










![© 2018 data Artisans
HEAP STATE TABLE ARCHITECTURE
- Hash buckets (Object[]), 4B-8B per slot
- Load factor <= 75%
- Incremental rehash
Entry
Entry
Entry
12](https://image.slidesharecdn.com/ff18b-180919132318/85/Tuning-Flink-For-Robustness-And-Performance-12-320.jpg)
![© 2018 data Artisans
HEAP STATE TABLE ARCHITECTURE
- Hash buckets (Object[]), 4B-8B per slot
- Load factor <= 75%
- Incremental rehash
Entry
Entry
Entry
▪ 4 References:
▪ Key
▪ Namespace
▪ State
▪ Next
▪ 3 int:
▪ Entry Version
▪ State Version
▪ Hash Code
K
N
S
4 x (4B-8B)
+3 x 4B
+ ~8B-16B (Object overhead)
Object sizes and
overhead.
Some objects might
be shared.
13](https://image.slidesharecdn.com/ff18b-180919132318/85/Tuning-Flink-For-Robustness-And-Performance-13-320.jpg)
















































Tuning Flink For Robustness And Performance
- 1. STEFAN RICHTER @STEFANRRICHTER SEPT 4, 2018 TUNING FLINK FOR ROBUSTNESS AND PERFORMANCE 1
- 2. © 2018 data Artisans GENERAL MEMORY CONSIDERATIONS 2
- 3. © 2018 data Artisans BASIC TASK SCHEDULING SRC-0 SRC-1 keyBy Source Stateful Map MAP-1 MAP-2 MAP-0 SNK-2 SNK-1 SNK-0 Sink TaskManager 0 TaskManager 1 Slot 0 Slot 1 Slot 0 Slot 1 JVM Process JVM Process 3
- 4. © 2018 data Artisans BASIC TASK SCHEDULING SRC-0 SRC-1 keyBy Source Stateful Map MAP-1 MAP-2 MAP-0 SNK-2 SNK-1 SNK-0 Sink TaskManager 0 TaskManager 1 Slot 0 Slot 1 Slot 0 Slot 1 JVM Process JVM Process 4
- 5. © 2018 data Artisans TASK MANAGER PROCESS MEMORY LAYOUT Task Manager JVM Process Java Heap Off Heap / Native Flink Framework etc. Network Buffers Timer State Keyed State Typical Size 5
- 6. © 2018 data Artisans TASK MANAGER PROCESS MEMORY LAYOUT Task Manager JVM Process Java Heap Off Heap / Native Flink Framework etc. Network Buffers Timer State Keyed State Typical Size % ??? % ??? ∑ ??? 6
- 7. © 2018 data Artisans TASK MANAGER PROCESS MEMORY LAYOUT Task Manager JVM Process Java Heap Off Heap / Native Flink Framework etc. Network Buffers Timer State Keyed State Typical Size 7
- 8. © 2018 data Artisans TASK MANAGER PROCESS MEMORY LAYOUT Task Manager JVM Process Java Heap Off Heap / Native Flink Framework etc. Network Buffers Timer State Keyed State Typical Size 8
- 9. © 2018 data Artisans STATE BACKENDS 9
- 10. © 2018 data Artisans FLINK KEYED STATE BACKENDS CHOICES Based on Java Heap Objects Based on RocksDB 10
- 11. © 2018 data Artisans HEAP KEYED STATE BACKEND CHARACTERISTICS • State lives as Java objects on the heap. • Organized as chained hash table, key ↦ state. • One hash table per registered state. • Supports asynchronous state snapshots through copy-on-write MVCC. • Data is de/serialized only during state snapshot and restore. • Highest performance. • Affected by garbage collection overhead / pauses. • Currently no incremental checkpoints. • Memory overhead of representation. • State size limited by available heap memory. 11
- 12. © 2018 data Artisans HEAP STATE TABLE ARCHITECTURE - Hash buckets (Object[]), 4B-8B per slot - Load factor <= 75% - Incremental rehash Entry Entry Entry 12
- 13. © 2018 data Artisans HEAP STATE TABLE ARCHITECTURE - Hash buckets (Object[]), 4B-8B per slot - Load factor <= 75% - Incremental rehash Entry Entry Entry ▪ 4 References: ▪ Key ▪ Namespace ▪ State ▪ Next ▪ 3 int: ▪ Entry Version ▪ State Version ▪ Hash Code K N S 4 x (4B-8B) +3 x 4B + ~8B-16B (Object overhead) Object sizes and overhead. Some objects might be shared. 13
- 14. © 2018 data Artisans HEAP STATE TABLE SNAPSHOT MVCC Original Snapshot A C B Entry Entry Entry Copy of hash bucket array is snapshot overhead 14
- 15. © 2018 data Artisans HEAP STATE TABLE SNAPSHOT MVCC Original Snapshot A C B D No conflicting modification = no overhead 15
- 16. © 2018 data Artisans HEAP STATE TABLE SNAPSHOT MVCC Original Snapshot A’ C B D A Modifications trigger deep copy of entry - only as much as required. This depends on what was modified and what is immutable (as determined by type serializer). Worst case overhead = size of original state table at time of snapshot. 16
- 17. © 2018 data Artisans HEAP BACKEND TUNING CONSIDERATIONS • Chose type serializer with efficient copy-method (for copy-on-write). • Flag immutability of objects where possible to avoid copy completely. • Flatten POJOs / avoid deep objects. Reduces object overheads and following references = potential cache misses. • GC choice/tuning can help. Follow future GC developments. • Scale-out using multiple task manager per node to support larger state over multiple heap backends rather than having fewer and large heaps. 17
- 18. © 2018 data Artisans ROCKSDB KEYED STATE BACKEND CHARACTERISTICS • State lives as serialized byte-strings in off-heap memory and on local disk. • Key-Value store, organized as log-structured merge tree (LSM-tree). • Key: serialized bytes of <Keygroup, Key, Namespace>. • Value: serialized bytes of the state. • One column family per registered state (~table). • LSM naturally supports MVCC. • Data is de/serialized on every read and update. • Not affected by garbage collection. • Relative low overhead of representation. • LSM naturally supports incremental snapshots. • State size limited by available local disk space. • Lower performance (~order of magnitude compared to Heap state backend). 18
- 19. © 2018 data Artisans ROCKSDB ARCHITECTURE WAL WAL Memory Persistent Store Active MemTable WriteOp In Flink: - disable WAL and sync - persistence via checkpoints 19
- 20. © 2018 data Artisans ROCKSDB ARCHITECTURE Local Disk WAL WAL Compaction Memory Persistent Store Flush In Flink: - disable WAL and sync - persistence via checkpointsActive MemTable ReadOnly MemTable WriteOp Full/Switch SST SST SSTSST Merge 20
- 21. © 2018 data Artisans ROCKSDB ARCHITECTURE Local Disk WAL WAL Compaction Memory Persistent Store Flush In Flink: - disable WAL and sync - persistence via checkpointsActive MemTable ReadOnly MemTable WriteOp Full/Switch SST SST SSTSST Merge Set per column family (~table) 21
- 22. © 2018 data Artisans ROCKSDB ARCHITECTURE ReadOp Local Disk WAL WAL Compaction Memory Persistent Store Flush Merge Active MemTable ReadOnly MemTable Full/Switch WriteOp SST SST SSTSST In Flink: - disable WAL and sync - persistence via checkpoints 22
- 23. © 2018 data Artisans ROCKSDB ARCHITECTURE Active MemTable ReadOnly MemTable WriteOp ReadOp Local Disk WAL WAL Compaction Memory Persistent Store Full/Switch Read Only Block Cache Flush SST SST SSTSST Merge In Flink: - disable WAL and sync - persistence via checkpoints 23
- 24. © 2018 data Artisans ROCKSDB RESOURCE CONSUMPTION • One RocksDB instance per keyed operator subtask. • block_cache_size: • Size of the block cache. • write_buffer_size: • Max. size of a MemTable. • max_write_buffer_number: • The maximum number of MemTables in memory before flush to SST files. • Indexes and bloom filters (optional). • Table Cache: • Caches open file descriptors to SST files. Default: unlimited! 24
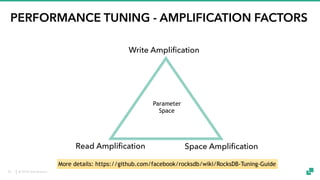
- 25. © 2018 data Artisans PERFORMANCE TUNING - AMPLIFICATION FACTORS Write Amplification Read Amplification Space Amplification More details: https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide Parameter Space 25
- 26. © 2018 data Artisans PERFORMANCE TUNING - AMPLIFICATION FACTORS Write Amplification Read Amplification Space Amplification More details: https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide Parameter Space Example: More compaction effort = increased write amplification and reduced read amplification 26
- 27. © 2018 data Artisans GENERAL PERFORMANCE CONSIDERATIONS • Efficient type serializer and serialization formats. • Decompose user-code objects: business logic / efficient state representation. • Extreme: „Flightweight Pattern“, e.g. wrapper object that interprets/manipulates stored byte array on the fly and uses only byte-array type serializer. • File Systems: • Working directory on fast storage, ideally local SSD. Could even be memory file system because it is transient for Flink. EBS performance can be problematic. • Checkpoint directory: Persistence happens here. Can be slower but should be fault tolerant. 27
- 28. © 2018 data Artisans TIMER SERVICE 28
- 29. © 2018 data Artisans HEAP TIMERS ▪ 2 References: ▪ Key ▪ Namespace ▪ 1 long: ▪ Timestamp ▪ 1 int: ▪ Array Index K N Object sizes and overhead. Some objects might be shared. Binary heap of timers in array Peek: O(1) Poll: O(log(n)) Insert: O(1)/O(log(n)) Delete: O(n) Contains O(n) Timer 29
- 30. © 2018 data Artisans HEAP TIMERS ▪ 2 References: ▪ Key ▪ Namespace ▪ 1 long: ▪ Timestamp ▪ 1 int: ▪ Array Index K N Object sizes and overhead. Some objects might be shared. Binary heap of timers in array HashMap<Timer, Timer> : fast deduplication and deletes Key Value Peek: O(1) Poll: O(log(n)) Insert: O(1)/O(log(n)) Delete: O(log(n)) Contains O(1) MapEntry Timer 30
- 31. © 2018 data Artisans HEAP TIMERS Binary heap of timers in array HashMap<Timer, Timer> : fast deduplication and deletes MapEntry Key Value Snapshot (net data of a timer is immutable) Timer 31
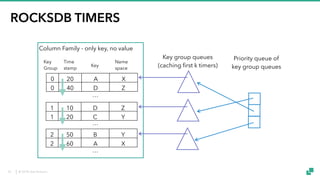
- 32. © 2018 data Artisans ROCKSDB TIMERS 0 20 A X 0 40 D Z 1 10 D Z 1 20 C Y 2 50 B Y 2 60 A X … … Key Group Time stamp Key Name space … Lexicographically ordered byte sequences as key, no value Column Family - only key, no value 32
- 33. © 2018 data Artisans ROCKSDB TIMERS 0 20 A X 0 40 D Z 1 10 D Z 1 20 C Y 2 50 B Y 2 60 A X … … Key Group Time stamp Key Name space Column Family - only key, no value Key group queues (caching first k timers) Priority queue of key group queues … 33
- 34. © 2018 data Artisans 3 TASK MANAGER MEMORY LAYOUT OPTIONS Task Manager JVM Process Java Heap Off Heap / Native Flink Framework etc. Network Buffers Timer State Keyed State Task Manager JVM Process Java Heap Off Heap / Native Flink Framework etc. Network Buffers Timer State Keyed State Task Manager JVM Process Java Heap Off Heap / Native Flink Framework etc. Network Buffers Keyed State Timer State 34
- 35. © 2018 data Artisans FULL / INCREMENTAL CHECKPOINTS 35
- 36. © 2018 data Artisans FULL CHECKPOINT Checkpoint 1 A B C D A B C D @t1 36
- 37. © 2018 data Artisans FULL CHECKPOINT Checkpoint 1 Checkpoint 2 A B C D A B C D A F C D E @t1 @t2 A F C D E 36
- 38. © 2018 data Artisans FULL CHECKPOINT G H C D Checkpoint 1 Checkpoint 2 Checkpoint 3 I E A B C D A B C D A F C D E @t1 @t2 @t3 A F C D E G H C D I E 36
- 39. © 2018 data Artisans FULL CHECKPOINT G H C D Checkpoint 1 Checkpoint 2 Checkpoint 3 I E A B C D A B C D A F C D E @t1 @t2 @t3 A F C D E G H C D I E 36
- 40. © 2018 data Artisans FULL CHECKPOINT G H C D Checkpoint 1 Checkpoint 2 Checkpoint 3 I E A B C D A B C D A F C D E @t1 @t2 @t3 A F C D E G H C D I E 36
- 41. © 2018 data Artisans FULL CHECKPOINT OVERVIEW • Creation iterates and writes full database snapshot as stream to stable storage. • Restore reads data as stream from stable storage and re-inserts into backend. • Each checkpoint is self contained, size is proportional to size of full state. • Optional: compression with Snappy. 37
- 42. © 2018 data Artisans INCREMENTAL CHECKPOINT Checkpoint 1 A B C D A B C D @t1 𝚫 38
- 43. © 2018 data Artisans INCREMENTAL CHECKPOINT Checkpoint 1 Checkpoint 2 A B C D A B C D A F C D E E F @t1 @t2 builds upon 𝚫𝚫 38
- 44. © 2018 data Artisans INCREMENTAL CHECKPOINT G H C D Checkpoint 1 Checkpoint 2 Checkpoint 3 I E A B C D A B C D A F C D E E F G H I @t1 @t2 @t3 builds upon builds upon 𝚫𝚫 𝚫 38
- 45. © 2018 data Artisans INCREMENTAL CHECKPOINT G H C D Checkpoint 1 Checkpoint 2 Checkpoint 3 I E A B C D A B C D A F C D E E F G H I @t1 @t2 @t3 builds upon builds upon 𝚫𝚫 𝚫 38
- 46. © 2018 data Artisans INCREMENTAL CHECKPOINT G H C D Checkpoint 1 Checkpoint 2 Checkpoint 3 I E A B C D A B C D A F C D E E F G H I @t1 @t2 @t3 builds upon builds upon 𝚫𝚫 𝚫 38
- 47. © 2018 data Artisans INCREMENTAL CHECKPOINTS WITH ROCKSDB Local Disk Compaction Memory Flush Incremental checkpoints: Observe created/deleted SST files since last checkpoint Active MemTable ReadOnly MemTable Full/Switch SST SST SSTSST Merge 39
- 48. © 2018 data Artisans INCREMENTAL CHECKPOINT OVERVIEW • Expected trade-off: faster* checkpoints, slower* recovery • Creation only copies deltas (new local SST files) to stable storage. • Write amplification because we also upload compacted SST files so that we can prune checkpoint history. • Sum of all increments that we read from stable storage can be larger than the full state size. Deletes are also explicit as tombstones. • But no rebuild required because we simply re-open the RocksDB backend from the SST files. • SST files are snappy-compressed by default. 40
- 49. © 2018 data Artisans LOCAL RECOVERY 41
- 50. © 2018 data Artisans CHECKPOINTING WITHOUT LOCAL RECOVERY keyBy Source Stateful Operation Stable Storage Snapshot Snapshot Checkpoint 42
- 51. © 2018 data Artisans RESTORE WITHOUT LOCAL RECOVERY keyBy Source Stateful Operation Stable Storage Checkpoint 43
- 52. © 2018 data Artisans RESTORE WITHOUT LOCAL RECOVERY keyBy Source Stateful Operation Stable Storage Restore Restore Checkpoint 44
- 53. © 2018 data Artisans CHECKPOINTING WITH LOCAL RECOVERY keyBy Source Stateful Operation Stable Storage Snapshot Snapshot Checkpoint 45
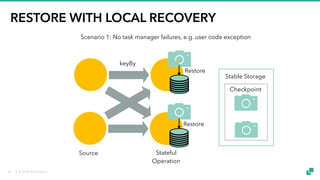
- 54. © 2018 data Artisans RESTORE WITH LOCAL RECOVERY keyBy Source Stateful Operation Stable Storage Checkpoint Restore Restore Scenario 1: No task manager failures, e.g. user code exception 46
- 55. © 2018 data Artisans RESTORE WITH LOCAL RECOVERY keyBy Source Stateful Operation Stable Storage Checkpoint Restore Restore Scenario 2: With task manager failure, e.g. disk failure 47
- 56. © 2018 data Artisans LOCAL RECOVERY TAKEAWAY POINTS • Works with both state backends, for full and incremental checkpoints. • Keeps a local copy of the snapshot. Typically, this comes at the cost of mirroring the snapshot writes to remote storage also to local storage. • Restore with LR avoids the transfer of state from stable to local storage. • LR works particularly well with RocksDB incremental checkpoints. • No new local files created, existing files might only live a bit longer. • Opening database from local, native table files - no ingestion / rebuild. • Under TM failure recovery still bounded by slowest restore, but still saves a lot of resources! 48
- 57. © 2018 data Artisans REINTERPRET STREAM AS KEYED STREAM 49
- 58. © 2018 data Artisans REINTERPRETING A DATASTREAM AS KEYED KeyedStream<T, K> reinterpretAsKeyedStream( DataStream<T> stream, KeySelector<T, K> keySelector) env.addSource(new InfiniteTupleSource(1000)) .keyBy(0) .map((in) -> in) .timeWindow(Time.seconds(3)); DataStreamUtils.reinterpretAsKeyedStream( env.addSource(new InfiniteTupleSource(1000)) .keyBy(0) .filter((in) -> true), (in) -> in.f0) .timeWindow(Time.seconds(3)); Problem: Will not compile because we can no longer ensure a keyed stream! Solution: Method to explicitly give (back) „keyed“ property to any data stream Warning: Only use this when you are absolutely sure that the elements in the reinterpreted stream follow exactly Flink’s keyBy partitioning scheme for the given key selector! 50
- 59. © 2018 data Artisans REINTERPRETING A DATASTREAM AS KEYED KeyedStream<T, K> reinterpretAsKeyedStream( DataStream<T> stream, KeySelector<T, K> keySelector) env.addSource(new InfiniteTupleSource(1000)) .keyBy(0) .map((in) -> in) .timeWindow(Time.seconds(3)); DataStreamUtils.reinterpretAsKeyedStream( env.addSource(new InfiniteTupleSource(1000)) .keyBy(0) .filter((in) -> true), (in) -> in.f0) .timeWindow(Time.seconds(3)); Problem: Will not compile because we can no longer ensure a keyed stream! Solution: Method to explicitly give (back) „keyed“ property to any data stream Warning: Only use this when you are absolutely sure that the elements in the reinterpreted stream follow exactly Flink’s keyBy partitioning scheme for the given key selector! 50
- 60. © 2018 data Artisans IDEA 1 - REDUCING SHUFFLES Stateful Filter Stateful Map Window keyBy (shuffle) keyBy Window ( Stateful Map ( Stateful Filter ) ) keyBy (shuffle) keyBy (shuffle) 51
- 61. © 2018 data Artisans IDEA 1 - REDUCING SHUFFLES Stateful Filter Stateful Map Window Stateful Filter Stateful Map Window reinterpret as keyed reinterpret as keyed keyBy (shuffle) keyBy (shuffle) keyBy (shuffle) keyBy (shuffle) 52
- 62. © 2018 data Artisans IDEA 2 - PERSISTENT SHUFFLE Job 1 Job 2 Source Kafka Sink Kafka Source Keyed Op … … … keyBy partition 0 partition 1 partition 2 reinterpret as keyed 53
- 63. © 2018 data Artisans IDEA 2 - PERSISTENT SHUFFLE Job 1 Job 2 … … … partition 0 partition 1 partition 2 Job 2 becomes embarrassingly parallel and can use fine grained recovery! Source Kafka Sink Kafka Source Keyed Op keyBy reinterpret as keyed 54
- 64. THANK YOU! @StefanRRichter @dataArtisans @ApacheFlink WE ARE HIRING data-artisans.com/careers