SplunkSummit 2015 - A Quick Guide to Search Optimization
7 likes6,315 views

This document provides an overview and tips for optimizing searches in Splunk. It discusses how to scope searches more narrowly through techniques like limiting the time range and including specific indexes, sourcetypes, and fields. This helps reduce the amount of data that needs to be scanned to find search results. The document also recommends using inclusionary search terms rather than exclusionary ones when possible to improve performance. Additional optimization strategies covered include using smarter search modes and defining fields on segmented boundaries.



























![Duplicate Structured
Fields
• Sometimes
both
indexed
extractions
and
search
time
parsing
are
enabled
for
a
CSV
or
JSON
sourcetype.
This
is
repeated
unnecessary
work, and
confusing
• Diagnostic:
duplicate
data
in
multivalued
fields
• Good
Practice:
Disable
the
search time
KV
• Example:
[my_custom_indexed_csv]
# required on SH
KV_MODE=csv
# required on forwarder
INDEXED_EXTRACTIONS = CSV
28
[my_custom_indexed_csv]
# required on SH
KV_MODE=none
# required on forwarder
INDEXED_EXTRACTIONS = CSV](https://image.slidesharecdn.com/dronro5bqx6gg6ajmpfs-signature-d8747f38f04819e461ddbf32c20a89b43b526e163682739594a7b133bb300650-poli-151216053521/85/SplunkSummit-2015-A-Quick-Guide-to-Search-Optimization-28-320.jpg)

![Basic Regular
Expression
Best
Practice
Examples
AfterBefore
• ’
(?P<messageid>[^
]+) •
^S+s+d+s+dd:dd:dd
s+w+[d+]s+w+s+'d+
.d+.d+s+(?P<messageid
>[^
]+)
30](https://image.slidesharecdn.com/dronro5bqx6gg6ajmpfs-signature-d8747f38f04819e461ddbf32c20a89b43b526e163682739594a7b133bb300650-poli-151216053521/85/SplunkSummit-2015-A-Quick-Guide-to-Search-Optimization-30-320.jpg)




![Weak:
Strong:
Pretty
Searches:
foreach is
Clean
35
…| timechart span=1h limit=0 sum(eval(b/pow(1024,3))) as size by
st
…| timechart span=1h limit=0 sum(b) by st
| foreach * [ eval <<FIELD>> = '<<FIELD>>' / pow( 1024 , 3 ) ]](https://image.slidesharecdn.com/dronro5bqx6gg6ajmpfs-signature-d8747f38f04819e461ddbf32c20a89b43b526e163682739594a7b133bb300650-poli-151216053521/85/SplunkSummit-2015-A-Quick-Guide-to-Search-Optimization-35-320.jpg)





![Weak:
Strong:
Faster
Searching:
Avoid
Subsearches
41
index=burch | eval blah=yay
| append [ search index=simon | eval blah=duh ]
( index=burch … ) OR ( index=simon …)
| eval blah=case( index==”burch" , "yay" , index==”simon" ,
"duh" )](https://image.slidesharecdn.com/dronro5bqx6gg6ajmpfs-signature-d8747f38f04819e461ddbf32c20a89b43b526e163682739594a7b133bb300650-poli-151216053521/85/SplunkSummit-2015-A-Quick-Guide-to-Search-Optimization-41-320.jpg)













![Joins :
Example
• Before:
– Search
A
|
fields
TxnId,Queue |
join
TxnId [
search
B
or
C
|
stats
min(_time)
as
start_time,
max(_time)
as
end_time by
TxnId |
eval total_time =
end_time -‐
start_time]
|
table
total_time,Queue
• After
– A
OR
B
OR
C
|
stats
values(Queue)
as
Queue
range(_time)
as
duration
by TxnId
• With more
exact
semantics:
– A
OR
B
OR
C
|
stats
values(Queue)
as
Queue
range(eval(if(searchmatch("B
OR
C"),
_time,
null())))
as
duration
55](https://image.slidesharecdn.com/dronro5bqx6gg6ajmpfs-signature-d8747f38f04819e461ddbf32c20a89b43b526e163682739594a7b133bb300650-poli-151216053521/85/SplunkSummit-2015-A-Quick-Guide-to-Search-Optimization-55-320.jpg)
![Reading
Job
Inspector
-‐ search.join
56
Search.join =
Time
to
apply
join
to
search
How
do
you
optimize
this?
• Consider
a
dataset
that
is
mostly
error
free
and
has
a
single
unique
identifier
for
related
records
• Errors
tie
into
the
unique
identifier
• Find
the
details
of
all
errors
• Use
a
subsearch to
first
get
a
list
of
unique
identifiers
with
errors:
• index=foo
sourcetype=bar
[search
index=foo
sourcetype=bar
ERROR
|
top
limit=0
id
|
fields
id]](https://image.slidesharecdn.com/dronro5bqx6gg6ajmpfs-signature-d8747f38f04819e461ddbf32c20a89b43b526e163682739594a7b133bb300650-poli-151216053521/85/SplunkSummit-2015-A-Quick-Guide-to-Search-Optimization-56-320.jpg)
![Using
subsearch effectively
• Consider
a
dataset
that
is
mostly
error
free
and
has
a
single
unique
identifier
for
related
records
• Errors
tie
into
the
unique
identifier
• Find
the
details
of
all
errors
• Use
a
subsearch to
first
get
a
list
of
unique
identifiers
with
errors:
• index=foo
sourcetype=bar
[search
index=foo
sourcetype=bar
ERROR
|
top
limit=0
id
|
fields
id]
57](https://image.slidesharecdn.com/dronro5bqx6gg6ajmpfs-signature-d8747f38f04819e461ddbf32c20a89b43b526e163682739594a7b133bb300650-poli-151216053521/85/SplunkSummit-2015-A-Quick-Guide-to-Search-Optimization-57-320.jpg)
![Reading
Job
Inspector
-‐ Subsearch Example
58
Search.rawdata=
Time
to
read
actual
events
from
rawdata
files
How
do
you
optimize
this?
• Consider
a
dataset
that
is
mostly
error
free
and
has
a
single
unique
identifier
for
related
records
• Errors
tie
into
the
unique
identifier
• Find
the
details
of
all
errors
• Use
a
subsearch to
first
get
a
list
of
unique
identifiers
with
errors:
• index=foo
sourcetype=bar
[search
index=foo
sourcetype=bar
ERROR
|
top
limit=0
id
|
fields
id]](https://image.slidesharecdn.com/dronro5bqx6gg6ajmpfs-signature-d8747f38f04819e461ddbf32c20a89b43b526e163682739594a7b133bb300650-poli-151216053521/85/SplunkSummit-2015-A-Quick-Guide-to-Search-Optimization-58-320.jpg)










































































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to SplunkSummit 2015 - A Quick Guide to Search Optimization (20)




















Ad
More from Splunk (20)




















Recently uploaded (20)




















SplunkSummit 2015 - A Quick Guide to Search Optimization
- 1. Copyright © 2014 Splunk, Inc. A Quick Guide To Search Optimization Naman Joshi Snr Sales Engineer
- 2. Disclaimer 2 During the course of this presentation, we may make forward looking statements regarding future events or the expected performance of the company. We caution you that such statements reflect our current expectations and estimates based on factors currently known to us and that actual events or results could differ materially. For important factors that may cause actual results to differ from those contained in our forward-‐looking statements, please review our filings with the SEC. The forward-‐looking statements made in the this presentation are being made as of the time and date of its live presentation. If reviewed after its live presentation, this presentation may not contain current or accurate information. We do not assume any obligation to update any forward looking statements we may make. In addition, any information about our roadmap outlines our general product direction and is subject to change at any time without notice. It is for informational purposes only and shall not, be incorporated into any contract or other commitment. Splunk undertakes no obligation either to develop the features or functionality described or to include any such feature or functionality in a future release.
- 3. Agenda • Search Scoping: A little background on Splunk Internals • Search Optimization tools: SOS and Job inspector • Laying the groundwork for: Regular Expression optimization • Beyond the basics: • Joining Data • Transactions with Stats • Optimizing transaction • Bonus: • Using tstats
- 4. Who’s This Dude? Naman Joshi [email protected] Senior Sales Engineer • Splunk user since 2008 • Started with Splunk in Feb 2014 • Former Splunk customer in the Financial Services Industry • Lived previous lives as a Systems Administrator, Engineer, and Architect
- 5. Philosophy behind Search Optimization Don't feel the need to optimize every single search -‐ focus on those which are frequently used and have the best potential for speedup. -‐ KISS Understand the whole problem Know a small number of tricks well 5
- 6. How Can We Make Things Faster? For all Searches: • Change the physics (do something different) • Reduce the amount of work done (optimize the pipeline) In distributed Splunk environments particularly: • How can we ensure as much work as possible is distributed? • How can we ensure as little data as possible is moved? 6
- 10. Anatomy of a Search 10 Disk
- 12. The Basics – Search Scoping
- 13. Time Range • Splunk organizes events into buckets by time, which contain events • The shorter the time range the fewer buckets will be read • !!Common Practice: Searches running over all time!!
- 14. Time Range • Good Practice: Scope to an appropriate shorter time range (using time range picker or earliest=/latest= or _index_earliest=/_index_latest=) • Speedup Metric: 30x – 365x • Example: All Time -‐> Week to Date 14
- 15. Scope on Metadata Fields • Index is a special field, controlling which disk location will be read to get results • All events in Splunk have sourcetypeand source fields and including these will improve speed and precision • Common Practice: Often roles include ‘All-‐ non internal indexes’, no index or sourcetype specfier • Diagnostic: look for searches without explicit index= clauses 15
- 16. Scope on Metadata Fields • Good practice: include a specific index=, sourcetype= set of fields. If using multiple related sourcetypes, use eventtypes which also include a sourcetypescope • Expected Speedup: 2x – 10x • Example – Before : MID=* – After: index=cisco sourcetype=cisco:esa:textmail MID=* – Using Eventtypes: index=cisco eventtype=cisco_esa_email with (sourcetype="cisco:esa:textmail" OR sourcetype=cisco:esa:legacy) AND (MID OR ICID OR DCID) 16
- 17. Search Modes • Splunk’s search modes control Splunk’s tendency to extract fields, with verbose being the most expansive and exploratory and fast being the least • Diagnostic: request.custom.display.page.search.mode= verbose • Common Practice: Verbose Mode left on after using • Good Practice: Use Smart or Fast mode (dashboard searches do this automatically) • Speedup Metric: 2x -‐5x 17
- 18. Inclusionary Search Terms • Inclusionary search terms specify events to keep • Exclusionary search terms specify events to remove • Exclusions are appropriate for many use cases (interactive usage, exclusion of known errors, specificity) 18
- 19. Inclusionary Search Terms • Diagnostic: Large scan numbers versus final events • Good Practice: Mostly inclusionary terms, small or no exclusionary terms • Speedup Metric: 2x -‐20x 19
- 20. Field Usage • Define fields on segmented boundaries where possible • Splunk will try to turn field=value into value, can be customized with fields.conf/segmentors.conf • Diagnostic: check the base lispy in your search.log 20
- 21. Field Usage • Good practise: Repeat field values as search terms if required, or use fields.conf • Example: – Before: guid=942032a0-‐4fd3-‐11e5-‐acd9-‐0002a5d5c5 – After: (index=server sourcetype=logins 942032a0-‐4fd3-‐11e5-‐acd9-‐0002a5d5c5 guid=942032a0-‐4fd3-‐11e5-‐acd9-‐0002a5d5c5) OR (index=client eventtype=client-‐login source=/var/log/client/942032a0-‐4fd3-‐11e5-‐acd9-‐ 0002a5d5c5) 21
- 22. The Basics: Search Scoping Tools
- 23. A Word On Monitoring Searches 23 How do we easily identify less than optimal searches? ● SOS (Pre 6.1 Users) ● Distributed Management Console ● Job Inspector
- 24. Measuring Search Using the Splunk Search Inspector 24 Copyright*©*2011,*Splunk*Inc.* Listen*to * Using*the*Search*Inspector* 3* Timings*from*distributed* Remote*timeline* Timings*from*the*search* command.* Timings from distributed peers Timings from the search command * Using*the*Search*Inspector* Timings*from*distributed*p Remote*timeline* Timings*from*the*search* command.* Key Metrics: • Completion Time • Number of Events Scanned • Search SID Job Inspector
- 25. Job Inspector Walkthrough – Search Command 25 Rawdata: Improving I/O and CPU load KV: Are field extractions efficient Lookups: Used appropriately Autolookupscausing issues Typer: Inefficient Eventtypes Alias: Cascading alias
- 27. Field Extractions Most fields are extracted by regular expressions. Some regular expression operations are much better performing than others. Field extractions can overlap – multiple TA’s on the same source type for example. Fields can also be from indexed extractions or structured search time parsing, as well as calculated (eval) fields and lookups 27
- 28. Duplicate Structured Fields • Sometimes both indexed extractions and search time parsing are enabled for a CSV or JSON sourcetype. This is repeated unnecessary work, and confusing • Diagnostic: duplicate data in multivalued fields • Good Practice: Disable the search time KV • Example: [my_custom_indexed_csv] # required on SH KV_MODE=csv # required on forwarder INDEXED_EXTRACTIONS = CSV 28 [my_custom_indexed_csv] # required on SH KV_MODE=none # required on forwarder INDEXED_EXTRACTIONS = CSV
- 29. Basic Regular Expression Best Practice • Backtracking is expensive • Diagnostic: high kv time • Good Practices: – Prefer + to * – Extract multiple fields together where they appear and are used together – Simple expressions are usually better (e.g. IP addresses) – Anchor cleanly – Test and benchmark for accuracy and speed 29
- 30. Basic Regular Expression Best Practice Examples AfterBefore • ’ (?P<messageid>[^ ]+) • ^S+s+d+s+dd:dd:dd s+w+[d+]s+w+s+'d+ .d+.d+s+(?P<messageid >[^ ]+) 30
- 31. Reading Job Inspector -‐ search.kv 31 Search.KV= Time taken to apply field extractions to events How do you optimize this? Regex optimizations • Avoid Backtracking • Use + over * • Avoid greedy operators .*? • Use of Anchors ^ $ • Non Capturing groups for repeats • Test! Test! Test!
- 34. Weak: Strong: Pretty Searches: Keep it Kosher 34 … | rename machine as “host for later” | sort “host for later” | timechart count by “host for later” span=1h …| timechart span=1h count by machine | sort machine | rename machine as “host for later” • new pipe = new line + space + pipe • | <command> <params> <processing> • cosmetics at end
- 35. Weak: Strong: Pretty Searches: foreach is Clean 35 …| timechart span=1h limit=0 sum(eval(b/pow(1024,3))) as size by st …| timechart span=1h limit=0 sum(b) by st | foreach * [ eval <<FIELD>> = '<<FIELD>>' / pow( 1024 , 3 ) ]
- 36. Weak: Strong: Pretty Searches: coalesce’s Cooler Than if 36 …| eval size = if( isnull(bytes) , if( isnull(b) , "N/A" , b ) , bytes ) …| eval size = coalesce( bytes , b , "N/A" )
- 37. Weak: Strong: Faster Searching: Less is More 37 iphone | stats count by action | search action=AppleWebKit iphone action=AppleWebKit | stats count
- 38. Weak: Strong: Faster Search: Be Specific 38 iphone | stats count by action index=oidemo host=dmzlog.splunktel.com sourcetype=access_combined source=/opt/apache/log/access_combined.log iphone user_agent="*iphone*” | stats count by action Time selector and eventtypes/tags!
- 39. Weak: Strong: Faster Searching: Require Fields 39 iphone | stats count by action phone=iphone action=* | stats count by action Wrong Results: Pulls both phone=iphone and user_agent=*iphone*
- 40. Weak: Strong: Faster Searching: Stats vs dedup/transaction 40 … phone=* | dedup phone | table phone | sort phone … phone=* | stats count by phone, host | fields - count … phone=* | transaction host | table host, phone
- 41. Weak: Strong: Faster Searching: Avoid Subsearches 41 index=burch | eval blah=yay | append [ search index=simon | eval blah=duh ] ( index=burch … ) OR ( index=simon …) | eval blah=case( index==”burch" , "yay" , index==”simon" , "duh" )
- 42. Weak: Strong: Faster Searching: NOT NOTs 42 index=burch NOT blah=yay index=burch blah=duh index=burch blah!=yay
- 43. Weak: Strong: Search Commands: Transaction 43 …| transaction host Mo data, Mo problems! …| transaction maxspan=10m maxevents=100 …
- 44. Weak: Strong: Search Commands: Time and Units 44 …| eval new_time = <ridiculous string edits> …| convert ctime(*ime) …| bin span=1h _time …| eval pause = tostring( pause , “duration” )
- 45. Weak: Strong: Search Commands: Metadata 45 index=* | stats count by host | metadata index=* type=hosts
- 46. Weak: Strong: Search Commands: Eventcount 46 index=* | stats count by index | eventcount summarize=false index=*
- 47. Accurate Results: Snap-‐To Times StrongWeak 47
- 48. Accurate Results: Time Fields StrongWeak 48
- 49. Accurate Results: Realistic Alerts StrongWeak 49 • Static conditions – | where count>10 • Spam – Avg Actionable: • stddev • percXX Find anomalies when outside statistical “normal” Plug: Tom LaGatta
- 50. Lookups: Best Practice • Use gzipped CSV for large lookups • Add automatic lookups for commonly used fields • Scope time based lookups cleanly • Order lookup table by ‘key’ first then values • When building lookups, use inputlookup and stats to combine (particularly useful for ‘tracker’ type lookups) • Splunk will index large lookups 50
- 51. Reading Job Inspector -‐ search.lookups 51 Search.lookups = Time to apply lookups to search How do you optimize this? • Use Appropriately (at end of search) • Autolookups maybe causing issues
- 52. Joins: Overview Splunk has a join function which is often used by people with two kinds of data that they wish to analyze together. It's often less efficient than alternative approaches. • Join involves setting up a subsearch • Join is going to join all the data from search a and search b, usually we only need a subset • Join often requires all data to be brought back to the search head 52
- 53. Joins With Stats: Good Practice • values(field_name) Is great • range(_time) Is often a good duration • dc(sourcetype) Is a good way of knowing if you actually joined multiple sources up or only have one part of your dataset • eval Can be nested inside your stats expression • searchmatch Is nice for ad-‐hoc grouping, could also use eventtypes if disciplined 53
- 54. Stats & Values 54 index=_internal sourcetype=splunkd OR sourcetype=scheduler | stats values(user) AS user values(group) AS group values(run_time) AS run_time by date_hour Values returns all of the distinct values of the field specified Return the values of the existing user field and call the resulting field user Group all of the previous fields by the date_hour field ● Use |stats values(<field name>) -‐or-‐ |stats list(<field name>) instead of | join ● values(): returns distinct values in lexicographical order ● list(): returns all values and preserves the order
- 55. Joins : Example • Before: – Search A | fields TxnId,Queue | join TxnId [ search B or C | stats min(_time) as start_time, max(_time) as end_time by TxnId | eval total_time = end_time -‐ start_time] | table total_time,Queue • After – A OR B OR C | stats values(Queue) as Queue range(_time) as duration by TxnId • With more exact semantics: – A OR B OR C | stats values(Queue) as Queue range(eval(if(searchmatch("B OR C"), _time, null()))) as duration 55
- 56. Reading Job Inspector -‐ search.join 56 Search.join = Time to apply join to search How do you optimize this? • Consider a dataset that is mostly error free and has a single unique identifier for related records • Errors tie into the unique identifier • Find the details of all errors • Use a subsearch to first get a list of unique identifiers with errors: • index=foo sourcetype=bar [search index=foo sourcetype=bar ERROR | top limit=0 id | fields id]
- 57. Using subsearch effectively • Consider a dataset that is mostly error free and has a single unique identifier for related records • Errors tie into the unique identifier • Find the details of all errors • Use a subsearch to first get a list of unique identifiers with errors: • index=foo sourcetype=bar [search index=foo sourcetype=bar ERROR | top limit=0 id | fields id] 57
- 58. Reading Job Inspector -‐ Subsearch Example 58 Search.rawdata= Time to read actual events from rawdata files How do you optimize this? • Consider a dataset that is mostly error free and has a single unique identifier for related records • Errors tie into the unique identifier • Find the details of all errors • Use a subsearch to first get a list of unique identifiers with errors: • index=foo sourcetype=bar [search index=foo sourcetype=bar ERROR | top limit=0 id | fields id]
- 59. Key Items To Consider In Job Inspector 59
- 60. Job Inspector Conclusions: Search Command Summary 60 Component Description index look in tsidx files for where to read in rawdata rawdata read actual events from rawdata files kv apply fields to the events filter filter out events that don’t match (e.g., fields, phrases) alias rename fields according to props.conf lookups create new fields based on existing field values typer assign eventtypes to events tags assign tags to events
- 61. 61 Metric Description Area to review createProvider Queue The time to connect to all search peers. Peer conductivity fetch The time spent waiting for or fetching events from search peers. Faster Storage stream.remote The time spent executing the remote search in a distributed search environment, aggregated across all peers. evaluate The time spent parsing the search and setting up the data structures needed to run the search. Possible bundle issues Job Inspector Conclusions: Distributed Search Summary
- 62. Job Inspector / Search.log 62 FIeld Description Area to review remoteSearch The parallelizable portion of the search Maximize the parallelizable part. Base lispy / keywords The tokens used to read data from the index and events Ensure contains field tokens eventSearch The part of the search for selecting data reportSearch The part of the search for processing data
- 64. Stats vs Transaction 64 Search Goal: compute statistics on the duration of web session (JSESSIONID=unique identifier): > | stats range(_time) as duration by JSESSIONID | chart count by duration span=log2 > sourcetype=access_combined | transaction JSESSIONID | chart count by duration span=log2 Not so Great: Much Better:
- 65. Use Stats To Maximal Effect • Replace simple transaction or join usage with stats • Stats count range(_time) dc(sourcetype) values(field) values(error) by unique_id – Gives you duration – range(_time) – Find incomplete ‘transactions’ with dc(sourcetype) – Find errors with values(error) – Find context with values(field) 65
- 66. Use Stats To Maximal Effect • Consider using a base stats before expensive operations like eventstats or transaction or another stats: – | eval orig_time = _time | bucket _time span=1h| stats count range(orig_time) as duration by unique_id _time | eventstats avg(duration) as avg | where duration>avg 66
- 67. Reading Job Inspector -‐ Stats Example 67 Search.rawdata = Time to read actual events from rawdata files How do you optimize this? • Filtering as much as possible • Add Peers • Allocating more CPU, improving I/O
- 68. For More Info • 68
- 69. Bonus: Using tstats • When using indexed extractions, data can be queried with tstats, allowing you to produce stats directly without a prior search • Similarly data models can be queried with tstats (speedup on accelerated data models) • Bonus: tstats is available against host source sourcetype and _time for all data (see also the metadata/metasearch command) • Good Practice: – Use tstats directly for reporting searches where available – Read just the columns you need – Multiple queries usually better than a datacube style search 69
- 70. Key Take away: Search Best Practice 70 > be=selective AND be=specific | … Narrow time range > foo bar > host=web sourcetype=access* Use Summary Indexing Use Report Accel or Summary Indexing Use Fast/Smart Mode where Possible Bad Behavior Good Behavior Performance Improvement Comment index=xyz 10-‐50% Index and default fields source=www -‐24h@h 365x 30x Limit Time Range > foo bar 30% Combine Searches Fast/Smart 20-‐50% Fast Mode A AND C AND D AND E 5-‐50% Avoid NOTS Data Models and Report Acceleration Summary Indexing All Time Searches >* > foo | search bar Verbose Mode Use Intelligently Use Sparingly 1000% 1000% Searches over large datasets Searches over long periods A NOT B
- 71. Thankyou!
- 72. Typical “my Splunk is not performing well” conversation A: My Splunk is slow. B: Okay, so what exactly is slow? A: I dunno, it just feels slow…maybe I’ll just get some SSDs. 72
- 73. 73 Splunk, like all distributed computing systems, has various bottlenecks that manifest themselves differently depending on workloads being processed. -‐ Winston Churchill
- 74. Identifying performance bottlenecks • Understand data flows – Splunk operations pipelines • Instrument – Capture metrics for relevant operations • Run tests • Draw conclusions – Chart and table metrics, looks for emerging patterns • Make recommendations 74 Splunk > data Ingest (Indexing) Consume (Search)
- 75. Put that in your pipeline and process it 75 Input UTF-‐8 Converter Line Breaker Header Extraction Output Splunk data flows thru several such pipelines before it gets indexed Pipeline Data
- 76. A ton of pipelines 76 TRANSFORMS-‐xxx SEDCMD ANNOTATE_PUNCT LINE_BREAKER TRUNCATE SHOULD_LINEMERGE BREAK_ONLY_BEFORE MUST_BREAK_AFTER TIME_*
- 77. Index-‐time processing 77 Event Breaking Timestamp Extraction Typing LINE_BREAKER <where to break the stream> SHOULD_LINEMERGE <enable/disable merging> MAX_TIMESTAMP_LOOKAHEAD <# chars in to look for ts> TIME_PREFIX <pattern before ts> TIME_FORMAT <strptime format string to extract ts> ANNOTATE_PUNCT <enable/disable punct:: extraction>
- 78. Testing: dataset A 78 • 10M syslog-‐like events: . . . Sat, 06 Apr 2014 15:55:39 PDT <syslog message > Sat, 06 Apr 2014 15:55:40 PDT <syslog message > Sat, 06 Apr 2014 15:55:41 PDT <syslog message > . . . • Push data thru: – Parsing > Merging > Typing Pipelines ê Skip Indexing – Tweak various props.conf settings • Measure MLA: MAX_TIMESTAMP_LOOKAHEAD = 30 TP: TIME_PREFIX = ^ TF: TIME_FORMAT = %a, %d %b %Y %H:%M:%S %Z LM: SHOULD_LINEMERGE = false AP: ANNOTATE_PUNCT = false
- 79. Index-‐time pipeline results 79 44 51 51 105 105 179 190 0 20 40 60 80 100 120 140 160 180 200 MLA + LM + TF + AP MLA + LM + TF + TP MLA + LM + TF MLA + LM + TP MLA + LM MLA Default Time (s) MLA: MAX_TIMESTAMP_LOOKAHEAD = 30 TP: TIME_PREFIX = ^ TF: TIME_FORMAT = %a, %d %b %Y %H:%M:%S %Z LM: SHOULD_LINEMERGE = false AP: ANNOTATE_PUNCT = false ~4 X
- 80. 80 Time (s) Performance Flexibility • All pre-‐indexing pipelines are expensive at default settings. • Price of flexibility • If you’re looking for performance, minimize generality • LINE_BREAKER • SHOULD_LINEMERGE • MAX_TIMESTAMP_LOOKAHEAD • TIME_PREFIX • TIME_FORMAT
- 81. Next: let’s index a dataset B 81 • Generate a much larger dataset (1TB) – High cardinality, ~380 Bytes/event, 2.86B events • Forward to indexer as fast as possible – Indexer: ê 12 [email protected] HT ê 12GB RAM, ê 14x15KRPM @146GB/ea – No other load on the box • Measure
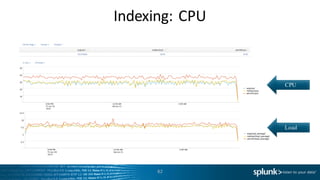
- 84. Indexing Test Findings 84 • CPU Utilization – ~35% in this case, 4-‐5 Real CPU Cores • IO Utilization – Characterized by both reads and writes but not as demanding as search. Note the splunk-‐optimize process. • Ingestion Rate – 22MB/s – “Speed of Light” – no search load present on the server
- 85. Index Pipeline Parallelization 85 • Splunk 6.3+ can maintain multiple independent pipelines sets ê i.e. same as if each set was running on its own indexer • If machine is under-‐utilized (CPU and I/O), you can configure the indexer to run 2 such sets. • Achieve roughly double the indexing throughput capacity. • Try not to set over 2 • Be mindful of associated resource consumption
- 86. Indexing Test Conclusions 86 • Distribute as much as you can – Splunk scales horizontally • Enable more pipelines but be aware of compute tradeoff • Tune event breaking and timestamping attributes in props.conf whenever possible • Faster disk (ex. SSDs) would not have necessarily improved indexing throughput by much • Faster, but not more, CPUs would have improved indexing throughput – modulo pipeline parallelization
- 87. Next: Searching 87 • Real-‐life search workloads are extremely complex and very varied to be profiled correctly • But, we can generate arbitrary workloads covering a wide spectrum of resource utilization and profile those instead. Actual profile will fall somewhere in between. IO CPU
- 88. Search pipeline (High Level) 88 Some preparatory steps here Write temporary results to dispatch directory Find buckets based on search timerange Return progress to SH splunkd Repeat until search completes For each bucket check tsidx for events that match LISPY and find rawdata offset For each bucket read journal.gz at offsets supplied by previous step Filter events to match the search string (+ eventtyping tagging) Process events: st rename, extract, report, kv, alias, eval, lookup, subsecond
- 89. Search pipeline boundedness 89 Some preparatory steps here Write temporary results to dispatch directory Find buckets based on search timerange Repeat until search completes For each bucket check tsidx for events that match LISPY and find rawdata offset For each bucket read journal.gz at offsets supplied by previous step Filter events to match the search string (+ eventtyping tagging) Process events: st rename, extract, report, kv, alias, eval, lookup, subsecond Return progress to SH splunkd IO
- 90. Search pipeline boundedness 90 Some preparatory steps here Write temporary results to dispatch directory Find buckets based on search timerange Repeat until search completes For each bucket check tsidx for events that match LISPY and find rawdata offset For each bucket read journal.gz at offsets supplied by previous step Filter events to match the search string (+ eventtyping tagging) Process events: st rename, extract, report, kv, alias, eval, lookup, subsecond IO CPU + Memory Return progress to SH splunkd
- 91. Search Types 91 • Dense – Characterized predominantly by returning many events per bucket index=web | stats count by clientip • Sparse – Characterized predominantly by returning some events per bucket index=web some_term | stats count by clientip • Rare – Characterized predominantly by returning only a few events per index index=web url=onedomain* | stats count by clientip
- 92. Okay, let’s test some searches 92 • Use our already indexed data – It contains many unique terms with predictable term density • Search under several term densities and concurrencies – Term density: 1/100, 1/1M, 1/100M – Search Concurrency: 4 – 60 – Searches: ê Rare: over all 1TB dataset ê Dense: over a preselected time range • Repeat all of the above while under an indexing workload • Measure
- 93. Dense Searches 93 What’s going on here? % CPU Util. vs. Concurrency (1/100) % IO Wait vs. Concurrency (1/100)
- 94. Dense Searches 94 What’s going on here? % CPU Util. vs. Concurrency (1/100) % IO Wait vs. Concurrency (1/100) CPU Bound
- 95. Dense Searches with Indexing 95 Indexing off Indexing on Test Type Indexing off Indexing on diff Avg. Search Time 40.58s 43.85s +8.6% Hitting 100% earlier % CPU Util. vs. Concurrency (searching 1/100) Indexing Thruput vs. Concurrency (searching 1/100) SpeedOfLight 1/100
- 96. Dense Search Test Conclusions 96 • Dense workloads are CPU bound • Dense workloads (reporting, trending etc.) play relatively “okay” with indexing – While indexing throughput decreases by ~40% search time increases only marginally • Faster disk wont necessarily help as much here – Majority of time in dense searches is spent in CPU decompressing rawdata + other SPL processing • Faster and more CPUs would have improved overall performance
- 97. Rare Searches 97 1/100M 1/M Reads/s (sar) % IO Wait % CPU Util. vs. Concurrency
- 98. Rare Searches 98 % CPU Util. vs. Concurrency 1/100M 1/M Reads/s (sar) % IO Wait IO Bound
- 99. Rare Searches with Indexing 99 % CPU Util. vs. Concurrency 1/100M 1/M Reads/s (sar) % IO Wait
- 100. More numbers 100 Density 1/1M 1/100M Test Type Indexing off Indexing on diff Indexing off Indexing on diff Avg Search Time 1041s 1806s +73.5% 231s 304s +31.6% 1/100M SpeedOfLight 1/1M Indexing Thruput (KB/s) vs. Concurrency
- 101. Rare Search Conclusions 101 • Rare workloads (investigative, ad-‐hoc) are IO bound • Rare workloads (high IO wait) do not play well with indexing – Search time increases significantly when indexing is on. Also, indexing throughput takes an equal hit on the opposite direction. • 1/100M searches have a lesser impact on IO than 1/1M. • When indexing is on, in 1/1M case search time increases more substantially vs. 1/100M. Search and indexing are both contenting for IO. • In case of 1/100M, bloomfilters save precious IO which, in turn, allows for a better indexing throughput. – Bloomfilters are special data structures that indicate with 100% certainty that a term does not exist in a bucket (effectively telling the search process to skip that bucket). – Note the higher CPU consumption during 1/100M searches with indexing on • Faster disks would have definitely helped here • More CPUs would not have improved performance by much
- 102. Is my search CPU or IO bound? 102 Guideline in absence of full instrumentation • command.search.rawdata~ CPU Bound – Others: .kv, .typer, .calcfields, • command.search.index~ IO Bound
- 103. Top Takeways/Re-‐Cap 10 3 • Indexing – Distribute – Splunk scales horizontally – Tune event breaking and timestamp extraction – Faster CPUs will help with indexing performance • Searching – Distribute – Splunk scales horizontally – Dense Search Workloads ê CPU Bound, better with indexing than rare workloads ê Faster and more CPUs will help – Rare Search Workloads ê IO Bound, not that great with indexing ê Bloomfilters help significantly ê Faster disks will help • Performance – Avoid generality, optimize for expected case and add hardware whenever you can Term Density CPU IO Use case What Helps? Trending, reporting over long term etc. More distribution Faster, more CPUs Ad-‐hoc analysis, investigative type More distribution Faster Disks, SSDs