

















![November 27, 2019
Benchmark Setup
• BigBench (TPCx-BB) Benchmark [Ghazal et al. 2013]
End-to-end, application-level Big Data benchmark
Utilizing structured, semi-structured and unstructured data
30 analytical queries implemented primarily in HiveQL
Scale Factor 1000 = 1TB
Query Types Queries Number of Queries
Pure HiveQL
6,7,9,11,12,13,14,
15,16,17,21,22,23,24
14
HiveQL /UDTF 1 1
HiveQL /Python 2,3,4,8,29,30 6
HiveQL /Spark MLlib 5,20,25,26,28 5
HiveQL /OpenNLP 10,18,19,27 4
[Ghazal et al. 2013] Ahmad Ghazal, Tilmann
Rabl, Minqing Hu, Francois Raab, Meikel
Poess, Alain Crolotte, and Hans-Arno
Jacobsen. 2013. BigBench: Towards An
Industry Standard Benchmark for Big Data
Analytics. In SIGMOD 2013.
BigBench source code:
https://github.com/BigData-Lab-Frankfurt/Big-Bench-Setup
19](https://image.slidesharecdn.com/fileformatsslidesonline-191127173808/85/The-Impact-of-Columnar-File-Formats-on-SQL-on-Hadoop-Engine-Performance-A-Study-on-ORC-and-Parquet-19-320.jpg)





























































Ad
More Related Content
What's hot (20)
Similar to The Impact of Columnar File Formats on SQL-on-Hadoop Engine Performance: A Study on ORC and Parquet (20)


















Ad
More from t_ivanov (8)








Ad
Recently uploaded (20)













![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)






The Impact of Columnar File Formats on SQL-on-Hadoop Engine Performance: A Study on ORC and Parquet
- 1. November 27, 2019 The Impact of Columnar File Formats on SQL-on-Hadoop Engine Performance: A Study on ORC and Parquet* Todor Ivanov ([email protected]) and Matteo Pergolesi * Published in the journal Concurrency and Computation: Practice and Experience 2019, Wiley Online Library: https://onlinelibrary.wiley.com/doi/pdf/10.1002/cpe.5523
- 2. November 27, 2019 About me Dr. Todor Ivanov Senior Researcher, Lab CTO @ Frankfurt Big Data Lab www.bigdata.uni-frankfurt.de/ivanov/ • Big Data benchmarking / Performance optimizations • Complex distributed software systems (Hadoop, Spark etc.) • Storage and processing of data-intensive applications • Virtualization & Cloud Computing 2
- 3. November 27, 2019 Agenda 1. Motivation & Background 2. Experimental Setup 3. Experimental Results 4. Discussion & Open Questions 5. Lessons Learned 3
- 4. November 27, 2019 Row-based storage (Traditional Approach) • To select a subset of columns, all rows need to be read! • Data compression or encoding is inefficient because different data types are stored sequentially! How to store data? A B C D a1 b1 c1 d1 a2 b2 c2 d2 ... ... ... ... aN bN cN dN block1 block2 ... blockN Foot er row1 row2 ... rowN Row group 1 Row group 2 4
- 5. November 27, 2019 Column-based storage • It is efficient to scan only a subset of columns! • Data encoding and compression algorithms can take advantage of the data type knowledge and homogeneity! How to store data? A B C D a1 b1 c1 d1 a2 b2 c2 d2 ... ... ... ... aN bN cN dN block1 block2 ... blockN Foot er Row group 1 Row group 2 Column A Chunk Column B Chunk ... Column D Chunk 5
- 6. November 27, 2019 Columnar File Formats and SQL-on-Hadoop Engines • ORC and Parquet are: open source, general purpose columnar file formats take advantage of data encoding and compression strategies can be used or integrated with any data processing framework or engine • Hive and SparkSQL are: open source, SQL-on-Hadoop engines efficiently query data stored in columnar file formats (typically in HDFS) provide SQL-like dialect (called HiveQL) to work with structured data offer a high-level abstraction on top of processing engine (like MapReduce and Spark) 6
- 7. November 27, 2019 SQL-on-Hadoop Engines Open Source • Apache Hive • Hive-on-Tez • Hive-on-Spark • Apache Pig • Pig-on-Tez • Pig-on-Spark • Apache Spark SQL • Apache Impala • Apache Drill • Apache Tajo • Apache Phoenix • Phoenix-on-Spark • Facebook Presto • Apache Flink • Apache Kylin • Apache MRQL • Splout SQL • Cascading Lingual • Apache HAWQ • Druid • Kudu Commercial • IBM Big SQL • Microsoft PolyBase • Teradata Aster SQL-MapReduce • SAP HANA Integration & Vora • Oracle Big Data SQL • RainStor • Jethro • Splice Machine 7
- 8. November 27, 2019 SQL-on-Hadoop Engines + Default File Format Observations: ORC is favored by Hive and Presto Parquet is first choice for SparkSQL and Impala 8
- 9. November 27, 2019 Related Studies Contrary to other studies, we compared ORC and Parquet File Formats by executing each file format on the same processing engine! VS Summary of related work 9
- 10. November 27, 2019 Objective: Investigate how the overall performance of an engine (Hive or SparkSQL) is influenced: by changing the columnar file format type or by using a different columnar file format configuration 10
- 11. November 27, 2019 Experimental Setup
- 12. November 27, 2019 Hybrid Benchmark Methodology • The general approach consists of 4 phases: Phase 1 - Platform Setup Phase 2 - Workload Preparation Phase 3 - Workload Execution Phase 4 - Evaluation 12
- 13. November 27, 2019 Phase 1 - Platform Setup • Install and configure all hardware and software components. For example: Operating System, Network, Programming Frameworks, e.g. Java Environment Big Data System under test 13
- 14. November 27, 2019 Phase 2 - Workload Preparation • Install and configure the Big Data Benchmark Setup the workload parameters (e.g. Scale Factor, query type, workload type, ) Generate the test data using typically data generator • Configure the Big Data platform under test to address the benchmark scenario 14
- 15. November 27, 2019 Phase 3 - Workload Execution • Perform benchmark experiments repeated 3 or more times to ensure the representativeness of the results to make sure that there are no cache effects or undesired influences between the consecutive test executions • Before repeating an experiment make sure: to reset (generate new) test data for each test run to clear the caches to assure consistent state • Measure latency (execution time) as an average of the 3 or more executions measure the standard deviation between the 3 or more executions to check the representativeness of the result. 15
- 16. November 27, 2019 Phase 4 - Evaluation • Evaluation and validation of the benchmark results benchmark metrics (typically execution time and throughput) resource utilization statistics (CPU, Network, I/O and Memory) • Use of graphical representations (charts and diagrams) for further results investigation and analysis. 16
- 17. November 27, 2019 Experimental Setup • Hardware Configuration - 4 node cluster Setup Description Summary Total Nodes: 4 x Dell PowerEdge T420 Total Processors/ Cores/Threads: 5 CPUs/ 30 Cores/ 60 Threads Total Memory: 4x 32GB = 128 GB Total Number of Disks: 13 x 1TB,SATA, 3.5 in, 7.2K RPM, 64MB Cache Total Storage Capacity: 13 TB Network: 1 GBit Ethernet • Software Configuration Ubuntu Server 14.04.1. LTS Cloudera Hadoop Distribution (CDH 5.11) Hive 1.1.0 and SparkSQL 2.3.0 Parquet 1.5 OpenNLP 1.6.0 17
- 18. November 27, 2019 CDH Cluster Configuration • Todor Ivanov and Max-Georg Beer, Evaluating Hive and Spark SQL with BigBench, Frankfurt Big Data Lab, Technical Report No.2015-2, arXiv:1512.08417. • Todor Ivanov and Max-Georg Beer, Performance Evaluation of Spark SQL using BigBench, in Proceedings of the 6th Workshop on Big Data Benchmarking (6th WBDB), June 16-17, 2015, Toronto, Canada. Component Parameter Final Configuration YARN yarn.nodemanager.resource.memory-mb 31GB yarn.scheduler.maximum-allocation-mb 31GB yarn.nodemanager.resource.cpu-vcores 11 Spark master yarn num-executors 9 executor-cores 3 executor-memory 9GB spark.serializer org.apache.spark.serializer. KryoSerializer MapReduce mapreduce.map.java.opts.max.heap 3GB mapreduce.reduce.java.opts.max.heap 3GB mapreduce.map.memory.mb 4GB mapreduce.reduce.memory.mb 4GB Hive Client Java Heap Size 2GB 18
- 19. November 27, 2019 Benchmark Setup • BigBench (TPCx-BB) Benchmark [Ghazal et al. 2013] End-to-end, application-level Big Data benchmark Utilizing structured, semi-structured and unstructured data 30 analytical queries implemented primarily in HiveQL Scale Factor 1000 = 1TB Query Types Queries Number of Queries Pure HiveQL 6,7,9,11,12,13,14, 15,16,17,21,22,23,24 14 HiveQL /UDTF 1 1 HiveQL /Python 2,3,4,8,29,30 6 HiveQL /Spark MLlib 5,20,25,26,28 5 HiveQL /OpenNLP 10,18,19,27 4 [Ghazal et al. 2013] Ahmad Ghazal, Tilmann Rabl, Minqing Hu, Francois Raab, Meikel Poess, Alain Crolotte, and Hans-Arno Jacobsen. 2013. BigBench: Towards An Industry Standard Benchmark for Big Data Analytics. In SIGMOD 2013. BigBench source code: https://github.com/BigData-Lab-Frankfurt/Big-Bench-Setup 19
- 20. November 27, 2019 The Default File Format Configurations • Very different Default configurations: ORC uses ZLIB compression Parquet does not use any compression The goal is to setup ORC and Parquet with similar configurations! 20
- 21. November 27, 2019 Setup ORC and Parquet with similar Configurations • We focus on 3 parameters: row group size (increased to 256MB) page size (unit for encoding and compression) data compression strategy (use Snappy Compression) 21
- 22. November 27, 2019 Data Loading Times (with Hive) • Trade-off between time taken to generate the data and the size of the generated data. • ORC with Default configuration (using ZLIB compression) and Parquet with Snappy configuration achieve the best performance in terms of time and data size! 22
- 23. November 27, 2019 Experimental Roadmap & Testing Duration • 2 columnar file formats (ORC and Parquet) • 3 test configurations (Default, No Compression and Snappy Compression) • 30 queries (all BigBench queries) • 2 SQL-on-Hadoop engines (Hive and SparkSQL) • 3 runs per configuration (representativeness of the results) Summing all Total Execution Times results in ~701 hours (29.2 days) of testing time! Configuration Default No Compression Snappy Compression File Format ORC Parquet ORC Parquet ORC Parquet BigBench Queries 30 30 30 Average Total Execution Time per Run (hours) on Hive 24 26 24 26 24 25 Average Total Execution Time per Run (hours) on SparkSQL 12 15 15 14 15 14 Number of Runs 3 3 3 Total Execution Time (hours) 108 124 116 120 116 117 23
- 24. November 27, 2019 Hive Experiments
- 25. November 27, 2019 Hive - Pure HiveQL • Default Conf.: ORC performs better (~14.8%) than Parquet, but the configurations are not comparable! • For No compression and Snappy Conf.: ORC still performs better than Parquet, but with smaller difference (~9.5%) and (~7.8%) respectively. Overall the ORC format performs better on Hive and benefits from using Snappy compression! 40 30 16 12 26 27 6 4 62 15 20 28 8 20 43 32 16 14 29 30 7 4 62 15 21 28 9 23 41 30 16 13 27 28 5 4 62 14 20 31 8 21 44 34 20 14 35 33 9 5 62 18 25 28 12 26 44 34 21 14 35 33 9 5 62 18 25 28 13 26 43 34 16 14 30 31 9 4 61 17 24 28 11 25 0 10 20 30 40 50 60 70 Q06 Q07 Q09 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q21 Q22 Q23 Q24 Execution Times (minutes) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. 25
- 26. November 27, 2019 Hive - HiveQL/Python • Default Conf.: ORC performs better (~8.4%) than Parquet. • For No compression and Snappy Conf.: ORC still performs better than Parquet, but with smaller difference (~6.9%) and (~5.1%) respectively. Both formats benefit from using Snappy compression! Overall the ORC format performs better on Hive and benefits from using Snappy compression! 12 170 76 155 41 38 250 14 172 79 156 44 40 250 13 171 76 155 42 39 249 18 183 91 171 49 40 259 17 184 90 172 49 40 258 16 180 85 167 45 40 253 0 50 100 150 200 250 300 Q01 Q02 Q03 Q04 Q08 Q29 Q30 Execution Times (minutes) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. 26
- 27. November 27, 2019 Hive - HiveQL/OpenNLP • Default Conf.: Parquet performs better (~24.7%) than ORC. • No compression Conf.: Parquet performs slightly better than ORC. • Snappy Conf.: Both file formats perform worse compared to the No compression configuration! Overall using compression with both ORC and Parquet worsens the performance for all queries! 33 50 13 2 23 46 10 2 30 48 12 2 18 45 9 1 19 47 9 1 30 50 12 2 0 10 20 30 40 50 60 Q10 Q18 Q19 Q27 Execution Times (minutes) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. 27
- 28. November 27, 2019 Hive - HiveQL/Spark MLlib • For all configurations ORC performs better than Parquet, except Q28, which performs equal independent of configuration! • Both formats benefit from using Snappy compression! Overall the ORC format performs better on Hive and benefits from using Snappy compression! 147 65 34 24 6 148 68 38 26 6 146 66 35 25 6 153 69 42 30 6 154 69 42 30 6 149 69 41 28 6 0 50 100 150 200 Q05 Q20 Q25 Q26 Q28 Execution Times (minutes) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. 28
- 29. November 27, 2019 Spark Experiments
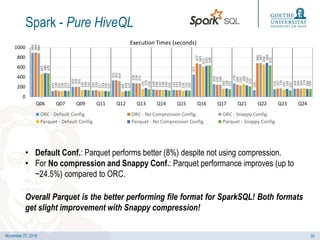
- 30. November 27, 2019 Spark - Pure HiveQL • Default Conf.: Parquet performs better (8%) despite not using compression. • For No compression and Snappy Conf.: Parquet performance improves (up to ~24.5%) compared to ORC. Overall Parquet is the better performing file format for SparkSQL! Both formats get slight improvement with Snappy compression! 894 114 202 126 331 278 148 141 451 254 270 135 155 164 894 130 199 134 331 274 138 133 677 245 244 680 167 166 884 116 201 117 314 271 143 139 665 246 233 687 170 164 467 118 136 121 105 155 138 118 613 163 262 654 145 174 480 123 140 116 118 176 140 132 630 168 232 688 160 160 475 117 135 110 122 150 126 125 636 155 210 635 132 154 0 200 400 600 800 1000 Q06 Q07 Q09 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q21 Q22 Q23 Q24 Execution Times (seconds) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. 30
- 31. November 27, 2019 Spark - HiveQL/Python • Default Conf.: ORC performs better (∼28.1%) than Parquet, except Q1 and Q8. • For No compression and Snappy Conf.: It is hard to say which format performs better! • Queries Q2 and Q30 are highly unstable on Spark when using the Parquet file format! 137 15644 2709 6319 913 203 6837 127 19471 2750 7375 911 197 8690 122 19441 2713 6727 900 199 9368 127 19287 2683 7062 675 504 15253 146 15937 2737 7032 712 517 11588 128 17580 2653 6752 639 184 11539 0 5000 10000 15000 20000 25000 Q01 Q02 Q03 Q04 Q08 Q29 Q30 Execution Times (seconds) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. 31
- 32. November 27, 2019 Spark - HiveQL/OpenNLP • Default Conf.: Parquet performs better than ORC, because it uses uncompressed data (like in Hive results). • No compression Conf.: Parquet still performs better (∼10.7%) than ORC. • Snappy Conf.: All queries perform similar on both formats, except Q10 which is better on ORC. Overall using compression with both ORC and Parquet worsens the performance for all queries (similar to Hive)! 1994 2711 521 140 2026 2699 526 138 2070 2836 535 139 976 2011 525 103 1633 2519 530 128 3075 2721 537 145 0 1000 2000 3000 4000 Q10 Q18 Q19 Q27 Execution Times (seconds) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. 32
- 33. November 27, 2019 Spark - HiveQL/Spark MLlib • For Default and No compression Conf.: ORC performs slightly better than Parquet! • Snappy Conf.: Parquet performance improves (~4.6%) compared to ORC, because of the use of Snappy compression. Overall Parquet benefits from using Snappy compression compared to ORC! 618 343 462 272 304 1842 343 453 266 297 1811 345 440 281 308 1825 298 359 374 309 1900 299 363 365 326 1787 294 346 290 322 0 500 1000 1500 2000 Q05 Q20 Q25 Q26 Q28 Execution Times (seconds) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. 33
- 34. November 27, 2019 In-depth Query Analysis
- 35. November 27, 2019 In-depth Query Analysis We perform a deeper query investigation on one representative query from each of the four query types in BigBench: • Q08 (MapReduce/Python) • Q10 (HiveQL/OpenNLP), • Q12 (Pure HiveQL) and • Q25 (HiveQL/Spark MLlib). Spark History Server Performance Analysis Tool (PAT) Source Code 35
- 36. November 27, 2019 Source Code lines 12-16 lines 19-42 lines 45-48 lines 51-75 Stages 0 1 2 3 4 5 6 7 8 9 10 11 12 13 Tasks 1 2 1 1402 200 200 2 978 200 1 200 200 200 1 Duration 3 sec. 4 sec. 4 sec. 5.8 min. 6.3 min. 4 sec. 0.2 sec. 1.9 min. 13 sec. 65 ms. 2 sec. 22 sec. 9 sec. 0.2 sec. Operations HiveTableScan (HadoopRDD, 4x MapPartitionsRDD ) HiveTableScan (HadoopRDD, 4x MapPartitionsRDD) HiveTableScan (HadoopRDD, 5x MapPartitionsRDD ) HiveTableScan (HadoopRDD, 5x MapPartitionsRDD) Exchange(ShuffledRowRDD), MapPartitionsRDD , ScriptTransformation(MapP artitionsRDD ), MapPartitionsRDD Exchange(MapPartitionsRDD) Exchange (ShuffledRowRDD), MapPartitionsRDD HiveTableScan (HadoopRDD, 5x MapPartitionsR DD) HiveTableScan (HadoopRDD, 4x MapPartitionsR DD) HiveTableScan (HadoopRDD, 5x MapPartitionsR DD) Exchange (ShuffledRowRDD ), 2x MapPartitionsRD D HiveTableScan (HadoopRDD, 4x MapPartitionsRD D) HiveTableScan (HadoopRDD, 5xMapPartitions RDD) 2xExchange (ShuffledRowRDD), 2xMapPartitionsRDD, SortMergeJoin (ZippedPartitionsRDD 2), 2xMapPartitionsRDD Exchange (ShuffledRow RDD), MapPartitions RDD Input 1142.0 KB 3.2 KB 17.0 KB 95.7 GB 3.2 KB 8.3 GB 3.7 GB 225.4 MB 3.7 GB Output 2.1 KB 15.2 GB 225.4 MB 3.7 GB 25.0 B Shuffle Read 15.2 GB 142.1 MB 11.5 KB 2.1 GB 11.5 KB Shuffle Write 142.1 MB 11.5 KB 135.3 MB 1973.8 MB 11.5 KB Q08 ORC No Compression CREATE TABLE ${hiveconf:TEMP_TABLE1} AS SELECT d_date_sk FROM date_dim d WHERE d.d_date >= ’${hiveconf:q08_startDate}’ AND d.d_date <= ’${hiveconf:q08_endDate}’; CREATE TABLE ${hiveconf:TEMP_TABLE2} AS SELECT DISTINCT wcs_sales_sk FROM ( FROM ( SELECT wcs_user_sk , (wcs_click_date_sk * 86400L + wcs_click_time_sk) AS tstamp_inSec , wcs_sales_sk , wp_type FROM web_clickstreams LEFT SEMI JOIN ${hiveconf:TEMP_TABLE1} date_filter ON (wcs_click_date_sk = date_filter.d_date_sk and wcs_user_sk IS NOT NULL) JOIN web_page w ON wcs_web_page_sk = w.wp_web_page_sk DISTRIBUTE BY wcs_user_sk SORT BY wcs_user_sk ,tstamp_inSec ,wcs_sales_sk ,wp_type ) q08_map_output REDUCE wcs_user_sk ,tstamp_inSec ,wcs_sales_sk ,wp_type USING ’python q08_filter_sales_with_reviews_viewed_before.py review ${hiveconf:q08_seconds_before_purchase}’ AS (wcs_sales_sk BIGINT) ) sales_which_read_reviews; CREATE TABLE IF NOT EXISTS ${hiveconf:TEMP_TABLE3} AS SELECT ws_net_paid , ws_order_number FROM web_sales ws JOIN ${hiveconf:TEMP_TABLE1} d ON ( ws.ws_sold_date_sk = d.d_date_sk); DROP TABLE IF EXISTS ${hiveconf:RESULT_TABLE}; CREATE TABLE ${hiveconf:RESULT_TABLE} ( q08_review_sales_amount BIGINT , no_q08_review_sales_amount BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ’,’ LINES TERMINATED BY ’n’ STORED AS ${env:BIG_BENCH_hive_default_fileformat_result_table} LOCATION ’${hiveconf:RESULT_DIR}’; INSERT INTO TABLE ${hiveconf:RESULT_TABLE} SELECT q08_review_sales.amount AS q08_review_sales_amount , q08_all_sales.amount - q08_review_sales.amount AS no_q08_review_sales_amount FROM ( SELECT 1 AS id, SUM(ws_net_paid) as amount FROM ${hiveconf:TEMP_TABLE3} allSalesInYear LEFT SEMI JOIN ${hiveconf:TEMP_TABLE2} salesWithViewedReviews ON allSalesInYear.ws_order_number = salesWithViewedReviews.wcs_sales_sk ) q08_review_sales JOIN ( SELECT 1 AS id, SUM(ws_net_paid) as amount FROM ${hiveconf:TEMP_TABLE3} allSalesInYear ) q08_all_sales ON q08_review_sales.id = q08_all_sales.id; Spark execution plan statistics for all queries available in Evaluation-summary.xlsx - https://github.com/BigData-Lab-Frankfurt/ColumnarFileFormatsEvaluation 36
- 37. November 27, 2019 0 10 20 30 40 50 60 70 80 90 100 0 6 12 20 26 32 40 46 52 60 66 72 80 86 92 100 106 112 120 126 132 140 146 152 160 166 172 180 186 192 200 206 212 220 226 232 240 246 252 260 266 272 280 286 292 300 306 312 320 326 332 340 346 352 360 366 372 380 386 392 400 CPUUtilization% Time (sec) Spark SQL IOwait% System% User% Source Code lines 15 - 25 lines 28 - 38 lines 48 -58 MLLib Stages Id0 Id1 Id2 Id3 Id4 Id5 Id6 Id7 Id8 Id9 Id11 Id12 48 Stages Tasks 1 682 200 200 1 977 200 200 400 200 200 200 9600 Duration 3 sec. 54 sec. 15 sec. 6 sec. 0.3 sec. 56 sec. 10 sec. 4 sec. 3 sec. 1 sec. 1 sec. 3 sec. 59 sec. Input 849.8 KB 7.7 GB 849.8 KB 7.8 GB 158.5 MB Output 79.2 MB 79.2 MB 79.3 MB Shuffle Read 2.0 GB 1054.8 MB 2.0 GB 1058.3 MB 132.2 MB 132.2 MB 64.9 MB Shuffle Write 2.0 GB 1054.8 MB 2.0 GB 1058.3 MB 132.2 MB 64.9 MB Q25 Parquet Snappy PAT resource utilization statistics for all queries in selected-queries-resource.pdf - https://github.com/BigData-Lab-Frankfurt/ColumnarFileFormatsEvaluationNovember 19 37
- 38. November 27, 2019 In-depth Analysis of query Q10 Description: For all products, extract sentences from its product reviews that contain positive or negative sentiment and display for each item the sentiment polarity of the extracted sentences (POS OR NEG) together with the sentence and word in sentence leading to this classification. • Selects all product reviews from “product_reviews” table and uses a UDF to extract sentiment. • No temporary tables, works directly and only on file format data. • Result is not compressed. 1994 2711 521 140 2026 2699 526 138 2070 2836 535 139 976 2011 525 103 1633 2519 530 128 3075 2721 537 145 0 1000 2000 3000 4000 Q10 Q18 Q19 Q27 Execution Times (seconds) ORC - Default Config. ORC - No Compression Config. ORC - Snappy Config. Parquet - Default Config. Parquet - No Compression Config. Parquet - Snappy Config. abnormal behavior with Parquet 38
- 39. November 27, 2019 BigBench Q10 - HiveQL/OpenNLP -- Resources ADD JAR ${env: BIG_BENCH_QUERIES_DIR }/ Resources / opennlp -maxent -3.0.3. jar; ADD JAR ${env: BIG_BENCH_QUERIES_DIR }/ Resources / opennlp -tools -1.6.0. jar; ADD JAR ${env: BIG_BENCH_QUERIES_DIR }/ Resources / bigbenchqueriesmr .jar; CREATE TEMPORARY FUNCTION extract_sentiment AS ’io. bigdatabenchmark .v1. queries .q10 . SentimentUDF ’; -- CREATE RESULT TABLE . Store query result externally in output_dir / qXXresult / DROP TABLE IF EXISTS ${ hiveconf : RESULT_TABLE }; CREATE TABLE ${ hiveconf : RESULT_TABLE } ( item_sk BIGINT , review_sentence STRING , sentiment STRING , sentiment_word STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ’,’ LINES TERMINATED BY ’n’ STORED AS ${env : BIG_BENCH_hive_default_fileformat_result_table } LOCATION ’${ hiveconf : RESULT_DIR }’; -- the real query part INSERT INTO TABLE ${ hiveconf : RESULT_TABLE } SELECT item_sk , review_sentence , sentiment , sentiment_word FROM ( SELECT extract_sentiment ( pr_item_sk , pr_review_content ) AS ( item_sk , review_sentence , sentiment , sentiment_word ) FROM product_reviews ) extracted ORDER BY item_sk , review_sentence , sentiment , sentiment_word ; 39
- 40. November 27, 2019 Query Q10 – Performance Analysis Tool (PAT) • Cluster resources (CPU, Disk, Memory, etc.) are underutilized with both file formats. Snappy Configuration 40
- 41. November 27, 2019 Query Q10 – Spark History Server • Compare the ORC and Parquet executions with Snappy Configuration: • Both file formats utilize different function for data retrieval: HiveTableScan vs. FileScanRDD • Parquet performs an extra stage with strange functions! further investigation of the UDF source code will be necessary File Format Parquet Configuration Snappy Total Time 51 min. Source Code lines 23-30 Stages 0 1 2 3 Tasks 28 6 28 200 Duration 18 min. 15 min. 17 min. 18 sec. Operations FileScanRDD, 5x MapPartitionsRDD FileScanRDD, 4x MapPartitionsRDD, PartitionPruningRDD, PartitionwiseSampledRDD FileScanRDD, 3x MapPartitionsRDD Exchange(ShuffledRow RDD), MapPartitionsRDD File Format ORC Configuration Snappy Total Time 37 min. Source Code lines 23-30 Stages 0 1 2 Tasks 9 9 200 Duration 18 min. 18 min. 19 sec. Operations HiveTableScan (HadoopRDD, 3xMapPartitionsRDD), Generate(MapPartitionsRDD), Exchange(3x MapPartitionsRDD) HiveTableScan (HadoopRDD, 3xMapPartitionsRDD), Generate(MapPartitionsRDD), Exchange( MapPartitionsRDD) Exchange(ShuffledRowRDD ), MapPartitionsRDD 41
- 42. November 27, 2019 Discussion & Open Questions
- 43. November 27, 2019 Our Approach for Benchmarking File Formats 1. Make sure the new engine offers support for the file formats under test (ORC and Parquet). 2. Choose a benchmark or test workload representing your use case and suitable for the comparison. 3. Set the file format configurations accordingly (with or without compression). 4. Generate the data and make sure that it is consistent with the file configuration using the file format (ORC and Parquet) tools. 5. Perform the experiments (at least 3 times) and calculate the average execution times. 6. Compare the time differences from the two file formats using the performance improvement and compressions improvement metrics and make conclusions. 7. Select queries compatible with your specific use-case. Execute them while collecting resource utilization data and perform in-depth query evaluation to spot bottlenecks and problems. 43
- 44. November 27, 2019 Is BigBench suitable for file format comparisons? Based on our experimental results, we can conclude that BigBench is a good choice for comparing file formats on SQL-on-Hadoop engines mainly for two reasons: • structured and unstructured data influence the query performance in particularly in combination with compression (Q10). • the BigBench variety of 30 different workloads (use cases) divided in four categories based on implementation type. 44
- 45. November 27, 2019 Open Questions • Is there a need for a specialized micro-benchmark to better investigate the file format features? • If yes, what should this benchmark include in terms of data types and operations? • What are the file format features that such a benchmark should stress (for example block size, compression etc.)? 45
- 47. November 27, 2019 Lessons Learned (1) In most cases using Snappy compression improves the performance on both file formats and both engines, except for the OpenNLP query type! Using ZLIB compression brings up to 60.2% improvement with ORC, while Parquet achieves up to 7% improvement with Snappy. Queries Q02 and Q30 perform unstable on Spark! (need to be investigated) The ‘‘out-of-the-box’’ Default file format configurations of ORC and Parquet are not comparable and should be used with caution! 47
- 48. November 27, 2019 Lessons Learned (2) Our experiments show that ORC generally performs better on Hive, while Parquet achieves best performance with SparkSQL. Our experiments confirm that the file format selection and its configuration significantly affect the overall performance! Comparison between Spark execution plans should be supported natively by both visual means and resource utilization statistics. Automated comparison (diff operation) between query executions will be extremely helpful! 48
- 49. November 27, 2019 ACKNOWLEDGMENTS This research was supported by the Frankfurt Big Data Lab (Chair for Databases and Information Systems - DBIS) at the Goethe University Frankfurt. Special thanks for the help and valuable feedback to Sead Izberovic, Thomas Stokowy, Karsten Tolle, Roberto V. Zicari (Frankfurt Big Data Lab), Pinar Tözün (IBM Almaden Research Center, San Jose, CA, USA), and Nicolas Poggi (Barcelona Super Computing Center). 49
- 50. November 27, 2019 References & More Details Classifying, Evaluating and Advancing Big Data Benchmarks (Doctoral Thesis, Todor Ivanov) online: http://publikationen.ub.uni-frankfurt.de/frontdoor/index/index/docId/51157 The main thesis contributions cover various relevant aspects from: • understanding the current challenges in the Big Data platforms, • choosing the most appropriate benchmark to stress test Big Data technologies, • investigating and evaluating multiple technology components by applying standardized and novel Big Data benchmarks and • tuning the relevant platform components to process and store more efficiently data. 50
- 51. 27. November 2019 Thank you for your attention! Questions?