Tutorial-DeepLearning-PCSJ-IMPS2016
11 likes5,018 views

Deep Learning Tutorial at 2016/11/17






































































![シーンラベリング
[Yamashita, 2016] 73](https://image.slidesharecdn.com/deeplearning-161119113901/85/Tutorial-DeepLearning-PCSJ-IMPS2016-73-320.jpg)
![シーンラベリング
74[Yamashita, 2016]](https://image.slidesharecdn.com/deeplearning-161119113901/85/Tutorial-DeepLearning-PCSJ-IMPS2016-74-320.jpg)



![ヘテロジニアスラーニング(4)
ヘテロジニアスラーニングによる歩行者検出と部位推定
1
0.0001 0.001 0.01 0.1 1 10
MissRate
False Positive per Image
回帰型DCNN 31.77%
単体のDCNN 38.38%
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
Daimler
Mono-‐Pedestrian
Benchmark
Dataset
の評価結果
距離[m] 距離推定結果[m] 誤差[%]
5 4.89 2.2
10 9.26 5.3
15 14.12 5.8
回帰型Deep Convolutional Neural Networkによる人検出と部位の位置推定, 2015 78](https://image.slidesharecdn.com/deeplearning-161119113901/85/Tutorial-DeepLearning-PCSJ-IMPS2016-78-320.jpg)







Tutorial-DeepLearning-PCSJ-IMPS2016
- 2. 研究グループ紹介 Machine Perception and Robotics Group 2 2014年度 学科を超えた研究グループを発足 藤吉弘亘教授 山下隆義講師 山内悠嗣助手 教員3名 博士課程後期 3名 博士課程前期 2名 秘書1名 学部4年生 19名 学部3年生 20名 ロボット理工学科 ロボット理工学科 情報工学科
- 3. MPRGについて Machine Perception and Robotics Group 3 http://mprg.jp
- 4. MPRGについて Machine Perception and Robotics Group 4 機械知覚 ロボティクス
- 5. 機械学習を利用した研究 Machine Perception and Robotics Group 5 機械知覚 ロボティクス ディープラーニング,SVMなどの 機械学習による画像認識 内積演算のバイナリ処理化によるSVMの高速化
- 6. MPRGについて Machine Perception and Robotics Group 6 機械知覚 ロボティクス 産業・生活支援ロボットのための 画像認識 ピッキングアイテムの認識 (Amazon Picking Challenge)
- 7. Amazon Picking Challenge 2016 7
- 8. 機械学習を利用した研究 Machine Perception and Robotics Group 8 機械知覚 ロボティクス 産業・生活支援ロボットのための 画像認識 Weighted Hough Forestによる把持判定・追加学習
- 9. ディープラーニングの現在(1) 画像認識のベンチマークでトップ Convolution Pooling Softmax Other GoogLeNet(2014) ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 9 Team year Error (top-‐5) SuperVision 2012 15.3% Clarifai 2013 11.2% VGG – Oxford (16 layers) 2014 7.32% GoogLeNet (19 layers) 2014 6.67% Residual Net. 2015 3.57% human expert 5.1% Residual Net(2015)
- 14. ディープラーニング現在(6) 14 Learning a Deep Convolutional Network for Image Super-Resolution, in Proceedings of European Conference on Computer Vision (ECCV), 2014 超解像
- 15. ディープラーニングの現在(7) Deep Convolutional Generative Adversarial Network(DCGAN) 入力画像例 10分後 半日後 ノイズのような画像から顔画像を自動的に生成
- 16. ディープラーニングの現在(8) Deep Q- Network 16 V. Mnih et al., "Playing atari with deep reinforcement learning
- 20. 画像分野でのディープラーニング 全てのルーツは 福島邦彦、位置ずれに影響されないパターン認識機構の神経回路のモデル --- ネオコグニトロン ---電子通信学会論文誌A, vol. J62-A, no. 10, pp. 658-665,1979. Y. LeCun, et.al. “Gradient-based Learning Applied to Document Recognition”, Proc. of The IEEE, 1998. ネオコグニトロン 畳み込みニューラルネットワーク 20
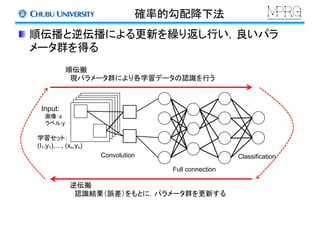
- 21. 畳み込みニューラルネットワーク 初期の研究(今も同じ) 畳み込み、サブサンプリング、全結合の層から構成 手書き文字認識に応用 Y. LeCun, et.al. “Gradient-based Learning Applied to Document Recognition”, Proc. of The IEEE, 1998.
- 22. 畳み込み層(1) カーネルをスライドさせて画像に畳み込む 近接の画素とのみ結合する(局所受容野) Convolution Response f Input image Feature map10x10 kernel 3x3 8x8 Activation function Convolutions
- 23. 畳み込み層(1) カーネルをスライドさせて画像に畳み込む 近接の画素とのみ結合する(局所受容野) Convolution Response f Input image Feature map10x10 kernel 3x3 8x8 Activation function Convolutions
- 24. 畳み込み層(1) カーネルをスライドさせて画像に畳み込む 近接の画素とのみ結合する(局所受容野) Convolution Response f Input image Feature map10x10 kernel 3x3 8x8 Activation function Convolutions
- 25. 畳み込み層(2) 画像全体にフィルタを畳み込む -1 0 1 -2 0 2 -1 0 1 例えば ソーベルフィルタ Convolution Layerのフィルタは, 学習により獲得
- 26. 畳み込み層(3) カーネルをスライドさせて画像に畳み込む 近接の画素とのみ結合する(局所受容野) カーネルは複数でも良い Activation functionInput image Feature map10x10 8x8 Convolution Response kernel 3x3 f f f Convolutions
- 28. 活性化関数 シグモイド関数 Rectified Linear Unit(ReLU) Leaky ReLU 古くから使われている サチると勾配が消滅 画像認識でよく使われる 学習が速く、勾配がサチる ことがない f (xi ) = max(xj,0)f (xi ) = 1 1+e −xj Convolutions f(x) = max(↵x, x) (0 < ↵ < 1) f(xi) = max(↵xi, xi) ReLUを改良した活性化関 数 負の値を出力
- 29. プーリング層 Feature mapのサイズを縮小させる Max pooling 2x2の領域 での最大値 Average pooling 2x2の領域 での平均値 Sampling 89 56 65 18 24 9 121 77 43 22 32 18 181 56 42 35 45 19 210 166 101 67 79 56 121 65 32 210 101 79 89 56 65 18 24 9 121 77 43 22 32 18 181 56 42 35 45 19 210 166 101 67 79 56 86 37 21 153 61 50
- 30. 全結合層 x1 x2 x3 xi h1 h2 hj 各ノードとの結合重み 例えば、、 は を算出し、 activation functionに与えて値を得る 全結合型の構成 hj = f (WT x + bj ) Full connection w11 w12 w21 w1j w22w31 w32 w3 j wij wi2 wi1
- 34. 物体認識 http://image-net.org ImageNetのデータセットを利用して1000クラスの物体認識を行う ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 34
- 35. ディープラーニングによる物体認識 AlexNet ILSVRC2012で優勝 8層(畳み込み5層,全結合3層)の構造 Team year Error (top-‐5) SuperVision(AlexNet) 2012 15.3% 1層目のフィルタ A. Krizhevsky, ImageNet Classification with Deep Convolutional Neural Networks, NIPS2012 35
- 36. ディープラーニングによる物体認識 Team year Error (top-‐5) SuperVision 2012 15.3% Clarifai 2013 11.2% VGG – Oxford (16 layers) 2014 7.32% 3x3のフィルタを2層積層すると 5x5のフィルタと等価になる AlexNetとほぼ等価の構成 VGG16 ILSVRC2014で2位 16層と深い構造 K. Simonyan, Very Deep Convolutional Networks for Large-Scale Image Recognition, ICLR2015 36
- 37. ディープラーニングによる物体認識 Convolution Pooling Softmax Other Inception module Team year Error (top-‐5) SuperVision 2012 15.3% Clarifai 2013 11.2% VGG – Oxford (16 layers) 2014 7.32% GoogLeNet (22layers) 2014 6.67% 3x3 convolutions 5x5 convolutions Filter concatenation Previous layer 3x3 max pooling 1x1 convolutions 1x1 convolutions 1x1 convolutions 1x1 convolutions C. Szegedy, Going Deeper with Convolutions, CVPR2015 GoogLeNet Inception モジュールを9つ積層 途中の層の誤差を求め,下位層まで誤差を伝播 37
- 38. ディープラーニングによる物体認識 Team year Error (top-‐5) SuperVision 2012 15.3% Clarifai 2013 11.2% VGG – Oxford (16 layers) 2014 7.32% GoogLeNet (22layers) 2014 6.67% Residual Net. 2015 3.57% human expert 5.1% K. He, Deep Residual Learning for Image Recognition, CVPR2016 Residual Network 特定層への入力をバイパスして上位層へ与える 逆伝播時に誤差を下位層に直接与えることができる 38
- 40. 標識認識 German Traffic Sign Recognition Benchmarkで人を上回る性能 Multi-Column Deep Neural Network for Traffic Sign Classification,IJCNN2011 METHODS ACCURACY Multi-Column Deep Neural Network 99.46% Human Performance 98.84% Multi-Scale CNN 98.31% Random Forest 96.14% LDA on HOG 95.68% 0.71 0.17 0.03 0.09 0.89 0.03 0.01 0.07 0.85 0.09 0.02 0.04 複数のCNNを利用して精度向上 学習の手間:大 メモリサイズ:大 処理時間:大 40
- 41. 標識認識 一つのネットワークを仮想的に複数のネットワークにする Ensemble Median Inference Fukui, Pedestrian Detection Based on Deep Convolutional Neural Network with Ensemble Inference Network, IV2015 METHODS ACCURACY Multi-Column Deep Neural Network 99.46% Human Performance 98.84% Multi-Scale CNN 98.31% Random Forest 96.14% LDA on HOG 95.68% 0.71 0.17 0.03 0.09 41
- 42. 標識認識 METHODS ACCURACY Random Droput+Dn’MI 99.22% Multi-Column Deep Neural Network 99.46% Human Performance 98.84% Multi-Scale CNN 98.31% Random Forest 96.14% LDA on HOG 95.68% 0.89 0.03 0.01 0.07 0.71 0.17 0.03 0.09 0.85 0.09 0.02 0.04 複数ネットワーク利用時と同等性能 学習の手間:小 メモリサイズ:小 処理時間:中 一つのネットワークを仮想的に複数のネットワークにする Ensemble Median Inference STEP1:全結合層のネットワークを複数生成 STEP2:各クラスの確率を累積する Fukui, Pedestrian Detection Based on Deep Convolutional Neural Network with Ensemble Inference Network, IV2015 42
- 43. 標識認識 人の目でも分かりにくい標識でも認識可能 Dropout Random Dropout + EIN 0 20 40 60 80 100 0 20 40 60 80 100 0 20 40 60 80 100 0 20 40 60 80 100 0 20 40 60 80 100 0 20 40 60 80 100 0 20 40 60 80 100 0 20 40 60 80 100 Input imageFukui, Pedestrian Detection Based on Deep Convolutional Neural Network with Ensemble Inference Network, IV2015 43
- 46. 前段の検出手法 Aggregate Channel Features (ACF) ・入力画像からチャンネル特徴量を生成(LUV, 勾配強度,勾配ヒストグラム) ・生成したチャンネル特徴量から特徴ピラミッドを作成 ・Boosted treeによりチャンネル特徴量から歩行者検出に有効な 特徴量を選択 46
- 48. 10 -3 10 -2 10 -1 10 0 10 1 .05 .10 .20 .30 .40 .50 .64 .80 1 false positives per image missrate 30% ACF-Caltech+ 16% ACF-Caltech+ -AlexNet ディープラーニングを利用した歩行者検出 Caltech Pedestrian Detection Benchmarkにおける性能 48Fukui, 2016
- 51. S. Zhang , How Far are We from Solving Pedestrian Detection?, CVPR2016 ディープラーニングを利用した歩行者検出 人と機械学習手法との比較 51
- 52. 一般物体検出 • Selective Searchにより物体候補を検出 • CNNで抽出した特徴量をSVMでクラス識別 R−CNN 4つのステップから構成 1)局所領域の切り出し 2)領域の変形 3)CNNによる特徴抽出 4)SVMによる識別 R. Girshick, Rich feature hierarchies for accurate object detection and semantic segmentation, CVPR2014
- 53. R-CNNの課題 処理時間がかかる • 1画像あたり:47秒 (VGGネットを使用時) 学習・検出プロセスが複雑 • 処理ごとに個別の学習とデータの準備が必要 特徴抽出 (CNN) 特徴抽出 (CNN) 特徴抽出 (CNN) 物体識別 (SVM) 物体識別( SVM) 物体識別 (SVM) 入力画像 領域切り出し 領域変形 背景 人 馬 領域ごとに実行 座標補正 ( 回帰) 座標補正 ( 回帰) R. Girshick, Rich feature hierarchies for accurate object detection and semantic segmentation, CVPR2014
- 54. Fast R-CNN 特徴抽出処理をまとめて行うことで高速化 • R-CNNと比べて10-100倍高速 学習・検出プロセスをシンプルに • 領域切り出しの処理をCNNの構成で行う(SVMなし) 特徴抽出 (CNN) 特徴座標 識別層・回帰層 (CNN) 入力画像 領域切り出し 領域変形 物体:背景 座標情報 (-1,-1,-1,-1) 物体:人 座標情報 (10,3,40,100) 物体:馬 座標情報 (5,100,80,20) 領域ごとに実行 識別層・回帰層 (CNN) 識別層・回帰層 (CNN) R. Girshick,, Fast RCNN, ICCV2015
- 55. Fast R-CNN 特徴抽出処理をまとめて行うことで高速化 • R-CNNと比べて10-100倍高速 学習・検出プロセスをシンプルに • 領域切り出しの処理をCNNの構成で行う(SVMなし) 特徴抽出 (CNN) 特徴座標 識別層・回帰層 (CNN) 入力画像 領域切り出し 領域変形 物体:背景 座標情報 (-1,-1,-1,-1) 物体:人 座標情報 (10,3,40,100) 物体:馬 座標情報 (5,100,80,20) 領域ごとに実行 識別層・回帰層 (CNN) 識別層・回帰層 (CNN)Selective Searchによる切り出し =>この処理が時間かかる R. Girshick,, Fast RCNN, ICCV2015
- 56. Faster R-CNN 領域切り出しもCNNで行うことでさらなる高速化 • R-CNNと比べて10-100倍高速 学習・検出プロセスをさらにシンプルに • すべてをCNNで行う 特徴抽出 (CNN) 検出層 (全結合) 入力画像 回帰層 (全結合) 識別層 (Fast R-CNN) Region Proposal Network S. Ren,, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, NIPS2015
- 57. Region Proposal Network(RPN) 特徴抽出 (CNN) 入力画像 CNNで抽出した特徴マップ上の各注目点について 検出:k個のアンカーに対する物体か否か 回帰:k個のアンカーに対する座標 を行う 形状は1:1,1:2,2:1の3種類 大きさは128, 256, 512の3スケール アンカー=注目領域の形状と 大きさのパターン S. Ren,, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, NIPS2015
- 58. Faster R-CNNによる物体検出例 S. Ren,, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, NIPS2015
- 59. Faster R-CNNによる物体検出の速度 • 特徴マップ作成をVGGで行った場合,selective searchの 場合よりも約10倍高速化 • ZFを特徴マップ作成に利用するとさらに3倍高速化 59
- 60. YOLO GPU上でリアルタイムでの一般物体検出(22ms) 画像全体をCNNに入力 グリッドごとに物体らしさと矩形を算出 各グリッドがどの物体クラスかを判定 NMSでグリッドを選択し,物体矩形として出力 You Only Look Once: Unified, Real-Time Object Detection, CVPR2016
- 61. YOLOの処理の流れ 入力画像 各グリットでの矩形と 物体クラスを算出 CNN 矩形算出結果 各グリッドの代表クラスを算出 各グリッドの代表矩形を選択 NMSで出力矩形を選択 You Only Look Once: Unified, Real-Time Object Detection, CVPR2016
- 62. YOLOの出力内容 各グリッドは, • 矩形(x,y,幅,高さ) • 物体らしさ をクラスの数だけ出力する 各グリッドは, 複数の矩形を出力することも可能 Pascal VOCの場合 グリッド数:7x7 矩形数:2 クラ数数:20 出力ユニット数:1470 (7 x 7 x (2 x 5 + 20) = 7 x 7 x 30 tensor) You Only Look Once: Unified, Real-Time Object Detection, CVPR2016
- 63. YOLOによる検出結果例 63 You Only Look Once: Unified, Real-Time Object Detection, 2016
- 64. YOLOの精度 Pascal 2007 mAP Speed DPM v5 33.7 .07 FPS 14 s/img R-CNN 66.0 .05 FPS 20 s/img Fast R-CNN 70.0 .5 FPS 2 s/img Faster R-CNN 73.2 7 FPS 140 ms/img YOLO 63.4 69.0 45 FPS 22 ms/img You Only Look Once: Unified, Real-Time Object Detection, CVPR2016
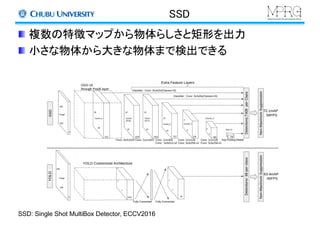
- 65. SSD 複数の特徴マップから物体らしさと矩形を出力 小さな物体から大きな物体まで検出できる SSD: Single Shot MultiBox Detector, ECCV2016
- 66. ディープラーニングベース手法の比較 SSD: Single Shot MultiBox Detector, ECCV2016
- 67. SSDによる検出結果例
- 69. シーンラベリング 69 V. Badrinarayanan, SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling, 2015
- 70. シーンラベリング手法 Fully Convolutional Neural Network プーリング層後の特徴マップを拡大し,結合 70J. Long, Fully Convolutional Networks for Semantic Segmentation, CVPR2015
- 71. SegNet エンコーダ・デコーダの構成 Max Poolingを行う時に位置情報を記憶 最大値&圧縮前の位置情報を参照 データがない座標には「0」を補完 71 V. Badrinarayanan, SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling, 2015
- 72. Cityscapes 車載用セグメンテーションのデータセット → 既存のセグメンテーションデータセット(CamVid)より,大規模 Dataset URL : https://www.cityscapes-dataset.com/ 50都市で撮影 30クラスのラベリング 評価には19クラスを利用 (頻出頻度の低いクラスは対象外) The Cityscapes Dataset for Semantic Urban Scene Understanding 72M. Cordts, The Cityscapes Dataset for Semantic Urban Scene Understanding, CVPR2016
- 75. ヘテロジニアスラーニング(1) ディープラーニングのメリット 複数の異なる情報を同時に学習・認識できる 年齢と性別の同時推定 Convolution Layer Fully Connection Layer Male or Female input samples Age 75Heterogeneous Learningと重み付き誤差関数の導入による顔画像解析, 2015
- 76. ヘテロジニアスラーニング(2) 出力情報の種類を増やすことが可能 Convolution Layer Fully Connection Layer Male or Female input samples Age Race Smile degree 76 ディープラーニングのメリット 複数の異なる情報を同時に学習・認識できる Heterogeneous Learningと重み付き誤差関数の導入による顔画像解析, 2015
- 78. ヘテロジニアスラーニング(4) ヘテロジニアスラーニングによる歩行者検出と部位推定 1 0.0001 0.001 0.01 0.1 1 10 MissRate False Positive per Image 回帰型DCNN 31.77% 単体のDCNN 38.38% 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 Daimler Mono-‐Pedestrian Benchmark Dataset の評価結果 距離[m] 距離推定結果[m] 誤差[%] 5 4.89 2.2 10 9.26 5.3 15 14.12 5.8 回帰型Deep Convolutional Neural Networkによる人検出と部位の位置推定, 2015 78
- 79. ヘテロジニアスラーニング(5) 歩行者の属性推定 Task.2 身体の向き推定 Task.3 顔の向き推定 Task.4 性別認識 Task.5 傘の所持認識 Task.1 歩行者部位位置推定 全結合層 傘をさしているか 男性 女性 : 歩行者部位検出 ( 頭と両足 ) 身体の向き ( 前 , 後 , 左 , 右 ) 顔の向き ( 前 , 後 , 左 , 右 ) 識別するタスク Pedestrian Attribute Recognition for an Unbalanced Dataset Using Mini-Batch Training with Rarity Rate, 2016 79
- 83. 83
- 84. 畳み込み層(1) カーネルをスライドさせて画像に畳み込む 近接の画素とのみ結合する(局所受容野) Convolution Response f Input image Feature map10x10 kernel 3x3 8x8 Activation function Convolutions
- 85. プーリング層 Feature mapのサイズを縮小させる Max pooling 2x2の領域 での最大値 Average pooling 2x2の領域 での平均値 Lp pooling f (xi ) = ( I(i, j)p *G(i, j)) 1 p i=1 m ∑ j=1 n ∑ Sampling ピークをより強調