Thai Word Embedding with Tensorflow
2 likes2,092 views

This document discusses using word embeddings and the Word2Vec model for natural language processing tasks in TensorFlow. It explains that word embeddings are needed to understand relationships between words as text, unlike images, does not provide inherent relationships between symbols like pixels. Word2Vec is an efficient predictive model that learns word embeddings from raw text using either the Continuous Bag-of-Words or Skip-Gram architecture and negative sampling to discriminate real from imaginary words during training. The tutorial aims to teach how to perform NLP tasks in TensorFlow using Word2Vec to learn word embeddings from a text corpus.


















































Ad
More Related Content
What's hot (20)
Similar to Thai Word Embedding with Tensorflow (20)


















Ad
More from Kobkrit Viriyayudhakorn (20)








![[Lecture 3] AI and Deep Learning: Logistic Regression (Coding)](https://cdn.slidesharecdn.com/ss_thumbnails/lecture3empty-180216132805-thumbnail.jpg?width=560&fit=bounds)
![[Lecture 4] AI and Deep Learning: Neural Network (Theory)](https://cdn.slidesharecdn.com/ss_thumbnails/lecture4ink-180216131712-thumbnail.jpg?width=560&fit=bounds)
![[Lecture 2] AI and Deep Learning: Logistic Regression (Theory)](https://cdn.slidesharecdn.com/ss_thumbnails/lecture2-ink-180216131533-thumbnail.jpg?width=560&fit=bounds)









Ad
Recently uploaded (20)




















Thai Word Embedding with Tensorflow
- 1. TensorFlow + NLP Language Vector Space Model (Word2Vec) Tutorial
- 2. Goal of this tutorial • Learn how to do NLP in Tensorflow • Learning Word embeddings that can extracting relationship between discrete atomic symbols (words) from the textual corpus.
- 4. NLP in Deep Learning • Word Embeddings is needed for NLP Deep Learning. Why? • Image and audio are already provide useful information for relationship between instance (pixels, frames) • A pixel value of #FF0000 is very similar to #FE0000, since both are red. We can compute the difference automatically. • Text does not provide useful information about the relationships between individual symbols. • 'cat' represented as Id537, 'dog' represented as Id143, Computer don’t know relationship between Id537 and Id143.
- 6. Vector Space Model • Find the relationship between discrete symbols (in this case, words). • Two proposed methods. • Count-based method. • How often the same word co-occurs with its neighbor words in a large text corpus. (e.g., Latent Semantic Analysis) • Predictive-based method. • Trying to predict the words from its neighbors (e.g., Neural Probabilistic language model).
- 7. Word2Vec • Computationally-efficient predictive model for learning word embedding from raw text. • Make by Tomas Mikolov at Google. • 2 Flavors • Continuous Bag-of-Words (CBOW) • Skip-Gram model
- 8. CBOW • Continuous Bag-of-Words (CBOW) • Predict target words from source context words. • Input: "The cat sits on the ______" • Output: mat • Example, 3-gram CBOW = (the,cat) =>sits, (cat,sits)=>on, (sits, on)=> the, (on, the)=> mat • Better for small dataset.
- 9. Skip-Gram model • Skip-Gram model • Predict source context words from target words. • Input: sits • Output: "The cat ____ on the mats" • Example, 1-skip 3-gram Skip-Gram = (the,sits)=>cat, (cat,on)=>sits, (sits, the)=> on, (on, mats)=> the • Better for large dataset. We use this in the slide.
- 10. Noise-Contrastive Training for Vector Space Model • We are using Gradient decent method for binary regression to modeling word-relationship models. (Neural Network) • To discriminates the real target words (that exists in the skip-gram model) and the imaginary noise words (that non-exists in the skip-gram model) => We use the following objective function (maximum it)
- 12. Input • Batch Training, For e.g., Windows Size = 9 • "the quick brown fox jumped over the lazy dog" • 1-skip 3-gram Skip-Gram = (the,brown)=>quick, (quick, fox)=>brown, (brown,jumpted)=> fox,... • Dataset: (quick, the), (quick, brown), (brown, quick), (brown, fox),...
- 13. Loop • (quick, the), (quick, brown), (brown, quick), (brown, fox),... • For each loop, Random pick word that not in windows set as the negative sampling. Then, Stochastic Gradient Descent method adjust the weight for maximum the above objective function.
- 14. Tensorflow code
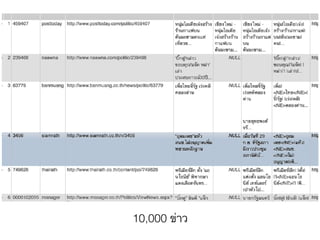
- 16. 10,000 ข่าว
- 17. Clean Data
- 18. Step 0
- 19. Step 30,000