Track Welcome: Operating Dynamic Infrastructure [FutureStack]
0 likes182 views

Track Welcome: Operating Dynamic Infrastructure Speaker: Matthew Flaming, VP of Engineering, New Relic
























![How New Relic Develops Language Agents [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/belinda893nrfs16hownrbuildslanguageagents111716a-161202201817-thumbnail.jpg?width=560&fit=bounds)
![Make Browsers Cry: How to Make a Modern Web App Painfully Slow [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/claysmith875nrfs16makebrowserscrysmith111516dh-161202201024-thumbnail.jpg?width=560&fit=bounds)
![Track Welcome: New Relic: Analytics for Everyone [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/rebeccacampbell897analyticsforeveryone11116dhrcedit-161201215455-thumbnail.jpg?width=560&fit=bounds)
![Track Welcome: Developing Breakthrough Customer Experiences [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/belinda880nrfs16devbreakthroughcustexp111616dh2-161202200716-thumbnail.jpg?width=560&fit=bounds)
![Track Welcome: New Relic 101 [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/darren-c-nrfs16nr101901111516final-161201212600-thumbnail.jpg?width=560&fit=bounds)


![Lew Cirne, FS16 Keynote [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/fs16sfkeynotelewshare1-161206235025-thumbnail.jpg?width=560&fit=bounds)










![The Full Story: Managing Change at 100MPH [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/879shipirodigitaldilemma111516b-161201215752-thumbnail.jpg?width=560&fit=bounds)







More Related Content
What's hot (19)
Similar to Track Welcome: Operating Dynamic Infrastructure [FutureStack] (17)

![Increasing MTBLS with New Relic [FutureStack16 NYC]](https://cdn.slidesharecdn.com/ss_thumbnails/nrinfrastructure101080816v3081516-160815233622-thumbnail.jpg?width=560&fit=bounds)












More from New Relic (19)



![FutureStack Tokyo 19 -[事例講演]株式会社リクルートライフスタイル:年間9300万件以上のサロン予約を支えるホットペッパービューティ...](https://cdn.slidesharecdn.com/ss_thumbnails/newrelicfuturestacktokyokabutoya20190314-190403084958-thumbnail.jpg?width=560&fit=bounds)
![FutureStack Tokyo 19 -[New Relic テクニカル講演]モニタリングと可視化がデジタルトランスフォーメーションを救う! - サ...](https://cdn.slidesharecdn.com/ss_thumbnails/fssasaki20190312-190403080804-thumbnail.jpg?width=560&fit=bounds)
![FutureStack Tokyo 19 -[特別講演]システム開発によろこびと驚きの連鎖を](https://cdn.slidesharecdn.com/ss_thumbnails/creditsaisonononewrelicfuturestacktokyo20190314-190402055010-thumbnail.jpg?width=560&fit=bounds)
![FutureStack Tokyo 19 -[パートナー講演]アマゾン ウェブ サービス ジャパン株式会社: New Relicを活用したAWSへのアプリ...](https://cdn.slidesharecdn.com/ss_thumbnails/awsmorookanewrelicfuturestacktokyo20190314-190401092319-thumbnail.jpg?width=560&fit=bounds)












Recently uploaded (20)




















Track Welcome: Operating Dynamic Infrastructure [FutureStack]
- 1. Dynamic Infrastructure Matthew Flaming, VP Site Engineering @mflaming
- 2. This document and the information herein (including any information that may be incorporated by reference) is provided for informational purposes only and should not be construed as an offer, commitment, promise or obligation on behalf of New Relic, Inc. (“New Relic”) to sell securities or deliver any product, material, code, functionality, or other feature. Any information provided hereby is proprietary to New Relic and may not be replicated or disclosed without New Relic’s express written permission. Such information may contain forward-looking statements within the meaning of federal securities laws. Any statement that is not a historical fact or refers to expectations, projections, future plans, objectives, estimates, goals, or other characterizations of future events is a forward-looking statement. These forward-looking statements can often be identified as such because the context of the statement will include words such as “believes,” “anticipates,”, “expects” or words of similar import. Actual results may differ materially from those expressed in these forward-looking statements, which speak only as of the date hereof, and are subject to change at any time without notice. Existing and prospective investors, customers and other third parties transacting business with New Relic are cautioned not to place undue reliance on this forward-looking information. The achievement or success of the matters covered by such forward-looking statements are based on New Relic’s current assumptions, expectations, and beliefs and are subject to substantial risks, uncertainties, assumptions, and changes in circumstances that may cause the actual results, performance, or achievements to differ materially from those expressed or implied in any forward-looking statement. Further information on factors that could affect such forward-looking statements is included in the filings New Relic makes with the SEC from time to time. Copies of these documents may be obtained by visiting New Relic’s Investor Relations website at ir.newrelic.com or the SEC’s website at www.sec.gov. New Relic assumes no obligation and does not intend to update these forward-looking statements, except as required by law. New Relic makes no warranties, expressed or implied, in this document or otherwise, with respect to the information provided.
- 3. A Brief History of Ops
- 4. A Brief History of Ops
- 5. A Brief History of Ops
- 6. A Brief History of Ops
- 8. • HW issues • OS upgrades • Disk space • CPU usage • HW issues • OS upgrades • Disk space • CPU usage • Network issues • Noisy neighbors • OS upgrades • Disk space • CPU usage • Network issues • SOA complexity • HW issues • Noisy neighbors • OS upgrades • Disk space • CPU usage • Network issues • SOA complexity • Container issues
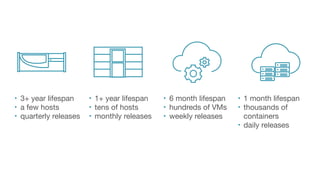
- 9. • 3+ year lifespan • a few hosts • quarterly releases • 1+ year lifespan • tens of hosts • monthly releases • 6 month lifespan • hundreds of VMs • weekly releases • 1 month lifespan • thousands of containers • daily releases
- 11. “oh sh*t, scale, complexity, and volatility are eating us alive!” “Our architecture needs to be built for scale and volatility, while reducing complexity.” Dynamic Infrastructure dynamic infrastructure
- 12. Dynamic Infrastructure is a Design Pattern Phoenix Servers Compute as a Uniform Resource
- 13. Know Your Herd
- 18. TOMORROW Is An Inexact Science
- 19. Thank you. Matthew Flaming, VP Site Engineering @mflaming
- 20. APPENDIX