The Face of Nanomaterials: Insightful Classification Using Deep Learning - Angelo Ziletti
1 like418 views

Artificial intelligence is emerging as a new paradigm in materials science. This talk describes how physical intuition and (insightful) machine learning can solve the complicated task of structure recognition in materials at the nanoscale.

















![18
● A standard n-layer neural network applies to the input data a series of linear
and non-linear transformations in successions:
– non-linear operators: ReLU, sigmoid, max-pooling, softmax.
– : weight matrices and bias vectors
● Neural networks have been extremely successful in a large variety of task
(computer vision, speech recognition, machine translation, etc)
● For image recognition: Convolutional Neural Network (ConvNets)[1]
Prediction model: neural network
[1] LeCun et al., Neural Comput. 1, 541 (1989)](https://image.slidesharecdn.com/zilettipydataberlinjuly6noextra-180720224158/85/The-Face-of-Nanomaterials-Insightful-Classification-Using-Deep-Learning-Angelo-Ziletti-18-320.jpg)








![28
● Dataset 1:
– Includes ~90 chemical elements
– Different nanomaterials’ sizes
● Dataset numbers:
– 10,517 images; 7 classes
– 90% training, 10% validation (randomly)
– ConvNet runtime: train: ~80min, pred. ~70 ms @img
The pristine dataset
Training accuracy [%] Validation accuracy [%]
100.0 100.0](https://image.slidesharecdn.com/zilettipydataberlinjuly6noextra-180720224158/85/The-Face-of-Nanomaterials-Insightful-Classification-Using-Deep-Learning-Angelo-Ziletti-28-320.jpg)
![29
● Dataset 2: dataset 1 with added defects
– Random displacements: up to st. dev. 0.06 Å
– Random vacancies: up to 25%
– Substitutions (randomly change the type of
atom: e.g. C -> H)
● Dataset numbers:
– 105,170 images
– 7 classes
The defective dataset (test set)
Training accuracy [%] Test accuracy [%]
No Training 100.0](https://image.slidesharecdn.com/zilettipydataberlinjuly6noextra-180720224158/85/The-Face-of-Nanomaterials-Insightful-Classification-Using-Deep-Learning-Angelo-Ziletti-29-320.jpg)














































Ad
More Related Content
What's hot (20)
Similar to The Face of Nanomaterials: Insightful Classification Using Deep Learning - Angelo Ziletti (20)


















Ad
More from PyData (20)




















Ad
Recently uploaded (20)




















The Face of Nanomaterials: Insightful Classification Using Deep Learning - Angelo Ziletti
- 1. The Face of Nanomaterials: Insightful Classification Using Deep Learning Dr. Angelo Ziletti Deputy Group Leader in Data Science for Materials Fritz Haber Institute of the Max Planck Society Berlin, Germany Berlin, July 8th , 2018
- 3. 3 ● Ruled by the laws of Quantum Physics What is a nanomaterial? International Organization for Standardization (ISO) "Material with any external dimension in the nanoscale or having internal structure in a size range from approximately 1 nm to 100 nm." (A human hair is approximately 80,000- 100,000 nanometers wide)
- 4. 4 Why are nanomaterials important? LEDs Nobel Prize Physics 2014 (blue LED) Lasers Nobel Prize Physics 1964, 1981 Computers Nobel Prize Physics 1956 (transistor) Levitating Trains Nobel Prize Physics 1972 (th. superconductivity) … and many others...
- 5. 5 ● Graphene: – Single layer of graphite (carbon), 1-atom thick – strongest material ever discovered (tensile strength= 130GPa) – lowest known resistivity at room temperature – better heat conductor than silver and copper – 97% transparent An example: two-dimensional materials Nobel Prize 2010 Model Experiment Fabrication
- 7. 7 ● Given an atomic arrangement in a nanomaterial, determine the (“most similar”) prototype among the following classes: The goal Body-centered-tetragonal (139) Body-centered-tetragonal (141) Hexagonal Simple cubic Face-centered-cubic Diamond Body-centered-cubic Rhombohedral
- 8. 8 Structures are quite (very?) similar Simple cubic Body-centered cubic Face-centered cubic
- 9. 9 Structures are quite (very?) similar Simple cubic Body- centered cubic Face- centered cubic Ref: B. A. Averill and P. Eldredge, Chemistry: Principles, Patterns, and Applications, Prentice Hall (2007)
- 10. 10 And with atom removals/deformations... Simple cubic Body-centered cubic Face-centered cubic
- 12. 12 ● Nanomaterials are complex, non-rigid, three-dimensional objects with periodically repeated structures (like the brick of a house) ● A good representation of nanomaterials must be: – invariant with respect to system size – stable with respect to deformations and atoms removal Feature Engineering for periodic 3D objects Perfect structure 25% atoms removed Random deformation
- 13. 13 ● … and ideally: – the representation is compact – nanomaterials belonging to a similar class have a similar representation ● Learning symmetries by data augmentation? ... but for each structure we would need to give: – Nanomaterials of different sizes – All (!) distorted configurations → a huge amount of data (and no learning guarantee) Feature Engineering for periodic 3D objects
- 14. 14 The diffraction fingerprint: intuition Crystal structure to classify Diffraction fingerprint Simulated radiation ● Rotate the crystal structure of 45° and (-45°) about the x,y, and z axis ● Calculate the diffraction pattern (~Fourier Transform) for each rotation: – around x-axis – around y-axis – around z-axis ● Sum the results in a RGB image Ziletti et al., Nature Communications, in press; arXiv: 1709.02298 (2018).
- 15. 15 The diffraction fingerprint: results Body-centered-tetragonal (139) Body-centered-tetragonal (141) Rhombohedral/Hexagonal Simple cubic Face-centered-cubic Diamond Body-centered-cubic Ziletti et al., Nature Communications, in press; ArXiv: 1709.02298 (2018).
- 16. 16 The method workflow Nanomaterials Image (diffraction fingerprint) representation Nanomaterial class (or “most similar”) classification Prediction model: convolutional neural network Representation: given a nanomaterial we calculate its diffraction fingerprint
- 17. Part IV: The Classification Model
- 18. 18 ● A standard n-layer neural network applies to the input data a series of linear and non-linear transformations in successions: – non-linear operators: ReLU, sigmoid, max-pooling, softmax. – : weight matrices and bias vectors ● Neural networks have been extremely successful in a large variety of task (computer vision, speech recognition, machine translation, etc) ● For image recognition: Convolutional Neural Network (ConvNets)[1] Prediction model: neural network [1] LeCun et al., Neural Comput. 1, 541 (1989)
- 19. 19 How do we (humans) subconsciously classify an image? Looking for identifiable (pre-learned) features (e.g. for dogs: paws, 4 legs) ConvNets: human analogy How does a computer classify an image? Looking at low level features (edges and curves), and then build more abstract concepts though a series of (convolutional) layers.
- 20. 20 Computing a convolution Ref: V. Dumoulin, F. Visin, A guide to convolution arithmetic for deep learning, https://arxiv.org/abs/1603.07285 (2016) ● Slide kernel throughout the image ● For each position in the image: – Element-wise multiplication between image and kernel – Sum of all elements (within the region) Output Input Kernel
- 21. 21 Computing a convolution: example Ref: V. Dumoulin, F. Visin, A guide to convolution arithmetic for deep learning, https://arxiv.org/abs/1603.07285 (2016)
- 22. 22 Convolution and kernels: ex. 1
- 23. 23 Convolution and kernels: ex. 2
- 24. 24 Convolutional layer recap ● Convolution is spatial filtering ● Different filters (weights) extract different characteristics of the input → multiple filters ● Complexity of the filters increases layer by layer ● Filters learned minimizing the training error ● Multiple conv. Layers: – 1st layer: input=image → low-level filters (e.g. curve or straight edges) – 2nd layer: input=activation map → higher level filters (e.g. semicircles: curve+straight edges, squares) – nth layer: high level filters (e.g. face)
- 25. 25 Pooling layer ● Replaces the output at a certain location with a summary statistic of the nearby outputs ● Makes the representations smaller (downsampling) ● Different poolings: e.g. max pooling, average pooling ● It is not crucial and can be avoided Images from Stanford CS231n: Convolutional Neural Networks for Visual Recognition (http://cs231n.github.io/convolutional-networks/)
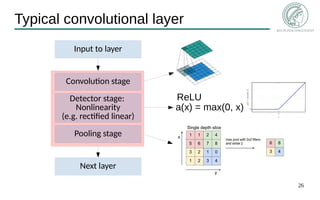
- 26. 26 Typical convolutional layer Input to layer Convolution stage Detector stage: Nonlinearity (e.g. rectified linear) Pooling stage Next layer a(x) = max(0, x) ReLU
- 27. 27 Our ConvNet Ziletti et al., Nature Communications, in press; arXiv: 1709.02298 (2018).
- 28. 28 ● Dataset 1: – Includes ~90 chemical elements – Different nanomaterials’ sizes ● Dataset numbers: – 10,517 images; 7 classes – 90% training, 10% validation (randomly) – ConvNet runtime: train: ~80min, pred. ~70 ms @img The pristine dataset Training accuracy [%] Validation accuracy [%] 100.0 100.0
- 29. 29 ● Dataset 2: dataset 1 with added defects – Random displacements: up to st. dev. 0.06 Å – Random vacancies: up to 25% – Substitutions (randomly change the type of atom: e.g. C -> H) ● Dataset numbers: – 105,170 images – 7 classes The defective dataset (test set) Training accuracy [%] Test accuracy [%] No Training 100.0
- 30. 30 Structural transitions (1/2) Prototypes generated from the AFLOW Library of Crystallographic Prototypes: Mehl et al., Comput. Mater. Sci. 136, S1 (2016)
- 31. 31 Structural transitions (2/2) Prototypes generated from the AFLOW Library of Crystallographic Prototypes: Mehl et al., Comput. Mater. Sci. 136, S1 (2016)
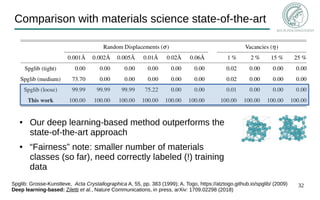
- 32. 32 Comparison with materials science state-of-the-art ● Our deep learning-based method outperforms the state-of-the-art approach ● “Fairness” note: smaller number of materials classes (so far), need correctly labeled (!) training data Spglib: Grosse-Kunstleve, Acta Crystallographica A, 55, pp. 383 (1999); A. Togo, https://atztogo.github.io/spglib/ (2009) Deep learning-based: Ziletti et al., Nature Communications, in press, arXiv: 1709.02298 (2018)
- 33. Part V: Opening the Black Box
- 34. 34 Back-projection to image space Method: Zeiler and Fergus, European Conf. on Computer Vision, Springer, 2014. ● Project feature activities back to the input pixel space
- 35. 35 “Going backwards” in a convolutional layer Method: Zeiler and Fergus, European Conf. on Computer Vision, Springer, 2014. TransposedConvolution: Im et al., Generating images with recurrent adversarial networks, arXiv: 1602.05110 (2016) Input to layer Convolution Pooling Next layer Nonlinearity Reconstruction Fractionally strided convolution Unpooling Layer above reconstruction Nonlinearity Forward pass Going backwards: reconstruction Also called: - Transposed convolution - Backward strided convolution - Deconvolution In Tensorflow: tf.nn.conv2d_transpose
- 36. 36 Attentive response maps: forward pass ● Forward pass of the image – for each pooling layer: store pool switches – for conv. layer of interest (e.g. last): ● calculate filters’ activations ● order filters by activation value – select the top most-activated filters Method: Zeiler and Fergus, European Conf. on Computer Vision, Springer, 2014. Application to anatomy classification: Kumar et al., IEEE Int. Symp. on Biomed. Imaging, arXiv: 1611.06284 (2018) Application to materials science: Ziletti et al., Nature Communications, in press, arXiv: 1709.02298 (2018) Input image ClassificationConv Layer 1 Conv Layer 2 Last Conv Layer FC Layers ...
- 37. 37 Attentive response maps: back-projection Input image Conv Layer 1 Conv Layer 2 Last Conv Layer ... ● Back-propagate to image space the top most-activated filters – for max-pooling layers→ unpooling – for convolutional layers→ fractionally strided convolution Method: Zeiler and Fergus, European Conf. on Computer Vision, Springer, 2014. Application to anatomy classification: Kumar et al., IEEE Int. Symp. on Biomed. Imaging, arXiv: 1611.06284 (2018) Application to materials science: Ziletti et al., Nature Communications, in press, arXiv: 1709.02298 (2018)
- 38. 38 Attentive response maps: per-pixel max Input image Conv Layer 1 Conv Layer 2 Last Conv Layer ... ● Compute the per-pixel max of these back-projected maps Max Individual response maps Attentive response map Method: Zeiler and Fergus, European Conf. on Computer Vision, Springer, 2014. Application to anatomy classification: Kumar et al., IEEE Int. Symp. on Biomed. Imaging, arXiv: 1611.06284 (2018) Application to materials science: Ziletti et al., Nature Communications, in press, arXiv: 1709.02298 (2018)
- 39. 39 Attentive response maps (Summary) ● Forward pass of the image – for each pooling layer: store pool switches – for conv. layer of interest (e.g. last): ● calculate filters’ activations ● order filters by activation value – select the top most-activated filters ● Back-propagate to image space the top most-activated filters – for max-pooling layers→ unpooling – for convolutional layers→ fractionally strided convolution ● Compute the per-pixel max of these back-projected maps Method: Zeiler and Fergus, European Conf. on Computer Vision, Springer, 2014. Application to anatomy classification: Kumar et al., IEEE Int. Symp. on Biomed. Imaging, arXiv: 1611.06284 (2018) Application to materials science: Ziletti et al., Nature Communications, in press, arXiv: 1709.02298 (2018)
- 40. 40 Understanding ConvNets Devinder Kumar (University of Waterloo, Canada) Attentive response maps Input image Layer 1 Layer 2 Layer 3 Layer 4 Layer 5 Layer 6 green red Ziletti et al., Nature Communications, in press; ArXiv: 1709.02298 (2018).
- 41. 41 Understanding ConvNets Devinder Kumar (University of Waterloo, Canada)Attentive response maps (RGB) Input image Layer 1 Layer 2 Layer 3 Layer 4 Layer 5 Layer 6 Ziletti et al., Nature Communications, in press; ArXiv: 1709.02298 (2018).
- 42. 42 What did the ConvNet learn? ● Sum of the last convolutional layer attentive response maps: ● has learned nanomaterials templates automatically from the data ● uses the same landmarks a materials scientist would use although never explicitly instructed to do so Our ConvNet:
- 43. 43 ● The challenge ● How to represent a nanomaterial ● Convolutional Networks ● Opening the black-box Summary
- 44. 44 NumFOCUS made this possible
- 45. 45 Acknowledgments Luca Ghiringhelli Matthias Scheffler H2020 NOMAD This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 676580. Devinder Kumar
- 46. Dr. Angelo Ziletti Fritz Haber Institute of the Max Planck Society, Berlin, Germany Insightful Classification of Crystal Structures Using Deep Learning Ziletti et al., Nature Communications, in press (2018). Online: https://arxiv.org/abs/1709.02298 [email protected]