Storage and-compute-hdfs-map reduce
Download as PPTX, PDF3 likes659 views

High-level overview of Apache Hadoop: HDFS, MapReduce and YARN, used for a University of Washington extension class.









































































































Ad
More Related Content
What's hot (20)
Similar to Storage and-compute-hdfs-map reduce (20)


















Ad
Recently uploaded (20)
![Pixologic ZBrush Crack Plus Activation Key [Latest 2025] New Version](https://cdn.slidesharecdn.com/ss_thumbnails/fashionevolution2-250322112409-f76abaa7-250428124909-b51264ff-250504160528-fc2bb1c5-thumbnail.jpg?width=560&fit=bounds)







![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)











Ad
Storage and-compute-hdfs-map reduce
- 1. Storage and Compute: HDFS, MapReduce October 14, 2015 Chris Nauroth email: [email protected] twitter: @cnauroth
- 2. © Hortonworks Inc. 2011 About Me Chris Nauroth • Member of Technical Staff, Hortonworks – Apache Hadoop committer, PMC member – Apache ZooKeeper committer – Apache Software Foundation member – Major contributor to HDFS ACLs, Windows compatibility, and operability improvements • Hadoop user since 2010 – Prior employment experience deploying, maintaining and using Hadoop clusters Page 2 Architecting the Future of Big Data
- 3. © Hortonworks Inc. 2011 Agenda • History of Hadoop • HDFS: Hadoop Distributed File System – High-Level Architecture – Recent Features – Storage Architecture Evolution • MapReduce – High-Level Architecture – Computational Model • YARN – High-Level Architecture – Recent Features Page 3 Architecting the Future of Big Data
- 5. © Hortonworks Inc. 2011 History of Hadoop • Inspired by scalable storage and compute infrastructure developed at Google – The Google File System http://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf – MapReduce: Simplified Data Processing on Large Clusters http://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf • Hadoop project created in 2005 as an offshoot of the Nutch search engine project • Yahoo was initial main user, followed by uptake by Facebook and others • Expanded to include a huge ecosystem of related projects • Now deployed widely in a variety of settings • Developed in open source in Apache Software Foundation – Contributors and committers come from diverse interests in industry and research. – Anyone can contribute! Page 5 Architecting the Future of Big Data
- 6. Data Storage and Resource Management HDFS (storage) works closely with MapReduce (data processing) to provide scalable, fault-tolerant, cost-efficient storage for big data. Ver: 2.6.0 YARN is the process resource manager and is designed to be co-deployed with HDFS such that there is a single cluster, providing the ability to move the computation resource to the data Pig (scripting) is a high-level language (Pig Latin) for data analysis programs, and infrastructure for evaluating these programs via map-reduce. Ver: 0.14.0 Hive (SQL) Provides data warehouse infrastructure, enabling data summarization, ad-hoc query and analysis of large data sets. The query language, HiveQL (HQL), is similar to SQL. Ver: 0.14.0 HCatalog (SQL) Table &storage management layer that provides users of Pig, MapReduce and Hive with a relational view of data in HDFS. Hbase (NoSQL) Non-relational database that provides random real-time access to data in very large tables. HBase is transactional and allows updates, inserts and deletes. HBase includes support for SQL through Phoenix. Ver: 0.98.4 Accumulo (NoSQL) Based on Google's BigTable design, features a few novel improvements on the BigTable design in the form of cell-based access control Ver: 1.6.1 Data Access Phoenix a SQL skin over HBase delivered as a client- embedded JDBC driver targeting low latency queries over HBase data. Ver: 4.2.0 Who’s Who in the Zoo Tez (SQL) leverages the MapReduce paradigm to enable the execution complex Directed Acyclic Graphs (DAG) of tasks. Tez eliminates unnecessary tasks, synchronization barriers and I/O to HDFS, speeding up data processing. Ver: 0.5.2 Map Reduce a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a Hadoop cluster. Ver: 2.6.0 Spark is an open-source data analytics cluster computing framework Spark provides primitives for in-memory cluster computing that allows user programs to load data into a cluster's memory and query it repeatedly, making it well suited to machine learning algorithms Ver: 1.2.1 Solr is an open source enterprise search platform from the Apache Lucene project. It includes full-text search, hit highlighting, faceted search, dynamic clustering, database integration, and rich document handling. And provides distributed search and index replication. Data Engines
- 7. Security Knox (perimeter security) is a REST gateway for Hadoop providing network isolation, SSO, authentication, authorization and auditing functions. Ver: 0.5.0 Ranger (security management) is a framework to monitor and manage security assets across a cluster. It provides central administration, monitoring and security hooks for Hadoop applications. Ver: 0.4.0 Operations & Management Oozie (job scheduling) Oozie enables administrators to build complex data transformations, enables greater control over long- running jobs and can schedule repetitions of those jobs. Ver: 4.1.0. Ambari (cluster management) is an operational framework to provision, manage and monitor Hadoop clusters. It includes a web interface for administrators to start/stop/test services and change configurations. Ver: 1.7.0 Zookeeper is a distributed configuration and synchronization service and a naming registry for distributed. Distributed applications use Zookeeper to store and mediate updates to important configuration information. Ver: 3.4.6 Hue (Hadoop Use Experience) Web interface that supports Apache Hadoop and its ecosystem. Hue aggregates the most common Apache Hadoop components into a single interface and targets the user experience. Ver: 2.6.1 Who’s Who in the Zoo Storm (data streaming). Distributed real-time computation system for processing fast, large streams of data. Storm topologies can be written in any programming language. Ver: 0.9.3 Governance & Integration Falcon is a data governance engine that defines Oozie data pipelines, monitors those pipelines (in coordination with Ambari), and tracks those pipelines for dependencies and audits. Ver: 0.6.0 Scoop is a tool that efficiently transfers bulk data between Hadoop and structured datastores such as relational databases. Ver: 1.4.5 Flume is a distributed service to collect, aggregate and move large amounts of streaming data into HDFS. Ver: 1.5.2 Kafka (data streaming). A high-throughput distributed messaging system. Apache Kafka is publish-subscribe messaging rethought as a distributed commit log Ver: 0.8.1.1
- 8. Libraries File Formats Avro A data serialization system. Provides, Rich data structures.A compact, fast, binary data format. A container file, to store persistent data. Ver: 1.7.4 Mahout is a suite of machine learning libraries designed to be scalable and robust Ver: 0.9.0 ORC The Optimized Row Columnar (ORC) file format, part of Hive, provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data. Ver: 0.14.0 Thrift is a data serialization system that allows you to define data types and service interfaces in a simple definition file. Ver: 0.13.0 Thrift Cascading is an application development platform for building Data applications on Apache Hadoop. Ver: Who’s Who in the Zoo
- 10. © Hortonworks Inc. 2011 HDFS High-Level Architecture • NameNode – HDFS master service – Centralized storage of all file system metadata (inodes, paths, permissions, etc.) – Transaction Logging – Checkpointing – Rack Awareness – Health tracking of DataNodes – Deployed in redundant pairs for high availability • DataNode – Block level storage of file content – 128 MB typical block size – Blocks replicated to multiple DataNodes for fault tolerance – Highly scalable: add/remove DataNodes to scale up/down • Client – Interacts with NameNode and DataNodes to provide read and write access to file system – Multiple options available: Java RPC client, WebHDFS REST API, LibHDFS for native code, NFS mountable Page 10 Architecting the Future of Big Data
- 11. © Hortonworks Inc. 2011 HDFS High-Level Architecture NameNode DataNode 1 Block 1 Block 2 DataNode 2 Block 3 Block 4 DataNode 3 Block 4 Block 2 DataNode 4 Block 1 Block 3 DataNode 5 Block 4 Block 2 DataNode 6 Block 1 Block 3 • File split into blocks of 128 • Each block replicated 3x NameNode High Availability
- 12. © Hortonworks Inc. 2011 HDFS High Level Architecture • Fault Tolerance – End-to-end checksum verification of data on write and read – Background checksum verification of all stored replicas to detect bit rot – Corrupt replicas are declared invalid, and a new replica is created by copying another known good replica • Misreplication – Blocks may be under-replicated after failure of a DataNode – Blocks may be over-replicated after restoring a failed DataNode into service – Misreplicated blocks are detected automatically – Misreplication is corrected by copying another known good replica or deleting superfluous replicas • Balance – Over time, a cluster may develop hot spots: DataNodes storing a much greater proportion of blocks – Hotspots cause sub-optimal utilization of storage – Can reduce overall job throughput due to high contention on the same disks – HDFS favors placement of new replicas on under-utilized volumes – A balancer tool can be run to restore balance across a cluster by moving replicas of old files Page 12 Architecting the Future of Big Data
- 14. © Hortonworks Inc. 2011 HDFS Snapshots • HDFS Snapshots – A snapshot is a read-only point-in-time image of part of the file system – Performance: snapshot creation is instantaneous, regardless of data size or subtree depth – Reliability: snapshot creation is atomic – Scalability: snapshots do not create extra copies of data blocks – Useful for protecting against accidental deletion of data • Example: Daily Feeds hdfs dfs -ls /daily-feeds Found 5 items drwxr-xr-x - chris supergroup 0 2014-10-13 14:36 /daily-feeds/2014-10-13 drwxr-xr-x - chris supergroup 0 2014-10-13 14:36 /daily-feeds/2014-10-14 drwxr-xr-x - chris supergroup 0 2014-10-13 14:37 /daily-feeds/2014-10-15 drwxr-xr-x - chris supergroup 0 2014-10-13 14:37 /daily-feeds/2014-10-16 drwxr-xr-x - chris supergroup 0 2014-10-13 14:37 /daily-feeds/2014-10-17 Page 14 Architecting the Future of Big Data
- 15. © Hortonworks Inc. 2011 HDFS Snapshots • Create a snapshot after each daily load hdfs dfsadmin -allowSnapshot /daily-feeds Allowing snaphot on /daily-feeds succeeded hdfs dfs -createSnapshot /daily-feeds snapshot-to-2014-10-17 Created snapshot /daily-feeds/.snapshot/snapshot-to-2014-10-17 • User accidentally deletes data for 2014-10-16 hdfs dfs -ls /daily-feeds Found 4 items drwxr-xr-x - chris supergroup 0 2014-10-13 14:36 /daily-feeds/2014-10-13 drwxr-xr-x - chris supergroup 0 2014-10-13 14:36 /daily-feeds/2014-10-14 drwxr-xr-x - chris supergroup 0 2014-10-13 14:37 /daily-feeds/2014-10-15 drwxr-xr-x - chris supergroup 0 2014-10-13 14:37 /daily-feeds/2014-10-17 Page 15 Architecting the Future of Big Data
- 16. © Hortonworks Inc. 2011 HDFS Snapshots • Snapshots to the rescue: the data is still in the snapshot hdfs dfs -ls /daily-feeds/.snapshot/snapshot-to-2014-10-17 Found 5 items drwxr-xr-x - chris supergroup 0 2014-10-13 14:36 /daily- feeds/.snapshot/snapshot-to-2014-10-17/2014-10-13 drwxr-xr-x - chris supergroup 0 2014-10-13 14:36 /daily- feeds/.snapshot/snapshot-to-2014-10-17/2014-10-14 drwxr-xr-x - chris supergroup 0 2014-10-13 14:37 /daily- feeds/.snapshot/snapshot-to-2014-10-17/2014-10-15 drwxr-xr-x - chris supergroup 0 2014-10-13 14:37 /daily- feeds/.snapshot/snapshot-to-2014-10-17/2014-10-16 drwxr-xr-x - chris supergroup 0 2014-10-13 14:37 /daily- feeds/.snapshot/snapshot-to-2014-10-17/2014-10-17 • Restore data from 2014-10-16 hdfs dfs -cp /daily-feeds/.snapshot/snapshot-to-2014-10-17/2014-10-16 /daily-feeds Page 16 Architecting the Future of Big Data
- 17. © Hortonworks Inc. 2011 HDFS ACLs • Existing HDFS POSIX permissions good, but not flexible enough – Permission requirements may differ from the natural organizational hierarchy of users and groups. • HDFS ACLs augment the existing HDFS POSIX permissions model by implementing the POSIX ACL model. – An ACL (Access Control List) provides a way to set different permissions for specific named users or named groups, not only the file’s owner and file’s group. Page 17 Architecting the Future of Big Data
- 18. © Hortonworks Inc. 2011 HDFS File Permissions Example • Authorization requirements: –In a sales department, they would like a single user Maya (Department Manager) to control all modifications to sales data –Other members of sales department need to view the data, but can’t modify it. –Everyone else in the company must not be allowed to view the data. • Can be implemented via the following: Read/Write perm for user maya User Group Read perm for group sales File with sales data
- 19. © Hortonworks Inc. 2011 HDFS ACLs • Problem –No longer feasible for Maya to control all modifications to the file – New Requirement: Maya, Diane and Clark are allowed to make modifications – New Requirement: New group called executives should be able to read the sales data –Current permissions model only allows permissions at 1 group and 1 user • Solution: HDFS ACLs –Now assign different permissions to different users and groups Owner Group Others HDFS Directory … rwx … rwx … rwx Group D … rwx Group F … rwx User Y … rwx
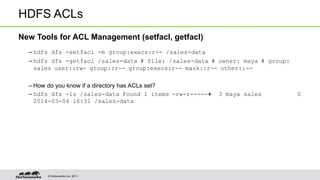
- 20. © Hortonworks Inc. 2011 HDFS ACLs New Tools for ACL Management (setfacl, getfacl) – hdfs dfs -setfacl -m group:execs:r-- /sales-data – hdfs dfs -getfacl /sales-data # file: /sales-data # owner: maya # group: sales user::rw- group::r-- group:execs:r-- mask::r-- other::-- – How do you know if a directory has ACLs set? – hdfs dfs -ls /sales-data Found 1 items -rw-r-----+ 3 maya sales 0 2014-03-04 16:31 /sales-data
- 21. © Hortonworks Inc. 2011 HDFS ACLs Best Practices • Start with traditional HDFS permissions to implement most permission requirements. • Define a smaller number of ACLs to handle exceptional cases. • A file with an ACL incurs an additional cost in memory in the NameNode compared to a file that has only traditional permissions. Page 21 Architecting the Future of Big Data
- 22. © Hortonworks Inc. 2011 Reporting DataNode Volume Failures • Configuring dfs.datanode.failed.volumes.tolerated > 0 enables a DataNode to keep running after volume failures • DataNode is still running, but capacity is degraded • HDFS already provided a count of failed volumes for each DataNode, but no further details • Apache Hadoop 2.7.0 provides more information: failed path, estimated lost capacity and failure date/time • An administrator can use this information to prioritize cluster maintenance work Page 22 Architecting the Future of Big Data
- 23. © Hortonworks Inc. 2011 Reporting DataNode Volume Failures Page 23 Architecting the Future of Big Data New
- 24. © Hortonworks Inc. 2011 Reporting DataNode Volume Failures Page 24 Architecting the Future of Big Data
- 25. © Hortonworks Inc. 2011 Reporting DataNode Volume Failures Page 25 Architecting the Future of Big Data
- 26. © Hortonworks Inc. 2011 Reporting DataNode Volume Failures • Everything in the web UI is sourced from standardized Hadoop metrics – Each DataNode publishes its own metrics – NameNode publishes aggregate information from every DataNode • Metrics accessible through JMX or the HTTP /jmx URI • Integrated in Ambari • Can be integrated into your preferred management tools and ops dashboards Page 26 Architecting the Future of Big Data
- 27. HDFS Storage Architecture Evolution
- 28. © Hortonworks Inc. 2011 HDFS Reads Page 28 Architecting the Future of Big Data
- 29. © Hortonworks Inc. 2011 HDFS Short-Circuit Reads Page 29 Architecting the Future of Big Data
- 30. © Hortonworks Inc. 2011 HDFS Short-Circuit Reads Page 30 Architecting the Future of Big Data
- 31. © Hortonworks Inc. 2011 Shortcomings of Existing RAM Utilization • Lack of Control – Kernel decides what to retain in cache and what to evict based on observations of access patterns. • Sub-optimal RAM Utilization – Tasks for multiple jobs are interleaved on the same node, and one task’s activity could trigger eviction of data that would have been valuable to retain in cache for the other task. Page 31 Architecting the Future of Big Data
- 32. © Hortonworks Inc. 2011 Centralized Cache Management • Provides users with explicit control of which HDFS file paths to keep resident in memory. • Allows clients to query location of cached block replicas, opening possibility for job scheduling improvements. • Utilizes off-heap memory, not subject to GC overhead or JVM tuning. Page 32 Architecting the Future of Big Data
- 33. © Hortonworks Inc. 2011 Using Centralized Cache Management • Pre-Requisites – Native Hadoop library required, currently supported on Linux only. – Set process ulimit for maximum locked memory. – Configure dfs.datanode.max.locked.memory in hdfs-site.xml, set to the amount of memory to dedicate towards caching. • New Concepts – Cache Pool – Contains and manages a group of cache directives. – Has Unix-style permissions. – Can constrain resource utilization by defining a maximum number of cached bytes or a maximum time to live. – Cache Directive – Specifies a file system path to cache. – Specifying a directory caches all files in that directory (not recursive). – Can specify number of replicas to cache and time to live. Page 33 Architecting the Future of Big Data
- 34. © Hortonworks Inc. 2011 Using Centralized Cache Management Page 34 Architecting the Future of Big Data
- 35. © Hortonworks Inc. 2011 Using Centralized Cache Management • CLI: Adding a Cache Pool > hdfs cacheadmin -addPool common-pool Successfully added cache pool common-pool. > hdfs cacheadmin -listPools Found 1 result. NAME OWNER GROUP MODE LIMIT MAXTTL common-pool cnauroth cnauroth rwxr-xr-x unlimited never Page 35 Architecting the Future of Big Data
- 36. © Hortonworks Inc. 2011 Using Centralized Cache Management • CLI: Adding a Cache Directive > hdfs cacheadmin -addDirective -path /hello-amsterdam -pool common-pool Added cache directive 1 > hdfs cacheadmin -listDirectives Found 1 entry ID POOL REPL EXPIRY PATH 1 common-pool 1 never /hello-amsterdam Page 36 Architecting the Future of Big Data
- 37. © Hortonworks Inc. 2011 Using Centralized Cache Management • CLI: Removing a Cache Directive > hdfs cacheadmin -removeDirective 1 Removed cached directive 1 > hdfs cacheadmin -removeDirectives -path /hello-amsterdam Removed cached directive 1 Removed every cache directive with path /hello-amsterdam Page 37 Architecting the Future of Big Data
- 38. © Hortonworks Inc. 2011 Centralized Cache Management Behind the Scenes Page 38 Architecting the Future of Big Data
- 39. © Hortonworks Inc. 2011 Centralized Cache Management Behind the Scenes • Block files are memory-mapped into the DataNode process. > pmap `jps | grep DataNode | awk '{ print $1 }'` | grep blk 00007f92e4b1f000 124928K r--s- /data/dfs/data/current/BP-1740238118-127.0.1.1- 1395252171596/current/finalized/blk_1073741827 00007f92ecd21000 131072K r--s- /data/dfs/data/current/BP-1740238118-127.0.1.1- 1395252171596/current/finalized/blk_1073741826 Page 39 Architecting the Future of Big Data
- 40. © Hortonworks Inc. 2011 Centralized Cache Management Behind the Scenes • Pages of each block file are 100% resident in memory. > vmtouch /data/dfs/data/current/BP-1740238118-127.0.1.1- 1395252171596/current/finalized/blk_1073741826 Files: 1 Directories: 0 Resident Pages: 32768/32768 128M/128M 100% Elapsed: 0.001198 seconds > vmtouch /data/dfs/data/current/BP-1740238118-127.0.1.1- 1395252171596/current/finalized/blk_1073741827 Files: 1 Directories: 0 Resident Pages: 31232/31232 122M/122M 100% Elapsed: 0.00172 seconds Page 40 Architecting the Future of Big Data
- 41. © Hortonworks Inc. 2011 HDFS Zero-Copy Reads • Applications read straight from direct byte buffers, backed by the memory-mapped block file. • Eliminates overhead of intermediate copy of bytes to buffer in user space. • Applications must change code to use a new read API on DFSInputStream: public ByteBuffer read(ByteBufferPool factory, int maxLength, EnumSet<ReadOption> opts) Page 41 Architecting the Future of Big Data
- 42. © Hortonworks Inc. 2011 Heterogeneous Storage Goals • Extend HDFS to support a variety of Storage Media • Applications can choose their target storage • Use existing APIs wherever possible Page 42 Architecting the Future of Big Data
- 43. © Hortonworks Inc. 2011 Interesting Storage Media Page 43 Architecting the Future of Big Data Cost Example Use case Spinning Disk (HDD) Low High volume batch data Solid State Disk (SSD) 10x of HDD HBase Tables RAM 100x of HDD Hive Materialized Views Your custom Media ? ?
- 44. © Hortonworks Inc. 2011 HDFS Storage Architecture - Before Page 44 Architecting the Future of Big Data
- 45. © Hortonworks Inc. 2011 HDFS Storage Architecture - Now Page 45 Architecting the Future of Big Data
- 46. © Hortonworks Inc. 2011 Storage Preferences • Introduce Storage Type per Storage Medium • Storage Hint from application to HDFS –Specifies application’s preferred Storage Type • Advisory • Subject to available space/quotas • Fallback Storage is HDD –May be configurable in the future Page 46 Architecting the Future of Big Data
- 47. © Hortonworks Inc. 2011 Storage Preferences (continued) • Specify preference when creating a file –Write replicas directly to Storage Medium of choice • Change preference for an existing file –E.g. to migrate existing file replicas from HDD to SSD Page 47 Architecting the Future of Big Data
- 48. © Hortonworks Inc. 2011 Quota Management • Extend existing Quota Mechanisms • Administrators ensure fair distribution of limited resources Page 48 Architecting the Future of Big Data
- 49. © Hortonworks Inc. 2011 File Creation with Storage Types Page 49 Architecting the Future of Big Data
- 50. © Hortonworks Inc. 2011 Move existing replicas to target Storage Type Page 50 Architecting the Future of Big Data
- 51. Storage Policy Definition Allows mapping between Dataset and Storage Type Directory => Storage Type(s) File => Storage Type(s) Defines Creation Fallback Strategy Strategy for when blocks are allocated and written Where to write blocks when first Storage Type is out of space Defines Replication Fallback Strategy Strategy for when blocks are replicated Where to store block replicas when first Storage Type is out of space
- 52. © Hortonworks Inc. 2011 Storage Policies: Archival DISK DISK DISK DISK DISK DISK DISK DISK DISK ARCHIVE ARCHIVE ARCHIVE ARCHIVE ARCHIVE ARCHIVE ARCHIVE ARCHIVE ARCHIVE Warm 1 replica on DISK, others on ARCHIVE Hot All replicas on DISK Cold All replicas on ARCHIVE HDP Cluster
- 53. © Hortonworks Inc. 2011 Storage Policies: Archival DISK DISK DISK DISK DISK DISK DISK DISK DISK ARCHIVE ARCHIVE ARCHIVE ARCHIVE ARCHIVE ARCHIVE HDP Cluster Warm 1 replica on DISK, others on ARCHIVE DataSet A Cold All replicas on ARCHIVE DataSet B A A A ARCHIVE ARCHIVE ARCHIVE B B B
- 54. © Hortonworks Inc. 2011 Storage Policy: SSD SSD DISK DISK SSD DISK DISK SSD DISK DISK SSD DISK DISK SSD DISK DISK HDP Cluster A SSD DISK DISK A A SSD All replicas on SSDDataSet A
- 55. © Hortonworks Inc. 2011 Store Intermediate Data in Memory Application Process Memory Tier Write block to memory Lazy persist block to disk RAM_DISK For data writes: - Need low latency writes - Where data is re-generatable Example Scenarios being explored: - Hive on Tez - Spark on Tez
- 57. © Hortonworks Inc. 2011 MapReduce High-Level Architecture • JobTracker – MapReduce master service – Resource Management – Job Scheduling – Task Execution Monitoring – Job History • TaskTracker – Task Execution – Highly scalable: add/remove TaskTrackers to scale up/down • Client – Interacts with JobTracker for job submission and progress tracking Page 57 Architecting the Future of Big Data
- 58. MapReduce High Level Architecture • JobTracker – Manages cluster resources and job scheduling • TaskTracker – Per-node agent – Manage tasks
- 59. © Hortonworks Inc. 2011 MapReduce High-Level Architecture • Data Locality – MapReduce TaskTracker is co-located with HDFS DataNode – JobTracker attempts to schedule tasks to read blocks present on the same physical node to avoid extra cost of transferring over the network – Traditional data processing architectures pull the data to the computation. MapReduce pushes the computation to the data. • Fault Tolerance – Task attempt monitoring and retries – Speculative execution Page 59 Architecting the Future of Big Data
- 61. © Hortonworks Inc. 2011 MapReduce Computational Model • Parallel, distributed algorithm for scalable data processing – Data set distributed across multiple nodes in the cluster – MapReduce jobs consist of multiple tasks, running in parallel on multiple nodes – Naturally fault tolerant: if an individual task fails, just reattempt it and resume the job • Map function – <KEYIN, VALUEIN> -> <KEYOUT, VALUEOUT>* – Typical actions: filter, transform, count • Reduce function – <KEYIN, VALUEIN*> -> <KEYOUT, VALUEOUT>* – Typical actions: aggregate, index • Shuffle – Each reducer task fetches a partition of the map phase output from each completed mapper task • Sort – Inputs to the reducer are sorted by key, so that all values corresponding to a key can be grouped – Shuffle and sort are coupled, not separate phases. Map outputs are merge sorted while the shuffle fetches them. Page 61 Architecting the Future of Big Data
- 62. © Hortonworks Inc. 2011 MapReduce Computational Model • Combiner – <KEYIN, VALUEIN*> -> <KEYOUT, VALUEOUT>* – Acts like a “local reducer” that runs inside the mapper task – Typical actions: pre-aggregation – Optional component that can save network bandwidth by shrinking amount of data transferred during shuffle – Typically requires a commutative function, such as addition, because individual mapper task will not have access to all values corresponding to a key • Distributed cache – Pre-distributes specific files to each node running a task of the job – Optimizes access to those files, because access is always local instead of remote – Useful for distribution of “side files” that are distinct from the main job input, such as dimension tables • Compression – Framework includes built-in support for compression and decompression of map input files, intermediate map outputs and reducer output files – Compression reduces network bandwidth consumption at the cost of increased CPU utilization – gzip, bz2, lzo, Snappy, etc. (pluggable) Page 62 Architecting the Future of Big Data
- 63. © Hortonworks Inc. 2011 MapReduce Computational Model • Example: Word Count • Input Files $ bin/hadoop fs -cat /user/joe/wordcount/input/file01 Hello World Bye World $ bin/hadoop fs -cat /user/joe/wordcount/input/file02 Hello Hadoop Goodbye Hadoop • Running the Job $ bin/hadoop jar wc.jar WordCount /user/joe/wordcount/input /user/joe/wordcount/output • Output Files $ bin/hadoop fs -cat /user/joe/wordcount/output/part-* Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2 Page 63 Architecting the Future of Big Data
- 64. © Hortonworks Inc. 2011 MapReduce Computational Model • Map Task 1 Output <Hello, 1> <World, 1> <Bye, 1> <World, 1> • Map Task 2 Output <Hello, 1> <Hadoop, 1> <Goodbye, 1> <Hadoop, 1> • Reduce Task 1 Output <Bye, 1> <Goodbye, 1> <Hadoop, 2> <Hello, 2> <World, 2> Page 64 Architecting the Future of Big Data
- 66. Map Reduce V1 Architecture • JobTracker – Manages cluster resources and job scheduling • TaskTracker – Per-node agent – Manage tasks
- 67. Map Reduce V1 Issues • Scalability – Maximum Cluster size – 4,000 nodes – Maximum concurrent tasks – 40,000 – Coarse synchronization in JobTracker • Coarse Grained Resource Management • Single point of failure – Mitigated by High Availability • Restart is very tricky due to complex state
- 68. © Hortonworks Inc. 2011 Hadoop The Project HADOOP 1.0 HDFS (redundant, reliable storage) MapReduce (cluster resource management & data processing) HDFS (redundant, reliable storage) YARN (cluster resource management) MapReduce (data processing) Others (data processing) HADOOP 2.0 Page 68 Moving Beyond Map reduce
- 69. © Hortonworks Inc. 2011 YARN • Resource Manager – Global resource scheduler – Hierarchical queues • Node Manager – Per-machine agent – Manages the life-cycle of container – Container resource monitoring • Application Master – Per-application – Manages application scheduling and task execution – E.g. MapReduce Application Master
- 70. Capacity Scheduler Configuration Root$Queue Max$Queue$Capacity Guaranteed$Queue$ Capacity Sub$Queue ROOT yarn.scheduler.capacity.root.capacity=100 yarn.scheduler.capacity.root.queues=adhoc,batch,prod ADHOC yarn.scheduler.capacity.root.adhoc.acl_submit_applications=* yarn.scheduler.capacity.root.adhoc.capacity=25 yarn.scheduler.capacity.root.adhoc.maximum-capacity=50 yarn.scheduler.capacity.root.adhoc.state=RUNNING yarn.scheduler.capacity.root.adhoc.user-limit-factor=2 PROD yarn.scheduler.capacity.root.prod.acl_administer_queue=yarn yarn.scheduler.capacity.root.prod.acl_submit_applications=yarn,mapred yarn.scheduler.capacity.root.prod.capacity=50 yarn.scheduler.capacity.root.prod.queues=reports,ops PROD - Reports yarn.scheduler.capacity.root.prod.reports.state=RUNNING yarn.scheduler.capacity.root.prod.reports.capacity=80 yarn.scheduler.capacity.root.prod.reports.maximum-capacity=100 yarn.scheduler.capacity.root.prod.reports.user-limit-factor=3 yarn.scheduler.capacity.root.prod.reports.minimum-user-limit-percent=20 yarn.scheduler.capacity.prod.reports.maximum-applications = 1 ROOT yarn.scheduler.capacity.root.capacity = 100 ADHOC yarn.scheduler.capacity. root.adhoc.maximum- capacity = 50 yarn.scheduler.capa city.root.adhoc.capac ity = 25 BATCH yarn.scheduler.ca pacity.root.batch. maximum- capacity = 75 yarn.scheduler .capacity.root.b atch.capacity = 25 PROD yarn.scheduler.capacity.root.prod.reports.maximum -capacity = 100 yarn.scheduler.capacity.root.prod.ops.maximum- capacity = 50 yarn.scheduler.capacity.root.prod.capacity = 50 yarn.scheduler.capacity .root.prod.reports.capac ity = 80 yarn.scheduler.c apacity.root.prod .ops.capacity = 20
- 72. YARN Timeline Server • Storage and retrieval of YARN application status information • Covers both current status and historical information • Addresses MapReduce v1 scalability bottleneck of storing job status information in JobTracker • Includes 2 kinds of status information – Generic - Application start/stop - Attempts - Container information – Application-specific - Varies depending on specific application running in YARN - MapReduce map tasks, reduce tasks, counters, etc.
- 73. Node Labels What • Admin associates a label with a set of nodes (NodeManager). –1 node :: n labels AND 1 label :: n nodes • Admin allows (sets ACLs) for apps scheduled to a Capacity Scheduler Queue to schedule on labeled nodes • Admin can enforce (set Default) that all apps scheduled to a Queue be scheduled on label ‘A’ nodes Why • Need a mechanism to enforce node-level isolation • Account for resource contention amongst non-YARN managed resources • Account for hardware or software constraints
- 74. CGroup Isolation What • Admin enables CGroups for CPU Isolation for all YARN application workloads Why • Applications need guaranteed access to CPU resources • To ensure SLAs, need to enforce CPU allocations given to an Application container
- 75. © Hortonworks Inc. 2011 Summary • History of Hadoop – Scalable storage and compute infrastructure – Expanded to include a large ecosystem of related projects • HDFS: Hadoop Distributed File System – Scalable and fault tolerant distributed storage – Evolving to support new storage architectures • MapReduce – Parallel, distributed, scalable data processing – Computational model implemented in terms of a map function and a reduce function • YARN – Evolution of MapReduce infrastructure – Scalable execution of distributed applications on Hadoop cluster nodes – Backward-compatible with MapReduce v1, but also supports applications other than MapReduce Page 75 Architecting the Future of Big Data
- 76. Thank you Q&A
Editor's Notes
- #3: First, a quick introduction. My name is Chris Nauroth. I’m a software engineer on the HDFS team at Hortonworks. I’m an Apache Hadoop committer and PMC member. I’m also an Apache Software Foundation member. Some of my major contributions include HDFS ACLs, Windows compatibility and various operability improvements. Prior to Hortonworks, I worked for Disney and did an initial deployment of Hadoop there. As part of that job, I worked very closely with the systems engineering team responsible for maintaining those Hadoop clusters, so I tend to think back to that team and get excited about things I can do now as a software engineer to help make that team’s job easier. I’m also here with Suresh Srinivas, one of the founders of Hortonworks, and a long-time Hadoop committer and PMC member. He has a lot of experience supporting some of the world’s largest clusters at Yahoo and elsewhere. Together with Suresh, we have experience supporting Hadoop clusters since 2008.
- #4: For today’s agenda, I’d like to start by sharing some analysis that we’ve done of support case trends. In that analysis, we’re going to see that some common patterns emerge, and that’s going to lead into a discussion of configuration best practices and software improvements. In the second half of the talk, we’ll move into a discussion of key learnings and best practices around how recent HDFS features can help prevent problems or manage day-to-day maintenance.
- #6: For today’s agenda, I’d like to start by sharing some analysis that we’ve done of support case trends. In that analysis, we’re going to see that some common patterns emerge, and that’s going to lead into a discussion of configuration best practices and software improvements. In the second half of the talk, we’ll move into a discussion of key learnings and best practices around how recent HDFS features can help prevent problems or manage day-to-day maintenance.
- #17: By convention, snapshots can be referenced as a file system path under sub-directory “.snapshot”.
- #18: If you’ve used POSIX ACLs on a Linux file system, then you already know how it works in HDFS too.
- #24: Here is a screenshot pointing out a change in the HDFS web UI: Total Datanode Volume Failures is a hyperlink. Clicking that jumps to…
- #25: …this new screen listing the volume failures in detail. We can see the path of each failed storage location, and an estimate of the capacity that was lost. I think of this screen being used by a system engineer as a to-do list as part of regular cluster maintenance.
- #26: Here is what it looks like when there are no volume failures. I included this picture, because this is what we all want it to look like. Of course, it won’t always be that way.