TEXT SENTIMENTS FOR FORUMS HOTSPOT DETECTION
0 likes5 views

The paper proposes a novel method for detecting online hotspot forums by utilizing sentiment analysis on text data from forums, integrating k-means clustering and a support vector machine with particle swarm optimization (svm-pso) for classification. It focuses on distinguishing between hotspot and non-hotspot forums based on user engagement metrics and sentiment values. Experimental results demonstrate the effectiveness of the proposed approach over traditional classification algorithms, achieving high consistency and accuracy in identifying popular forums over specific time windows.
![International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012
DOI : 10.5121/ijist.2012.2304 53
TEXT SENTIMENTS FOR FORUMS HOTSPOT
DETECTION
K. Nirmala Devi1
and Dr. V. Murali Bhaskarn2
1
Department of CSE, Kongu Engineering College, Perundurai, Erode, Tamil Nadu
k_nirmal@kongu.ac.in
2
Principal, Paavai College of Engineering, Pachal, Namakkal, Tamil Nadu
murali66@gmail.com
ABSTRACT
The user generated content on the web grows rapidly in this emergent information age. The evolutionary
changes in technology make use of such information to capture only the user’s essence and finally the
useful information are exposed to information seekers. Most of the existing research on text information
processing, focuses in the factual domain rather than the opinion domain. In this paper we detect online
hotspot forums by computing sentiment analysis for text data available in each forum. This approach
analyses the forum text data and computes value for each word of text. The proposed approach combines
K-means clustering and Support Vector Machine with PSO (SVM-PSO) classification algorithm that can be
used to group the forums into two clusters forming hotspot forums and non-hotspot forums within the
current time span. The proposed system accuracy is compared with the other classification algorithms such
as Naïve Bayes, Decision tree and SVM. The experiment helps to identify that K-means and SVM-PSO
together achieve highly consistent results.
KEYWORDS
Sentiment analysis, SVM-PSO, hot spot, k-means, Text mining
1. INTRODUCTION
Data mining is the process of nontrivial extraction of implicit, previously unknown, and
potentially useful information from data that can help the businesses to make proactive and
knowledge driven decisions. It uses machine learning, statistical and visualization techniques to
discover and present knowledge that previously went unnoticed. Opinion mining is an important
sub discipline within data mining and natural language processing (NLP), which automatically
extracts, classifies, and understands the opinion generated by various users. These techniques also
help to enhance the value of existing information resources that can be integrated with new
products and systems as they are brought on-line.
The growth of tremendous amount of online information from various forums has made very
difficult for the customers to acquire information that are useful to them. This has motivated on
the detection of hotspot forums [5] where useful information are quickly made available for those
customers which might make them benefit in decision making process. In topic-based
classification, topic related words are important.](https://image.slidesharecdn.com/2312ijist04-240104111310-879741c1/85/TEXT-SENTIMENTS-FOR-FORUMS-HOTSPOT-DETECTION-1-320.jpg)
![International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012
54
Efficient statistical and machine learning techniques can be applied to process the enormous
amount of online data. An emergent technique called Emotional polarity computation also
known as sentiment analysis [6] can also be performed during online text mining. However, in
opinion classification, topic-related words are not very important. But, opinion words that
indicate positive or negative opinions are important, e.g., great, excellent, amazing, horrible, bad,
worst, etc. Most of the methodologies for opinion mining apply some forms of machine learning
techniques for classification.
Customized-algorithms specifically for opinion classification have also been developed, which
exploit opinion words and phrases together with some scoring functions. In this paper we detect
the hotspot forums by computing text sentiment analysis. This method quantifies the user
attention on any forum with which hotspot forums can be identified. The proposed work is then
integrated with K-means clustering and Support Vector Machine with Particle Swarm
Optimization (SVM-PSO) algorithm. It optimally groups the forums into two clusters, forming
hotspot forums and non-hotspot forums within each time window.
The rest of the paper is structured as follows: Section 2 discusses related works that describes
various existing semantic orientation- based sentiment classification approaches. The proposed
Support Vector Machine along with Particle Swarm Optimization (SVM-PSO) algorithm is
discussed in Section 3. The experimental results were discussed in Section 4. Finally Section 5
concludes the paper.
2. RELATED WORK
This section focuses various streams of related work such as analysis of review mining, sentiment
classification, machine learning techniques for predicting hotspots.
2.1. Analysis of Review Mining
Mining of online reviews has become a flourishing frontier in today’s environment as it can
provide a solid basis for predicting future events. For example Zhou et al in 2005 [1] has stated
that online reviews became more useful and influence the sales as it provides important
information about the product to potential consumers.
A multi-knowledge based approach is proposed where WordNet, statistical analysis and movie
knowledge are integrated. The experimental results have shown the effectiveness of the approach
in movie review mining and summarizing.
Hu et al [4], in his work has proposed a method in which a generated and semantic orientation
labelled list containing only adjectives are used for analysing. Finally it is observed that machine
learning is used to depict the interacting structure of reviews.
2.2. Sentiment Classification
The documents available on the web can be classified based on various metrics including topics,
authors, structures, and so forth. Classification based on sentiments has become a new frontier to
text mining community. The task of sentiment classification is to determine the semantic
orientations of words, sentences or documents. Most of the early work on this topic used words as
the processing unit.](https://image.slidesharecdn.com/2312ijist04-240104111310-879741c1/85/TEXT-SENTIMENTS-FOR-FORUMS-HOTSPOT-DETECTION-2-320.jpg)
![International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012
55
An automatic sentiment classification at document level has been done by Pang and
Vaithyanathan[7] in which several machine learning approaches are used with common text
features to classify movie reviews from IMDB. It has been pointed out that direct marketing is a
promotion process which has motivated customers to place orders through various channels [6,9].
In order to work for this, one is needed to have an accurate customer segmentation based on a
good understanding of the customers, so that relevant product information can be delivered to
different customer segments. Thelwall et al. [11] has stated that analysing Twitter has given
insights into why certain events resonate with the people.
It is found that the customers, who are used to having only a limited range of product choices due
to physical and/or time constraints, are now facing the problem of information overload. An
effective way of increasing customer satisfaction and consequently customer loyalty has been
done that has helped the customers identify products according to their interests. This again has
called for the provision of personalized product recommendations [8, 9]. Hofmann and Puzicha in
their work have used the Latent Class Model (LCM) to circumvent the aforementioned problems.
Paltoglou and Thelwall [2,10] have explored in their work that incorporating sentiment
information into Vector Space Model (VSM) values using supervised methods was helpful for
sentiment analysis.
2.3. Machine Learning Techniques for Predicting Hot Spots
For predicting online hotspot forums two machine learning techniques [5] have been proposed by
Nan Li and Dash. It includes K-means and SVM. Unlike other learning methods, SVM’s
performance is related not to the number of features in the system, but to the margin with which it
separates the data. SVM [3] achieves a clustering result by exactly classifying each forum as
either hotspot forum or non-hotspot forum.
3. PROPOSED WORK
The proposed work helps in detecting hotspot forums and achieves highly consistent results by
applying an efficient optimization algorithm with SVM-PSO. Figure 1 depicts the conceptual
diagram of proposed approach.](https://image.slidesharecdn.com/2312ijist04-240104111310-879741c1/85/TEXT-SENTIMENTS-FOR-FORUMS-HOTSPOT-DETECTION-3-320.jpg)




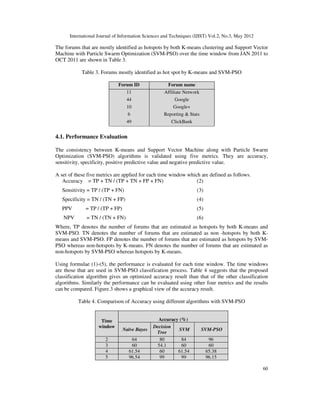
![International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012
61
6 60 62.22 60 73.33
7 84.38 80.99 81.25 84.38
8 68.57 64 65.71 68.57
9 90 93.1 94.59 94.59
10 48.65 58.2 60 74
Figure 3. Accuracy comparison while using SVM-PSO and other algorithms
5. CONCLUSIONS
This paper proposes a new approach for predicting hotspot forums. In this approach emotional
polarity of the text is obtained by computing a value for each piece of text. After calculating the
sentiment values the method is then integrated with K-means clustering and SVM-PSO
classification algorithms for forums cluster analysis. Computation indicates both K-means and
SVM-PSO produce consistent grouping results. Thus the efficient detection of hotspot
forums based on sentiment analysis might make internet social network members benefit in the
decision making process.
REFERENCES
[1] Chaovalit P. and Zhou L.(2005), “Movie review mining: a comparison between supervised and
unsupervised classification approaches”, Proceedings of the 38th Hawaii International Conference on
System Sciences.
[2] Paltoglou and Thelwall M.(2010), “A study of information retrieval weighting schemes for sentiment
analysis”, In Proceedings of the ACL, pp 1386–1395.
[3] Nirmala Devi K ., Preethi T., and Murali Bhaskaran V.(2012), “A semantic enhanced approach for
online hotspot forums detection”, Proceedings of second International Conference on Recent Trends
in Information Technology ,pp 497-501.
[4] Hu M., and Liu B.(2004), “Mining and summarizing customer reviews”, Proceedings of ACM
Transactions on Knowledge and Data Engineering, pp168-177.
[5] Nan Li., and Wu Dash D. (2010) “Using text mining and sentiment analysis for online forums hotspot
detection and forecast” Decision Support Systems 48, pp 354–368.](https://image.slidesharecdn.com/2312ijist04-240104111310-879741c1/85/TEXT-SENTIMENTS-FOR-FORUMS-HOTSPOT-DETECTION-9-320.jpg)
![International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012
62
[6] Li, M. Huang, and X. Zhu. (2010) “Sentiment analysis with global topics and local dependency”, In
Proceedings of AAAI, pp 1371–1376.
[7] Pang B., Lee L., Vaithyanathan S.(2002), “Thumbs up? Sentiment classification using machine
learning techniques”, Proceedings of the Conference on Empirical Methods in Natural Language
Processing, pp 79-86.
[8] Popescu A. and Etzioni O.(2005), “Extracting product features and opinions from reviews”,
Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp339-346.
[9] Sindhwani S. and Mellville A.(2008), “Document-Word Co regularization for Semi-supervised
Sentiment Analysis”, Eighth IEEE International Conference on Publication, pp1025 – 1030.
[10] Thelwall M., Kevan B., Paltoglou G., Cai D., Kappas A.(2010), “Sentiment strength detection in
short informal text”, Journal of the American Society for Information Science and Technology,
pp2544–2558.
[11] Thelwall M., Buckley K., and Paltoglo G.(2011), “Sentiment in Twitter Events”, Journal of the
American Society for Information Science and Technology, 62(2), pp 406–418.
Authors
Dr. V.Murali Bhaskaran, M.E., Ph.D., Principal, Paavai College of Engineering, Pachal,
Namakkal-637 018, India, He obtained his Bachelors degree in Computer Science and
Engineering,” from Bharathidasan University, Thiruchirapalli and MS in Computer
Science from BITS, Pilani and Masters Degree in Computer Science and Engineering from
Bharathiyar University, Coimbatore. He completed PhD in Network Security from
Bharathiyar University, Coimbatore. He presented 22 papers in National and International
Conferences. He published 14 papers in international journals. He is presently working as
a Principal of Paavai College of Engineering, Pachal, Namakkal. He received the “Best Staff” award for
the year 1991- 1992 at Sathyabama Engineering College, Chennai. and 2002-2003 in Kongu Engineering
College, Perundurai. He is guiding 10 research scholars and his area of interest is Cryptography and
Network Security, High Speed Networks, and Computer Architecture.
K. Nirmala Devi, M.C.A, M.E., (Ph.D)., Assistant Professor(SLG), Kongu Engineering
College, Perundurai, Erode-638 052, India. She obtained her Bachelors degree in
Computer Science from Bharathiar University, Coimbatore and Masters of Computer
Applications from Bharathiar University, Coimbatore and M.E degree in CSE from Anna
University, Chennai. She is currently doing research in Data mining under Anna
University, Coimbatore. She is presently working as a Assistant Professor(SLG ) in the
Department of Computer Science and Engineering, Kongu Engineering College,
Perundurai, Tamilnadu, India. Her area of interest is Data mining, Soft Computing, Data structures and
analysis of algorithms, and Compiler Design. She has presented papers in National and international
conferences and also published papers in national and international journals.](https://image.slidesharecdn.com/2312ijist04-240104111310-879741c1/85/TEXT-SENTIMENTS-FOR-FORUMS-HOTSPOT-DETECTION-10-320.jpg)
TEXT SENTIMENTS FOR FORUMS HOTSPOT DETECTION
- 1. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 DOI : 10.5121/ijist.2012.2304 53 TEXT SENTIMENTS FOR FORUMS HOTSPOT DETECTION K. Nirmala Devi1 and Dr. V. Murali Bhaskarn2 1 Department of CSE, Kongu Engineering College, Perundurai, Erode, Tamil Nadu [email protected] 2 Principal, Paavai College of Engineering, Pachal, Namakkal, Tamil Nadu [email protected] ABSTRACT The user generated content on the web grows rapidly in this emergent information age. The evolutionary changes in technology make use of such information to capture only the user’s essence and finally the useful information are exposed to information seekers. Most of the existing research on text information processing, focuses in the factual domain rather than the opinion domain. In this paper we detect online hotspot forums by computing sentiment analysis for text data available in each forum. This approach analyses the forum text data and computes value for each word of text. The proposed approach combines K-means clustering and Support Vector Machine with PSO (SVM-PSO) classification algorithm that can be used to group the forums into two clusters forming hotspot forums and non-hotspot forums within the current time span. The proposed system accuracy is compared with the other classification algorithms such as Naïve Bayes, Decision tree and SVM. The experiment helps to identify that K-means and SVM-PSO together achieve highly consistent results. KEYWORDS Sentiment analysis, SVM-PSO, hot spot, k-means, Text mining 1. INTRODUCTION Data mining is the process of nontrivial extraction of implicit, previously unknown, and potentially useful information from data that can help the businesses to make proactive and knowledge driven decisions. It uses machine learning, statistical and visualization techniques to discover and present knowledge that previously went unnoticed. Opinion mining is an important sub discipline within data mining and natural language processing (NLP), which automatically extracts, classifies, and understands the opinion generated by various users. These techniques also help to enhance the value of existing information resources that can be integrated with new products and systems as they are brought on-line. The growth of tremendous amount of online information from various forums has made very difficult for the customers to acquire information that are useful to them. This has motivated on the detection of hotspot forums [5] where useful information are quickly made available for those customers which might make them benefit in decision making process. In topic-based classification, topic related words are important.
- 2. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 54 Efficient statistical and machine learning techniques can be applied to process the enormous amount of online data. An emergent technique called Emotional polarity computation also known as sentiment analysis [6] can also be performed during online text mining. However, in opinion classification, topic-related words are not very important. But, opinion words that indicate positive or negative opinions are important, e.g., great, excellent, amazing, horrible, bad, worst, etc. Most of the methodologies for opinion mining apply some forms of machine learning techniques for classification. Customized-algorithms specifically for opinion classification have also been developed, which exploit opinion words and phrases together with some scoring functions. In this paper we detect the hotspot forums by computing text sentiment analysis. This method quantifies the user attention on any forum with which hotspot forums can be identified. The proposed work is then integrated with K-means clustering and Support Vector Machine with Particle Swarm Optimization (SVM-PSO) algorithm. It optimally groups the forums into two clusters, forming hotspot forums and non-hotspot forums within each time window. The rest of the paper is structured as follows: Section 2 discusses related works that describes various existing semantic orientation- based sentiment classification approaches. The proposed Support Vector Machine along with Particle Swarm Optimization (SVM-PSO) algorithm is discussed in Section 3. The experimental results were discussed in Section 4. Finally Section 5 concludes the paper. 2. RELATED WORK This section focuses various streams of related work such as analysis of review mining, sentiment classification, machine learning techniques for predicting hotspots. 2.1. Analysis of Review Mining Mining of online reviews has become a flourishing frontier in today’s environment as it can provide a solid basis for predicting future events. For example Zhou et al in 2005 [1] has stated that online reviews became more useful and influence the sales as it provides important information about the product to potential consumers. A multi-knowledge based approach is proposed where WordNet, statistical analysis and movie knowledge are integrated. The experimental results have shown the effectiveness of the approach in movie review mining and summarizing. Hu et al [4], in his work has proposed a method in which a generated and semantic orientation labelled list containing only adjectives are used for analysing. Finally it is observed that machine learning is used to depict the interacting structure of reviews. 2.2. Sentiment Classification The documents available on the web can be classified based on various metrics including topics, authors, structures, and so forth. Classification based on sentiments has become a new frontier to text mining community. The task of sentiment classification is to determine the semantic orientations of words, sentences or documents. Most of the early work on this topic used words as the processing unit.
- 3. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 55 An automatic sentiment classification at document level has been done by Pang and Vaithyanathan[7] in which several machine learning approaches are used with common text features to classify movie reviews from IMDB. It has been pointed out that direct marketing is a promotion process which has motivated customers to place orders through various channels [6,9]. In order to work for this, one is needed to have an accurate customer segmentation based on a good understanding of the customers, so that relevant product information can be delivered to different customer segments. Thelwall et al. [11] has stated that analysing Twitter has given insights into why certain events resonate with the people. It is found that the customers, who are used to having only a limited range of product choices due to physical and/or time constraints, are now facing the problem of information overload. An effective way of increasing customer satisfaction and consequently customer loyalty has been done that has helped the customers identify products according to their interests. This again has called for the provision of personalized product recommendations [8, 9]. Hofmann and Puzicha in their work have used the Latent Class Model (LCM) to circumvent the aforementioned problems. Paltoglou and Thelwall [2,10] have explored in their work that incorporating sentiment information into Vector Space Model (VSM) values using supervised methods was helpful for sentiment analysis. 2.3. Machine Learning Techniques for Predicting Hot Spots For predicting online hotspot forums two machine learning techniques [5] have been proposed by Nan Li and Dash. It includes K-means and SVM. Unlike other learning methods, SVM’s performance is related not to the number of features in the system, but to the margin with which it separates the data. SVM [3] achieves a clustering result by exactly classifying each forum as either hotspot forum or non-hotspot forum. 3. PROPOSED WORK The proposed work helps in detecting hotspot forums and achieves highly consistent results by applying an efficient optimization algorithm with SVM-PSO. Figure 1 depicts the conceptual diagram of proposed approach.
- 4. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 56 Figure 1. Conceptual diagram of the proposed approach 3.1. Pre processing The data set used in our experimental research is acquired from forums.digitalpoint.com and after data cleaning they are formatted to 37 different forums and 1616 threads. The data collection is initiated by crawling the forum names of first 50 forums. The parsed forum names are then stored in a table. Then all the thread posts and the reply posts contained in the corresponding web pages are parsed and they are stored separately in a table. After crawling process is achieved data cleaning is done where noise data and irrelevant data are manually removed. Noise data include forums with picture postings that are not clearly shown online. Irrelevant data are from forums where the posting contents are not related to the forum threads at all. The threads that have no replies and the forums that have no threads across the time window are also removed. The data before cleaning and after cleaning are listed in Table 1. Finally after cleaning, 37 forums are narrowed down within the time span from January to October and each time window is of a month length over the year 2011. Table 1. Data view before cleaning and after cleaning Before cleaning After cleaning Time period 2007 Jan to 2011 Oct 2011 Jan to 2011 Oct Number of forums 50 37 Number of threads 2430 1616 Number of replies 39239 19370 K-means clustering model SVM-PSO classification model Predicted cluster using K-means Cluster analysis Class analysis Result comparison and evaluation Sentiment values for postings Identified binary classes (hotspots, non-hotspots) Text data collected from forums
- 5. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 57 3.2. Feature Extraction The pre-processing work is followed by feature extraction process. For each forum five features are extracted across each time window such as the number of threads, the average number of replies of threads, the average sentiment value of threads, the fraction of positive threads among all the threads and the fraction of negative threads among all the threads. Sentiment value for each thread can be calculated by computing text sentiment. 3.3. Sentiment Computation on Forum Text Feature extraction includes text sentiment analysis which aims at calculating an integer value for each piece of text. It is a semantic orientation based approach where the sentiment values for all keywords are added to achieve the sentiment value for the whole article. The replies of thread are decomposed into a set of keywords. For each keyword a sentiment value is assigned. The sum of the sentiment values for all the keywords will give the sentiment value for the thread. Suppose for a thread t, its replies are decomposed into a set of key words. For each key word wi (i=1, 2,...,n) let the sentiment value be si. Then the sentiment value St of the thread t can be calculated as using Eq.(1) Calculation of sentiment value is based on SentiStrength. SentiStrength is an algorithm for text sentiment analysis that helps in estimating the sentiment values for texts. 3.4. Forum Clustering Using K-means After the features are extracted clustering can be carried out using K-means algorithm in Rapid miner tool. Each forum may be represented as a data point in a vector space. During the feature extraction process a vector is used to represent the emotional polarity of any forum and it is composed of five elements: the number of threads, the average number of replies of threads, the average sentiment value of threads, the fraction of positive threads among all the threads and the fraction of negative threads among all the threads. These datasets are given as the input to the k- means clustering where a clustered view of all the forums is obtained. The hotspot and non- hotspot forums being obtained, within each time window are those closest to the theoretical centres of clusters. 3.5. Forum Classification using SVM-PSO Classification can be carried out using Support Vector Machine with Particle Swarm Optimization (SVM-PSO) algorithm. PSO is a computational method that optimizes a problem by iteratively trying to improve a candidate solution with regard to a given measure of quality. The proposed work PSO aims at optimizing the accuracy of SVM classifier. The standard SVM-PSO takes a set of input data and it optimally predicts, for each given input, which of two possible classes comprises the input. SVM-PSO is employed to realize hotspot forecasting. In order to forecast the hotspot forums within the current time window the clustering result obtained by K-means approach from the previous time window is used. SVM-PSO performs forum classification iteratively and tries to find the optimized solution. For each SVM-PSO, the input is a forum’s representation vector and the optimized output is achieved by classifying each forum as either hotspot forum or non-hotspot
- 6. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 58 forum. The accuracy in predicting hotspot forums is improved with the proposed model and the consistency of the model is validated for its performance. 4. EXPERIMENTAL RESULT The data that we have collected for our empirical studies are from forums.digital point.com. A list of posts in the form of threads and replies has been crawled from January 2007 to October 2011. The data view before and after cleaning is depicted in Table1. After cleaning the data are narrowed to 37 forums from January 2011 to October 2011 and then the features are extracted that includes computing sentiment values for threads. The feature extraction is then followed by K-means clustering and classification using Support Vector Machine with Particle Swarm Optimization (SVM-PSO) among the 37 leaf forums for each time window in 2011. Clustering and classification is done using Rapid miner tool. The results that have been obtained using Support Vector Machine with Particle Swarm Optimization (SVM-PSO) present a noticeable consistency with the results achieved by K-means clustering. The forums that are most popular among the users based on average number of threads include ‘Search Marketing, Publisher Network, adcenter, General Marketing’, etc. The forums that are popular based on average number of replies include ‘Affiliate Programs-Google, Affiliate Network, Payments, Google-Google+’, etc. The classification model for forums from forums.digitalpoint.com is shown in Figure 2. Figure 2. Classification model using SVM-PSO
- 7. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 59 Table 2 shows the initial data view for user attention that consists of average number of threads and average number of replies for the 37 forums across the 10 time windows. Table 2. Data view for forums over time window Forum Id Forum name Avg num of threads Avg num of replies 4 Guidelines / Compliance 4.0 9.475 5 Placement / Reviews / Examples 4.9 4.71428 6 Reporting & Stats 4.8 14.89583 7 Payments 4.2 17.95238 8 AdWords 5.0 8.48 9 Analytics 4.2 8.61904 10 Google-Google+ 4.5 16.28888 11 Affiliate Network 4.8 22.22916 12 Sitemaps 4.4 9.40909 13 Google API 4.6 9.19565 14 Product Search 4.5 14.48888 16 Publisher Network 5.0 14.48 17 Search Marketing 5.1 9.74509 18 Yahoo API 4.9 9.26530 20 AdCenter 5.0 11.82 21 All Other Search Engines 4.6 16.82608 23 Solicitations & Announcements 3.8 9.07894 24 ODP / DMOZ 4.8 12.20833 26 General Marketing 5.0 10.74 28 Keywords 4.6 7.97826 29 Sandbox 4.3 8.46511 32 Facebook API 3.0 13.4 33 Twitter 3.0 14.26666 34 Social Network-Google+ 4.4 10.36363 35 Link Development 4.7 14.89361 37 Digital Point Ads 4.0 9.5 38 Google AdWords 3.3 4.18181 39 Yahoo Search Marketing 3.7 9.59459 40 Microsoft adCenter 3.6 7.75 43 Commission Junction 4.7 10.06382 44 Affiliate Programs-Google 4.3 23.79069 45 Pepperjam 4.4 10.29545 46 Azoogle 3.8 13.02631 47 Amazon 4.3 14.06976 48 EBay 4.2 9.30952 49 ClickBank 4.9 14.22448 50 Chitika 4.5 9.77777
- 8. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 60 The forums that are mostly identified as hotspots by both K-means clustering and Support Vector Machine with Particle Swarm Optimization (SVM-PSO) over the time window from JAN 2011 to OCT 2011 are shown in Table 3. Table 3. Forums mostly identified as hot spot by K-means and SVM-PSO Forum ID Forum name 11 44 10 6 49 Affiliate Network Google Google+ Reporting & Stats ClickBank 4.1. Performance Evaluation The consistency between K-means and Support Vector Machine along with Particle Swarm Optimization (SVM-PSO) algorithms is validated using five metrics. They are accuracy, sensitivity, specificity, positive predictive value and negative predictive value. A set of these five metrics are applied for each time window which are defined as follows. Accuracy = TP + TN / (TP + TN + FP + FN) (2) Sensitivity = TP / (TP + FN) (3) Specificity = TN / (TN + FP) (4) PPV = TP / (TP + FP) (5) NPV = TN / (TN + FN) (6) Where, TP denotes the number of forums that are estimated as hotspots by both K-means and SVM-PSO. TN denotes the number of forums that are estimated as non -hotspots by both K- means and SVM-PSO. FP denotes the number of forums that are estimated as hotspots by SVM- PSO whereas non-hotspots by K-means. FN denotes the number of forums that are estimated as non-hotspots by SVM-PSO whereas hotspots by K-means. Using formulae (1)-(5), the performance is evaluated for each time window. The time windows are those that are used in SVM-PSO classification process. Table 4 suggests that the proposed classification algorithm gives an optimized accuracy result than that of the other classification algorithms. Similarly the performance can be evaluated using other four metrics and the results can be compared. Figure.3 shows a graphical view of the accuracy result. Table 4. Comparison of Accuracy using different algorithms with SVM-PSO Time window Accuracy (%) Naïve Bayes Decision Tree SVM SVM-PSO 2 64 80 84 96 3 60 54.1 60 60 4 61.54 60 61.54 65.38 5 96.54 99 99 96.15
- 9. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 61 6 60 62.22 60 73.33 7 84.38 80.99 81.25 84.38 8 68.57 64 65.71 68.57 9 90 93.1 94.59 94.59 10 48.65 58.2 60 74 Figure 3. Accuracy comparison while using SVM-PSO and other algorithms 5. CONCLUSIONS This paper proposes a new approach for predicting hotspot forums. In this approach emotional polarity of the text is obtained by computing a value for each piece of text. After calculating the sentiment values the method is then integrated with K-means clustering and SVM-PSO classification algorithms for forums cluster analysis. Computation indicates both K-means and SVM-PSO produce consistent grouping results. Thus the efficient detection of hotspot forums based on sentiment analysis might make internet social network members benefit in the decision making process. REFERENCES [1] Chaovalit P. and Zhou L.(2005), “Movie review mining: a comparison between supervised and unsupervised classification approaches”, Proceedings of the 38th Hawaii International Conference on System Sciences. [2] Paltoglou and Thelwall M.(2010), “A study of information retrieval weighting schemes for sentiment analysis”, In Proceedings of the ACL, pp 1386–1395. [3] Nirmala Devi K ., Preethi T., and Murali Bhaskaran V.(2012), “A semantic enhanced approach for online hotspot forums detection”, Proceedings of second International Conference on Recent Trends in Information Technology ,pp 497-501. [4] Hu M., and Liu B.(2004), “Mining and summarizing customer reviews”, Proceedings of ACM Transactions on Knowledge and Data Engineering, pp168-177. [5] Nan Li., and Wu Dash D. (2010) “Using text mining and sentiment analysis for online forums hotspot detection and forecast” Decision Support Systems 48, pp 354–368.
- 10. International Journal of Information Sciences and Techniques (IJIST) Vol.2, No.3, May 2012 62 [6] Li, M. Huang, and X. Zhu. (2010) “Sentiment analysis with global topics and local dependency”, In Proceedings of AAAI, pp 1371–1376. [7] Pang B., Lee L., Vaithyanathan S.(2002), “Thumbs up? Sentiment classification using machine learning techniques”, Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp 79-86. [8] Popescu A. and Etzioni O.(2005), “Extracting product features and opinions from reviews”, Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp339-346. [9] Sindhwani S. and Mellville A.(2008), “Document-Word Co regularization for Semi-supervised Sentiment Analysis”, Eighth IEEE International Conference on Publication, pp1025 – 1030. [10] Thelwall M., Kevan B., Paltoglou G., Cai D., Kappas A.(2010), “Sentiment strength detection in short informal text”, Journal of the American Society for Information Science and Technology, pp2544–2558. [11] Thelwall M., Buckley K., and Paltoglo G.(2011), “Sentiment in Twitter Events”, Journal of the American Society for Information Science and Technology, 62(2), pp 406–418. Authors Dr. V.Murali Bhaskaran, M.E., Ph.D., Principal, Paavai College of Engineering, Pachal, Namakkal-637 018, India, He obtained his Bachelors degree in Computer Science and Engineering,” from Bharathidasan University, Thiruchirapalli and MS in Computer Science from BITS, Pilani and Masters Degree in Computer Science and Engineering from Bharathiyar University, Coimbatore. He completed PhD in Network Security from Bharathiyar University, Coimbatore. He presented 22 papers in National and International Conferences. He published 14 papers in international journals. He is presently working as a Principal of Paavai College of Engineering, Pachal, Namakkal. He received the “Best Staff” award for the year 1991- 1992 at Sathyabama Engineering College, Chennai. and 2002-2003 in Kongu Engineering College, Perundurai. He is guiding 10 research scholars and his area of interest is Cryptography and Network Security, High Speed Networks, and Computer Architecture. K. Nirmala Devi, M.C.A, M.E., (Ph.D)., Assistant Professor(SLG), Kongu Engineering College, Perundurai, Erode-638 052, India. She obtained her Bachelors degree in Computer Science from Bharathiar University, Coimbatore and Masters of Computer Applications from Bharathiar University, Coimbatore and M.E degree in CSE from Anna University, Chennai. She is currently doing research in Data mining under Anna University, Coimbatore. She is presently working as a Assistant Professor(SLG ) in the Department of Computer Science and Engineering, Kongu Engineering College, Perundurai, Tamilnadu, India. Her area of interest is Data mining, Soft Computing, Data structures and analysis of algorithms, and Compiler Design. She has presented papers in National and international conferences and also published papers in national and international journals.