The design and implementation of modern column oriented databases
Download as PPTX, PDF0 likes149 views

An attempt to break down the paper on the design of column-oriented databases into simpler terms. https://stratos.seas.harvard.edu/files/stratos/files/columnstoresfntdbs.pdf https://blog.acolyer.org/2018/09/26/the-design-and-implementation-of-modern-column-oriented-database-systems/






























![Arithmetic operations. Other operators that may be used in the select clause in an SQL
query, i.e., math operators (such as +,-*,/) also exploit the columnar layout to perform those
actions eciently. However, in these cases, because such operators typically need to operate
on groups of columns, e.g., select A+B+C From R ..., they typically have to materialize
intermediate results for each action. For example, in our previous example, a inter=add(A,B)
operator will work over columns A and B creating an intermediate result column which will
then be fed to another res=add(C,inter) operator in order to perform the addition with
column C and to produce the final result. Vectoriza-
tion helps in minimizing the memory footprint of intermediate results at any given time, but it
has been shown that it may also be beneficial to on-the-fly transform intermediate results
into column-groups in order to work with (vectors of) multiple columns [101], avoiding
materialization of intermediate results completely. In our example above, we can create a
column-group of the qualifying tuples from all columns (A, B, C) and perform the sum
operation in one go.](https://image.slidesharecdn.com/thedesignandimplementationofmoderncolumn-orienteddatabases-210704125132/85/The-design-and-implementation-of-modern-column-oriented-databases-33-320.jpg)
































Ad
More Related Content
What's hot (20)
Similar to The design and implementation of modern column oriented databases (20)


















Ad
Recently uploaded (20)




















Ad
The design and implementation of modern column oriented databases
- 1. The Design and implementation of modern column- oriented databases An unexamined query plan is not worth executing - Socrates The DBA
- 2. Outline of the paper History, trends and performance issues Predecessors of modern column- oriented databases. Discussions on MonetDB, VectorWise Introduction What are columnar stores? Benefits and Materialization issues Column store architectures Common architecture patterns for column store architectures Column store internals and advanced techniques Vectorized Execution. Compiled Queries. Compression. Late Materialization.
- 3. What is column-oriented store? Column-store systems completely vertically partition a database into a collection of individual columns that are stored separately.
- 4. Data transfer costs are often the major performance bottlenecks in database systems, At the same time database schemas are becoming complex with fat tables containing hundreds of attributes, a column-store is likely to be much more efficient at executing queries… that touch only a subset of a table’s attributes.
- 5. Benefits Fetch the columns you need. Easier to compress data of similar type and kind. Direct operation on compressed data. Database cracking and adaptive indexing. Performs really well with vectorized queries and compiled queries using SIMD. Sorted columnar data yields faster filters.
- 6. Various layouts in columnar stores Storing column per file with implicit or explicit ids.
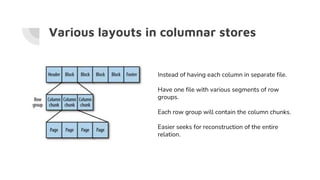
- 7. Various layouts in columnar stores Instead of having each column in separate file. Have one file with various segments of row groups. Each row group will contain the column chunks. Easier seeks for reconstruction of the entire relation.
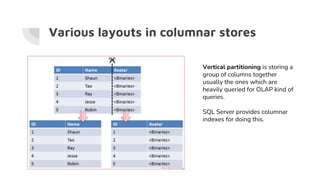
- 8. Various layouts in columnar stores Vertical partitioning is storing a group of columns together usually the ones which are heavily queried for OLAP kind of queries. SQL Server provides columnar indexes for doing this.
- 9. Materialization tradeoff - Reconstruction of rows Row store - One seek per record. (When location of the required page is known) Column store - n columns require n seeks to construct a record. However, as more and more records are accessed, the transfer time begins to dominate the seek time, and a column-oriented approach begins to perform better than a row- oriented approach. For this reason, column-stores are typically used in analytic applications, with queries that scan a large fraction of individual tables and compute aggregates or other statistics over them.
- 10. Databases always try to reduce random seeks. If a seek should happen then the scans after the seeked position should yield more desired data.
- 11. Summary Different layouts - column per file, group of columns per file and row groups Materialization tradeoff - more seeks might be used for reconstruction of rows.
- 12. Problem - Do I have to materialize intermediate results when each operator is applied? Using variables to store intermediate results when each operator is applied is bad. Storing in variables means flushing results to main memory. And for each operation loading it again into caches from main memory. Von Neumann Tube
- 13. Solutions What is getting pushed or pulled? Data is getting pushed or pulled towards the operators. To avoid storing intermediate results when each operator is applied. Instructions are chained so that operations can be applied relation at a time or a vector at a time. Operate on data while it is in the cache and avoid flushing intermediate results in main memory. Pull based query model Push based query model
- 14. Volcano iterator model - A pull based model It is pull based model. Data is pulled by operators. Control flows downwards and data flows upwards. Data Driven. Implemented using an iterator pattern. Problem - Too many virtual functions calls.
- 15. Push model Data is pushed towards operators. Each stage calls .consume() on next operator. Demand driven. Implemented using visitor pattern. Control flows upwards and data flows upwards. Reduced number of calls, as flow is from bottom to top. Pull model requires many .next calls to reach predicate. What if the row is discarded? Too many function calls got wasted.
- 16. Example of push model
- 17. Column stores work better with push model. https://arxiv.org/pdf/1610.09166v1.pdf
- 18. Vectorized Queries Why introduced? Volcano iterator model is a row by row processing. If query execution code is too big and general it will have too many CPU instructions. If a cache miss occurs for executing on each row then the cost is too much. Thus, batch the rows together so that even if instruction cache miss occurs it will be for a batch of records. Execution code which is written generally to support any schema type often reeks of too much abstraction and branching. And thus leads to too many instructions.
- 19. Compiled Queries They solved the instruction cache miss problems. By generating the query execution code tailored to the query. They took it as a compiler problem. Load only those instructions which are required for the query.
- 20. Column stores work best when compiled queries are generated to execute on data as vectors while adhering to the push model. Spark does that.
- 21. Column stores and hybrid execution Reduced interpretation overhead. The amount of function calls performed by the query interpreter goes down by a factor equal to the vector size compared to the tuple-at-a-time model. Better cache locality. Compiler optimization opportunities - using SIMD, loop pipelining, loop unrolling
- 22. Compression It is easier to compress same kind and type of data. Compression techniques used widely on columnar stores: Delta Encoding - Have a base value and store deltas afterwards. Works good on large monotonic values. Dictionary Encoding - Encoding a set of values to an integer. Enums and strings with restricted domain. Run Length Encoding - Storing the start position and the number of times the item has appeared after the start position. Columns with repeated values. Status flags etc Bit Vector Encoding - Basically a bitmap Patching Technique - Encode the outliers in dictionary encoding with an escape value in the beginning.
- 23. Working on compressed data Create an interface to define engines which are more compression aware and can operate on compressed data. Example The query engine with support for working on RLE data could have methods such as getSize() isSorted() isOneValue() getDistinctValues() getSum() etc SUM, AGG, MUL etc straightforward operations can be easily performed on RLE encoded data. A compression block contains a buffer of column data in compressed format and provides an API that allows the buffer to be accessed by query operators in several ways…
- 24. Late Materialization Stitching together columns from same of various tables to form the result set.
- 26. Late materialisation advantages Late materialisation has four main advantages: 1. Due to selection and aggregation operations, it may be possible to avoid materialising some tuples altogether 2. It avoids decompression of data to reconstruct tuples, meaning we can still operate directly on compressed data where applicable 3. It improves cache performance when operating directly on column data 4. Vectorized optimisations have a higher impact on performance for fixed-length attributes. With columns, we can take advantage of this for any fixed-width columns. Once we move to row-based representation, any variable-width attribute in the row makes the whole tuple variable-width. Hybrid materialization? Materialize right side and late materialization of left side as it is already sorted
- 27. Joins The most straightforward way to implement a column-oriented join is for (only) the columns that compose the join predicate to be input to the join. In the case of hash joins (which is the typical join algorithm used) this results in much more compact hash tables which in turn results in much better access patterns during probing; a smaller hash table leads to less cache misses.
- 29. Redundant column representation Columns that are sorted according to a particular attribute can be filtered much more quickly on that attribute. By storing several copies of each column sorted by attributes heavily used in an application’s query workload, substantial performance gains can be achieved. C-store calls groups of columns sorted on a particular attribute projections.
- 30. Database cracking and adaptive indexing An alternative to sorting columns up front is to adaptively and incrementally sort columns as a side effect of query processing. “Each query partially reorganizes the columns it touches to allow future queries to access data faster.” For example, if a query has a predicate A n where n ≥ 10, it only has to search and crack only the last part of the column. In the following example, query Q1 cuts the column in three pieces and then query Q2 further enhances the partitioning.
- 32. Group-by, Aggregation and Arithmetic Operations Group-by. Group-by is typically a hash-table based operation in modern column-stores and thus it exploits similar properties as discussed in the previous section. In particular, we may create a compact hash table, i.e., where only the grouped attribute can be used, leading in better access patterns when probing. Aggregations. Aggregation operations make heavy use of the columnar layout. In particular, they can work on only the relevant column with tight for-loops. For example, assume sum(), min(), max(), avg() operators; such an operator only needs to scan the relevant column (or intermediate result which is also in a columnar form), maximizing the utilization of memory bandwidth.
- 33. Arithmetic operations. Other operators that may be used in the select clause in an SQL query, i.e., math operators (such as +,-*,/) also exploit the columnar layout to perform those actions eciently. However, in these cases, because such operators typically need to operate on groups of columns, e.g., select A+B+C From R ..., they typically have to materialize intermediate results for each action. For example, in our previous example, a inter=add(A,B) operator will work over columns A and B creating an intermediate result column which will then be fed to another res=add(C,inter) operator in order to perform the addition with column C and to produce the final result. Vectoriza- tion helps in minimizing the memory footprint of intermediate results at any given time, but it has been shown that it may also be beneficial to on-the-fly transform intermediate results into column-groups in order to work with (vectors of) multiple columns [101], avoiding materialization of intermediate results completely. In our example above, we can create a column-group of the qualifying tuples from all columns (A, B, C) and perform the sum operation in one go.
- 34. Updates/Deletes Deleting and Updating data in compressed columns is difficult. Append only log with multi version. Frequent compaction. ROS and WOS. Using in-memory sorted data structure for updates and deletes. Later flush the changes. Using the same query on delta and last snapshot separately and merging the results.
- 35. Conclusions As it is evident by the plethora of those features, modern column stores go beyond simply storing data one column-at-a-time; they provide a completely new database architecture and execution engine tailored for modern hardware and data analytics. compression is much more effective when applied at one column-at-a-time or vectorization and block processing help minimize cache misses and instruction misses even more when carrying one column-at-a-time Late materialization is ambitious but cannot be done for more complex queries. Much research is needed in this section.
Editor's Notes
- #3: What is column store? Benefits Physical layous
- #4: Each column in a separate file.
- #7: Explicit ids are good for materialization. To stich together the columns to obtain the rows.
- #8: Explicit ids are good for materialization. To stitch together the columns to obtain the rows.
- #10: The other kind of materialization is intermediate storing of data in variables.
- #18: The idea is to filter data quickly and as early as possible.