THE 4 X 4 SEMANTIC MODEL : Semantics to Empower Services Science: Using Semantics at Middleware, Web Services and Business Levels
Download as PPT, PDF0 likes271 views

Keynote at the 9th International Conference on Enterprise Information Systems, Funchal, Portugal, June 12–16, 2007.















































































Ad
More Related Content
What's hot (8)
Viewers also liked (19)





Ad
Similar to THE 4 X 4 SEMANTIC MODEL : Semantics to Empower Services Science: Using Semantics at Middleware, Web Services and Business Levels (20)




















Ad
Recently uploaded (20)




















THE 4 X 4 SEMANTIC MODEL : Semantics to Empower Services Science: Using Semantics at Middleware, Web Services and Business Levels
- 1. THE 4 X 4 SEMANTIC MODEL “ Semantics to Empower Services Science: Using Semantics at Middleware, Web Services and Business Levels ” Keynote at 9th International Conference on Enterprise Information Systems , Funchal, Madeira – Portugal, 12-16, June 2007. Amit Sheth* Kno.e.sis center, Wright State University, Dayton, OH Thanks: paper with Karthik Gomadam
- 2. Outline Motivation The Four Tiers Modeling, Enactment, Partner Services and Execution The Four Types Of Semantics Data, Functional, Non-Functional and Execution The 4 X 4 Model Unifying the four tiers using the four types of semantics The 4 X 4 Model In Action
- 3. Motivation Organizations are often involved in complex business transactions with various partners across the world For example, the business decisions are made in the US, technical and support services are in India and suppliers come from China. Variety of factors can affect the business objectives of an organization. Business processes need to more agile and dynamic
- 4. Motivation Supplier 1: Supplier 2: Technical Services Partner Gaming Manufacturer Initially, Supplier 1 is cheaper. If the manufacturer cannot relate to this change and react to it, the process of part procurement will be sub-optimal. The change in system, however must be done by Technical Services partner in India. CHALLENGE is to: Create enactment consistent with business objectives Correlate and reflect changes across different participating entities Be able to create agile and dynamic processes Change in Chinese Currency Makes supplier two cheaper!!
- 5. The Hard Problem Create partner-level requirements that are consistent with those of the business process Verify the correctness of the enactment with respect to the business process modeling Select and configure the partners at run time Identify and adapt efficiently to the various events that affect the optimality of the business process
- 6. Outline Motivation The Four Tiers Modeling, Enactment, Partner Services and Execution The Four Types Of Semantics Data, Functional, Non-Functional and Execution The 4 X 4 Model Unifying the four tiers using the four types of semantics The 4 X 4 Model In Action
- 7. The Four Tiers What do I want to do? How am I going to it? Who are my partners in this? What is my environment for execution?
- 8. The Four Tiers Business Specifications Tier (referred to as business process tier in the paper) Functional and non-functional aspects of the business specification are captured at this level. Example: Develop a SOA based solution for procuring various components to manufacture gaming hardware requests with the following constraints / requirements Must support XGP graphic processing Minimum 100 Gb disk space Product must never be out of inventory with retailers Level 3 security
- 9. The Four Tiers Workflow Tier Actual workflow enactment of the specification. Partners based on “ What they do” are identified. Not Who Example: Partners for the parts ordering specification are Suppliers for Graphics processor, Gaming Chip, Disk drive, Forecasting partner (to give retailer stock information and demand forecasting). Process level specification is broken down into partner level specification What to do when something goes wrong with this enactment (Adaptation and event identification)
- 10. The Four Tiers Workflow Tier (Contd..) Example partner requirement Disk Drive Partner: Must be able to do a purchase order for hard drives Will send PORequest according to Rosetta PO and expect a POResponse conforming to RosettaNet Communication must be over secure 128 bit encrypted channel. (Non-functional requirement) Disk capacity must be at least 100 Gb (non-functional)
- 11. The Four Tiers Partner Services Tier Captures the capabilities and requirements of potential partner services. Example of Disk drive service Accept input in Rosetta RequestPO and ebXML RequestPO formats and output in Rosetta POResponse format (data) Request purchase order for Hard drives (Functional) 128 Bit SSL communication Drives with capacities 80, 100 and 120 Gb
- 12. The Four Tiers Middleware Services Tier Captures the services offered by containing middleware systems. Includes capabilities related to deployment, security, load balancing, message routing and forwarding, service selection and switch, policy based message handling and event management.
- 13. Outline Motivation The Four Tiers Of A Business Process Modeling, Enactment, Partner Services and Execution The Four Types Of Semantics Data, Functional, Non-Functional and Execution The 4 X 4 Model Unifying the four tiers using the four types of semantics The 4 X 4 Model In Action
- 14. What does Semantics bring to the table? Better Reuse Semantic descriptions of services to help find relevant services Better Interoperability Beyond syntax to semantics, mapping of data exchanged between the services (very time consuming without semantics, just as XML in WSDL gives syntactic interoperability, SAWSDL gives semantic interoperability) Configuration/Composition Enable dynamic binding of partners Some degree of automation across process lifecycle Process Configuration (Discovery and Constraint analysis) Process Execution (Addressing run time heterogeneities like data heterogeneities.)
- 15. What does Semantics bring to the table? Better Reuse Semantic descriptions of services to help find relevant services Better Interoperability Beyond syntax to semantics, mapping of data exchanged between the services (very time consuming without semantics, just as XML in WSDL gives syntactic interoperability, SAWSDL gives semantic interoperability) Configuration/Composition Enable dynamic binding of partners Some degree of automation across process lifecycle Process Configuration (Discovery and Constraint analysis) Process Execution (Addressing run time heterogeneities like data heterogeneities.)
- 16. Semantics to Web Services: The ingredients Conceptual Model/Ontology An agreed upon model that captures the semantics of domain Common Nomenclature Domain Knowledge (facts) XML based service description Standards and specifications like WSDL for web service description, WS-Agreement for capturing agreements etc. Annotate the service description
- 17. SAWSDL at a glance Ack: Jacek Kopecky
- 18. Annotating types modelReference to establish a semantic association liftingSchemaMapping and loweringSchemaMapping to provide mappings between XML and semantic model <wsdl:types> (...) < complexType name=“Address"> <sequence> < element name=“StreetAd1“ type="xsd:string"/> < element name=“StreetAd2" type="xsd:string"/> ........... </sequence> < /complexType > (...) </wsdl:types> Address StreetAddress xsd:string xsd:string OWL ontology hasCity hasStreetAddress hasZip WSDL complex type element semantic match
- 19. Why use SAWSDL Build on existing Web Services standards using only extensibility elements Mechanism independent of the semantic representation language (though OWL is supported well) SAWSDL provides an elegant solution Help integration by providing mapping to agreed upon domain models (ontologies, standards like Rosetta Net, ebXML) Better documentation by adding functional annotation Ease in tool upgrades e.g. wsif / axis invocation Is a W3C candidate recommendation
- 20. What can we support or demonstrate today API for handling SAWSDL documents: SAWSDL4J Tool for annotating WSDL services to produce SAWSDL: Radiant and for discovery: Lumina Using SAWSDL with UDDI for Discovery: MWSDIr Using SAWSDL with Apache Axis for Data Mediation Using SAWSDL with WS-BPEL for run-time binding Early Examples of SAWSDL annotated services: biomedical research Also: Semantic Tools for Web Services by IBM alphaWorks WSMO Studio , more mentioned by Jacek
- 21. Modeling : Using Radiant
- 22. Execution: WS Discovery using Lumina (MWSDI)
- 23. Execution: WS Discovery using Lumina (MWSDI)
- 25. User specified mappings from Web service message element to semantic model concept (say OWL Ontology) upcast : from WS message element to OWL concept Downcast : from OWL concept to WS message element Execution: Data Mediation <POOntology:has_StreetAddress rdf:datatype="xs:string"> { fn:concat($a/streetAddr1 , " ", $a/streetAddr2 ) } </POOntology:has_StreetAddress>
- 27. Web services interoperate by re-using these mappings. Ontologies now a vehicle for Web services to resolve message level heterogeneities Execution: Data Mediation
- 28. Four types of semantics Data Semantics: What are the inputs and outputs of a service Functional Semantics: What does a service do? Non-Functional Semantics: The non-functional requirements and capabilities of a service Execution Semantics: What is the execution context and the task skeleton (execution states) associated with this service
- 29. Semantics for Technical Services Development / Description / Annotation WSDL, WSDL-S, SAWSDL, WSMO, OWL-S METEOR-S (MWSAF) Execution, Adaptation and Mediation BPWS4J, activeBPEL, WSMX METEOR-S Publication / Discovery (Semantic) UDDI METEOR-S (MWSDI) Composition, Configuration and Negotiation BPEL, WS-Agreement, WS-Policy METEOR-S (MWSCF)
- 30. Semantics for Technical Services Data / Information Semantics Development / Description / Annotation Execution, Adaptation and Mediation BPWS4J, activeBPEL. WSMX METEOR-S WSDL, SAWSDL, (OWL-S, WSMO, WSDL-S) METEOR-S (MWSAF) Composition, Configuration and Negotiation BPEL, WS-Agreement, WS-Policy METEOR-S (MWSCF) Publication / Discovery (Semantic) UDDI METEOR-S (MWSDI)
- 31. Semantics for Technical Services Functional Semantics Development / Description / Annotation Execution, Adaptation and Mediation BPWS4J, activeBPEL, WSMX METEOR-S WSDL, WSDL-S, SAWSDL, WSMO, OWL-S METEOR-S (MWSAF) Composition, Configuration and Negotiation BPEL, WS-Agreement, WS-Policy METEOR-S (MWSCF) Publication / Discovery (Semantic) UDDI METEOR-S (MWSDI)
- 32. Semantics for Technical Services Non Functional Semantics Development / Description / Annotation Execution, Adaptation and Mediation BPWS4J, activeBPEL, WSMX METEOR-S WSDL, WSDL-S, SAWSDL, WSMO, OWL-S METEOR-S (MWSAF) Composition, Configuration and Negotiation BPEL, WS-Agreement, WS-Policy METEOR-S (MWSCF) Publication / Discovery (Semantic) UDDI METEOR-S (MWSDI)
- 33. Semantics for Technical Services Execution Semantics Development / Description / Annotation Execution, Adaptation and Mediation BPWS4J, activeBPEL, WSMX METEOR-S WSDL, WSDL-S, SAWSDL, WSMO, OWL-S METEOR-S (MWSAF) Composition, Configuration and Negotiation BPEL, WS-Agreement, WS-Policy METEOR-S (MWSCF) Publication / Discovery (Semantic) UDDI METEOR-S (MWSDI)
- 34. Semantics for Technical Services Semantics Required for Web Processes Development / Description / Annotation Execution, Adaptation and Mediation BPWS4J, activeBPEL, WSMX METEOR-S WSDL, WSDL-S, SAWSDL, WSMO, OWL-S METEOR-S (MWSAF) Execution Semantics QoS Semantics Functional Semantics Data / Information Semantics Composition, Configuration and Negotiation BPEL, WS-Agreement, WS-Policy METEOR-S (MWSCF) Publication / Discovery (Semantic) UDDI METEOR-S (MWSDI)
- 35. Outline Motivation The Four Tiers Of A Business Process Modeling, Enactment, Partner Services and Execution The Four Types Of Semantics Data, Functional, Non-Functional and Execution The 4 X 4 Model Unifying the four tiers using the four types of semantics The 4 X 4 Model In Action
- 36. Semantics for the 4 X 4 Model Currently, each tier has its own standard modeling language, e.g. UML or BPMN at Business Process Tier, BPEL for Workflow Enactment Tier, SAWSDL/ WSDL at Partner Services Tier and config files/WSDL at Middleware Services Tier Becomes hard to correlate different pieces of the puzzle A semantically enriched model that allows us to capture the semantics at each of the four tiers
- 37. The 4 X 4 Model The 4 X 4 model does not intend to replace any of the current languages. It is a way to add additional description. Can be represented by using semantic templates. That brings us to What are semantic Templates?
- 38. Semantic templates A way of capturing data / functional /non-functional / execution semantics
- 39. Example of a semantic template in the supply chain domain
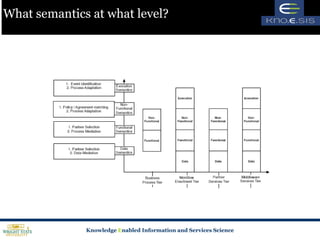
- 40. What semantics at what level?
- 41. Why the semantics? Business Specification Tier: Need is to capture the functional and non-functional specification. Hence we capture functional and non-functional semantics. Workflow enactment Tier: Captures the data flow, control flow and the partner level specifications. Also addresses adaptation. Hence we need all four types of semantics.
- 42. Why the semantics? Partner Services Tier: Must allow description of partner services including inputs, outputs, what the service offers and the non-functional guarantees and requirements. Data, Functional and Non-Functional semantics Middleware Services Tier: Must advertise middleware level capabilities and the policies associated with them. Data mediation can be thought of a middleware level service. Adaptation capabilities must be built into middleware. All four semantics are needed at this level.
- 43. Outline Motivation The Four Tiers Of A Business Process Modeling, Enactment, Partner Services and Execution The Four Types Of Semantics Data, Functional, Non-Functional and Execution The 4 X 4 Model Unifying the four tiers using the four types of semantics The 4 X 4 Model In Action
- 44. 4 X4 Model in Action
- 45. 4 X 4 Model in Action Semantic Templates for capturing process and partner level specifications SAWSDL used for SOAP based WS in Semantic publishing and discovery of services Dynamic binding Adaptation Data mediation SA-REST (XML + Microformats) Smashups Integration of REST based services Enhanced policy descriptions Service selection Process adaptation (Adaptation policies)
- 46. 4 x4 Model in Action: Summary Example A Manufacturer needs to order various components Model business specifications Model Partner specifications Capture adaptation rules and events Needs to include human elements Needs to capture the risk involved in various actions and estimate the probability of various events. Enact and execute business process How to capture and understand the System, Service and Human aspects ? The 4 x 4 Model presents an unified model that integrates the different tiers, that allows to semantically relate the different components across different layers
- 47. Illustrating Dynamic Configuration Being able to bind partners to a workflow during execution time Key tasks include Modeling Creating process and partner level specifications Workflows created with partners described using semantic template Execution Discovery of partners (To be able to discover, we need to address publication as well) Address data heterogeneity Optimization and Adaptation
- 48. Conclusions: The 4 x 4 Model in a Nutshell The four tiers in Business process modeling are identified as Business Process Tier, Workflow Enactment tier, Partner Services Tier and Middleware Services Tier Four types of semantics in SOA lifecycle Data, Functional, Non-Functional and Execution 4 x 4 Model integrates the four tiers in business process modeling with the four types of semantics Creates a unified construct to relate the different tiers Can be captured using Semantic Templates For SOAP services, Semantic Templates are defined using SAWSDL and Policy constructs For REST services, Semantic Tempaltes are defined using XML and Microformats (RDFA)
- 49. Conclusion: What does Semantics Bring to the Table? Better Reuse Semantic descriptions of services to help find relevant services Allows to study data, functional and non-functional variations between the different tiers Better Interoperability Beyond syntax to semantics, mapping of data exchanged between the services (very time consuming without semantics, just as XML in WSDL gives syntactic interoperability, SAWSDL gives semantic interoperability) Functional mediation to address different interaction protocols Configuration/Composition Enable dynamic binding of partners Create (S)Mashups dynamically Optimization and adaptation during run time Verify enactments against corresponding business process specifications
- 50. Some degree of automation across process lifecycle Process Configuration (Discovery and Constraint analysis) Process Execution (Addressing run time heterogeneities and exceptions) Conclusion: What does Semantics Bring to the Table?
Editor's Notes
- #8: In Role of Semantics for Workflow Enactment Tier: change consistence to consistency. In Technologies for Business Process Tier, add BPMN
- #10: What Who point: In the insurance example, the fact that we need a DMV partner, a credit bureau and cc processing are identified. Who are the actual partners that we will bind to is not. This is deferred to execution time. This is important to understand the dynamism of the 4 X 4.
- #11: What Who point: In the insurance example, the fact that we need a DMV partner, a credit bureau and cc processing are identified. Who are the actual partners that we will bind to is not. This is deferred to execution time. This is important to understand the dynamism of the 4 X 4.
- #12: What Who point: In the insurance example, the fact that we need a DMV partner, a credit bureau and cc processing are identified. Who are the actual partners that we will bind to is not. This is deferred to execution time. This is important to understand the dynamism of the 4 X 4.
- #18: In a state beyond a proposal
- #30: Intalio n3 : Completer BPMS..design, deploy, execute, analyze and optimize processes…brochure says it supports BPML specification
- #45: This picture illustrates the coming together of the 4 tiers of business process and how the 4 types of semantics facilitates this. At the heart of this modeling, is the grounding to ontologies. Further this slide also illustrates the interaction between the different tiers. The specifications in the process tier are enacted as workflows in the enactment tier. These workflows are deployed in a middleware that provides deployment and messaging services. The partner services are also deployed in middleware systems. In addition to these, the middleware services tier providers services such as discovery and mediation and message routing. Process Modeling Tier: Conventional workflow specifications or Mashup/Smashup specifications are captured at this tier. Conventional workflow specifications are captured using semantic templates for SOAP services while Smashup specifications are captured using micro-format enhanced SAREST. Workflow Enactment Tier: Based on the process level specifications, partner level specifications are created and workflows are enacted with these partner level specifications. The various tasks in the workflow are described by the operations in the corresponding semantic template. For example, in a supply chain workflow for procuring various components, the partner level specifications for each component is captured. A workflow is then created where a task corresponding to a functional requirement in the partner level specifications. In the context of light weight services, Smashups are created to enact out service compositions. Service compositions are captured as client side objects, which are annoated with micro formats. The service at the server side based on the semantics of the client side objects that are sent to it, invokes the relevant services in the order while making sure of the interaction and role. Service discovery and process configuration is done using the partner level specifications. Adaptation strategies such as events that are relevant, event subscription and notification management are done based on the functional and non-functional processs and partner level specifications. Partner service tier: IN the classical service context, partner services capture their capabilities and requirements in SAWSDL. In case of light weight services, annotated pages with RDFA and annotated XML inputs/ output allows for publication and discovery of these services. Middleware Services Tier: The capabilities of the middleware to support semantic web services, deployment, message processing, event handling and data mediation can be captured. As we can see in the example, the middleware services tier provides container services for both the enacted workflow as well as for partner services.
- #49: fo