Trivadis TechEvent 2016 Apache Kafka - Scalable Massage Processing and more! by Guido Schmutz
0 likes399 views

In this presentation Guido Schmutz talks about Apache Kafka, Kafka Core, Kafka Connect, Kafka Streams, Kafka and "Big Data"/"Fast Data Ecosystems, Confluent Data Platform and Kafka in Architecture.
































































Ad
More Related Content
What's hot (20)
Similar to Trivadis TechEvent 2016 Apache Kafka - Scalable Massage Processing and more! by Guido Schmutz (20)


![[Big Data Spain] Apache Spark Streaming + Kafka 0.10: an Integration Story](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataspainapachesparkstreamingkafka0-171117095800-thumbnail.jpg?width=560&fit=bounds)

![Building streaming data applications using Kafka*[Connect + Core + Streams] b...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingstreamingdataapplicationsusingapachekafka-171011211455-thumbnail.jpg?width=560&fit=bounds)













Ad
More from Trivadis (20)




















Ad
Recently uploaded (20)




















Trivadis TechEvent 2016 Apache Kafka - Scalable Massage Processing and more! by Guido Schmutz
- 1. BASEL BERN BRUGG DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. GENF HAMBURG KOPENHAGEN LAUSANNE MÜNCHEN STUTTGART WIEN ZÜRICH Apache Kafka Scalable Message Processing and more! Guido Schmutz @gschmutz guidoschmutz.wordpress.com
- 2. Agenda 1. Introduction & Motivation 2. Kafka Core 3. Kafka Connect 4. Kafka Streams 5. Kafka and ”Big Data” / ”Fast Data” Ecosystem 6. Confluent Data Platform 7. Kafka in Architecture 8. Summary Apache Kafka - Scalable Message Processing and more!3
- 3. Introduction & Motivation Apache Kafka - Scalable Message Processing and more!4
- 4. A little story of a “real-life” customer situation Traditional system interact with its clients and does its work Implemented using legacy technologies (i.e. PL/SQL) New requirement: • Offer notification service to notify customer when goods are shipped • Subscription and inform over different channels • Existing technology doesn’t fit delivery Logistic System Oracle Mobile Apps Sensor ship sort 5 Rich (Web) Client Apps D B schedule Logic (PL/SQL) delivery Apache Kafka - Scalable Message Processing and more!5
- 5. A little story of a “real-life” customer situation Events are “owned” by traditional application (as well as the channels they are transported over) Implement notification as a new Java-based application/system But we need the events ! => so let’s integrate delivery Logistic System Oracle Mobile Apps Sensor ship sort 6 Rich (Web) Client Apps D B schedule Notification Logic (PL/SQL) Logic (Java) delivery SMS Email … Apache Kafka - Scalable Message Processing and more!6
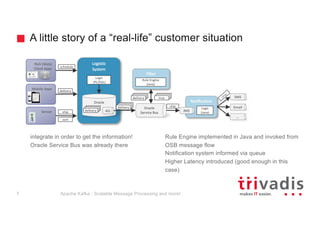
- 6. A little story of a “real-life” customer situation integrate in order to get the information! Oracle Service Bus was already there Rule Engine implemented in Java and invoked from OSB message flow Notification system informed via queue Higher Latency introduced (good enough in this case) delivery Logistic System Oracle Oracle Service Bus Mobile Apps Sensor AQship sort 7 Rich (Web) Client Apps D B schedule Filter Notification Logic (PL/SQL) JMS Rule Engine (Java) Logic (Java) delivery shipdelivery delivery true SMS Email … Apache Kafka - Scalable Message Processing and more!7
- 7. A little story of a “real-life” customer situation Treat events as first-class citizens Events belong to the “enterprise” and not an individual system => Catalog of Events similar to Catalog of Services/APIs !! Event (stream) processing can be introduced and by that latency reduced! delivery Logistic System Oracle Oracle Service Bus Mobile Apps Sensor AQship sort 8 Rich (Web) Client Apps D B schedule Filter Notification Logic (PL/SQL) JMS Rule Engine (Java) Logic (Java) delivery shipdelivery delivery true SMS Email … Apache Kafka - Scalable Message Processing and more!8
- 8. Treat Events as Events and share them! delivery Logistic System Oracle Oracle Service Bus Mobile Apps Sensor ship sort 9 Rich (Web) Client Apps D B schedule Filter Notification Logic (PL/SQL) JMS Rule Engine (Java) Logic (Java) delivery ship delivery true SMS Email … Event Bus/Hub Stream/Event Processing Apache Kafka - Scalable Message Processing and more!9
- 9. Treat Events as Events,share and make use of them! delivery Logistic System Oracle Mobile Apps Sensor ship sort 10 Rich (Web) Client Apps D B schedule Filter Notification Logic (PL/SQL) Rule Engine (Java) Logic (Java) delivery SMS Email … Event Bus/Hub Stream/Event Processing notifiableDelivery notifiableDelivery delivery Apache Kafka - Scalable Message Processing and more!10
- 10. Kafka Stream Data Platform Source: Confluent Apache Kafka - Scalable Message Processing and more!11
- 11. Kafka Core Apache Kafka - Scalable Message Processing and more!12
- 12. Apache Kafka - Overview Distributed publish-subscribe messaging system Designed for processing of real time activity stream data (logs, metrics collections, social media streams, …) Initially developed at LinkedIn, now part of Apache Does not use JMS API and standards Kafka maintains feeds of messages in topics Apache Kafka - Scalable Message Processing and more!13
- 13. Apache Kafka - Motivation LinkedIn’s motivation for Kafka was: • “A unified platform for handling all the real-time data feeds a large company might have.” Must haves • High throughput to support high volume event feeds. • Support real-time processing of these feeds to create new, derived feeds. • Support large data backlogs to handle periodic ingestion from offline systems. • Support low-latency delivery to handle more traditional messaging use cases. • Guarantee fault-tolerance in the presence of machine failures. Apache Kafka - Scalable Message Processing and more!14
- 14. Kafka High Level Architecture The who is who • Producers write data to brokers. • Consumers read data from brokers. • All this is distributed. The data • Data is stored in topics. • Topics are split into partitions, which are replicated. Kafka Cluster Consumer Consumer Consumer Producer Producer Producer Broker 1 Broker 2 Broker 3 Zookeeper Ensemble Apache Kafka - Scalable Message Processing and more!15
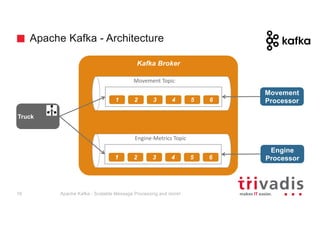
- 15. Apache Kafka - Architecture Kafka Broker Movement Processor Movement Topic Engine-Metrics Topic 1 2 3 4 5 6 Engine Processor1 2 3 4 5 6 Truck Apache Kafka - Scalable Message Processing and more!16
- 16. Apache Kafka - Architecture Kafka Broker Movement Processor Movement Topic Engine-Metrics Topic 1 2 3 4 5 6 Engine Processor Partition 0 1 2 3 4 5 6 Partition 0 1 2 3 4 5 6 Partition 1 Movement Processor Truck Apache Kafka - Scalable Message Processing and more!17
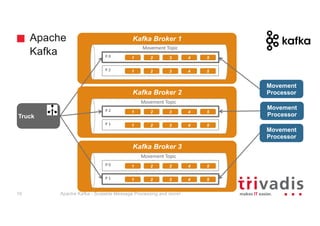
- 17. Apache Kafka Kafka Broker 1 Movement Processor Truck Movement Topic P 0 Movement Processor 1 2 3 4 5 P 2 1 2 3 4 5 Kafka Broker 2 Movement Topic P 2 1 2 3 4 5 P 1 1 2 3 4 5 Kafka Broker 3 Movement Topic P 0 1 2 3 4 5 P 1 1 2 3 4 5 Movement Processor Apache Kafka - Scalable Message Processing and more!18
- 18. Apache Kafka - Architecture • Write Ahead Log / Commit Log • Producers always append to tail • think append to file Kafka Broker Movement Topic 1 2 3 4 5 Truck 6 6 Apache Kafka - Scalable Message Processing and more!19
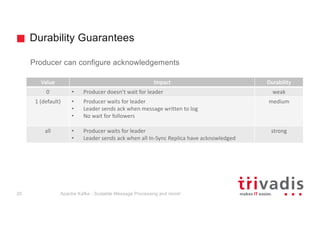
- 19. Durability Guarantees Producer can configure acknowledgements Value Impact Durability 0 • Producer doesn’t wait for leader weak 1 (default) • Producer waits for leader • Leader sends ack when message written to log • No wait for followers medium all • Producer waits for leader • Leader sends ack when all In-Sync Replica have acknowledged strong Apache Kafka - Scalable Message Processing and more!20
- 20. Apache Kafka - Partition offsets Offset: messages in the partitions are each assigned a unique (per partition) and sequential id called the offset • Consumers track their pointers via (offset, partition, topic) tuples Consumer Group A Consumer Group B Apache Kafka - Scalable Message Processing and more!21 Source: Apache Kafka
- 21. Data Retention – 3 options 1. Never 2. Time based (TTL) log.retention.{ms | minutes | hours} 3. Size based log.retention.bytes 4. Log compaction based (entries with same key are removed) kafka-topics.sh --zookeeper localhost:2181 --create --topic customers --replication-factor 1 --partitions 1 --config cleanup.policy=compact Apache Kafka - Scalable Message Processing and more!22
- 22. Apache Kafka – Some numbers Kafka at LinkedIn => over 1800+ broker machines / 79K+ Topics Kafka Performance at our own infrastructure => 6 brokers (VM) / 1 cluster • 445’622 messages/second • 31 MB / second • 3.0405 ms average latency between producer / consumer 1.3 Trillion messages per day 330 Terabytes in/day 1.2 Petabytes out/day Peak load for a single cluster 2 million messages/sec 4.7 Gigabits/sec inbound 15 Gigabits/sec outbound http://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines https://engineering.linkedin.com/kafka/running-kafka-scale Apache Kafka - Scalable Message Processing and more!23
- 23. Kafka Connect Apache Kafka - Scalable Message Processing and more!26
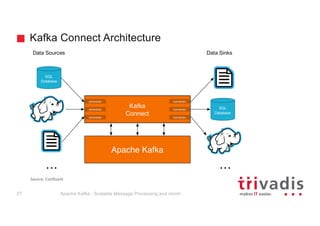
- 24. Kafka Connect Architecture Apache Kafka - Scalable Message Processing and more!27 Source: Confluent
- 25. Kafka Connector Hub – Certified Connectors Source: http://www.confluent.io/product/connectors Apache Kafka - Scalable Message Processing and more!28
- 26. Kafka Connector Hub – Additional Connectors Source: http://www.confluent.io/product/connectors Apache Kafka - Scalable Message Processing and more!29
- 27. Kafka Streams Apache Kafka - Scalable Message Processing and more!30
- 28. Kafka Streams • Designed as a simple and lightweight library in Apache Kafka • no external dependencies on systems other than Apache Kafka • Leverages Kafka as its internal messaging layer • agnostic to resource management and configuration tools • Supports fault-tolerant local state • Event-at-a-time processing (not microbatch) with millisecond latency • Windowing with out-of-order data using a Google DataFlow-like model Apache Kafka - Scalable Message Processing and more!31
- 29. Kafka Streams Architecture Apache Kafka - Scalable Message Processing and more!32 Source: Confluent
- 30. Kafka and ”Big Data” / ”Fast Data” Ecosystem Apache Kafka - Scalable Message Processing and more!33
- 31. Kafka and the Big Data / Fast Data ecosystem Kafka integrates with many popular products / frameworks • Apache Spark Streaming • Apache Flink • Apache Storm • Apache NiFi • Streamsets • Apache Flume • Oracle Stream Analytics • Oracle Service Bus • Oracle GoldenGate • Spring Integration Kafka Support • …Storm built-in Kafka Spout to consume events from Kafka Apache Kafka - Scalable Message Processing and more!34
- 32. Confluent Platform Apache Kafka - Scalable Message Processing and more!35
- 33. Confluent Data Platform 3.0 Apache Kafka - Scalable Message Processing and more!36 Source: Confluent
- 34. Kafka in Architecture Apache Kafka - Scalable Message Processing and more!37
- 35. Hadoop Clusterd Hadoop Cluster Hadoop Cluster Customer Event Hub – taking Velocity into account Location Social Click stream Sensor Data Billing & Ordering CRM / Profile Marketing Campaigns Call Center Mobile Apps Batch Analytics Streaming Analytics Event Hub Event Hub Event Hub NoSQL Parallel Processing Distributed Filesystem Stream Analytics NoSQL Reference / Models SQL Search Dashboard BI Tools Enterprise Data Warehouse Search Online & Mobile Apps File Import / SQL Import Weather Data Apache Kafka - Scalable Message Processing and more!38
- 36. Weather Data SQL Import Hadoop Clusterd Hadoop Cluster Hadoop Cluster Location Social Click stream Sensor Data Billing & Ordering CRM / Profile Marketing Campaigns Call Center Mobile Apps Batch Analytics Streaming Analytics Event Hub Event Hub Event Hub NoSQL Parallel Processing Distributed Filesystem Stream Analytics NoSQL Reference / Models SQL Search Dashboard BI Tools Enterprise Data Warehouse Search Online & Mobile Apps Customer Event Hub – mapping of technologies Apache Kafka - Scalable Message Processing and more!39
- 37. Summary Apache Kafka - Scalable Message Processing and more!40
- 38. Summary • Kafka can scale to millions of messages per second, and more • Easy to start with for a PoC • A bit more to invest to setup production environment • Monitoring is key • Vibrant community and ecosystem • Fast pace technology • Confluent provides Kafka Distribution Apache Kafka - Scalable Message Processing and more!41
- 39. Guido Schmutz Technology Manager [email protected] Apache Kafka - Scalable Message Processing and more!42 @gschmutz guidoschmutz.wordpress.com