Spark Streaming with Cassandra
23 likes3,791 views

Spark streaming can be used for near-real-time data analysis of data streams. It processes data in micro-batches and provides windowing operations. Stateful operations like updateStateByKey allow tracking state across batches. Data can be obtained from sources like Kafka, Flume, HDFS and processed using transformations before being saved to destinations like Cassandra. Fault tolerance is provided by replicating batches, but some data may be lost depending on how receivers collect data.





















![Yes, it is that easy
case class WordCount(time: Long, word: String, count: Int)
val paragraphs: DStream[String] = stream.map { case (_, paragraph) => paragraph}
val words: DStream[String] = paragraphs.flatMap(_.split( """s+"""))
val wordCounts: DStream[(String, Long)] = words.countByValue()
val topWordCounts: DStream[WordCount] = wordCounts.transform((rdd, time) =>
val mappedWordCounts: RDD[(Int, WordCount)] = rdd.map {
case (word, count) =>
(count.toInt, WordCount(time.milliseconds, word, count.toInt))
}
val topWordCountsRDD: RDD[WordCount] = mappedWordCounts
.sortByKey(ascending = false).values
)
topWordsStream.saveToCassandra("meetup", "word_counts")
topWordsStream.print()](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-24-320.jpg)

![DStream[Bean].count()
count 4 3
1s 1s 1s 1s](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-26-320.jpg)
![DStream[Bean].count()
count 4 3
1s 1s 1s 1s](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-27-320.jpg)
![DStream[Orange].union(DStream[Apple])
union
1s 1s](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-28-320.jpg)
![Other stateless operations
• join(DStream[(K, W)])
• leftOuterJoin(DStream[(K, W)])
• rightOuterJoin(DStream[(K, W)])
• cogroup(DStream[(K, W)])
are applied on pairs of corresponding μBatches](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-29-320.jpg)
![transform, transformWith
• DStream[T].transform(RDD[T] => RDD[U]): DStream[U]
• DStream[T].transformWith(DStream[U], (RDD[T], RDD[U]) => RDD[V]): DStream[V]
allow you to create new stateless operators](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-30-320.jpg)
![DStream[Blue].transformWith
(DStream[Red], …): DStream[Violet]
1-A 2-A 3-A
1-B 2-B 3-B
1-A x 1-B 2-A x 2-B 3-A x 3-B](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-31-320.jpg)
![DStream[Blue].transformWith
(DStream[Red], …): DStream[Violet]
1-A 2-A 3-A
1-B 2-B 3-B
1-A x 1-B 2-A x 2-B 3-A x 3-B](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-32-320.jpg)
![DStream[Blue].transformWith
(DStream[Red], …): DStream[Violet]
1-A 2-A 3-A
1-B 2-B 3-B
1-A x 1-B 2-A x 2-B 3-A x 3-B](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-33-320.jpg)









![Yes, it is still easy to do
case class WordCount(time: Long, word: String, count: Int)
val paragraphs: DStream[String] = stream.map { case (_, paragraph) => paragraph}
val words: DStream[String] = paragraphs.flatMap(_.split( """s+"""))
val wordCounts: DStream[(String, Long)] = words.countByValueAndWindow(Seconds(10), Seconds(2))
val topWordCounts: DStream[WordCount] = wordCounts.transform((rdd, time) =>
val mappedWordCounts: RDD[(Int, WordCount)] = rdd.map {
case (word, count) =>
(count.toInt, WordCount(time.milliseconds, word, count.toInt))
}
val topWordCountsRDD: RDD[WordCount] = mappedWordCounts
.sortByKey(ascending = false).values
)
topWordsStream.saveToCassandra("meetup", "word_counts")
topWordsStream.print()](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-44-320.jpg)
![DStream stateful operator
• DStream[(K, V)].updateStateByKey
(f: (Seq[V], Option[S]) => Option[S]): DStream[(K, S)]
A
1
B
2
A
3
C
4
A
5
B
6
A
7
B
8
C
9
• R1 = f(Seq(1, 3, 5), Some(7))
• R2 = f(Seq(2, 6), Some(8))
• R3 = f(Seq(4), Some(9))
A
R1
B
R2
C
R3](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-45-320.jpg)
![Total word count example
case class WordCount(time: Long, word: String, count: Int)
def update(counts: Seq[Long], state: Option[Long]): Option[Long] = {
val sum = counts.sum
Some(state.getOrElse(0L) + sum)
}
val totalWords: DStream[(String, Long)] =
stream.map { case (_, paragraph) => paragraph}
.flatMap(_.split( """s+"""))
.countByValue()
.updateStateByKey(update)
val topTotalWordCounts: DStream[WordCount] =
totalWords.transform((rdd, time) =>
rdd.map { case (word, count) =>
(count, WordCount(time.milliseconds, word, count.toInt))
}.sortByKey(ascending = false).values
)
topTotalWordCounts.saveToCassandra("meetup", "word_counts_total")
topTotalWordCounts.print()](https://image.slidesharecdn.com/sparkstreamingwithcassandra-141001233540-phpapp01/85/Spark-Streaming-with-Cassandra-46-320.jpg)







Spark Streaming with Cassandra
- 2. …applies where you need near-realtime data analysis
- 3. Spark vs Spark Streaming zillions of bytes gigabytes per second static dataset stream of data
- 4. What can you do with it? applications sensors web mobile phones intrusion detection malfunction detection site analytics network metrics analysis fraud detection dynamic process optimisation recommendations location based ads log processing supply chain planning sentiment analysis spying
- 5. What can you do with it? applications sensors web mobile phones intrusion detection malfunction detection site analytics network metrics analysis fraud detection dynamic process optimisation recommendations location based ads log processing supply chain planning sentiment analysis spying
- 6. Almost Whatever Source You Want Almost Whatever Destination You Want
- 9. so, let’s see how it works
- 10. DStream - A continuous sequence of micro batches DStream μBatch (ordinary RDD) μBatch (ordinary RDD) μBatch (ordinary RDD) Processing of DStream = Processing of μBatches, RDDs
- 11. 9 8 7 6 5 4 3 2 1 Receiver Interface between different stream sources and Spark
- 12. 9 8 7 6 5 4 3 2 1 Receiver Spark memory boundary Block Manager Interface between different stream sources and Spark
- 13. 9 8 7 6 5 4 3 2 1 Receiver Spark memory boundary Block Manager Replication and building μBatches Interface between different stream sources and Spark
- 14. Spark memory boundary Block Manager
- 15. Spark memory boundary Block Manager Blocks of input data 9 8 7 6 5 4 3 2 1
- 16. Spark memory boundary Block Manager Blocks of input data 9 8 7 6 5 4 3 2 1 μBatch made of blocks 9 8 7 6 5 4 3 2 1
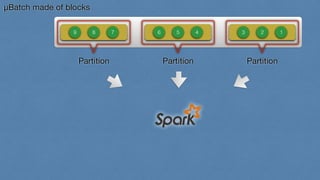
- 17. μBatch made of blocks 9 8 7 6 5 4 3 2 1
- 18. μBatch made of blocks 9 8 7 6 5 4 3 2 1 Partition Partition Partition
- 19. μBatch made of blocks 9 8 7 6 5 4 3 2 1 Partition Partition Partition
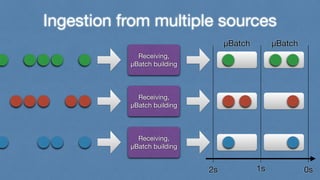
- 20. Ingestion from multiple sources Receiving, μBatch building Receiving, μBatch building Receiving, μBatch building
- 21. Ingestion from multiple sources Receiving, μBatch building Receiving, μBatch building Receiving, μBatch building μBatch μBatch 2s 1s 0s
- 22. A well-worn example • ingestion of text messages • splitting them into separate words • count the occurrence of words within 5 seconds windows • save word counts from the last 5 seconds, every 5 second to Cassandra, and display the first few results on the console
- 23. how to do that ? well…
- 24. Yes, it is that easy case class WordCount(time: Long, word: String, count: Int) val paragraphs: DStream[String] = stream.map { case (_, paragraph) => paragraph} val words: DStream[String] = paragraphs.flatMap(_.split( """s+""")) val wordCounts: DStream[(String, Long)] = words.countByValue() val topWordCounts: DStream[WordCount] = wordCounts.transform((rdd, time) => val mappedWordCounts: RDD[(Int, WordCount)] = rdd.map { case (word, count) => (count.toInt, WordCount(time.milliseconds, word, count.toInt)) } val topWordCountsRDD: RDD[WordCount] = mappedWordCounts .sortByKey(ascending = false).values ) topWordsStream.saveToCassandra("meetup", "word_counts") topWordsStream.print()
- 25. DStream stateless operators (quick recap) • map • flatMap • filter • repartition • union • count • countByValue • reduce • reduceByKey • joins • cogroup • transform • transformWith
- 26. DStream[Bean].count() count 4 3 1s 1s 1s 1s
- 27. DStream[Bean].count() count 4 3 1s 1s 1s 1s
- 29. Other stateless operations • join(DStream[(K, W)]) • leftOuterJoin(DStream[(K, W)]) • rightOuterJoin(DStream[(K, W)]) • cogroup(DStream[(K, W)]) are applied on pairs of corresponding μBatches
- 30. transform, transformWith • DStream[T].transform(RDD[T] => RDD[U]): DStream[U] • DStream[T].transformWith(DStream[U], (RDD[T], RDD[U]) => RDD[V]): DStream[V] allow you to create new stateless operators
- 31. DStream[Blue].transformWith (DStream[Red], …): DStream[Violet] 1-A 2-A 3-A 1-B 2-B 3-B 1-A x 1-B 2-A x 2-B 3-A x 3-B
- 32. DStream[Blue].transformWith (DStream[Red], …): DStream[Violet] 1-A 2-A 3-A 1-B 2-B 3-B 1-A x 1-B 2-A x 2-B 3-A x 3-B
- 33. DStream[Blue].transformWith (DStream[Red], …): DStream[Violet] 1-A 2-A 3-A 1-B 2-B 3-B 1-A x 1-B 2-A x 2-B 3-A x 3-B
- 34. Windowing slide 0s 1s 2s 3s 4s 5s 6s 7s By default: window = slide = μBatch duration window
- 35. Windowing slide 0s 1s 2s 3s 4s 5s 6s 7s By default: window = slide = μBatch duration window
- 36. Windowing slide 0s 1s 2s 3s 4s 5s 6s 7s By default: window = slide = μBatch duration window
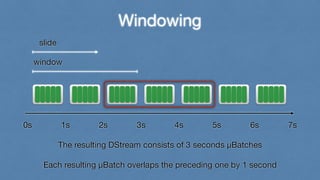
- 37. Windowing slide window 0s 1s 2s 3s 4s 5s 6s 7s The resulting DStream consists of 3 seconds μBatches ! Each resulting μBatch overlaps the preceding one by 1 second
- 38. Windowing slide window 0s 1s 2s 3s 4s 5s 6s 7s The resulting DStream consists of 3 seconds μBatches ! Each resulting μBatch overlaps the preceding one by 1 second
- 39. Windowing slide window 0s 1s 2s 3s 4s 5s 6s 7s The resulting DStream consists of 3 seconds μBatches ! Each resulting μBatch overlaps the preceding one by 1 second
- 40. Windowing slide window 1 2 3 4 5 6 7 8 window 1 2 3 4 5 6 3 4 5 6 7 8 μBatch appears in output stream every 1s ! It contains messages collected during 3s 1s
- 41. Windowing slide window 1 2 3 4 5 6 7 8 window 1 2 3 4 5 6 3 4 5 6 7 8 μBatch appears in output stream every 1s ! It contains messages collected during 3s 1s
- 42. DStream window operators • window(Duration, Duration) • countByWindow(Duration, Duration) • reduceByWindow(Duration, Duration, (T, T) => T) • countByValueAndWindow(Duration, Duration) • groupByKeyAndWindow(Duration, Duration) • reduceByKeyAndWindow((V, V) => V, Duration, Duration)
- 43. Let’s modify the example • ingestion of text messages • splitting them into separate words • count the occurrence of words within 10 seconds windows • save word counts from the last 10 seconds, every 2 second to Cassandra, and display the first few results on the console
- 44. Yes, it is still easy to do case class WordCount(time: Long, word: String, count: Int) val paragraphs: DStream[String] = stream.map { case (_, paragraph) => paragraph} val words: DStream[String] = paragraphs.flatMap(_.split( """s+""")) val wordCounts: DStream[(String, Long)] = words.countByValueAndWindow(Seconds(10), Seconds(2)) val topWordCounts: DStream[WordCount] = wordCounts.transform((rdd, time) => val mappedWordCounts: RDD[(Int, WordCount)] = rdd.map { case (word, count) => (count.toInt, WordCount(time.milliseconds, word, count.toInt)) } val topWordCountsRDD: RDD[WordCount] = mappedWordCounts .sortByKey(ascending = false).values ) topWordsStream.saveToCassandra("meetup", "word_counts") topWordsStream.print()
- 45. DStream stateful operator • DStream[(K, V)].updateStateByKey (f: (Seq[V], Option[S]) => Option[S]): DStream[(K, S)] A 1 B 2 A 3 C 4 A 5 B 6 A 7 B 8 C 9 • R1 = f(Seq(1, 3, 5), Some(7)) • R2 = f(Seq(2, 6), Some(8)) • R3 = f(Seq(4), Some(9)) A R1 B R2 C R3
- 46. Total word count example case class WordCount(time: Long, word: String, count: Int) def update(counts: Seq[Long], state: Option[Long]): Option[Long] = { val sum = counts.sum Some(state.getOrElse(0L) + sum) } val totalWords: DStream[(String, Long)] = stream.map { case (_, paragraph) => paragraph} .flatMap(_.split( """s+""")) .countByValue() .updateStateByKey(update) val topTotalWordCounts: DStream[WordCount] = totalWords.transform((rdd, time) => rdd.map { case (word, count) => (count, WordCount(time.milliseconds, word, count.toInt)) }.sortByKey(ascending = false).values ) topTotalWordCounts.saveToCassandra("meetup", "word_counts_total") topTotalWordCounts.print()
- 47. Obtaining DStreams • ZeroMQ • Kinesis • HDFS compatible file system • Akka actor • Twitter • MQTT • Kafka • Socket • Flume • …
- 48. Particular DStreams are available in separate modules GroupId ArtifactId Latest Version org.apache.spark spark-streaming-kinesis-asl_2.10 1.1.0 org.apache.spark spark-streaming-mqtt_2.10 1.1.0 all (7) org.apache.spark spark-streaming-zeromq_2.10 1.1.0 all (7) org.apache.spark spark-streaming-flume_2.10 1.1.0 all (7) org.apache.spark spark-streaming-flume-sink_2.10 1.1.0 org.apache.spark spark-streaming-kafka_2.10 1.1.0 all (7) org.apache.spark spark-streaming-twitter_2.10 1.1.0 all (7)
- 49. If something goes wrong…
- 50. Fault tolerance The sequence of transformations is known to Spark Streaming μBatches are replicated once they are received Lost data can be recomputed
- 51. But there are pitfalls • Spark replicates blocks, not single messages • It is up to a particular receiver to decide whether to form the block from a single message or to collect more messages before pushing the block • The data collected in the receiver before the block is pushed will be lost in case of failure of the receiver • Typical tradeoff - efficiency vs fault tolerance
- 52. Built-in receivers breakdown Pushing single messages Can do both Pushing whole blocks Kafka Akka RawNetworkReceiver Twitter Custom ZeroMQ Socket MQTT
- 53. Thank you ! Questions? ! http://spark.apache.org/ https://github.com/datastax/spark-cassandra-connector http://cassandra.apache.org/ http://www.datastax.com/