TensorFlowで逆強化学習
32 likes17,894 views

TensorFlow 勉強会 (4) の発表資料です。 途中の動画を見るには↓の元ファイルを御覧ください。 https://docs.google.com/presentation/d/1CWHjeiDJovG4ymuaoGCFLiBcSHNuNccMQQYkoFtpHxc/pub?start=false&loop=false&delayms=3000








































![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=560&fit=bounds)






Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to TensorFlowで逆強化学習 (7)







Ad
TensorFlowで逆強化学習
- 2. 自己紹介 名前: 太田 満久 (おおたまん) 所属: 株式会社ブレインパッド 職種: エンジニアと分析官の間くらい 経歴: 博士(理学) => エンジニア => なんでも屋 - 広告関連の自社サービス開発 - 自然言語処理周りのアルゴリズム開発 - 機械学習・統計分析 - 深層学習 2
- 4. アジェンダ 1. 自己紹介 2. 逆強化学習とは 3. 逆強化学習の実例 4. 論文紹介 5. 簡単な例での実装 4
- 5. 逆強化学習とは 5
- 6. 「良い」ということ 場面や状況によって、様々な「良い」がある。 - 囲碁で勝った - ビデオゲームを攻略した - お客様に喜んでもらえた - いい論文が書けた - いい感じに運転できた 6
- 7. 「良い」の定量化 「良い」を定量的に定義できれば、強化学習を用いて「良い」状態に導くことができる - 囲碁 - 勝つと +1、負けると -1 - ビデオゲーム - 攻略したら +1 - 広告の最適化 - クリックしてくれたら +1 - 2足歩行ロボット - 転ばずに進めた距離 = 良さ 7
- 8. 「良い」の定義 現実には「良い」を定量的に定義することが難しい場面も多い XXX会社の◯◯が△△で ... で、ここんとこだけいい感じにして おいてね。 はい! (いい感じってなんやねん ) 8
- 9. 逆強化学習の目的 逆強化学習(Inverse Reinforcement Learning, IRL)とは、エキスパート(熟練者)の行動 をもとに、どの状態がどれくらい「良い」のかを推定すること 「良さ」を定量的に定義できれば、熟練者によく似た行動を生成することができる。(徒弟 学習) - 自動運転の場合 - どのレーンを走るべきか、ポリシーが人によって違う。そのレーンを選択した「理由」を逆強化 学習で求める、模倣することができる - ナビの場合 - 目的地までの時間、燃費、道の広さなど、複数の要因の組み合わせで経路の「良さ」がきま る。運転履歴から、何を重視しているかを推定し、模倣することができる - 非ゴール指向型対話の場合 - カウンセリングのようにゴールが明確でない対話の適切な「良さ」を定義できる 9
- 10. 強化学習と逆強化学習の関係 強化学習では、所与の「報酬 = 良さ」を元に、最適な戦略を推定する 逆強化学習では、最適な戦略から「報酬 = 良さ」を推定する ※ 推定された報酬から強化学習を用いて最適な行動を生成することもできる. 報酬 最適な行動 強化学習 逆強化学習 10
- 11. 逆強化学習の実例 11
- 12. ラジコン(ヘリコプター)の自律運転 熟練者の操縦ログから、アクロバット飛 行を学習 ✔ 「Split-S」や「Snap Roll」などの技を 披露 ✔ 熟練者以上に一貫した飛行が可能 Learning for Control from Multiple Demonstrations, Adam Coates, Pieter Abbeel, and Andrew Y. Ng. ICML, 2008. 12
- 13. 行動予測 人の行動軌跡から、「人の好む経路」を 学習 ✔ 行き先を指定して、「どの経路を通る か」を推定できる ✔ 芝生、歩道 … などの属性の価値を 推定しているので、別シーンへの適用 も可能 Kris Kitani, Brian D. Ziebart, J. Andrew Bagnell, and Martial Hebert, "Activity Forecasting," European Conference on Computer Vision (ECCV), October, 2012. 13
- 14. 安全運転 生活道路の危険予知運転をモデル化 ✔ 逆強化学習を用いた、ドライバーの 運転行動に基づいたモデル化 ✔ 安全に対する明確な基準がない生活 道路に対応 M. Shimosaka, T. Kaneko, K. Nishi. “Modeling risk anticipation and defensive driving on residential roads with inverse reinforcement learning.,” (ITSC 2014) 14
- 15. 論文紹介 15
- 16. 論文概要 タイトル: Maximum Entropy Deep Inverse Reinforcement Learning 著者: Markus Wulfmeier, Peter Ondruska, Ingmar Posner ✔ IRL の1手法である Maximum Entropy IRL を拡張 ✔ ニューラルネットを用い、複雑で非線形な報酬関数を近似 ✔ 簡単な実験で現時点で State of Art な手法(GPIRL)と同等以上の精度が、 高速に得られた 16
- 18. アルゴリズムのポイント1 熟練者は以下の確率で経路を選択していると仮定 この仮定により、報酬の不定性を解消できる (Ziebart et al., 2008) 18 ζ: 経路 r: 報酬 si: i番目の状態 Z: 分配関数 報酬の不定性 ある経路を最適(報酬が最大となる)とするような報酬は、複数設定できる。例えばすべての状態に対して r = 0 の 場合、どんな経路をとったとしても報酬の累積は 0 であり、すべての経路が最適となる。 逆強化学習では、こういった価値のない報酬を除外しなければならない。
- 19. アルゴリズムのポイント2 熟練者の経路の尤度を最大化する報酬を推定する 通常の誤差逆伝搬によりθを最適化できる 19 θ: ニューラルネットの変数 D: 熟練者の経路 μ: 状態頻度 g: 報酬の推定関数 正則化項 状態頻度の差とgの勾配の積となっている
- 20. 報酬の推定にニューラルネットを用いるメリット ✔ 現時点で State of Art な手法(GPIRL)と同等以上の精度が、高速に得られる ✔ 複雑で非線形な報酬関数でも推定することができる - 先行研究では、人が作成した特徴量の線形結合に限られていた ✔ 特徴量の抽出もニューラルネットの中で行うことができる - タスクごとに特徴量を人が作成する必要がない - 誤差逆伝搬法により、特徴量の抽出も同時に学習することができる 20
- 21. 簡単な例での実装 21
- 22. 問題設定 以下の要領で、迷路を逆強化学習で解 く 1. 強化学習により、迷路を解くエー ジェント(熟練者)を生成 2. 逆強化学習により、エージェントの 軌跡から報酬を推定 3. 推定された報酬から、最適な経路 を計算 22 スタート ゴール
- 24. 強化学習によるエージェント生成 ゴールのみに報酬(+1)を設定し、強化 学習によって最適な経路を通るエー ジェントを生成する ✔ 学習初期はランダムに探索 ✔ 学習後期はほぼ最適な経路を通る 24
- 25. 逆強化学習による報酬推定 強化学習で得たエージェントの軌跡をも とに、各座標の報酬を推定 特徴量: 座標(x, y)、タイプ(壁、道、ス タート、ゴール) ネットワーク : 2層のFC ✔ ゴールに最も高い報酬がふられた ー 初期値依存性が強く結果が安定しな い(ゴールは常に高報酬) 25
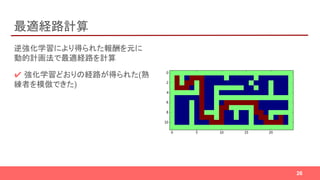
- 27. まとめ ✔ 逆強化学習という手法を紹介 ✔ 熟練者の行動から報酬を推定する ✔ 逆強化学習と深層学習を組み合わせた論文 (Deep MaxEnt IRL) を紹介 ✔ 論文を元に Deep MaxEnt IRL を実装 ✔ 迷路の例で動作を確認 27
- 28. 参考文献 逆強化学習を用いた生活道路における危険予知運転モデリング Apprenticeship Learning via Inverse Reinforcement Learning Inverse Reinforcement Learning Maximum Entropy Deep Inverse Reinforcement Learning 強化学習をベイズで理解する 28