Transactional operations in Apache Hive: present and future

Apache Hive is an enterprise data warehouse build on top of Hadoop. Hive supports insert, update, delete, and merge SQL operations with transactional semantics and read operations that run at snapshot isolation. The well defined semantics of these operations in the face of failure and concurrency are critical to building robust application on top of Apache Hive. In the past there were many preconditions to enabling these features which meant giving up other functionality. The need to make these tradeoffs is rapidly being eliminated. This talk will describe the intended use cases, architecture of the implementation, recent improvements and new features build for Hive 3.0. For example, bucketing transactional tables, while supported, is no longer required. Performance overhead of using transactional tables is nearly eliminated relative to identical non-transactional tables. We’ll also cover Streaming Ingest API, which allows writing batches of events into a Hive table without using SQL. Speaker Eugene Koifman, Hortonworks, Principal Software Engineer
































































More Related Content
What's hot (20)
Similar to Transactional operations in Apache Hive: present and future (20)


















More from DataWorks Summit (20)



















Recently uploaded (20)




















Transactional operations in Apache Hive: present and future
- 1. 1 © Hortonworks Inc. 2011–2018. All rights reserved Transactional Operations in Apache Hive DataWorks Summit, San Jose 2018 • Eugene Koifman
- 2. 2 © Hortonworks Inc. 2011–2018. All rights reserved Agenda • A bit of history • Current Functionality • Design • Future Plans • Closing Remarks
- 3. 3 © Hortonworks Inc. 2011–2018. All rights reserved Early Hive • Transactions • ACID: Atomicity, Consistency, Isolation, Durability • Atomicity - Rely on File System ‘rename’ • Insert into T partition(p=1) select …. - OK • Dynamic Partition Write – not OK • Multi-Insert statement – not OK • FROM <expr> Insert into A select … Insert Into B select … • Isolation - Lock Manager • S/X locks – not good for long running analytics
- 4. 4 © Hortonworks Inc. 2011–2018. All rights reserved Early Hive – Changing Existing Data • Drop <…> • Insert Overwrite = Truncate + Insert • Gets expensive if done often on small % of data
- 5. 5 © Hortonworks Inc. 2011–2018. All rights reserved Goals • Support ACID properties • Support SQL Update/Delete/Merge • Low rate of transactions • Not OLTP • Not a replacement for MySql or HBase
- 6. 6 © Hortonworks Inc. 2011–2018. All rights reserved Features – Hive 3
- 7. 7 © Hortonworks Inc. 2011–2018. All rights reserved Transactional Tables • Not all tables support transactional semantics • Managed Tables • No External tables or Storage Handler (Hbase, Druid, etc) • Fully ACID compliant • Single statement transactions • Cross partition/cross table transactions • Snapshot Isolation • Between Serializable and Repeatable Read
- 8. 8 © Hortonworks Inc. 2011–2018. All rights reserved Transactional Tables – Full CRUD Supports Update/Delete/Merge CREATE TABLE T(a int, b int) STORED AS ORC TBLPROPERTIES ('transactional'='true'); • Restrictions • Managed Table • Table cannot be sorted • Currently requires ORC File but anything implementing • AcidInputFormat/AcidOutputFormat • Bucketing is optional! • If upgrading from Hive 2 • Requires Major Compaction before Upgrading
- 9. 9 © Hortonworks Inc. 2011–2018. All rights reserved Transactional Tables – Insert only CREATE TABLE T(a int, b int) TBLPROPERTIES ('transactional'='true’, ‘transactional_properties’=‘insert_only’); • Managed Table • Any storage format
- 10. 10 © Hortonworks Inc. 2011–2018. All rights reserved Transactional Tables – Convert from flat tables ALTER TABLE T SET TBLPROPERTIES ('transactional'='true') ALTER TABLE T(a int, b int) SET TBLPROPERTIES ('transactional'='true’, ‘transactional_properties’=‘true’); • Metadata Only operation • Compaction will eventually rewrite the table
- 11. 11 © Hortonworks Inc. 2011–2018. All rights reserved Transactional Tables - New In Hive 3 • Alter Table Add Partition… • Alter Table T Concatenate • Alter Table T Rename To…. • Export/Import Table • Non-bucketed tables • Load Data… Into Table … • Insert Overwrite • Fully Vectorized • Create Table As … • LLAP Cache • Predicate Push Down
- 12. 12 © Hortonworks Inc. 2011–2018. All rights reserved Design – Hive 3
- 13. 13 © Hortonworks Inc. 2011–2018. All rights reserved Transactional Tables – Insert Only • Transaction Manager • Begin transaction and obtain a Transaction ID • For each table, get a Write ID – determines location to write to create table TM (a int, b int) TBLPROPERTIES ('transactional'='true', 'transactional_properties'='insert_only'); insert into TM values(1,1); insert into TM values(2,2); insert into TM values(3,3); tm ── delta_0000001_0000001_0000 └── 000000_0 ── delta_0000002_0000002_0000 └── 000000_0 ── delta_0000003_0000003_0000 └── 000000_0
- 14. 14 © Hortonworks Inc. 2011–2018. All rights reserved Transaction Manager • Transaction State • Open, Committed, Aborted • Reader at Snapshot Isolation • A snapshot is the state of all transactions • High Water Mark + List of Exceptions tm ── delta_0000001_0000001_0000 └── 000000_0 ── delta_0000002_0000002_0000 └── 000000_0 ── delta_0000003_0000003_0000 └── 000000_0 Atomicity & Isolation
- 15. 15 © Hortonworks Inc. 2011–2018. All rights reserved Full CRUD • No in-place Delete - Append-only file system • Isolate readers from writers
- 16. 16 © Hortonworks Inc. 2011–2018. All rights reserved ROW__ID • CREATE TABLE acidtbl (a INT, b STRING) STORED AS ORC TBLPROPERTIES ('transactional'='true'); Metadata Columns original_write_id bucket_id row_id current_write_id User Columns col_1: a : INT col_2: b : STRING ROW__ID
- 17. 17 © Hortonworks Inc. 2011–2018. All rights reserved Create • INSERT INTO acidtbl (a,b) VALUES (100, “foo”), (200, “xyz”), (300, “bee”); ROW__ID a b { 1, 0, 0 } 100 “foo” { 1, 0, 1 } 200 “xyz” { 1, 0, 2 } 300 “bee” delta_00001_00001/bucket_0000
- 18. 18 © Hortonworks Inc. 2011–2018. All rights reserved Delete • DELETE FROM acidTbl where a = 200; ROW__ID a b { 1, 0, 0 } 100 “foo” { 1, 0, 1 } 200 “xyz” { 1, 0, 2 } 300 “bee” ROW__ID a b { 1, 0, 1 } null null delta_00001_00001/bucket_0000 delete_delta_00002_00002/bucket_0000 Readers skip deleted rows
- 19. 19 © Hortonworks Inc. 2011–2018. All rights reserved Update • Update = delete + insert UPDATE acidTbl SET b = “bar” where a = 300; ACID_PK a b { 1, 0, 0 } 100 “foo” { 1, 0, 1 } 200 “xyz” { 1, 0, 2 } 300 “bee” delta_00001_00001/bucket_0000 ACID_PK a b { 2, 0, 0 } 300 “bar” ACID_PK a b { 1, 0, 2 } null null delta_00003_00003/bucket_0000 delete_delta_00003_00003/bucket_0000
- 20. 20 © Hortonworks Inc. 2011–2018. All rights reserved Read • Ask Transaction Manager for Snapshot Information • Decide which deltas are relevant • Take all the files in delta_x_x/ and split them into chunks for each processing Task to work with • Localize all delete events from each delete_deleta_x_x/ to each task • Highly Compressed with ORC • Filter out all Insert events that have matching delete events • Requires an Acid aware reader – thus AcidInputFormat
- 21. 21 © Hortonworks Inc. 2011–2018. All rights reserved Design - Compactor • More Update operations = more delete events – make reads more expensive • Insert operations don’t add read overhead
- 22. 22 © Hortonworks Inc. 2011–2018. All rights reserved Design - Compactor • Compactor rewrites the table in the background • Minor compaction - merges delta files into fewer deltas • Major compactor merges deltas with base - more expensive • This amortizes the cost of updates and self tunes the tables • Makes ORC more efficient - larger stripes, better compression • Compaction can be triggered automatically or on demand • There are various configuration options to control when the process kicks in. • Compaction itself is a Map-Reduce job Key design principle is that compactor does not affect readers/writers • Cleaner process – removes obsolete files • Requires Standalone metastore
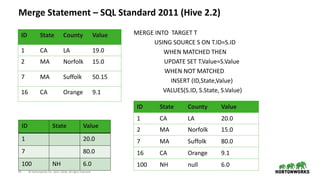
- 23. 23 © Hortonworks Inc. 2011–2018. All rights reserved Merge Statement – SQL Standard 2011 (Hive 2.2) ID State County Value 1 CA LA 19.0 2 MA Norfolk 15.0 7 MA Suffolk 50.15 16 CA Orange 9.1 ID State Value 1 20.0 7 80.0 100 NH 6.0 MERGE INTO TARGET T USING SOURCE S ON T.ID=S.ID WHEN MATCHED THEN UPDATE SET T.Value=S.Value WHEN NOT MATCHED INSERT (ID,State,Value) VALUES(S.ID, S.State, S.Value) ID State County Value 1 CA LA 20.0 2 MA Norfolk 15.0 7 MA Suffolk 80.0 16 CA Orange 9.1 100 NH null 6.0
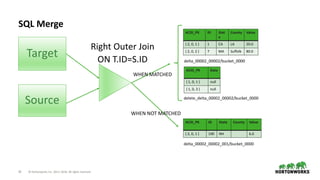
- 24. 24 © Hortonworks Inc. 2011–2018. All rights reserved SQL Merge Target Source ACID_PK ID Stat e County Value { 2, 0, 1 } 1 CA LA 20.0 { 2, 0, 2 } 7 MA Suffolk 80.0 ACID_PK ID State County Value { 2, 0, 1 } 100 NH 6.0 delta_00002_00002/bucket_0000 delta_00002_00002_001/bucket_0000 Right Outer Join ON T.ID=S.ID ACID_PK Data { 1, 0, 1 } null { 1, 0, 3 } null delete_delta_00002_00002/bucket_0000 WHEN MATCHED WHEN NOT MATCHED
- 25. 25 © Hortonworks Inc. 2011–2018. All rights reserved Merge Statement Optimizations • Semi Join Reduction • aka Dynamic Runtime Filtering • On Tez only T.ID=S.ID Target Source ID in (1,7,100) T.ID=S.ID Target Source
- 26. 26 © Hortonworks Inc. 2011–2018. All rights reserved Design - Concurrency • Inserts are never in conflict since Hive does not enforce unique constraints • Write Set tracking to prevent Write-Write conflicts in concurrent transactions • Lock Manager • DDL operations acquire eXclusive locks – metadata operations • Read operations acquire Shared locks
- 27. 27 © Hortonworks Inc. 2011–2018. All rights reserved Tooling • SHOW COMPACTIONS • Hadoop Job ID • SHOW TRANSACTIONS • SHOW LOCKS • What a lock is blocked on • ABORT TRANSACTIONS txnid1, txnid2….
- 28. 28 © Hortonworks Inc. 2011–2018. All rights reserved Other Subsystems • Result Set Caching • Is it valid for current reader? • Materialized Views • Incremental View Manitenance • Spark • HiveWarehouseConnector: HS2 + LLAP
- 29. 29 © Hortonworks Inc. 2011–2018. All rights reserved Streaming Ingest API • Connection – Hive Table • Begin transaction • Commit/Abort transaction • org.apache.hive.streaming.StreamingConnection • Writer • Write records • org.apache.hive.streaming.RecordWriter • Append Only via this API • Update/Delete via SQL • Optimized for Write operations • Requires more aggressive Compaction for efficient reads • Supports dynamic partitioning in a single transaction
- 30. 30 © Hortonworks Inc. 2011–2018. All rights reserved Limitations • Transaction Manager • State is persisted in the metastore RDBMS • Begin/Commit/Abort • Metastore calls
- 31. 31 © Hortonworks Inc. 2011–2018. All rights reserved Future
- 32. 32 © Hortonworks Inc. 2011–2018. All rights reserved Future Work • Multi statement transactions, i.e. BEGIN TRANSACTION/COMMIT/ROLLBACK • Performance • Smarter Compaction • Finer grained concurrency management/conflict detection • Read Committed w/Lock Based scheduling • Better Monitoring/Alerting • User define Primary Key • Transactional Tables sorted on PK
- 33. 33 © Hortonworks Inc. 2011–2018. All rights reserved Further Reading
- 34. 34 © Hortonworks Inc. 2011–2018. All rights reserved Etc • Documentation • https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions • https://cwiki.apache.org/confluence/display/Hive/Streaming+Data+Ingest+V2 • Follow/Contribute • https://issues.apache.org/jira/browse/HIVE- 14004?jql=project%20%3D%20HIVE%20AND%20component%20%3D%20Transactions • [email protected] • [email protected]
- 35. 35 © Hortonworks Inc. 2011–2018. All rights reserved Credits • Alan Gates • Sankar Hariappan • Prasanth Jayachandran • Eugene Koifman • Owen O’Malley • Saket Saurabh • Sergey Shelukhin • Gopal Vijayaraghavan • Wei Zheng
- 36. 36 © Hortonworks Inc. 2011–2018. All rights reserved Thank You