Testing Machine Learning-enabled Systems: A Personal Perspective
2 likes1,193 views

Keynote presentation at the IEEE Int. Conference on Software Testing, Verification and Validation (ICST), 2021

























































)
RoadTopology
(CR = [10 40](m))
“non-critical” 31%
“critical” 69%
“non-critical” 72%
“critical” 28%](https://image.slidesharecdn.com/icst-briand-keynotetalk-210419110746/85/Testing-Machine-Learning-enabled-Systems-A-Personal-Perspective-58-320.jpg)














![DNN Heatmaps
• Generate heatmaps that capture the extent to which the pixels of
an image impacted on a specific result
• Limitations:
• Heatmaps should be manually inspected to determine the reason for
misclassification
• Underrepresented (but dangerous) failure causes might be unnoticed
• DNN debugging (i.e., improvement) not automated
73
An heatmap can show that long hair
is what caused a female doctor to be
classified as nurse [Selvaraju'16]](https://image.slidesharecdn.com/icst-briand-keynotetalk-210419110746/85/Testing-Machine-Learning-enabled-Systems-A-Personal-Perspective-73-320.jpg)




















































Ad
More Related Content
What's hot (20)
Similar to Testing Machine Learning-enabled Systems: A Personal Perspective (20)


















Ad
More from Lionel Briand (20)




















Ad
Recently uploaded (20)

![Download Wondershare Filmora Crack [2025] With Latest](https://cdn.slidesharecdn.com/ss_thumbnails/neo4j-howkgsareshapingthefutureofgenerativeaiatawssummitlondonapril2024-240426125209-2d9db05d-250419-250428115407-a04afffa-thumbnail.jpg?width=560&fit=bounds)


















Testing Machine Learning-enabled Systems: A Personal Perspective
- 1. Testing ML-enabled Systems: A Personal Perspective Lionel Briand http://www.lbriand.info ICST 2021
- 2. Acknowledgments 2 Hazem Fahmy Fabrizio Pastore Mojtaba Bagherzadeh Fitash Ul Haq Shiva Nejati Donghwan Shin
- 3. Published Reviews • Zhang et al. "Machine learning testing: Survey, landscapes and horizons." IEEE Transactions on Software Engineering (2020). • Riccio et al. "Testing machine learning based systems: a systematic mapping." Empirical Software Engineering 25, no. 6 (2020): 5193-5254. 3
- 5. Importance • ML components are increasingly part of safety- or mission- critical systems (ML-enabled systems - MLS) • Many domains, including aerospace, automotive, health care, … • Many ML algorithms, supervised vs. unsupervised, classification vs regression, etc. • But increasing use of deep learning and reinforcement learning 5
- 6. Example Applications in Automotive • Object detection, identification, classification, localization and prediction of movement • Sensor fusion and scene comprehension, e.g., lane detection • Driver monitoring • Driver replacement • Functional safety, security • Powertrains, e.g., improve motor control and battery management 6 Tian et al. 2018
- 7. ML-enabled Systems (MLS) 7 Sensors Controller Actuators Decision Sensors /Camera Environment ADAS
- 8. Testing Levels • Levels: Input, model, integration, system (Riccio et al., 2020) • Research largely focused on model testing • Integration: Issues that arise when multiple models and components are integrated • System: Test the MLS in its target environment, in-field or simulated • Cross-cutting concerns: scalability, realism 8
- 9. Information Access • Black-box: Model inputs and outputs • Data-box: Training and test set originally used (Riccio et al., 2020) • White-box: runtime state (neuron activation), hyperparameters, weight and biases • In practice, data-box and white-box access are not always guaranteed, e.g., third party provider 9
- 10. ML Model Testing Objectives • Correctness of classifications and predictions (regression) • Robustness (to noise or attacks) • Fairness (e.g., gender, race …) • Efficient: Learning and prediction speed • Failures: imperfect training (training set, overfitting …), hyper- parameters, model structure … • But what do these failures really entail for the system? 10
- 11. Challenges: Overview • Behavior driven by training data and learning process • Neither specifications nor code • Huge input space, especially for autonomous systems • Test suite adequacy, i.e., when is it good enough? • Automated oracles • Model results may be hard to interpret 11
- 12. Challenges 12
- 13. Large Input Space • Inputs take a variety of forms: images, code, text, simulation configuration parameters, … • Incredibly large input spaces • Cost of test execution (including simulation) can be high • Labelling effort, when no automation is possible, is high 13
- 14. 14 Automated Emergency Braking System (AEB) 14 “Brake-request” when braking is needed to avoid collisions Decision making Vision (Camera) Sensor Brake Controller Objects’ position/speed
- 15. AEB Input-Output Domain 15 - intensity: Real SceneLight Dynamic Object 1 - weatherType: Condition Weather - fog - rain - snow - normal «enumeration» Condition - field of view: Real Camera Sensor RoadSide Object - roadType: RT Road 1 - curved - straight - ramped «enumeration» RT - v0: Real Vehicle - x0: Real - y0: Real - θ: Real - v0: Real Pedestrian - x: Real - y: Real Position 1 * 1 * 1 1 - state: Boolean Collision Parked Cars Trees - simulationTime: Real - timeStep: Real Test Scenario AEB - certainty: Real Detection 1 1 1 1 1 1 1 1 «positioned» «uses» 1 1 - AWA Output Trajectory Environment inputs Mobile object inputs Outputs
- 16. Inputs: Adversarial or “Natural”? • Adversarial inputs: Focus on robustness, e.g., to noise or attacks • Natural inputs: Focus on functional aspects, e.g., functional safety 16
- 17. Adversarial Examples • Szegedy et al. first indicated an intriguing weakness of DNNs in the context of image classification • “Applying an imperceptible perturbation to a test image is possible to arbitrarily change the DNN’s prediction” 17 Adversarial example due to noise (Goodfellow et al., 2014)
- 18. Adversarial Inputs • Input changes that are not expected to lead to any (significant) change in model prediction or decision • Are often not realistic • Techniques: Image processing, image transformations (GAN), fuzzing … • Many papers, most not in software engineering venues 18
- 19. “Natural” Inputs • Functional aspects • Inputs should normally be realistic • May suffer from the oracle problem, i.e., what should be the expected classification or prediction for new inputs? 19
- 20. Generating Realistic Inputs • Characterizing and measuring realism (naturalness) of inputs • Domain-specific, semantic-preserving transformations • Metamorphic transformations and relations • High fidelity simulator 20
- 21. Single-Image Test Inputs • Several works have proposed in the context of ADAS, where the test inputs are generated by applying label-preserving changes to existing already-labeled data (Tian et al., Zhang et al., 2018) 21 Original image Test image (generated by adding fog)
- 22. Testing via Physics-based Simulation 22 ADAS (SUT) Simulator (Matlab/Simulink) Model (Matlab/Simulink) ▪ Physical plant (vehicle / sensors / actuators) ▪ Other cars ▪ Pedestrians ▪ Environment (weather / roads / traffic signs) Test input Test output time-stamped output
- 23. Test Scenarios • Most of existing research focus on • Testing DNN components, not systems containing them • Label-preserving changes, e.g., to images • Limited in terms of searching for functional (safety) violations • Research accounting for the impact of object dynamics (e.g., car speed) in different scenarios (e.g., specific configurations of roads) is limited. • ISO/PAS Road vehicles SOTIF requirements: In-the-loop testing of “relevant” scenarios in different environmental conditions 23
- 24. Test Adequacy Criteria • Work focused on DNNs, many papers (~30 criteria) • Neuron activation values, comparison of training and test data • Questionable empirical evaluations • Evaluations focused on finding adversarial inputs • Require access to the DNN internals and sometimes the training set. Not realistic in many practical settings. 24
- 25. Examples • Neuron coverage: counts activated neurons over total neurons (Tian et al., 2018) -- coarse and easy to achieve • Variants of neuron coverage: based on activation distributions during training, inspired by combinatorial testing, e.g., k- multisection neuron coverage and t-way combination sparse coverage (Ma et al., 2018) • Surprise adequacy: relying on the training data, calculate diversity of test inputs using continuous neuron activation values (Kim et al. 2019) 25
- 26. DeepImportance Coverage 26 The Importance-Driven test adequacy criterion of DeepImportance is satisfied when all combinations of important neurons clusters are exercised Gerasimou et al., 2020
- 27. Limitations • Code coverage assumes: • (1) the homogeneity of inputs covering the same part of a program • (2) the diversity of inputs as indicated by coverage metrics • According to Li et al. (2019): • these assumptions break down for DNNs and adversarial inputs • Using coverage and found adversarial inputs as a measure of robustness is questionable • There is a weak correlation between coverage and misclassification for natural inputs • Scalability for the most complex coverage metrics? 27
- 28. What is the purpose of coverage adequacy criteria?
- 29. Use Cases • Adequacy of test suites: Is the coverage metric a good indicator of “quality” (e.g., robustness, safety) for a DNN? • Guiding test generation to optimize coverage • Simulator: Search the configuration parameter space • Input transformations: Explore the space of possible transformations, e.g., weather and light transformations on road images • Support test selection, e.g., from image banks, a subset of images to be labelled, such as to optimize coverage 29
- 30. Comparison Criteria • Criteria: • Performance (accuracy, correlation …) • Prerequisites and assumptions , e.g., activation functions • Supported DNN architectures • Computational complexity • Instance-level or set-level analysis • Automation level • Existing empirical studies are not systematic and consistent 30
- 31. Use Cases vs. Performance • Model-level performance: mispredictions and misclassifications must be evaluated in the context of each use case • Test adequacy: correlation between coverage and mispredictions detected • Test selection: mispredictions detected for a given test set size • Test generation: cost-effectiveness of mispredictions detection, e.g., pace of increase in detections as test suite increases (e.g., APFD) 31
- 32. Failures in MLS • Model level: misclassifications, square error (regression) • Uncertainty inherent to ML training • What is a failure then in an MLS? • Expected robustness of MLS to ML errors • Domain-specific definition of failure at system level • MLS failures result from both mispredictions and effectiveness of countermeasures, e.g., safety monitors 32
- 33. Example: Key-points Detection • DNNs used for key-points detection in images • Many applications, e.g., face recognition • Testing: Find test suite that causes DNN to poorly predict as many key-points as possible within time budget • Impact of poor predictions on MLS? Alternative key-points can be used for the same purpose. 33 Ground truth Predicted
- 34. Oracles (1) • It may be difficult to manually determine the correct outputs of a model for a (large) set of inputs • Effort-intensive, third-party data labelling companies • Comparing multiple DNN implementations (practical? Effective?) • Semantic-preserving mutations, metamorphic transformations. May require domain expertise. 34
- 35. Oracles (2) • Domain-specific requirements, e.g., system safety violations • Simulators can help automate the oracle, if they have sufficient fidelity. Common in many industrial domains. • Mispredictions may be unavoidable, and accepted 35
- 36. Example: Key-points Detection 36 Input Generator Simulator Input (vector) DNN Fitness Calculator Actual Key-points Positions Predicted Key-points Positions Fitness Score (Error Value) Test Image Most Critical Test Input
- 37. Offline and Online Testing • For many MLS, considering single inputs is not adequate. Sequences must be considered as context. • Offline testing is less expensive but does not account for physical dynamics and cumulative effects of prediction uncertainty over time. • How do offline and online testing results differ and complement each other? 37 Offline Online
- 38. Simulation • A necessity for testing in most domains, e.g., avionics • Reduce cost and risk • Level of fidelity • Completeness and realism (scenario space) • Level of control through configuration parameters • Run-time efficiency • Technology varies widely across domains 38
- 39. Simulation+DNN Examples 39 Pylot + Carla Apollo + LGSVL High-fidelity simulators Carla LGSVL DNN-based ADAS Pylot: many DNN models Apollo: 20 DNN models
- 40. Offline vs. Online Testing? • How do offline and online testing results differ and complement each other? • For the same simulator-generated datasets, we compared the offline and online testing results 40 Fitash Ul Haq Shiva Nejati Donghwan Shin
- 41. Offline vs. Online Testing? • With online testing, in a closed-loop context, small prediction errors accumulate, eventually causing a critical lane departure • The experimental results imply that offline testing cannot properly reveal safety violations in ADAS-DNNs: It is too optimistic • But offline testing is the main focus of published research Online Testing Result Offline Testing Result
- 42. ML and Functional Safety • Requires to assess risks in a realistic fashion • Account for conditions and consequences of failures • Is the uncertainty associated with an ML model acceptable? • With ML, automated support is required, given the difficulties in interpreting model test results 42
- 43. Explaining Misclassifications • Based on visual heatmaps: use colors to capture the extent to which different features contribute to the misclassification of the input. • State-of-the-art • black-box techniques: perturbations of input image • white-box techniques: backward propagation of prediction score • They require, in our context, unreasonable amounts of manual analysis work to help explain safety violations based on image heatmaps 43 Black sheep misclassified as cow
- 44. Empirical Studies • Relatively few studies in industrial contexts, despite the widespread use of ML • Lesser focus on integration and system testing levels, much more studies at the model level • Limited domains: Focus on digit recognition and image classification at the model level, ADAS and a few other autonomous systems at the system level • No widespread agreement on how to perform such studies – every paper is different, e.g., Li et al. 2019 44
- 46. What are the factors affecting MLS testing solutions?
- 47. Objectives • Robustness to noise (e.g., sensors) and attacks? • Requirements (e.g., safety) violations • Testing level 47
- 48. Constraints • Importance of environment dynamics • Availability of simulator with sufficient fidelity • Availability of a data bank, e.g., road images • Access to model internal details, training set • Domain expertise, e.g., required for metamorphic transformations 48
- 49. Test Generation: Strategies • Input mutation with semantic-preserving transformations, e.g., changing weather or lighting conditions in images, adversarial attacks • Metamorphic transformations and relations, e.g., rotation of coordinates for drone control • Meta-heuristic search, for example through the configuration space of a simulator or an image bank 49
- 50. Many papers make general claims without clearly positioning themselves in the problem space
- 51. Example 1 • Robustness to real-world changes on images, e.g., weather, light, on automated driving decisions, e.g., steering angle • No oracle problem (classification or prediction should not change) • Solution: Generation with Generative Adversarial Network • Challenges: Limited to label-preserving changes to existing images, offline testing 51
- 52. Example 1 52 Snowy and rainy scenes synthesized by Generative Adversarial Network (GAN) Zhang et al. 2018
- 53. Example 2 • Autonomous driving system with important dynamics in the environments • Compliance with safety requirements • Online testing is therefore required • Availability of a high-fidelity simulator • No access to model internal information • Challenges: Computational complexity due to simulator, large input space 53
- 54. Example 2 54 ADAS (SUT) Simulator (Matlab/Simulink) Model (Matlab/Simulink) ▪ Physical plant (vehicle / sensors / actuators) ▪ Other cars ▪ Pedestrians ▪ Environment (weather / roads / traffic signs) Test input Test output time-stamped output Shiva Nejati Raja Ben Abdessalem Annibale Panichella
- 55. 55 Automated Emergency Braking System (AEB) 55 “Brake-request” when braking is needed to avoid collisions Decision making Vision (Camera) Sensor Brake Controller Objects’ position/speed
- 56. Our Approach • We use multi-objective search algorithm (NSGAII). • Objective Functions: • We use decision tree classification models to speed up the search and explain violations. • Each search iteration calls simulation to compute objective functions. 56 1. Minimum distance between the pedestrian and the field of view 2. The car speed at the time of collision 3. The probability that the object detected is a pedestrian
- 57. Multiple Objectives: Pareto Front 57 Individual A Pareto dominates individual B if A is at least as good as B in every objective and better than B in at least one objective. Dominated by x F1 F2 Pareto front x • A multi-objective optimization algorithm (e.g., NSGA II) must: • Guide the search towards the global Pareto-Optimal front. • Maintain solution diversity in the Pareto-Optimal front.
- 58. Decision Trees 58 Partition the input space into homogeneous regions All points Count 1200 “non-critical” 79% “critical” 21% “non-critical” 59% “critical” 41% Count 564 Count 636 “non-critical” 98% “critical” 2% Count 412 “non-critical” 49% “critical” 51% Count 152 “non-critical” 84% “critical” 16% Count 230 Count 182 vp 0 >= 7.2km/h vp 0 < 7.2km/h ✓p 0 < 218.6 ✓p 0 >= 218.6 RoadTopology(CR = 5, Straight, RH = [4 12](m)) RoadTopology (CR = [10 40](m)) “non-critical” 31% “critical” 69% “non-critical” 72% “critical” 28%
- 59. Genetic Evolution Guided by Classification 59 Initial input Fitness computation Classification Selection Breeding
- 60. Search Guided by Classification 60 Test input generation (NSGA II) Evaluating test inputs Build a classification tree Select/generate tests in the fittest regions Apply genetic operators Input data ranges/dependencies + Simulator + Fitness functions (candidate) test inputs Simulate every (candidate) test Compute fitness functions Fitness values Test cases revealing worst case system behaviors + A characterization of critical input regions
- 61. Generated Decision Trees 61 GoodnessOfFit RegionSize 1 5 6 4 2 3 0.40 0.50 0.60 0.70 tree generations (b) 0.80 7 1 5 6 4 2 3 0.00 0.05 0.10 0.15 tree generations (a) 0.20 7 GoodnessOfFit -crt 1 5 6 4 2 3 0.30 0.50 0.70 tree generations (c) 0.90 7 The generated critical regions consistently become smaller, more homogeneous and more precise over successive tree generations of NSGAII-DT
- 62. Engineers’ Feedback • The characterizations (decision trees) of the different critical regions can help with: (1) Debugging the system model (2) Identifying possible hardware changes to increase ADAS safety (3) Providing proper warnings to drivers 62
- 63. Meta-heuristic Search • An important solution element in MLS testing as well, perhaps even more important given the lack of specifications and code for ML components • Search guided by: • coverage, e.g., DNN neuron coverage • (safety) requirements • Research: Comparisons of white-box and black-box approaches? • Though in practice this is determined by practical considerations 63
- 64. Example: Key-points Detection •Automatically detecting key-points in an image or a video, e.g., face recognition, drowsiness detection • Key-point Detection DNNs (KP-DNNs) are widely used to detect key-points in an image •It is essential to check how accurate KP-DNNs are when applied to various test data 64 Ground truth Predicted
- 65. Problem Definition • In the drowsiness or gaze detection problem, each Key-Point (KP) may be highly important for safety • Each KP leads to a requirement and test objective • For our subject DNN, we have 27 requirements • Goal: cause the DNN to mis-predict as many key-points as possible • Solution: many-objective search algorithms combined with simulator 65 Fitash Ul Haq Donghwan Shin
- 66. Overview 66 Input Generator Simulator Input (vector) DNN Fitness Calculator Actual Key-points Positions Predicted Key-points Positions Fitness Score (Error Value) Most Critical Test Input Test Image
- 67. Results • Our approach is effective in generating test suites that cause the DNN to severely mispredict more than 93% of all key-points on average • Not all mispredictions can be considered failures … • Some key-points are more severely predicted than others, detailed analysis revealed two reasons: • Under-representation of some key-points (hidden) in the training data • Large variation in the shape and size of the mouth across different 3D models (more training needed) 67
- 68. Interpretation • Regression trees • Detailed analysis to find the root causes of high NE value, e.g., shadow on the location of KP26 is the cause of high NE value • The average MAE from all the trees is 0.01 (far less than the pre-defined threshold: 0.05) with average tree size of 25.7. Excellent accuracy, reasonable size. 68 Image Characteristics Condition NE ! = 9 ∧ # < 18.41 0.04 ! = 9 ∧ # ≥ 18.41 ∧ $ < −22.31 ∧ % < 17.06 0.26 ! = 9 ∧ # ≥ 18.41 ∧ $ < −22.31 ∧ 17.06 ≤ % < 19 0.71 ! = 9 ∧ # ≥ 18.41 ∧ $ < −22.31 ∧ % ≥ 19 0.36 Representative rules derived from the decision tree for KP26 (M: Model-ID, P: Pitch, R: Roll, Y: Yaw, NE: Normalized Error) (A) A test image satisfying the first condition (B) A test image satisfying the third condition NE = 0.013 NE = 0.89
- 69. Search techniques are determined by the above-mentioned problem definition factors
- 70. Safety Engineering for ML Systems • Understand conditions of critical failures in various settings • Simulator: In terms of configuration parameters • Real images: In terms of the presence of concepts • Required for risk assessment • Research: Techniques to achieve such understanding 70
- 71. Typical DNN Evaluation • Example with images 71 Step A. DNN Training DNN model Step B. DNN Testing Error-inducing test set images Training set images Test set images DNN accuracy
- 72. Identification of Unsafe Situations • Current practice is based on manual root cause analysis: identification of the characteristics of the system inputs that induce the DNN to generate erroneous results • manual inspection is error prone (many images) • automated identification of such characteristics is the objective of research on DNN safety analysis approaches 72
- 73. DNN Heatmaps • Generate heatmaps that capture the extent to which the pixels of an image impacted on a specific result • Limitations: • Heatmaps should be manually inspected to determine the reason for misclassification • Underrepresented (but dangerous) failure causes might be unnoticed • DNN debugging (i.e., improvement) not automated 73 An heatmap can show that long hair is what caused a female doctor to be classified as nurse [Selvaraju'16]
- 74. Heatmap-based Unsupervised Debugging of DNNs (HUDD) Rely on hierarchical agglomerative clustering to identify the distinct root causes of DNN errors in the heatmaps of internal DNN layers and use this information to automatically retrain the DNN 74 Hazem Fahmy Fabrizio Pastore Mojtaba Bagherzadeh
- 75. • Classification • Gaze Detection • Open/Closed Eyes Detection • Headpose detection • Regression • Landmarks detection 75 90 270 180 0 45 22.5 67.5 337.5 315 292.5 247.5 225 202.5 157.5 135 112.5 Top Center B o t t o m L e f t Bottom Center B o t t o m R i g h t Top Right Middle Right T o p L e f t Middle Left Example Applications
- 76. 76 Step1. Heatmap based clustering Root cause clusters C1 Step 5. Label images Step 4. Identify Unsafe Images Error-inducing TestSet images + TrainSet images Unsafe Set: improvement set images belonging to the root cause clusters C2 C3 Simulator execution Step 3. Generate new images Collection of field data Improvement set: new images (unlabeled) C1 C2 C3 Labeled Unsafe Set C1 C2 C3 Step 6. DNN Retraining Legend: Manual Step Automated Step Data flow Step 2. Inspection of subset of cluster elements. Training set images Balanced Labeled Unsafe Set C1 C2 C3 Improved DNN model Step 6. Bootstrap Resampling HUDD
- 77. for both the input and the internal layers 77 77 • Classification • Regression (worst landmark propagation) Heatmap Generation
- 78. Heatmap Clustering 78 LRP Agglomerative Hierarchical Clustering ... ... Clusters for Layer 1 Comparison to identify Best Layer for Clustering Heatmaps at Layer 1 Layer 1 Layer N ... Clusters for Layer N Distance Matrices Error-inducing test set images Root Cause Clusters Heatmaps at Layer N
- 79. Clusters identify different problems Cluster 1 (angle ~157.5) borderline cases Cluster3 (closed eyes) incomplete training set 79 Cluster 2 (eye middle center) incomplete set of classes
- 80. Safety analysis techniques are driven by the type of inputs and how risk is evaluated
- 81. MLS Robustness • Inherent uncertainty in ML models • Research: Testing robustness and mitigation mechanisms in MLS for misclassifications or mispredictions • Goal: We want to learn, as accurately as possible, the subspace in the space defined by I’ and O’ that leads to system safety violations • Applications: This is expected to help guide and focus the testing of B and implement safety monitors for it. 81
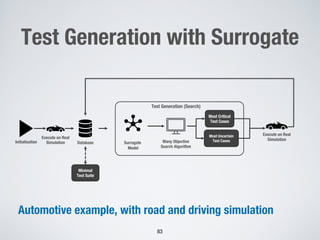
- 82. Surrogate Models • Online testing, coupled with a simulator, is highly important in many domains, such as autonomous driving systems. • E.g., more likely to find safety violations • But online testing is computationally expensive • Surrogate model: Model that mimics the simulator, to a certain extent, while being much less computationally expensive • Research: Combine search with surrogate modeling to decrease the computational cost of testing 82
- 83. Test Generation with Surrogate Automotive example, with road and driving simulation 83 Initialisation Execute on Real Simulation Database Execute on Real Simulation Surrogate Model Many Objective Search Algorithm Most Critical Test Cases Most Uncertain Test Cases Test Generation (Search) Minimal Test Suite
- 84. Oracles • Automation is key • Learn metamorphic relations from user interactions, e.g., with active learning? • Methodologies for stochastic oracles • Comparisons of different types of oracles, e.g., metamorphic relations, simulator output, in different situations 84
- 85. Empirical Studies • Methodological issues, e.g., mutations • Non-determinism in training • Generalizability (benchmarks etc.) • Computational costs and scalability of solutions should be assessed, not just fault detection effectiveness • Evaluation of models in MLS context 85
- 86. Conclusions 86
- 87. Testing Community • It contributes by adapting techniques from classical software testing • SBST • Adequacy criteria • Metamorphic testing • Mutation analysis • Empirical methodology for software testing 87
- 88. Re-Focus Research (1) • But, as usual, research is taking the path of least resistance but we need to shift the focus to increase impact • More focus on integration and system testing • Not only model accuracy, but model-induced risks within a system • Safety engineering in MLS • More focus on black-box approaches • Comparisons between white-box and black box approaches 88
- 89. Re-Focus Research (2) • More industrial case studies, especially outside the automotive domain • Beyond the perception layer, the control aspects need to be considered as well • Online testing for autonomous systems, with hardware-in- the-loop • Scalability issues, e.g., due to simulations, large networks • Beyond stateless DNNs: Reinforcement learning … 89
- 90. Testing ML-enabled Systems: A Personal Perspective Lionel Briand http://www.lbriand.info ICST 2021
- 91. References 91
- 92. Selected References • Briand et al. "Testing the untestable: model testing of complex software-intensive systems." In Proceedings of the 38th international conference on software engineering companion, pp. 789-792. 2016. • Ul Haq et al. "Comparing offline and online testing of deep neural networks: An autonomous car case study." In 2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST), pp. 85-95. IEEE, 2020. • Ul Haq et al. "Can Offline Testing of Deep Neural Networks Replace Their Online Testing?." arXiv preprint arXiv:2101.11118 (2021). • Ul Haq et al. "Automatic Test Suite Generation for Key-points Detection DNNs Using Many-Objective Search." ACM International Symposium on Software Testing and Analysis (ISSTA 2021), preprint arXiv:2012.06511 (2020). • Fahmy et al. "Supporting DNN Safety Analysis and Retraining through Heatmap-based Unsupervised Learning." IEEE Transactions on Reliability, Special section on Quality Assurance of Machine Learning Systems, preprint arXiv:2002.00863 (2020). • Ben Abdessalem et al., "Testing Vision-Based Control Systems Using Learnable Evolutionary Algorithms”, ICSE 2018 • Ben Abdessalem et al., "Testing Autonomous Cars for Feature Interaction Failures using Many-Objective Search”, ASE 2018 92
- 93. Selected References • Goodfellow et al. "Explaining and harnessing adversarial examples." arXiv preprint arXiv:1412.6572 (2014). • Zhang et al. "DeepRoad: GAN-based metamorphic testing and input validation framework for autonomous driving systems." In 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), 2018. • Tian et al. "DeepTest: Automated testing of deep-neural-network-driven autonomous cars." In Proceedings of the 40th international conference on software engineering, 2018. • Li et al. “Structural Coverage Criteria for Neural Networks Could Be Misleading”, IEEE/ACM 41st International Conference on Software Engineering: New Ideas and Emerging Results (NIER) • Kim et al. "Guiding deep learning system testing using surprise adequacy." In IEEE/ACM 41st International Conference on Software Engineering (ICSE), 2019. • Ma et al. "DeepMutation: Mutation testing of deep learning systems." In 2018 IEEE 29th International Symposium on Software Reliability Engineering (ISSRE), 2018. • Zhang et al. "Machine learning testing: Survey, landscapes and horizons." IEEE Transactions on Software Engineering (2020). • Riccio et al. "Testing machine learning based systems: a systematic mapping." Empirical Software Engineering 25, no. 6 (2020) • Gerasimou et al., “Importance-Driven Deep Learning System Testing”, IEEE/ACM 42nd International Conference on Software Engineering, 2020 93
- 94. Backup 94
- 95. Testing in ISO 26262 • Several recommendations for testing at the unit and system levels • e.g., Different structural coverage metrics, black-box testing • However, such testing practices are not adequate for MLS • The input space of ADAS is much larger than traditional automotive systems. • No specifications or code for DNN components. • MLS may fail without the presence of a systematic fault, e.g., inherent limitations, incomplete training. • Imperfect environment simulators. • Traditional testing notions (e.g., coverage) are not clear for DNN components. 95
- 96. SOTIF • ISO/PAS 21448:2019 standard: Safety of the intended functionality (SOTIF). • Autonomy: Huge increase in functionalities relying on advanced sensing, algorithms (ML), and actuation. • SOTIF accounts for limitations and risks related to nominal performance of sensors and software: • The inability of the function to correctly comprehend the situation and operate safely; this also includes functions that use machine learning algorithms; • Insufficient robustness of the function with respect to sensor input variations or diverse environmental conditions. 96