The Next Generation of Data Processing and Open Source
3 likes1,179 views

The document discusses Apache Beam, a solution for next generation data processing. It provides a unified programming model for both batch and streaming data processing. Beam allows data pipelines to be written once and run on multiple execution engines. The presentation covers common challenges with historical data processing approaches, how Beam addresses these issues, a demo of running a Beam pipeline on different engines, and how to get involved with the Apache Beam community.







































The Next Generation of Data Processing and Open Source
- 1. The Next Generation of Data Processing & Open Source James Malone, Google Product Manager, Apache Beam PPMC Eric Schmidt, Google Developer Relations
- 2. Agenda 1 2 3 4 5 6 The Last Generation - Common historical challenges in large-scale data processing The Next Generation - How large-scale data processing should work Apache Beam - A solution for next generation data processing Why Beam matters - A gaming example to show the power of the Beam model Demo - Lets run a Beam pipeline on 3 engines in 2 separate clouds Things to Remember - Recap and how you can get involved 2
- 3. 3 Common historical challenges in large-scale data processing 01 The Last Generation
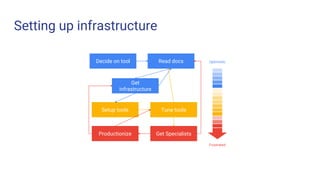
- 4. Decide on tool Read docs Get infrastructure Setup tools Tune tools Productionize Get Specialists Optimistic Frustrated Setting up infrastructure
- 5. Batch model Streaming model Batch use case Streaming use case Streaming engine Batch engine Batch output Streaming output Join output Optimistic Frustrated Programming models
- 6. Data model Data pipeline Execution engine 1 Data model Data pipeline Execution engine 1 Data model Data pipeline Execution engine 1 FrustratedHappy Data pipeline portability
- 7. Infrastructure is a pain Models are disconnected Pipelines are not portable 7
- 8. 8 How data processing should work 02 The Next Generation
- 9. 9 Infrastructure is a pain an afterthought Models are disconnected unified Pipelines are not portable portable
- 10. Skim docs Decide on product Start service Optimistic Happy Setting up infrastructure
- 11. Unified model Batch use case Runner(s) Streaming use case Output Optimistic Happy A flexible (unified) model
- 12. Data model Data pipeline Execution engine Execution engine Execution engine Happy Happier Portable data pipelines
- 13. Why does this matter? More time can be dedicated to examining data for actionable insights Less time is spent wrangling code, infrastructure, and tools used to process data Hands-on with data Cloud setup and customization
- 14. 14 A solution for next generation data processing 03 Apache Beam (incubating)
- 15. What is Apache Beam? 1. The (unified stream + batch) Dataflow Beam programming model 2. Java and Python SDKs 3. Runners for Existing Distributed Processing Backends a. Apache Flink (thanks to dataArtisans) b. Apache Spark (thanks to Cloudera & PayPal) c. Google Cloud Dataflow (fast, no-ops) d. Local (in-process) runner for testing + Future runners for Beam - Apache Gearpump, Apache Apex, MapReduce, others! 15
- 16. The Apache Beam vision 1. End users: who want to write pipelines in a language that’s familiar. 2. SDK writers: who want to make Beam concepts available in new languages. 3. Runner writers: who have a distributed processing environment and want to support Beam pipelines 16 Beam Model: Fn Runners Apache Flink Apache Spark Beam Model: Pipeline Construction Other LanguagesBeam Java Beam Python Execution Execution Google Cloud Dataflow Execution
- 17. Joining several threads into Beam 17 MapReduce BigTable DremelColossus FlumeMegastore SpannerPubSub Millwheel Cloud Dataflow Cloud Dataproc Apache Beam
- 18. Creating an Apache Beam community Collaborate - Beam is becoming a community-driven effort with participation from many organizations and contributors Grow - We want to grow the Beam ecosystem and community with active, open involvement so beam is a part of the larger OSS ecosystem Learn - We (Google) are also learning a lot as this is our first data-related Apache contribution ;-)
- 19. Apache Beam Roadmap 02/01/2016 Enter Apache Incubator End 2016 Beam pipelines run on many runners in production uses Early 2016 Design for use cases, begin refactoring Mid 2016 Additional refactoring, non-production uses Late 2016 Multiple runners execute Beam pipelines 02/25/2016 1st commit to ASF repository 06/14/2016 1st incubating release June 2016 Python SDK moves to Beam
- 20. 20 An example to show the power of the Beam model 04 Why Beam Matters
- 21. Apache Beam - A next generation model 21 Improved abstractions let you focus on your business logic Batch and stream processing are both first-class citizens -- no need to choose. Clearly separates event time from processing time.
- 22. Processing time vs. event time 22
- 23. Beam model - asking the right questions 23 What results are calculated? Where in event time are results calculated? When in processing time are results materialized? How do refinements of results relate?
- 24. The Beam model - what is being computed? 24 PCollection<KV<String, Integer>> scores = input .apply(Sum.integersPerKey());
- 25. The Beam model - what is being computed? 25
- 26. The Beam model - where in event time? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) .apply(Sum.integersPerKey());
- 27. The Beam model - where in event time?
- 28. The Beam model - when in processing time? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)) .triggering(AtWatermark())) .apply(Sum.integersPerKey());
- 29. The Beam model - when in processing time?
- 30. The Beam model - how do refinements relate? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)) .triggering(AtWatermark() .withEarlyFirings(AtPeriod(Duration.standardMinutes(1))) .withLateFirings(AtCount(1))) .accumulatingFiredPanes()) .apply(Sum.integersPerKey());
- 31. The Beam model - how do refinements relate?
- 32. Customizing what where when how 32 3 Streaming 4 Streaming + Accumulation 1 Classic Batch 2 Windowed Batch
- 33. Apache Beam - the ecosystem 33http://beam.incubator.apache.org/capability-matrix
- 34. 34 Lets run a Beam pipeline on 3 engines in 2 separate locations 05 Demo
- 35. 35 Created 1 Beam pipeline Ran that one pipeline on three execution engines in two places ● Google Cloud Platform ○ Google Cloud Dataflow ○ Apache Spark on Google Cloud Dataproc ● Local ○ Apache Beam local runner ○ Apache Flink 100% portability, 0 problems What we just did
- 36. 36 Recap and how you can get involved 06 Things to remember
- 37. Apache Beam is designed to provide potable pipelines with a unified programming model 37
- 38. Get involved with Apache Beam 38 Apache Beam (incubating) http://beam.incubator.apache.org The World Beyond Batch 101 & 102 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102 Join the Beam mailing lists! [email protected] [email protected] Join the Apache Beam Slack channel https://apachebeam.slack.com Follow @ApacheBeam on Twitter
- 39. A special thank you 39 A special thank you to Frances Perry and Tyler Akidau for sharing Apache Beam content which was used in this presentation.
- 40. 40 Thank you