janelia Farm) 2014 On-Disk Sort Record Fastest Open Source Engine for sorting a PB
- 11. Machine Learning highlights Source: Why you should use Sparkfor Machine Learning
- 12. Source: Toyota Customer 360 Insightson Apache Spark and MLlib Performance • Original batch job: 160 hours • Same Job re-written using Apache Spark: 4 hours ML task • Prioritize incoming social media in real-time using Spark MLlib (differentiate campaign, feedback, product feedback, and noise) • ML life cycle: Extract features and train: • V1: 56%Accuracy ->V9: 82%Accuracy • RemoveFalse Positives andSemanticAnalysis (similarity between concepts)
- 13. Example analysis: Population vs. housing price Links Simplifying Machine Learning with Databricks Blog Post Population vs. Price Multi-chart SparkSQL Notebook Population vs. Price Linear Regression Python Notebook
- 16. Scatterplot import numpy as np import matplotlib.pyplot as plt x = data.map(lambda p: (p.features[0])).collect() y = data.map(lambda p: (p.label)).collect() from pandas import * from ggplot import * pydf = DataFrame({'pop':x,'price':y}) p = ggplot(pydf, aes('pop','price')) + geom_point(color='blue') display(p)
- 17. Linear Regression with SGD Define and Build Models # Import LinearRegression class from pyspark.ml.regression import LinearRegression # Define LinearRegression model lr = LinearRegression() # Build two models modelA = lr.fit(data, {lr.regParam:0.0}) modelB = lr.fit(data, {lr.regParam: 100.0})
- 18. Linear Regression with SGD Make Predictions # Make predictions predictionsA = modelA.transform(data) display(predictionsA)
- 19. Linear Regression with SGD Evaluate the Models from pyspark.ml.evaluation import RegressionEvaluator evaluator = RegressionEvaluator(metricName="mse") MSE = evaluator.evaluate(predictionsA) print("ModelA: Mean Squared Error = " + str(MSE)) ModelA: Mean Squared Error = 16538.4813081 ModelB: Mean Squared Error = 16769.2917636
- 20. Scatterplot with plotting Regression Models p = ggplot(pydf, aes('pop','price')) + geom_point(color='blue') + geom_line(pydf, aes('pop','predA'), color='red') + geom_line(pydf, aes('pop','predB'), color='green') + scale_x_log(10) + scale_y_log10() display(p)
- 21. Learning more about MLlib Guides & examples • Example workflow using ML Pipelines (Python) • Power plant data analysis workflow (Scala) • The above 2 links are part of the Databricks Guide, which contains many more examples and references. References • Apache Spark MLlib User Guide • The MLlib User Guide containscodesnippetsfor almost all algorithms, as wellas links to API documentation. • Meng et al. “MLlib: Machine Learning in Apache Spark.” 2015. http://arxiv.org/abs/1505.06807 (academic paper) 21
- 22. Combining the Strengths of MLlib, scikit-learn, & R
- 23. 23 Greatlibraries à Business investment • Education • Tooling & workflows
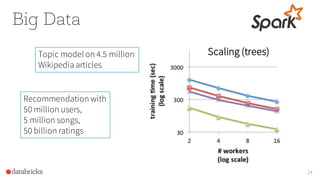
- 24. Big Data 24 Scaling (trees)Topic model on 4.5 million Wikipedia articles Recommendation with 50 million users, 5 million songs, 50 billion ratings
- 25. Big Data & MLlib • More data à higher accuracy • Scalewith business (# users,available data) • Integrate with production systems 25
- 26. Bridging the gap How do you get from a single-machine workload to a distributed one? 26 At school: Machine Learning with R on my laptop The Goal: Machine Learning on a huge computing cluster
- 27. Wish list • Run original code on a production environment • Use distributed data sources • Distribute ML workload piece by piece • Use familiar algorithms & APIs 27
- 28. Our task 28 Sentiment analysis Given a review (text), Predict the user’srating. Data from https://snap.stanford.edu/data/web-Amazon.html
- 29. Our ML workflow 29 Text This scarf I bought is very strange. When I ... Label Rating = 3.0 Tokenizer Words [This, scarf, I, bought, ...] Hashing Term-Freq Features [2.0, 0.0, 3.0, ...] Linear Regression Prediction Rating = 2.7
- 30. Our ML workflow 30 Cross Validation Linear Regression Feature Extraction regularization parameter: {0.0, 0.1, ...}
- 31. Cross validation 31 Cross Validation ... Best Linear Regression Linear Regression #1 Linear Regression #2 Feature Extraction Linear Regression #3
- 32. Cross validation 32 Cross Validation ... Best Linear Regression Linear Regression #1 Linear Regression #2 Feature Extraction Linear Regression #3
- 33. Distribute cross validation 33 Cross Validation ... Best Linear Regression Linear Regression #1 Linear Regression #2 Feature Extraction Linear Regression #3
- 34. Repeating this at home This demo used: • Spark 1.6 • spark-sklearn (on Spark Packages) (on PyPi) The notebookfrom the demo is available here: • sklearn integration • MLlib + sklearn: Distribute Everything! The Amazon Reviews data20K and test4K datasets were created and can be used within the databricks-datasets with permission from Professor Julian McAuley @ UCSD. Source: Image-based recommendations onstyles and substitutes.J.McAuley,C. Targett, J. Shi, A. van den Hengel.SIGIR, 2015. 34
- 35. Integrations we mentioned Data sources • Spark DataFrames: Conversionsbetween pandas(local data) & Spark (distributed data) • MLlib: Conversionsbetween scipy & MLlib data types Model selection / tuning • spark-sklearn: Automatically distribute cross-validation Python API • MLlib: Distributed learning algorithmswith familiarAPIs • spark-sklearn: Conversionsbetween scikit-learn & MLlib models 35
- 36. Integrations with R DataFrames • Conversionsbetween R(local) & Spark (distributed) • SQL queriesfrom R 36 model <- glm(Sepal_Length ~ Sepal_Width + Species, data = df, family = "gaussian") head(filter(df, df$waiting < 50)) ## eruptions waiting ##1 1.750 47 ##2 1.750 47 ##3 1.867 48 API for calling MLlib algorithms from R • Linear & logistic regression supported in Spark 1.6 • More algorithmsin development
- 37. Learning more about integrations Python,pandas & scikit-learn • spark-sklearn documentation and blog post • Spark DataFrame Python API & pandas conversions • Databricks Guide on using scikit-learn and other libraries with Spark R • Spark R API User Guide (DataFrames & ML) • Databricks Guide: Spark R overview + docs & examples for each function TensorFlow onApache Spark (Deep Learningin Python) • Blog post explaining how to run TensorFlow on top of Spark, with example code 37
- 38. MLlib roadmap highlights Workflow • Simplify building and customizing ML Pipelines. Key models • Improve inspection for generalized linear models (linear & logistic regression). Language APIs • Support Pipeline persistence (saving & loading Pipelines and Models) in the Python API. Spark 2.0RoadmapJIRA: https://issues.apache.org/jira/browse/SPARK-12626
- 39. More resources • Databricks Guide • ApacheSpark User Guide • Databricks Community Forum • Training courses:public classes,MOOCs, & private training • Databricks Community Edition: Free hosted Apache Spark. Join the waitlist for the beta release! 39
- 40. Thanks!