Stream Processing Handson Workshop - Flink SQL Hands-on Workshop (Korean)
0 likes25 views

Hands-on Workshop: Stream Processing Made Easy with Flink SQL on Confluent Cloud


















































Stream Processing Handson Workshop - Flink SQL Hands-on Workshop (Korean)
- 1. Welcome to the Flink SQL Hands-on Workshop
- 2. Hands-on Workshop: Stream Processing Made Easy with Flink SQL on Confluent Cloud June 17, Seoul
- 3. HyunSoo Kim Senior Solutions Engineer Confluent Korea Junhee Shin Solutions Engineer Confluent Korea Today’s Hosts and Speakers Jupil Hwang Senior Solutions Engineer Confluent Korea
- 4. 13:30 14:00 14:30 15:30 15:40 16:40 17:00 Check-in, Setup (On-site) Intro: What is “Shift Left”? Hands-on Part 1: Getting Started with Flink Break Hands-on Part 2: Advanced Features of Flink Tea Time Close the Door 4 Agenda - Workshop
- 5. 만약 Confluent Cloud 계정이 없다면, Confluent Cloud 계정은 여기에서 생성하세요: https://www.confluent.io/get-started/ Remember? Prerequisites?
- 6. AWS/Azure/GCP 에서 구동하는 Confluent Cloud 가 필요합니다. ● Schema Registry가 활성화된 환경(Environment)에서 ● 여러 개의 Kafka Topic들이 존재하고 ● Flink를 기반으로 가상의 Data를 생성합니다. 이를 위해, Terraform 스크립트가 제공되며 실습에 필요한 기본 셋팅은 Terraform으로 자동 생성됩니다. Remember? Prerequisites?(계속)
- 7. Workshop은 여기에서 시작하세요: “repo_url” https://github.com/confluentinc/confluent-cloud-flink-workshop https://buly.kr/GksQXW8 워크숍이 끝난 후에는 Cluster, Flink Pool 등 Confluent Cloud 리소스를 정리하는 것을 잊지 마세요. (Prerequisites 매뉴얼에 삭제하는 명령어가 제공됩니다!) Remember? Prerequisites?(계속)
- 8. Cloud resource management API Keys
- 9. Cloud resource management API Keys Name 및 Description 입력 후 생성 생성 후 다운로드 받으세요.
- 10. Cloud resource management API Keys & Terraform 예) terraform.tfvars 예시
- 11. Intro: What is “Shift Left”?
- 13. 13 ….하지만 데이터 스트리밍 플랫폼이 없으면 잘못된 데이터가 조직 전체에 퍼져 나갑니다 마치 호수 위에 있는 집에 진흙 발자국을 남기는 것과 마찬가지죠! Data Warehouse Data Lake “Lakehouse” Scalable and high performance for queries and historical analyses Scalable and flexible for storing unstructured data Combines the advantages of DWH and DL
- 14. 오늘날의 데이터 파이프라인 접근 방식은 데이터 문제의 근본 원인입니다 Domain 1 Database Domain 2 Database Domain 3 Database Data Lake Lake House Data Mart Data Warehouse ML/AI Reports & Dashboards Domain 4 Database OPERATIONAL SYSTEMS ETL/ELT PIPELINES ANALYTICAL SYSTEMS
- 15. DATA WAREHOUSE / DATA LAKE ML/AI Dashboards OPERATIONAL DATA Poor decision making with stale data 5 / 30 / 60 min batch ingestion Poor lineage and governance and increasing pipeline sprawl Cascading data pollution and failures Time Batch 1 Process Batch 2 Process Batch 3 Process Batch 4 Process Time Batch 1 Process Batch 2 Process Batch 3 Process Batch 4 Process Time Batch 1 Process Batch 2 Process Batch 3 Process Batch 4 Process Time Batch 1 Process Batch 2 Process Batch 3 Process Batch 4 Process Complex remodelling and reprocessing = $$$ ‘JUST-ENOUGH’ CLEANSED DATA READY-TO-USE BUSINESS DATA RAW DATA DUMPS ANIMATED SLIDE Reports ELT 파이프라인은 취약하고 느리며 비효율적입니다
- 16. Domain 1 Database Domain 2 Database Domain 3 Database Data Lake Lake House Data Mart Data Warehouse ML/AI Reports & Dashboards Domain 4 Database OPERATIONAL SYSTEMS ETL/ELT PIPELINES ANALYTICAL SYSTEMS REVERSE ETL More batch tools are bolted on to reverse the flow of data – from data warehouses and data lakes back to operational systems and apps – for “real-time” use cases 최신 애플리케이션에서는 데이터가 ‘Upstream'로 흐르도록 해야 하는 경우도 존재합니다
- 17. Batch Data Pipeline의 문제 불량 데이터 및 수동 고장 수리 부실한 거버넌스 및 데이터 접근성 중앙 집중식 고정 중복되고 비용이 많이 드는 처리 오래되고 신뢰할 수 없는 데이터 Batch 수집 및 대상지에서의 중복 처리로 인해 데이터 충실도 및 거버넌스 문제가 있는 거대한 Point-to-point 연결 혼란 Operational Databases ELT ETL Raw Cleansed Business- ready Raw Cleansed Data Warehouse / Data Lake rETL rETL ML/AI Reports & Dashboards
- 18. 데이터 스트리밍을 통해 실시간 및 안정적인 데이터 파이프라인을 구축하세요 Operational Databases Business- ready Data Warehouse / Data Lake 데이터를 한 번 구축하고 신뢰할 수 있게 만들어 어디서든 사용할 수 있습니다. 데이터 생성 후 밀리초 이내에 소스에서 처리 및 거버넌스를 전환하세요. PROCESS GOVERN STREAM Universal Data Products Operational Databases, SaaS Apps, Custom Apps, AI Systems… Cleansed Microservices ML/AI Reports & Dashboards Cleansed 데이터 정리 및 유지 관리 감소 더욱 강화된 데이터 신뢰 및 자율성 효율적인 처리 및 낮은 지출 유비쿼터스 데이터 흐름 실시간 데이터 웨어하우징 CONNECT CONNECT CONNECT
- 19. Confluent 데이터 스트리밍 플랫폼의 장점 Streaming Continuously capture and share real-time data everywhere - to your data warehouse, data lake and operational systems and apps Schema Management Reduce faulty data downstream by enforcing quality checks and controls in the pipeline with data contracts Flink Continuously process real-time data, the moment it’s created, for well- curated reusable data products Data Portal Enable anyone with the right access controls to effortlessly explore and use real-time data products for greater data autonomy Tableflow Simplify representing your operational data as a ready-to-use Iceberg table in just one-click Stream Lineage Understand the complex data relationships and the data journey to ensure trustworthiness Focus of today’s session
- 20. How Shift Left Works 데이터를 한 번 쓰고 스트림이나 테이블로 읽어보세요 Stream processing (Focus of today’s session) Data Stream Data Product Schema Registry Tableflow (Iceberg) Third Party Compute Engines Databases Log data & messaging systems Custom Apps & Microservices Operational Apps & Data Systems Stream (Kafka) Event-Driven Design Decoupled Architecture Connect Connect Connect Data Warehouses / Data Lakes Stream (Kafka) COMING SOON READ AS READ AS Stream Lineage Stream Catalog Data Portal Immutable Logs Enterprise Resource Planning systems Connect
- 21. Reduce DWH / DL costs by ingesting data from operational systems and apps, attaching schema, and processing it with Flink, in order to share high- quality streams to analytics systems (e.g., SNOW, DBricks) in real time Continuously analyze and update results as data streams are produced for real-time dashboarding via a RT analytics DB (e.g., Druid, Rockset, Pinot) ● Ad/campaign performance ● Content performance ● Quality monitoring of Telco networks ● Large-scale graph analysis Analyze data streams over time windows to detect patterns and react to incoming events by triggering computations, state updates, or external actions (i.e., microservices) Description Sample Use Cases (Technical and Business) Category Real-time Analytics ● Real-time search index building ● ML pipelines ● Data warehouse modernization ● Database modernization ● Data lake ingestion ● Reporting and analytics Data Pipelines (“Shift Left”) Event Driven Applications ● Fraud detection ● Anomaly detection ● Alerting/notifications ● Routing ● Business process monitoring ● Bad experience detection 스트림 처리를 통해 비즈니스 가치와 관련된 광범위한 사용 사례를 지원합니다
- 22. Kafka Streams ksqlDB Kafka ecosystem Client library deployed to Java Runtime. Self hosted. Input and output data are stored in single Kafka cluster. Java Open Source Standalone SQL engine built on top of Kafka Streams. Input and output data are stored in single Kafka cluster SQL Community Source Flink Flink Framework and distributed engine for stateful computations over unbounded and bounded data streams Java, Python, SQL Open Source 22 Kafka를 위한 스트림 처리(Stream Processing)
- 23. Real-time Data A Sale A Shipment A Trade A Customer Experience Real-Time Backend Operations Real-time Stream Processing 실시간 서비스는 스트림 처리에 의존합니다
- 24. DATA IN MOTION 스트리밍 애플리케이션 Apache Flink Apache Kafka DATA AT REST 애플리케이션 레이어 컴퓨팅 레이어 스토리지 레이어 전통적인 데이터베이스 파일 시스템 웹 애플리케이션 스트림 처리는 Kafka의 컴퓨팅 계층 역할을 하여 실시간 애플리케이션 및 파이프라인을 지원합니다
- 25. 디지털 네이티브 기업은 Flink를 활용하여 시장을 혁신하고 경쟁 우위를 확보하고 있습니다 UBER: 실시간 가격 NETFLIX: 맞춤형 추천 STRIPE: 실시간 사기 탐지
- 26. Scalability and Performance Fault Tolerance Flink는 상위 5개 Apache 프로젝트 중 하나이며 강력한 개발자 커뮤니티를 보유하고 있습니다. Unified Processing Flink는 엄청난 규모의 스트림 처리 워크로드를 지원할 수 있습니다. Language Flexibility Flink의 내결함성 메커니즘은 장애를 효과적으로 처리하고 고가용성을 제공할 수 있도록 보장합니다. Flink는 150개 이상의 내장 기능을 통해 Java, Python 및 SQL을 지원하므로 개발자는 원하는 언어로 작업할 수 있습니다. Flink는 하나의 기술을 통해 스트림 처리(stream processing), 일괄 처리(batch processing) 및 임시 분석(ad-hoc analytics)을 지원합니다. 많은 조직들은 성능과 풍부한 기능 세트 때문에 Flink를 선택합니다
- 27. 0 50,000 100,000 150,000 2020 2021 2022 2016 2017 2018 Flink Kafka Two Apache Projects, Born a Few Years Apart Monthly Unique Users Flink의 성장은 스트리밍 데이터의 사실상 표준인 Kafka의 성장을 반영합니다 Fortune 500대 기업 중 75% 이상이 Kafka를 사용하는 것으로 추정 Kafka를 사용하는 100,000개 이상의 조직 41,000명 이상의 Kafka 모임 참석자 750개 이상의 Kafka 개선 제안(KIP) Apache Kafka를 위한 12,000개 이상의 Jiras
- 29. Confluent Cloud for Apache Flink® 간편한 서버리스 스트림 처리 업계 유일의 클라우드 네이티브 서버리스 Flink 서비스로 고품질의 재사용 가능한 데이터 스트림을 손쉽게 구축하세요 스트림 처리의 사실상 표준인 Flink를 사용하여 데이터 스트림을 손쉽게 필터링, 분석 및 풍부하게 만드십시오 인프라 관리의 복잡성 없이 모든 규모에서 고성능 및 효율적인 스트림 처리를 구현합니다 완벽하게 통합된 모니터링, 보안 및 거버넌스를 갖춘 통합 플랫폼으로 Kafka와 Flink를 경험해 보세요 Now available on all 3 clouds
- 30. Lab에서는 제3자 리셀러를 위한 데이터 제품을 만듭니다 ● 이 lab은 Amazon과 Walmart와 같은 유명 공급업체의 제품을 제공하는 타사 리셀러에 중점을 둡니다. ○ 첫 번째 lab에서는 사용 가능한 다양한 데이터 소스를 살펴보고 데이터를 집계하기 위한 임시(ad-hoc) 쿼리를 작성합니다. ○ 두 번째 lab에서는 Flink의 고급 기능을 자세히 살펴봅니다. 다양한 유형의 조인을 사용하여 몇 가지 데이터 제품을 생성합니다. 먼저, 유효하지 않은 결제 내역이 있는 주문을 필터링합니다. 그런 다음 고객 프로모션 및 충성도 레벨을 계산합니다. ● The Architecture ○ 이 lab은 모두 Confluent Cloud에서 실행됩니다. ○ 데이터는 제품, 고객, 주문, 결제라는 네 개의 스트리밍 테이블에 실시간으로 입력됩니다.
- 32. Step 1: Deduplicating Orders
- 33. Step 2: Create valid_orders table with Flink Joins
- 34. Step 3: Data Enrichment
- 35. Step 4: Promotions Calculation
- 36. Step 5: Data pipeline observability
- 37. Step 6: Loyalty Levels Calculation
- 38. 사용할 도구들: Console Workspace, Shell, Monitoring 39 Cloud Console Workspace Flink Shell Flink Monitoring
- 39. 운영 : Autoscale, Increase without Downtime ● Autoscale within CFUs ● Increase CFUs without downtime ● Delete Pool(s)
- 40. Flink에서 스트리밍 데이터가 어떻게 변환되고 처리되는지 시각적으로 추적 데이터 흐름을 시각화하고 이해하기 위한 도구인 Stream Lineage는 Flink와 통합되어 Flink 쿼리를 통해 흐르는 메시지의 계보를 캡처하고 표시하여 사용자가 다음을 수행할 수 있도록 합니다: ● 각 데이터 흐름이 어디에서 시작되었는지 추적합니다. ● Flink가 데이터 흐름을 어떻게 변환하는지 추적합니다. ● 각 데이터 흐름이 어디에서 끝나는지 관찰합니다. Inspect a Flink query Track how data flows to and from Flink
- 41. Recap
- 42. 시간 경과에 따른 처리량 용량 수요 리소스 활용률 극대화 및 과도한 프로비저닝 방지 변화하는 비즈니스 요구 사항에 맞게 탄력적으로 확장 가장 복잡한 워크로드의 요구 사항을 충족하도록 자동으로 확장 또는 축소 • 활용도가 낮은 인프라 리소스 방지 • 규모를 최소화하는 가격 정책으로 사용한 리소스에 대해서만 비용 지불 0 CFU MAX CFUs
- 43. 브라우저 기반 SQL 인터페이스를 사용하여 Kafka 데이터 탐색 및 쿼리 SQL Workspaces는 Flink SQL을 사용하여 모든 Confluent Cloud 데이터를 동적으로 탐색하고 상호 작용할 수 있는 직관적이고 유연한 UI를 제공합니다. ● 쿼리를 저장하여 나중에 다시 검토하고 작업할 수 있습니다. ● 단일 뷰에서 여러 실시간 쿼리를 동시에 실행하세요. ● SQL 중심 관점에서 환경 메타데이터를 검사하세요.
- 44. 대화형 테이블을 사용하여 쿼리 결과를 탐색하고 시각화 Flink SQL Workspaces용 대화형 테이블을 사용하면 각 쿼리의 출력 데이터를 스캔, 분석 및 프로파일링하여 개발 및 문제 해결 프로세스를 간소화할 수 있습니다. ● 데이터 탐색 및 프로파일링 간소화 ● 데이터 추세 및 분포에 대한 즉각적인 인사이트 확보 ● 문제 해결 및 모니터링 강화
- 45. Actions를 사용하여 일반적인 사용 사례에 대한 스트림 처리 작업의 배포를 간소화합니다 Deduplicate topic Generate a topic containing only unique records from an input topic Mask fields Generate a topic containing masked fields from an input topic Filter topic Filter a topic based on a given set of conditions Apply a transformation Transform a topic based on a set of provided expressions COMING SOON Actions provide pre-packaged, turnkey stream processing workloads that run on Flink
- 46. 사용자 정의 함수를 사용하여 Flink SQL 기능 확장 사용자 정의 함수(UDF)를 사용하면 Flink SQL에서 기본적으로 지원되지 않는 복잡한 논리를 구현하기 위한 사용자 정의 함수를 생성할 수 있습니다. ● 특정 사용 사례에 맞춰 처리 ● 여러 애플리케이션에서 재사용 ● 선호하는 프로그래밍 언어로 작업 Java UDF SQL query EARLY ACCESS NOTE: Early Access is open to a limited number of candidates. Only Java and scalar functions are supported initially. Python support planned for 2H ‘24. UDF arguments UDF result
- 47. Table API(Open Preview)는 Java 또는 Python에서 프로그래밍 방식의 제어를 제공하여 기존 코드베이스에 원활하게 통합할 수 있는 풍부한 연산 및 변환 기능을 제공합니다. ● 익숙한 구조를 사용하여 스트리밍 애플리케이션을 구축합니다. ● 명령형 프로그래밍 방식을 활용합니다. ● 구조적이고 강력한 형식의 설계를 통해 개발, 테스트 및 유지 관리를 간소화합니다. Table API 지원을 통해 서버리스 Flink 접근성 확대 Track status of Table API statements Use full capabilities of modern IDEs
- 48. 고급 SQL 스트리밍 연산자 51 Time Windows Pattern Matching Streaming Joins ● Time-based windows ● Event-density windows ● Event-based windows: every single event can trigger a new window ● Complex Event Processing ● See sample ● Stream-to-stream joins ● Temporal joins ● Lookup joins ● Versioned joins
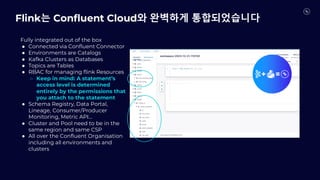
- 49. Fully integrated out of the box ● Connected via Confluent Connector ● Environments are Catalogs ● Kafka Clusters as Databases ● Topics are Tables ● RBAC for managing flink Resources ○ Keep in mind: A statement’s access level is determined entirely by the permissions that you attach to the statement ● Schema Registry, Data Portal, Lineage, Consumer/Producer Monitoring, Metric API… ● Cluster and Pool need to be in the same region and same CSP ● All over the Confluent Organisation including all environments and clusters Flink는 Confluent Cloud와 완벽하게 통합되었습니다
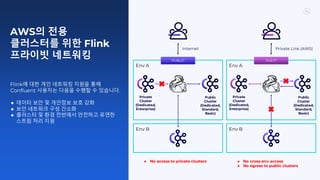
- 50. AWS의 전용 클러스터를 위한 Flink 프라이빗 네트워킹 Flink에 대한 개인 네트워킹 지원을 통해 Confluent 사용자는 다음을 수행할 수 있습니다. ● 데이터 보안 및 개인정보 보호 강화 ● 보안 네트워크 구성 간소화 ● 클러스터 및 환경 전반에서 안전하고 유연한 스트림 처리 지원 Env A Env A Env B Env B PUBLIC PLATT Internet Private Link (AWS) Private Cluster (Dedicated, Enterprise) Public Cluster (Dedicated, Standard, Basic) Private Cluster (Dedicated, Enterprise) Public Cluster (Dedicated, Standard, Basic) ● No access to private clusters ● No cross-env access ● No egress to public clusters
- 51. 55 Flink, KStreams 및 ksqlDB의 주요 차이점 Attribute CP Flink CC Flink Kafka Streams ksqlDB Description Stream processing framework developed independent of Apache Kafka Embeddable client library for Java applications that is part of the Apache Kafka project Stream processing framework that exposes Kafka Streams functionality through SQL Processing modes ● Unified stream and batch processing ● Supports reads from multiple Kafka clusters ● Stream processing only ● Supports reads from single Kafka cluster ● Stream processing only ● Supports reads from single Kafka cluster Pricing ● Restore state after failure from most recent incremental snapshot ● Restore state after failure by replaying all messages ● Restore state after failure by replaying all messages CFLT deployment model ● Self-managed offering with Confluent Platform ● Fully managed ● No cluster deployment, scales to zero ● Self-managed ● Embeddable client library with no cluster ● Fully managed and self- managed ● Separate cluster deployment Language flexibility ● Full support of all Flink APIs (SQL, Table API, DataStream, ProcessFunction) ● ANSI-compliant SQL ● Java UDFs EA ● Table API Open preview ● Java (more flexible than SQL, but more complex) ● SQL syntax inspired by ANSI SQL We recommend Confluent Cloud for Apache Flink for all new cloud workloads