Training Deep Networks with Backprop (D1L4 Insight@DCU Machine Learning Workshop 2017)
3 likes589 views

The document discusses the training of deep neural networks using backpropagation and stochastic gradient descent methods. It provides practical tips on hyperparameter selection and training strategies while highlighting challenges such as overfitting and slow convergence. Tools like Caffe, Torch, Theano, and TensorFlow are mentioned for implementing these techniques effectively.





























Training Deep Networks with Backprop (D1L4 Insight@DCU Machine Learning Workshop 2017)
- 1. Kevin McGuinness [email protected] Research Fellow Insight Centre for Data Analytics Dublin City University DEEP LEARNING WORKSHOP Dublin City University 27-28 April 2017 Training Deep Networks with Backprop Day 1 Lecture 4 1
- 5. Fitting deep networks to data We need an algorithm to find good weight configurations. This is an unconstrained continuous optimization problem. We can use standard iterative optimization methods like gradient descent. To use gradient descent, we need a way to find the gradient of the loss with respect to the parameters (weights and biases) of the network. Error backpropagation is an efficient algorithm for finding these gradients. Basically an application of the multivariate chain rule and dynamic programming. In practice, computing the full gradient is expensive. Backpropagation is typically used with stochastic gradient descent.
- 6. Gradient descent If we had a way to compute the gradient of the loss with respect to the parameters, we could use gradient descent to optimize 6
- 7. Stochastic gradient descent Computing the gradient for the full dataset at each step is slow ● Especially if the dataset is large! For most losses we care about, the total loss can be expressed as a sum (or average) of losses on the individual examples The gradient is the average of the gradients on individual examples 7
- 8. Stochastic gradient descent SGD: estimate the gradient using a subset of the examples ● Pick a single random training example ● Estimate a (noisy) loss on this single training example (the stochastic gradient) ● Compute gradient wrt. this loss ● Take a step of gradient descent using the estimated loss 8
- 9. Stochastic gradient descent Advantages ● Very fast (only need to compute gradient on single example) ● Memory efficient (does not need the full dataset to compute gradient) ● Online (don’t need full dataset at each step) Disadvantages ● Gradient is very noisy, may not always point in correct direction ● Convergence can be slower Improvement ● Estimate gradient on small batch of training examples (say 50) ● Known as mini-batch stochastic gradient descent 9
- 10. Finding the gradient with backprop Combination of the chain rule and dynamic programming Chain rule: allows us to find gradient of the loss with respect to any input, activation, or parameter Dynamic programming: reuse computations from previous steps. You don’t need to evaluate the full chain for every parameter.
- 11. The chain rule Easily differentiate compositions of functions. 11
- 12. The chain rule
- 13. The chain rule
- 14. The chain rule
- 16. Modular backprop You could use the chain rule on all the individual neurons to compute the gradients with respect to the parameters and backpropagate the error signal. Much more useful to use the layer abstraction Then define the backpropation algorithm in terms of three operations that layers need to be able to do. This is called modular backpropagation
- 19. Linear layer
- 20. ReLU layer
- 21. Modular backprop Using this idea, it is possible to create many types of layers ● Linear (fully connected layers) ● Activation functions (sigmoid, ReLU) ● Convolutions ● Pooling ● Dropout Once layers support the backward and forward operations, they can be plugged together to create more complex functions Convolution Input Error (L) Gradients ReLU Linear Gradients Output Error (L+1) 21
- 22. Implementation notes Caffe and Torch Libraries like Caffe and Torch implement backpropagation this way To define a new layer, you need to create an class and define the forward and backward operations Theano and TensorFlow Libraries like Theano and TensorFlow operate on a computational graph To define a new layer, you only need to specify the forward operation. Autodiff is used to automatically infer backward. You also don't need to implement backprop manually in Theano or TensorFlow. It uses computational graph optimizations to automatically factor out common computations. 22
- 23. Practical tips for training deep nets 23
- 24. Choosing hyperparameters Can already see we have lots of hyperparameters to choose: 1. Learning rate 2. Regularization constant 3. Number of epochs 4. Number of hidden layers 5. Nodes in each hidden layer 6. Weight initialization strategy 7. Loss function 8. Activation functions 9. … :( Choosing these is a bit of an art. Good news: in practice many configurations work well There are some reasonable heuristics. E.g 1. Try 0.1 for the learning rate. If this diverges, divide by 3. Repeat. 2. Try an existing network architecture and adapt it for your problem 3. Try overfit the data with a big model, then regularize You can also do a hyperparameter search if you have enough compute: ● Randomized search tends to work well
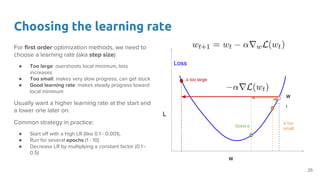
- 25. Choosing the learning rate For first order optimization methods, we need to choose a learning rate (aka step size) ● Too large: overshoots local minimum, loss increases ● Too small: makes very slow progress, can get stuck ● Good learning rate: makes steady progress toward local minimum Usually want a higher learning rate at the start and a lower one later on. Common strategy in practice: ● Start off with a high LR (like 0.1 - 0.001), ● Run for several epochs (1 - 10) ● Decrease LR by multiplying a constant factor (0.1 - 0.5) w L Loss w t α too large Good α α too small 25
- 26. Training and monitoring progress 1. Split data into train, validation, and test sets ○ Keep 10-30% of data for validation 2. Fit model parameters on train set using SGD 3. After each epoch: ○ Test model on validation set and compute loss ■ Also compute whatever other metrics you are interested in, e.g. top-5 accuracy ○ Save a snapshot of the model 4. Plot learning curves as training progresses 5. Stop when validation loss starts to increase 6. Use model with minimum validation loss epoch Loss Validation loss Training loss Best model 26
- 27. Divergence Symptoms: ● Training loss keeps increasing ● Inf, NaN in loss Try: ● Reduce learning rate ● Zero center and scale inputs/targets ● Check weight initialization strategy (monitor gradients) ● Numerically check your gradients ● Clip gradient norm w L Loss wt α too large 27
- 28. Slow convergence Symptoms: ● Training loss decreases slowly ● Training loss does not decrease Try: ● Increase learning rate ● Zero center and scale inputs/targets ● Check weight initialization strategy (monitor gradients) ● Numerically check gradients ● Use ReLUs ● Increase batch size ● Change loss, model architecture w L Loss wt 28
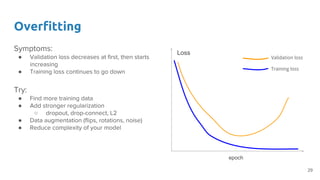
- 29. Overfitting Symptoms: ● Validation loss decreases at first, then starts increasing ● Training loss continues to go down Try: ● Find more training data ● Add stronger regularization ○ dropout, drop-connect, L2 ● Data augmentation (flips, rotations, noise) ● Reduce complexity of your model epoch Loss Validation loss Training loss 29
- 30. Underfitting Symptoms: ● Training loss decreases at first but then stops ● Training loss still high ● Training loss tracks validation loss Try: ● Increase model capacity ○ Add more layers, increase layer size ● Use more suitable network architecture ○ E.g. multi-scale architecture ● Decrease regularization strength epoch Loss Validation loss Training loss 30
- 31. Questions? 31